Pymysql将爬取到的信息存储到数据库中
爬取平台为电影天堂
获取到的数据仅为测试学习而用
爬取内容为电影名和电影的下载地址
创建表时需要建立三个字段即可
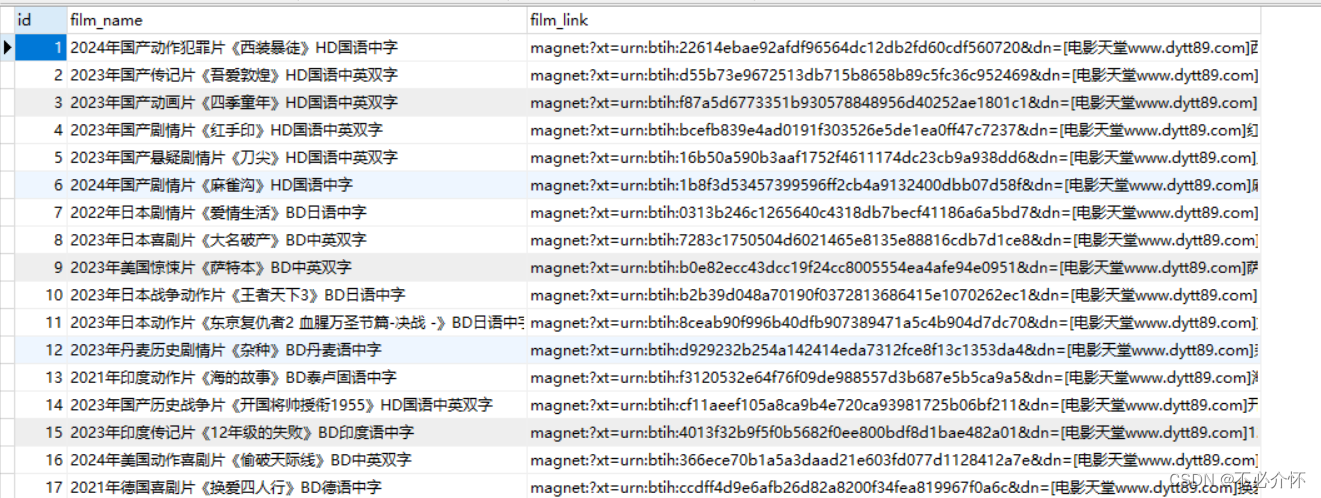
import urllib.request
import re
import pymysqldef film_exists(film_name, film_link):"""判断插入的数据是否已经存在"""sql = "select id from movie_link where film_name=%s and film_link=%s limit 1"result_num = my_cur.execute(sql, [film_name, film_link])# 使用sql语句查询获取到的电影名和下载地址,如果查询到有一条数据就表示数据已经存在,返回Trueif result_num:return Trueelse:return Falsedef create_date_table():"""创建数据库和数据表"""# 查看数据库是否存在,存在不创建,继续创建数据表。不存在创建,并创建表。exits = my_cur.execute("SHOW DATABASES LIKE 'movie_db';")if not exits:my_cur.execute("create database movie_db charset=utf8;")print("数据库建立成功")my_cur.execute("use movie_db;")my_cur.execute("""create table if not exists movie_link(id int(11) primary key auto_increment,film_name varchar(255) not null,film_link varchar(255) not null)charset=utf8;""")print("数据表建立成功")else:print("数据库已经存在,继续创建数据表")my_cur.execute("use movie_db;")my_cur.execute("""create table if not exists movie_link(id int(11) primary key auto_increment,film_name varchar(255) not null,film_link varchar(255) not null)charset=utf8;""")print("数据表建立成功")def add_films(film_name, film_link):"""向数据表中插入数据"""sql = "insert into movie_link values (null,%s,%s);"result_insert = my_cur.execute(sql, [film_name, film_link])# 如果插入成功返回值应该为影响的行数,不为零就代表插入成功if result_insert:print("插入成功:", film_name)def down_view():# 打开网页respon_data = urllib.request.urlopen("https://dy2018.com/0/")# 解码respon_decode = respon_data.read().decode("gbk")# 正则表达式获取下载页面网址films_data = re.findall(r"<a href=\"(.*)\" class=\"ulink\" title=\"(.*)\">", respon_decode)# 创建字典存储当前页的电影名和下载页面网址films_dict = {}count = 1# 将电影名和下载页网址从列表中拆包for films_url, films_name in films_data:# 拼接下载页面网站films_url = "https://www.dy2018.com/" + films_url# 打开下载页面respon_films_data = urllib.request.urlopen(films_url)# 解码respon_deown = respon_films_data.read().decode("gbk")# 使用正则提取下载地址down_url = re.search(r">(magnet:.*\.mp4)</a>", respon_deown)# 将电影名和下载地址存入字典films_dict[films_name] = down_url.group(1)print("已爬取第%s个资源" % count)count += 1return films_dictdef main():# 爬取信息并用字典介接收down_dict = down_view()# 创建数据库和数据表create_date_table()my_cur.execute("use movie_db;")# 将字典中的数据遍历取出,进行判断、添加for film_name, film_link in down_dict.items():if film_exists(film_name, film_link):print("电影[%s]保存失败" % film_name)continueadd_films(film_name, film_link)if __name__ == '__main__':# 建立连接my_sql = pymysql.connect(host="localhost", user="root", password="123456")# 创建游标对象my_cur = my_sql.cursor()main()# 一定要提交,否则数据不会被保存my_sql.commit()my_cur.close()my_sql.close()
将数据库中的数据当作固定页面返回
import socket
import pymysqldef request_headler(new_client_socket, ip_port):request_data = new_client_socket.recv(1024).decode()# 接收客户端浏览器发送的请求# 判断协议是否为空if not request_data:print("%s用户已下线" % str(ip_port))new_client_socket.close()return# 拼接响应的报文# 响应行respon_line = "HTTP/1.1 200 OK\r\n"# 响应头respon_header = "Server:Python\r\n"respon_header += "Content-Type:text/html; charset=utf-8\r\n"# 响应空行respon_blank = "\r\n"# 响应主体respon_body=""result = my_cur.execute("select * from movie_link;")result_data = my_cur.fetchall()for data in result_data:respon_body += ("%s、%s <a href=%s>%s</a><br>" % (data[0], data[1], data[2],data[2]))# 发送响应报文respon_data = (respon_line + respon_header + respon_blank + respon_body).encode()new_client_socket.send(respon_data)def main():# 创建套接字tcp_sderver_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置端口重用、tcp_sderver_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 绑定端口tcp_sderver_socket.bind(("", 8080))# 设置监听,让套接字由主动变为被动接收tcp_sderver_socket.listen(128)# 接受客户端的请求 定义函数request_handler()while True:new_client_socket, ip_port = tcp_sderver_socket.accept()print("新用户%s来了" % str(ip_port))request_headler(new_client_socket, ip_port)# 关闭操作if __name__ == "__main__":my_db = pymysql.connect(host="localhost", user="root", password="123456", database="movie_db")my_cur = my_db.cursor()main()my_cur.close()my_db.close()
相关文章:
Pymysql将爬取到的信息存储到数据库中
爬取平台为电影天堂 获取到的数据仅为测试学习而用 爬取内容为电影名和电影的下载地址 创建表时需要建立三个字段即可 import urllib.request import re import pymysqldef film_exists(film_name, film_link):"""判断插入的数据是否已经存在""&qu…...
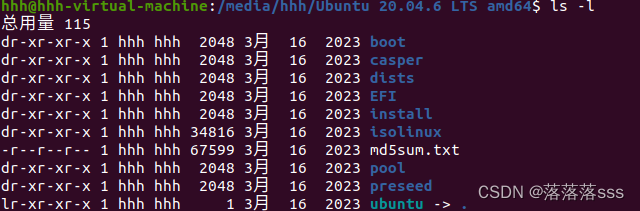
linux中常用的命令
一:tree命令 (码字不易,关注一下吧,w~~w) 以树状形式查看指定目录内容。 tree --树状显示当前目录下的文件信息。 tree 目录 --树状显示指定目录下的文件信息。 注意: tree只能查看目录内容,不能…...
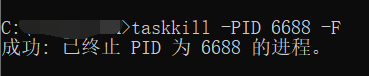
关闭idea之后,项目还在运行,端口被占用
今天在写项目的时候,中途安装了一个插件,而且插件显示需要重启idea,重启的时候项目正在运行,重启之后发现idea没有显示有项目正在运行,当我要开启项目的时候,发现无法开启,显示端口被占用了&…...
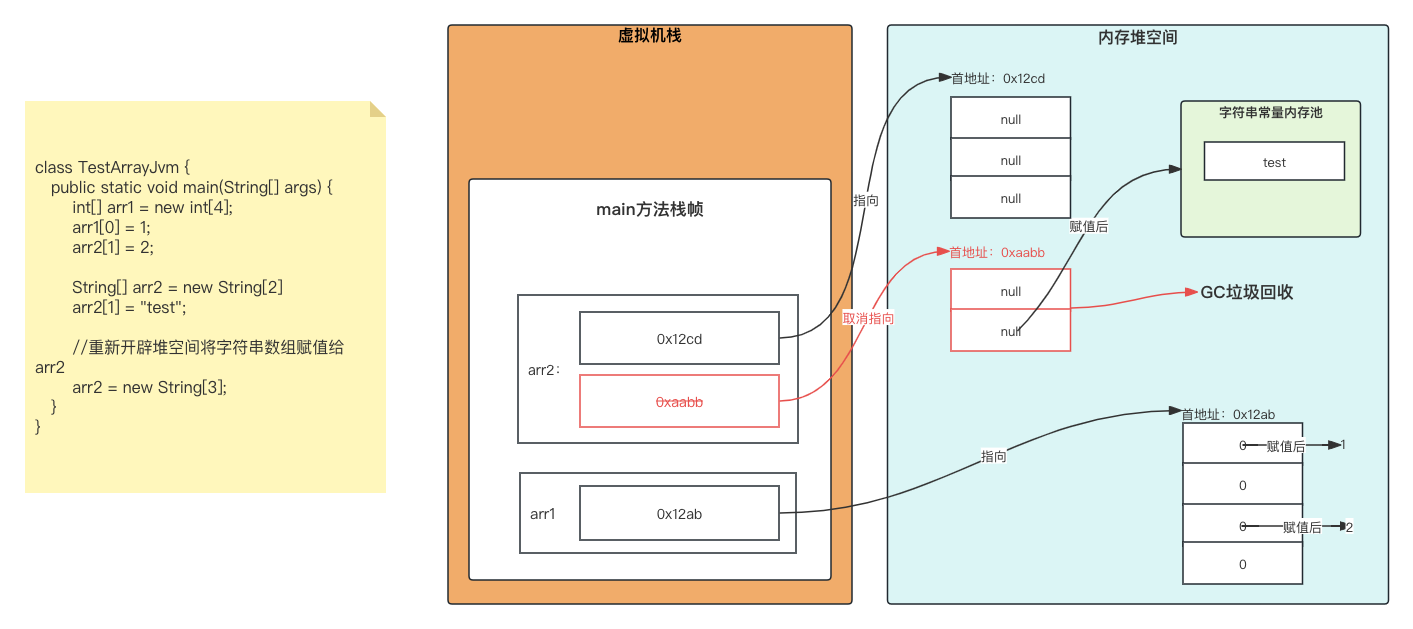
Java的JVM学习一
一、java中的内存结构如何划分 栈和堆的区别: 栈负责处理运行,堆负债处理存储。 区域名称作用虚拟机栈用于存储正在执行的每个Java方法,以及其方法的局部变量表等。局部变量表存放了便器可知长度的各种基本数据类型,对象引用&am…...
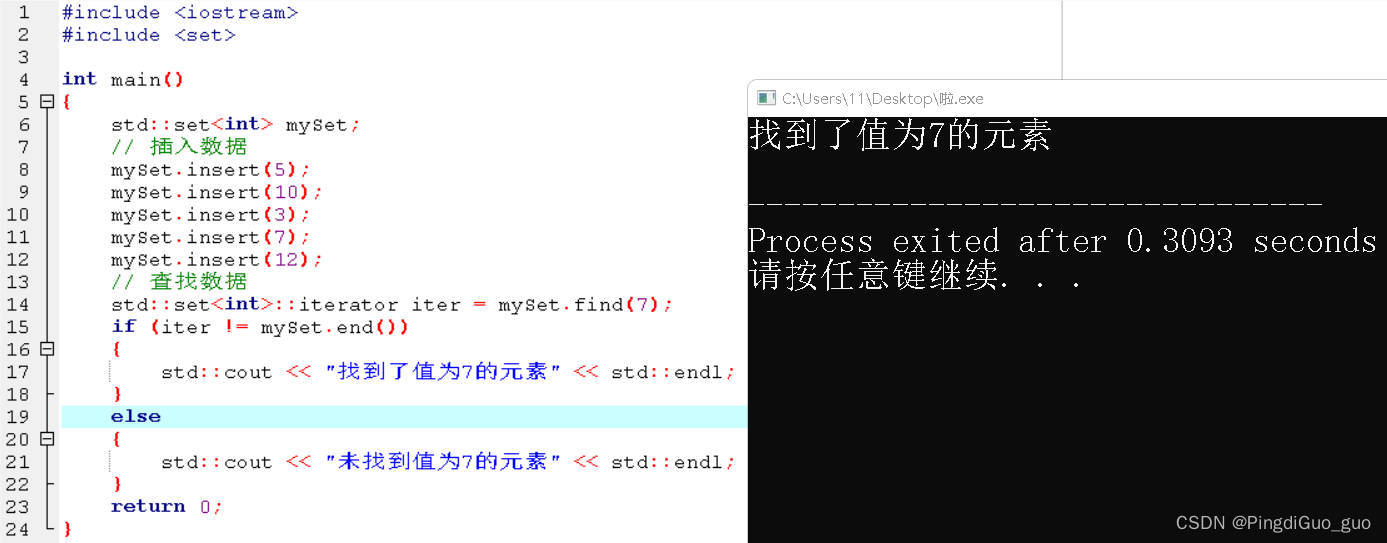
C++之平衡二叉搜索树查找
个人主页:[PingdiGuo_guo] 收录专栏:[C干货专栏] 大家好,我是PingdiGuo,今天我们来学习平衡二叉搜索树查找。 目录 1.什么是二叉树 2.什么是二叉搜索树 3.什么是平衡二叉搜索树查找 4.如何使用平衡二叉搜索树查找 5.平衡二叉…...
如何将Mac连接到以太网?这里有详细步骤
在Wi-Fi成为最流行、最简单的互联网连接方式之前,每台Mac和电脑都使用以太网电缆连接。这是Mac可用端口的标准功能。 如何将Mac连接到以太网 如果你的Mac有以太网端口,则需要以太网电缆: 1、将电缆一端接入互联网端口(可以在墙…...
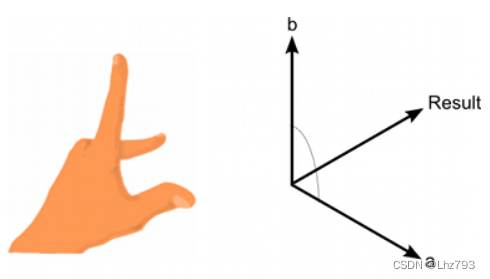
Unity点乘和叉乘
目录 前言 点乘 一、点乘是什么? 二、应用 三、使用步骤 1.代码示例 叉乘 一、叉乘是什么? 二、应用 三、使用步骤 1.代码示例 总结 前言 Unity中经常会用到向量的运算来计算目标的方位,朝向,角度等相关数据࿰…...

【ACL 2023】Enhancing Document-level EAE with Contextual Clues and Role Relevance
【ACL 2023】Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance 论文:https://aclanthology.org/2023.findings-acl.817/ 代码:https://github.com/LWL-cpu/SCPRG-master Abstract 与句子级推理相比&…...
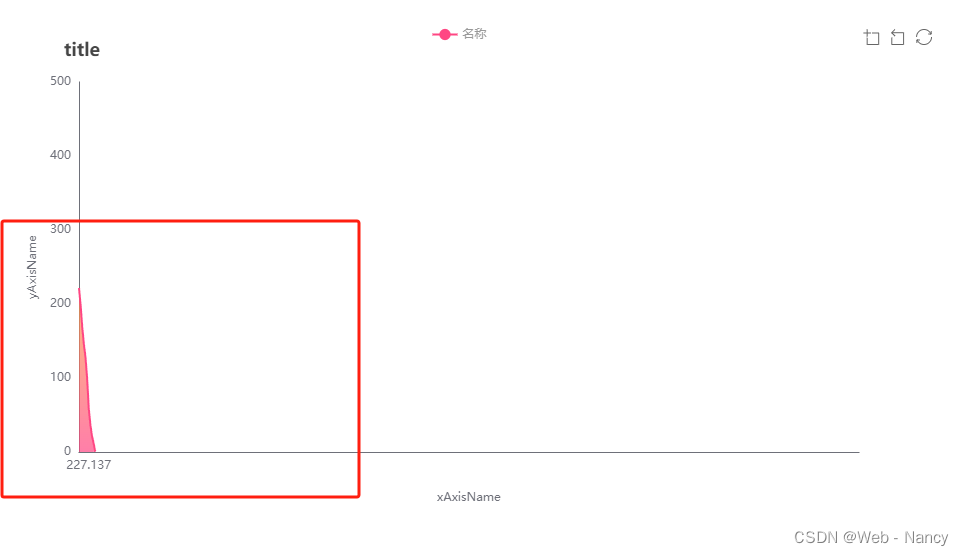
Vue ECharts X轴 type为value的数据格式 + X轴固定间隔并向上取整十位数 - 附完整示例
ECharts:一个基于 JavaScript 的开源可视化图表库。 目录 效果 一、介绍 1、官方文档:Apache ECharts 2、官方示例 二、准备工作 1、安装依赖包 2、示例版本 三、使用步骤 1、在单页面引入 echarts 2、指定容器并设置容器宽高 3、数据处理&am…...
)
统计成绩(c++题解)
题目描述 半期考试结束了,几多欢喜几多愁!作为竞赛的选手,迟早是要经历大风大浪的,这点小小的涟漪无须太在意。但是对于成绩,还是要好好的分析一下的。 有N个学生,每个学生的数据包括学号、姓名、3门课的…...

【Qt】—— Hello World程序的实现
目录 (一)使⽤"按钮"实现 1.1 纯代码方式实现 1.2 可视化操作实现 (二)使⽤"标签"实现 2.1 纯代码方式实现 2.2 可视化操作实现 (一)使⽤"按钮"实现 1.1 纯代码方式实…...

谷歌浏览器网站打不开,显示叹号
问题: 您与此网站之间建立的连接不安全请勿在此网站上输入任何敏感信息(例如密码或信用卡信息),因为攻击者可能会盗取这些信息。 了解详情 解决方式: 网上有很多原因,亲测为DNS问题,设置&…...

怎么去除图片中不需要的部分?这三种高效方法快来试一下
在数字图像处理的浩瀚世界中,去除图片中不必要部分的任务,宛如一幅细致的画卷,需精心描绘。这些不必要部分,可能是背景、水印、无关紧要物体或错误部分,它们如同图片中的瑕疵,需要被巧妙地修饰或去除。这不…...

yolov5导出onnx模型问题
为了适配C工程代码,我在导出onnx模型时,会把models/yolo.py里面的forward函数改成下面这样, #转模型def forward(self, x):z [] # inference outputfor i in range(self.nl):x[i] self.m[i](x[i]) # convbs, _, ny, nx x[i].shape # x(…...
JS第一课简单看看这是啥东西
1.什么是JavaScript JS是一门编程语言,是一种运行在客户端(浏览器)的编程语言,主要是让前端的画面动起来,注意HTML和CSS不是编程语言,他俩是一种标记语言。JS只要有浏览器就能运行不用跟Python或者Java一样上来装一个jdk或者Pyth…...

2023年常用网络安全政策标准整合
文章目录 前言一、政策篇(一)等级保护(二)关键信息基础设施保护(三)数据安全(四)数据出境安全评估(五)网络信息安全(六)应急响应(七)网络安全专用产品检测认证制度(八)个人信息保护(九)商用密码二、标准篇前言 2023年,国家网络安全政策和标准密集发布,逐渐…...
Redis -- 背景知识
“知识就是力量” -- 弗朗西斯培根 目录 特性 为啥Redis快? 应用场景 Redis不能做什么? Redis是在内存中存储数据的一个中间件,用作为数据库,也可以用作为缓存,在分布式中有很高的威望。 特性 In-memory data structures&…...
如何在Shopee平台上进行手机类目选品?
在Shopee平台上进行手机类目的选品是一个关键而复杂的任务。卖家需要经过一系列的策略和步骤,以确保选品的成功和销售业绩的提升。下面将介绍一些有效的策略,帮助卖家在Shopee平台上进行手机类目选品。 先给大家推荐一款shopee知虾数据运营工具知虾免费…...

班级管理神器,教师在线发布系统
现如今,班级管理也需要与时俱进。传统的管理方式不仅效率低下,而且容易出错。为了更好地管理班级,教师需要一个强大的工具来帮助他们发布信息和管理学生。 发布系统是一款专门为教师设计的数字化管理工具。通过系统,老师们就可以…...

【Spring Boot 3】异步线程任务
【Spring Boot 3】异步线程任务 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花费或多或…...

卡梅德生物技术快报|噬菌体随机肽库筛选实战:花生过敏原 Ara h 5 模拟表位鉴定全流程
摘要本文面向生物研发、体外诊断、蛋白质工程开发者,系统讲解噬菌体随机肽库筛选过敏原模拟表位完整工程化流程:从问题分析、实验设计、关键参数到结果验证,提供可复现技术方案,基于真实研究数据,聚焦高可靠性表位筛选…...
第3小节:超高纯氟化钙材料难点)
0603光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)第3小节:超高纯氟化钙材料难点
第六篇:EUV超精密光学系统(S级 长期死磕突破) 第3小节:超高纯氟化钙材料难点(深紫外配套核心,全维度死磕解析) 前置硬核声明 氟化钙单晶(CaF₂)是DUV深紫外光刻核心光学基…...

LicenseFinder高级配置指南:自定义许可证规则与决策继承
LicenseFinder高级配置指南:自定义许可证规则与决策继承 【免费下载链接】LicenseFinder Find licenses for your projects dependencies. 项目地址: https://gitcode.com/gh_mirrors/li/LicenseFinder LicenseFinder是一款强大的开源许可证管理工具…...

2026年数字孪生升级版:三维重构透明建筑实时重构跟踪定位
2026数字孪生升级:三维重构透明建筑实时重构跟踪定位结合2026年数字孪生技术前沿迭代趋势,围绕实景三维重构、建筑透明可视化、场景实时重构、全域跟踪定位四大核心能力,完成新一代数字孪生体系技术升级。彻底解决传统数字孪生静态滞后、建筑…...

讯飞星辰 Coding Plan 邀请码
邀请码:MAAS-CE9B96C2可点击链接 前往页面:https://maas.xfyun.cn/packageSubscription?inviteCodeMAAS-CE9B96C2(优惠:使用邀请码购买 Coding Plan,可获得支付金额等额礼品卡,可用于平台模型调用抵扣&…...

如何三步实现AI虚拟试衣:OOTDiffusion从安装到实战的完整指南
如何三步实现AI虚拟试衣:OOTDiffusion从安装到实战的完整指南 【免费下载链接】OOTDiffusion [AAAI 2025] Official implementation of "OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on" 项目地址: https://…...

以灵活测试方案打造共享实验室,强化槟城IC设计生态系统
益莱储(Electro Rent) InvestPenang|IC 设计验证与特性表征共享实验室马来西亚槟城正积极推进其成为亚洲领先的半导体枢纽。在 InvestPenang 主导的「Penang Silicon Design 5KM(PSD5KM)」计划下,全新的 I…...

反向传播:从轮廓到精雕细琢
反向传播:从轮廓到精雕细琢模型知道损失值之后,怎么调整自己的参数?上一篇文章我们讲了损失函数——它像一个指南针,告诉模型"你离正确答案还有多远"。 那知道偏了之后,模型该怎么调整自己的参数?…...

告别臃肿:Win11Debloat让你的Windows 11系统焕然一新
告别臃肿:Win11Debloat让你的Windows 11系统焕然一新 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and cus…...

终极指南:如何用WinDiskWriter快速制作Windows启动盘并绕过硬件限制
终极指南:如何用WinDiskWriter快速制作Windows启动盘并绕过硬件限制 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI &…...