【C++干货铺】哈希结构在C++中的应用
目录
unordered系列关联式容器
unordered_map
unordered_map的接口说明
1.unordered_map的构造
2. unordered_map的容量
3. unordered_map的迭代器
4. unordered_map的元素访问
5. unordered_map的查询
6. unordered_map的修改操作
7. unordered_map的桶操作
底层结构
哈希概念
哈希冲突
哈希函数
常见哈希函数
哈希冲突解决
闭散列
字符串转整形
闭散列的模拟实现
开散列(拉链法)
开散列的实现
开散列与闭散列比较

unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到log2(N),即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同,本文中只对unordered_map和unordered_set进行介绍,unordered_multimap和unordered_multiset学生可查看文档介绍。
unordered_map
unordered_map的文档介绍
1. unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。
2. 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
3. 在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
4. unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
5. unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value。
6. 它的迭代器至少是前向迭代器。
unordered_map的接口说明
1.unordered_map的构造
| 函数声明 | 功能介绍 |
| unordered_map | 构造不同格式的unordered_map对象 |
2. unordered_map的容量
| 函数声明 | 功能介绍 |
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
3. unordered_map的迭代器
| 函数声明 | 功能介绍 |
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
4. unordered_map的元素访问
| 函数声明 | 功能介绍 |
| operator[] | 返回与key对应的value,没有一个默认值 |
注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶
中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,
将key对应的value返回。
5. unordered_map的查询
| 函数声明 | 功能介绍 |
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为key的键值对的个数 |
6. unordered_map的修改操作
| 函数声明 | 功能介绍 |
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器中的元素 |
7. unordered_map的桶操作
| 函数声明 | 功能介绍 |
| size_t bucket_count()const | 返回哈希桶中桶的总个数 |
| size_t bucket_size(size_t n)const | 返回n号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素key所在的桶号 |
底层结构
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素
时,必须要经过关键码的多次比较。顺序查找时间复杂度为,平衡树中为树的高度,即
,搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立
一一映射的关系,那么在查找时通过该函数可以很快找到该元素。当向该结构中:
- 插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
- 搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置
取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称
为哈希表(Hash Table)(或者称散列表)
例如:数据集合{1,7,6,4,5,9}
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
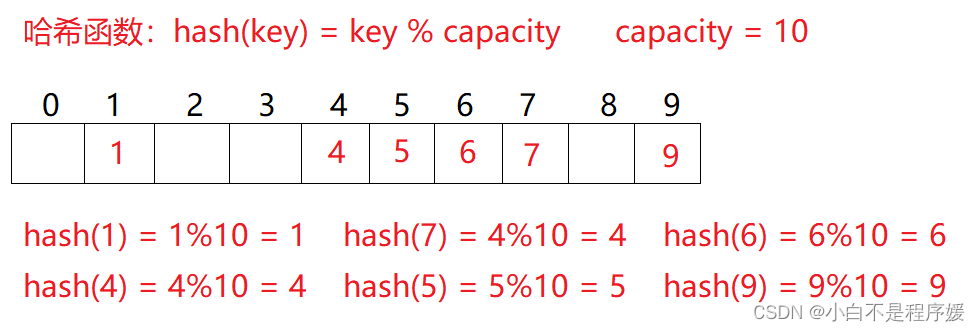
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
哈希冲突
对于两个数据元素的关键字即:和
,有
,但有:
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
1. 直接定址法--(常用)
取关键字的某个线性函数为散列地址:
- 优点:简单、均匀
- 缺点:需要事先知道关键字的分布情况
- 使用场景:适合查找比较小且连续的情况
2. 除留余数法--(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:,将关键码转换成哈希地址
3. 平方取中法--(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;
再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
4. 折叠法--(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这
几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况
5. 随机数法--(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即,其中
random为随机数函数。
通常应用于关键字长度不等时采用此法
6. 数学分析法--(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定
相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只
有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散
列地址。例如:
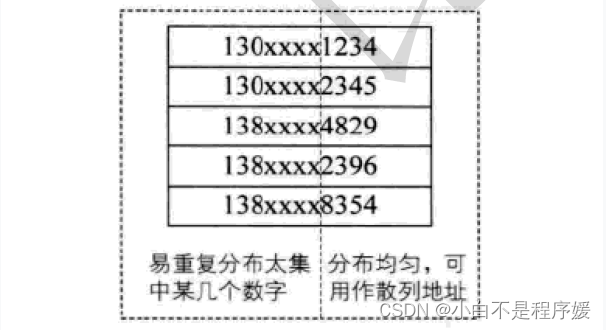
假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是 相同
的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现 冲突,还
可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环移
位、前两数与后两数叠加(如1234改成12+34=46)等方法。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的
若干位分布较均匀的情况
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
哈希冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列
闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。
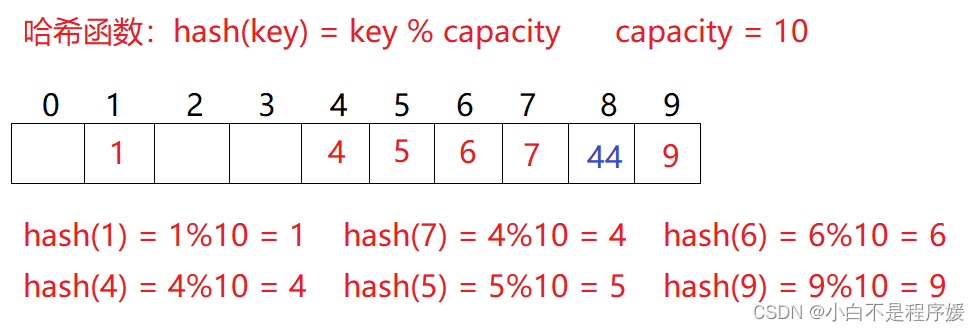
1. 线性探测
比如2.1中的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,hashAddr为4,
因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
插入
- 通过哈希函数获取待插入元素在哈希表中的位置
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素
会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影
响。因此线性探测采用标记的伪删除法来删除一个元素。
扩容
散列表的载荷因子定义为:
=填入表中的元素个数/散列表的长度
α 是散列表装满成都的标志因子。由于表长是定值,α αα 与“填入表中的元素个数”成正比,所以,α 越大,表明填入表中的元素越多,产生冲突的可能性就越大,但是空间利用率越高;反之,α 越小,表明填入表中的元素越少,产生冲突的可能性就越小,但是空间浪费会比较多。实际上,散列表的平均查找长度是载荷因子 α 的函数,只是不同处理冲突的方式有不同的函数。
对于闭散列(开放定址法),载荷因子是特别重要的因素,应严格限制在 0.7 − 0.8以下。超过 0.8查表时的 CPU 缓存不命中按照指数曲线上升。因此,一些采用开放定址法的 hash 库,如 Java 的系统库限制了载荷因子为 0.75,超过此值将 resize 散列表。
字符串转整形
在模拟实现闭散列之前我们呢还有一个问题要解决就是如果我们传入的参数为字符串该如何进行取余运算呢?
这还不简单将字符串中的每个字符对应的ASCII码值加起来不就是这个字符串对应的整数么;其实这种办法不是很可行。我们忽略了一点:“abc" 和 ”acb" 两个字符串中的字符是一样的,那么对应转换后的整形也是一样的,但是这两个字符串不一样啊。还有一种情况 “abc" 和”bbb" 这两个字符串也是上面的情况,但是两个字符串根本不一样。
这里我们可以参考:字符串哈希算法
闭散列的模拟实现
#include<vector>
//闭散列法解决hash冲突//参数为整形(负数进行强转换)
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//HashFunc<string>//对于字符串的处理
//abb bab 根据阿斯克码值换算后一样
template<>
//模板特化
struct HashFunc<string>
{size_t operator()(const string& key){// BKDRsize_t hash = 0;for (auto e : key){hash *= 31;hash += e;}cout << key << ":" << hash << endl;return hash;}
};
namespace close_address
{//每个位置的状态enum Status{EMPTY,//空EXIST,//存在DELETE//删除};//每个位置存放的数据template<class K, class V>struct HashData{pair<K, V> _kv;Status _s; //状态};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public://构造函数HashTable(){_tables.resize(10);}bool Insert(const pair<K, V>& kv){//普通的容器不存相同的两个元素//先判断在不在if (Find(kv.first))return false;// 负载因子0.7就扩容if (_n * 10 / _tables.size() == 7){//新的容器扩为原来的2倍。size_t newSize = _tables.size() * 2;//size就会发生变化 需要重新计算旧表在新表中的位置HashTable<K, V, Hash> newHT;//设置新表的容量newHT._tables.resize(newSize);// 遍历旧表//将旧表中的元素插入到新表中for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._s == EXIST){newHT.Insert(_tables[i]._kv);}}//交换旧表和新表_tables.swap(newHT._tables);}Hash hf;// 线性探测size_t hashi = hf(kv.first) % _tables.size();//发生碰撞了while (_tables[hashi]._s == EXIST){hashi++;//防止越界hashi %= _tables.size();}//进行元素的放入_tables[hashi]._kv = kv;_tables[hashi]._s = EXIST;++_n;return true;}HashData<K, V>* Find(const K& key){//防止参数为负值或者stringHash hf;//寻找在容器中的位置size_t hashi = hf(key) % _tables.size();while (_tables[hashi]._s != EMPTY){if (_tables[hashi]._s == EXIST&& _tables[hashi]._kv.first == key){return &_tables[hashi];}//可能会发生冲突继续向后寻找hashi++;//防止越界hashi %= _tables.size();}return NULL;}// 伪删除法bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret){ret->_s = DELETE;--_n;return true;}else{return false;}}void Print(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._s == EXIST){//printf("[%d]->%d\n", i, _tables[i]._kv.first);cout << "[" << i << "]->" << _tables[i]._kv.first << ":" << _tables[i]._kv.second << endl;}else if (_tables[i]._s == EMPTY){printf("[%d]->\n", i);}else{printf("[%d]->D\n", i);}}cout << endl;}private:vector<HashData<K, V>> _tables;size_t _n = 0; // 存储的关键字的个数};闭散列总结
- 线性探测优点:实现非常简单,
- 线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率低。
二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:%m 或者
%m。其中:i = 1,2,3...,
是通过散列函数 Hash(x) 对元素的关键码 key 进行计算得到的位置,m是表的大小。
研究表明:当表的长度为质数且表装载因子 α 不超过 0.5 时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表满的情况,但在插入时必须确保表的装载因子 α 不超过 0.5,如果超出,必须考虑增容。因此,闭散列最大的缺陷局势空间利用率比较低,这也是哈希的缺陷。
开散列(拉链法)
开散列又叫拉链法,首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
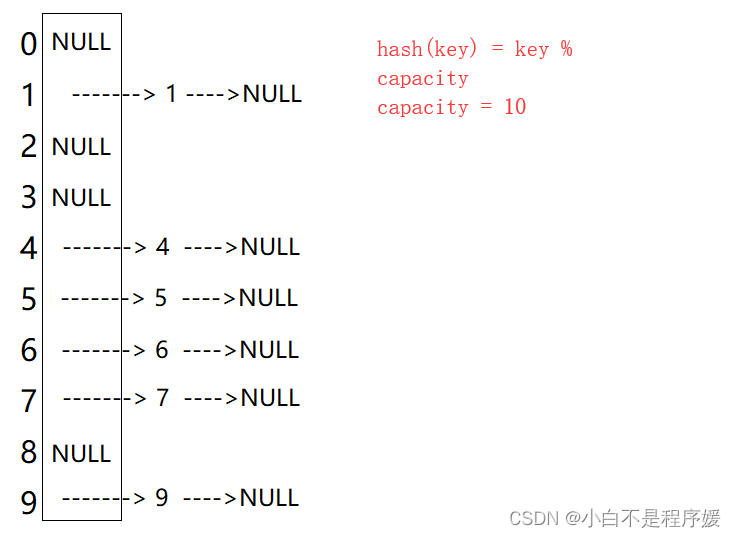
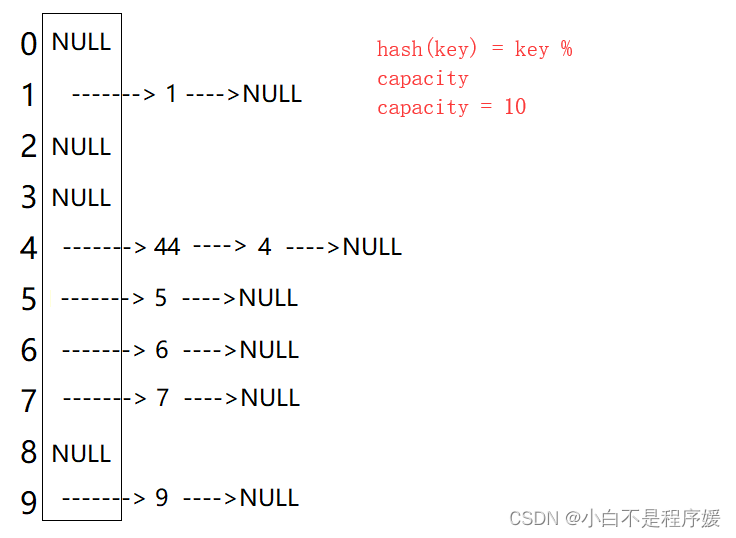
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
开散列的实现
namespace hash_bucket
{template<class K, class V>//每个结点中包含指向下个结点的指针和所要存放的数据struct HashNode{HashNode* _next;pair<K, V> _kv;//结点的构造函数HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};//传入的参数类型可能为stringtemplate<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public://HashTable(){_tables.resize(10);}//析构~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}//插入bool Insert(const pair<K, V>& kv){//先查找表中是否存在if (Find(kv.first))return false;Hash hf;//扩容操作// 负载因子最大到1//if (_n*10 / _tables.size() == 7)if (_n == _tables.size()){//size_t newSize = _tables.size() * 2;//HashTable<K, V> newHT;//newHT._tables.resize(newSize);遍历旧表//for (size_t i = 0; i < _tables.size(); i++)//{// Node* cur = _tables[i];// while(cur)// {// newHT.Insert(cur->_kv);// cur = cur->_next;// }//}//_tables.swap(newHT._tables);//开辟新表vector<Node*> newTables;newTables.resize(_tables.size() * 2, nullptr);// 遍历旧表for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;//旧表元素在新表上的位置size_t hashi = hf(cur->_kv.first) % newTables.size();//头插cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = hf(kv.first) % _tables.size();Node* newnode = new Node(kv);// 头插newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}//单链表查找操作Node* Find(const K& key){Hash hf;size_t hashi = hf(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return NULL;}bool Erase(const K& key){Hash hf;size_t hashi = hf(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}void Some(){size_t bucketSize = 0;size_t maxBucketLen = 0;size_t sum = 0;double averageBucketLen = 0;for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur){++bucketSize;}size_t bucketLen = 0;while (cur){++bucketLen;cur = cur->_next;}sum += bucketLen;if (bucketLen > maxBucketLen){maxBucketLen = bucketLen;}}averageBucketLen = (double)sum / (double)bucketSize;printf("all bucketSize:%d\n", _tables.size());printf("bucketSize:%d\n", bucketSize);printf("maxBucketLen:%d\n", maxBucketLen);printf("averageBucketLen:%lf\n\n", averageBucketLen);}private:vector<Node*> _tables;size_t _n = 0;};//template<class K, class V>//class HashTable//{// typedef HashNode<K, V> Node;//private:// //struct bucket// //{// // forwad_list<pair<K, V>> _lt;// // set<pair<K, V>> _rbtree;// // size_t len = 0; // 超过8,放到红黑树// //};// //vector<bucket> _tables;// //vector<forwad_list<pair<K, V>>> _tables;// vector<Node*> _tables;// size_t _n = 0;//};void TestHT1(){HashTable<int, int> ht;int a[] = { 4,14,24,34,5,7,1,15,25,3 };for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(13, 13));cout << ht.Find(4) << endl;ht.Erase(4);cout << ht.Find(4) << endl;}
}开散列的增容
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可
能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希
表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点,
再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可
以给哈希表增容。
开散列与闭散列比较
应用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销。事实上:由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <=0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间。
今天给大家分享介绍了C++中的unordered_map(set)的底层哈希结构。如果觉得文章还不错的话,可以三连支持一下,个人主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的三连支持就是我前进的动力!
相关文章:
【C++干货铺】哈希结构在C++中的应用
目录 unordered系列关联式容器 unordered_map unordered_map的接口说明 1.unordered_map的构造 2. unordered_map的容量 3. unordered_map的迭代器 4. unordered_map的元素访问 5. unordered_map的查询 6. unordered_map的修改操作 7. unordered_map的桶操作 底层结构 …...

蓝桥杯算法赛第4场小白入门赛强者挑战赛
蓝桥杯算法赛第4场小白入门赛&强者挑战赛 小白1小白2小白3强者1小白4强者2小白5强者3小白6强者4强者5强者6 链接: 第 4 场 小白入门赛 第 4 场 强者挑战赛 小白1 直接用C内置函数即可。 #include <bits/stdc.h> using namespace std;#include <bits…...

【每日一题】6.LeetCode——轮转数组
📚博客主页:爱敲代码的小杨. ✨专栏:《Java SE语法》|《数据结构与算法》 ❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️ 🙏小杨水平有限,欢…...

Java编程练习之类的封装2
1.封装一个股票(Stock)类,大盘名称为上证A股,前一日的收盘点是2844.70点,设置新的当前值如2910.02点,控制台既要显示以上信息,又要显示涨跌幅度以及点数变化的百分比。运行效果如下:…...

Banana Pi BPI-R4开源路由器开发板快速上手用户手册,采用联发科MT7988芯片设计
介绍 Banana Pi BPI-R4 路由器板采用 MediaTek MT7988A (Filogic 880) 四核 ARM Corex-A73 设计,4GB DDR4 RAM,8GB eMMC,板载 128MB SPI-NAND 闪存,还有 2x 10Gbe SFP、4x Gbe 网络端口,带 USB3 .2端口,M.2…...
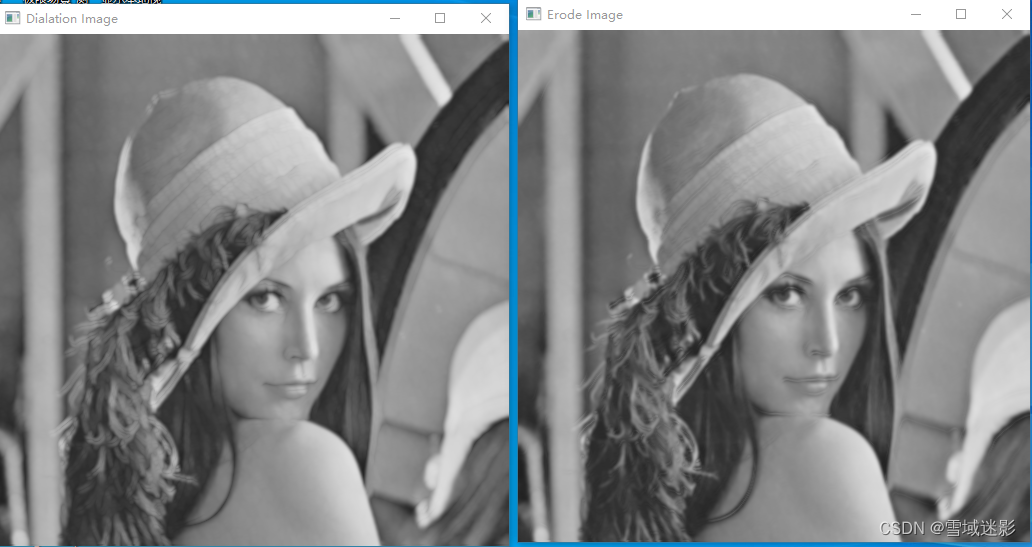
C#使用OpenCvSharp4库中5个基础函数-灰度化、高斯模糊、Canny边缘检测、膨胀、腐蚀
C#使用OpenCvSharp4库中5个基础函数-灰度化、高斯模糊、Canny边缘检测、膨胀、腐蚀 使用OpenCV可以对彩色原始图像进行基本的处理,涉及到5个常用的处理: 灰度化 模糊处理 Canny边缘检测 膨胀 腐蚀 1、测试图像lena.jpg 本例中我们采用数字图像处…...

蓝桥杯2024/1/31----第十届省赛题笔记
题目要求: 1、 基本要求 1.1 使用大赛组委会提供的国信长天单片机竞赛实训平台,完成本试题的程序设计 与调试。 1.2 选手在程序设计与调试过程中,可参考组委会提供的“资源数据包”。 1.3 请注意: 程序编写、调试完成后选手…...
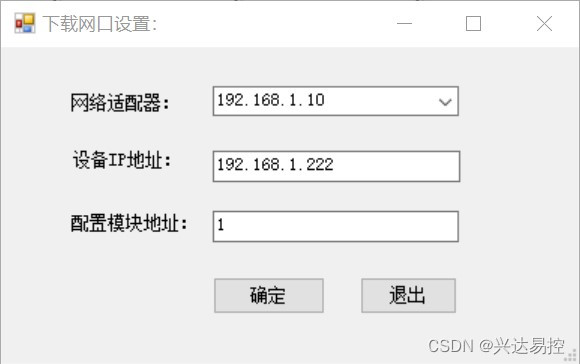
CANopen转Profinet网关实现原理与CANopen主站配置方法
CANopen转Profinet网关(XD-COPNm20)具有Profinet从站功能的设备。CANopen是一种通用的工业网络协议,而Profinet是以太网上的一种通信协议,两者在工业自动化领域具有广泛的应用。CANopen转Profinet网关的主要作用是实现CANopen设备…...

Mysql单行函数练习
数据表 链接:https://pan.baidu.com/s/1dPitBSxLznogqsbfwmih2Q 提取码:b0rp --来自百度网盘超级会员V5的分享 单行函数练习 单行函数(一行数据返回一个结果) #1.显示系统时间(注:日期时间) #2.查询员工工号,姓名,工资以及提高百分之20后的结果(new…...

C++ 11新特性之完美转发
概述 在C编程语言的演进过程中,C 11标准引入了一系列重大革新,其中之一便是“完美转发”机制。这一特性使得模板函数能够无损地传递任意类型的实参给其他函数或构造函数,从而极大地增强了C在泛型编程和资源管理方面的灵活性与效率。 完美转发…...
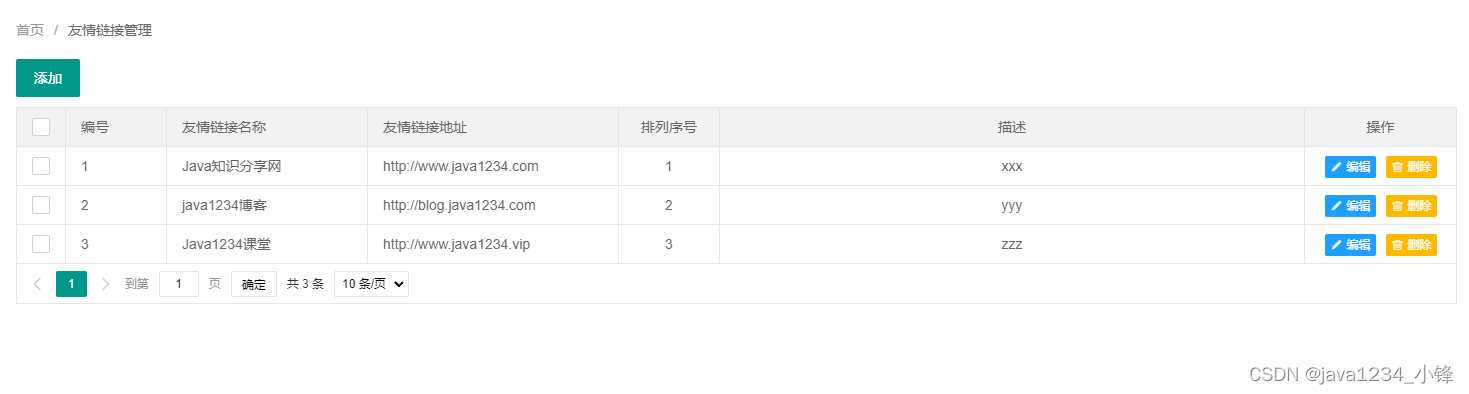
python222网站实战(SpringBoot+SpringSecurity+MybatisPlus+thymeleaf+layui)-友情链接管理实现
锋哥原创的SpringbootLayui python222网站实战: python222网站实战课程视频教程(SpringBootPython爬虫实战) ( 火爆连载更新中... )_哔哩哔哩_bilibilipython222网站实战课程视频教程(SpringBootPython爬虫实战) ( 火…...
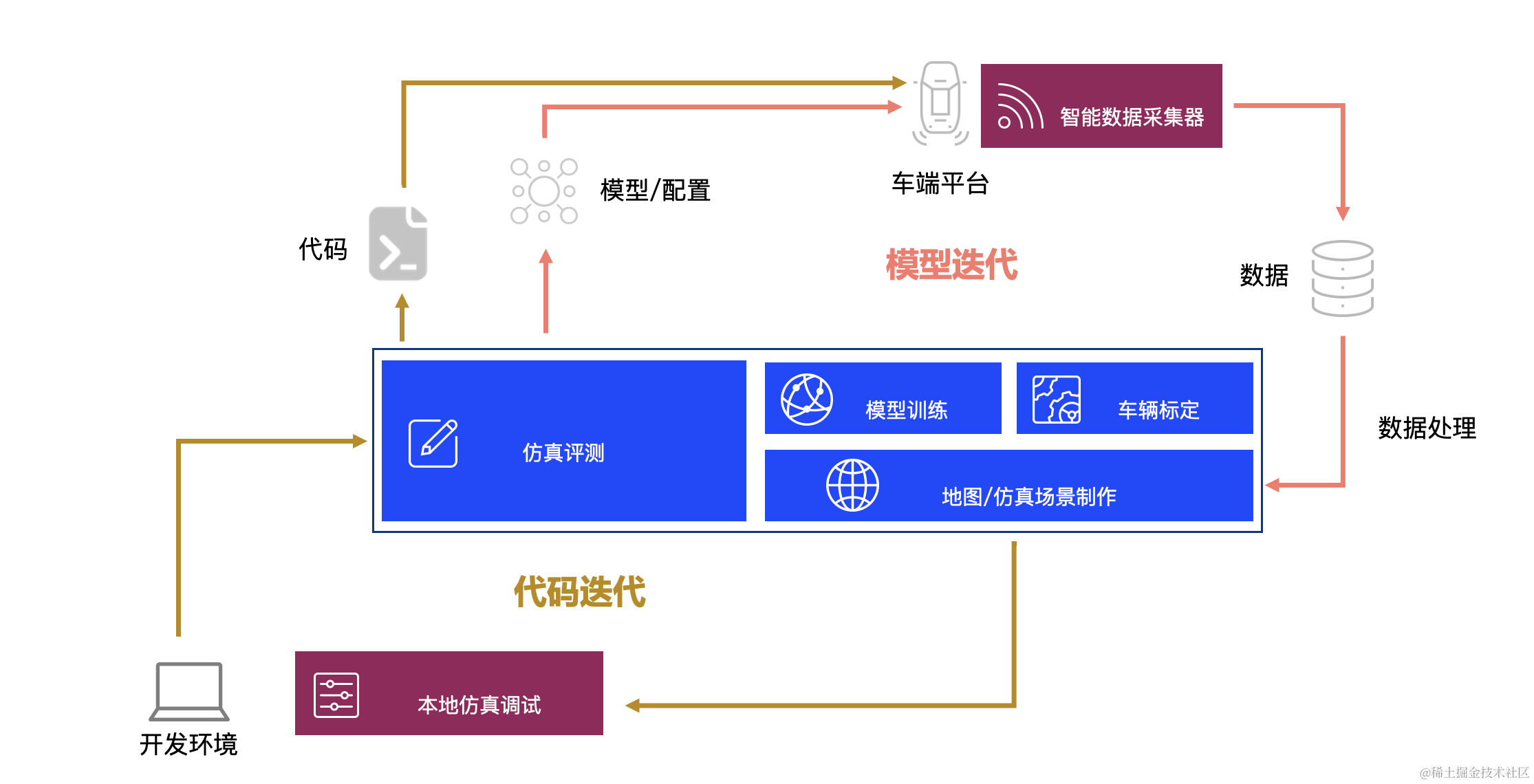
【百度Apollo】探索自动驾驶:深入解析Apollo开放平台架构的博客指南
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《linux深造日志》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下…...
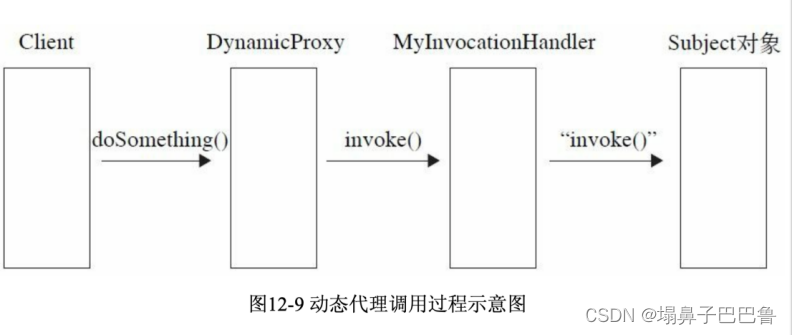
代理模式详解(重点解析JDK动态代理)
- 定义 在解析动态代理模式之前,先简单看下整个代理模式。代理模式分为普通代理、强制模式、动态代理模式。其中动态代理模式主要实现方式为Java JDK提供的JDK动态代理,第三方类库提供的,例如CGLIB动态代理。 代理模式就是为其他对象提供一种…...

【大厂AI课学习笔记】1.3 人工智能产业发展(2)
(注:腾讯AI课学习笔记。) 1.3.1 需求侧 转型需求:人口红利转化为创新红利。 场景丰富:超大规模且多样的应用场景。主要是我们的场景大,数据资源丰富。 抗疫加速:疫情常态化,催生新…...

【Python】一个简单的小案例:实现将两张图片合并为一张
使用时保证已经安装了opencv-python import cv2bg "BG.jpg" # 背景图名称 fg "FG.jpg" # 前景图名称 output_filename "new.jpg" # 合成后图片名称img_bg cv2.imread(bg) # 读取背景图 img_fg cv2.imread(fg) # 读取前景图# 读取背景…...

不同的强化学习模型适配与金融二级市场的功能性建议
DQN ES DDPG A2C TD3 SAC QMIX MADDPG PPO CQL IMPALA 哪个模型适合进行股票操作 在考虑使用哪种模型进行股票操作时,需要考虑模型的特点、适用场景以及实现复杂度等因素。以下是对您列出的几种强化学习模型的简要概述,以帮助您做出选择: DQ…...
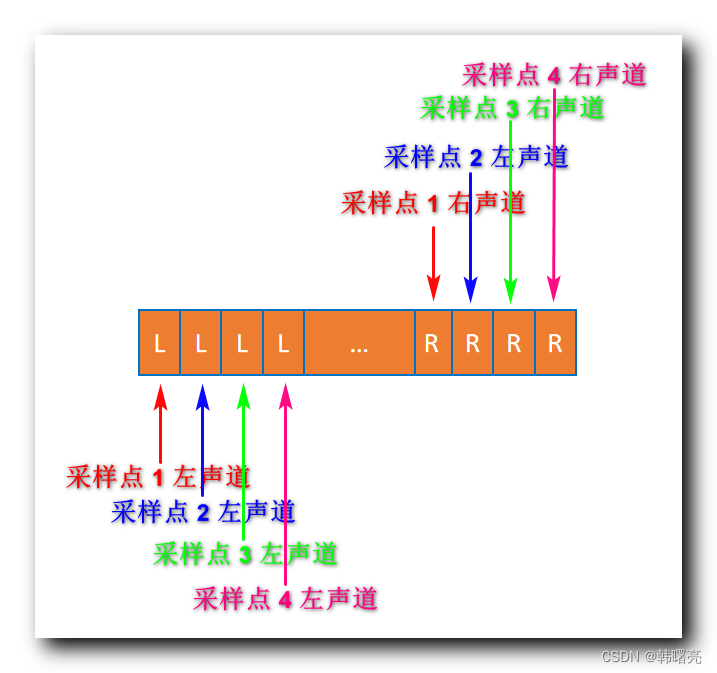
【音视频原理】音频编解码原理 ③ ( 音频 比特率 / 码率 | 音频 帧 / 帧长 | 音频 帧 采样排列方式 - 交错模式 和 非交错模式 )
文章目录 一、音频 比特率 / 码率1、音频 比特率2、音频 比特率 案例3、音频 码率4、音频 码率相关因素5、常见的 音频 码率6、视频码率 - 仅做参考 二、音频 帧 / 帧长1、音频帧2、音频 帧长度 三、音频 帧 采样排列方式 - 交错模式 和 非交错模式1、交错模式2、非交错模式 一…...

spring常用语法
etl表达式解析 if (rawValue ! null && rawValue.startsWith("#{") && entryValue.endsWith("}")) { // assume its spel StandardEvaluationContext context new StandardEvaluationContext(); context.setBeanResolver(new Be…...
【计算机毕业设计】128电脑配件销售系统
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...
换个思维方式快速上手UML和 plantUML——类图
和大多数朋友一样,Jeffrey 在一开始的时候也十分的厌烦软件工程的一系列东西,对工程化工具十分厌恶,觉得它繁琐,需要记忆很多没有意思的东西。 但是之所以,肯定有是因为。对工程化工具的不理解和不认可主要是基于两个逻…...

告别定长接收!手把手教你修改S32K344 RTD 2.0.0的LPUART驱动,实现串口空闲中断接收不定长数据
突破S32K344串口接收限制:实战LPUART空闲中断改造指南 在车载ECU开发中,我们经常遇到传感器发送不定长数据帧的场景——比如OBD诊断仪的响应报文、胎压传感器的动态数据包。传统定长接收方案不仅浪费内存,更会导致数据截断或拼接错误。最近在…...

Atomic-Server API完全参考:开发者必备的接口文档指南
Atomic-Server API完全参考:开发者必备的接口文档指南 【免费下载链接】atomic-server An open source headless CMS / real-time database. Powerful table editor, full-text search, and SDKs for JS / React / Svelte. 项目地址: https://gitcode.com/gh_mirr…...

到底什么是 AI 测试?AI 测试与传统测试的区别?
过去两年,AI已经从"加分项"变成了"必选项"。 不只是大厂,二线公司、甚至传统行业的测试团队都在要求:"能熟练使用AI工具提效"。 更关键的是,面试的玩法也变了。现在的技术面试早就跳出了 “考 AI 零…...

GPT-4的1.8万亿参数与2%稀疏激活原理揭秘
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作AI算力爆炸的佐证,也常被误读为“模型只用了一丁点参数,所以还有…...

CLIP实战指南:零样本图文检索与跨模态应用落地
1. 这不是又一个“多模态模型”名词解释,而是你真正能用起来的CLIP实战指南如果你最近在做图像搜索、零样本分类、图文匹配、跨模态检索,或者哪怕只是想给自家图库自动打标签、给设计稿配文案、给电商商品图生成合规描述——那CLIP绝不是论文里那个高冷的…...
守护进程的实践指南)
不止于Windows:用QtService源码打造跨平台(Windows/Linux)守护进程的实践指南
不止于Windows:用QtService源码打造跨平台守护进程的实践指南 在当今多平台开发环境中,Qt框架因其卓越的跨平台能力而备受青睐。但当我们从GUI应用转向后台服务开发时,许多开发者会发现一个尴尬的现实:Windows服务与Linux守护进程…...

HarmonyOS万能卡片开发实战:游戏状态桌面实时展示与交互实现
1. 项目概述:当游戏遇见万能卡片最近在HarmonyOS 3.1上折腾一个挺有意思的东西:把游戏的关键信息,比如角色状态、资源数量、离线收益,甚至是一键快捷操作,直接做成一个“万能卡片”放在桌面上。这可不是简单的应用图标…...

用 MinIO 搭建 S3 兼容对象存储服务
用 MinIO 搭建 S3 兼容对象存储服务 分类:开源项目部署 MinIO 适合附件、备份归档和 S3 兼容对象文件。这类主题真正跑起来并不难,难的是上线后稳定、可备份、能排错。本文按实操方式整理一套可以直接落地的流程,默认你已经会登录 Linux 服务…...

GEO生成引擎优化:当品牌竞争从搜索结果页迁移到大模型对话窗口
当生成式AI成为信息的首要分发渠道,你的品牌还只盯着SEO吗?一、用户获取信息的路径,已经变了过去十几年,我们习惯了"搜索关键词 → 浏览结果页 → 点击进入网站"这条线性路径。SEO(搜索引擎优化)…...

边缘AI加速:CGRA架构与近似计算技术解析
1. 项目概述在边缘计算和人工智能快速发展的今天,如何设计高能效的硬件架构来支持复杂的神经网络推理任务,成为了一个关键挑战。传统的ASIC方案虽然性能优异,但缺乏灵活性;而通用处理器又难以满足能效要求。粗粒度可重构架构(CGRA…...