计网——应用层
应用层
应用层协议原理
网络应用的体系结构
-
客户-服务器(C/S)体系结构
-
对等体(P2P)体系结构
-
C/S和P2P体系结构的混合体
客户-服务器(C/S)体系结构
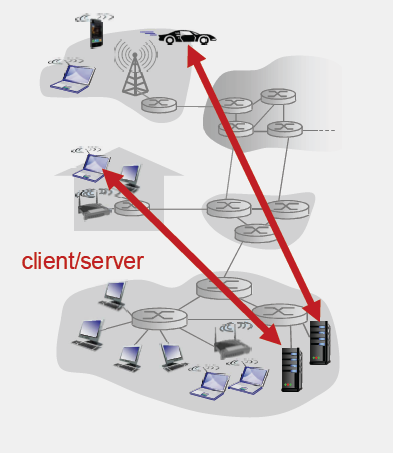
服务器
- 服务器是一台一直运行的主机,需要较高的可靠性。
- 服务器有一个固定IP地址和一个周知的端口号,以便客户端可以找到并连接到它。
- 扩展性:服务器场/数据中心。为了处理大量的并发请求,服务器可能部署在服务器场或数据中心内,为其提供必要的硬件,带宽和电力资源。但是,尽管服务器可以通过增加更多硬件资源来扩展,但这种扩展性是有限的。当服务器处理能力达到一定的阈值后,性能可能会急剧下降,这通常是因为硬件资源的限制、软件的并发处理能力限制或网络带宽的瓶颈。
客户端
- 主动通信:客户端软件主动向服务器发起请求并与之通信。客户端发出请求后,服务器响应这些请求并提供所需的服务或数据。
- 间歇性连接:客户端可能并不总是在线。例如,一台个人电脑可能只在用户需要时连接到互联网。
- 动态IP地址:客户端通常不需要固定IP地址,特别是家庭用户和移动用户,它们可能从互联网服务提供商获得动态分配的IP地址。
- 与其他客户端的通信:在纯粹的C/S模型中,客户端一般不会直接与其他客户端通信,所有的交互都是通过服务器进行中转。
对等体(P2P)体系结构
P2P模式区别于传统的C/S模式,在P2P模式中每个结点(或对等体)既可以作为客户端也可以作为服务端。
P2P体系的主要特征
- 分布式服务:P2P网络中没有一直运行的中心服务器。相反,每个节点都提供一部分网络所需的服务。
- 对等通信:任意两个节点都可以进行通信,这意味每个节点都可以向其他节点请求服务,同时也能提供服务。
- 每个结点既是客服端优势服务器
- 自拓展性:新加入的节点带来了新的服务能力,同时这些新节点也会带来新的服务请求,增加网络的负载。
- 间歇性连接和动态IP:P2P网络中的节点不保证一直在线,并且它们的IP地址可能会改变。这是因为许多P2P网络的节点是用户的个人设备,例如家用电脑或移动设备。
- 由于P2P网络的去中心化特性,它们通常难以管理。例如,没有一个中心点可以有效地实施安全策略或确保服务质量。
使用P2P网络的例子:
- Gnutella:一种流行的文件共享P2P网络,它允许用户直接交换文件。
- 迅雷(Xunlei):一种集成了P2P下载和多种下载协议的下载管理软件,主要在中国使用。
C/S和P2P体系结构的混合体
Napster混合体系结构
-
文件搜索:集中式
- 资源注册:用户将自己的文件资源注册在中心服务器上,这样其他用户就可以知道哪些资源可用。
- 查询资源:当用户想要找到特定的文件时,他们会向中心服务器查询资源的位置。服务器作为中央索引,响应查询并提供文件所在的主机地址。
-
文件传输:P2P
- 直接传输:文件的实际传输是在两个对等节点(Peer)之间进行的,而不经过中心服务器。
即时通信
- 在线检测:集中式
- 用户上线注册:当用户上线时,他们会向中心服务器注册自己的IP地址,这样服务器就能跟踪哪些用户当前在线。
- 查找在线好友:用户可以询问中心服务器,以确定他们的好友是否在线,以及好友的当前IP地址。
- 两个用户之间聊天
- 直接通信:P2P
混合体系结构的优势
- 效率与可扩展性:通过利用集中式服务器进行资源索引和管理,混合体系结构提高了搜索效率。同时,P2P的文件传输减轻了服务器的负载,提高了整体系统的可扩展性。
- 资源发现:集中式服务器提供了快速的资源发现机制,使用户能够高效地找到他们需要的内容。
- 负载分散:文件传输在用户之间直接进行,分散了带宽使用,降低了对中央服务器资源的需求
进程通信
定义:
指在主机上运行的应用程序的实例。每个进程都是一个正在执行的程序,它具有自己的代码和数据空间,以及其他系统资源,如文件描述符和网络连接。
进程间通信:
-
同一主机内:在同一主机内,进程间通信(IPC)机制允许进程互相交换数据。这通常是由操作系统提供支持的,包括管道、消息队列、共享内存等方式。
-
不同主机:在不同主机上的进程通过网络进行通信,常见的是通过交换报文的方式。这种通信要求使用网络协议来确保数据的正确传输。
- OS通信服务:操作系统提供的网络通信服务允许进程通过网络接口发送和接收消息。
- 应用协议:进程根据特定的应用层协议交换消息,如HTTP、FTP、SMTP等。这些协议定义了数据交换的格式和规则。
- 传输层服务:传输层如TCP或UDP为进程提供端到端的通信能力。TCP提供可靠的、面向连接的服务,而UDP提供不可靠的、无连接的服务。
-
客户端服务器进程
客户端进程
- 发起通信:客户端进程是指主动发起通信的进程。在Web浏览的场景中,当你点击一个链接时,浏览器(客户端进程)会向服务器发送请求。
服务器进程
- 等待连接:服务器进程是指在网络端口上监听并等待连接请求的进程。当服务器进程接收到请求时,它会响应并可能提供所请求的服务。
注意事项
- P2P架构中的进程:即使在P2P架构中,也存在客户端和服务器进程的概念。在P2P网络中的每个节点都可能同时运行客户端和服务器进程,客户端进程发起请求,服务器进程响应请求。
分布式进程通信需要解决的问题
问题一:进程标识和寻址问题(服务用户)
- 服务用户:进程需要被唯一标识以便用户或其他进程可以找到它们。
- 寻址:进程必须有一个方式来寻址其他进程,这通常涉及到IP地址和端口号。在IP网络中,IP地址确定主机,端口号确定主机上的特定进程。
问题二:传输层与应用层的服务接口(服务)
- 服务位置:层间接口的服务接入点(Service Access Point, SAP),在TCP/IP网络中,这通常是指socket。
- 服务形式:应用程序接口(Application Programming Interface, API),在TCP/IP网络中,这通常是指socket API。API定义了应用程序可以用来请求网络服务的函数和过程。
问题三:如何使用传输层提供的服务,实现应用进程之间的报文交换,实现应用(用户使用服务)
- 应用层协议:定义了报文的格式、含义以及发送和接收报文的时序。应用层协议规定了如何封装数据,如何解释接收到的数据,以及在通信过程中各个步骤的顺序。
- 程序编写:开发者需要编写程序,使用操作系统提供的API来调用网络基础设施。这些调用实现了报文的发送和接收,满足了应用层协议定义的时序和逻辑。
问题1:对进程进行编址(Addressing)
在网络通信中,为了确保报文正确送达目的地,我们需要准确地标识网络中的进程。这个过程称为对进程进行编址或地址分配。
进程为了接受报文,必须有一个标识,即SAP(发送需要标识)。
主要组成:
-
主机标识:每台主机在网络中都有一个唯一的标识,即IP地址。在IPv4中,这是一个32位的数字,通常以点分十进制形式表示,比如
192.168.1.1。 -
进程标识:
- 端口号:由于单个主机上可能同时运行多个网络应用进程,仅靠IP地址无法区分这些进程。因此,需要端口号来唯一标识主机上的具体进程。端口号是一个16位的数字,与IP地址一起用来定义网络中的一个端节点(endpoint)。
- 传输层协议:指定进程使用的传输层协议(如TCP或UDP),确保数据正确的传输。
某些端口号被预先分配给特定的服务。例如,HTTP服务通常使用端口80,而FTP服务使用端口21。
-
端节点标识:
- IP地址+端口号:一个进程可以通过其所在主机的IP地址加上自己的端口号来进行唯一标识。这种组合确保了在网络中可以找到并与特定的进程通信。
-
通信实体:
- 任何两个主机进程之间的通信都可以被视为两个端节点之间的通信。
问题二:传输层提供的服务——需要穿过层间的信息

层间接口必须携带信息
当应用层的进程向另一个进程发送数据时,它需要向传输层提供一系列明确的信息,以便传输层可以正确地处理和封装这些数据。这些信息包括:
- 要传输的报文
- 服务数据单元(SDU):这是从应用层传递到传输层的数据,传输层将其封装成协议数据单元(PDU)以供网络传输。
- 谁传的:发送方的应用进程标识,IP + TCP(UDP)端口
- 源IP地址:发送方主机的IP地址。
- 源端口:标识发送方应用进程的端口号。这通常是一个短暂的端口,由操作系统在应用程序发起网络通信时分配。
- 传给谁:接收方的应用进程标识,对方的IP + TCP(UDP)端口
- 目标IP地址:接收方主机的IP地址。
- 目标端口:标识接收方应用进程的端口号。
传输层实体的封装过程
传输层实体(TCP或UDP)会创建一个新的段(对于TCP)或数据报(对于UDP),这个过程称为封装。
- 封装内容
- 源端口号和目标端口号:这些信息被包括在TCP段或UDP数据报的头部,用于确保数据在到达目的主机后能够被发送到正确的应用进程。
- 数据:来自应用层的原始数据将被放入TCP段或UDP数据报的数据部分。
- 与IP层的交互
- IP地址交付:封装好的TCP段或UDP数据报会被传输到网络层(IP层)。网络层使用提供的源IP和目标IP地址来进一步封装数据,确保它可以在网络中正确路由到目标主机。
问题二:传输层提供的服务——层间信息的代表
如果每次通过Socket API发送报文时都需要手动指定完整的信息(如源IP、源端口、目标IP、目标端口),过于繁琐易错,不便于管理。
为了简化这一流程,引入了Socket的概念。Socket在这里充当一个标识符或句柄(handle),类似于操作系统重文件操作的句柄。
当操作系统打开一个文件时,它返回一个句柄,程序通过这个句柄进行读写操作。同理,Socket就是网络通信的句柄。
TCP Socket
在TCP/IP模型中,两个进程间的通信在开始之前需要建立一个连接,这就是TCP协议的特性,确保了数据的可靠传输。
- 一旦TCP连接建立,两个进程之间的通信就可以在这个稳定的连接上持续进行。这种通信关系是持久的,并且在通信期间是稳定的。
在操作系统级别,这个通信关系通常用一个整数(Socket描述符)来本地表示,这样就减少了应用程序处理的复杂性。
- 使用Socket的方法最小化了应用层和传输层之间需要传递的信息量。在建立了TCP连接后,程序只需要操作这个Socket,而不是每次通信都指定完整的网络层信息。
- TCP Socket的操作只涉及源IP、源端口、目标IP和目标端口的信息,这在内部已经由操作系统和网络堆栈维护。
TCP Socket的定义
- TCP socket是TCP/IP网络中,用于实现两个进程间可靠通信的端点。
- 每个TCP socket由一个四元组唯一定义,这个四元组包括源IP地址、源端口号、目标IP地址、目标端口号。
TCP Socket的特点:
- 通信前,两个进程必须先建立连接,这个过程称为“三次握手”。
- 连接一旦建立,两个进程之间的通信就可以在这个稳定的连接上进行。
- 通信结束后,双方会通过“四次挥手”的过程来关闭连接。
下面是TCP Socket通信机制概念图,展示了TCP Socket在应用层和传输层之间提供了一个接口。
通信流程:程序(一个进程)首先创建创建一个socket,并指定目标IP和端口,通过这个socket,程序可以发起一个到服务器的连接请求,连接成功后,双方就可以开始数据交换。
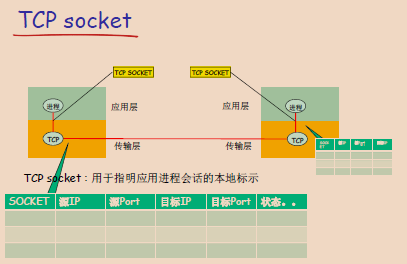
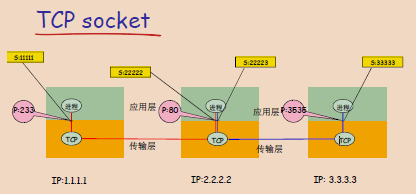
如图,主机1具有IP地址 1.1.1.1,这台主机的一个进程想要与主机2进行通信,为此它创建一个源端口号为233的TCP socket 11111,主机1的进程使用这个socket发送数据到主机2的IP地址 2.2.2.2为端口号为80的服务。而主机2收到来及主机1的请求后,主机2使用端口号为80的TCP socket22222来回复主机1。
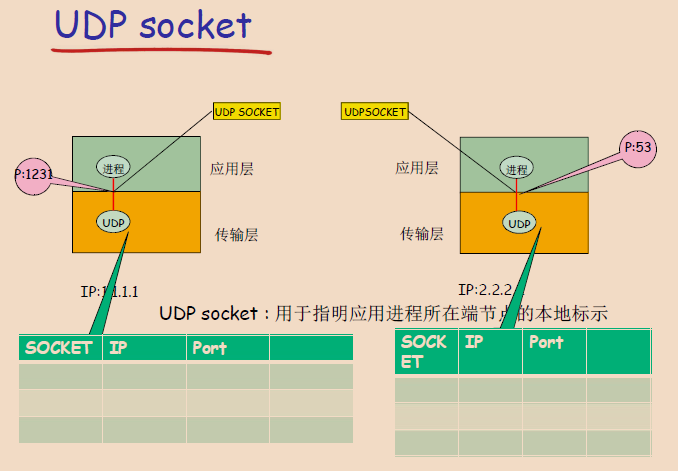
UDP Socket
UDP是一个无连接的网络服务,允许两个进程之间的通信而无需建立连接。
在UDP中,每个发送的数据包(报文)都是独立传输的,而且每个数据包都可能被发送到不同的目标进程。
- 由于UDP报文是独立传输的,前后两个报文可能被发送给同一个或者不同的接收进程。这意味着接收方不能仅凭接收到的报文顺序来重建发送方的会话状态。
因此,UDP Socket只能由一个整数(socket描述符)来标识本地应用实体。
并且,使用UDP Socket传递给传输层的信息量最小。基本上,只需要知道源端的IP地址和端口号。
尽管UDP不需要建立连接,但在发送报文时,发送方必须指定目标的IP地址和端口号,这样数据才能被正确地路由到接收方的进程。
接收方在接收到数据包时,传输层会提供发送方的IP和端口号,以便应用层知道数据来自哪里,并且可以选择如何响应。
UDP Socket的定义
UDP socket是一种网络通信端点,用于通过UDP协议发送和接收数据。与TCP socket不同,UDP socket不需要在通信前建立连接。
UDP Socket的标识
- UDP socket在操作系统层面是由一个“2元组”(IP地址和端口号)标识的。这个2元组定义了数据包的发送或接收端点。
- 源端的应用程序在创建UDP socket时会指定一个端口号,操作系统会与应用程序所在的主机的IP地址一起使用这个端口号来标识这个socket。
发送数据报的过程:
- 当应用程序准备发送数据时,它使用已创建的UDP socket。因为这个socket已经与一个特定的IP地址和端口号关联,应用程序不需要在每次发送数据时重新指定自己的IP和端口号。
- 不过,每次发送数据时,应用程序必须指定目标的IP地址和UDP端口号。这是因为UDP是无连接的,每个发送的数据报可能都有一个不同的目的地。
套接字(Socket)
套接字是计算机网络中的一个抽象层,它为应用层进程提供了发送和接收数据的方法。它是应用层与传输层之间的接口。
套接字的作用:
- 套接字将复杂的网络通信过程封装起来,提供了一个简单的接口供应用程序使用,无需处理网络协议的细节。
- 它允许应用程序仅通过简单的发送和接收操作来完成复杂的网络数据交换。
网络协议栈:
- 每个发送和接收数据的应用程序都有自己的网络协议栈。
- 网络协议栈负责处理各种网络通信规则和过程,包括数据的封装、寻址、路由以及错误处理等。
端到端的通信:
- 套接字提供了端到端的通信。当一个应用程序进程想要和另一个进程通信时,它们通过Internet使用各自的套接字进行数据交换。

问题三:如何使用传输层提供的服务实现应用
- 定义应用层协议:
应用层协议定义了运行在不同端系统上的应用如何相互交换报文。它规定了报文的格式、字段的语义以及发送和响应报文的时序规则。
- 编制程序:
程序需要通过应用编程接口(API)调用网络基础设施,来发送和接收报文,以及实现应用所需的时序和逻辑。
应用层协议
-
定义了:运行在不同端系统上的应用进程如何相互交换报文。
- 报文类型:定义了通信过程中需要交换的报文类型,例如请求报文和应答报文。
- 报文语法:指定了报文中各个字段的结构,包括字段的顺序、类型、大小等。
- 字段语义:解释了各个字段的含义,即如何解释这些字段中的数据。
- 报文处理规则:规定了进程何时和如何发送报文,以及如何对收到的报文进行响应。
-
应用协议的作用
- 应用层协议是构成一个完整网络应用的多个部分之一。
- 例如,在Web应用中,HTTP协议定义了客户端和服务器之间的通信规则。Web客户端(如浏览器)、Web服务器和网页内容(如HTML)也是应用的组成部分。
公开协议与专用协议
公开协议(Open Protocol):
- 这些协议由RFC(Request for Comments)文档定义,并且是公开的,这意味着任何人都可以使用这些协议来创建兼容的软件和设备。
- 公开协议的例子包括HTTP(Web通信)和SMTP(电子邮件传输),它们支持不同厂商和应用之间的互操作性。
专用协议(Dedicated Protocol):
- 专用或私有协议不公开,通常是由单个组织控制并且可能只用于其产品内部。
- 如:Skype使用的是一种专用协议,它的具体实现细节并不公开,这可能限制了与其他产品或服务的互操作性。
如何描述传输层的服务
某些应用(如:文本信息),要求数据绝对可靠,不能有任何丢失。
有些应用(如:音频)能容忍一定程度的数据丢失。
保证吞吐量:一些应用,如流媒体视频,需要有保证的最小吞吐量,以确保流畅播放。
弹性吞吐量:有些应用,如文件下载,可以适应网络吞吐量的变化,即当网络条件好时可以提高速度,网络条件差时可以减速。
低时延:实时应用,如网络电话(VoIP)或在线游戏,要求传输延迟非常低,以保持良好的用户体验。
高时延容忍:如电子邮件或网页浏览,用户通常可以接受稍长的延迟。

Internet 传输层提供的服务
TCP 服务
- 可靠传输:TCP提供可靠的数据传输服务,保证数据的正确顺序和完整性。
- 流量控制:确保发送方的数据传输速度不会超过接收方的处理能力。
- 拥塞控制:在网络拥塞时减少数据的发送,防止网络拥堵加剧。
- 连接导向:在数据传输前,需要在发送方和接收方之间建立连接。
- 不能提供的服务:TCP不提供时间保证、最小吞吐保证和安全性(如加密)。
UDP服务
- 不可靠数据传输:UDP不保证数据包的顺序或完整性。
- 不提供的服务:UDP没有流量控制、拥塞控制,也不保证带宽或低延迟。
- 无需连接:UDP不需要在传输数据前建立连接,减少了延迟。
为什么要有UDP?
UDP存在的必要性
UDP的存在有几个关键的必要性和优势:
- 能够区分不同的进程,而IP服务不能
虽然IP协议提供了主机到主机的通信,但它本身不能区分一台主机上运行的不同应用进程。UDP在端到端的通信基础上,通过端口号区分了不同的应用进程。这允许同一网络层IP地址的不同进程接收其特定的数据包。
- 无需建立连接
省去了建立连接的时间,使得UDP非常适合需要快速数据交换的事务性应用,如DNS查询。
- 不保证可靠性
UDP不提供数据重发机制,如果数据包在传输中丢失,UDP不会尝试重新发送。这缺乏可靠性的特点使UDP适合那些对实时性要求高的应用,比如实时视频或语音通信,这些应用可以容忍一些数据包的丢失而无需等待重发,这样可以减少延迟。
- 没有拥塞控制和流量控制
UDP允许应用程序以其决定的速度发送数据,而不会因网络拥塞而降低速度。这与TCP不同,TCP会根据网络状况动态调整数据发送速度,以避免过多的数据包引起网络拥塞。

安全TCP
TCP和UDP
加密:标准的TCP和UDP本身不提供加密功能。
明文传输:由于TCP和UDP不加密数据,所有通过互联网的数据传输都是透明的,可以被任何路由数据包的中间节点读取。
SSL(安全套阶层)
实现在TCP之上:SSL是在TCP协议之上实现的,它在传输层和应用层之间提供一个加密层。这个加密层为TCP连接提供了安全性增强。
私密性:SSL使用加密算法确保数据在传输过程中的私密性,防止数据被未经授权的第三方读取。
数据完整性:SSL提供完整性检查,确保数据在传输过程中没有被篡改。
端到端鉴别:SSL支持使用数字证书进行端到端鉴别,这确保了通信双方的身份。
SSL在应用层的使用
- SSL库:应用程序可以使用SSL库(如OpenSSL)来实现安全通信。这些库利用TCP协议提供的通信服务,但在发送数据前先进行加密。
- SSL socket API:应用程序通过特定的API可以将数据交给socket进行通信。如果应用程序使用SSL socket API,那么SSL层将负责在数据发送到网络之前将其加密。
Web和HTTP
Web页面通常是由多个对象组成,这些对象可能是HTML文件,JPEG图像、可执行的客户端程序(如Java小程序)…
一个Web页面通常有一个HTML文件,这个HTML文件通过超链接引用又包含了若干个对象嵌入在HTML文件中。
每个Web对象都可以通过一个URL进行引用和访问。URL指定了如何找到和访问互联网上的资源。
URL 格式
- 协议名(Prot):如
http或https,定义了客户端和服务器之间通信的协议。- 用户名(user):用于认证的用户名,通常和密码一起出现。
- 口令(psw):与用户名对应的密码,用于访问控制。
- 主机名:资源所在的服务器地址,如
www.someSchool.edu。- 端口(port):服务器上服务监听的端口号。如果未指定,将使用协议的默认端口。
- 路径名:资源在服务器上的具体位置,如
/someDept/pic.gif。

HTTP概述
HTTP,或超文本传输协议,是Web上使用的主要应用层协议。它基于客户端/服务器模型工作,涉及Web浏览器(客户端)和Web服务器之间的交互。
在以HTTP为背景下的客服/服务器模式的通讯过程:
- 客户端角色
首先客服端(通常是Web浏览器)启动通信过程。用户输入URL或点击链接,浏览器将这些动作转换为HTTP请求。HTTP使用TCP协议来保证数据传输的可靠性,并向服务器的特定端口发起连接。建立连接后,浏览器将HTTP请求发送到服务器。请求包含请求方式(如GET、POST)、目标资源的URL和HTTP版本,还可能包含请求头(如用户代理、接受的内容类型)和请求体(通常用于POST请求)。
- 服务器角色
服务器接收到HTTP请求后,首先解析请求并定位请求的资源。然后服务器想客户端发送HTTP响应,包括一个状态码(如200表示成功),响应头(包含有关响应的元数据)和响应体(请求的资源内容)。如果请求的是一个文档或图像,该资源将作为响应体传输。对于动态内容,服务器可能会实时生成响应。
- TCP连接的维护和关闭
- 持久连接:在HTTP/1.1及更新版本中,默认使用持久连接(Keep-Alive),允许在同一连接上发送多个请求和响应,减少了连接和断开的次数。
- 连接关闭:如果客户端或服务器决定结束会话,它们将关闭TCP连接。在HTTP/1.0中,每个请求/响应后通常会关闭连接。
无状态协议
HTTP是一个无状态协议,意味着服务器不保存任何关于客户端请求的状态信息。
为了客服这一限制,Web应用通常使用Cookie来维护用户状态。
HTTP链接
非持久HTTP
-
HTTP/1.0协议
-
每个请求/响应都需要建立一个新的TCP连接,请求完成后立即关闭TCP连接。
最多只能在一个TCP连接上发送一个对象,如果需要下载多个对象就需要建立多个TCP连接。
这样做的好处是可以减少服务器的资源消耗,因为每个TCP连接都需要占用一定的缓冲区和变量。但是,这样做的缺点是会增加客户端和服务器之间的网络延迟,因为每次发送一个请求都需要重新建立新的TCP连接。
持久HTTP
-
HTTP/1.1协议
-
连接可以用于多个请求/响应,会保持一段时间再关闭。
多个对象可以在一个TCP连接上述传输,不需要每个对象建立新连接。
优点包括:1. 减少了建立和关闭连接的消耗和延迟,特别是高延迟的网络下,性能得到显著提高。
非持久连接
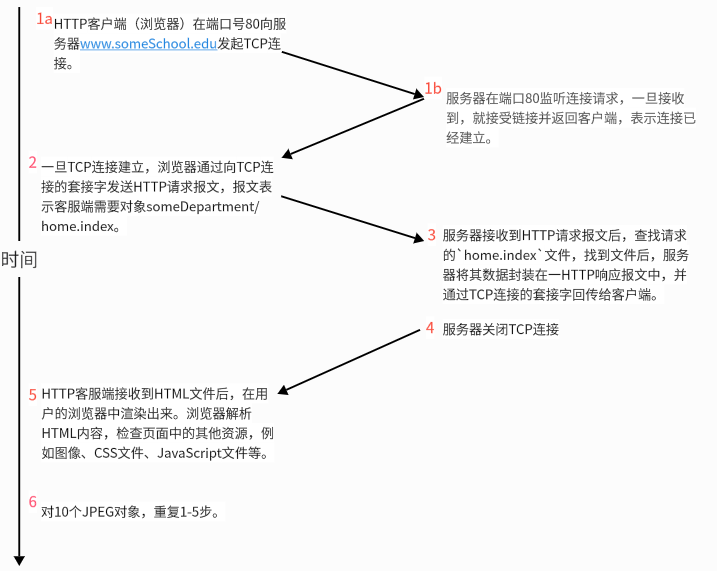
非持久HTTP连接操作的过程:
假设用户输入URL:www.someSchool.edu/someDept/home.index(包含文本和10个JPEG图像的引用。)
HTTP客户端(浏览器)在端口号80向服务器 www.someSchool.edu发起TCP连接。
这个连接的建立大约需要一个往返时间(RTT)。
服务器在端口80监听连接请求,一旦接收到,就接受链接并返回客户端,表示连接已经建立。
一旦TCP连接建立,浏览器通过向TCP连接的套接字发送HTTP请求报文,报文表示客服端需要对象 someDepartment/home.index。
服务器接收到HTTP请求报文后,查找请求的 home.index文件,找到文件后,服务器将其数据封装在一HTTP响应报文中,并通过TCP连接的套接字回传给客户端。
一旦响应报文发送完成,服务器关闭TCP连接。
HTTP客服端接收到HTML文件后,在用户的浏览器中渲染出来。
浏览器解析HTML内容,检查页面中的其他资源,例如图像、CSS文件、JavaScript文件等。
对10个JPEG对象,重复 1 − 5 1-5 1−5 步。
响应时间(RTT)模型
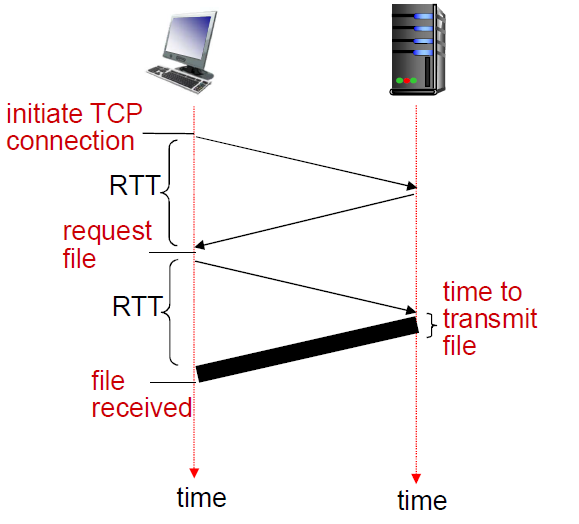
往返时间RTT(round-trip time):RTT是指一个小的分组从客户端出发到服务器,然后再返回客户端的总时间。(传输时间忽略)
非持久HTTP连接的响应时间组成:
-
第一个RTT用于初始化TCP连接。
客户端发送一个SYN包到服务器,等待服务器响应SYN-ACK,然后客户端回复ACK以完成三次握手。
-
第二个RTT用于发送HTTP请求并等待HTTP响应。
一旦TCP连接建立,客户端发送HTTP GET请求,并等待服务器回复包含所请求文件的HTTP响应。
-
最后,文件的传输时间取决于文件大小和网络带宽。
总的响应时间是2RTT加上文件的传输时间。
持久连接
非持久HTTP的缺点:
- 每个对象需要两个RTT
- 操作系统必须为每个TCP连接分配资源,包括内存和处理器时间。
- 为了减少加载时间,浏览器通常会同时打开多个TCP连接来并行获取引用的对象。
持久HTTP的优点:
- 服务器发送响应后,仍保持TCP连接。
- 在相同客户端和服务器之间的后续请求和响应报文通过相同的连接进行传送。
- 当客户端遇到引用对象时,它可以立即在保持打开状态的TCP连接上发送请求,而不需要等待前一个相应完成。
持久HTTP的两种模式
在持久HTTP下,有两种主要的请求/响应模式:非流水方式和流水方式。
在非流水方式的持久HTTP中,客户端需要等待前一个响应被完全接受后,才能发出下一个请求。这个模式下每个引用对象的获取还是需要花费一个RTT。
流水方式,是HTTP/1.1的默认模式。这种模式下客户端不必等待前一个响应,可以连续不断地发送多个HTTP请求。所有引用(小)对象只花费一个RTT是可能的。
HTTP 报文
HTTP有两种类型的报文:请求、响应
HTTP请求报文
HTTP请求报文由ASCII码组成,(人能阅读)
请求报文的组成部分

-
请求行:包含方法(如GET、POST、HEAD)、请求的资源URL以及HTTP版本。例如:
GET /somedir/page.html HTTP/1.1 -
首部行:包含了各种首部字段,用来传递关于请求、客户端、所请求资源的额外信息。常见的首部行包括:
Host: 指定请求的服务器的域名。User-agent: 标识发出请求的浏览器或其他客户端。Connection: 指示连接的类型,如close表示不持久连接。Accept-language: 指定客户端优先接受的语言,例如法语(fr)。
-
换行回车符:在首部行后,使用一个单独的换行回车符(通常是
\r\n)来表示报文头部的结束。 -
实体正文(在请求报文中可能不存在):如果是POST或PUT等类型的请求,实体正文会包含发送给服务器的数据,如表单内容。
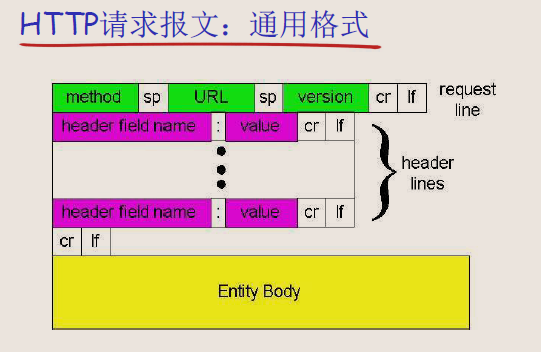
通过HTTP协议向服务器提交表单数据的两种方法
描述了通过HTTP协议向服务器提交表单数据的两种方法:使用POST方法和使用URL查询字符串(通常与GET方法结合使用)。
POST方式:
- 用户通过Web表单输入数据时,这些数据会被包装在HTTP请求的实体正文(entity body)中。
- 用户点击提交后,表单数据被发送到服务器。POST请求的实体主体不会显示在URL中。
例如,如果有一个表单是用于搜索动物,用户可能会在表单中输入"monkeys"和"banana"作为搜索词,这些词会被包含在POST请求的实体主体中发送到服务器。
URL方式:
- 方法:GET,用于请求服务器上的资源。
- 用户的输入被添加到URL的查询字符串部分,并通过请求行的URL字段发送。这种方法将所有的参数和参数值作为URL的一部分,通常用于搜索查询和页面请求。
- 在查询字符串中,参数和它们的值通过特定的格式附加到URL之后。参数之间通常由
&符号分隔,参数名和参数值之间由=符号连接。
例如:
www.somesite.com/animalsearch?monkeys&banana:这个URL中,"monkeys"和"banana"是添加到查询字符串的搜索参数,但没有明确的参数名。http://www.baidu.com/s?wd=xx+yy+zzz&cl=3:在这个例子中,“wd”和“cl”是参数名,“XX+YY+zzz”和“3”是这些参数的值。在URL中,空格通常被替换为+符号或者%20。
方法类型
在HTTP协议中,方法类型定义了客户端可以对服务器上的资源执行的操作。不同版本的HTTP协议支持不同的方法集合。
以下是HTTP/1.0和HTTP/1.1中常见方法类型:
HTTP/1.0:
- GET:
- 用于请求访问服务器上的指定资源。发送的请求中包含URL,服务器响应该请求并返回URL指定的内容。
- GET请求可以通过URL传递参数,常用于网页请求和简单的数据检索。
- POST:
- 用于向服务器提交要被处理的数据。例如,可以是表单数据或者文件上传。
- 数据包含在请求的实体主体(entity body)中,并不会显示在URL中。
- HEAD:
- 类似于GET方法,但服务器在响应中只返回首部。这意味着响应中不包含实体主体部分。
- HEAD请求常用于故障跟踪(如检查页面是否存在)、查看资源类型或者检查响应首部。
HTTP/1.1:
- GET、POST、HEAD
- PUT:
- 允许客户端将文件上传到服务器中指定的URL。
- 如果指定URL的文件已存在,则PUT方法通常会覆盖它。如果文件不存在,服务器可能会根据请求创建一个新的资源。
- DELETE:
- 请求服务器删除指定URL的资源。
- 实际上,是否执行删除操作取决于服务器的配置和权限设置。这意味着即使客户端发出了DELETE请求,服务器也可能拒绝这个请求。
HTTP响应报文
HTTP响应报文由服务器发送给客户端,以响应客户端之前发出的请求。报文的结构通常包括状态行、首部行,以及可选的消息正文。
响应报文的组成部分:
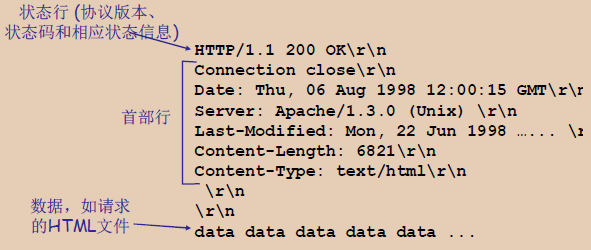
-
状态行:包含协议版本、状态码、状态文本。
HTTP/1.1 200 OK\r\n- 协议版本(HTTP/1.1):指明了服务器使用的HTTP协议的版本。
- 状态码(200):这是一个三位数字的代码,表示请求处理的结果。状态码200表示请求已经成功被服务器处理。
- 状态文本(OK):对状态码的简短文本描述,200状态码对应的是“OK”,表示请求成功。
每个部分之间用空格分隔,并且状态行以回车换行符(
\r\n)结束。 -
首部行:紧随状态行之后的是一系列的首部行,它们提供了关于服务器和响应的额外信息
- Connection:
close告诉客户端,服务器将在完成本次响应后关闭TCP连接。 - Date: 提供了服务器发送响应的日期和时间。
- Server: 描述了服务器的软件信息,这里是运行在Unix系统上的Apache 1.3.0服务器。
- Last-Modified: 说明了请求的资源最后一次被修改的时间,这对于缓存机制非常重要。
- Content-Length: 响应正文的长度,这里是6821字节。
- Content-Type: 响应正文的MIME类型,这里是
text/html,表示发送的是一个HTML文档。
每个首部行由首部名、冒号、空格以及首部值组成,并且每一行都以
\r\n结束。 - Connection:
-
首部行和消息正文之间有一个空行(
\r\n),标记着首部的结束和消息正文的开始。 -
消息正文:包含了实际的响应内容,如请求的HTML页面。
- 消息正文的具体内容应与首部行中的
Content-Type和Content-Length一致。
- 消息正文的具体内容应与首部行中的
HTTP响应状态码
状态码是标准化的,它们被分为几个不同的类别,从1xx(信息性状态码)到5xx(服务器错误)。
-
200 OK
请求成功,请求对象包含在响应报文的后续部分
-
301 Moved Permanently
请求的对象已经被永久转移了; 新的URL在响应报文的Location: 首部行中指定
客户端软件自动用新的URL去获取对象
-
400 Bad Request
一个通用的差错代码,表示该请求不能被服务器解读
-
404 Not Found
请求的文档在该服务器上未被找到
-
505 HTTP Version Not Supported
这个状态码表示服务器不支持或者拒绝支持请求消息中使用的HTTP协议版本。
通常发生在客户端使用服务器不支持的新版本或者过时的HTTP版本时。
Cookies
Cookies在用户与服务器之间维持状态时发挥着关键作用,尤其是在HTTP这种无状态的协议中。
Cookies的4个组成部分:
- HTTP响应中的Cookie首部行:
- 当用户第一次访问支持Cookies的网站时,服务器通过HTTP响应报文中的
Set-Cookie首部行向用户浏览器发送一个或多个Cookies。这些Cookies通常包含一个唯一的标识符,用来识别用户。
- 当用户第一次访问支持Cookies的网站时,服务器通过HTTP响应报文中的
- HTTP请求中的Cookie首部行:
- 一旦用户的浏览器接收到Cookies,并且用户再次请求同一网站的资源时,浏览器会自动将之前保存的Cookies附加在HTTP请求的首部行中,发送回服务器。这样服务器就可以读取这些Cookies,并识别出是哪位用户再次发起请求。
- 用户端的Cookie文件:
- 用户的浏览器会在本地存储Cookies,通常每个网站都有自己的Cookies。这些Cookies包含了用户的登录信息、偏好设置、购物车内容等,它们存储在用户设备上的特定目录中。
- Web站点的后端数据库:
- 服务器端会有一个数据库来存储与Cookies相关的信息。当收到含有特定Cookie的请求时,服务器可以查询数据库,了解用户的偏好、购物历史、账户信息等。
例子:
- 假设有一个用户,我们称她为Susan。Susan通常使用同一台PC和Internet Explorer浏览器上网。
- 当Susan首次访问一个电子商务网站时,她的浏览器通过HTTP请求向服务器请求页面。
- 服务器响应这个请求,同时在HTTP响应中使用
Set-Cookie首部行发送一个唯一的ID作为Cookie。- Susan的浏览器存储了这个Cookie,并在之后每次请求该网站时,都会在HTTP请求中包含这个Cookie。
- 服务器收到含有Cookie的请求后,检索后端数据库,识别Susan的ID,并根据存储的信息定制响应(例如加载她的购物车内容)。
Cookies能带来什么:
- 用户验证
- 购物车
- 推荐
- 用户状态(Web e-mail)
如何维持状态
- 协议端节点:在客户端和服务器端,多个事务或会话之间的状态信息通过Cookies在HTTP报文中被携带,以此方式维持状态。
- HTTP报文中的Cookies:HTTP请求和响应报文中的
Cookie和Set-Cookie首部行被用来传输Cookies,从而实现在无状态的HTTP协议中维护用户状态的目的。
Cookies与隐私:
- Cookies通过允许网站跟踪用户的行为和偏好来增强用户体验,但这也可能影响用户的隐私。
- 网站可能会将收集到的信息用于非原始意图的目的,或者出售给第三方(如广告公司),这可能导致用户的浏览习惯和个人信息被非授权方访问。
- 使用Cookies的搜索引擎和广告网络能够在用户访问各种网站时跟踪他们的活动,进而建立起用户的行为模式,这可能用于目标广告或其他形式的营销活动。
Cookies的工作流程
下面来讲解Cookies在客户端和服务器之间如何工作以及他们是如何在HTTP请求和响应中被发送的。
- 用户首次访问服务器:
- 用户通过浏览器访问一个网站,浏览器发送一个普通的HTTP请求到服务器。
- 服务器设置Cookie:
- 服务器响应用户的请求,并在HTTP响应中通过
Set-cookie首部行发送一个Cookie。例如,Set-cookie: 1678,其中1678可能是分配给用户的唯一标识符。
- 服务器响应用户的请求,并在HTTP响应中通过
- 浏览器存储Cookie:
- 用户的浏览器接收到这个Cookie并将其存储起来。这个Cookie将与服务器的域名相关联。
- 后续的请求:
- 当用户再次访问该服务器时(或者请求服务器上的其他资源),浏览器会在新的HTTP请求中包含之前保存的Cookie。这通过
Cookie首部行完成,如Cookie: 1678。
- 当用户再次访问该服务器时(或者请求服务器上的其他资源),浏览器会在新的HTTP请求中包含之前保存的Cookie。这通过
- 服务器识别用户:
- 服务器接收到新的请求后,识别出
Cookie首部行,它可以查找后端数据库中与该Cookie相对应的用户信息,比如用户的偏好设置、账户信息等。
- 服务器接收到新的请求后,识别出
- 个性化内容的提供:
- 基于Cookie提供的信息,服务器可以为用户提供个性化的内容,例如,向用户显示一个个性化的购物车,或者根据用户的浏览历史推荐商品。
Web缓存(代理服务器)
Web缓存是一种特殊的网络服务,它存储过去请求的Web资源副本,如网页、图片和文件。当Web缓存存在时,它可以作为客户端和原始服务器(origin server)之间的中间实体,即充当代理服务器。
工作原理:
- 用户在浏览器中进行设置,以通过缓存(代理服务器)访问Web
- 当浏览器向Internet发送HTTP请求时,这些请求会被发送到配置的缓存
- 缓存会检查它是否有请求的对象的副本:
- 如果有,缓存直接将对象返回给客户端,不需要从原始服务器获取,从而减少了访问时间。
- 如果没有,缓存将向原始服务器发出请求,获得对象后存储在本地,并将对象返回给客户端。
Web缓存的位置
- 作为客户端:对用户的浏览器来说,缓存作为获取资源的来源。
- 作为服务器:对原始服务器来说,缓存作为请求资源的客户端。
好处:
- 减少请求响应时间: 缓存降低了用户从请求资源到接收资源所需的时间。
- 减少内部网络流量: 在一个机构内部网络安装缓存可以减少进出Internet的流量,因为内部用户请求的许多资源可能直接从缓存获取。
- 优化内容提供: 缓存可以使内容提供商即使没有高性能的基础设施也能有效提供内容。流行内容的副本存储在缓存中,降低了原始服务器的负担,并为用户提供了更快的访问速度。
条件GET方法
条件GET方法用于主要用于判断缓存中的对象是否为最新版本,从而决定是否需要从原始服务器重新下载该对象。
工作原理:
- 目标:
- 主要目的是避免不必要地重新发送数据。如果缓存服务器上的对象副本是最新的,那么从原始服务器获取相同的对象就没有必要。
- 缓存器的请求:
- 当缓存服务器向原始服务器发送HTTP请求时,它会在请求中包含一个特殊的头部:
If-Modified-Since: <date>。 - 这个头部指定了缓存服务器上该对象的最后修改日期。
- 当缓存服务器向原始服务器发送HTTP请求时,它会在请求中包含一个特殊的头部:
- 服务器的响应:
- 如果自指定日期以来对象没有被修改,服务器会响应一个状态码
304 Not Modified。这意味着对象自上次缓存以来没有发生变化,因此不需要重新下载。 - 如果对象自上次缓存以来已被修改,服务器会发送一个正常的响应,通常是
200 OK,并附带最新的数据。
- 如果自指定日期以来对象没有被修改,服务器会响应一个状态码
例子
- 对象未修改:
- 缓存服务器发送HTTP请求,包含
If-Modified-Since: <date>。- 原始服务器发现对象自指定日期以来未修改。
- 响应为
HTTP/1.0 304 Not Modified,不包含对象数据。- 缓存服务器继续使用其缓存副本。
- 对象已修改:
- 缓存服务器发送类似的请求。
- 原始服务器检测到对象已被修改。
- 发送
HTTP/1.0 200 OK响应,附带最新的数据。- 缓存服务器更新其缓存副本。
重要性和效益:
- 减少带宽使用:避免不必要的数据传输。
- 快速响应:如果数据未修改,可以立即从缓存提供,无需等待网络传输。
- 节省服务器资源:服务器不需要发送完整的数据,只需发送状态响应,减少了处理和带宽的需求。
FTP
FTP(File Transfer Protocol):文件传输协议
FTP的定义:FTP是一种网络协议,用于在客户端和服务器之间传输文件。它可以将文件上传到远程主机或从远程主机下载文件。
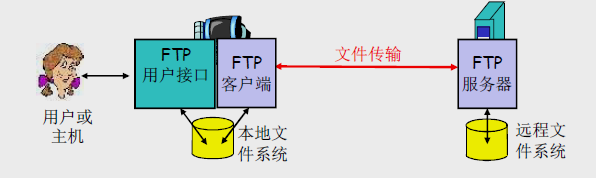
客户端/服务器模式:
- 客户端:用户使用客户端软件发起与服务器的连接,以进行文件传输。
- 服务器:远程主机运行FTP服务器软件,响应客户端请求并管理文件传输。
标准:FTP协议的细节和规范在RFC 959文档中有所描述,这是FTP通信标准的正式定义。
端口号:FTP服务器通常在网络上的21号端口上监听来自客户端的连接请求。
FTP: 控制连接与数据连接分开

FTP客户端与FTP服务器的连接
- FTP客户端通过端口21与FTP服务器建立控制连接(这个控制连接用于传输命令和控制信息,而不是文件数据本身),并使用TCP为传输协议。
身份确认和命令传输
- 客户端通过控制连接进行身份确认(通常发送用户名和密码来实现)。
- 一旦控制连接建立,客户端可以通过它发送命令来请求服务器上的操作,如获取目录列表(LIST)。
文件传输过程
- 当客户端请求文件传输时(使用RETR命令下载或STOP命令上传文件),服务器会响应该命令,并建立一个新的数据连接用于传输文件本身。
- 这个新的连接在端口20上。
- 每次文件传输结束后,服务器都会关闭那个特定的数据连接。对于每一个新的文件传输请求,都需要打开一个新的数据连接。
控制连接的特点
- 带外(out of band)传送:控制连接被认为是“带外”传送,这意味着它和数据传输使用不同的通道。即使在文件数据正在传输时,控制信息也能独立传送,互不干扰。
服务器的状态维护
FTP是一个有状态的协议,这意味着服务器会为每个客户端会话维护状态信息。这包括客户端的当前工作目录、账户信息和任何特定于会话的设置或历史记录。这样做允许在多个请求之间保持连续性和上下文。
FTP 命令、响应
- 命令样例:
- USER username:用于发送用户名进行身份认证。
- PASS password:用于发送密码进行身份认证。
- LIST:请求服务器返回远程主机当前目录的文件列表。
- RETR filename:从远程主机的当前目录检索(下载)文件。(gets)
- STOR filename:向远程主机的当前目录存放(上传)文件。(puts)
- 返回码样例:这些是FTP操作中返回的状态码,类似于HTTP状态码。
- 331 Username OK, password required:用户名正确,需要密码。
- 125 Data connection already open; transfer starting:数据连接已打开;传输开始。
- 425 Can’t open data connection:无法打开数据连接。
- 452 Error writing file:写入文件时出错。
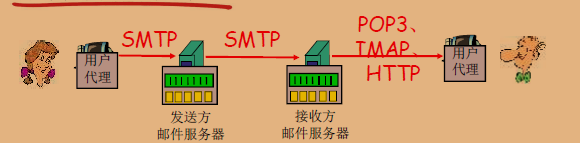
电子邮件系统主要由三个核心组件:用户代理、邮件服务器和简单邮件传输协议(SMTP)。
- 用户代理(User Agent)
- 它是用户与电子邮件系统交互的界面,允许用户撰写、编辑和阅读邮件。
- 邮件服务器(Mail Server)
- 邮件服务器负责管理邮箱中的邮件,包括维护发送给用户的邮件。
- 邮件服务器会有一个输出报文队列,用于保持待发送的邮件报文,确保他们可以按顺序发送给接收者。
- SMTP协议:邮件服务器之间利用SMTP协议来发送电子邮件报文。
- 客户端角色:发送方邮件服务器,在SMTP对话中充当客户端,发起连接并发送邮件到接收方服务器。
- 服务器角色:接收端邮件服务器,在SMTP对话中充当服务器,接收来自发送方服务器的邮件。
电子邮件系统的工作流程通常如下:
- 用户使用用户代理撰写一封电子邮件。
- 用户发送邮件后,邮件被传送到自己的邮件服务器。
- 用户的邮件服务器将邮件放入输出队列。
- 邮件服务器使用SMTP协议与接收方的邮件服务器建立连接。
- 发送方邮件服务器将邮件传送给接收方邮件服务器。
- 接收方邮件服务器将邮件保存起来,等待最终接收者通过其用户代理检索。
SMTP
SMTP使用TCP在邮件客户端和服务器之间传输邮件。默认情况下,SMTP通信使用的端口号是25。
SMTP允许直接从发送方的邮件服务器传输电子邮件到接收方的邮件服务器,不需要中间的转发步骤。
传输的三个阶段:
- 握手:建立连接的初始步骤,通常涉及发送方服务器向接收方服务器发送问候消息。
- 传输报文:实际的邮件内容传输阶段,发送方服务器向接收方服务器发送邮件数据。
- 关闭:传输结束后,发送方服务器会发送命令以关闭与接收方服务器的SMTP会话。
命令/响应交互:
- 命令:SMTP客户端(发送方服务器)发送的指令是以ASCII文本格式编码的。
- 响应:SMTP服务器对命令的回应包括状态码和状态信息。
报文必须是7位 A S C I I ASCII ASCII码
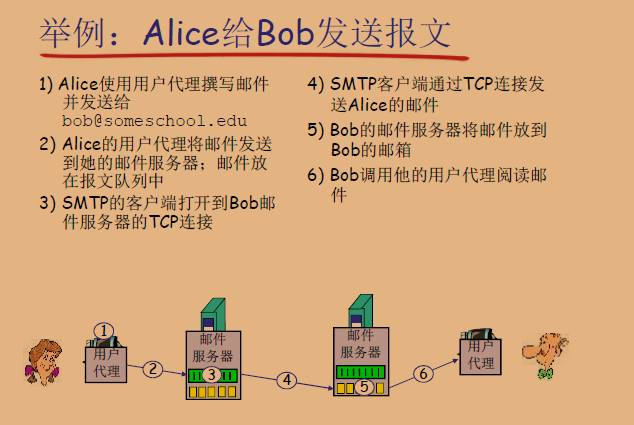
简单的SMTP交互
S: 220 hamburger.edu:服务器(S)向客户端(C)发送一个220响应码,表示SMTP服务已准备好。C: HELO crepes.fr:客户端发送HELO命令和自己的域名,开始SMTP会话。S: 250 Hello crepes.fr, pleased to meet you:服务器响应250,表示成功,并对客户端发出的HELO命令进行确认。C: MAIL FROM:<alice@crepes.fr>:客户端指定发件人的电子邮件地址。S: 250 alice@crepes.fr... Sender ok:服务器再次响应250,确认发件人地址是有效的。C: RCPT TO:<bob@hamburger.edu>:客户端指定收件人的电子邮件地址。S: 250 bob@hamburger.edu... Recipient ok:服务器确认收件人地址是有效的。C: DATA:客户端请求开始邮件内容的传输。S: 354 Enter mail, end with "." on a line by itself:服务器响应354,指示客户端开始发送邮件内容,以单独一行的点号(“.”)结束。- 客户端发送邮件正文,每行代表邮件的一部分,以一个单独的点号(“.”)行结束。
S: 250 Message accepted for delivery:服务器接收了完整的邮件内容,响应250表示消息已被接受用于传递。C: QUIT:客户端发送QUIT命令,请求关闭连接。S: 221 hamburger.edu closing connection:服务器响应221,表示它即将关闭连接。
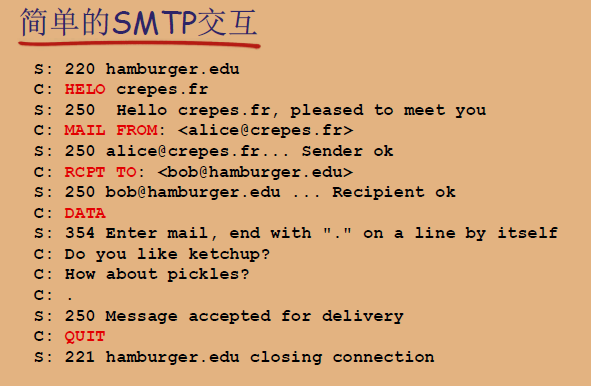
SMTP总结
- SMTP使用持久连接
- SMTP要求报文(首部和主体)为7位ASCII编码
- SMTP服务器使用CRLF.CRLF决定报文的尾部
HTTP比较:
- HTTP:拉(pull):HTTP通常用于客户端从服务器“拉取”数据,如当你请求一个网页时。
- SMTP:推(push):SMTP则是用于“推送”数据,如发送电子邮件到一个或多个接收者。
- 二者都是ASCII形式的命令/响应交互、状态码
- HTTP:每个对象封装在各自的响应报文中
- SMTP:多个对象包含在一个报文中
邮件报文格式
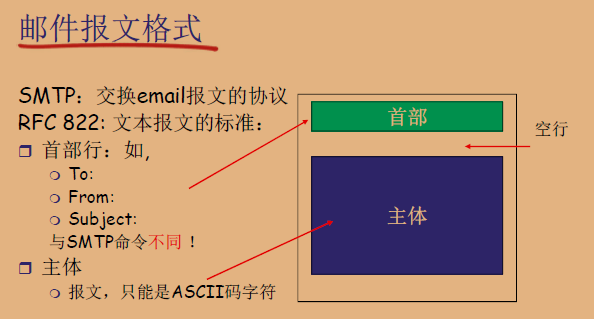
首部行:
- To: 指明邮件的接收者。
- From: 指明邮件的发送者。
- Subject: 邮件的主题,简短描述邮件的内容。
报文格式:多媒体拓展

MIME:多媒体邮件扩展(multimedia mail extension)是一种标准,它扩展了电子邮件的功能,允许发送和接收非ASCII字符集的内容,比如多媒体文件。
- 首部中的MIME声明: 在电子邮件的头部信息中,通过额外的行来声明邮件内容的MIME类型。这些声明包括:
- MIME-Version: 这行指明了邮件使用的MIME版本,通常是"1.0"。
- Content-Type: 这行说明了随邮件发送的媒体类型。例如,
image/jpeg表明附件是一个JPEG格式的图片。 - Content-Transfer-Encoding: 这行表明了邮件内容的编码方式。
base64是一种编码方法,它允许将二进制数据转换成ASCII文本格式,这样就可以通过SMTP发送。
- 编码的数据: 电子邮件的主体部分包含了经过编码的数据。如果是base64编码,这部分将包含由字母、数字、加号(
+)和斜线(/)组成的字符,以及在数据的最后用于填充的等号(=)。 - 多媒体数据的类型、子类型和参数声明: MIME类型由类型和子类型组成,可以提供关于文件格式的额外信息。例如,
image/jpeg中的image是类型,jpeg是子类型。
邮件访问协议
用于从服务器访问和管理邮件。常见的邮件访问协议包括:
POP (Post Office Protocol): 邮局访问协议,其规范被定义在RFC 1939中。
IMAP (Internet Mail Access Protocol): 互联网邮件访问协议,定义在RFC 1730中。
HTTP (HyperText Transfer Protocol)
POP3协议
POP3(邮局协议版本3)常用于接收电子邮件,它包含两个主要阶段:用户确认阶段和事务处理阶段。
用户确认阶段
- 客户端命令:
user: 客户端发送用户名以申明用户身份。pass: 客户端发送口令来完成认证。
- 服务器响应:
+OK: 表示成功的响应。-ERR: 表示发生错误的响应。
事务处理阶段
- 客户端命令:
list: 请求邮件列表,服务器响应每封邮件的编号和大小。retr: 根据邮件编号检索邮件内容。dele: 删除指定编号的邮件。quit: 退出会话。
POP3在默认模式下,客户端连接到邮件服务器,下载所有新邮件,并将它们从服务器上删除。这意味着一旦下载,邮件只存在于本地设备上,不再服务器上。
由于邮件被下载并从服务器删除,如果用户更换设备,他们将无法访问那些已下载的邮件。这限制了从多个设备访问邮件的能力。
用户可以配置客户端在下载邮件后在服务器上保留邮件的副本。这允许用户在不同设备上访问邮件,但不同步邮件的状态(如已读/未读)。
POP3在会话中是无状态的。
IMAP(Internet Mail Access Protocol)
IMAP 是一种更现代且功能更丰富的邮件协议,它支持复杂的邮件管理操作:
- 邮件与文件夹的关联:IMAP 允许将邮件存储在服务器上的特定文件夹中,用户可以像在本地文件系统上一样管理这些邮件。
- 目录组织:用户可以在服务器上创建、删除或重命名文件夹,并在这些文件夹中组织邮件。这种组织结构对于管理大量邮件非常有用。
- 读取邮件组件:IMAP 允许用户只下载邮件的某个部分,如仅获取邮件的标题、结构或单个附件,而无需下载整个邮件。这对于带宽有限的情况非常有用。
- 有状态会话:IMAP 会话是有状态的,这意味着服务器将跟踪用户的会话状态,包括用户在会话期间对邮件执行的所有操作。因此,当用户在不同的客户端或设备上登录时,他们会看到相同的邮件状态和组织结构。
总结:
- POP3——本地管理文件夹
- IMAP——远程管理文件夹
DNS(Domain Name System)
DNS的必要性
- 标识网络设备:IP地址用于唯一标识互联网上的设备,如主机和路由器
- 由于IP地址由数字组成,不便人类记忆(没有意义)
- 人类更倾向于使用有意义的字符串(如域名)来标识网络上的设备。如
tianmeng@pku.edu,cn所在的邮件服务器www.pku.edu.cn。 - 人类用户提供要访问机器的“字符串”名称。
- DNS负责转换成二进制的网络地址。
DNS需要解决的三个问题
- 如何命名设备
- 使用有意义的字符串:好记,便于人类使用。
- 层次化命名:解决一个平面命名的重名问题。如,在
www.example.com中,com是顶级域名,example是二级域名,而www是子域名。
- 如何完成名字到IP地址的转换
- 分布式的数据库维护和响应名字查询。
- 如何维护:增加或者删除一个域,需要在域名系统中做哪些工作。
DNS的历史
ARPANET的名字解析解决方案
- 在ARPANET中,每台计算机都被赋予了一个没有层次的唯一字符串作为主机名。这些名字构成了一个平面命名空间,没有嵌套或分级的结构。
- 当时的名字解析是通过一个中央的“维护站”来管理的,该站点负责维护一张包含主机名和对应IP地址映射的文件:Hosts.txt
- 网络上的每台主机需要定期从这个维护站下载Hosts.txt文件,以便本地解析主机名到IP地址。
ARPANET解决方案的问题
随着网络的扩大,原始的名字解析方法开始显示出其局限性:
- 主机名分配困难:没有层次的命名空间意味着所有主机名都在同一级别上,这使得随着主机数量的增加,命名冲突和分配变得苦难
- 文件的管理、发布、查找都很麻烦:每台主机都需要定期更新本地的Hosts.txt文件,这不仅在宽带上是一种浪费,而且查找时也不如动态解析高效。
DNS的整体思路和目标
DNS的主要思路:
- 层次化、基于域的命名机制。
- 若干分布式的数据库完成名字到IP地址的转换:名字到IP地址的转换不是集中在一个单一的位置完成,而是通过一个全球性的分布式数据库实现。这些数据库位于全世界的多个DNS服务器上。
- 运行在UDP之上:DNS查询通常使用用户数据报协议(UDP)在端口号53上进行。
- 虽然DNS是互联网核心功能的一部分,它实际上是作为一个应用层协议来实现的。DNS的复杂性被处理在网络的边缘,即在端用户设备的软件或在相应的服务器上。
DNS主要目的:
- 实现主机名与IP地址的转换(name/IP translate):核心功能是将人类可读的主机名(如
www.example.com)转换为机器可读的IP地址(如192.0.2.1),以便网络通信可以正常进行。其他目的:
- 主机别名(Host aliasing)到规范名字的转换:DNS允许将一个主机的别名(如一个简化的名字)转换为其规范的域名。
- 邮件服务器别名到邮件服务器的正规名字的转换。
- 负载均衡(Load Distribution):DNS还可以用于负载均衡,通过返回不同的IP地址响应来分散到特定主机的流量。
问题一:DNS命名空间(The DNS Name Space)
DNS域名结构
- 层次结构:DNS采用了层次树状的结构来命名网络上的设备。这样帮助避免了平面命名空间可能出现的重名问题。
- I n t e r n e t Internet Internet根被划分为了几百个顶级域(Top-Level Domains, TLDs),TLDs分为两大类:
- 通用顶级域(gTLDs):如
.com、.edu、.gov等,这些是最常见的域名后缀,任何个人或机构都可以注册。 - 国家顶级域(ccTLDs):如
.cn、.us、.nl、.jp等,这些通常为特定国家或地区保留。
- 通用顶级域(gTLDs):如
- 在每个TLD下,可以有多个子域(Subdomains),这些子域通常代表组织的不同部门或服务。
- 树状结构的叶节点代表单个的主机,这些是实际设备的网络地址。

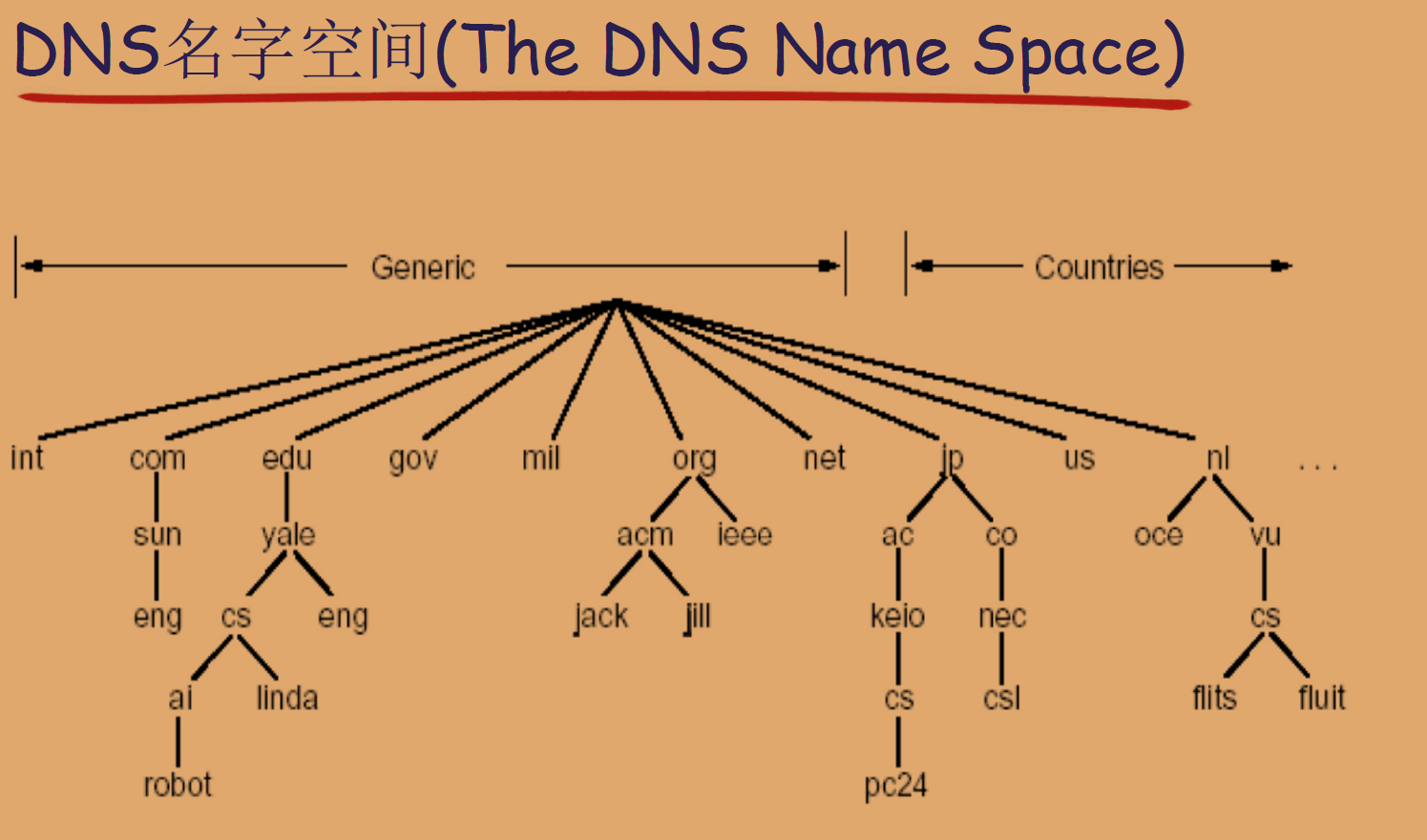
域名(Domain Name)
- 从下向上的结构:从本域往上,直到树根(TLD)。
- 中间使用" . . . "间隔不同的级别。
示例:ustc.edu.cn、auto.ustc.edu.cn、www.auto.ustc.edu.cn。 - 域的域名与主机的域名:域名可以用来标识一个域(如
ustc.edu.cn代表中国科学技术大学的域),也可以用来指向域上的一个具体主机(如www.ustc.edu.cn指向学校的主页服务器)。
域名的管理
每个顶级域(TLD)都负责管理其下的子域。比如,.jp是日本的国家顶级域,它下面可以划分为多个子域,如 ac.jp(通常用于学术机构)、co.jp(通常用于商业公司)。同样,.cn是中国的国家顶级域,它也可以被划分为如 edu.cn(教育机构)和 com.cn(商业组织)等子域。
创建一个新的子域时,需要得到上一级域的授权。例如,如果某个学校想要创建 school.edu.cn这个子域,它需要从负责 .edu.cn的注册机构获得授权。
域与物理网络的关系
- 独立于物理网络:域名系统的结构是基于逻辑上的组织界限,而非物理网络的布局。域名的组织和分配不受物理网络结构的限制。
- 域和网络的独立性
- 主机跨网络:属于某个特定域的主机可能分散在世界各地的不同物理网络上。例如,一家国际公司的各个分支机构可能都在不同国家,但使用同一域名下的不同子域。
- 网络跨域:一个物理网络上的不同主机可能属于不同的域。例如,一个大学校园网络中可能有教育部门(edu),也可能有商业合作项目(com)。
将域名管理与物理网络解耦使得域名系统非常灵活。它可以根据组织的需求来划分和管理域名,而不受地理位置或网络拓扑的限制。
问题2:解析问题-名字服务器(Name Server)
名字服务器的问题
- 可靠性问题: 单点故障的问题。如果一个名字服务器宕机,它负责的域可能无法访问。
- 扩展性问题: 通信容量问题。随着请求数量的增加,单个名字服务器可能难以应对负载。
- 维护问题: 远距离的集中式数据库问题。数据库距离用户越远,检索信息所需的时间就越长。
区域(Zone)
- 区域的划分: 区域的划分由区域管理员决定。这允许分布式管理并减少任何单一服务器的负载。
- DNS名称空间的划分: DNS名称空间被划分为不重叠的区域,每个区域都是DNS分层树结构的一部分。
- 名字服务器:
- 每个区域都有一个名字服务器,维护着其各自区域的权威记录。权威记录是提供对区域内域名查询的确定性数据集。
- 名字服务器可以放置在其区域之外,以确保可靠性,这有助于减轻单点故障问题。

名称空间中的区域划分
- 权威DNS服务器: 这些服务器属于组织,提供可以访问的主机名和IP地址之间的映射(如网站和电子邮件服务器)。
- 组织可以选择自己维护其DNS服务器,或者由服务提供 商维护。
顶级域(TLD)服务器
顶级域服务器负责存储顶级域名的信息,通常包括顶级域名(如“.com”,“.org”,“.net”,“.edu”,和“.gov”)和国家代码顶级域名(例如“.cn”,“.uk”,“.fr”,“.ca”,“.jp”)。
Network Solutions公司负责维护“.com”TLD服务器。
Educause公司是负责维护“.edu”TLD服务器的组织。
区域名字服务器维护资源记录
区域名字服务器(也称区域DNS服务器)是负责管理特定DNS区域内部的域名解析信息的服务器。这些服务器维护者资源记录(Resource Records, RR),资源记录是DNS中的基本信息单元,包含了映射域名到IP地址(以及其他类型的映射)的数据。
资源记录(Resource Records)
- 作用:维护域名到IP地址(其他)的映射关系。
- 位置:这些记录位于名字服务器(Name Server)的分布式数据库中。
RR格式:( d o m a i n n a m e , t t l , t y p e , c l a s s , V a l u e domain_name, ttl, type, class, Value domainname,ttl,type,class,Value)
-
Domain_name(域名):记录相关联的域名
-
T t l Ttl Ttl, time to live(生存实现):表示资源记录在DNS缓存中的存活时间,过了这个时间,缓存记录会被删除,必须重新查询权威DNS服务器获取新的记录。
TTL告诉其他服务器在多长时间内可以缓存这条记录,而不是每次需要时都像DNS服务器查询,这样做的目的如下:
- 缓存的目的:缓存DNS记录的主要目的是提高性能。当一个递归服务器查询DNS记录并收到回应时,它会将这些信息存储在本地缓存中。如果在TTL到期之前有对同一域名的查询请求,递归服务器就可以直接从缓存中提供答案,而不是再次进行全球性的DNS查询。这减少了解析时间,降低了对权威服务器的查询压力,从而提高了整个DNS解析过程的效率。
- 删除的目的:删除(或更新)缓存的目的是保持数据一致性。如果域名对应的IP地址或其他相关信息发生了变化,老的信息仍然存储在DNS缓存中可能会导致用户无法访问该域名或者被错误地导航到旧的IP地址。因此,当TTL值到期,缓存的记录会被删除,确保下次查询会从权威服务器获取最新的信息。
-
Class(类别): 表示记录的类别,对于互联网(Internet),其值通常为IN,代表Internet。
-
Value(值):根据不同**类型(type)**的资源记录。
-
Type(类型): 表示资源记录的类型。
资源记录类型
Type = A
- Name 为主机名
- Value 是主机的IPv4地址
Type = NS (Name Server)
- Name 是域名(如foo.com)
- Value 是该域名的权威名称服务器地址。告诉DNS查询这个特定的权威服务器是哪一个。
Type = CNAME(Canonical Name)
- Name 是别名
- Value 是该别名的规范名字。例如例如
www.ibm.com的规范名字为servereast.backup2.ibm.com。
Type = MX(Mail Exchange)
- Value 为Name对应的邮件服务器的别名的正规名字。

DNS大致工作过程
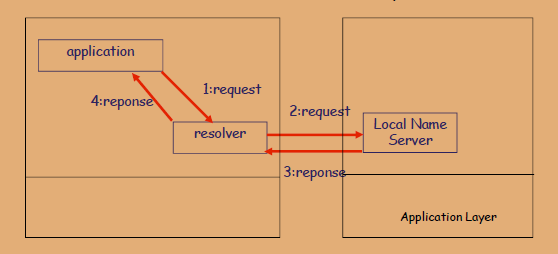
-
应用程序发起请求:应用调用 解析器(resolver)
应用程序需要访问一个域名(如:example.com),为了将域名解析成IP地址,应用程序回想系统中的解析器(Resolver)发送一个解析请求。 -
解析器向本地名称服务器发出请求:
解析器抽到请求后,就会向配置的本地名称服务器(Local Name Server)发出一个DNS查询。这个查询是封装在UDP协议的数据包中,通常使用53号端口。 -
本地名称服务器处理请求并相应:
本地名称服务器首先会查看自己的缓存,看是否有对应的记录。如果没有,它会进一步向上级DNS服务器查询(如根服务器、顶级域名服务器、权威名称服务器),直到找到答案。当本地名称服务器获得了域名对应的IP地址,它会将这个信息作为响应发回给解析器。 -
解析器将响应返回给应用程序:
解析器收到从本地名称服务器发来的包含IP地址的响应后,就会将这个IP地址提供给发起请求的应用程序。随后,应用程序就可以使用这个IP地址与目标服务器建立连接。
本地名字服务器(Local Name Server)
本地名字服务器是DNS的一个关键组件,主要有以下特征:
-
非层次结构性质
本地名字服务器并不严格属于DNS的层次结构。本地名字服务器更多地起到一个中介的角色,在解析过程中相当于一种桥梁作用。 -
与ISP关联
几乎每个互联网服务提供商(ISP),都会提供一个本地DNS服务供其用户使用。这些本地DNS服务器也被成为“默认名字服务器”。 -
DNS查询的第一站
当一个主机发起一个DNS查询时,这个查询首先被送到其配置的本地DNS服务器。 -
代理作用
如果本地DNS服务器中没有缓存所需的信息,它会作为代理,将查询转发到DNS层次结构中的其他服务器,例如向根服务器、TLD服务器或权威名字服务器查询,直到找到相应的记录。一旦本地服务器接收到这些信息,它会将结果返回给发起查询的主机,并将记录存入缓存以加快未来的查询过程。
名字服务器(Name Server)
**名字解析过程**
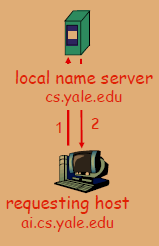
-
情况1:如果请求的域名在本地名字服务器所管理的区域内部,它将能够直接解析该域名并返回结果给请求主机。
-
情况2:缓存解析(cashing):如果请求的域名不在本地名字服务器的区域内,本地名字服务器会查看其缓存记录。如果该域名最近被解析过,并且缓存的记录仍然有效(即没有超过TTL),本地名字服务器会使用这个缓存记录来回应请求。
当与本地名字服务器不能解析名字时,联系根名字服务器顺着根-TLD一直找到 权威名字服务器。
递归查询和迭代查询
递归查询(Recursive Query):
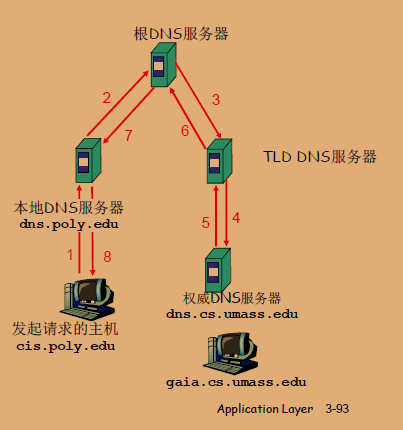
在递归递归查询中,客户端请求其本地DNS服务器解析一个域名。本地DNS服务器将负责整个查询过程:
- 它首先检查自己的缓存,如果找到了相应记录,就会返回结果。
- 如果没有缓存记录,它将向根服务器发起查询。
- 根服务器通常不直接回答查询结果,而是告诉本地DNS服务器去哪个TLD服务器查询。
- 本地DNS服务器然后向TLD服务器查询,TLD服务器再指向权威DNS服务器。
- 本地DNS服务器继续向权威DNS服务器查询,直到获取结果。
- 完成查询后,本地DNS服务器将结果返回给客户端,并将结果缓存以供将来查询。
在这个过程中,客户端只与本地DNS服务器交互,所有的查询负担都放在了这个服务器上。
由于互联网上的每个DNS解析请求都可能涉及到根服务器,导致根服务器承受巨大的查询压力。其解决方法是迭代查询。
迭代查询(Iterative Query)
在迭代查询中,客户端请求本地DNS服务器解析一个域名,但过程稍有不同:
- 本地DNS服务器首先检查自己的缓存,如果找到了相应记录,就直接返回结果。
- 如果没有缓存记录,本地DNS服务器将向根服务器发起查询。
- 根服务器不会进行查询,而是告诉本地DNS服务器下一个查询应当联系的TLD服务器的地址。
- 本地DNS服务器随后直接联系TLD服务器,TLD服务器也同样指出下一个联系的权威DNS服务器的地址,而不是查询结果。
- 这一过程持续进行,直到本地DNS服务器联系到权威DNS服务器并得到最终的查询结果。
- 最后,本地DNS服务器将结果返回给客户端,并可能缓存此结果。
迭代查询中,本地DNS服务器每次查询都会得到指向下一个应当联系的服务器的指示,而不是最终结果。每一步它都需要根据上一个服务器的指示继续向下查询。
DNS 协议报文
DNS协议中查询和响应报文的报文格式相同。
报文首部
- 标识符(ID):16位的字段,用于标识请求,以便客户端可以将响应和原始查询匹配起来,保证DNS和响应的一致性。
- flags(标志位):这些标志位包含多个控制表示:
- 查询/应答(QR)位: 指示该报文是查询(0)还是响应(1)。
- 希望递归(RD)位: 表明发起查询的客户端希望DNS服务器进行递归查询。
- 递归可用(RA)位: 在响应中设置,表明DNS服务器可以进行递归查询。
- 权威应答(AA)位: 如果响应来自权威DNS服务器,此位被设置。
- 问题数(# questions):报文中的问题部分的问题数量。
- 回答资源记录数(#answer RRs):回答部分包含的资源记录数量。
- 权威资源记录数(# authority RRs):权威资源记录的数量,这些记录来自权威DNS服务器。
- 附加资源记录数(# authority RRs):附加信息部分包含的资源记录数量,这些信息包含了有关查询的附加帮助信息。
报文的具体内容包括:
- 问题部分(questions):
- 包含一个或多个查询的详细信息,每个查询通常包括请求解析的域名和查询类型(如A、MX、CNAME等)。
- 回答部分(answers):
- 如果是响应报文,这部分包含了对查询的回答,即所请求的域名的资源记录。
- 权威部分(authority):
- 包含权威DNS服务器的资源记录,提供了关于域名的权威性信息。
- 附加信息部分(additional info):
- 可能包含一些额外的资源记录,如名称服务器的地址或其他相关记录,有助于加快域名解析过程。
提高性能:缓存
在DNS系统中,性能的一个重要优化是使用缓存。缓存是一种机制,它允许名字服务器存储最近查询过的域名到IP地址的映射信息。这样,当同一个或者相近的查询再次发生时,服务器可以直接从缓存中提供答案,而不必每次都进行完整的查询。这减少了对上游服务器,特别是根服务器和TLD服务器的查询需求,从而大大提高了效率。
缓存的优点:
- 减少延迟: 由于直接从本地缓存中获取答案,响应时间更快,用户体验更好。
- 减轻服务器负担: 减少了对权威服务器的查询次数,帮助分散了请求负荷,避免了服务器过载。
缓存可能引起的问题:
- 数据过时: 如果域名的映射信息发生了变化(比如IP地址更改),缓存中的数据可能会过时,这意味着用户可能得不到正确的解析结果。
- 一致性问题: 缓存的信息可能与权威源记录不一致,导致解析错误。
解决方案:
-
使用TTL: 每个DNS记录都有一个称为“生存时间”(Time to Live,TTL)的值,这个值告诉服务器应该缓存记录多长时间。一旦TTL到期,缓存的记录就会被删除(或标记为过时),这样在下次有查询请求时,服务器就会重新从权威服务器获取最新信息。
TTL的默认设置: TTL的值可以由域名的管理员设置,不过它通常有一个默认值,比如48小时。这意味着两天后,缓存的信息将被视为无效,需要重新查询。
问题3:维护问题:新增一个域
当需要引入一个新的子域时,如“Network Utopia”,这个过程如下:
-
注册域名:
首先为新域名" n e t w o r k u t o p i a . c o m networkutopia.com networkutopia.com"选择一个或多个权威DNS服务器,并向域名注册机构提供选择的权威DNS服务器的主机名和IP地址。 -
更新顶级域名服务器
注册机构将在".com"顶级域的DNS服务器中为"$networkutopia.com$"添加两条资源记录(Resources Records,RRs):- 一个NS记录,指定" n e t w o r k u t o p i a . c o m networkutopia.com networkutopia.com"的权威DNS服务器(例如,dns1.networkutopia.com)。
- 一个A记录,提供权威DNS服务器(dns1.networkutopia.com)的IP地址(例如,212.212.212.1)。
-
配置权威DNS服务器
在"$networkutopia.com$"的权威DNS服务器上,需要配置DNS记录,使得所有人都能解析到该域下提供的服务。- 对于网站服务,配置一个类型为A的记录,这个记录将
www.networkutopia.com映射到一个IP地址,允许互联网用户通过浏览器访问网站。 - 对于邮件服务,配置一个类型为MX的记录,这个记录指定了处理
networkutopia.com域内电子邮件的邮件服务器地址(例如,mail.networkutopia.com)。
- 对于网站服务,配置一个类型为A的记录,这个记录将
攻击DNS
对于DNS的攻击方式,主要包括分布式拒绝服务(DDoS)攻击、重定向攻击和利用DNS基础设施进行的DDoS攻击。
DDoS攻击:
- 对根服务器进行流量轰炸:
- 在这种攻击中,攻击者试图通过发送大量的流量(如ping请求)来使根服务器超载。尽管这种攻击听起来可能很危险,但实际上这些尝试往往没有成功,原因包括:
- 根服务器的防御: 根服务器通常配置有流量过滤器和防火墙,能够识别并阻止恶意流量。
- 本地DNS服务器的缓存: 大多数本地DNS服务器会缓存顶级域(TLD)服务器的IP地址,所以在大多数情况下根本不需要查询根服务器。
- 在这种攻击中,攻击者试图通过发送大量的流量(如ping请求)来使根服务器超载。尽管这种攻击听起来可能很危险,但实际上这些尝试往往没有成功,原因包括:
- 向TLD服务器流量轰炸攻击:
- 攻击者发送大量的查询请求给TLD服务器。这种攻击可能比对根服务器的攻击更有潜在危险,因为TLD服务器数量比根服务器少,可能更容易受到影响。然而,由于大多数DNS查询可以由缓存解决,所以这种攻击的效果通常也是有限的。
重定向攻击:
- 中间人攻击(Man-in-the-Middle, MitM):
- 攻击者截获DNS查询并伪造回答,将用户导向恶意站点,这可能是为了窃取用户信息或者散播恶意软件。
- DNS缓存投毒(DNS Cache Poisoning):
- 攻击者向DNS服务器发送伪造的响应,以使服务器缓存虚假的查询结果。如果成功,这会导致所有依赖该服务器的客户端在查询时被导向错误的IP地址。
- 这种攻击在技术上较为困难,需要在正确的时刻截获并伪造响应。
利用DNS基础设施进行DDoS:
- 反射放大攻击:
- 攻击者伪造受害者的IP地址发起DNS查询请求,目标DNS服务器或其他响应服务器返回比查询大得多的响应到受害者的IP地址。这种攻击利用了DNS协议中响应报文通常比查询报文大的特性,从而放大攻击流量。
- 虽然这种攻击方法可以产生较大流量,但其效果通常有限,因为它需要控制大量的被感染机器并利用合适的DNS服务器。
P2P应用
纯P2P架构
纯P2P模式有以下特点:
- 没有(或极少)一直运行的服务器。
- 任意端系统都可以直接连接和交换数据。
- 利用peer的服务能力,网络的负载和资源由网络的所有peers共同承担,每个peer都贡献其资源、带宽…
- Peer结点间歇上网,每次IP地址都有可能变化。
纯P2P的例子有:
- 文件分发(如BitTorrent)
- 流媒体(如KanKan)
- VoIP(如Skype)
文件分发 :C/S vs P2P
问题:从一台服务器向N个节点(peer)分发一个大小为F的文件所需要的时间。
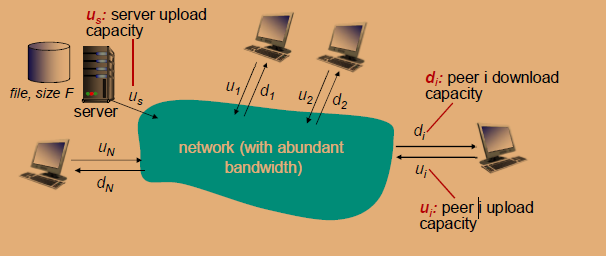
文件分发时间 :C/S
C/S模型中,一台服务器负责向多个客户端发送文件。这个分发过程的时间取决于服务器的上载带宽(us)和客户端的下载带宽(di)。
- 服务器的上载带宽(us):服务器发送文件到一个客户端所需的时间是文件大小(F)除以服务器的上载带宽(us)。要发送到N个客户端,就需要这个时间乘以N,因为服务器需要依次发送每一个文件副本。
- 客户端的下载带宽(di):每个客户端需要下载文件的副本。如果考虑所有客户端中下载带宽最小的那个(dmin),则该客户端完成下载所需的时间将是文件大小(F)除以这个最小的下载带宽(dmin)。
在C/S模式下,文件分发给所有客户端所需要的总时间至少是服务器发送N个副本所需时间和所有客户端中下载带宽最小的那个客户端下载文件所需的最大值。表达式为:
D c − s > max { N F u s , F d m i n } D_{c-s} > \max\left\{\frac{NF}{u_s}, \frac{F}{d_{min}}\right\} Dc−s>max{usNF,dminF}
- 如果服务器的上载带宽是限制因素,即$ \frac{NF}{u_s} > \frac{F}{d_{min}} $,则总时间由服务器发送所有副本的时间决定。
- 如果客户端中的最小下载带宽是限制因素,即 $ \frac{F}{d_{min}} > \frac{NF}{u_s}$,则总时间由下载带宽最小的客户端完成下载的时间决定。
文件分发时间: P2P模式
在P2P模式下的文件分发时间,有以下几个取决因素:
-
服务器传输:服务器至少需要上载一个文件的副本。这样,至少一个客户端可以开始拥有文件的副本并开始将其分发给其他节点。
- 发送一个拷贝的时间为 $\frac{F}{u_s} KaTeX parse error: Can't use function '\(' in math mode at position 5: ,其中 \̲(̲ F KaTeX parse error: Can't use function '\)' in math mode at position 1: \̲)̲ 是文件大小, u_s$ 是服务器的上载带宽。
-
客户端传输:在P2P网络中,每个客户端在下载了文件拷贝之后,也能成为一个上载源,帮助分发文件。
- 每个客户端必须下载一个文件的副本,最慢的客户端(带宽最小的客户端,$d_{min} 下载时间是 下载时间是 下载时间是 \frac{F}{d_{min}} $。
-
总体下载量:考虑到所有客户端的总下载量为 N F NF NF,因为每个客户端都需要一个文件的副本。
-
总体上载带宽:不仅服务器可以上载,所有客户端也可以提供上载带宽,总上载带宽是服务器上载带宽与所有客户端上载带宽之和,即 $u_s + \sum u_i $,其中 $\sum u_i $是所有客户端上载带宽的总和。
在P2P模式下,分发文件所需的时间 D P 2 P D_{P2P} DP2P 是以上三个时间中的最大值:
$ D_{P2P} > \max\left{\frac{F}{u_s}, \frac{F}{d_{min}}, \frac{NF}{u_s + \sum u_i}\right} $
P2P模式通常能更有效地分发文件,特别是当有大量的客户端同时在线时,因为它能利用所有客户端的上载带宽,而不仅仅是服务器的带宽。这样,随着客户端数量的增加,网络的分发能力也相应增加。
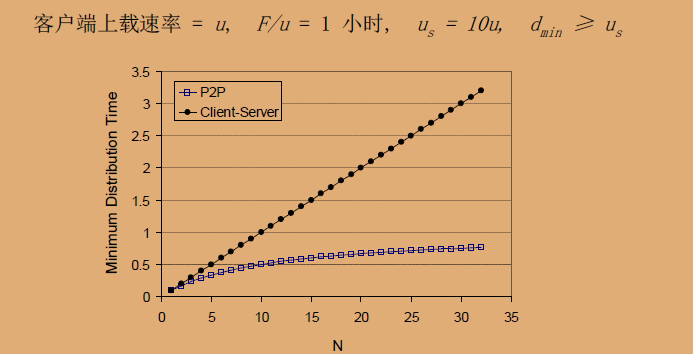
P2P(对等网络)与客户端-服务器(C/S)模型在文件分发时间上的对比图表:
BitTorrent
BitTorrent是一种点对点(Peer-to-Peer, P2P)通信协议,用于高效地分发大量数据,避免了依赖于单个服务器的需求。它通过将文件分散成许多小块来分发,每个用户下载的同时也会上传,增加网络的整体带宽和文件的可用性
BitTorrent协议的工作原理:
-
用户想要下载一个文件时,首先连接到一个中央服务器(tracker),这个服务器跟踪所有分享该文件的用户(peer)的信息。用户(Alice)通过tracker了解哪些peer拥有文件的不同部分,并与这些peers建立连接来交换文件块。
-
当Alice加入torrent网络,开始时她没有任何文件块。她的客户端会向tracker注册,并获取其他正在分享该文件的peers列表。之后,Alice的客户端会尝试与这些peers建立直接的连接,并开始下载文件块。同时,为了遵守协议,Alice也会上传她已经下载的文件块给其他peers,这样她就参与到了整个网络中的文件分发。
-
为了提高效率,BitTorrent使用了一种“稀有块优先”(rarest first)的策略,即优先下载在网络中较为稀缺的文件块,以确保所有文件块都有较好的可用性和分发速度。此外,BitTorrent 还采用了“对等交换”(tit-for-tat)策略,即用户的客户端会优先向那些向其提供数据的peers上传数据,以鼓励共享和交换,这是一种激励机制,确保网络中的资源分享是活跃和平衡的。
稀缺块优先策略:
在任意给定时间背景下,网络中的某些文件块可能会比其他快更稀缺(更少),或者说持有这个文件块的用户少(用户没上线),而没有足够的资源上传这块,导致下载过程的停滞。为了解决稀缺块缺少问题,稀缺块优先策略是通过监控网络中的文件块分布,确定哪些块是稀有的,客户端优先下载这些稀缺块,从而确保这些块在网络中更广泛地分布。对等交换策略
为了解决”免费搭车“问题,需要一种激励机制,对等交换策略的引入正是为了激励用户贡献自己的带宽,并为网络中的其他用户提供文件块。这个策略基于经济学中的互惠原则,意在建立一个互助合作的网络环境。对等交换策略的解决办法是通过跟踪上传到每个对等方的数据量,并优先分配下载带宽给那些贡献更多上传带宽的用户。如果用户不上传,或者上传很少,他们的下载优先级会降低,从而激励用户参与文件的上传。
关键点:
- 种子文件(Torrent)和跟踪器(Tracker):
- 一个用户创建一个种子文件(.torrent),包含目标文件的元数据(如文件名,大小,分块信息)以及tracker的信息。
- Tracker是一个服务器,它不存储文件内容,但跟踪哪些用户拥有文件的哪些部分。
- 开始下载:
- 用户在下载文件时,需要先加载“.torrent”文件到BItTorrent客户端后,BItTorrent会联系Tracker来获取用于文件快的Peers信息。
- 文件块是文件被分割的一小部分,通常每块大小为256KB。
- 效率问题:
- BitTorrent的效率在于它能够同时利用多个用户的上传带宽,这意味着随着用户数量的增加,网络的整体带宽也会增加。
- 这种方式对网络资源的使用非常高效,允许文件快速地在用户之间传播。
P2P文件共享
例子:
Alice使用P2P软件打算下载一个MP3文件,Alice的P2P客户端通过Internet搜索其他用户Peers共享文件列表,找到并选择了一个拥有这个MP3文件的Peers(Bob),文件从Bob的PC传送到Alice的笔记本上(HTTP),当Alice下载的同时,Alice也会上传已经下载的文件部分给掐他Peers。
所有的Peers都是服务器 == 可拓展性好。
上面的例子中,存在两个问题:
- 如何定位所需资源
- 如何处理对等方的加入与离开
可能解决的方案:
- 集中式
- 分散式
- 半分散式
P2P:集中式目录
Napster的集中是文件设计
-
当对等方连接到网络时,他会向中心服务器提供其IP地址和它所拥有的内容(如音乐文件、视频等)的列表。
-
当用户Alice查询一个MP3文件时,服务器会查找哪些对等方拥有这个文件,并将这些信息提供给Alice。
-
根据服务器提供的信息,Alice可以直接从拥有该文件的对等方那里请求并下载文件。
文件的传输是点对点的,即直接从Bob的点到传输到Alice的电脑,而不是经过中央服务器。
集中式目录存在的问题:
- 单点故障:因为所有的查询和索引都依赖于一个中心服务器,所以如果这个中心服务器出现故障,整个网络的定位功能就会收到影响,用户无法查找或下载文件。
- 性能瓶颈:随着用户数量的增加,中心服务器可能会遇到性能瓶颈。他需要处理大量的查询和响应,服务器无法及时处理,导致延迟或服务中断。
- 侵犯版权问题:Napster的设计使得它能够轻松地索引和共享受版权保护的内容,这导致了侵犯版权的问题。
完全分散式 查询泛洪:Gnutella
Gnutella 网络的特点
- 全分布式:
Gnutella网络没有中心服务器,所有操作都是在用户之间直接进行的,这种结构使得网络非常去中心化。 - 开放文件共享协议:
Gnutella是一个开放的协议,许多Gnutella客户端实现了Gnutella协议,类似HTTP有许多游览器。
Gnutella网络的工作原理
-
覆盖网络(Overlay Network):
- 如果两个节点之间有一个TCP连接,那么在覆盖网络中,这两个节点之间就有一条边。
- 所有活动的节点和它们之间的边构成了覆盖网络。这些边并不是物理连接,而是逻辑上的直接通信路径。
- 通常,一个节点会与少于10个其他节点建立连接。
-
协议的操作:
- 查询:节点通过已有的TCP连接发送查询报文来寻找文件。
- 查询转发:对等方转发查询报文,使查询可以扩散到网络中更远的地方。
- 查询命中:当一个节点拥有查询中请求的文件时,它会沿着查询来的相反路径返回一个查询命中报文,包含文件的位置信息。
- 文件传输:当查询命中报文被接收后,请求文件的节点可以直接通过HTTP协议从文件持有者那里下载文件。
-
对等方加入网络:
-
新对等方X首先需要发现已经存在于Gnutella网络中的其他对等方:使用可用对等方列表。
- X自己维护一张对等方列表(这个列表基于X之间的交互,记录了那些经常在线的对等方。)
- X可以联系维持列表的Gnutella站点,从中获取对等方的信息。
-
X获取了对等方列表,它会尝试与列表上的对等方建立TCP连接。X会依次尝试列表中的IP地址,直到成功建立起至少一个TCP连接为止。(这个连接通常是通过标准的网络握手过程建立的。)
-
连接建立后,X会想已建立连接的对等方Y发送一个Ping报文。
-
在Gnutella网络中,所有收到Ping报文的对等方会回应一个Pong报文。
Pong报文会包含对等方的IP地址、它共享的文件数量以及文件的总字节数,
-
X会从多个对等方接收到Pong报文,通过这些Pong报文,X利用这些网络信息与更多的对等方建立TCP连接。
-
由于每个查询都会被广播到多个对等方,大量的查询可能会导致网络负担过重。为了防止网络被过度的查询流量淹没,Gnutella协议使用了限制范围的洪泛查询。这意味着查询报文在网络中传播的距离是有限制的,以减少网络的负担。
半分散式 KaZaA
KaZaA网络,它使用了一种称为“超级节点”(Super Nodes)或组长的结构来优化搜索和文件传输过程。
KaZaA网络的结构
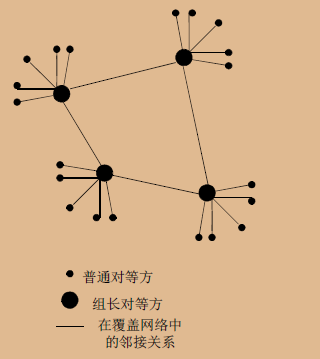
- 对等方和组长(超级结点):
- 在KaZaA网络中,每个对等方(普通用户的计算机)要么作为一个组长,要么隶属于一个组长。组长是选择的或自愿的,通常是因为它们拥有更好的网络连接和资源。
- 每个对等方与其组长之间有TCP连接,组长之间也相互有TCP连接。
- 内容跟踪和查询转发:
- 组长负责跟踪所有子节点(隶属的对等方)的内容。
- 当查询发生时,组长将负责处理其子节点发出的查询,并将这些查询转发到其他组长,这样可以在网络中寻找到请求的文件。
KaZaA的查询过程
- 文件标识:在KaZaA网络中,每个文件都通过一个唯一标识的散列标识码来标识,这个标识码是基于文件内容生成的,确保了文件的唯一性。文件描述符则提供文件的元数据信息,如文件名、类型、大小等。
- 当用户想要搜索文件时,他们的KaZaA客户端会向其所连接的组长发送一个包含搜索关键字的查询。这个查询包含用户希望查找的文件类型或名称的一部分。
- 组长节点接收到查询请求后,会在本地索引中查找匹配的文件。如果找到匹配项,组长会将这些文件的元数据、散列标识码和存储该文件的对等方的IP地址作为查询相应发送会客户端。
- 如果组长在本地没有找到匹配的文件,它可能会将查询转发给其他组长结点。这些组长也会在自己的索引中查找匹配的文件,并将找到的匹配以查询命中的形式响应给原始查询的组长。
- 当客户端收到一个或多个查询命中响应后,他将根据提供的信息选择想要下载的文件。然后客户端会向拥有该文件的对等方发送一个HTTP请求来下载文件。这个请求会包含文件的散列标识码,以确保下载的是正确的文件。
KaZaA的一些机制
KaZaA网络使用了一些机制来提高文件共享的效率和鼓励用户参与。这些小技巧包括请求排队、激励优先权和并行下载。
- 请求排队:
- 为了更有效地管理上载带宽并提供平等的服务给各个用户,KaZaA实施了请求排队系统。这意味着如果多个用户想要从同一个节点上载同一个文件,他们可能会被放入一个队列中。
- 这个系统限制了同时进行的上载数量,确保每个正在传输的文件都能从上载节点获得足够的带宽,从而提高了文件传输的速度和效率。
- 激励优先权:
- KaZaA通过给予那些愿意分享文件的用户更高的下载优先权来激励用户上载文件。这种方法鼓励用户不仅下载文件,也上传文件给其他用户。
- 这个激励机制加强了系统的整体扩展性,因为它促使用户贡献自己的资源,从而增加了网络上可用的资源总量。
- 并行下载:
- KaZaA支持从多个对等方同时下载同一个文件的不同部分。这利用了HTTP协议的字节范围首部(Byte Range Headers),允许客户端请求文件的特定部分。
- 通过并行下载,用户可以同时从多个源接收数据,这样可以更快地完成整个文件的下载。这不仅减少了对单一节点的依赖,也提高了下载过程的鲁棒性。
DHT:Distributed Hash Table(分布式散列表)
DHT是一种分布式存储系统,它提供了一种键值对(key-value pair)存储的方法,允许进行快速的查找操作。DHT在多个应用中非常有用,尤其是在P2P网络中,因为它能够在没有中心服务器的情况下,高效地处理节点的加入和离开,以及数据的存储和检索。
DHT的核心概念
键值对
在DHT中,数据以键值对的形式存储。键(Key)是数据的唯一标识符,而值(Value)则是与键相关联的数据内容,可以是文件的位置、数据的内容或者是其它任何需要存储的信息。
哈希函数
DHT使用哈希函数来决定数据应当存储在网络中的哪个位置。哈希函数将键转换成一个固定长度的数字标识符,该标识符通常是一个很大的整数。哈希函数需要具备一定的属性,如均匀性,确保数据能够均匀分布在所有节点上,减少冲突,以及不可逆性,保护原始数据的安全。
节点
在DHT中,每个参与的计算机或服务器被称为一个“节点”(Node)。每个节点负责存储一部分键值对,这一部分由哈希函数计算得出。
数据分布
当一个键值对被添加到DHT时,它会被存储在哈希值与之最接近的节点上。这意味着每个节点都会存储一个哈希值范围内的所有键值对。这种方法确保了即使某个节点不可用,也可以从其他节点找到数据。
DHT的工作原理
查找过程
当需要查找一个键对应的值时,发起查询的节点会根据哈希函数和键来确定应当查询的节点。然后,它会向这个节点发起一个查询请求。如果这个节点拥有这个键的数据,它就会返回相应的值;如果没有,则可能会将查询请求转发给其他可能有这个数据的节点。
维护和拓扑
为了保持网络的健康和高效,DHT网络需要不断地进行维护。这包括处理节点的加入和退出、数据的复制和迁移、以及定期的健康检查等。
DHT的特点
可扩展性
DHT非常适合大规模的网络,因为它能够在节点数目大幅增加时保持高效的性能。
容错性
DHT通过数据复制和其他机制来提高容错性。即使个别节点失败或离开网络,整个网络仍然可以正常工作。
自我组织
DHT网络能够自动地处理节点的加入和退出,无需人为干预。
DHT广泛应用于各种P2P系统,比如文件共享服务BitTorrent的追踪器就是通过DHT来实现的。
结构化P2P和非结构化P2P
非结构化P2P
非结构化P2P这类网络没有固定的网络拓扑结构或严格的资源组织方式。节点以随机的方式连接,文件和资源的分布也是随机的。
非结构化P2P包括:
- 集中化目录(Napster)
- 完全分散式(Gnutella)
- 半分散式(KaZaA)
非结构化的特点是:
- 节点连接随机
- 通常使用洪泛搜索(flooding)来发现资源
- 在网络规模增大,效率降低
- 网络对于结点的频繁加入和离开(波动)非常鲁棒,因为没有固定的结构
结构化P2P
结构化P2P网络使用严格定义的拓扑结构和算法来组织资源和节点,其中最著名的是分布式散列表(DHT)。
特点:
- 网络拓扑:网络有固定的、数学上定义好的拓扑结构,如环形、树形或其他几何结构。
- 资源定位:每个资源(通过其键的哈希值)和节点都有确定的位置和责任,资源查找可以快速且精确。
- 可扩展性:结构化P2P网络设计有很好的可扩展性,能够高效地处理大规模网络。
- 鲁棒性:通过复制和其他机制,即使在节点频繁变动的情况下也能保证数据的完整性和可用性。
- 典型应用:BitTorrent的DHT网络、IPFS(星际文件系统)。
优点:
- 高效的搜索:查询时间通常可以预测,与网络大小对数相关。
- 流量较少:由于有目的性的路由,网络流量更加高效。
- 负载均衡:网络负载相对均匀分布在所有节点上。
CDN
视频流化服务(如Netflix和YouTube)在现代互联网中占据了巨大的份额。这些服务器需要将大量数据传输给全球范围内的用户,这就带来了一系列挑战,尤其是在规模性和异构性方面。
-
规模性:
单个服务器或数据中心无法处理如此巨大的用户基础和数据量。这主要是因为:- 带宽限制:单个服务器的出站带宽是有限的,无法支持数以亿计的用户同时请求数据。
- 地理位置:用户遍布全球,单个地点的服务器无法提供低延迟的服务。
- 故障和维护:任何服务器或系统都可能出现故障,一个集中式的系统更容易因为单点故障而导致服务中断。
-
异构性:
- 用户设备的多样性:用户使用不同的设备(如智能手机、电脑)以及不同类型的网络连接(如有线、无线、移动数据)。
- 带宽的不一致性:不同用户的网络速度和稳定性差异很大,从高速宽带到受限的移动数据都有。
解决方案:分布式的,应用层面的基础设施。
多媒体:视频
视频 概念:由一系列固定速度显示的图像组成的序列。(e.g.:24images/sec)
网络视频特点:
- 高码率:视频通常具有比音频高得多的网络带宽需求。
- 视频通常可压缩,减少所需带宽的同时,保证质量。
- 主导网络流量:视频内容占据了网络流量的大部分,超过90%。
数字化图像和编码:
-
数字图像由像素(Picture Elements)的阵列组成,每个像素使用若干个bits来表示其颜色和亮度。
-
编码:通过利用图像内部和图像之间的冗余来减少所需的比特数,从而实现压缩。
- 空间冗余:图像内部像素之间的相似性,比如大面积相同颜色的区域可以更高效地编码。
- 时间冗余:连续帧之间的相似性,由于物体或场景变化较小,可以只传输变化的部分而非每一帧的全部数据。
这里的冗余是指数据中那些不必要或者重复的信息,这部分信息可以通过编码算法被去除或简化以减少文件大小。
空间编码例子:如果一幅图像主要由同一颜色组成(比如紫色),那么不需要发送每个像素的颜色值。相反,只需要发送颜色值一次和这个颜色重复的次数(N)。
时间编码例子:当传输视频时,如果连续两帧(frame i 和 frame i+1)之间只有少量的变化,那么就没有必要发送整个frame i+1的数据。可以只发送从frame i到frame i+1之间发生变化的部分。
下面是两种视频编码时考虑的比特率控制方法:
- CBR(恒定比特率)
- 预测性好:由于比特率是固定的,因此很容易预测视频文件的大小和网络带宽的需求。
- 流媒体友好:流媒体服务(如直播)通常优先选择CBR,因为它保证了数据流的连贯性和稳定性,减少了缓冲和延迟问题。
- VBR(可变比特率)
- 与CBR不同,VBR根据视频内容的复杂度动态调整比特率。
- VBR能够更加有效地利用带宽,只在需要保持视频质量的时候增加比特率。
- VBR通常能提供比CBR更好的视频质量,特别是在视频内容变化显著时。
存储视频的流化服务
存储视频的流化服务是指将视频文件保存在服务器上,以便用户可以通过互联网按需进行流式播放的服务。这种服务允许用户随时随地观看内容,不需要完整地下载整个视频文件。
多媒体流化服务:DASH
DASH(Dynamic Adaptive Streaming over HTTP)是一种先进的多媒体流化技术,也称为自适应流或自适应比特率流。它允许高质量的视频流通过普通的HTTP网络传输,同时能动态适应用户的网络条件。
DASH的工作原理:
- 视频文件处理:
- 视频被切割成一系列较小的文件块,每个块包含视频的一小部分。
- 每个块都已多种不同的比特率独立编码,通常有8-10种不同的质量级别,以适应不同网络速度和用户需求。
- 告示文件(Manifest file):
- 告示文件是一种索引文件,它描述了所有可用的视频块及其相关信息,包括每个块的URL和每个质量级别的比特率。
- 客户端首先下载这个告示文件,以了解可用的视频质量选项和响应的快。
- 客户端操作:
- 客户端在开始播放前获取告示文件,并周期性地测量从服务器到客户端的带宽。
- 根据当前的网络带宽,客户端会决定请求哪一个质量级别的视频块。如果网络条件良好,客户端会请求高比特率(高质量)的块;如果网络条件差,客户端则请求低比特率的块。
- 客户端会智能地决定何时请求数据块,以保持播放的连贯性并避免缓冲(即视频暂停等待更多数据的情况)。
DASH的优点
- 自适应性:DASH允许视频播放质量根据实时网络条件自动调整,从而提供尽可能好的观看体验。
- 灵活性:由于是基于HTTP,DASH可以利用现有的网络基础设施,如CDN,以增加传输效率和可靠性。
- 用户体验:通过避免视频缓冲和提供最佳可用质量,DASH改善了用户体验。
DASH的实施
客户端在播放视频时不断监控网络状况,并动态请求最合适的视频块。这种“智能”客户端可以:
- 确定何时请求新的数据块,以避免缓存不足或溢出的情况。
- 选择何种编码速率的视频块,根据当前可用带宽请求相应质量的视频。
- 决定从哪个服务器请求数据块,通常是从最近的CDN节点或带宽较大的服务器获取。
Content Distribution Networks 内容分发网络
挑战:服务器如何通过网络向上百万用户同时流化视频内容(上百万视频内容)?
选择1:mega-server(单个超级服务中心)
这种选择可能包括一下几个问题:
- 服务器到客户端路径上跳点较多,瓶颈链路的带宽小可能导致视频播放中断。
- 网络中存在多个相同视频的副本,导致低效的带宽利用和高运营的成本。
- 存在单点故障风险和性能瓶颈。
- 周边网络拥塞问题。
这种方法结构简单,但不具备可拓展性,难以适应不断增长的用户和数据需求。
选择2:CDN
使用CDN技术在整个网络中部署多个缓存节点,将内容存储得更靠近用户。
- enter deep:将CDN服务器深入到许多接入网
- 更接近用户,数量多,离用户近,管理困难。
- bring home:在少数关键位置部署服务器簇。
- 通过在流量交换的核心位置部署服务器集群,可以优化流量路由,提高数据传输效率。
CDN的优化方式
- 内容复制:CDN在不同地理位置的多个服务器上存储内容的副本。确保内容靠近用户,减少延迟,加快内容传输速度。
- 重定向机制:当用户请求内容(视频)时,CDN会将请求重定向到最近或最合适的存有内容副本的服务器。
- 缓存:CDN节点会缓存内容,当用户请求之前已经请求过的内容时,CDN可以直接冲缓存中提供,而不需要再次从源服务器获取。
- 负载均衡:CDN在多个服务器之间分配用户请求和流量,防止任意单一服务器过载。
CDN 的工作原理
- 内容请求:用户通过点击网站上的视频链接等方式发起内容请求。
- DNS解析:用户设备联系域名系统(DNS)将站点的域名解析为IP地址。
- 定位内容:用户的请求被定向到合适的CDN节点。
- 内容传递:一旦确定了最近或最合适的CDN节点,请求的内容就从这个节点传递到用户的设备。如果节点上没有内容,CDN可能会从源服务器或父节点获取,然后传递给用户。
- 处理网络拥塞:如果直接到内容的路径发生拥塞,CDN有能力重新路由请求到较少拥塞的节点或通过替代路径。
- 更新内容:CDN定期从源服务器更新其缓存的内容,确保用户接收到内容的最新版本。
Socket 编程
Socket编程是一种网络编程的方式,它允许应用程序通过网络发送和接收数据。Sockets是应用层与TCP/IP协议族传输层之间的抽象层,使得程序员可以不必处理协议的细节而进行网络通信。
在传输层服务中主要有两种socket类型:
- TCP:可靠的、字节流的服务。
- UDP:不可靠(数据UDP数据报)服务。
TCP套接字编程
TCP(传输控制协议)提供了一种可靠的服务,确保从一个进程发送到另一个进程的数据能够按序、可靠地传输。
TCP套接字编程的过程:
-
服务器设置:
服务器进程必须首先启动并运行,以便可以监听和接受客户端的连接请求。然后服务器创建一个套接字,这个套接字仅用于接受新的连接请求,通常被称为“欢迎套接字”。服务器将这个欢迎套接字与本地端口绑定,这个客户端就知道向哪个端口发送连接请求。服务器在欢迎套接字上进行阻塞式等待,即进入等到状态,直到客户端发起连接请求。
-
客户端发起连接
客户端创建一个本地套接字,操作系统会为其分配一个端口号(自动的,即“隐式绑定”)。然后客户端指定要连接的服务器的IP地址和端口号。客户端会调用连接(connect)API,请求与服务器的指定端口和IP地址建立TCP连接。
-
服务器接受连接
当客户端的连接请求到达服务器时,服务器接受请求,解除阻塞状态,并返回一个新的套接字。这个新套接字专门用于与请求的客户端进行通信。通过返回新的套接字,服务器可以继续在欢迎套接字上监听其他的连接请求,允许它与多个客户端同时通信。同时,服务器可以使用源IP地址和源端口号来区分不同的客户端。
-
TCP连接建立:
当连接请求被接受,客户端和服务器之间建立了一个TCP连接,这时客户端的套接字和服务器的新套接字已经连接,可以开始数据交换。
-
数据传输:
一旦TCP连接建立,客户端和服务器之间就形成了一条可靠的通信“管道”。双方可以通过这条管道按需发送字节流,无需担心数据的顺序、可靠性问题。
-
数据传输完成后,客户端和服务器将关闭他们的套接字,并释放资源。
下面介绍两个在网络编程中常用的数据结构,sockaddr_in 和 hostent。他们应用于进行地址和端口的配置以及域名解析。
sockadd_in
sockaddr_in 是一个用于存储地址和端口的数据结构,在IPv4通信中非常重要。下面是该数据结构每个字段的说明。
short sin_family:地址族。u_short sin_port:端口号。struct in_addr sin_addr:IP地址。这是一个结构体,它包含了一个无符号长整型的字段,用于存储网络接口的IPv4地址。char sin_zero[8]:填充字段,确保sockaddr_in的总长度与sockaddr结构相同。这个字段不用于网络通信,只是为了保持内存对齐,通常设置为0。
hostent
hostent 结构用于保存域名解析函数的返回信息,它在域名到IP地址的转换过程中使用:
char *h_name:官方的主机名。char **h_aliases:主机的别名列表,是一个以NULL结尾的数组。int h_addrtype:地址类型,通常是AF_INET。int h_length:地址的长度,对于IPv4来说,通常是4字节。char **h_addr_list:IP地址列表,是一个以NULL结尾的数组。对于IPv4,每个地址是一个4字节的数。h_addr是h_addr_list的第一个地址的别名,用于历史兼容。
当使用如gethostbyname()这样的函数时,如果您查询的是主机名,它会返回一个指向hostent结构的指针。然后,您可以取出h_addr_list中的第一个地址(h_addr),并将其复制到sockaddr_in结构的sin_addr字段中,以用于创建网络连接。
例子:C客户端(TCP)
#include <stdio.h>
#include <stdlib.h> // 标准库(用于 atoi 函数)
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h> // Internet地址族
#include <netdb.h> // 网络数据库操作int main(int argc, char *argv[])
{struct sockaddr_in sad; // 用来保存服务器IP地址的结构int clientSocket; // 套接字描述符struct hostent *ptrh; // 指向主机表条目的指针char Sentence[128]; // 发送数据的缓冲区char modifiedSentence[128]; // 接收数据的缓冲区int port; // 端口号char *host; // 主机名指针if (argc != 3) {fprintf(stderr, "Usage: %s <Server IP> <Server Port>\n", argv[0]);exit(1);}host = argv[1];port = atoi(argv[2]);// Create a socketclientSocket = socket(PF_INET, SOCK_STREAM, 0);if (clientSocket < 0) {fprintf(stderr, "Error: Socket creation failed.\n");exit(1);}// Clear sockaddr structurememset((char *)&sad, 0, sizeof(sad)); sad.sin_family = AF_INET; // Set family to Internetsad.sin_port = htons((u_short)port); // Set port number// Convert host name to equivalent IP address and copy to sadptrh = gethostbyname(host);if (ptrh == NULL) {fprintf(stderr, "Error: Invalid host name.\n");close(clientSocket);exit(1);}memcpy(&sad.sin_addr, ptrh->h_addr, ptrh->h_length);// Connect the socket to the specified serverif (connect(clientSocket, (struct sockaddr *)&sad, sizeof(sad)) < 0) {fprintf(stderr, "Error: Connection failed.\n");close(clientSocket);exit(1);}// Read a sentence from the userprintf("Enter a line of text:\n");fgets(Sentence, sizeof(Sentence), stdin);// Send the line to the serverif (write(clientSocket, Sentence, strlen(Sentence) + 1) < 0) {fprintf(stderr, "Error: Failed to send data.\n");close(clientSocket);exit(1);}// Read the server's replyif (read(clientSocket, modifiedSentence, sizeof(modifiedSentence)) < 0) {fprintf(stderr, "Error: Failed to receive data.\n");close(clientSocket);exit(1);}// Output the modified sentenceprintf("FROM SERVER: %s\n", modifiedSentence);// Close the connectionclose(clientSocket);return 0;
}
C服务器(TCP):
#include <stdio.h> // 标准输入输出定义
#include <stdlib.h> // 标准库(用于 atoi 函数)
#include <string.h> // 内存操作
#include <unistd.h> // UNIX标准函数定义
#include <sys/socket.h> // 套接字主要头文件
#include <netinet/in.h> // Internet地址族
#include <netdb.h> // 网络数据库操作void capitalizeSentence(char *str); // 假设此函数定义为将字符串转换为大写int main(int argc, char *argv[])
{struct sockaddr_in sad; // 结构体保存服务器的IP地址struct sockaddr_in cad; // 结构体保存客户端地址int welcomeSocket, connectionSocket; // 套接字描述符socklen_t alen; // 地址长度char clientSentence[128]; // 客户端发送的句子char capitalizedSentence[128]; // 服务器将要发送回去的句子int port; // 端口号if (argc != 2) {fprintf(stderr, "Usage: %s <Server Port>\n", argv[0]);exit(1);}port = atoi(argv[1]);// 创建套接字welcomeSocket = socket(PF_INET, SOCK_STREAM, 0);if (welcomeSocket < 0) {fprintf(stderr, "Error: Socket creation failed.\n");exit(1);}// 清零 sockaddr 结构memset((char *)&sad, 0, sizeof(sad));sad.sin_family = AF_INET; // 设置地址族为Internetsad.sin_addr.s_addr = INADDR_ANY; // 设置本地IP地址sad.sin_port = htons((u_short)port); // 设置端口号// 绑定套接字if (bind(welcomeSocket, (struct sockaddr *)&sad, sizeof(sad)) < 0) {fprintf(stderr, "Error: Binding failed.\n");close(welcomeSocket);exit(1);}// 监听套接字if (listen(welcomeSocket, 10) < 0) { // 10是最大客户端排队数fprintf(stderr, "Error: Listening failed.\n");close(welcomeSocket);exit(1);}// 服务器主循环while(1) {alen = sizeof(cad);// 接受连接connectionSocket = accept(welcomeSocket, (struct sockaddr *)&cad, &alen);if (connectionSocket < 0) {fprintf(stderr, "Error: Accept failed.\n");continue;}// 读取客户端句子if (read(connectionSocket, clientSentence, sizeof(clientSentence)) < 0) {fprintf(stderr, "Error: Reading from socket failed.\n");close(connectionSocket);continue;}// 转换句子为大写capitalizeSentence(clientSentence);strcpy(capitalizedSentence, clientSentence); // 假设转换已完成// 发送转换后的句子回客户端if (write(connectionSocket, capitalizedSentence, strlen(capitalizedSentence)+1) < 0) {fprintf(stderr, "Error: Writing to socket failed.\n");}// 关闭连接close(connectionSocket);}// 关闭欢迎套接字close(welcomeSocket);return 0;
}// 假设capitalizeSentence函数的实现
void capitalizeSentence(char *str) {// 逻辑实现将str中的每个字符转换为大写
}
UDP套接字编程
UDP在客户端和服务器之间没有连接,不进行握手。
发送端需要再每个UDP数据报中指定接收方的IP地址和端口号,服务器接收到数据报后,必须从该数据报中提取发送端的IP地址和端口号。
UDP数据报可能丢失或乱序,没有内建的重传和顺序控制机制。
进程视角看UDP服务:
UDP为客户端和服务器提供不可靠的字节组的传送服务。
UDP的客户端和服务器之间的套接字交互过程较为简单,因为它不需要建立和维护一个连接。下面是详细的交互过程:
客户端
-
创建UDP套接字:
客户端通过调用
socket()函数创建一个数据报套接字,指定PF_INET作为协议族和SOCK_DGRAM作为套接字类型。int clientSocket = socket(PF_INET, SOCK_DGRAM, 0); -
构造服务器地址:
客户端需要知道服务器的IP地址和端口号,因此它将这些信息填入一个
sockaddr_in结构体中。使用函数inet_pton()来将点分十进制的IP地址转换为网络字节顺序的二进制形式,端口号则用htons()转换为网络字节顺序。 -
发送数据:
使用
sendto()函数,客户端将数据发送到指定的服务器地址和端口号。在sendto()调用中,客户端必须提供包含服务器地址的sockaddr_in结构体,以及该结构体的大小。sendto(clientSocket, message, messageLength, 0, (struct sockaddr *)&serverAddr, sizeof(serverAddr)); -
接受相应:
客户端可以选择性地使用
recvfrom()函数等待并接收服务器的响应。这个函数也会返回发送端的地址信息,客户端可以使用这些信息来验证响应的来源。recvfrom(clientSocket, buffer, bufferLength, 0, (struct sockaddr *)&fromAddr, &addrLength); -
关闭套接字:
通信完成后,客户端关闭套接字释放资源。
close(clientSocket);
客户端交互的完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>#define SERVER_PORT 9876 // 服务器的端口号
#define SERVER_IP "127.0.0.1" // 服务器的IP地址
#define MAXLINE 1024int main(int argc, char *argv[])
{int sockfd;struct sockaddr_in serveraddr;char sendline[MAXLINE], recvline[MAXLINE];int n;// 创建UDP套接字sockfd = socket(AF_INET, SOCK_DGRAM, 0);// 设置服务器地址memset(&serveraddr, 0, sizeof(serveraddr));serveraddr.sin_family = AF_INET;serveraddr.sin_addr.s_addr = inet_addr(SERVER_IP);serveraddr.sin_port = htons(SERVER_PORT);while (fgets(sendline, MAXLINE, stdin) != NULL) {// 发送数据到服务器sendto(sockfd, sendline, strlen(sendline), 0, (struct sockaddr *) &serveraddr, sizeof(serveraddr));// 从服务器接收响应n = recvfrom(sockfd, recvline, MAXLINE, 0, NULL, NULL);recvline[n] = 0; // null terminatefputs(recvline, stdout);}// 关闭套接字close(sockfd);return 0;
}
服务器
-
创建UDP套接字: 类似于客户端,服务器也通过调用
socket()函数来创建一个UDP套接字。 -
绑定套接字: 服务器使用
bind()函数将其套接字绑定到一个地址和端口上,这样它就可以在该端口上接收到达的数据报。bind(serverSocket, (struct sockaddr *)&serverAddr, sizeof(serverAddr)); -
等待数据: 服务器使用
recvfrom()函数等待来自客户端的数据。当数据报到达时,recvfrom()会填充一个sockaddr_in结构体,其中包含了发送端的地址信息。recvfrom(serverSocket, buffer, bufferLength, 0, (struct sockaddr *)&clientAddr, &addrLength); -
发送响应: 服务器处理接收到的数据后,可以使用
sendto()函数发送响应回客户端。在sendto()调用中,服务器提供客户端的地址信息,以确保响应能被发送到正确的目的地。sendto(serverSocket, response, responseLength, 0, (struct sockaddr *)&clientAddr, sizeof(clientAddr));
服务器交互的完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>#define SERVER_PORT 9876 // 服务器的端口号
#define MAXLINE 1024int main(int argc, char *argv[])
{int sockfd;struct sockaddr_in serveraddr, clientaddr;char msg[MAXLINE];socklen_t clientlen;int n;// 创建UDP套接字sockfd = socket(AF_INET, SOCK_DGRAM, 0);// 设置服务器地址memset(&serveraddr, 0, sizeof(serveraddr));serveraddr.sin_family = AF_INET;serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);serveraddr.sin_port = htons(SERVER_PORT);// 绑定套接字到地址bind(sockfd, (struct sockaddr *) &serveraddr, sizeof(serveraddr));while (1) {clientlen = sizeof(clientaddr);// 接收来自客户端的数据n = recvfrom(sockfd, msg, MAXLINE, 0, (struct sockaddr *) &clientaddr, &clientlen);msg[n] = 0; // null terminateprintf("Received: %s", msg);// 将接收到的消息发送回客户端sendto(sockfd, msg, n, 0, (struct sockaddr *) &clientaddr, clientlen);}// 关闭套接字(理论上服务器是不会停止的,但这是一个好习惯)close(sockfd);return 0;
}
在这整个交互过程中,UDP协议不保证数据包的顺序、可靠传输或是数据包不重复。因此,任何必要的可靠性措施(如确认回执、重传机制等)都需要在应用层实现。UDP的优势在于它的轻量级和低延迟特性,非常适合那些对时效性要求高的应用,如视频会议或在线游戏。
相关文章:
计网——应用层
应用层 应用层协议原理 网络应用的体系结构 客户-服务器(C/S)体系结构 对等体(P2P)体系结构 C/S和P2P体系结构的混合体 客户-服务器(C/S)体系结构 服务器 服务器是一台一直运行的主机,需…...

算法面试八股文『 基础知识篇 』
博客介绍 近期在准备算法面试,网上信息杂乱不规整,出于强迫症就自己整理了算法面试常出现的考题。独乐乐不如众乐乐,与其奖励自己,不如大家一起嗨。以下整理的内容可能有不足之处,欢迎大佬一起讨论。 PS:…...
docker-学习-4
docker学习第四天 docker学习第四天1. 回顾1.1. 容器的网络类型1.2. 容器的本质1.3. 数据的持久化1.4. 看有哪些卷1.5. 看卷的详细信息 2. 如何做多台宿主机里的多个容器之间的数据共享2.1. 概念2.2. 搭NFS服务器实现多个容器之间的数据共享的详细步骤2.3. 如果是多台机器&…...
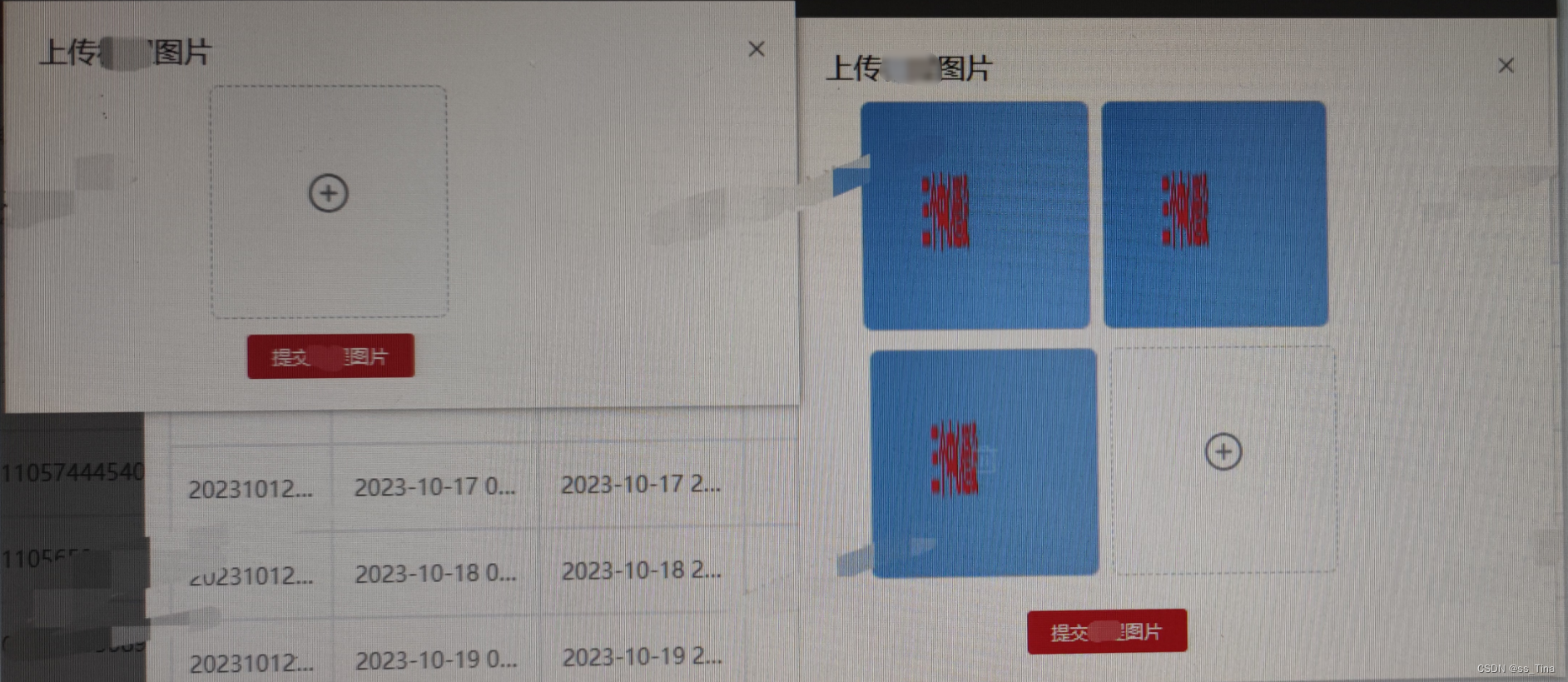
el-upload子组件上传多张图片(上传为files或base64url)
场景: 在表单页,有图片需要上传,表单的操作行按钮中有上传按钮,点击上传按钮。 弹出el-dialog进行图片的上传,可以上传多张图片。 由于多个表单页都有上传多张图片的操作,因此将上传多图的el-upload定义…...

2024美赛数学建模C题思路源码——网球选手的动量
这题挺有意思,没具体看比赛情况,打过比赛的人应该都知道险胜局(第二局、第五局逆转局)最影响心态的,导致第3、5局输了 模型结果需要证明这样的现象 赛题目的 赛题目的:分析网球球员的表现 问题一.球员在比赛特定时间表现力 问题分析 excel数据:每个时间段有16场比赛,…...

金三银四_程序员怎么写简历_写简历网站
你们在制作简历时,是不是基本只关注两件事:简历模板,还有基本信息的填写。 当你再次坐下来更新你的简历时,可能会发现自己不自觉地选择了那个“看起来最好看的模板”,填写基本信息,却没有深入思考如何使简历更具吸引力。这其实是一个普遍现象:许多求职者仍停留在传统简历…...

echarts条形图添加滚动条
效果展示: 测试数据: taskList:[{majorDeptName:测试,finishCount:54,notFinishCount:21}, {majorDeptName:测试,finishCount:54,notFinishCount:21}, {majorDeptName:测试,finishCount:54,notFinishCount:21}, {majorDeptName:测试,finishCount:54,notFinishCount:21}, {maj…...

Java 使用Soap方式调用WebService接口
pom文件依赖 <dependencies><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.13.0</version></dependency><!-- https://mvnrepository.com/artif…...

2024美赛数学建模所有题目思路分析
美赛思路已更新,关注后可以获取更多思路。并且领取资料 C题思路 首先,我们要理解势头是什么。简单来说,势头是一方在比赛中因一系列事件而获得的动力或优势。在网球中,这可能意味着连续赢得几个球,或是在比赛的某个关…...

Docker容器引擎(5)
目录 一.docker-compose docker-compose的三大概念: yaml文件格式: json文件格式: docker-compose 配置模板文件常用的字段: 二.Docker Compose 环境安装: 查看版本: 准备好nginx 的dockerfile的文…...
百分点科技:《数据科学技术: 文本分析和知识图谱》
科技进步带来的便利已经渗透到工作生活的方方面面,ChatGPT的出现更是掀起了新一波的智能化浪潮,推动更多智能应用的涌现。这背后离不开一个朴素的逻辑,即对数据的收集、治理、建模、分析和应用,这便是数据科学所重点研究的对象——…...
LabVIEW传感器通用实验平台
LabVIEW传感器通用实验平台 介绍了基于LabVIEW的传感器实验平台的开发。该平台利用LabVIEW图形化编程语言和多参量数据采集卡,提供了一个交互性好、可扩充性强、使用灵活方便的传感器技术实验环境。 系统由硬件和软件两部分组成。硬件部分主要包括多通道数据采集卡…...
向日葵企业“云策略”升级 支持Android 被控策略设置
此前,贝锐向日葵推出了适配PC企业客户端的云策略功能,这一功能支持管理平台统一修改设备设置,上万设备实时下发实时生效,很好的解决了当远程控制方案部署后,想要灵活调整配置需要逐台手工操作的痛点,大幅提…...

51单片机通过级联74HC595实现倒计时秒表Protues仿真设计
一、设计背景 近年来随着科技的飞速发展,单片机的应用正在不断的走向深入。本文阐述了51单片机通过级联74HC595实现倒计时秒表设计,倒计时精度达0.05s,解决了传统的由于倒计时精度不够造成的误差和不公平性,是各种体育竞赛的必备设…...

深信服技术认证“SCCA-C”划重点:深信服云计算关键技术
为帮助大家更加系统化地学习云计算知识,高效通过云计算工程师认证,深信服特推出“SCCA-C认证备考秘笈”,共十期内容。“考试重点”内容框架,帮助大家快速get重点知识。 划重点来啦 *点击图片放大展示 深信服云计算认证(…...

Redis stream特性了解
在发布订阅中我们了解到发布订阅模式存在的无法持久化保存消息和对于离线重连的客户端不能读取历史消息的缺陷,以下就来了解一下stream是如何解决这个问题的 steam是类似于仅添加log的数据结构,提供了以下基本命令 XADD: 添加新条目到stream # 语法xadd…...

苍穹外卖项目可以写的简历和如何优化简历
文章目录 重点写中规写添加自己个性的项目面试会问道的问题 我是一名双非大二计算机本科生,希望我的分享对你有帮助,点赞关注不迷路。 简历编写一直是很多人求职人的心病,我自己上学期有一门课程是去校内企业面试,当时我就感受出…...

C++:智能指针
C在用引用取缔掉指针的同时,模板的引入带给了指针新的发挥空间 智能指针简单的来说就是带有不同特性和内存管理的指针模板 unique_ptr 1.不能有多个对象指向一块内存 2.对象释放时内部指针指向地址也随之释放 3.对象内数据只能通过接口更改绑定 4.对象只能接收右值…...
用户界面(UI)、用户体验(UE)和用户体验(UX)的差异
对一个应用程序而言,UX/UE (user experience) 设计和 UI (user interface) 设计非常重要。UX设计包括可视化布局、信息结构、可用性、图形、互动等多个方面。UI设计也属于UX范畴。正是因为三者在一定程度上具有重叠的工作内容,很多从业多年的设计师都分不…...
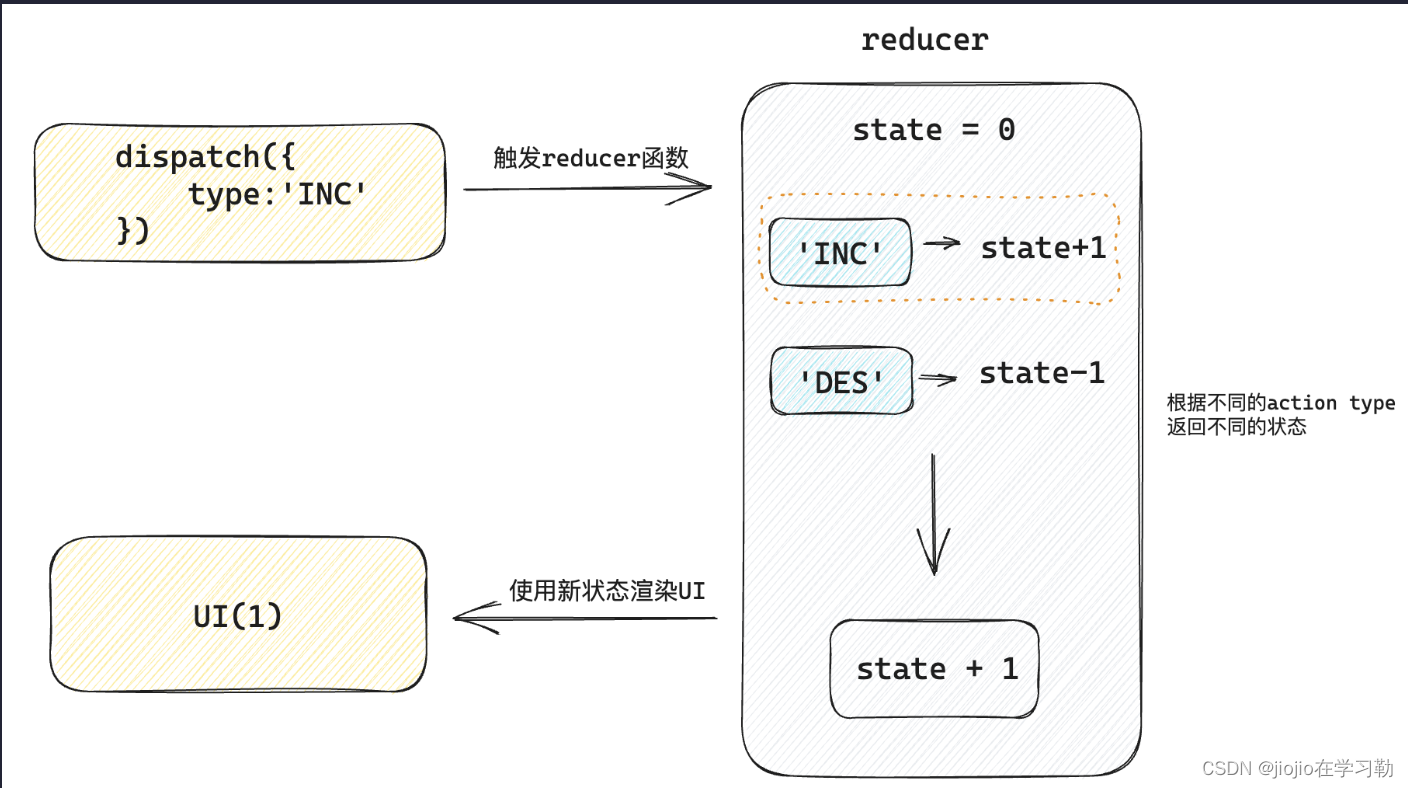
react 之 UseReducer
UseReducer作用: 让 React 管理多个相对关联的状态数据 import { useReducer } from react// 1. 定义reducer函数,根据不同的action返回不同的新状态 function reducer(state, action) {switch (action.type) {case INC:return state 1case DEC:return state - 1de…...

Redux Framework未来展望:探索v5版本的新特性和发展方向
Redux Framework未来展望:探索v5版本的新特性和发展方向 【免费下载链接】redux-framework Redux is a simple, truly extensible options framework for WordPress themes and plugins! 项目地址: https://gitcode.com/gh_mirrors/re/redux-framework Redux…...

【大模型12步学习路线 · 第12步 · ②代码篇】Qwen3-VL + ColQwen2.5 + Qdrant 多模态 RAG 全栈实战
【大模型12步学习路线 第12步 ②代码篇】Qwen3-VL + ColQwen2.5 + Qdrant 多模态 RAG 全栈实战 系列定位:「大模型正确学习顺序」12 步系列 第 12 步 多模态 的 ②代码篇。 前置阅读:①原理篇 —— VLM 全景 + Multimodal RAG 三大架构。 本篇产出:Qwen3-VL-8B 视觉问答上手…...

剪映专业版教程:制作数据结构快速排序算法原理演示视频
前言 今天教大家用剪映制作数据结构快速排序算法的原理演示视频。一趟冒泡排序只能使一个元素排序到位,而快速排序在一趟操作后不仅能使某个元素排序到位,还能将序列划分为两个子序列——所有比该元素小的都在左边,所有比该元素大的都在右边…...
)
别再只会画矩形了!用Leaflet+L.geoJSON搞定复杂行政区遮罩(含飞地处理)
突破Leaflet遮罩技术瓶颈:复杂行政区与飞地处理的终极方案 当我们面对真实世界中的行政区划数据时,理想化的矩形遮罩显得力不从心。中国行政区划的复杂性——飞地、嵌套洞、不规则边界——要求开发者掌握更高级的地图遮罩技术。本文将带您深入Leaflet的L…...
手机版通用)
真・三国无双 起源 官方正版2026最新版pc免费下载(看到请立即转存 资源随时失效)手机版通用
下载链接 破局与重塑:——《真・三国无双 起源》制作团队、玩法架构与竞品技术对标 作为光荣特库摩(Koei Tecmo)旗下最具代表性的动作砍杀IP最新作,《真・三国无双 起源》(Dynasty Warriors: Origins)在延…...

使用 Taotoken 管理多个 API Key 并设置访问权限与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 管理多个 API Key 并设置访问权限与审计 在开发和集成大模型应用时,一个常见的需求是为不同的应用、环境…...

在nodejs后端服务中集成taotoken调用多模型ai能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用多模型AI能力 基础教程类,面向使用Node.js构建Web服务或应用的后端开发者&#x…...
)
告别Rviz!用Webviz+Docker打造可远程访问的ROS数据监控面板(附TurtleBot3实战配置)
告别Rviz!用WebvizDocker打造可远程访问的ROS数据监控面板(附TurtleBot3实战配置) 机器人开发团队常面临一个痛点:如何在会议室大屏、异地成员的平板电脑或开发者的笔记本上,实时共享SLAM建图、传感器数据或导航状态&…...
)
保姆级教程:在K8s集群上部署Triton Inference Server服务(含TensorRT加速配置)
生产级K8s集群部署Triton Inference Server全流程指南 在AI模型工业化落地的浪潮中,如何将训练好的模型高效、稳定地部署到生产环境,成为众多技术团队面临的共同挑战。本文将聚焦Kubernetes集群环境,详细拆解NVIDIA Triton Inference Server…...

IPBan:企业级服务器安全防护解决方案的架构设计与实现
IPBan:企业级服务器安全防护解决方案的架构设计与实现 【免费下载链接】IPBan Since 2011, IPBan is the worlds most trusted, free security software to block hackers and botnets. With both Windows and Linux support, IPBan has your dedicated or cloud se…...