Qt|大小端数据转换
后面打算写Qt关于网络编程的博客,网络编程就绕不开字节流数据传输,字节流数据的传输一般是根据协议来定义对应的报文该如何组包,那这就必然牵扯到了大端字节序和小端字节序的问题了。不清楚的大小端的可以看一下相关资料:大小端模式_百度百科 (baidu.com)。
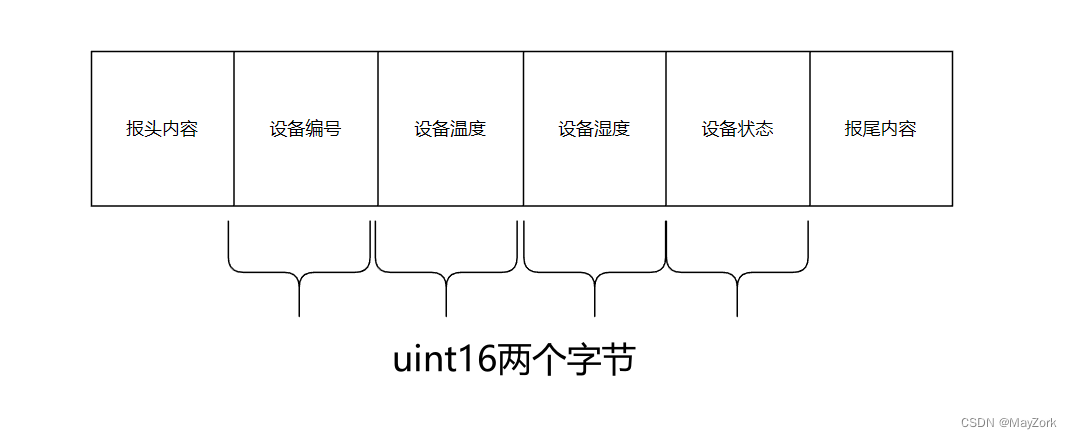
这里看一个具体的例子比如某个报文协议是这样定的:
| 报头 | ... |
| 设备编号 | U16(两个字节) |
| 设备温度 | U16(两个字节) |
| 设备湿度 | U16(两个字节) |
| 设备状态 | U16(两个字节) |
| 报尾 | ... |
那么传输过程的报文结构,除去头尾之外应该是这样的:
代码报文结构体这样定义
struct DeviceData {quint16 number;quint16 temperature;quint16 humidness;quint16 status;
};然后简单测试一下
QByteArray data;DeviceData d;d.number = 0x1234;d.temperature = 0x5678;d.humidness = 0x4321;d.status = 0x8756;data.append(reinterpret_cast<char *>(&d), sizeof(DeviceData));qDebug() << data.toHex();编译运行查看一下打印结果:

如果看了前面关于大小端的资料应该就会明白为什么这里打印结果是“3412785621435687”,这里也有一个参考的文章:大小端格式由编译器,操作系统还是CPU决定的?答案是CPU_大端cpu采用小端编译链-CSDN博客我的机器cpu,如果不采取任何处理,这里输出的确实是小端数据,如果是大端那么就会输出对应的“1234567843218756”。如果上文中举例的协议定的就是小端数据传输那么就是这样写,无需做任何处理。如果是大端数据传输则需要做对应的处理。同样上文中还存在一个问题,比如设备编号协议里面定的是无符号一个字节即uint8类型的。那么结构体将会这样定义:
struct DeviceData {quint8 number;quint16 temperature;quint16 humidness;quint16 status;
};测试代码:
QByteArray data;DeviceData d;d.number = 0x12;d.temperature = 0x5678;d.humidness = 0x4321;d.status = 0x8756;data.append(reinterpret_cast<char *>(&d), sizeof(DeviceData));qDebug() << data.toHex();这里将结构体转QByteArray使用了reinterpret_cast,可以自己查一下static_cast、dymatic_cast、reinterpret_cast以及Qt的qobject_cast有什么区别。同样还可以使用QByteArray的setRawData方法:
QByteArray data;
data.setRawData(reinterpret_cast<char *>(&d), sizeof(DeviceData));
结果也是一样的。
将对应QByteArray转回结构体直接使用memcpy即可。例如上面的例子:
DeviceData dd;
memcpy(&dd, data.constData(), sizeof(DeviceData));
打印输出:

为什么打印是这样,可以先看看这个结构体的大小,打印 sizeof(DeviceData)可以看到是8个字节,结构体成员一个quint8,三个quint16,大小:1+2+2+2为什么是8而不是7, 这个就需要了解关于字节对齐的知识了:字节对齐_百度百科 (baidu.com)
直接采用1字节对齐:
#pragma pack(push, 1);
struct DeviceData {quint8 number;quint16 temperature;quint16 humidness;quint16 status;
};
#pragma pack(pop);再查看打印:
![]()
然后sizeof(DeviceData)也是7了(这里使用1字节对齐会影响效率)。·
回到关于大小端的问题,代码里面采用的是结构体转QByteArray,这样就牵扯到了依靠系统自己的大小端来处理了,代码不灵活。可以写一个通用的方法来根据需求转换对应需要的字节序。
方法一:
思路是一个字节一个字节进行拷贝使用QByteArray的append方法以及位移操作。
比如一个无符号四字节的quint32 u32=0x12345678(大端就是12345678,小端就是78563412),先执行下列代码:
quint32 u32 = 0x12345678;QByteArray data;data.append(u32);qDebug() << data.toHex();查看打印:

也就是说QByteArray的 append方法在这种情况下并不会将整数 u32 转换为字节流,而是将整数的低字节(最低有效字节)追加到 QByteArray中。
转化为小端数据:
| 原生数据 | 操作 | 原生数据 | QByteArray进行append追加 |
| 12345678 | 右移0位 | 12345678 | 78 |
| 12345678 | 右移8位 | 00123456 | 7856 |
| 00123456 | 右移16位 | 00001234 | 785634 |
| 00001234 | 右移24位 | 00000012 | 78563412 |
转化为大端数据:
| 原生数据 | 操作 | 原生数据 | QByteArray进行append追加 |
| 12345678 | 右移24位 | 00000012 | 12 |
| 12345678 | 右移16位 | 00001234 | 1234 |
| 00123456 | 右移8位 | 00123456 | 123456 |
| 00001234 | 右移0位 | 12345678 | 12345678 |
对应代码:
quint32 u32 = 0x12345678;//输出小端数据QByteArray littleEndian;littleEndian.append(u32);littleEndian.append(u32 >> 8);littleEndian.append(u32 >> 16);littleEndian.append(u32 >> 24);qDebug() << "little:" << littleEndian.toHex();//输出大端数据QByteArray bigEndian;bigEndian.append(u32 >> 24);bigEndian.append(u32 >> 16);bigEndian.append(u32 >> 8);bigEndian.append(u32);qDebug() << "bigEndian:" << bigEndian.toHex();编译运行查看打印:

对应转回同理,下面是完整代码:
quint32 u32 = 0x12345678;//输出小端数据QByteArray littleEndian;littleEndian.append(u32);littleEndian.append(u32 >> 8);littleEndian.append(u32 >> 16);littleEndian.append(u32 >> 24);qDebug() << "littleEndian:" << littleEndian.toHex();quint32 u32x = 0;u32x |= static_cast<quint8>(littleEndian[0]);u32x |= (static_cast<quint8>(littleEndian[1]) << 8);u32x |= (static_cast<quint8>(littleEndian[2]) << 16);u32x |= (static_cast<quint8>(littleEndian[3]) << 24);qDebug() << "ori data:" << u32x;//输出大端数据QByteArray bigEndian;bigEndian.append(u32 >> 24);bigEndian.append(u32 >> 16);bigEndian.append(u32 >> 8);bigEndian.append(u32);qDebug() << "bigEndian:" << bigEndian.toHex();quint32 u32y = 0;u32y |= (static_cast<quint8>(bigEndian[0]) << 24);u32y |= (static_cast<quint8>(bigEndian[1]) << 16);u32y |= (static_cast<quint8>(bigEndian[2]) << 8);u32y |= static_cast<quint8>(bigEndian[3]);qDebug() << "ori data:" << u32y;编译运行查看打印:

305419896对应的16进制就是0x12345678:

其他数据类型同理,这里写成模板函数:
template <typename T>
static QByteArray toData(const T &value, bool isLittle) {QByteArray data;for (int i = 0; i < sizeof(T); ++i) {int bitOffset = (isLittle) ? i : sizeof(T) - i - 1;data.append(value >> bitOffset * 8);}return data;
}template <typename T>
static void fromData(const QByteArray &data, bool isLittle, T &value) {for (int i = 0; i < sizeof(T); ++i) {int bitOffset = (isLittle) ? i : sizeof(T) - i - 1;value |= (static_cast<quint8>(data[i]) << bitOffset * 8);}
}上面例子代码改为:
quint32 u32 = 0x12345678;//输出小端数据QByteArray littleEndian = toData(u32, true);qDebug() << "littleEndian:" << littleEndian.toHex();quint32 u32x = 0;fromData(littleEndian, true, u32x);qDebug() << "ori data:" << u32x;//输出大端数据QByteArray bigEndian = toData(u32, false);qDebug() << "bigEndian:" << bigEndian.toHex();quint32 u32y = 0;fromData(bigEndian, false, u32y);qDebug() << "ori data:" << u32y;编译运行查看打印:

跟前面的一致。
方法二:
思路是使用QDataStream的读写数据,然后借助QDataStream的setByteOrder方法,具体就不多细讲,直接看模板函数:
template <typename T>
QByteArray toData1(T value, bool isLittle) {QByteArray data;QDataStream stream(&data, QIODevice::WriteOnly);if (isLittle)stream.setByteOrder(QDataStream::LittleEndian);elsestream.setByteOrder(QDataStream::BigEndian);stream << value;return data;
}template <typename T>
void fromData1(const QByteArray &data, bool isLittle, T &value) {QDataStream stream(data);if (isLittle)stream.setByteOrder(QDataStream::LittleEndian);elsestream.setByteOrder(QDataStream::BigEndian);stream >> value;
}将上面例子改为使用这两个方法:
quint32 u32 = 0x12345678;//输出小端数据QByteArray littleEndian = toData1(u32, true);qDebug() << "littleEndian:" << littleEndian.toHex();quint32 u32x = 0;fromData1(littleEndian, true, u32x);qDebug() << "ori data:" << u32x;//输出大端数据QByteArray bigEndian = toData1(u32, false);qDebug() << "bigEndian:" << bigEndian.toHex();quint32 u32y = 0;fromData1(bigEndian, false, u32y);qDebug() << "ori data:" << u32y;编译运行查看打印:

与方法一结果一致。
方法三:
借助Qt的QtEndian:

首先qt有判断当前CPU是大端还是小端的宏:

例如:
#if Q_BYTE_ORDER == Q_BIG_ENDIANqDebug() << "current endian is big";
#endif#if Q_BYTE_ORDER == Q_LITTLE_ENDIANqDebug() << "current endian is little";
#endif编译运行查看打印:

因为我的是x86是小端。
对应Qt也有一些大小端转换的方法:
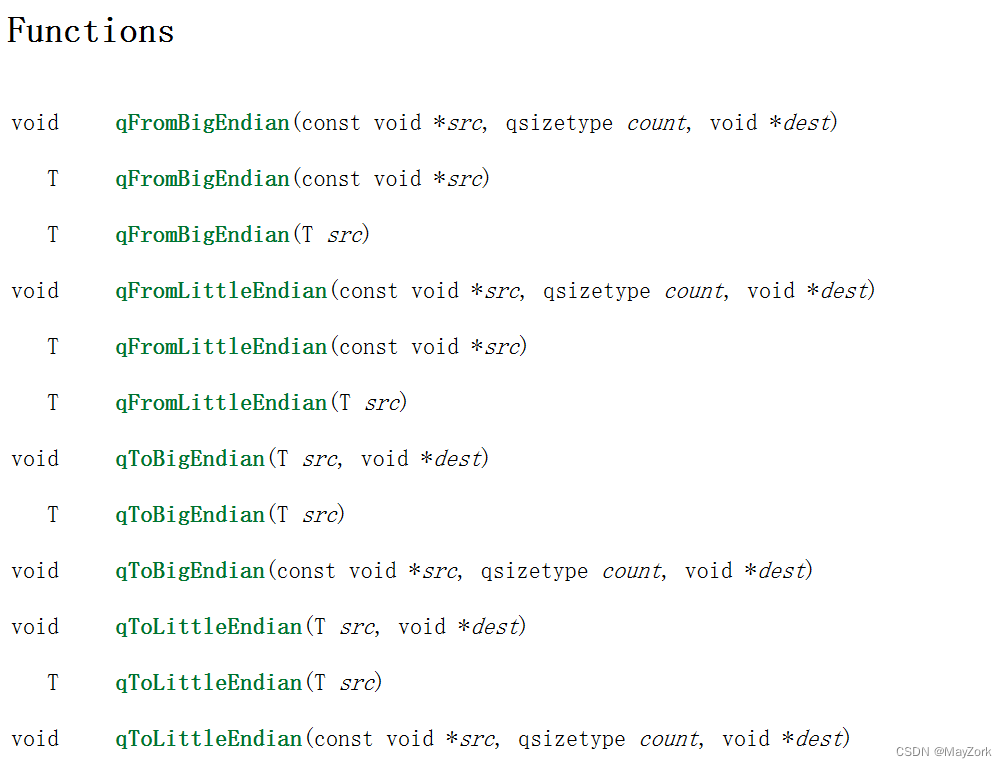
具体使用有兴趣的可以探究一下,我没有过多研究Qt的这个。
相关文章:
Qt|大小端数据转换
后面打算写Qt关于网络编程的博客,网络编程就绕不开字节流数据传输,字节流数据的传输一般是根据协议来定义对应的报文该如何组包,那这就必然牵扯到了大端字节序和小端字节序的问题了。不清楚的大小端的可以看一下相关资料:大小端模…...

禅道添加自定义字段
1,数据库表 zt_story 添加自定义字段 bakDate1,bakDate2,bakDate3,bakDate4 2,在 /opt/lampp/htdocs/zentaopms/extension/custom/story/ext/config 中添加bakDate.php文件 <?php $config->story->datatab…...

蓝桥杯2024/1/26笔记-----基于PCF8591的电压采集装置
功能实现要求: 每次建好工程文件夹,里边包含User(放工程文件,mian.c,可以在这里写如同我这个文章的文本文档)、Driver(存放底层文件如Led.c,Led.h等) 新建的工程先搭建框…...
【一】esp32芯片开发板环境搭建
1、esp32的源码在github上的地址 不同的芯片支持的源码版本不一样,需要根据自己的实际的esp32开发板的芯片下载不用版本的代码 esp32支持多种开发方式,如arduino,ESP-IDF等。官方推荐使用idf开发,ESP-IDF 是乐鑫官方推出的物联网开…...
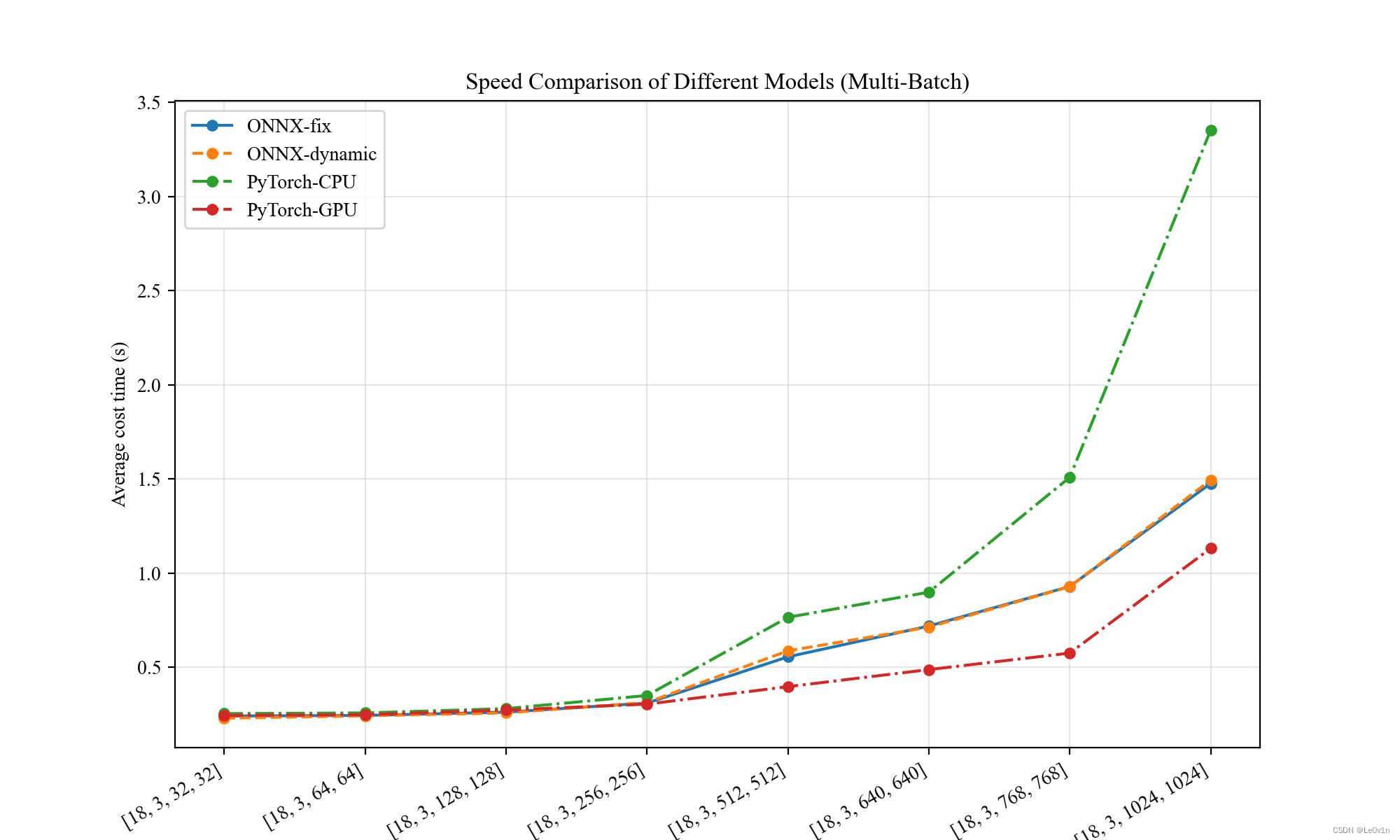
PyTorch2ONNX-分类模型:速度比较(固定维度、动态维度)、精度比较
图像分类模型部署: PyTorch -> ONNX 1. 模型部署介绍 1.1 人工智能开发部署全流程 #mermaid-svg-bAJun9u4XeSykIbg {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-bAJun9u4XeSykIbg .error-icon{fill:#552222;}…...

Docker命令快车道:一票通往高效开发之旅
欢迎登上 Docker 命令快车!在这趟旅程中,你不仅会学会如何驾驭 Docker 这辆神奇的车,还会发现如何让你的开发旅程变得更加轻松愉快。现在,请系好安全带,我们即将出发! Docker 是什么 Docker 就像是一辆超…...

IP类接口大全,含免费次数
IP查询 IP归属地-IPv4高精版:根据IP地址查询归属地信息,支持到中国地区(不含港台地区)街道级别,包含国家、省、市、区县、详细地址和运营商等信息。IP归属地-IPv4区县级:根据IP地址查询归属地信息…...

LLMs 的记忆和信息检索服务器 Motorhead
LLMs 的记忆和信息检索服务器 Motorhead 1. 为什么使用 Motorhead?2. 通过 Docker 启动 Motorhead3. Github 地址4. python 使用示例地址 1. 为什么使用 Motorhead? 使用 LLMs构建聊天应用程序时,每次都必须构建记忆处理。Motorhead是协助该…...
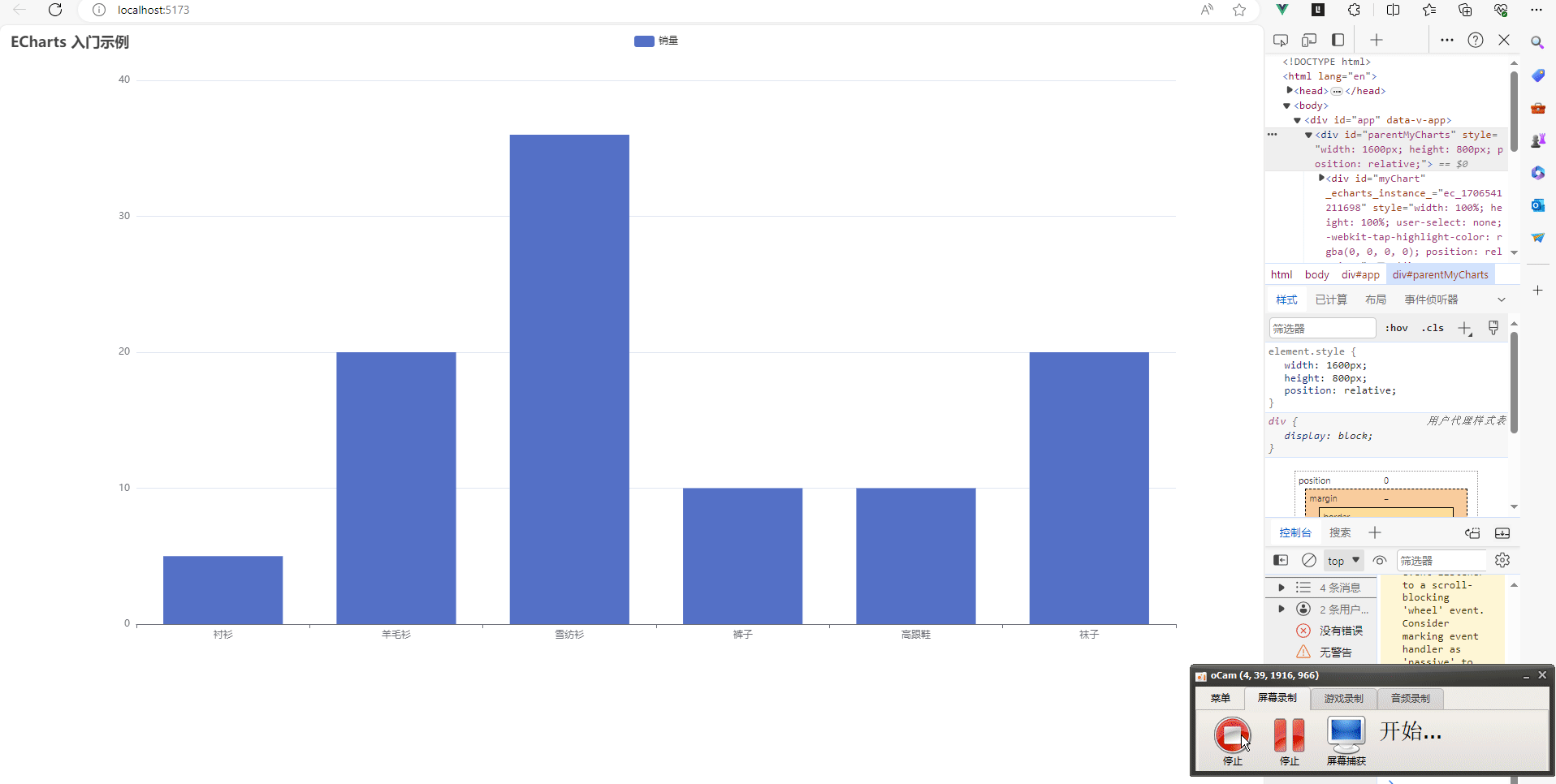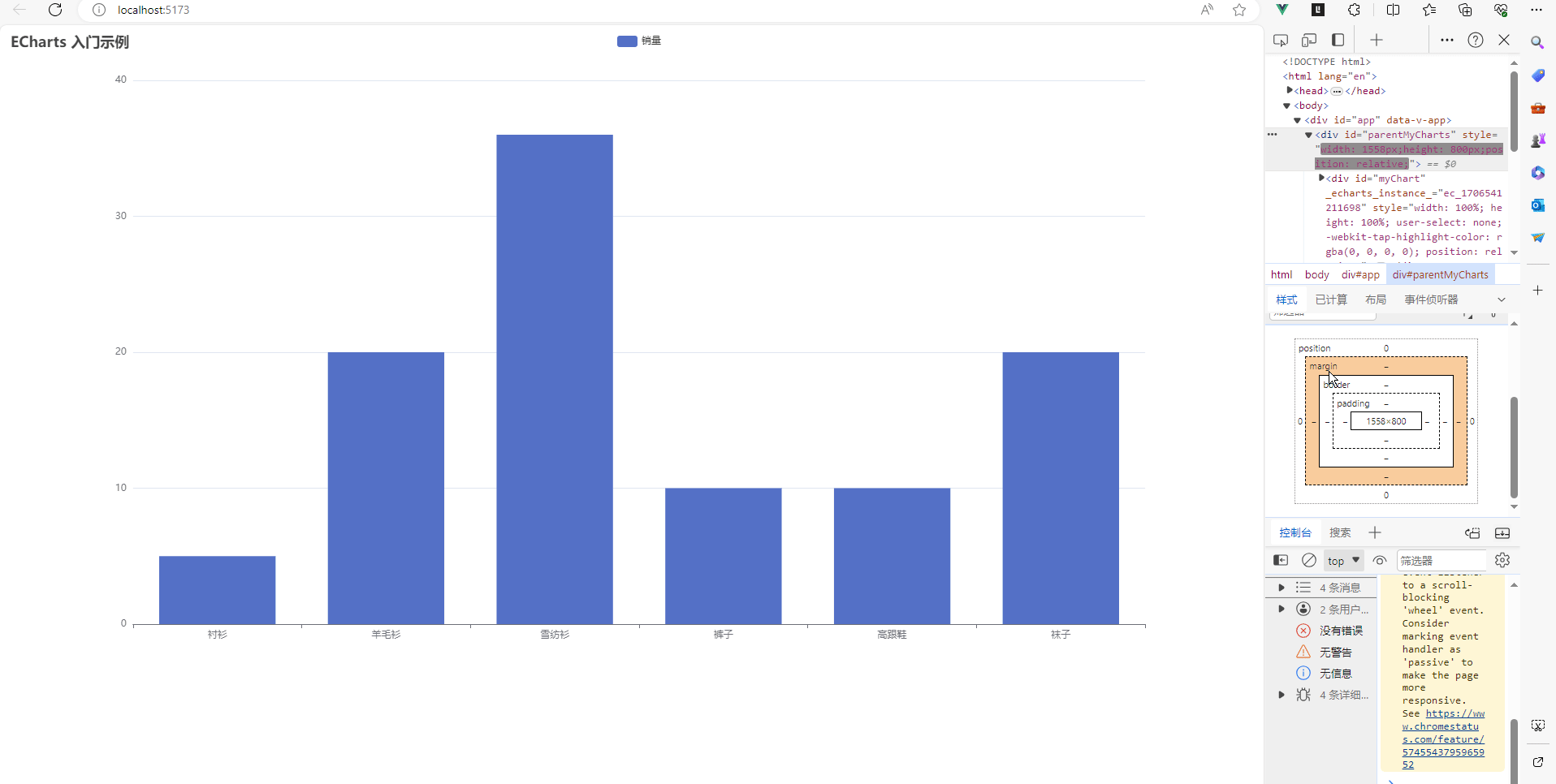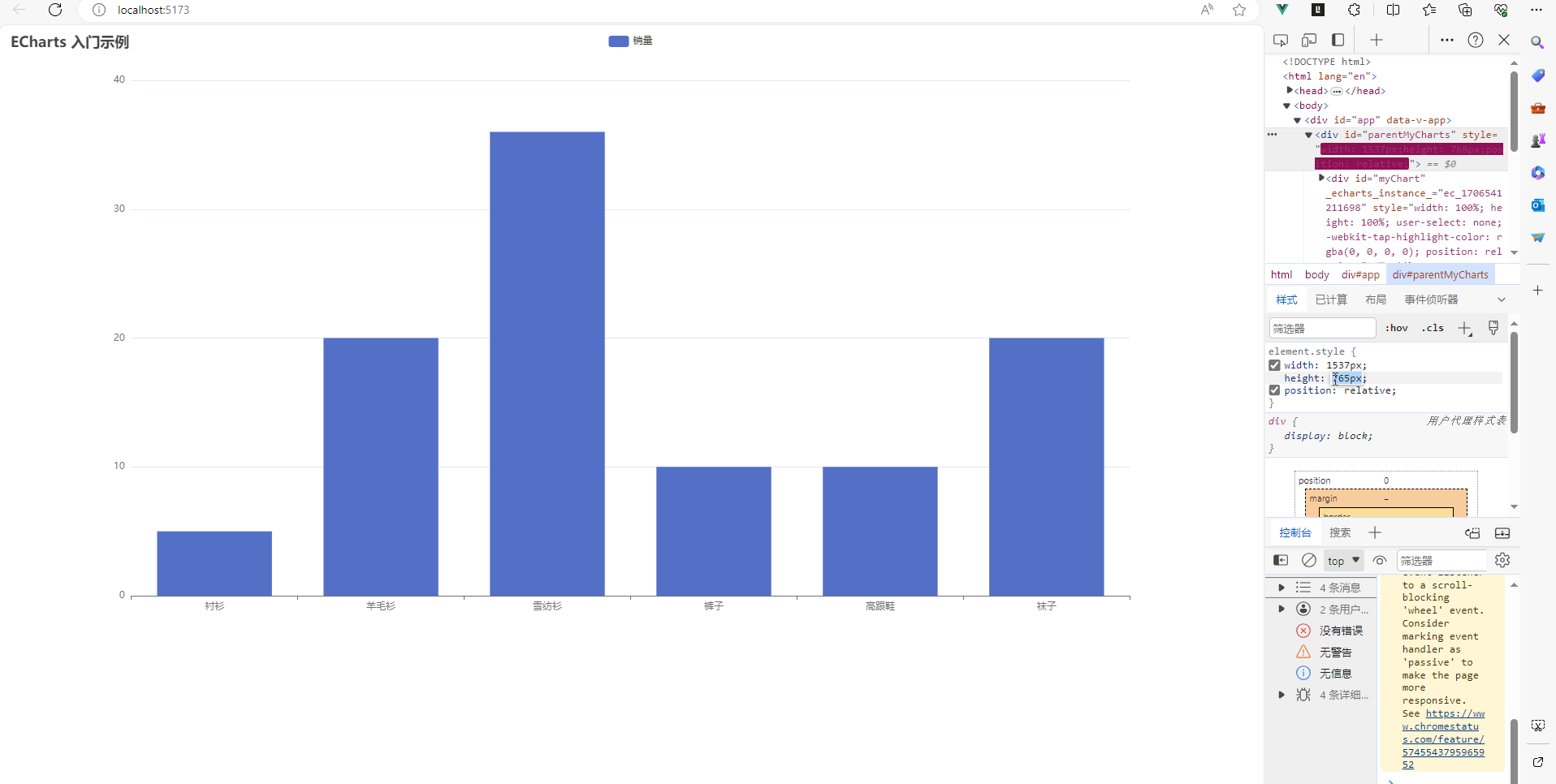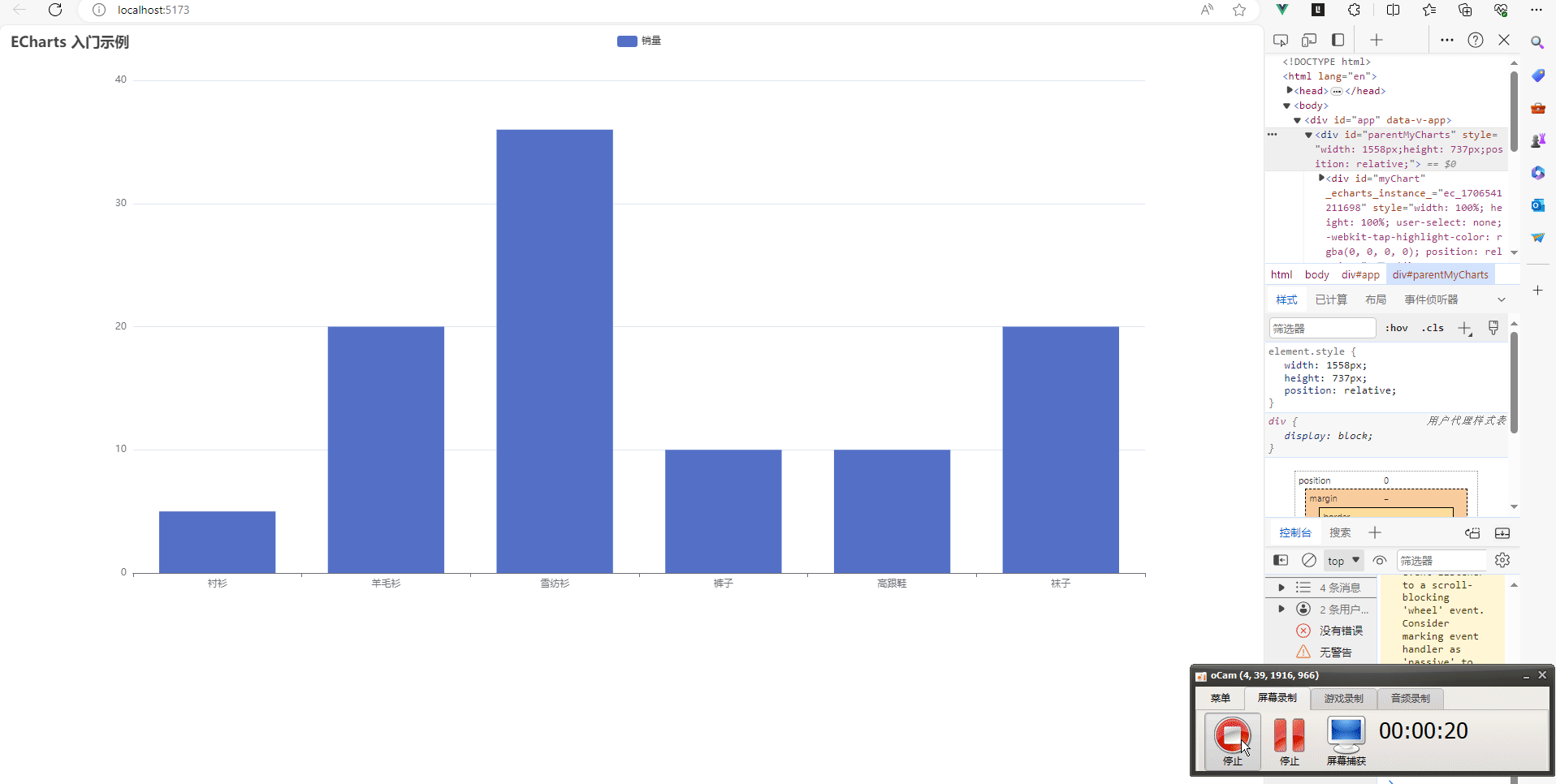
vue3项目中让echarts适应div的大小变化,跟随div的大小改变图表大小
目录如下 我的项目环境如下利用element-resize-detector插件监听元素大小变化element-resize-detector插件的用法完整代码如下:结果如下 在做项目的时候,经常会使用到echarts,特别是在做一些大屏项目的时候。有时候我们是需要根据div的大小改…...

springboot启动异常
Error creating bean with name ‘dataSource’ org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name dataSource: Unsatisfied dependency expressed through field basicProperties; nested exception is org.springframew…...

直播主播之互动率与促单
直播互动率是衡量直播间观众参与度的重要指标,通常指的是直播间的观众点赞、评论以及转发的数量。互动率越高,表明观众参与度越高,直播间的人气值也相应越高。 为了提升直播互动率,主播可以采取以下策略: 1.积极引导观众参与互动…...
Android 基础技术——Bitmap
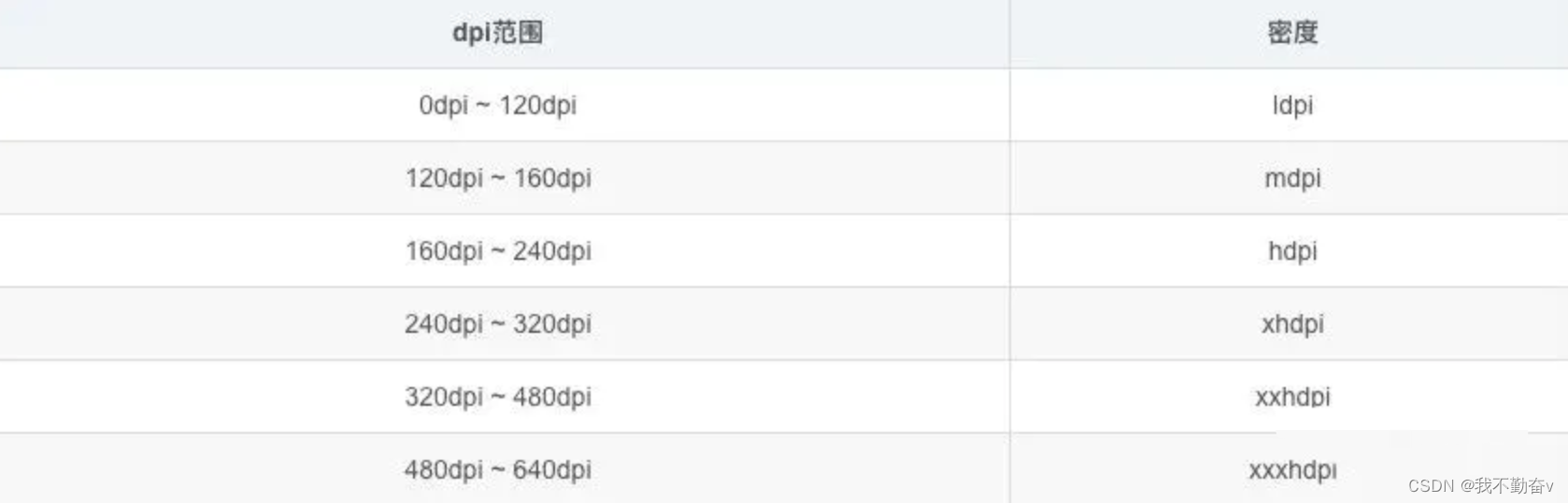
笔者希望做一个系列,整理 Android 基础技术,本章是关于 Bitmap Bitmap 内存如何计算 占用内存 宽 * 缩放比例 * 高 * 缩放比例 * 每个像素所占字节 缩放比例 设备dpi/图片所在目录的dpi Bitmap加载优化?不改变图片质量的情况下怎么优化&am…...

数据结构奇妙旅程之七大排序
꒰˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱ ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客 本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN …...

【JavaScript】Generator
MDN-Generator Generator对象由生成器函数返回,并且它符合可迭代协议和迭代器协议。 Generator-核心语法 核心语法: 定义生成器函数获取generator对象yield表达式的使用通过for of获取每一个yield的值 // 1. 通过function* 创建生成器函数 function* foo() {//…...

河南省考后天网上确认,请提前准备证件照哦
✔报名时间:2024年1月18号一1月24号 ✔报名确认和缴费:2024年1月 31号一2月4号 ✔准考证打印:2024年3月12号一3月17号 ✔笔试时间:2024年3月16日-2024年3月17日。 ✔面试时间:面试时间拟安排在2024年5月中旬 报名网址&…...

【前端】防抖和节流
防抖 防抖用于限制连续触发的事件的执行频率。当一个事件被触发时,防抖会延迟一定的时间执行对应的处理函数。如果在延迟时间内再次触发了同样的事件,那么之前的延迟执行将被取消,重新开始计时。 总结:在单位时间内频繁触发事件,只有最后一次生效 场景 :用户在输入框输…...

【网络】:网络套接字(UDP)
网络套接字 一.网络字节序二.端口号三.socket1.常见的API2.封装UdpSocket 四.地址转换函数 网络通信的本质就是进程间通信。 一.网络字节序 我们已经知道,内存中的多字节数据相对于内存地址有大端和小端之分, 磁盘文件中的多字节数据相对于文件中的偏移地址也有大端小端之分,网…...

Linux编程 1/2 数据结构
数据结构: 程序 数据结构 算法 1.数据结构: 1.时间复杂度: 数据量的增长与程序运行时间增长所呈现的比例函数,则称为时间渐进复杂度函数简称时间复杂度 O(c) > O(logn)> O(n) > O(nlogn) > O(n^2) > O(n^3) > O(2^n) 2.空间复杂度: 2.类…...

【UE Niagara】实现闪电粒子效果的两种方式
目录 效果 步骤 方式一(网格体渲染器) (1)添加网格体渲染器 (2)修改粒子显示方向 (3)添加从上到下逐渐显现的效果 (4)粒子颜色变化 方式二࿰…...
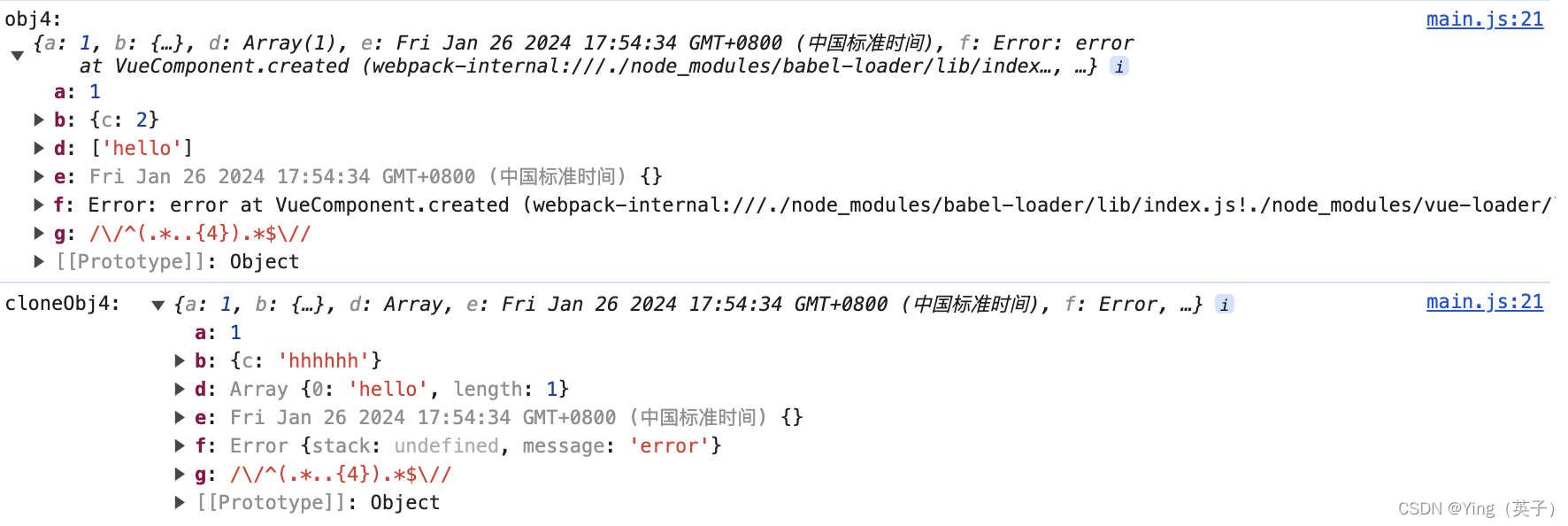
js数组/对象的深拷贝与浅拷贝
文章目录 一、js中的深拷贝和浅拷贝二、浅拷贝1、Object.assign()2、利用es6扩展运算符(...) 二、深拷贝1、JSON 序列化和反序列化2、js原生代码实现3、使用第三方库lodash等 四、总结 一、js中的深拷贝和浅拷贝 在JS中,深拷贝和浅拷贝是针对…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

2026这6款神级降AIGC平台大公开,一键让AIGC率直逼绝对安全线!
步入 2026 年,学术圈的风向早已不是从前的模样。曾经大家还在为查重率发愁,如今却陷入了更棘手的困境——如何在不破坏论文专业性的前提下,彻底消除 AI 痕迹?随着 AIGC 检测技术不断进化,高校对论文的审核标准也愈发严…...
)
别再纠结了!给激光焊接新手讲透单模和多模激光到底怎么选(附M²因子解读)
激光焊接设备选型指南:单模与多模激光的实战抉择 当你第一次站在激光焊接设备采购的十字路口,面对"单模"和"多模"这两个专业术语时,那种迷茫感我深有体会。五年前,我作为产线技术负责人,需要为汽车…...

如何快速无损转换B站m4s视频:完整工具使用指南
如何快速无损转换B站m4s视频:完整工具使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他设备…...
运营管理与服务保障平台建设方案)
低空旅游观光与低空通勤(eVTOL)运营管理与服务保障平台建设方案
本方案旨在为eVTOL载具构建集运营管理、空中交通管制、安全保障与乘客服务于一体的数字化平台。通过微服务架构、5G-A融合感知、空域网格化与零信任安全等核心技术,解决高密度飞行中的资源调度与安全冲突问题。目标实现毫秒级冲突解算与15分钟内快速周转,…...
)
Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践)
更多请点击: https://codechina.net 第一章:Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践) Lindy效应在自动化系统设计中揭示了一个关键洞察:越久经考验的实践,其未来预期寿命越长。Lindy多步…...
——仅限首批500名开发者开放》)
企业级Veo 2提示词治理框架(含合规校验/版本回溯/效果归因三模块)——仅限首批500名开发者开放》
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词治理框架的核心定位与演进逻辑 Veo 2提示词治理框架并非单纯的技术工具升级,而是面向AIGC生产环境规模化、合规化与可审计化需求的战略性基础设施重构。其核心定位在于将离散、经…...
:setup / onboard 与本地配置初始化)
OpenClaw 源码解析(五):setup / onboard 与本地配置初始化
1. 本期目标 上一期我们分析了 OpenClaw 的 CLI 启动链路:用户输入 openclaw 命令后,程序会先经过 entry.ts、run-main、Commander Program 构建和命令注册流程,然后再进入具体命令逻辑。 这一期继续往下看,重点分析两个最基础的…...