PySpark(三)RDD持久化、共享变量、Spark内核制度,Spark Shuffle
目录
RDD持久化
RDD 的数据是过程数据
RDD 缓存
RDD CheckPoint
共享变量
广播变量
累加器
Spark 内核调度
DAG
DAG 的宽窄依赖和阶段划分
内存迭代计算
Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用?
Spark为什么比MapReduce快?
Spark并行度
Spark Shuffle
Hash Shuffle
Sort Shuffle
RDD持久化
RDD 的数据是过程数据
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失
RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了
这个特性可以最大化的利用资源,老旧RDD没用了 就从内存中清理,给后续的计算腾出内存空间.
例如下面这个例子,生成rdd4的时候, rdd3已经被销毁了,然后下面rdd5需要调用rdd3的时候,只能从rdd->rdd2->rdd3再重新生成一次rdd3
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)rdd2 = rdd.map(lambda x:(x[0],x[1]+2))rdd3 = rdd2.distinct()rdd4 = rdd3.filter(lambda x:x[1]>5)print(rdd4.collect())# [('a', 8)]rdd5 = rdd3.glom()print(rdd5.collect())# [[('a', 5), ('a', 8)], [('a', 3), ('b', 4)], [('b', 3), ('c', 3)]]RDD 缓存
RDD的缓存技术:Spark提供了缓存AP1,可以让我们通过调用AP1,将指定的RDD数据保留在内存或者硬盘上缓存的API
最开始要引入:from pyspark.storagelevel import StorageLevel

缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上
但是,这个保存在设定上是认为不安全的,缓存的数据在设计上是 认为 有丢失风险的
所以,缓存有一个特点就是: 其保留RDD之间的血缘(依赖)关系
一旦缓存丢失可以基于血缘关系的记录重新计算这个RDD的数据
缓存如何丢失:
在内存中的缓存是不安全的,比如断电计算任务内存不足把缓存清理给计算让路硬盘中因为硬盘损坏也是可能丢失的
RDD缓存采用的是分散存储,也就是每一个executor都会将其处理的部分RDD存放在自己的内存或硬盘中
RDD CheckPoint
CheckPoint技术也是将RDD的数据保存起来,但是它仅支持硬盘存储
并且:它被设计认为是安全的,不保留 血缘关系
checkPoint存储RDD数据,是集中收集各个分区数据进行存储而缓存是分散存储,也就是说先将executor中的数据收集起来(比如收集到hdfs),然后再进行存储
缓存和CheckPoint的对比
- CheckPoint不管分区数量多少,风险是一样的,缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行HDFS是高可靠存储,checkPoint被认为是安全的.
- checkPoint不支持内存缓存可以缓存如果写内存性能比checkPoint要好一些
- CheckPoint因为设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留
sc.setCheckpointDir("hdfs://node1:8020/checkpoint")#设置存储位置rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)rdd2 = rdd.map(lambda x:(x[0],x[1]+2))rdd3 = rdd2.distinct()rdd3.checkpoint()共享变量
广播变量
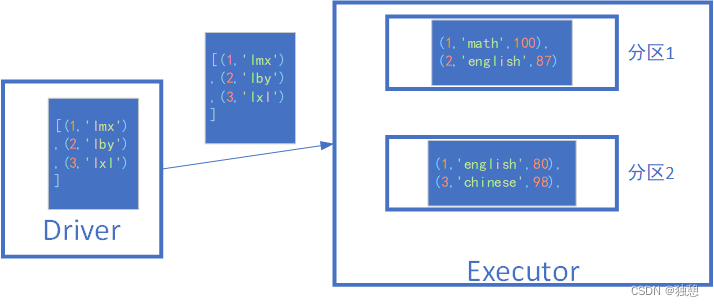
假如有下面一个场景,需要根据stu_ifo将score_ifo中的数字替换为名字,注意这里是本地数据stu_ifo与RDD数据联合处理
stu_ifo = [(1,'lmx'),(2,'lby'),(3,'lxl')]score_ifo = sc.parallelize([(1,'math',100),(2,'english',87),(1,'english',80),(3,'chinese',98),(2, 'chinese', 68),(1, 'chinese', 88)])def func(data):for i in stu_ifo:if data[0] == i[0]:return (i[1],data[1],data[2])get = score_ifo.map(func)print(get.collect())一般情况下, 如果一个executor里面有多个分区的情况,那么每个分区都要向driver申请一份本地数据,然而由于executor内部的数据是共享的,这样就会多申请了一份stu_ifo

只需要将stu_ifo标记为广播变量,就可以解决这个问题。只会向一个executor发送一次数据
只需要在之前声明:
stu_if_breadcast = sc.broadcast(stu_ifo)然后使用的时候:
stu_if_breadcast.value使用这个方法,可以节省IO次数以及executor内存
上述代码变为:
stu_ifo = [(1,'lmx'),(2,'lby'),(3,'lxl')]stu_if_breadcast = sc.broadcast(stu_ifo)score_ifo = sc.parallelize([(1,'math',100),(2,'english',87),(1,'english',80),(3,'chinese',98),(2, 'chinese', 68),(1, 'chinese', 88)])def func(data):for i in stu_if_breadcast.value:if data[0] == i[0]:return (i[1],data[1],data[2])get = score_ifo.map(func)print(get.collect())累加器
针对下面这种场景,我希望每map一次,我的num加1:
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],2)def countt(data):global numnum+=1print(num)return dataprint(rdd.map(countt).collect())print(num)# 1# 2# 3# 4# 5# 1# 2# 3# 4# 5# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# 0观察结果,由于分区的情况,在每个executor内num都加到了5,但是最后的num却还是0
因为加1操作只会发生在 executor 中,而最后打印的是driver中的num,所以还是0
这里可以使用spark的累加器变量:
num = sc.accumulator(0) #累加器rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],2)def countt(data):global numnum+=1return datardd.map(countt).collect()print(num)# 10Spark 内核调度
DAG
DAG:有向无环图
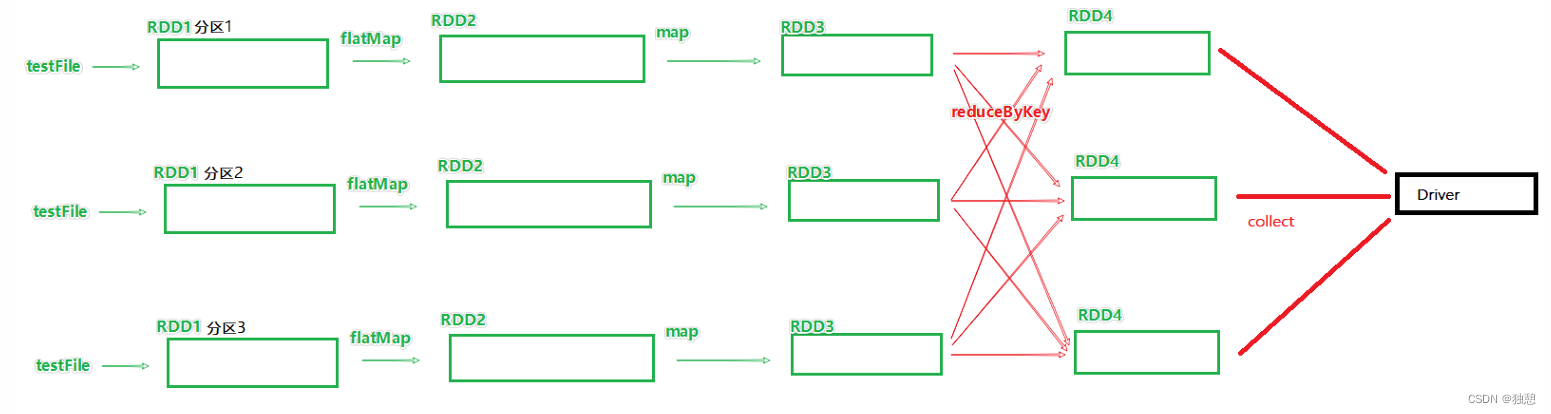
在spark中,每一个 action算子都会将前面的一串rdd依赖链条执行起来,这些执行链条其实就是DAG
有多少个action算子,就有多少个执行链条(JOB),就有多少个DAG
如果一个代码中,写了n个Action,那么这个代码运行起来产生n个JOB,每个JOB有自己的DAG个代码运行起来,在Spark中称之为: Application
spark中数据都是分区的,所以实际上每一个job都是带有分区关系的DAG
DAG 的宽窄依赖和阶段划分
RDD的前后关系分为 宽依赖和窄依赖
窄依赖:父RDD的一个分区,全部 将数据发给子RDD的一个分区
宽依赖:父RDD的一个分区将数据发给子RDD的多个分区
宽依赖还有一个别名: shuffle
对于Spark来说会根据DAG,按照宽依赖划分不同的DAG阶段
划分依据:从后向前,遇到宽依赖 就划分出一个阶段称之为stage
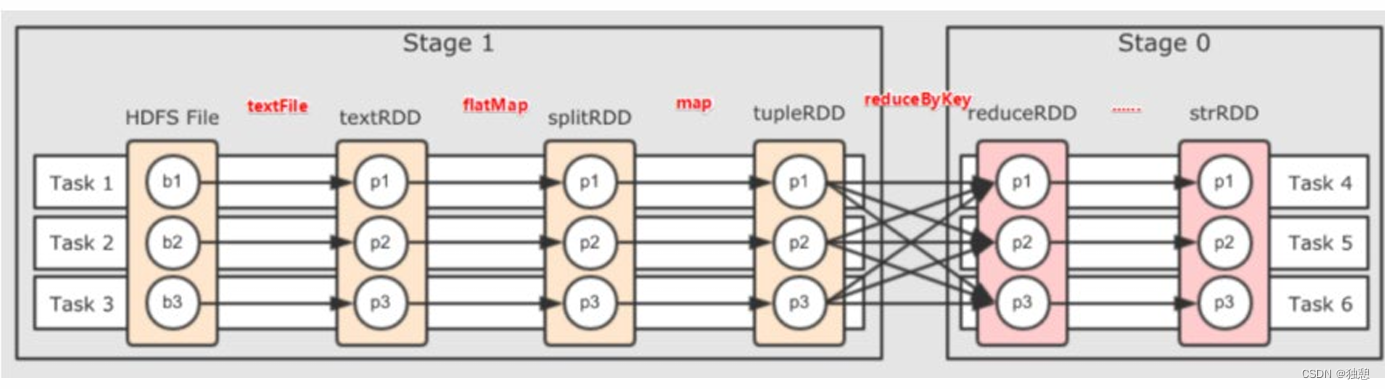 可以看到,在阶段内都是 窄依赖,这有助于构建内存迭代管道
可以看到,在阶段内都是 窄依赖,这有助于构建内存迭代管道
内存迭代计算
在执行上图的程序时,最优的方式肯定是task1,2,3,4,5,6都在独立且单独的线程中完成(还存在另外一种情况,比如b1->p1,p1->下一个p1是不同的线程,那可能会在线程中存在网络IO调用,影响性能)
task1 中rdd1rdd2 rdd3 的选代计算,都是由一个task(线程完成),这一阶段的这一条线,是纯内存计算.如上图,task1 task2 task3,就形成了三个并行的内存计算管道
Spark默认受到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数如果全局并行度是3,其实大部分算子分区都是3
注意:Spark一般推荐只设置全局并行度,不要再算子上设置并行度除了一些排序算子外,计算算子就让他默认开分区就可以了.
Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用?
- Spark会产生DAG图
- DAG图会基于分区和宽窄依赖关系划分阶段
- 一个阶段的内部都是 窄依赖,窄依赖内,如果形成前后1:1的分区对应关系就可以产生许多内存选代计算的管道
- 这些内存迭代计算的管道,就是一个个具体的执行Task
- 一个Task是一个具体的线程,任务跑在一个线程内,就是走内存计算了
Spark为什么比MapReduce快?
- Spark的算子丰富,MapReduce算子匮乏(Map和Reduce),MapReduce这个编程模型,很难在一套MR中处理复杂的任务.很多的复杂任务,是需要写多个MapReduce进行串联多个MR串联通过磁盘交互数据
- Spark可以执行内存迭代,算子之间形成DAG 基于依赖划分阶段后,在阶段内形成内存选代管道.但是MapReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的
Spark并行度
Spark的并行: 在同一时间内, 有多少个task在同时运行
并行度:并行能力的设置
比如设置并行度6,其实就是要6个task并行在跑在有了6个task并行的前提下,rdd的分区就被规划成6个分区了
优先级从高到低:
代码中
客户端提交参数中
配置文件中
默认(1,但是不会全部以1来跑,多数时候基于读取文件的分片数量来作为默认并行度)
 集群如何规划并行度?
集群如何规划并行度?
结论:设置为CPU总核心的2~10倍
为什么要设置最少2倍?
CPU的一个核心同一时间只能干一件事情所以,在100个核心的情况下,设置100个并行,就能让CPU 100%出力这种设置下如果task的压力不均衡,某个task先执行完了就导致某个CPU核心空闲
所以,我们将Task(并行)分配的数量变多,比如800个并行,同一时间只有100个在运行,700个在等待.但是可以确保某个task运行完了.后续有task补上,不让cpu闲下来,最大程度利用集群的资源
Spark Shuffle
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上 还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及 到序列化反序列化、跨节点网络IO以及磁盘读写IO等。

Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是 Child Stage的第一步。
在Spark的中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。ShuffleManager随着 Spark的发展有两种实现的方式,分别为HashShuffleManager和SortShuffleManager,因此spark的Shuffle有Hash Shuffle和Sort Shuffle两种。
Hash Shuffle
未经优化的hashShuffleManager:
HashShuffle是根据task的计算结果的key值的hashcode%ReduceTask来决定放入哪一个区分,这样保证相同的数据 一定放入一个分区,根据下游的task决定生成几个文件,先生成缓冲区文件在写入磁盘文件,再将block文件进行合并。
一个task内部会根据hash分类,然后将不同类的数据放入不同的磁盘文件,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的,也就是下图所产生的的block file
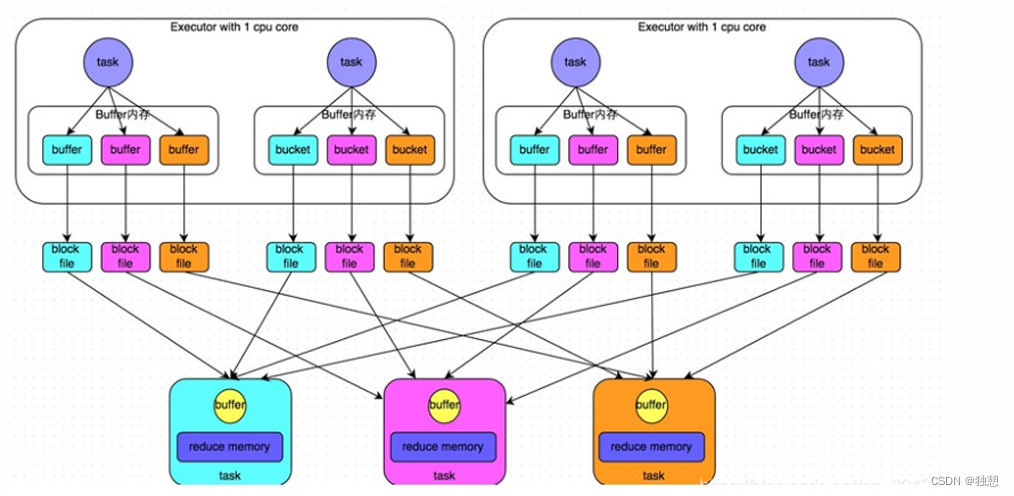
优化的hashShuffleManager:
在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概 念,每个shuffleFileGroup会对应一批磁盘文件,每一个Group磁盘文件的数量与下游stage的task数量是相同的。
其实说到底就是其在executor内部就会进行数据的汇合操作,大大减少了磁盘文件的生成

Sort Shuffle
(1)该模式下,数据会先写入一个内存数据结构中(默认5M),此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内 存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。
(2)接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话 ,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
(3)排序 在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。 (4)溢写 排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数 据的形式分批写入磁盘文件。
(5)merge 一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之 前所有的临时磁盘文件都进行合并成1个磁盘文件,这就是merge过程。 由于一个task就只对应一个磁盘文件,也就意味着该task为Reduce端的stage的task准备的数据都在这一个文件中, 因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
说到底最大的区别就是,一个task只会生成一个磁盘文件和一个索引文件,大大降低了磁盘占有和网络IO数量
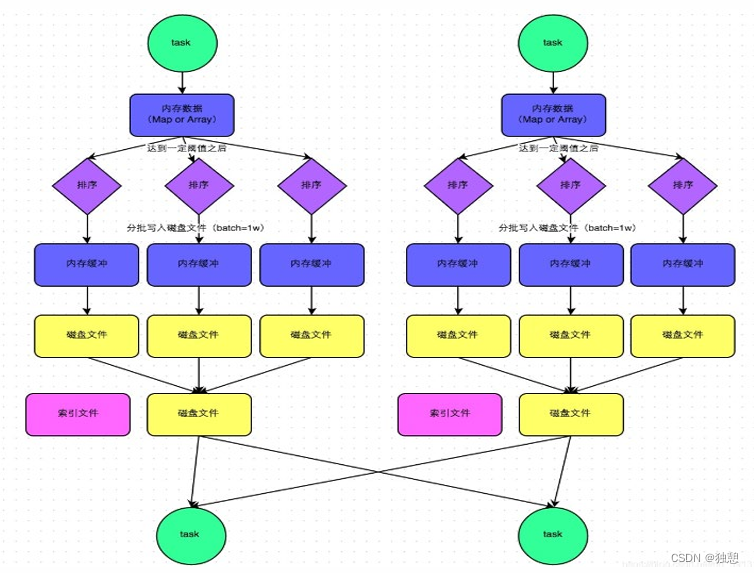
Sort Shuffle bypass机制
bypass运行机制的触发条件如下:
1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
2)不是map combine聚合的shuffle算子(比如reduceByKey有map combie)(这种算子不需要排序)
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash,然后根据key的hash值, 将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的 。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件, 只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同;
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作, 也就节省掉了这部分的性能开销。
相关文章:
PySpark(三)RDD持久化、共享变量、Spark内核制度,Spark Shuffle
目录 RDD持久化 RDD 的数据是过程数据 RDD 缓存 RDD CheckPoint 共享变量 广播变量 累加器 Spark 内核调度 DAG DAG 的宽窄依赖和阶段划分 内存迭代计算 Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用? Spark为什么比MapReduce快? Spar…...

详解MYSQL中的平均值组大小
文章目录 平均值组大小了解平均值组大小MySQL什么时候会使用平均值组大小平均值组大小对于索引选取的影响平均值组大小 了解平均值组大小 总数据量 / 值组 = 平均值组大小 值组是一组具有相同键前缀值的行,及所有相等的键为一个值组。总数据量为全表数据量MySQL什么时候会使…...
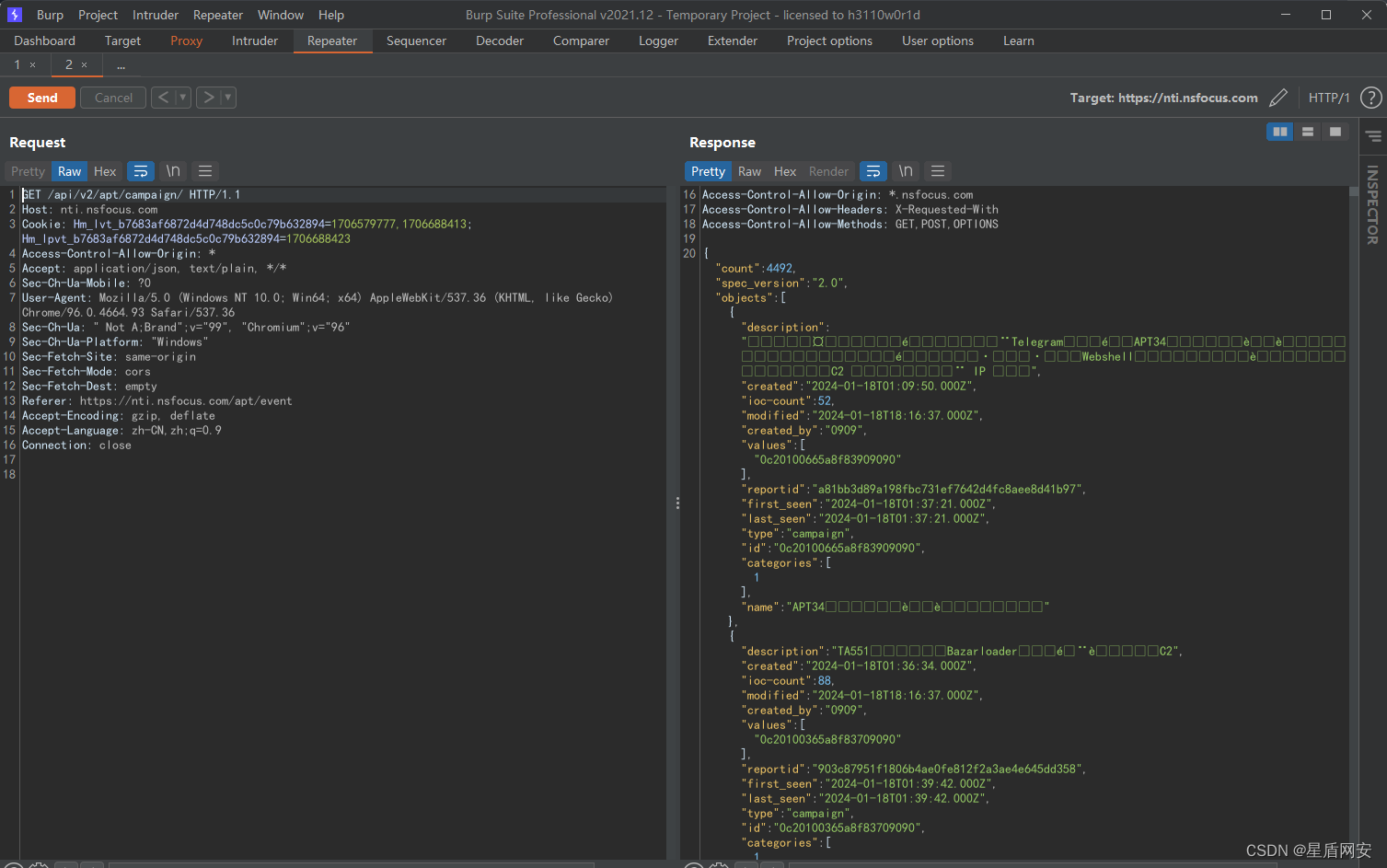
【爬虫专区】批量下载PDF (无反爬)
天命:只要没反爬,一切都简单 这次爬取的是绿盟的威胁情报的PDF 先看一下结构,很明显就是一个for循环渲染 burp抓包会发现第二次接口请求 接口请求一次就能获取到了所有的数据 然后一个循环批量下载数据即可,其实没啥难度的 imp…...
自动增长冲突)
PostgreSQL解决序列(自增id)自动增长冲突
背景 一般表的id主键我们都是设置为自增序列。 但是如果我们在插入一些数据的时候手动指定id,那么自增序列不会跟随我们手动设置的id增长。 就会出现下次不设置id的时候自增到我们手动指定的id导致主键冲突bug 举个例子 现在数据有 id123 现在我们手动插入数…...
1.0 Zookeeper 分布式配置服务教程
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。 ZooKeeper 的架构通过冗余服务实现高可用性。 Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高…...

(Flutter 常用插件整理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Flutter 常用插件整理 # Flutter 城市列表,联系人列表,索引&悬停 https://github.com/flutterchina/azlistviewazlistview: ^2.0.0# Dart 汉字转拼音 https://github.com/flutterchina/lpinyinlpinyin…...
vue2.0+使用md-edit编辑器
前言:小刘开发过程中,如果是博客项目一般是会用到富文本。众多富文本中,小刘选择了markdown,并记录分享了下来。 # 使用 npm npm i kangc/v-md-editor -Smain.js基本配置import VueMarkdownEditor from kangc/v-md-editor; import…...

Java设计模式大全:23种常见的设计模式详解(二)
本系列文章简介: 设计模式是在软件开发过程中,经过实践和总结得到的一套解决特定问题的可复用的模板。它是一种在特定情境中经过验证的经验和技巧的集合,可以帮助开发人员设计出高效、可维护、可扩展和可复用的软件系统。设计模式提供了一种在…...
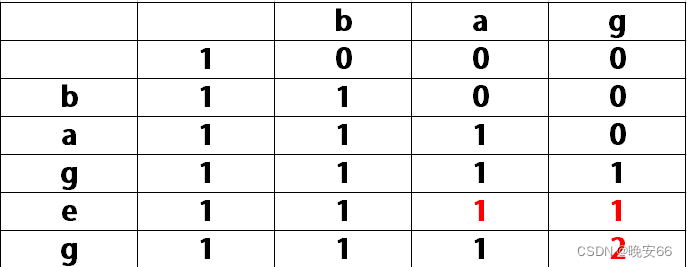
【算法与数据结构】718、1143、1035、392、115、LeetCode最长重复子数组+最长公共子序列+不相交的线+判断子序列+不同的子序列
文章目录 一、718、最长重复子数组二、1143、最长公共子序列三、1035、不相交的线四、392、判断子序列五、115、不同的子序列六、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、718、最长重复子数组 思路分析࿱…...

OCR文本纠错思路
文字错误类别:多字 少字 形近字 当前方案 文本纠错思路 简单: 一、构建自定义词典,提高分词正确率。不在词典中,也不是停用词,分成单字的数据极有可能是错字(少部分可能是新词)。错字与前后的…...

【java批量导出pdf】优化方案
问题情境: 项目中存在web页面点击一键导出,导出所有数据对应的pdf文件,由于有些pdf文件是实时生成的,之前最简答的写法for循环处理速度太慢,超过了nginx配置的最大响应时间了,且对用户交互体验上很不友好&…...
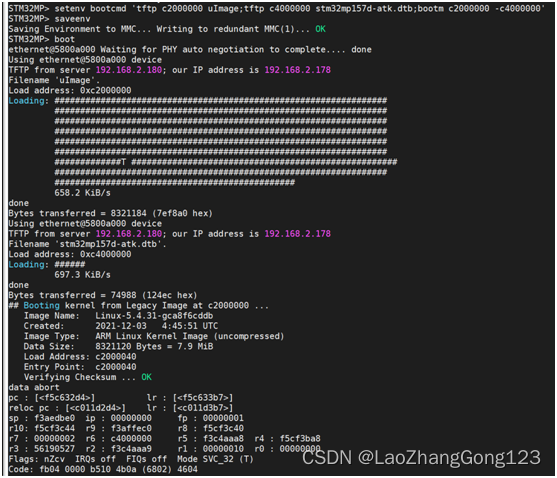
Linux第42步_移植ST公司uboot的第3步_uboot命令测试,搭建nfs服务器和tftp服务器
测试uboot命令,搭建nfs服务器和tftp服务器,是测试uboot非常关键的一步。跳过这一节,后面可能要踩坑。 一、输入“help回车”,查询uboot所支持的命令 二、输入“? bootz回车”,查询“bootz”怎么用 注意:和…...
)
C++枚举算法(3)
我家的门牌号 题目描述: 我家住在一条短胡同里,这条胡同的门牌号从1开始顺序编号。 若所有的门牌号之和减去我家门牌号的两倍,恰好等于n,求 我家的门牌号及总共有多少家。 数据保证有唯一解。 输入 一个正整数n。n < 100000。…...
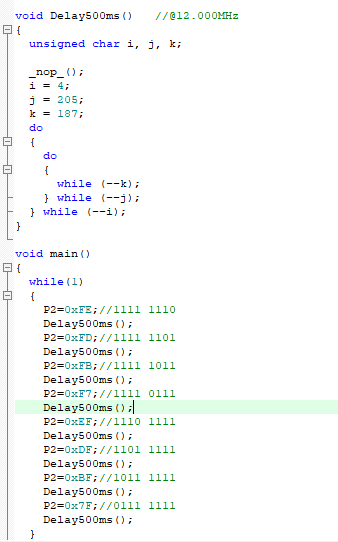
【51单片机】LED的三个基本项目(LED点亮&LED闪烁&LED流水灯)(3)
前言 大家好吖,欢迎来到 YY 滴单片机系列 ,热烈欢迎! 本章主要内容面向接触过单片机的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! YY的《C》专栏YY的《C11》专栏YY的…...

Day 17------C语言收尾之链表的删除、位运算、预处理、宏定义
链表 空链表: 注意:函数不能返回局部变量的地址 操作: 1.创建空链表 2.头插 3.尾插 4.链表遍历 5.链表的长度 free:释放 删除: 头删 void popFront(struct Node *head) { //1.p指针变量指向首节点 //2.断…...
python_蓝桥杯刷题记录_笔记_全AC代码_入门5
前言 关于入门地刷题到现在就结束了。 题单目录 1.P1579 哥德巴赫猜想(升级版) 2.P1426 小鱼会有危险吗 1.P1579 哥德巴赫猜想(升级版) 一开始写的代码是三重循环,结果提交上去一堆地TLE,然后我就给减少…...

二叉树的详解
二叉树 【本节目标】 掌握树的基本概念掌握二叉树概念及特性掌握二叉树的基本操作完成二叉树相关的面试题练习 树型结构(了解) 概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。…...

【第三十五节】idea项目的创建以及setting和Project Structure的设置
项目创建 Project Structure的设置 点击file ~ Project Structure 进入...

【c++】跟webrtc学引用计数
rtc::RefCountInterface 接口类 G:\CDN\rtcCli\m98\src\rtc_base\ref_count.h引用计数想形成一种树状结构 // Interfaces where refcounting is part of the public api should // inherit this abstract interface. The implementation of these // methods is usually provid…...
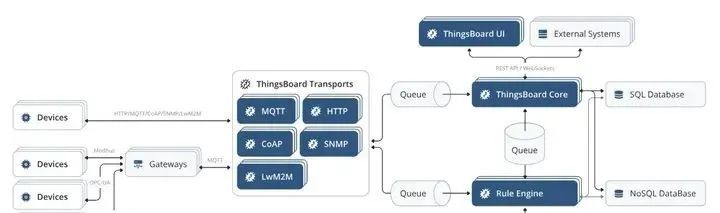
开源免费的物联网网关 IoT Gateway
1. 概述 物联网网关,也被称为IOT网关,是一种至关重要的网络设备。在物联网系统中,它承担着连接和控制各种设备的重要任务,将这些设备有效地连接到云端、本地服务器或其他设备上。它既能够在广域范围内实现互联,也能在…...

Ostrakon-VL终端效果展示:深夜食堂风格终端打印输出全过程录屏
Ostrakon-VL终端效果展示:深夜食堂风格终端打印输出全过程录屏 1. 像素特工终端概览 在零售与餐饮行业的数字化转型浪潮中,我们开发了这款基于Ostrakon-VL-8B多模态大模型的Web交互终端。与传统工业级UI不同,我们采用了高饱和度的像素艺术风…...

GT New Horizons材质包精选:10款提升沉浸体验的视觉升级方案
GT New Horizons材质包精选:10款提升沉浸体验的视觉升级方案 【免费下载链接】GT-New-Horizons-Modpack A big progressive questing modpack for Minecraft 1.7.10 balanced around the mod GregTech. 项目地址: https://gitcode.com/GitHub_Trending/gt/GT-New-…...

汽车动力性能计算工具插件:一键测算电机需求与整车性能,工程师专属轻量级辅助软件
温馨提示:文末有联系方式插件核心功能亮点 本款汽车动力性系统专用计算小工具,可精准推演电机功率与扭矩需求,同步输出整车加速性能、最大爬坡度、最高稳定车速等关键动力参数,覆盖常规工况与典型驱动场景,满足前期方案…...
Pixel Epic智识终端效果展示:跨领域研报生成一致性与专业性验证
Pixel Epic智识终端效果展示:跨领域研报生成一致性与专业性验证 1. 产品概览与核心价值 Pixel Epic智识终端是一款基于AgentCPM-Report大模型构建的专业研究报告生成工具。与传统AI工具不同,它创新性地采用了像素RPG游戏的美学设计,将枯燥的…...

从‘过拟合’到‘稳如狗’:聊聊EEG情感识别中数据增强与噪声注入的那些坑
从‘过拟合’到‘稳如狗’:EEG情感识别中的数据增强与噪声注入实战指南 当你第一次看到训练集准确率突破95%的EEG情感识别模型,在实际测试中面对新用户时表现却像从未训练过一样糟糕,这种落差感想必每个从业者都深有体会。个体差异就像一把双…...

从SolidWorks到ROS:六自由度机械臂URDF模型转换实战指南
1. 从SolidWorks到ROS的桥梁:URDF模型转换概述 当你费尽心思在SolidWorks中完成了六自由度机械臂的三维建模,看着那些精密的齿轮和连杆在软件中流畅转动时,脑海中可能已经浮现出它在ROS环境中大展身手的场景。但问题来了:如何让这…...

GLM-4v-9b效果展示:直播带货截图→话术分析+转化点提炼
GLM-4v-9b效果展示:直播带货截图→话术分析转化点提炼 1. 模型能力概览 GLM-4v-9b是智谱AI在2024年开源的多模态视觉-语言模型,拥有90亿参数。这个模型最大的特点是能够同时理解图片和文字,支持中英文多轮对话,在11201120高分辨…...

终极Übersicht小部件调试指南:10个实用工具和高效方法
终极bersicht小部件调试指南:10个实用工具和高效方法 【免费下载链接】uebersicht ˈyːbɐˌzɪt 项目地址: https://gitcode.com/gh_mirrors/ue/uebersicht bersicht是一款强大的macOS桌面小部件工具,让开发者能够在桌面上创建和运行自定义小部…...

猫抓cat-catch:高效媒体捕获与资源下载全指南
猫抓cat-catch:高效媒体捕获与资源下载全指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓cat-catch是一款专注于网页媒体资源捕…...

Comsol 脉冲激光诱导等离子体仿真模型:探索微观世界的奇妙之旅
Comsol脉冲激光诱导等离子体仿真模型 利用脉冲激光作为热源,在氩气环境中诱导产生等离子体,主要体现出等离子体的密度、等离子体温度等参数 可以为激光诱导等离子体提供准确的参考在科研与工程领域,对脉冲激光诱导等离子体的深入研究有着举足…...