数据库(SQL)
目录
1 触发器
1.1 触发器简介
1.2 触发器的创建
语法
说明
1.3 示例
2 存储过程
2.1 什么是存储过程(函数)
2.1.1 存储过程和存储函数的区别
2.2 优势
2.3 应用场景
2.4 存储过程的创建和使用
说明
各参数类型所实现的存储过程
无参数无返回的存储过程
有参数无返回的存储过程
无参数有返回的存储过程
有参数有返回的存储过程
INOUT
3 存储函数
3.1 存储函数的概念
3.2 创建和使用
基本语法
参数说明
调用存储函数
语法结构如下
3.3 示例
3.4 删除
4 游标
优点
原理
4.1 如何声明游标
4.2 打开游标
4.3 使用游标
4.4 关闭
语法和格式
4.5 游标的应用
1 触发器
1.1 触发器简介
触发器是一种比较特殊的存储过程,它的执行不是由程序调用,也不是手工调用,而是通过事件来进行触发
比如说:对一张表进行(增、删、改),去激活它的执行
触发器经常应用在加强数据完整性、和业务规则中
如:
当一个学生表中添加了一个学生信息的时候,那么对应的学生数目肯定会有所改变。像这样的情况,我们就可以针对学生表创建一个触发器:以确保每次增加一个学生记录的时候,就执行一次关于学生总数的计算操作,从而确保学生总数与记录数的一致性
1.2 触发器的创建
语法
CREATE TRIGGER 触发器名称 BEFORE|AFTER 触发事件ON 表名 FOR EACH ROWBEGIN触发器程序体;END说明
| <触发器名称> | 参考索引名名称 || 表命名 |
| BEFORE|AFTER | 触发器时机 |
| INSERT DELETE UPDATE | 触发的事件 |
| ON 表名 | 在那张表上建立触发器 |
| FOR EACH ROW | 触发器执行间隔策略———子句通知触发器,每隔一行执行一次动作,并不是对整个表执行 |
| 触发器程序体 | 要触发的SQL语句 |
1.3 示例
#当前有两张表 student student_count
#每当学生表中有记录增加(减少)时那么学生行数的这个表,需要进行最新的行数统计
1.创建表
CREATE TABLE student(id int auto_increment primary key not null,name varchar(40)
);CREATE TABLE student_count(totle int
);
#添加一条学生信息
INSERT INTO student (name) VALUES('jack_1');
INSERT INTO student_count VALUES(1);
#后面student表的添加语句与前面的一致
#而student_count语句全都会变为UPDATE格式
#故创建触发器:
CREATE TRIGGER student_insert_trigger AFTER INSERTON student FOR EACH ROWBEGINUPDATE student_count SET totle = totle+1;END;
#查看触发器是否已存在SHOW TRIGGERS;
#我们插入若干条数据进行测试
INSERT INTO student (name) VALUES('jack_2'),('jack_3'),('jack_4'),('jack_5'),('jack_6'),('jack_7'),('jack_8'),('jack_9'),('jack_10');
#套用语法完成删除的触发器
CREATE TRIGGER student_delete_trigger AFTER DELETEON student FOR EACH ROWBEGINUPDATE student_count SET totle = totle-1;END;
#示例2:职员表 (工号,姓名,性别,年龄) <===> 工资表 (工资编号,姓名,工资5000)
对职工进行添加时 工资表中也要体现当前职工的信息
对职工进行修改时 工资表中也要一并修改当前职工的信息
对职工进行解聘时 工资表中也要一并删除当前员工的工资信息
#创建职工表
CREATE TABLE tab1(id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(20),sex ENUM('m','f'),age INT
);
#创建工资表
CREATE TABLE tab2(id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(20),salary DOUBLE(10,2)
);
#创建触发器1 INSERT 对职工进行添加时 工资表中也要体现当前职工的信息
CREATE TRIGGER tab1_insert_trigger AFTER INSERT ON tab1FOR EACH ROWBEGININSERT INTO tab2 VALUES (NULL,new.name,5000);END;测试用户新增
INSERT INTO tab1 VALUES (1,'AA','f',18);
新增完成后我们检查tab2会发现有变化#创建触发器2 UPDATE 对职工进行修改时 工资表中也要刷新当前职工的信息
CREATE TRIGGER tab1_update_triggerAFTER UPDATE ON tab1FOR EACH ROWBEGINUPDATE tab2 SET name = new.name WHERE name = old.name;END;测试用户修改
UPDATE tab1 SET name = 'FF' WHERE name = 'BB';
修改完成后我们检查tab2会发现有变化#创建触发器3 DELETE 对职工进行删除时 工资表中也要刷新当前职工信息
CREATE TRIGGER tab1_delete_triggerAFTER DELETE ON tab1FOR EACH ROWBEGINDELETE FROM tab2 WHERE name = old.name;END;2 存储过程
2.1 什么是存储过程(函数)
存储过程是,事先经过了编译并以对象的形式存储在数据库中的一段SQL语句的集合
调用存储过程可以简化应用开发人员的很多工作,减少了数据在数据库和应用服务器之间的传输,对于提高数据的处理能力具有很强的好处
2.1.1 存储过程和存储函数的区别
| 存储过程可以不设返回值,而存储函数必须要设置返回值 |
| 存储过程的参数 IN OUT INOUT 类型,而存储函数的参数只能是 IN |
2.2 优势
存储过程只在创建时编译一次,而常规的SQL命令每执行一次就会编译一次,所以它能够提高执行效率
简化复杂操作,支持封装
复用性极强
安全性高,可指定其使用权
2.3 应用场景
在并发量较小的情况下,很少使用。在并发量较高的情况下,多采用存储过程或存储函数
2.4 存储过程的创建和使用
CREATE PROCEDURE 函数名(形式参数列表)BEGIN函数体END;说明
参数列表类型 [IN OUT INOUT] 参数名 类型
IN 输入参数
OUT 输出参数
INOUT 该参数在调用方法时充当了实参变量,在方法调用完毕返回结果时又充当了接受返回值的变量CALL函数名(实际参数列表)各参数类型所实现的存储过程
无参数无返回的存储过程
#查询当前学生人数
CREATE PROCEDURE p1()BEGINSELECT COUNT(*) FROM student;END; 有参数无返回的存储过程
#创建一张测试表
CREATE TABLE t1(id int,name varchar(50)
);CREATE PROCEDURE autoinsert(IN num INT)BEGINDECLARE i INT DEFAULT 1; WHILE(i<=num)DOINSERT INTO t1 VALUES(i,md5(i));SET i = i+1;END WHILE;END; 无参数有返回的存储过程
#查询当前学生人数
CREATE PROCEDURE p2(OUT num INT)BEGINSELECT COUNT(*) INTO num FROM student;END;有参数有返回的存储过程
#统计指定班级编号的学生人数
CREATE PROCEDURE p3(IN num1 INT,OUT num2 INT)BEGIN SELECT COUNT(*) INTO num2 FROM student WHERE student.GradeID = num1;END;INOUT
CREATE PROCEDURE p4(INOUT num INT)BEGIN IF(num IS NOT NULL) thenSET num = num+1;ELSESELECT 100 INTO NUM;END IF; END; CREATE PROCEDURE p5(INOUT num INT)BEGIN SELECT COUNT(*) INTO num FROM student WHERE student.GradeID = num;END;3 存储函数
3.1 存储函数的概念
MySQL存储函数(自定义函数),函数一般用于计算机和返回一个值,可以将经常需要使用的计算或功能写成一个函数。函数的存储过程类似
3.2 创建和使用
在MySQL中创建存储函数使用的关键字是 CREATE FUNCTION
基本语法
CREATE FUNCTION 函数名([参数名 参数类型,参数名 参数类型 ....])RETURNS type[characterintic ...]BEGINroutine_bodyEND;参数说明
| RETURNS type | 返回值的类型 |
| characteristic | 指定存储函数的特性 |
| routine_body | SQL代码内容 |
调用存储函数
在MySQL中,存储函数的使用方法与MySQL内部函数的使用方法基本相同
用户自定义的存储函数与MySQL内部函数性质相同
区别在于,存储函数是用户自定义的;而内部函数是由MySQL自带
语法结构如下
SELECT NOW();SELECT 函数名(实际参数列表)3.3 示例
注意:
MySQL开启 bin-log 后,调用存储过程或者函数以及触发器时,会出现错误号为 1418 的错误
解决方法:
信任子程序的创建者,禁止创建、修改子程序时对SUPER权限的要求:在客户端上执行 SET GLOBAL log_bin_trust_function_creators = 1;
#无参数有返回值
#统计 student 表中行数
CREATE FUNCTION myf1() RETURNS INT
BEGINDECLARE num INT DEFAULT 0; SELECT COUNT(*) INTO num FROM student;RETURN num;
END; #有参数有返回值
#根据学生姓名查询学生学号
CREATE FUNCTION myf2(stuName VARCHAR(20)) RETURNS INT
BEGINDECLARE num INT; SELECT id INTO num FROM student WHERE name = stuName;RETURN num;
END;
3.4 删除
DROP FUNCTION myf2;4 游标
游标实际上是一种能够从包括多条数据记录的结构集中每次提取一条记录的机制(遍历)
| 使用游标(cursor)的一个主要原因就是把集合操作转换成单个记录处理方式 |
| 游标充当指针的作用 |
| 尽管游标能遍历结果中的所有行,但是他一次只能指向一行 |
| 使用SQL语言从数据库中检索数据后,结果放在内存的一块区域中,而且结果往往是一个含有多个记录的集合 |
| 游标机制允许用户逐行地访问这些记录,按照用户自己的意愿来显示和处理这些记录 |
优点
| 允许程序对由查询语句 select 返回的行集合中的每一行执行相同或不同的操作,而不是对整个行集合执行同一个操作 |
| 提供对基于游标位置的表中的行进行删除和更新的能力 |
| 游标实际上作为面向集合的数据库管理系统(RDBMS)和面向行的程序设计之间的桥梁,使这两种处理方式通过游标沟通起来 |
原理
游标就是把数据按照指定要求提取出相应的数据集,然后逐条进行数据处理
4.1 如何声明游标
DECLARE cursor_name CURSOR FOR select_statement (table)4.2 打开游标
声明游标后,想从游标中提前数据,必须打开游标 OPEN
OPEN cursor_name;注意:
当我们执行了打开游标的操作后,游标并不是指向第一条记录,而是指向第一条记录的前边
在程序内,一个游标可以打开多次,用户打开游标后,其他用户或程序可能正在更新数据,所以有时候可能导致用户每次打开游标时,显示的结果不同
4.3 使用游标
当用户顺利打开游标后,可以使用 FETCH...INTO 语句进行数据的读取
# 这条语句用户指定的打开游标并读取下一行,且前进游标指针。
FETCH cursor_name INTO value1[,value2.....]4.4 关闭
游标使用完毕后,要及时的关闭,在MySQL中,使用 CLOSE 关键字关闭游标
语法和格式
CLOSE cursor_name;CLOSE 用于释放游标所有的内部资源和内存,因此每个游标在不需要的时候,就要及时的关闭
关闭的游标 如果没有重新打开,那么不能进行第二次的使用,但是已经声明过的游标不需要再次声明了,用 OPEN 语句打开就行
如果忘记关闭,MySQL将会到达 END 语句时自动关闭。游标关闭后,就不能使用 FETCH 去进行游标的遍历了
4.5 游标的应用
示例:
编写两个表 sys_user 和 user 表,编写其存储过程。当两个表id值一样的时候,将 user 表内的name 字段值同步成 sys_user 表的 name 字段值
#1创建sys_user表并注入一些数据
CREATE TABLE sys_user(id INT(11) NOT NULL AUTO_INCREMENT,username VARCHAR(200) NOT NULL,PRIMARY KEY(id)
)ENGINE=InnoDB AUTO_INCREMENT = 4 DEFAULT CHARSET = utf8;INSERT INTO sys_user (username) VALUES ('AA'),('BB'),('CC'),('DD'),('EE'),('FF'),('GG');CREATE TABLE user(id INT(11) DEFAULT NULL,name VARCHAR(200) DEFAULT NULL
)ENGINE=InnoDB DEFAULT CHARSET = utf8;INSERT INTO user VALUES (1,'OO'),(2,'PP'),(3,'QQ'),(4,'RR'),(5,'SS'),(6,'TT'),(7,'UU');创建存储过程 user_test,并创建游标 cur_test
CREATE PROCEDURE user_test()
BEGIN-- 定义变量DECLARE sys_user_id BIGINT;DECLARE sys_user_name VARCHAR(11);DECLARE done INT;-- 创建游标,并存储数据DECLARE cur_test CURSOR FOR SELECT id AS user_id,user_name AS sys_user_name FROM `sys_user`;-- 游标中的内容执行完后将 done 设置为 1 DECLARE CONTINUE HANDLER FOR NOT FOUND SET done=1;-- 打开游标OPEN cur_test;-- 执行循环posLoop:LOOP-- 判断是否结束循环IF done=1 THENLEAVE posLoop;END IF;-- 取游标中的值FETCH cur_test INTO sys_user_id,sys_user_name;-- 执行更新操作UPDATE `user` SET NAME=sys_user_name WHERE id=sys_user_id;END LOOP posLoop;-- 释放游标 CLOSE cur_test;
END相关文章:
)
数据库(SQL)
目录 1 触发器 1.1 触发器简介 1.2 触发器的创建 语法 说明 1.3 示例 2 存储过程 2.1 什么是存储过程(函数) 2.1.1 存储过程和存储函数的区别 2.2 优势 2.3 应用场景 2.4 存储过程的创建和使用 说明 各参数类型所实现的存储过程 无参数无返…...

如何用Docker+jenkins 运行 python 自动化?
1.在 Linux 服务器安装 docker 2.创建 jenkins 容器 3.根据自动化项目依赖包构建 python 镜像(构建自动化 python 环境) 4.运行新的 python 容器,执行 jenkins 从仓库中拉下来的自动化项目 5.执行完成之后删除容器 前言 环境准备 Linux 服务器一台(我的是 CentOS7)…...

uniapp瀑布流实现
1. 图片瀑布流: 不依赖任何插件,复制即可见效: <template><view class"page"><view class"left" ref"left"><image class"image" v-for"(item,i) in leftList" :k…...
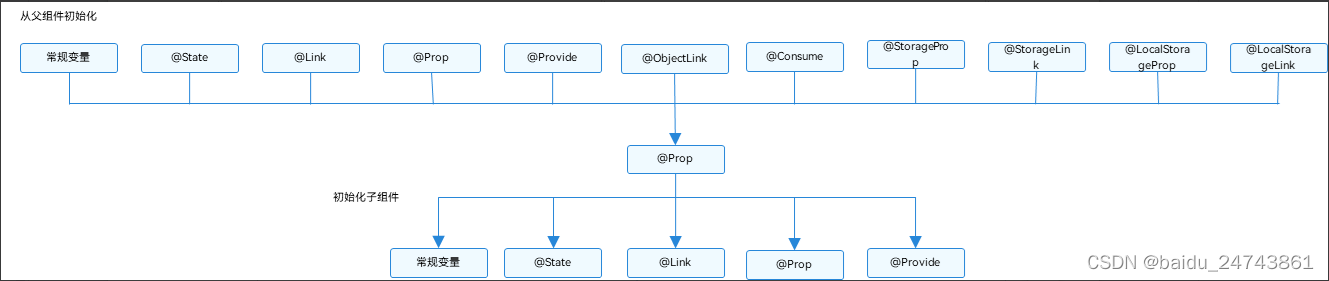
鸿蒙:@Link装饰器-父子双向同步
子组件中被Link装饰的变量与其父组件中对应的数据源建立双向数据绑定。从API version 9开始,该装饰器支持在ArkTS卡片中使用。 需要注意:Link装饰的变量与其父组件中的数据源共享相同的值。Link装饰器不能在Entry装饰的自定义组件中使用。 一、装饰器使…...

Leetcode--27
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面…...
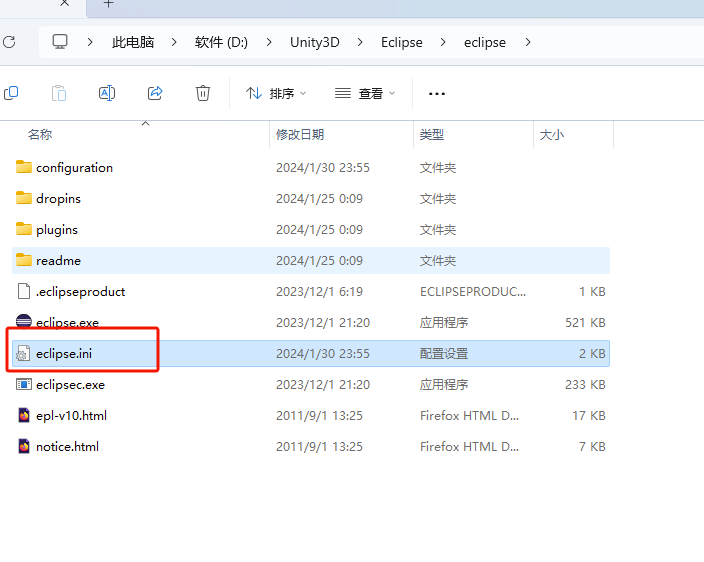
使用Eclipse搞Android项目报错
相信现在都没什么人还会用Eclipse来开发的了。 不过安装完后,打开Eclipse会提示我的Jdk版本不符合 --------------------------- Incompatible JVM --------------------------- Version 1.8.0_391 of the JVM is not suitable for this product. Version: 17 or g…...

import sys是什么
import sys语句 允许你使用sys模块提供的各种功能,从而更好地与Python解释器和操作系统底层进行交互。通过熟练掌握sys模块的使用,可以大大提高Python开发的效率和灵活性。 sys模块 是Python的内置模块之一,用于与Python解释器和系统环境交…...
Python爬虫:XPath基本语法
XPath(XML Path Language)是一种用于在XML文档中定位元素的语言。它使用路径表达式来选择节点或节点集,类似于文件系统中的路径表达式。 不啰嗦,讲究使用,直接上案例。 导入 pip3 install lxmlfrom lxml import etr…...
UML/SysML建模工具更新情况(截至2024年1月)(1)UModel 2024
最近一段时间更新的工具有: 工具最新版本:Umple 1.33.0 更新时间:2024年1月10日 工具简介 自称“Model-Oriented Programming”,把图形和文本结合起来,支持Java、PHP和Ruby代码生成,可以在线使用…...

ubuntu20-github不通问题
github不通 一直在github下载失败 Git报错fatal unable to connect to github.com: github.com[0: 20.205.243.166] >>> alsa-ucm-conf v1.2.6.3 Downloading(卡在这里,很烦啊) 然后搜了很多文档,然后以下操作: 1.GitHub.com - GitHub: Lets build from here Git…...
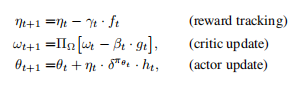
【MAC】Multi-Level Monte Carlo Actor-Critic阅读笔记
基本思想: 利用多层次蒙特卡洛方法(Multi-Level Monte Carlo,MLMC)和Actor-Critic算法,解决平均奖励强化学习中的快速混合问题。 快速混合? 在强化学习中,当我们说一个策略"混合得快"…...

[GN] 设计模式—— 创建型模式
文章目录 创建型模式单例模式 -- 确保对象唯一性例子优化饿汉式懒汉式 优缺点使用场景 简单工厂模式例子:优化优缺点适用场景 工厂方法模式 -- 多态工厂的实现例子优缺点优化适用场景 抽象工厂模式 -- 产品族的创建例子优缺点适用场景 总结 创建型模式 单例模式 –…...

链表——超详细
一、无头单向非循环链表 1.结构(两个部分): typedef int SLTDataType; typedef struct SListNode {SLTDataType data;//数据域struct SListNode* next;//指针域 }SLNode; 它只有一个数字域和一个指针域,里面数据域就是所存放的…...
【刷题】 leetcode 面试题 08.05.递归乘法
递归乘法 1 题目描述2 思路一(返璞归真版)3 思路二(二进制乘法器版)4 思路三(变态版)Thanks♪(・ω・)ノ谢谢阅读下一篇文章见!!! 1 题目…...
C语言实现希尔排序算法(附带源代码)
希尔排序 希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。 希尔排序是基于插入排序的以下两点性质而提出改进方法的: 插入排序在对几乎已经排好序的数据操作时,效率高࿰…...
:取taxlist对象的子集)
R语言【taxlist】——subset():取taxlist对象的子集
Package taxlist version 0.2.4 Description taxlist对象的子集将通过逻辑操作或模式匹配来完成。子集可以引用包含在插槽taxonNames、taxonRelations或taxonTraits中的信息。 Usage ## S4 method for signature taxlist subset(x,subset,slot "names",keep_child…...

单片机学习笔记---定时器计数器(含寄存器)工作原理介绍(详解篇2)
目录 T1工作在方式2时 T0工作在方式3时 四种工作方式的总结 定时计数器对输入信号的要求 定时计数器对的编程的一个要求 关于初值计算的问题 4种工作方式的最大定时时间的大小 关于编程方式的问题 实例分析 实例1 实例2 T1工作在方式2时 51单片机,有两个…...

《动手学深度学习(PyTorch版)》笔记4.1
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...

OpenAI发布新模型!ChatGPT性能重磅提升,API大幅降价,GPT-4 「变懒」被修复
OpenAI 对ChatGPT进行了大更新:推出了新一代的嵌入模型,对GPT-4 Turbo模型进行了更新,并将很快对GPT-3.5 Turbo的API进行大幅降价,GPT-4「变懒」行为也被修复。 接下来二狗就带大家看看ChatGPT的这次详细更新。 推出新的嵌入模型…...
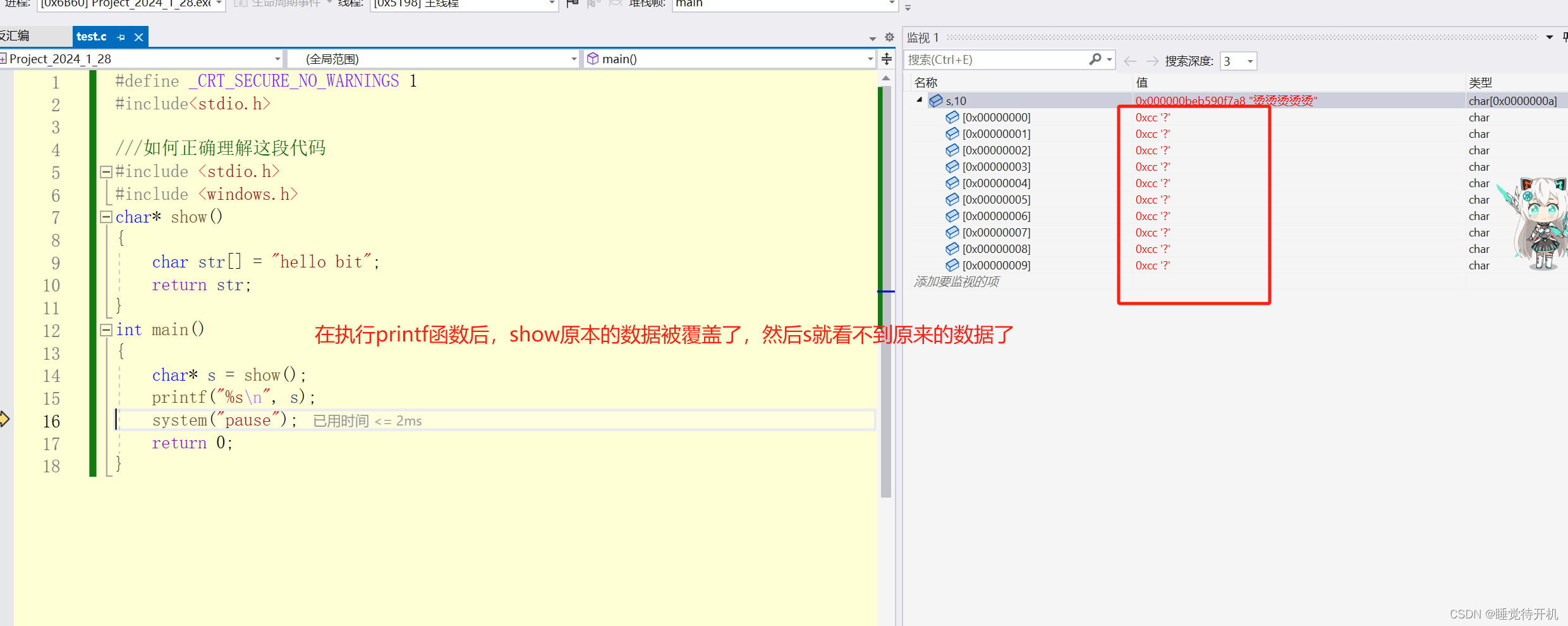
【C深度解剖】计算机数据下载和删除原理
简介:本系列博客为C深度解剖系列内容,以某个点为中心进行相关详细拓展 适宜人群:已大体了解C语法同学 作者留言:本博客相关内容如需转载请注明出处,本人学疏才浅,难免存在些许错误,望留言指正 作…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

基于Arduino与433MHz射频的智能灯光定时系统设计与实现
1. 项目概述:告别机械定时器,打造智能灯光管家家里前后院的照明,还有出门度假时屋内的几盏灯,过去一直靠四个老旧的机械定时器来管理。说实话,这玩意儿用起来真是费劲。它的核心问题在于“死板”——你设定好晚上7点开…...

掌握Umi-OCR:5分钟上手开源免费离线文字识别工具
掌握Umi-OCR:5分钟上手开源免费离线文字识别工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。…...
提升你的图表专业度?)
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度?
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度? 在数据驱动的决策时代,图表不仅是科研论文中的证据载体,更是商业汇报中的说服工具。我曾见证一位生物统计学家将同一组临床试验数据呈现给三种不同受众&…...

【RT-DETR实战】070、模型分析工具:PyTorch Profiler性能分析
上周在部署RT-DETR到边缘设备时遇到一个诡异现象:模型推理时延波动极大,有时30ms,偶尔突然跳到200ms。 盯着代码看了半天没发现逻辑问题,数据流也正常。这种时候,靠猜是没用的,必须上性能分析工具——PyTorch Profiler。 今天我们就来聊聊怎么用它揪出那些藏在细节里的…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

C51对Maxim 390远内存绝对地址访问的三种方案
1. 深入解析C51对Maxim 390远内存的绝对地址访问 在嵌入式开发中,对特定内存地址的直接操作是底层控制的关键技术。以Maxim(原Dallas Semiconductor)DS80C390为代表的增强型8051架构,其24位地址空间的远内存(Far Memor…...

5分钟掌握res-downloader:跨平台资源下载的终极指南
5分钟掌握res-downloader:跨平台资源下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否经常在…...

如何用500KB工具完全替代AWCC:AlienFX Tools终极指南
如何用500KB工具完全替代AWCC:AlienFX Tools终极指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 你是否厌倦了Alienware Command Cente…...