T05垃圾收集算法与垃圾收集器ParNew CMS
垃圾收集算法与垃圾收集器ParNew & CMS
垃圾收集算法
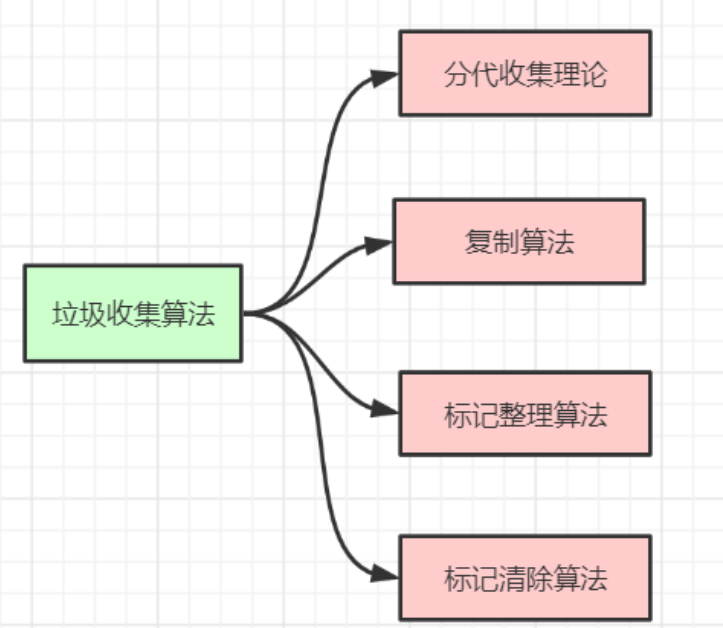 #### f
#### f
分代收集理论
-
当前虚拟机的垃圾收集都采用分代收集算法。根据对象存活周期不同将内存分为几块,一般将java堆分为新生代和老年代,然后根据各个年代的特点选择不同的垃圾收集算法。
-
在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法。只需要付出少量对象的复制成本就可以完成每次垃圾收集。
-
而老年代的对象存活记录是比较高的,而且没有额外的空间对它进行担保,所以必须选择“标记-清除”和”标记整理“算法进行垃圾收集。
-
“标记-清除”或“标记-整理”算法会比复制算法慢10倍以上
标记-复制算法
- 将内存分为大小相同的两块,每次使用一块。当这一块的内存使用完后,就将还存活的对象复制到另一去,然后再把使用的空间一次清理掉。这样就使每次回收的内存回收都是对内存区间的一般进行回收。
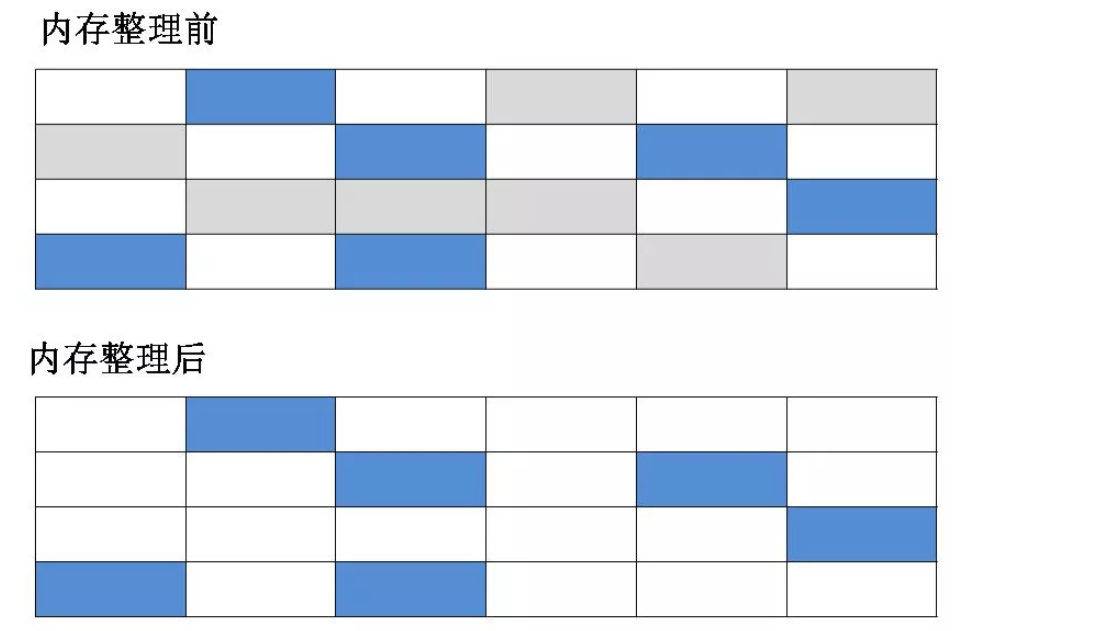
标记-清除算法
-
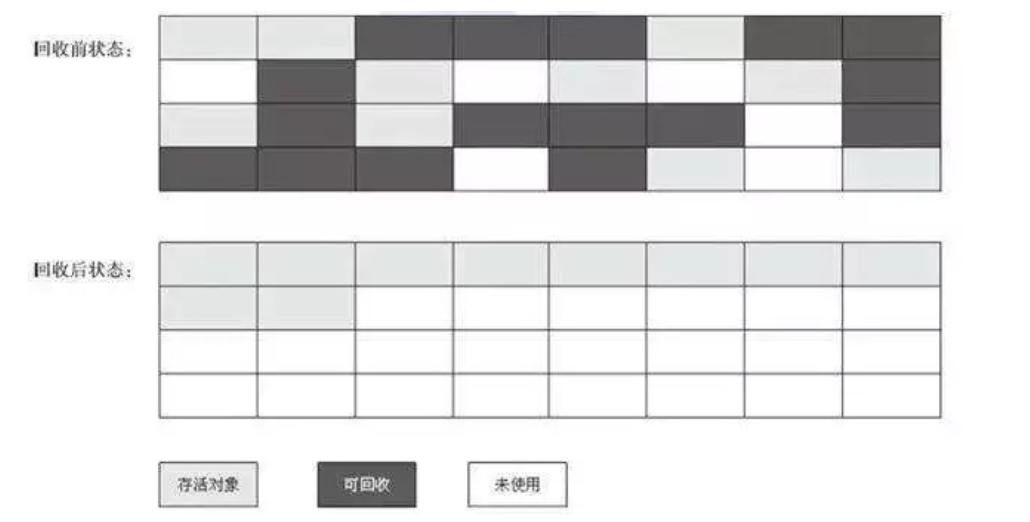
算法分为“标记”和“清除”阶段:标记存活的对象,统一回收所有未被标记的对象;也可以反过来,标记出所有需要回收的对象,在标记完成之后统一回收所有被标记的对象。它是最基础的收集算法。
-
会带来两个明显的问题
- 效率问题:如果需要标记的对象过多,效率不高
- 空间问题:标记清除后会产生大量不连续的碎片
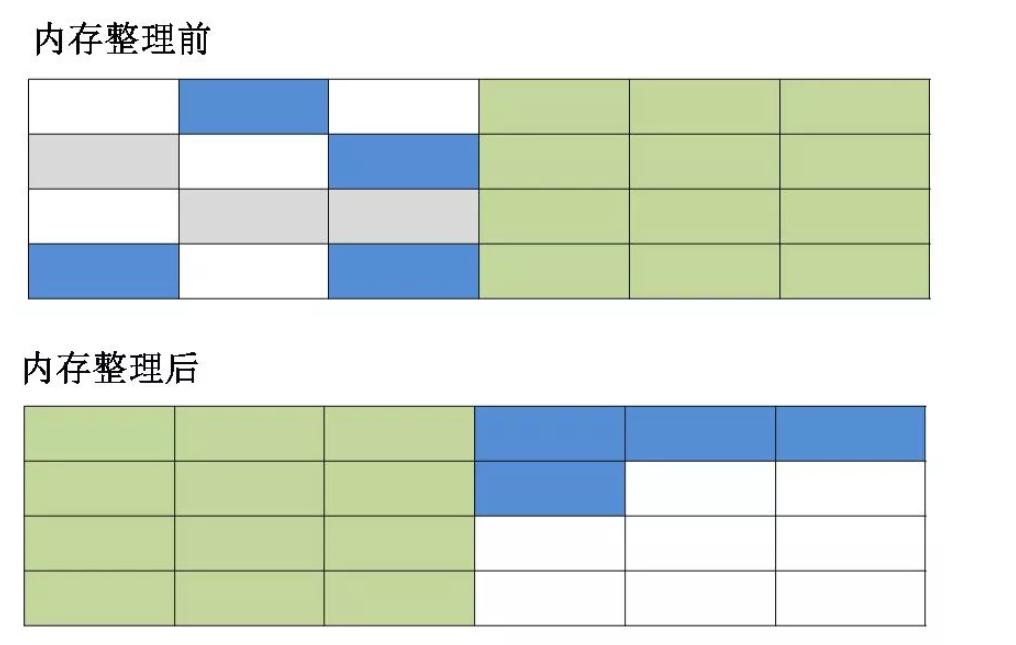
标记-整理
- 标记过程和”标记-清除算法“一样,但后续的步骤不熟直接对可回收对象进行回收,而是让所有存活的对象向另一端移动,然后清理掉端边界以外的内存
垃圾收集器
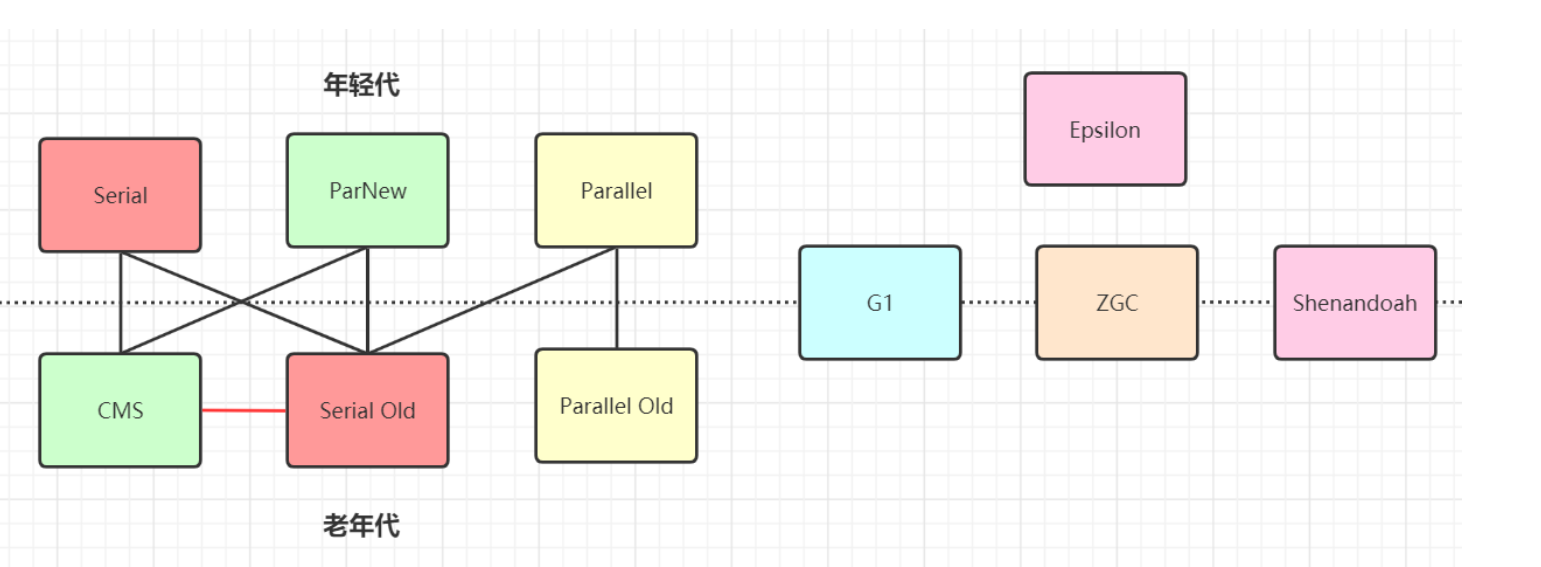
收集算法是内存回收的方法论,垃圾收集器是内存回收的具体实现
能做的是根据具体的应用选择适合自己的垃圾收集器
Serial收集器(-XX:+UseSericalGC -XX:+UseSerialOldGC)
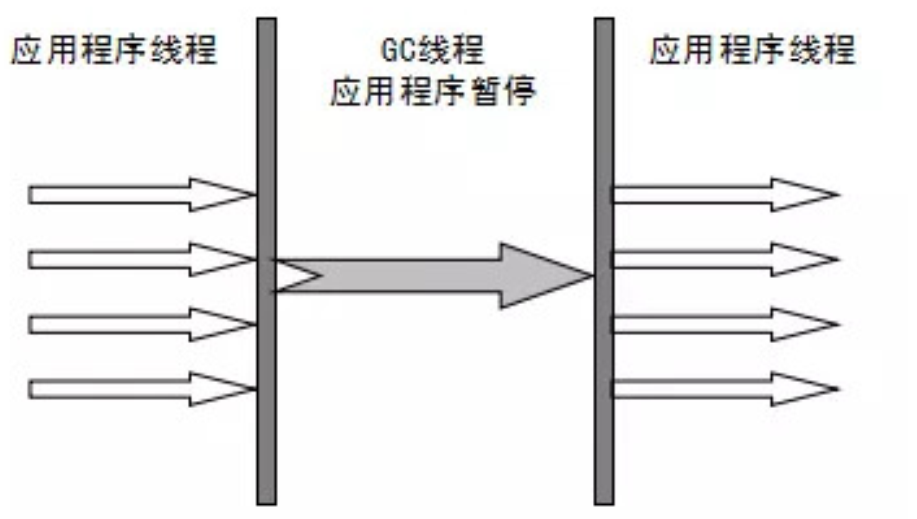
Serial(串行)收集器是最基本的,历史最悠久的垃圾收集器。它只会用一条线程去完成垃圾收集工作,它在进行垃圾收集的时候必须暂停其他所有的“工作线程”(Stop the World),直到它收集结束。
新生代复制算法,老年代采用标记-整理算法
Serial Old收集器是Serial收集器的老年代版本,它同样是一个单线程收集器。
它主要有两个用途:一种用途是在JDK1.5以及以前的版本中与Parallel Scavenge收集器搭配使用,另一种用途是作为CMS收集器的后备方案。
Parallel Scavenge收集器(-XX:+UseParallelGC(年轻代), -XX:+UseParallelOldGC(老年代))
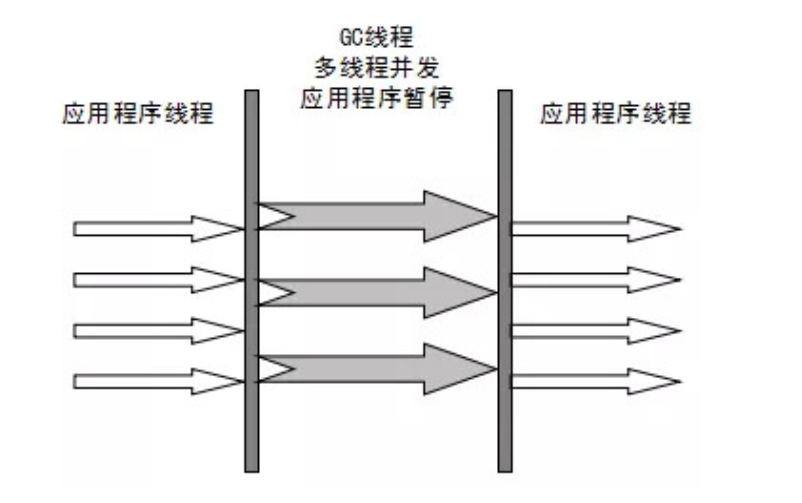
Parallel收集器就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和Serial收集器类似。默认的收集线程数跟CPU核数相同,也可以用参数(-XX:ParallelGCThreads)指定收集线程数,但是一般不推荐修改
Parallel Scavenge收集器关注点是吞吐量(高效利用CPU)。CMS等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值,Parallel Scavenge收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量。
新生代采用复制算法,老年代采用标记-整理算法
Parallel Old收集器是Parallel Scavenge收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量以及CPU资源的场合,都可以优先考虑Parallel Scavenge收集器和Parallel Old收集器(JDK8默认的新生代和老年代收集器)
ParNew收集器(-XX:+UseParNewGC)
ParNew收集器其实跟Parallel收集器很类似,区别主要在于它可以和CMS收集器配合使用
新生代采用复制算法
除了Serial收集器外,只有它能与CMS收集器配合工作
CMS收集器(-XX:+UseConcMarkSweepGC(老年代))
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它是HotSpot虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
CMS是“标记-清除”算法实现的,它的运作过程分为四个阶段
-
初始标记:暂停所有的其他线程(STW),并记录下GC Roots直接能应用的对象,速度很快
-
并发标记:并发标记阶段就是从GC Roots的直接关联对象开始遍历整个对象图的过程,整个过程耗时较长但是不需要停顿用户线程,可以与垃圾收集线程一起并发运行。(用户线程继续运行,可能会有已经标记过的对象状态发生改变)
-
重新标记:重新标记就是为了修正并发标记期间因为用户线程继续运行而导致标记产生变动的那一部分对象的标记记录(主要是处理漏标问题),这个阶段的停顿时间一般比初始标记时间稍长,远远比并发标记阶段时间短,主要用到三色标记里的增量更新算法做重新标记
-
并发清理:开启用户线程,同时GC线程会对未标记的区域做清扫。这个阶段如果有新增对象会被标记为黑色不做任何处理。
-
并发重置:重置本次GC过程中的标记数据
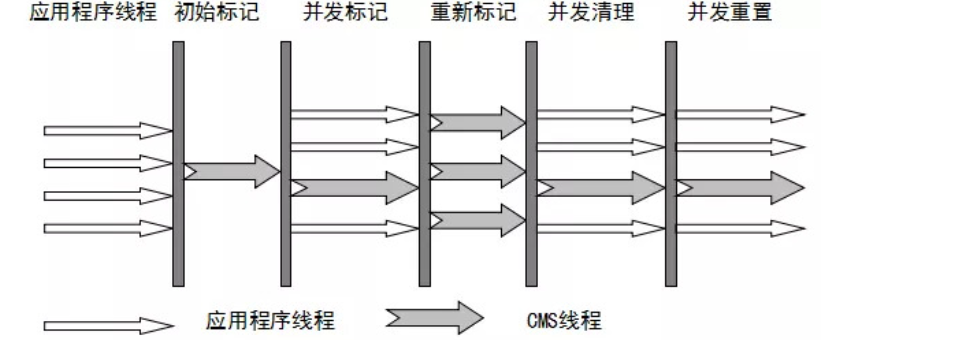
主要优点:并发收集,低停顿
缺点:
- 对CPU资源敏感(会和服务器抢资源)
- 无法处理浮动垃圾(在并发标记和并发清理阶段有产生垃圾,这种浮动垃圾只能等到下一次GC再清理了)
- 它使用的回收算法“标记-清除”算法会导致收集结束后会有大量的空间碎片产生,当然可以通过参数-XX:+UseCMSCompactAtFullCollection可以让JVM在执行完成标记清除后再做整理
- 执行过程中的不确定性,会存在上一次垃圾回收还没执行完,然后垃圾回收又被触发的情况,特别是在并发标记和并发清理阶段出现,一边回收,系统一边运行,也许还没回收完再次触发Full GC,也就是“concurrent mode failure”,此时会进入stop the world,用serial Old垃圾收集器来收集
CMS相关参数
- -XX:+UseConcMarkSweepGC:启用cms
- -XX:ConcGCThreads:并发的GC线程数
- -XX:+UseCMSCompactAtFullCollection:FullGC之后做压缩整理(减少碎片)
- -XX:CMSFullGCsBeforeCompaction:多少次FullGC之后压缩一次,默认是0,代表每次FullGC后都会压缩一次
- -XX:CMSInitiatingOccupancyFraction: 当老年代使用达到该比例时会触发FullGC(默认是92,这是百分比)
- -XX:+UseCMSInitiatingOccupancyOnly:只使用设定的回收阈值(-XX:CMSInitiatingOccupancyFraction设定的值),如果不指定,JVM仅在第一次使用设定值,后续则会自动调整
- -XX:+CMSScavengeBeforeRemark:在CMS GC前启动一次minor gc,降低CMS GC标记阶段**(也会对年轻代一起做标记,如果在minor gc就干掉了很多对垃圾对象,标记阶段就会减少一些标记时间)**时的开销,一般CMS的GC耗时 80%都在标记阶段
- -XX:+CMSParallellnitialMarkEnabled:表示在初始标记的时候多线程执行,缩短STW
- -XX:+CMSParallelRemarkEnabled:在重新标记的时候多线程执行,缩短STW;
亿级流量电商系统如何优化JVM参数设置(ParNew + CMS)
大型电商系统后端现在一般都是拆分为多个子系统部署的,比如,商品系统,库存系统,订单系统,促销系统,会员系统等等。
我们这里以比较核心的订单系统为例
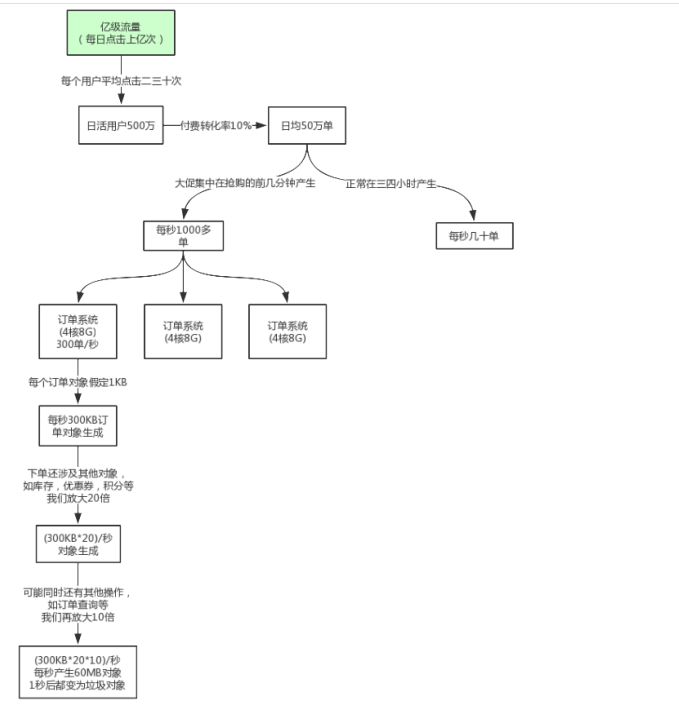
对于8G内存,我们一般是分配4G内存给JVM,正常的JVM参数配置如下:
-Xms3072M -Xmx3072M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8
,这样设置可能会由于动态对象年龄判断原则导致频繁full gc。
于是我们可以更新下JVM参数设置:
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8
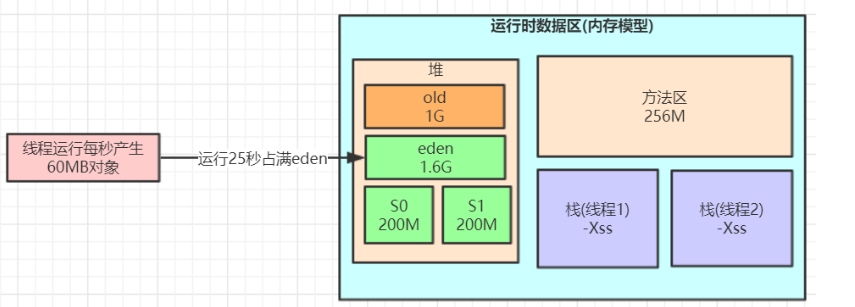
这样就降低了因为对象动态年龄判断原则导致的对象频繁进入老年代的问题,很多优化就是让短期存活的对象尽量留着survivor里面,不要进入老年代,这样在minor GC的时候这些对象都会被回收,不会进入老年代从而导致full GC
对于对象年龄应该为多少才移动到老年代比较合适,本例中一次minor gc要间隔二三十秒,大多数对象一般在几秒内就会变为垃圾,完全可以将默认的15岁改小一点,比如改为5,那么意味着对象要经过5次minor gc才会进入老年代,整个时间也有一两分钟了,如果对象这么长时间都没被回收,完全可以认为这些对象是会存活的比较长的对象,可以移动到老年代,而不是继续一直占用survivor区空间。
对于多大的对象直接进入老年代(参数-XX:PretenureSizeThreshold),这个一般可以结合你自己系统看下有没有什么大对象生成,预估下大对象的大小,一般来说设置为1M就差不多了,很少有超过1M的大对象,这些对象一般就是你系统初始化分配的缓存对象,比如大的缓存List,Map之类的对象。
可以适当调整JVM参数如下:
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=5 -XX:PretenureSizeThreshold=1M
对于JDK8默认的垃圾回收器是-XX:+UseParallelGC(年轻代)和-XX:+UseParallelOldGC(老年代),如果内存较大(超过4个G,只是经验值),系统对停顿时间比较敏感,我们可以使用ParNew+CMS(-XX:+UseParNewGC -XX:+UseConcMarkSweepGC**)**
对于老年代CMS的参数如何设置我们可以思考下,首先我们想下当前这个系统有哪些对象可能会长期存活躲过5次以上minor gc最终进入老年代。
无非就是那些Spring容器里的Bean,线程池对象,一些初始化缓存数据对象等,这些加起来充其量也就几十MB。
还有就是某次minor gc完了之后还有超过一两百M的对象存活,那么就会直接进入老年代,比如突然某一秒瞬间要处理五六百单,那么每秒生成的对象可能有一百多M,再加上整个系统可能压力剧增,一个订单要好几秒才能处理完,下一秒可能又有很多订单过来。
我们可以估算下大概每隔五六分钟出现一次这样的情况,那么大概半小时到一小时之间就可能因为老年代满了触发一次Full GC,Full GC的触发条件还有我们之前说过的老年代空间分配担保机制,历次的minor gc挪动到老年代的对象大小肯定是非常小的,所以几乎不会在minor gc触发之前由于老年代空间分配担保失败而产生full gc,其实在半小时后发生full gc,这时候已经过了抢购的最高峰期,后续可能几小时才做一次FullGC。
对于碎片整理,因为都是1小时或几小时才做一次FullGC,是可以每做完一次就开始碎片整理,或者两到三次之后再做一次也行。
综上,只要年轻代参数设置合理,老年代CMS的参数设置基本都可以用默认值,如下所示:
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=5 -XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=92 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3
垃圾收集算法底层算法实现
三色标记
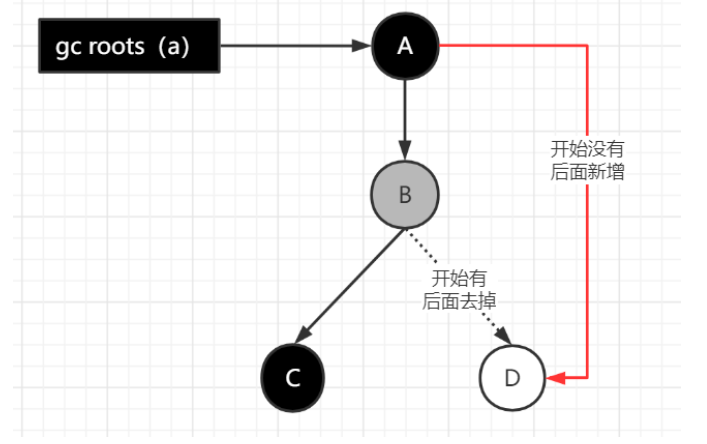
在并发标记的过程中,因为标记期间应用线程还在继续跑,对象间的引用可能发生变化,多标和漏标的情况就有可能发生,漏标的问题主要引入三色标记来解决
三色标记是把GC Roots可达性分析遍历对象过程中遇到的对象,按照”是否访问过“这个条件标记成以下三种颜色
- 黑色:表示对象已经被垃圾收集器访问过,且这个对象的所有引用都已经被扫描过。黑色的对象代表以及扫描过,它是安全存活的,如果有其他对象那个引用指向了黑色对象,无需重新扫描一遍。黑色对象不能直接(不经过灰色对象)指向某个白色对象
- 灰色:表示对象已经被垃圾收集器访问过,但这个对象至少存在一个引用还没有被扫描到
- 白色:表示对象尚未被垃圾收集器访问过。在可达性分析刚刚开始的阶段,所有的对象但是白色的,若在分析结束阶段,仍然是白色的对象,即代表不可达
/*** 垃圾收集算法细节之三色标记* 为了简化例子,代码写法可能不规范,请忽略* Created by 诸葛老师*/
public class ThreeColorRemark {public static void main(String[] args) {A a = new A();//开始做并发标记D d = a.b.d; // 1.读a.b.d = null; // 2.写a.d = d; // 3.写}
}class A {B b = new B();D d = null;
}class B {C c = new C();D d = new D();
}class C {
}class D {
}
多标-浮动垃圾
在并发标记过程中,如果由于方法运行结束导致部分局部变量(GC、Roots)被销毁,这个GC Roots引用的对象之前又被扫描过(被标记未非垃圾对象),那么本次GC不会回收这部分内存,这部分本应该回收但是没有回收到的内存,被称之为”浮动垃圾“。浮动垃圾并不会影响垃圾回收的正确性,只是需要等到下一轮垃圾回收才会被清除
另外,针对并发标记(还有并发清理)开始后产生的新对象,通常做法是直接全部当成黑色,本轮不会进行清除。这部分对象期间可能也会变为垃圾,这也算浮动垃圾的一部分
漏标-读写屏障
- 漏标会导致被引用的对象被当成垃圾误删除,必须解决,有两种解决方法:增量更新和原始快照
- 增量更新就是当黑色对象插入新的指向白色对象的引用关系时,就将这个新插入的引用记录下来,等并发扫描结束之后,再将这些记录过的引用关系中的黑色对象为根,重新扫描一次,可用简单理解为:黑色对象一旦新插入了指向白色对象的引用后,它就变为灰色对象了
- 原始快照就是当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用记录下来,在并发扫描结束后,再将这些记录过的引用关系中的灰色对象为根,再扫描一次,这样就能扫描到白色的对象,将白色的对象直接标记为黑色(目的就是让这种对象在本次GC清理中能活下来,待下一轮GC的时候重新扫描,这个对象也有可能是浮动垃圾)
- 以上无论是对引用关系记录的插入还是删除,虚拟机的记录操作都是通过写屏障实现的
写屏障
- 给某个对象的成员变量赋值时,底层代码
/**
* @param field 某对象的成员变量,如 a.b.d
* @param new_value 新值,如 null
*/
void oop_field_store(oop* field, oop new_value) { *field = new_value; // 赋值操作
}
所谓的写屏障,就是指在赋值操作前后,加入一些处理
void oop_field_store(oop* field, oop new_value) { pre_write_barrier(field); // 写屏障-写前操作*field = new_value; post_write_barrier(field, value); // 写屏障-写后操作
}
写屏障实现SATB
当对象B的成员变量的引用发生变化时,比如引用消失(a.b.d = null),可以利用写屏障,将B原来成员变量的引用对象D记录下来
void pre_write_barrier(oop* field) {oop old_value = *field; // 获取旧值remark_set.add(old_value); // 记录原来的引用对象
}
写屏障实现增量更新
当对象的成员变量的引用发生变化时,比如新增引用(a.d = d),我们可以利用写屏障,将A新的成员变量引用对象D记录下来
void post_write_barrier(oop* field, oop new_value) { remark_set.add(new_value); // 记录新引用的对象
}
读屏障
oop oop_field_load(oop* field) {pre_load_barrier(field); // 读屏障-读取前操作return *field;
}
读屏障是直接针对第一步,D d = a.b.d,当读取成员变量时,都记录下来
void pre_load_barrier(oop* field) { oop old_value = *field;remark_set.add(old_value); // 记录读取到的对象
}
现代追踪式(可达性分析)的垃圾回收器几乎都借鉴了三色标记的算法思想,尽管实现的方式不尽相同:比如白色/黑色集合一般都不会出现(但是有其他体现颜色的地方)、灰色集合可以通过栈/队列/缓存日志等方式进行实现、遍历方式可以是广度/深度遍历等等。
对于读写屏障,以Java HotSpot VM为例,其并发标记时对漏标的处理方案如下:
- CMS:写屏障 + 增量更新
- G1,Shenandoah:写屏障 + SATB
- ZGC:读屏障
记忆集与卡表
在新生代做GCRoots可达性扫描过程中可能会碰到跨代引用的对象,这种如果又去对老年代再去扫描效率太低了。
为此,在新生代可以引入记录集(Remember Set)的数据结构(记录从非收集区到收集区的指针集合),避免把整个老年代加入GCRoots扫描范围。事实上并不只是新生代、 老年代之间才有跨代引用的问题, 所有涉及部分区域收集(Partial GC) 行为的垃圾收集器, 典型的如G1、 ZGC和Shenandoah收集器, 都会面临相同的问题。
垃圾收集场景中,收集器只需通过记忆集判断出某一块非收集区域是否存在指向收集区域的指针即可,无需了解跨代引用指针的全部细节。
hotspot使用一种叫做“卡表”(Cardtable)的方式实现记忆集,也是目前最常用的一种方式。关于卡表与记忆集的关系, 可以类比为Java语言中HashMap与Map的关系。
卡表是使用一个字节数组实现:CARD_TABLE[ ],每个元素对应着其标识的内存区域一块特定大小的内存块,称为“卡页”。
hotSpot使用的卡页是2^9大小,即512字节
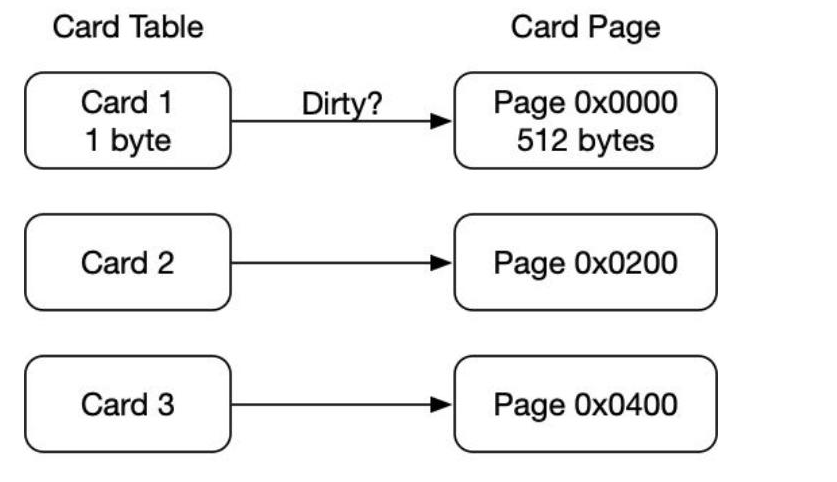
一个卡页中可包含多个对象,只要有一个对象的字段存在跨代指针,其对应的卡表的元素标识就变成1,表示该元素变脏,否则为0.
GC时,只要筛选本收集区的卡表中变脏的元素加入GCRoots里。
卡表的维护
卡表变脏上面已经说了,但是需要知道如何让卡表变脏,即发生引用字段赋值时,如何更新卡表对应的标识为1。
Hotspot使用写屏障维护卡表状态。
相关文章:
T05垃圾收集算法与垃圾收集器ParNew CMS
垃圾收集算法与垃圾收集器ParNew & CMS 垃圾收集算法 #### f 分代收集理论 当前虚拟机的垃圾收集都采用分代收集算法。根据对象存活周期不同将内存分为几块,一般将java堆分为新生代和老年代,然后根据各个年代的特点选择不同的垃圾收集算法。 在新…...

每日一道面试题:Java中序列化与反序列化
写在开头 哈喽大家好,在高铁上码字的感觉是真不爽啊,小桌板又拥挤,旁边的小朋友也比较的吵闹,影响思绪,但这丝毫不影响咱学习的劲头!哈哈哈,在这喧哗的车厢中,思考着这样的一个问题…...

论文阅读:Vary-toy论文阅读笔记
目录 引言整体结构图方法介绍训练vision vocabulary阶段PDF数据目标检测数据 训练Vary-toy阶段Vary-toy结构数据集情况 引言 论文:Small Language Model Meets with Reinforced Vision Vocabulary Paper | Github | Demo 说来也巧,之前在写论文阅读&…...
【Linux】开始使用 vim 吧!!!
Linux 1 what is vim ?2 vim基本概念3 vim的基本操作 !3.1 vim的快捷方式3.1.1 复制与粘贴3.1.2 撤销与剪切3.1.3 字符操作 3.2 vim的光标操作3.3 vim的文件操作 总结Thanks♪(・ω・)ノ感谢阅读下一篇文章见!…...

多线程面试合集
前言 前文介绍了JVM相关知识,本文将重点介绍多线程相关知识以及工作中的一些经验。 多线程面试合集 什么是多线程?为什么我们需要多线程? 多线程是指在一个进程中同时执行多个线程,每个线程可以执行不同的任务。多线程可以提高…...

从微服务到云原生
很多文章介绍云原生概念,说它包含微服务,又包含了其它几个方面的东西,还扯到文化层面、组织层面和技术层面,搞技术的人一听到公司文化问题和组织部门问题,就十分地晕眩,不能让我好好地坐下来写写代码、搞搞…...
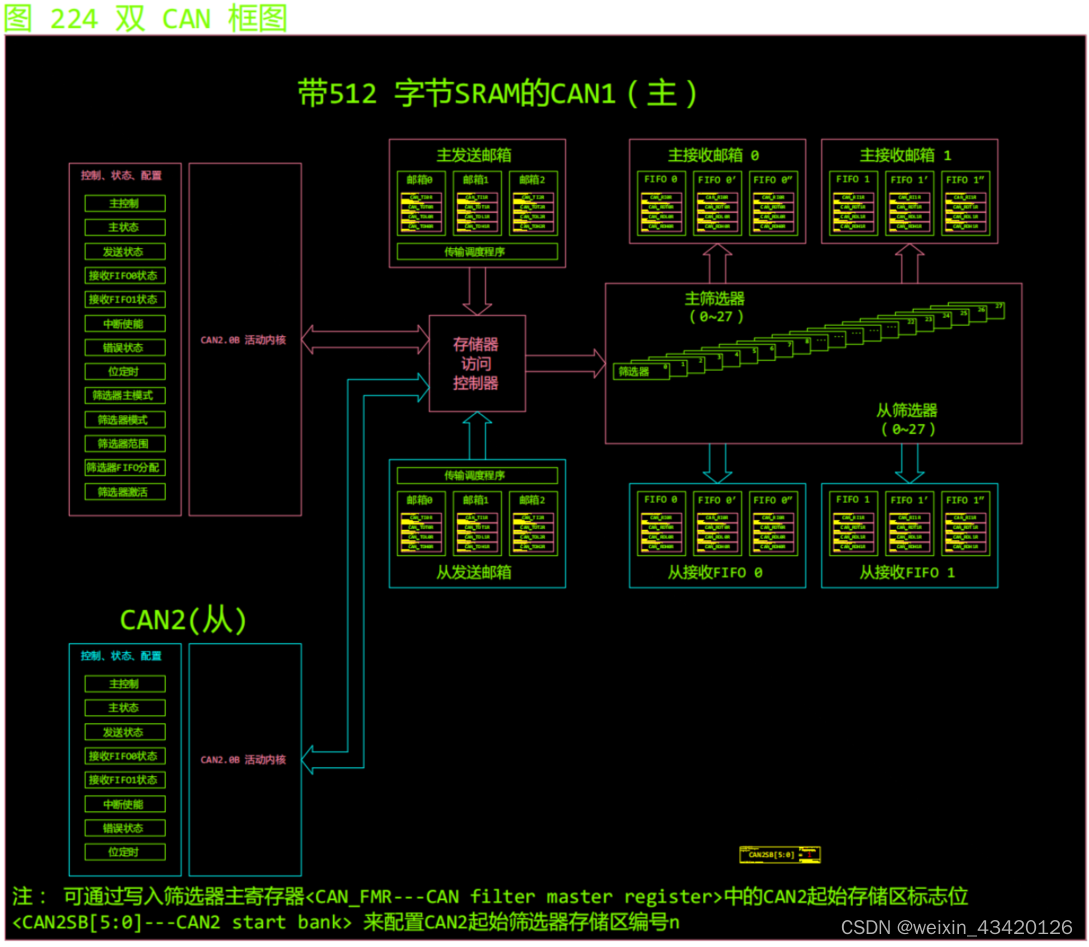
bxCAN 主要特性
bxCAN 主要特性 ● 支持 2.0 A 及 2.0 B Active 版本 CAN 协议 ● 比特率高达 1 Mb/s ● 支持时间触发通信方案 发送 ● 三个发送邮箱 ● 可配置的发送优先级 ● SOF 发送时间戳 接收 ● 两个具有三级深度的接收 FIFO ● 可调整的筛选器组: — CAN1 和…...

武忠祥2025高等数学,基础阶段的百度网盘+视频及PDF
考研数学武忠祥基础主要学习以下几个方面的内容: 1.微积分:主要包括极限、连续、导数、积分等概念,以及它们的基本性质和运算方法。 2.线性代数:主要包括向量、向量空间、线性方程组、矩阵、行列式、特征值和特征向量等概念,以及它们的基本…...
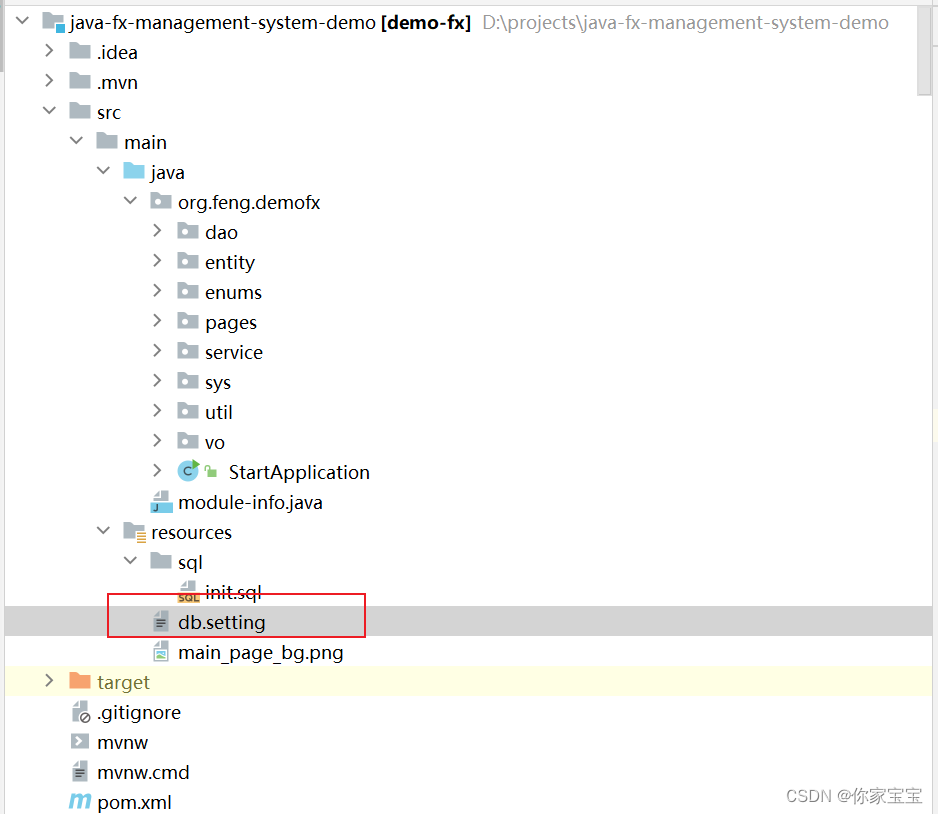
用JavaFX写了一个简易的管理系统
文章目录 前言正文一、最终效果1.1 主页面1.2 动物管理页面-初始化1.3 动物管理页面-修改&新增1.4 动物管理页面-删除&批量删除 二、核心代码展示2.1 启动类2.2 数据库配置-db.setting2.3 日志文本域组件2.4 自定义表格视图组件2.5 自定义分页组件2.6 动物管理页面2.7 …...

第二百九十回
文章目录 1. 概念介绍2. 方法与细节2.1 实现方法2.2 具体细节 3. 示例代码4. 内容总结 我们在上一章回中介绍了"如何混合选择多个图片和视频文件"相关的内容,本章回中将介绍如何通过相机获取视频文件.闲话休提,让我们一起Talk Flutter吧。 1. …...
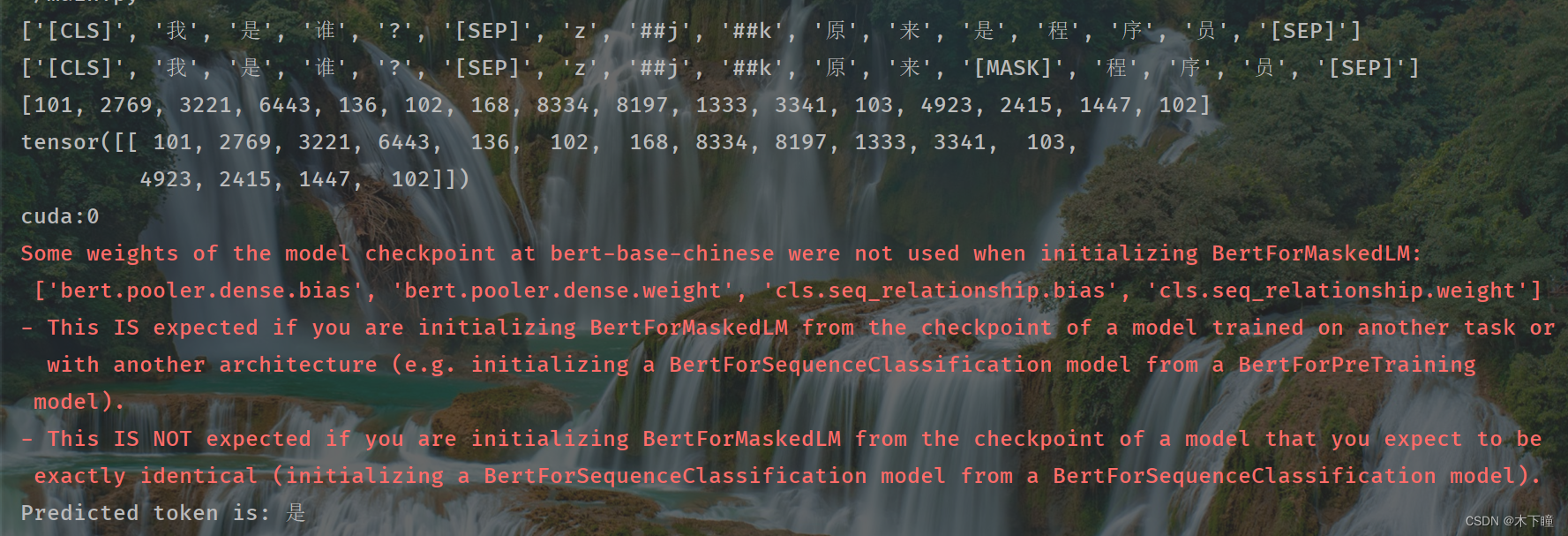
bert实现完形填空简单案例
使用 bert 来实现一个完形填空的案例,使用预训练模型 bert-base-chinese ,这个模型下载到跟代码同目录下即可,下载可参考:bert预训练模型下载-CSDN博客 通过这个案例来了解一下怎么使用预训练模型来完成下游任务,算是对…...
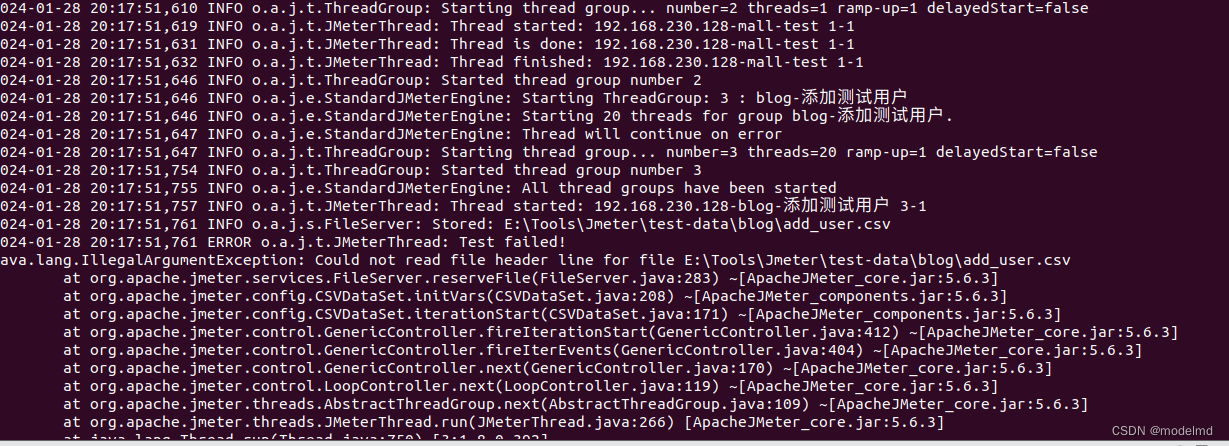
Jmeter 分布式测试
Jmeter单机进行压测,受到单台机器的性能影响,Jmeter支持分布式测试,用一个控制节点去控制多个工作节点去模拟更多的用户。 版本信息 内容版本号JDK1.8Jmeter5.6.2 分布式测试原理 jmeter 官网对分布式测试有说明,jmeter分布式…...

在 Ubuntu 上安装 Docker Engine
系列文章目录 前言 要在 Ubuntu 上开始使用 Docker Engine,请确保满足先决条件,然后按照安装步骤进行操作。 一、先决条件 注意事项 如果您使用 ufw 或 firewalld 管理防火墙设置,请注意当您使用 Docker 暴露容器端口时,这些端口…...

Mac安装nvm,安装多个不同版本node,指定node版本
一.安装nvm brew install nvm二。配置文件 touch ~/.zshrc echo export NVM_DIR~/.nvm >> ~/.zshrc echo source $(brew --prefix nvm)/nvm.sh >> ~/.zshrc三.查看安装版本 nvm -vnvm常用命令如下:nvm ls :列出所有已安装的 node 版本nvm…...

【开源】基于JAVA+Vue+SpringBoot的智慧家政系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、系统展示四、核心代码4.1 查询家政服务4.2 新增单条服务订单4.3 新增留言反馈4.4 小程序登录4.5 小程序数据展示 五、免责说明 一、摘要 1.1 项目介绍 基于微信小程序JAVAVueSpringBootMySQL的智慧家政系统࿰…...

Python NLP深度学习进阶:自然语言处理
自然语言处理(Natural Language Processing,NLP)是人工智能领域中的一个重要分支,涉及到处理和理解人类语言的方法和技术。随着深度学习的快速发展,NLP的研究和应用也在不断进步。 在Python中,有许多强大的…...
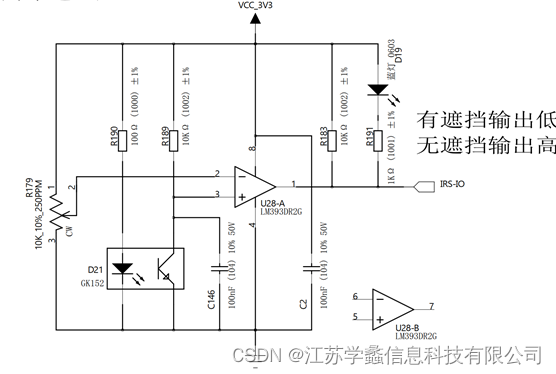
STM32单片机基本原理与应用(三)
矩阵键盘工作原理 矩阵键盘由多个独立按键组成,按键的一端接地,一端接MCU的GPIO。当按键没有被按下时,电路其实是一个断路,将单片机该引脚设置成输入上拉状态,读到的电平为高电平。当按下按键时,引脚会被拉…...

Android studio布局详解
文章目录 一、Android studio布局详解二、Android studio六大布局案例三、优缺点四、热门文章 一、Android studio布局详解 Android Studio是一种用于开发Android应用程序的集成开发环境(IDE),用于设计和编辑Android应用程序的用户界面布局。在Android …...

第四篇:怎么写express的路由(接口+请求)
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 📘 引言: Ǵ…...

算法学习记录:有关树的基础
前言: 算法学习记录不是算法介绍,本文记录的是从零开始的学习过程(见到的例题,代码的理解……),所有内容按学习顺序更新,而且不保证正确,如有错误,请帮助指出。 学习工具…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...