oracle数据库慢查询SQL
目录
场景:
环境:
慢SQL查询一:
问题一:办件列表查询慢
分析:
解决方法:
问题二:系统性卡顿
分析:
解决方法:
慢SQL查询二
扩展:
场景:
线上环境出现办件列表查询非常慢大概要1分钟才刷出来,及很多功能都出现系统性卡顿。
环境:
oracle数据库,工作表历史表act_hi_proinst单表数据量一百多万
慢SQL查询一:
select *
from (select v.sql_id,
v.sql_text,
v.sql_fulltext,
v.FIRST_LOAD_TIME,
v.last_load_time,
v.elapsed_time,
v.cpu_time,
v.disk_reads,
v.EXECUTIONS,
v.LOADS,
v.cpu_time / v.executions / 1000 / 1000 ave_cpu_time,
v.ELAPSED_TIME / v.executions / 1000 / 1000 ave_time
from v$sql v) a
where a.last_LOAD_TIME > '2024-01-01/00:00:00' and ave_time > 5 and a.executions > 0 order by ave_time desc;
其中各字段含义如下:
v.sql_text: 包含SQL语句的文本内容
v.sql_fulltext: 包含完整的SQL语句文本内容
v.FIRST_LOAD_TIME: SQL语句第一次加载到共享池中的时间
v.last_load_time: SQL语句最后一次加载到共享池中的时间
v.elapsed_time: SQL语句的总执行时间(以微秒为单位)
v.cpu_time: SQL语句的总CPU执行时间(以微秒为单位)
v.disk_reads: SQL语句的总磁盘读取次数
v.EXECUTIONS: SQL语句的总执行次数
v.LOADS: SQL语句的总加载次数
ave_cpu_time: 每次执行的平均CPU执行时间(以秒为单位)
ave_time: 每次执行的平均总执行时间(以秒为单位)
问题一:办件列表查询慢
办件查询列表主要涉及到如下两个SQL语句
select * from (select a.*,rownum as num from (select RES.* ,H.NAME_ as bizName, H.XZQ_ as bizXzq, H.DUE_DATE_ as bizDueDate, H.PROC_DEF_KEY_ as bizProcDefKey, H.CATEGORY_ as bizCategory, H.DATUM_TYPE_ as bizDatumType, H.START_USER_ID_ as bizStartUserId, H.DEPT_CODE_ as bizDeptCode,H.F1_ as bizF1, H.F2_ as bizF2, H.F3_ as bizF3, H.F4_ as bizF4, H.F5_ as bizF5, H.F6_ as bizF6, H.F7_ as bizF7, H.F8_ as bizF8, H.F9_ as bizF9, H.F10_ as bizF10, H.F11_ as bizF11, H.F12_ as bizF12, H.F13_ as bizF13, H.F14_ as bizF14,H.F15_ as bizF15, H.F16_ as bizF16, H.F17_ as bizF17, H.F18_ as bizF18, H.F19_ as bizF19, H.F20_ as bizF20from gisqbpm.ACT_HI_PROCINST RESleft join gisqbpm.ACT_HI_BIZ_PROCINST H on H.PROC_INST_ID_ = RES.PROC_INST_ID_)a where rownum<15 )b where b.num>0线上测试1.58秒
select count(RES.ID_) from gisqbpm.ACT_HI_PROCINST RES, gisqbpm.ACT_HI_BIZ_PROCINST H where H.PROC_INST_ID_ = RES.PROC_INST_ID_; 但是分页查询总数的sql语句执行五次,5.932s,3.78s,2.89s, 2.5s,1.9s
分析:
原因是前端刚打开办件查询列表时,由于查询总数的sql语句,没有任何过滤条件导致两种表只有关联查询并没有过滤故全表扫描耗时较长。
解决方法:
由于两张关联表中数据是一对一的,因此如果仅仅考虑第一次查询慢的问题,直接可以去掉关联,单表查询的总数就可以了。
但是事与愿违,这只能解决办件查询第一进入的问题,如果有条件参数过滤的话(关联表的参数)还要加上这个关联表,后端改动有点大。
因此建议线上前端处理办件查询第一次进入时带上时间范围。
问题二:系统性卡顿
描述也不算是系统系卡顿吧,有写接口还是比较快的,只能说有很多重要的操作反应都很慢,下面是获取的当天的慢SQL。

这里挑选了几个耗时较长的简单的分析(这里面的sql是另外一个部门的)
DECLARE job BINARY_INTEGER := :job; next_date DATE := :mydate; broken BOOLEAN := FALSE;
BEGIN pro_inert_rybjlcx_sed; :mydate := next_date; IF broken THEN :b := 1; ELSE :b := 0; END IF; END;
1.该SQL执行(Execution)一次 ,加载(LOADS)一次 平均耗时将近一个小时。执行 pro_inert_rybjlcx_sed慢
SELECT COUNT(0) FROM (SELECT * FROM (select * from v_fwdyaq where 1=1) WHERE 1=1 )
2..该SQL执行(Execution)11次 ,加载(LOADS)216次 平均每次执行耗时接近半个小时。需要对该语句重点优化
DECLARE job BINARY_INTEGER := :job; next_date DATE := :mydate; broken BOOLEAN := FALSE;
BEGIN sms_ts; :mydate := next_date; IF broken THEN :b := 1; ELSE :b := 0; END IF; END;
3.该SQL执行(Execution)四次 ,加载(LOADS)2次 平均每次执行耗时25秒。加载较频繁需要重点优化行 sms_ts操作
SELECT COUNT(DISTINCT "A2"."QLBSM") FROM "BDCDJ"."DJFZ_CQZS" "A2","BDCDJ"."QLR" "A1" WHERE "A2"."QLBSM"="A1"."QLBSM" AND "A2"."QSZT"=1 AND TRIM("A2"."BDCQZH")=:1 AND "A1"."QLRMC" LIKE :2
4.该SQL执行(Execution)317次 ,加载(LOADS)29次 平均每次执行耗时9秒。执行和加载较频繁需要重点优化行
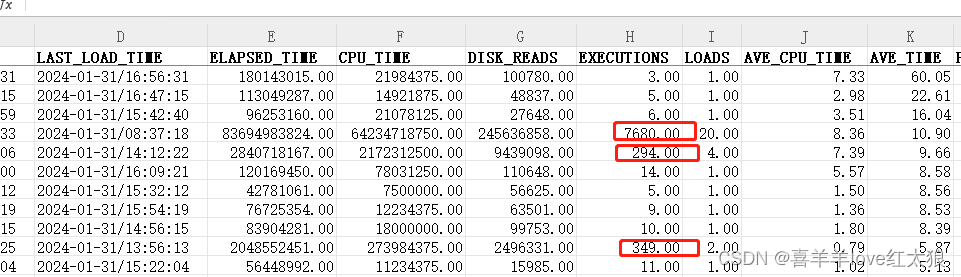
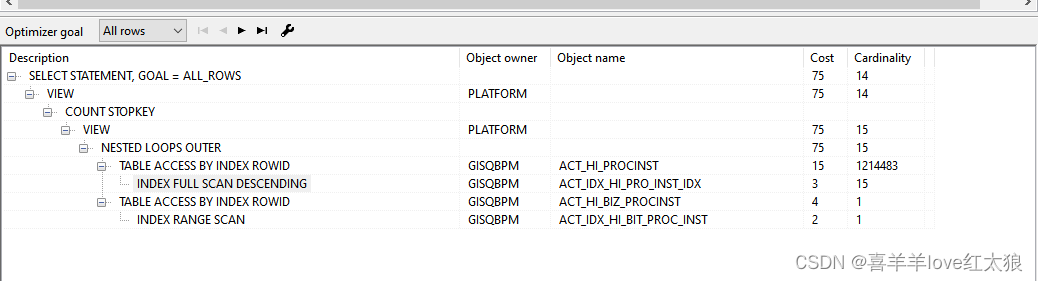
select * from ( select a.*, ROWNUM rnum from ( select RES.*, H.NAME_ as bizName, H.XZQ_ as bizXzq, H.DUE_DATE_ as bizDueDate, H.PROC_DEF_KEY_ as bizProcDefKey, H.CATEGORY_ as bizCategory, H.DATUM_TYPE_ as bizDatumType, H.START_USER_ID_ as bizStartUserId, H.F1_ as bizF1, H.F2_ as bizF2, H.F3_ as bizF3,H.F4_ as bizF4, H.F5_ as bizF5, H.F6_ as bizF6, H.F7_ as bizF7, H.F8_ as bizF8, H.F9_ as bizF9, H.F10_ as bizF10, H.F11_ as bizF11, H.F12_ as bizF12, H.F13_ as bizF13, H.F14_ as bizF14, H.F15_ as bizF15, H.F16_ as bizF16, H.F17_ as bizF17, H.F18_ as bizF18, H.F19_ as bizF19, H.F20_ as bizF20 from ACT_HI_PROCINST RES left join ACT_HI_BIZ_PROCINST H on H.PROC_INST_ID_ = RES.PROC_INST_ID_ WHERE (RES.DELETE_REASON_ <> :1 or RES.DELETE_REASON_ is null) order by RES.START_TIME_ desc ) a where ROWNUM < :2) where rnum >= :3分页查询语句执行了7680次,平均每次执行10s,看SQL执行计划走了时间字段,然而线上没有,线上加上索引线上执行为0.1秒
分析:
线上START_TIME_ 列没有走索引
解决方法:
添加索引
慢SQL查询二
select *
from (select v.sql_id,
v.SQL_FULLTEXT,
v.EXECUTIONS,
v.ELAPSED_TIME / v.executions / 1000 / 1000 ave_time,
v.parsing_user_id,
last_LOAD_TIME
from v$sql v) a
where a.last_LOAD_TIME > '2024-02-01/00:00:00' and ave_time > 5 and a.executions > 0
and a.parsing_user_id=(SELECT user_id FROM all_users where username='GISQBPM')
order by ave_time desc;
扩展:
1.loads 和execution的区别于联系?
loads:表示SQL语句在共享池中被加载的次数。每当一个SQL语句被解析并放入共享池中,loads的值就会增加。这个值可以帮助您了解一个SQL语句被重复使用的频率。
executions:表示SQL语句被执行的次数。每当一个SQL语句被实际执行,executions的值就会增加。这个值可以帮助您了解一个SQL语句在实际执行过程中的频率。
2. 同一个SQL为什么会被重复加入到共享池
在Oracle数据库中,同一个SQL语句可能会被重复加入到共享池的原因有以下几点:
绑定变量不同:如果SQL语句使用了绑定变量,即在SQL语句中使用了占位符,那么不同的绑定变量值会导致不同的SQL语句被加入到共享池中。
SQL语句文本不同:即使SQL语句的逻辑相同,但如果SQL语句的文本不同(比如空格、大小写等),Oracle也会将它们当作不同的SQL语句进行处理。
不同的解析环境:在不同的解析环境下,相同的SQL语句可能会被多次解析并加载到共享池中,比如在不同的会话或者不同的数据库连接中。
共享池空间不足:如果共享池空间不足,Oracle可能会根据一些策略进行SQL语句的淘汰和重新加载,这也会导致同一个SQL语句被重复加载到共享池中。
相关文章:
oracle数据库慢查询SQL
目录 场景: 环境: 慢SQL查询一: 问题一:办件列表查询慢 分析: 解决方法: 问题二:系统性卡顿 分析: 解决方法: 慢SQL查询二 扩展: 场景: 线…...

C语言搭配EasyX实现贪吃蛇小游戏
封面展示 内部展示 完整代码 #define _CRT_SECURE_NO_WARNINGS #include<easyx.h> #include<stdio.h> #include<mmsystem.h> #pragma comment (lib,"winmm.lib") #define width 40//宽有40个格子 #define height 30//长有40个格子 #define size 2…...
# 软件安装-Linux搭建nginx(单机版)
软件安装-Linux搭建nginx(单机版) 安装版本:nginx-1.24.0 文章目录 软件安装-Linux搭建nginx(单机版)一、Nginx包下载二、创建用户1.新建组和用户2.设置用户密码3.登录自己创建的目录三、安装依赖组件四、安装Nginx五、启动Nginx六、配置Nginx一、Nginx包下载 1. nginx-1.24下…...

成熟的汽车制造供应商协同平台 要具备哪些功能特性?
汽车行业是一个产业链长且“重”的行业,整个业务流程包括了研发、设计、采购、库存、生产、销售、售后等一系列环节,在每一个环节都涉及到很多信息交换的需求。对内要保证研发、采购、营销等业务环节信息流通高效安全,对外要与上、下游合作伙…...

React16源码: React中处理ref的核心流程源码实现
ref的实现过程 1 )概述 在更新流程当中如何去设置ref上面的对象的过程在我们创建fiber的时候去处理ref这个属性那我们什么时候创建fiber对象? 就是我们去更新某一个节点,然后要去调和它的子节点的时候这个时候我们会对每一个子节点去创建这个fiber对象…...
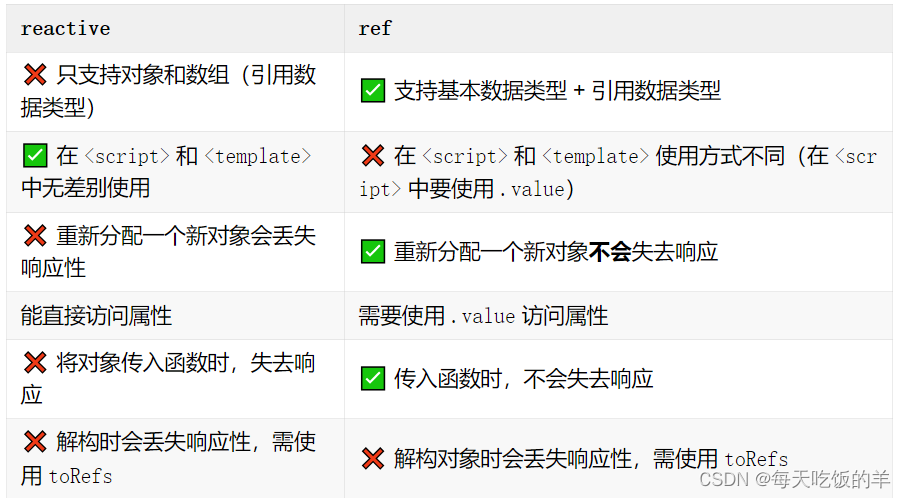
ref和reactive
看尤雨溪说:为什么Vue3 中应该使用 Ref 而不是 Reactive?...

掌握数据预测的艺术:线性回归模型详解
线性回归是统计学中用于建模两个或多个变量之间线性关系的一种方法,广泛应用于数据分析、机器学习等领域。从数学建模的角度出发,线性回归旨在找到一个线性方程,最好地描述自变量(或称为解释变量、特征变量)和因变量(或称为目标变量)之间的关系。本文将通过Python代码示…...
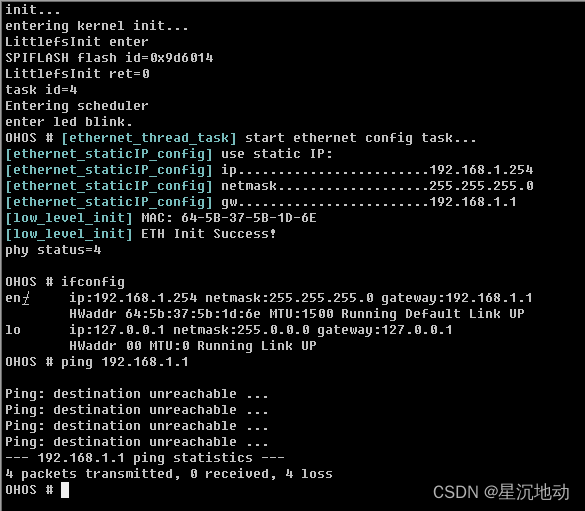
STM32F407移植OpenHarmony笔记8
继上一篇笔记,成功开启了littlefs文件系统,能读写FLASH上的文件了。 今天继续研究网络功能,让控制台的ping命令能工作。 轻量级系统使用的是liteos_m内核lwip协议栈实现网络功能,需要进行配置开启lwip支持。 lwip的移植分为两部分…...

C++:输入流/输出流
C流类库简介 C为了克服C语言中的scanf和printf存在的缺点。,使用cin/cout控制输入/输出。 cin:表示标准输入的istream类对象,cin从终端读入数据。cout:表示标准输出的ostream类对象,cout向终端写数据。cerrÿ…...
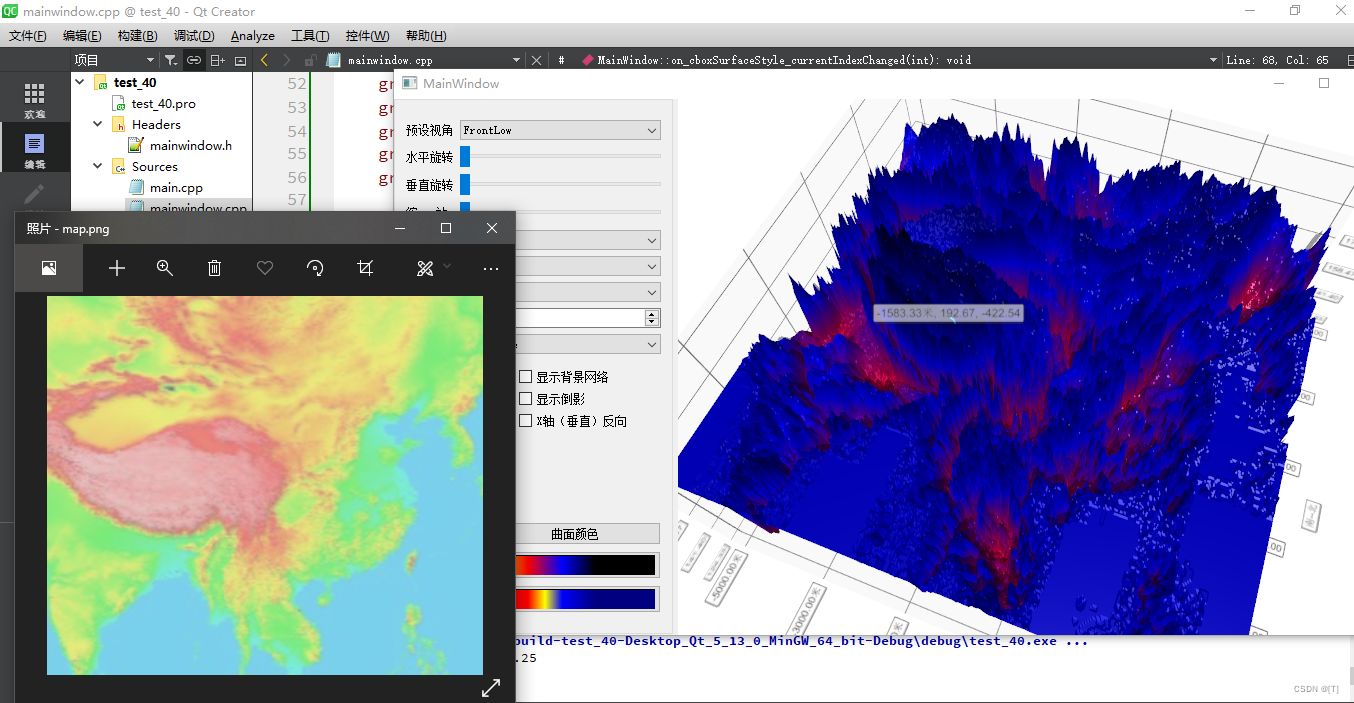
十、Qt三维图表
一、Data Visualization模块概述 Data Visualization的三维显示功能主要有三种三维图形来实现,三各类的父类都是QAbstract3DGraph,从QWindow继承而来。这三类分别是:三维柱状图Q3DBar三维空间散点Q3DScatter三维曲面Q3DSurface 1、相关类的…...

CMake官方教程中文翻译 Step 6: Adding Support for a Testing Dashboard
鉴于自己破烂的英语,所以把cmake的官方文档用 谷歌翻译 翻译下来方便查看。 英语好的同学建议直接去看cmake官方文档(英文)学习:地址 点这里 或复制:https://cmake.org/cmake/help/latest/guide/tutorial/index.html …...

【leetcode】完全背包总结
本文内容参考了代码随想录,并进行了自己的总结。 完全背包 关键点 ● 每件物品有若干种状态:不选、选 1 件、选 2 件、…、选 n 件 代码 在代码上,只有重量的遍历方向和 01 背包不一样: for(int i 0; i < nums.length; i…...
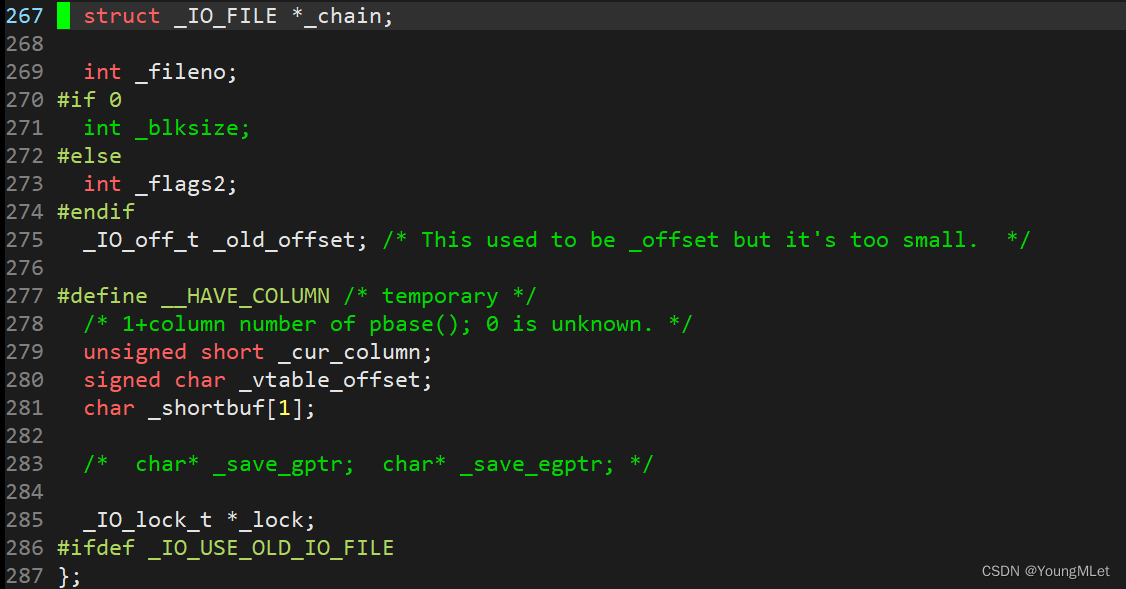
【Linux】理解系统中一个被打开的文件
文件系统 前言一、C语言文件接口二、系统文件接口三、文件描述符四、struct file 对象五、stdin、stdout、stderr六、文件描述符的分配规则七、重定向1. 重定向的原理2. dup23. 重谈 stderr 八、缓冲区1. 缓冲区基础2. 深入理解缓冲区3. 用户缓冲区和内核缓冲区4. FILE 前言 首…...
k8s kubeadm部署安装详解
目录 kubeadm部署流程简述 环境准备 步骤简述 关闭 防火墙规则、selinux、swap交换 修改主机名 配置节点之间的主机名解析 调整内核参数 所有节点安装docker 安装依赖组件 配置Docker 所有节点安装kubeadm,kubelet和kubectl 定义kubernetes源并指定版本…...

RT-DETR算法优化改进: 下采样系列 | 一种新颖的基于 Haar 小波的下采样HWD,有效涨点系列
💡💡💡本文独家改进:HWD的核心思想是应用Haar小波变换来降低特征图的空间分辨率,同时保留尽可能多的信息,与传统的下采样方法相比,有效降低信息不确定性。 💡💡💡使用方法:代替原始网络的conv,下采样过程中尽可能包括更多信息,从而提升检测精度。 RT-DET…...

CocosCreator3.8源码分析
Cocos Creator架构 Cocos Creator 拥有两套引擎内核,C 内核 和 TypeScript 内核。C 内核用于原生平台,TypeScript 内核用于 Web 和小游戏平台。 在引擎内核之上,是用 TypeScript 编写的引擎框架层,用以统一两套内核的差异…...
(已解决)spingboot 后端发送QQ邮箱验证码
打开QQ邮箱pop3请求服务:(按照QQ邮箱引导操作) 导入依赖(不是maven项目就自己添加jar包): <!-- 邮件发送--><dependency><groupId>org.springframework.boot</groupId><…...

【蓝桥杯冲冲冲】[NOIP2001 普及组] 装箱问题
蓝桥杯备赛 | 洛谷做题打卡day26 文章目录 蓝桥杯备赛 | 洛谷做题打卡day26题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示思路 题解代码我的一些话 [NOIP2001 普及组] 装箱问题 题目描述 有一个箱子容量为 V V V,同时有 n n n 个物品,每…...

2024牛客寒假算法基础集训营1
文章目录 A DFS搜索M牛客老粉才知道的秘密G why外卖E 本题又主要考察了贪心B 关鸡C 按闹分配 今天的牛客,说是都是基础题,头昏昏的,感觉真不会写,只能赛后补题了 A DFS搜索 写的时候刚开始以为还是比较难的,和dfs有关…...

元素的显示与隐藏,精灵图,字体图标,CSSC三角
元素的显示与隐藏 类似网站广告,当我们点击关闭就不见了,但是我们重新刷新页面,会重新出现 本质:让元素在页面中隐藏或者显示出来。 1.display显示隐藏 2.visibility显示隐藏 3.overflow溢出显示隐藏 1.display属性(…...

如何快速掌握大规模移动应用开发:10个核心技巧与最佳实践
如何快速掌握大规模移动应用开发:10个核心技巧与最佳实践 【免费下载链接】discussions Discussions about projects, technologies, and processes around building large-scale mobile apps 项目地址: https://gitcode.com/gh_mirrors/di/discussions GitH…...

深入解析Doom3.gpl数学库:向量、矩阵与四元数的高效实现
深入解析Doom3.gpl数学库:向量、矩阵与四元数的高效实现 【免费下载链接】doom3.gpl Doom 3 GPL source release 项目地址: https://gitcode.com/gh_mirrors/do/doom3.gpl Doom3.gpl作为经典游戏引擎的开源项目,其数学库为3D图形渲染、物理模拟和…...
)
YOLO11导出TFLite格式:移动端轻量级部署,如何将YOLO11转换为TFLite格式,并测试推理效果全面实战(一)
🎬 Clf丶忆笙:个人主页 🔥 个人专栏:《YOLOv11全栈指南:从零基础到工业实战》 ⛺️ 努力不一定成功,但不努力一定不成功! 文章目录 一、YOLO11与TFLite技术概述 1.1 TFLite格式技术解析 1.2 YOLO11转TFLite的应用价值 二、环境准备与依赖安装 2.1 Python环境配置 2…...
)
Python 3.14 JIT编译器调优实战:从默认0.8x到2.4x加速,7步完成生产环境级配置(附官方未公开env变量清单)
第一章:Python 3.14 JIT编译器性能调优配置详解Python 3.14 引入了实验性内置 JIT 编译器(基于 GraalPython 兼容层与自研 Pyston-style 动态优化后端),默认处于禁用状态,需通过环境变量与运行时参数显式启用并精细调优…...

OpenClaw跨平台控制:Qwen3-14B管理多台设备的自动化流
OpenClaw跨平台控制:Qwen3-14B管理多台设备的自动化流 1. 为什么需要集中化设备管理? 去年搭建家庭实验室时,我手头逐渐积累了三台不同用途的设备:一台跑深度学习模型的Ubuntu服务器、一台存储数据的NAS,还有一台偶尔…...

不满意Oh My Zsh启动卡顿,来试试Starship吧城
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...
✅)
计算机毕业设计:Python气象数据可视化与采集管理系统 Flask框架 数据分析 可视化 爬虫 气象数据分析(建议收藏)✅
博主介绍:✌全网粉丝50W,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,…...

操作系统工程师成长:从兴趣到创新的四重境界
1. 操作系统工程师的成长路径:从兴趣到创新的四重境界在科技行业的金字塔尖,操作系统开发一直被视为"皇冠上的明珠"。作为一名在这个领域摸爬滚打二十余年的老兵,我见证了Linux从实验室玩具成长为数字世界基石的完整历程。每当年轻…...

用好AI的五个习惯
五个习惯一、善于拆解问题核心逻辑:AI是执行者,人是设计者。对项目的全流程和细节了如指掌,能够将复杂的大问题拆解为具体的、AI可执行的子任务。二、上下文管理大师核心逻辑:理解模型极限,追求高效输出。当前AI模型&a…...

DAC8562双通道16位SPI数模转换器驱动库详解
1. DAC8562系列双通道16位SPI数模转换器驱动库深度解析DAC8562是德州仪器(TI)推出的一款高精度、低功耗、双通道16位串行输入数模转换器(DAC),采用标准SPI接口通信,广泛应用于工业控制、测试测量、音频信号…...