AI大语言模型学习笔记之三:协同深度学习的黑魔法 - GPU与Transformer模型
Transformer模型的崛起标志着人类在自然语言处理(NLP)和其他序列建模任务中取得了显著的突破性进展,而这一成就离不开GPU(图形处理单元)在深度学习中的高效率协同计算和处理。
Transformer模型是由Vaswani等人在2017年提出的,其核心思想是自注意力机制(self-attention mechanism),它在处理序列数据时能够捕捉长距离依赖关系,从而在NLP等任务中取得了优异的性能。
而GPU(图形处理单元)在这一突破性进展中发挥了重要作用。深度学习模型的训练通常需要大量的计算资源,而传统的中央处理单元(CPU)由于硬件架构的差异和并行处理性能的限制,在处理需要大量矩阵乘法和其他张量操作的高度并行深度学习任务时速度较慢。

而图形处理单元(GPU)是专门设计用于高度并行计算的专用芯片,特别适合加速深度学习任务。由于Transformer模型具有大量的参数,会对大规模的数据进行大量的高速并行计算和训练,GPU的并行处理能力就为大模型的训练提供了巨大的加速,因此更适合深度学习工作负载,使研究人员和工程师能够充分利用GPU的性能进行模型训练。

在训练大规模的Transformer模型时,使用GPU可以大幅缩短训练时间,加速模型的研发和部署过程。
因此,Transformer模型在NLP和序列建模任务中的成功与GPU的协同处理密不可分,为深度学习领域的发展和应用带来了显著的影响。
那么,在进行Transformer模型的深度学习任务时,GPU是如何运作的呢?下面我尝试通过一个简单的例子看看是否能够说明各个部件是如何协同工作的。
GPU在Transformer中的角色
Transformer 模型是一种基于自注意力机制的深度神经网络架构,其庞大的参数量和复杂的计算要求对计算机的计算能力的要求非常高。
我们知道目前使用的PC电脑或者服务器主要的计算处理模块都是CPU(中央处理单元),平常用来玩玩游戏、听听音乐、看电影、刷个剧不在话下,用来做专业设计、剪辑短视频、编辑文档、打印文件等工作也是得心应手。

之所以PC能干这么多不同的事情,主要是因为普通电脑的CPU(中央处理单元)在其架构设计时主要注重了多用途性能和通用的计算能力。CPU被设计成适用于各种任务,包括通用计算、图形界面处理、文件管理、音视频编码解码等。
而当我们进行 AI 深度学习任务时就不一样了。
深度学习的崛起引入了大规模的神经网络和复杂的模型结构,这导致了更多的参数和更复杂的计算图,通常涉及到大规模的矩阵乘法和张量运算,为了提升计算速度,这些操作通常是多个运算并行进行的,对计算机的并行能力提出了很高的要求。
诸如ChatGPT和GPT-4这样最先进的 AI 生成式预训练大语言模型涉及上万亿到上百万亿的参数和海量的数据,通常需要构建及其庞大的 AI GPU Cluster 集群才能满足计算、训练和推理需求,对 GPU 的计算能力要求更是堪称天花板级别的。

传统CPU虽然具有一些多核心,而且每个核心挺强的,但是数量确实少了点,难以满足深度学习大规模并行计算的需求。与此不同,现代GPU专注于大规模并行计算,拥有许多小型处理单元,使得它们在处理深度学习任务时更为高效。
就拿 英特尔(Intel) 和 英伟达(NVIDIA)2023年各自发布的最新一代架构和核心处理器:
Intel® Xeon® Platinum 8593Q 和 NVIDIA H100 Tensor Core GPU 来说,核心数量和浮点运算性能对比如下:

| 处理器 | 核心数量 | FP64 FLOPS | FP32 FLOPS | TF32 FLOPS |
|---|---|---|---|---|
| Intel Xeon 8593Q CPU | 64 核128 线程 | 5.04 TFLOPS (每秒5.04万亿次) | 4.96 TFLOPS (每秒4.96万亿次) | 4.94 TFLOPS (每秒4.94万亿次) |
| NVIDIA H100 GPU | 18432 个 CUDA 核心 576个Tensor张量核心 | 60 TFLOPS (每秒60万亿次) | 60 PFLOPS (每秒60万亿次) | 1000 PFLOPS(每秒1000万亿次) |

其中,FP64 表示双精度浮点运算,FP32 表示单精度浮点运算,TF32 表示混合精度浮点运算。
从上面的表格可以看出,NVIDIA H100 GPU 在 FP64 和 FP32 两个精度下的每秒浮点运算次数都比 Intel Xeon 8593Q 高出一个数量级(10倍)还要多,在 TF32 精度下的每秒浮点运算次数高出了约200多倍。这意味着 NVIDIA H100 GPU 在浮点计算方面具有明显的优势。
而传统的 CPU 架构在面对 AI 深度学习这种大数据量高并发张量计算时可能就显得力不从心,因为它们的设计更注重于处理多样化且频繁切换的任务,而非大规模数据的并行计算。
另外,深度学习框架和库通常会使用针对GPU设计的特定指令集和特殊优化,而这些优化使得GPU处理器更好地与深度学习任务协同工作。相较之下,CPU在这方面的优化可能比较有限,导致在同样进行深度学习任务时性能较慢。
因此,GPU 处理器在 Transformer 模型中的角色主要体现在其强大的并行计算能力,使得处理大规模、高度并行的深度学习任务变得高效和可行。这为深度学习在一系列自然语言处理(NLP)大模型和其他序列建模任务中的成功进展提供了重要的计算基础。
并行化的自注意力机制
Transformer中的自注意力机制(Self-Attention)是其核心组成部分之一,用于建立输入序列中每个元素与其他元素之间的关联。
为了更好的理解Transformer中的自注意力机制(Self-Attention),让我从一个简单的例子开始。假设你说了一句话:“我爱北京天安门”。我们想知道这句话中的每个词与其他词的关系。
在传统的自然语言处理(NLP)模型中,会将这句话的每个词转换为一个向量,然后使用这些向量来计算词与词之间的关系。例如,我们可以计算“我”与“爱”之间的关系。
在注意力计算(Attention Computation)中,查询向量 ( q ) 与输入序列 ( H = [h_1, h_2, …, h_n] ) 之间的计算用于权重分配,以便更加关注输入序列中与查询相关的部分。在机器翻译任务中,尤其是基于 Seq-to-Seq 模型的机器翻译任务,查询向量 ( q ) 通常是解码器(Decoder)端前一个时刻的输出状态向量。
我们考虑一个简化的注意力计算过程,其中使用了点积注意力(Dot-Product Attention)的形式:
Attention ( q , H ) = Softmax ( q ⋅ H T d ) ⋅ H \text{Attention}(q, H) = \text{Softmax}\left(\frac{q \cdot H^T}{\sqrt{d}}\right) \cdot H \ Attention(q,H)=Softmax(dq⋅HT)⋅H
其中,( · ) 表示矩阵乘法, ( H T ) \ (H^T) \ (HT) 表示输入序列的转置, ( d ) \ (\sqrt{d} ) \ (d) 用于缩放,以防止点积的数值过大。Softmax 函数用于将点积的结果转化为权重分布。
在机器翻译中,( q ) 可以是解码器的前一个时刻的隐藏状态,而 ( H ) 是编码器的所有隐藏状态。这样,计算得到的注意力权重将反映出解码器当前时刻对编码器各个时刻隐藏状态的关注程度。
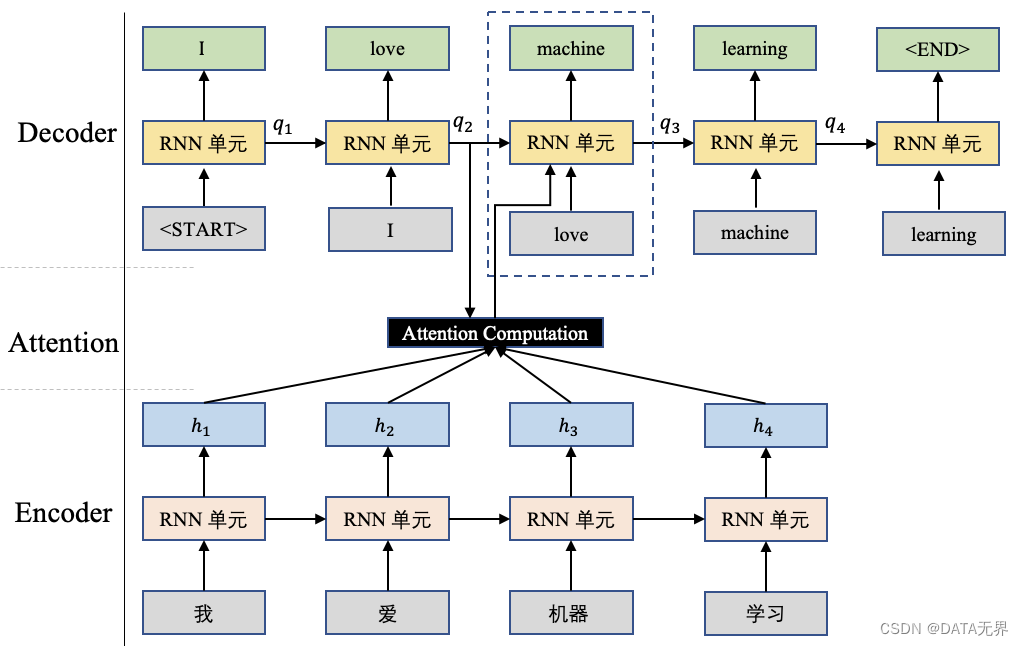
通过将查询向量 ( q ) 与输入序列 ( H ) 进行点积计算,并使用 Softmax 函数生成权重分布,注意力机制使得模型能够自动关注输入序列中与当前解码器状态相关的部分,这对于更好地捕捉输入和输出序列之间的关联关系非常有帮助。
但是,这种方法存在一个问题。它假设每个词与其他词的关系都是相同的。例如,它假设“我”与“爱”的关系与“爱”与“北京”的关系相同。
自注意力机制(self-Attention)可以解决这个问题。它允许模型根据每个词的上下文来计算词与词之间的关系。
在我们的例子中,自注意力机制可以计算“我”与“爱”之间的关系,同时考虑“北京”和“天安门”这两个词。例如,它可以发现“我”与“爱”之间的关系更强,因为它们都是动词。
在自注意力机制中,采用了查询-键-值(Query-Key-Value)的机制,其中查询向量(Query vector)可以根据输入信息进行生成,而不是事先确定。
BERT(Bidirectional Encoder Representations from Transformers)是一个使用自注意力机制的预训练模型,下面让我们简要讨论BERT中的自注意力机制。
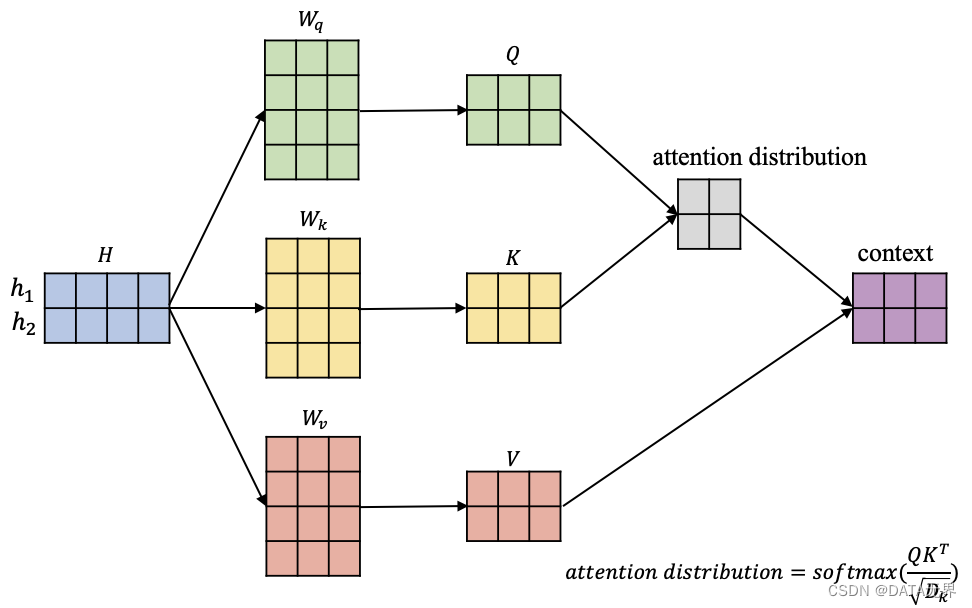
在上图中,我们有输入信息
H = [ h 1 , h 2 ] \ H = [h_1, h_2] \ H=[h1,h2]
其中蓝色矩阵的每一行代表一个对应的输入向量。此外,图中还有三个矩阵
W q , W k , W v \ W_q, W_k, W_v \ Wq,Wk,Wv
它们负责将输入信息 ( H ) 依次转换到相应的查询空间
Q = [ q 1 , q 2 ] \ Q = [q_1, q_2] \ Q=[q1,q2]
键空间
K = [ k 1 , k 2 ] \ K = [k_1, k_2] \ K=[k1,k2]
值空间
V = [ v 1 , v 2 ] \ V = [v_1, v_2] \ V=[v1,v2]
[ q 1 = h 1 W q , q 2 = h 2 W q ] ⇒ Q = H W q [ k 1 = h 1 W k , k 2 = h 2 W k ] ⇒ K = H W k [ v 1 = h 1 W v , v 2 = h 2 W v ] ⇒ V = H W v \begin{align*} [q_1 = h_1W_q, q_2 = h_2W_q] & \Rightarrow Q = HW_q \\ [k_1 = h_1W_k, k_2 = h_2W_k] & \Rightarrow K = HW_k \\ [v_1 = h_1W_v, v_2 = h_2W_v] & \Rightarrow V = HW_v \\ \end{align*} [q1=h1Wq,q2=h2Wq][k1=h1Wk,k2=h2Wk][v1=h1Wv,v2=h2Wv]⇒Q=HWq⇒K=HWk⇒V=HWv
在获得输入信息在不同空间的表示 ( Q, K, ) 和 ( V ) 后,我们以 ( h_1 ) 为例,计算这个位置的一个 attention 输出向量 ( \text{context}_1 ),它代表在这个位置模型应该重点关注的内容,如图3所示。
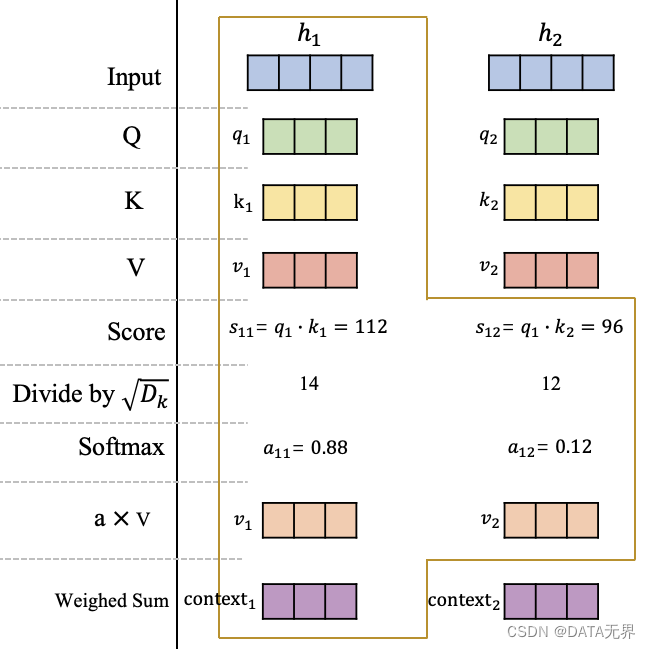
可以看到,在获得原始输入 ( H ) 在查询空间、键空间和值空间的表示 ( Q, K, ) 和 ( V ) 后,计算 ( q_1 ) 在 ( h_1 ) 和 ( h_2 ) 的分数 ( s_{11} ) 和 ( s_{12} ),这里的分数计算采用的是点积操作。
然后将分数进行缩放并使用 softmax 进行归一化,获得在 ( h_1 ) 这个位置的注意力分布: ( a_{11} ) 和 ( a_{12} ),它们代表模型当前在 ( h_1 ) 这个位置需要对输入信息 ( h_1 ) 和 ( h_2 ) 的关注程度。最后,根据该位置的注意力分布对 ( v_1 ) 和 ( v_2 ) 进行加权平均,获得最终在 ( h_1 ) 这个位置的 Attention 向量 ( \text{context}_1 )。
同理,可以获得第2个位置的 Attention 向量 ( \text{context}_2 ),或者继续扩展输入序列获得更多的 ( \text{context}_i ),原理都是一样的。
讨论到这里,相信你已经知道什么是注意力机制了,但为了更正式一点,我重新组织一下注意力机制的计算过程。
自注意力机制的计算过程可以分为以下几个步骤:
- 将每个词转换为一个向量。
- 计算每个词与其他词之间的相似度。
- 使用相似度来计算每个词的注意力权重。
- 使用注意力权重来加权每个词的向量。
最终,每个词都会得到一个加权后的向量,这个向量包含了该词与其他词的关系。
假设当前有输入信息 ( H = [h_1, h_2, …, h_n] ),我需要使用自注意力机制获取每个位置的输出
context = [ context 1 , context 2 , . . . , context n ] \text{context} = [\text{context}_1, \text{context}_2, ..., \text{context}_n] context=[context1,context2,...,contextn]
首先,需要将原始输入映射到查询空间 ( Q )、键空间 ( K ) 和值空间 ( V ),相关计算公式如下:
Q = H W q = [ q 1 , q 2 , . . . , q n ] K = H W k = [ k 1 , k 2 , . . . , k n ] V = H W v = [ v 1 , v 2 , . . . , v n ] \begin{align*} Q & = HW_q = [q_1, q_2, ..., q_n] \\ K & = HW_k = [k_1, k_2, ..., k_n] \\ V & = HW_v = [v_1, v_2, ..., v_n] \\ \end{align*} QKV=HWq=[q1,q2,...,qn]=HWk=[k1,k2,...,kn]=HWv=[v1,v2,...,vn]
接下来,计算每个位置的注意力分布,并将相应结果进行加权求和:
context i = ∑ j = 1 n softmax ( s ( q i , k j ) ) ⋅ v j \text{context}_i = \sum_{j=1}^n \text{softmax}(s(q_i, k_j)) \cdot v_j contexti=j=1∑nsoftmax(s(qi,kj))⋅vj
其中 ( s(q_i, k_j) ) 是经过上述点积、缩放后的分数值。
最后,为了加快计算效率,可以使用矩阵计算的方式,一次性计算出所有位置的 Attention 输出向量:
context = softmax ( Q K T / d ) V \text{context} = \text{softmax}(QK^T/\sqrt{d})V context=softmax(QKT/d)V
这就是自注意力机制(self-Attention)的原理。
在进行自注意力计算时,GPU处理器的并行计算能力就可以大显身手了。以一个批次大小为64的例子为例,GPU处理器能够同时计算64个样本中每个样本的自注意力,加速整个模型的训练过程。
# 伪代码示例:Transformer中的自注意力计算
import torch
import torch.nn.functional as Fdef self_attention(Q, K, V):attention_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(Q.size(-1))attention_weights = F.softmax(attention_scores, dim=-1)output = torch.matmul(attention_weights, V)return output# 在GPU上进行自注意力计算
Q_gpu = Q.to('cuda')
K_gpu = K.to('cuda')
V_gpu = V.to('cuda')output_gpu = self_attention(Q_gpu, K_gpu, V_gpu)
这里,Q、K、V是输入序列的查询、键和值的表示,通过GPU上的矩阵乘法和softmax计算,同时处理多个样本的注意力权重。
多头注意力的并行化
Transformer模型中还引入了多头注意力机制,通过并行计算多个注意力头,提高了模型的表示能力。GPU处理器的并行计算能力极大地加速了多头注意力的计算,每个注意力头都可以在不同的GPU核心上独立计算。
# 伪代码示例:Transformer中的多头注意力计算
class MultiHeadAttention(torch.nn.Module):def __init__(self, num_heads, hidden_size):# 初始化多个注意力头self.attention_heads = [self_attention(Q, K, V) for _ in range(num_heads)]def forward(self, input):# 并行计算多个注意力头outputs = [attention_head(input) for attention_head in self.attention_heads]# 合并多个头的输出output = torch.cat(outputs, dim=-1)return output# 在GPU上进行多头注意力计算
multihead_attention_gpu = MultiHeadAttention(num_heads=8, hidden_size=256).to('cuda')
output_gpu = multihead_attention_gpu(input_gpu)
在上述示例中,每个注意力头的计算可以独立地在GPU上进行,最后再通过GPU处理器的并行计算能力将它们合并。
CUDA流的优化
GPU通过CUDA流式处理的机制实现了高效的计算,这在Transformer模型的训练中尤为重要。例如,当进行反向传播时,GPU能够异步执行计算任务,从而实现数据的流水线处理,极大地提升了大模型的整体训练效率。
# 伪代码示例:反向传播过程中的CUDA流处理
loss.backward()
optimizer.step()# 在GPU上异步执行计算任务
torch.cuda.synchronize()
上述代码中,反向传播和优化步骤进行了异步执行,通过torch.cuda.synchronize()等待计算完成,确保了计算的正确性。
GPU在Transformer 大模型中的协同计算处理任务中功不可没,其在架构和功能设计中体现出的强大的并行计算、流式处理和多头注意力的优势,堪称黑魔法,为AI 大模型的深度学习任务提供了强大的堪称黑魔法般的加持。
通过以上的例子来理解 GPU 在 Transformer 模型中的运行和处理机制,我们能够更加深入地体会深度学习和大语言模型这一魔法舞台的精彩。
正是在GPU的协同处理的魔法加持下,Transformer模型才得以在自然语言处理等领域创造出一系列令人瞩目的成果,极大地推进了诸如ChatGPT、Claude、Gemini、LLama、Vicuna 等杰出的生成式 AI 大模型的研究进展和部署应用。
相关文章:
AI大语言模型学习笔记之三:协同深度学习的黑魔法 - GPU与Transformer模型
Transformer模型的崛起标志着人类在自然语言处理(NLP)和其他序列建模任务中取得了显著的突破性进展,而这一成就离不开GPU(图形处理单元)在深度学习中的高效率协同计算和处理。 Transformer模型是由Vaswani等人在2017年…...
c++阶梯之auto关键字与范围for
auto关键字(c11) 1. auto关键字的诞生背景 随着程序的逐渐复杂,程序代码中用到的类型也越来越复杂。譬如: 类型难以拼写;含义不明确容易出错。 比如下面一段代码: #include <string> #include &…...

第八篇:node模版引擎Handlebars及他的高级用法(动态参数)
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 📘 引言: …...

css3 属性 backface-visibility 的实践应用
backface-visibility 是一个用于控制元素在面对屏幕不同方向时的可见性的CSS3特性。它有两个可能的值: visible:当元素不面向屏幕(即背面朝向用户)时,元素的内容是可以被看到的。hidden:当元素不面向屏幕…...

嵌入式学习第十七天
C语言小项目: 制作俄罗斯方块小游戏(全部) 主函数部分 #include <stdio.h> #include <unistd.h> #include <string.h> #include <signal.h> #include <stdlib.h> #include <time.h> #include "b…...
使用Python的Turtle模块简单绘制烟花效果
import turtle import random# 初始化屏幕 screen turtle.Screen() screen.bgcolor("black") screen.title("烟花模拟")# 创建一个Turtle来绘制烟花 firework turtle.Turtle() firework.hideturtle() firework.speed(0) # 设置绘图速度为最快# 绘制烟花…...

数学建模-退火算法和遗传算法
退火算法和遗传算法 一.退火算法 退火算法Matlab程序如下: [W]xlsread(D:100个目标经度纬度);>> x[W(:,1)];>> y[W(:,2)];>> w[x y];;d1[70, 40];>> w[d1;w;d1]ww*pi/180;%角度化成弧度dzeros(102);%距离矩阵初始化for i1:101…...

Qt开源版 vs 商业版 详细比较!!!!
简单整理Qt开源版与商业版有哪些差别,仅供参考。 简单对比 开源版商业版许可证大部分采用对商业使用不友好的LGPLv3具备商业许可证保护代码专有许可证相关大部分模块使用LGPLv3和部分模块使用GPL组成仅第三方开源组件使用Qt的其他许可证Qt模块功能支持支持技术支持…...

华为云CodeArts Snap荣获信通院优秀大模型案例及两项荣誉证书
2024年1月25日,中国人工智能产业发展联盟智能化软件工程工作组(AI for Software Engineering,下文简称AI4SE)在京召开首届“AI4SE创新巡航”活动。在活动上,华为云大模型辅助系统测试代码生成荣获“2023AI4SE银弹优秀案…...
)
小程序的应用、页面、组件生命周期(超全版)
小程序生命周期 应用的生命周期 onLaunch: 初始化小程序完成时触发,且全局只触发一次; onShow: 小程序初始化完成(启动)或从后台切换到前台显示时触发; onHide: 小程序从前台切换到后台隐藏时触发(如切换…...
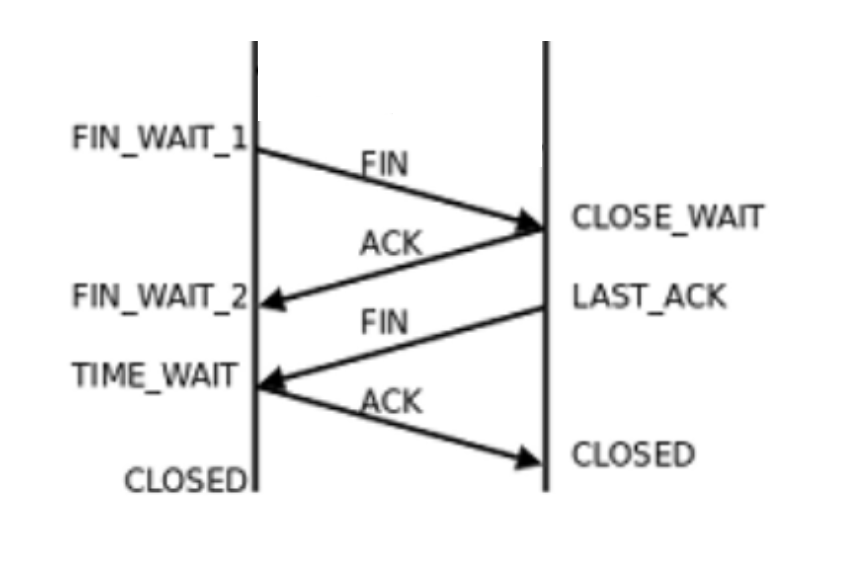
TCP四次握手
TCP 协议在关闭连接时,需要进行四次挥手的过程,主要是为了确保客户端和服务器都能正确地关闭连接。 # 执行流程 四次挥手的具体流程如下: 客户端发送 FIN 包:客户端发送一个 FIN 包,其中 FIN 标识位为 1,…...
EBC金融英国CEO:高波动性周期下,如何寻找市场的稳定性?
利率主导的市场,将在2024年延续。目前,固收市场对于降息的定价,正通过利率传导至不同资产中。尽管市场迫切利用通胀去佐证降息,但各国央行仍囿于通胀目标的政策桎梏。政策和市场预期的博弈将继续牵动市场脉搏,引发价格…...
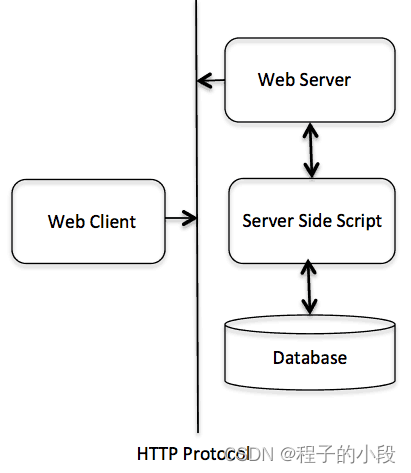
C++ Web 编程
什么是 CGI? 公共网关接口(CGI),是一套标准,定义了信息是如何在 Web 服务器和客户端脚本之间进行交换的。CGI 规范目前是由 NCSA 维护的,NCSA 定义 CGI 如下:公共网关接口(CGI&…...
docker笔记整理
Docker 安装 添加yum源 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 安装docker yum -y install docker-ce docker-ce-cli containerd.io docker-compose-plugin 启动docker systemctl start docker 查看docker状态 s…...

什么是git,怎样下载安装?
简介: 应用场景: 应用场景:团队企业开发 作用: 安装: 1.网址:Git - Downloads 很卡很慢 2.可以选择镜像网站下载(推荐) CNPM Binaries Mirror...

Camille-学习笔记-测试流程和测试设计
## 测试用例学习路线 startmindmap * 测试用例 ** 黑盒测试方法论 *** 等价类 *** 边界值 *** 因果图 *** 判定表 *** 场景法 *** 基于模型的测试 ** 白盒测试方法论 ** 测试用例基础概念 ** 测试用例设计 ** 面试测试用例设计 ** 常用测试策略与测试手段 endmindmap **测试用…...
【Python笔记-设计模式】建造者模式
一、说明 又称生成器,是一种创建型设计模式,使其能够分步骤创建复杂对象。允许使用相同的创建代码生成不同类型和形式的对象。 (一) 解决问题 对象的创建问题:当一个对象的构建过程复杂,且部分构建过程相互独立时,可…...
【LVGL源码移植】
LVGL源码移植 ■ LVGL源码移植一:下载LVGL源码二:修改LVGL文件夹1: 将这5个文件,复制到一个新的文件夹2: 简化文件,减少内存消耗(去除不必要的文件)3: 为了规范化,我们将下列文件进行重命名 三&…...

双非本科准备秋招(14.2)—— 进程与线程
进程 进程是运行着的程序,是程序在操作系统的一次执行过程,进程是操作系统分配资源的基本单位。 启动一个java程序,操作系统就会创建一个java进程 进程也可以看作一个程序的实例,大部分程序可以运行多个实例进程,比如记…...
数据结构和算法笔记5:堆和优先队列
今天来讲一下堆,在网上看到一个很好的文章,不过它实现堆是用Golang写的,我这里打算用C实现一下: Golang: Heap data structure 1. 基本概念 满二叉树(二叉树每层节点都是满的): 完全二叉树&a…...

SK海力士:从行业寒冬到AI风口逆袭,多重风险下能否穿越下一轮行业变局?
SK海力士:从行业寒冬到AI风口的逆袭与隐忧,能否穿越下一轮行业变局?2025年至今,全球资本市场最魔幻的黑马行业,当属存储芯片。在其中,全球第二大存储巨头SK海力士,是最大受益者之一。2025年&…...
)
AI接口语义漂移预警机制:奇点大会强制要求的3项Schema自治协议(含OpenAPI 3.1.2扩展草案)
更多请点击: https://intelliparadigm.com 第一章:AI原生API设计规范:2026奇点智能技术大会接口设计最佳实践 AI原生API不再是对传统RESTful接口的简单增强,而是以模型能力为中心、语义驱动、具备自解释与自适应特性的新型接口范…...

Windows与Office一键激活终极指南:KMS_VL_ALL_AIO智能脚本完整教程
Windows与Office一键激活终极指南:KMS_VL_ALL_AIO智能脚本完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活和Office办公软件激活而烦恼吗?…...

NS-USBLoader完整指南:Switch文件传输、RCM注入和文件管理的终极解决方案
NS-USBLoader完整指南:Switch文件传输、RCM注入和文件管理的终极解决方案 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: https://gi…...

ABAQUS多孔介质渗流分析保姆级教程:从渗透系数设置到Soil分析步详解
ABAQUS多孔介质渗流分析实战指南:从零搭建渗流模型 第一次打开ABAQUS进行多孔介质分析时,面对密密麻麻的参数选项,大多数工程师都会感到无从下手。渗流分析作为岩土工程、生物力学等领域的基础仿真需求,其核心难点不在于理论复杂度…...

从思维链到思维图:大语言模型推理范式的跃迁与实践
1. 项目概述:从“思维链”到“思维图”的范式跃迁如果你最近在关注大语言模型(LLM)的应用前沿,特别是如何让它们更可靠、更聪明地解决复杂问题,那么“思维链”(Chain-of-Thought, CoT)这个概念你…...

SingleFile:一键保存完整网页,打造永不丢失的数字图书馆
SingleFile:一键保存完整网页,打造永不丢失的数字图书馆 【免费下载链接】SingleFile Web Extension for saving a faithful copy of a complete web page in a single HTML file 项目地址: https://gitcode.com/gh_mirrors/si/SingleFile 你是否…...

FreeRTOS项目踩坑实录:我的低功耗设计是如何被‘空闲任务’和‘Tickless模式’拯救的
FreeRTOS低功耗实战:从STOP模式异常到Tickless模式优化 记得第一次在STM32上尝试FreeRTOS低功耗设计时,我信心满满地启用了STOP模式,结果设备唤醒后直接卡死。屏幕上的日志仿佛在嘲笑我的无知——原来RTOS的低功耗远不是简单调用HAL_PWR_Ente…...

为AI Agent构建文件交付通道:OpenClaw File Links Tool部署与集成指南
1. 项目概述:为AI Agent构建专属文件交付通道如果你正在开发或使用AI Agent,比如AutoGPT、Claude Desktop的MCP工具,或者任何需要执行文件操作(如数据分析、文档生成、网页抓取)的自动化程序,那么一个核心痛…...

LibreDWG:解放AutoCAD文件的瑞士军刀,3个实用场景教你玩转开源CAD处理
LibreDWG:解放AutoCAD文件的瑞士军刀,3个实用场景教你玩转开源CAD处理 【免费下载链接】libredwg Official mirror of libredwg. With CI hooks and nightly releases. PRs ok 项目地址: https://gitcode.com/gh_mirrors/li/libredwg 还在为无法打…...