2024年1月27日~2月2日周报
一、前言
上周主要完成了SeisInvNet加强版论文的阅读,并尝试跑了一下代码。
本周阅读师兄的论文《DD-Net》,并尝试思考新的点子修改网络架构。
二、DD-Net阅读情况
标题:Dual decoder network with curriculumlearning for full waveform inversion(具有课程学习功能的用于全波形反演的双解码器网络DD-Net)
期刊:IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING(IEEE地球科学与遥感汇刊)
源代码:github.com/fansmale/ddnet
本文设计了一个具有两个解码器的U形网络,以获取速度模型的速度值和地层边界信息。解码器的反馈将在编码器处组合以增强边缘空间信息的编码。另外,通过组织三个难度级别的数据,将课程学习引入网络训练。由易到难的训练过程增强了网络的数据拟合。此外,通过预网络降维器(野外采集时采样点和检波器数量差异果茶,共炮点道集图像纵横比过大,通过多个卷积组成的降维结构来压缩时间维度)将网络应用于低分辨率地震观测。在SEG盐数据集和OpenFWI的四个合成数据集上进行了实验。
在SEG盐和OpenFWI数据集上进行实验,其中使用四个指标:MSE,MAE,UIQ和LPIPS。同时,使用两个DL-FWI网络—FCNVMB和InversionNet,与DD-Net网络进行了比较。结果表明:
- 1)DD-Net网络在不同数据集上的表现优于同行;
- 2)课程学习和DL-FWI的集成提高了网络的学习能力;
- 3)双解码器有助于重建速度模型中的边缘细节;
- 4)DD-Net网络对各种数据具有良好的泛化能力。
2.1 DD-Net网络架构
DD-Net的架构如下图所示,其基本思想来自Unet,具有明显的左右高度对称的编解码器结构,整体结构呈Y形。

图1. 用于反演的DD-Net的深度网络架构。每个立方体的宽度表示图像中通道的数量,在立方体下方以蓝色标记。黑色数字表示当前网络层的图像大小(如400 × 301输入)。图上方的箭头是卷积和池化操作的简化表示。其中,红色箭头表示三个连续的固定操作,即卷积,BN(批量归一化)和ReLU。蓝色立方体代表编码器的信息,橙色代表解码器。红色虚线框指示两部分通道的级联操作。黑色虚线箭头指示输入到解码器的特征的源,在此期间原始解码器维度被扩展。
传统的U-Net进行图像分割时,存在轮廓粗糙和不连续的问题。不同的解码器将U-Net变成一个多任务学习环境,子任务解码器还可以为主任务或后续任务提供参数上下文。左侧的编码器组件负责地震数据的压缩过程,将29炮的地震观测记录压缩成1024维的抽象结构化信息。右边的两个解码器使用不同的想法来解释高维抽象信息。第一解码器的目标是常规的速度模型,是预测的主要解码器,关注速度值的准确拟合。然后,Canny轮廓提取后的二进制速度模型进一步用作第二解码器的拟合目标。该解码器将用作训练轮廓信息的辅助解码器。轮廓解码器以确保分割预测的平滑性。
网络中有两个基本操作,即卷积和反卷积,分别用于编码器和解码器。
(a)在编码器中,重复卷积充分利用地震波形中的连续信息。BN在卷积后对输入网络的数据子集进行归一化,从而提高收敛性。ReLU激活函数通过删除一些网络节点来保证层到层的非线性。同时,通过多个ReLU的非线性叠加,该深度网络可以近似波动方程的映射。
(b)在解码器中,反卷积操作可以将高度压缩的信息扩展为更高分辨率的图像,同时保留尽可能多的信息。跳跃连接用于获得更高分辨率的编码器特征。此外,较浅的卷积层保留了不同炮之间的细粒度差异。因此,作为附加通道的较浅层的特征图可进一步引导解码器描述重叠检测区域的边界信息。表I列出了神经网络的一些详细参数设置。
表1 DD-Net网络层详细配置

共炮点道集通常与极大的纵横比相关联。对于一些检波器数量较少的低分辨率观测值,直接使用插值进行下采样可能会导致一些信息丢失。因此,本文建立了一个修改版本的DD网络与降维器为1000×70低分辨率的观测,根据检波器的数量将其命名为DD-Net 70。
在图2中,DD-Net 70在网络前面扩展了一个预网络降维器。同时,引入非方形卷积来压缩时间维度(图像高度),确保地震数据被约束到与速度模型相同的大小。降维器将使用多个卷积来协调,以防止由一个卷积压缩引起的信息丢失。这种设置类似于InversionNet,但本文将其推广到U-Net结构。
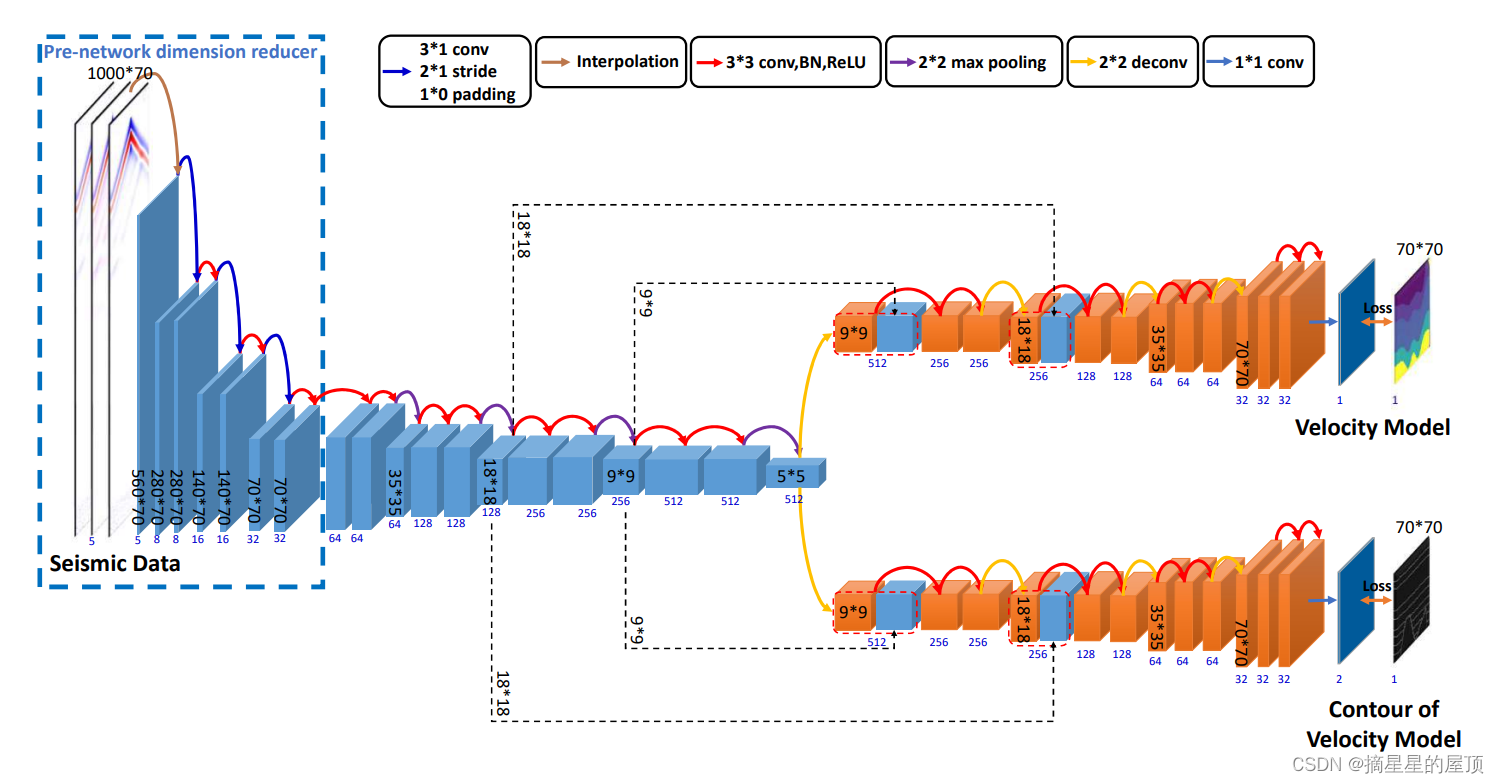
图2. 用于反演的DD-Net 70的深度网络架构。其结构与DD-Net类似(如图1所示)。不同之处在于左侧的预网络降维器。此外,非方卷积用于辅助图下方的降维器。然后,网络的输入和输出大小分别变为1000 × 70和70 × 70。
2.2 损失函数
为处理不同的解码器的不同任务,本文提出了一个新的联合损失函数的网络架构。该损失函数由均方误差(MSE)和交叉熵损失函数组成。第一解码器直接输出单通道图像。它使用地面真实情况与预测速度模型执行一对一像素差异损失计算。第二解码器输出双通道图像。这两个通道相互作用以模拟速度模型的轮廓信息。事实上,相关研究已经证明了交叉熵损失服务于速度重建中的二进制分类子任务的可行性。
首先,MSE损失函数是用于描述颜色相似性的常见损失函数,即:
(1)
其中表示输出速度模型的像素数。
和
分别表示地震数据及其相应的地面真实速度模型。
表示每次迭代中同时要训练的数据数量,即批量大小。
表示地震数据
到预测速度模型
的网络确定的映射。此外,
表示第k-th个解码器输出中的预测速度模型的第j-th个声道。因此,
是由地震数据
预测的速度模型与实际速度模型之间的残差。
第二,交叉熵损失函数提供了与差异损失相反的轮廓拟合思想,即:
(2)
其中是通过对第二解码器的两个通道执行softmax而获得的,即:
(3)
在等式中(2)是速度模型
的轮廓结构。图3(a)和图3(b)分别示出了
和
的结构。
是
的反转颜色,一致地将
和
表示为二元掩码算子
。同时,1-si和si被表示为预测灰度图像
,使用
从
中提取注意信息。在条件概率方面,在等式(2)中方程中的p(·)作为:
(4)
轮廓越明显,越大。为了确保此时的损失较小,交叉熵损失引入了负熵。因此,公式(4)经常被替换为:
(5)

图三. 速度模型及其等值线的示例。(a)是模拟的速度模型;以及(b)是通过Canny获得的该速度模型的轮廓结构。Canny的双阈值分别设置为10和15。
对于具有大的边缘偏差的样本,交叉熵损失更多地受到惩罚。这确保了拟合损失可以集中在轮廓上,而不是全局计算残差。同时,轮廓在图像中的像素比例很小。这可能导致轮廓图像中像素的不平衡分布。与均方误差相比,交叉熵损失更好地考虑了不同类的差异,更公平地考虑了轮廓和背景信息。这种类似的轮廓损失函数的设计已经在图像分割领域中实践。
最后,通过超参数α1和α2将这两个损失函数结合,即,
(6)
这两个参数的比例可根据不同的情况进行调整。为了预测准确的速度模型,一些网络可以使用非归一化速度模型进行训练和预测。此时,两个解码器损耗的数量级差异可能非常大。如SEG盐模型未归一化时,设置为
,但对于归一化的OpenFWI模型,该值常设置为10或
。
2.3 课程学习
1)FWI的课程学习:在传统的机器学习中,呈现给网络的数据集的难度属性往往是随机的。因此,它的复杂性和网络的当前学习状态被忽略。然而,课程学习以阶段性适应的理念改变了这一不足,并在许多领域取得了可观的成果。它试图逐渐增加训练数据集的难度,以确保有效的拟合。具体来说,一开始从一个相对简单的数据集开始训练网络。这有助于网络快速收敛,并防止局部最优解被卡住。然后,随着网络达到一定的性能水平,逐渐引入更复杂的数据集。
如果仅使用单炮点,则网络获得的地下信息是波覆盖的局部区域。因此,本文利用多个炮点反馈的地震波反射记录来联合预测整个地下区域。然而,在一些深度学习策略中,单炮数据也可以用来实现一定的预测效果。这意味着网络可以通过学习构建从局部波形和频率到整个速度模型的记忆映射。虽然从物理角度来看,这种映射并不合适,但它可以用作网络学习的试点。它引导网络从时域波形到速度模型留下基本的风格印象。这一过程符合课程学习的理念。
2)地震数据的预定义课程学习:网络中课程学习技术的使用必须指定两个组件的详细信息[30]。
- 难度测量器:难度测量器告诉我们哪些数据是困难的,可以决定不同数据的优先级。
- 训练调度器:训练调度器告诉我们何时以及需要训练什么难度的数据,还告诉网络所选数据的训练参数,包括epoch数和学习率。
目前,根据测量器和调度器是定制的还是数据驱动的,课程学习可以细分为预定义课程学习和自动课程学习。由于缺乏描述地震数据难度的先验知识,本文使用预定义的课程学习。在具体的课程设置上,采取了三个阶段。

图4. 基于FWI的预定义课程过程。中间的橙色区域演示了如何将地震数据处理为三阶段数据。橘色框中不同颜色箭头代表不同操作。蓝色和黄色箭头分别表示添加噪声和放大幅度。q表示模拟检测时的震源数,相当于网络输入通道数。右侧显示了如何将三级数据排列到网络中。由橘色和绿色箭头形成的圆圈表示训练过程中阶段的迭代,迭代将执行三次。一次迭代为训练提供多个批次。
(a)具有失真信息的单次激发数据:地震观测记录由个共炮点道集组成,从中获得了第
个记录。首先,对该记录进行噪声放大和振幅放大,得到两个畸变记录。第二,复制每个失真记录的
个副本和原始记录的
个副本。最后,将这三者连接起来,以获得
个观察记录的组合。
(b)单炮数据:取地震观测记录中的第条记录。然后,得到这个记录的
个副本。这些副本作为一个整体通过连接用作该阶段的数据。
(c)多炮数据:直接使用炮点的地震观测记录作为本阶段的数据。由于网络的输入端口是确定的,所以每一级的课程数据总是携带
个通道。
将单炮数据放置在多炮数据之前有两个考虑因素:
- 一方面,单炮数据在多个副本之后被馈送到网络中。输入层中彼此不同的通道越少,网络捕获输入之间差异所需的训练样本就越少。因此,与多炮数据相比,单炮数据具有更快的拟合能力。
- 另一方面,虽然单炮数据检测的地层区域有限,但它可以作为多炮数据训练的风格指南。首先通过不完全信息和短期训练,从波形到速度模型建立一个初始的认知网络。此外,在单次激发数据之前设置失真信息的动机类似于数据增强。网络的鲁棒性通过预训练原始数据的混合噪声版本来确保。
自定义训练调度器为不同阶段设置不同的训练时期:首先,调度程序将数据按顺序集馈送到网络。同时,输入网络的数据将被独立训练。其次,当训练时期的数量达到预定义的上界时,执行新一轮的调度。不同数据集内的数据分布存在显著差异。因此,网络对三级数据也存在明显的适应性差距。出于这个原因,不同的调度信息如下:
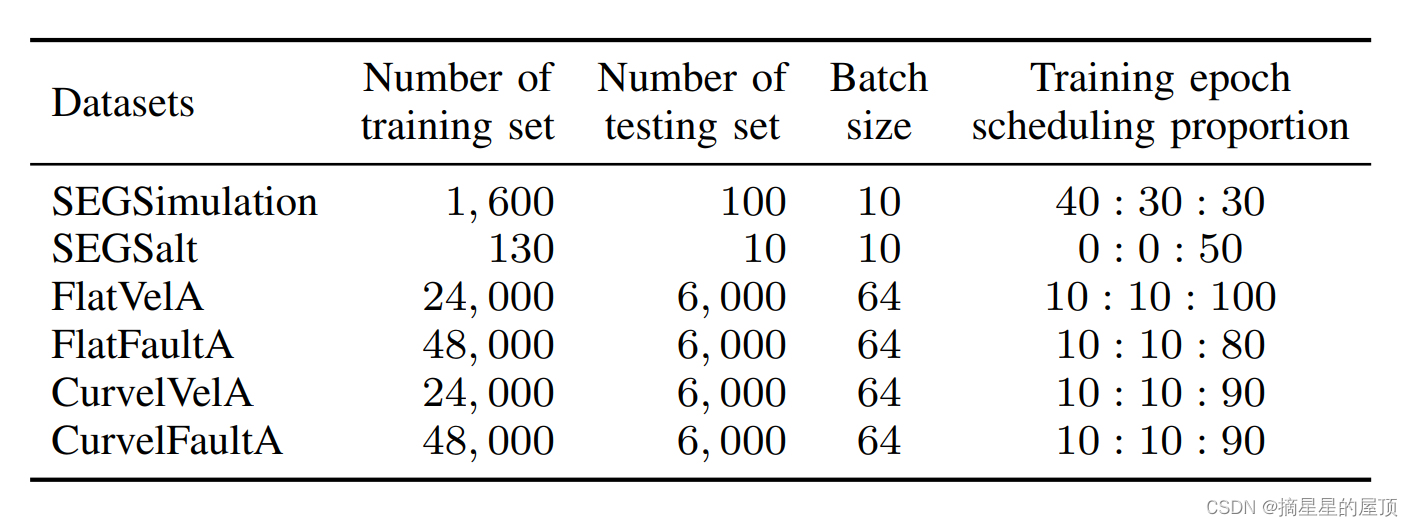
表2 DD-Net和DD-Net 70的训练配置。第五列指示子部分III-C中的三个任务的训练时期比例。
三、创意收集
3.1 CRF
【在一些方法中,CRF被添加在解码器的末尾以确保空间关联】CRF(Conditional Random Field,条件随机场)是一种用于序列标注和分割的统计模型,常用于自然语言处理(NLP)和图像处理等领域。CRF模型能够考虑标签之间的依赖关系,并利用这些依赖关系来提高标注或分割的准确性。在CRF模型中,定义了一个条件概率分布,用于描述给定输入序列下输出标签序列的概率。CRF通过特征函数来捕捉输入序列与输出标签之间的依赖关系,并利用这些特征函数来计算条件概率。
CRF模型可以用于各种任务,如命名实体识别(NER)、词性标注(POS tagging)、分词(word segmentation)等。在这些任务中,CRF能够有效地利用上下文信息,并考虑标签之间的约束关系,从而提高标注的准确性。
CRF模型通常使用最大似然估计来训练参数,并采用动态规划算法(如Viterbi算法)来高效地进行推断和预测。在深度学习时代,CRF也常常与神经网络模型(如循环神经网络RNN、卷积神经网络CNN等)结合使用,形成端到端的训练框架,进一步提升模型的性能。
需要注意的是,CRF模型虽然功能强大,但在某些复杂场景下,其计算复杂度较高,可能需要进行优化和调整。此外,CRF模型也需要合适的特征工程来捕捉输入序列与输出标签之间的依赖关系,这对于模型性能的提升至关重要。
3.2 Canny边缘检测
在DD-Net论文中第二个解码器用于辅助提取训练轮廓信息,提到了一种算法:Canny 边缘检测(Canny的双阈值分别设置为10和15),它是一种使用多级边缘检测算法检测边缘的方法,其检测步骤如下:
(1)灰度化与去噪:将噪声过滤掉,噪声会影响边缘检测的准确性;通常需要对图像进行滤波以去除噪声。滤波的目的是平滑一些纹理较弱的非边缘区域,以便得到更准确的边缘。在实际处理过程中,通常采用高斯滤波去除图像中的噪声。在滤波过程中,通过滤波器对像素点周围的像素计算加权平均值,获取最终滤波结果。滤波器的大小也是可变的,高斯核的大小对于边缘检测的效果具有很重要的作用。滤波器的核越大,边缘信息对于噪声的敏感度就越低。不过,核越大,边缘检测的定位错误也会随之增加。通常来说,一个 5×5 的核能够满足大多数的情况。
(2)计算梯度的幅度与方向:梯度的方向与边缘的方向是垂直的;
(3)非极大值抑制:即适当地让边缘“变瘦”。获得了梯度的幅度和方向后,遍历图像中的像素点,去除所有非边缘的点。在具体实现时,逐一遍历像素点,判断当前像素点是否是周围像素点中具有相同梯度方向的最大值,并根据判断结果决定是否抑制该点。通过以上描述可知,该步骤是边缘细化的过程。针对每一个像素点:
- 若该点是正/负梯度方向上的局部最大值,则保留该点;
- 若不是,则抑制该点(归零);
(4)确定边缘:使用双阈值算法确定最终的边缘信息。完成上述步骤后,图像内的强边缘已在当前获取的边缘图像内。但一些虚边缘可能也在边缘图像内。这些虚边缘可能是真实图像产生的,也可能是由于噪声所产生的。对于噪声,必须将其剔除。设置两个阈值,高阈值 maxVal与低阈值 minVal。根据当前边缘像素的梯度值(指的是梯度幅度)与这两个阈值之间的关系,判断边缘的属性。具体步骤为:
① 如果当前边缘像素的梯度值大于或等于 maxVal,则将当前边缘像素标记为强边缘。
② 如果当前边缘像素的梯度值介于 maxVal 与 minVal 之间,则将当前边缘像素标记为虚
边缘(需要保留)。
③ 如果当前边缘像素的梯度值小于或等于 minVal,则抑制当前边缘像素。
在上述过程中得到了虚边缘,需要对其做进一步处理。一般通过判断虚边缘与强边缘是否连接,来确定虚边缘到底属于哪种情况。通常情况下,如果一个虚边缘:
- 与强边缘连接,则将该边缘处理为边缘。
- 与强边缘无连接,则该边缘为弱边缘,将其抑制。
Canny函数及其使用:OpenCV提供了函数cv2.Canny()来实现Canny边缘检测,如下所示:
edges = cv.Canny( image, threshold1, threshold2[, apertureSize[, L2gradient]])
其中:
- edges:计算得到的边缘图像。
- image: 8 位输入图像。
- threshold1:表示处理过程中的第一个阈值。
- threshold2:表示处理过程中的第二个阈值。
- apertureSize:表示 Sobel 算子的孔径大小。
- L2gradient:计算图像梯度幅度(gradient magnitude)的标识。其默认值为 False。如果为 True,则使用更精确的 L2 范数进行计算(即两个方向的导数的平方和再开方),否则使用 L1 范数(直接将两个方向导数的绝对值相加)。
学习参考:OpenCV——Canny边缘检测(cv2.Canny())_opencv canny-CSDN博客。
3.3 CBAM注意力机制
CBAM( Convolutional Block Attention Module )是一种轻量级注意力模块的提出于2018年,它可以在空间维度和通道维度上进行Attention操作。如下图所示,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。

# 通道注意力模块
# 首先对输入数据分别进行平均池化和最大池化操作,然后分别对这两个结果进行卷积和ReLU激活,最后将两个结果相加并通过Sigmoid激活函数得到最终的输出
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):""":param in_planes: 输入特征图的通道数:param ratio:"""super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1) # 定义一个自适应平均池化层,输出尺寸在1×1self.max_pool = nn.AdaptiveMaxPool2d(1) # 定义自适应最大池化层,输出尺寸在1×1# 定义一个2D卷积层:输入通道数为in_planes,输出通道数为in_planes // ratio(输入通道数除以比率),卷积核大小为1x1,不使用偏置项self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)self.relu1 = nn.ReLU() # 激活函数# 定义一个2D卷积层self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid() # 激活函数def forward(self, x):# 数据首先通过平均池化层,然后通过卷积层和ReLU激活函数,再经过另一个卷积层得到avg_outavg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))# 数据首先通过最大池化层,然后同样经过卷积层和ReLU激活函数,再经过另一个卷积层得到max_outmax_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))out = avg_out + max_out# 对输出应用Sigmoid激活函数并返回结果return self.sigmoid(out)# 空间注意力模块
# 该模块首先对输入的张量计算平均值和最大值,然后将这两个值拼接起来输入到一个卷积层中,最后通过 Sigmoid 激活函数得到每个位置的权重
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):""":param kernel_size: 参数用于指定卷积核的大小,这里默认值为7"""super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'# 根据 kernel_size 的值,计算卷积的 padding 值。若 kernel_size 是7,则 padding 为3;若 kernel_size 是3,则 padding 为1。padding = 3 if kernel_size == 7 else 1# self.conv1 是一个卷积层,输入通道数为2(由 x 的维度决定),输出通道数为1,卷积核大小为 kernel_size,padding 为上面计算的 padding 值,且不使用偏置项(bias=False)self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 7,3 3,1self.sigmoid = nn.Sigmoid() # Sigmoid 激活函数def forward(self, x):# 对输入 x 沿着维度1(通常是通道维度)取平均值,得到 avg_outavg_out = torch.mean(x, dim=1, keepdim=True)# 对输入 x 沿着维度1取最大值,得到最大值 max_out 和对应的索引(这里未使用索引)max_out, _ = torch.max(x, dim=1, keepdim=True)# 将 avg_out 和 max_out 沿着维度1拼接起来,得到新的张量 xx = torch.cat([avg_out, max_out], dim=1)# 将拼接后的张量 x 输入到卷积层 self.conv1 中,得到输出x = self.conv1(x)# 使用 Sigmoid 激活函数对卷积层的输出进行激活,得到最终的空间注意力权重return self.sigmoid(x)# 首先使用通道注意力机制增强特征图的通道表示,然后使用空间注意力机制增强特征图的空间表示。
# 通过这种方式,CBAM可以自适应地关注输入特征图的特定通道和空间位置,从而提供更有效的特征表示。
class CBAM(nn.Module):# in_planes:输入特征图通道数def __init__(self, in_planes, ratio=16, kernel_size=7):""":param in_planes: 输入特征图的通道数:param ratio: 控制注意力机制强度的参数,默认值为16:param kernel_size: 空间注意力模块中卷积核的大小,默认值为7"""super(CBAM, self).__init__()# 通道注意力模块,它接收输入特征图,计算每个通道的重要性得分,并将这些得分应用于输入特征图,从而得到经过通道注意力增强的特征图。self.ca = ChannelAttention(in_planes, ratio)# 空间注意力模块,它接收经过通道注意力增强的特征图,计算每个位置的重要性得分,并将这些得分应用于特征图,从而得到经过空间注意力增强的特征图。self.sa = SpatialAttention(kernel_size)def forward(self, x):# 输入特征图 x 通过通道注意力模块 self.ca,得到经过通道注意力增强的特征图# 将经过通道注意力增强的特征图与原始特征图相乘,得到新的特征图out = x * self.ca(x)# 新的特征图通过空间注意力模块 self.sa,得到最终经过空间注意力增强的特征图# 注意:这里的“相乘”实际上是逐元素相乘,即Hadamard积(element-wise multiplication),目的是保留原始特征图的激活信息,同时增加新的注意力权重信息result = out * self.sa(out)return result3.4 网络模块的设计
- 串联:串联模块的制作比较简单,只需要将多个模块串联加起来,在通过一些横向连接即可。
- 并联/变形:变形模块可以通过卷积、transformer、通道注意力、空间注意力等便捷技术实现,也可以通过contact进行通道合并,还可以通过通道划分系数(具体每个模块的权重与系数是如何划分的,可完成一些消融实验)。
- 交互:交互模块则可以通过cnn、transformer、fusion等设计实现。
四、小结
- 毕业设计任务书
- 评价指标很多,在之后如何进行选择,在某些尝试中,并不是所有的指标都表现得好,根据结果进行合适的选择吗?
- 根据近两周的学习与尝试,对网络架构的修改有了更深的理解,也更加明白许老师之前说的加入一些组件的时候效果不一定好,对参数的调整是一些漫长的过程。
相关文章:
2024年1月27日~2月2日周报
一、前言 上周主要完成了SeisInvNet加强版论文的阅读,并尝试跑了一下代码。 本周阅读师兄的论文《DD-Net》,并尝试思考新的点子修改网络架构。 二、DD-Net阅读情况 标题:Dual decoder network with curriculumlearning for full waveform in…...

红黑树,以及其在C++的set、map等数据结构中应用
红黑树介绍: 红黑树(Red-Black Tree)是一种自平衡的二叉搜索树,它在插入和删除操作后通过一系列的旋转和着色操作来维持平衡。红黑树的命名来自于节点上的额外颜色属性,每个节点要么是红色,要么是黑色。 红…...

C++(11)——内存管理
C内存分布 我们先看一段代码以及相关问题。 这道题的答案是多少呢? 答案在这里哦,看一下有没有问题呀。如果这么简单的题做错了,怕不是要被电击一下。 C内存管理方式 我们知道C语言中动态内存管理的方式是 malloc realloc calloc free 这几…...

《C++ Primer Plus》《3、数据处理》
文章目录 0 前言1 简单变量1.1变量名1.2整型1.3整型short,int,long和long long1.4无符号类型1.5选择整型类型1.6整型字面值1.7C如何确定常量的类型1.8char类型:字符和小整数1.9bool类型 2 cost限定符3浮点数3.1书写浮点数3.2浮点类型3.3浮点常量3.4浮点数的优缺点 4…...
Java 正则匹配sql
文章目录 正则匹配sql表名称insert intoupdate 正则表达式什么时候要加^$ 在线正则校验 正则匹配sql表名称 insert into insert into PING_TABLE (CODE, NAME) VALUES(0, 待提交),(1, 审核中),(2, 审核通过),(3, 已驳回); regex -> insert\sinto\s(\w)\s*\(?update upda…...

服务器入门
入门服务器管理涉及到一系列基础概念和技能,这包括操作系统、网络配置、安全性、远程访问等。以下是一些建议,可以帮助你开始学习服务器管理: ### 1. **选择合适的操作系统:** - 大多数服务器使用 Linux 操作系统,…...

云端录制直播流视频,上传云盘
前言 哪一天我心血来潮,想把我儿子学校的摄像头视频流录制下来,并保存到云盘上,这样我就可以在有空的时候看看我儿子在学校干嘛。想到么就干,当时花了一些时间开发了一个后端服务,通过数据库配置录制参数,…...
【靶场实战】Pikachu靶场XSS跨站脚本关卡详解
Nx01 系统介绍 Pikachu是一个带有漏洞的Web应用系统,在这里包含了常见的web安全漏洞。 如果你是一个Web渗透测试学习人员且正发愁没有合适的靶场进行练习,那么Pikachu可能正合你意。 Nx02 XSS跨站脚本概述 Cross-Site Scripting 简称为“CSS”ÿ…...

蓝桥杯每日一题-----数位dp
前言 今天浅谈一下数位dp的板子,我最初接触到数位dp的时候,感觉数位dp老难了,一直不敢写,最近重新看了一些数位dp,发现没有想象中那么难,把板子搞会了,变通也会变的灵活的多! 引入…...
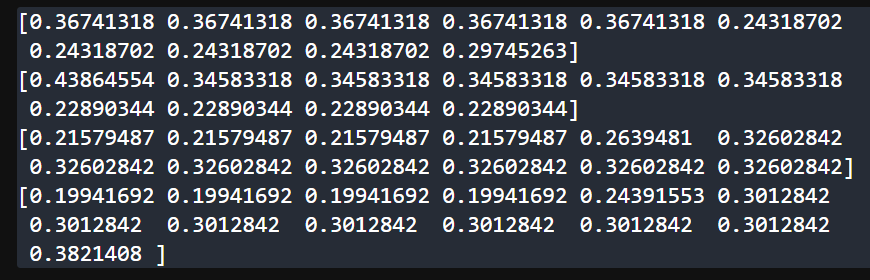
sklearn 计算 tfidf 得到每个词分数
from sklearn.feature_extraction.text import TfidfVectorizer# 语料库 可以换为其它同样形式的单词 corpus [list(range(-5, 5)),list(range(-6,4)),list(range(12)),list(range(13))]# corpus [ # [Two, wrongs, don\t, make, a, right, .], # [The, pen, is, might…...

Qt拖拽事件,实现控件内项的相互拖拽
文章目录 1拖拽演示2 步骤3 实现 这里主要以QTableview控件为例,实现表格内数据的相互拖拽。 1拖拽演示 2 步骤 自定以QTableView类,在自定义类中重写拖拽事件: void dropEvent(QDropEvent *event); void dragEnterEvent(QDragEnterEvent *…...

基于MATLAB实现的OFDM仿真调制解调,BPSK、QPSK、4QAM、16QAM、32QAM,加性高斯白噪声信道、TDL瑞利衰落信道
基于MATLAB实现的OFDM仿真调制解调,BPSK、QPSK、4QAM、16QAM、32QAM,加性高斯白噪声信道、TDL瑞利衰落信道 相关链接 OFDM中的帧(frame)、符号(symbol)、子载波(subcarriers)、导频…...
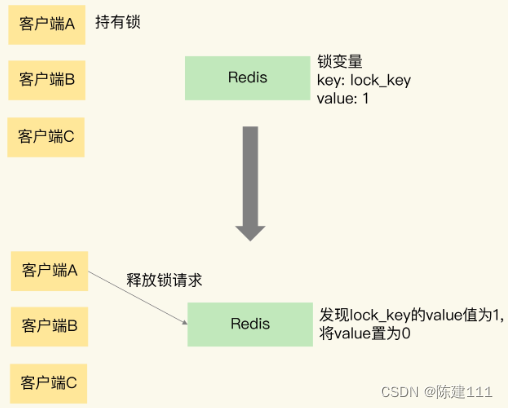
Redis核心技术与实战【学习笔记】 - 21.Redis实现分布式锁
概述 在《20.Redis原子操作》我们提到了应对并发问题时,除了原子操作,还可以通过加锁的方式,来控制并发写操作对共享数据的修改,从而保证数据的正确性。 但是,Redis 属于分布式系统,当有多个客户端需要争…...

17.Golang channel的基本定义及使用
目录 概述实践无缓冲 channel代码结果 缓冲 channel代码结果 channel的关闭特点代码结果range代码结果 select channel代码结果 结束 概述 此篇文章介绍 channel 的用法 无缓冲 channel缓冲 channelchannel的关闭特点range channelselect channel 每一种,配上完整…...

Linux - iptables 防火墙
一. 安全技术和防火墙 1.安全技术 入侵检测系统(Intrusion Detection Systems):特点是不阻断任何网络访问,量化、定位来自内外网络的威胁情况,主要以提供报警和事后监督为主,提供有针对性的指导措施和安全…...

如何在FBX剔除Lit.shader依赖
1)如何在FBX剔除Lit.shader依赖 2)Unity出AAB包(PlayAssetDelivery)模式下加载资源过慢问题 3)如何在URP中正确打出Shader变体 4)XLua打包Lua文件粒度问题 这是第371篇UWA技术知识分享的推送,精…...

cesium-测量高度垂直距离
cesium做垂直测量 完整代码 <template><div id"cesiumContainer" style"height: 100vh;"></div><div id"toolbar" style"position: fixed;top:20px;left:220px;"><el-breadcrumb><el-breadcrumb-i…...

Adobe Illustrator CEP插件开发入门指南
引言 Adobe Creative Cloud(创意云)中的Illustrator作为一款全球领先的矢量图形设计软件,为设计师提供了丰富的功能和无限的创作可能性。为了进一步增强其功能并满足个性化工作流程需求,Adobe引入了Common Extensibility Platform…...
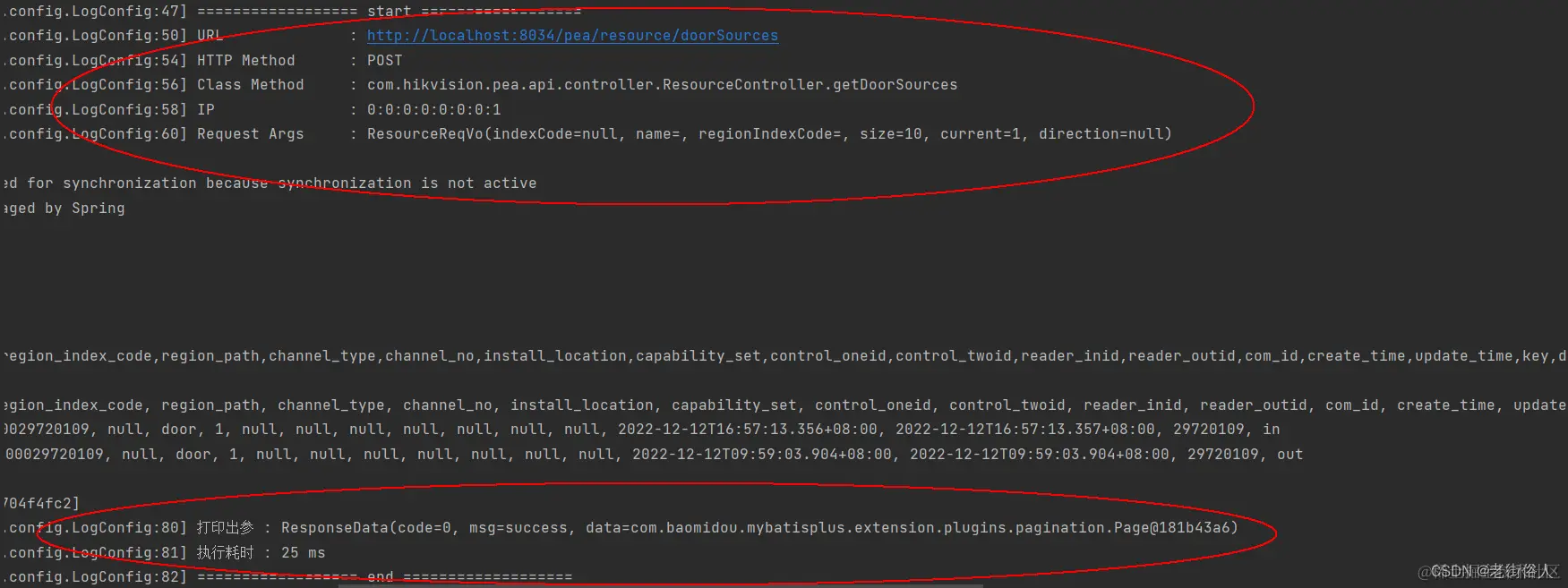
【Spring】自定义注解 + AOP 记录用户的使用日志
目录 编辑 自定义注解 AOP 记录用户的使用日志 使用背景 落地实践 一:自定义注解 二:切面配置 三:Api层使用 使用效果 自定义注解 AOP 记录用户的使用日志 使用背景 (1)在学校项目中,安防平台…...

linux互斥锁:递归锁,非递归锁用法详解
在实际的项目中经常涉及到共享资源,共享资源被多个线程访问会出现竞争现象;为了解决竞争和保护共享资源常用的机制之一就是互斥锁! 互斥锁又分为递归锁和非递归锁,互斥锁默认是非递归锁,也是我们常用的上锁方式。那么什么是递归锁和非递归锁呢? 非递归锁(Non-recursive …...

GetQzonehistory:QQ空间数据备份工具全指南
GetQzonehistory:QQ空间数据备份工具全指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 一、价值定位:数字记忆的守护者 1.1 数据永存的必要性 在数字时代&…...

效率提升实测:OpenClaw+百川2-13B-4bits将周报时间从2小时缩短到15分钟
效率提升实测:OpenClaw百川2-13B-4bits将周报时间从2小时缩短到15分钟 1. 为什么我要折腾自动化周报 每周五下午,我的日历上总有一个雷打不动的"周报时间"。这个两小时的"酷刑"包括:翻遍Git提交记录、整理会议纪要碎片…...

Nunchaku-flux-1-dev时序预测可视化:结合LSTM生成数据趋势图
Nunchaku-flux-1-dev时序预测可视化:结合LSTM生成数据趋势图 你有没有遇到过这种情况?辛辛苦苦用LSTM模型跑出了一份股票价格预测数据,或者是一份未来一周的天气变化趋势,结果拿给老板或者同事看的时候,他们对着密密麻…...

DeepSeek-OCR-2算力优化部署:支持多GPU并行解析提升吞吐量方案
DeepSeek-OCR-2算力优化部署:支持多GPU并行解析提升吞吐量方案 1. 为什么需要多GPU并行解析? 如果你用过单张显卡跑DeepSeek-OCR-2,可能会遇到这样的场景:公司财务部门一次性发来50张发票扫描件,行政部需要处理100页…...

新手程序员福音:coze-loop智能优化代码,附详细修改说明
新手程序员福音:coze-loop智能优化代码,附详细修改说明 1. 为什么新手程序员需要代码优化工具 刚入行的程序员常常面临一个困境:写出的代码虽然能运行,但质量参差不齐。要么效率低下,要么难以维护,要么存…...

H5游戏整合平台源码:70款游戏一键搭建,支持流量主变现的完整解决方案
一、平台概述与核心优势这套H5游戏整合平台源码是一套全面、实用且零门槛的一站式解决方案。它专为站长、开发者、创业团队及游戏爱好者打造,无需分散搜罗各类零散源码,一次获取即可拥有70余款经典H5网页小游戏。所有源码均基于原生H5技术开发࿰…...

Llama-3.2V-11B-cot参数详解:官方最优推理配置+冲突参数自动剔除机制说明
Llama-3.2V-11B-cot参数详解:官方最优推理配置冲突参数自动剔除机制说明 1. 项目概述 Llama-3.2V-11B-cot是基于Meta Llama-3.2V-11B-cot多模态大模型开发的高性能视觉推理工具,专为双卡RTX 4090环境深度优化。该工具通过一系列技术创新,解…...

极简配置:OpenClaw快速接入Phi-3-mini-128k-instruct的HTTP接口
极简配置:OpenClaw快速接入Phi-3-mini-128k-instruct的HTTP接口 1. 为什么选择Phi-3-mini-128k-instruct 上周我在调试一个自动化文档处理流程时,发现现有的大模型响应速度跟不上我的实时需求。经过几轮测试,最终选择了微软开源的Phi-3-min…...

obsidian-skills培训管理:培训用户使用技能的方法
obsidian-skills培训管理:培训用户使用技能的方法 【免费下载链接】obsidian-skills Agent skills for Obsidian. Teach your agent to use Markdown, Bases, JSON Canvas, and use the CLI. 项目地址: https://gitcode.com/GitHub_Trending/ob/obsidian-skills …...

嵌入式工程师职业发展:原厂与方案商技术深度对比
1. 嵌入式工程师的职业抉择:原厂与方案商深度对比最近一位工作三年的嵌入式工程师朋友分享了他的求职经历,让我感触颇深。他在方案商做了三年应用开发后,最终选择跳槽到芯片原厂。这个决定背后,反映了很多嵌入式工程师都会面临的职…...