记elasticsearch CPU负载100%问题
记elasticsearch CPU负载100%问题
- 环境:
- 问题表现:
- 初步排查:
- 日志
- 查询hot_thread
- 深入
- 查询当前elasticsearch正在运行的Task
- 查看Task详情
- 解决问题
- 对导致问题的原因的几个猜测
- 问题复现:
- 导致问题的原因。
- json导入规则问题
- json导入规则问题解决
- 中英文非ndjson格式数据上传问题
- 中英文非ndjson格式数据问题解决
- reference
- 附录
- elasticsearch,index基本数据格式
- elasticsearch的analyzer
环境:
单台2核4G的阿里云ecs,部署单node的elasticsearch+kibana。
测试环境,刚上手elasticsearch学习用。本来是构建LLM的RAG系统的,结果突然来了个100%CPU占用,而且居高不下,没办法,干回老本行,运维工程师,启动!
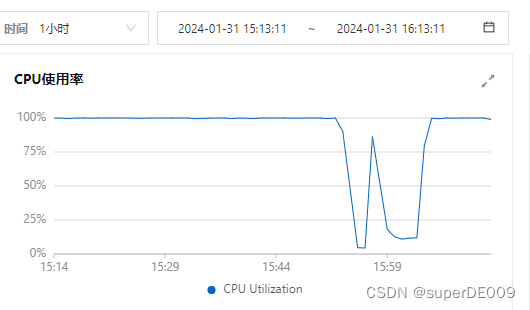
问题表现:
在上午9.50分开始,阿里云控制台可看见ecs的CPU从原本的4%占用左右,快速飙到了100%,并且长时间居高不下。

初步排查:
日志
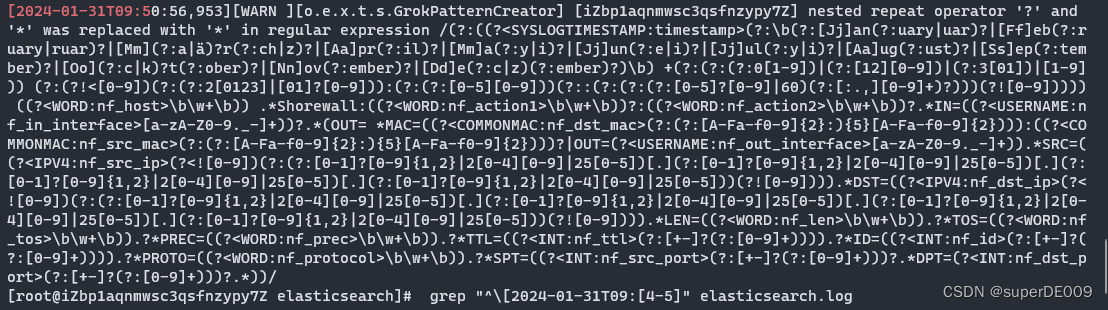
先看日志,通过正则筛选elasticsearch.log中9.40-50分中的所有日志。
cd /var/log/elasticsearch
grep "^\[2024-01-31T09:[4-5]" elasticsearch.log
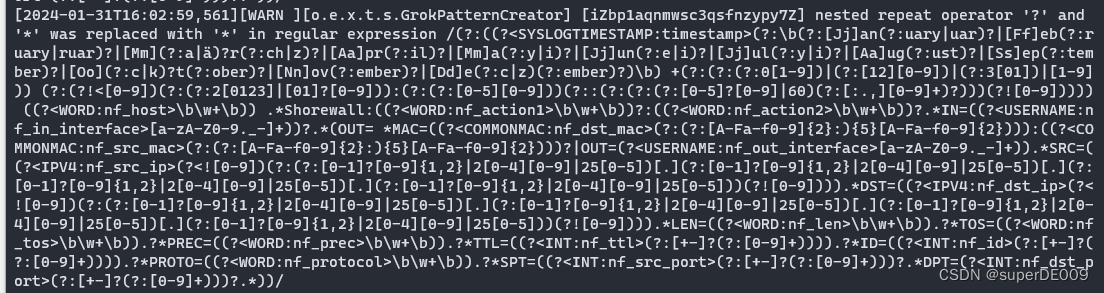
可以见到,日志中有多段如下日志。其主要内容是Grok在对非结构化数据的正则匹配,提取信息。而我从未进行过任何的Grok配置与操作。
查询hot_thread
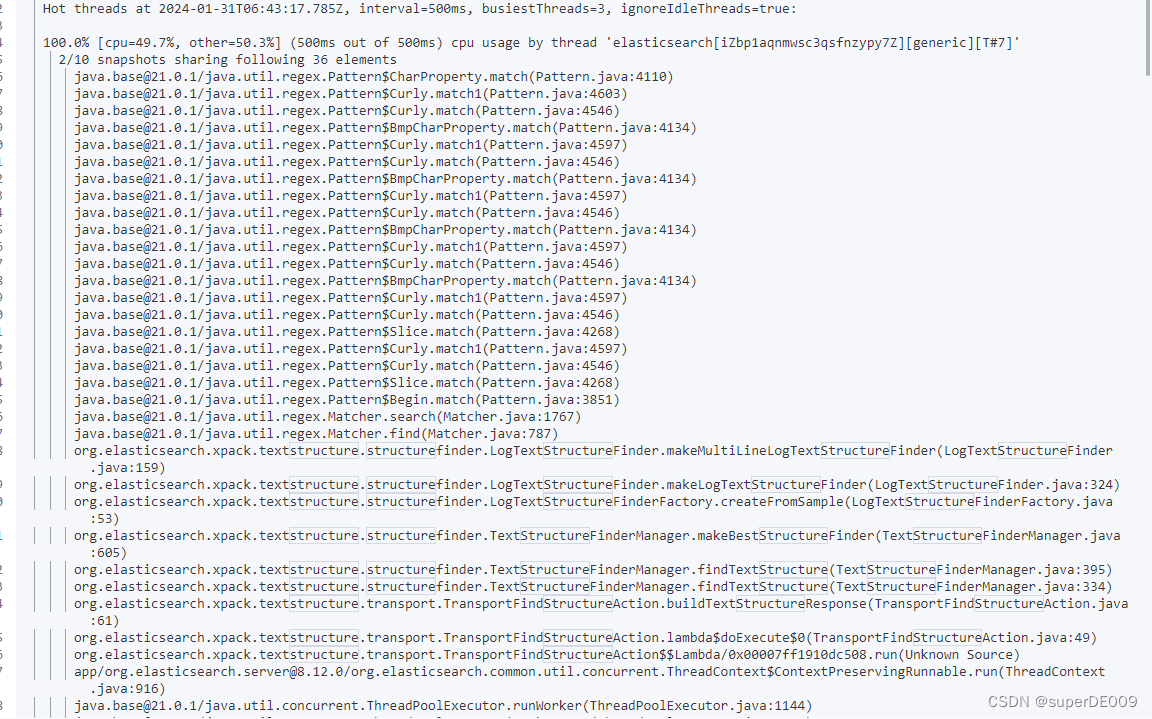
elasticsearch的API中,提供了一个查询当前node中资源占用量大的进程的接口。
GET /_nodes/hot_threads
查询结果如下,可以详细看到,这些进程大部分都在进行正则匹配的工作,和之前log中看到的一致。并且,下方textstructure.structurefinder这个类,即是Gork提取非结构化数据信息的类。
深入
查询当前elasticsearch正在运行的Task
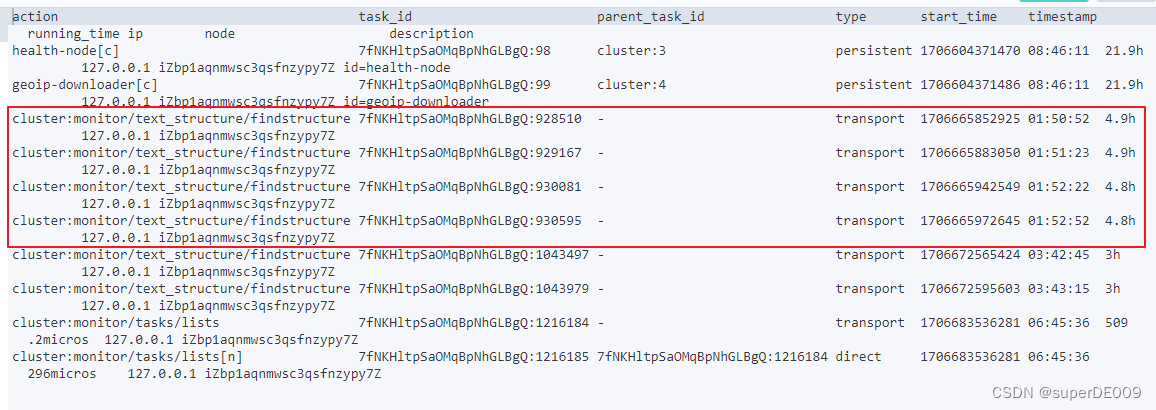
通过API,可以详细的查找到当前elasticsearch中,正在运行的Task的详细内容。
GET /_cat/tasks?v&detailed=true
可以看到,其中存在几个text_structure/findstructure的Task,和hot_thread中看到的一致,并且启动的时间也基本对应CPU升高的时间。
查看Task详情
通过通配符匹配,查询这几个Task的详细信息。
GET /_tasks?detailed=true&actions=*/text_structure/findstructure
可以看到,这几个任务的Type为Transport的类型。
从elasticsearch文档中,可以看到,Transport类型的任务的主要功能是:

到这,卡住了
transport类型,一般的node之间通信的任务,但是我是单node
所以我又找到,发现我创建的index,默认replica=1,即分片有一个备份,而我是单node,备份必须是存储在不同的node上,导致备份分片一直不能被分配,使得index状态处于yellow状态。
但是不确定这个和我当前的任务是否有关系
好了,更新的replica,但是问题还在,现在index都是绿的了
解决问题
重启解决问题,重启后,所有的structurefinder进程都消失了
OK,不用查了,es崩了,直接重启了。
在此之前,还检查了是否是pipeline的问题,但是pipeline都没有在使用。
OK,重启了,之前看到的structurefinder进程都没有了,CPU也降下来。
问题虽然解决,但是还是不知道为啥。
对导致问题的原因的几个猜测
几个怀疑:看看之后我会不会再复现这个问题
- 多副本问题,导致有副本切片一直没有合适的node分配(但是不应该占用CPU啊?
- 因为导入的时候,使用了默认的pipeline,导致对导入的数据,进行的非结构化分析和提取,导致CPU占用高。(但是,不应该一直持续存在吧?
- 中间有玩了一次,kibanaUI界面,添加集成,直接上传了一个json格式的问题,不知道是不是这个问题。返回的结果是失败,说需要结构化的数据?并且是请求超时(我认为这个最有可能)。
问题复现:
因为对于原因3最为怀疑,而且确实时间点也对的上,就是上传完之后开始CPU飙升,同时上传失败的返回也确实怪怪的。所以重新上传。
json内容:值为中文的unicode

重新上传之后,仍然是以下的问题。
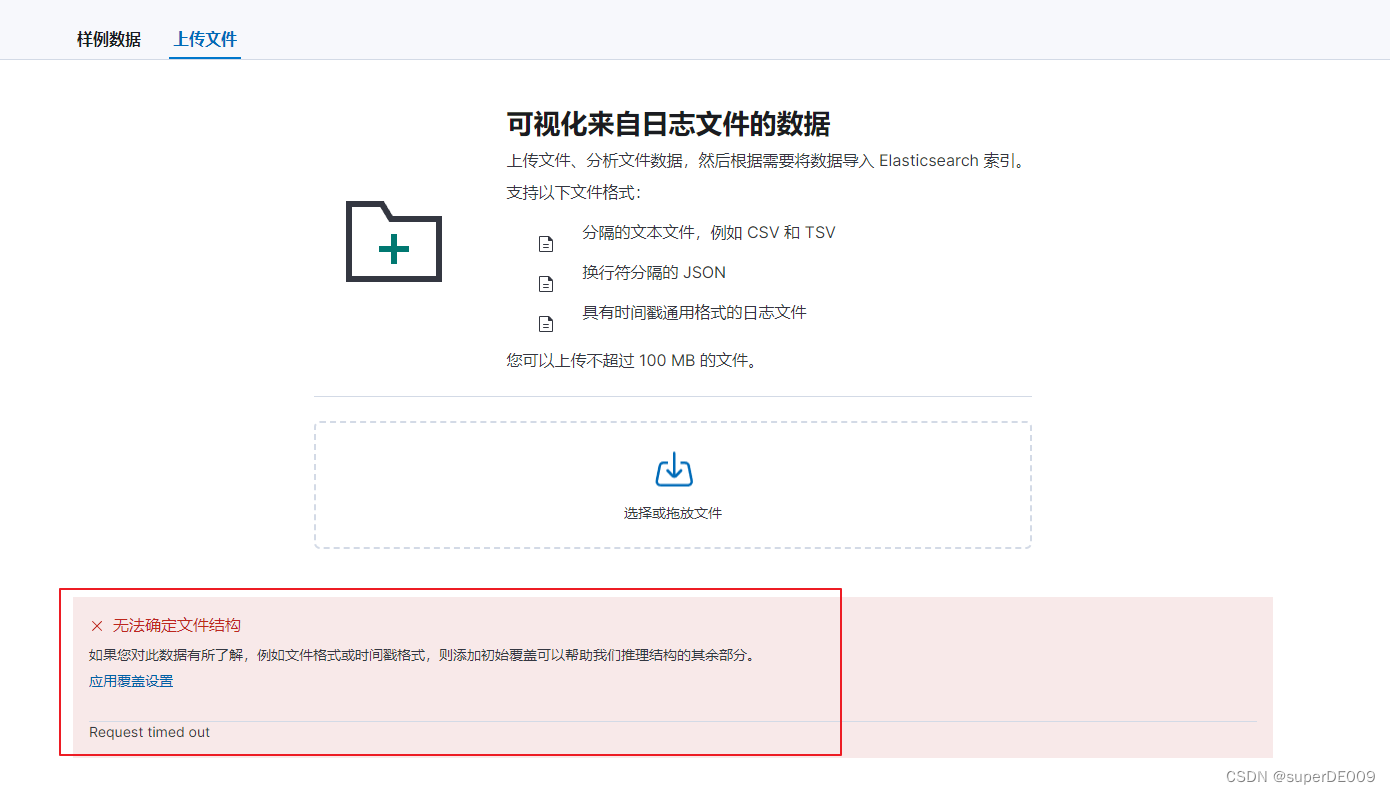
再次查看,发现CPU又100%负载了。并且之前的structurefinder进程又出现:

导致问题的原因。
那么基本可以确定,就是在解析上传的文件时,通过grok尝试解析,失败后,却没有关闭进程。从而导致CPU不断被占用。
而上图UI界面中返回的Request:time out 基本可以确定是structurefinder在尝试解析json内容时,花费的时间太久从而返回的time out。
json导入规则问题
只是问题是,为什么我的json文件,会解析这么久,并且仍然没有结束。上午的解析进程,最长的一个运行了近6个消失,但是仍然没有结果。
我的json文件,是python直接dump出来的,并且json格式校验也没有问题。
json导入规则问题解决
因为es要求的上传的json格式为ndjson。即换行符分割的json,每一行都是一个完整的json对象。
而我上传的,只是传统json格式,导致无法解析。
中英文非ndjson格式数据上传问题
仍然还有一个问题没有解决:
当一个英文的非ndjson格式的json被上传时,会报错非ndjson格式。直接返回,没有timeout
当一个unicode中文的非ndjson的json被上传时,会直接无限等待,导致CPU100%占用,返回timeout。并且后台持续存在一个task在进行解析,并且不结束,占用CPU100%
中英文非ndjson格式数据问题解决
我又去看了一遍hot_thread,可以看到这里的进程中,主要的函数是log Text Structure Finder。即对log的格式解析。
在上传文件时,es有明确,可以上传带标准时间戳格式的log问题。

由此推测:当unicode的json被上传后,不符合ndjson,但是不知为何,被当作了log去解析,而又并非log,导致了一些奇奇怪怪的bug,导致解析的进程无限等待,并没有进入任何一个错误返回。从而导致timeout,同时解析的进程卡死,CPU占用100%
而英文可能更方便,所以并没有触发这个bug。
reference
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/high-cpu-usage.html#high-cpu-usage
聊聊 Elasticsearch 中的任务管理机制
red-yellow-cluster-status
你所不知道的ndJSON:序列化与管道流
附录
elasticsearch,index基本数据格式
{"settings": {"analysis": {"analyzer": {"default": {"type": "simple" //整个index使用的analyzer},"default_search": {"type": "whitespace" //默认对这个index的搜索关键字使用的analyzer 也就是分词,tokenizer+去停用词等操作。}}},"number_of_shards": 3,// 分片存储,将数据分块,存储在集群中,搜索时,将请求发向对应的分片,类似hadoop(也能增加搜索时的并行性)"number_of_replicas": 1 // 副本,即整个集群上,不同机器中存储副本。默认为1,即有一个副本,但是,副本必须存在不同的机器上,单node,多余的副本会无法被alloc,导致node状态为yellow},"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_smart" //对单个field定义分析器,仅对该field生效。},"field1": {"type": "keyword"},"field2": {"type": "date"}}}
}
elasticsearch的analyzer
analyzer主要做分词,去除停用词等数据预处理的工作。
默认有一个standard,whitespace,simple,等
分别对应不同的分词方法。
但是,都不支持中文分词,所以,只用中文文本数据,一定要使用ik分词的插件,否则分词效果差会非常影响搜索的准确性。
具体安装配置IK分词器的方法详见:
ElasticSearch中文分词
相关文章:
记elasticsearch CPU负载100%问题
记elasticsearch CPU负载100%问题 环境:问题表现:初步排查:日志查询hot_thread 深入查询当前elasticsearch正在运行的Task查看Task详情解决问题对导致问题的原因的几个猜测问题复现:导致问题的原因。json导入规则问题json导入规则…...

回归预测 | Matlab实现OOA-CNN-LSTM-Attention鱼鹰算法优化卷积长短期记忆网络注意力多变量回归预测(SE注意力机制)
回归预测 | Matlab实现OOA-CNN-LSTM-Attention鱼鹰算法优化卷积长短期记忆网络注意力多变量回归预测(SE注意力机制) 目录 回归预测 | Matlab实现OOA-CNN-LSTM-Attention鱼鹰算法优化卷积长短期记忆网络注意力多变量回归预测(SE注意力机制&…...

PyTorch、NCNN、CV::Mat三者张量的shape
目录 一、PyTorch二、NCNN三、CV::Mat 一、PyTorch 在 PyTorch 中,张量(Tensor)的形状通常按照 (N, C, H, W) 的顺序排列,其中: N 是批量大小(batch size) C 是通道数(channel numb…...

社交平台内容创作未来会有哪些方向?
内容为王的时代下,企业如果想要通过社交平台占据用户心智,可以找到适合自己的内容营销策略,好的内容能够与消费者建立信任关系,今天 媒介盒子就来和大家聊聊:社交平台内容创作的方向。 一、 内容逐渐细分 相比于原来…...
MySQL温故篇(一)SQL语句基础
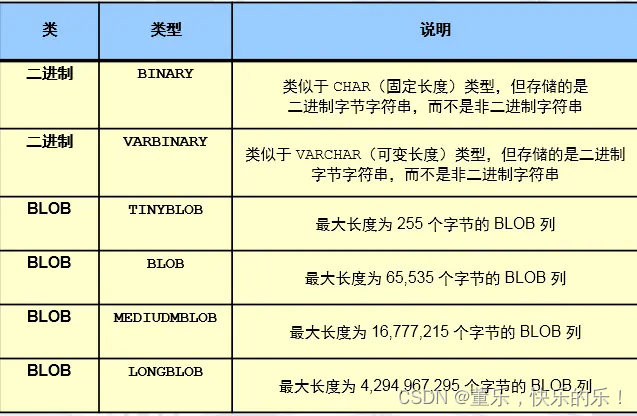
一、SQL语句基础 1、SQL语言分类 DDL:数据定义语言 DCL:数据控制语言 DML:数据操作语言 DQL:数据的查询语言 2、数据类型 3、字符类型 char(11) : 定长 的字符串类型,在存储字符串时,最大字符长度11个&a…...

C 检查小端存储还是大端
#include <stdio.h>int main() {unsigned int i 1;char *c (char*)&i;if (*c) printf("小端字节序\n");elseprintf("大端字节序\n");return 0; }该程序就是利用了强转舍弃 我们首先定义了一个无符号整数i并将其初始化为1。然后,…...
)
【ETOJ P1021】树的遍历 题解(有向图+深度优先搜索+广度优先搜索)
题目描述 给定一棵大小为 n n n,根为 1 1 1 的树,求出其按照 dfs 和 bfs 进行遍历时的顺序。 请将所有出点按照编号从小到大排序后进行遍历。 dfs 为深度优先搜索,bfs 为宽度优先搜索。 输入格式 一个整数 n n n,表示点的…...
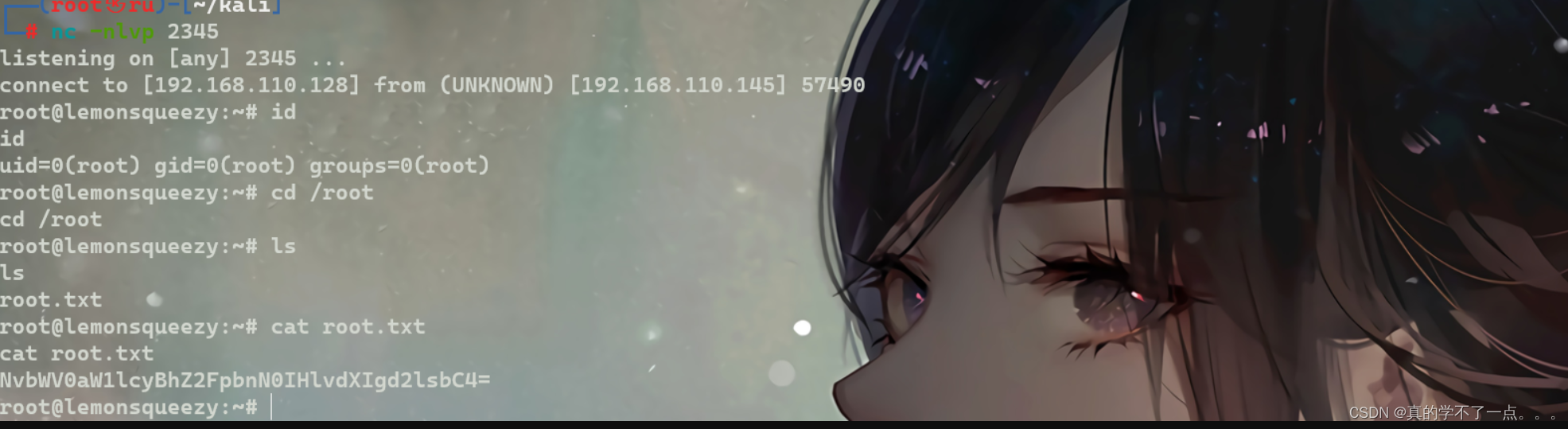
红队渗透靶机:LEMONSQUEEZY: 1
目录 信息收集 1、arp 2、nmap 3、nikto 4、whatweb 目录扫描 1、dirsearch 2、gobuster WEB phpmyadmin wordpress wpscan 登录wordpress 登录phpmyadmin 命令执行 反弹shell 提权 get user.txt 信息收集 本地提权 信息收集 1、arp ┌──(root㉿ru)-[~…...

【Servlet】——Servlet API 详解
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【Servlet】 本专栏旨在分享学习Servlet的一点学习心得,欢迎大家在评论区交流讨论💌 目录 一、HttpServlet二、Htt…...

oracle主库增加redo组数
redo log(重做日志): 重做日志:简单来说就是,将oracle数据库的DML、DDL(数据库操作语言,数据库定义i语言)操作记录在日志中,方便恢复及备库使用,以组的方式管…...

lua只读表
参考《programming in lua》13.4.5中,详细介绍了只读表的用法。建立一个函数,传入一个table,传出一个代理table,其__index指向传入的table,__newIndex直接报error即可: --输入一个table,输出一…...
的全面指南)
探索深度学习的边界:使用 TensorFlow 实现高效空洞卷积(Atrous Convolution)的全面指南
空洞卷积(Atrous Convolution),在 TensorFlow 中通过 tf.nn.atrous_conv2d 函数实现,是一种强大的工具,用于增强卷积神经网络的功能,特别是在处理图像和视觉识别任务时。这种方法的核心在于它允许网络以更高…...

HarmonyOS案例:摇杆游戏
本案例主要演示如何通过一系列的动画效果以及运算实现摇杆控制组件同步运动的功能,界面简陋无需在意。 欢迎大家的阅读和评价,也欢迎大佬们批评、指正,我将继续努力,奉上更加专业的、高效的代码案例。 import curves from ohos.c…...

Elasticsearch:构建自定义分析器指南
在本博客中,我们将介绍不同的内置字符过滤器、分词器和分词过滤器,以及如何创建适合我们需求的自定义分析器。更多关于分析器的知识,请详细阅读文章: 开始使用 Elasticsearch (3) Elasticsearch: analyzer…...
Git系列---远程操作
📙 作者简介 :RO-BERRY 📗 学习方向:致力于C、C、数据结构、TCP/IP、数据库等等一系列知识 📒 日后方向 : 偏向于CPP开发以及大数据方向,欢迎各位关注,谢谢各位的支持 引用 1.理解分布式版本控制…...
kafka客户端生产者消费者kafka可视化工具(可生产和消费消息)
点击下载《kafka客户端生产者消费者kafka可视化工具(可生产和消费消息)》 1. 前言 因在工作中经常有用到kafka做消息的收发,每次调试过程中,经常需要查看接收的消息内容以及人为发送消息,从网上搜寻了一下࿰…...

【从0上手Cornerstone3D】如何使用CornerstoneTools中的工具之工具介绍
简单介绍一下在Cornerstone中什么是工具,工具是一个未实例化的类,它至少实现了BaseTool接口。 如果我们想要在我们的代码中使用一个工具,则必须实现以下两个步骤: 使用Cornerstone的顶层addTool函数添加未实例化的工具 将工具添…...
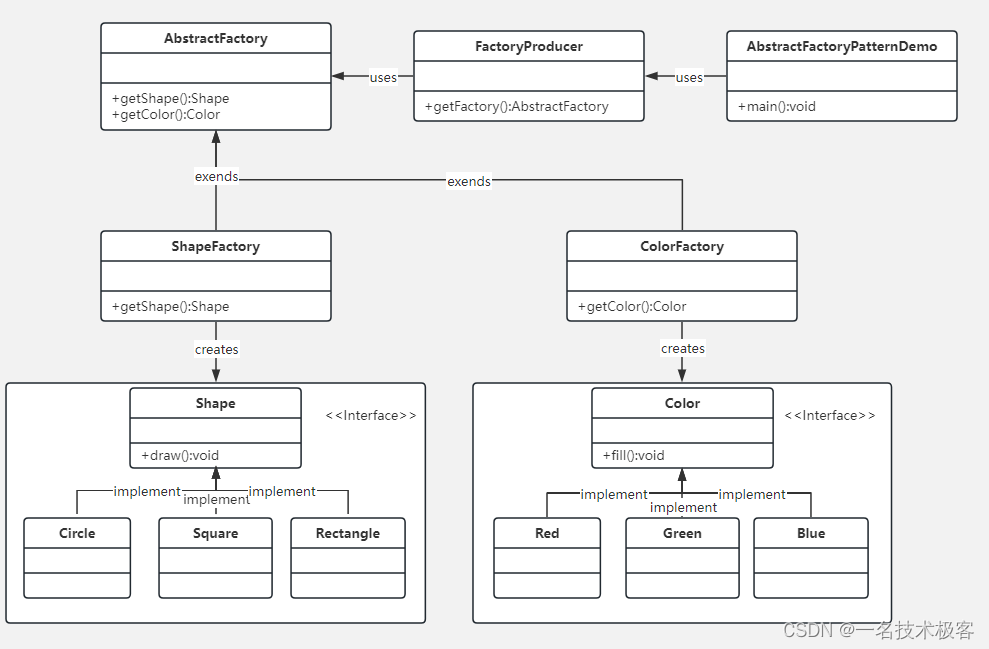
02-Java抽象工厂模式 ( Abstract Factory Pattern )
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂 该超级工厂又称为其他工厂的工厂 在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类 每个生成的工厂都能按照工厂模式提供对象 …...
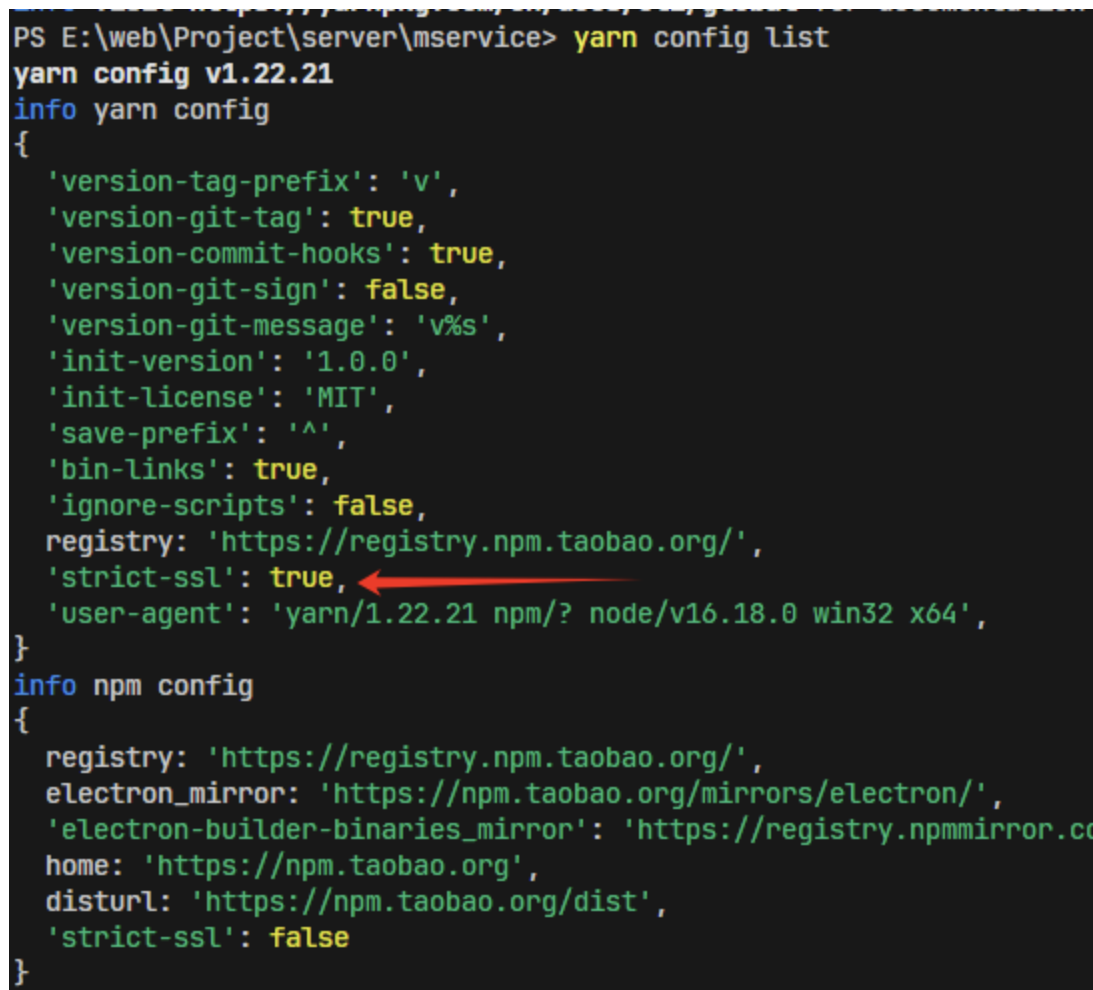
yarn/npm certificate has expired
目录 报错 原因:HTTPS 证书验证失败 方法 a.检查网络安全软件:可能会拦截或修改 HTTPS 流量 b.strict-ssl:false关闭验证【临时方法】 报错 info No lockfile found. [1/4] Resolving packages... error Error: certificate has expired at TLS…...

第十三篇【传奇开心果系列】Python的OpenCV库技术点案例示例:光流估计
传奇开心果短博文系列 系列短博文目录Python的OpenCV库技术点案例示例:光流估计短博文目录前言一、光流估计介绍二、Lucas-Kanade光流介绍和示例代码三、Horn-Schunck光流介绍和示例代码四、cv::calcOpticalFlowPyrLK()函数实现光流估计介绍和示例代码五、光流估计用于运动分析…...

SEO_避开常见SEO误区,让你的优化更高效
SEO误区:避开常见陷阱,让你的优化更高效 在当前互联网营销的环境中,搜索引擎优化(SEO)是一个至关重要的环节。无论你是一个新手还是有一些经验的网站管理者,都会遇到各种各样的SEO误区。这些误区不仅可能浪…...

LeetCode 二叉搜索树双神题通关!有序数组转平衡 BST + 验证 BST,小白递归一把梭
前言 二叉搜索树(BST)是算法刷题的高频必考知识点!今天给大家带来两道最经典、最基础的 BST 题目,全程用最简单的递归实现,代码干净、思路直白,不用死记硬背,看完就能直接写! 一道教…...

并联型有源电力滤波器APF的三相三线制模型及其Simulink仿真研究——基于瞬时无功功率理论...
并联型有源电力滤波器APF三相三线模型都包括,simulink仿真利用基于瞬时无功功率理论的ip-iq谐波检测算法,对三相三线制并联型APF控制系统进行建模与Matlab仿真最近在搞三相三线制并联型APF的仿真,发现基于ip-iq谐波检测的方案确实挺有意思。这…...
2026-04-03 全国各地响应最快的 BT Tracker 服务器(联通版)
数据来源:https://bt.me88.top 序号Tracker 服务器地域网络响应(毫秒)1http://211.75.210.221:6969/announce江苏镇江联通222http://60.249.37.20:80/announce广东肇庆联通273udp://132.226.6.145:6969/announce宁夏银川联通724http://93.158.213.92:1337/announce…...

使用vue3+ts构建企业级文件传输管理系统:状态管理、性能优化与用户体验的深度实践
使用vue3+ts构建企业级文件传输管理系统:状态管理、性能优化与用户体验的深度实践 在现代企业应用中,文件传输是核心功能之一。一个高效的传输管理系统不仅需要处理大量文件,还需提供直观的状态反馈、灵活的操作选项和流畅的用户体验。今天,我将分享一个基于Vue 3和TypeSc…...

定时任务XXL-Job
目录为什么是XXL-Job?SpringBoot 整合XXL-Job1)环境准备2)SpringBoot 项目依赖3)application.yml 配置4)XXL-Job 配置类5)定时任务业务类(核心代码)6)调度中心Web可视化界…...

性能测试专家养成记:工具、思维、实战全解析
在软件质量保障体系中,性能测试正从一个可选的“加分项”演变为关乎用户体验与业务存续的“必答题”。对于广大软件测试从业者而言,成长为一名性能测试专家,不仅意味着技术深度的拓展,更代表着从“验证功能”到“保障体验”乃至“…...

2025届最火的十大AI写作工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作这个特定的场景之内,精确地挑选恰当的AI论文平台,能够极其…...

星闪实战指南:10分钟掌握WS63 SDK任务调度与调试技巧
1. 星闪WS63 SDK任务调度基础 第一次接触星闪WS63 SDK的任务调度功能时,我完全被各种API搞晕了。经过几个项目的实战,才发现这套任务管理系统设计得非常巧妙。简单来说,它就像个智能管家,能帮你把各种工作安排得井井有条。 任务调…...

自动化抢票工具:从技术原理到实战部署的全流程解析
自动化抢票工具:从技术原理到实战部署的全流程解析 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 在票务销售场景中,人工操作面临三大核心痛点:页面刷新延迟导…...