DS:经典算法OJ题(1)

创作不易,友友们给个三连呗!!
本文为经典算法OJ题练习,大部分题型都有多种思路,每种思路的解法博主都试过了(去网站那里验证)是正确的,大家可以参考!!
一、移除元素(力扣)
经典算法OJ题:移除元素
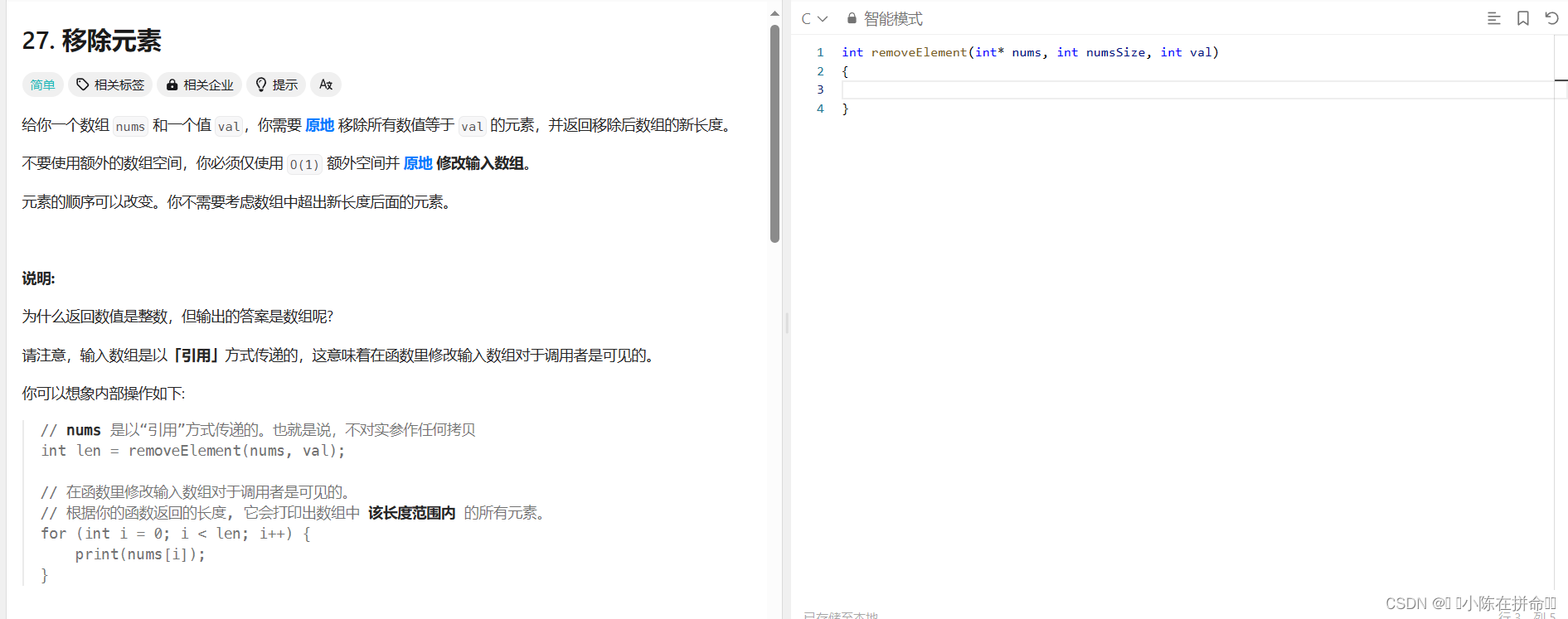 思路1:遍历数组,找到一个元素等于val,就把后面的所有元素往前挪,类似顺序表实现中的指定位置删除!
思路1:遍历数组,找到一个元素等于val,就把后面的所有元素往前挪,类似顺序表实现中的指定位置删除!
//思路1:遍历数组,找到一个元素等于val,就把后面的所有元素往前挪,类似顺序表实现中的指定位置删除!
int removeElement(int* nums, int numsSize, int val)
{for (int i = 0; i < numsSize; i++)//用来遍历{if (nums[i] == val)//要挪动,而且是从前往后挪{for (int j = i; j < numsSize - 1; j++)nums[j] = nums[j + 1];//从前往后挪numsSize--;//挪完长度-1i--;//挪动后新的数据还在原来的位置,所以不能让i往前走!!}}return numsSize;
}思路2:(双指针法)利用双指针,第一个指针引路,第二个指针存放想要的元素(不等于val的元素)(较优)
//思路2:(双指针法)利用双指针,第一个指针引路,第二个指针存放想要的元素(不等于val的元素)
int removeElement(int* nums, int numsSize, int val)
{int src = 0;//用来探路,src即原操作数int dst = 0;//用来存放想要的数据,dst即目标操作数while (src < numsSize){if (nums[src] == val){src++;//找到val就src走}else{nums[dst] = nums[src];//dst接收想要的数据//找不到就两个都走dst++;src++;}}//此时dst恰好就是数组的新长度return dst;
}二、合并两个有序数组(力扣)
经典算法OJ题:合并两个有序数组

思路1:num2全部存储到num1中,再统一进行排序(qsort)
int int_cmp(const void* p1, const void* p2)//比较方法
{return (*(int*)p1 - *(int*)p2);//返回值来影响qsort
}void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{int i = m;//指向数组1后面的空位置int j = 0;//指向数组2while (i < m + n){nums1[i] = nums2[j];i++;j++;}//循环结束说明插入完成,使用快速排序qsort(nums1, m + n, sizeof(int), int_cmp);
}思路2:合并的时候顺便排序,利用3个指针,l1用来遍历数组1,l2用来遍历数组2,比大小之后的数据用l3记录。(较优)
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{int l1=m-1;//从1数组的最后一个有效数据往前int l2=n-1;//从2数组的最后一个有效数据往前int l3=n+m-1;//从1数组的最后一个元素开始往前while(l1>=0 && l2>=0)//l1和l2其中一个遍历完就得跳出循环{//从后往前比大小
if(nums1[l1]>nums2[l2])nums1[l3--]=nums1[l1--];
elsenums1[l3--]=nums2[l2--];}//循环结束后,有两种情况,一种是l1先遍历完,此时l2要接着插进去,//另一种是l2先遍历完,此时l1就不需要处理了while(l2>=0)nums1[l3--]=nums2[l2--];
}三、移除链表元素(力扣)
经典算法OJ题:移除链表元素
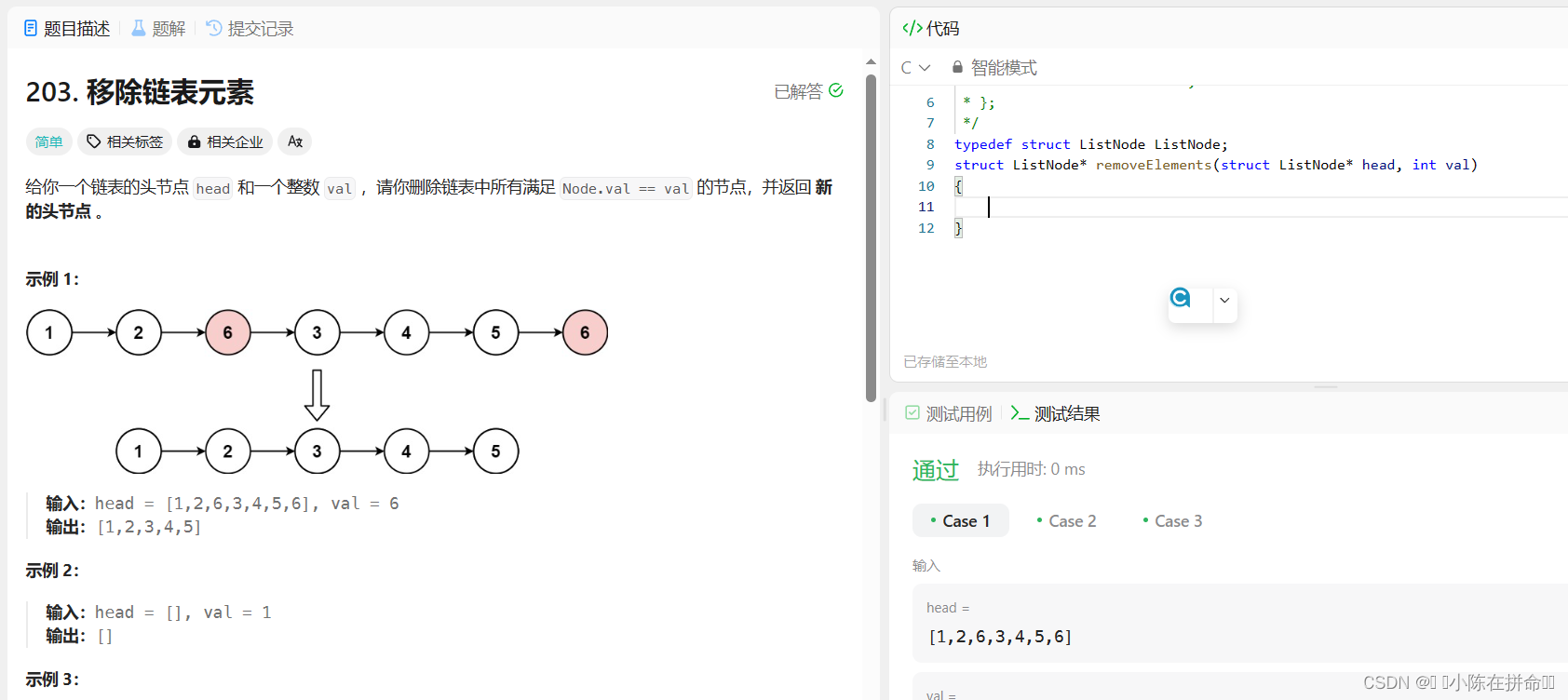
思路1:遍历原链表,遇到val就删除,类似单链表的指定位置删除
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{//考虑头节点就是val的情况while(head!=NULL&&head->val==val)head=head->next;//此时头节点不可能是val//当链表为空if(head==NULL)return head;//当链表不为空时ListNode*pcur=head;//用来遍历链表ListNode*prev=NULL;//用来记录前驱结点while(pcur){//当找到val时if(pcur->val==val){prev->next=prev->next->next;//前驱结点指向pucr的下一个结点free(pcur);//删除的结点被释放pcur=prev->next;//继续指向新的结点}//没找到val时else{prev=pcur;//往后走之前记录前驱结点pcur=pcur->next;//pcur往前遍历}}return head;
}思路2:定义一个不带头新链表,将不为val的结点尾插进去
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{ListNode*pcur=head;//用来遍历链表//定义新链表的头尾指针ListNode*newhead=NULL;//用来记录头ListNode*newtail=NULL;//用来尾插新链表while(pcur)
{if(pcur->val!=val)//不满足val则插入到新链表{//一开始链表是空的if(newhead==NULL)newhead=newtail=pcur;//链表不为空了,开始尾插else{newtail->next=pcur;//尾插newtail=newtail->next;//尾插后向后挪动}}pcur=pcur->next;//pcur要遍历往后走
}
//插入完后要加NULL!还要避免newtail是空的情况
if(newtail)
newtail->next=NULL;
return newhead;
}思路3:给原链表创造一个哨兵结点,然后遍历,遇到val就删(和思路1比较,多了一个哨兵,稍优于思路1)
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{ListNode*newhead=(ListNode*)malloc(sizeof(ListNode));//创建一个新的哨兵节点newhead->next=head;//哨兵接头ListNode*pcur=head;//用来遍历链表ListNode*prev=newhead;//记录前驱结点
while(pcur)
{//遇到了,开始删除
if(pcur->val==val)
{prev->next=pcur->next;free(pcur);pcur=prev->next;
}
//如果没遇到val,都往后走
else
{prev=pcur;pcur=pcur->next;
}
}
//循环结束,删除完成
ListNode*ret=newhead->next;//释放哨兵结点前记住需要返回的结点
free(newhead);
newhead=NULL;
return ret;
}思路4:定义一个带头新链表,将不为val的结点尾插进去(和思路2相比较,多了一个哨兵)(较优)
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{ListNode*newhead,*newtail;newhead=newtail=(ListNode*)malloc(sizeof(ListNode));//创建一个新的哨兵节点ListNode*pcur=head;//用来遍历链表while(pcur){if(pcur->val!=val){//找打不为val的值 开始尾插newtail->next=pcur;newtail=newtail->next;}pcur=pcur->next;//没找到就往后找}newtail->next=NULL;ListNode*ret=newhead->next;//释放哨兵时记住返回值free(newhead);newhead=NULL;return ret;
}四、反转链表(力扣)
经典算法OJ题:反转链表
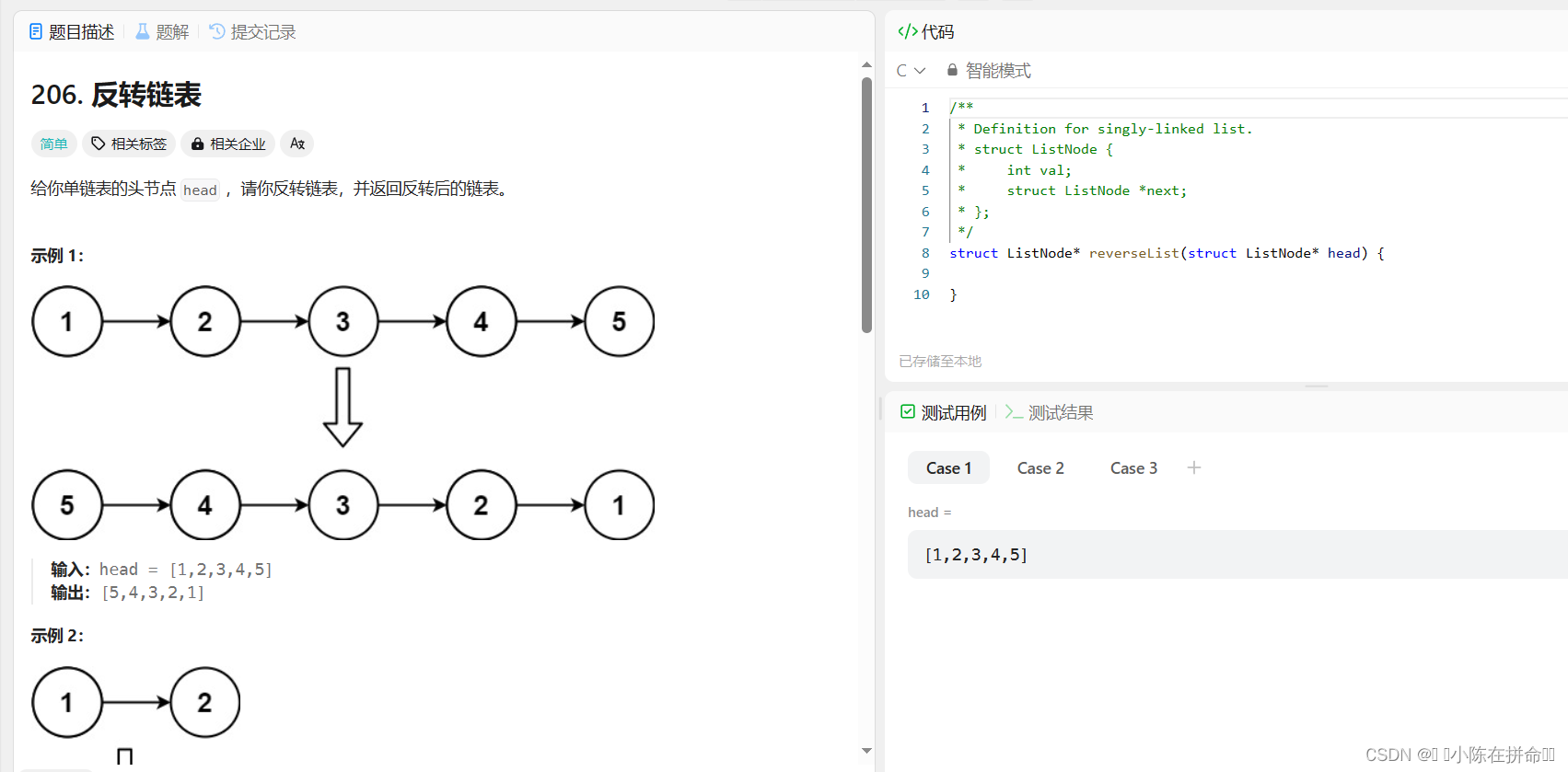
思路1:利用带头单链表头插法,建立一个新的带头结点的单链表L,扫描head链表的所有结点,每扫描一个结点就创造一个s结点并将值赋给s结点然后头插法插入新链表L中,得到的就是逆序的head链表
typedef struct ListNode ListNode;ListNode*BuyNode(int x)//封装创建新结点的函数{ListNode*newnode=(ListNode*)malloc(sizeof(ListNode));newnode->next=NULL;newnode->val=x;return newnode;}
struct ListNode* reverseList(struct ListNode* head)
{ListNode*pcur=head;//用来遍历ListNode*newhead=BuyNode(-1);//创建哨兵结点ListNode*temp=NULL;//充当临时变量while(pcur)
{temp=BuyNode(pcur->val);//创建新结点接收pur的值//头插temp->next=newhead->next;newhead->next=temp;//pcur往后走pcur=pcur->next;//pcur往后走
}
ListNode*ret=newhead->next;//哨兵位释放之前保存头节点
free(newhead);
newhead=NULL;
return ret;
}思路2:利用带头单链表头插法,建立一个新的带头结点的单链表L,扫描head链表的所有结点,每扫描一个结点就头插法插入新链表L中,得到的就是逆序的head链表(相比思路1多了个哨兵,稍优于思路1)
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{//如果链表为空if(head==NULL)return head;//如果链表不为空ListNode*newhead,*newtail;//一个哨兵,一个记录尾巴方便后面置NULL;newhead=(ListNode*)malloc(sizeof(ListNode));//创建哨兵结点newhead->next=head;//哨兵和原来的头节点连接起来newtail=head;//newtail记住一开始的head,方便后面连接NULLListNode*pcur=head->next;//pcur用来遍历(从第二个)ListNode*temp=NULL;//用来记录下一个遍历点while(pcur){temp=pcur->next;//连接前,先记住下一个结点的位置//头插 插在哨兵结点和原来头结点的中间newhead->next=pcur;pcur->next=head;head=pcur;//头插进来的成为哨兵结点后面的新头pcur=temp;//pcur从原先链表的下一个结点开始继续遍历}newtail->next=NULL;//要记得给尾巴结点连接NULL;free(newhead);newhead=NULL;return head;
}思路3:利用不带头链表头插法,扫描head链表的所有结点,每扫描一个结点就头插法插入新链表L中,得到的就是逆序的head链表(较优)
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{//如果链表为空if(head==NULL)return head;//如果链表不为空ListNode*pcur=head->next;//用来遍历ListNode*ptail=head;//用来记录尾巴,方便后面置NULL;ListNode*temp;//记录遍历的结点while(pcur){temp=pcur->next;//头插到head前面
pcur->next=head;
head=pcur;
pcur=temp;}ptail->next=NULL;return head;
}思路4:利用3个指针,分别记录前驱结点、当前结点、后继结点,改变原链表的指针指向(最优)
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{//链表为空的时候if(head==NULL)return head;//链表不为空的时候,创建3个指针,分别指向前驱、当前、后继结点
ListNode*p1,*p2,*p3;
p1=NULL;//前驱
p2=head;//当前
p3=head->next;//后继
while(p2)
{//改变指向
p2->next=p1;
//向后挪动
p1=p2;
p2=p3;
//考虑p3为NULL的时候
if(p3)
p3=p3->next;
}
return p1;
}五、合并两个有序链表(力扣)
经典算法OJ题:合并两个有序链表
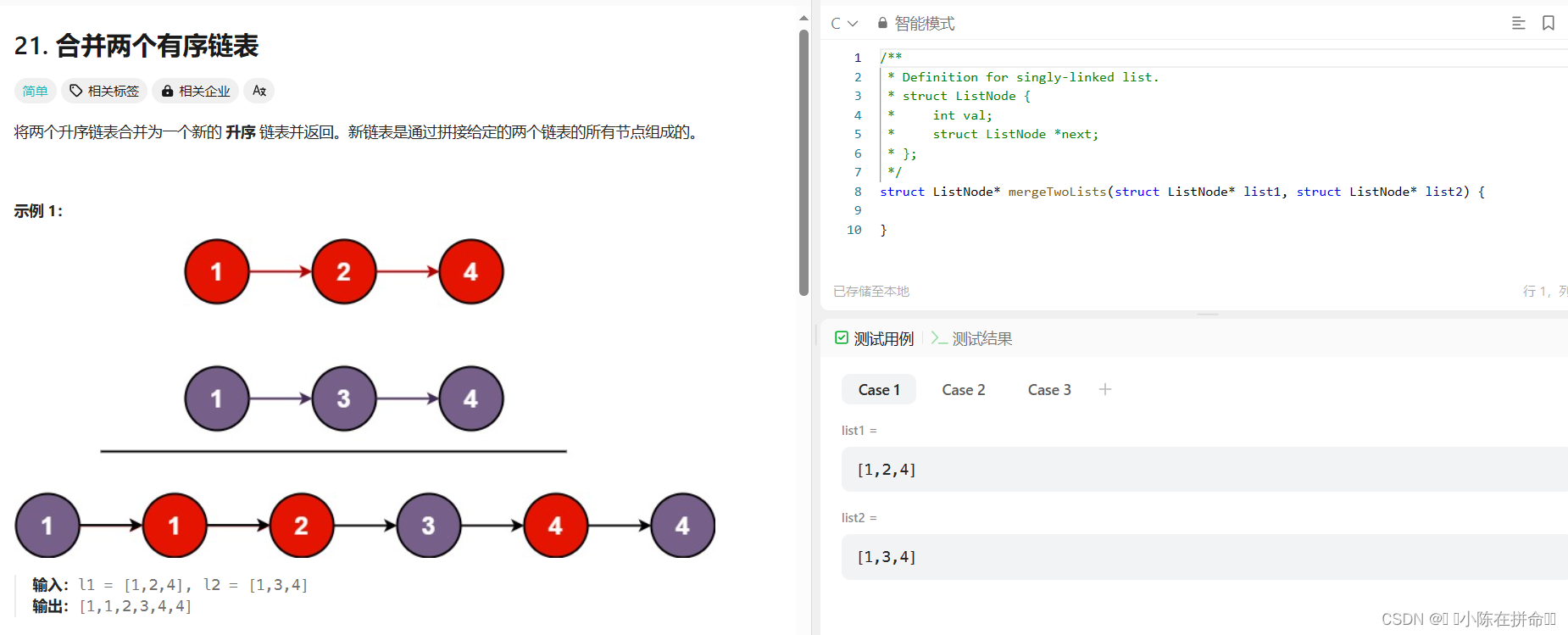
思路1:创建一个哨兵节点,双指针判断两组数据的大小,因为是把 list2 的节点插入 list1 ,所以只要当 list1 指向的数大于 list2 的数,就把当前 list2 节点插入 list1 的前面。循环判定条件,只要双指针中有一个为空就跳出循环,即有一个指针到了节点末端。若 list1 先结束,表示剩下 list2 的数都比 list1 里的数大,直接把 list2 放到 list1后即可若 list2 先结束,即表示已经合并完成。
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{ListNode*newhead=(ListNode*)malloc(sizeof(ListNode));//创建一个新的哨兵结点newhead->next=list1;//哨兵点与list1相连接ListNode*p1=list1;//利用p1遍历链表1ListNode*p2=list2;//利用p2遍历链表2ListNode*prev=newhead;//prev记录前驱结点ListNode*temp=NULL;//充当临时变量,暂时保存list2的指向while(p1&&p2)//p1和p2有一个为NULL了就必须跳出循环{
if(p1->val>p2->val)//list2插入list1该元素前面
{temp=p2->next;//记住p2指针的遍历点//尾插prev->next=p2;p2->next=p1;//尾插完成往前走prev=p2;p2=temp;
}
//找不到时,prev和p1都往后走
else
{p1=p1->next;prev=prev->next;
}}
//跳出循环后有两种可能,一种是p1先为NULL,一种是p2先为NULL
//此时prev恰好走到尾结点
//如果p2为NULL,说明已经结束!如果p1为NULL,此时尾插p2在prev后面
if(p1==NULL)
prev->next=p2;
ListNode*ret=newhead->next;//哨兵位要释放,返回前要记录newhead->next
free(newhead);
newhead=NULL;
return ret;
}思路2:定义一个带头新链表(方便返回),两个指针分别指向两组数组,逐个比较,较小的尾插到新的链表中,循环判断条件,只要有一个指针为NULL就跳出循环,无论是 list1 结束还是 list2 结束,只需要把剩下的部分接在新链表上即可。(较优)
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{ListNode*newhead,*newptail;newhead= newptail=(ListNode*)malloc(sizeof(ListNode));//创建一个新的哨兵结点//newptail是用来尾插的ListNode*p1=list1;//利用p1遍历链表1ListNode*p2=list2;//利用p2遍历链表2while(p1&&p2)//p1和p2有一个为NULL了就必须跳出循环{
if(p1->val<p2->val)
{newptail->next=p1;//尾插newptail=newptail->next;//插入后newptail往后走p1=p1->next;//插入后p1往后走
}
else
{newptail->next=p2;//尾插newptail=newptail->next;//插入后newptail往后走p2=p2->next;//插入后p2往后走
}}
//跳出循环后有两种可能,一种是p1先为NULL,一种是p2先为NULL
//在newtail后面插入不为NULL的链表。
newptail->next=(p1==NULL?p2:p1);
ListNode*ret=newhead->next;//哨兵位要释放,返回前要记录newhead->next
free(newhead);
newhead=NULL;
return ret;
}六、链表的中间结点(力扣)
经典算法OJ题:链表的中间结点

思路1:统计链表中结点的个数,然后除以2找到中间结点
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{int count=0;//用来记录总共的结点数量ListNode*pcur=head;//用来遍历while(pcur){pcur=pcur->next;count++;}//此时计算出count,除以2count=count/2;//此时count代表中间结点的位置while(count){head=head->next;count--;}return head;
}思路2:(快慢指针法),创建两个指针一开始都指向头节点,一个一次走一步,一个一次走两步,当快指针为NULL时,慢指针指向的就是中间的位置(较优)
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
ListNode*fast,*slow;
fast=slow=head;//都指向头结点
while(fast!=NULL&&fast->next!=NULL)//存在一个就得跳出循环
//而且顺序不能反!!!因为与运算符从前往后运算
{fast=fast->next->next;//走两步slow=slow->next;//走一步
}
//循环结束slow正好指向中间结点
return slow;
}七、分割链表(力扣)
经典算法OJ题:分割链表
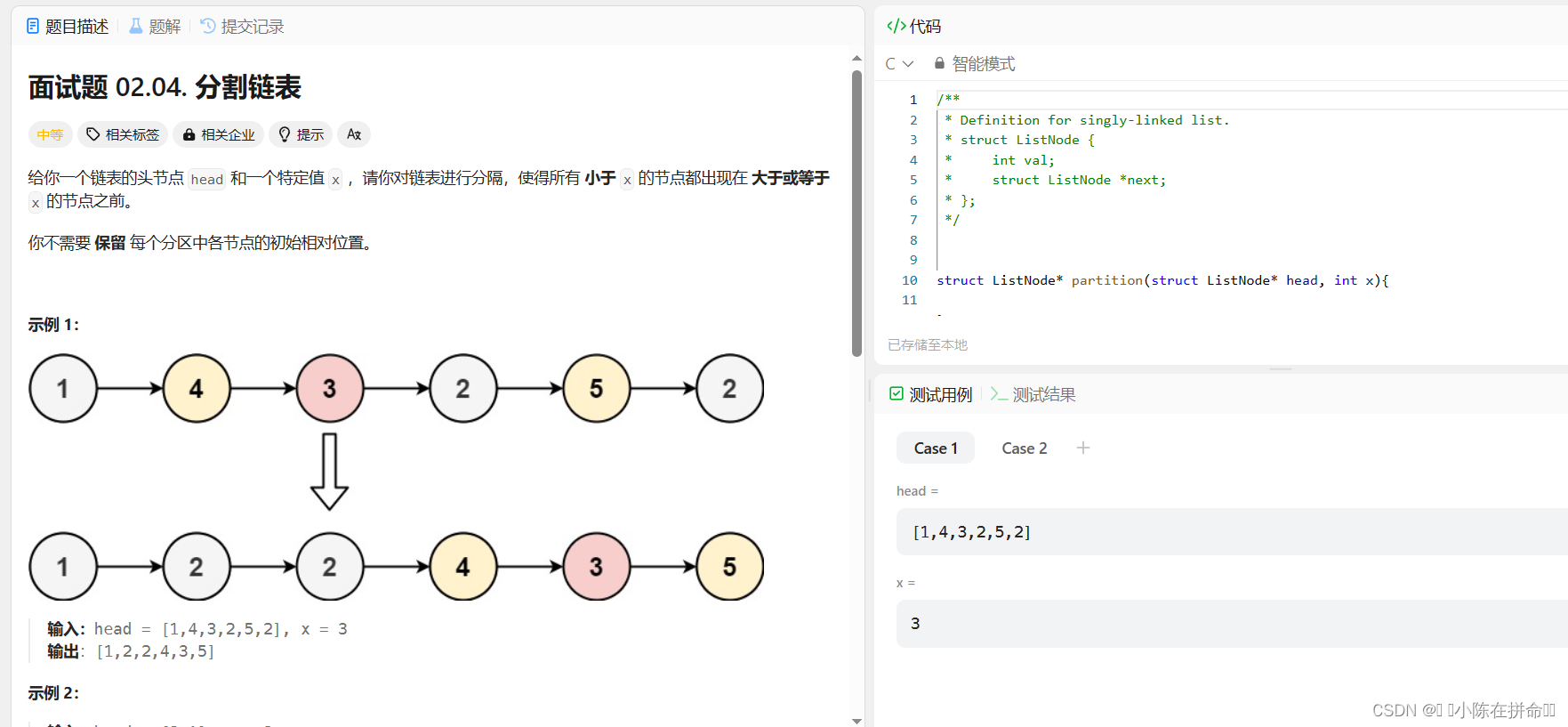
思路1:创建一个新链表,遍历原链表,小的头插,大的尾插。
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x)
{//链表为空if(head==NULL)return head;//链表不为空
ListNode*pcur,*newtail;
pcur=newtail=head;//pcur用来遍历 newtail用来尾插
while(pcur)
{ListNode * temp=pcur->next;if(pcur->val<x){
//头插pcur->next=head;head=pcur;//pcur成为新的头}
//尾插else{newtail->next=pcur;newtail=newtail->next;}pcur=temp;//继续遍历
}
newtail->next=NULL;
return head;
}思路2:创建两个新链表,遍历原链表,大的尾插大链表,小的尾插小链表,最后合并在一起。
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x)
{if(head==NULL)return head;ListNode*bighead,*bigtail,*smallhead,*smalltail;bighead=bigtail=(ListNode*)malloc(sizeof(ListNode));//大链表哨兵smallhead=smalltail=(ListNode*)malloc(sizeof(ListNode));//小链表哨兵ListNode*pcur=head;//pcur用来遍历while(pcur){if(pcur->val<x)//尾插小链表{smalltail->next=pcur;smalltail=smalltail->next;}else//尾插大链表{bigtail->next=pcur;bigtail=bigtail->next;}pcur=pcur->next;//继续往下走}//遍历完成,连接大小链表smalltail->next=bighead->next;bigtail->next=NULL;ListNode*ret=smallhead->next;//记住返回值free(bighead);free(smallhead);return ret;
}八、环形链表的约瑟夫问题(牛客)
经典算法OJ题:环形链表的约瑟夫问题
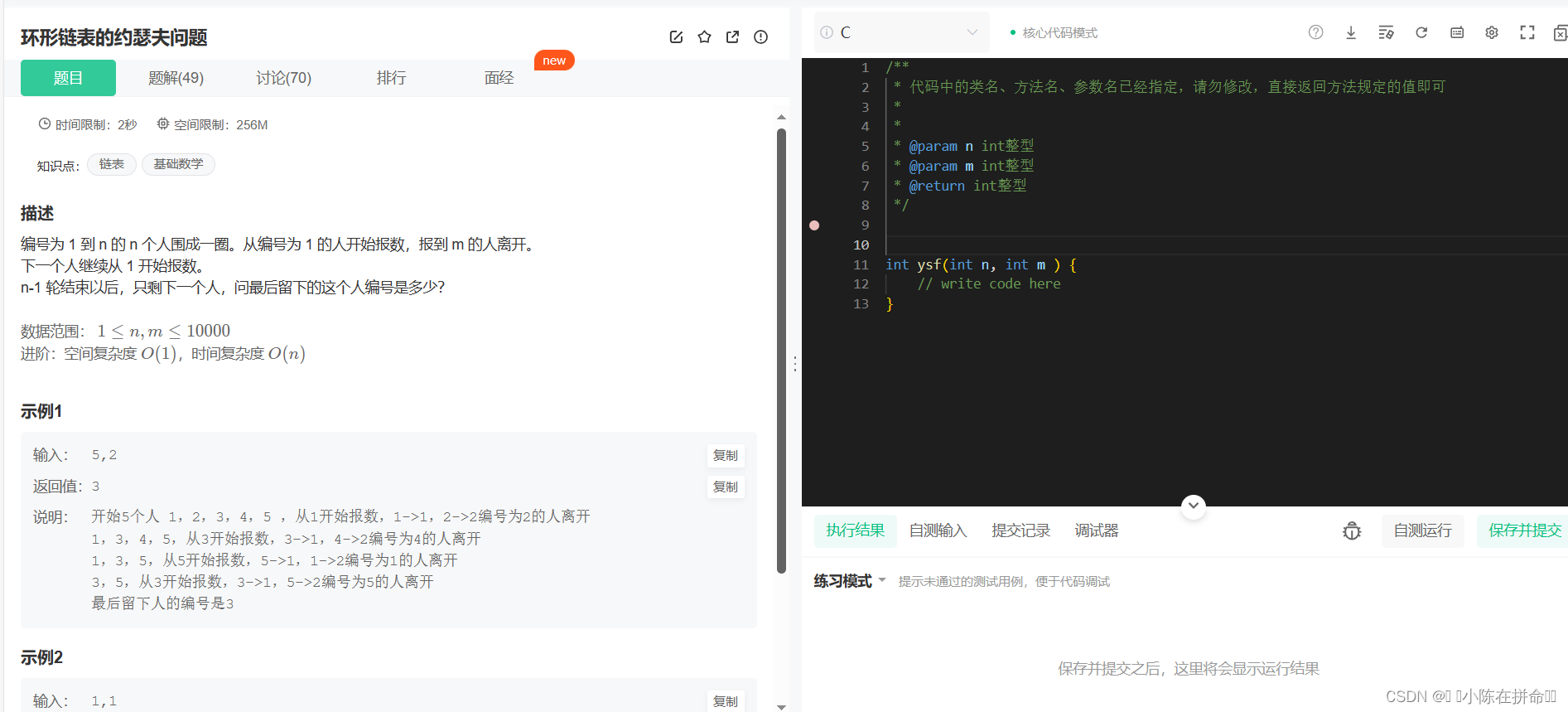
思路:创建一个不带头的单向链表,每逢m就删除
typedef struct ListNode ListNode;
ListNode * BuyNode(int x)//创建结点的函数
{
ListNode *newnode=(ListNode *)malloc(sizeof(ListNode));
newnode->next=newnode;
newnode->val=x;
return newnode;
}
int ysf(int n, int m ) {// write code here//创建一个不带头的单向循环链表ListNode *phead=BuyNode(1);//创建一个头节点ListNode *ptail=phead;//用来遍历for(int i=2;i<=n;i++){ptail->next=BuyNode(i);ptail=ptail->next;}//创建完后要首尾相连ptail->next=phead;ListNode *pcur=phead;//pcur用来遍历ListNode *prev=NULL;//用来记录前驱结点int count=1;//用来数数while(pcur->next!=pcur)//结束条件是场上只剩下一个人{if(count==m){//指定位置删除prev->next=pcur->next;free(pcur);pcur=prev->next;count=1;//重新数}else{prev=pcur;pcur=pcur->next;count++;}
}
//此时pcur是场上唯一还在的结点
return pcur->val;
}九、总结
1、顺序表背景的OJ题较为简单,因为顺序表底层是数组,有连续存放的特点,一方面指针运算偏移比较容易(可以多往指针的方向思考),另一方面就是我可以根据下标去拿到我想要的元素,无论是从前遍历还是从后遍历还是从中间都很方便!所以解题思路容易一些,而单链表只能通过指向,并且非双向的链表想从后面或者中间遍历会比较吃力!
2、顺序表背景的题,如果涉及到指定位置插入或者是指定位置删除,需要大量挪动数据,多层for循环比较麻烦,有时候可以往指针运算去思考!
3、链表背景的题,涉及到有关中间结点的,一般是快慢指针!!
4、关于链表的头插,如果是两个链表根据情况插入到一个新链表的头插,那么创建一个哨兵位结点会比较容易点,因为这样可以避免一开始就得换头结点。如果是在原链表的基础上头插,因为原链表是存在头节点的,这个时候不设哨兵位就会简单点,因为可以直接换头。
5、关于链表的尾插,一般需要设置一个tail指针往后遍历。
6、关于链表的指定位置插入或删除,需要记录前驱结点,这个时候需要除了需要考虑头节点为NULL的情况,还要考虑链表只有一个结点的情况,因为这个时候也没有前驱结点,这个时候如果运用哨兵就不需要考虑只有一个结点的情况,因为哨兵位可以充当头结点的前驱结点。
7、哨兵链表容易记住起始地址
相关文章:
DS:经典算法OJ题(1)
创作不易,友友们给个三连呗!! 本文为经典算法OJ题练习,大部分题型都有多种思路,每种思路的解法博主都试过了(去网站那里验证)是正确的,大家可以参考!! 一、移…...

最好理解文章——什么是闭包?
学习Javascript闭包(Closure) 闭包(closure)是Javascript语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现。 一、变量的作用域 要理解闭包,首先必须理解Javascript特殊的变量作用…...

Git 教程 | 将本地修改后的文件推送到 Github 指定远程分支上
Git 是一种分布式版本控制系统,用于敏捷高效地处理任何大小的项目。它是由 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的开源版本控制软件。Git 的本地克隆就是一个完整的版本控制存储库,无论脱机还是远程都能轻松工作。开发人员会在本地提交其工…...

漏洞原理linux操作系统的SqlMap工具的使用
漏洞原理linux操作系统的SqlMap工具的使用 Linux操作系统基础操作链接: 1024一篇通俗易懂的liunx命令操作总结(第十课)-CSDN博客 kali的IP地址:192.168.56.1 实操 # kali中使用sqlmap http://192.168.56.1/ sqlmap -u http://192.168.56.1/news/show.php?id46 sqlmap -u …...
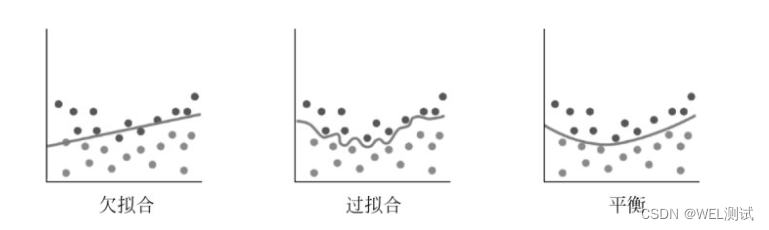
【机器学习】欠拟合与过拟合
过拟合:模型在训练数据上表现良好对不可见数据的泛化能力差。 欠拟合:模型在训练数据和不可见数据上泛化能力都很差。 欠拟合常见解决办法: (1)增加新特征,可以考虑加入特征组合、高次特征,以…...
【C++】C++入门基础讲解(二)
💗个人主页💗 ⭐个人专栏——C学习⭐ 💫点击关注🤩一起学习C语言💯💫 导读 接着上一篇的内容继续学习,今天我们需要重点学习引用。 1. 引用 在C中,引用是一种特殊的变量ÿ…...

Requestly工具快速提升前端开发与测试的效率
痛点 前端测试 在进行前端页面开发或者测试的时候,我们会遇到这一类场景: 在开发阶段,前端想通过调用真实的接口返回响应在开发或者生产阶段需要验证前端页面的一些 异常场景 或者 临界值 时在测试阶段,想直接通过修改接口响应来…...

Node+Express写分页接口
后端逻辑 router.js文件 const express require(express); const router express.Router();//导入函数处理,数据 const articleMessage require(../router_handle/artcle)//文章列表 router.get(/list,articleMessage.articleList)module.exports router; router_handle.js…...

ifconfig 主机ip url记录
ifconfig 容器Pods相关主机与url信息 一文搞懂网络知识,IP、子网掩码、网关、DNS、端口号_关于ip,网关。端口-CSDN博客 计算机网络知识之URL、IP、子网掩码、端口号_ip地址和url-CSDN博客 阅读看下以上文章 由此可知 1.主机ip 10.129.22.124 10.129.22 是网段…...
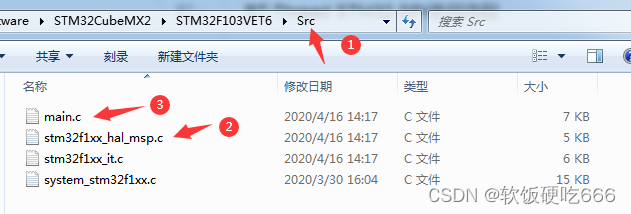
RT-Thread: STM32 SPI使用流程
1.添加驱动 ①点开设置界面 ②勾选看门 SPI 驱动 ③点击保存 ④查看添加的驱动文件 drv_spi.c 2.打开驱动头文件定义 ①打开配置文件 ②打开定义 3.打开需要开启的SPI总线 打开 drivers 目录下的 board.h 用SPI搜索,找到如下文字,打开对应的宏。 /*-…...
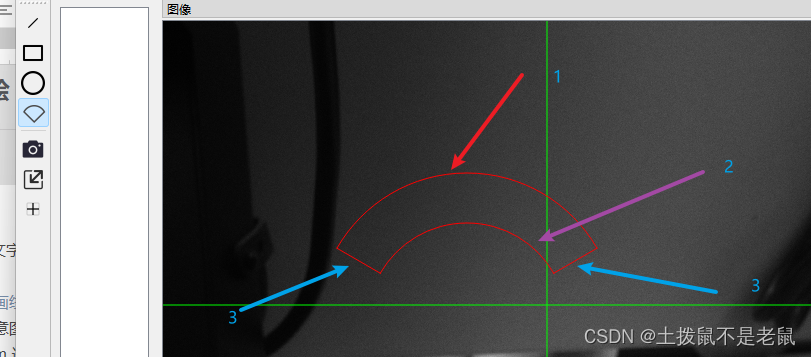
Qt 基于海康相机 的视频标绘
需求: 基于 视频 进行 标注,从而进行测量。 曾经搞在线教育时,尝试在视频上进行文字或者图形的绘制,但是发现利用Qt widget 传sdk 句柄的方式,只能使用窗口叠加的方式(Qt 基于海康相机的视频绘图_海康相…...
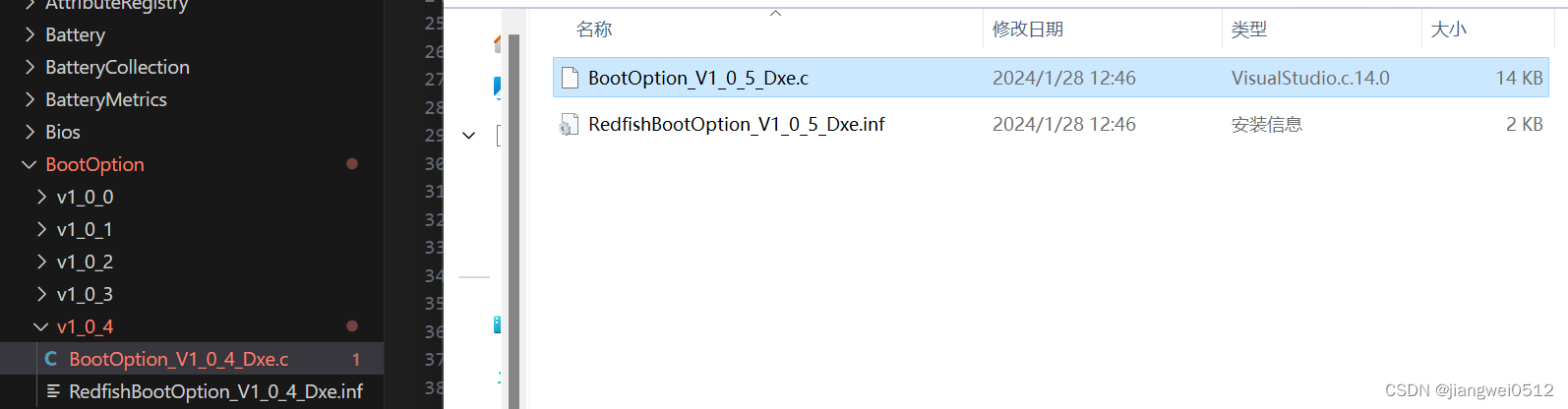
【UEFI实战】Redfish的BIOS实现——生成EDK数据
生成Redfish文件 Redfish数据的表示形式,最常用的是JSON。将JSON表示的数据转换成C语言可以操作的结构体,是必不可少的步骤。当然如果手动转换的话,需要浪费大量的时间,因此DMTF组织开发了一个工具,用于将JSON数据快速…...
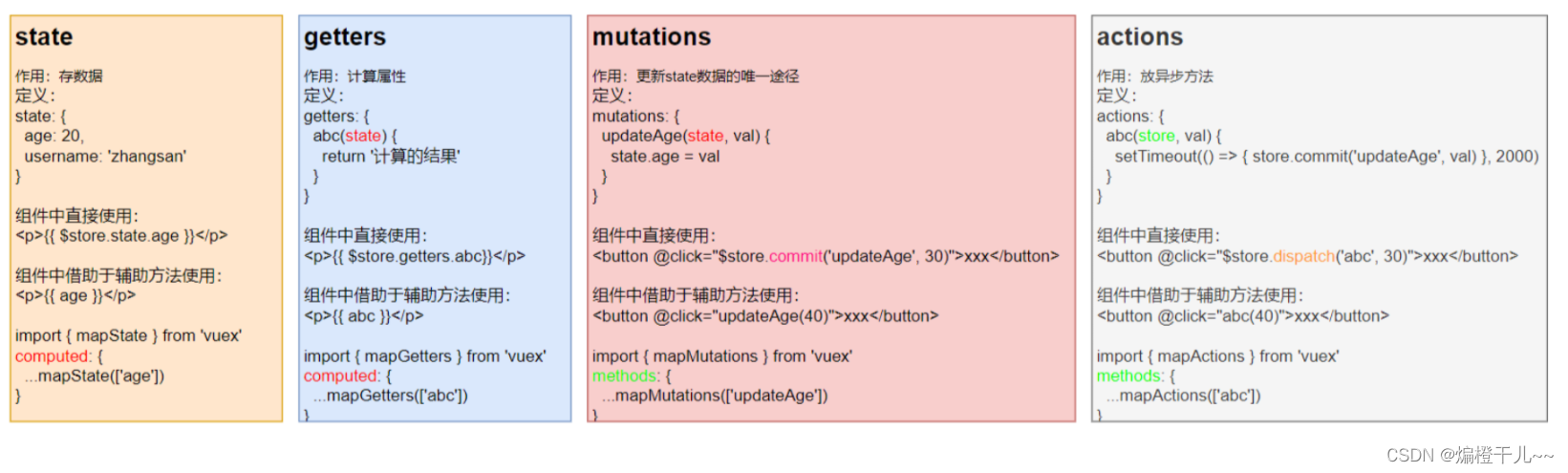
VUE--VUEX
一、什么是Vuex Vuex就是一个vue的状态(数据)管理工具,是vue项目实现大范围数据共享的技术方案。能够方便、高效的实现组件之间的数据共享。 Vuex的好处: (1)数据的存储一步到位,不需要层层传递…...
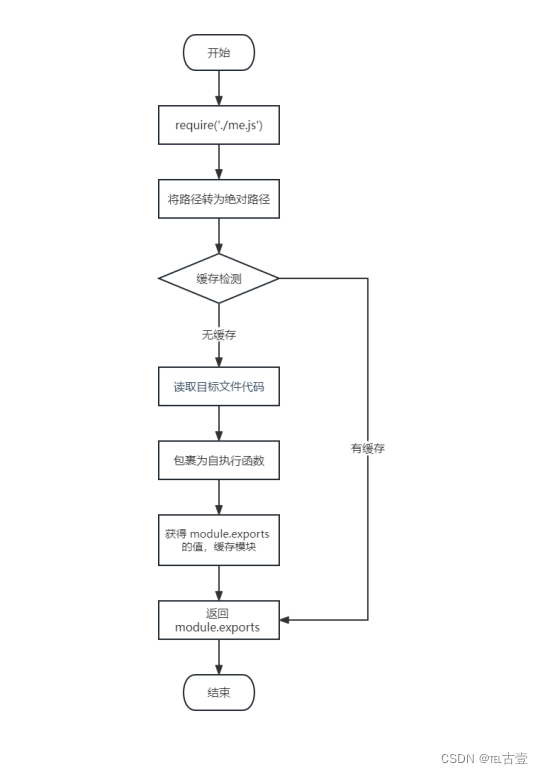
【NodeJS】004- NodeJS的模块化与包管理工具
模块化 1. 介绍 1.1.什么是模块化与模块 ? 将一个复杂的程序文件依据一定规则(规范)拆分成多个文件的过程称之为 模块化 其中拆分出的 每个文件就是一个模块 ,模块的内部数据是私有的,不过模块可以暴露内部数据以便其他模块使用 1.2 什么是模块化项目 ? 编码时是按照模…...
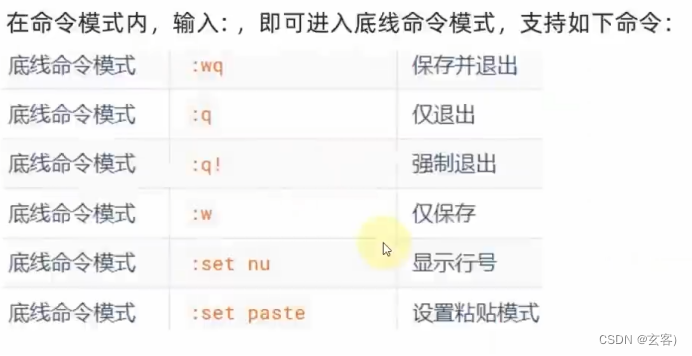
Linux浅学笔记02
目录 grep-wc-管道符 echo-tail-重定向符 vi编辑器 grep-wc-管道符 grep命令(过滤文件内容) //更准确的来说,是筛选包括“所需字符”的一句内容或多句内容。 语法:grep [-n] 关键字 文件路径 //-n:可选,表示在结果中匹配的行…...

速盾:服务器CDN加速配置的技术文章
CDN(内容分发网络)是一种通过分布在不同地理位置的服务器来加速网站内容传输的技术。在本文中,我们将介绍如何使用服务器CDN加速配置,以提高网站的性能和用户体验。 一、什么是CDN加速? CDN加速是通过将网站的静态内…...

【服务器Midjourney】创建部署Midjourney网站
目录 🌺【前言】 🌺【准备】 🌺【宝塔搭建MJ】 🌼1. 给服务器添加端口 🌼2. 使用Xshell连接服务器 🌼3. 安装docker 🌼4. 安装Midjourney程序 🌼5. 绑定域名+申请SSL证书 🌼6. 更新网站...

羊奶的营养成分和食疗价值
羊奶的营养成分和食疗价值 羊奶是一种营养非常丰富的乳制品,含有多种人体所需的营养成分,具有较高的食疗价值。下面将详细介绍羊奶的营养成分和其对人体健康的益处。 羊奶富含蛋白质,不仅含有人体所需的必需氨基酸,而且其蛋白质…...

23寒假预备役第二次测试
目录 B - Leftover Recipes C - We Got Everything Covered! D - A Balanced Problemset? E - Lame King F - Grid Ice Floor B - Leftover Recipes 问题描述 你的冰箱里有N种食材。我们将它们称为食材1、……和食材N。你有Qi克的食材i。 你可以制作两种菜肴。制…...

测试用例相关问题
1.什么是测试用例 测试用例是指对一项特定的软件产品进行测试任务的描述,体现测试方案、方法、技术和策略。其内容包括测试目标、测试环境、输入数据、测试步骤、预期结果、测试脚本等,最终形成文档。简单地认为,测试用例是为某个特殊目标而…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

全球无障碍宣传日:iOS 26 辅助功能大升级,这些实用小功能你用过吗?
辅助功能发展与升级很多人对辅助功能的印象还停留在 "小白点",但随着 iPhone 进入全面屏时代,它逐渐变得陌生。实际上,Apple 每年都会为其增添功能,方便身体有障人士使用 iPhone。而且,这些功能不仅惠及有障…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...