python爬虫学习之解析_BeautifulSoup
目录
一、bs4的基本使用
(1)导入
(2)创建对象
二、节点定位
1、根据标签名查找节点
2、基本函数使用
(1)find
(2)find_all
(3)select
三、节点信息
1、获取节点内容
2、获取节点属性
附:bs4的基本使用.html
四、bs4的应用
注:Python3.10+,使用 Beautiful Soup 时出现错误“AttributeError 'collections' has no attribute 'Callable'”。
在 python 3.10+ 中,collections.Callable已移至collections.abc.Callable 。
故推荐用Python3.10以下版本。
一、bs4的基本使用
(1)导入
from bs4 import BeautifulSoup
(2)创建对象
--服务器响应的文件生成对象
soup = BeautifulSoup(response.read().decode(),'lxml')
--本地文件生成对象
#默认打开文件的编码格式是gbk,故在打开文件的时候要指定编码
soup = BeautifulSoup(open('bs4的基本使用.html',encoding='utf-8'),'lxml')
二、节点定位
1、根据标签名查找节点
#找到的是第一个符合条件的数据 print(soup.a)
#获取标签的属性和属性值 print(soup.a.attrs)
2、基本函数使用
(1)find
#找到的是第一个符合条件的数据
print(soup.find('a')) #和soup.a差不多
#根据title的值来找到对应的标签对象
print(soup.find('a',title = "A1"))
#根据class的值来找到对应的标签对象
#注意class需要添加下划线
print(soup.find('a',class_ = "A2"))
(2)find_all
# 返回的是一个列表 并且返回了所有的a标签
print(soup.find_all('a'))#如果需要获取多个标签的数据,则需要在find_all的参数中添加的是列表的数据
print(soup.find_all(['a','span']))#limit是查找前几个数据
print(soup.find_all('li',limit=2))
(3)select
#select会返回一个列表,并且会返回多个数据
print(soup.select('a')) #和find差不多#类选择器
#可以通过.代表class
print(soup.select('.A2'))#可以通过#代表id
print(soup.select('#L1'))#属性选择器
#查找li标签中有id的标签
print(soup.select('li[id]'))#查找到li标签中id为L1的标签
print(soup.select('li[id="L1"]'))# 层级选择器
#后代选择器 查找div下面的li 返回的是一个列表
print(soup.select('div li'))#子代选择器
#某标签的第一级子标签
# warning:在大多数编程语言中需要div > ul >li 这样写,但是在bs4中,可以写div>ul>li。
print(soup.select('div>ul>li'))# 获取多个标签的数据
print(soup.select('a,span'))
#区别 同find_all 一样输出
print(soup.find_all(['a','span']))
三、节点信息
1、获取节点内容
obj = soup.select('#d1')[0]
#如果标签对象中,只有内容那么string和get_text()都可以使用
#如果标签对象中,除了内容还有标签,那么string就会输出NONE
print(obj.string)
print(obj.get_text())
2、获取节点属性
obj = soup.select('#p1')[0]
#name是标签的名字
print(obj.name)
#将属性值作为一个字典返回
print(obj.attrs)#获取节点的属性
obj = soup.select('#p1')[0]
print(obj.attrs.get('class'))
print(obj.get('class'))
print(obj['class'])
附:bs4的基本使用.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body><div><ul><li id="L1">张三</li><li id="L2">李四</li><li>王五</li><a href="" id="" class="A2">蜀道之南718</a><span>万事如意</span></ul></div><a href="" title="A1">百度</a><div id="d1"><span>恭贺新禧</span></div><p id="p1" class="p1">大吉大利</p>
</body>
</html>四、bs4的应用
用bs4来爬取麦当当的所有汉堡品类
import urllib.requesturl = "https://www.mcdonalds.com.cn/index/Food/menu/burger"response = urllib.request.urlopen(url)content = response.read().decode('utf-8')from bs4 import BeautifulSoupsoup = BeautifulSoup(content,'lxml')#//span[@class="name"]/text()
name_list = soup.select('.name')for name in name_list:print(name.get_text())相关文章:

python爬虫学习之解析_BeautifulSoup
目录 一、bs4的基本使用 (1)导入 (2)创建对象 二、节点定位 1、根据标签名查找节点 2、基本函数使用 (1)find (2)find_all (3)select 三、节点信息 1、获取节…...

2024美赛数学建模赛题解读常用模型算法
回归拟合预测 拟合预测是建立一个模型去逼近实际数据序列的过程,适用于发展性的体系。建立模型时,通常都要指定一个有明确意义的时间原点和时间单位。而且,当t趋向于无穷大时,模型应当仍然有意义。将拟合预测单独作为一类体系研究…...

NoSQL 数据库管理系统和模型的比较
前些天发现了一个人工智能学习网站,通俗易懂,风趣幽默,最重要的屌图甚多,忍不住分享一下给大家。点击跳转到网站。 NoSQL 数据库管理系统和模型的比较 介绍 当大多数人想到数据库时,他们通常会想到传统的关系数据库…...
)
数据库(SQL)
目录 1 触发器 1.1 触发器简介 1.2 触发器的创建 语法 说明 1.3 示例 2 存储过程 2.1 什么是存储过程(函数) 2.1.1 存储过程和存储函数的区别 2.2 优势 2.3 应用场景 2.4 存储过程的创建和使用 说明 各参数类型所实现的存储过程 无参数无返…...

如何用Docker+jenkins 运行 python 自动化?
1.在 Linux 服务器安装 docker 2.创建 jenkins 容器 3.根据自动化项目依赖包构建 python 镜像(构建自动化 python 环境) 4.运行新的 python 容器,执行 jenkins 从仓库中拉下来的自动化项目 5.执行完成之后删除容器 前言 环境准备 Linux 服务器一台(我的是 CentOS7)…...

uniapp瀑布流实现
1. 图片瀑布流: 不依赖任何插件,复制即可见效: <template><view class"page"><view class"left" ref"left"><image class"image" v-for"(item,i) in leftList" :k…...
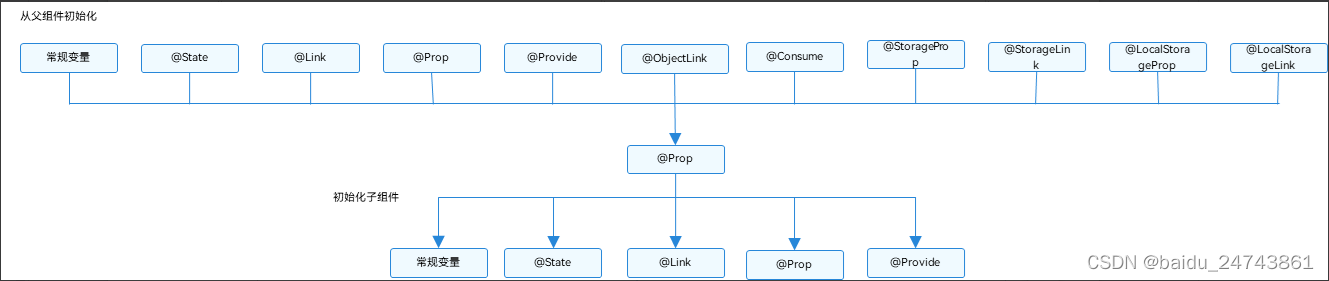
鸿蒙:@Link装饰器-父子双向同步
子组件中被Link装饰的变量与其父组件中对应的数据源建立双向数据绑定。从API version 9开始,该装饰器支持在ArkTS卡片中使用。 需要注意:Link装饰的变量与其父组件中的数据源共享相同的值。Link装饰器不能在Entry装饰的自定义组件中使用。 一、装饰器使…...

Leetcode--27
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面…...
使用Eclipse搞Android项目报错
相信现在都没什么人还会用Eclipse来开发的了。 不过安装完后,打开Eclipse会提示我的Jdk版本不符合 --------------------------- Incompatible JVM --------------------------- Version 1.8.0_391 of the JVM is not suitable for this product. Version: 17 or g…...

import sys是什么
import sys语句 允许你使用sys模块提供的各种功能,从而更好地与Python解释器和操作系统底层进行交互。通过熟练掌握sys模块的使用,可以大大提高Python开发的效率和灵活性。 sys模块 是Python的内置模块之一,用于与Python解释器和系统环境交…...
Python爬虫:XPath基本语法
XPath(XML Path Language)是一种用于在XML文档中定位元素的语言。它使用路径表达式来选择节点或节点集,类似于文件系统中的路径表达式。 不啰嗦,讲究使用,直接上案例。 导入 pip3 install lxmlfrom lxml import etr…...
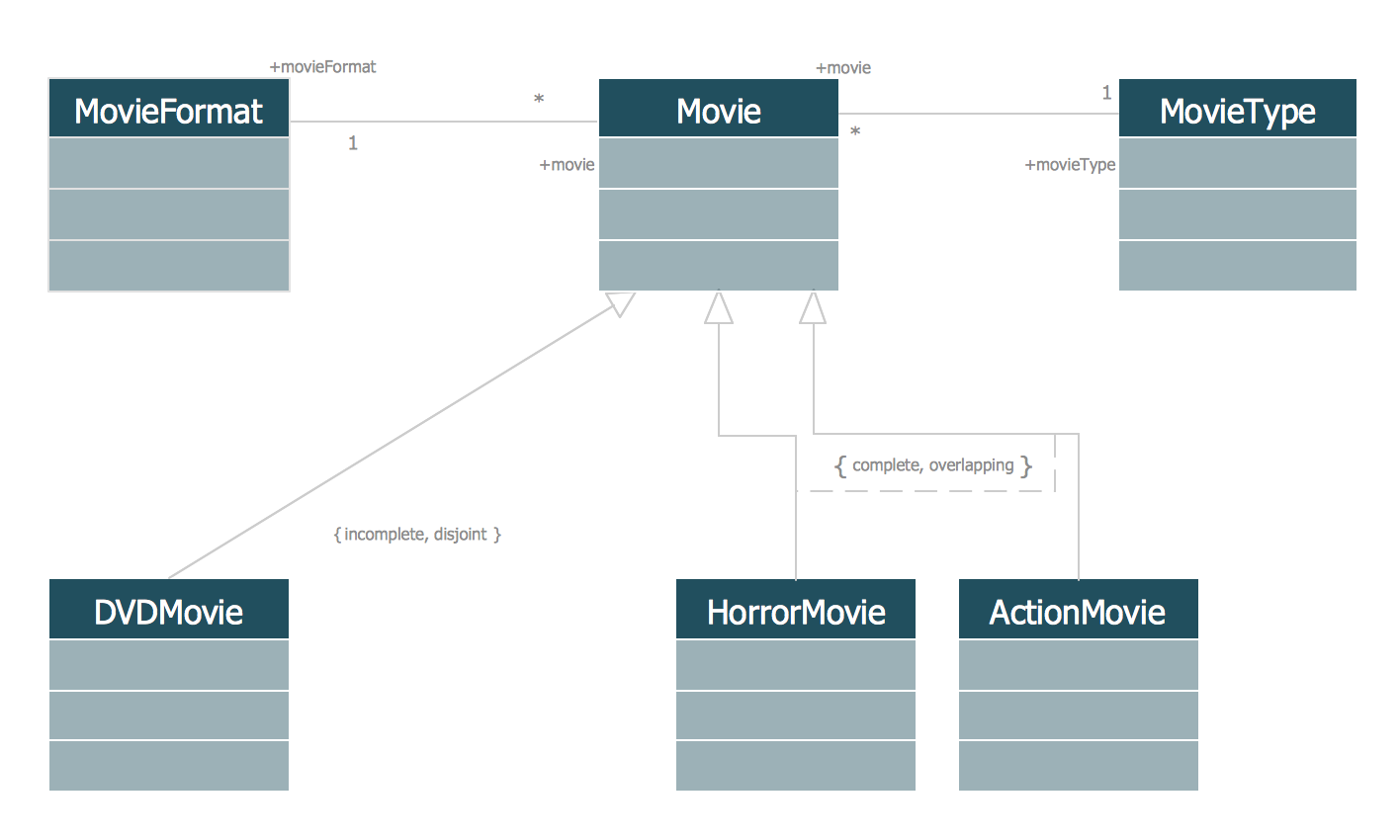
UML/SysML建模工具更新情况(截至2024年1月)(1)UModel 2024
最近一段时间更新的工具有: 工具最新版本:Umple 1.33.0 更新时间:2024年1月10日 工具简介 自称“Model-Oriented Programming”,把图形和文本结合起来,支持Java、PHP和Ruby代码生成,可以在线使用…...

ubuntu20-github不通问题
github不通 一直在github下载失败 Git报错fatal unable to connect to github.com: github.com[0: 20.205.243.166] >>> alsa-ucm-conf v1.2.6.3 Downloading(卡在这里,很烦啊) 然后搜了很多文档,然后以下操作: 1.GitHub.com - GitHub: Lets build from here Git…...
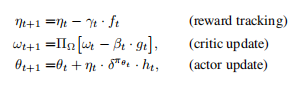
【MAC】Multi-Level Monte Carlo Actor-Critic阅读笔记
基本思想: 利用多层次蒙特卡洛方法(Multi-Level Monte Carlo,MLMC)和Actor-Critic算法,解决平均奖励强化学习中的快速混合问题。 快速混合? 在强化学习中,当我们说一个策略"混合得快"…...

[GN] 设计模式—— 创建型模式
文章目录 创建型模式单例模式 -- 确保对象唯一性例子优化饿汉式懒汉式 优缺点使用场景 简单工厂模式例子:优化优缺点适用场景 工厂方法模式 -- 多态工厂的实现例子优缺点优化适用场景 抽象工厂模式 -- 产品族的创建例子优缺点适用场景 总结 创建型模式 单例模式 –…...

链表——超详细
一、无头单向非循环链表 1.结构(两个部分): typedef int SLTDataType; typedef struct SListNode {SLTDataType data;//数据域struct SListNode* next;//指针域 }SLNode; 它只有一个数字域和一个指针域,里面数据域就是所存放的…...
【刷题】 leetcode 面试题 08.05.递归乘法
递归乘法 1 题目描述2 思路一(返璞归真版)3 思路二(二进制乘法器版)4 思路三(变态版)Thanks♪(・ω・)ノ谢谢阅读下一篇文章见!!! 1 题目…...
C语言实现希尔排序算法(附带源代码)
希尔排序 希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。 希尔排序是基于插入排序的以下两点性质而提出改进方法的: 插入排序在对几乎已经排好序的数据操作时,效率高࿰…...
:取taxlist对象的子集)
R语言【taxlist】——subset():取taxlist对象的子集
Package taxlist version 0.2.4 Description taxlist对象的子集将通过逻辑操作或模式匹配来完成。子集可以引用包含在插槽taxonNames、taxonRelations或taxonTraits中的信息。 Usage ## S4 method for signature taxlist subset(x,subset,slot "names",keep_child…...

单片机学习笔记---定时器计数器(含寄存器)工作原理介绍(详解篇2)
目录 T1工作在方式2时 T0工作在方式3时 四种工作方式的总结 定时计数器对输入信号的要求 定时计数器对的编程的一个要求 关于初值计算的问题 4种工作方式的最大定时时间的大小 关于编程方式的问题 实例分析 实例1 实例2 T1工作在方式2时 51单片机,有两个…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...

3分钟掌握抖音视频批量下载:解放双手的素材收集革命
3分钟掌握抖音视频批量下载:解放双手的素材收集革命 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为一个个手动保存抖音视频而烦恼吗?想要高效收集创作者素材却苦于没有合适的…...

英雄联盟回放播放难题终极解决方案:ROFLPlayer完整使用指南
英雄联盟回放播放难题终极解决方案:ROFLPlayer完整使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟旧…...

中兴新支点NewStartOS初体验:从激活到日常使用,聊聊这个国产Linux桌面的真实感受
中兴新支点NewStartOS深度体验:一个技术爱好者的真实使用笔记第一次启动中兴新支点NewStartOS时,那个简洁的登录界面就给我留下了不错的印象。作为一个长期在Windows和macOS之间切换的用户,这次尝试国产Linux桌面系统,更像是一次充…...
如何在macOS上免费安装HSTracker:终极炉石传说套牌追踪器完整指南
如何在macOS上免费安装HSTracker:终极炉石传说套牌追踪器完整指南 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 还在为炉石传说对局中记不住对手出牌而烦恼…...

OpenPLC虚拟PLC:5分钟搭建开源工业控制器的完整指南
OpenPLC虚拟PLC:5分钟搭建开源工业控制器的完整指南 【免费下载链接】OpenPLC Software for the OpenPLC - an open source industrial controller 项目地址: https://gitcode.com/gh_mirrors/op/OpenPLC 想要零成本学习工业自动化?OpenPLC虚拟PL…...

终极指南:如何用ESP32打造专业级蓝牙游戏手柄
终极指南:如何用ESP32打造专业级蓝牙游戏手柄 【免费下载链接】ESP32-BLE-Gamepad Bluetooth LE Gamepad library for the ESP32 项目地址: https://gitcode.com/gh_mirrors/es/ESP32-BLE-Gamepad 你是否曾经想过用ESP32开发板制作一个自定义的游戏控制器&am…...

如何将B站缓存视频从m4s格式无损转换为通用MP4?
如何将B站缓存视频从m4s格式无损转换为通用MP4? 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾遇到过这样的情况࿱…...