Iceberg从入门到精通系列之二十一:Spark集成Iceberg
Iceberg从入门到精通系列之二十一:Spark集成Iceberg
- 一、在 Spark 3 中使用 Iceberg
- 二、添加目录
- 三、创建表
- 四、写
- 五、读
- 六、Catalogs
- 七、目录配置
- 八、使用目录
- 九、替换会话目录
- 十、使用目录特定的 Hadoop 配置值
- 十一、加载自定义目录
- 十二、SQL 扩展
- 十三、运行时配置-读选项
- 十四、运行时配置-写选项
- 十五、Spark Procedures
- 十六、元数据管理
Iceberg的最新版本是1.4.3。
Spark 是目前用于 Iceberg 操作的功能最丰富的计算引擎。建议您开始使用 Spark,通过示例了解 Iceberg 概念和功能。您还可以在多引擎支持页面下查看将 Iceberg 与其他计算引擎结合使用的文档。
一、在 Spark 3 中使用 Iceberg
要在 Spark shell 中使用 Iceberg,请使用 --packages 选项:
spark-shell --packages org.apache.iceberg:iceberg-spark-runtime-3.2_2.12:1.4.3
如果想在 Spark 安装中包含 Iceberg,请将iceberg-spark-runtime-3.2_2.12 Jar 添加到 Spark 的 jars 文件夹中。
二、添加目录
Iceberg 附带了目录,使 SQL 命令能够管理表并按名称加载它们。使用spark.sql.catalog.(catalog_name)下的属性配置目录。
此命令为 $PWD/warehouse 下的表创建一个名为 local 的基于路径的目录,并向 Spark 的内置目录添加对 Iceberg 表的支持:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.2_2.12:1.4.3\--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \--conf spark.sql.catalog.spark_catalog.type=hive \--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog \--conf spark.sql.catalog.local.type=hadoop \--conf spark.sql.catalog.local.warehouse=$PWD/warehouse
三、创建表
要在 Spark 中创建第一个 Iceberg 表,请使用 Spark-sql shell 或 Spark.sql(…) 运行 CREATE TABLE 命令:
CREATE TABLE local.db.table (id bigint, data string) USING iceberg
Iceberg 目录支持全系列 SQL DDL 命令,包括:
- CREATE TABLE … PARTITIONED BY
- CREATE TABLE … AS SELECT
- ALTER TABLE
- DROP TABLE
四、写
创建表后,使用 INSERT INTO 插入数据:
INSERT INTO local.db.table VALUES (1, 'a'), (2, 'b'), (3, 'c');
INSERT INTO local.db.table SELECT id, data FROM source WHERE length(data) = 1;
Iceberg 还向 Spark、MERGE INTO 和 DELETE FROM 添加了行级 SQL 更新:
MERGE INTO local.db.target t USING (SELECT * FROM updates) u ON t.id = u.id
WHEN MATCHED THEN UPDATE SET t.count = t.count + u.count
WHEN NOT MATCHED THEN INSERT *
这段代码是一个使用 MERGE INTO 语句进行数据合并的示例。它将来自更新表的数据合并到目标表中。具体的操作如下:
- 使用子查询
(SELECT * FROM updates) u获取更新表的数据,并将其作为源表使用。 - 使用目标表
local.db.target作为目标表进行更新。 - 使用
ON t.id = u.id来指定源表和目标表之间的连接条件。这里使用了id列作为连接条件。 - 当连接条件匹配时,执行
WHEN MATCHED分支的操作。这里使用UPDATE SET t.count = t.count + u.count将目标表中的count列的值增加源表中对应行的count值。 - 当连接条件不匹配时,执行
WHEN NOT MATCHED分支的操作。这里使用INSERT *将源表中的数据插入到目标表中。
总之,这段代码通过 MERGE INTO 语句将更新表的数据合并到目标表中,根据连接条件进行更新或插入操作。
Iceberg 支持使用新的 v2 DataFrame 写入 API 写入 DataFrame:
spark.table("source").select("id", "data").writeTo("local.db.table").append()
支持旧的写入 API,但不推荐。
五、读
要使用 SQL 读取,请在 SELECT 查询中使用 Iceberg 表名称:
SELECT count(1) as count, data
FROM local.db.table
GROUP BY data
SQL 也是检查表的推荐方法。要查看表中的所有快照,请使用快照元数据表:
SELECT * FROM local.db.table.snapshots
+-------------------------+----------------+-----------+-----------+----------------------------------------------------+-----+
| committed_at | snapshot_id | parent_id | operation | manifest_list | ... |
+-------------------------+----------------+-----------+-----------+----------------------------------------------------+-----+
| 2019-02-08 03:29:51.215 | 57897183625154 | null | append | s3://.../table/metadata/snap-57897183625154-1.avro | ... |
| | | | | | ... |
| | | | | | ... |
| ... | ... | ... | ... | ... | ... |
+-------------------------+----------------+-----------+-----------+----------------------------------------------------+-----+
支持 DataFrame 读取,现在可以使用 Spark.table 按名称引用表:
val df = spark.table("local.db.table")
df.count()
六、Catalogs
Spark 添加了一个 API 来插入用于加载、创建和管理 Iceberg 表的表目录。 Spark 目录是通过在spark.sql.catalog 下设置Spark 属性来配置的。
这将创建一个名为 hive_prod 的 Iceberg 目录,该目录从 Hive 元存储加载表:
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://metastore-host:port
# omit uri to use the same URI as Spark: hive.metastore.uris in hive-site.xml
以下是名为rest_prod 的 REST 目录示例,该目录从 REST URL http://localhost:8080 加载表:
spark.sql.catalog.rest_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.rest_prod.type = rest
spark.sql.catalog.rest_prod.uri = http://localhost:8080
Iceberg 还支持 HDFS 中基于目录的目录,可以使用 type=hadoop 进行配置:
spark.sql.catalog.hadoop_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hadoop_prod.type = hadoop
spark.sql.catalog.hadoop_prod.warehouse = hdfs://nn:8020/warehouse/path
基于 Hive 的目录仅加载 Iceberg 表。要在同一 Hive 元存储中加载非 Iceberg 表,请使用会话目录。
七、目录配置
通过添加属性spark.sql.catalog.(catalog-name) 及其值的实现类来创建和命名目录。
Iceberg 提供了两种实现:
- org.apache.iceberg.spark.SparkCatalog 支持 Hive Metastore 或 Hadoop 仓库作为目录
- org.apache.iceberg.spark.SparkSessionCatalog 在 Spark 的内置目录中添加了对 Iceberg 表的支持,并将非 Iceberg 表委托给内置目录
两个目录均使用嵌套在目录名称下的属性进行配置。 Hive 和 Hadoop 的常见配置属性有:
| 属性 | 值 | 描述 |
|---|---|---|
| spark.sql.catalog.catalog-name.type | hive, hadoop or rest | 底层 Iceberg 目录实现、HiveCatalog、HadoopCatalog、RESTCatalog 或在使用自定义目录时保持未设置 |
| spark.sql.catalog.catalog-name.catalog-impl | 自定义 Iceberg 目录实现。如果 type 为 null,则 Catalog-impl 不得为 null。 | |
| spark.sql.catalog.catalog-name.io-impl | 自定义 FileIO 实现。 | |
| spark.sql.catalog.catalog-name.metrics-reporter-impl | 自定义 MetricsReporter 实现。 | |
| spark.sql.catalog.catalog-name.default-namespace | default | 目录的默认当前命名空间 |
| spark.sql.catalog.catalog-name.uri | thrift://host:port | Hive 类型目录的 Hive 元存储 URL、REST 类型目录的 REST URL |
| spark.sql.catalog.catalog-name.warehouse | hdfs://nn:8020/warehouse/path | 仓库目录的基本路径 |
| Spark.sql.catalog.catalog-name.cache-enabled | true or false | 是否启用目录缓存,默认值为true |
| spark.sql.catalog.catalog-name.cache.expiration-interval-ms | 30000 (30 seconds) | 缓存的目录条目过期的持续时间;仅当启用缓存为 true 时才有效。 -1 禁用缓存过期,0 完全禁用缓存,无论是否启用缓存。默认值为 30000(30 秒) |
| spark.sql.catalog.catalog-name.table-default.propertyKey | 属性键 propertyKey 的默认 Iceberg 表属性值,如果未覆盖,将在此目录创建的表上设置该值 | |
| Spark.sql.catalog.catalog-name.table-override.propertyKey | 属性键 propertyKey 的强制 Iceberg 表属性值,用户无法覆盖该值 |
八、使用目录
目录名称在 SQL 查询中用于标识表。在上面的示例中, hive_prod 和 hadoop_prod 可用于为将从这些目录加载的数据库和表名称添加前缀。
SELECT * FROM hive_prod.db.table
Spark 3 跟踪当前目录和命名空间,表名称中可以省略它们。
USE hive_prod.db;
SELECT * FROM table
要查看当前目录和命名空间,请运行 SHOW CURRENT NAMESPACE。
九、替换会话目录
要将 Iceberg 表支持添加到 Spark 的内置目录,请配置 Spark_catalog 以使用 Iceberg 的 SparkSessionCatalog。
spark.sql.catalog.spark_catalog = org.apache.iceberg.spark.SparkSessionCatalog
spark.sql.catalog.spark_catalog.type = hive
Spark 的内置目录支持 Hive Metastore 中跟踪的现有 v1 和 v2 表。这将 Spark 配置为使用 Iceberg 的 SparkSessionCatalog 作为该会话目录的包装器。当表不是 Iceberg 表时,将使用内置目录来加载它。
此配置可以对 Iceberg 和非 Iceberg 表使用相同的 Hive Metastore。
十、使用目录特定的 Hadoop 配置值
与使用 Spark.hadoop.* 配置 Hadoop 属性类似,在使用 Spark 时,可以通过添加带有前缀 Spark.sql.catalog.(catalog-name).hadoop 的目录属性来设置每个目录的 Hadoop 配置值。 *。这些属性将优先于使用spark.hadoop.*全局配置的值,并且仅影响Iceberg表。
spark.sql.catalog.hadoop_prod.hadoop.fs.s3a.endpoint = http://aws-local:9000
十一、加载自定义目录
Spark 支持通过指定catalog-impl 属性来加载自定义Iceberg Catalog 实现。这是一个例子:
spark.sql.catalog.custom_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.custom_prod.catalog-impl = com.my.custom.CatalogImpl
spark.sql.catalog.custom_prod.my-additional-catalog-config = my-value
十二、SQL 扩展
Iceberg 0.11.0 及更高版本向 Spark 添加了一个扩展模块,以添加新的 SQL 命令,例如存储过程的 CALL 或 ALTER TABLE … WRITE ORDERED BY。
使用这些 SQL 命令需要使用以下 Spark 属性将 Iceberg 扩展添加到您的 Spark 环境:
| Spark 扩展属性 | Iceberg扩展实施 |
|---|---|
| spark.sql.extensions | org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions |
十三、运行时配置-读选项
配置 DataFrameReader 时会传递 Spark 读取选项,如下所示:
// time travel
spark.read.option("snapshot-id", 10963874102873L).table("catalog.db.table")
| Spark选项 | 默认值 | 描述 |
|---|---|---|
| snapshot-id | (latest) | 要读取的表快照的快照 ID |
| as-of-timestamp | (latest) | 以毫秒为单位的时间戳;使用的快照将是此时的当前快照。 |
| split-size | 根据表属性 | 覆盖此表的 read.split.target-size 和 read.split.metadata-target-size |
| lookback | 根据表属性 | 覆盖此表的 read.split.planning-lookback |
| file-open-cost | 根据表属性 | 覆盖此表的 read.split.open-file-cost |
| vectorization-enabled | 根据表属性 | 覆盖此表的 read.parquet.vectorization.enabled |
| batch-size | 根据表属性 | 覆盖此表的 read.parquet.vectorization.batch-size |
| stream-from-timestamp | (none) | 流式传输的时间戳(以毫秒为单位);如果在最旧的已知祖先快照之前,则将使用最旧的 |
十四、运行时配置-写选项
配置 DataFrameWriter 时会传递 Spark 写入选项,如下所示:
df.write.option("write-format", "avro").option("snapshot-property.key", "value").insertInto("catalog.db.table")
| Spark选项 | 默认值 | 描述 |
|---|---|---|
| write-format | 表 write.format.default | 用于此写入操作的文件格式;parquet, avro, or orc |
| target-file-size-bytes | 根据表属性 | 覆盖此表的 write.target-file-size-bytes |
| check-nullability | true | 设置字段可空检查 |
| snapshot-property.custom-key | null | 在快照摘要中添加具有自定义键和相应值的条目(仅 DSv2 需要快照属性。前缀) |
| fanout-enabled | false | 覆盖此表的 write.spark.fanout.enabled |
| check-ordering | true | 检查输入模式和表模式是否相同 |
| isolation-level | null | 数据帧覆盖操作所需的隔离级别。 null => 不检查(对于幂等写入),serializable => 检查目标分区中的并发插入或删除,snapshot => 检查目标分区中的并发删除。 |
| validate-from-snapshot-id | null | 如果设置了隔离级别,则为用于检查表中并发写入冲突的基本快照的 ID。应该是从表中进行任何读取之前的快照。可以通过 Table API 或 Snapshots 表获取。如果为空,则使用表中最旧的已知快照。 |
| compression-codec | Table write.(fileformat).compression-codec | 覆盖此写入的此表的压缩编解码器 |
| compression-level | Table write.(fileformat).compression-level | 对于此写入,覆盖此表的 Parquet 和 Avro 表的压缩级别 |
| compression-strategy | Table write.orc.compression-strategy | 针对此写入覆盖此表的 ORC 表压缩策略 |
CommitMetadata 提供了一个接口,用于在 SQL 执行期间将自定义元数据添加到快照摘要中,这对于审计或更改跟踪等目的非常有用。如果属性以 snapshot-property. 开头,则该前缀将从每个属性中删除。这是一个例子:
import org.apache.iceberg.spark.CommitMetadata;Map<String, String> properties = Maps.newHashMap();
properties.put("property_key", "property_value");
CommitMetadata.withCommitProperties(properties,() -> {spark.sql("DELETE FROM " + tableName + " where id = 1");return 0;},RuntimeException.class);
十五、Spark Procedures
要在 Spark 中使用 Iceberg,请首先配置 Spark 目录。存储过程仅在 Spark 3 中使用 Iceberg SQL 扩展时可用。
可以通过 CALL 从任何配置的 Iceberg 目录中使用过程。所有过程都在命名空间系统中。
CALL 支持按名称(推荐)或按位置传递参数。不支持混合位置参数和命名参数。
命名参数
所有过程参数均已命名。按名称传递参数时,参数可以按任何顺序,并且可以省略任何可选参数
CALL catalog_name.system.procedure_name(arg_name_2 => arg_2, arg_name_1 => arg_1)
位置参数
按位置传递参数时,只有结尾参数可以省略(如果它们是可选的)。
CALL catalog_name.system.procedure_name(arg_1, arg_2, ... arg_n)
快照管理
rollback_to_snapshot
将表回滚到特定快照 ID。
要回滚到特定时间,请使用 rollback_to_timestamp。
此过程会使所有引用受影响表的缓存 Spark 计划失效。
| 参数名称 | Required | Type | 描述 |
|---|---|---|---|
| table | ✔️ | string | 要更新的表的名称 |
| snapshot_id | ✔️ | long | 要回滚到的快照 ID |
| Output Name | Type | 描述 |
|---|---|---|
| previous_snapshot_id | long | 回滚前当前快照ID |
| current_snapshot_id | long | 新的当前快照 ID |
将表 db.sample 回滚到快照 ID 1:
CALL catalog_name.system.rollback_to_snapshot('db.sample', 1)
rollback_to_timestamp
将表回滚到某个时间的当前快照。
| 参数名称 | Required | Type | 描述 |
|---|---|---|---|
| table | ✔️ | string | 要更新的表的名称 |
| timestamp | ✔️ | timestamp | 要回滚到的时间戳 |
| Output Name | Type | 描述 |
|---|---|---|
| previous_snapshot_id | long | 回滚前当前快照ID |
| current_snapshot_id | long | 新的当前快照 ID |
将 db.sample 回滚到特定的日期和时间。
CALL catalog_name.system.rollback_to_timestamp('db.sample', TIMESTAMP '2021-06-30 00:00:00.000')
set_current_snapshot
设置表的当前快照 ID。
与回滚不同,快照不需要是当前表状态的祖先。
CALL catalog_name.system.set_current_snapshot('db.sample', 1)
cherrypick_snapshot
从现有快照创建新快照,而不更改或删除原始快照。
只能选择追加和动态覆盖快照。
CALL catalog_name.system.cherrypick_snapshot('my_table', 1)
CALL catalog_name.system.cherrypick_snapshot(snapshot_id => 1, table => 'my_table' )fast_forward
将一个分支的当前快照快进到另一个分支的最新快照。
CALL catalog_name.system.fast_forward('my_table', 'main', 'audit-branch')
十六、元数据管理
许多维护操作可以使用 Iceberg 存储过程来执行。
过期快照
Iceberg 中的每次写入/更新/删除/更新插入/压缩都会生成一个新快照,同时保留旧数据和元数据以进行快照隔离和时间旅行。 expire_snapshots 过程可用于删除不再需要的旧快照及其文件。
此过程将删除旧快照以及这些旧快照唯一需要的数据文件。这意味着expire_snapshots过程永远不会删除未过期快照仍然需要的文件。
| 参数名称 | Required | Type | 描述 |
|---|---|---|---|
| table | ✔️ | string | 要更新的表的名称 |
| older_than | timestamp | 删除快照之前的时间戳(默认:5 天前) | |
| retain_last | int | 无论old_than如何,要保留的祖先快照数量(默认为1) | |
| max_concurrent_deletes | int | 用于删除文件操作的线程池的大小(默认情况下,不使用线程池) | |
| stream_results | boolean | 当为true时,删除文件将通过RDD分区发送到Spark驱动程序(默认情况下,所有文件将发送到Spark驱动程序)。建议将此选项设置为 true,以防止 Spark 驱动程序因文件大小而导致 OOM | |
| snapshot_ids | array of long | 即将过期的快照 ID 数组。 |
如果省略old_than和retain_last,则将使用表的过期属性。仍被分支或标签引用的快照将不会被删除。默认情况下,分支和标签永远不会过期,但可以使用表属性history.expire.max-ref-age-ms更改它们的保留策略。主分支永远不会过期。
| 输出名称 | 类型 | 描述 |
|---|---|---|
| deleted_data_files_count | long | 该操作删除的数据文件数量 |
| deleted_position_delete_files_count | long | 本次操作删除的位置删除文件数量 |
| deleted_equality_delete_files_count | long | 本次操作删除的等式删除文件数量 |
| deleted_manifest_files_count | long | 此操作删除的清单文件数 |
| deleted_manifest_lists_count | long | 此操作删除的清单列表文件数 |
删除早于特定日期和时间的快照,但保留最后 100 个快照:
CALL hive_prod.system.expire_snapshots('db.sample', TIMESTAMP '2021-06-30 00:00:00.000', 100)
删除快照 ID 为 123 的快照(注意该快照 ID 不应该是当前快照):
CALL hive_prod.system.expire_snapshots(table => 'db.sample', snapshot_ids => ARRAY(123))
删除孤立文件
用于删除 Iceberg 表的任何元数据文件中未引用的文件,因此可以被视为“孤立”文件。
通过在此表上执行remove_orphan_files 命令的试运行而不实际删除它们,列出所有要删除的候选文件:
CALL catalog_name.system.remove_orphan_files(table => 'db.sample', dry_run => true)
删除 tablelocation/data 文件夹中表 db.sample 未知的所有文件。
CALL catalog_name.system.remove_orphan_files(table => 'db.sample', location => 'tablelocation/data')
重写数据文件
Iceberg 跟踪表中的每个数据文件。更多的数据文件会导致更多的元数据存储在清单文件中,而小数据文件会导致不必要的元数据量和文件打开成本的低效查询。
Iceberg 可以使用 Spark 和 rewriteDataFiles 操作并行压缩数据文件。这会将小文件组合成较大的文件,以减少元数据开销和运行时文件打开成本。
| 参数名称 | Required | Type | 描述 |
|---|---|---|---|
| table | ✔️ | string | 要更新的表的名称 |
| strategy | string | 策略的名称 - binpack 或 sort。默认为 binpack 策略 | |
| sort_order | string | 对于 Zorder,请在 zorder() 中使用逗号分隔的列列表。 (Spark 3.2 及以上版本支持)示例:zorder(c1,c2,c3)。否则,以逗号分隔排序顺序,格式为 (ColumnName SortDirection NullOrder)。其中 SortDirection 可以是 ASC 或 DESC。 NullOrder 可以是 NULLS FIRST 或 NULLS LAST。默认为表的排序顺序 | |
| options | map<string, string> | 用于操作的选项 | |
| where | string | 谓词作为用于过滤文件的字符串。请注意,所有可能包含与过滤器匹配的数据的文件都将被选择进行重写 |
常规选项
| 名称 | 默认值 | 描述 |
|---|---|---|
| max-concurrent-file-group-rewrites | 5 | 同时重写的最大文件组数 |
| partial-progress.enabled | false | 启用在整个重写完成之前提交文件组 |
| partial-progress.max-commits | 10 | 如果启用部分进度,则允许此重写产生的最大提交量 |
| use-starting-sequence-number | true | 使用压缩开始时快照的序列号,而不是新生成的快照的序列号 |
| rewrite-job-order | none | 根据该值强制重写作业顺序。如果 rewrite-job-order=bytes-asc,则先重写最小的作业组。如果 rewrite-job-order=bytes-desc,则先重写最大的作业组。如果 rewrite-job-order=files-asc,则首先重写文件最少的作业组。如果 rewrite-job-order=files-desc,则首先重写文件最多的作业组。如果 rewrite-job-order=none,则按照它们的顺序重写作业组已计划(无特定顺序)。 |
| target-file-size-bytes | 536870912(512 MB,表属性中 write.target-file-size-bytes 的默认值) | 目标输出文件大小 |
| min-file-size-bytes | 目标文件大小的 75% | 无论任何其他标准如何,低于此阈值的文件都将被考虑重写 |
| max-file-size-bytes | 目标文件大小的 180% | 无论任何其他条件如何,大小高于此阈值的文件都将被考虑重写 |
| min-input-files | 5 | 无论其他条件如何,超过此文件数量的任何文件组都将被重写 |
| rewrite-all | false | 强制重写所有提供的文件,覆盖其他选项 |
| max-file-group-size-bytes | 107374182400 (100GB) | 单个文件组中应重写的最大数据量。整个重写操作根据分区被分解为多个部分,并根据文件组的大小在分区内分解。这有助于分解非常大的分区的重写,否则由于集群的资源限制,这些分区可能无法重写。 |
| delete-file-threshold | 2147483647 | 需要与数据文件关联才能考虑重写的最小删除次数 |
排序策略选项
| 名称 | 默认值 | 描述 |
|---|---|---|
| compression-factor | 1.0 | Shuffle 分区的数量以及 Spark 排序创建的输出文件的数量取决于此文件重写器中使用的输入数据文件的大小。由于压缩,磁盘文件大小可能无法准确表示输出中文件的大小。此参数允许用户调整用于估计实际输出数据大小的文件大小。大于 1.0 的系数将生成比我们根据磁盘文件大小预期的更多的文件。小于 1.0 的值将创建比我们基于磁盘大小预期的文件少的文件。 |
| shuffle-partitions-per-file | 1 | 用于每个输出文件的随机分区数。 Iceberg 将使用自定义合并操作将这些已排序的分区重新拼接成单个已排序的文件。 |
使用 zorder sort_order 的排序策略选项
| 名称 | 默认值 | 描述 |
|---|---|---|
| var-length-contribution | 8 | 从可变长度类型的输入列考虑的字节数(字符串、二进制) |
| max-output-size | 2147483647 | ZOrder 算法中交织的字节数 |
Output
| 名称 | 默认值 | 描述 |
|---|---|---|
| rewritten_data_files_count | int | 通过该命令重写的数据数 |
| added_data_files_count | int | 此命令写入的新数据文件的数量 |
| rewritten_bytes_count | long | 该命令写入的字节数 |
| failed_data_files_count | int | partial-progress.enabled为true时重写失败的数据文件数量 |
例子
使用默认的bin-packing重写算法重写表db.sample中的数据文件,合并小文件,同时根据表的默认写入大小拆分大文件。
CALL catalog_name.system.rewrite_data_files('db.sample')
通过使用与 bin-pack 相同的默认值对 id 和 name 上的所有数据进行排序来重写表 db.sample 中的数据文件,以确定要重写的文件。
CALL catalog_name.system.rewrite_data_files(table => 'db.sample', strategy => 'sort', sort_order => 'id DESC NULLS LAST,name ASC NULLS FIRST')
通过 zOrdering 在 c1 和 c2 列上重写表 db.sample 中的数据文件。使用与 bin-pack 相同的默认值来确定要重写哪些文件。
CALL catalog_name.system.rewrite_data_files(table => 'db.sample', strategy => 'sort', sort_order => 'zorder(c1,c2)')
在任何需要重写的文件超过 2 个或更多的分区中,使用 bin-pack 策略重写表 db.sample 中的数据文件。
CALL catalog_name.system.rewrite_data_files(table => 'db.sample', options => map('min-input-files','2'))
重写表db.sample中的数据文件,并选择可能包含与过滤器(id = 3且name =“foo”)匹配的数据的文件进行重写。
CALL catalog_name.system.rewrite_data_files(table => 'db.sample', where => 'id = 3 and name = "foo"')
重写清单
重写表的清单以优化扫描计划。
清单中的数据文件按分区规范中的字段排序。此过程使用 Spark 作业并行运行。
| 参数说明 | Required | Type | 说明 |
|---|---|---|---|
| table | ✔️ | string | 要更新的表的名称 |
| use_caching | boolean | 运行期间使用Spark缓存(默认为true) |
输出
| 参数说明 | Type | 说明 |
|---|---|---|
| rewritten_manifests_count | int | 由该命令重写的清单数量 |
| added_mainfests_count | int | 此命令写入的新清单文件的数量 |
重写表 db.sample 中的清单,并将清单文件与表分区对齐。
CALL catalog_name.system.rewrite_manifests('db.sample')
重写表 db.sample 中的清单并禁用 Spark 缓存。这样做可以避免执行器上的内存问题。
CALL catalog_name.system.rewrite_manifests('db.sample', false)
重写位置删除文件
Iceberg可以重写位置删除文件,这有两个目的:
- 小压缩:将小位置的删除文件压缩为较大的文件。这减少了清单文件中存储的元数据的大小以及打开小删除文件的开销。
- 删除悬空删除:过滤掉引用不再有效的数据文件的位置删除记录。在 rewrite_data_files 之后,指向重写数据文件的位置删除记录并不总是被标记为删除,并且可以通过表的实时快照元数据保持跟踪。这称为“悬空删除”问题。
| 参数说明 | Required | Type | 说明 |
|---|---|---|---|
| table | ✔️ | string | 要更新的表的名称 |
| options | map<string, string> | 程序使用的选项 |
重写期间,悬空删除始终会被过滤掉。
| 名称 | 默认值 | 描述 |
|---|---|---|
| max-concurrent-file-group-rewrites | 5 | 同时重写的最大文件组数 |
| partial-progress.enabled | false | 启用在整个重写完成之前提交文件组 |
| partial-progress.max-commits | 10 | 如果启用部分进度,则允许此重写产生的最大提交量 |
| rewrite-job-order | none | 根据该值强制重写作业顺序。如果 rewrite-job-order=bytes-asc,则先重写最小的作业组。如果 rewrite-job-order=bytes-desc,则先重写最大的作业组。如果 rewrite-job-order=files-asc,则首先重写文件最少的作业组。如果 rewrite-job-order=files-desc,则首先重写文件最多的作业组。如果 rewrite-job-order=none,则按照它们的顺序重写作业组已计划(无特定顺序)。 |
| target-file-size-bytes | 67108864(64MB,表属性中 write.delete.target-file-size-bytes 的默认值) | 目标输出文件大小 |
| min-file-size-bytes | 目标文件大小的 75% | 无论任何其他标准如何,低于此阈值的文件都将被考虑重写 |
| max-file-size-bytes | 目标文件大小的 180% | 无论任何其他条件如何,大小高于此阈值的文件都将被考虑重写 |
| min-input-files | 5 | 无论其他条件如何,超过此文件数量的任何文件组都将被重写 |
| rewrite-all | false | 强制重写所有提供的文件,覆盖其他选项 |
| max-file-group-size-bytes | 107374182400 (100GB) | 单个文件组中应重写的最大数据量。整个重写操作根据分区被分解为多个部分,并根据文件组的大小在分区内分解。这有助于分解非常大的分区的重写,否则由于集群的资源限制,这些分区可能无法重写。 |
Output
| 输出名称 | Type | 描述 |
|---|---|---|
| rewritten_delete_files_count | int | 通过此命令删除的删除文件数 |
| added_delete_files_count | int | 通过此命令添加的删除文件数 |
| rewritten_bytes_count | long | 通过此命令删除的删除文件的字节数 |
| added_bytes_count | long | 通过此命令添加的所有新删除文件的字节数 |
重写位置删除表db.sample中的文件。这会选择符合默认重写标准的位置删除文件,并写入目标大小 target-file-size-bytes 的新文件。悬空删除将从重写的删除文件中删除。
CALL catalog_name.system.rewrite_position_delete_files('db.sample')
重写表 db.sample 中的所有位置删除文件,写入新文件 target-file-size-bytes。悬空删除将从重写的删除文件中删除。
CALL catalog_name.system.rewrite_position_delete_files(table => 'db.sample', options => map('rewrite-all', 'true'))
重写位置删除表db.sample中的文件。这会选择分区中的位置删除文件,其中需要根据大小标准重写 2 个或更多位置删除文件。悬空删除将从重写的删除文件中删除。
CALL catalog_name.system.rewrite_position_delete_files(table => 'db.sample', options => map('min-input-files','2'))
migrate
将表替换为加载了源数据文件的 Iceberg 表。
表架构、分区、属性和位置将从源表复制。
如果任何表分区使用不支持的格式,迁移将会失败。支持的格式有 Avro、Parquet 和 ORC。现有数据文件被添加到 Iceberg 表的元数据中,并且可以使用从原始表架构创建的名称到 ID 映射来读取。
要在测试时保持原始表完整,请使用快照创建共享源数据文件和架构的新临时表。
默认情况下,原始表保留为名称 table_BACKUP_。
| 参数说明 | Required | Type | 说明 |
|---|---|---|---|
| table | ✔️ | string | 要迁移的表的名称 |
| properties | map<string, string> | 新 Iceberg 表的属性 | |
| drop_backup | boolean | 当 true 时,原始表将不会保留作为备份(默认为 false) | |
| backup_table_name | string | 将保留作为备份的表的名称(默认为 table_BACKUP_) |
输出:
| 输出名称 | Type | 描述 |
|---|---|---|
| migrated_files_count | long | 附加到 Iceberg 表的文件数 |
例子
将 Spark 默认目录中的表 db.sample 迁移到 Iceberg 表,并添加属性“foo”设置为“bar”:
CALL catalog_name.system.migrate('spark_catalog.db.sample', map('foo', 'bar'))
将当前目录中的 db.sample 迁移到 Iceberg 表,而不添加任何其他属性:
CALL catalog_name.system.migrate('db.sample')
add_files
尝试直接将文件从 Hive 或基于文件的表添加到给定的 Iceberg 表中。与 migrate 或 snapshot 不同,add_files 可以从一个或多个特定分区导入文件,并且不会创建新的 Iceberg 表。此命令将为新文件创建元数据,但不会移动它们。此过程不会分析文件的架构来确定它们是否确实与 Iceberg 表的架构匹配。完成后,Iceberg 表将把这些文件视为 Iceberg 拥有的文件集的一部分。这意味着任何后续的 expire_snapshot 调用都将能够物理删除添加的文件。如果可以进行迁移或快照,则不应使用此方法。
请记住,add_files 过程将从仅添加一次的每个文件中获取 Parquet 元数据。如果您使用分层存储(例如 Amazon S3 智能分层存储类),将从存档中检索底层文件,并将在设定的时间段内保留在较高层上。
register_table
为已存在但没有相应目录标识符的metadata.json 文件创建目录条目。
将新表注册为 db.tbl 到spark_catalog,指向metadata.json文件路径/to/metadata/file.json。
CALL spark_catalog.system.register_table(table => 'db.tbl',metadata_file => 'path/to/metadata/file.json'
)
元数据信息
ancestors_of
报告指定快照的父级实时快照ID
获取当前快照的所有快照祖先(默认)
CALL spark_catalog.system.ancestors_of('db.tbl')
获取特定快照的所有快照祖先
CALL spark_catalog.system.ancestors_of('db.tbl', 1)
CALL spark_catalog.system.ancestors_of(snapshot_id => 1, table => 'db.tbl')
Change Data Capture
创建变更日志视图
创建一个包含给定表中的更改的视图。
| 参数名称 | Required | Type | 说明 |
|---|---|---|---|
| table | ✔️ | string | 变更日志的源表的名称 |
| changelog_view | string | 要创建的视图的名称 | |
| options | map<string, string> | 要使用的 Spark 读取选项图 | |
| net_changes | boolean | 是否输出净变化(更多信息见下文)。默认为 false。 | |
| compute_updates | boolean | 是否计算更新前/更新后图像(有关详细信息,请参阅下文)。默认为 false。 | |
| identifier_columns | array | 用于计算更新的标识符列的列表。如果参数compute_updates设置为true并且未提供identifier_columns,则将使用表的当前标识符字段。 | |
| remove_carryovers | boolean | 是否删除结转行(有关详细信息,请参阅下文)。默认为 true。自 1.4.0 起已弃用,将在 1.5.0 中删除;请查询 SparkChangelogTable 以查看结转行 |
以下是常用的 Spark 读取选项列表:
- start-snapshot-id:独占的启动快照ID。如果未提供,它将从表的第一个快照中读取。
- end-snapshot-id:包含的结束快照id,默认为表的当前快照。
- start-timestamp:唯一的开始时间戳。如果未提供,它将从表的第一个快照中读取。
- end-timestamp:包含的结束时间戳,默认为表的当前快照。
输出:
| 输出名称 | Type | 描述 |
|---|---|---|
| changelog_view | string | 创建的变更日志视图的名称 |
根据快照 1(不包括)和快照 2(包括)之间发生的更改创建变更日志视图 tbl_changes。
CALL spark_catalog.system.create_changelog_view(table => 'db.tbl',options => map('start-snapshot-id','1','end-snapshot-id', '2')
)
根据时间戳 1678335750489(不包括)和 1678992105265(包括)之间发生的更改创建变更日志视图 my_changelog_view。
CALL spark_catalog.system.create_changelog_view(table => 'db.tbl',options => map('start-timestamp','1678335750489','end-timestamp', '1678992105265'),changelog_view => 'my_changelog_view'
)
创建一个更改日志视图,根据标识符列 id 和 name 计算更新。
CALL spark_catalog.system.create_changelog_view(table => 'db.tbl',options => map('start-snapshot-id','1','end-snapshot-id', '2'),identifier_columns => array('id', 'name')
)
创建变更日志视图后,您可以查询该视图以查看快照之间发生的更改。
SELECT * FROM tbl_changes
SELECT * FROM tbl_changes where _change_type = 'INSERT' AND id = 3 ORDER BY _change_ordinal
请注意,更改日志视图包括更改数据捕获 (CDC) 元数据列,这些列提供有关正在跟踪的更改的附加信息。这些列是:
- _change_type:更改的类型。它具有以下值之一:INSERT、DELETE、UPDATE_BEFORE 或 UPDATE_AFTER。
- _change_ordinal:更改的顺序
- _commit_snapshot_id:发生更改的快照 ID
这是相应结果的示例。显示第一个快照插入了2条记录,第二个快照删除了1条记录。

创建计算净更改的变更日志视图。它删除中间更改并仅输出净更改。
CALL spark_catalog.system.create_changelog_view(table => 'db.tbl',options => map('end-snapshot-id', '87647489814522183702'),net_changes => true
)
对于净更改,上述更改日志视图仅包含以下行,因为 Alice 被插入到第一个快照中并在第二个快照中被删除。

Carry-over Rows
该过程默认删除结转行。结转行是使用写时复制时行级操作(MERGE、UPDATE 和 DELETE)的结果。例如,给定一个包含 row1 (id=1, name=‘Alice’) 和 row2 (id=2, name=‘Bob’) 的文件。对 row2 进行写时复制删除需要擦除该文件并将 row1 保留在新文件中。更改日志表将其报告为以下两行,尽管这不是对该表的实际更改。
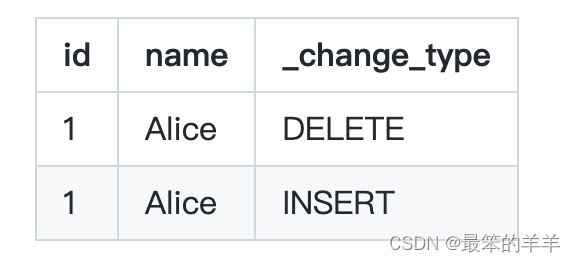
要查看结转行,请按如下方式查询 SparkChangelogTable:
SELECT * FROM spark_catalog.db.tbl.changes
更新前/后图像
该过程计算更新前/更新后图像(如果已配置)。更新前/更新后图像是从一对删除行和插入行转换而来的。标识符列用于确定插入和删除记录是否引用同一行。如果两条记录共享相同的标识列值,则它们被视为同一行的之前和之后状态。您可以在表模式中设置标识符字段,也可以将它们作为过程参数输入。
以下示例显示了使用标识符列 (id) 进行更新前/更新后图像计算,其中具有相同 id 的行删除和插入被视为单个更新操作。具体来说,假设我们有以下两行:

在这种情况下,该过程将更新之前的行标记为 UPDATE_BEFORE 图像,将更新之后的行标记为 UPDATE_AFTER 图像,从而产生以下更新前/更新后图像:

相关文章:
Iceberg从入门到精通系列之二十一:Spark集成Iceberg
Iceberg从入门到精通系列之二十一:Spark集成Iceberg 一、在 Spark 3 中使用 Iceberg二、添加目录三、创建表四、写五、读六、Catalogs七、目录配置八、使用目录九、替换会话目录十、使用目录特定的 Hadoop 配置值十一、加载自定义目录十二、SQL 扩展十三、运行时配置…...
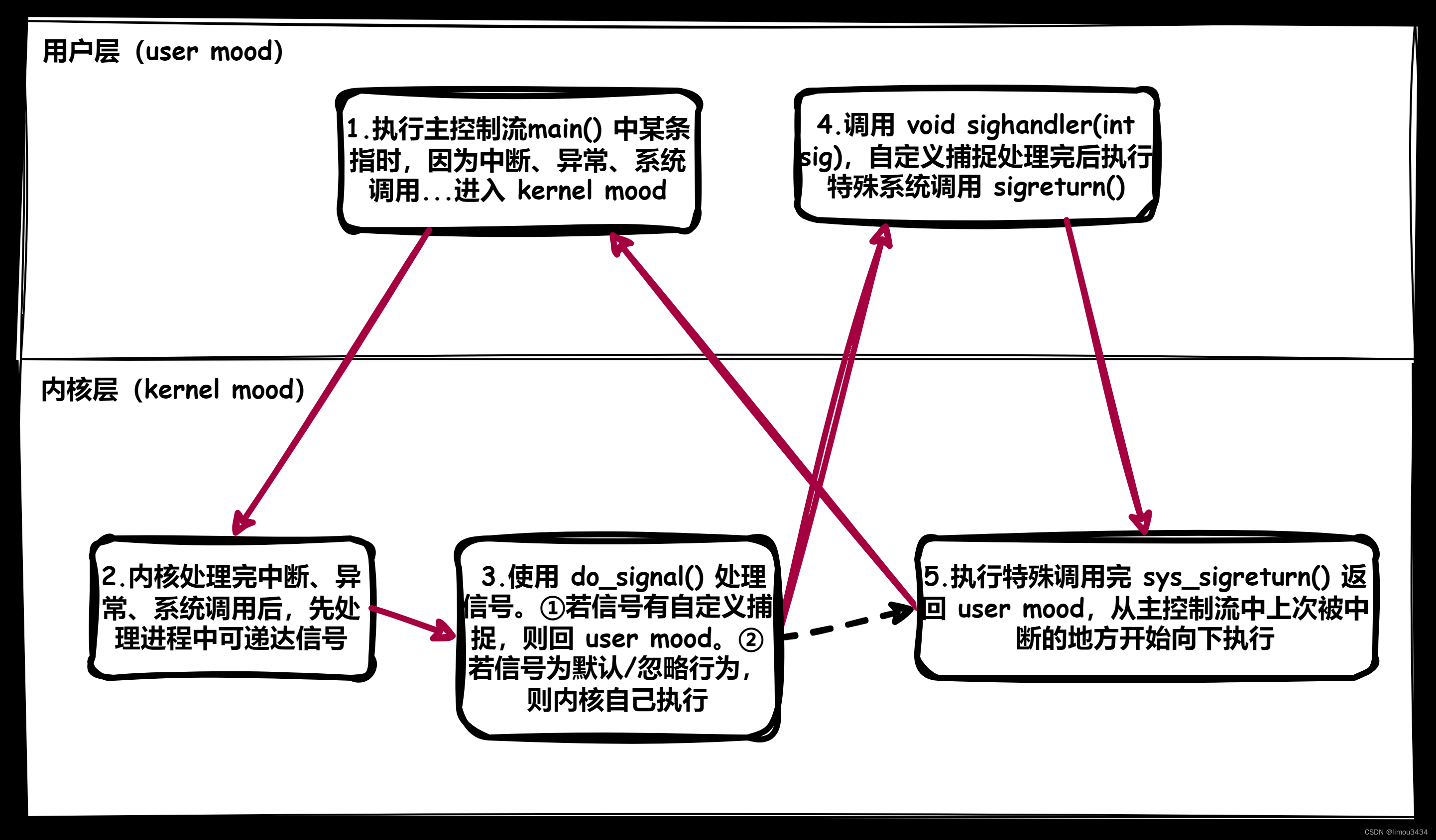
Linux的进程信号
注意:首先需要提醒一个事情,本节提及的进程信号和下节的信号量没有任何关系,请您区分对待。 1.信号概念 1.1.生活中的信号 我们在生活中通过体验现实,记忆了一些信号和对应的处理动作,这意味着信号有以下相关的特点&…...

svn常用命令及过滤文件 global ignore pattern
SVN常用命令详解和global ignore pattern Subversion(SVN)是一个版本控制系统,广泛用于软件开发项目中。它能够追踪文件的变更,并且允许多人在同一个项目中协同工作。以下是一些常用的SVN命令及其用法。 1. 检出代码 要从SVN服…...
)
【QT+QGIS跨平台编译】之二十九:【HDF5+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、HDF5介绍二、文件下载三、文件分析四、pro文件一、HDF5介绍 HDF5(层次数据格式第5版)是一种用于存储和组织大量数据的文件格式和技术集合。它由美国国家超级计算应用中心(NCSA)开发,旨在解决复杂数据的存储和分布问题。HDF5支持各种数据类型,能够有效地存储…...
React 中实现拖拽功能-插件 react-beautiful-dnd
拖拽功能在平时开发中是很常见的,这篇文章主要使用react-beautiful-dnd插件实现此功能。 非常好用,附上GitHub地址:https://github.com/atlassian/react-beautiful-dnd 安装及引入 // 1.引入 # yarn yarn add react-beautiful-dnd# npm npm…...
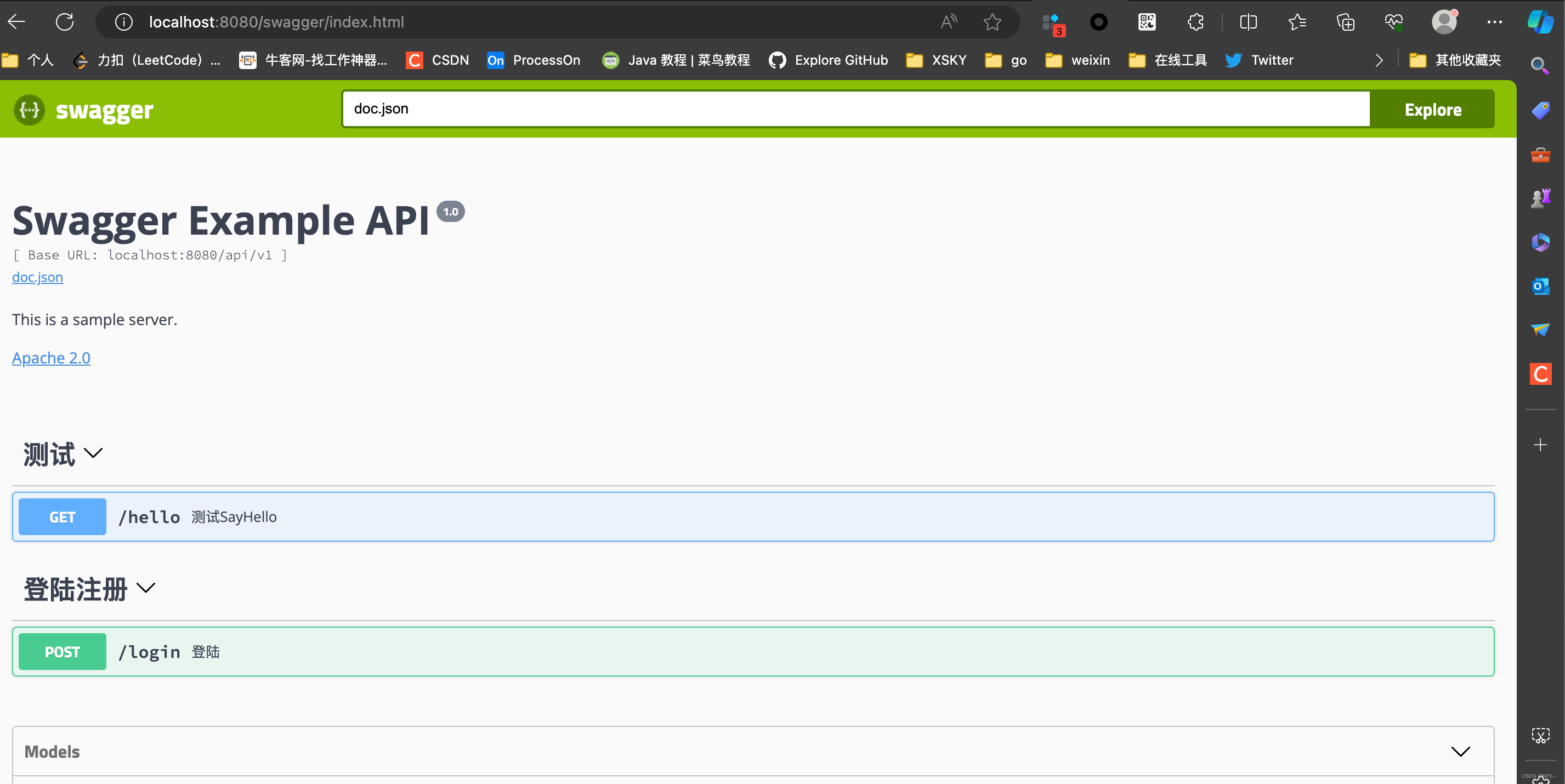
golang 引入swagger(iris、gin)
golang 引入swagger(iris、gin) 在开发过程中,我们不免需要调试我们的接口,但是有些接口测试工具无法根据我们的接口变化而动态变化。文档和代码是分离的。总是出现文档和代码不同步的情况。这个时候就可以在我们项目中引入swagge…...
Java开发IntelliJ IDEA2023
IntelliJ IDEA 2023是一款强大的集成开发环境(IDE),专为Java开发人员设计。它提供了许多特色功能,帮助开发人员更高效地编写、测试和调试Java应用程序。以下是一些IntelliJ IDEA 2023的特色功能: 智能代码编辑器&…...
)
LeetCode LCP 30.魔塔游戏:贪心(优先队列)
【LetMeFly】LCP 30.魔塔游戏:贪心(优先队列) 力扣题目链接:https://leetcode.cn/problems/p0NxJO/ 小扣当前位于魔塔游戏第一层,共有 N 个房间,编号为 0 ~ N-1。每个房间的补血道具/怪物对于血量影响记于…...

Oracle的权限
通过用户登录plsql工具后,如果在创建视图(或其他对象)时,没有指明视图或对象的用户,该视图或对象将直接创建在当前登录用户下。 GRANT SELECT ON user2.table1 TO user1;//将用户2的表1的select权限给用户1 GRANT ALL ON user2.table1 TO u…...
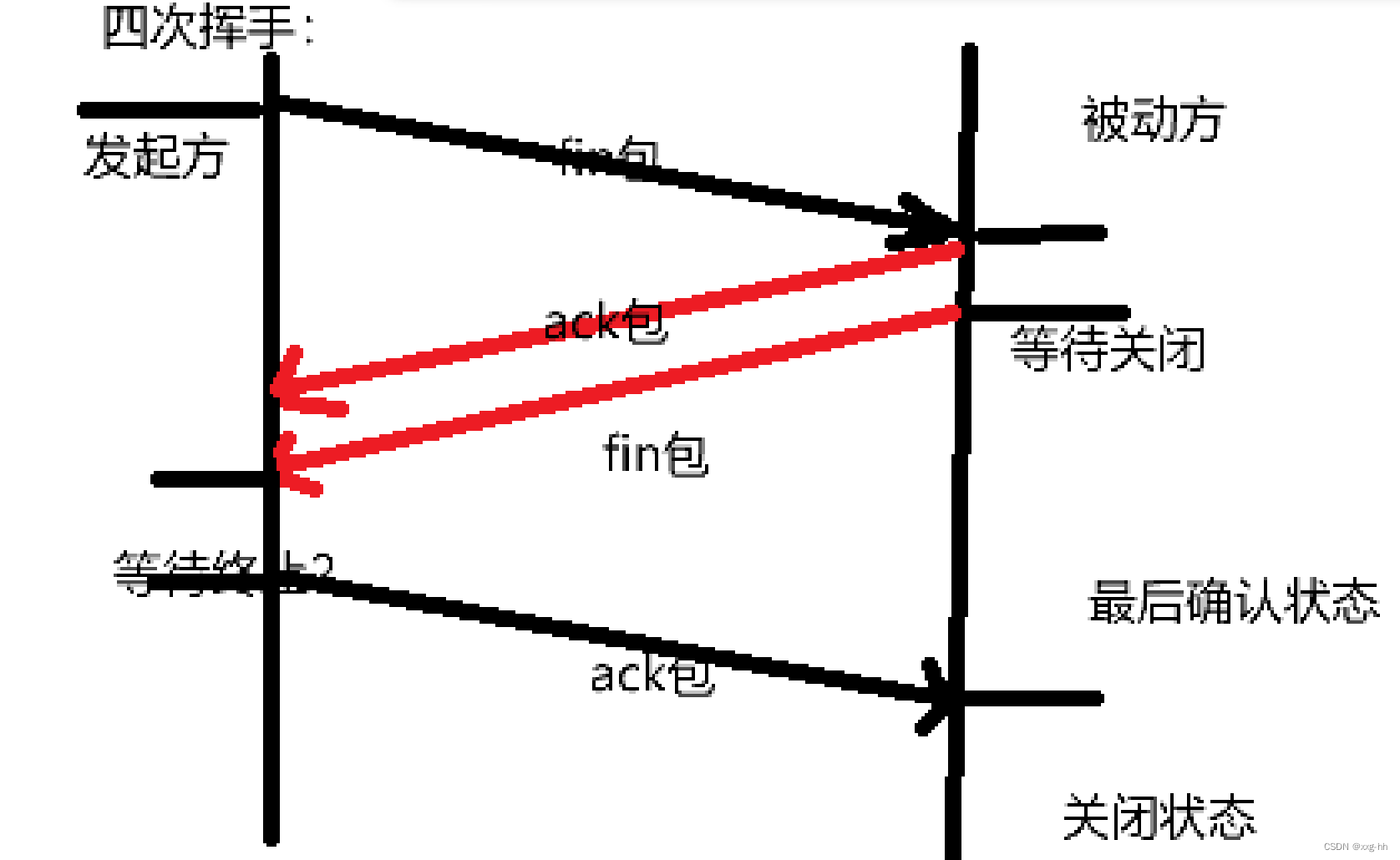
20240206三次握手四次挥手
TCP和UDP异同点 相同点:同属于传输层的协议 不同点: TCP ----> 稳定 1> 提供面向连接的,可靠的数据传输服务 2> 传输过程中,数据无误、数据无丢失、数据无失序、数据无重复 1、TCP会给每个数据包编上编号ÿ…...
Navicat的使用教程,操作详解
这篇文章主要针对mysql数据库。 在使用Navicat之前,首先要确保你在本地已经安装好了,mysql数据库,安装教程可以参考我的另一篇博文 在windows平台上mysql的安装教程-CSDN博客 1.Navicat连接你的数据库 连接名,随便写,…...

Git―基本操作
Git ⛅认识 Git⛅安装 GitCentos(7.6)Ubuntu ⛅Git―基本操作创建本地仓库🍂配置本地仓库🍂工作区, 暂存区, 版本库🍂版本库工作区 添加文件🍂查看文件🍂修改文件🍂版本回退🍂☃️案例 撤销修改…...

【PostgreSQL内核学习(二十六) —— (共享数据缓冲区)】
共享数据缓冲区 概述共享数据缓冲区管理共享缓冲区管理的核心功能包括: 共享数据缓冲区的组织结构初始化共享缓冲池BufferDesc 结构体InitBufferPool 函数 如何确定请求的数据页面是否在缓冲区中?BufferTag 结构体RelFileNode 结构体ForkNumber 结构体Re…...
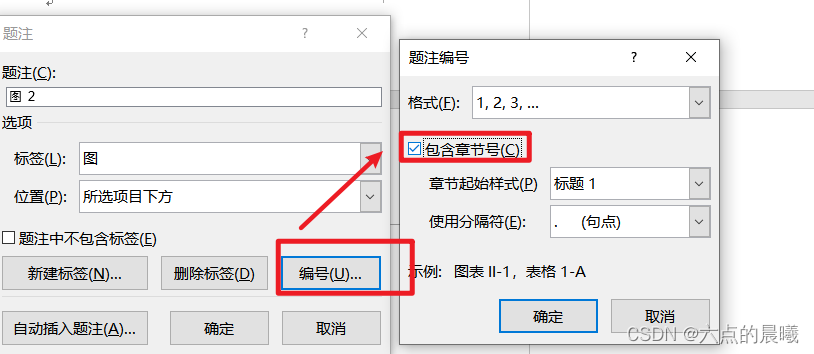
word调整论文格式的记录
页眉的分章显示内容 效果: 步骤: 确保“显示/隐藏的标记”符号打开点亮 前提是章节前面有“分节符(下一页)”,没有则添加,在菜单栏“布局”——》“下一页” 添加页眉,双击页眉,选…...

android.MediaMuxer时间裁剪
使用MediaMuxer裁剪视频_安卓muxer 裁剪视频画布-CSDN博客 关键步骤 mediaExtractor.seekTo(beginTime, MediaExtractor.SEEK_TO_PREVIOUS_SYNC);long presentTimeUs mediaExtractor.getSampleTime(); if (presentTimeUs > endTime)break; 功能代码 VideoView videoVie…...

【蓝桥杯选拔赛真题91】Scratch筛选数据 第十五届蓝桥杯scratch图形化编程 少儿编程创意编程选拔赛真题解析
目录 scratch筛选数据 一、题目要求 编程实现 二、案例分析 1、角色分析...

英语学习——16组英语常用短语
第1组:look look at 看 look for 寻找 look up 查阅,向上看 look out 向外看,小心 look after 照顾 look like 看起来像 look through 浏览 look into 向里看 look around 环顾四周 look forward to 期盼 look ahead 向前看 Look…...
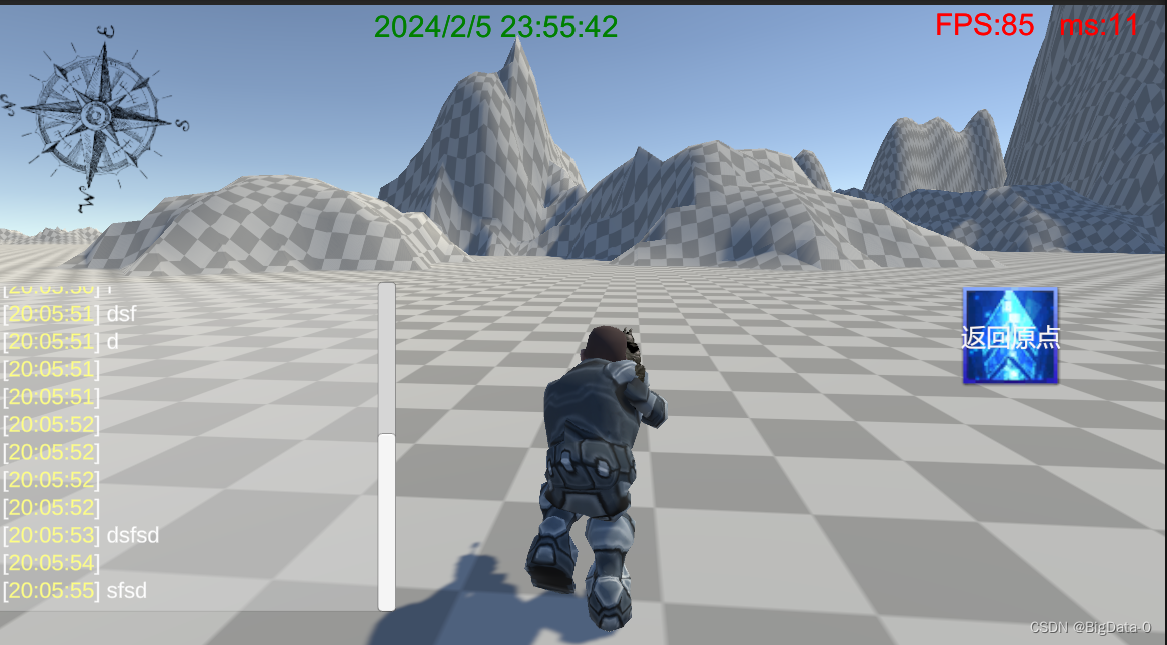
unity 增加系统时间显示、FPS帧率、ms延迟
代码 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;using UnityEngine;public class Frame : MonoBehaviour {// 记录帧数private int _frame;// 上一次计算帧率的时间private float _lastTime;// 平…...
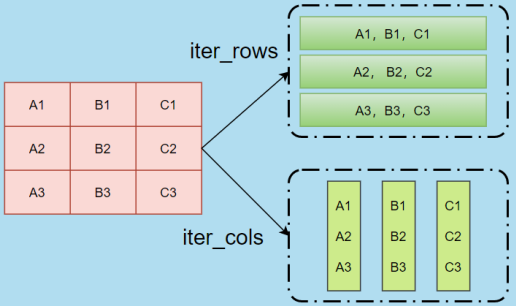
【Python基础】文件详解(文件基础、csv文件、时间处理、目录处理、excel文件、jsonpicke、ini配置文件)
文章目录 (一)文件详解1 快速入门文件操作1.1 快速实现文件读取1.2 快速实现文件写入 2 文件打开方式详解2.1 open方法2.2 打开方式2.3 文件读写操作2.3.1 基本读写2.3.2 读写方式打开2.3.3 实现重复读取 3 文件编码问题4 文件读写方法4.1 文件读取方式4…...
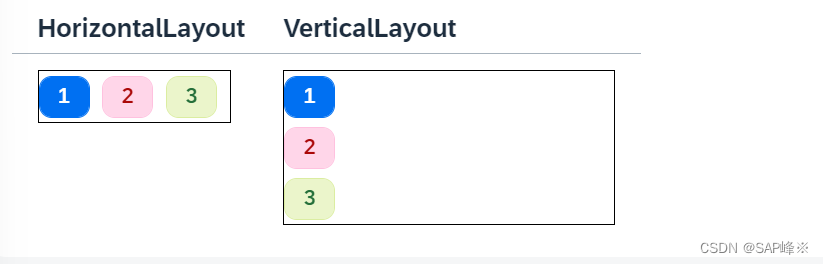
[UI5 常用控件] 05.FlexBox, VBox,HBox,HorizontalLayout,VerticalLayout
文章目录 前言1. FlexBox布局控件1.1 alignItems 对齐模式1.2 justifyContent 对齐模式1.3 Direction1.4 Sort1.5 Render Type1.6 嵌套使用1.7 组件等高显示 2. HBox,VBox3. HorizontalLayout,VerticalLayout 前言 本章节记录常用控件FlexBox,VBox,HBox,Horizontal…...

华为 eNSP 安装全攻略:Windows 11 25H2 完美适配
本教程适用范围 ✅ Windows 7(所有版本)✅ Windows 10(所有版本)✅ Windows 11 23H2 及以下✅ Windows 11 24H2(OS 内部版本 ≥ 26100.3624)✅ Windows 11 25H2❌ Windows 11 24H2(OS 内部版本…...

数谷智能和爱莫科技,非标准数据 AI 定制处理谁更强?
在数字化转型步入“深水区”的今天,企业面临的最大挑战不再是标准化的数据库信息,而是占据企业数据总量 80% 以上的“非标准数据”。这些数据散落在手写单据、非结构化合同、复杂的网页信息、甚至是不规则的工业图像中。如何高效、精准地处理这些非标数据…...

降低AI检测率哪个工具好?10款免费工具2026亲测,亲测有用
很多同学在写论文时都会遇到同一个难题:用AI辅助写完的内容,一查AIGC率高到离谱,被导师打回要求整改。后台最近也收到不少私信问:怎么才能有效降低AI检测率?有没有靠谱的免费降AI率工具推荐? 我自己当初也踩…...
)
【MySQL】第五节 - 事务实战详解:从基础到并发控制(附 Navicat 可运行实验脚本)
《MySQL 事务实战详解:从基础到并发控制(附 Navicat 可运行实验脚本)》 为什么你必须掌握 MySQL 事务? 在现代应用系统中,数据一致性是核心诉求。事务(Transaction) 是保证数据完整性的“黄金…...

shjshxksxjxbf
一、OpenAI 1.OpenAI是什么简单来说,OpenAI 大模型 是由美国人工智能公司 OpenAI 开发的一系列大型语言模型(LLMs) 。你可以把它们想象成拥有巨大“知识储备”和“学习能力”的超级大脑,它们被训练用来理解和生成人类语言…...

果实采摘机械手的设计【论文+CAD图纸+Creo三维+外文文献翻译】
果实采摘机械手作为现代农业装备领域的重要创新,其核心作用在于解决传统人工采摘效率低、劳动强度大、成本高等问题。通过机械结构与控制系统的协同设计,该设备可模拟人手抓取动作,精准完成果实识别、定位、采摘及收集全流程,显著…...
 汇总)
ISO/SAE 21434:2021(道路车辆 - 网络安全工程) 汇总
一、前言、引言(非正文章节)前言:标准制定背景、适用范围、与 ISO 26262(功能安全)的协同关系引言:网络安全对道路车辆 E/E 系统的必要性、全生命周期覆盖、风险导向原则二、正文核心章节(1–15…...

SerialLCD库深度解析:SerLCD v2.5串口LCD驱动实践
1. SerialLCD 库技术解析:面向嵌入式系统的 SparkFun SerLCD v2.5 串口 LCD 驱动深度实践 1.1 背景与工程定位 SerialLCD 是一个专为 SparkFun SerLCD v2.5 硬件模块设计的轻量级串口 LCD 控制库,其原始实现源自 Arduino.cc Playground 社区维护的 Ser…...

Music Tag Web:智能音乐元数据管理工具解决音乐收藏混乱难题
Music Tag Web:智能音乐元数据管理工具解决音乐收藏混乱难题 【免费下载链接】music-tag-web 音乐标签编辑器,可编辑本地音乐文件的元数据(Editable local music file metadata.) 项目地址: https://gitcode.com/gh_mirrors/mu/…...

IP被封禁?5招快速恢复访问权限
使用网站或平台时,如果你突然遇到“Your IP has been banned(您的IP已被封禁)”的提示,通常意味着该平台已经限制了你当前网络的访问权限。很多人第一反应是账号出问题,但实际上,IP封禁针对的是网络环境&am…...