PyTorch2ONNX-分类模型:速度比较(固定维度、动态维度)、精度比较
1. 模型部署介绍
1.1 人工智能开发部署全流程
1.2 模型部署平台和芯片介绍
- 设备:PC、浏览器、APP、小程序、服务器、嵌入式开发板、无人车、无人机、Jetson Nano、树莓派、机械臂、物联网设备
- 厂商:
- 英特尔(Intel):主要生产 CPU(中央处理器)和一些 FPGA(现场可编程门阵列)芯片。代表作品包括 Intel Core 系列 CPU 和 Xeon 系列服务器 CPU,以及 FPGA 产品如 Intel Stratix 系列。
- 英伟达(NVIDIA):以 GPU(图形处理器)为主打产品,广泛应用于图形渲染、深度学习等领域。代表作品包括 NVIDIA GeForce 系列用于游戏图形处理,NVIDIA Tesla 和 NVIDIA A100 用于深度学习加速。
- AMD:主要生产 CPU 和 GPU。代表作品包括 AMD Ryzen 系列 CPU 和 AMD EPYC 系列服务器 CPU,以及 AMD Radeon 系列 GPU 用于游戏和专业图形处理。
- 苹果(Apple):生产自家设计的芯片,主要包括苹果 M 系列芯片。代表作品有 M1 芯片,广泛应用于苹果的 Mac 电脑、iPad 和一些其他设备。
- 高通(Qualcomm):主要生产移动平台芯片,包括移动处理器和调制解调器。代表作品包括 Snapdragon 系列芯片,用于智能手机和移动设备。
- 昇腾(Ascend):由华为生产,主要生产 NPU(神经网络处理器),用于深度学习任务。代表作品包括昇腾 910 和昇腾 310。
- 麒麟(Kirin):同样由华为生产,主要生产手机芯片,包括 CPU 和 GPU。代表作品包括麒麟 9000 系列,用于华为旗舰手机。
- 瑞芯微(Rockchip):主要生产 VPU(视觉处理器)和一些移动平台芯片。代表作品包括 RK3288 和 RK3399,广泛应用于智能显示、机器人等领域。
| 芯片名 | 英文名 | 中文名 | 厂商 | 主要任务 | 是否训练 | 是否推理 | 算力 | 速度 |
|---|---|---|---|---|---|---|---|---|
| CPU | Central Processing Unit(CPU) | 中央处理器 | 各大厂商 | 通用计算 | 是 | 是 | 高 | 中等 |
| GPU | Graphics Processing Unit(GPU) | 图形处理器 | NVIDIA、AMD等 | 图形渲染、深度学习加速 | 是 | 是 | 高 | 高 |
| TPU | Tensor Processing Unit(TPU) | 张量处理器 | 谷歌 | 机器学习中的张量运算 | 是 | 是 | 高 | 高 |
| NPU | Neural Processing Unit(NPU) | 神经网络处理器 | 华为、联发科等 | 深度学习模型的性能提升 | 是 | 是 | 高 | 中等 |
| VPU | Vision Processing Unit(VPU) | 视觉处理器 | 英特尔、博通等 | 图像和视频处理 | 否 | 是 | 中等 | 中等 |
| DSP | Digital Signal Processor(DSP) | 数字信号处理器 | 德州仪器、高通等 | 数字信号处理、音频信号处理 | 否 | 是 | 中等 | 中等 |
| FPGA | Field-Programmable Gate Array(FPGA) | 现场可编程门阵列 | 英特尔、赛灵思等 | 可编程硬件加速器 | 是 | 是 | 高 | 中等 |
1.3 模型部署的通用流程
2. 使用 ONNX 的意义
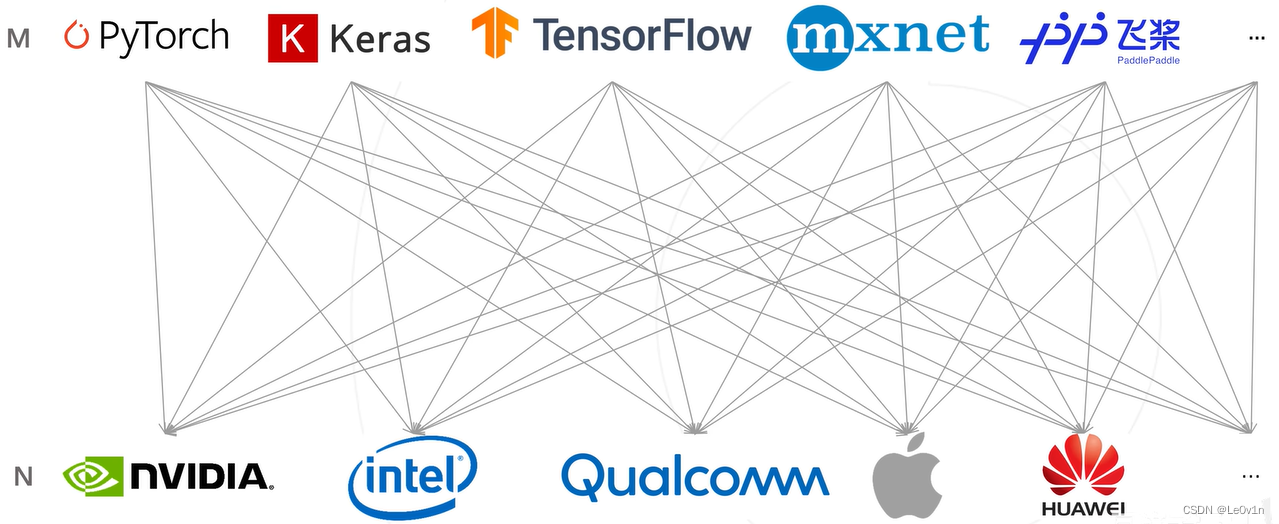
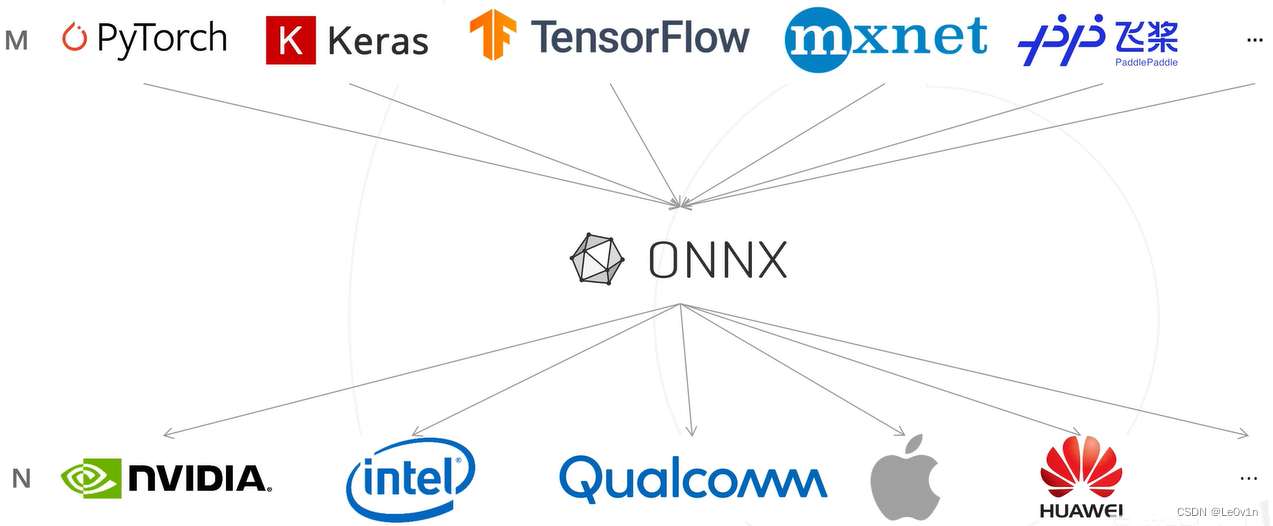
从这两张图可以很明显的看到,当有了中间表示 ONNX 后,从原来的 M × N M \times N M×N 变为了 M + N M + N M+N,让模型部署的流程变得简单。
3. ONNX 的介绍
开源机器学习通用中间格式,由微软、Facebook(Meta)、亚马逊、IBM 共同发起的。它可以兼容各种深度学习框架,也可以兼容各种推理引擎和终端硬件、操作系统。
4. ONNX 环境安装
pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple
5. PyTorch → ONNX
5.1 将一个分类模型转换为 ONNX
import torch
from torchvision import modelsdevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(f"正在使用的设备: {device}")# 创建一个训练好的模型
model = models.resnet18(pretrained=True) # ImageNet 预训练权重
model = model.eval().to(device)# 构建一个输入
dummy_input = torch.randn(size=[1, 3, 256, 256]).to(device) # [N, B, H, W]# 让模型推理
output = model(dummy_input)
print(f"output.shape: {output.shape}")# 使用 PyTorch 自带的函数将模型转换为 ONNX 格式
onnx_save_path = 'ONNX/saves/resnet18_imagenet.onnx' # 导出的ONNX模型路径
with torch.no_grad():torch.onnx.export(model=model, # 要转换的模型args=dummy_input, # 模型的输入f=onnx_save_path, # 导出的ONNX模型路径 input_names=['input'], # ONNX模型输入的名字(自定义)output_names=['output'], # ONNX模型输出的名字(自定义)opset_version=11, # Opset算子集合的版本(默认为17))print(f"ONNX 模型导出成功,路径为:{onnx_save_path}")
正在使用的设备: cpu
/home/leovin/anaconda3/envs/wsl/lib/python3.8/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.warnings.warn(
/home/leovin/anaconda3/envs/wsl/lib/python3.8/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet18_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet18_Weights.DEFAULT` to get the most up-to-date weights.warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /home/leovin/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 44.7M/44.7M [00:03<00:00, 13.9MB/s]
output.shape: torch.Size([1, 1000])
ONNX 模型导出成功,路径为:ONNX/saves/resnet18_imagenet.onnx
💡 Tips:
- opset 算子集不同版本区别: Operators.md
- 虽然说 PyTorch 在提醒
pretrained=True将会被弃用,可以使用weights=weights=ResNet18_Weights.DEFAULT或weights=ResNet18_Weights.IMAGENET1K_V1来代替。但很明显前者比较方便,后者还需要查看对应的版本号,比较麻烦 😂
接下来我们使用 Netron 查看一下这个模型:
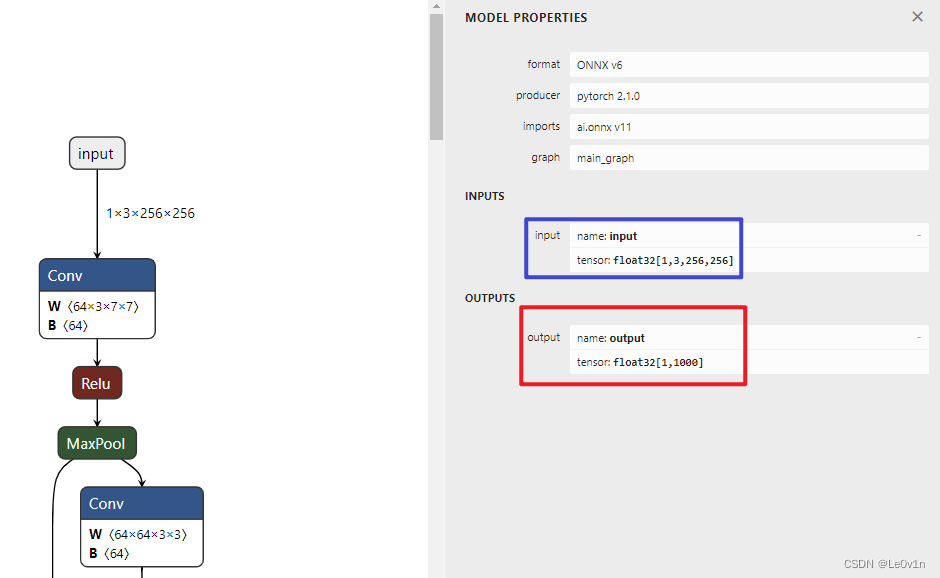
原图链接为:resnet18_imagenet.png
ImageNet 数据集有 1000 个类别
5.2 检查一个模型导出是否正确
import onnx# 读取导出的模型
onnx_path = 'ONNX/saves/resnet18_imagenet.onnx' # 导出的ONNX模型路径
onnx_model = onnx.load(onnx_path)# 检查模型是否正常
onnx.checker.check_model(onnx_model)print(f"模型导出正常!")
模型导出正常!
我们在《onnx基础》中已经讲过
check_model()这个函数,它可以检查 ONNX 模型,如果该函数发现模型错误,则会抛出异常,
5.3 修改动态维度
前面我们导出的 ONNX 模型中,输入的维度是固定的:[1, 3, 256, 256],那么此时这个 ONNX 的输入就被限制了:
- 如果我们想要多 Batch 的输入 → 不行
- 如果我们输入的图片是灰度图 → 不行
- 如果我们输入的图片尺寸不是 256×256 → 不行
而 torch.onnx.export() 这个函数也帮我解决了这个问题,它有一个名为 dynamic_axis 的参数,我们看一下官网对该参数的描述:
dynamic_axes (dict[string, dict[int, string]] or dict[string, list(int)], default empty dict) –
By default the exported model will have the shapes of all input and output tensors set to exactly match those given in
args. To specify axes of tensors as dynamic (i.e. known only at run-time), setdynamic_axesto a dict with schema:
- KEY (str): an input or output name. Each name must also be provided in input_names or output_names.
- VALUE (dict or list): If a dict, keys are axis indices and values are axis names. If a list, each element is an axis index.
dynamic_axes(dict[string, dict[int, string]]或dict[string, list(int)],默认为空字典)–
默认情况下,导出的模型将使所有输入和输出张量的形状完全匹配
args中给定的形状。要将张量的轴指定为动态(即仅在运行时知道),请将dynamic_axes设置为一个具有以下结构的字典:
- KEY(str):输入或输出的名称。每个名称还必须在
input_names或output_names中提供。- VALUE(dict或list):如果是字典,则键是轴索引,值是轴名称。如果是列表,则每个元素是轴索引。
下面我们用一下这个参数:
import torch
from torchvision import models
import onnxdevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(f"正在使用的设备: {device}")# 创建一个训练好的模型
model = models.resnet18(pretrained=True) # ImageNet 预训练权重
model = model.eval().to(device)# 构建一个输入
dummy_input = torch.randn(size=[1, 3, 256, 256]).to(device) # [N, B, H, W]# 让模型推理
output = model(dummy_input)
print(f"output.shape: {output.shape}\n")# ------ 使用 PyTorch 自带的函数将模型转换为 ONNX 格式
onnx_save_path = 'ONNX/saves/resnet18_imagenet-with_dynamic_axis.onnx' # 导出的ONNX模型路径
with torch.no_grad():torch.onnx.export(model=model, # 要转换的模型args=dummy_input, # 模型的输入f=onnx_save_path, # 导出的ONNX模型路径 input_names=['input'], # ONNX模型输入的名字(自定义)output_names=['output'], # ONNX模型输出的名字(自定义)opset_version=11, # Opset算子集合的版本(默认为17)dynamic_axes={ # 修改某一个维度为动态'input': {0: 'B', 2: 'H', 3: 'W'} # 将原本的 [1, 3, 256, 256] 修改为 [B, 3, H, W]})print(f"ONNX 模型导出成功,路径为:{onnx_save_path}\n")# ------ 验证导出的模型是否正确
# 读取导出的模型
onnx_model = onnx.load(onnx_save_path)# 检查模型是否正常
onnx.checker.check_model(onnx_model)print(f"模型导出正常!")
正在使用的设备: cpu
output.shape: torch.Size([1, 1000])ONNX 模型导出成功,路径为:ONNX/saves/resnet18_imagenet-with_dynamic_axis.onnx模型导出正常!
此时我们再用 Netron 看一下这个模型:
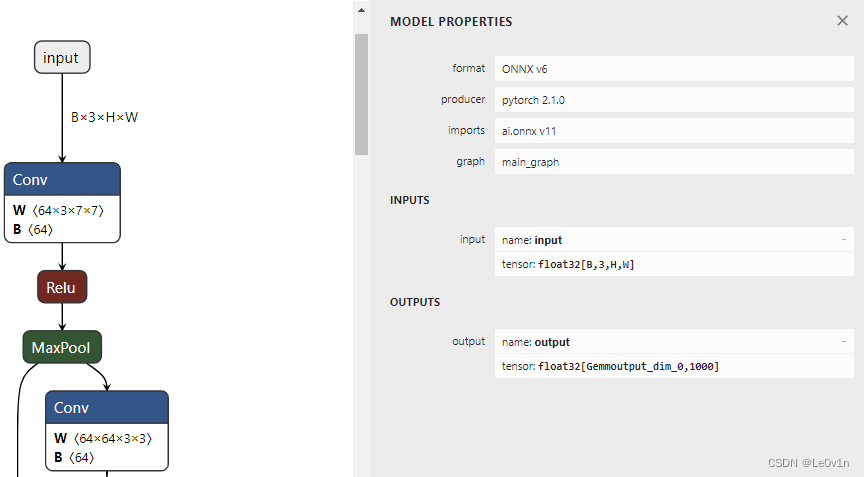
可以看到,输入的 Batch、Height、Width 均变为了动态维度,即只有当模型运行的时候才知道输入的这三个维度具体的值。
6. ONNX Runtime 部署:推理单张图片
import os
import random
import numpy as np
from PIL import Image
import onnxruntime
from torchvision import transforms
import torch
import torch.nn.functional as F
import pandas as pd# ==================================== 加载 ONNX 模型,创建推理会话 ====================================
ort_session = onnxruntime.InferenceSession(path_or_bytes='ONNX/saves/resnet18_imagenet-fix_axis.onnx') # ort -> onnxruntime# ==================================== 模型冷启动 ====================================
dummy_input = np.random.randn(1, 3, 256, 256).astype(np.float32)
ort_inputs = {'input': dummy_input}
ort_output = ort_session.run(output_names=['output'], input_feed=ort_inputs)[0] # 输出被[]包围了,所以需要取出来
print(f"模型冷启动完毕! 其推理结果的shape为: {ort_output.shape}")# ==================================== 加载真正的图像 ====================================
images_folder = 'Datasets/Web/images'
images_list = [os.path.join(images_folder, img) for img in os.listdir(images_folder) if img.lower().endswith(('.jpg', '.png', '.webp'))]img_path = images_list[random.randint(0, len(images_list)-1)]
img = Image.open(fp=img_path)# ==================================== 图像预处理 ====================================
# 定义预处理函数
img_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(256),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # imagenet专用std=[0.229, 0.224, 0.225]), # imagenet专用
])# 对图片进行预处理
input_img = img_transform(img)
print(f"input_img.type: {type(input_img)}")
print(f"input_img.shape: {input_img.shape}")# 为图片添加batch维度
input_img = torch.unsqueeze(input_img, dim=0)# ==================================== ONNX模型推理 ====================================
# 因为ONNXRuntime需要的是numpy而非torch的tensor, 所以将其转换为numpy
input_img = input_img.numpy()
print(f"input_img.type: {type(input_img)}")
print(f"input_img.shape: {input_img.shape}")# 模型推理图片
ort_inputs = {'input': input_img, }
ort_results = ort_session.run(output_names=['output'], input_feed=ort_inputs)[0] # 得到 1000 个类别的分数
print(f"模型推理完毕! 此时结果的shape为:{ort_results.shape}")# ==================================== 后处理 ====================================
# 使用 softmax 函数将分数转换为概率
ort_results_softmax = F.softmax(input=torch.from_numpy(ort_results), dim=1)
print(f"经过softmax后的输出的shape为:{ort_results_softmax.shape}")# 取概率最大的前 n 个结果
n = 3
top_n = torch.topk(input=ort_results_softmax, k=n)probs = top_n.values.numpy()[0]
indices = top_n.indices.numpy()[0]print(f"置信度最高的前{n}个结果为:\t{probs}\n"f"对应的类别索引为:\t\t{indices}")# ==================================== 显示类别 ====================================
df = pd.read_csv('Datasets/imagenet_classes_indices.csv')idx2labels = {}
for idx, row in df.iterrows():# idx2labels[row['ID']] = row['class'] # 英文标签idx2labels[row['ID']] = row['Chinese'] # 中文标签print(f"=============== 推理结果 ===============\n"f"图片路径: {img_path}")
for i, (class_prob, idx) in enumerate(zip(probs, indices)):class_name = idx2labels[idx]text = f"\tNo.{i}: {class_name:<30} --> {class_prob:>.4f}"print(text)
模型冷启动完毕! 其推理结果的shape为: (1, 1000)
input_img.type: <class 'torch.Tensor'>
input_img.shape: torch.Size([3, 256, 256])
input_img.type: <class 'numpy.ndarray'>
input_img.shape: (1, 3, 256, 256)
模型推理完毕! 此时结果的shape为:(1, 1000)
经过softmax后的输出的shape为:torch.Size([1, 1000])
置信度最高的前3个结果为: [9.9472505e-01 7.4335985e-04 5.2123831e-04]
对应的类别索引为: [673 662 487]
=============== 推理结果 ===============
图片路径: Datasets/Web/images/mouse.jpgNo.0: 鼠标,电脑鼠标 --> 0.9947No.1: 调制解调器 --> 0.0007No.2: 移动电话,手机 --> 0.0005
💡 图片链接:Web/images
💡 ImageNet 类别文件链接:imagenet_classes_indices.csv
7. ONNX Runtime 和 PyTorch 速度对比
- 不同尺度下单张图片推理 --> 对比代码链接
- 不同尺度下多张图片推理 --> 对比代码链接
实验环境:
- CPU:Intel i5-10400F @ 2.90 GHz
- Memory: 8 x 2 = 16GB
- Disk: SSD
- GPU: RTX 3070 O8G
- OS: Windows 10 (WSL)
- Device: CPU
- 模型推理次数: 50
7.1 ResNet-18
实验结果
| Input Shape | ONNX(fix) | ONNX(fix+sim) | ONNX(dyn) | ONNX(dyn+sim) | PyTorch(CPU) | PyTorch(GPU) |
|---|---|---|---|---|---|---|
| [1, 3, 32, 32] | 0.0577s | 0.0597s | 0.0592s | 0.0585s | 0.0688s | 0.0787s |
| [1, 3, 64, 64] | 0.0605s | 0.0593s | 0.0588s | 0.0621s | 0.0700s | 0.0723s |
| [1, 3, 128, 128] | 0.0705s | 0.0686s | 0.0699s | 0.0694s | 0.0762s | 0.0760s |
| [1, 3, 256, 256] | 0.0784s | 0.0811s | 0.0797s | 0.0789s | 0.0949s | 0.0813s |
| [1, 3, 512, 512] | 0.1249s | 0.1241s | 0.1251s | 0.1256s | 0.1686s | 0.0996s |
| [1, 3, 640, 640] | 0.1569s | 0.1525s | 0.1572s | 0.1579s | 0.2242s | 0.0863s |
| [1, 3, 768, 768] | 0.1986s | 0.1946s | 0.1985s | 0.2038s | 0.2933s | 0.0956s |
| [1, 3, 1024, 1024] | 0.2954s | 0.2957s | 0.3094s | 0.3045s | 0.4871s | 0.1047s |
| [16, 3, 32, 32] | 0.2540s | 0.2545s | 0.2558s | 0.2498s | 0.2570s | 0.2473s |
| [16, 3, 64, 64] | 0.2811s | 0.2745s | 0.2696s | 0.2655s | 0.2824s | 0.2553s |
| [16, 3, 128, 128] | 0.3595s | 0.3181s | 0.3143s | 0.3544s | 0.3817s | 0.3518s |
| [16, 3, 256, 256] | 0.7315s | 0.7112s | 0.6767s | 0.6122s | 0.7169s | 0.3469s |
| [16, 3, 512, 512] | 1.3042s | 1.2586s | 1.1813s | 1.1949s | 1.6609s | 0.4270s |
| [16, 3, 640, 640] | 1.6340s | 1.6429s | 1.6659s | 1.6693s | 2.3923s | 0.5292s |
| [16, 3, 768, 768] | 2.2843s | 2.2830s | 2.3325s | 2.3303s | 3.9278s | 1.7851s |
| [16, 3, 1024, 1024] | 3.9132s | 3.9742s | 3.9668s | 3.9104s | 6.7532s | 3.6507s |
画图结果
⚠️ 在
[18, 3, 768, 768]、 时,PyTorch(CPU) 因为内存不足导致只能推理 1 次而非 50 次⚠️ 在
[18, 3, 1024, 1024]、 时,PyTorch(CPU) 和 PyTorch(GPU) 因为内存不足导致只能推理 1 次而非 50 次
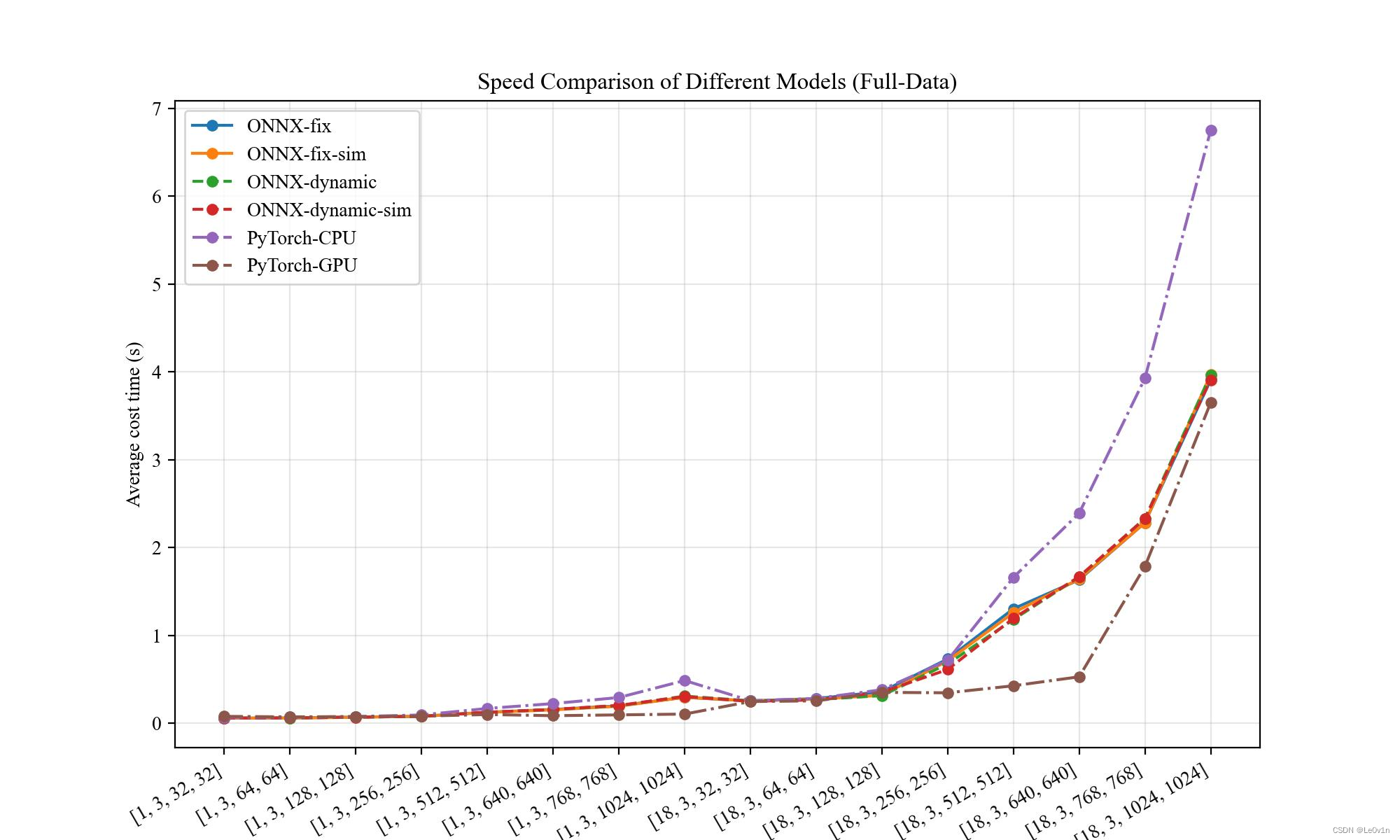
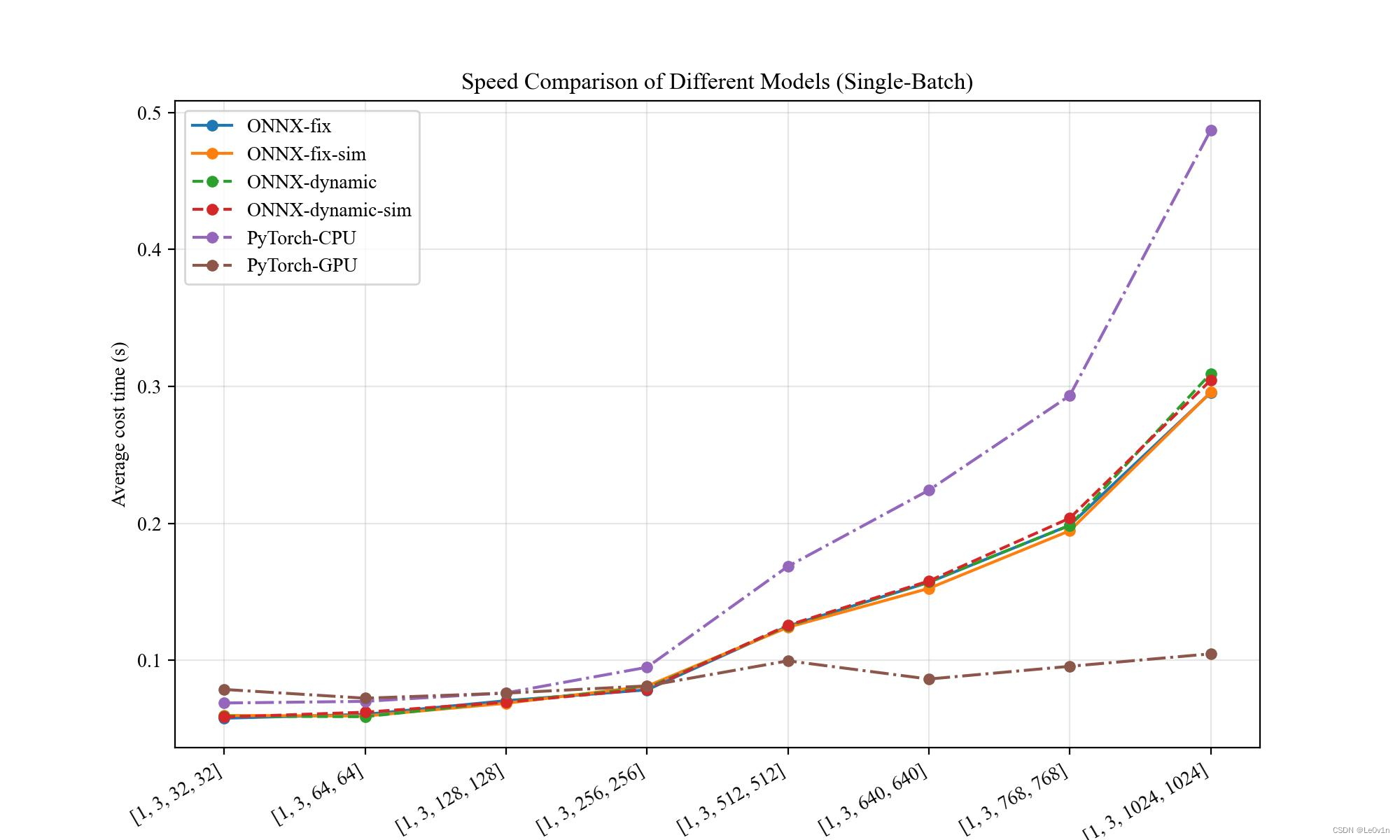
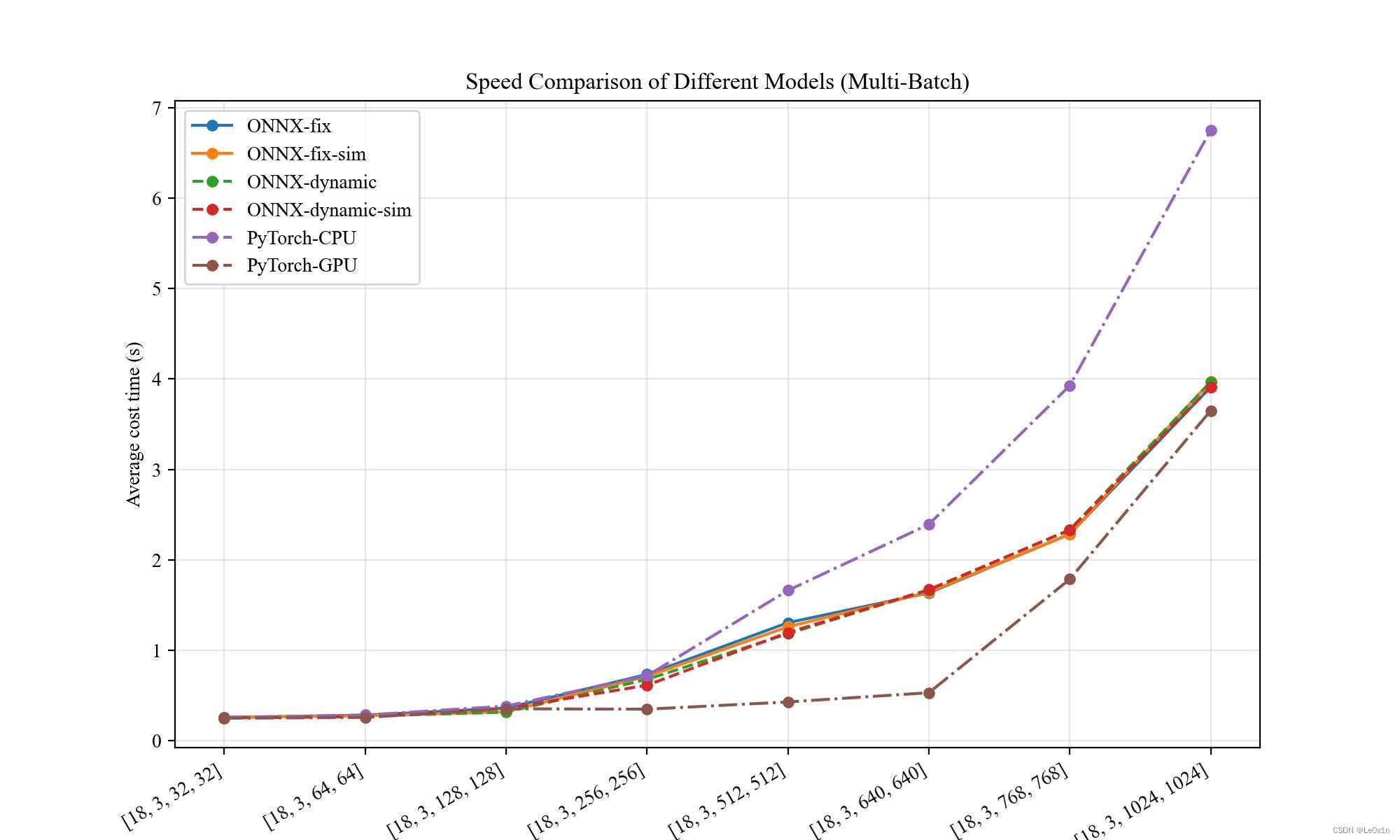
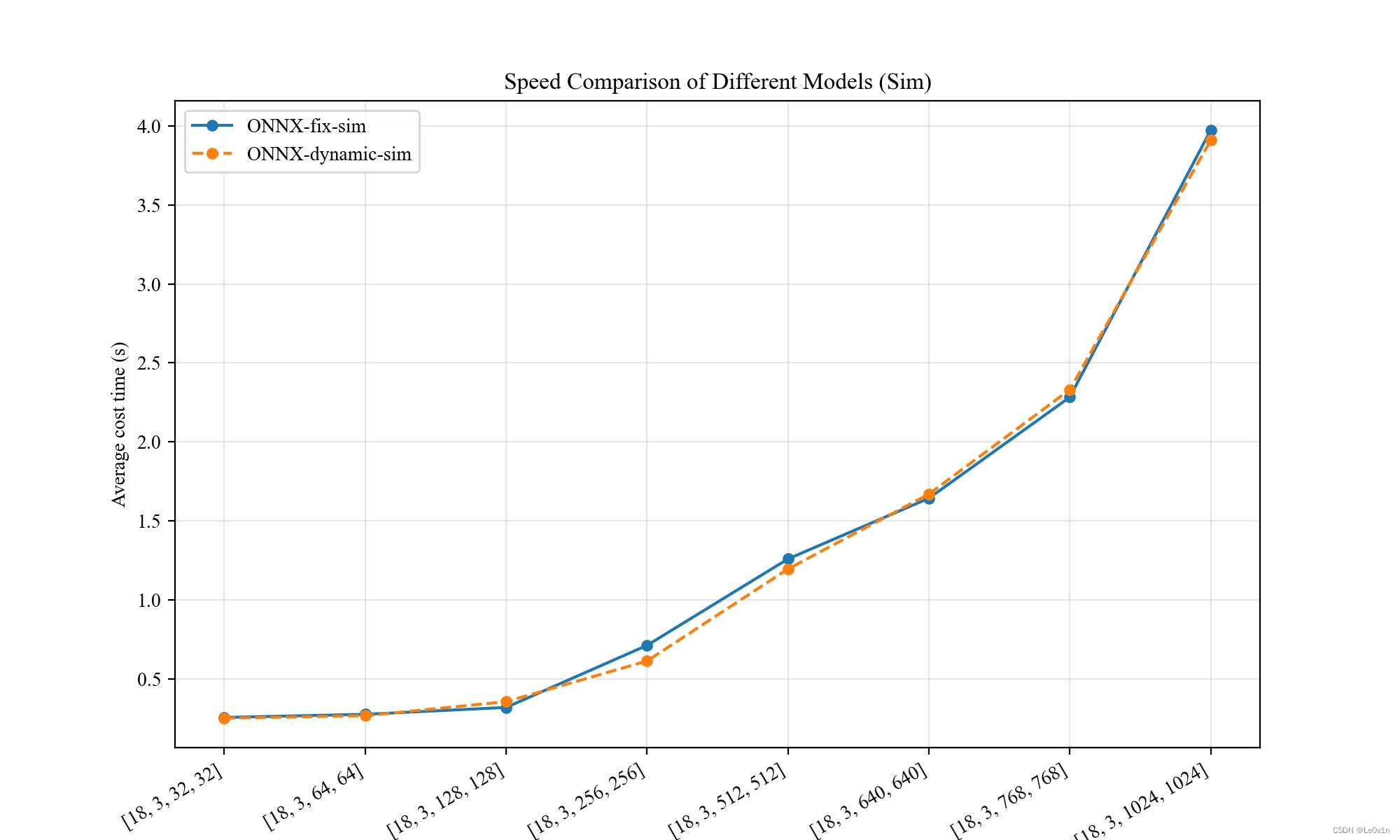
结论:
- 〔单 Batch〕
- 静态维度和动态维度相差不大
- 当图片尺寸在 [32, 32] ~ [256, 256] 之间时,ONNX 速度比 PyTorch-GPU 速度要快;当图片尺寸大于 [256, 256] 时,PyTorch-GPU 拥有绝对的优势
- 当图片尺寸小于 [64, 64] 时,PyTorch-CPU 速度快于 PyTorch-GPU;当图片尺寸大于 [64, 64] 时,PyTorch-GPU 速度快于 PyTorch-CPU
- 无论在什么时候,ONNX 速度均快于 PyTorch-CPU
- 〔多 Batch〕
- 静态维度和动态维度相差不大
- 当图片尺寸小于 [128, 128] 时,ONNX、PyTorch-CPU、PyTorch-GPU 三者很难有区别(实际上 PyTorch-GPU 速度要慢一些,因为要将模型和输入放到 GPU 中,这部分会划分几秒钟的时间)
- 当图片尺寸大于 [128, 128] 时,GPU 逐渐扩大优势(由于 OOM 的原因,[18, 3, 1024, 1024] 下 PyTorch-GPU 只推理了一次,因此速度被拉平了很多。在显存足够充裕的情况下,PyTorch-GPU 的速度是碾压其他方法的)
- 当图片尺寸大于 [256, 256] 时,PyTorch-CPU 的速度远远慢于 ONNX
- 〔Sim 前后〕
- 可以发现,在使用
python -m onnxsim前后差距不大
- 可以发现,在使用
- 〔总结〕
- 在使用 CPU 进行推理时,建议使用 ONNX 进行,因为不光速度有优势,而且对内存的占用也比 PyTorch-CPU 要小的多
- 在进行多 Batch 推理时,如果有 GPU 还是使用 PyTorch-GPU,这样会缩减大量的时间(⚠️ GPU 在加载模型和输入时可能会比较耗时)
- ⚠️ 在使用
python -m onnxsim前后差距不大
7.2 MobileNetV3-Small
接下来我们在 MobileNetV3-Small 上也进行相同的实验。
⚠️ 因为
opset=11不支持hardsigmoid算子,在官网上查询后,我们使用opset=17⚠️ 在使用
opset=17时可能会报错,报错原因一般是当前 PyTorch 版本低导致的,可以创建一个新的环境,使用最新的 PyTorch(也可以不实验,直接看我得结论就行 😂)
| Input Shape | ONNX(fix) | ONNX(dyn) | PyTorch(CPU) | PyTorch(GPU) |
|---|---|---|---|---|
| [1, 3, 32, 32] | 0.0575s | 0.0619s | 0.0636s | 0.0731s |
| [1, 3, 64, 64] | 0.0585s | 0.0591s | 0.0643s | 0.0701s |
| [1, 3, 128, 128] | 0.0611s | 0.0597s | 0.0629s | 0.0700s |
| [1, 3, 256, 256] | 0.0627s | 0.0622s | 0.0690s | 0.0731s |
| [1, 3, 512, 512] | 0.0714s | 0.0703s | 0.0841s | 0.0765s |
| [1, 3, 640, 640] | 0.0776s | 0.0785s | 0.0975s | 0.0823s |
| [1, 3, 768, 768] | 0.0867s | 0.0861s | 0.1138s | 0.0851s |
| [1, 3, 1024, 1024] | 0.1103s | 0.1126s | 0.1630s | 0.0958s |
| [16, 3, 32, 32] | 0.2410s | 0.2295s | 0.2538s | 0.2446s |
| [16, 3, 64, 64] | 0.2443s | 0.2421s | 0.2576s | 0.2481s |
| [16, 3, 128, 128] | 0.2618s | 0.2576s | 0.2804s | 0.2727s |
| [16, 3, 256, 256] | 0.3097s | 0.3131s | 0.3502s | 0.3043s |
| [16, 3, 512, 512] | 0.5556s | 0.5873s | 0.7655s | 0.3970s |
| [16, 3, 640, 640] | 0.7191s | 0.7130s | 0.8988s | 0.4877s |
| [16, 3, 768, 768] | 0.9293s | 0.9285s | 1.5091s | 0.5754s |
| [16, 3, 1024, 1024] | 1.4768s | 1.4945s | 3.3530s | 1.1316s |
画图结果
⚠️ 在
[18, 3, 1024, 1024]、 时,PyTorch(CPU) 因为内存不足导致只能推理 1 次而非 50 次
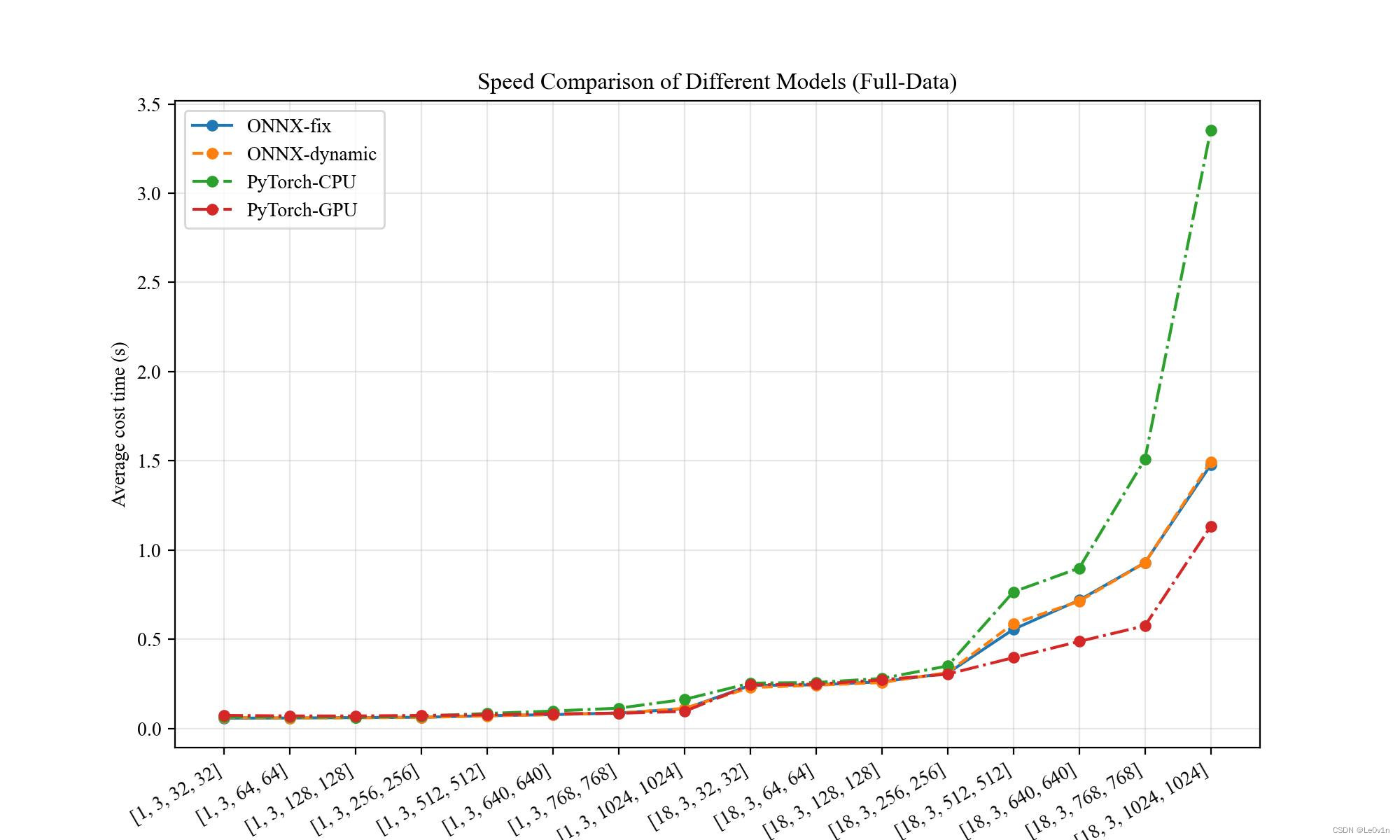
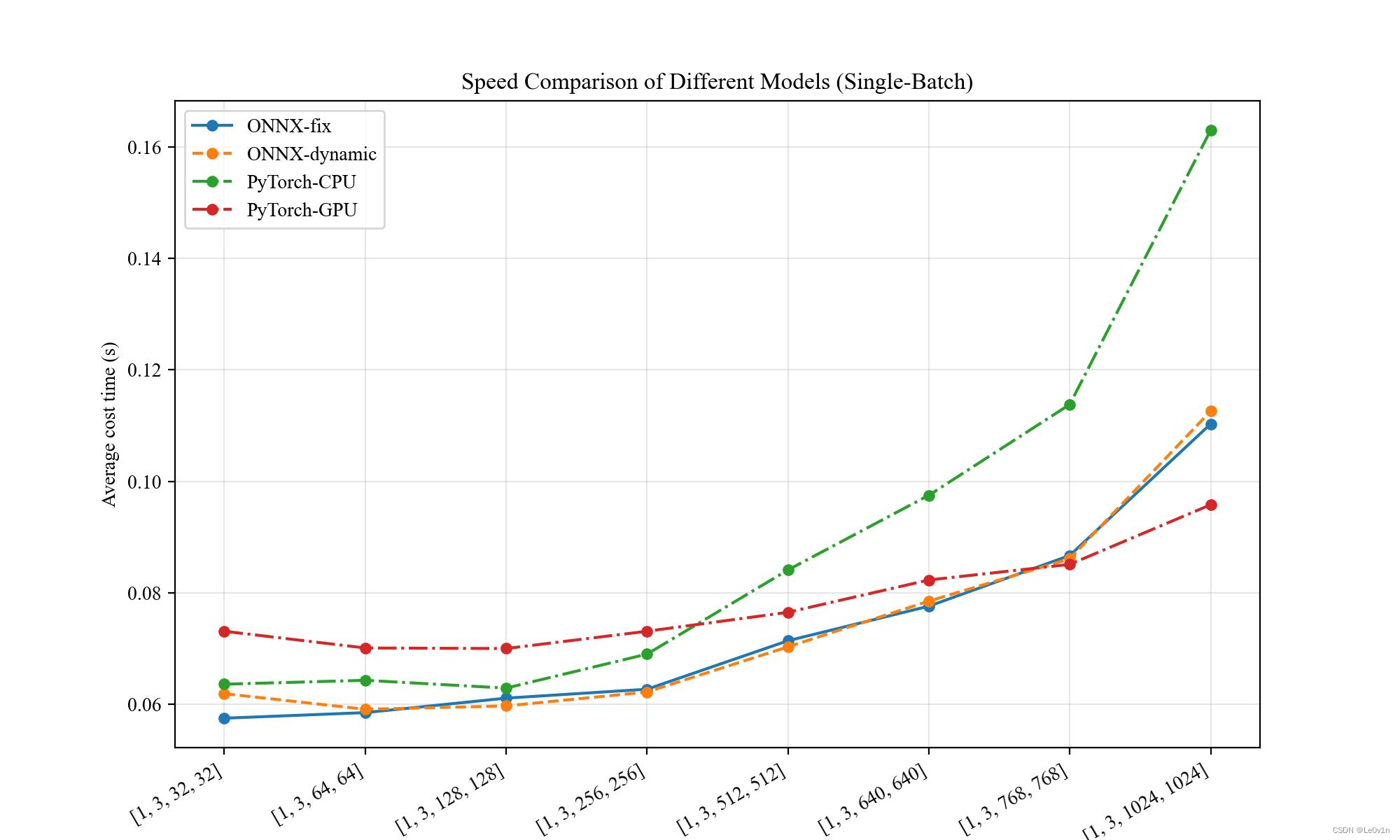
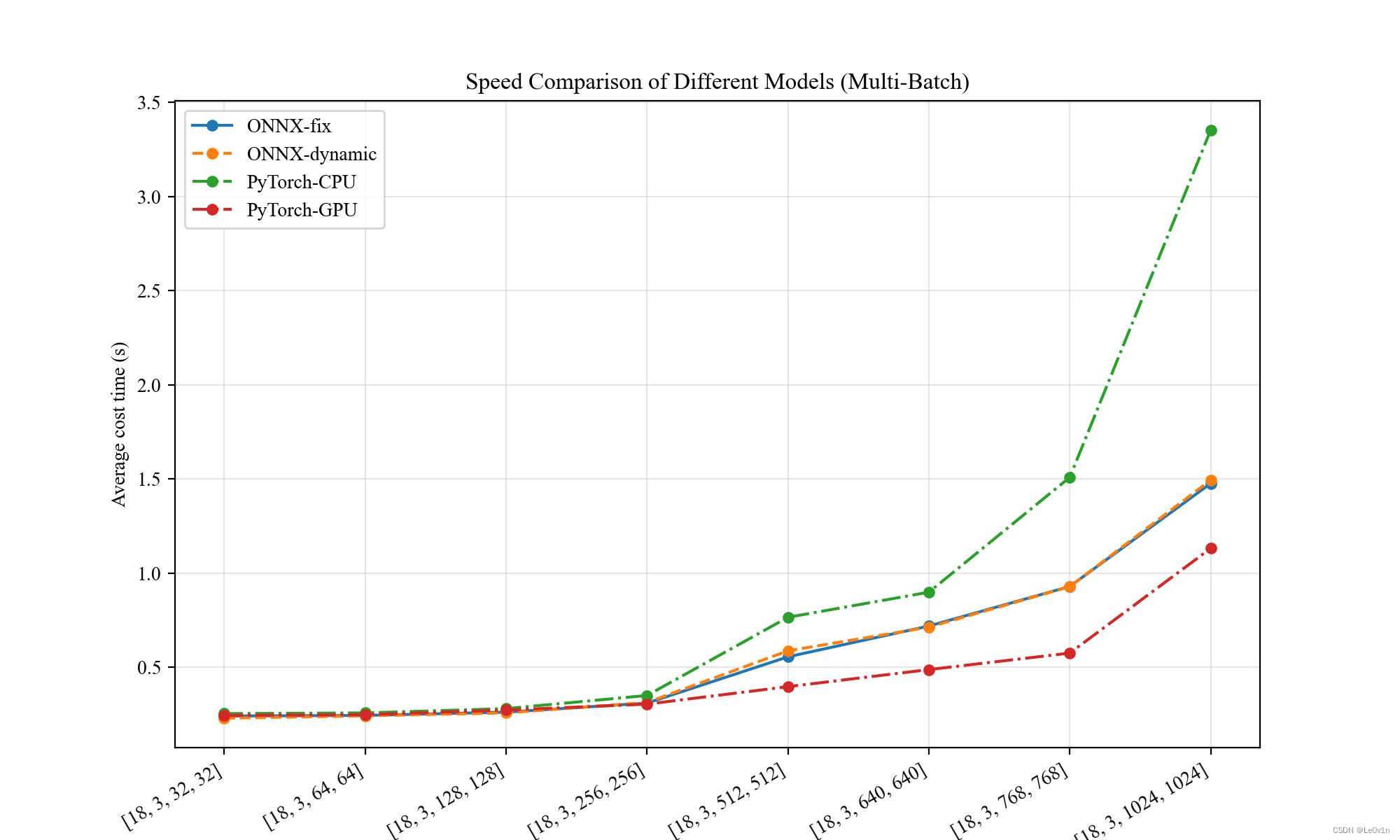
其实可以发现,与 ResNet18 的结论是一致的。
7.3 为什么 python -m onnxsim 没有效果
我们看一下这个过程:
-------------- ResNet-18 --------------
python -m onnxsim ONNX/saves/resnet18-dynamic_dims.onnx ONNX/saves/resnet18-dynamic_dims-sim.onnx
Simplifying...
Finish! Here is the difference:
┏━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓
┃ ┃ Original Model ┃ Simplified Model ┃
┡━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩
│ Add │ 8 │ 8 │
│ Constant │ 42 │ 42 │
│ Conv │ 20 │ 20 │
│ Flatten │ 1 │ 1 │
│ Gemm │ 1 │ 1 │
│ GlobalAveragePool │ 1 │ 1 │
│ MaxPool │ 1 │ 1 │
│ Relu │ 17 │ 17 │
│ Model Size │ 44.6MiB │ 44.6MiB │
└───────────────────┴────────────────┴──────────────────┘
-------------- MobileNetV3-Small --------------
python -m onnxsim ONNX/saves/mobilenetv3small-dynamic_dims.onnx ONNX/saves/mobilenetv3small-dynamic_dims-sim.onnx
Simplifying...
Finish! Here is the difference:
┏━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓
┃ ┃ Original Model ┃ Simplified Model ┃
┡━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩
│ Add │ 6 │ 6 │
│ Constant │ 108 │ 108 │
│ Conv │ 52 │ 52 │
│ Flatten │ 1 │ 1 │
│ Gemm │ 2 │ 2 │
│ GlobalAveragePool │ 10 │ 10 │
│ HardSigmoid │ 9 │ 9 │
│ HardSwish │ 19 │ 19 │
│ Mul │ 9 │ 9 │
│ Relu │ 14 │ 14 │
│ Model Size │ 9.7MiB │ 9.7MiB │
└───────────────────┴────────────────┴──────────────────┘
可以看到,其实根本没有变化,所以速度也没有提升。
⚠️ ONNX 文件变大了可能是因为
onnxsim放了一些东西在模型中,但对模型性能没有影响。
8. ONNX 与 PyTorch 精度对比
我们现在有如下的模型:
weights.pth: PyTorch 权重weights.onnx: ONNX 权重weights-sim.onnx: ONNX 精简后的权重
模型的关系如下:
现在我们想要搞清楚,这样转换后的模型精度是怎么样的?
import os
import argparse
import numpy as np
import pandas as pd
from PIL import Image
import onnxruntime
import torch
import torch.nn.functional as F
from torchvision import transforms, models
from rich.progress import track# ==================================== 参数 ====================================
parser = argparse.ArgumentParser()
parser.add_argument('--image_folder_path', type=str, default='Datasets/Web/images', help='图片路径')
parser.add_argument('--input-shape', type=int, nargs=2, default=[256, 256])
parser.add_argument('--verbose', action='store_true', help='')
args = parser.parse_args() # 解析命令行参数onnx_weights = 'ONNX/saves/model-dynamic_dims.onnx'
onnx_weights_sim = 'ONNX/saves/model-dynamic_dims-sim.onnx'
# ==============================================================================# 定义模型
onnx_model = onnxruntime.InferenceSession(path_or_bytes=onnx_weights)
onnx_model_sim = onnxruntime.InferenceSession(path_or_bytes=onnx_weights_sim)
pytorch_model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1).eval() # ⚠️ 一定要 .eval
# pytorch_model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)# 定义预处理函数
img_transform = transforms.Compose([transforms.Resize(args.input_shape[-1]),transforms.CenterCrop(args.input_shape[-1]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # imagenet专用std=[0.229, 0.224, 0.225]), # imagenet专用
])image_list = [os.path.join(args.image_folder_path, img) for img in os.listdir(args.image_folder_path) \if img.lower().endswith(('.jpg', '.jpeg', '.png', '.webp'))]for img_idx, image_path in track(enumerate(image_list), description='Precision Comparison'):# 读取图片img = Image.open(fp=image_path) # 读取图片input_img = img_transform(img)input_img = input_img.unsqueeze(0)print(f"inputs.type: {type(input_img)}") if args.verbose else ...print(f"inputs.shape: {input_img.shape}") if args.verbose else ...model_ls = ['pt', 'onnx', 'onnx-sim']for model_name in model_ls:if model_name != 'pt':if not isinstance(input_img, np.ndarray):input_img = input_img.numpy()model_input = {'input': input_img, }model_result = onnx_model.run(output_names=['output'], input_feed=model_input)[0]else:model_result = pytorch_model(input_img)if not isinstance(model_result, torch.Tensor):model_result = torch.from_numpy(model_result)model_result_softmax = F.softmax(input=model_result, dim=1) # [1, 1000]# 取概率最大的前 n 个结果n = 3top_n = torch.topk(input=model_result_softmax, k=n, dim=1)probs = top_n.values.detach().numpy()[0] # torch.Size([18, 3])indices = top_n.indices.detach().numpy()[0] # torch.Size([18, 3])print(f"probs: {probs}") if args.verbose else ...print(f"indices: {indices}") if args.verbose else ...df = pd.read_csv('Datasets/imagenet_classes_indices.csv')idx2labels = {}for _, row in df.iterrows():idx2labels[row['ID']] = row['Chinese'] # 中文标签print(f"============================== 推理结果-{model_name} ==============================") if args.verbose else ..._results = []for i, (prob, idx) in enumerate(zip(probs, indices)):class_name = idx2labels[idx]text = f"No.{i}: {class_name:<30} --> {prob:>.5f}" if args.verbose else ..._results.append(prob)print(text)print(f"=====================================================================") if args.verbose else ...with open("ONNX/saves/Precision-comparison.txt", 'a') as f:if model_name == 'pt':f.write(f"|[{img_idx+1}] {os.path.basename(image_path)}"f"|{_results[0]:>.5f}</br>{_results[1]:>.5f}</br>{_results[2]:>.5f}")elif model_name == 'onnx':f.write(f"|{_results[0]:>.5f}</br>{_results[1]:>.5f}</br>{_results[2]:>.5f}")else:f.write(f"|{_results[0]:>.5f}</br>{_results[1]:>.5f}</br>{_results[2]:>.5f}|\n")
实验结果:
| 图片名称 | PyTorch | ONNX | ONNX-sim |
|---|---|---|---|
| [1] book.jpg | 0.739730.050490.02358 | 0.739730.050490.02358 | 0.739730.050490.02358 |
| [2] butterfly.jpg | 0.897040.047720.01542 | 0.897040.047720.01542 | 0.897040.047720.01542 |
| [3] camera.jpg | 0.276580.177090.10925 | 0.276580.177090.10925 | 0.276580.177090.10925 |
| [4] cat.jpg | 0.277730.183930.17254 | 0.277730.183930.17254 | 0.277730.183930.17254 |
| [5] dog.jpg | 0.517870.253840.05929 | 0.517870.253840.05929 | 0.517870.253840.05929 |
| [6] dogs_orange.jpg | 0.352890.301140.07791 | 0.352890.301140.07791 | 0.352890.301140.07791 |
| [7] female.jpg | 0.156000.080310.04808 | 0.156000.080310.04808 | 0.156000.080310.04808 |
| [8] free-images.jpg | 0.455950.176260.08414 | 0.455950.176260.08414 | 0.455950.176260.08414 |
| [9] gull.jpg | 0.647110.233240.04430 | 0.647110.233240.04430 | 0.647110.233240.04430 |
| [10] laptop-phone.jpg | 0.493790.354050.06063 | 0.493790.354050.06063 | 0.493790.354050.06063 |
| [11] monitor.jpg | 0.516780.441930.02232 | 0.516780.441930.02232 | 0.516780.441930.02232 |
| [12] motorcycle.jpg | 0.317120.224350.15631 | 0.317120.224350.15631 | 0.317120.224350.15631 |
| [13] mouse.jpg | 0.994730.000740.00052 | 0.994730.000740.00052 | 0.994730.000740.00052 |
| [14] panda.jpg | 0.945590.031990.00561 | 0.945590.031990.00561 | 0.945590.031990.00561 |
| [15] share_flower_fullsize.jpg | 0.788060.056910.02483 | 0.788060.056910.02483 | 0.788060.056910.02483 |
| [16] tiger.jpeg | 0.617490.380010.00052 | 0.617490.380010.00052 | 0.617490.380010.00052 |
可以看到,转换前后模型并没有精度的丢失。
9. 〔拓展知识〕为什么 .pt 模型在推理时一定要 .eval()?
在PyTorch中,.eval() 是一个用于将模型切换到评估(inference)模式的方法。在评估模式下,模型的行为会有所变化,主要体现在两个方面:Dropout 和 Batch Normalization。
-
Dropout:
- 在训练阶段,为了防止过拟合,通常会使用 dropout 策略,即在每个训练步骤中,以一定的概率随机丢弃某些神经元的输出。
- 在推理阶段,我们希望获得模型的确定性输出,而不是在每次推理时都丢弃不同的神经元。因此,在推理时应该关闭 dropout。通过调用
.eval(),PyTorch 会将所有 dropout 层设置为评估模式,即不进行随机丢弃。
-
Batch Normalization:
- Batch Normalization(批标准化)在训练时通过对每个 mini-batch 进行标准化来加速训练,但在推理时,我们通常不是基于 mini-batch 进行预测,因此需要使用整个数据集的统计信息进行标准化。
- 在
.eval()模式下,Batch Normalization 会使用训练时计算的移动平均和方差,而不是使用当前 mini-batch 的统计信息。
因此,为了确保在推理时得到一致和可靠的结果,需要在推理之前调用 .eval() 方法,以确保模型处于评估模式,关闭了 dropout,并使用适当的 Batch Normalization 统计信息。
举个例子,对于一张猫咪图片而言,如果我们的 .pt 模型没有开启 .eval() 就进行推理,那么得到的结果如下:
============================== 推理结果-pt ==========================
No.0: 桶 --> 0.00780
No.1: 手压皮碗泵 --> 0.00680
No.2: 钩爪 --> 0.00601
====================================================================
probs: [0.27773306 0.18392678 0.17254312]
indices: [281 285 287]
============================== 推理结果-onnx ========================
No.0: 虎斑猫 --> 0.27773
No.1: 埃及猫 --> 0.18393
No.2: 猞猁,山猫 --> 0.17254
====================================================================
probs: [0.27773306 0.18392678 0.17254312]
indices: [281 285 287]
============================== 推理结果-onnx-sim ====================
No.0: 虎斑猫 --> 0.27773
No.1: 埃及猫 --> 0.18393
No.2: 猞猁,山猫 --> 0.17254
====================================================================
可以看到,对于 ONNX 模型而言,推理相对来说是比较正确的。但对于 PyTorch 模型,推理与猫无关了,所以 ⚠️ 在推理时开启 .eval() 是非常重要的!
参考
- 图像分类模型部署-Pytorch转ONNX
- Pytorch图像分类模型部署-ONNX Runtime本地终端推理
相关文章:
PyTorch2ONNX-分类模型:速度比较(固定维度、动态维度)、精度比较
图像分类模型部署: PyTorch -> ONNX 1. 模型部署介绍 1.1 人工智能开发部署全流程 #mermaid-svg-bAJun9u4XeSykIbg {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-bAJun9u4XeSykIbg .error-icon{fill:#552222;}…...

Docker命令快车道:一票通往高效开发之旅
欢迎登上 Docker 命令快车!在这趟旅程中,你不仅会学会如何驾驭 Docker 这辆神奇的车,还会发现如何让你的开发旅程变得更加轻松愉快。现在,请系好安全带,我们即将出发! Docker 是什么 Docker 就像是一辆超…...

IP类接口大全,含免费次数
IP查询 IP归属地-IPv4高精版:根据IP地址查询归属地信息,支持到中国地区(不含港台地区)街道级别,包含国家、省、市、区县、详细地址和运营商等信息。IP归属地-IPv4区县级:根据IP地址查询归属地信息…...

LLMs 的记忆和信息检索服务器 Motorhead
LLMs 的记忆和信息检索服务器 Motorhead 1. 为什么使用 Motorhead?2. 通过 Docker 启动 Motorhead3. Github 地址4. python 使用示例地址 1. 为什么使用 Motorhead? 使用 LLMs构建聊天应用程序时,每次都必须构建记忆处理。Motorhead是协助该…...
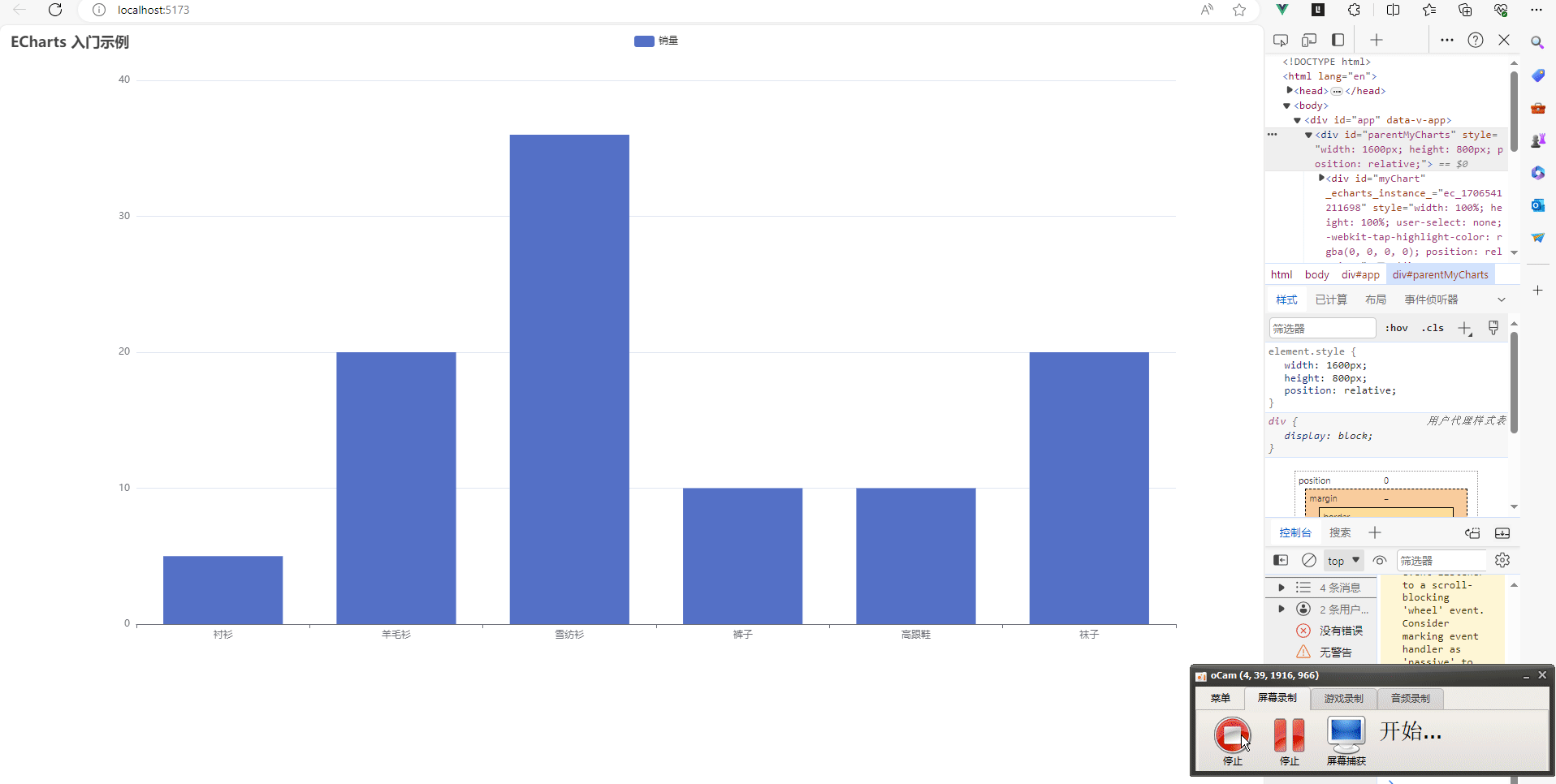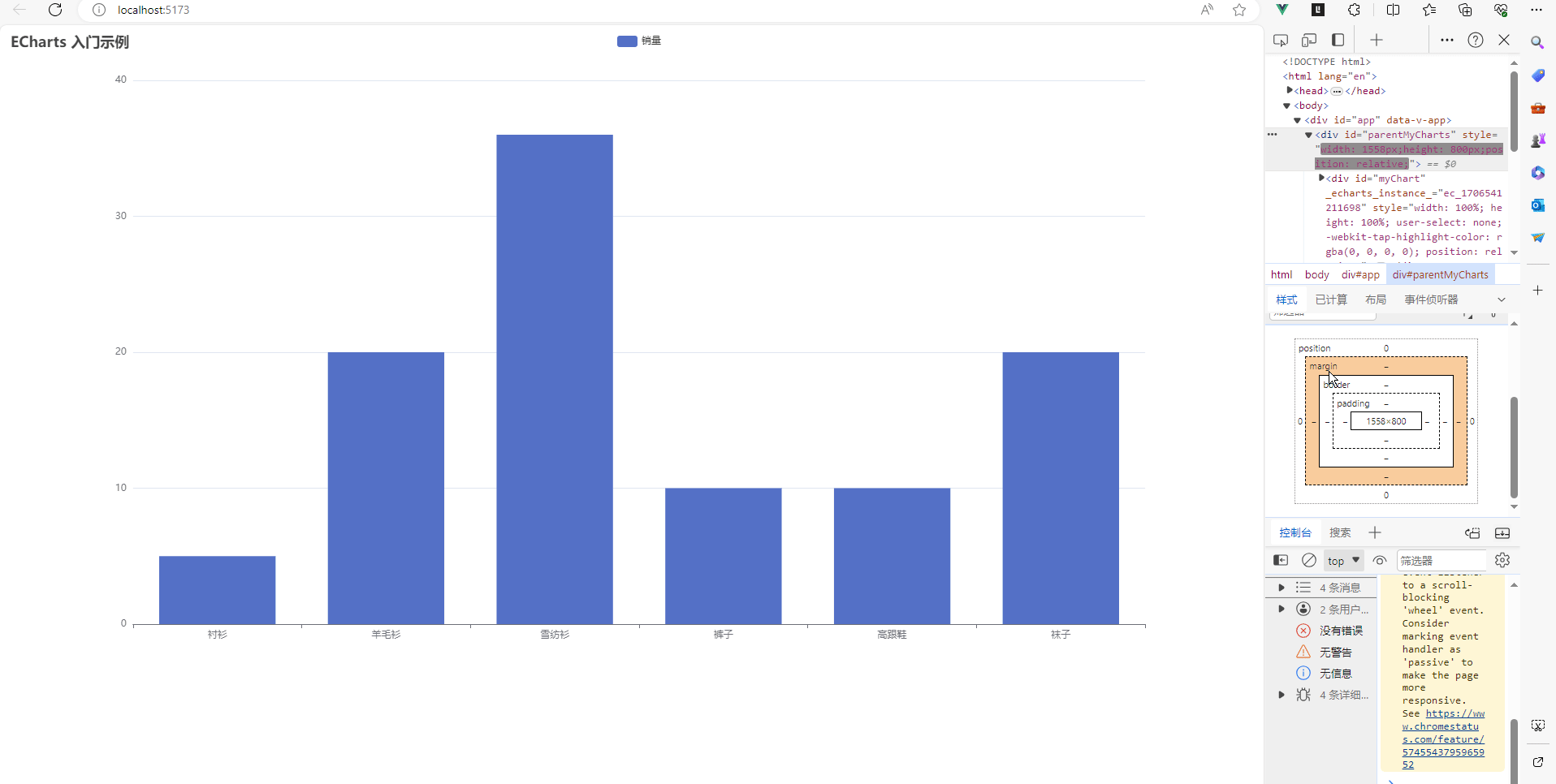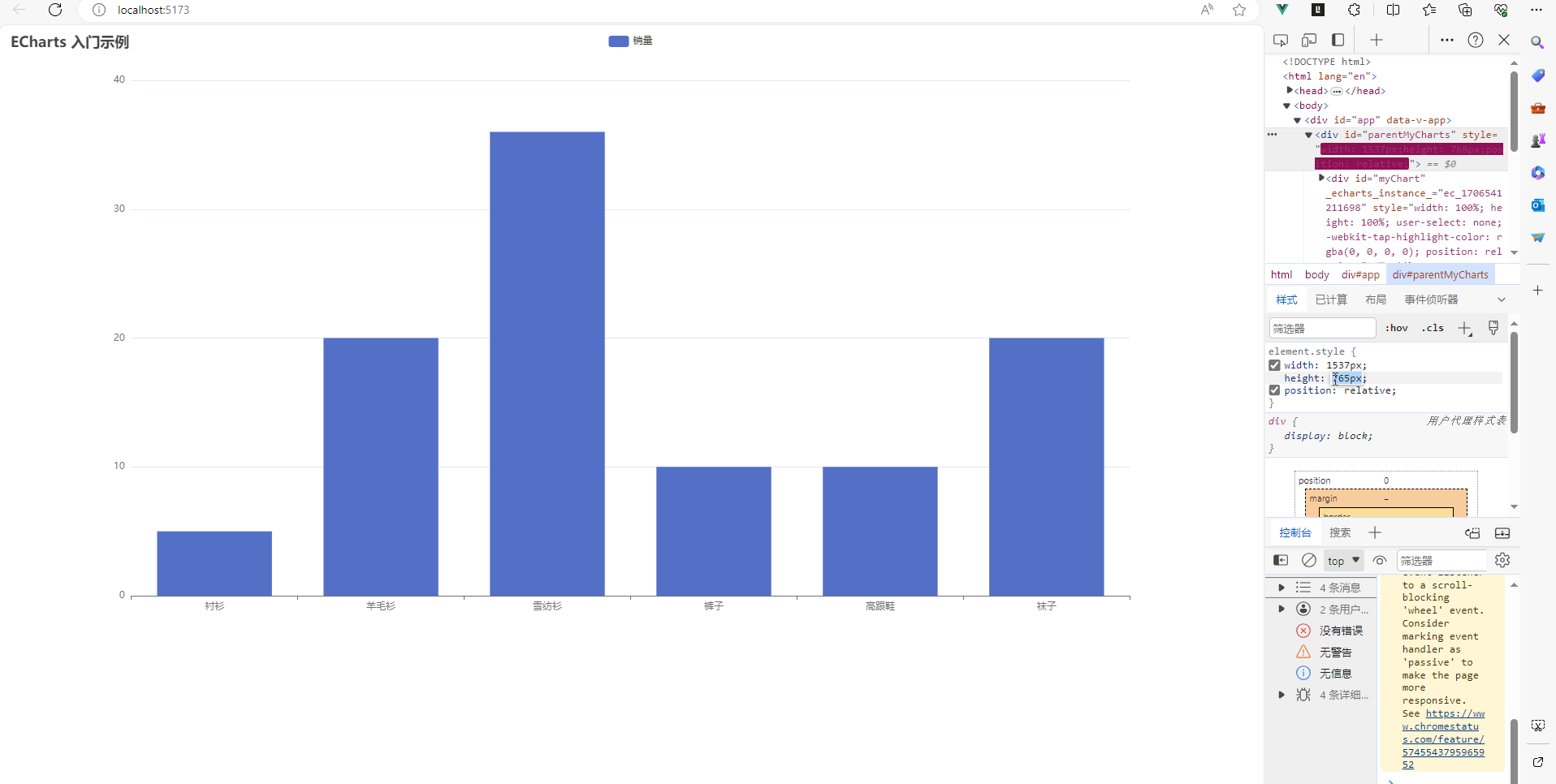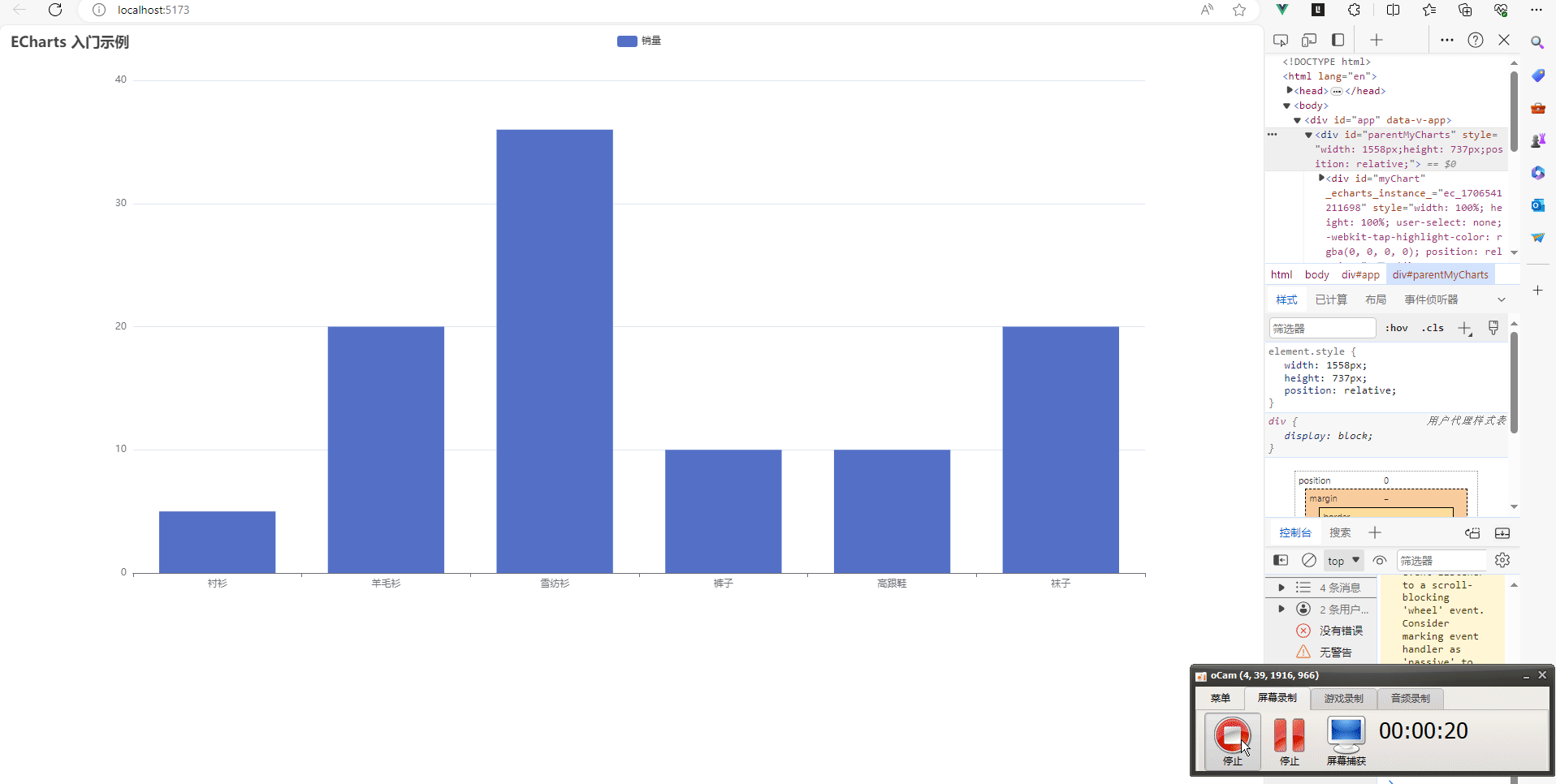
vue3项目中让echarts适应div的大小变化,跟随div的大小改变图表大小
目录如下 我的项目环境如下利用element-resize-detector插件监听元素大小变化element-resize-detector插件的用法完整代码如下:结果如下 在做项目的时候,经常会使用到echarts,特别是在做一些大屏项目的时候。有时候我们是需要根据div的大小改…...

springboot启动异常
Error creating bean with name ‘dataSource’ org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name dataSource: Unsatisfied dependency expressed through field basicProperties; nested exception is org.springframew…...

直播主播之互动率与促单
直播互动率是衡量直播间观众参与度的重要指标,通常指的是直播间的观众点赞、评论以及转发的数量。互动率越高,表明观众参与度越高,直播间的人气值也相应越高。 为了提升直播互动率,主播可以采取以下策略: 1.积极引导观众参与互动…...
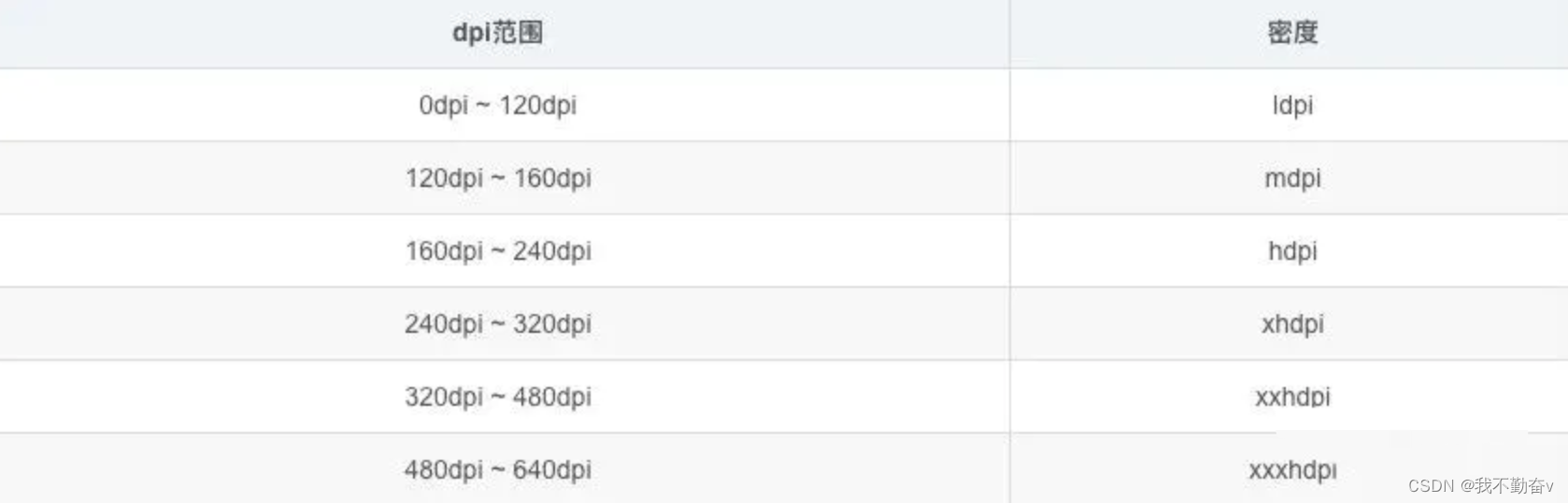
Android 基础技术——Bitmap
笔者希望做一个系列,整理 Android 基础技术,本章是关于 Bitmap Bitmap 内存如何计算 占用内存 宽 * 缩放比例 * 高 * 缩放比例 * 每个像素所占字节 缩放比例 设备dpi/图片所在目录的dpi Bitmap加载优化?不改变图片质量的情况下怎么优化&am…...

数据结构奇妙旅程之七大排序
꒰˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱ ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客 本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN …...

【JavaScript】Generator
MDN-Generator Generator对象由生成器函数返回,并且它符合可迭代协议和迭代器协议。 Generator-核心语法 核心语法: 定义生成器函数获取generator对象yield表达式的使用通过for of获取每一个yield的值 // 1. 通过function* 创建生成器函数 function* foo() {//…...

河南省考后天网上确认,请提前准备证件照哦
✔报名时间:2024年1月18号一1月24号 ✔报名确认和缴费:2024年1月 31号一2月4号 ✔准考证打印:2024年3月12号一3月17号 ✔笔试时间:2024年3月16日-2024年3月17日。 ✔面试时间:面试时间拟安排在2024年5月中旬 报名网址&…...

【前端】防抖和节流
防抖 防抖用于限制连续触发的事件的执行频率。当一个事件被触发时,防抖会延迟一定的时间执行对应的处理函数。如果在延迟时间内再次触发了同样的事件,那么之前的延迟执行将被取消,重新开始计时。 总结:在单位时间内频繁触发事件,只有最后一次生效 场景 :用户在输入框输…...

【网络】:网络套接字(UDP)
网络套接字 一.网络字节序二.端口号三.socket1.常见的API2.封装UdpSocket 四.地址转换函数 网络通信的本质就是进程间通信。 一.网络字节序 我们已经知道,内存中的多字节数据相对于内存地址有大端和小端之分, 磁盘文件中的多字节数据相对于文件中的偏移地址也有大端小端之分,网…...

Linux编程 1/2 数据结构
数据结构: 程序 数据结构 算法 1.数据结构: 1.时间复杂度: 数据量的增长与程序运行时间增长所呈现的比例函数,则称为时间渐进复杂度函数简称时间复杂度 O(c) > O(logn)> O(n) > O(nlogn) > O(n^2) > O(n^3) > O(2^n) 2.空间复杂度: 2.类…...

【UE Niagara】实现闪电粒子效果的两种方式
目录 效果 步骤 方式一(网格体渲染器) (1)添加网格体渲染器 (2)修改粒子显示方向 (3)添加从上到下逐渐显现的效果 (4)粒子颜色变化 方式二࿰…...
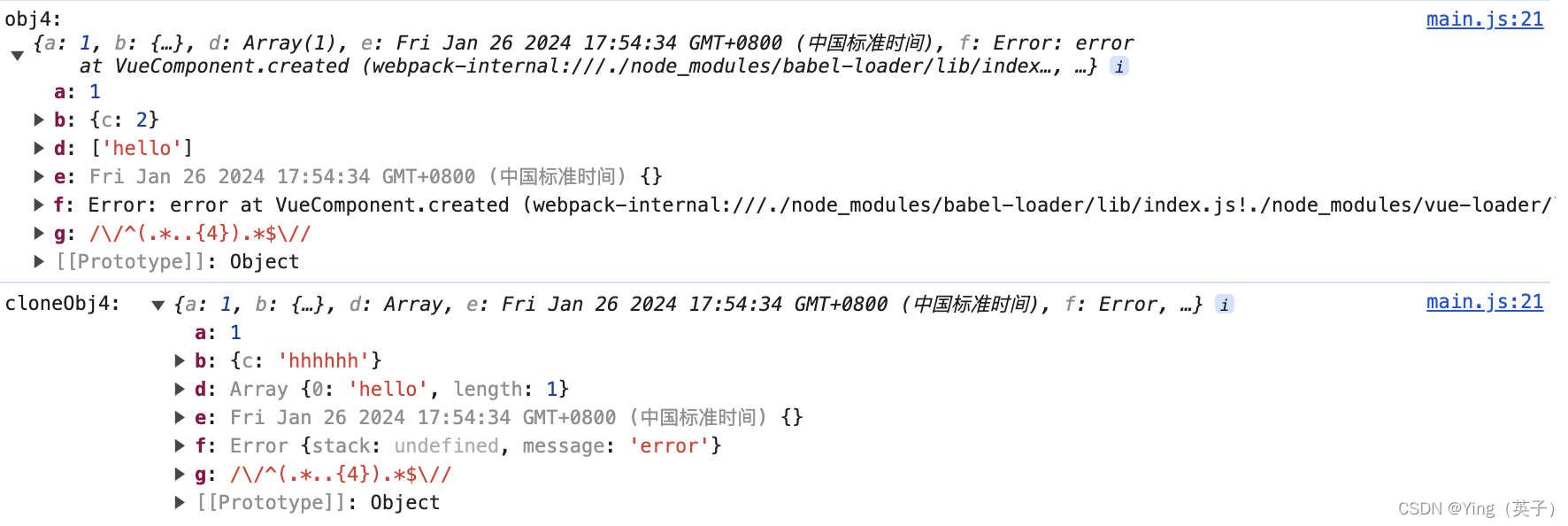
js数组/对象的深拷贝与浅拷贝
文章目录 一、js中的深拷贝和浅拷贝二、浅拷贝1、Object.assign()2、利用es6扩展运算符(...) 二、深拷贝1、JSON 序列化和反序列化2、js原生代码实现3、使用第三方库lodash等 四、总结 一、js中的深拷贝和浅拷贝 在JS中,深拷贝和浅拷贝是针对…...
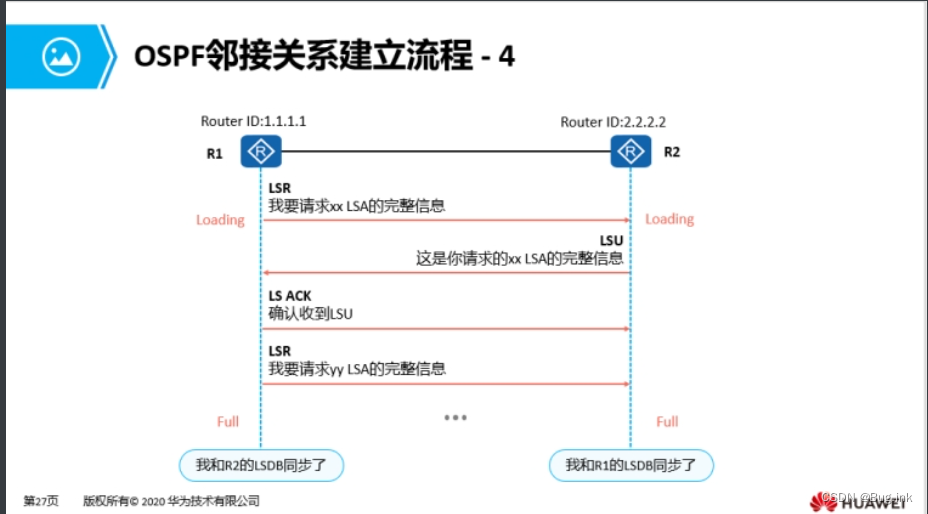
HCIA学习第六天:OSPF:开放式最短路径优先协议
OSPF:开放式最短路径优先协议 无类别链路状态IGP动态路由协议 1.距离矢量协议:运行距离矢量协议的路由器会周期性的泛洪自己的路由表。通过路由的交互,每台路由器从相邻的路由器学习到路由,并且加载进自己的路由表中;…...
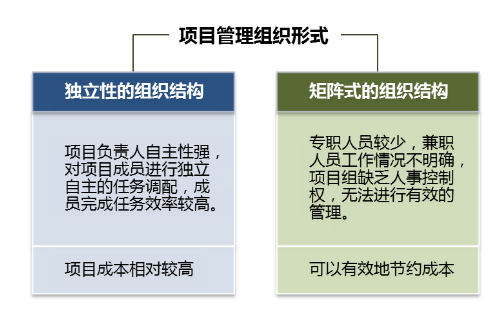
从四个方面来解决企业在项目管理中遇到的各类问题
案例背景:某建筑集团有限公司成立于1949年,拥有国家房屋建筑工程施工总承包一级、建筑装修装饰工程专业承包一级、市政公用工程施工总承包一级资质。是一家集建筑施工、设备安装、装饰装潢、仿古建筑、房地产开发、建材试验为一体的具有综合生产能力的建…...
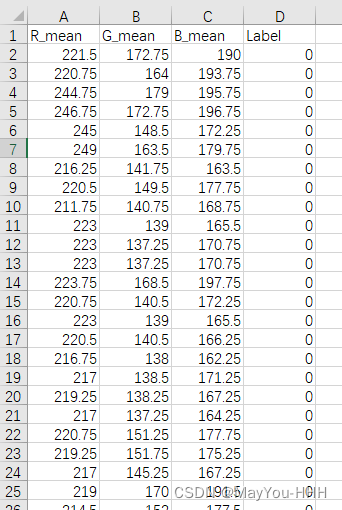
使用代码取大量2*2像素图片各通道均值,存于Excel文件中。
任务是取下图RGB各个通道的均值及标签(R, G,B,Label),其中标签由图片存放的文件夹标识。由于2*2像素图片较多,所以将结果放置于Excel表格中,之后使用SVM对他们进行分类。 from PIL import Image import os …...

React16源码: React中commit阶段的commitBeforeMutationLifecycles的源码实现
commitBeforeMutationLifecycles 1 )概述 在 react commit 阶段的 commitRoot 第一个while循环中调用了 commitBeforeMutationLifeCycles现在来看下,里面发生了什么 2 )源码 回到 commit 阶段的第一个循环中,在 commitRoot 函数…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...