Oracle篇—普通表迁移到分区表(第五篇,总共五篇)
☘️博主介绍☘️:
✨又是一天没白过,我是奈斯,DBA一名✨
✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️
❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣️❣️❣️

哈喽各位小伙伴,经过前面几篇文章的介绍,我详细地介绍了分区表和分区索引的基本概念、创建方法、分区索引的重建和管理,以及一些常用的检查语句。通过这些知识的学习,我们为将普通表迁移到分区表奠定了坚实的基础。
分区表是一个非常强大的功能,它允许我们将数据映射到不同的物理磁盘上,从而分散 IO,提高数据的可管理性、可用性和性能。通过合理地使用分区表,我们可以更有效地管理和查询大规模数据,同时还能提高数据库的性能和稳定性。
现在,让我们探索如何将现有的普通表数据迁移到分区表中。这个过程可能会涉及到数据转换、索引重建等一系列复杂操作。但是,只要我们掌握了正确的方法和技巧,就能够顺利地完成这个任务。
因为分区技术需要介绍的太多,那么我将分成五篇来进行介绍,以便大家因为篇幅过长而感到阅读疲惫。五篇的内容分别如下:
第一篇:分区表和分区索引的介绍和分类
第二篇:分区表的管理
第三篇:分区索引的重建和管理
第四篇:分区表和分区索引常用的检查语句
第五篇:普通表迁移到分区表(当前篇)
目录
方式一:通过expdp/impdp将普通表数据迁移到分区表(非在线方式,需要停止相关表的业务)
案例:将非分区表table_m5转为hash分区表
方式二:通过SQL语句insert into...select插入的方式将普通表数据迁移到分区表(非在线方式,需要停止相关表的业务)
案例:将非分区表table_m5转为间隔分区表
方式三(重点):通过dbms_redefinition在线重定义的方式将普通表数据迁移到分区表(在线方式,不需要停止相关表的业务,可以进行在线迁移)
案例:将非分区表table_m10转为range分区表
普通表数据迁移到分区表的方式今天我介绍三种,三种方式各有优势,我将一一详细介绍。
方式一:通过expdp/impdp将普通表数据迁移到分区表。这种属于非在线方式,需要停止相关表的业务
方式二:通过SQL语句insert into...select插入的方式将普通表数据迁移到分区表。这种属于非在线方式,需要停止相关表的业务
方式三(重点):通过dbms_redefinition在线重定义的方式将普通表数据迁移到分区表。这种属于在线方式,不需要停止相关表的业务,可以进行在线迁移

废话不多说
one
two
three
开始今天的内容!!!
先回顾一下分区表的优点、缺点、特性和什么时候用分区表(设计原则)
分区表的优点、缺点、特性:
(1)由于将数据分散到各个分区中,减少了数据损坏的可能性;
(2)可以对单独的分区进行备份和恢复;
(3)可以将分区映射到不同的物理磁盘上,来分散 IO;
(4)提高可管理性、可用性和性能。
(5)缺点:已经存在的表没有方法可以直接转化为分区表。不过Oracle提供了在线重定义表的功能。
(6)特殊性:含有LONG、LONGRAW数据类型的表不能进行分区,一般分区类型为:varchar,varchar2,number,date
(7)每个表的分区或子分区数的总数不能超过1023个。
什么时候用分区表(设计原则):
(1)单表过大,当表的大小超过2GB,或对于OLTP系统,表的记录超过1000万,都应考虑对表进行分区。
(2)历史数据据需要剥离的,表中包含历史数据,新的数据被增加到新的分区中。
(3)查询特征非常明显,比如是按整年、整月或者按某个范围!
(4)基于表的大部分查询应用,只访问表中少量的数据。
(5)按时间段删除成批的数据,例如按月删除历史数据。
(6)按时间周期进行表空间的备份时,将分区与表空间建立对应关系。
(7)如果一个表中大部分数据都是只读数据,通过对表进行分区,可将只读数据存储在只读表空间中,对于大数据库的备份是非常有益的。
(8)对于经常执行并行查询的表应考虑进行分区。
(9)当对表的部分数据可用性要求很高时,应考虑进行表分区。
方式一:通过expdp/impdp将普通表数据迁移到分区表(非在线方式,需要停止相关表的业务)
10g引入了最新的数据泵(Data Dump)技术。它可以通过使用并行,在效率上要比exp/imp要高。可以跨平台迁移(能够在不同硬件平台上的oracle之间传递数据),支持全库、用户、表级的备份与恢复。对于数据泵(Data Dump)的相关参数这篇我不做具体介绍,如果想了解的小伙伴可以私聊我,我安排一篇文章来专门去讲数据泵
案例:将非分区表table_m5转为hash分区表
(1)查看表数据和索引
SQL> select count(*) from table_m5;
SQL> select * from dba_indexes where table_name='TABLE_M5'; ---有索引
(2)通过expdp导出表table_m5。为了保证数据一致性,需要对table_m5加锁防止对该表的操作,或者业务去停止相关该表的操作
创建数据泵directory并赋权:
SQL> create directory bk as ' /home/oracle' ;
SQL> grant all on directory bk to public;
导出数据:
[oracle@11g ~]$ expdp \"/ as sysdba\" directory=bk dumpfile=expdp_orcl_table_%U.dmp tables=username.table_m5 parallel=2 cluster=n
(3)重命名原表(切记不要删除,便于分区错误后恢复),并创建分区表(与旧表的结构一致)
SQL> alter table table_m5 rename to table_m5_old; ---重命名原表(4)将表结构、索引、约束的DDL语句全部复制:
SQL> select dbms_metadata.get_ddl('TABLE','TABLE_M5_OLD','USERNAME') from dual;SQL> select TABLE_NAME,TABLE_TYPE,INDEX_NAME from dba_indexes where table_name='TABLE_M5_OLD';
SQL> select TABLE_NAME,CONSTRAINT_NAME,CONSTRAINT_TYPE from dba_constraints where table_name='TABLE_M5_OLD';
SQL> select dbms_metadata.get_ddl('INDEX','索引名','USERNAME') from dual;
SQL> select dbms_metadata.get_ddl('CONSTRAINT','约束名','USERNAME') from dual;(5)创建hash分区表
SQL>
CREATE TABLE "USERNAME"."TABLE_M5" ("ID" NUMBER(20,0) NOT NULL ENABLE, "NAME" VARCHAR2(20) NOT NULL ENABLE, "AGE" NUMBER(10,0) NOT NULL ENABLE, "SEX" VARCHAR2(10) NOT NULL ENABLE, "CARDID" NUMBER(30,0) NOT NULL ENABLE, "JOINDATE" DATE NOT NULL ENABLE, "REGION" VARCHAR2(12) NOT NULL ENABLE, "TEL" VARCHAR2(12) NOT NULL ENABLE, "EMAIL" VARCHAR2(30) NOT NULL ENABLE, "RECOMMEND" VARCHAR2(10), "IDENTIFIER" VARCHAR2(100), PRIMARY KEY ("ID")
)
partition by hash(cardid)
partitions 2;SQL> alter table TABLE_M5 add primary key (ID); ---通过plsql查看的旧表结构,但主键创建在最下面,一定要创建(6)导入表,验证数据
[oracle@11g ~]$ impdp \"/ as sysdba\" directory=bk dumpfile=expdp_orcl_table_01.dmp,expdp_orcl_table_02.dmp table_exists_action=append
SQL> select * from dba_part_tables where table_name='TABLE_M5'; ---记录分区的表的信息
SQL> select * from DBA_tab_partitions where table_name='TABLE_M5'; ---记录表的分区的信息
SQL> select * from dba_part_indexes where table_name='TABLE_M5'; ---查询分区的索引信息(原普通索引还在) SQL> select count(*) from TABLE_M5;SQL> select count(*) from TABLE_M5 partition(SYS_P221); ---hash分区名自动分配,通过DBA_tab_partitions
SQL> select count(*) from TABLE_M5 partition(SYS_P222); ---hash分区名自动分配,通过DBA_tab_partitions(7)创建分区索引。
SQL> create index table_m5_index on table_m5(cardid) local;
SQL> select index_name,status from dba_indexes where table_name='TABLE_M5'; ---N/A:分区索引。分区索引有无有效需要查看dba_ind_partitions视图的status列:usable有效,unusable无效SQL> select * from dba_part_indexes where table_name='TABLE_M5';
SQL> select * from dba_ind_partitions where index_name='TABLE_M5_INDEX';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_M5_INDEX';
方式二:通过SQL语句insert into...select插入的方式将普通表数据迁移到分区表(非在线方式,需要停止相关表的业务)
INSERT INTO...SELECT语句在SQL中用于将一个表中的数据插入到另一个表中。它结合了INSERT语句和SELECT语句的功能,允许从源表中检索数据并将其插入到目标表中。但是这种方式不适合数据量很大的表插入,对于几百万的小表,或者机器性能很强上千万的表也是适合的。
案例:将非分区表table_m5转为间隔分区表
(1)查看表数据和索引
SQL> select count(*) from table_m5;
SQL> select * from dba_indexes where table_name='TABLE_M5'; ---有索引
(2)重命名原表(切记不要删除,便于分区错误后恢复),并创建分区表(与旧表的结构一致)
SQL> alter table table_m5 rename to table_m5_old; ---重命名原表(3)将表结构、索引、约束的DDL语句全部复制:
SQL> select dbms_metadata.get_ddl('TABLE','TABLE_M5_OLD','USERNAME') from dual;SQL> select TABLE_NAME,TABLE_TYPE,INDEX_NAME from dba_indexes where table_name='TABLE_M5_OLD';
SQL> select TABLE_NAME,CONSTRAINT_NAME,CONSTRAINT_TYPE from dba_constraints where table_name='TABLE_M5_OLD';
SQL> select dbms_metadata.get_ddl('INDEX','索引名','USERNAME') from dual;
SQL> select dbms_metadata.get_ddl('CONSTRAINT','约束名','USERNAME') from dual;(4)创建间隔分区表
SQL>
CREATE TABLE "USERNAME"."TABLE_M5" ("ID" NUMBER(20,0) NOT NULL ENABLE, "NAME" VARCHAR2(20) NOT NULL ENABLE, "AGE" NUMBER(10,0) NOT NULL ENABLE, "SEX" VARCHAR2(10) NOT NULL ENABLE, "CARDID" NUMBER(30,0) NOT NULL ENABLE, "JOINDATE" DATE NOT NULL ENABLE, "REGION" VARCHAR2(12) NOT NULL ENABLE, "TEL" VARCHAR2(12) NOT NULL ENABLE, "EMAIL" VARCHAR2(30) NOT NULL ENABLE, "RECOMMEND" VARCHAR2(10), "IDENTIFIER" VARCHAR2(100), PRIMARY KEY ("ID")
)
partition by range(joindate)
interval (numtoyminterval(1,'month') )
(
partition p_001 values less than (to_date('2015-01-01','YYYY-MM-DD')),
partition p_002 values less than (to_date('2015-02-01','YYYY-MM-DD')),
partition p_003 values less than (to_date('2015-03-01','YYYY-MM-DD'))
);SQL> alter table TABLE_M5 add primary key (ID); ---通过plsql查看的旧表结构,但主键创建在最下面,一定要创建(5)insert导入表,验证数据。为了保证数据一致性,需要对table_m5加锁防止对该表的操作,或者业务去停止相关该表的操作
SQL> insert into table_m5 select * from table_m5_old;
SQL> commit;SQL> select * from dba_part_tables where table_name='TABLE_M5'; ---记录分区的表的信息
SQL> select * from DBA_tab_partitions where table_name='TABLE_M5'; ---记录表的分区的信息。根据分区字段joindate的时间,自动创建按1个月创建分区
SQL> select count(*) from TABLE_M5;
SQL> select count(*) from TABLE_M5 partition(P_001); ---间隔分区名自动分配,通过DBA_tab_partitions
SQL> select count(*) from TABLE_M5 partition(P_002); ---间隔分区名自动分配,通过DBA_tab_partitions

(6)创建分区索引。
SQL> create index table_m5_index on table_m5(cardid) local;
SQL> select index_name,status from dba_indexes where table_name='TABLE_M5'; ---N/A:分区索引。分区索引有无有效需要查看dba_ind_partitions视图的status列:usable有效,unusable无效SQL> select * from dba_part_indexes where table_name='TABLE_M5';
SQL> select * from dba_ind_partitions where index_name='TABLE_M5_INDEX';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_M5_INDEX';
方式三(重点):通过dbms_redefinition在线重定义的方式将普通表数据迁移到分区表(在线方式,不需要停止相关表的业务,可以进行在线迁移)
在高可用系统中,改变表的定义是一件比较棘手事,尤其是对于7×24系统。Oracle提供的基本语法基本可以满足一般性修改,但是对于把普通堆表改为分区表,把索引组织表修改为堆表等操作就无法完成了。而且对于被大量DML语句访问的表,9i版本开始提供了在线重定义表功能,通过调用DBMS_REDEFINITION包,可以在修改表结构的同时允许DML操作。
dbms_redefinition在线重定义能保证数据的一致性,在大部分时间内,表都可以正常进行DML操作。只在切换的瞬间锁表,具有很高的可用性这种方法具有很强的灵活性,对各种不同的需要都能满足。而且,可以在切换前进行相应的授权并建立各种约束,可以做到切换完成后不再需要任何额外的管理操作。
dbms_redefinition进行分表转换可以实现真正意义上的0秒不停机切换而且完全保证数据一致性,只是在dbms_redefinition.finish_redef_table时有短暂的独占表锁定
在线重定义表具有以下功能:
(1)修改表的存储参数
(2)将表转移到其他表空间
(3)增加并行查询选项
(4)增加或删除分区
(5)重建表以减少碎片
(6)将堆表改为索引组织表或相反的操作
(7)增加或删除一个列
注:调用DBMS_REDEFINITION包需要EXECUTE_CATALOG_ROLE角色,除此之外,还需要CREATE ANY TABLE、ALTER ANY TABLE、DROP ANY TABLE、 LOCKANY TABLE和SELECT ANY TABLE的权限。
使用在线重定义的一些限制条件:
(1)必须有足够的空间容纳表的两个副本。
(2)不能修改主键列。
(3)表必须有主键(ORA-12089: cannot online redefine table with no primary key)
(4)必须在同一用户中进行重新定义,跨用户不行。
(5)在重新定义操作完成之前,添加的新列不能变为非NULL。
(6)表不能包含long、bfile或用户定义的类型。
(7)不能重新定义群集表。
(8)不能重新定义SYS或系统模式中的表。
(9)不能重定义带有物化视图日志或在其上定义物化视图的表
(10)重新定义时无法进行数据的水平子设置。
(11)数据库若是rac,只需在其中一个节点的数据库上实施。
(12)实施中部分命令执行时间较长,命令一旦执行后请不要中断命令的执行一条命令执行完毕后,不能再次重复执行该命令。
(13)执行命令的数据库用户需要为sys或者system用户
在线重定义的操作流程如下(建议在10.2.0.5/11.2.0.1+上操作,BUG少):
(1)创建基础表A,如果存在,就不需要操作。
(2)创建中间的分区表B。
(3)开始重定义,将基表A的数据导入中间分区表B。
(4)结束重定义,此时在DB的Name Directory里,已经将2个表进行了交换。即此时基表A成了分区表,我们创建的中间分区表B成了普通表。此时我们可以删除我们创建的中间表B。它已经是普通表。
案例:将非分区表table_m10转为range分区表
(1)查看表数据和索引
SQL> select count(*) from table_m10;
SQL> select * from dba_indexes where table_name='TABLE_M10'; ---有索引
(2)创建中间range分区表(这里的中间表不是传统意义上的临时表,而是真真实实存在的分区表,为了将普通表的数据过渡)
SQL> select dbms_metadata.get_ddl('TABLE','TABLE_M10','USERNAME') from dual; 只需要查看表结构,因为可以通过DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS包的形式将索引、触发器、约束、权限复制,在下面操作
SQL> CREATE TABLE "USERNAME"."TABLE_M10_LS"("ID" NUMBER(20,0) NOT NULL ENABLE,"NAME" VARCHAR2(20) NOT NULL ENABLE,"AGE" NUMBER(10,0) NOT NULL ENABLE,"SEX" VARCHAR2(10) NOT NULL ENABLE,"CARDID" NUMBER(30,0) NOT NULL ENABLE,"JOINDATE" DATE NOT NULL ENABLE,"REGION" VARCHAR2(12) NOT NULL ENABLE,"TEL" VARCHAR2(12) NOT NULL ENABLE,"EMAIL" VARCHAR2(30) NOT NULL ENABLE,"RECOMMEND" VARCHAR2(10),"IDENTIFIER" VARCHAR2(100),PRIMARY KEY ("ID"))
partition by range (ID)
(
partition P10000 values less than (10010000),
partition P20000 values less than (10020000),
partition P30000 values less than (10030000),
partition P40000 values less than (10040000),
partition P50000 values less than (10050000),
partition P_MAX values less than (MAXVALUE)
);(3)进行表重定义操作
一、检查table_m10是否可以进行重定义(只是验证原表是否可以通过dbms_redefinition进行重定义操作的条件)
SQL> begindbms_redefinition.can_redef_table('USERNAME','TABLE_M10');end;/
二、对table_m10进行重定义(同步原表数据到中间分区表)
SQL> begindbms_redefinition.start_redef_table(uname => 'USERNAME', ---表所属的用户orig_table => 'TABLE_M10', ---要重新组织表的名称int_table => 'TABLE_M10_LS', ---中间表的名称options_flag => dbms_redefinition.cons_use_pk); ---使用主键约束来重定义表(按照这个标准即可)。options_flag有两个选项: --dbms_redefinition.cons_use_pk:在重定义时,创建的物化视图是基于主键的刷新 --dbms_redefinition.cons_use_rowid:在重定义时,创建的物化视图是基于rowid刷新。如果表启用了行迁移,数据会乱掉,不建议使用end;/
(4)复制原表的上的依赖关系(包括索引、触发器、约束、权限等)
SQL> declarenum_errors pls_integer;beginDBMS_REDEFINITION.COPY_TABLE_DEPENDENTS(uname => 'USERNAME',orig_table => 'TABLE_M10',int_table => 'TABLE_M10_LS',copy_indexes =>dbms_redefinition.cons_orig_params, --copy索引copy_triggers => TRUE, ---copy触发器copy_constraints => TRUE, ---copy约束copy_privileges => TRUE, ---copy表的权限ignore_errors => TRUE, num_errors => num_errors);end;/(5)同步原表与中间表的数据(dbms_redefinition.start_redef_table操作时,如果表中有数据,那么会消耗很长的时间,因此原表还在DML操作,中间分区表不是最新的数据,所以要同步最新的数据)
SQL> begindbms_redefinition.sync_interim_table( uname => 'USERNAME',orig_table => 'TABLE_M10',int_table => 'TABLE_M10_LS');end;/(6)结束重定义(此操作就是将原表和中间表进行表名转换,原普通表变为了分区表,中间分区表变为了普通表。注:转换只能进行一次,不能回切,会报错)
注:finish_redef_table过程中,原始表被短暂锁定(独占锁定)。如果在第五步sync_interim_table后原表还有DML操作(insert插入),那么第六步就是先独占锁定表,然后再执行一次sync_interim_table数据同步到中间表,保证两表之间的数据完全一致(0秒不停机切换而且数据也会保证一致性,只是有短暂的锁表),之后进行表名转换
SQL> begindbms_redefinition.finish_redef_table( uname => 'USERNAME',orig_table => 'TABLE_M10',int_table => 'TABLE_M10_LS');end;/(7)验证table_m10数据并验证是否分区。在dbms_redefinition.finish_redef_table结束重定义的时候,原表的结构直接继承了中间分区表的结构,中间分区表则变成了普通表,分区操作在秒级
SQL> select count(*) from TABLE_M10; ---并对比TABLE_M10_LS数据查看是否缺少
SQL> select * from dba_part_tables where table_name='TABLE_M10'; ---记录分区的表的信息
SQL> select * from DBA_tab_partitions where table_name='TABLE_M10'; ---记录表的分区的信息
SQL> select * from dba_part_indexes where table_name='TABLE_M10'; ---查询分区的索引信息(原普通索引还在) SQL> select count(*) from TABLE_M10 partition(P10000); ---range分区名,通过DBA_tab_partitions
SQL> select count(*) from TABLE_M10 partition(P20000); ---range分区名,通过DBA_tab_partitions(8)创建分区索引。
SQL> create index table_m5_index on table_m5(cardid) local;
SQL> select index_name,status from dba_indexes where table_name='TABLE_M5'; ---N/A:分区索引。分区索引有无有效需要查看dba_ind_partitions视图的status列:usable有效,unusable无效SQL> select * from dba_part_indexes where table_name='TABLE_M5';
SQL> select * from dba_ind_partitions where index_name='TABLE_M5_INDEX';
SQL> select index_name,partition_name,status from dba_ind_partitions where index_name='TABLE_M5_INDEX';(9)删除table_m10_ls中间表(已经由分区表变为了普通表)
SQL> drop table TABLE_M10_LS;相关文章:
Oracle篇—普通表迁移到分区表(第五篇,总共五篇)
☘️博主介绍☘️: ✨又是一天没白过,我是奈斯,DBA一名✨ ✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️ ❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣…...

作为开发人的我们,怎么可以不了解这些?
必备技能: 文章结尾处,有资源获取方式 Spring Spring是一个轻量级的Java框架,它可以用于开发各种Java应用程序。Spring提供了丰富的功能,包括IoC容器、AOP、事务管理、Web开发、安全管理等等。Spring的IoC容器可以…...

基于 Echarts 的 Python 图表库:Pyecahrts交互式的日历图和3D柱状图
文章目录 概述一、日历图和柱状图介绍1. 日历图基本概述2. 日历图使用场景3. 柱状图基本概述4. 柱状图使用场景 二、代码实例1. Pyecharts绘制日历图2. Pyecharts绘制2D柱状图3. Pyecharts绘制3D柱状图 总结 概述 本文将引领读者深入了解数据可视化领域中的两个强大工具&#…...
web应用课——(第四讲:中期项目——拳皇)
代码AC Git地址:拳皇——AC Git链接...
Python爬虫http基本原理
Python爬虫逆向系列(更新中):http://t.csdnimg.cn/5gvI3 HTTP 基本原理 在本节中,我们会详细了解 HTTP 的基本原理,了解在浏览器中敲入 URL 到获取网页内容之间发生了什么。了解了这些内容,有助于我们进一…...
iOS17使用safari调试wkwebview
isInspectable配置 之前开发wkwebview的页面的时候一直使用safari调试,毕竟jssdk交互还是要用这个比较方便,虽说用一个脚本插件没问题。不过还是不太方便。 但是这个功能突然到了iOS17之后发现不能用了,还以为又是苹果搞得bug,每…...
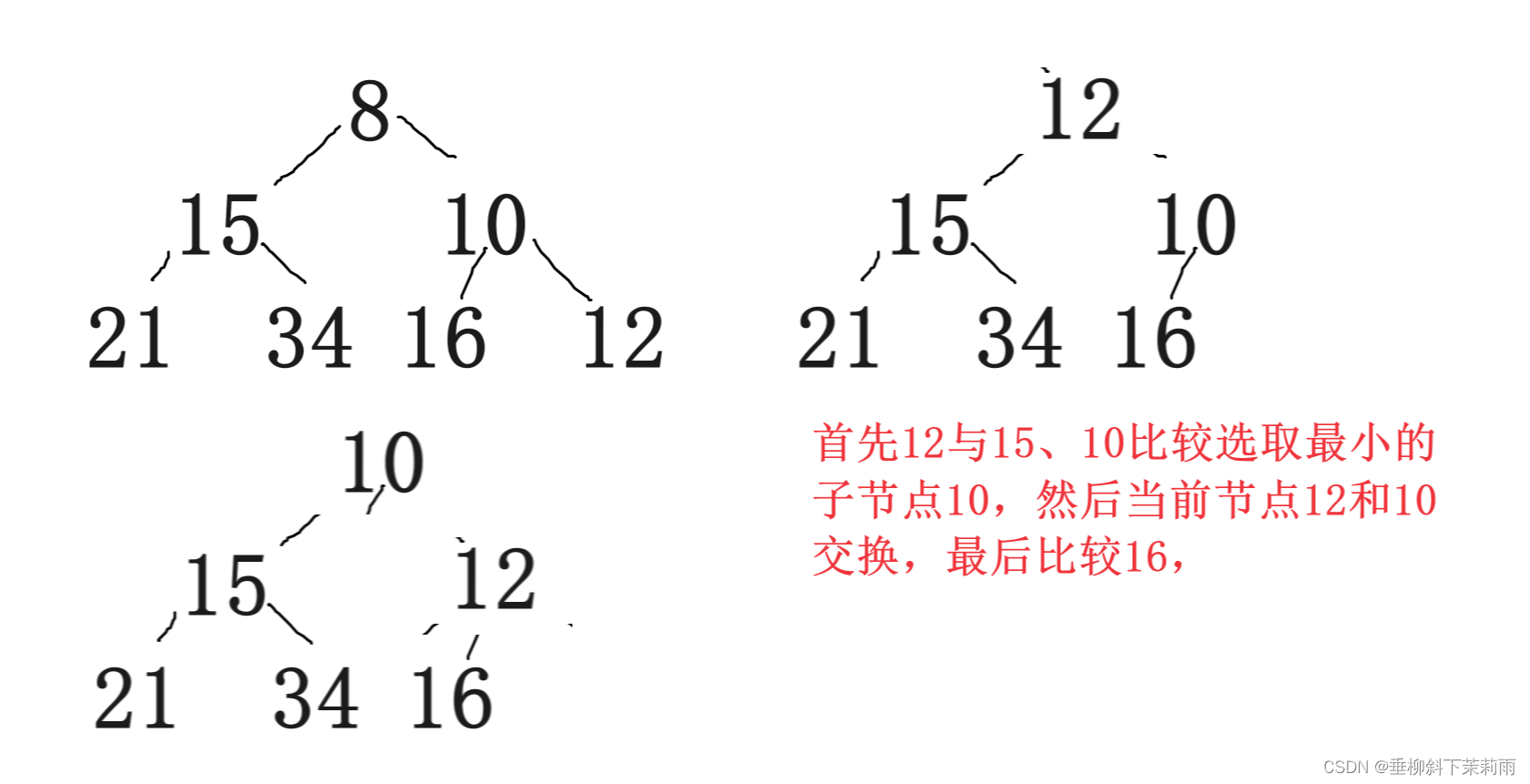
二叉树(1)
1 树概念及结构 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。 把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。 有一个特殊的结点&a…...

ArcGIS Pro字段编号相关代码
字段属于SHP文件的重要组成部分,在某些时候需要对字段进行编号,这里为大家介绍一下字段编号相关的代码,希望能对你有所帮助。 数据来源 教程所使用的数据是从水经微图中下载的POI数据,除了POI数据,常见的GIS数据都可…...

AJAX-URL查询参数
定义:浏览器提供给服务器的额外信息,让服务器返回浏览器想要的数据 http://xxxx.com/xxx/xxx?参数名1值1&参数名2值2 axios语法 使用axios提供的params选项 注意:axios在运行时把参数名和值,会拼接到url?参数名值 axios(…...
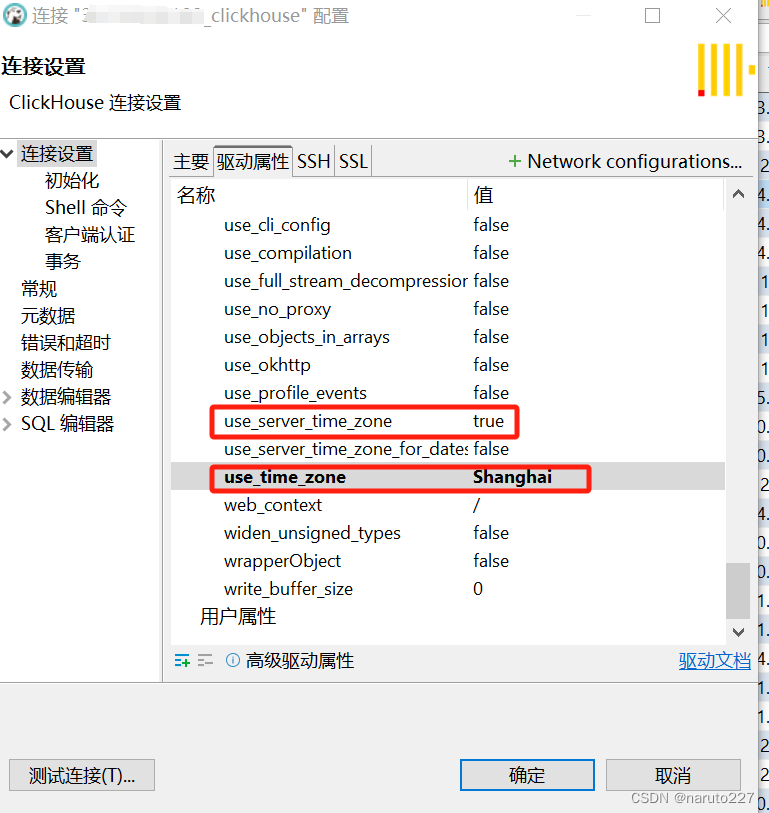
DBeaver连接ClickHouse,时间少了8小时
文章目录 业务场景问题描述解决办法 业务场景 表字段time,类型为Datetime,插入时间格式为“yyyy-MM-dd HH:mm:ss” 问题描述 插入表中的时间比正常给的时间少了8小时。如,给定时间为: 2024-01-30 14:52:08 在表中显示的时间为&…...
)
week03day03(文件操作、正则表达式1)
一、文件操作 1.数据持久化(数据本地化) -- 将数据保存在硬盘 程序中的数据默认是保存在运行内存中的,保存在运行内存中的数据在程序运行结束后会自动释放。如果希望在程序结束后,数据仍可以使用&…...

【数据分享】1929-2023年全球站点的逐年最高气温数据(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、湿度等指标,其中又以气温指标最为常用!说到气温数据,最详细的气温数据是具体到气象监测站点的气温数据! 之前我们分享过1929-2023年全球气象站…...
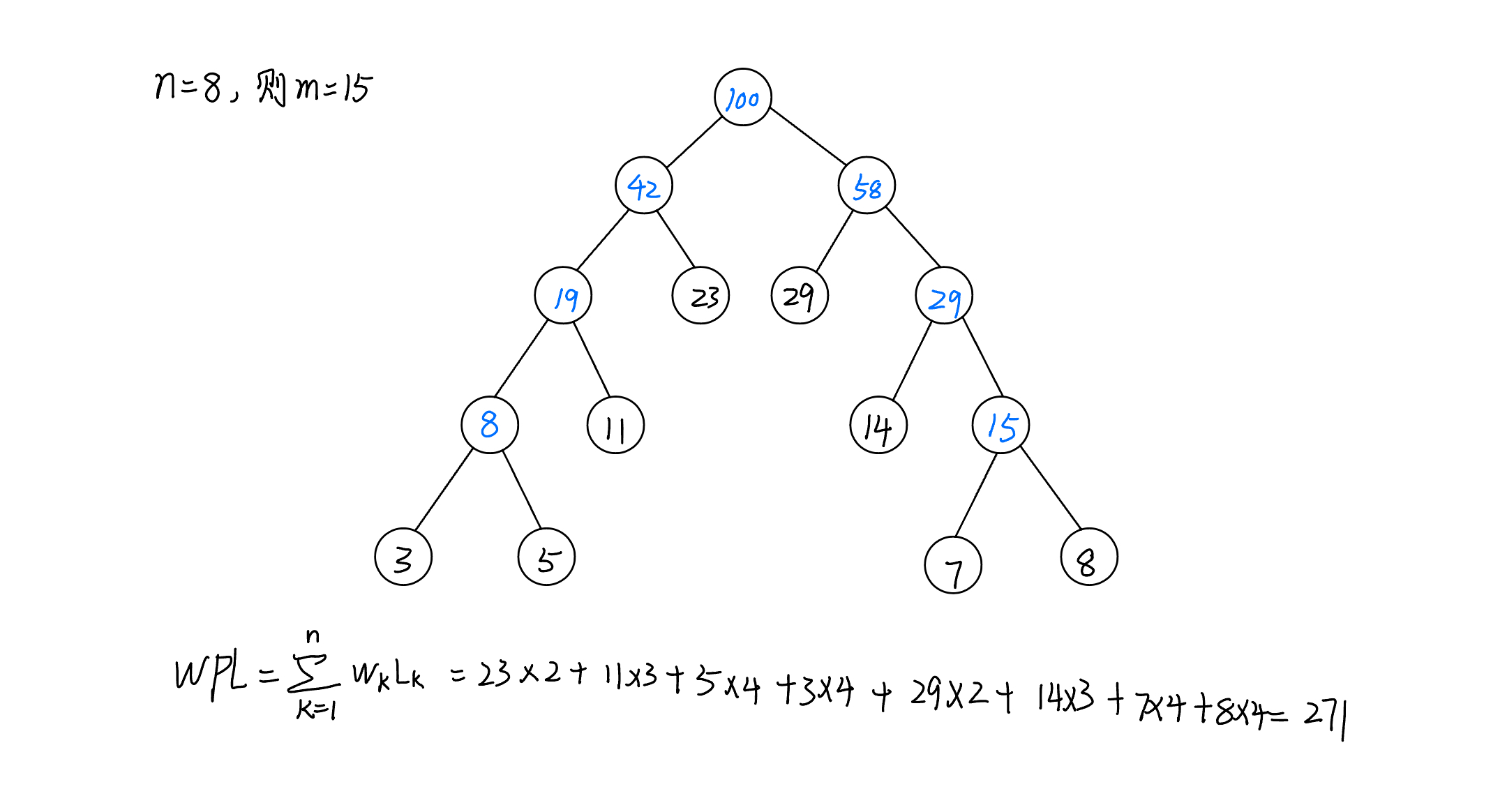
数据结构—基础知识:哈夫曼树
文章目录 数据结构—基础知识:哈夫曼树哈夫曼树的基本概念哈夫曼树的构造算法哈夫曼树的构造过程哈夫曼算法的实现算法:构造哈夫曼树 数据结构—基础知识:哈夫曼树 哈夫曼树的基本概念 哈夫曼(Huffman)树又称最优树&…...
复习提纲24)
计算机网络(第六版)复习提纲24
3 传输控制协议TCP概述 A TCP最主要的特点 1 面向连接的传输层协议 2 每一条TCP连接只能有两个端点,且只能是点对点的 3 提供可靠交付的服务(无差错、不丢失、不重复、不乱序) 4 全双工通信,两端设有发送缓存和接收缓存 5 面向字节…...

[机器学习]TF-IDF算法
一.TF-IDF算法概述 什么是TF-IDF? 词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)是一种常用于文本处理的统计方法,可以评估一个单词在一份文档中的重要程度。简单来说就是可以用于文档关键词的提…...

Loadbalancer如何优雅分担服务负荷
欢迎来到我的博客,代码的世界里,每一行都是一个故事 Loadbalancer如何优雅分担服务负荷 前言Loadbalancer基础:数字世界的分配大师1. 分发请求:2. 健康检查:3. 会话保持:4. 可伸缩性:5. 负载均衡…...
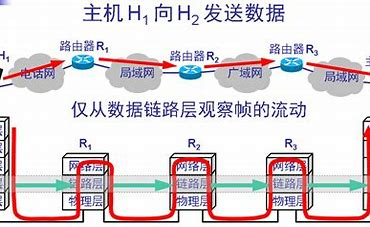
计算机网络——链路层(1)
计算机网络——链路层(1) 小程一言专栏链接: [link](http://t.csdnimg.cn/ZUTXU)前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家, [跳转到网站](https://www.captainbed.…...
OpenCV 0 - VS2019配置OpenCV
1 配置好环境变量 根据自己的opencv的安装目录配置 2 新建一个空项目 3 打开 视图->工具栏->属性管理器 4 添加新项目属性表 右键项目名(我这是opencvdemo)添加新项目属性表,如果有配置好了的属性表选添加现有属性表 5 双击选中Debug|x64的刚添加的属性表 6 (重点)添…...

eCos flash模拟EEPROM实现NV系统
Flash需要擦除的原因:先擦除后写入的原因是为了工业上制作方便,即物理实现方便。 #include <cyg/infra/diag.h> #include <cyg/io/flash.h> #include <stdarg.h> #include <stdio.h> #include <stdlib.h> // SPI flash…...

【MongoDB】跨库跨表查询(python版)
MongoDB跨表跨库查询 1.数据准备:2.跨集合查询3.跨库查询应该怎么做? 讲一个简单的例子,python连接mongodb做跨表跨库查询的正确姿势 1.数据准备: use order_db; db.createCollection("orders"); db.orders.insertMan…...

深入FFmpeg封装层:AVFormatContext与avformat_alloc_output_context2的幕后工作解析
深入FFmpeg封装层:AVFormatContext与avformat_alloc_output_context2的幕后工作解析 在音视频处理领域,FFmpeg无疑是开发者最得力的工具之一。但真正掌握其精髓的开发者都知道,仅仅会调用API是远远不够的。当你在调试一个自定义封装器时&…...

数据库AI方向探索-MCP原理解析DB方向实战
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...
)
L2-047 锦标赛(递归解法)
L2-047 锦标赛分数 25作者 DAI, Longao单位 杭州百腾教育科技有限公司有 2k 名选手将要参加一场锦标赛。锦标赛共有 k 轮,其中第 i 轮的比赛共有 2k−i 场,每场比赛恰有两名选手参加并从中产生一名胜者。每场比赛的安排如下:对于第 1 轮的第 …...

GHCJS与Emscripten集成:构建高性能Web应用的最佳实践
GHCJS与Emscripten集成:构建高性能Web应用的最佳实践 【免费下载链接】ghcjs Haskell to JavaScript compiler, based on GHC 项目地址: https://gitcode.com/gh_mirrors/gh/ghcjs GHCJS是一个强大的Haskell到JavaScript编译器,它基于GHC…...

GTE-Chinese-Large镜像免配置实战:从启动到API调用的全流程详细步骤
GTE-Chinese-Large镜像免配置实战:从启动到API调用的全流程详细步骤 1. 镜像概述与核心价值 GTE-Chinese-Large是阿里达摩院推出的专门针对中文场景优化的文本向量化模型。这个镜像最大的特点就是开箱即用——所有依赖环境、模型文件、Web界面都已经预先配置好&am…...

万象熔炉 | Anything XL快速上手:拖拽上传参考图进行ControlNet扩展
万象熔炉 | Anything XL快速上手:拖拽上传参考图进行ControlNet扩展 安全声明:本文仅讨论本地化部署的AI图像生成技术,所有数据处理均在用户本地设备完成,不涉及任何网络传输或云端服务,确保数据隐私和安全。 1. 工具简…...

新手必看!AutoGen Studio界面详解与模型配置全流程
新手必看!AutoGen Studio界面详解与模型配置全流程 1. AutoGen Studio简介 AutoGen Studio是一个低代码AI智能体开发平台,它基于AutoGen AgentChat框架构建,旨在帮助开发者快速创建、配置和组合AI代理。通过直观的可视化界面,用…...

基于Fluent的SLM过程模拟:涵盖案例研究、热源UDF及粉末导入技术详解
基于fluent的slm过程模拟,包含案例,热源udf,粉末的导入都有涉及。在增材制造领域,选择性激光熔化(SLM)技术因其高精度和复杂形状的制造能力而备受关注。今天,我们就来聊聊如何基于Fluent进行SLM…...

OpenClaw技能市场探秘:Qwen3.5-9B适配的十佳插件
OpenClaw技能市场探秘:Qwen3.5-9B适配的十佳插件 1. 为什么需要关注Qwen3.5-9B适配插件? 上周我在调试一个自动化周报生成流程时,发现同样的任务脚本在Qwen3.5-9B上运行时,效率比预期低了40%。经过排查才发现,我使用…...

从进度到资源:7款适合PMO的项目集管理系统
本文将深入对比7大项目集管理系统:PingCode、Worktile、GanttPRO、奥博思、TAPD、Trello、氚云 在管理大型、跨部门的复杂项目时,PMO(项目管理办公室)常面临资源冲突、信息孤岛和进度失控的挑战。传统的单项目管理工具已难以承载组…...