Pytroch 自写训练模板适合入门版 包含十五种经典的自己复现的一维模型 1D CNN
训练模板
在毕业之前,决定整理一下手头的代码,自己做1D-CNN这吗久,打算开源一下自己使用的1D-CNN的代码,包括用随机数生成一个模拟的数据集,到自己写的一个比较好的适合入门的基础训练模板,以及自己复现的所有1D-CNN经典模型进行开源,代码已经上传到了GitHub上,接下来我逐个文件进行讲解。由于写的过于详细导致,写完了之后发现最后写了1万9000多字,都超过我本科论文字数了。如果有问题或者有什么写的不完善的地方欢迎里留言交流。
https://github.com/StChenHaoGitHub/1D_Pytorch_Train_demo.git
LeNet-AlexNet-ZFNet: LeNet-AlexNet-ZFNet一二维复现pytorch
VGG: VGG一二维复现pytorch
GoogLeNet: GoogLeNet一二维复现pytorch
ResNet: ResNet残差网络一二维复现pytorch-含残差块复现思路分析
DenseNet: DenseNet一二维复现pytorch
Squeeze: SqueezeNet一二维复现pytorch
文章目录
- 训练模板
- 1.生成模拟数据集-Create_dataset.py
- 2.数据集打包-Package_dataset.py
- 3.训练代码分解讲解
- 3.1导入需要的工具包
- 3.2 读取数据
- 3.3 划分训练集和测试集
- 3.4 数据库加载类的实现
- 3.5 构建dataloader
- 3.6 选择训练设备
- 3.7 选择训练模型
- 3.8 损失函数的选择
- 3.9 优化器的选择
- 3.10 初始化保存训练集准确率和测试集准确率的列表
- 3.11 训练函数详解(关键)
- 3.12 测试函数解释
- 3.13 进行训练
- 3.14 绘制训练测试准确率曲线
- 4.训练完整代码
- 经验总结
- 结束
1.生成模拟数据集-Create_dataset.py
首先在没有数据集的情况下,我们通过最简单的方式来生成一个数据集代码,数据集包含两部分,包括训练的值和标签,训练的值用data表示,训练的标签用label表示
Create_dataset.py其包含代码如下
import numpy as np
# 模拟的样本数量
numbers = 100
# 模拟的样本通道数
channels = 3
# 模拟的信号长度
length = 224
# 模拟的类别
classes = 2# 生成随机数据 生成的数据维度为(数量,通道,长度)
data = np.random.randn(numbers,channels,length)
# 生成标签
label = np.random.randint(0,classes,numbers)# 将数据和标签保存到Dataset文件夹里
np.save('Dataset/data.npy',data,allow_pickle=True)
np.save('Dataset/label.npy',label,allow_pickle=True)
np.random.randn 示例代码如下
import numpy as np
data = np.random.randn(100,3,244)
print(data.shape)
# (100, 3, 244)
使用np.random.randint生成标签,改代码的作用是生成numbers个包含于[0,classes)的整数
label = np.random.randint(0,classes,numbers)
np.random.randint 示例代码如下
import numpy as nplabel = np.random.randint(0, 2, 10)
print(label)
# [0 0 0 1 1 0 1 0 0 0]
运行之后我们在Dataset文件夹下生成了两个npy文件
2.数据集打包-Package_dataset.py
在pytorch的训练之前,我们需要一个函数将数据和标签打包在一起也就是形成一组[值,标签],的形式,方便之后对数据进行划分和训练,这是一个默认的通用的规范,如果你是新手,你只需要知道这吗做就对了。
Package_dataset.py代码如下
import numpy as np
def package_dataset(data, label):dataset = [[i, j] for i, j in zip(data, label)]# channel numberchannels = data[0].shape[0]# data lengthlength = data[0].shape[1]# data classesclasses = len(np.unique(label))return dataset, channels, length, classesif __name__ == '__main__':data = np.load('Dataset/data.npy')label = np.load('Dataset/label.npy')dataset, channels, length, classes = package_dataset(data, label)print(channels, length, classes)# 3 224 2
其中输入的数据为data和label返回的是dataset,channels,length,classes
在之后的训练模型的初始化过程我们会用到channels通道数,length特征长度,classes类别个数这三个值
下面的代码是打包值和标签的代码
dataset = [[i, j] for i, j in zip(data, label)]
如果要是新手看着会有点抽象这里也是举一个简单的例子,通过zip()和列表生成式,得到了多个[值,标签]构成的dataset
data = [[1, 2, 3],[3, 1, 3],[1, 2, 3]]label = [0,1,0]dataset = [[i, j] for i, j in zip(data, label)]print(dataset)
#[[[1, 2, 3], 0], [[3, 1, 3], 1], [[1, 2, 3], 0]]
3.训练代码分解讲解
3.1导入需要的工具包
接下来我们一步一步给出训练代码种的各个部分,首先导入一些用到的工具包
import numpy as np
import torch
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, Dataset,random_split
导入我们自己写的打包数据集的API
from Package_dataset import package_dataset
导入模型,这里的模型可以根据需要自己选择,如果你是新手就知道这部分都是各种模型就完事了
from Models.LeNet import LeNet
from Models.AlexNet import AlexNet
from Models.ZFNet import ZFNet
from Models.VGG19 import VGG19
from Models.GoogLeNet import GoogLeNet
from Models.ResNet50 import ResNet50
from Models.DenseNet import DenseNet
from Models.SqueezeNet import SqueezeNet
from Models.Mnasnet import MnasNetA1
from Models.MobileNetV1 import MobileNetV1
from Models.MobileNetV2 import MobileNetV2
from Models.MobileNetV3 import MobileNetV3_large, MobileNetV3_small
from Models.shuffuleNetV1 import shuffuleNetV1_G3
from Models.shuffuleNetV2 import shuffuleNetV2
from Models.Xception import Xception
3.2 读取数据
加载数据,把值和标签读取进来
data = np.load('Dataset/data.npy')
label = np.load('Dataset/label.npy')
3.3 划分训练集和测试集
设置训练集和测试集的划分比例dataset_partition_rate。0.7就是训练集和测试集7:3划分
训练轮数总轮数epoch_number
和训练多少轮进行一次测试,这个值为show_result_epoch,为什么需要设置这个值,因为有些时候训练的太快了,如果每一轮都打印,先不说效率问题,就是一直打印你也看不清上面的字
dataset_partition_rate = 0.7
epoch_number = 1000
show_result_epoch = 10
使用我们之前介绍的自己写的APIpackage_dataset,输出dataset, channels, length, classes
dataset为打包好的数据,channels为每个值的通道维度的个数length为通道特征长度,classes训练类别
dataset, channels, length, classes = package_dataset(data, label)
划分数据集,划分数据集使用的是torch.utils.data.random_split,其中random_split函数要输入两个参数,一个是dataset也就是待划分的数据集,还有要传进去一个列表lengths,这个里面要传入的是你要划分出的训练集和测试集的样本的数量,我们之前定义的dataset_partition_rate表示的是训练集样本占总样本的比例,所以需要通过int(len(dataset) * dataset_partition_rate)来获得训练集的样本数量,而且为了保证训练集和测试集的样本总数为数据集样本数量,则需要通过数据集的样本总数减去训练集的样本数量test_len = int(len(dataset)) - train_len,这块如果理解不过来可以简单停下来思考一下。
# partition dataset
train_len = int(len(dataset) * dataset_partition_rate)
test_len = int(len(dataset)) - train_len
train_dataset, test_dataset = random_split(dataset=dataset, lengths=[train_len, test_len])
编写数据库加载类,这个东西是干嘛用的,简单的来说这个类的作用是将原始数据(假定为一系列值和标签的配对)转换为PyTorch能够理解和操作的格式。这使得这些数据可以被PyTorch的数据加载器(DataLoader)等工具用于训练机器学习模型,例如在批处理、随机洗牌和并行处理数据等方面。这个东西也可以直接理解为一个固定的API,并不需要详细了解原理,知道是干什么用的即可。
3.4 数据库加载类的实现
# 数据库加载
class Dataset(Dataset):def __init__(self, data):self.len = len(data)self.x_data = torch.from_numpy(np.array(list(map(lambda x: x[0], data)), dtype=np.float32))self.y_data = torch.from_numpy(np.array(list(map(lambda x: x[-1], data)))).squeeze().long()def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self):return self.len
加载dataloder,train_dataset和test_dataset是random_split对输入的dataset依照我们设置的比例,划分出的训练集和测试集,其除了与dataset包含的训练样本的数量不一样之外,其每个训练样本的数据格式还是一样的都是[值,标签]
Train_dataset = Dataset(train_dataset)这句话官方或者最准确的表达是通过实例化Dataset,创建了一个针对 train_dataset 数据准备 的 特定数据集对象。好吧我也觉得有点不是person话。
这里也不需要纠结就理解成需要通过Dataset分别处理一下train_dataset和test_dataset,然后将分别得到的Train_dataset和Test_dataset,然后再把这两个东西扔到DataLoader里,实例化DataLoader里面有常用到的两个需要设置的变量,shuffle设置为Ture就是对输入的训练集或者测试集进行打乱,然后batch_size指的是训练中使用的Mini-Batch策略种batch的大小。
3.5 构建dataloader
Train_dataset = Dataset(train_dataset)
Test_dataset = Dataset(test_dataset)
dataloader = DataLoader(Train_dataset, shuffle=True, batch_size=50)
testloader = DataLoader(Test_dataset, shuffle=True, batch_size=50)
3.6 选择训练设备
选择训练设备,是选择CPU训练还是GPU训练,下面代码的作用是如果cuda可用一般来说也就是你安装的pytorch是GPU版本的那就默认设备是GPU,如果没有GPU,那torch.cuda.is_available()会返回False就会选择CPU,一般来说我们使用自己的笔记本,或者台式机的时候都是只有一个显卡,如果你的设备是服务器,且安装了多个显卡的情况下,这里的cuda:0可以设置成成其他编号的cuda例如cuda:1 cuda:2以此类推
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
3.7 选择训练模型
此时之前我们在Package_dataset种返回channels,length,classes的作用就出来了,在对模型进行实例化的部分,会需要用到这些参数,在如果在模型构建的过程中使用了自适应池化层,一般就不需要传入样本点数,也就是值的长度,因此一般有两种情况,初始化需要输入通道数,类别个数,和值的长度也就在一维种的样本点个数,或者只需要输入通道数,和类别个数。
其中model.to(device)是将模型部署到我们上一步选择的device上
# 模型初始化
# model = LeNet(in_channels=channels, input_sample_points=length, classes=classes)
# model = AlexNet(in_channels=channels, input_sample_points=length, classes=classes)
# model = AlexNet(in_channels=channels, input_sample_points=length, classes=classes)
# model = ZFNet(in_channels=channels, input_sample_points=length, classes=classes)
# model = VGG19(in_channels=channels, classes=classes)
# model = GoogLeNet(in_channels=channels, classes=classes)
# model =ResNet50(in_channels=channels, classes=classes)
# model =DenseNet(in_channels=channels, classes=classes)
# model =SqueezeNet(in_channels=channels, classes=classes)
# model =MobileNetV1(in_channels=channels, classes=classes)
# model =MobileNetV2(in_channels=channels, classes=classes)
# model =MobileNetV3_small(in_channels=channels, classes=classes)
# model =MobileNetV3_large(in_channels=channels, classes=classes)
# model =shuffuleNetV1_G3(in_channels=channels, classes=classes)
# model =Xception(in_channels=channels, classes=classes)
model =shuffuleNetV2(in_channels=channels, classes=classes)
model.to(device)
3.8 损失函数的选择
损失函数的选择,在对模型实例化了之后需要进一步选择一下用于计算模型训练出的结果和实际结果的不一致程度,也就是损失的大小,下面的代码里使用的交叉误熵损失函数,同时这个损失函数也可以认为是一个模型所以也可以把损失函数使用和将模型移动到 GPU上同样的方法将损失函数也移动到GPU上。在多分类任务中,损失函数直接选用交叉误熵就可以了。
criterion = torch.nn.CrossEntropyLoss()
criterion.to(device)
3.9 优化器的选择
优化器选择,由于深度学习算法的核心思想就是反向传播和梯度下降,其中值得使用的就两种,一种Adam一种SGD加动量,其他的不需要尝试。
# 优化器选择
# optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
3.10 初始化保存训练集准确率和测试集准确率的列表
初始化两个列表,这两个列表分别用于存储训练集准确率和测试集准确率,最终代码中,每间隔show_result_epoch轮保存一次训练准确率和测试准确率,打印一次训练集和测试集的准确率
train_acc_list = []
test_acc_list = []
3.11 训练函数详解(关键)
接下来就是最难的部分训练函数的部分了,我会逐个非常细致的讲解,将train函数进行额外的拆解,如果你是小白希望你不要被吓退,看懂这个你就超越了绝大多出只会复制粘贴的人了。首先train函数需要传入的一个参数就是epoch,这个参数是当前的轮数,这个参数的作用是用来判断当前的训练轮数是否为show_result_epoch的整数倍,如果话计算该次训练训练集和准确率和测试集的准确率。
def train(epoch):
设置模型为train模式,之后在预测测试集的时候会执行model.eval()函数,两种状态主要会影响Dorpout和BatchNormilze,以Dorpout为例如果在train模式下,Droput每次预测时候丢提的节点是随机的,但是在eval模式下他丢弃哪个节点是固定的。如果想用复现测试集的结果则必须在训练和测试的时候添加模式切换代码,否则会复现不出结果
model.train()
train_correct正确的训练集样本个数,train_total用来保存的是所有样本总数,
train_correct = 0train_total = 0
模型的训练步骤,也是整个代码最核心的部分,就是这部分代码实现了深度学习训练的功能下面逐行解释
for data in dataloader:train_data_value, train_data_label = datatrain_data_value, train_data_label = train_data_value.to(device), train_data_label.to(device)train_data_label_pred = model(train_data_value)loss = criterion(train_data_label_pred, train_data_label)optimizer.zero_grad()loss.backward()optimizer.step()
dataloader = DataLoader(Train_dataset, shuffle=True, batch_size=50)
从迭代器种读取打包好的数据假设dataloder的长度为 n n n,这个dataloder是这个代码过来的,可以看到里面的batch_size设置的大小为50,假设我们输入进去的Train_dataset长度为70,则最后dataloder可以通过迭代得到一个长度为50的样本和一个长度为20的样本,假设batch_size设置的值为10,则,会返回7个长度为10的样本,假设batch_size值设为100,则返回一个长度为70的他并非v恶霸,总结一下,一共会得到三种情况。
- 当
batch_size的值大于DataLoader()的输入的第一个参数Train_dataset或者Test_dataset的长度的时候,迭代器只迭代一次数据,数据的大小是输入的Train_dataset或者Test_dataset的长度,也就是只起到打乱的一下的作用,但是没有使用mini_batch策略 - 当
batch_size的值小于DataLoader()的输入的第一个参数Train_dataset或者Test_dataset的长度,且输入的Train_dataset或者Test_dataset的长度是batch_size的整数倍的时候,假设输入的Dataloader的dataset长度为 n n nbatch_size大小为 b b b,迭代次数 t = n ∣ b t=n|b t=n∣b,这个 ∣ | ∣代表的是整除,也就是可以迭代 t t t次每次迭代的数据长度为 b b b - 当
batch_size的值小于DataLoader()的输入的第一个参数Train_dataset或者Test_dataset的长度,且输入的Train_dataset或者Test_dataset的长度不是batch_size的整数倍的时候,同样假设Dataloader的dataset长度为 n n nbatch_size大小为 b b b,则迭代次数是 t + 1 t+1 t+1次同样 t = n ∣ b t=n|b t=n∣b,前 t t t次的迭代出的数据长度为 b b b,最后一次的迭代的数据长度为 n − t × b n-t×b n−t×b
for data in dataloader:
对于每次迭代得到的数据进行下面的操作
首先data数据内包含两个值,一个这个batch中的值另一个是这个batch中的标签
train_data_value, train_data_label = data
之后将得到的值和标签都放到device中
train_data_value, train_data_label = train_data_value.to(device), train_data_label.to(device)
然后调用模型进行预测train_data_label_pred为预测到的结果,这里要说一下这个结果的数据维度是(len(data),classes),len(data)本地迭代到的data的数据长度,classes是该分类任务的类别数量。
train_data_label_pred = model(train_data_value)
调用criterion损失函数计算损失,新手注意输入的预测值和真实标签不是预测标签和真实标签
loss = criterion(train_data_label_pred, train_data_label)
梯度清零,调用optimizer的zero_grad方法,将为每一个可学习参数保存的梯度都清楚到,需要独立拆除这一步的原因据说是保留的目的是有一些任务需要累计反向传播的梯度。
optimizer.zero_grad()
反向传播梯度,通过反向传播给每一个学习参数都分配一个梯度
loss.backward()
参数更新,使用梯度与原有的参数作用一下得到这一轮学习之后的参数,作用的方式就是执行以下梯度下降,具体作用的方式和选用的优化器有关。
optimizer.step()
下面是计算准确率和测试的部分,epoch为当前训练轮次,show_result_epoch为多少轮查看一次训练集和测试集的准确率还有损失,并且把训练集和测试集的损失记录下来绘制一个准确率的变化曲线。
if epoch % show_result_epoch == 0:
通过torch.max来获得预测的标签,torch.max返回两个值一个是最大的概率probability,一个是最大值的索引predicted,也就是我们认为的标签。
probability, predicted = torch.max(train_data_label_pred.data, dim=1)
torch.max示例代码如下
import torchdata = torch.Tensor([[0.6, 0.4],[0.3, 0.7]])probability, predicted = torch.max(data.data, dim=1)print(probability)
# tensor([0.6000, 0.7000])
print(predicted)
# tensor([0, 1])
将本次训练的样本个数记录到保存训练样本总个数的变量train_total,至于后面跟着的size(0)是表示的是读取Tensor维度第一个值,例如train_data_label_pred维度为(20,2)20为本次的batch大小2,为类别数量,train_data_label_pred.size(0)就是把20取出来。
train_total += train_data_label_pred.size(0)
记录预测正确样本的个数predicted == train_data_label将预测标签和真实标签对比,这是一个语法首先这两个Tensor的长度得一致,之后会返回一个包含Ture和Flase的数组,对应位置预测的标签相同为Ture预测的标签不同为False,之后在(predicted == train_data_label)加一个.sum()返回的就是预测正确的样本的个数,一个简单的例子如下.item()返回Tensor中的值。
train_correct += (predicted == train_data_label).sum().item()
import torchpredicted = torch.Tensor([0, 1, 1, 0, 1])
train_data_label = torch.Tensor([0, 0, 1, 0, 1])print(predicted == train_data_label)
# tensor([ True, False, True, True, True])
print((predicted == train_data_label).sum())
# tensor(4)
print((predicted == train_data_label).sum().item())
# 4
计算训练集准确率并添加到train_acc_list中,train_correct为预测正确的数量,train_total为预测的样本总数,round的作用是作用域浮点数取小数点后多少位。
train_acc = round(100 * train_correct / train_total, 4)train_acc_list.append(train_acc)
打印准确率和损失
print('=' * 10, epoch // 10, '=' * 10)print('loss:', loss.item())print(f'Train accuracy:{train_acc}%')
那吗训练函数的完整代码如下,解读完毕
def train(epoch):model.train()train_correct = 0train_total = 0for data in dataloader:train_data_value, train_data_label = datatrain_data_value, train_data_label = train_data_value.to(device), train_data_label.to(device)train_data_label_pred = model(train_data_value)loss = criterion(train_data_label_pred, train_data_label)optimizer.zero_grad()loss.backward()optimizer.step()if epoch % show_result_epoch == 0:probability, predicted = torch.max(train_data_label_pred.data, dim=1)train_total += train_data_label_pred.size(0)train_correct += (predicted == train_data_label).sum().item()train_acc = round(100 * train_correct / train_total, 4)train_acc_list.append(train_acc)print('=' * 10, epoch // 10, '=' * 10)print('loss:', loss.item())print(f'Train accuracy:{train_acc}%')test()
3.12 测试函数解释
同理测试函数除了没有反向传播计算损失和训练过程之外,其他基本一致,其中唯一多的就是在进入调用迭代器读取测试集样本之前多轮一个with torch.no_grad()用于关闭梯度改变相关的功能,这里我刚看的时候也疑惑我没有进行反向传播为什么还需要锁以下梯度,通过查找,得到的答案是即使不使用梯度对参数进行更新如果不把梯度这块给锁上PyTorch默认会跟踪和存储用于自动梯度计算的中间值会影响运算效率,也要避免在一定情况下即使不用优化器更新梯度也可能会造成梯度的改变,因此使用torch.no_grad()是必要的。
def test():model.eval()test_correct = 0test_total = 0with torch.no_grad():for testdata in testloader:test_data_value, test_data_label = testdatatest_data_value, test_data_label = test_data_value.to(device), test_data_label.to(device)test_data_label_pred = model(test_data_value)test_probability, test_predicted = torch.max(test_data_label_pred.data, dim=1)test_total += test_data_label_pred.size(0)test_correct += (test_predicted == test_data_label).sum().item()test_acc = round(100 * test_correct / test_total, 3)test_acc_list.append(test_acc)print(f'Test accuracy:{(test_acc)}%')
3.13 进行训练
为了不让打印出现第0次训练整体变成了(1, epoch_number+1),这块不难但有时候要是懵住了或者就想知道为啥的话,俺就改成range(epoch_number)跑一下看看即可。
for epoch in range(1, epoch_number+1):train(epoch)
3.14 绘制训练测试准确率曲线
plt.plot(np.array(range(epoch_number//show_result_epoch)) * show_result_epoch, train_acc_list)
plt.plot(np.array(range(epoch_number//show_result_epoch)) * show_result_epoch, test_acc_list)
plt.legend(['train', 'test'])
plt.title('Result')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
训练轮数为1000,最终结果如下,由于我们的数据是随机生成的二分类数据集,所以测试集的准确率最终在50%上下移动。

4.训练完整代码
希望您在看下面的完整代码之前可以先查看上面的内容,之后您看下面的代码再也不会恐惧会有一种通透的感觉。
import numpy as np
import torch
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, Dataset,random_split
from Package_dataset import package_datasetfrom Models.LeNet import LeNet
from Models.AlexNet import AlexNet
from Models.ZFNet import ZFNet
from Models.VGG19 import VGG19
from Models.GoogLeNet import GoogLeNet
from Models.ResNet50 import ResNet50
from Models.DenseNet import DenseNet
from Models.SqueezeNet import SqueezeNet
from Models.Mnasnet import MnasNetA1
from Models.MobileNetV1 import MobileNetV1
from Models.MobileNetV2 import MobileNetV2
from Models.MobileNetV3 import MobileNetV3_large, MobileNetV3_small
from Models.shuffuleNetV1 import shuffuleNetV1_G3
from Models.shuffuleNetV2 import shuffuleNetV2
from Models.Xception import Xceptiondata = np.load('Dataset/data.npy')
label = np.load('Dataset/label.npy')dataset_partition_rate = 0.7
epoch_number = 1000
show_result_epoch = 10dataset, channels, length, classes = package_dataset(data, label)# partition dataset
train_len = int(len(dataset) * dataset_partition_rate)
test_len = int(len(dataset)) - train_len
train_dataset, test_dataset = random_split(dataset=dataset, lengths=[train_len, test_len])# 数据库加载
class Dataset(Dataset):def __init__(self, data):self.len = len(data)self.x_data = torch.from_numpy(np.array(list(map(lambda x: x[0], data)), dtype=np.float32))self.y_data = torch.from_numpy(np.array(list(map(lambda x: x[-1], data)))).squeeze().long()def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self):return self.len# 数据库dataloader
Train_dataset = Dataset(train_dataset)
Test_dataset = Dataset(test_dataset)
dataloader = DataLoader(Train_dataset, shuffle=True, batch_size=50)
testloader = DataLoader(Test_dataset, shuffle=True, batch_size=50)
# 训练设备选择GPU还是CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 模型初始化
# model = LeNet(in_channels=channels, input_sample_points=length, classes=classes)
# model = AlexNet(in_channels=channels, input_sample_points=length, classes=classes)
# model = AlexNet(in_channels=channels, input_sample_points=length, classes=classes)
# model = ZFNet(in_channels=channels, input_sample_points=length, classes=classes)
# model = VGG19(in_channels=channels, classes=classes)
# model = GoogLeNet(in_channels=channels, classes=classes)
# model =ResNet50(in_channels=channels, classes=classes)
# model =DenseNet(in_channels=channels, classes=classes)
# model =SqueezeNet(in_channels=channels, classes=classes)
# model =MobileNetV1(in_channels=channels, classes=classes)
# model =MobileNetV2(in_channels=channels, classes=classes)
# model =MobileNetV3_small(in_channels=channels, classes=classes)
# model =MobileNetV3_large(in_channels=channels, classes=classes)
# model =shuffuleNetV1_G3(in_channels=channels, classes=classes)
# model =Xception(in_channels=channels, classes=classes)
model =shuffuleNetV2(in_channels=channels, classes=classes)
model.to(device)# 损失函数选择
criterion = torch.nn.CrossEntropyLoss()
criterion.to(device)
# 优化器选择
# optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)train_acc_list = []
test_acc_list = []# 训练函数
def train(epoch):model.train()train_correct = 0train_total = 0for data in dataloader:train_data_value, train_data_label = datatrain_data_value, train_data_label = train_data_value.to(device), train_data_label.to(device)train_data_label_pred = model(train_data_value)loss = criterion(train_data_label_pred, train_data_label)optimizer.zero_grad()loss.backward()optimizer.step()if epoch % show_result_epoch == 0:probability, predicted = torch.max(train_data_label_pred.data, dim=1)train_total += train_data_label_pred.size(0)train_correct += (predicted == train_data_label).sum().item()train_acc = round(100 * train_correct / train_total, 4)train_acc_list.append(train_acc)print('=' * 10, epoch // 10, '=' * 10)print('loss:', loss.item())print(f'Train accuracy:{train_acc}%')test()# 测试函数
def test():model.eval()test_correct = 0test_total = 0with torch.no_grad():for testdata in testloader:test_data_value, test_data_label = testdatatest_data_value, test_data_label = test_data_value.to(device), test_data_label.to(device)test_data_label_pred = model(test_data_value)test_probability, test_predicted = torch.max(test_data_label_pred.data, dim=1)test_total += test_data_label_pred.size(0)test_correct += (test_predicted == test_data_label).sum().item()test_acc = round(100 * test_correct / test_total, 3)test_acc_list.append(test_acc)print(f'Test accuracy:{(test_acc)}%')for epoch in range(1, epoch_number+1):train(epoch)plt.plot(np.array(range(epoch_number//show_result_epoch)) * show_result_epoch, train_acc_list)
plt.plot(np.array(range(epoch_number//show_result_epoch)) * show_result_epoch, test_acc_list)
plt.legend(['train', 'test'])
plt.title('Result')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
经验总结
- 优化器只有Adam和SGD加动量值得尝试SGD动量一般设置为0.9
- 提升准确率最快的方法是在数据预处理时对数据进行归一化,其次是在卷积层后加批量归一化
BatchNormalize - 出现准确率一致无变化也就是梯度消失的情况时候将ReLu函数改成LeakLyRelu
- 对于一维数据来说基础模型中ResNet往往准确率最高
- 在模型上堆砌注意力机制和循环神经网络这种大概率会提升准确率如果你是想做点好的出来不推荐使用
- 报cuda memory 错误是batch_size设大了,或者内存占用多了,重启不行就改小batch_size
- bat_size卷积层数量等超参数设置为处理的核数量的整数倍,一般为32的倍数
结束
之后在考虑要不要弄一个二维的,还是在专栏里继续做一维模型复现的讲解,然后我开个投票到时候哪个多我更新哪个方向。
相关文章:
Pytroch 自写训练模板适合入门版 包含十五种经典的自己复现的一维模型 1D CNN
训练模板 在毕业之前,决定整理一下手头的代码,自己做1D-CNN这吗久,打算开源一下自己使用的1D-CNN的代码,包括用随机数生成一个模拟的数据集,到自己写的一个比较好的适合入门的基础训练模板,以及自己复现的…...

【30秒看懂大数据】变量
简单说 变量是指研究或观察中可能发生变化的事物、属性或特征,它们可以用来描述数据或现象的不同方面。 举例理解 一位热衷于烹饪的大厨老李,经常尝试不同的菜肴来满足不同顾客的口味。 1. 老李明白,每种食材都等同于一个重要的变量…...

Redis - 多集群数据源配置
目录 前言依赖yml配置redis多集群数据源配置类思考 redis工具类 前言 工作时有一个项目配置了多个redis数据源,使用时出现了指定了使用副数据源,数据却依然使用了主数据源的情况。经过排查,发现配置流程较为繁琐易错,此处做一个记…...

五大架构风格之四-虚拟机架构风格
虚拟机架构风格: 虚拟机架构风格是一种软件架构,它通过模拟完整的计算机系统(包括硬件)来运行程序。这种风格的核心是虚拟机监控器。如最出名的虚拟机VM,在使用虚拟机架构,一个或多个虚拟机可以在单一物理主…...

在 C# 中 checked 和 unchecked 关键字
在 C# 中,checked 和 unchecked 是用于控制整数运算溢出检查的关键字。它们允许我们明确指定在进行整数运算时是否要检查溢出,以及如何处理溢出情况。 默认情况下,C# 中的整数运算是未检查的,也就是说,当运算结果溢出…...
【算法分析与设计】跳跃游戏
📝个人主页:五敷有你 🔥系列专栏:算法分析与设计 ⛺️稳中求进,晒太阳 题目 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断…...

openssl3.2 - helpdoc - P12证书操作
文章目录 openssl3.2 - helpdoc - P12证书操作概述笔记/doc/html/man1/CA.pl.htmlCA.pl -newcaCA.pl -newreqCA.pl -signCA.pl -pkcs12 "My Test Certificate"/doc/html/man1/openssl-pkcs12.html备注END openssl3.2 - helpdoc - P12证书操作 概述 D:\3rd_prj\cryp…...
【产业实践】使用YOLO V5 训练自有数据集,并且在C# Winform上通过onnx模块进行预测全流程打通
使用YOLO V5 训练自有数据集,并且在C# Winform上通过onnx模块进行预测全流程打通 效果图 背景介绍 当谈到目标检测算法时,YOLO(You Only Look Once)系列算法是一个备受关注的领域。YOLO通过将目标检测任务转化为一个回归问题,实现了快速且准确的目标检测。以下是YOLO的基…...
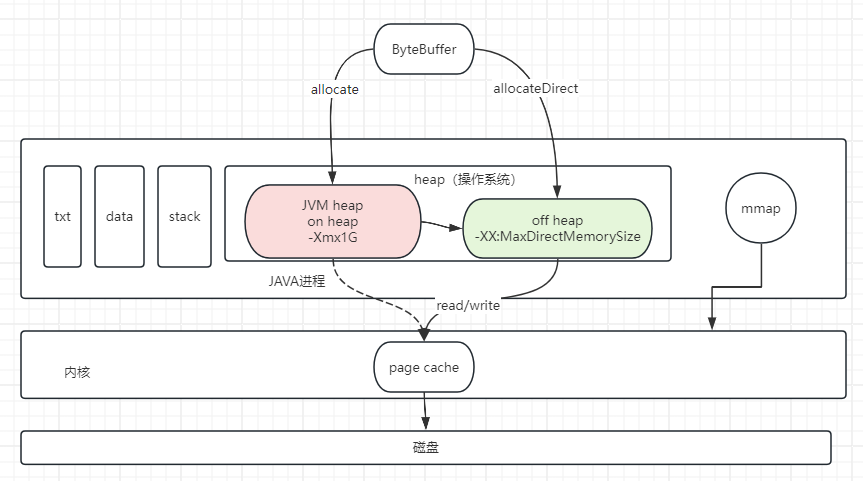
【操作系统】HeapByteBuffer和DirectByteBuffer的区别
DirectByteBuffer和HeapByteBuffer是Java NIO中ByteBuffer的两种实现方式。 HeapByteBuffer是在Java堆上分配的字节缓冲区,它使用数组来存储数据。HeapByteBuffer的优点是它具有良好的兼容性和可移植性,且在大多数情况下性能表现良好。它适用于大部分的…...

C++并发编程 -2.线程间共享数据
本章就以在C中进行安全的数据共享为主题。避免上述及其他潜在问题的发生的同时,将共享数据的优势发挥到最大。 一. 锁分类和使用 按照用途分为互斥、递归、读写、自旋、条件变量。本章节着重介绍前四种,条件变量后续章节单独介绍。 由于锁无法进行拷贝…...
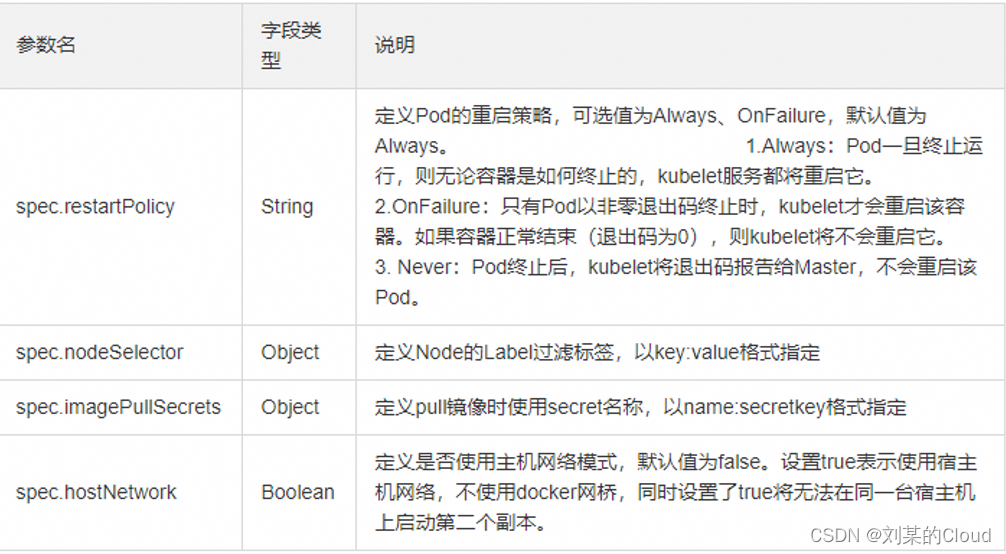
Kubernetes-资源清单
一、k8s中的资源 什么是资源清单 我们跟kubernetes集群进行交互的时候,我们需要给K8S集群传输数据,传输信息,K8S才能按照我们的要求来运行,这个传输的文件,基本上都会通过资源清单进行传递。资源清单是我们跟集群进行…...

ABAP 笔记--内表结构不一致,无法更新数据库MODIFY和UPDATE
目录 ABAP 笔记内表结构不一致,无法更新数据库MODIFY和UPDATE ABAP 笔记 内表结构不一致,无法更新数据库 MODIFY和UPDATE 如果是使用MODIFY或者UPDATE...
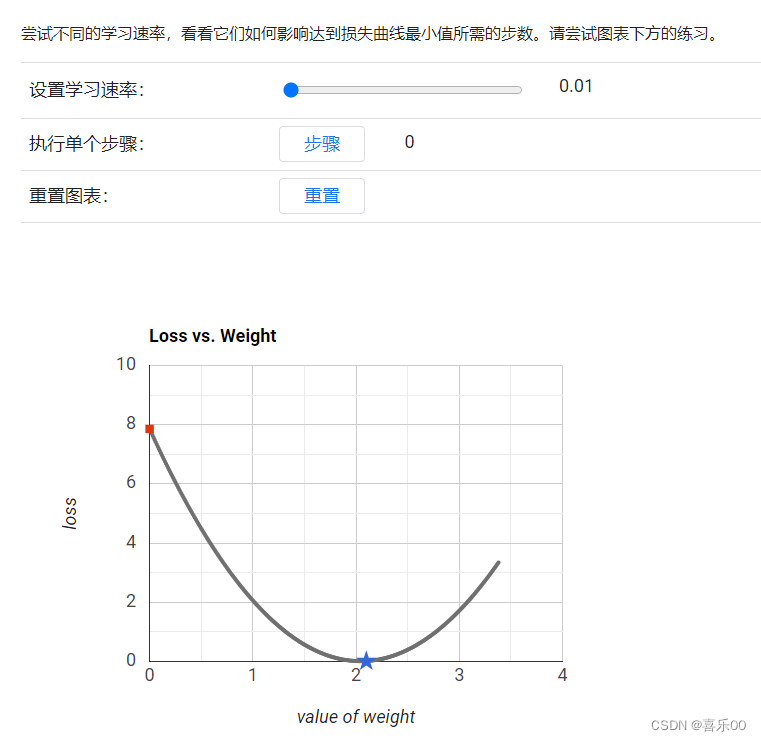
机器学习-3降低损失(Reducing Loss)
机器学习-3降低损失(Reducing Loss) 学习内容来自:谷歌ai学习 https://developers.google.cn/machine-learning/crash-course/framing/check-your-understanding?hlzh-cn 本文作为学习记录1.降低损失:迭代方法 迭代学习 下图展示了机器学习算法用于训…...
-高精度-减-高精度)
蓝桥杯备战(AcWing算法基础课)-高精度-减-高精度
目录 前言 1 题目描述 2 分析 2.1 第一步 2.2 第二步 3 代码 前言 详细的代码里面有自己的理解注释 1 题目描述 给定两个正整数(不含前导 00),计算它们的差,计算结果可能为负数。 输入格式 共两行,每行包含一…...
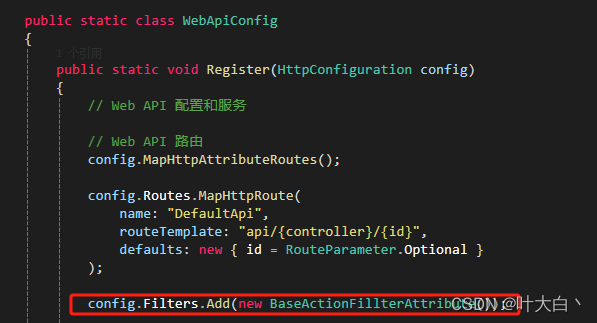
AspNet web api 和mvc 过滤器差异
最近在维护老项目。定义个拦截器记录接口日志。但是发现不生效 最后发现因为继承的 ApiController不是Controller 只能用 System.Web.Http下的拦截器生效。所以现在总结归纳一下 Web Api: System.Web.Http.Filters.ActionFilterAttribute 继承该类 Mvc: System.Web.Mvc.Ac…...
HarmonyOS应用/服务发布:打造多设备生态的关键一步
目前 前言HarmonyOS 应用/服务发布的重要性使用HarmonyOS 构建跨设备的应用生态前期准备工作简述发布流程生成签名文件配置签名信息编译构建.app文件上架.app文件到AGC结束语 前言 随着智能设备的快速普及和多样化,以及编程语言的迅猛发展,构建一个无缝…...
【数据结构】双向带头循环链表实现及总结
简单不先于复杂,而是在复杂之后。 文章目录 1. 双向带头循环链表的实现2. 顺序表和链表的区别 1. 双向带头循环链表的实现 List.h #pragma once #include <stdio.h> #include <assert.h> #include <stdlib.h> #include <stdbool.h>typede…...
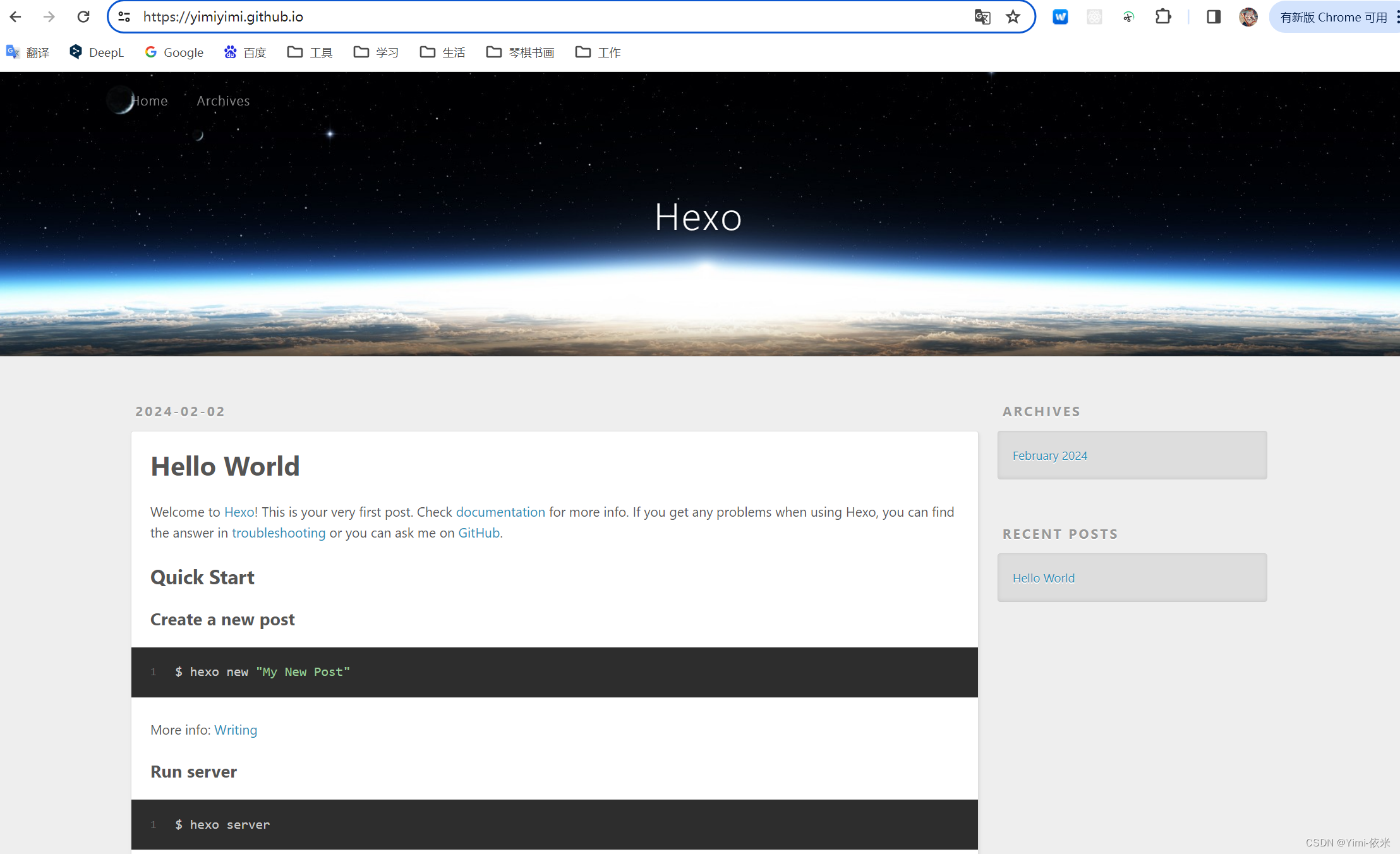
创建自己的Hexo博客
目录 一、Github新建仓库二、支持环境安装Git安装Node.js安装Hexo安装 三、博客本地运行本地hexo文件初始化本地启动Hexo服务 四、博客与Github绑定建立SSH密钥,并将公钥配置到github配置Hexo与Github的联系检查github链接访问hexo生成的博客 一、Github新建仓库 登…...
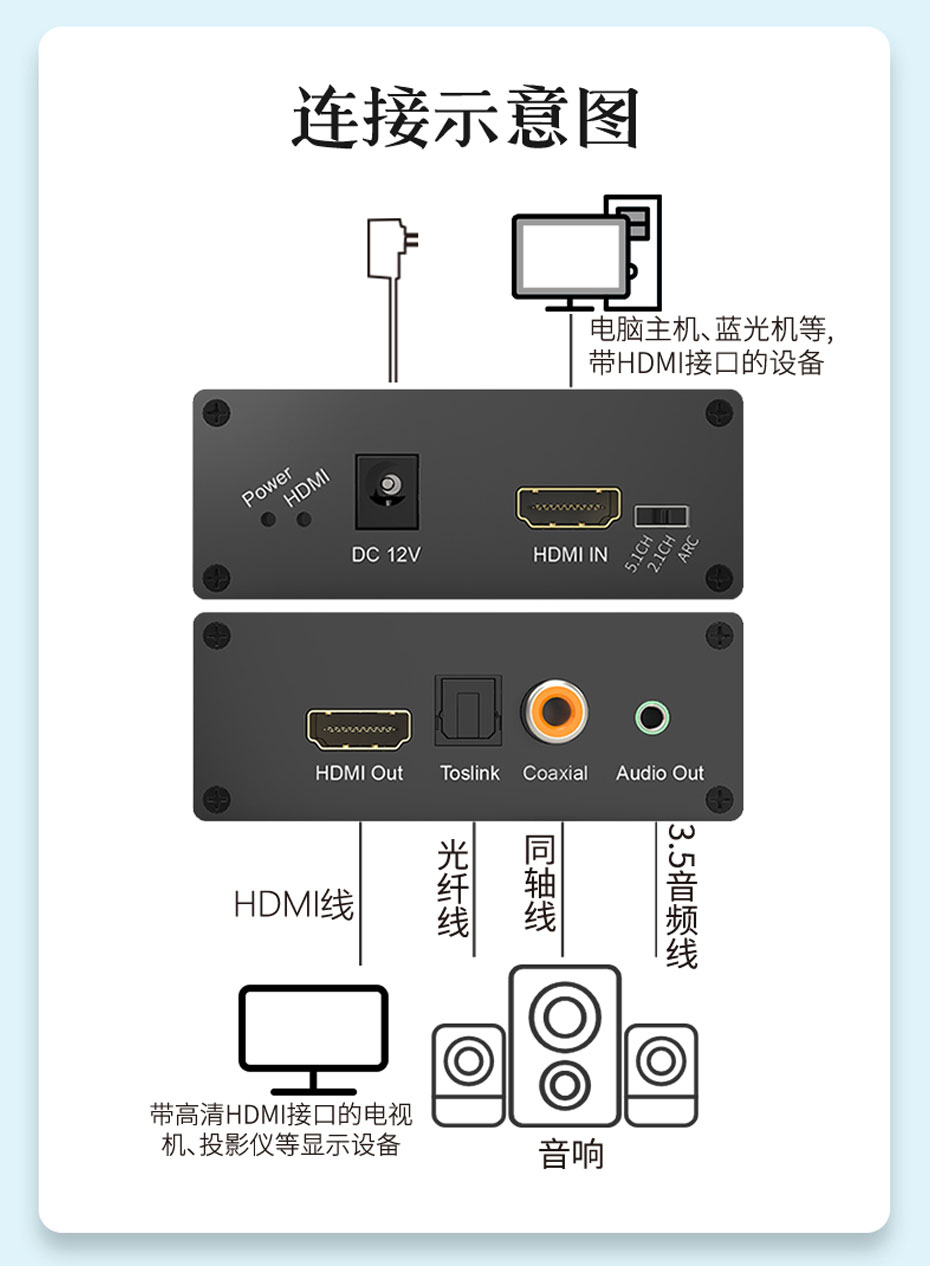
音箱、功放播放HDMI音频解决方案之HDMI音频分离器HHA
HDMI音频分离器HHA简介 HDMI音频分离器HHA具有一路HDMI信号输入,转换成一路HDMI信号、一路5.1光纤音频信号、一路5.1 SPDIF/同轴音频信号和一路模拟左右声道立体声信号输出,同时还支持EDID存储及兼容HDCP功能;分辨率最高支持1920*1080p&#…...
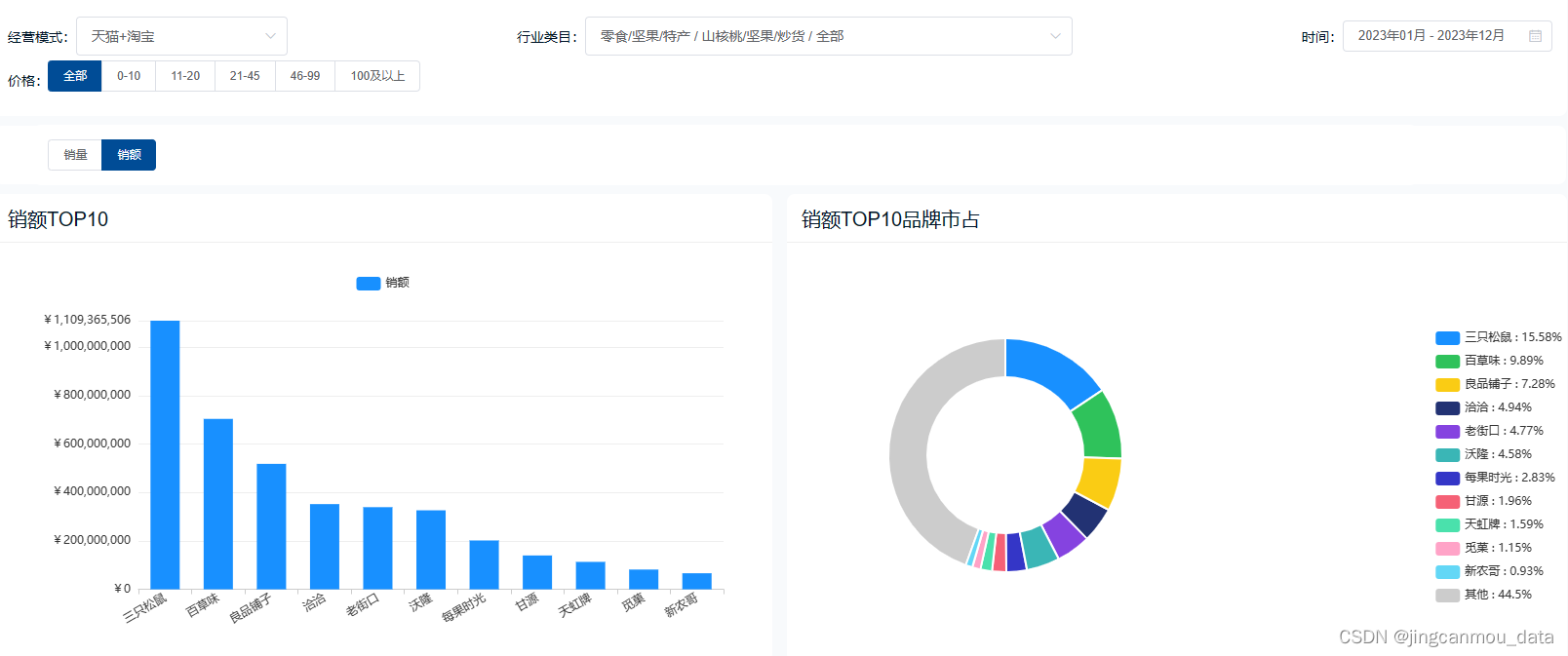
天猫数据分析:2023年坚果炒货市场年销额超71亿,混合坚果成多数消费者首选
近年来,随着人们生活水平和健康意识的提升,在休闲零食市场中,消费者们也越来越关注食品的营养价值,消费者这一消费偏好的转变也为坚果炒货食品行业带来了发展契机。 整体来看,坚果炒货市场的体量较大。根据鲸参谋电商…...
)
告别模型臃肿:手把手教你用vLLM部署NVFP4量化的DeepSeek模型(附完整配置)
实战指南:NVFP4量化DeepSeek模型在vLLM中的高效部署 当你在深夜调试一个70B参数的模型时,服务器内存占用突然从480GB骤降到120GB——这不是魔法,而是NVFP4量化带来的真实效果。作为Blackwell架构引入的革命性4-bit格式,NVFP4正在…...

【深度学习新浪潮】OpenClaw架构与技术关键点全解析:为什么它能成功,而前代框架纷纷折戟?
引言 在AI Agent从概念走向落地的过程中,AutoGPT、LangChain早期版本、BabyAGI等框架一度掀起热潮,但始终难以实现规模化、稳定化的实际生产落地。OpenClaw作为MIT主导开源的本地优先AI执行网关,上线后迅速成为现象级开源项目,其核…...

用快马快速构建战网更新睡眠模式诊断工具原型
最近在帮朋友排查战网(Battle.net)客户端更新卡顿的问题时,发现"更新服务进入了睡眠模式"这个提示特别常见。作为开发者,如果能快速验证各种修复方案的有效性,会大大提升排查效率。今天就用InsCode(快马)平台来快速搭建一个诊断工具…...

seo发布网站和传统推广方式相比有什么优势
SEO发布网站与传统推广方式相比有哪些优势 在当今数字化时代,网络已经成为人们获取信息和消费产品的重要途径。如何在众多的网站中脱颖而出,吸引更多的目标用户,是每一个企业和品牌都面临的问题。在这种背景下,SEO发布网站和传统…...

新手福音:在快马平台跟随交互式教程轻松搞定openclaw安装
最近在学习openclaw这个工具时,发现很多教程要么太简略,要么步骤不完整,对新手特别不友好。后来在InsCode(快马)平台上发现可以创建交互式教程项目,就尝试做了一个完整的openclaw安装指南。整个过程比我预想的顺利很多,…...

如何用 GitHub Actions 自部署 GitHub Readme Stats,并统计私有仓库数据
目录背景介绍通过 GitHub Actions 自部署 GitHub Readme Stats如何使用 GitHub Actions 配置统计私有仓库数据1. 生成 Personal Access Token (PAT) 以统计私有仓库**如何生成 Personal Access Token (PAT)**:2. 使用 GitHub Secrets 存储 PAT3. 为什么默认配置无法…...

解放双手!U校园智能刷课工具全攻略:2分钟搞定网课必修题
解放双手!U校园智能刷课工具全攻略:2分钟搞定网课必修题 【免费下载链接】AutoUnipus U校园脚本,支持全自动答题,百分百正确 2024最新版 项目地址: https://gitcode.com/gh_mirrors/au/AutoUnipus 还在为U校园平台上堆积如山的网课任务而头疼吗&a…...

Pine Script交易策略开发实战指南:从零基础到自动化交易的完整路径
Pine Script交易策略开发实战指南:从零基础到自动化交易的完整路径 【免费下载链接】awesome-pinescript A Comprehensive Collection of Everything Related to Tradingview Pine Script. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-pinescript …...
:免疫共受体的核心机制与抗体药物研发逻辑)
CD4(分化簇4):免疫共受体的核心机制与抗体药物研发逻辑
CD4(分化簇4,Cluster of Differentiation 4)作为辅助性T细胞的关键标志物与免疫应答的核心共受体,不仅在适应性免疫中扮演“指挥官”角色,更是感染性疾病与自身免疫病药物研发的重要靶点。本文从分子结构、信号转导机制…...

【海洋空间信息工程概论 实验报告4】空间数据投影变换
上一篇:【海洋空间信息工程概论 实验报告3】海洋数据矢量化 目录 一、实验目的 二、实验环境 三、实验内容 实验步骤 编辑 实验心得 一、实验目的 由于数据源的多样性,当数据与我们研究、分析问题的空间参考系统(坐标系统、投影方式…...