单向非循环链表
1、顺序表遗留问题
1. 中间/头部的插入删除,时间复杂度为O(N)
2. 增容需要申请新空间,使用malloc、realloc等函数拷贝数据,释放旧空间。会有不小的消耗。
3. 当我们以2倍速度增容时,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,若下次只是插入5个数据,就会浪费95个数据大小的空间。
为了改进、弥补顺序表的缺点,我们发明了链表。
2、什么是链表
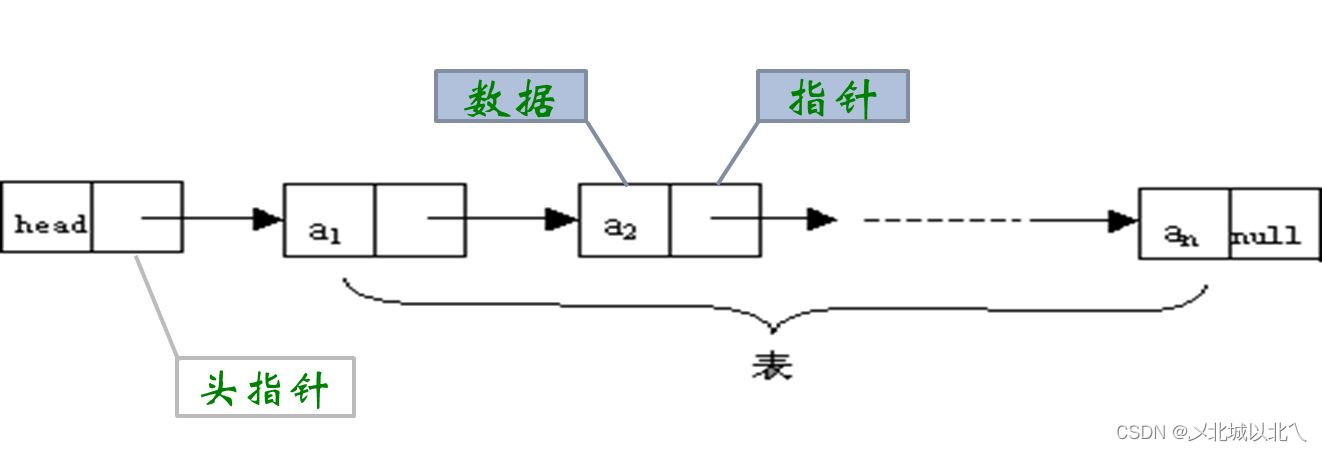
概念:物理顺序:链表是一种物理存储结构上非连续、非顺序的存储结构。
逻辑顺序:是通过链表中的指针链接次序实现的。


 3、接口函数以及结点的定义
3、接口函数以及结点的定义
typedef int SLTDataType;typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SListNode;//单链表打印
void SLTPrint(SListNode* phead);
//尾插
void SLTPushBack(SListNode** pphead,SLTDataType x);
//创建一个新结点的函数,并将新结点的数据初始化为x
SListNode* BuySLTNode(SLTDataType x);
//尾删
void SLTPopBack(SListNode** pphead);
//头插
void SLTPushFront(SListNode** pphead, SLTDataType x);
//头删
void SLTPopFront(SListNode** pphead);// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDataType x);// 单链表在pos位置之后插入x
void SListInsertAfter(SListNode* pos, SLTDataType x);// 单链表删除pos位置之后的值
void SListEraseAfter(SListNode* pos);//单链表在pos前面插入
void SListInsertBefore(SListNode** pphead, SListNode* pos, SLTDataType x);//单链表在删除在pos位置的值
void SListErasepos(SListNode** pphead, SListNode* pos);// 单链表的销毁
void SListDestroy(SListNode* plist);为了方便,我们将链表的数据类型定义为int,同时定义一个struct ListNode*类型的指针next,用来指向下一个结点。
由于链表不需要事前申请一块连续的空间,因此不需要初始化,只需定义一个SlistNode*类型的指针phead,作为链表的头指针,指向这个链表。
4、链表的打印
//单链表打印
void SLTPrint(SListNode* phead)
{SListNode* cur = phead;while (cur){printf("%d->", cur->data);cur = cur->next;}printf("NULL\n");}创建一个cur指针变量指向头结点,然后用cur=cur->next来遍历,打印完data后再到下一个,直到打印完最后一个data,cur指向最后结点的next(指向NULL)。为了便于前期理解,最后打印一个NULL。下文插入操作后,演示打印效果。
5、创建(Buy)一个新结点
//创建一个新结点的函数,并将新结点的数据初始化为x
SListNode* BuySLTNode(SLTDataType x)
{//建立一个新的结点,并将data初始化,next置为NULLSListNode* newnode = (SListNode*)malloc(sizeof(SListNode));if (NULL == newnode){perror("malloc fail");return NULL;}newnode->data = x;newnode->next = NULL;return newnode;
}先用malloc申请一个结点大小的空间,并将其交给一个newnode指针,确认申请成功后,对newnodd进行初始化,data=x,next置为NULL,(因为不知道要指向哪里,只是申请一个新结点,next指向的问题交给调用此函数的人来完成)。
然后将newnode返回,使用的人用某个结点的next指向它,就可以链接一个新结点。
6、尾插
//尾插
void SLTPushBack(SListNode** pphead,SLTDataType x)
{SListNode* tmp = BuySLTNode(x);if (NULL == tmp){return;}SListNode* newnode = tmp;//分情况,原来是否为空链表if (*pphead == NULL)//为空链表{*pphead = newnode;//建立phead与新结点的联系}else{//先找到原来的尾结点,然后建立其与新结点的联系SListNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}//找到原来的尾结点后tail->next = newnode;}}链表是为了改进顺序表中头插和中间插入效率而产生的,与顺序表是互补关系,顺序表尾插时直接插入即可,消耗很小。但链表尾插时,需要先进行找尾操作,然后再尾插新数据。
注意:第一个参数是SListNode** pphead,用来接收头指针的地址,这是一次传址调用,可以改变phead本身的内容,由于phead是头指针,改变的就是头指针指向的内容。
第一次尾插时,phead指向NULL,利用*pphead使其指向新的第一个结点。
如果用一个SListNode* plist来接收,只是phead的形参,即一份临时拷贝,用plist接收newnode,只是在尾插函数内部起作用,而对外部的phead无影响,结果变成尾插一大顿,phead仍然指向NULL。
若phead不为NULL,则创建一个tail指针进行找尾操作。找尾过程中,tail->next为NULL,则此时tail指向尾结点,将newnode赋给tail->next即完成尾插。
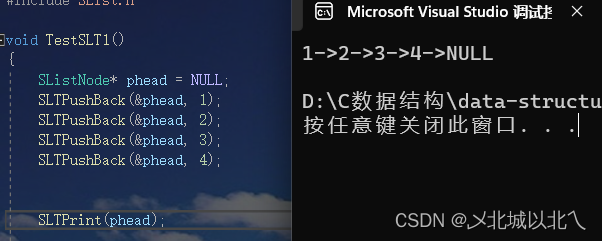
上图为尾插1234后的结果。
还有一点要注意:assert的使用,不能见到指针就用assert,有时传入的数据就是一个NULL,比如插入第一个元素时phead就是NULL,如果使用assert(phead),就会报错导致无法插入。
而对于pphead即phead的地址,是一定不为NULL,就可以进行assert(pphead)的操作。
注意*pphead与pphead的区别
7、尾删
//尾删
void SLTPopBack(SListNode** pphead)
{assert(pphead);//先检查pphead,再检查*pphead,若pphead为NULL,*pphead就会产生错误assert(*pphead);//若原来为空链表,则无法删除SListNode* cur = *pphead;//分情况,原来链表中有一个 还是 多个元素if (NULL == cur->next){free(cur);cur = NULL;*pphead = NULL;}else// 多个元素先找到倒数第二个{SListNode* pretail = *pphead;while (pretail->next->next != NULL){pretail = pretail->next;}free(pretail->next);pretail->next = NULL;}}先用assert确保phead不为NULL,即确保删除的不是空链表。
如果链表只有一个元素,free后,将phead置为NULL,使其成为空链表
当链表中有多个元素时,需要先找到尾结点的前一个元素pretail,方法是遍历,直到pretail->next->next为NULL,这里通过两个next,可以找到尾结点的那个next中的NULL,因此多个元素时使用这种方法,若只有一个元素则next的next会对NULL->,产生对于野指针解引用的错误。
总结:链表进行尾插尾删操作时,要先进行找尾,此过程需要遍历,效率较低,因此进行尾部操作时不如顺序表。
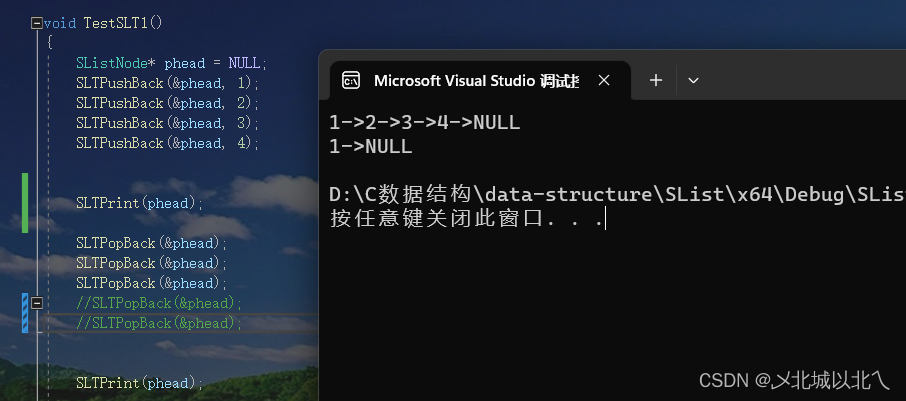
删除空链表时会报错。
8、头插
//头插
void SLTPushFront(SListNode** pphead, SLTDataType x)
{//先创造一个新结点SListNode* tmp = BuySLTNode(x);if (NULL == tmp){return;}SListNode* newnode = tmp;//分情况讨论,原来链表是否为空//if (NULL == *pphead)//{// //如果为空,直接将phead与新结点连接即可// *pphead = newnode;//}//else//{// //不为空,建立新结点与原来头结点的联系// //将phead与原来头结点的联系变为与新结点的联系// //原来A->B,现在A->C->B,先建立C->B,再建立A->C// newnode->next = *pphead;// *pphead = newnode;//}//是否为空都按不为空处理,next要么存原来头结点地址,要么为 NULLnewnode->next = *pphead;*pphead = newnode;
}链表的头插很简单,先buy一个新结点,然后将newnode->next指向原来的头结点,无论原来是否为NULL,再用phead指向这个新结点。
9、头删
//头删
void SLTPopFront(SListNode** pphead)
{assert(*pphead);SListNode* first = *pphead;*pphead = (*pphead)->next;free(first);first = NULL;
}
创建first指针指向头结点,然后将phead指向下一个结点,不论是否为NULL,然后free掉first。

10、查找
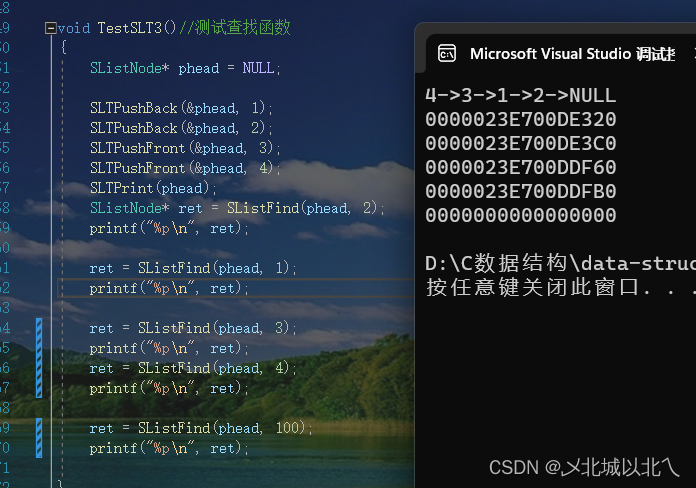
// 单链表查找
SListNode* SListFind(SListNode* phead, SLTDataType x)
{SListNode* cur = phead;while (NULL != cur){if (cur->data == x){return cur;}cur = cur->next;}return NULL;}利用cur遍历链表,如果找到x就返回cur,即存有x的结点的地址,没找到就继续遍历,cur==NULL时仍然未找到,则返回NULL。
11、指定位置pos后方插入数据
// 单链表在指定位置后方插入 不用遍历
void SListInsertAfter(SListNode* pos,SLTDataType x)
{assert(pos);SListNode* newnode = BuySLTNode(x);if (NULL == newnode){perror("ButSLTNode fail");return;}newnode->next = pos->next;pos->next = newnode;}将newnode->next连接pos的next,不论正负,然后将newnode赋给pos的next,此过程中不需要遍历,解决了顺序表在中间位置插入效率低的问题。
12、删除指定位置pos后方的数据
// 删除后面的 不用遍历
void SListEraseAfter(SListNode* pos)
{assert(pos);assert(pos->next != NULL);SListNode* del = pos->next;pos->next = del->next;free(del);del = NULL;//del为形参,是否置空影响不大,到函数外自动销毁,一般由使用者进行置空}必须保证pos->next不为NULL,因为是删除pos位置的下一个元素,则至少有2个元素,若只有一个,next为NULL,再解引用会变为野指针。
用del保存要删除的位置,将pos的next与要删除元素的下一个元素连接,不论是否为NULL,然后free掉del,完成删除,也不需要遍历。
总结:链表的优点在于头部以及中间位置的插入和删除不需要遍历,这里中间位置,实际是pos的下一个元素。
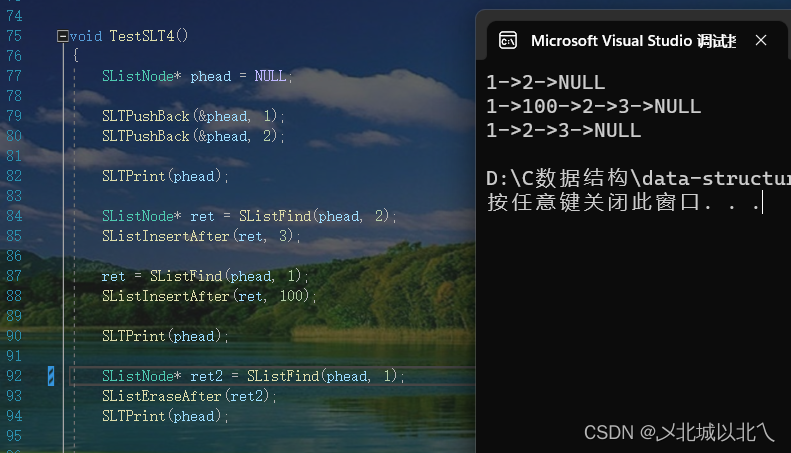
任意位置后方进行插入/删除,不涉及phead的改变,因此只需要传入phead即可。
13、在指定位置pos的前方插入元素
在前方插入删除涉及phead,因此传入&phead
//单链表指定位置之前插入元素,需要找prev
void SListInsertBefore(SListNode** pphead,SListNode* pos,SLTDataType x)
{assert(*pphead);//不能为空,否则Find找不到posassert(pos);SListNode* newnode = BuySLTNode(x);SListNode* prev = *pphead;if (pos == *pphead){newnode->next = pos;*pphead = newnode;}else//找到pos前一个位置{SListNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}newnode->next = pos;prev->next = newnode;}}若链表中只有一个元素,则会改变phead的指向,这里调用头插SLTPushFront也可以。
>=2个元素时,先找到prev,然后插入。
需要进行遍历找到prev。
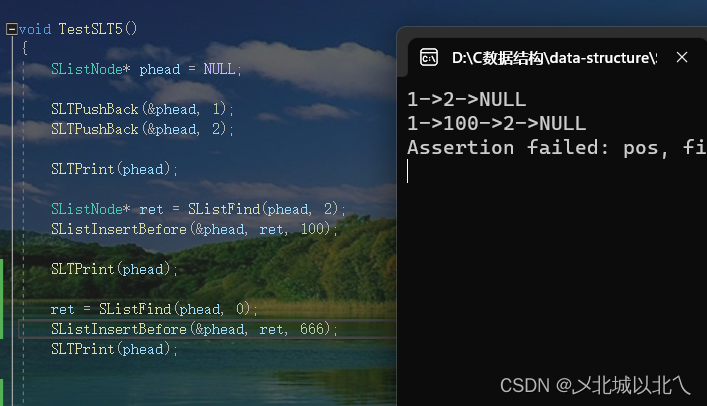
如果要找的位置pos是NULL,直接报错即可,是使用该函数的人的问题,函数只要完成应该完成的任务即可。
注意:假设传入的是plist,而不是它的地址,仍然用pphead接收,后续*pphead就会发生错误。因此可assert(pphead)。pphead实际上一定不为空,因此只要传入plist地址就要assert
14、删除指定位置pos的数据
//在指定位置pos的删除
void SListErasepos(SListNode** pphead, SListNode* pos)
{assert(pphead);assert(*pphead);assert(pos);SListNode* cur = *pphead;if (cur == pos){*pphead = pos->next;free(cur);cur = NULL;}else{SListNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);}} 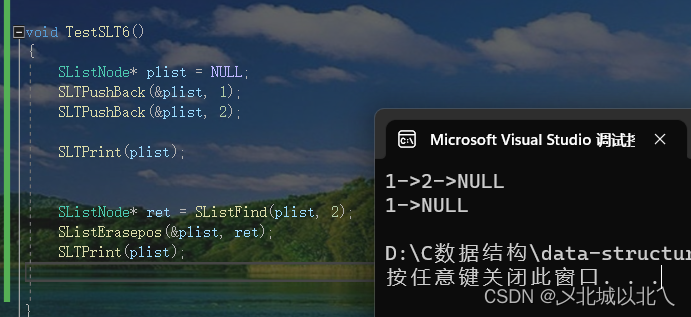
如果pos指向第一个结点,即为头删,也可以使用SLTPopFront头删函数
接收Find的ret在erase后可以置为NULL,在函数外部完成,内部为形参。在内部改变需要传pos的二级指针。
而对于pphead则只能传二级指针,在函数内部修改phead的指向。
销毁时,利用tmp指针变量销毁当前位置,然后next找到下一个位置,遍历销毁。
总结:尾插尾删头插头删都需要pphead,insertafter和eraseafter仅需要pos,查找和打印仅需要phead,insertbefore、erasepos需要pphead、pos。
pos phead pphead *pphead 的assert问题。
链表的优点缺点,某些位置是否需要遍历。
面试题:不告知phead,只知道pos,怎么在pos指向的数据之前插入数据?
例如原来为 1 2,pos指向2,可以在2的位置后插入3,然后将2、3两个data交换,结果为132,当然,此时pos指向的是3。
如果是删除不给phead删除pos当前位置,则将pos位置的值改为下一个位置的值,然后删除掉下一个位置的数据。(不能删除尾结点)
相关文章:
单向非循环链表
1、顺序表遗留问题 1. 中间/头部的插入删除,时间复杂度为O(N) 2. 增容需要申请新空间,使用malloc、realloc等函数拷贝数据,释放旧空间。会有不小的消耗。 3. 当我们以2倍速度增容时,势必会有一定的空间浪费。例如当前容量为100&a…...

Vue2的基本内容(一)
目录 一、插值语法 二、数据绑定 1.单向数据绑定 2.双向数据绑定 三、事件处理 1.绑定监听 2.事件修饰符 四、计算属性computed和监视属性watch 1.计算属性-computed 2.监视属性-watch (1)通过 watch 监听 msg 数据的变化 (2&a…...

蚁群算法优化最优值
%%%%%%%%%%%%%%蚁群算法求函数极值%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%初始化%%%%%%%%%%%%%%%%%%%%% clear all; %清除所有变量 close all; %清图 clc; %清屏 m 20; %蚂蚁个数 G 500; %最大迭代次数 Rho 0.9; %信息素蒸发系数 P0 0.2; %转移概率常数 XMAX 5; %搜索变量 x…...

Docker镜像的内部机制
Docker镜像的内部机制 镜像就是一个打包文件,里面包含了应用程序还有它运行所依赖的环境,例如文件系统、环境变量、配置参数等等。 环境变量、配置参数这些东西还是比较简单的,随便用一个 manifest 清单就可以管理,真正麻烦的是文…...
每日的时间安排规划
14:23 2023年3月4日星期六 开始 现在我要做一套试卷。模拟6级考试。 现在是: 16:22 2023年3月4日星期六。 做完了线上的试卷! 发现我真的是不太聪明的样子! 明明买的有历年真题,做真题就行了,还要做它们出的模拟的…...
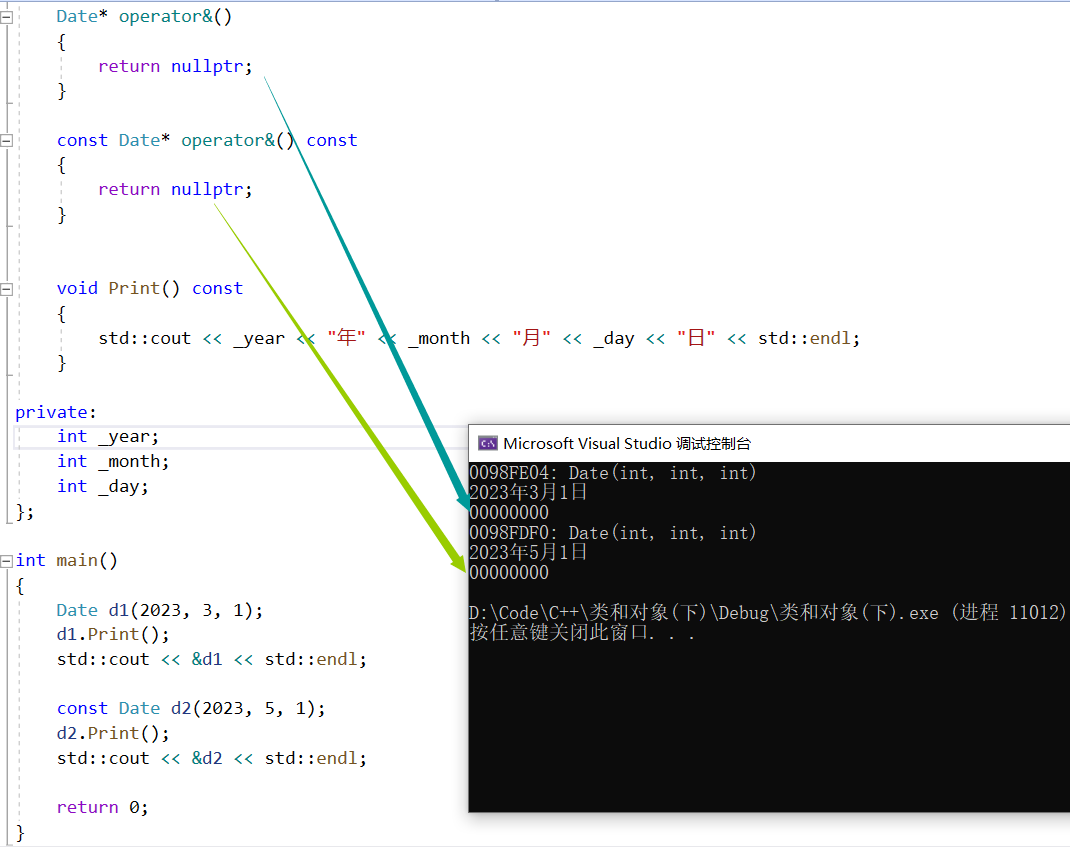
【C++】类和对象——六大默认成员函数
🏖️作者:malloc不出对象 ⛺专栏:C的学习之路 👦个人简介:一名双非本科院校大二在读的科班编程菜鸟,努力编程只为赶上各位大佬的步伐🙈🙈 目录前言一、类的6个默认成员函数二、构造…...

远程debug被arthas watch了的idea
开发工具idea端(2021.2.1) 远程调试 被 应用了 修改的arthas端 的 鸡idea端(2022.3.2) A. 鸡idea端 鸡idea: “D:\IntelliJ IDEA 2022.3.2\bin\idea64.exe” 中安装有目标插件 比如 RedisNew-2022.07.24.zip 对文件 “D:\IntelliJ IDEA 2022.3.2\bin\idea64.exe.vmoptions” 新…...
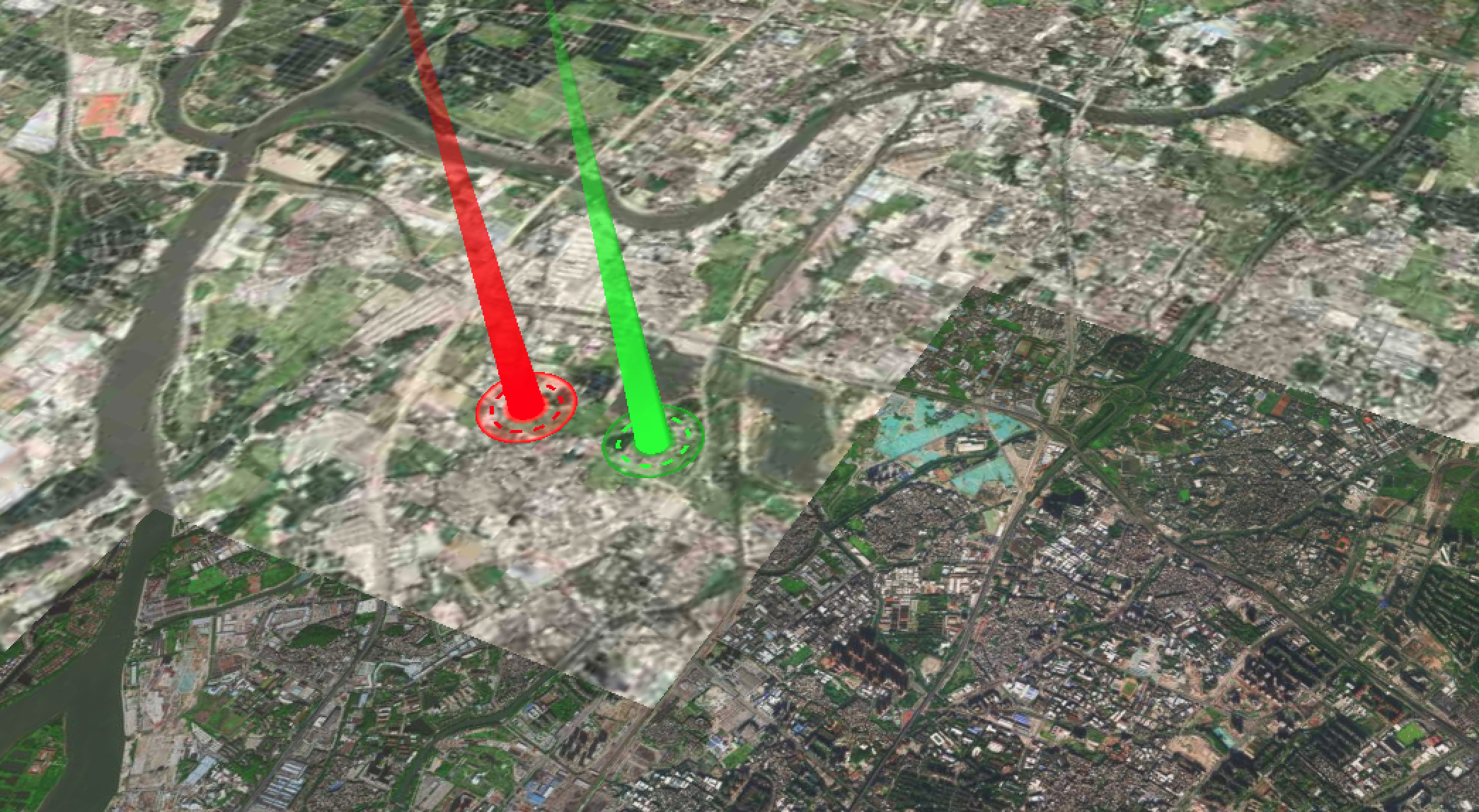
Cesium实现的光柱效果
Cesium实现的光柱效果 效果展示: 可以通过拼接两个entity来实现这个效果: 全部代码; index.html <!DOCTYPE html> <html><head><meta charset...
和splice())
你最爱记混的slice()和splice()
slice()方法:选取数组的一部分,并返回一个新数组 该方法不会改变原始数组,而是将截取到的元素封装到一个新数组中返回 语法:array.slice(start,end),参数的介绍如下: 语法:array.slice(start,end),参数的介绍如下: 1.start:截取开始的位置的索引,包含开始索引 2.…...

【LeetCode】剑指 Offer(15)
目录 题目:剑指 Offer 32 - II. 从上到下打印二叉树 II - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 32 - III. 从上到下打…...

【刷题笔记】之二分查找(搜索插入位置。在排序数组中查找元素的第一个和最后一个位置、x的平方根、有效的完全平方数)
1. 二分查找题目链接 704. 二分查找 - 力扣(LeetCode)给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -…...
)
一起Talk Android吧(第五百一十五回:绘制向外扩散的水波纹)
文章目录整体思路实现方法示例代码各位看官们大家好,上一回中咱们说的例子是"Java中的进制转换",这一回中咱们说的例子是"绘制向外扩散的水波纹"。闲话休提,言归正转, 让我们一起Talk Android吧! 整体思路 …...

基于粒子群改进的支持向量机SVM的情感分类识别,pso-svm情感分类识别
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 SVM应用实例,基于SVM的情感分类预测 代码 结果分析 展望 支持向量机SVM的详细原理 SVM的定义 支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型…...
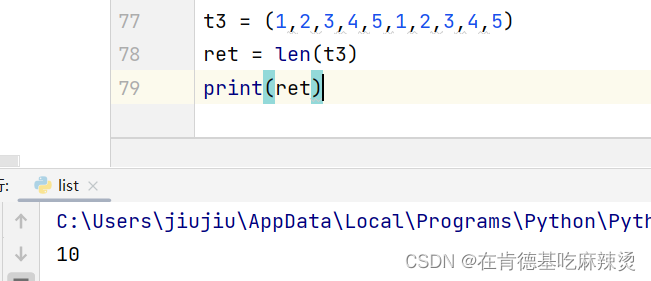
【python中的列表和元组】
文章目录前言一、列表及其使用1.列表的特点2. 列表的使用方法二、元组及其特点1.元组的类型是tuple1.元组的查找操作2. 计算元组某个元素出现的次数3.统计元组内元素的个数总结前言 本文着重介绍python中的列表和元组以及列表和元组之间的区别 一、列表及其使用 1.列表的特点…...

世界顶级五大女程序媛,不仅技术强还都是美女
文章目录1.计算机程序创始人:勒芙蕾丝伯爵夫人2.首位获得图灵奖的女性:法兰艾伦3.谷歌经典首页守护神:玛丽莎梅耶尔4.COBOL之母:葛丽丝穆雷霍普5.史上最强游戏程序媛-余国荔说起程序员的话,人们想到的都会是哪些理工科…...
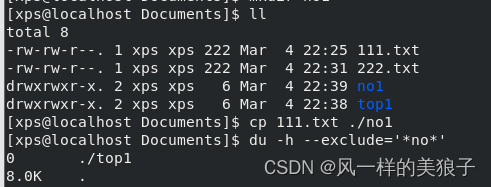
Linux- 系统随你玩之--文件管理-双生姐妹花
文章目录1、前言2、文件管理-双生姐妹花2.1、 df2.1.1、 df 语法2.1.1 、常用参数2.2、 du2.2.1、du 语法2.1.1、 常用参数2.3、双生姐妹花区别2.3.1、 查看文件统计 的计算方式不同2.3.2 、删除文件情况下统计结果 不同2.3.3 、针对双生姐妹花区别 结语3、双生姐妹花实操3.1 、…...
18、多维图形绘制
目录 一、三维图形绘制 (一)曲线图绘制plot3() (二)网格图绘制 mesh() (三)曲面图绘制 surf() (四)光照模型 surfl() (五)等值线图(等高线图)绘制 cont…...
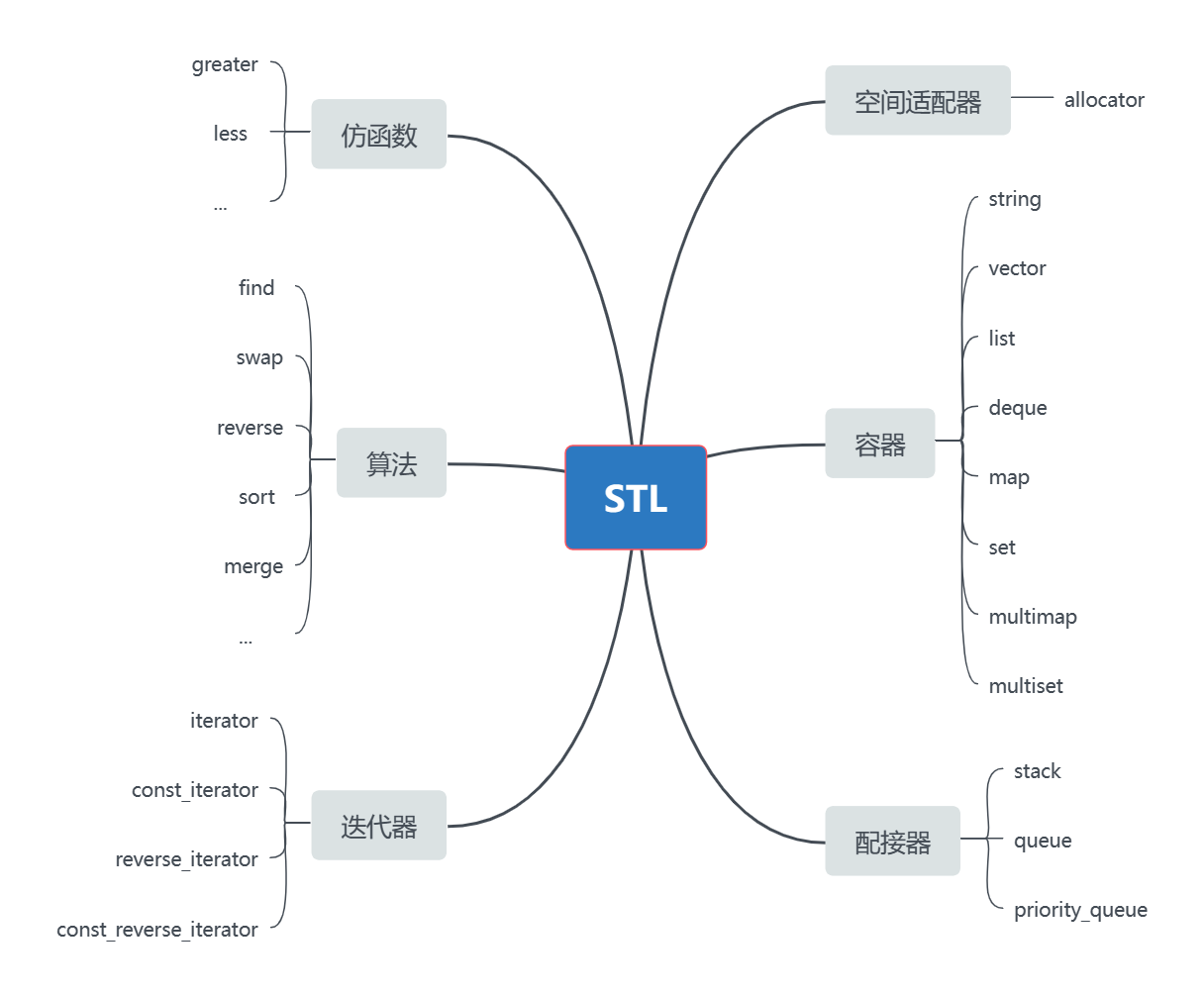
【C++】30h速成C++从入门到精通(STL介绍、string类)
STL简介什么是STLSTL(standard template libaray-标准模板库):是C标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。STL的版本原始版本Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本&…...

PMP是什么意思?适合哪些人学呢?
PMP简而言之,就是提高项目管理理论基础和实践能力的考试。 官方一点的说明呢,就是:PMP证书全称为Project Management Professional,也叫项目管理专业人士资格认证。 PMP证书由美国项目管理协会(PMI)发起,是严格评估项…...

【SpringBoot 事务不回滚?怎么解决?】
SpringBoot 事务不回滚可能有多种原因,下面列举一些常见的原因和对应的解决方法: 异常被捕获处理了 如果方法中抛出了异常,但是在方法中被捕获并处理了,那么事务不会回滚。解决方法是让异常继续抛出,或者使用 Transa…...

异质图对比学习在推荐系统中的实践:从理论到应用
1. 异质图对比学习:推荐系统的新引擎 第一次听说"异质图对比学习"这个词时,我正被公司推荐系统的冷启动问题折磨得焦头烂额。传统协同过滤在新用户面前就像个盲人,而基于内容的推荐又总是陷入"推荐相似商品"的怪圈。直到…...
TranslucentTB:重塑Windows任务栏视觉体验的轻量化方案
TranslucentTB:重塑Windows任务栏视觉体验的轻量化方案 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否曾遇到这样的困…...

5分钟快速上手:Awoo Installer - 你的Switch游戏安装神器
5分钟快速上手:Awoo Installer - 你的Switch游戏安装神器 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装而烦恼吗…...
)
别再到处找瓦片服务地址了!手把手教你用OpenLayers 7.x集成天地图和高德地图(附完整代码)
OpenLayers 7.x实战:深度解析天地图与高德地图集成方案 第一次接触地图开发时,最让我头疼的不是写代码,而是找不到正确的瓦片服务地址。那些看似简单的URL背后,藏着各种参数玄机——为什么别人的地图能正常显示中文标注࿱…...

终极指南:如何快速提升QuaggaJS在低分辨率图像下的条形码识别能力
终极指南:如何快速提升QuaggaJS在低分辨率图像下的条形码识别能力 【免费下载链接】quaggaJS An advanced barcode-scanner written in JavaScript 项目地址: https://gitcode.com/gh_mirrors/qu/quaggaJS QuaggaJS是一款强大的JavaScript条形码扫描库&#…...

如何永久保存微信聊天记录:WeChatMsg终极指南与数据守护方案
如何永久保存微信聊天记录:WeChatMsg终极指南与数据守护方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

3步重塑邮件体验:Markdown Here如何让技术沟通更优雅
3步重塑邮件体验:Markdown Here如何让技术沟通更优雅 【免费下载链接】markdown-here Google Chrome, Firefox, and Thunderbird extension that lets you write email in Markdown and render it before sending. 项目地址: https://gitcode.com/gh_mirrors/ma/m…...

MT5 Zero-Shot实战案例:跨境电商多语言商品描述中文初稿生成与改写优化
MT5 Zero-Shot实战案例:跨境电商多语言商品描述中文初稿生成与改写优化 1. 项目概述与核心价值 在跨境电商运营中,商品描述的多语言版本制作是一个耗时耗力的过程。传统方法需要先撰写中文初稿,然后逐条翻译成各种语言,不仅效率…...

编写程序实现智能乐器音准检测偏差时,提示“需要调音”,新手也能调好音。
1. 实际应用场景描述场景:一名吉他初学者刚刚买回一把新吉他,或者在干燥天气后琴弦音准发生了偏移。他不知道电子调音表如何使用,也不具备绝对音感。本系统功能:用户拨动琴弦(例如第 6 弦 E2),电…...

Phi-4-mini-reasoning应用场景:技术文档自动逻辑校验与漏洞推理辅助工具
Phi-4-mini-reasoning应用场景:技术文档自动逻辑校验与漏洞推理辅助工具 1. 模型概述 Phi-4-mini-reasoning是一款由微软开发的3.8B参数轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。该模型以"小参数、强推理、长上下文、低…...