机器学习本科课程 大作业 多元时间序列预测
1. 问题描述
1.1 阐述问题
对某电力部门的二氧化碳排放量进行回归预测,有如下要求
- 数据时间跨度从1973年1月到2021年12月,按月份记录。
- 数据集包括“煤电”,“天然气”,“馏分燃料”等共9个指标的数据(其中早期的部分指标not available)
- 要求预测从2022年1月开始的半年时间的以下各个部分的排放量
二氧化碳的排放情况具体分为九项指标:
- Coal Electric Power Sector CO2 Emissions(煤电力行业二氧化碳排放 )
- Natural Gas Electric Power Sector CO2 Emissions(天然气电力行业二氧化碳排放)
- Distillate Fuel, Including Kerosene-Type Jet Fuel, Oil Electric Power Sector CO2 Emissions(蒸馏燃料,包括喷气燃料、石油电力行业二氧化碳排放)
- Petroleum Coke Electric Power Sector CO2 Emissions(石油焦电力行业二氧化碳排放)
- Residual Fuel Oil Electric Power Sector CO2 Emissions(残余燃料油电力行业二氧化碳排放)
- Petroleum Electric Power Sector CO2 Emissions(石油电力行业二氧化碳排放)
- Geothermal Energy Electric Power Sector CO2 Emissions(地热能电力行业二氧化碳排放)
- Non-Biomass Waste Electric Power Sector CO2 Emissions(非生物质废物电力行业二氧化碳排放)
- Total Energy Electric Power Sector CO2 Emissions(总能源电力行业二氧化碳排放)
1.2 方案设计
- 由于9个指标之间存在相关性,对一个指标的未来值进行预测,除了考虑自身的历史值以外,还需要引入其他指标对该指标的影响。
- 数据量大、时间周期长,需要采用具有较强回归能力的、能够实现时间序列预测任务的机器学习模型。
1.3 方法概括
经过讨论研究,本次实验通过三种神经网络模型独立实现了多元时间序列回归预测任务,分别是:
| 模型 | 介绍 | 特点 |
|---|---|---|
| BP | 误差反向传播网络 | 通过多次学习获取非线性映射 |
| TCN | 时间卷积网络 | 因果卷积实现时间预测 |
| LSTM | 长短时记忆网络 | 门控结构保存长时记忆 |
通过从无到有建立模型、性能优化、模型比较等流程,小组成员强化了机器学习的基础知识,提升了机器学习相应技能的熟练程度,对机器学习的理论和部分模型的特性有了进一步的理解
2. BP神经网络(Backpropagation Neural Network)
2.1 模型原理
BP神经网络是一种前馈神经网络,采用反向传播算法进行训练。该网络由输入层、隐藏层和输出层组成。每个神经元与前一层的所有神经元相连接,每个连接都有一个权重,网络通过调整这些权重来学习输入与输出之间的映射关系。
BP神经网络通过反向传播(Backpropagation)计算模型输出与实际输出之间的误差,然后反向传播误差,调整网络参数以最小化误差。
在本次实验中,采取了500大小的隐藏层,以0.01学习率进行了2000轮的训练。
2.2.1数据处理
从xlsx读取数据,取前80%数据为训练集,后20%为测试集
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler# 读取xlsx文件
data = pd.read_excel("data.xlsx")
side = 192 # 有缺失部分的长度
side2 = 587 # 整个已知数据的长度
seq_len = 10
batch_size = 64
data = data.iloc[1:side2 + 1]# 提取全部列名
col_names = data.columns.values.tolist()
col_names = [col_names[i] for i in range(1, len(col_names))]
data_list = np.array(data[col_names].values.tolist())# 处理缺失值,用平均值填充
data_list[data_list == "Not Available"] = np.nan
data_list = data_list.astype(float)
imputer = SimpleImputer(strategy='mean', fill_value=np.nan)
data_imputed = imputer.fit_transform(data_list)# 标准化处理
scaler = StandardScaler()
data_normalized = scaler.fit_transform(data_imputed)# 划分训练集和测试集
data_len = len(data_normalized)
train_data = data_normalized[:int(0.75 * data_len)] # 取前75%作为训练集
test_data = data_normalized[int(0.75 * data_len):] # 取剩下25%作为测试集
2.3.2 定义画图函数
# 画出曲线
def plot_results(X_test, Y_test, W1, b1, W2, b2, scaler, col_names):Y_pred, _ = forward(X_test, W1, b1, W2, b2)Y_pred_original = scaler.inverse_transform(Y_pred)Y_test_original = scaler.inverse_transform(Y_test)f, ax = plt.subplots(nrows=3, ncols=3, figsize=(20, 10))for i in range(3):for j in range(3):ax[i, j].plot(Y_pred_original[:, 3 * i + j], label='predictions')ax[i, j].plot(Y_test_original[:, 3 * i + j], label='true')ax[i, j].set_title(col_names[3 * i + j])ax[i, j].legend()plt.tight_layout()plt.show()# 绘制Loss曲线
def plot_loss_curve(training_losses, testing_losses):plt.figure(figsize=(10, 6))plt.plot(training_losses, label='Training Loss', color='blue')plt.plot(testing_losses, label='Testing Loss', color='orange')plt.title('Training and Testing Loss Over Epochs')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.show()2.3.3 定义BP神经网络结构
# 参数初始化
def initialize_parameters(input_size, hidden_size, output_size):np.random.seed(42)W1 = np.random.randn(input_size, hidden_size) * 0.01b1 = np.zeros((1, hidden_size))W2 = np.random.randn(hidden_size, output_size) * 0.01b2 = np.zeros((1, output_size))return W1, b1, W2, b2# 前向传播
def forward(X, W1, b1, W2, b2):Z1 = np.dot(X, W1) + b1A1 = np.tanh(Z1)Z2 = np.dot(A1, W2) + b2return Z2, A1# 损失函数
def compute_loss(Y, Y_pred):m = Y.shape[0]loss = np.sum((Y - Y_pred) ** 2) / mreturn loss# 反向传播
def backward(X, A1, Y, Y_pred, W1, W2, b1, b2):m = X.shape[0]dZ2 = Y_pred - YdW2 = np.dot(A1.T, dZ2) / mdb2 = np.sum(dZ2, axis=0, keepdims=True) / mdA1 = np.dot(dZ2, W2.T)dZ1 = dA1 * (1 - np.tanh(A1) ** 2)dW1 = np.dot(X.T, dZ1) / mdb1 = np.sum(dZ1, axis=0, keepdims=True) / mreturn dW1, db1, dW2, db2# 梯度下降更新参数
def update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate):W1 -= learning_rate * dW1b1 -= learning_rate * db1W2 -= learning_rate * dW2b2 -= learning_rate * db2return W1, b1, W2, b2# 训练神经网络
def train_neural_network(X_train, Y_train, X_test, Y_test, input_size, hidden_size, output_size, epochs, learning_rate):W1, b1, W2, b2 = initialize_parameters(input_size, hidden_size, output_size)training_losses = []testing_losses = []start_time = time.time()for epoch in range(epochs):# 前向传播训练集Y_pred_train, A1_train = forward(X_train, W1, b1, W2, b2)# 计算训练集损失train_loss = compute_loss(Y_train, Y_pred_train)training_losses.append(train_loss)# 前向传播测试集Y_pred_test, _ = forward(X_test, W1, b1, W2, b2)# 计算测试集损失test_loss = compute_loss(Y_test, Y_pred_test)testing_losses.append(test_loss)# 反向传播和参数更新dW1, db1, dW2, db2 = backward(X_train, A1_train, Y_train, Y_pred_train, W1, W2, b1, b2)W1, b1, W2, b2 = update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate)# 打印每个epoch的损失print(f"Epoch {epoch + 1}/{epochs} - Training Loss: {train_loss:.10f} - Testing Loss: {test_loss:.10f}")end_time = time.time()training_duration = end_time - start_timeprint(f"用时 {training_duration:.2f} s")# 结束后,画出图像plot_loss_curve(training_losses, testing_losses)plot_results(X_test, Y_test, W1, b1, W2, b2, scaler, col_names)return W1, b1, W2, b2, training_losses, testing_losses2.3.4 模型训练流程及性能表现
# 将训练数据和测试数据准备为神经网络输入
X_train = train_data[:-seq_len]
Y_train = train_data[seq_len:]
X_test = test_data[:-seq_len]
Y_test = test_data[seq_len:]# 参数设置
input_size = X_train.shape[1]
hidden_size = 500
output_size = Y_train.shape[1]
epochs = 2000
learning_rate = 0.01# 训练神经网络
W1_final, b1_final, W2_final, b2_final, training_losses, testing_losses = train_neural_network(X_train, Y_train, X_test, Y_test, input_size, hidden_size, output_size, epochs, learning_rate)# 在训练完成后,使用训练好的模型对训练集和测试集进行预测
Y_pred_train, _ = forward(X_train, W1_final, b1_final, W2_final, b2_final)
Y_pred_test, _ = forward(X_test, W1_final, b1_final, W2_final, b2_final)# 将预测值逆归一化
Y_pred_train_original = scaler.inverse_transform(Y_pred_train)
Y_pred_test_original = scaler.inverse_transform(Y_pred_test)# 逆归一化训练集和测试集的真实值
Y_train_original = scaler.inverse_transform(Y_train)
Y_test_original = scaler.inverse_transform(Y_test)# 计算 MAE 和 MSE
mse_on_train = np.mean((Y_train_original - Y_pred_train_original) ** 2)
mse_on_test = np.mean((Y_test_original - Y_pred_test_original) ** 2)
mae_on_train = np.mean(np.abs(Y_train_original - Y_pred_train_original))
mae_on_test = np.mean(np.abs(Y_test_original - Y_pred_test_original))# 输出最终的 MAE 和 MSE
print(f"mse_on_train: {mse_on_train:.10f} mse_on_test: {mse_on_test:.10f}")
print(f"mae_on_train: {mae_on_train:.10f} mae_on_test: {mae_on_test:.10f}")3. TCN网络(Temporal Convolutional Network)
3.1 模型原理
TCN是一种基于卷积操作的神经网络,特别适用于处理时序数据。与传统的循环神经网络(RNN)和LSTM相比,TCN使用卷积层捕捉时序数据中的模式,从而更好地捕获长期依赖关系。
从结构上来说,TCN通常由一个或多个卷积层组成,卷积层的感受野逐渐增大,从而能够捕捉不同尺度的模式。此外,TCN还可以通过残差连接来加强梯度的流动,从而更容易训练深层网络。
3.2.1 数据处理
在第一个实验方案中,BP网络直接将整段历史信息输入给了模型;为了更充分地考虑数据集中的时序信息以及加快训练速度,TCN网络和LSTM采取了时间窗口的划分方式。
滑动窗口(rolling window)将时间序列划分为多个窗口,在每个窗口内进行训练和测试,如果存在较大的波动或季节性变化,而且这些变化的周期较长,使用滑动窗口可以更好地捕捉到这些特征。
TCN中,仍然设定前80%为训练数据,时间窗口大小为16
import pandas as pd
import numpy as np
import torch
from torch import optim
from torch.utils.data import Dataset, DataLoader,TensorDataset
import torch.nn as nn
from sklearn.preprocessing import StandardScaler, Normalizer
import matplotlib.pyplot as pltdef windows_split(data, seq_len):res = []label = []for i in range(len(data) - seq_len):res.append(data[i:i + seq_len])label.append(data[i + seq_len])res = np.array(res).astype(np.float32)label = np.array(label).astype(np.float32)return res, labeldata = pd.read_excel("data.xlsx")
side = 192 # 有缺失部分的长度
side2 = 587 # 整个已知数据的长度
seq_len = 16
batch_size = 64# 提取全部列名
col_names = data.columns.values.tolist()
col_names = [col_names[i] for i in range(1, len(col_names))]
data.replace("Not Available", np.nan, inplace=True)interpolated = data[col_names].interpolate(method='spline', order=3)
data_list = np.array(data[col_names].values.tolist())scalar = StandardScaler()
data_list = scalar.fit_transform(data_list)
data_list[np.isnan(data_list)] = 0data_split, label_split = windows_split(data_list[side:side2], seq_len)
data_split = np.transpose(data_split, (0, 2, 1))
length = data_split.shape[0]data_train = torch.Tensor(data_split[0:int(0.8 * length), :])
label_train = torch.Tensor(label_split[0:int(0.8 * length)])
data_test = torch.Tensor(data_split[int(0.8 * length):int(length), :])
label_test = torch.Tensor(label_split[int(0.8 * length):label_split.shape[0]])dataset_train = TensorDataset(data_train, label_train)
dataset_test = TensorDataset(data_test, label_test)train_loader = DataLoader(dataset_train, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset_test, batch_size=batch_size, shuffle=False)input_size = 9
output_size = 9
num_channels = [32, 64, 128, 256]
kernel_size = 3
dropout = 0
num_epochs = 200
3.2.2 模型定义
每层TCN定义为:[conv, chomp, relu, dropout]*2
学习率0.0001,训练轮数200
import torch
import torch.nn as nn
from torch.nn.utils import weight_normclass Chomp1d(nn.Module):def __init__(self, chomp_size):super(Chomp1d, self).__init__()self.chomp_size = chomp_sizedef forward(self, x):return x[:, :, :-self.chomp_size].contiguous()class TemporalBlock(nn.Module):def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):super(TemporalBlock, self).__init__()self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,stride=stride, padding=padding, dilation=dilation))self.chomp1 = Chomp1d(padding)self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(dropout)self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,stride=stride, padding=padding, dilation=dilation))self.chomp2 = Chomp1d(padding)self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(dropout)self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,self.conv2, self.chomp2, self.relu2, self.dropout2)self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else Noneself.relu = nn.ReLU()self.init_weights()def init_weights(self):self.conv1.weight.data.normal_(0, 0.01)self.conv2.weight.data.normal_(0, 0.01)if self.downsample is not None:self.downsample.weight.data.normal_(0, 0.01)def forward(self, x):out = self.net(x)res = x if self.downsample is None else self.downsample(x)return self.relu(out + res)class TemporalConvNet(nn.Module):def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2):super(TemporalConvNet, self).__init__()layers = []num_levels = len(num_channels)for i in range(num_levels):dilation_size = 2 ** iin_channels = num_inputs if i == 0 else num_channels[i-1]out_channels = num_channels[i]layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,padding=(kernel_size-1) * dilation_size, dropout=dropout)]self.network = nn.Sequential(*layers)def forward(self, x):return self.network(x)class TCN(nn.Module):def __init__(self, input_size, output_size, num_channels, kernel_size, dropout):super(TCN, self).__init__()self.tcn = TemporalConvNet(input_size, num_channels, kernel_size=kernel_size, dropout=dropout)self.linear = nn.Linear(num_channels[-1], output_size)def forward(self, inputs):"""Inputs have to have dimension (N, C_in, L_in)"""y1 = self.tcn(inputs) # input should have dimension (N, C, L)o = self.linear(y1[:, :, -1])return o3.2.3 模型训练流程及性能表现
model = TCN(input_size, output_size, num_channels, kernel_size, dropout)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.MSELoss()
criterion2 = nn.L1Loss()loss_train_list = []
loss_test_list = []
for i in range(num_epochs):model.train()n = 0loss_total = 0for data, label in train_loader:optimizer.zero_grad()pred = model(data)loss = criterion(pred, label)loss.backward()optimizer.step()n += 1loss_total += loss.item()loss_total /= nloss_train_list.append(loss_total)model.eval()loss_test_total = 0n = 0for data,label in test_loader:with torch.no_grad():pred = model(data)loss = criterion(pred, label)loss_test_total += loss.item()n+=1loss_test_total /= nloss_test_list.append(loss_test_total)print('epoch:{0}/{1} loss_train:{2} loss_test:{3}'.format(i + 1, num_epochs, loss_total,loss_test_total))model.eval()
prediction = model(data_test)
prediction = prediction.detach().numpy()
label_test = label_test.detach().numpy()prediction = scalar.inverse_transform(prediction)
label_test = scalar.inverse_transform(label_test)f,ax = plt.subplots(nrows=3,ncols=3,figsize=(10, 10))
for i in range(3):for j in range(3):ax[i,j].plot(prediction[:,3 * i + j],label = 'predictions')ax[i,j].plot(label_test[:,3 * i + j],label = 'true')ax[i,j].set_title(col_names[3 * i + j])ax[i,j].legend()
plt.tight_layout()
plt.show()plt.plot(loss_test_list,label = 'loss_on_test')
plt.plot(loss_train_list,label = 'loss_on_train')
plt.legend()
plt.show()prediction_train = model(data_train)
prediction_train = prediction_train.detach().numpy()
prediction_train = scalar.inverse_transform(prediction_train)
label_train = scalar.inverse_transform(label_train)mse_on_train = criterion(torch.Tensor(prediction_train),torch.Tensor(label_train))
rmse_on_train = torch.sqrt(mse_on_train)
mae_on_train = criterion2(torch.Tensor(prediction_train),torch.Tensor(label_train))mse_on_test = criterion(torch.Tensor(prediction),torch.Tensor(label_test))
rmse_on_test = torch.sqrt(mse_on_test)
mae_on_test = criterion2(torch.Tensor(prediction),torch.Tensor(label_test))print('mse_on_train:{0} mse_on_test:{1}'.format(mse_on_train,mse_on_test))
print('rmse_on_train:{0} rmse_on_test:{1}'.format(rmse_on_train,rmse_on_test))
print('mae_on_train:{0} mae_on_test:{1}'.format(mae_on_train,mae_on_test))# data_split = torch.Tensor(data_split)
# label_split = torch.Tensor(label_split)# prediction_rest = []
# windows = torch.cat((data_split[-1,:,1:],label_split[-1].unsqueeze(1)),dim = 1).unsqueeze(0)
# for i in range(6):
# pred = model(windows)
# prediction_rest.append(pred.detach().numpy().squeeze())
# windows = torch.cat((windows[-1,:,1:],torch.transpose(pred, 0, 1)),dim = 1).unsqueeze(0)# # print(prediction_rest)
# prediction_rest = np.array(prediction_rest)
# prediction_rest = scalar.inverse_transform(prediction_rest)# prediction_total = model(data_split)
# prediction_total = prediction_total.detach().numpy()
# label_split = label_split.detach().numpy()# prediction_total = scalar.inverse_transform(prediction_total)
# label_split = scalar.inverse_transform(label_split)
# f,ax = plt.subplots(nrows=3,ncols=3,figsize=(10, 10))# length = prediction_total.shape[0]
# for i in range(3):
# for j in range(3):
# ax[i,j].plot(range(length),prediction_total[:,3 * i + j],label = 'predictions')
# ax[i,j].plot(range(length),label_split[:,3 * i + j],label = 'true')
# ax[i,j].plot(range(length,length+6),prediction_rest[:,3 * i + j],label = 'rest')
# ax[i,j].set_title(col_names[3 * i + j])
# ax[i,j].legend()
# plt.tight_layout()
# plt.show()
4. LSTM网络
4.1 模型原理
LSTM是一种循环神经网络(RNN)的变体,专门设计用来解决长期依赖问题。LSTM引入了门控机制,包括输入门、遗忘门和输出门,以有效地控制信息的流动。
LSTM中的记忆单元可以保留和读取信息,使其能够更好地处理时序数据中的长期依赖关系。遗忘门可以选择性地遗忘先前的信息,输入门可以添加新的信息,输出门控制输出的信息。
4.2.1 数据处理
此部分与TCN相同,采取前80%为训练数据,后20%为测试集,时间窗口大小为16
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScalerdata = pd.read_excel("data.xlsx")empty = 192 # 有缺失部分的长度
side = 587 # 整个已知数据的长度
seq_len = 10
batch_size = 64# 提取全部列名
col_names = data.columns.values.tolist()
col_names = [col_names[i] for i in range(1, len(col_names))]
for col in col_names:data[col] = pd.to_numeric(data[col], errors='coerce').astype(float)# print(data)
data_list = np.array(data[col_names].values.tolist())
# print(data_list)
data_list = data_list[:data_list.shape[0]-6,:]
# print(data_list)
# print(type(data_list[1][1]))
scaler = StandardScaler()
data_list_scaled = scaler.fit_transform(data_list)
data_scaled = pd.DataFrame(data_list_scaled, columns=col_names)def get_data():return data_list
def get_data_scaled():data_list_scaled[np.isnan(data_list_scaled)] = 0# print(data_list_scaled)return data_list_scaled[192:588], data_list_scaleddef plot(prediction, label_test):plt.figure()f,ax = plt.subplots(nrows=3,ncols=3,figsize=(10, 10))for i in range(3):for j in range(3):ax[i,j].plot(label_test[:,3 * i + j],'b-', label = 'true')ax[i,j].plot(prediction[:,3 * i + j],'r-', label = 'predictions')ax[i,j].set_title(col_names[3 * i + j])ax[i,j].legend()plt.tight_layout()plt.show()def plot_loss(train_loss):plt.figure()plt.xlabel('epoch')plt.ylabel('loss')plt.title('Loss-Rate')temp_list = []for i in range(len(train_loss)):temp_list.append(train_loss[i].to('cpu').detach().numpy())plt.plot([i for i in range(len(train_loss))], temp_list, 'b-', label=u'train_loss')plt.legend() plt.show()def create_sliding_window(data, seq_len, test=False):"""## 创建滑动窗口,生成输入序列和对应的目标值。参数:- data: 输入的时序数据,形状为 (num_samples, num_features)- seq_len: 滑动窗口的大小返回:- X: 输入序列,形状为 (num_samples - seq_len, seq_len, num_features)- y: 目标值,形状为 (num_samples - seq_len, num_features)"""X, y = [], []num_samples, num_features = data.shapefor i in range(num_samples - seq_len):window = data[i : i + seq_len, :]target = data[i + seq_len, :]X.append(window)y.append(target)if test:X.append(X[len(X)-1])return np.array(X), np.array(y)def inverse_scale(data):return scaler.inverse_transform(data)
4.2.2 模型定义
import torch
import torch.nn as nn
import torch.optim as optim
import time
# 定义多层LSTM模型
class myLSTM(nn.Module):def __init__(self, input_size, hidden_size, num_layers=2, output_size=9):super(myLSTM, self).__init__()# self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)self.lstm_layers = nn.ModuleList([nn.LSTM(input_size=input_size if i == 0 else hidden_size,hidden_size=hidden_size,batch_first=True)for i in range(num_layers)])self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):for lstm_layer in self.lstm_layers:x, _ = lstm_layer(x)if len(x.shape) == 3:output = self.fc(x[:, -1, :]) # 取最后一个时间步的输出return outputelse:return xdef train_epoch(model, X_train, y_train, epochs=10, lr=0.001, criterion=nn.MSELoss(), optimizer=None):if optimizer == None:optimizer = optim.Adam(model.parameters(), lr=lr)print(model)# 训练模型train_loss = []t1 = time.time()for epoch in range(epochs):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()train_loss.append(loss)if (epoch + 1) % 5 == 0:print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')if (epoch + 1) % 20 == 0:t2 = time.time()print('当前耗时:{:.2f}s'.format(t2-t1))return train_loss
# X_train 的形状为 (samples, time_steps, features)
# y_train 的形状为 (samples, num_targets)4.2.3 模型训练及性能表现
相关参数:LSTM层数:3,隐藏层大小:2048,学习率:0.0005,训练轮数:400轮
import torch
import numpy as np
import matplotlib.pyplot as plt
ign_data, _ = get_data_scaled()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = 'cpu'
# ign_data.shape=(396, 9)# 超参数
input_size = 9 # 每个时间步的特征数:9
hidden_size = 2048 # 隐藏层大小
output_size = 9 # 输出特征数
epochs = 400 # 轮数
lr = 0.0005 # learing rate
num_layers = 3
model = myLSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, output_size=output_size).to(device)seq_len = 16 # 暂定窗口为16
X_, y_ = create_sliding_window(ign_data, seq_len=seq_len)split_rate = 0.8
split_idx = X_.shape[0]*split_rate
split_idx = round(split_idx)
# X_train = torch.tensor(X_, dtype=torch.float32)
# y_train = torch.tensor(y_, dtype=torch.float32)
X_train = torch.tensor(X_[:split_idx,:,:], dtype=torch.float32)
y_train = torch.tensor(y_[:split_idx,:], dtype=torch.float32)
X_test = torch.tensor(X_[split_idx:,:,:], dtype=torch.float32)
y_test = torch.tensor(y_[split_idx:,:], dtype=torch.float32)
# X_test = torch.tensor(ign_data[split_idx:,:,:], dtype=torch.float32)
# y_test = torch.tensor(ign_data[split_idx:,:], dtype=torch.float32)
# 训练模型
train_loss = train_epoch(model, X_train.to(device), y_train.to(device), epochs=epochs, lr=lr)
# 保存模型
torch.save(model.state_dict(),'LSTM-hidden2048-3-copy')plot_loss(train_loss)
model.eval()
with torch.no_grad():predictions = model(X_test.to(device))predictions = predictions.to('cpu').numpy()
# print(predictions)plot(prediction=predictions, label_test=y_test.numpy())
5. 实验结果
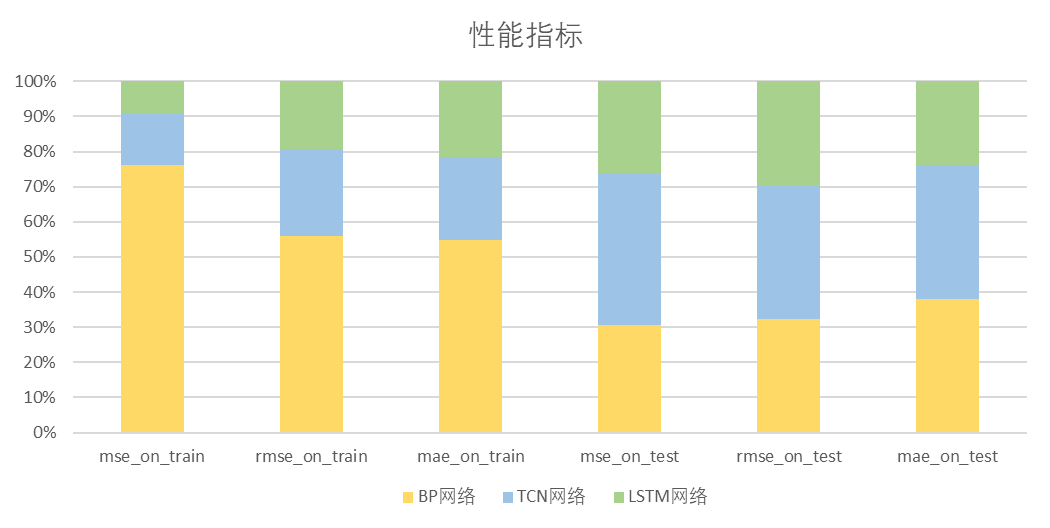
相关文章:
机器学习本科课程 大作业 多元时间序列预测
1. 问题描述 1.1 阐述问题 对某电力部门的二氧化碳排放量进行回归预测,有如下要求 数据时间跨度从1973年1月到2021年12月,按月份记录。数据集包括“煤电”,“天然气”,“馏分燃料”等共9个指标的数据(其中早期的部分…...

[office] excel中weekday函数的使用方法 #学习方法#微信#媒体
excel中weekday函数的使用方法 在EXCEL中Weekday是一个日期函数,可以计算出特定日期所对应的星期数。下面给大家介绍下Weekday函数作用方法。 01、比如,我在A84单元格输入一个日期,2018/5/9;那么,我们利用weekday计算…...

PAT-Apat甲级题1007(python和c++实现)
PTA | 1007 Maximum Subsequence Sum 1007 Maximum Subsequence Sum 作者 CHEN, Yue 单位 浙江大学 Given a sequence of K integers { N1, N2, ..., NK }. A continuous subsequence is defined to be { Ni, Ni1, ..., Nj } where 1≤i≤j≤K. The Maximum Su…...

洛谷:P2957 [USACO09OCT] Barn Echoes G
题目描述 The cows enjoy mooing at the barn because their moos echo back, although sometimes not completely. Bessie, ever the excellent secretary, has been recording the exact wording of the moo as it goes out and returns. She is curious as to just how mu…...

flinksqlbug : AggregateFunction udf Could not extract a data type from
org.apache.flink.table.api.ValidationException: SQL validation failed. An error occurred in the type inference logic of function ‘default_catalog.default_database.CollectSetSort’. org.apache.flink.table.api.ValidationException: An error occurred in the t…...

Aigtek高压放大器用途是什么呢
高压放大器在电子领域中扮演着至关重要的角色,其主要作用是将低电压信号放大到更高的电压水平。这种类型的放大器广泛用于各种应用中,以下是高压放大器的用途以及其关键作用的详细介绍。 1、科学研究和实验室应用: 高压放大器在科学研究和实验…...
c++ STL less 的视角
c less 函数在不同的地方感觉所起的作用是不一样的, 这中间原因是 less 的视角不一样, 下面尝试给出解释下, 方便记忆 1、 左右视角 符合 排序sort less(value, element) less 表示一种 “符合关系“, 表示sort 后…...
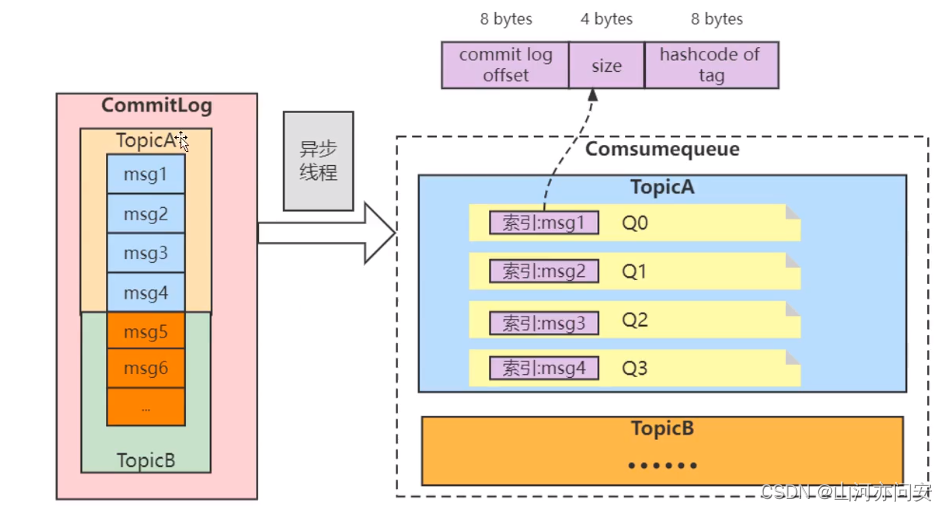
MQ面试题整理(持续更新)
1. MQ的优缺点 优点:解耦,异步,削峰 缺点: 系统可用性降低 系统引入的外部依赖越多,越容易挂掉。万一 MQ 挂了,MQ 一挂,整套系统崩 溃,你不就完了?系统复杂度提高 硬生…...

2401cmake,学习cmake2
步4:安装与测试 现在开始给项目添加安装规则和支持测试. 安装规则 安装规则非常简单:对MathFunctions,想安装库和头文件,对应用,想安装可执行文件和配置头. 所以在MathFunctions/CMakeLists.txt尾添加: install(TARGETS MathFunctions DESTINATION lib) install(FILES Mat…...

理解Jetpack Compose中的`remember`和`mutableStateOf`
理解Jetpack Compose中的remember和mutableStateOf 在现代Android开发中,Jetpack Compose已经成为构建原生UI的首选工具。它引入了一种声明式的编程模式,极大地简化了UI开发。在Compose的世界里,remember和mutableStateOf是两个非常关键的函…...

3D力导向树插件-3d-force-graph学习002
一、实现效果:节点文字同时展示 节点显示不同颜色节点盒label文字并存节点上添加点击事件 二、利用插件:CSS2DRenderer 提示:以下引入文件均可在安装完3d-force-graph的安装包里找到 三、关键代码 提示:模拟数据可按如下格式填…...
QXlsx Qt操作excel
QXlsx 是一个用于处理Excel文件的开源C库。它允许你在你的C应用程序中读取和写入Microsoft Excel文件(.xlsx格式)。该库支持多种操作,包括创建新的工作簿、读取和写入单元格数据、格式化单元格、以及其他与Excel文件相关的功能。 支持跨平台…...

Node.js 包管理工具
一、概念介绍 1.1 包是什么 『包』英文单词是 package ,代表了一组特定功能的源码集合 1.2 包管理工具 管理『包』的应用软件,可以对「包」进行 下载安装 , 更新 , 删除 , 上传 等操作。 借助包管理工具࿰…...
PyTorch 2.2 中文官方教程(十七)
(Beta)使用缩放点积注意力(SDPA)实现高性能 Transformer 原文:pytorch.org/tutorials/intermediate/scaled_dot_product_attention_tutorial.html 译者:飞龙 协议:CC BY-NC-SA 4.0 注意 点击这…...

Failed at the chromedriver@2.27.2 install script.
目录 【错误描述】Failed at the chromedriver2.27.2 install script. npm install报的错误 【解决方法】 删除node_modules文件夹npm install chromedriver --chromedriver_cdnurlhttp://cdn.npm.taobao.org/dist/chromedrivernpm install 【未解决】 下载该zip包运行这个&…...
OpenResty 安装
安装OpenResty 1.安装 首先你的Linux虚拟机必须联网 1)安装开发库 首先要安装OpenResty的依赖开发库,执行命令: yum install -y pcre-devel openssl-devel gcc --skip-broken2)安装OpenResty仓库 你可以在你的 CentOS 系统中…...
套路化编程 C# winform 自适应缩放布局
本例程实现基本的自适应缩放布局。 在本例程中你将会学习到如何通过鼠标改变界面比例(SplitContainer)、如何使用流布局(FlowLayoutPanel)排列控件,当然首先需要了解如何设置控件随窗口缩放。 目录 创建项目 编辑…...
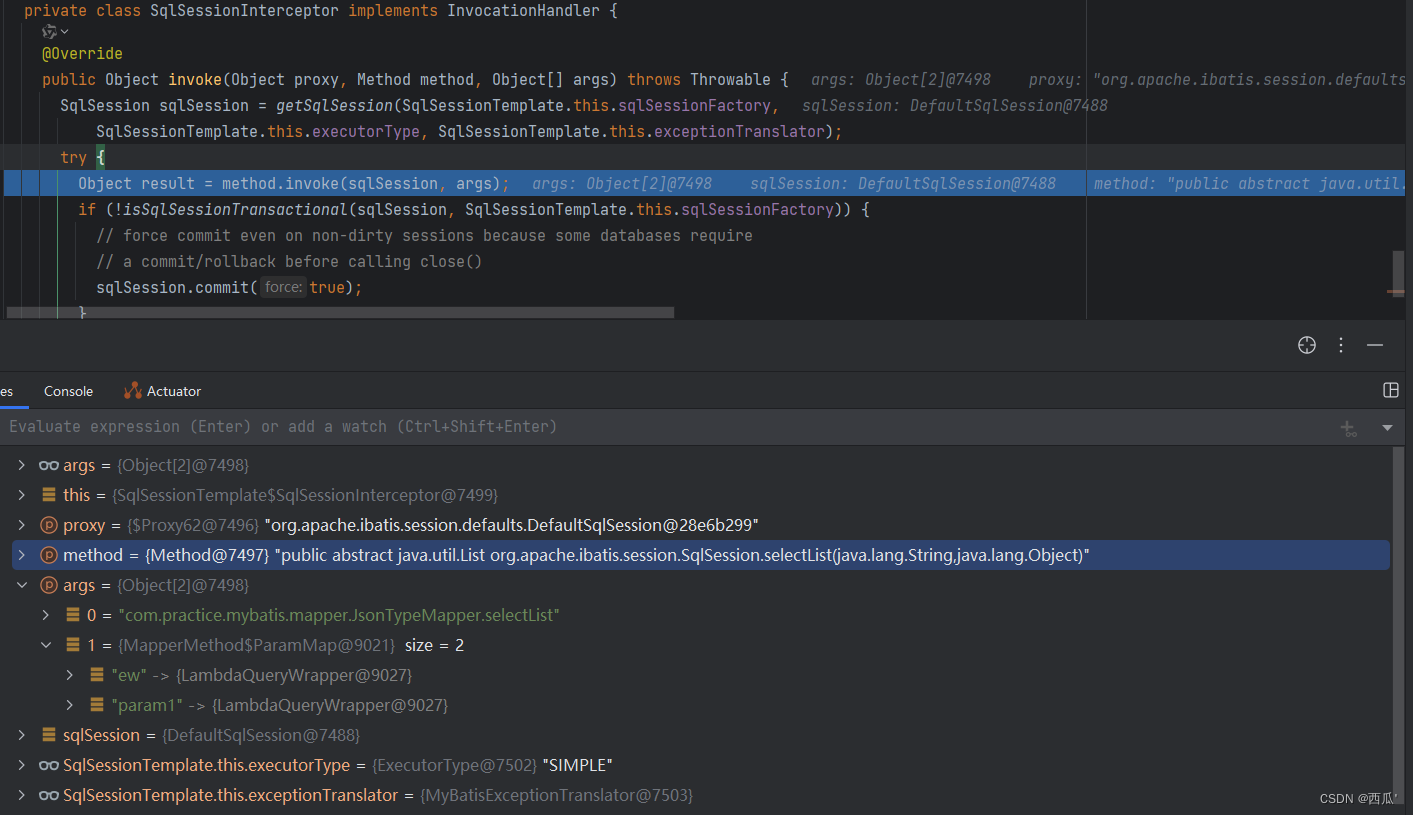
源码梳理(3)MybatisPlus启动流程
文章目录 1,MybatisPlus的使用示例2,BaseMapper方法的执行2,1 MybatisMapperProxy代理对象2.2 InvocationHandler接口(JDK动态代理)2.3 MapperMethodInvoker接口2.4 MybatisMapperMethod 3,SqlSession的执行流程3.1 Sq…...
《学成在线》微服务实战项目实操笔记系列(P1~P49)【上】
《学成在线》项目实操笔记系列【上】,跟视频的每一P对应,全系列12万字,涵盖详细步骤与问题的解决方案。如果你操作到某一步卡壳,参考这篇,相信会带给你极大启发。同时也欢迎大家提问与讨论,我会尽力帮大家解…...
两种添加删除属性字段的方法
水经微图(简称“微图”)中的图层均有属性字段,无论是复合图层,还是点线面图层的字段都可以根据实际情况进行添加或删除。 这里,就为你分享两种添加删除字段的方法。 添加删除字段方法一 当需要添加删除图层的属性字…...

MATLAB/Simulink 光伏混合储能的 VSG 构网型系统并网仿真探索
MATLAB/Simulink光伏混合储能的VSG构网型系统并网仿真 构网型储能系统由光伏模块进行发电,蓄电池和超级电容构成混合型储能系统,并网控制采用虚拟同步机VSG进行控制。 其中,混合储能HESS由蓄电池和超级电容组成,对光伏并网系统实现…...

org.springframework.web.HttpMediaTypeNotSupportedException: Content-Type ‘text/plain;charset=UTF-8‘
问题解决方案 解决方案 在 Postman 中修改设置: 保持选择 “raw”将右侧下拉框从 “Text” 改为 “JSON” 确保 Body 内容是有效的 JSON: {"id": 101 }这样 Postman 会自动设置 Content-Type: application/json,请求就能正常处理了…...

【RAG】基于 RAG 的知识库问答系统设计与实现
基于 RAG 的知识库问答系统设计与实现1. 系统介绍2. 技术与方法3. 核心功能代码片段3.1 知识库创建3.2 知识对话问答3.3 知识库清空4. 系统运行效果截图4.1 文件上传与知识库创建4.2 知识库问答4.3 文件删除与知识库清空总结项目代码地址:https://github.com/AI-Mee…...

节能模式!OpenClaw优化Qwen3-4B模型夜间任务功耗
节能模式!OpenClaw优化Qwen3-4B模型夜间任务功耗 1. 为什么需要关注OpenClaw的能耗问题 去年夏天,我的MacBook Pro在运行OpenClaw执行夜间数据整理任务时,风扇狂转的声音把我从睡梦中吵醒。摸到发烫的机身时,我突然意识到——这…...
)
避坑指南:从聚宽迁移到QMT必须知道的5个细节(含Redis连接异常处理)
从聚宽迁移到QMT的实战避坑指南:Redis连接与xtquant重连机制详解 当量化团队需要从聚宽平台迁移到QMT时,往往会遇到一系列技术细节上的挑战。本文将聚焦五个最容易被忽视但至关重要的技术环节,特别是Redis连接池管理和xtquant重连机制这两个直…...

天华新能冲刺港股:年营收75亿净利降56% 宁德时代是二股东 裴振华夫妻套现26亿
雷递网 雷建平 4月3日苏州天华新能源科技股份有限公司(简称:“天华新能”)日前递交招股书,准备在港交所上市。天华新能2014年在深交所上市,截至今日午盘,天华新能股价为58.6元,市值为487亿元。一…...

基于LCL滤波器的光伏三相逆变并网模型 1.模型由光伏系统,逆变器,LCL滤波器和交流主网组成 2
基于LCL滤波器的光伏三相逆变并网模型1.模型由光伏系统,逆变器,LCL滤波器和交流主网组成 2.光伏采用扰动观测法实现最大功率输出,逆变器采用恒定直流母线电压控制策略 实现以下目标: 1.光伏维持在最大功率输出。 2.逆变器实现直流…...

# 系列文10:突破Activiti限制!政务工作流任意流转,支持跳退
系列文10:突破Activiti限制!政务工作流任意流转,支持跳退回退 非科班野生程序员,深耕政务信息化20年,这套自研Java Web框架支撑过省级新农保、全国首例跨省医保结算等核心民生系统,18年稳定运行至今。本系…...

javascript之Dom查询操作1
1.通过Id获取单个元素假定要获取下面html代码里面id是div1的div标签内容语法是document.getElementById(Id值)<div id"div1">div1</div>let a document.getElementById("div1") console.log(a)2.根据name属性值获取语法是document.getElement…...
)
基于YOLOv10深度学习的植物叶片病害识别检测系统(YOLOv10+YOLO数据集+UI界面+Python项目+模型)
一、项目介绍 本项目基于先进的YOLOv10目标检测算法,开发了一套智能植物叶片病害识别检测系统。系统能够实现对38种不同植物叶片健康状况的实时检测与分类,包括多种常见病害及健康叶片。通过图形用户界面,用户可以方便地上传图片、视频或调用…...