聊聊java中的Eureka和Nacos
本文主要来自于黑马课程中
1.提供者与消费者
在服务调用关系中,会有两个不同的角色:
服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)
服务消费者:一次业务中,调用其它微服务的服务。(调用其它微服务提供的接口)

但是,服务提供者与服务 者的角色并不是绝对的,而是相对于业务而言。
如果服务A调用了服务B,而服务B又调用了服务C,服务B的角色是什么?
-
对于A调用B的业务而言:A是服务消费者,B是服务提供者
-
对于B调用C的业务而言:B是服务消费者,C是服务提供者
-
因此,服务B既可以是服务提供者,也可以是服务消费者。
2.Eureka注册中心
假如我们的服务提供者user-service部署了多个实例,如图:

大家思考几个问题:
-
order-service在发起远程调用的时候,该如何得知user-service实例的ip地址和端口?
-
有多个user-service实例地址,order-service调用时该如何选择?
-
order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?
-
2.1.Eureka的结构和作用
这些问题都需要利用SpringCloud中的注册中心来解决,其中最广为人知的注册中心就是Eureka,其结构如下:
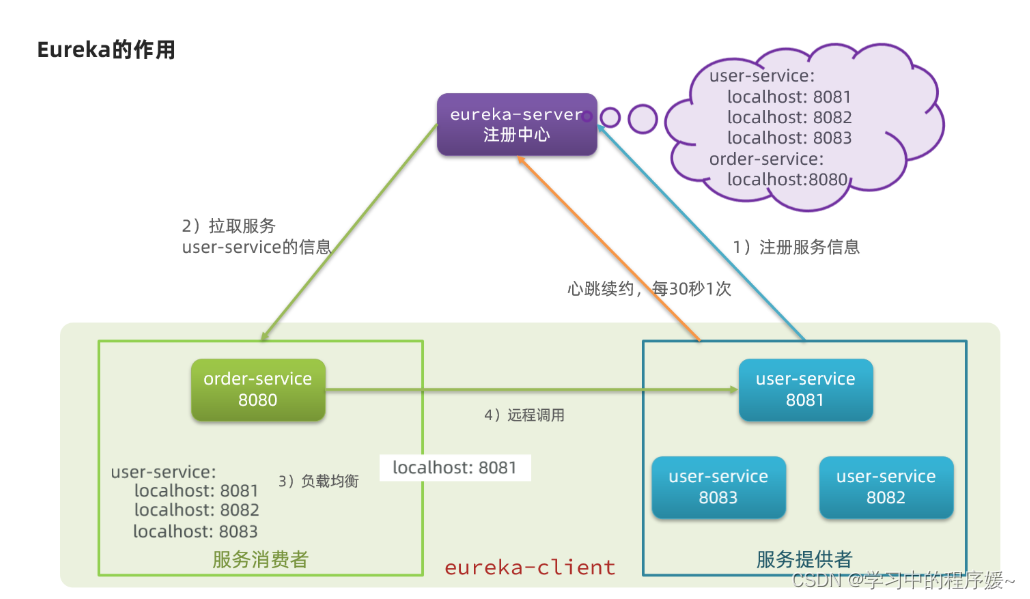
回答之前的各个问题。
问题1:order-service如何得知user-service实例地址?
获取地址信息的流程如下:
-
user-service服务实例启动后,将自己的信息注册到eureka-server(Eureka服务端)。这个叫服务注册
-
eureka-server保存服务名称到服务实例地址列表的映射关系
-
order-service根据服务名称,拉取实例地址列表。这个叫服务发现或服务拉取
-
问题2:order-service如何从多个user-service实例中选择具体的实例?
-
order-service从实例列表中利用负载均衡算法选中一个实例地址
-
向该实例地址发起远程调用
-
问题3:order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?
-
user-service会每隔一段时间(默认30秒)向eureka-server发起请求,报告自己状态,称为心跳
-
当超过一定时间没有发送心跳时,eureka-server会认为微服务实例故障,将该实例从服务列表中剔除
-
order-service拉取服务时,就能将故障实例排除了
-
注意:一个微服务,既可以是服务提供者,又可以是服务消费者,因此eureka将服务注册、服务发现等功能统一封装到了eureka-client端
因此,接下来我们动手实践的步骤包括:

2.2.搭建eureka-server
首先大家注册中心服务端:eureka-server,这必须是一个独立的微服务
2.2.1.创建eureka-server服务
在cloud-demo父工程下,创建一个子模块:

填写模块信息:
然后填写服务信息:
2.2.2.引入eureka依赖
引入SpringCloud为eureka提供的starter依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency>
2.2.3.编写启动类
给eureka-server服务编写一个启动类,一定要添加一个@EnableEurekaServer注解,开启eureka的注册中心功能:
package cn.itcast.eureka; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer; @SpringBootApplication @EnableEurekaServer public class EurekaApplication {public static void main(String[] args) {SpringApplication.run(EurekaApplication.class, args);} }2.2.4.编写配置文件
编写一个application.yml文件,内容如下:
server:port: 10086 spring:application:name: eureka-server eureka:client:service-url: defaultZone: http://127.0.0.1:10086/eureka2.2.5.启动服务
启动微服务,然后在浏览器访问:http://127.0.0.1:10086
看到下面结果应该是成功了:

2.3.服务注册
下面,我们将user-service注册到eureka-server中去。
1)引入依赖
在user-service的pom文件中,引入下面的eureka-client依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>
2)配置文件
在user-service中,修改application.yml文件,添加服务名称、eureka地址:
spring:application:name: userservice eureka:client:service-url:defaultZone: http://127.0.0.1:10086/eureka3)启动多个user-service实例
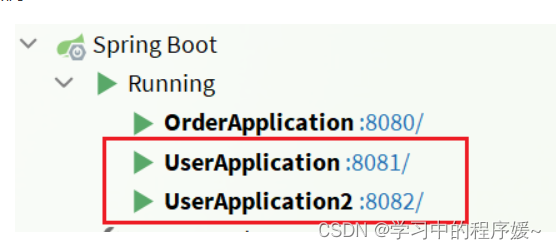
为了演示一个服务有多个实例的场景,我们添加一个SpringBoot的启动配置,再启动一个user-service。
首先,复制原来的user-service启动配置:

然后,在弹出的窗口中,填写信息:

现在,SpringBoot窗口会出现两个user-service启动配置:
不过,第一个是8081端口,第二个是8082端口。
启动两个user-service实例:
查看eureka-server管理页面:

2.4.服务发现
下面,我们将order-service的逻辑修改:向eureka-server拉取user-service的信息,实现服务发现。
1)引入依赖
之前说过,服务发现、服务注册统一都封装在eureka-client依赖,因此这一步与服务注册时一致。
在order-service的pom文件中,引入下面的eureka-client依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>
2)配置文件
服务发现也需要知道eureka地址,因此第二步与服务注册一致,都是配置eureka信息:
在order-service中,修改application.yml文件,添加服务名称、eureka地址:
spring:application:name: orderservice eureka:client:service-url:defaultZone: http://127.0.0.1:10086/eureka3)服务拉取和负载均衡
最后,我们要去eureka-server中拉取user-service服务的实例列表,并且实现负载均衡。
不过这些动作不用我们去做,只需要添加一些注解即可。
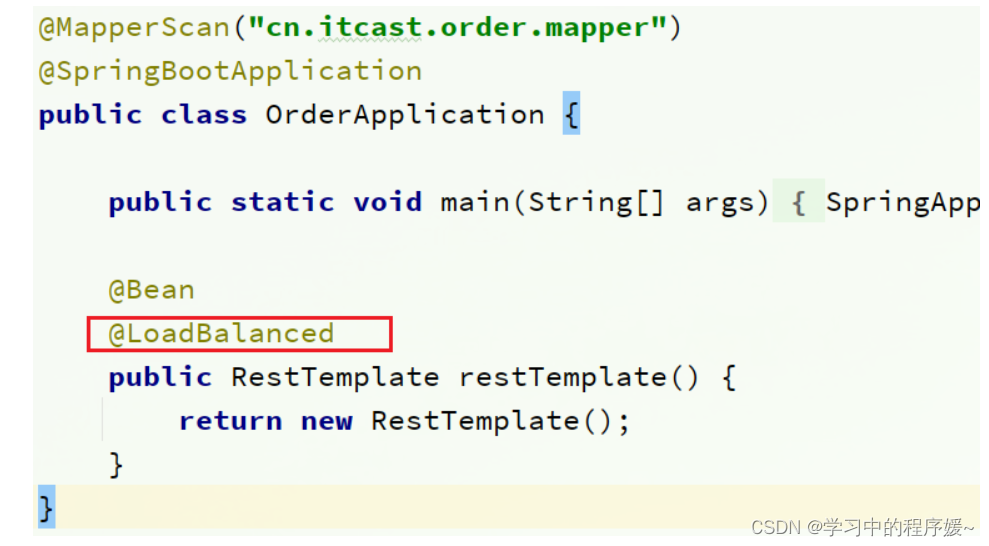
在order-service的OrderApplication中,给RestTemplate这个Bean添加一个@LoadBalanced注解:
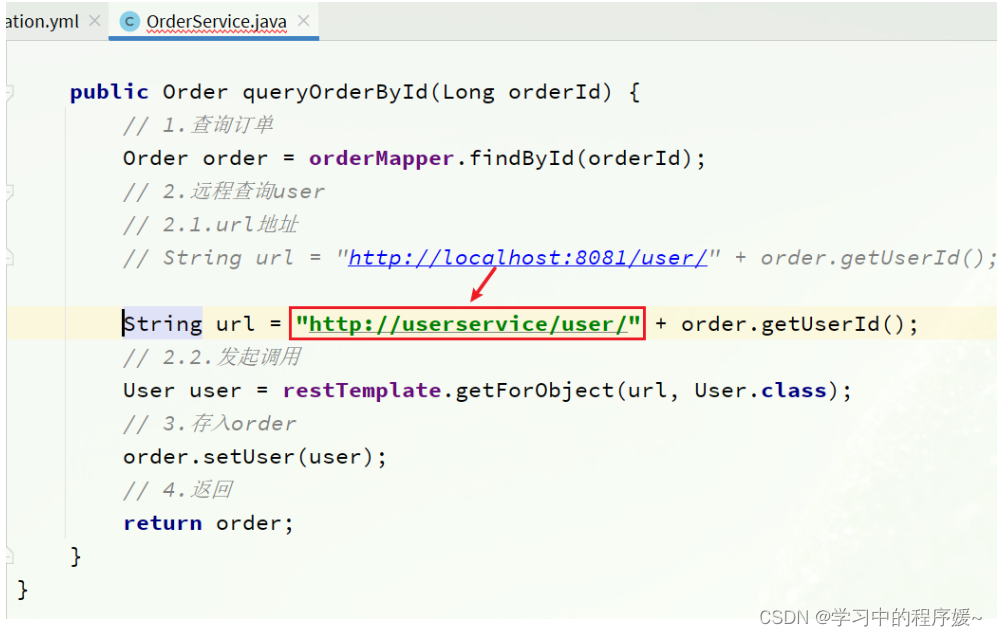
修改order-service服务中的cn.itcast.order.service包下的OrderService类中的queryOrderById方法。修改访问的url路径,用服务名代替ip、端口:
spring会自动帮助我们从eureka-server端,根据userservice这个服务名称,获取实例列表,而后完成负载均衡。
3.Ribbon负载均衡
上一节中,我们添加了@LoadBalanced注解,即可实现负载均衡功能,这是什么原理呢?
3.1.负载均衡原理
SpringCloud底层其实是利用了一个名为Ribbon的组件,来实现负载均衡功能的。

那么我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081的呢?
3.2.源码跟踪
为什么我们只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然有人帮我们根据service名称,获取到了服务实例的ip和端口。它就是
LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。我们进行源码跟踪:
1)LoadBalancerIntercepor

可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
-
request.getURI():获取请求uri,本例中就是 http://user-service/user/8 -
originalUri.getHost():获取uri路径的主机名,其实就是服务id,user-service -
this.loadBalancer.execute():处理服务id,和用户请求。 -
这里的
this.loadBalancer是LoadBalancerClient类型,我们继续跟入。2)LoadBalancerClient
继续跟入execute方法:
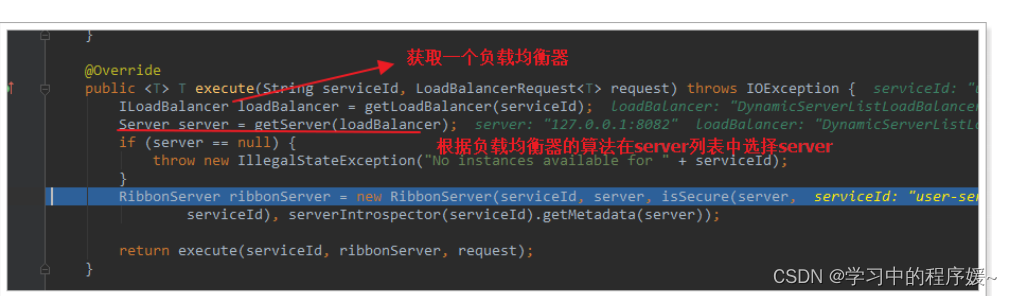
代码是这样的:
-
getLoadBalancer(serviceId):根据服务id获取ILoadBalancer,而ILoadBalancer会拿着服务id去eureka中获取服务列表并保存起来。
-
getServer(loadBalancer):利用内置的负载均衡算法,从服务列表中选择一个。本例中,可以看到获取了8082端口的服务
-
放行后,再次访问并跟踪,发现获取的是8081:

果然实现了负载均衡。
3)负载均衡策略IRule
在刚才的代码中,可以看到获取服务使通过一个
getServer方法来做负载均衡:
我们继续跟入:

继续跟踪源码chooseServer方法,发现这么一段代码:
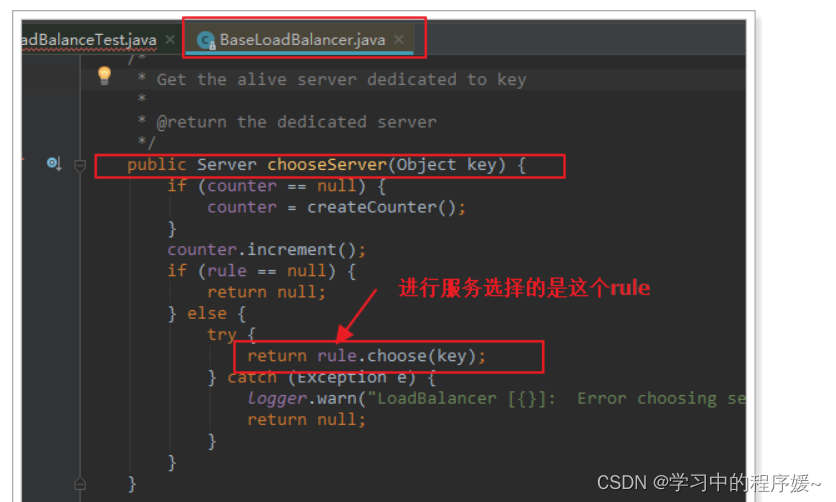
我们看看这个rule是谁:
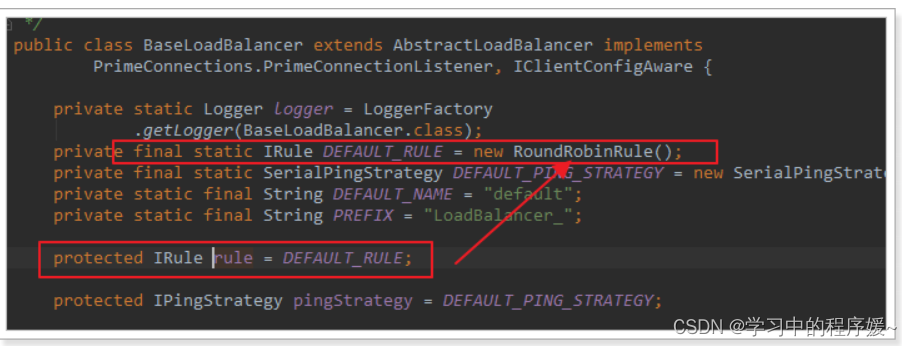
这里的rule默认值是一个
RoundRobinRule,看类的介绍:
这不就是轮询的意思嘛。
到这里,整个负载均衡的流程我们就清楚了。
4)总结
SpringCloudRibbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下:
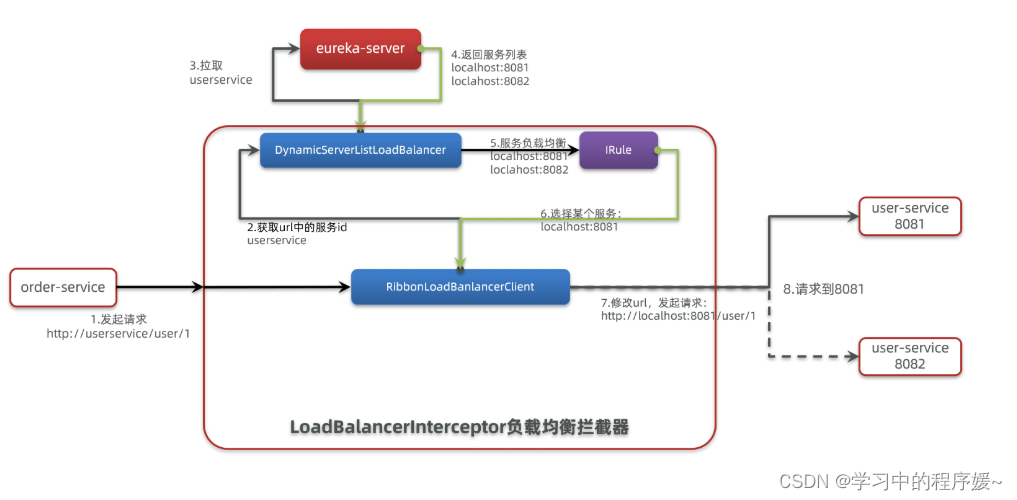
基本流程如下:
-
拦截我们的RestTemplate请求http://userservice/user/1
-
RibbonLoadBalancerClient会从请求url中获取服务名称,也就是user-service
-
DynamicServerListLoadBalancer根据user-service到eureka拉取服务列表
-
eureka返回列表,localhost:8081、localhost:8082
-
IRule利用内置负载均衡规则,从列表中选择一个,例如localhost:8081
-
RibbonLoadBalancerClient修改请求地址,用localhost:8081替代userservice,得到http://localhost:8081/user/1,发起真实请求
-
3.3.负载均衡策略
3.3.1.负载均衡策略
负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类:
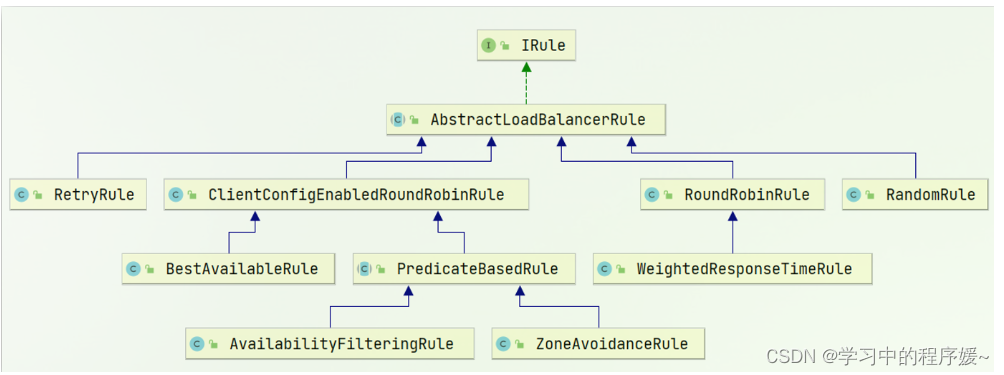
不同规则的含义如下:
内置负载均衡规则类 规则描述 RoundRobinRule 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 AvailabilityFilteringRule 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的<clientName>.<clientConfigNameSpace>.ActiveConnectionsLimit属性进行配置。 WeightedResponseTimeRule 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 ZoneAvoidanceRule 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 BestAvailableRule 忽略那些短路的服务器,并选择并发数较低的服务器。 RandomRule 随机选择一个可用的服务器。 RetryRule 重试机制的选择逻辑 默认的实现就是ZoneAvoidanceRule,是一种轮询方案
3.3.2.自定义负载均衡策略
通过定义IRule实现可以修改负载均衡规则,有两种方式:
-
代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
-
@Bean public IRule randomRule(){return new RandomRule(); } -
配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则:
-
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务ribbon:NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
注意,一般用默认的负载均衡规则,不做修改。
3.4.饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:eager-load:enabled: trueclients: userservice
4.Nacos注册中心
国内公司一般都推崇阿里巴巴的技术,比如注册中心,SpringCloudAlibaba也推出了一个名为Nacos的注册中心。
4.1.认识和安装Nacos
Nacos是阿里巴巴的产品,现在是SpringCloud中的一个组件。相比Eureka功能更加丰富,在国内受欢迎程度较高。

安装方式可以参考课前资料《Nacos安装指南.md》
4.2.服务注册到nacos
Nacos是SpringCloudAlibaba的组件,而SpringCloudAlibaba也遵循SpringCloud中定义的服务注册、服务发现规范。因此使用Nacos和使用Eureka对于微服务来说,并没有太大区别。
主要差异在于:
-
依赖不同
-
服务地址不同
-
1)引入依赖
在cloud-demo父工程的pom文件中的
<dependencyManagement>中引入SpringCloudAlibaba的依赖:<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>2.2.6.RELEASE</version><type>pom</type><scope>import</scope> </dependency>
然后在user-service和order-service中的pom文件中引入nacos-discovery依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>
注意:不要忘了注释掉eureka的依赖。
2)配置nacos地址
在user-service和order-service的application.yml中添加nacos地址:
spring:cloud:nacos:server-addr: localhost:8848
注意:不要忘了注释掉eureka的地址
3)重启
重启微服务后,登录nacos管理页面,可以看到微服务信息:
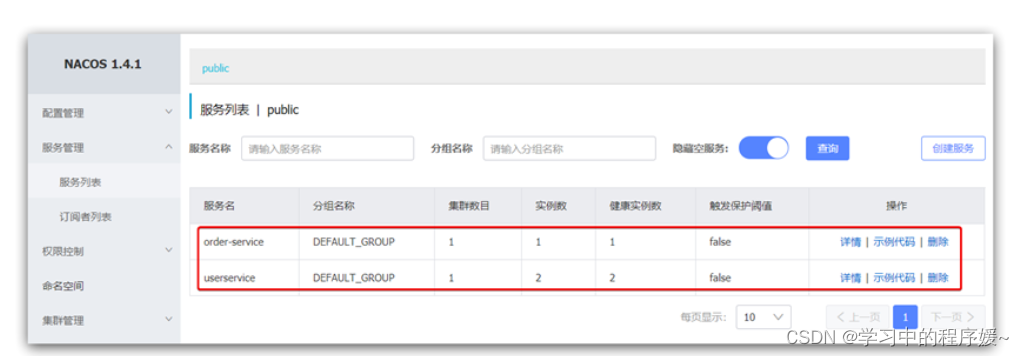
4.3.服务分级存储模型
一个服务可以有多个实例,例如我们的user-service,可以有:
-
127.0.0.1:8081
-
127.0.0.1:8082
-
127.0.0.1:8083
-
假如这些实例分布于全国各地的不同机房,例如:
-
127.0.0.1:8081,在上海机房
-
127.0.0.1:8082,在上海机房
-
127.0.0.1:8083,在杭州机房
-
Nacos就将同一机房内的实例 划分为一个集群。
也就是说,user-service是服务,一个服务可以包含多个集群,如杭州、上海,每个集群下可以有多个实例,形成分级模型,如图:

微服务互相访问时,应该尽可能访问同集群实例,因为本地访问速度更快。当本集群内不可用时,才访问其它集群。例如:

杭州机房内的order-service应该优先访问同机房的user-service。
4.3.1.给user-service配置集群
修改user-service的application.yml文件,添加集群配置:
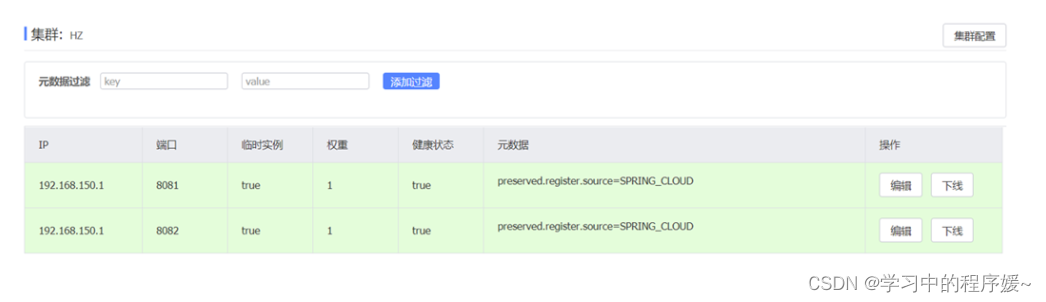
spring:cloud:nacos:server-addr: localhost:8848discovery:cluster-name: HZ # 集群名称
重启两个user-service实例后,我们可以在nacos控制台看到下面结果:
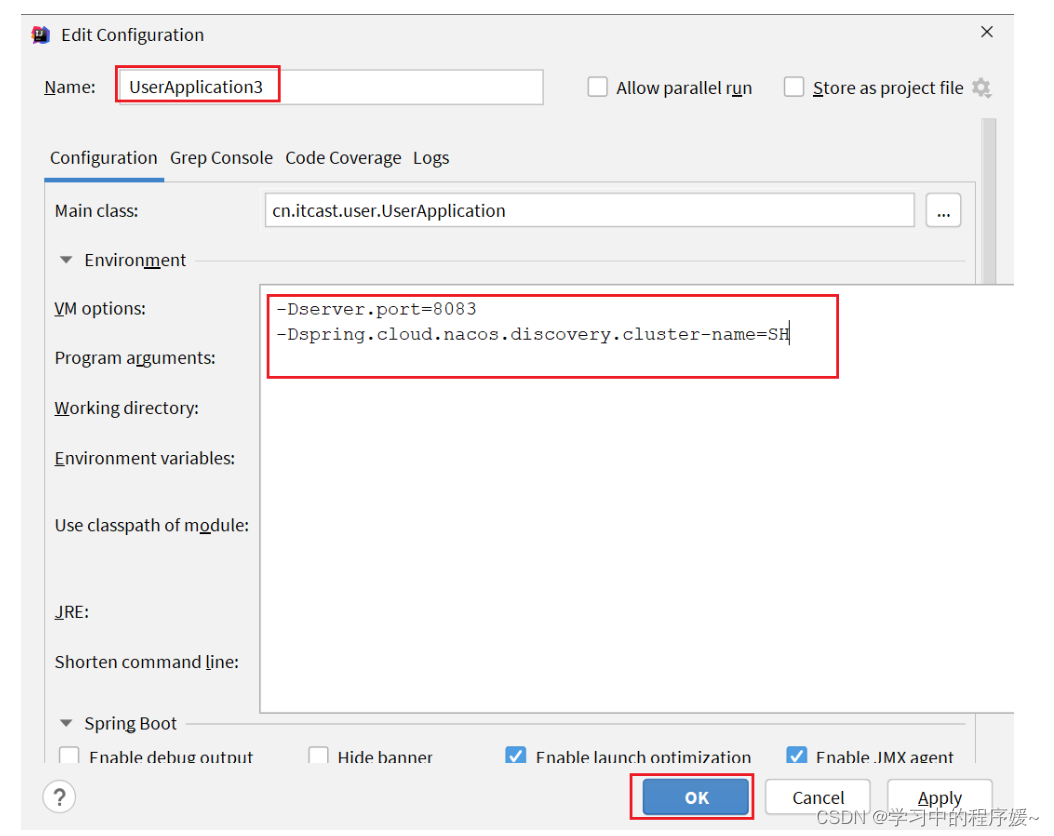
我们再次复制一个user-service启动配置,添加属性:
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH
配置如图所示:
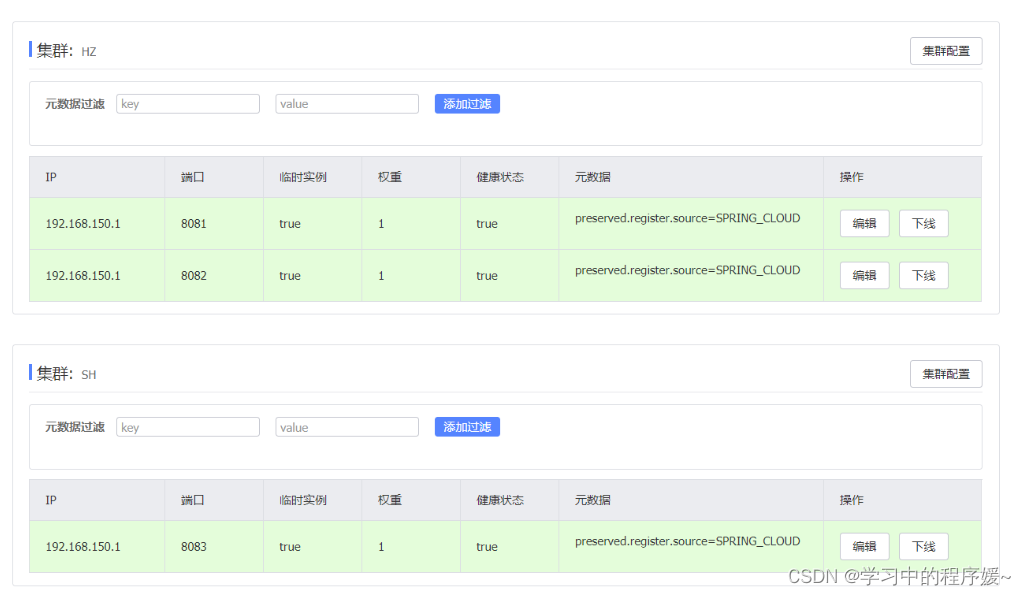
启动UserApplication3后再次查看nacos控制台:
4.3.2.同集群优先的负载均衡
默认的
ZoneAvoidanceRule并不能实现根据同集群优先来实现负载均衡。因此Nacos中提供了一个
NacosRule的实现,可以优先从同集群中挑选实例。1)给order-service配置集群信息
修改order-service的application.yml文件,添加集群配置:
spring:cloud:nacos:server-addr: localhost:8848discovery:cluster-name: HZ # 集群名称
2)修改负载均衡规则
修改order-service的application.yml文件,修改负载均衡规则:
userservice:ribbon:NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则
4.4.权重配置
实际部署中会出现这样的场景:
服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求。
但默认情况下NacosRule是同集群内随机挑选,不会考虑机器的性能问题。
因此,Nacos提供了权重配置来控制访问频率,权重越大则访问频率越高。
在nacos控制台,找到user-service的实例列表,点击编辑,即可修改权重:

在弹出的编辑窗口,修改权重:

注意:如果权重修改为0,则该实例永远不会被访问
4.5.环境隔离
Nacos提供了namespace来实现环境隔离功能。
-
nacos中可以有多个namespace
-
namespace下可以有group、service等
-
不同namespace之间相互隔离,例如不同namespace的服务互相不可见
-
4.5.1.创建namespace
默认情况下,所有service、data、group都在同一个namespace,名为public:
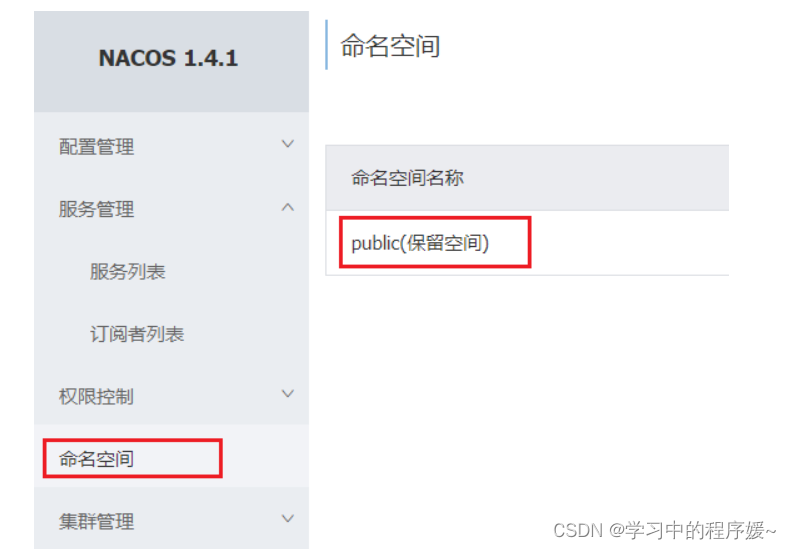
我们可以点击页面新增按钮,添加一个namespace:
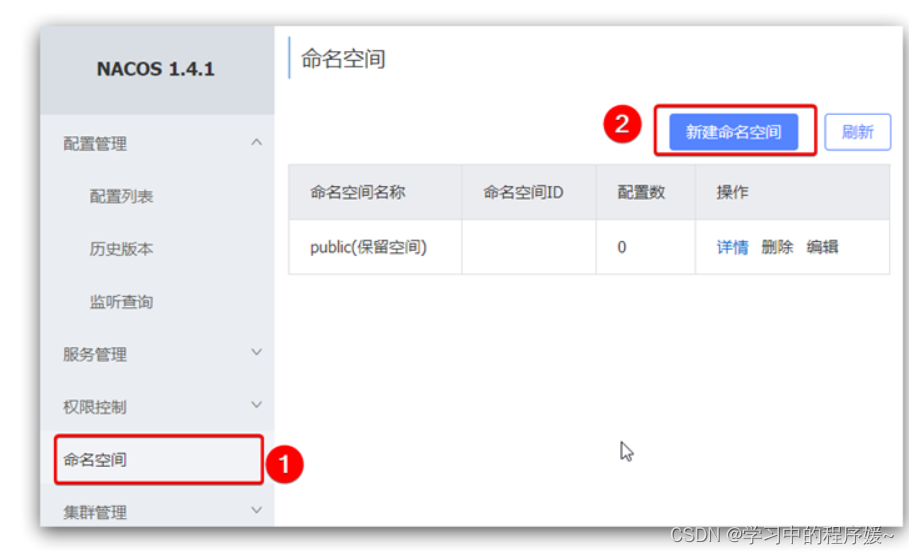
然后,填写表单:
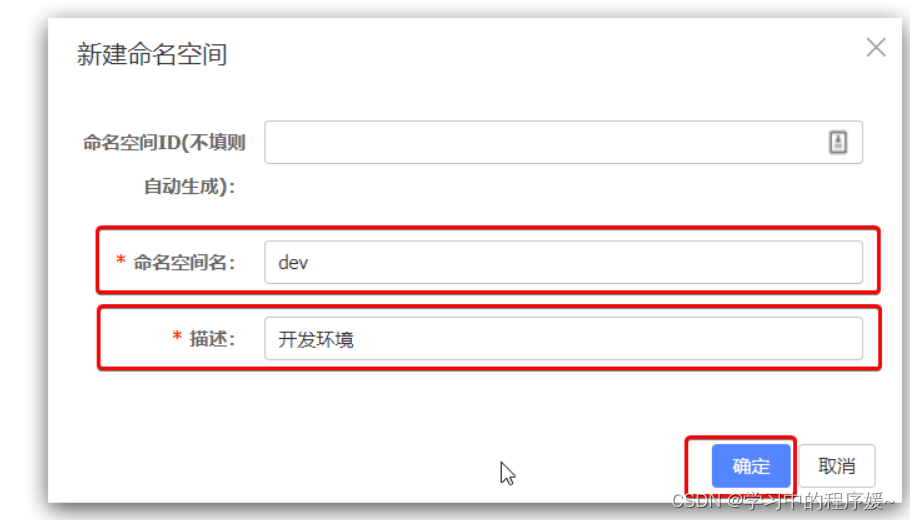
就能在页面看到一个新的namespace:

4.5.2.给微服务配置namespace
给微服务配置namespace只能通过修改配置来实现。
例如,修改order-service的application.yml文件:
spring:cloud:nacos:server-addr: localhost:8848discovery:cluster-name: HZnamespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 # 命名空间,填ID
重启order-service后,访问控制台,可以看到下面的结果:
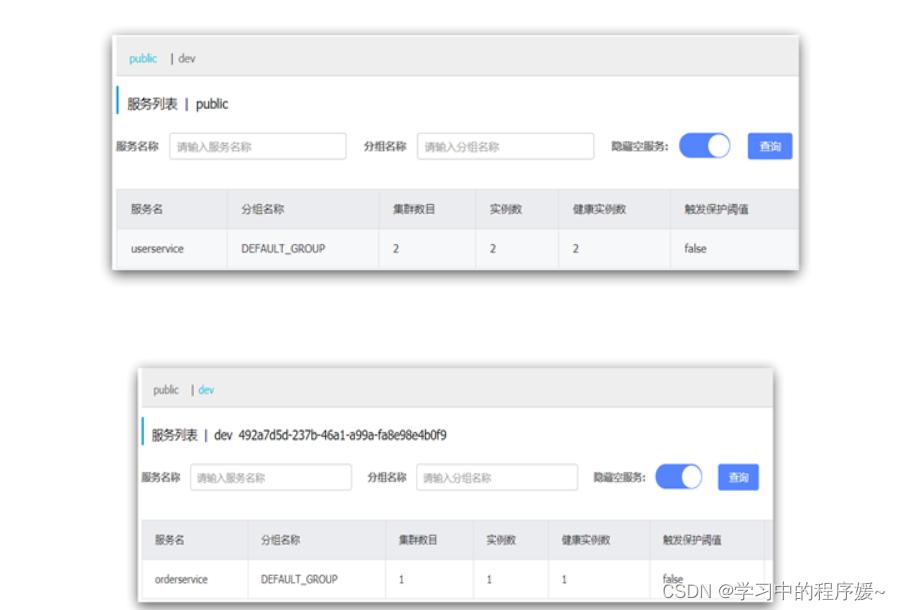
此时访问order-service,因为namespace不同,会导致找不到userservice,控制台会报错:

4.6.Nacos与Eureka的区别
Nacos的服务实例分为两种l类型:
-
临时实例:如果实例宕机超过一定时间,会从服务列表剔除,默认的类型。
-
非临时实例:如果实例宕机,不会从服务列表剔除,也可以叫永久实例。
-
配置一个服务实例为永久实例:
spring:cloud:nacos:discovery:ephemeral: false # 设置为非临时实例
Nacos和Eureka整体结构类似,服务注册、服务拉取、心跳等待,但是也存在一些差异:
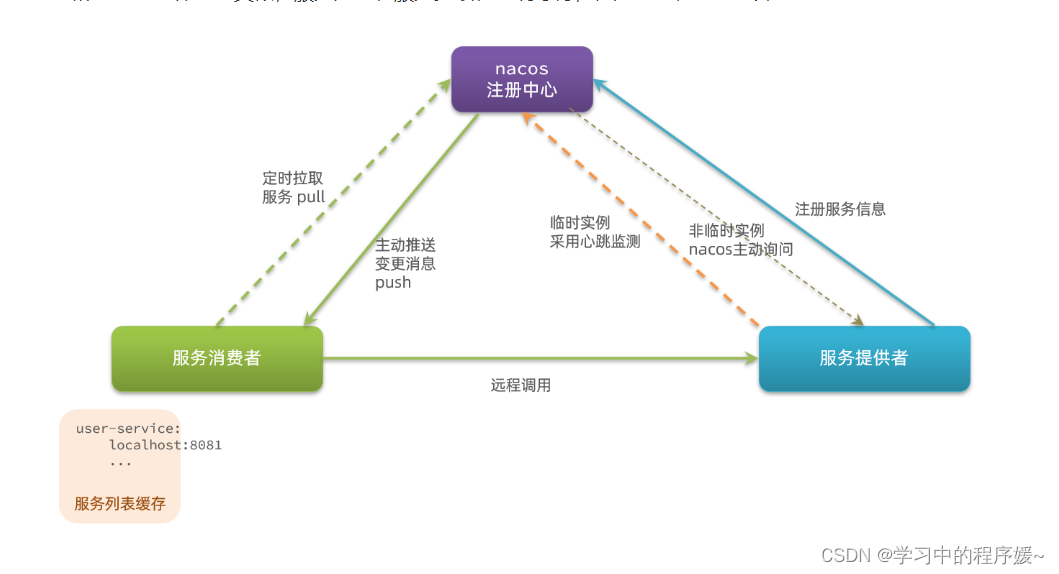
-
Nacos与eureka的共同点
-
都支持服务注册和服务拉取
-
都支持服务提供者心跳方式做健康检测
-
-
Nacos与Eureka的区别
-
Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
-
临时实例心跳不正常会被剔除,非临时实例则不会被剔除
-
Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
-
Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
-
相关文章:
聊聊java中的Eureka和Nacos
本文主要来自于黑马课程中 1.提供者与消费者 在服务调用关系中,会有两个不同的角色: 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务) 服务消费者:一次业务中࿰…...

系统架构设计师-21年-上午试题
系统架构设计师-21年-上午试题 更多软考资料 https://ruankao.blog.csdn.net/ 1 ~ 10 1 前趋图(Precedence Graph)是一个有向无环图,记为:→{(Pi,Pj)|Pi must complete before Pj may strat},假设系统中进程P{P1,P2,P3…...
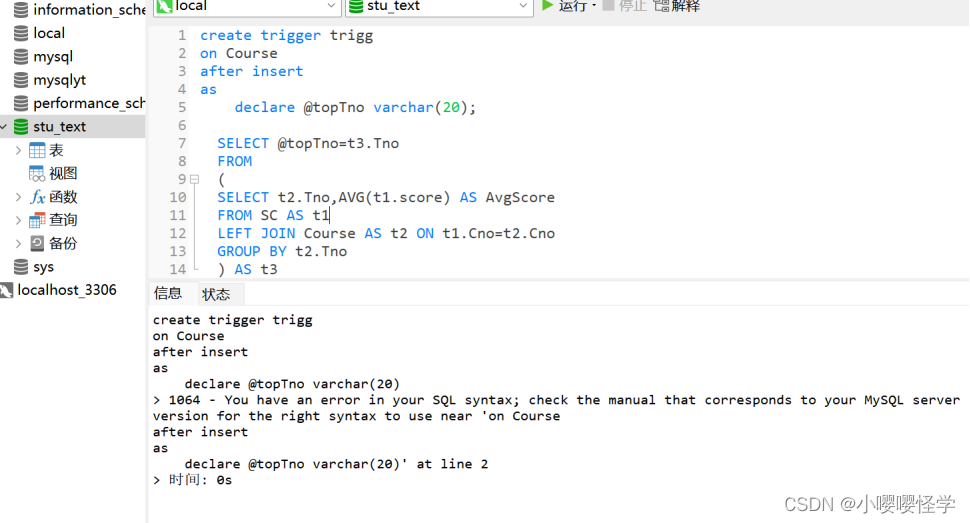
数据库MySQL查询设计||给定四个关联表,其定义和数据加载如下:-- 学生表 Student-- 选课表 SC
SQL查询设计 给定四个关联表,其定义和数据加载如下: -- 学生表 Student create table Student(Sno varchar(6), Sname varchar(10), Sdate datetime, Ssex varchar(10)); insert into Student values(01 , 赵雷 , 1999-01-01 , 男); insert into St…...
C#使用RabbitMQ-3_发布订阅模式(扇形交换机)
简介 发布订阅模式允许一个生产者向多个消费者发送消息。在RabbitMQ中实现发布订阅模式通常涉及以下几个关键组件: 生产者:负责生产并发送消息到RabbitMQ的Exchange(路由器)。Exchange:作为消息的中转站,…...
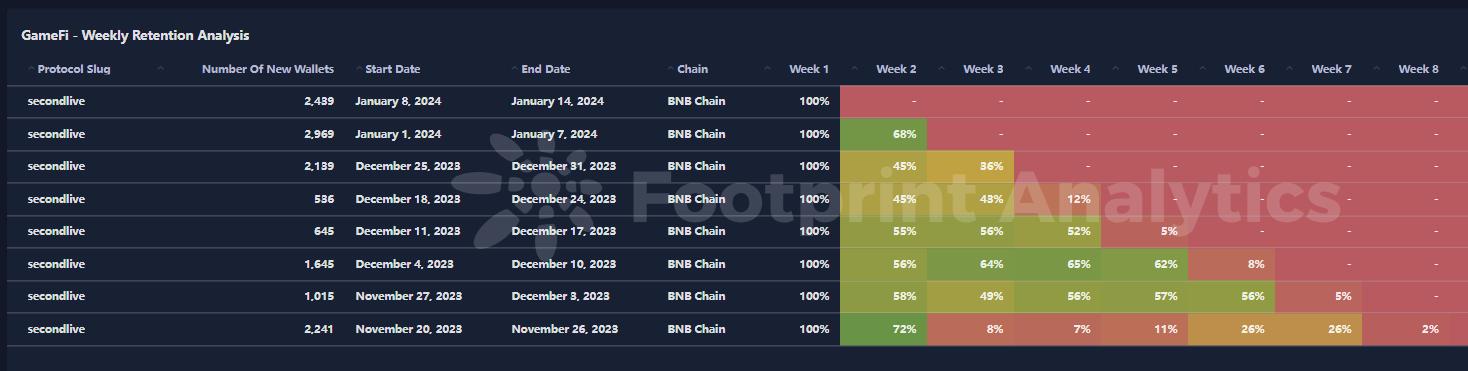
区块链游戏解说:什么是 SecondLive
数据源:SecondLive Dashboard 作者:lesleyfootprint.network 什么是 SecondLive SecondLive 是元宇宙居民的中心枢纽,拥有超过100 万用户的蓬勃社区。它的主要使命是促进自我表达,释放创造力,构建梦想中的平行宇宙…...

构建基于Flask的跑腿外卖小程序
跑腿外卖小程序作为现代生活中的重要组成部分,其技术实现涉及诸多方面,其中Web开发框架是至关重要的一环。在这篇文章中,我们将使用Python的Flask框架构建一个简单的跑腿外卖小程序的原型,展示其基本功能和实现原理。 首先&…...

【算法】Partitioning the Array(数论)
题目 Allen has an array a1,a2,…,an. For every positive integer k that is a divisor of n, Allen does the following: He partitions the array into n/k disjoint subarrays of length k. In other words, he partitions the array into the following subarrays: [a1,…...

ASP.NET Core 7 Web 使用Session
ASP.NET Core 好像不能像20年前那样直接使用Session函数,我使用如下方法 1、在NuGet安装以下2个包 2、在Program.cs注册 //注册Session builder.Services.AddSession(options > {options.IdleTimeout TimeSpan.FromMinutes(60);options.Cookie.HttpOnly fals…...

(1)SpringBoot学习——芋道源码
Spring Boot 的快速入门 一.、概述 使用 Spring Boot 可以很容易地创建出能直接运行的独立的、生产级别的基于 Spring 的应用。 二、快速入门 2.1 创建 Maven 项目 打开 IDEA,点击菜单 File -> New -> Project.来创建项目选择 Maven 类型,点击「…...

宏景eHR FrCodeAddTreeServlet SQL注入漏洞复现
前言 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使用。 一、产…...
STM32——I2C
通信协议见(STM32——SPI) 一、I2C协议 1.1 I2C协议介绍; I2C是(Inter IC Bus)是由Philips公司开发的一种通用数据总线; 有多根通信线; 一根SDA(串行通信线)…...

笔记本从零安装ubuntu server系统+环境配置
文章目录 前言相关链接ubuntu Server 安装教程屏幕自动息屏关上盖子不休眠MobaXterm外网SSH内网穿透IPV6远程 为什么我要笔记本装Linux为什么要换ubuntu Server版能否连接wifi之后Linux 配置清单总结 前言 之前装了个ubuntu desktop 版,发现没有命令行,…...

SQL 快速参考手册
SQL 语句语法AND / ORSELECT column_name(s) FROM table_name WHERE condition AND|OR conditionALTER TABLEALTER TABLE table_name ADD column_name datatype 或者: ALTER TABLE table_name DROP COLUMN column_name AS (alias)SELECT column_name AS column_alia…...

Linux/Windows系统无法git clone解决办法
一、Windows 1. 查找github和githubusercontent的IP地址 IP Tracer & Tracker - IP Address Lookup Made EasyIP Lookup Made Easy Using The Best IP Tracker – Trace An IP, Map The Location & Get Accurate Results When Using The Best IP Finderhttps://www.i…...
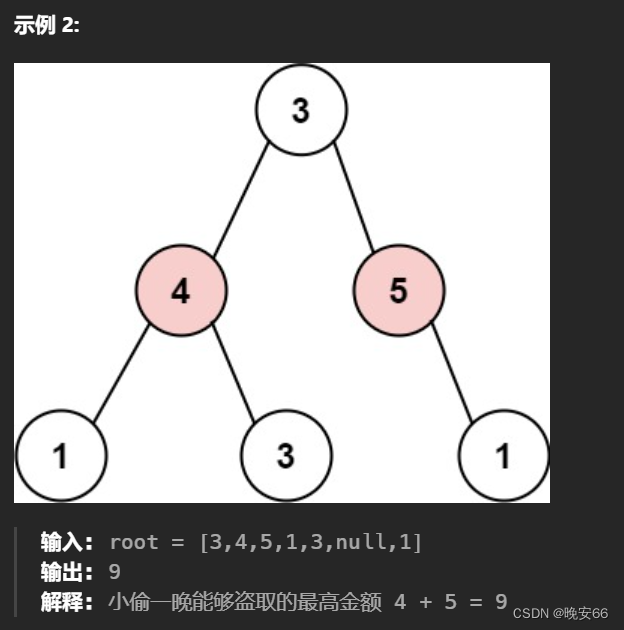
【算法与数据结构】198、213、337LeetCode打家劫舍I, II, III
文章目录 一、198、打家劫舍二、213、打家劫舍 II三、337、打家劫舍III三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、198、打家劫舍 思路分析:打家劫舍是动态规划的的经典题目。本题的难点在于递归公式…...

React、React Router、JSX 简单入门快速上手
React、React Router、JSX 简单入门快速上手 介绍特点 JSX使用js表达式渲染列表样式控制注意事项 入门脚手架创建react项目安装目录介绍入口文件解析 组件解析介绍函数式组件类组件 事件绑定注意点定义使用事件对象事件处理函数接收额外参数 组件状态状态的定义使用 组件通信父…...

从 0 开始搭建 React 框架
webpack 配置 不再赘述,可参考前三个文章(wenpack5 基本使用 1 - 3) 使用 react 安装 react、react-dom、babel/preset-react yarn add react react-dom babel/preset-react<!DOCTYPE html> <html lang"en"> <h…...

网站地址怎么改成HTTPS?
现在,所有类型的网站都需要通过 HTTPS 协议进行安全连接,而实现这一目标的唯一方法是使用 SSL 证书。如果您不将 HTTP 转换为 HTTPS,浏览器和应用程序会将您网站的连接标记为不安全。 但用户询问如何将我的网站从 HTTP 更改为 HTTPS。在此页…...
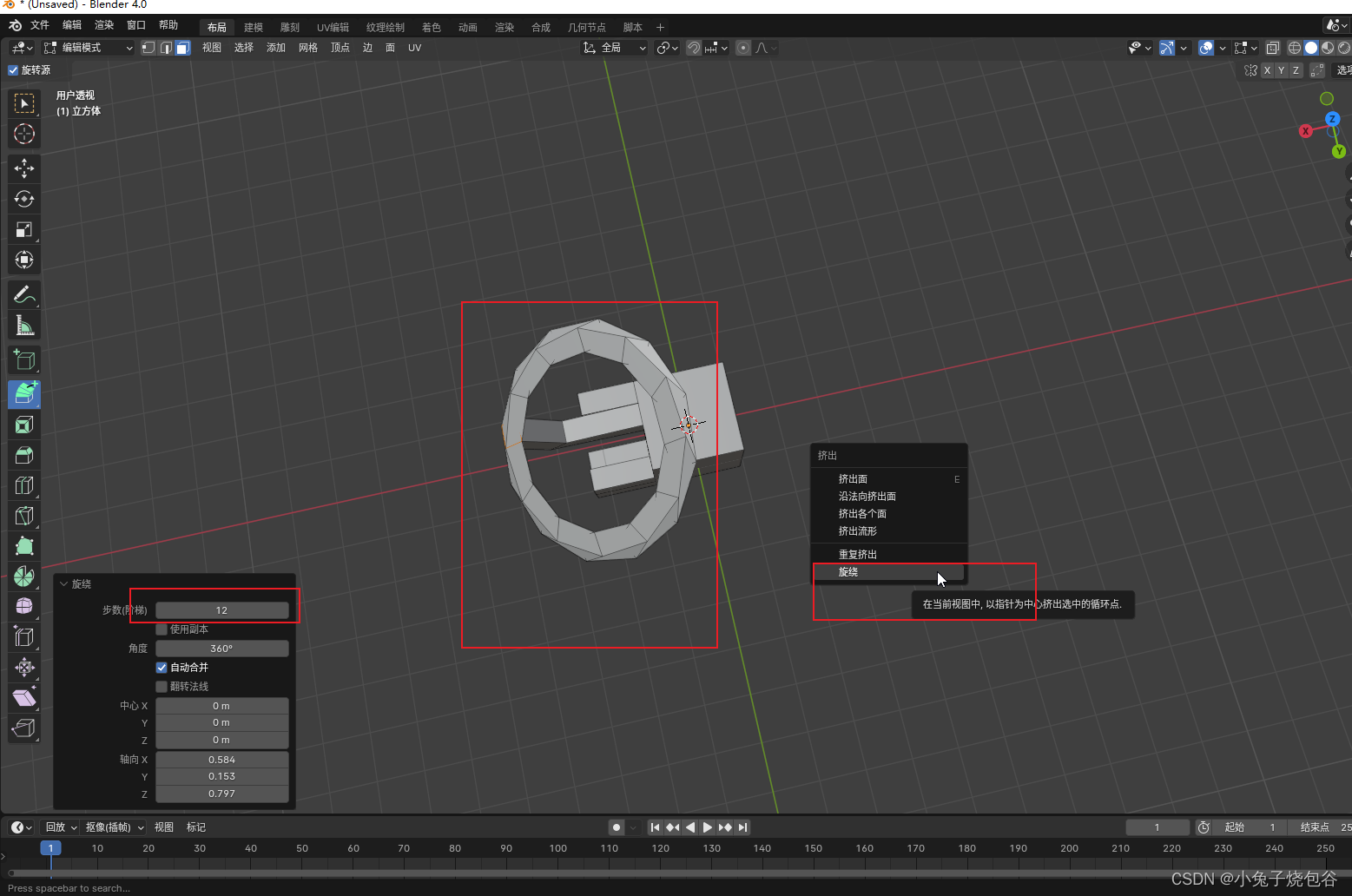
Blender教程(基础)-面的细分与删除、挤出选区-07
一、Blender之面的细分 新建一个立方体,在编辑模式下、选中一个面。 在选中的面上单击右键弹出细分选项,选择细分。 在选中细分后、会默认细分1次。修改细分次数在左下角 二、Blender之面的删除 选择中需要操作的面,在英文状态下按X键弹…...

QT自制软键盘 最完美、最简单、支持中文输入(二)
目录 一、前言 二、本自制虚拟键盘特点 三、中文输入原理 四、组合键输入 五、键盘事件模拟 六、界面 七、代码 7.1 frmKeyBoard 头文件代码 7.2 frmKeyBoard 源文件代码 八、使用示例 九、效果 十、结语 一、前言 由于系统自带虚拟键盘不一定好用,也不一…...

具身智能的发展趋势对就业市场的影响的时间线是怎样的?
一、时间线为什么是 2026–2027 / 2028–2029 / 2030?1)2026–2027:阵痛期(工业 / 物流先替代)核心依据:量产节奏 成本拐点 机构一致判断出货量预测:多家机构(IFR、高盛、麦肯锡&a…...

联想刃7000K BIOS隐藏选项终极解锁指南:3步开启完整高级权限
联想刃7000K BIOS隐藏选项终极解锁指南:3步开启完整高级权限 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 想要充分发…...

Cursor Pro工具完整指南:5步实现AI编程助手设备标识管理方案
Cursor Pro工具完整指南:5步实现AI编程助手设备标识管理方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...
))
GESP6级C++考试语法知识(二十六、广度优先搜索(一、认识BFS))
第一课《消息传播城——认识广度优先搜索 BFS》🌟一、故事开始:国王的紧急消息1、很久很久以前,有一座叫:🏰「消息传播城」的大王国。2、有一天,怪兽突然来袭!国王必须立刻通知所有村庄…...

如何在Mac上实现窗口置顶:Topit完整指南让多任务处理更高效
如何在Mac上实现窗口置顶:Topit完整指南让多任务处理更高效 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常需要在多个窗口之间来回切换&…...

卡方检验筛选高质量样本,提升小样本学习在机器文本检测中的性能
1. 项目概述与核心价值在自然语言处理的实际工作中,我们常常会遇到一个令人头疼的困境:手头的数据标注成本高昂,或者特定领域的样本本身就极其稀缺。这时候,小样本学习(Few-Shot Learning)就成了我们的“救…...
:零代码基础,用自然语言完成 Web UI 测试)
Midscene.js 实战(一):零代码基础,用自然语言完成 Web UI 测试
一、开篇:UI 自动化测试,真的不需要会写代码吗? 如果你做过 UI 自动化测试,下面这些场景一定感同身受: 页面改版了,之前精心编写的 XPath 选择器全部失效,脚本大修; 新来的测试同事不懂 CSS 选择器,写不了自动化脚本,培训成本居高不下; 产品经理提了个自动化需求,…...

Zotero中文文献管理神器:茉莉花插件3分钟快速上手指南
Zotero中文文献管理神器:茉莉花插件3分钟快速上手指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为Zotero无…...

UnrealPakViewer:深度剖析虚幻引擎资源包的5大可视化分析能力
UnrealPakViewer:深度剖析虚幻引擎资源包的5大可视化分析能力 【免费下载链接】UnrealPakViewer 查看 UE4 Pak 文件的图形化工具,支持 UE4 pak/ucas 文件 项目地址: https://gitcode.com/gh_mirrors/un/UnrealPakViewer UnrealPakViewer是一款专门…...

微信小程序逆向:基于Frida Hook WeChatAppHost.dll解密wxapkg
1. 这不是“破解”,而是一次对微信小程序加载机制的逆向观察WeChatAppHost.dll 是 Windows 版微信客户端中承载小程序运行环境的核心动态链接库,它不对外公开接口,也不提供调试符号,但却是所有小程序资源加载、解密、注入与执行的…...