[Python] 什么是KMeans聚类算法以及scikit-learn中的KMeans使用案例
什么是无监督学习?
无监督学习是机器学习中的一种方法,其主要目的是从无标签的数据集中发现隐藏的模式、结构或者规律。在无监督学习中,算法不依赖于任何先验的标签信息,而是根据数据本身的特征和规律进行学习和推断。无监督学习通常用于聚类、降维、异常检测等任务。在聚类中,算法会将相似的数据点归为一类;在降维中,算法会将高维数据映射到低维空间;在异常检测中,算法会发现与其他数据不同的离群点。无监督学习是与有监督学习相对应的,有监督学习则是依赖已知的标签信息进行学习和预测。
什么是聚类算法?
聚类算法是一种无监督学习方法,它将数据集中的对象按照相似性进行分组,即将相似的对象归为一类,不相似的对象归为不同的类别。聚类算法的目标是使得同一类内的对象相似度较高,而不同类之间的相似度较低。
聚类算法的一般步骤包括:
-
选择合适的相似性度量指标,常用的有欧氏距离、余弦相似度等。
-
初始化聚类中心,可以是随机选择数据集中的点或者通过其他方法来选择。
-
对每个数据点,计算其与聚类中心的相似度,并将其分配到最相似的聚类中心所在的类别。
-
根据已分配的数据点,更新聚类中心的位置,可以采用均值、中位数等方法。
-
重复步骤3和步骤4,直到达到某个停止条件,如收敛或达到最大迭代次数。
常见的聚类算法包括K-means、层次聚类、DBSCAN等。这些算法都有各自的特点和适用范围,需要根据具体的问题和数据来选择合适的算法。
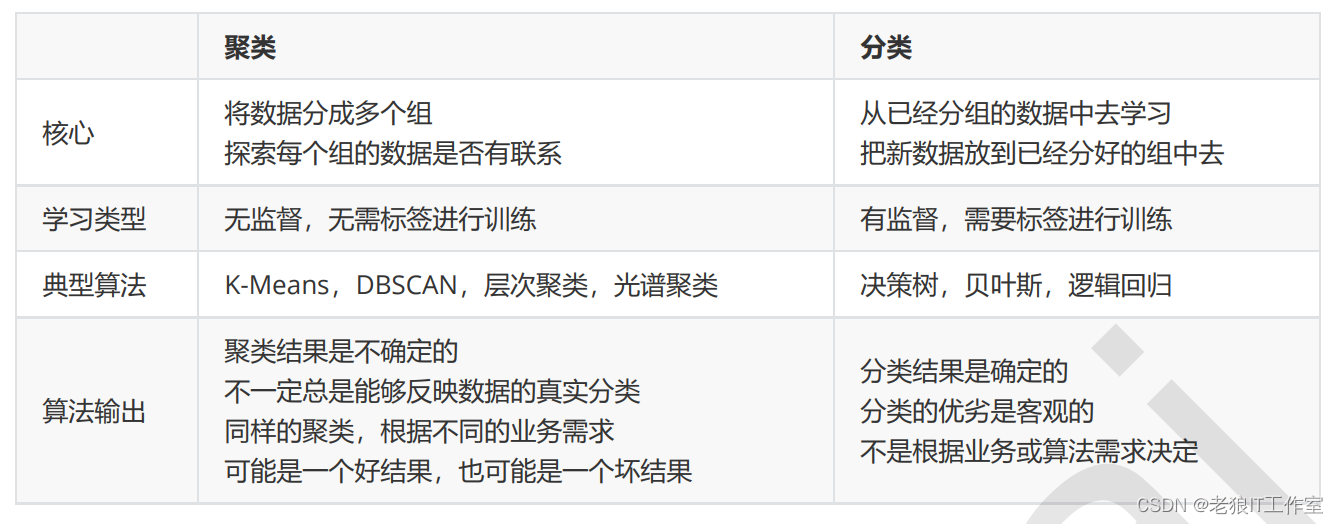
聚类和分类算法的比较
聚类和分类是机器学习中常用的两种数据分析方法,它们在目标、方法和应用方面有一些区别。
目标:
- 聚类的目标是将数据集中的对象划分为不同的组或类别,使得同一组内的对象相似度较高,不同组之间的相似度较低。聚类的目标是无监督的,即不依赖于已知的标签或类别信息。
- 分类的目标是将数据对象划分到预定义的类别中,也称为标签或类别预测。分类的目标是有监督的,即依赖于已知的标签或类别信息。
方法:
- 聚类方法通常是基于数据之间的相似度或距离来进行划分,常用的聚类方法有K-means、层次聚类、DBSCAN等。聚类方法通常不需要预先定义类别,而是通过计算数据之间的相似度来自动划分。
- 分类方法则是基于已知的类别信息和训练数据来构建一个分类模型,可以使用各种分类算法,如决策树、支持向量机、逻辑回归等。分类模型利用训练数据的特征和对应的类别标签来学习并预测新数据的类别归属。
应用:
- 聚类方法常用于数据探索、模式发现和相似性分析等领域。聚类可以帮助识别数据中潜在的群组或模式,发现数据的内在结构。
- 分类方法常用于分类预测、图像识别、文本分类等应用。分类可以将新的数据对象归类到已知的类别中,进行预测和判断。
需要注意的是,聚类和分类并不是完全互斥的方法,有些应用场景中,聚类结果可以作为分类的一种辅助工具,帮助确定类别或构建分类模型。同时,聚类和分类方法的选择也取决于问题的特点、数据的性质和可用的标签信息。
什么是K-means聚类算法?
K-means聚类算法是一种常见且简单的聚类算法,它将数据集中的对象根据欧氏距离划分为K个不同的类别。其基本思想是通过迭代的方式,不断调整每个类别的中心位置,使得同一类别内的数据点到其中心的距离最小。
K-means聚类算法的步骤如下:
-
随机选择K个聚类中心点,可以是从数据集中随机选择或者通过其他方法确定。
-
对于每个数据点,计算其与每个聚类中心的距离,并将其分配到距离最近的聚类中心所在的类别。
-
根据已分配的数据点,更新每个类别的聚类中心位置,通常是计算该类别内所有数据点的均值。
-
重复步骤2和步骤3,直到达到某个停止条件,如类别内的数据点不再发生变化或达到最大迭代次数。
K-means算法的优点是简单且易于理解,计算效率高。然而,K-means算法对初始聚类中心的选择比较敏感,可能会陷入局部最优解。此外,K-means算法要求数据点之间的距离度量要有意义,且每个类别的大小相对均衡。对于非球形的聚类结构,K-means算法的效果可能不理想。
因此,在应用K-means算法时,需要根据具体问题和数据的特点来选择合适的K值和初始聚类中心,以及对数据进行预处理和后处理来改善聚类结果。
KMeans聚类算法
KMeans是如何工作的?
作为聚类算法的典型代表,KMeans可以说是最简单的聚类算法没有之一,那它是怎么完成聚类的呢?

在KMeans算法中,簇的个数K是一个超参数,需要我们人为输入来确定。KMeans的核心任务就是根据我们设定好 的K,找出K个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。具体过程可以总结如下:

那什么情况下,质心的位置会不再变化呢?当我们找到一个质心,在每次迭代中被分配到这个质心上的样本都是一 致的,即每次新生成的簇都是一致的,所有的样本点都不会再从一个簇转移到另一个簇,质心就不会变化了。 这个过程在可以由下图来显示,我们规定,将数据分为4簇(K=4),其中白色X代表质心的位置:
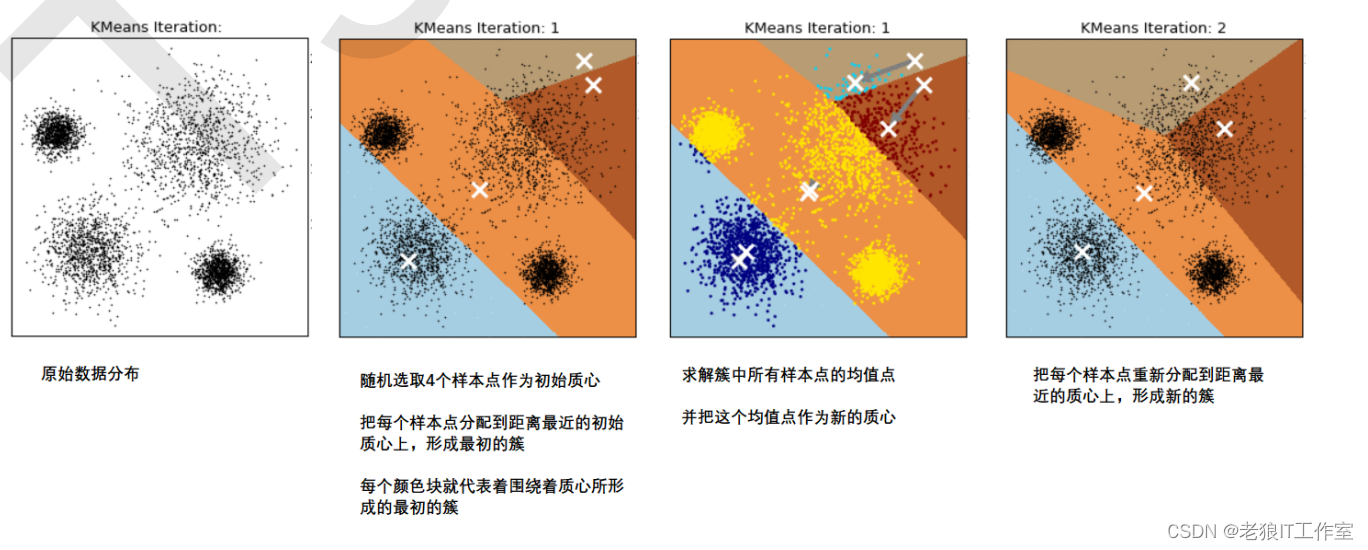
在数据集下多次迭代(iteration),模型就会收敛。第六次迭代之后,基本上质心的位置就不再改变了,生成的簇也 变得稳定。此时我们的聚类就完成了,我们可以明显看出,KMeans按照数据的分布,将数据聚集成了我们规定的 4类,接下来我们就可以按照我们的业务需求或者算法需求,对这四类数据进行不同的处理。
簇内误差平方和的定义和解惑
聚类算法聚出的类有什么含义呢?这些类有什么样的性质?我们认为,被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的,当聚类完毕之后,我们就要分别去研究每个簇中的样本都有什么样的性质,从而根据业务需求制定不同的商业或者科技策略。我们追求聚类算法“簇内差异小,簇外差异大”。而这个“差异“,由样本点到其所在簇的质心的距离来衡量。 对于一个簇来说,所有样本点到质心的距离之和越小,我们就认为这个簇中的样本越相似,簇内差异就越小。而距 离的衡量方法有多种,令表示簇中的一个样本点, 表示该簇中的质心,n表示每个样本点中的特征数目,i表示组 成点 的每个特征,则该样本点到质心的距离可以由以下距离来度量:

而在KMeans中,我们在一个固定的簇数K下,最小化总体平方和来求解最佳质心,并基于质心的存在去进行聚类。整体距离平方和的最小值其实可以使用梯度下降来求解。簇内平方和整体平方和是KMeans的损失函数。
scikit-learn中的KMeans
API Reference — scikit-learn 1.4.0 documentation
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans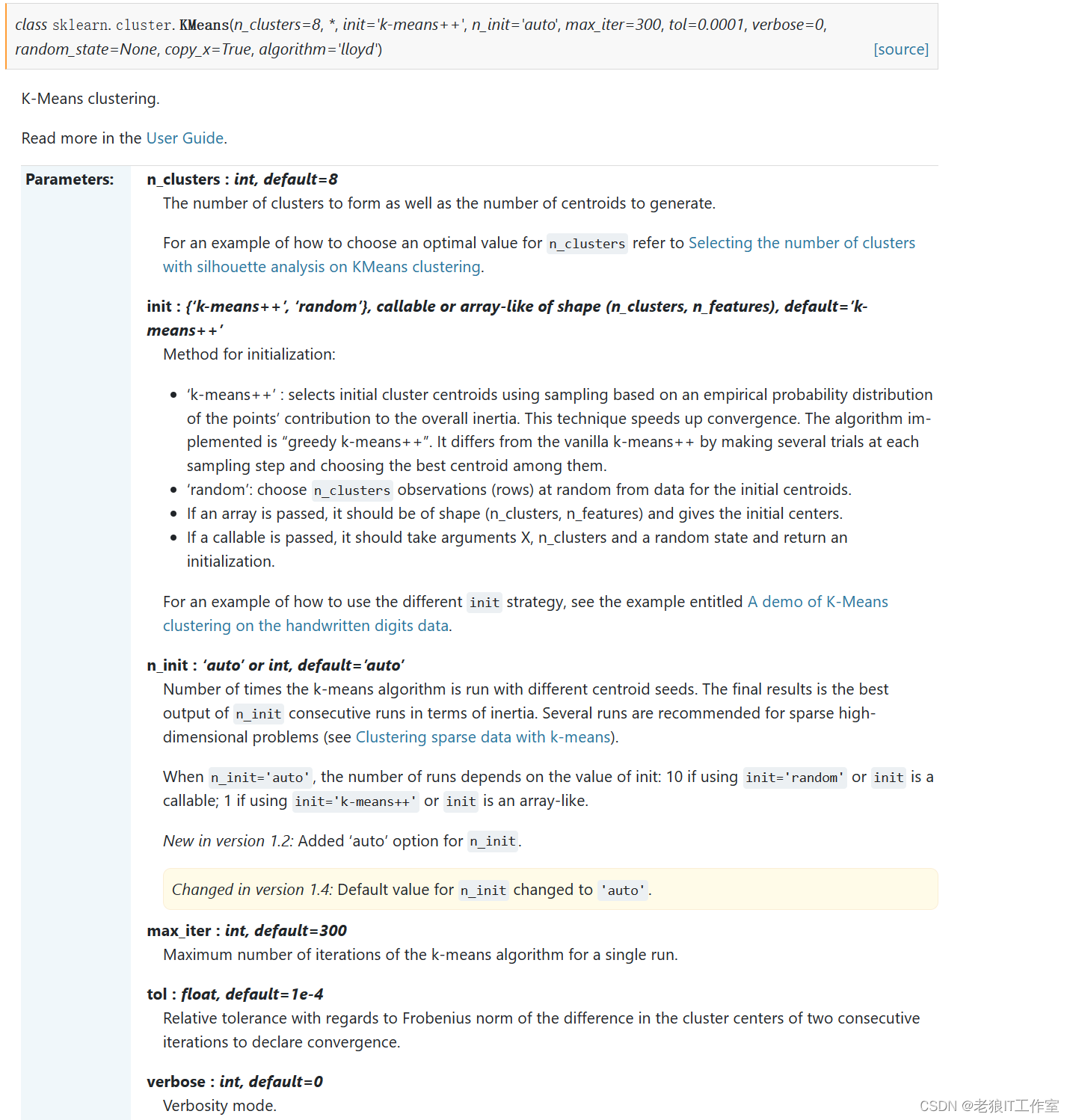
重要参数 - n_clusters
n_clusters是KMeans中的k,表示着我们告诉模型我们要分几类。这是KMeans当中唯一一个必填的参数,默认为8 类,但通常我们的聚类结果会是一个小于8的结果。通常,在开始聚类之前,我们并不知道n_clusters究竟是多少, 因此我们要对它进行探索。
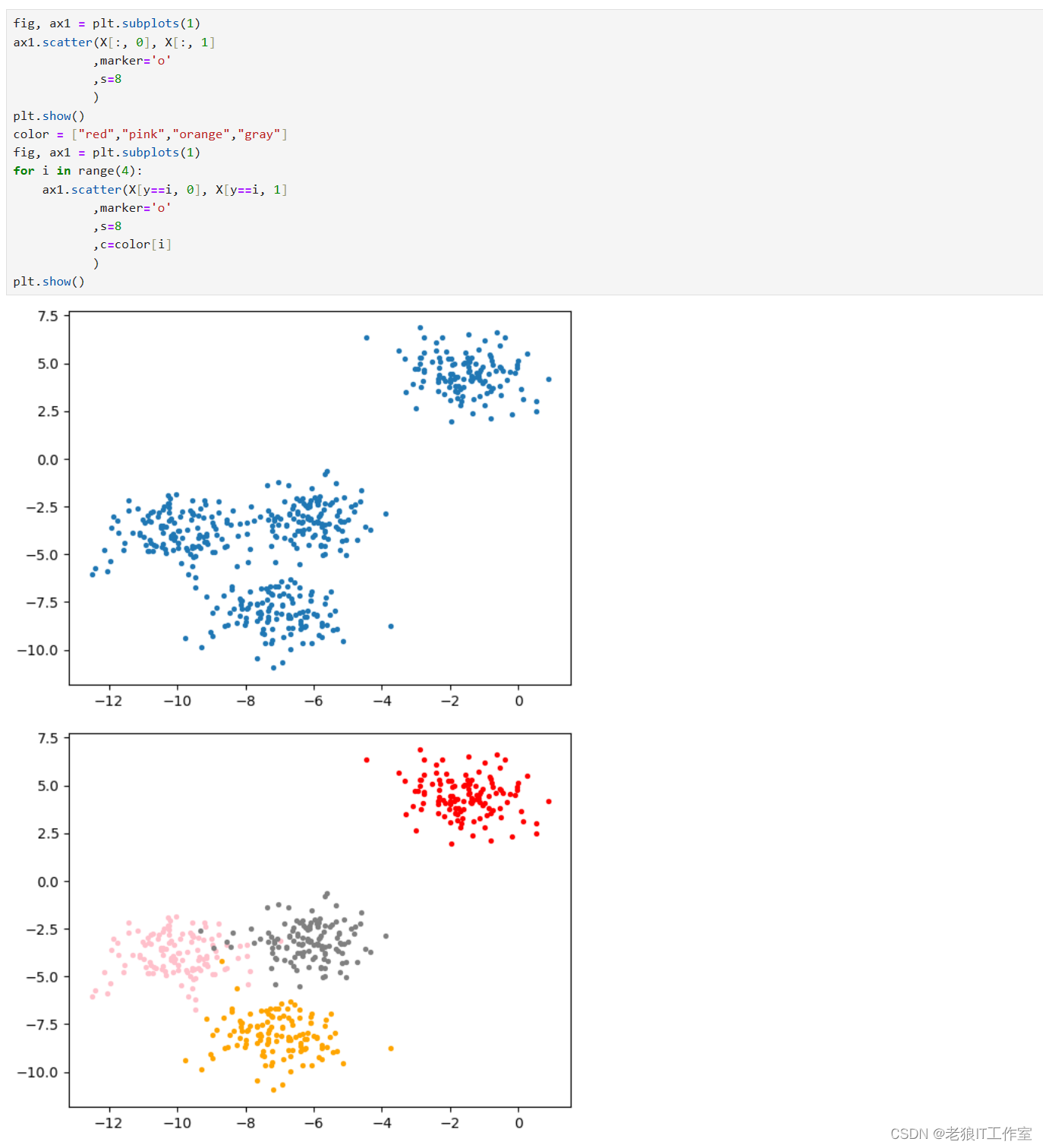
首先,我们来自己创建一个数据集。这样的数据集是我们自己创建,所以是有标签的。
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1],marker='o',s=8)
plt.show()
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(4):ax1.scatter(X[y==i, 0], X[y==i, 1],marker='o',s=8,c=color[i])
plt.show()
基于这个分布,我们来使用Kmeans进行聚类。首先,我们要猜测一下,这个数据中有几簇?
from sklearn.cluster import KMeans
n_clusters = 3
cluster = KMeans(n_clusters=n_clusters, random_state=0, n_init='auto').fit(X)
y_pred = cluster.labels_
y_pred[0:10]pre = cluster.fit_predict(X)
(pre == y_pred)[0:10]centroid = cluster.cluster_centers_
centroidinertia = cluster.inertia_
inertia
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):ax1.scatter(X[y_pred==i, 0], X[y_pred==i, 1],marker='o',s=8,c=color[i])
ax1.scatter(centroid[:,0],centroid[:,1],marker="x",s=15,c="black")
plt.show()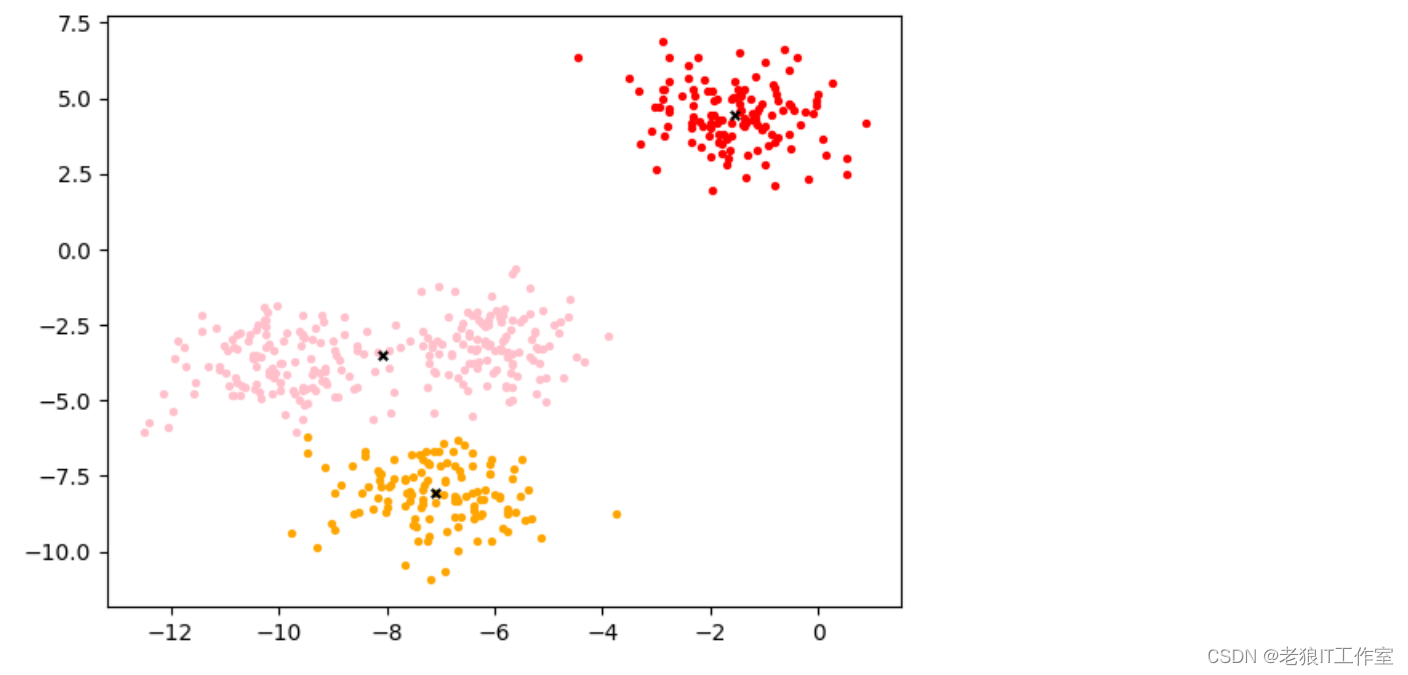
n_clusters = 4
cluster_ = KMeans(n_clusters=n_clusters, random_state=0, n_init='auto').fit(X)
y_pred_ = cluster_.labels_
y_pred_[0:10]centroid_ = cluster_.cluster_centers_
centroid_inertia_ = cluster_.inertia_
inertia_
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):ax1.scatter(X[y_pred_==i, 0], X[y_pred_==i, 1],marker='o',s=8,c=color[i])
ax1.scatter(centroid_[:,0],centroid_[:,1],marker="x",s=15,c="black")
plt.show()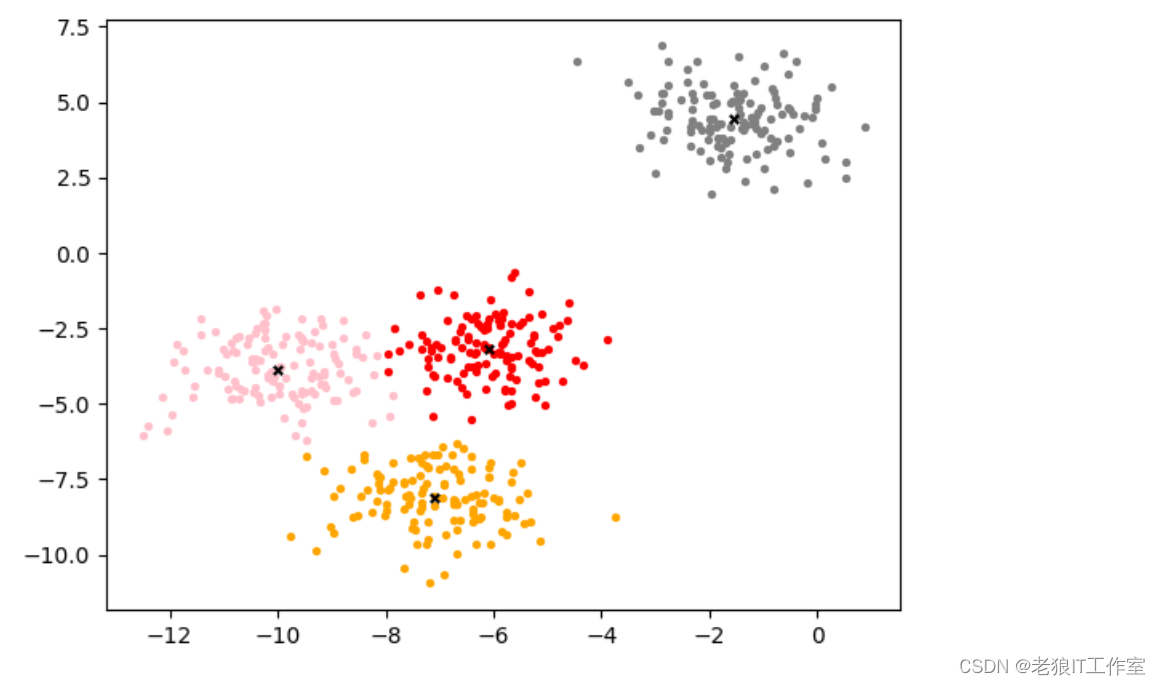
聚类算法的模型评估指标
KMeans的目标是确保“簇内差异小,簇外差异大”,我们就可以通过衡量簇内差异来衡量聚类的效 果。我们刚才说过,Inertia是用距离来衡量簇内差异的指标,因此,我们是否可以使用Inertia来作为聚类的衡量指 标呢?Inertia越小模型越好嘛。
可以,但是这个指标的缺点和极限太大。
首先,它不是有界的。我们只知道,Inertia是越小越好,是0最好,但我们不知道,一个较小的Inertia究竟有没有达到模型的极限,能否继续提高。
第二,它的计算太容易受到特征数目的影响,数据维度很大的时候,Inertia的计算量会陷入维度诅咒之中,计算量会爆炸,不适合用来一次次评估模型。
第三,Inertia对数据的分布有假设,它假设数据满足凸分布(即数据在二维平面图像上看起来是一个凸函数的样 子),并且它假设数据是各向同性的(isotropic),即是说数据的属性在不同方向上代表着相同的含义。但是现实中的数据往往不是这样。所以使用Inertia作为评估指标,会让聚类算法在一些细长簇,环形簇,或者不规则形状的流形时表现不佳:
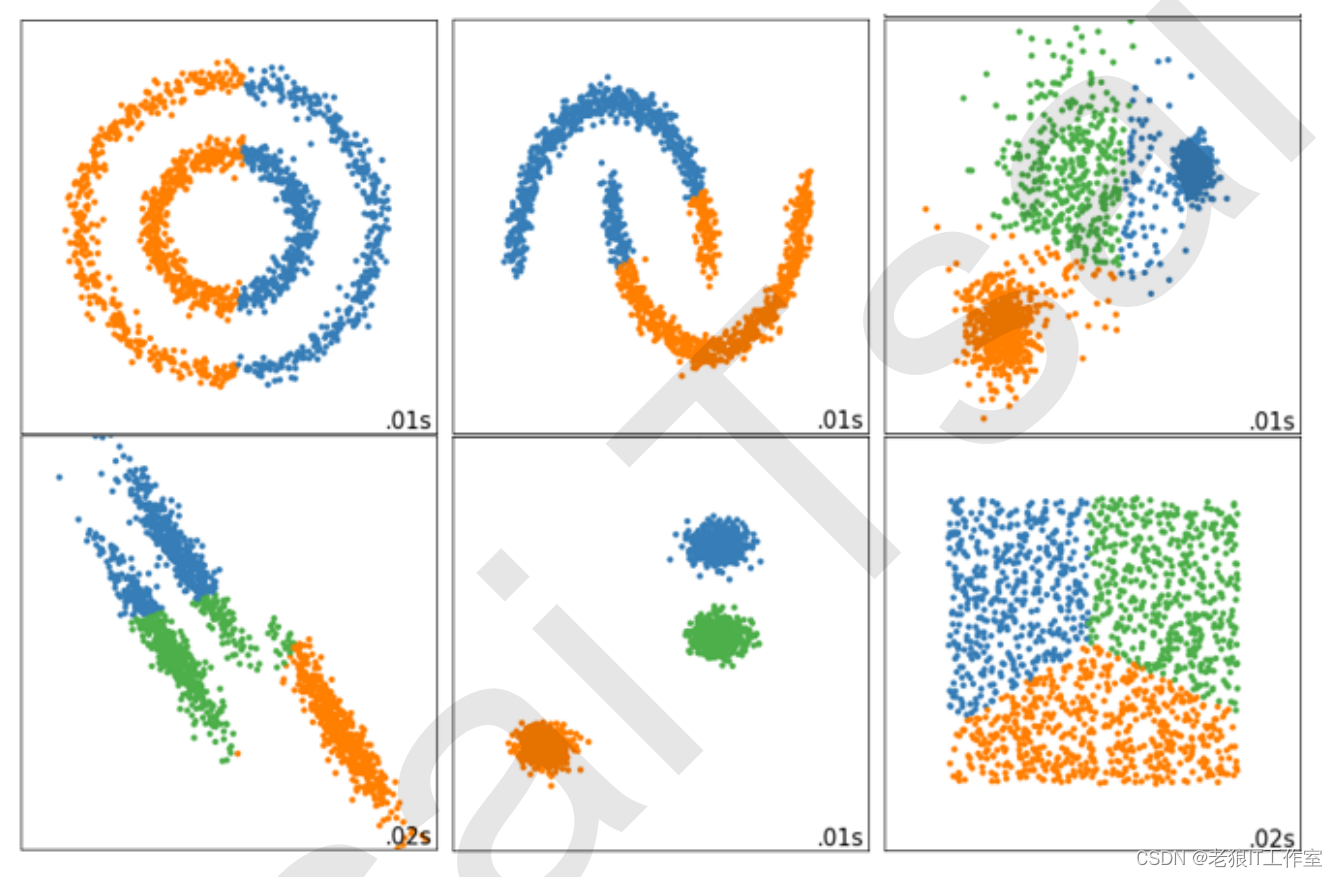
那我们可以使用什么指标呢?来使用轮廓系数。
在99%的情况下,我们是对没有真实标签的数据进行探索,也就是对不知道真正答案的数据进行聚类。这样的聚类,是完全依赖于评价簇内的稠密程度(簇内差异小)和簇间的离散程度(簇外差异大)来评估聚类的效果。其中轮廓系数是最常用的聚类算法的评价指标。
它是对每个样本来定义的,它能够同时衡量:
1)样本与其自身所在的簇中的其他样本的相似度a,等于样本与同一簇中所有其他点之间的平均距离
2)样本与其他簇中的样本的相似度b,等于样本与下一个最近的簇中得所有点之间的平均距离 根据聚类的要求”簇内差异小,簇外差异大“,我们希望b永远大于a,并且大得越多越好。 单个样本的轮廓系数计算为:
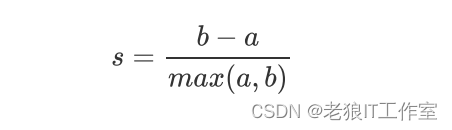
这个公式可以被解析为:
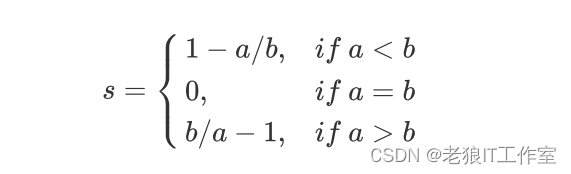
很容易理解轮廓系数范围是(-1,1),其中值越接近1表示样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似,当样本点与簇外的样本更相似的时候,轮廓系数就为负。当轮廓系数为0时,则代表两个簇中的样本相似度一致,两个簇本应该是一个簇。 如果一个簇中的大多数样本具有比较高的轮廓系数,则簇会有较高的总轮廓系数,则整个数据集的平均轮廓系数越高,则聚类是合适的。如果许多样本点具有低轮廓系数甚至负值,则聚类是不合适的,聚类的超参数K可能设定得太大或者太小。 在sklearn中,我们使用模块metrics中的类silhouette_score来计算轮廓系数,它返回的是一个数据集中,所有样本的轮廓系数的均值。但我们还有同在metrics模块中的silhouette_samples,它的参数与轮廓系数一致,但返回的是数据集中每个样本自己的轮廓系数。 我们来看看轮廓系数在我们自建的数据集上表现如何:
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
X[0:10]y_pred[0:10]silhouette_score(X,y_pred)cluster_.labels_[0:10]silhouette_score(X,cluster_.labels_)silhouette_samples(X,y_pred)[0:10]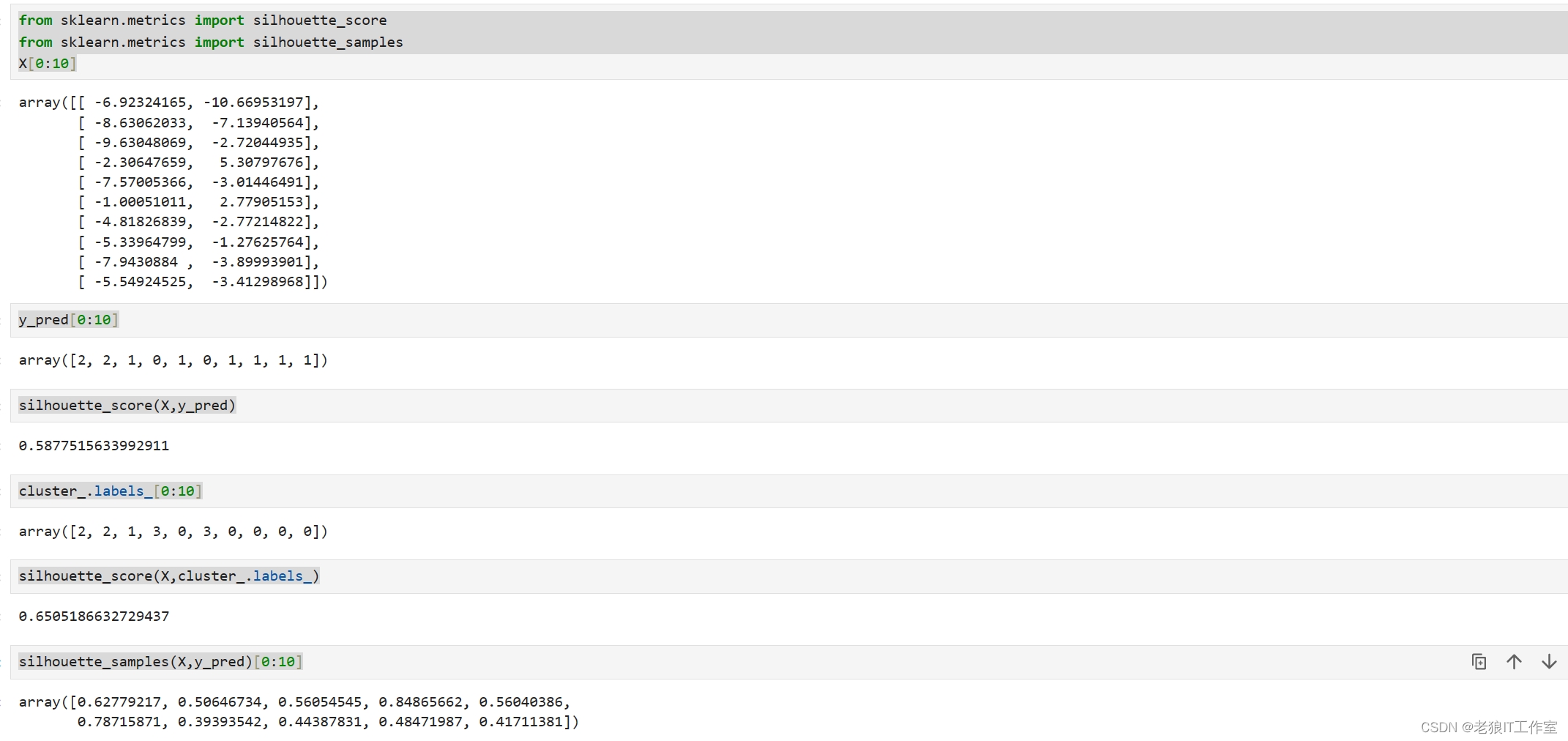
轮廓系数有很多优点,它在有限空间中取值,使得我们对模型的聚类效果有一个“参考”。并且,轮廓系数对数据的 分布没有假设,因此在很多数据集上都表现良好。但它在每个簇的分割比较清洗时表现最好。但轮廓系数也有缺陷,它在凸型的类上表现会虚高,比如基于密度进行的聚类,或通过DBSCAN获得的聚类结果,如果使用轮廓系数来衡量,则会表现出比真实聚类效果更高的分数。
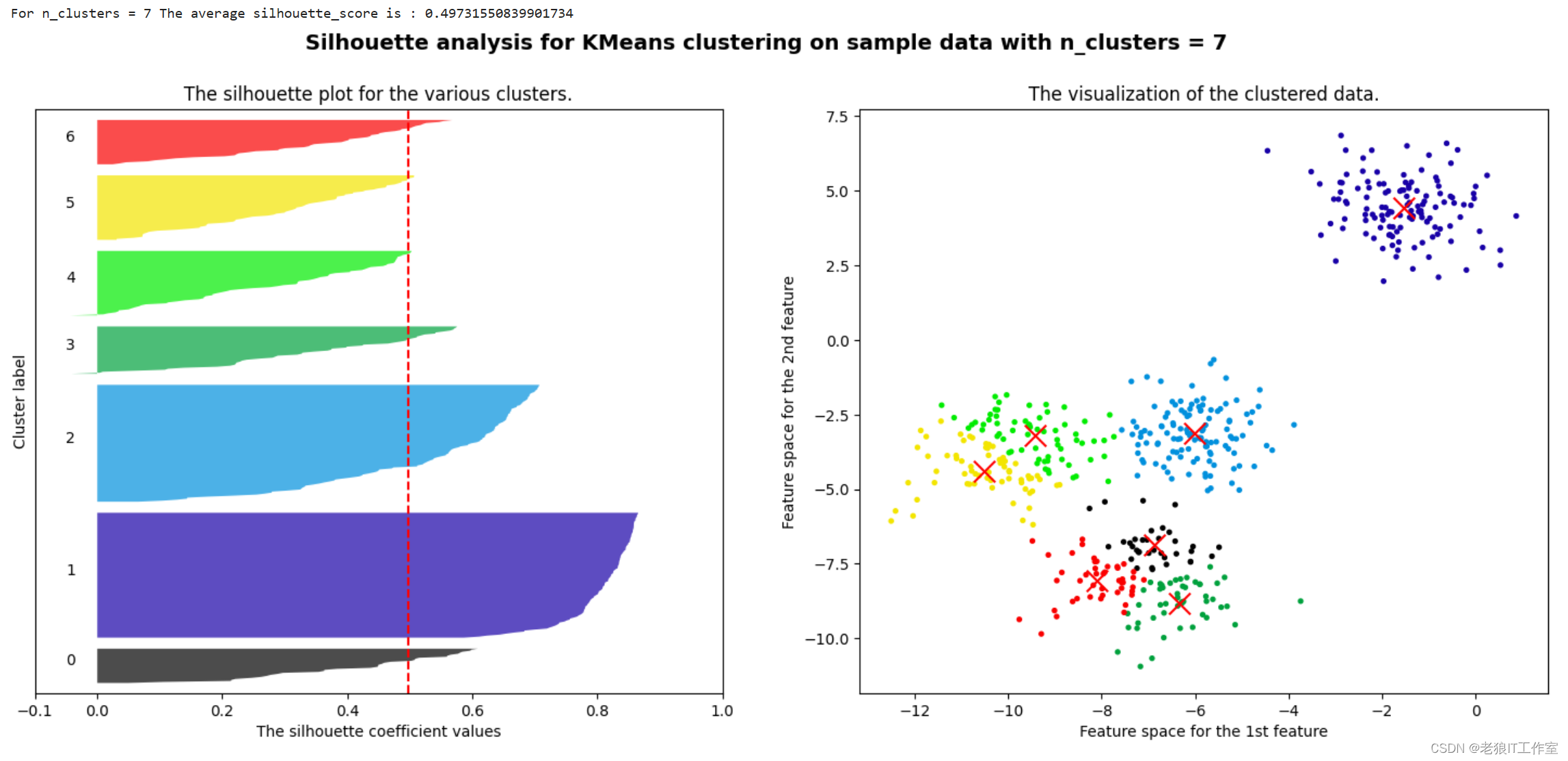
基于轮廓系数来选择n_clusters
我们通常会绘制轮廓系数分布图和聚类后的数据分布图来选择我们的最佳n_clusters。
# 基于轮廓系数来选择n_clustersfrom sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
n_clusters = 4
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
ax1.set_xlim([-0.1, 1])
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])clusterer = KMeans(n_clusters=n_clusters, random_state=10, n_init='auto').fit(X)
cluster_labels = clusterer.labels_
silhouette_avg = silhouette_score(X, cluster_labels)
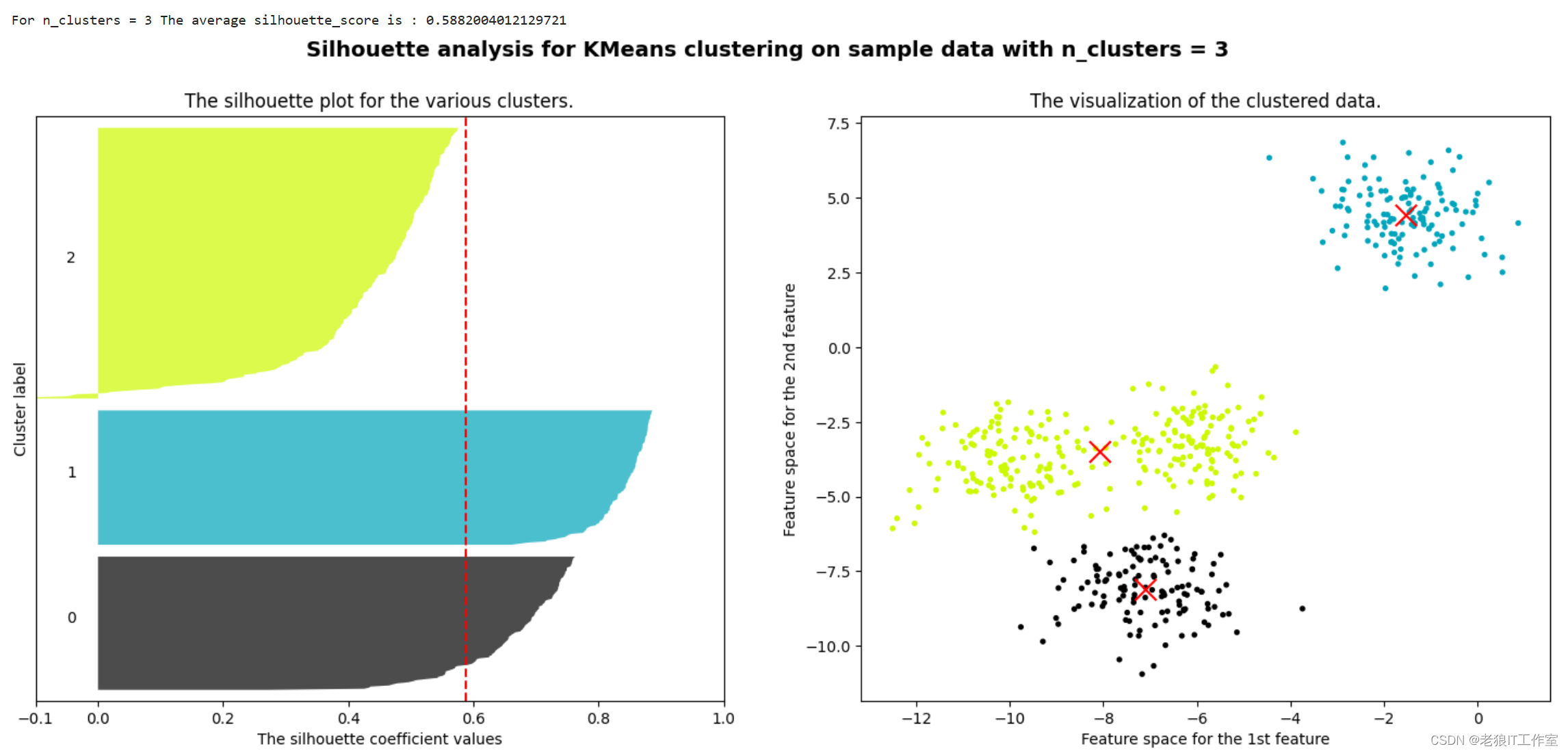
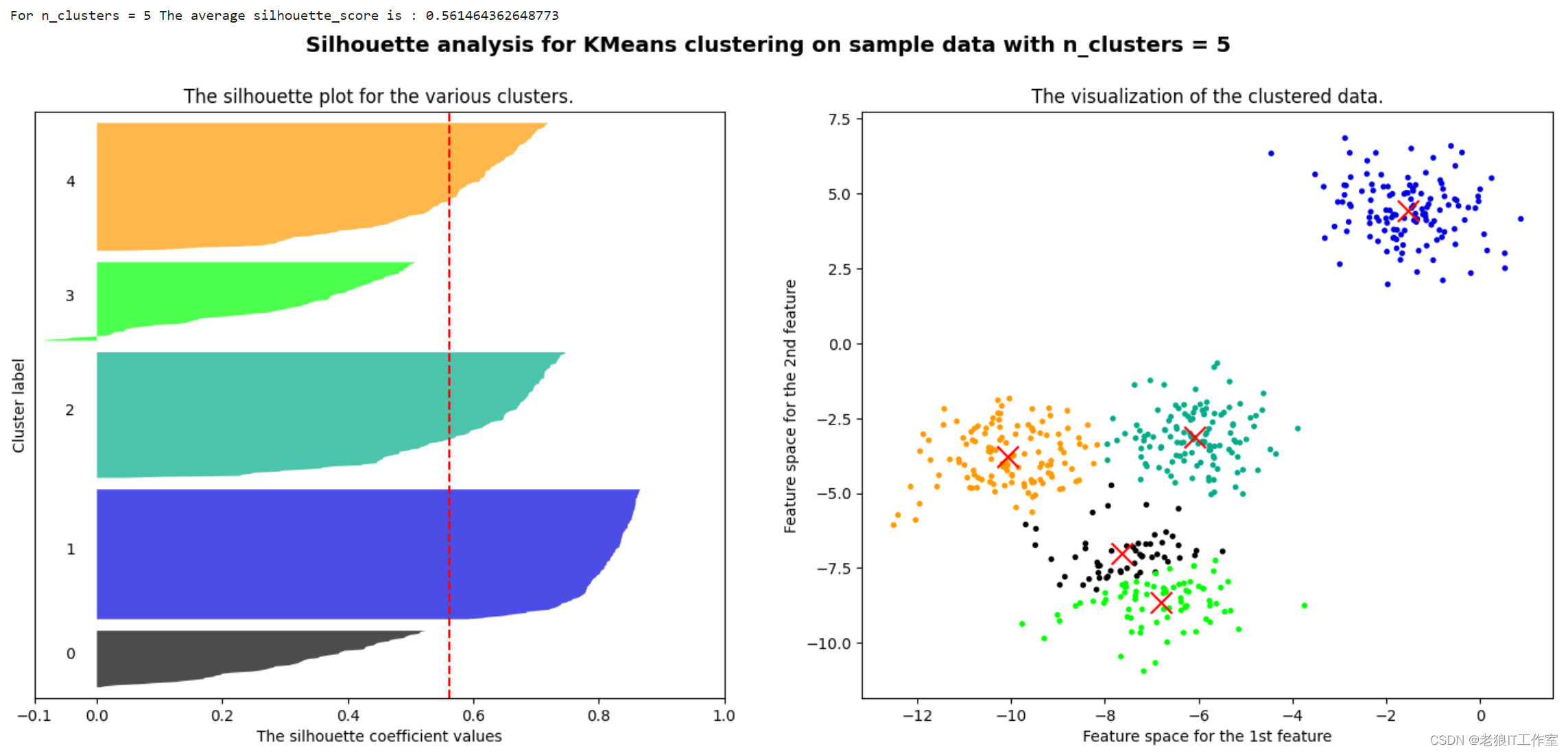
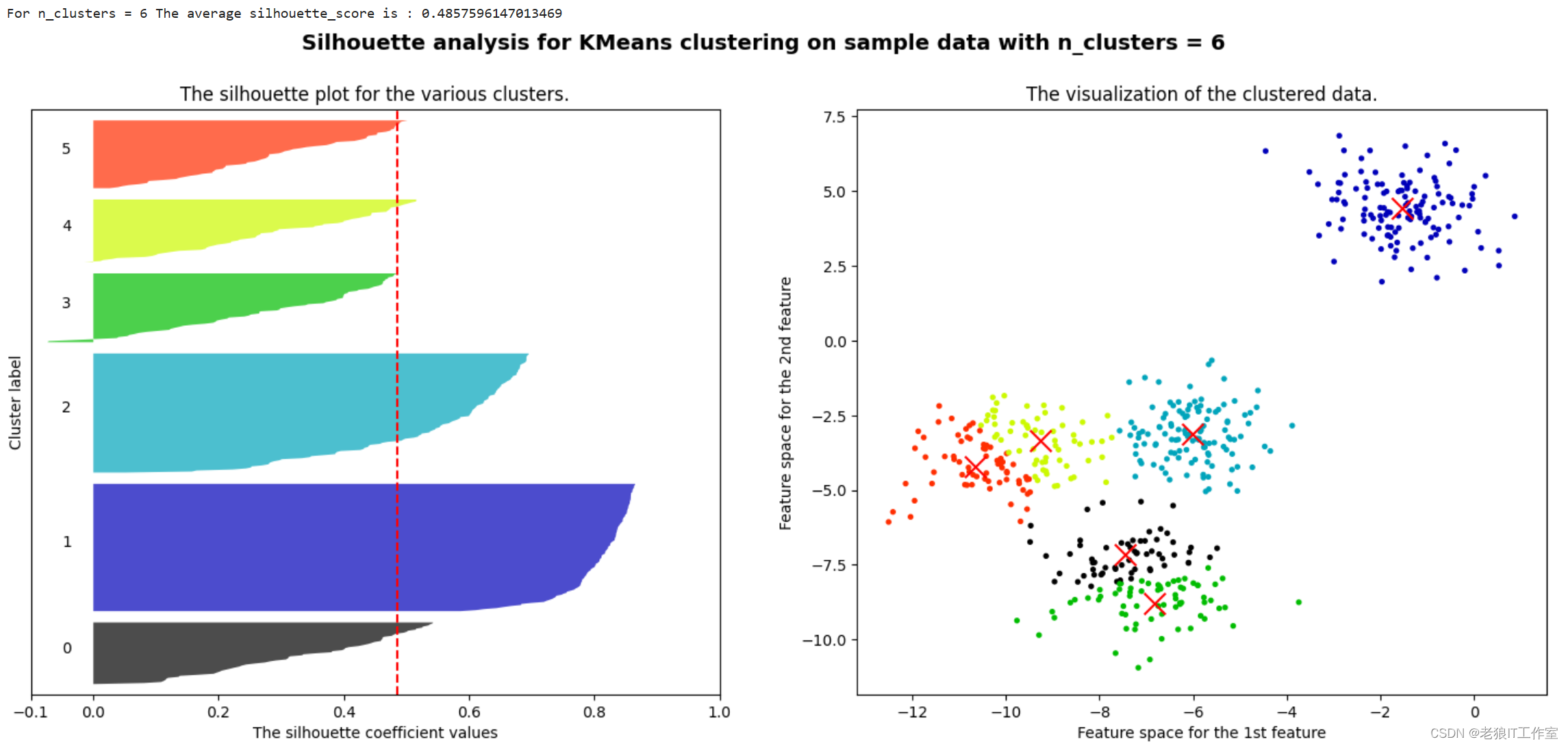
print("For n_clusters =", n_clusters,"The average silhouette_score is :", silhouette_avg)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(n_clusters):ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]ith_cluster_silhouette_values.sort()size_cluster_i = ith_cluster_silhouette_values.shape[0]y_upper = y_lower + size_cluster_icolor = cm.nipy_spectral(float(i)/n_clusters)ax1.fill_betweenx(np.arange(y_lower, y_upper),ith_cluster_silhouette_values,facecolor=color,alpha=0.7)ax1.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))y_lower = y_upper + 10ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1],marker='o' #点的形状,s=8 #点的大小,c=colors)
centers = clusterer.cluster_centers_
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data ""with n_clusters = %d" % n_clusters),fontsize=14, fontweight='bold')
plt.show()
将上述过程包装成一个循环,可以得到:
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
for n_clusters in [2,3,4,5,6,7]: n_clusters = n_clustersfig, (ax1, ax2) = plt.subplots(1, 2)fig.set_size_inches(18, 7)ax1.set_xlim([-0.1, 1])ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])clusterer = KMeans(n_clusters=n_clusters, random_state=10, n_init='auto').fit(X)cluster_labels = clusterer.labels_silhouette_avg = silhouette_score(X, cluster_labels)print("For n_clusters =", n_clusters,"The average silhouette_score is :", silhouette_avg)sample_silhouette_values = silhouette_samples(X, cluster_labels)y_lower = 10for i in range(n_clusters):ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]ith_cluster_silhouette_values.sort()size_cluster_i = ith_cluster_silhouette_values.shape[0]y_upper = y_lower + size_cluster_icolor = cm.nipy_spectral(float(i)/n_clusters)ax1.fill_betweenx(np.arange(y_lower, y_upper),ith_cluster_silhouette_values,facecolor=color,alpha=0.7)ax1.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))y_lower = y_upper + 10ax1.set_title("The silhouette plot for the various clusters.")ax1.set_xlabel("The silhouette coefficient values")ax1.set_ylabel("Cluster label")ax1.axvline(x=silhouette_avg, color="red", linestyle="--")ax1.set_yticks([])ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)ax2.scatter(X[:, 0], X[:, 1],marker='o' #点的形状,s=8 #点的大小,c=colors)centers = clusterer.cluster_centers_ax2.scatter(centers[:, 0], centers[:, 1], marker='x',c="red", alpha=1, s=200)ax2.set_title("The visualization of the clustered data.")ax2.set_xlabel("Feature space for the 1st feature")ax2.set_ylabel("Feature space for the 2nd feature")plt.suptitle(("Silhouette analysis for KMeans clustering on sample data ""with n_clusters = %d" % n_clusters),fontsize=14, fontweight='bold')plt.show() 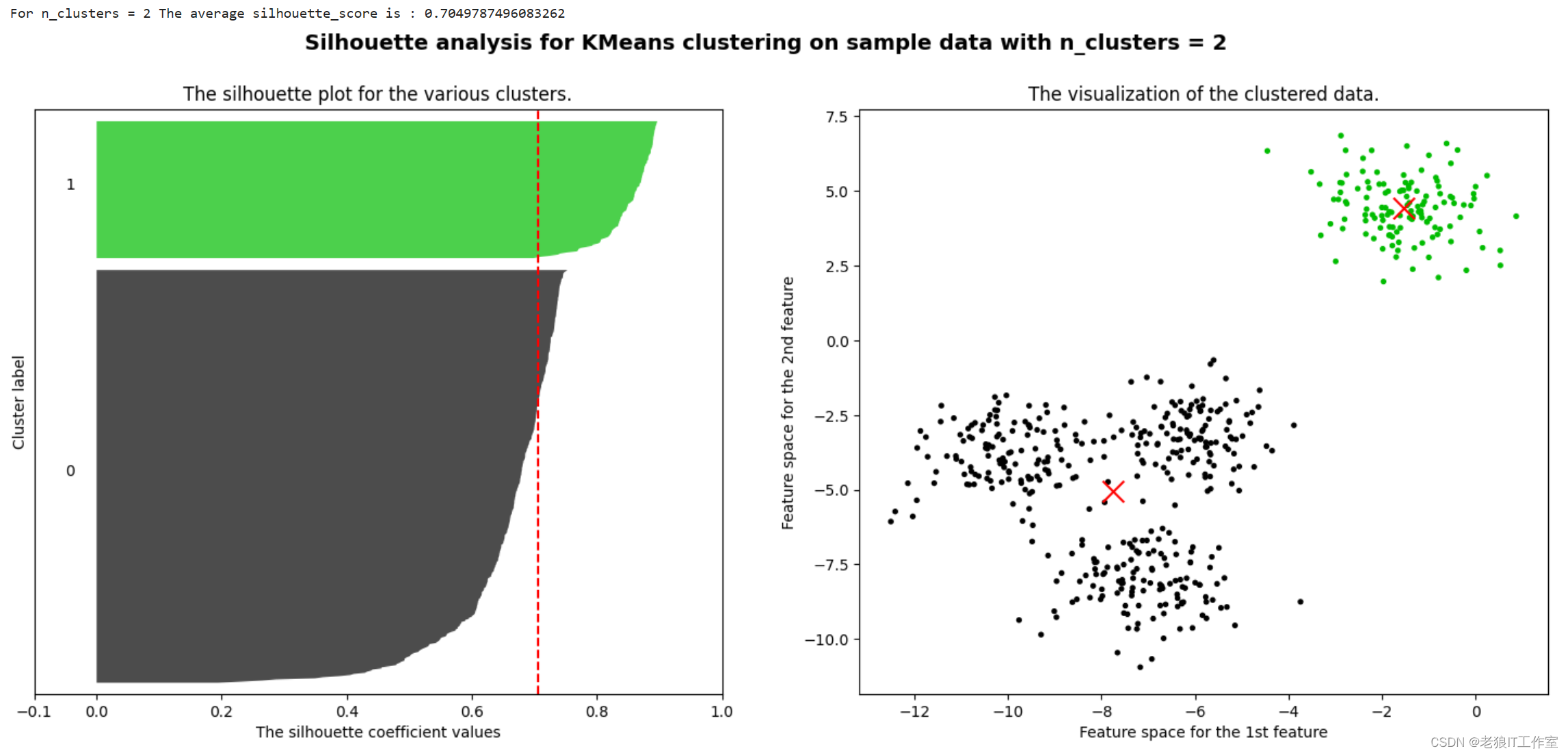

相关文章:
[Python] 什么是KMeans聚类算法以及scikit-learn中的KMeans使用案例
什么是无监督学习? 无监督学习是机器学习中的一种方法,其主要目的是从无标签的数据集中发现隐藏的模式、结构或者规律。在无监督学习中,算法不依赖于任何先验的标签信息,而是根据数据本身的特征和规律进行学习和推断。无监督学习…...
在 iOS 上安装自定企业级应用
了解如何安装您的组织创建的自定应用并为其建立信任。 本文适用于学校、企业或其他组织的系统管理员。 您的组织可以使用 Apple Developer Enterprise Program 创建和分发企业专用的 iOS 应用,以供内部使用。您必须先针对这些应用建立信任后,才能将其打…...

【Linux C | I/O模型】Unix / Linux系统的5种IO模型 | 图文详解
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

C++设计模式-简单工厂模式,工厂方法模式,抽象工厂模式
目录 简单工厂模式,工厂方法模式,抽象工厂模式 附: 简单工厂模式,工厂方法模式,抽象工厂模式 简单工厂模式:根据字符串参数返回对象。 工厂方法模式:创建一维对象,即一个工厂创建…...

java处理ppt方案详解
需求 需要系统中展示的ppt案例有一个动态展示的效果,也就是要有动画的交互,要求支持浏览器直接打开预览 背景 目前已经实现了前端上传pptx文件,后端解析为png的图片,前端掉接口返回对应的图片,模拟播放ppt的效果 各种尝…...

鸿蒙4.0.0 安装minitouch
鸿蒙4.0.0 安装minitouch ubuntu 系统 minitouch 地址 https://github.com/DeviceFarmer/minitouch 因为 鸿蒙4.0.0 对应安卓12 API版本31 所以启动 minitouch 需要 STFService 地址 https://github.com/openstf/STFService.apk 到release下载最新的STFService.apk &…...
前端excel带样式导出 exceljs 插件的使用
本来用的xlsx和xlsx-style两个插件,过程一步一个坑,到完全能用要消灭好多bug。这时发现了exceljs,真香😀 案例 <!DOCTYPE html> <html><head><meta charset"utf-8" /><meta name"view…...

用GOGS搭建GIT服务器
GOGS官网 Gogs: A painless self-hosted Git service 进入文件所在目录 cd /usr/local/develop 解压文件 tar -xvf gogs_0.13.0_linux_amd64.tar.gz 解压之后 进入gogs 目录 cd gogs 创建几个目录 userdata 存放用户数据 log文件存放进程日志 repositories 仓库根目…...

2024年美赛数学建模E题思路分析 - 财产保险的可持续性
# 1 赛题 问题E:财产保险的可持续性 极端天气事件正成为财产所有者和保险公司面临的危机。“近年来,世界已经遭受了1000多起极端天气事件造成的超过1万亿美元的损失”。[1]2022年,保险业的自然灾害索赔人数“比30年的平均水平增加了115%”。…...

哪种安全数据交换系统,可以满足信创环境要求?
安全数据交换系统是一种专门设计用于在不同网络环境之间安全传输数据的技术解决方案。这类系统确保数据在传输过程中的完整性、机密性和可用性,同时遵守相关的数据保护法规和行业标准。 使用安全数据交换系统的原因主要包括以下几点: 1、数据保护&#…...

OfficeWeb365 Readfile 任意文件读取漏洞
免责声明:文章来源互联网收集整理,请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该…...
机器学习基础、数学统计学概念、模型基础技术名词及相关代码个人举例
1.机器学习基础 (1)机器学习概述 机器学习是一种人工智能(AI)的分支,通过使用统计学和计算机科学的技术,使计算机能够从数据中学习并自动改进性能,而无需进行明确的编程。它涉及构建和训练机器…...
小埋的解密游戏的题解
目录 原题描述: 题目描述 输入格式 输出格式 样例 #1 样例输入 #1 样例输出 #1 样例 #2 样例输入 #2 样例输出 #2 提示 主要思路: 代码实现code: 原题描述: 题目描述 小埋最近在玩一个解密游戏,这个游戏…...
idea常用设置
1、内存优化 根据自己电脑本身的内存,对idea安装包里bin目录下的idea64.exe.vmoptions文件进行修改 -server -Xms256m -Xmx2048m -XX:MaxPermSize1024m -XX:ReservedCodeCacheSize256m -ea -Dsun.io.useCanonCachesfalse -Djava.Net.preferIPv4Stacktrue -Djsse.e…...

npm出现 Error: EISDIR: illegal operation on a directory, read
npm出现 Error: EISDIR: illegal operation on a directory, read 一、问题二、解决 一、问题 可能是由于运行了npm config set cafile ""之类的方法,造成了cafile为空 二、解决 文件位于C:\Users\用户名\ 下 找到c盘下的Users下的用户目录,进入找到.n…...
简易计算器的制作(函数指针数组的实践)
个人主页(找往期文章包括但不限于本期文章中不懂的知识点): 我要学编程(ಥ_ಥ)-CSDN博客 前期思路(菜单的制作等):利用C语言的分支循环少量的函数知识写一个猜数字的小游戏-CSDN博客 计算器的制作其实与游…...
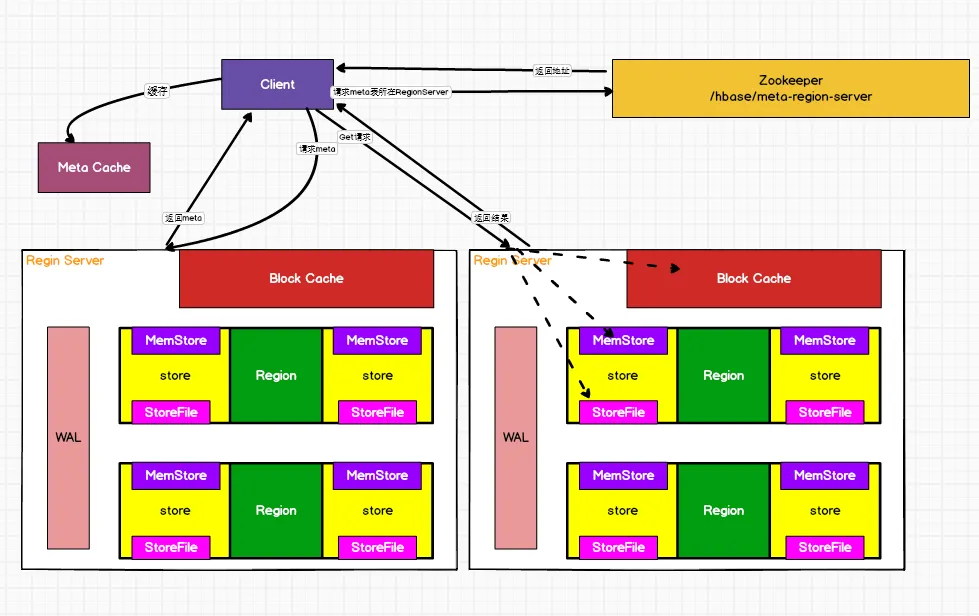
HBase相关面试准备问题
为什么选择HBase 1、海量存储 Hbase适合存储PB级别的海量数据,在PB级别的数,能在几十到几百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正是因为Hbase良好的扩展性,才为海量数据的存储提供了便利。 2、列式存储 这里的列式存储其实说的…...
和归一化(Normalization))
sklearn实现数据标准化(Standardization)和归一化(Normalization)
标准化(Standardization) sklearn的标准化过程,即包括Z-Score标准化,也包括0-1标准化,并且即可以通过实用函数来进行标准化处理,同时也可以利用评估器来执行标准化过程。接下来我们分不同功能以的不同实现…...
做技术的应该是没有什么你不会
这句话放在现在很多年轻人的观念来评价,肯定是错的。但小编一直捧为真理,也一直践行着。 我记不得这话可能也是谁给我讲的。 先讲故事吧。 小编刚参加工作是做技术支持,我所在公司是给一些软件开发企业提供智能卡读写机具,并配…...

MySQL进阶45讲【10】MySQL为什么有时候会选错索引?
1 前言 前面我们介绍过索引,在MySQL中一张表其实是可以支持多个索引的。但是,写SQL语句的时候,并没有主动指定使用哪个索引。也就是说,使用哪个索引是由MySQL来确定的。 大家有没有碰到过这种情况,一条本来可以执行得…...

FK-Onmyoji:阴阳师终极自动化护肝助手完整使用指南
FK-Onmyoji:阴阳师终极自动化护肝助手完整使用指南 【免费下载链接】FK-Onmyoji 阴阳师抗检测多功能脚本 项目地址: https://gitcode.com/gh_mirrors/fk/FK-Onmyoji 阴阳师玩家们,是否厌倦了重复枯燥的日常任务?FK-Onmyoji为您带来革命…...

SRWE:打破Windows窗口限制的智能编辑器
SRWE:打破Windows窗口限制的智能编辑器 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE SRWE(Simple Runtime Window Editor)是一款专为Windows系统设计的实时窗口编辑工具&am…...

Cyber Engine Tweaks:解决《赛博朋克2077》性能瓶颈与脚本扩展的技术方案
Cyber Engine Tweaks:解决《赛博朋克2077》性能瓶颈与脚本扩展的技术方案 【免费下载链接】CyberEngineTweaks Cyberpunk 2077 tweaks, hacks and scripting framework 项目地址: https://gitcode.com/gh_mirrors/cy/CyberEngineTweaks Cyber Engine Tweaks …...

Scroll Reverser终极指南:让Mac滚动方向完全掌控
Scroll Reverser终极指南:让Mac滚动方向完全掌控 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser Scroll Reverser是一款专为macOS设计的开源工具,能够独立…...

从概念到应用:基于openclaw101.dev功能构思在快马平台构建实战项目
今天想和大家分享一个实战项目经验——如何快速将openclaw101.dev这类技术理念转化为可交互的实际应用。最近我在InsCode(快马)平台上尝试构建了一个任务管理中心SPA,整个过程意外地顺畅,特别适合想快速验证产品原型的开发者。 项目构思 我选择了任务管理…...
颠覆式效率工具:BaiduPanFilesTransfers重构百度网盘批量管理流程
颠覆式效率工具:BaiduPanFilesTransfers重构百度网盘批量管理流程 【免费下载链接】BaiduPanFilesTransfers 百度网盘批量转存、分享和检测工具 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduPanFilesTransfers 在数字化办公与资源管理场景中ÿ…...

OpenClaw+千问3.5-35B-A3B-FP8:个人健康数据分析助手
OpenClaw千问3.5-35B-A3B-FP8:个人健康数据分析助手 1. 为什么需要个人健康数据分析助手 去年体检后,我面对几十页的检测报告和智能手环积累的三个月运动数据,突然意识到一个尴尬的事实:这些数据躺在不同平台里,既不…...

GitHub开源项目日报 · 2026年4月1日 · AI编程助手与语音模型引领榜单
本期榜单主要涵盖开发者工具、AI应用和实用库三大类项目。从终端编程助手到语音AI模型,从HTTP客户端到提示词资源库,展示了当前开源生态的多样化发展。超过10000星以上的项目有prompts.chat、Axios、Claude Code、Codex CLI、VibeVoice、Claude Code最佳实践指南、Claude Cod…...

科学护眼智能提醒:3个维度破解数字时代眼健康难题
科学护眼智能提醒:3个维度破解数字时代眼健康难题 【免费下载链接】ProjectEye 😎 一个基于20-20-20规则的用眼休息提醒Windows软件 项目地址: https://gitcode.com/gh_mirrors/pr/ProjectEye 在数字时代,我们每天面对屏幕的时间急剧增…...

学习Spring Ai的摸索实践
摸索AI(一)安装Ollama和本地大模型部署https://www.chendd.cn/blog/article/2012500757664628737.html摸索AI(二)Spring AI实现的Hello Worldhttps://www.chendd.cn/blog/article/2013071822723874817.html 摸索AI(三…...