【Deep Dive: Al Webinar】开源人工智能中赋能、透明性和可重复性三者之间的关系...


【深入探讨人工智能】网络研讨系列总共有 17 个视频。我们按照视频内容,大致上分成了 3 个大类:
1. 人工智能的开放、风险与挑战(4 篇)
2. 人工智能的治理(总共 12 篇),其中分成了几个子类:
a. 人工智能的治理框架(3 篇)
b. 人工智能的数据治理(4 篇)
c. 人工智能的许可证(4 篇)
d. 人工智能的法案(1 篇)
3. 炉边对谈-谁在构建开源人工智能?
今天发布的是第二个大类别 “人工智能的治理” 里的第一个子类别 “人工智能的治理框架” 的第三个视频:开源人工智能中赋能、透明性和可重复性三者之间的关系。
我们期盼如此分类,对读者的易读性有帮助,也欢迎读者们的反馈和指正。
--- 开源社.国际接轨组 ---


Stefano Maffulli:
欢迎来到由开源促进会主办的深入探讨人工智能网络研讨会系列。我是 Stefano Maffulli,开源促进会执行董事,今天我们将听到 Ivo Emanuilov 和 Jutta Suksi,关于开源人工智能以及它如何实现透明度和快速可重复性,希望你喜欢。最后我们会回答大家的问题。
Ivo Emanuilov:
大家好,欢迎来到这个会议,在开源促进会的深入探讨开源人工智能的网络研讨会系列中,我很高兴今天能和我的同事,来自 VTT 的 Jutta Suksi 一起来到这里。我们两人将分享我们对如何塑造开源人工智能的看法和见解。我的名字是 Ivo Emanuilov,我是比利时鲁汶大学的知识产权律师和研究员。在过去的十年里,我一直专注于知识产权法和技术法。除了作为律师的工作,我还就如何采购、部署和管理机器学习项目向公司提供咨询,包括使用开源技术。Jutta,介绍一下妳自己吧!
Jutta Suksi:
大家好。我叫 Jutta Suksi,我在芬兰技术研究中心 VTT 工作。我所在的团队名为“数据密集型经济”(Data Intensive Economy)。我对数据有两个观点。首先,我关注与数据相关的法律问题,我有技术律师的背景;除此之外,我还会关注与数据相关的设计方面和沟通方面,因为我也有设计和新媒体的学位。很高兴见到大家。
Ivo Emanuilov:
我们的议程上有很多内容。在接下来的幻灯片中,你可以看到我们基本上打算涵盖的内容。
首先,我们要从不同的角度来探讨人工智能如何构建这个技术过程中包含的组件。然后,在以下三个系列的深入研究中,我将讨论的话题是版权和训练数据是如何联系起来的。在人工智能的背景下,人工智能到底是不是 IP,如果是,究竟是什么样的 IP ? 最后,时间将进入我们关于开源人工智能应该是什么样的提议的细节,或者至少涵盖开源社区已经提供的一些常用模块。
然后 Jutta 将会讨论并加入到这三次深入探讨的题目之间,在不同的阶段和组成部分进行介绍。一旦我们提出了开源人工智能面貌的愿景,以及如何在许可证环境和其他监管要求方面与之进行交易也发挥着重要作用。Jutta,你可以开始了。
Jutta Suksi:
好的。几周前,我和我们的技术经理哈勒曼坐了下来。我们试图找出与人工智能相关的阶段和不同的组件,这样我们就能真正理解在人工智能开发周期的哪个阶段应该开放,这是我们得到的可视化结果。首先,当然,如果我们看看构建人工智能的各个阶段,我们有训练数据,还有未训练的模型需要训练。未训练的模型需要训练,然后我们得到训练后的模型,进一步的输入数据以获得输出,所以这些都是在一个非常高的水平上,生成人工智能的基本阶段。
但这并不能让我们走得更远,让我们再深入一点。如果我们看一下训练数据的上半部分,这也是我们获得训练数据之前的初步阶段。
首先,我们需要访问数据。我们需要准备数据,收集数据,并进行预处理工作。在我们得到训练过的数据之前还有很多工作要做。然后,在底部部分同样适用。我们需要建立未经训练的模型,构建组件、构建结构、优化事物。除此之外,我们还有一些问题。这些问题在数据方面或模型方面并不明显。我们有预定义的模型,我们需要知识表征。我这些都是在我们的过程中所需的一些内容,这只是其中一部分的命名。
好的,然后进入下一个阶段,看看我们从训练中得到了什么。除了训练模型之外,还有几个组件要么是生成的,要么是在这个过程中出现的。当然,我们有训练好的模型。但除此之外,我们有参数、权重、拓扑、激活函数和表示,甚至是重新表示。然后继续看输出。
最后,我们会得到一个问题的答案,但这个答案可以是数据,可以是代码,也可以是图像。所以我们有很多要处理的内容,我们能从中得到什么?我们应该把重点放在哪里?这就是我们心中所想的问题,或者也许 Ivo 你可以带我们第一次深入探讨,然后告诉我们应该在哪里集中精力?
Ivo Emanuilov:
谢谢你,Jutta。因此,第一次深入探讨的目的是提出一个问题,也就是我们应该对关于我们用来训练机器学习模型的数据集里可能存在的版权问题有多关注?所以基本上第一步,出于研究目的,我们采用这个众所周知的。以 Copilot 为例,这是微软提供的一项服务,它从本质上合成了代码片段,从自然语言提示中合成了完整的程序。
针对这项特定服务提出的问题是,公开可用的 GitHub 开源代码库是否符合发布此代码时规定的许可证条件。基本上,我们在互联网上有公共代码和文本,它被抓取并在模型中使用,然后模型生成代码。
用微软自己的话来说,你的代码应该被视为私有代码。这种从代码到数据再到代码的转变,基本上提出了如何处理这个问题。从一个阶段到另一个阶段的转变在法律上意味着什么? 正如你在下一张幻灯片的图中看到的,基本上是这个问题的简单答案:微软是否可以依靠法定豁免,可能并不重要,因为所有复制的部分都是特定的代码片段。
通常,由于代码受版权保护,需要程序作者的授权。但是,如果法律本身对作者的这一专有权有例外限制,那么作者说什么就不再重要了。因为立法者自己已经决定允许第三方在未经授权的情况下使用这个代码。
因此,很明显,至少到目前为止,在准备和管理数据时需要某种形式的复制。这是一种需要权利人授权的行为,除非存在这种豁免。至少在欧盟,我们有这样的豁免,也被称为数据挖掘豁免税,以及2019年版权指令的第三条和第四条。所以即使我们能克服遵守许可证条件的要求,如果出现例外情况,这也无关紧要,因为我们可以依靠相关法律。虽然问题仍然存在,但是这为训练模型创造了一个足够稳定的合法基础。
正如你所看到的,我在这里复制了该指令第四条规定的一部分,它控制了异常限制和数据挖掘。你可以在第二段看到基本上是这样写的,结果和抽象可能只保留必要的时间。现在我们必须非常仔细地思量是否考虑例如词嵌入。从法律赋予或不赋予这些词语的意义上来说,作为复制品的摘取。实质上,我们需要问的是在分词过程中是否以及何时进行了标记化,在把符号转换成数字表示的过程中。因此,受版权保护的材料是否被分解到无法再被重构或感知,从而成为与原始受保护作品分离的独立元素。现在,如果你的模型重新生成的代码与根据开源许可证发布的代码完全相同,那么显然您处于不同的场景中。至少,在宽松许可证的情况下,你可能必须遵守通知和署名要求,或者遵守互惠许可证的情况下的附加义务。
重要的是,计算机程序的代码改编,属于文本和数据挖掘的例外情况。因为这是新版权法中唯一一个试图协调改编权的领域。这意味着在实际操作中,即使模型生成了一个计算机程序与现有的代码非常相似。例如,存在于 GitHub 上的托管存储库中。然后,这将被软件适应的协调机制所捕获,它被例外所涵盖。所以本质上,我们在问一个问题,这属于机器学习过程的哪一层?因此,符合版权条件的主题就变成了别的东西,不符合条件的东西,毫无意义的数字,仅凭此无法重建原作品。换句话说,我们在问这个问题,当代码变成数字数据时,版权保护是否失效?
Jutta Suksi:
哪一边把我们带到了我们可以更详细地分析的阶段。我们可以在 AI 中找到什么样的属性层? Ivo 说的是幻灯片的左边。关于训练数据在整个过程中发生了什么?如果我们看一下过程的上方,我们可以清楚地看到数据,但我们也可以看到与数据接近的问题和组件。比如参数或权重,这些到底是不是数据? 在底部,你会发现版权和软件这个词。
问题仍然存在,特别是当我们谈论训练模型时。我们离软件换软件的世界还有多远? 在中间,我们有很多其他类别的组件。我们有图像数据,我们有答案,我们有知识表示,还有发生在机器和人类之间的事情。
所以从这个意义上说,我们可以尝试识别不同的参与者,看看发生了什么?那么,Ivo,你怎么看待我们在这里看到的这些层次和知识产权的混合性质?
Ivo Emanuilov:
跟你说的一样。我认为它是混合的,因为人工智能,至少以机器学习的形式,不受单一政权的统治,尤其是在知识产权方面。所以,版权问题并不存在于我们在这里看到的每一层链的每一步。
这就提出了一个问题,如果人工智能是一种混合知识产权,我们如何处理这个问题? 我认为欧盟法院,至少当涉及到你的时候,给了我们一些提示。这对我们的一些听众来说可能有点奇怪。
那就是电子游戏,这就是任天堂的例子。这是 2012 年的一个老案子,这个案件是2014 年由法院判决的, 但从本质上讲,该案件涉及电子游戏的技术保护措施。在判决书的一个段落中,法院给出了一个非常有趣的关于电子游戏的法律性质和知识产权性质的推理。所以,正如你在这里看到的,我将为你读一下,法院表示,电子游戏构成了复杂的主题。它不仅包括计算机程序,还包括图形和声音元素,虽然是用计算机语言加密的。
因此,原则上对人类不可读的内容具有独特的创造价值。这不能简单地归结为加密的问题。现在,法院继续说,就电子游戏的部分而言,图像和声音元素是其独创性的一部分,它们和整个作品都受版权保护,在这里引用的信息社会 (InfoSoc) 指令的背景下。那么这在实际中意味着什么呢?
人们普遍认为,这个决定基本上巩固了我们在欧洲版权法中的区别,至少在封闭主体体系和开放主体体系之间的区别。正如你在这张图中看到的,这个开放的知识产权体系基本上是一个系统,我喜欢称之为“包罗万象”,一个统一的方法, 这仅仅取决于原创性的标准。所以,我们对事物如何被客观化和以客观形式表达并不感兴趣,而是它是否符合原创性的标准。
就欧盟而言,这是关于知识创造的通告。所以理论是这样的,正如你在右边看到的,只要某样东西被认为是原创的,在版权法保护的意义上,它作为主题是什么并不重要,这是自动的,因为这是版权。那么这种方法和密切相关的主题处理方法,基本上是研究每个单独的元素。只要每个元素都是原创的,那么最终的电子游戏显然也是原创的。在开放主题方法中,你可以看到,事实上,我们关注的是混合物体,也就是电子游戏。然后,因为基本上它的大部分元素都适用于版权,以及媒体原创的门槛,那么我们就可以作为一个整体。在电子游戏的多媒体作品中申请版权,为什么会有不同呢?
首先,对我来说,在这两种情况下,单个元素无论如何都会被评估,得出混合对象是否为原物的结论。所以你至少需要有大多数符合这个标准的元素来为这个对象附加版权。然而,在统一的方法中,在开放的主题方法中,我认为也有可能捕捉到未受保护的主题。所以,把混合功能想象成一个强磁铁,吸引题材。从实际角度来看,这将会产生天壤之别。例如,电子游戏中的交易模式是否会受到保护。
因为在第一种封闭系统中,在主体系统的方法中,你可以通过它的视频作品,音频作品和文字作品看到这一点。你可以认为,基于这些,我们会认为电子游戏是原创的。因此,这是一个具有版权的主题,但却是一个奇怪的模式。它没有人类可读的源代码等等。这会被发现吗?可能不会。
在第二种情况下,人们可能会认为电子游戏的这种观点是一种混合知识产权,允许某些人对这种模式提出保护。显然,人工智能不同于电子游戏。但是,如果我们采用法院建议的方法。事实上,主题可能并不总是人类可读的。在这种情况下,我们不需要剥夺它的原创性或是其加密需求。那么,我认为欧洲版权法里的人工智能,至少可以被合理地视为一种混合学科。当然,我并不是说这是一个好的版权政策。
老实说,我个人对版权是否适合捕捉 AI 的细微差别持怀疑态度。当然,我们也必须谨慎地从一个案例中得出一般性结论。因为,非常重要的是,这不仅仅是一个关于电子游戏的原则上的案例,而是一个更具体的关于技术保护措施的案例。在这种情况下,法院必须处理的问题是电子游戏是否应该被深入探索分析,以及《信息社会指令》的一般制度,或《计算机程序指令》的特殊立法制度。
法院认为,《信息社会指令》在处理混合媒体作品时适用,而《计算机程序指令》只适用于纯软件。现在,在讨论的背景下,这提出了一个更有趣的问题,即我们是否应该将人工智能 ,或者至少是过程中的一些元素,如软件或一般版权合格的主题,纳入版权问题的范畴?
现在,许多人认为机器学习模型与计算机程序完全不同。我同意这个观点。然而,模型只是一个更长的技术过程中的中间输出,通常会产生一个功能性应用程序,然后通过 API 查询模型。所以在这种统一的方法下,考虑版权并不是不可能的。在应用程序层上扩展还可以扩展并捕获底层模型。
当然,除非我们认为模型仅仅是数学算法(而它们确实是),它们本质上是抽象的。如果我们谈论的是微调模型就不是这样的。例如,微调模型当然是非常具体的任务。
最后,我们面临两个问题。首先,如果我们遵循统一的方法,作为混合知识产权的人工智能,是否应该作为一个整体获得许可? 例如,假设的混合互惠许可如何在实践中发挥作用? 那么,对于一个完整的对应源代码的概念来说,它的数量是多少呢? 这些问题还不是很清楚。
第二个问题是,如果遵循我们都太熟悉的典型的知识产权主题体系。如果有版权保护的话,哪些元素可以并且应该受到版权保护,如何处理那些不受版权保护的主题,并且更重要的是如何进行交易。如何确保不同主题之间的许可证兼容性,这是一个特别复杂的问题。
Jutta Suksi:
这就引出了我们的下一部分,也就是今天的核心问题,如何为开源人工智能建立类似于开源软件的动力。对我来说,这个问题的核心似乎是,后期阶段是怎样的?我们在过程中得到的组件是怎样反馈到系统的开始的?人机交互问题里,最关键的是准备数据和构建模型的周期。因为其中一些问题需要由人类来解释,然后再返回到机器格式。所以问题是,我们能否通过研究这三个问题来实现以下目标:透明度、可实现性和可重复性。
另一个突然出现的问题,是我们所拥有的限制的作用。这在我们目前在该领域的许可证中是可见的。所以 Ivo 将介绍关于透明度,可实现性和可重复性的术语,之后我会就我们目前的限制和许可说几句话。
Ivo Emanuilov:
如果我们接受人工智能不是一个知识产权混合物,但它仅仅是计算产物的集合,其中一些可能有版权保护。那么我们面临的问题是如何实现开源的效果,而不仅是复制和支持开源软件的模式。所以这是为了达到效果,而不是仅仅复制我们在开源软件中拥有的东西。正是因为它具有挑战性,所以与代码不同,代码受某种程度上国际协调的版权法管辖,对于 AI 管道中的多个元素,我们没有类似的东西,不适合完全遵循版权框架的内容。
矛盾的是,也许对你们中的一些人来说,它就是国际版权法组织,这帮助开源获得了动力。开源许可证的普遍存在,本质上是基于一个潜在的假设,即代码中存在版权。从本质上讲,交易的正是这种版权。不管你是放弃你的权利,把它奉献给公共领域, 或者允许下游接收者有条件地或无条件地依赖于它。所有这些操作和活动,本质上都是在行使您对代码的版权。现在,由于我们还没有任何类似的人工智能技术,我们建议考虑开源对人工智能的影响。在这个意义上,在我们看来,三个基本原则应该是任何开源定义的核心。
第一个是,正如你提到的,透明度,我们把它理解为公开训练数据集组成的细节。例如,有关数据结构、体系结构算法、访问神经网络权重等的详细信息。所以这是技术意义上的透明,意味着这种程度的披露,有利于项目周围的社区重建模型。如果它是这样希望的话,这让我想到了第二个要素,即可实现性。
现在,赋能是一个类似于我们从专利法中了解到的原则。这可能会让你们中的一些人感到惊讶。披露的充分性,或者说细节的不足,可以让有相关技术的人重现。重要的是法律能够帮助实现所要求的发明,重要的是法律促进发明。但重点是,很明显,顶级开源社区很少有像专利办公室这样的机构能力。因此,以类似的方式实现这一点将是具有挑战性的,而且不太实际。如果我们把可实现性理解为公开,那么关于模型构建的足够的细节就被忽略了。至少理论上任何有计算资源人,都可以重建该模型。
我会允许一个可预测的标准,什么时候机器学习模型是开源的,什么时候不是。很明显的,赋能将依赖于环绕着项目,并渴望开源原则的社区来开发技术标准。但从本质上讲,这个想法归结为能够重建被称为开源的东西。因为从本质上讲,这就是传统开源软件许可中对源代码的访问权限。任何人都可以拿到代码,他们可以修改,他们可以重建它。但是本质上你通过提供对源代码的访问来实现。当然,我认为类似的方法也可以应用在这里。在 AI 的情况下,实现需求会有很大的不同。所以我们可以用一些例子,比如我们从 Hugging Face 中知道的卡片模型,其他类型的披露合作政策等等。所以,我想,它将比我们所拥有的开源软件更广泛。
第三个要素是可重复性。一个赋能关系的陈述。如果没有验证这个陈述的合理性的方法就没有什么意义。所以我可能会发表一些东西,并声称社区现在已经启用,他们实际上可以重建它。但除非他们持续追踪,否则是否能做到这一点,没有人会知道。现在,出于这个原因,我们提出可重复性作为开源人工智能的第三个原则。我们在这里讨论的不是一般的可重复性,而是更类似于我们所说的可复制构建。这是一组创建的软件开发实践,一个从源代码到二进制代码的自变量路径。当然,这一主张引起了对实际再训练的可行性的另一个关注。例如,从头开始和更新基本模型,这样的投入可能是巨大的。尤其是需要考虑到避免产生环境问题。是否有一种方法可以避免问题和促进可实现性,同时仍然确定有一些可重复性保证,以及在社区眼中,应该算作可重复性的令人信服的证据。
现在,无论如何,如果开源人工智能要复制成功的开源软件,然后下游用户应该能够依赖某种形式的社区保证。所以本质上,在这个角色中,社区围绕着开放项目,宣称开源的人工智能将发挥极其重要的作用,他们必须制定强有力的行为准则来处理这些问题。三个不同的要求,以及它们应该被认为已经满足的时间。所以从本质上讲,为了实现人工智能开源的效果,我们必须利用强大的政策及指令。这是非常有益的,我们知道最终会产生好的产品和好的软件。这是我们在过去几十年里在开源软件中看到的。
Jutta Suksi:
谢谢你!现在让我们来看看 AI 许可方案,以及我们可以从中学到什么。所以从数据方面来说,我想强调的第一件事是 2019 年的蒙特利尔数据许可证。有趣的是它关注的是数据,它不关注开放性,但它从数据方面给了我们一个视角,我觉得这很有趣。然后,再看 Big Science BLOOM Rail 许可证,我们可以发现限制的重点。这个我们还没怎么讲。下一个,开放权重宽松许可证 (Open weights permissive license),专注于权重,给了我们正在进行的人机交互一个非常重要的面向。
最后,我们有 OpenRAIL-DAMS 许可证,它关注的是限制。除此之外,它们还处理数据、可执行文件、模型和源代码的组合。如果我们要解释如何选择这些混合的大组合。如果我们试着把它映射到我们的通用线路图上,我们可以看到,最重要的部分是第一批许可证(如 OpenRAIL 许可证),它们就在那里,并且已经证明了它们的力量。
从第一批许可证中学习,以及因而发生的动态变化,是这项工作的核心。但是我们也应该从数据方面进行研究,并从蒙特利尔数据许可证中获取一些经验,看看我们为什么要有这些限制,以及我们为什么以及在哪里需要这些限制?例如,从 BLOOM Rail 许可证来看,更详细地了解权重。最后,看看所有这些东西的混合组合。尽管我认为我们可以从所有这些许可证中学习,我们应该学习如何构建开源人工智能。如果我继续往下看一些关于我们现在所处位置的随机观察。例如,关于许可证,我想强调的是,变化非常迅速。
因此,从这句话中,您可以看到 在几个月内 Open RAIL 许可证已经成为第二大使用类别,在宽松的开源软件许可证之后,这是一个非常迅速的变化。另一个观察来自监管方面。我们应该记住,我们别忘记世界各地的监管要求。人工智能正在受到监管。这里我们可以找到斯坦福大学的一项研究,他们研究了创建基础模型的提供者如何遵守欧盟人工智能法案草案。一个有趣的部分是,目前没有人做到这样的合规,但最接近的是 HuggingFace 的 BLOOM。
最后,还有一个我特别感兴趣的问题,或许也是 Ivo 所说的的核心所在,就是在法律方面和商业方面之间架起理解的桥梁。这是我们在 Zooom 项目中研究了一年的东西,我们即将公布初步结果,并开始为开发人员和企业开发实用工具和工具箱。
在这里,我们的重点确实是理解商业方面如何与法律方面协同工作。所以请浏览我们的网站,看看我们的详细结果。在此感谢你们所有人,现在是讨论和提问的时间了。
Ivo Emanuilov:
感谢大家收听!我们在问答环节见。


Ivo Emanuilov
IP lawyer / PhD researacher, KU Leuven Centre for IT & IP Law

Jutta Suksi
Senior Specialist, Legal and Design in Data Economy
VTT Technical Research Centre of Finland Ltd
作者丨Ivo Emanuilov、Jutta Suksi
翻译丨陈超群
审校丨刘天栋
视频丨陈玄
策划丨李思颖、罗蕊艳
编辑丨王梦玉
相关阅读 | Related Reading
【Deep Dive: AI Webinar】将SAFE-D原则应用于开源人工智能中
【Deep Dive: AI Webinar】基于LLM的推荐系统中的公平与责任:确保人工智能技术的使用合乎道德
【Deep Dive: AI Webinar】在开放开发的开源项目中引入 AI 的挑战
【Deep Dive: AI Webinar】开放 ChatGPT - 人工智能开放性运作的案例研究
开源社简介
开源社(英文名称为“KAIYUANSHE”)成立于 2014 年,是由志愿贡献于开源事业的个人志愿者,依 “贡献、共识、共治” 原则所组成的开源社区。开源社始终维持 “厂商中立、公益、非营利” 的理念,以 “立足中国、贡献全球,推动开源成为新时代的生活方式” 为愿景,以 “开源治理、国际接轨、社区发展、项目孵化” 为使命,旨在共创健康可持续发展的开源生态体系。
开源社积极与支持开源的社区、高校、企业以及政府相关单位紧密合作,同时也是全球开源协议认证组织 - OSI 在中国的首个成员。
自2016年起连续举办中国开源年会(COSCon),持续发布《中国开源年度报告》,联合发起了“中国开源先锋榜”、“中国开源码力榜”等,在海内外产生了广泛的影响力。

相关文章:
【Deep Dive: Al Webinar】开源人工智能中赋能、透明性和可重复性三者之间的关系...
【深入探讨人工智能】网络研讨系列总共有 17 个视频。我们按照视频内容,大致上分成了 3 个大类: 1. 人工智能的开放、风险与挑战(4 篇) 2. 人工智能的治理(总共 12 篇),其中分成了几个子类&…...
将Html页面转换为Wordpress页面
问题:我们经常会从html源码下载网站上获得我们想要的网站内容框架,以及部分诸如联系我们,About 等内页,但是在文章的发布上,则远不如Wordpress简便。而Wordpress尽管有各种模板,但修改又比较麻烦。解决方法…...
——样式)
Next.js 学习笔记(七)——样式
样式 Next.js 支持不同的应用程序样式设计方法,包括: 全局 CSS:对于有传统 CSS 使用经验的人来说,使用简单且熟悉,但随着应用程序的增长,可能会导致 CSS 包过大,难以管理样式。CSS 模块&#…...
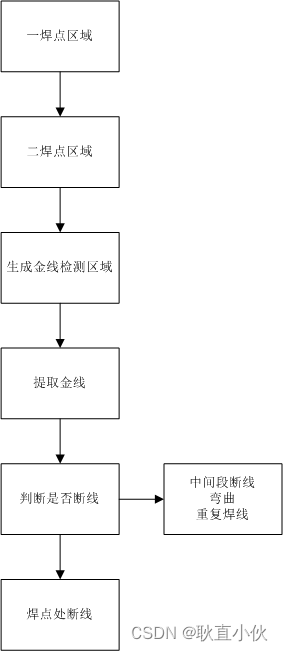
金线检测步骤
半导体行业,金线检测是必不可以少的一个检测项,除了焊点,die面,手指以外的必检项目. 重难点在于金线的提取,算法多种多样,找到适合才是关键,涉及到打光,图像处理,这里不做深入分析,软件和硬件配合好才能做的最好. 经典算法Block分析,结合图像检测. 高斯算法提取 边缘检测算法提…...
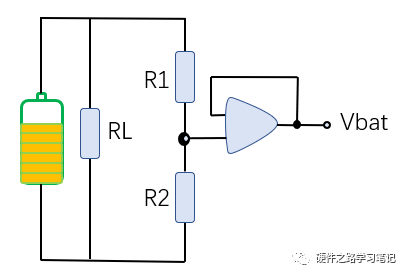
电池-电量监测基础知识
一、为何要进行电池电量监测 不知各位有没有想过为何现在手机电池和笔记本电脑电池不容易鼓包了?十年前还经常出现的电池鼓包最近像是消失了一样,其实是因为随着电量监测技术的发展,哪怕是最基本的电子设备也有电池侧和产品侧至少两级电量监测…...
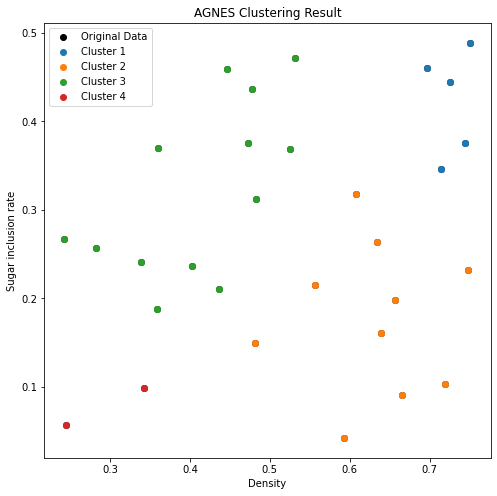
西瓜书学习笔记——层次聚类(公式推导+举例应用)
文章目录 算法介绍实验分析 算法介绍 层次聚类是一种将数据集划分为层次结构的聚类方法。它主要有两种策略:自底向上和自顶向下。 其中AGNES算法是一种自底向上聚类算法,用于将数据集划分为层次结构的聚类。算法的基本思想是从每个数据点开始࿰…...
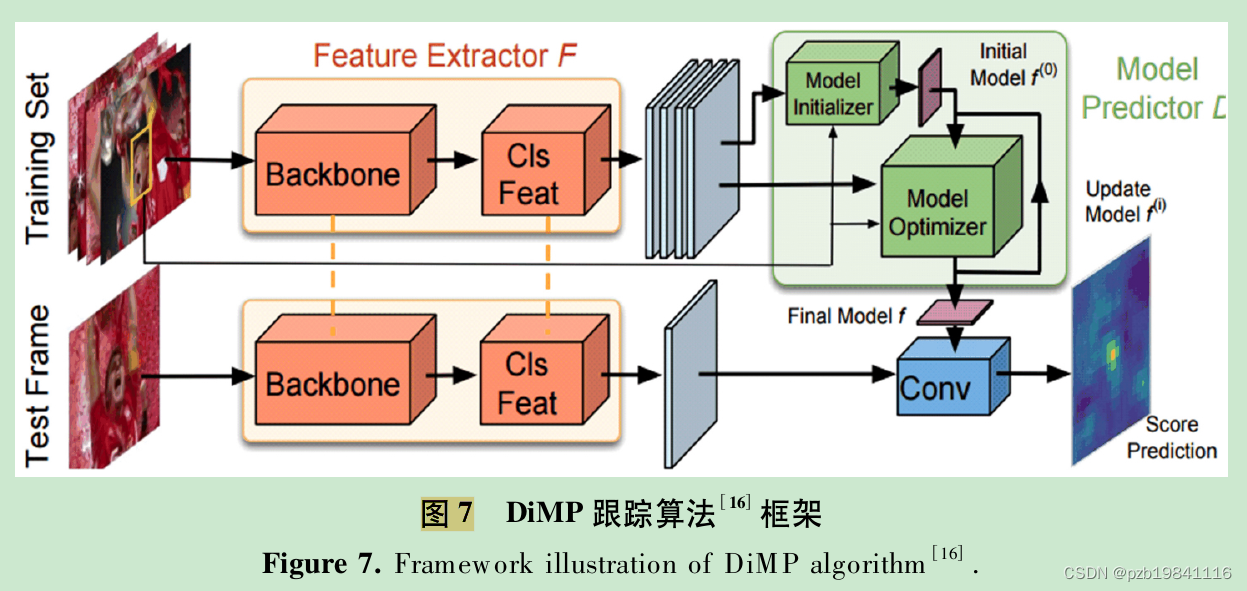
深度视觉目标跟踪进展综述-论文笔记
中科大学报上的一篇综述,总结得很详细,整理了相关笔记。 1 引言 目标跟踪旨在基于初始帧中指定的感兴趣目标( 一般用矩形框表示) ,在后续帧中对该目标进行持续的定位。 基于深度学习的跟踪算法,采用的框架包括相关滤波器、分类…...

【数据结构:顺序表】
文章目录 线性表顺序表1.1 顺序表结构的定义1.2 初始化顺序表1.3 检查顺序表空间1.4 打印1.5 尾插1.6 头插1.7 尾删1.8 头删1.9 查找1.10 指定位置插入1.11 删除指定位置数据1.12 销毁顺序表 数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一…...

android tts播报破音解决方案汇总
导航app引导中经常遇到破音,这里也将之前经历过的方案收集以下,方便以后选择: 1 对于开始和结尾破音: 可以用升降音来处理 两种方式 一种是 直接对开始和结束的时间段进行音量直接渐进改变。这里配的是200ms的渐变。 VolumeSha…...

2024年新提出的算法:一种新的基于数学的优化算法——牛顿-拉夫森优化算法|Newton-Raphson-based optimizer,NRBO
1、简介 开发了一种新的元启发式算法——Newton-Raphson-Based优化器(NRBO)。NRBO受到Newton-Raphson方法的启发,它使用两个规则:Newton-Raphson搜索规则(NRSR)和Trap Avoidance算子(TAO&#…...

笔记 | Clickhouse 命令行连接及查询
在 ClickHouse 中,可以使用命令行客户端执行查询。默认情况下,ClickHouse 的命令行客户端称为 clickhouse-client。下面是一些基本的步骤和示例,用于使用 clickhouse-client 进行查询。 首先,需要确保已经安装了 ClickHouse 服务…...

设计模式—行为型模式之责任链模式
设计模式—行为型模式之责任链模式 责任链(Chain of Responsibility)模式:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时&am…...
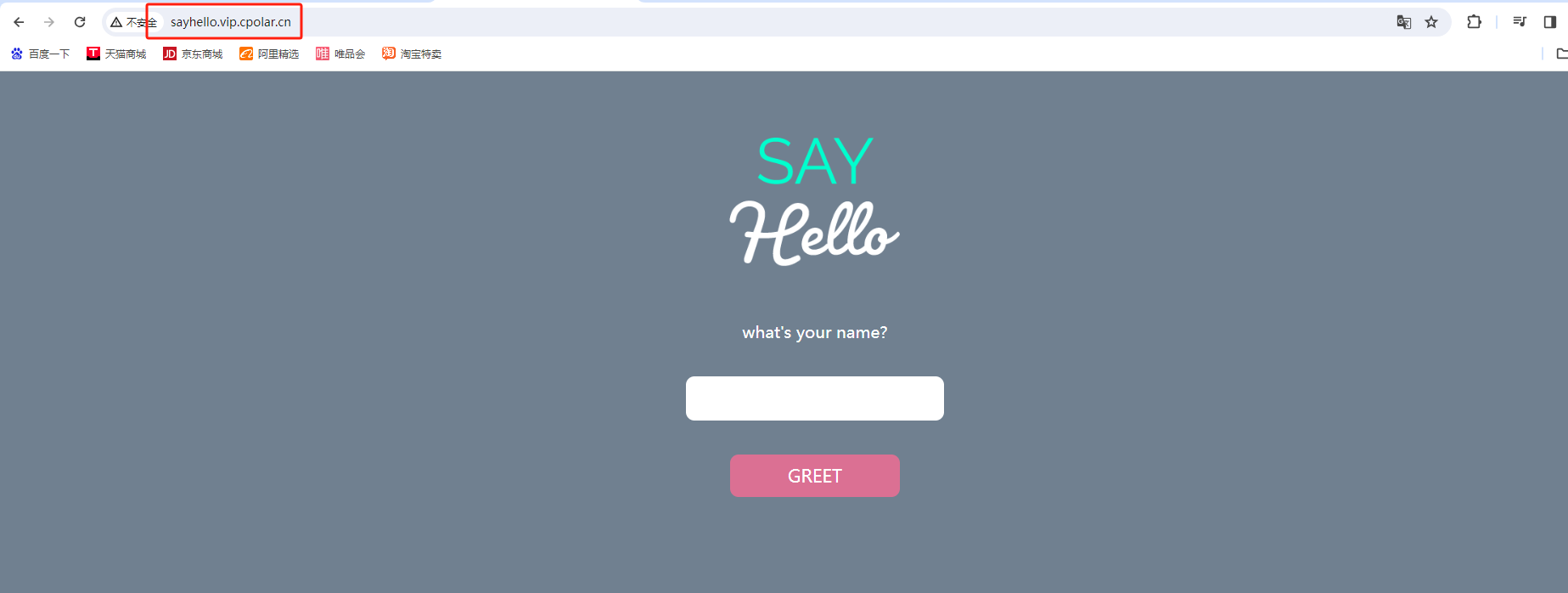
如何使用Python+Flask搭建本地Web站点并结合内网穿透公网访问?
文章目录 前言1. 安装部署Flask并制作SayHello问答界面2. 安装Cpolar内网穿透3. 配置Flask的问答界面公网访问地址4. 公网远程访问Flask的问答界面 前言 Flask是一个Python编写的Web微框架,让我们可以使用Python语言快速实现一个网站或Web服务,本期教程…...

【C语言】【力扣】刷题小白的疑问
一、力扣做题时的答案,没有完整的框架 疑问: 在学习C语言的初始,就知道C语言程序离不开下面这个框架,为什么力扣题的解答往往没有这个框架? #include <stdio.h>int main() {return 0; } 解答: 力扣平…...
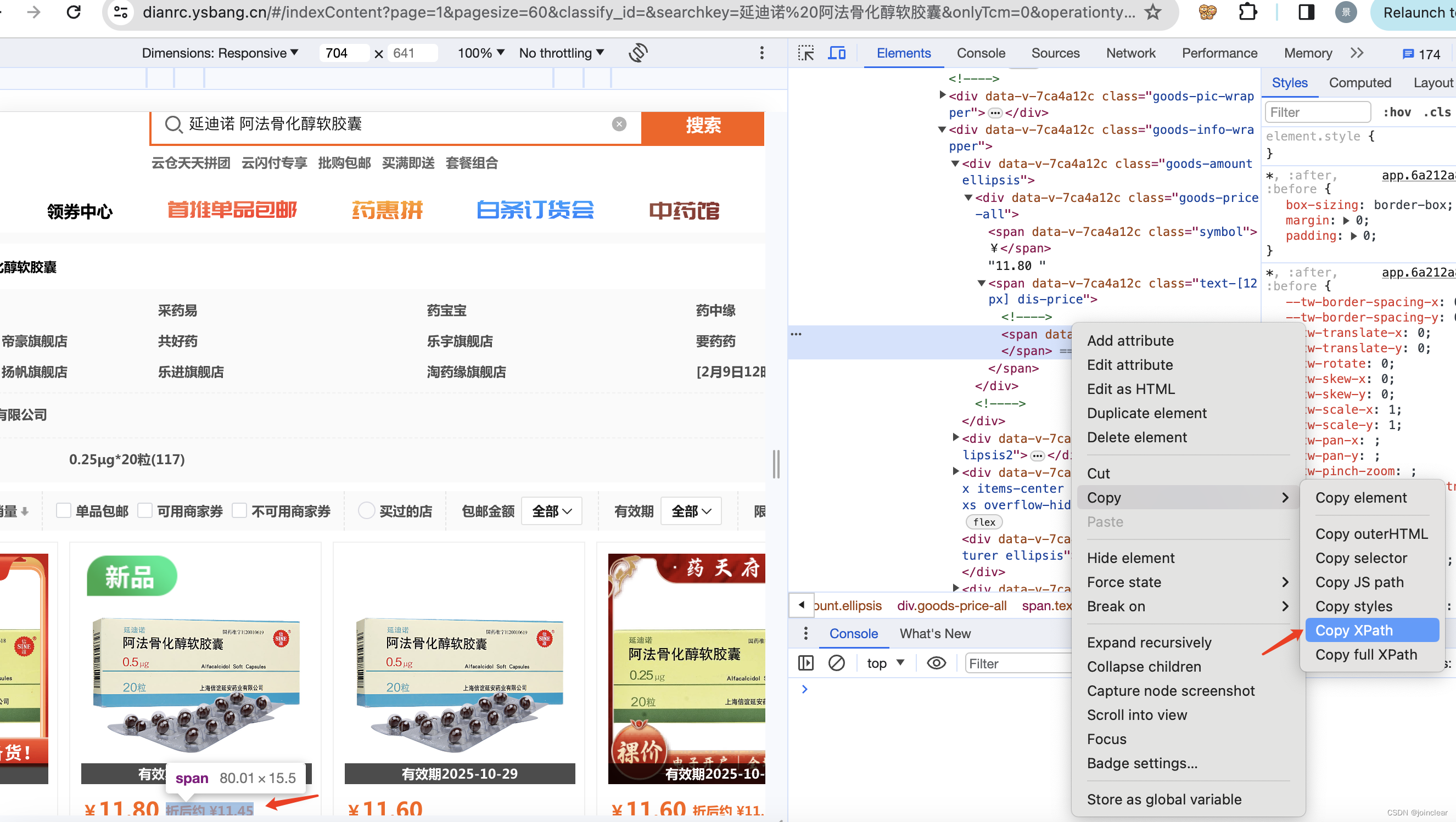
【Python】03快速上手爬虫案例三:搞定药师帮
文章目录 前言1、破解验证码2、获取数据 前言 提示:通过用户名、密码、搞定验证码,登录进药师帮网站,然后抓取想要的数据。 爬取数据,最终效果图: 1、破解验证码 使用药师帮测试系统:https://dianrc.ysb…...

C++异步编程
thread std::thread 类代表一个单独的执行线程。在创建与线程对象相关联时,线程会立即开始执行(在等待操作系统调度的延迟之后),从构造函数参数中提供的顶层函数开始执行。顶层函数的返回值被忽略,如果它通过抛出异常…...
P1141 01迷宫——洛谷(题解))
dfs专题(记忆化搜索)P1141 01迷宫——洛谷(题解)
题目描述 有一个仅由数字 00 与 11 组成的 ��nn 格迷宫。若你位于一格 00 上,那么你可以移动到相邻 44 格中的某一格 11 上,同样若你位于一格 11 上,那么你可以移动到相邻 44 格中的某一格 00 上。 你的任务是&#…...
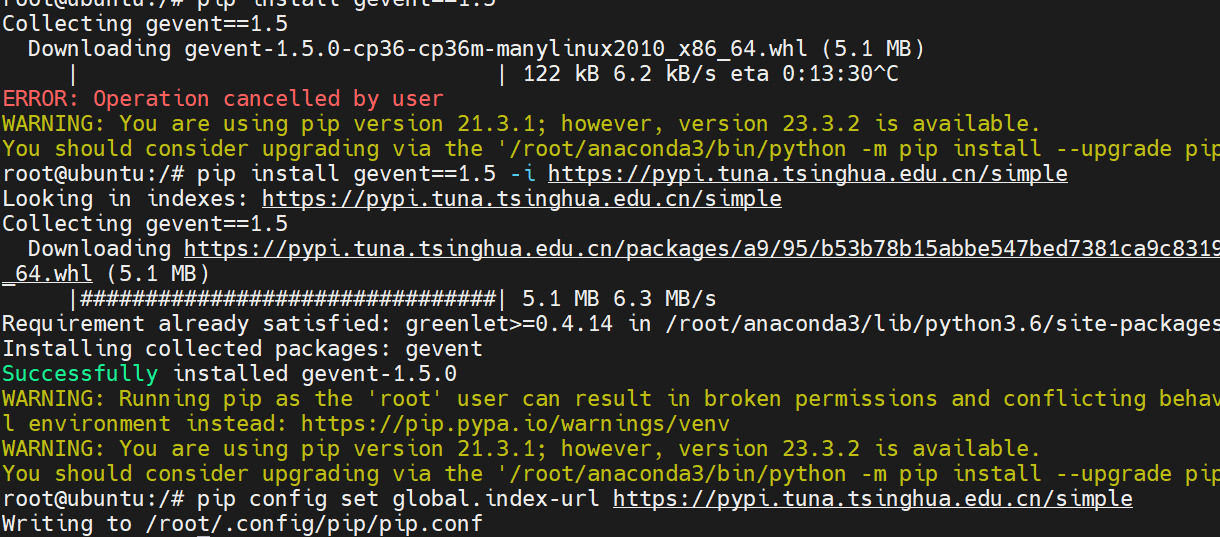
pip 安装出现报错 SSLError(SSLError(“bad handshake
即使设置了清华源: pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simplepip 安装包不能配置清华源,出现报错: Retrying (Retry(total2, connectNone, readNone, redirectNone, statusNone)) after connection broken by ‘SSLE…...
)
新概念英语第二册(46)
【New words and expressions】生词和短语(12) unload v. 卸(货) wooden adj. 木制的 extremely adv. 非常,极其 occur …...

动态规划入门题目
动态规划(记忆化搜索): 将给定问题划分成若干子问题,直到子问题可以被直接解决。然后把子问题的答保存下来以免重复计算,然后根据子问题反推出原问题解的方法 动态规划也称为递推(暴力深搜记忆中间状态结果…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造
如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造 【免费下载链接】redux-dynamic-modules Modularize Redux by dynamically loading reducers and middlewares. 项目地址: https://gitcode.com/gh_mirrors/re/redux-dynamic-modules Redux Dyn…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...

实战解锁:在Blender中掌握专业级MMD动画制作全流程
实战解锁:在Blender中掌握专业级MMD动画制作全流程 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools MMD …...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...
CI/CD流水线中的幽灵依赖——DeepSeek项目92%存在未声明的transitive risk,你中招了吗?
更多请点击: https://intelliparadigm.com 第一章:CI/CD流水线中的幽灵依赖——DeepSeek项目92%存在未声明的transitive risk,你中招了吗? 在现代CI/CD实践中,开发者常误以为 package.json 或 requirements.txt 中显式…...