Pandas进阶--map映射,分组聚合和透视pivot_table详解
文章目录
- 1.Pandas的map映射
- (1)映射
- (2)map充当运算工具
- 2.数据分组和透视
- (1)分组统计 - groupby功能 是pandas最重要的功能
- (2)聚合agg
- 3.透视表pivot_table
- (1)参数
- (2)根据胜负字段进行数据的分组,然后对每组数据进行均值计算
- (3)根据主客场字段进行数据分类后,对分类后的得分字段求最大值、篮板字段求均值和助攻字段求累加和操作
- (3)#获取所有队主客场的总得分
- (4)查看主客场下的总得分都是哪些具体球队的得分构成的
- (5)#查看主客场下的总得分都是哪些具体球队的得分构成的,对于空值,用0填充
- (6)多条件分类汇总操作
1.Pandas的map映射
(1)映射
- 映射就是指给一组数据中的每一个元素绑定一个固定的数据
给Series中的一组数据提供另外一种表现方式,或者说给其绑定一组指定的标签或字符串
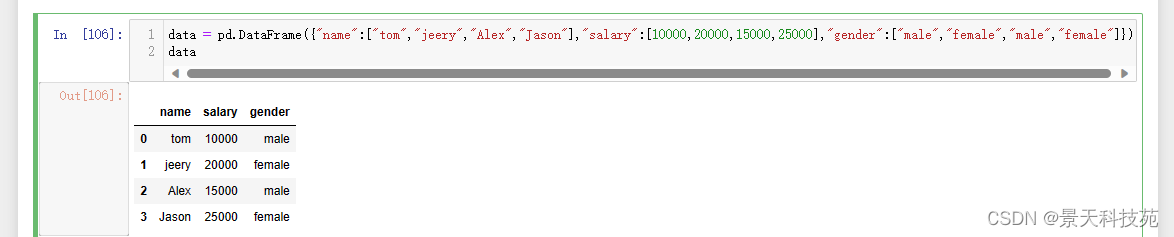
案例1:
创建一个df,两列分别是姓名和薪资。然后给其名字起对应的英文名,然后将英文的性别统一转换为中文的性别
data = pd.DataFrame({“name”:[“tom”,“jeery”,“Alex”,“Jason”],“salary”:[10000,20000,15000,25000],“gender”:[“male”,“female”,“male”,“female”]})
data
做映射
dic = {
“male”:“男”,
“female”:“女”
}
map可以将gender这组数据中的每个元素根据dic表示的关系,进行映射转换
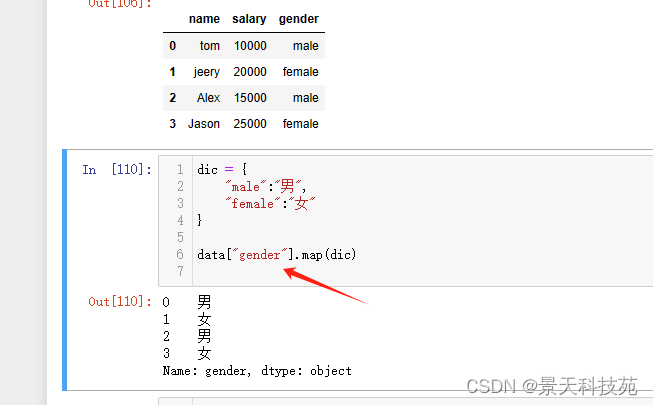
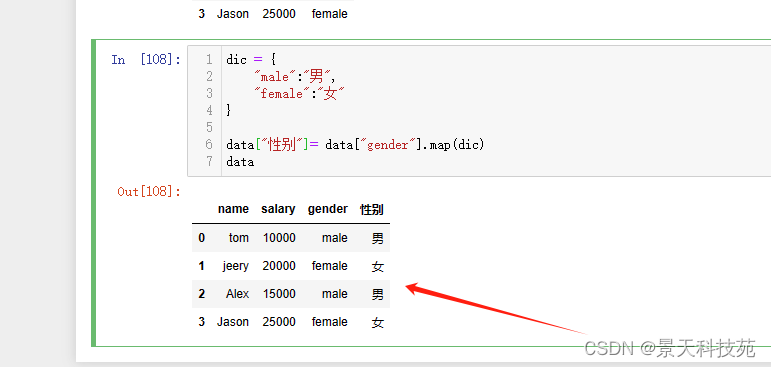
data[“性别”]= data[“gender”].map(dic)
data
案例2:
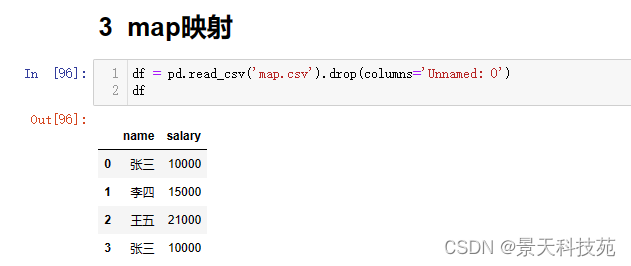
将文本中的名字映射出英文名字
首先根据本地文件创建个df
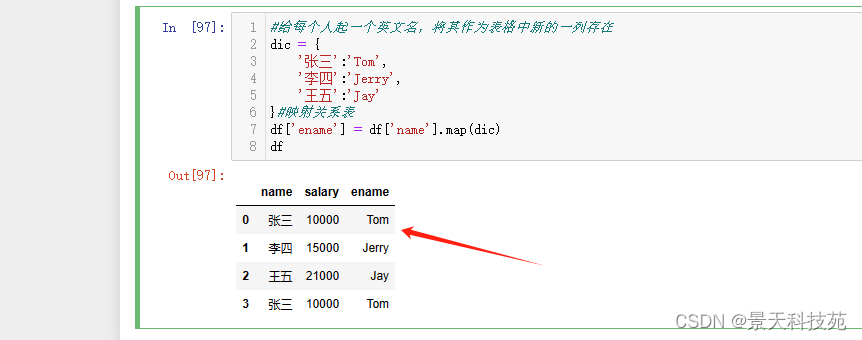
#给每个人起一个英文名,将其作为表格中新的一列存在
dic = {
‘张三’:‘Tom’,
‘李四’:‘Jerry’,
‘王五’:‘Jay’
}#映射关系表
df[‘ename’] = df[‘name’].map(dic)
df
(2)map充当运算工具
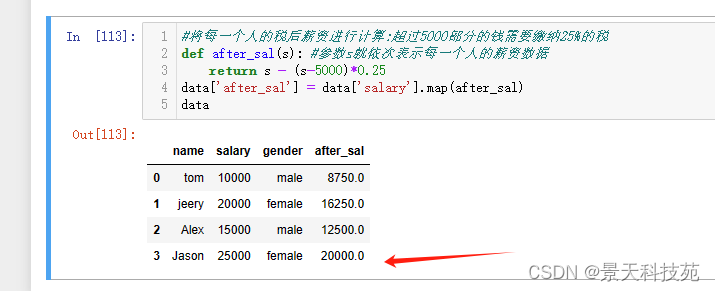
#将每一个人的税后薪资进行计算:超过5000部分的钱需要缴纳25%的税
def after_sal(s): #参数s就依次表示每一个人的薪资数据
return s - (s-5000)*0.25
data[‘after_sal’] = data[‘salary’].map(after_sal)
data
总结:map传入的参数是个字典,是做映射的。传入的是个函数名,是做运算用的
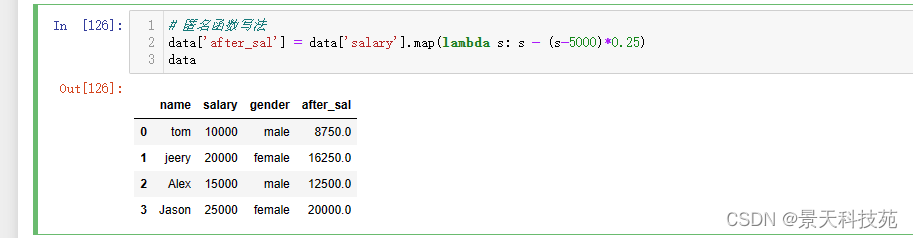
可以用匿名函数
#匿名函数写法
data[‘after_sal’] = data[‘salary’].map(lambda s: s - (s-5000)*0.25)
data
当然也可以用apply,新版的没有axis参数了
apply运算效率远远高于map,在数据数量级比较大的时候,经常用apply
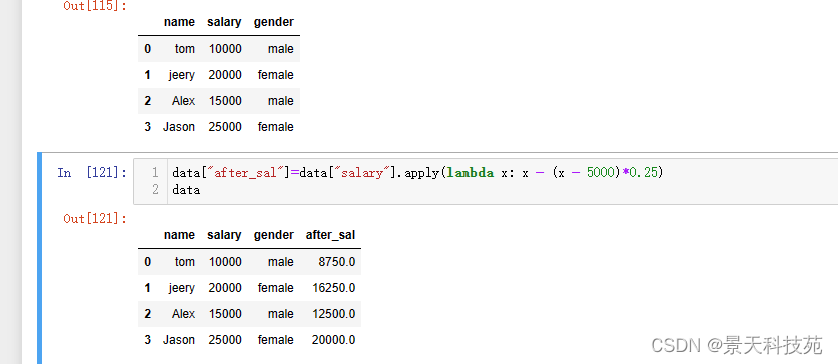
data[“after_sal”]=data[“salary”].apply(lambda x: x - (x - 5000)*0.25)
data
案例3:
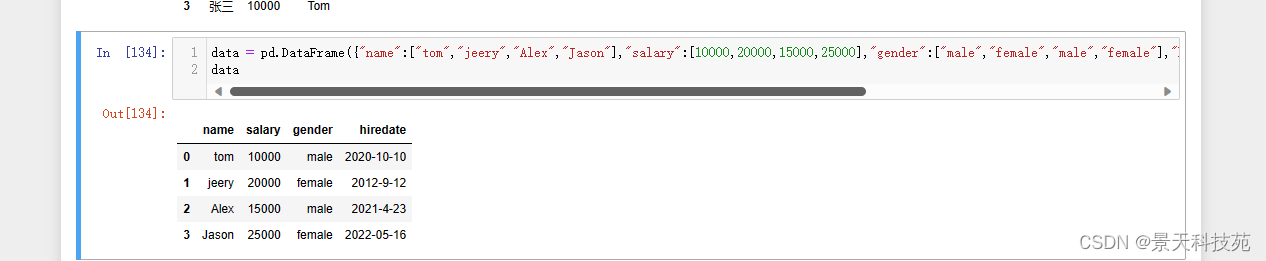
将每个人的入职日期加两年,目前入职日期是字符串类型数据
data = pd.DataFrame({“name”:[“tom”,“jeery”,“Alex”,“Jason”],“salary”:[10000,20000,15000,25000],“gender”:[“male”,“female”,“male”,“female”],“hiredate”:[“2020-10-10”,“2012–9-12”,“2021–4-23”,“2022-05-16”]})
data
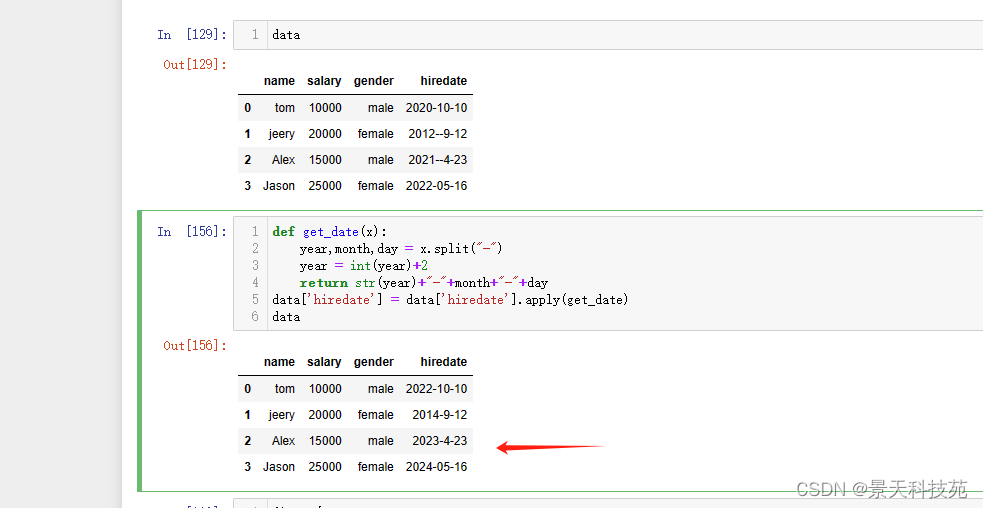
我们用apply来做
获取入职日期,根据- 做切分得到年份,加2
def get_date(x):
year,month,day = x.split(“-”)
year = int(year)+2
return str(year)+“-”+month+“-”+day
data[‘hiredate’] = data[‘hiredate’].apply(get_date)
data
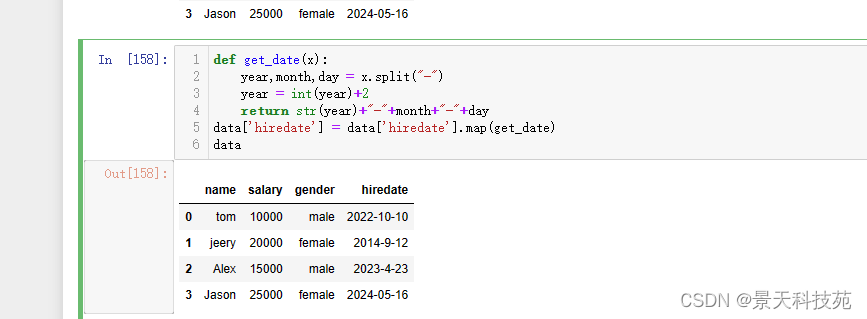
用map也可以
def get_date(x):
year,month,day = x.split(“-”)
year = int(year)+2
return str(year)+“-”+month+“-”+day
data[‘hiredate’] = data[‘hiredate’].map(get_date)
data
2.数据分组和透视
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
数据分类处理的核心:
groupby()函数
groups属性查看分组情况
(1)分组统计 - groupby功能 是pandas最重要的功能
① 根据某些条件将数据拆分成组
② 对每个组独立应用函数
③ 将结果合并到一个数据结构中
Dataframe在行(axis=0)或列(axis=1)上进行分组,将一个函数应用到各个分组并产生一个新值,然后函数执行结果被合并到最终的结果对象中。
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
api:
学习要善于掌握规律,你不管学什么函数,都要先学习其功能,参数,返回值都是啥。这样才能比较清晰的运用
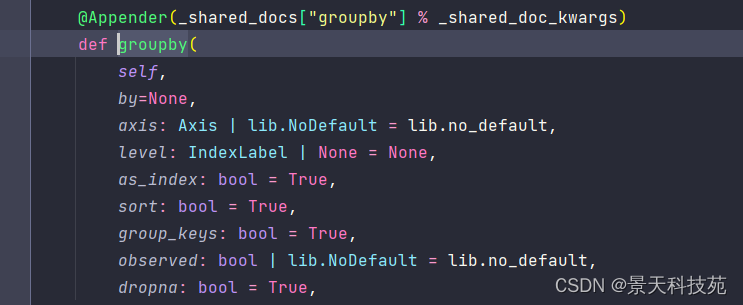
参数详解:
by参数用于指定要进行分组的列名,可以是一个列名或者多个列名的列表
axis参数用于指定分组方向,0表示行方向,1表示列方向
level参数用于指定分组级别
as_index参数用于指定分组后的结果是否作为DataFrame的索引
sort参数用于指定分组结果是否按照分组列进行排序
group_keys参数用于指定分组后是否保留分组键
squeeze参数用于指定是否移除单元素的分组
observed参数用于指定是否观察数据的层次结构
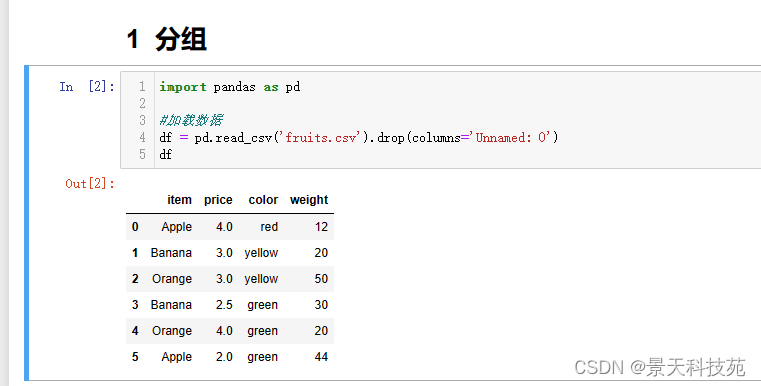
import pandas as pd
#加载数据
df = pd.read_csv(‘fruits.csv’).drop(columns=‘Unnamed: 0’)
df
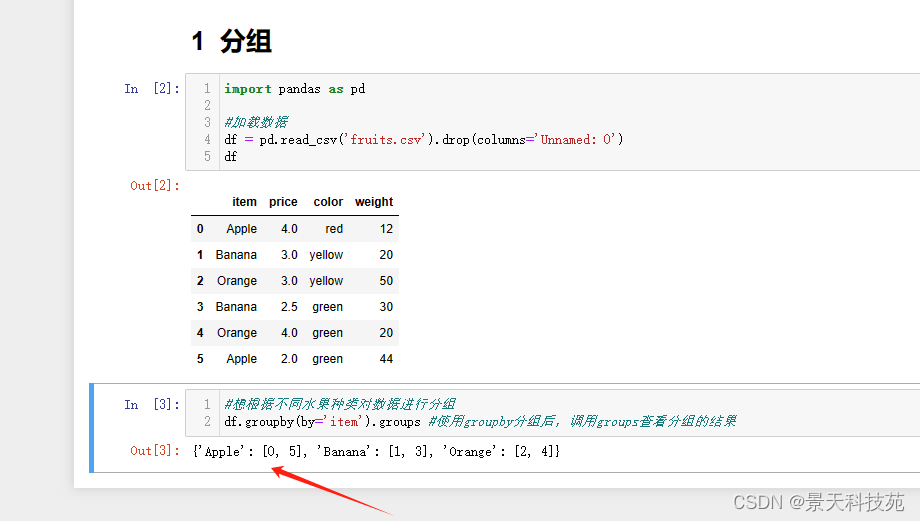
#想根据不同水果种类对数据进行分组
df.groupby(by=‘item’).groups #使用groupby分组后,调用groups查看分组的结果
Apple是 第0行和第5行。Banada 是第1行和第3行。Orange是第2行和第4行
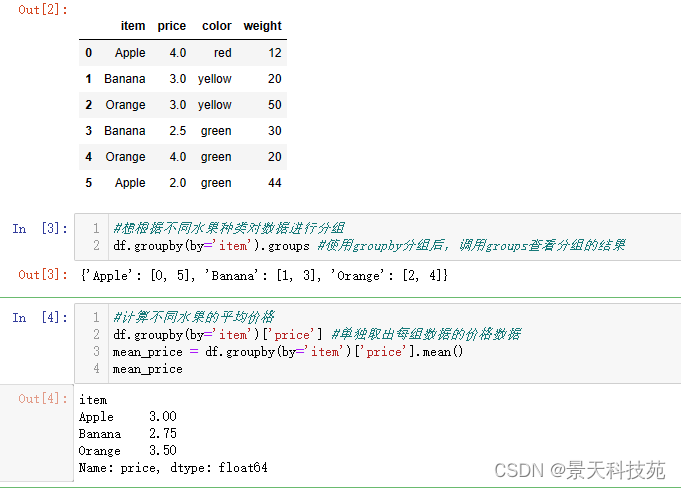
#计算不同水果的平均价格
df.groupby(by=‘item’)[‘price’] #单独取出每组数据的价格数据
mean_price = df.groupby(by=‘item’)[‘price’].mean() #求均值
mean_price
to_dict() 可以将dataframe转换为dict
mean_price.to_dict()
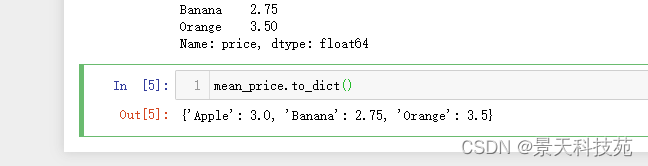
#将每种水果的平均价格汇总到原始表格中
现在无法直接将平均价格series数据直接插入到原始数据,因为数据结构不一样
此时就可以用到我们之前学的map
dic = {
‘Apple’:3.00,
‘Banana’:2.75,
‘Orange’:3.50
}
#dic = mean_price.to_dict()
df[‘mean_price’] = df[‘item’].map(dic)
df
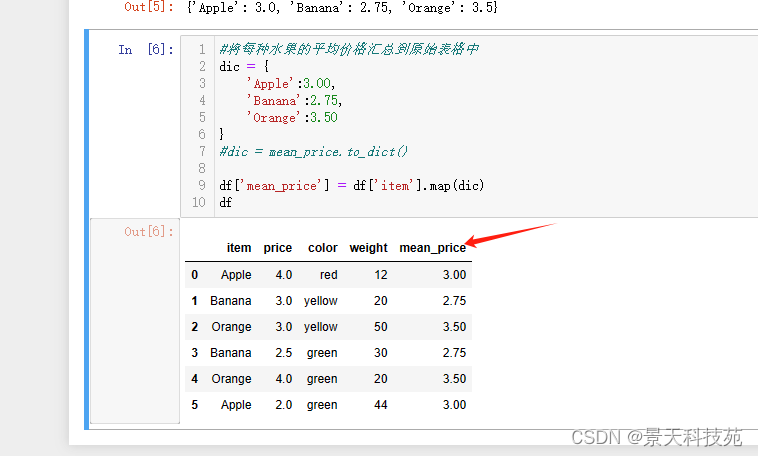
#计算不同颜色水果的最大重量
color_max_weight = df.groupby(by=‘color’)[‘weight’].max()
color_max_weight
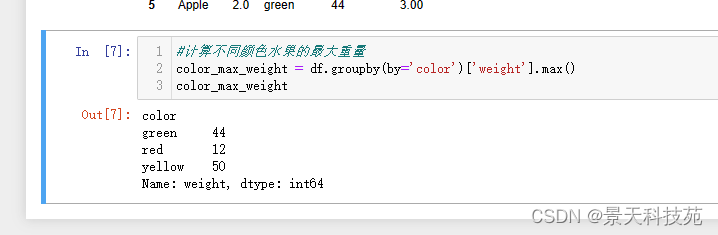
将不同颜色水果的最大重量也汇总到原始数据中
df[‘max_weight’] = df[‘color’].map(color_max_weight.to_dict())
df
使用groupby分组后,也可以使用功能transform和apply提供自定义函数实现更多运算
apply和transform的区别:
transform返回的结果是经过映射后的结果
apply返回的是没经过映射的结果
案例:
计算每种水果最大价格和最低价格的差值
def func(x): # 此时的x是每种水果的所有价格
return x.max()-x.min()
df [‘price_cha’] = df.groupby(by=“item”)[‘price’].transform(func)
df
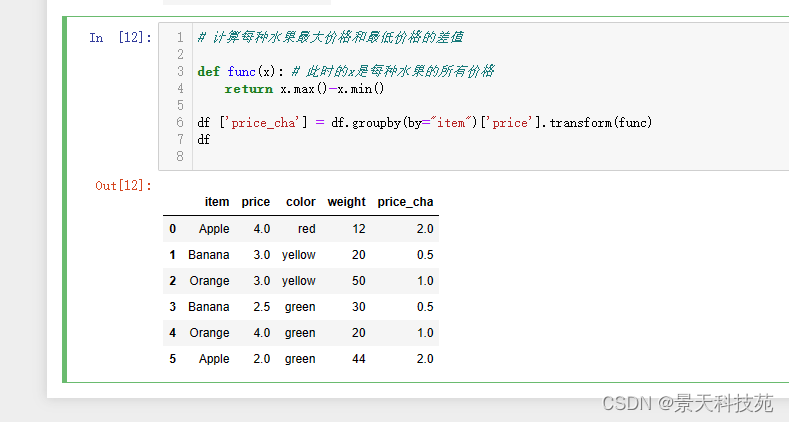
此时,用apply就得不到值
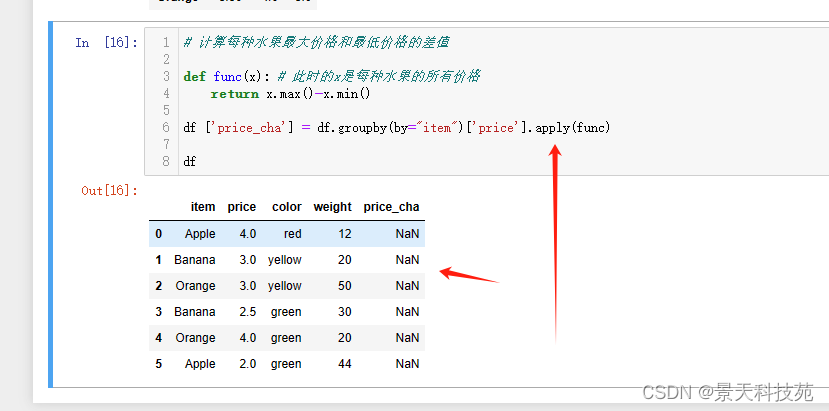
apply得到的值是:
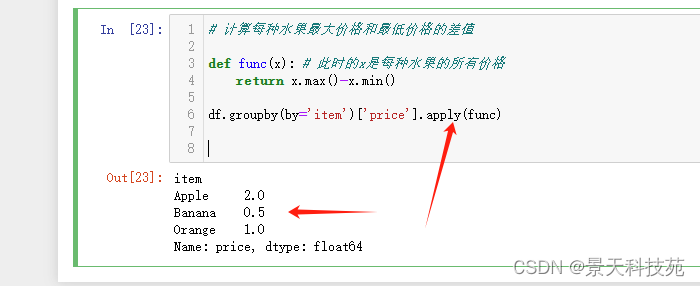
#计算每种水果最大价格和最低价格的差值
def func(x): # 此时的x是每种水果的所有价格
return x.max()-x.min()
df.groupby(by=‘item’)[‘price’].apply(func)
能得到结果,但是没经过映射,没法直接添加到原始数据。还需要转化成字典,使用map才能映射
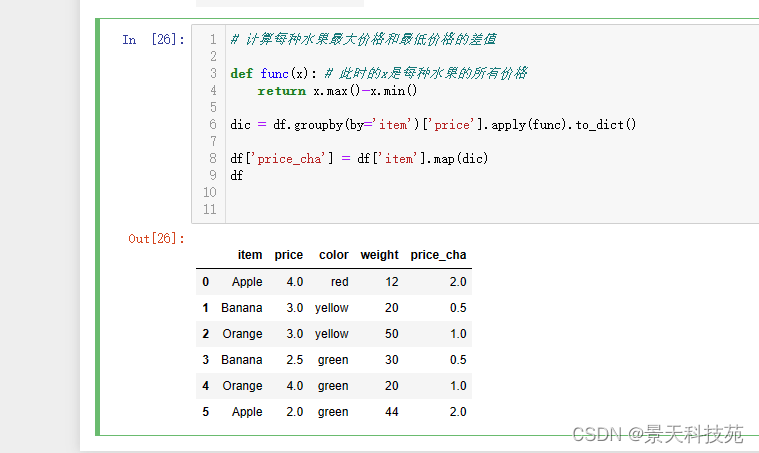
#计算每种水果最大价格和最低价格的差值
def func(x): # 此时的x是每种水果的所有价格
return x.max()-x.min()
dic = df.groupby(by=‘item’)[‘price’].apply(func).to_dict()
df[‘price_cha’] = df[‘item’].map(dic)
df
(2)聚合agg
对分组后的结果进行多种不同形式的聚合操作
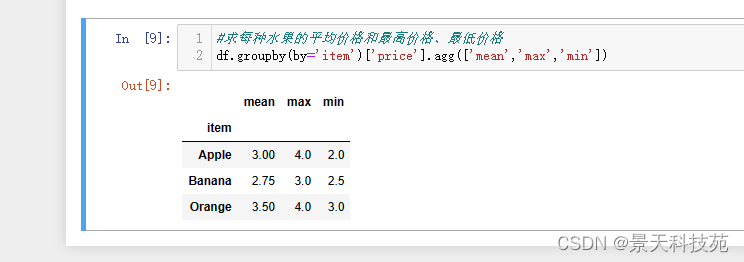
#求每种水果的平均价格和最高价格、最低价格
df.groupby(by=‘item’)[‘price’].agg([‘mean’,‘max’,‘min’])
3.透视表pivot_table
透视表是一种可以对数据动态排布并且分类汇总的表格格式。
或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
(1)参数
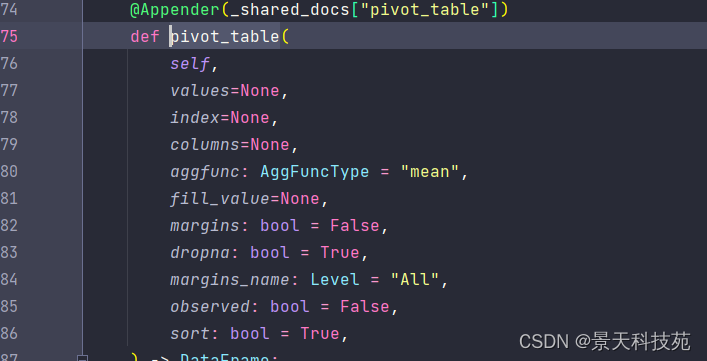
values:被计算的数据项,设定需要被聚合操作的列(需要显示的列) 对哪个值进行计算
index:每个pivot_table必须拥有一个index,必选参数,设定数据的行索引,可以设置多层索引,多次索引时按照需求确定索引顺序。 根据什么分类
columns:必选参数,设定列索引,用来显示字符型数据,和fill_value搭配使用。
aggfunc:聚合函数, pivot_table后新dataframe的值都会通过aggfunc进行运算。默认numpy.mean求平均。
fill_values:填充NA值(设定缺省值)。默认不填充,可以指定。
margins:添加行列的总计,默认FALSE不显示。TRUE显示。
dropna:如果整行都为NA值,则进行丢弃,默认TRUE丢弃。FALSE时,被保留。
margins_name:margins = True 时,设定margins 行/列的名称。‘all’ 默认值
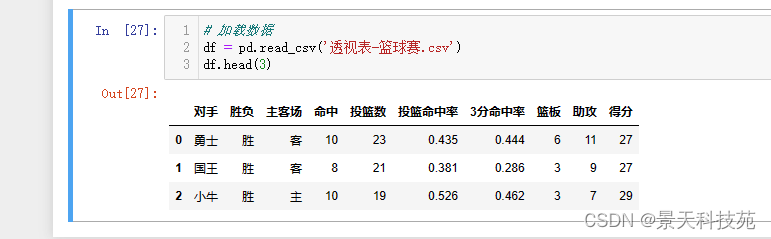
#加载数据
df = pd.read_csv(‘透视表-篮球赛.csv’)
df.head(3)
#根据对手分类,计算每个球队的平均分
新版的不能对字符串的列进行计算
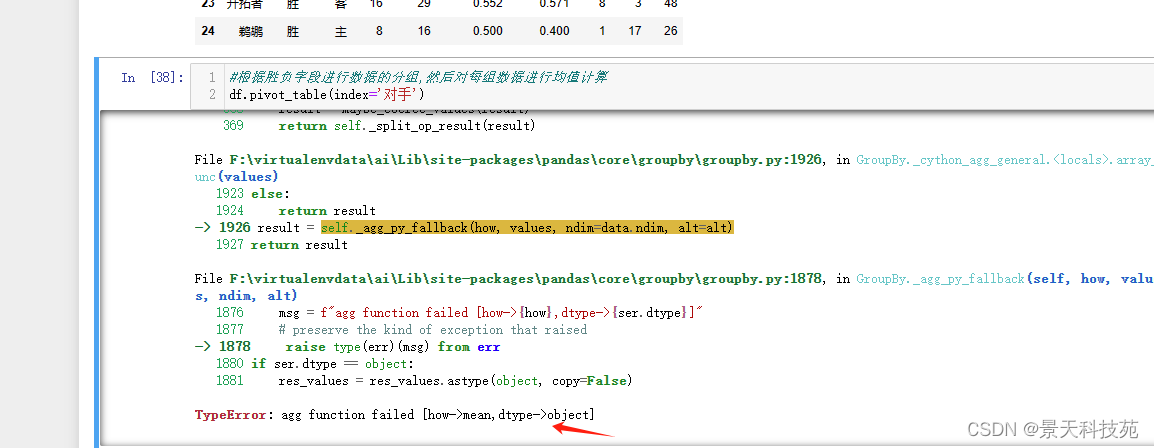
必须指定数字的列
df.pivot_table(index=‘对手’,values=‘得分’,aggfunc=‘mean’) #aggfunc默认是mean,求平均
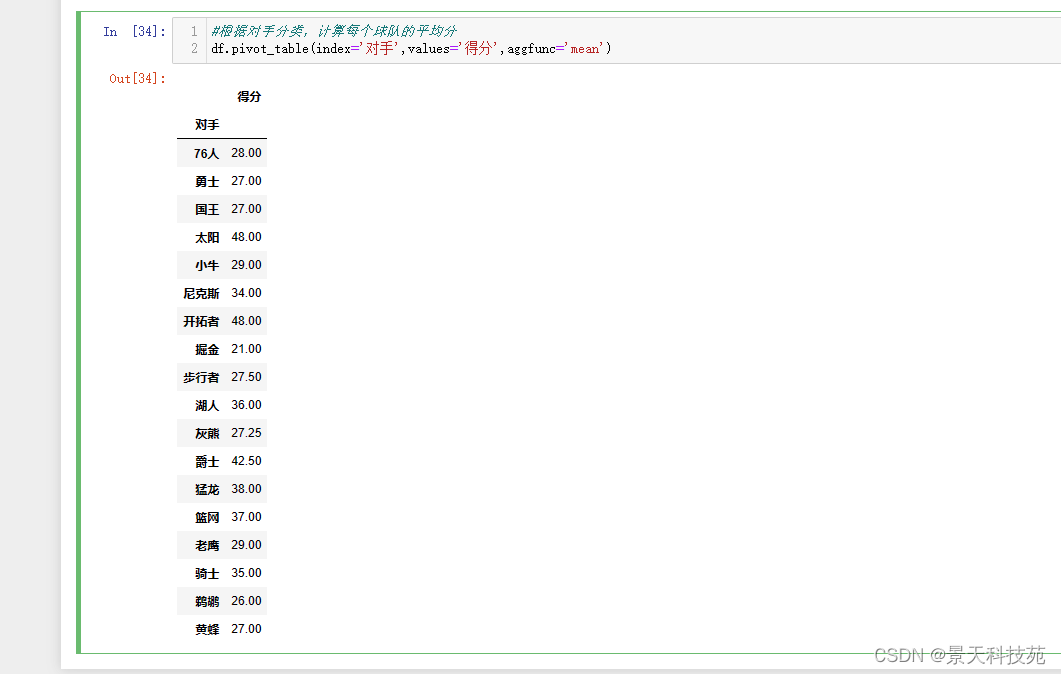
(2)根据胜负字段进行数据的分组,然后对每组数据进行均值计算
df.pivot_table(index=‘对手’,values=[‘命中’,‘投篮数’,‘投篮命中率’,‘3分命中率’,‘篮板’,‘助攻’,‘得分’])
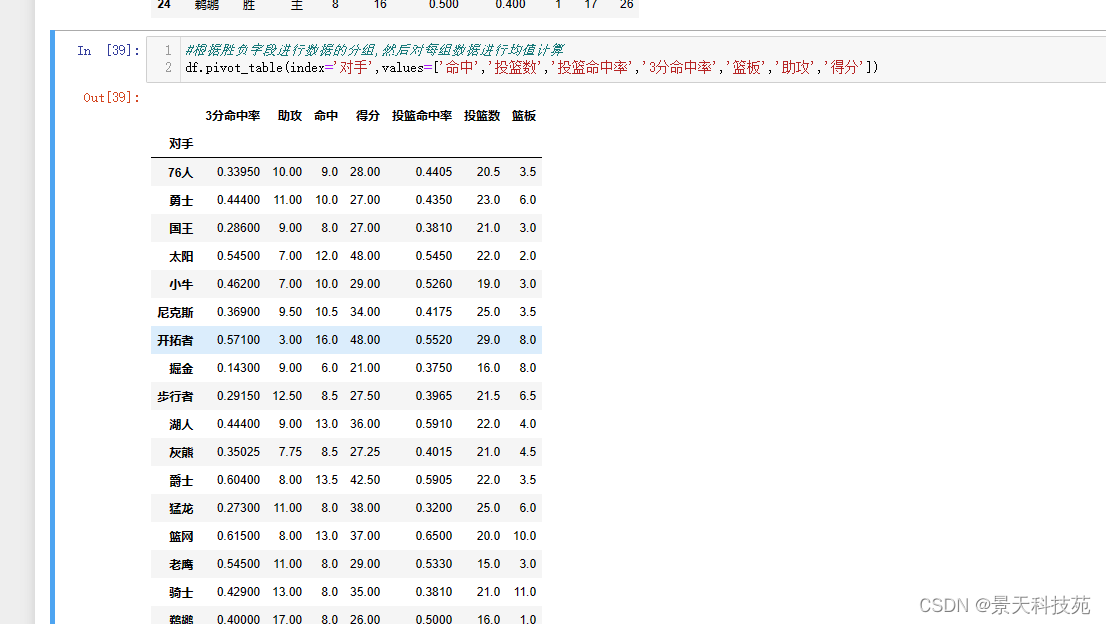
默认aggfunc只能举个一个参数,要想聚合多个参数,使用字典 。values这个字段就不要了
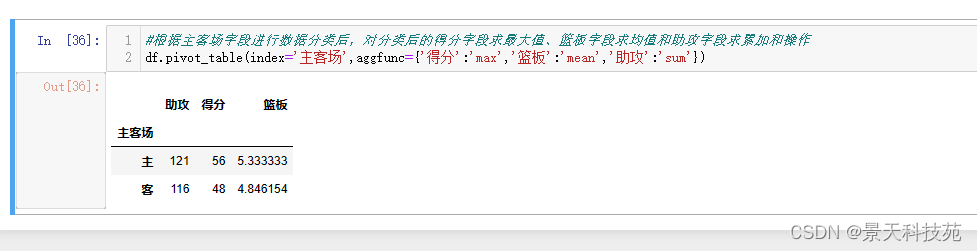
(3)根据主客场字段进行数据分类后,对分类后的得分字段求最大值、篮板字段求均值和助攻字段求累加和操作
df.pivot_table(index=‘主客场’,aggfunc={‘得分’:‘max’,‘篮板’:‘mean’,‘助攻’:‘sum’})
(3)#获取所有队主客场的总得分
df.pivot_table(index=‘主客场’,values=‘得分’,aggfunc=‘sum’)

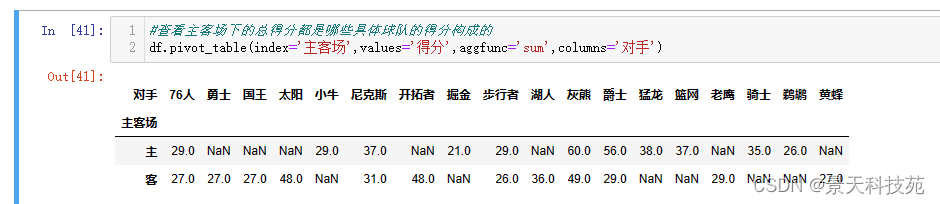
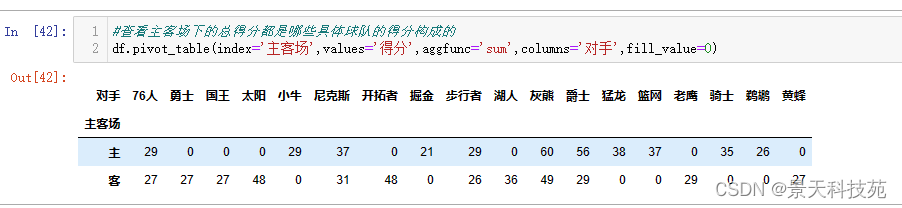
(4)查看主客场下的总得分都是哪些具体球队的得分构成的
df.pivot_table(index=‘主客场’,values=‘得分’,aggfunc=‘sum’,columns=‘对手’)
(5)#查看主客场下的总得分都是哪些具体球队的得分构成的,对于空值,用0填充
df.pivot_table(index=‘主客场’,values=‘得分’,aggfunc=‘sum’,columns=‘对手’,fill_value=0)
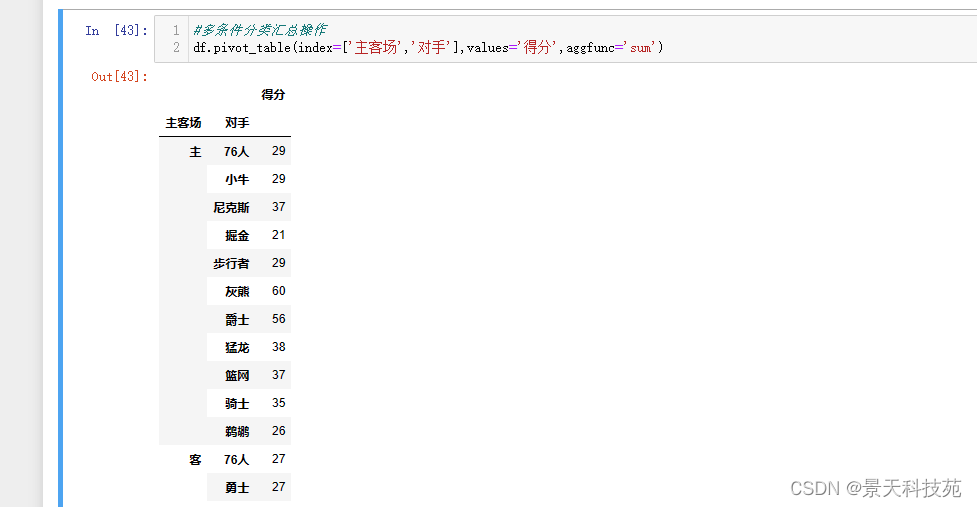
(6)多条件分类汇总操作
df.pivot_table(index=[‘主客场’,‘对手’],values=‘得分’,aggfunc=‘sum’)
相关文章:
Pandas进阶--map映射,分组聚合和透视pivot_table详解
文章目录 1.Pandas的map映射(1)映射(2)map充当运算工具 2.数据分组和透视(1)分组统计 - groupby功能 是pandas最重要的功能(2)聚合agg 3.透视表pivot_table(1)…...

Visual Studio 和Clion配置Cocos2d-x环境
Visual Studio 和Clion配置Cocos2d-x环境 我就不贴图片的,懒得上传图床。懒。开发环境: 系统: Window11 编译器: CMake MSVC 开发工具:Clion or Visual Studio 请自行配置好,Python2.7,和Cmake Cocos2d-x下载…...
【百度Apollo】本地调试仿真:加速自动驾驶系统开发的利器
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《linux深造日志》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下…...

ztest中ddof起什么作用
⭐️ statsmodels 中 ztest 基本使用 statsmodels 也是一个强大的统计分析库,提供了丰富的统计模型和检验功能。对于 Z 检验,statsmodels 提供了 ztest 函数。 以下是使用 statsmodels 进行 Z 检验的示例: from statsmodels.stats.weights…...

linux 主机无法联网问题
主机不能联网 一 查看当前ip ping路由 ifconfig wlan0 wlan0: flags4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 192.168.2.78 netmask 255.255.255.0 broadcast 192.168.2.255ping 192.168.2.1查看是否能ping通 二 查看路由表 route -n Destination G…...

2024/1/27 备战蓝桥杯 1-1
目录 求和 0求和 - 蓝桥云课 (lanqiao.cn) 成绩分析 0成绩分析 - 蓝桥云课 (lanqiao.cn) 合法日期 0合法日期 - 蓝桥云课 (lanqiao.cn) 时间加法 0时间加法 - 蓝桥云课 (lanqiao.cn) 扫雷 0扫雷 - 蓝桥云课 (lanqiao.cn) 大写 0大写 - 蓝桥云课 (lanqiao.cn) 标题…...
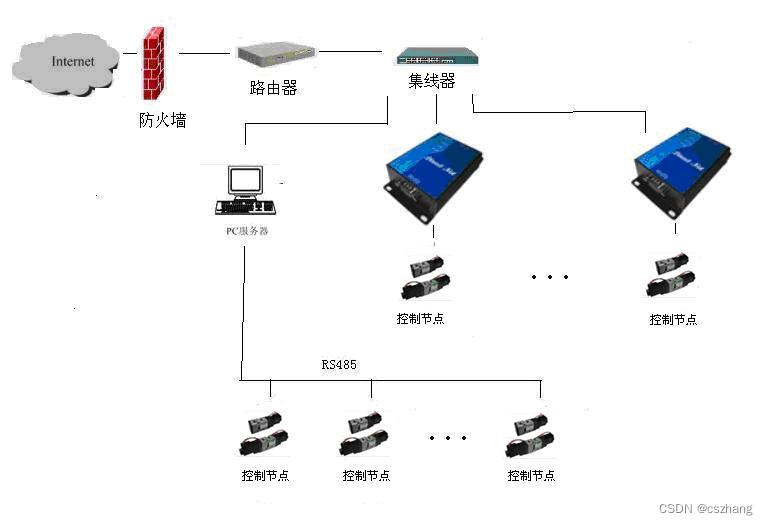
支持下一代网络IpV6的串口服务器,IpV6串口485接口转网口
和IPv4比较,IPv6有两个极具吸引力的特点:一个是IPv6采用的128位地址格式,而IPv4采用32位的地址格式,因此IPv6使地址空间增大了296;另一个是IPv6物联网数据业务具有更强的支持能力,成为未来物联网的重要协议…...

uniapp H5 实现上拉刷新 以及 下拉加载
uniapp H5 实现上拉刷新 以及 下拉加载 1. 先上图 下拉加载 2. 上代码 <script>import DragableList from "/components/dragable-list/dragable-list.vue";import {FridApi} from /api/warn.jsexport default {data() {return {tableList: [],loadingHi…...
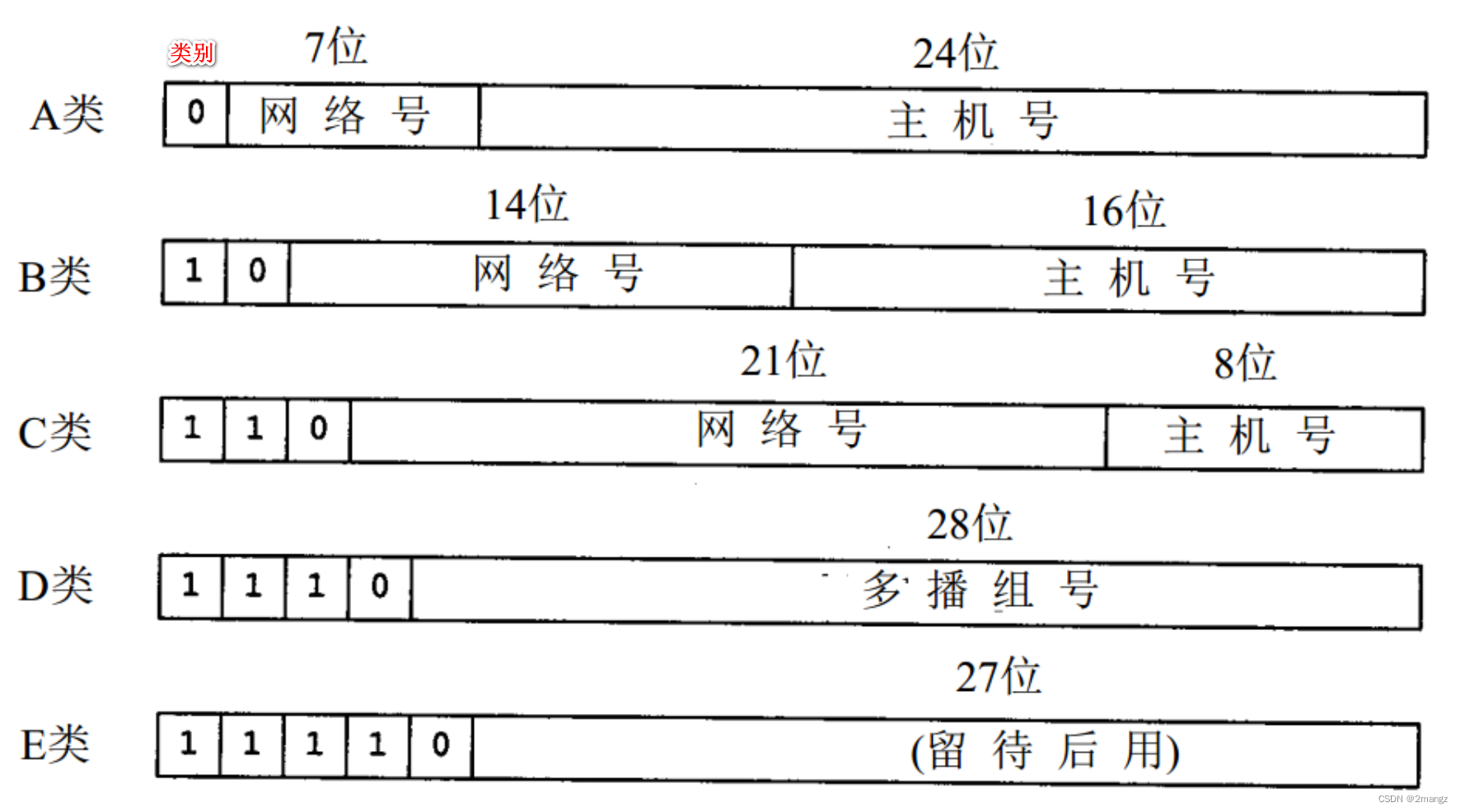
网络工程师必学知识:2、IPv4和IPv6地址划分
网络工程师必学知识:2、IPv4和IPv6地址划分 1.概述:2.IPv4:地址划分:有类划分,无类划分。一、有类划分:分为5类。ABCDE,掩码分别位8、16、24、28、27取值范围:出类别bit不变…...

Rust - 变量
不管学什么语言好像都得从变量开始,不过只需要懂得大概就可以了。 但在Rust里不先把变量研究明白后面根本无法进行… 变量绑定 变量赋值❌ 变量绑定✔️ Rust中没有“赋值”一说,而是称为绑定。 int a 3; //C中的变量赋值 a 3; //python中的…...

【Linux】压缩脚本、报警脚本
一、压缩搅拌 要求: 写一个脚本,完成如下功能 传递一个参数给脚本,此参数为gzip、bzip2或者xz三者之一; (1) 如果参数1的值为gzip,则使用tar和gzip归档压缩/etc目录至/backups目录中,并命名为/backups/etc…...

用Flask打造一个大模型智能问答WEB网站
目前已经有很多类似GPT的大模型开源,可以提供类似ChatGPT的智能问答功能。我也基于这些开源模型,用Flask来建立一个智能问答网站,可以方便用户建立自己的ChatGPT系统。 这个网站需要提供用户登录功能,对已登录的用户,可以在网站上提出问题,并由大模型处理后返回答案。演…...

学习python第三天
一.数据类型 1.获取数据类型 x 10 print(type(x))""" 输出 <class int> """2.复数类型(complex)详解 复数(Complex)是 Python 的内置类型,直接书写即可。换句话说,…...
(M)UNITY三段攻击制作
三段攻击逻辑 基本逻辑: 人物点击攻击按钮进入攻击状态(bool isAttack) 在攻击状态下, 一旦设置的触发器(trigger attack)被触发,设置的计数器(int combo)查看目前攻击…...
PHP的线程安全与非线程安全模式选哪个
曾经初学PHP的时候也很困惑对线程安全与非线程安全模式这块环境的选择,也未能理解其中意。近来无意中看到一个教程对线程安全(饿汉式),非线程安全(懒汉式)的描述,虽然觉得现在已经能够很明了透彻…...
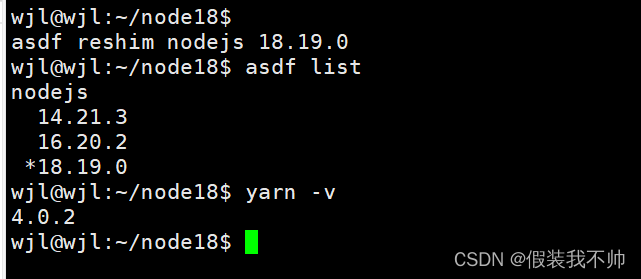
asdf安装不同版本的nodejs和yarn和pnpm
安装asdf 安装nodejs nodejs版本 目前项目中常用的是14、16和18 安装插件 asdf plugin add nodejs https://github.com/asdf-vm/asdf-nodejs.git asdf plugin-add yarn https://github.com/twuni/asdf-yarn.git可以查看获取所有的nodejs版本 asdf list all nodejs有很多找…...

Spring的事件监听机制
这里写自定义目录标题 1. 概述(重点)2. ApplicationEventMulticaster2.1 SimpleApplicationEventMulticaster2.2 AbstractApplicationEventMulticaster 3. ApplicationListener3.1 注册监听器3.2 自定义 4. SpringApplicationRunListeners 1. 概述&#…...
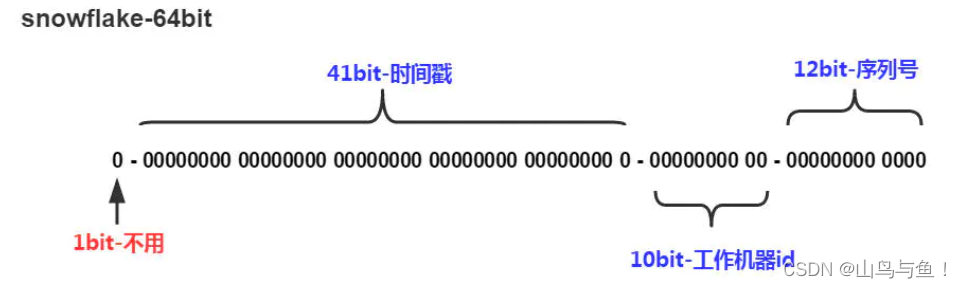
Zookeeper分布式命名服务实战
目录 分布式命名服务 分布式API目录 分布式节点的命名 分布式的ID生成器 分布式的ID生成器方案: 基于Zookeeper实现分布式ID生成器 基于Zookeeper实现SnowFlakeID算法 分布式命名服务 命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用Z…...
)
DEV-C++ ege.h库 绘图教程(六)
一、前情回顾 DEV-C ege.h库 绘图教程(一) DEV-C ege.h库 绘图教程(二) DEV-C ege.h库 绘图教程(三) DEV-C ege.h库 绘图教程(四) DEV-C ege.h库 绘图教程(五)…...

MySQL原理(一)架构组成之物理文件组成
目录 一、日志文件 1、错误日志 Error Log 1.1、作用: 1.2、开启关闭: 1.3、使用 2、二进制日志 Binary Log & Binary Log Index 2.1、作用: 2.2、开启关闭: 2.3、Binlog还有一些附加选项参数 (1&#x…...
)
机器学习---监督学习入门实验全攻略(小白友好版)
新晋码农一枚,小编会定期整理一些写的比较好的代码和知识点,作为自己的学习笔记,试着做一下批注和补充,转载或者参考他人文献会标明出处,非商用,如有侵权会删改!欢迎大家斧正和讨论!…...
理论,破解“限流“的底层逻辑)
短视频矩阵系统的信号密码:用数字信号处理(DSP)理论,破解“限流“的底层逻辑
你有没有想过一个问题:同样一条视频,A账号发了50万播放,B账号发了500播放。内容一样、时长一样、甚至发布时间都一样——到底差在哪?答案不在内容里,在信号里。今天用数字信号处理(DSP)的视角&a…...

Linux下BepInEx Mod部署原理与实战指南
1. 为什么Linux玩家总在Mod部署上卡住?——BepInEx不是“装上就能用”的玩具 BepInEx、Unity、Linux、Mod框架——这四个词凑在一起,对很多刚从Windows转战Linux的玩家或Mod开发者来说,几乎等于一道默认关闭的门。我第一次在Ubuntu 22.04上尝…...

从瑞芯微与飞凌嵌入式合作,看嵌入式核心板选型与产业协同
1. 项目概述:一次合作背后的产业逻辑最近,飞凌嵌入式在瑞芯微的合作伙伴大会上,拿下了“2024年度优秀合作奖”。这事儿在圈内不算大新闻,但如果你拆开来看,会发现它背后其实是一套非常经典的产业合作范本。它讲的不是某…...

谷歌“反重力”工具更新强行替换软件,用户恢复工作困难重重!
谷歌“反重力”工具更新强行替换软件,用户恢复工作困难重重!2026年5月21日,原本打算用“反重力”工具工作的用户,遭遇了谷歌的意外安排。前一天,谷歌在2026年I/O开发者大会上推出“反重力”工具新版本,将其…...

BBEdit 16 正式发布!新增百多项功能,部分用户可免费升级
产品 产品 BBEdit Yojimbo iPad 版 Yojimbo TextWrangler 支持 支持 BBEdit Yojimbo iPad 版 Yojimbo TextWrangler 产品下载 找回序列号 SDK 与开发者信息 公司书架 商店 商店 购物车 许可协议 Mac App Store 常见问题 销售政策 查找经销商 多用户许可证 联系我们 联系我们 找…...

量子机器学习噪声挑战与HPQS混合框架解析
1. 量子机器学习中的噪声挑战与HPQS解决方案量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,正在重新定义我们处理复杂模式识别问题的方式。与传统机器学习不同,QML利用量子态的叠加和纠缠特性,理论上可以在某些特定任务上实现指数级…...

Keil调试中局部变量修改限制的解决方案
1. 问题现象与背景解析在嵌入式开发过程中,调试环节往往占据整个开发周期的40%以上时间。作为Keil Vision的资深用户,我最近在调试一个基于C166架构的通信协议栈时,遇到了一个看似简单却令人困扰的问题:当我在receive_data函数内部…...

Keil MDK构建时间戳记录方案与实现
1. 项目概述:Keil MDK构建时间戳记录方案在嵌入式开发中,项目构建(Project Build)的时间管理是个容易被忽视却至关重要的细节。当我们需要调试复杂工程时,准确记录构建开始时间可以帮助我们同步调试日志;而…...

HA高可用架构:数字化转型的“隐性及格线”,你达标了吗?
数字化转型的核心是“业务在线、数据可用”,而这一切的前提,是HA(High Availability)高可用架构的支撑。在企业数字化进程中,ERP选型、CRM部署、低代码平台搭建、BI工具落地、API集成打通等动作,都是可见的…...