Python进阶--爬取下载人生格言(基于格言网的Python3爬虫)
目录
一、此处需要安装第三方库:
二、抓包分析及Python代码
1、打开人生格言网(人生格言-人生格言大全_格言网)进行抓包分析
2、请求模块的代码
3、抓包分析人生格言界面
4、获取目录页中各种类型的人生格言链接
5、获取下一页的链接
5、获取人生格言的具体内容
6、 下载保存
三、所有代码及具体步骤
1、具体步骤
2、所有代码如下:
3、运行结果
一、此处需要安装第三方库:
在Pycharm平台终端或者命令提示符窗口中输入以下代码即可安装
pip install requestspip install lxml- requests模块为请求库
- lxml库是一个HTML/XML的解析器,主要的功能是解析和提取 HTML/XML 数据
注: 此处需要用到lxml和正则表达式的知识,关于lxml库的使用和正则表达式,此处不进行详细说明,后续我将补充一篇博客来详细介绍。
二、抓包分析及Python代码
1、打开人生格言网(人生格言-人生格言大全_格言网)进行抓包分析
此处我们下载是文字,格言网是一个静态网页,人生格言的信息全都封装在源代码中,故此主要针对网页源代码进行分析爬取。不过我们首先要获取到网页内容的源代码,故此处采用requests模块的get方法即可。使用get方法,我们需要抓包分析获取url和user-agent即可
- url和user-agent的获取方法:
- 打开格言网的人生格言网站
- 按下F12键,打开开发者界面
- 此时由于翻译页面没有数据传输,属于静态页面,开发者界面也就没有任何数据传输的情况。
- 刷新一下,在开发者界面点击Network,选择all,点击第一个html信息条目,在header视图中可以找到url信息和user-agent信息
url:
user-agent:
2、请求模块的代码
import requests
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
url = 'http://www.mouxiao.com/renshenggeyan/index.html'
response = requests.get(url, headers=header)
print(response)3、抓包分析人生格言界面
在人生格言界面,可以看到:
- 有多种类型的人生格言,点击其中一个即可跳转到具体的格言内容中
- 有下一页的选项,点击下一页则跳转到下一页的多种类型的人生格言
- 下面还有其他栏目导航
这里,需要的是所有人生格言,即需要将人生格言栏目中的所有类型的格言全都下载下来。每种类型和下一页是通过跳转的方式,访问到具体的内容的。而跳转是通过链接的方式进行的,故只需要抓包分析,分析出链接所在位置,获取到这些链接。即可再通过requests请求模块,访问这些链接来下载具体的人生格言内容。
- 抓包分析:
采用以上方式,具体查找一下其他类型的链接所在位置。通过以上操作可以分析出链接都是藏标签<li>中的标签<a>中的href属性中且链接是以数字开头的,在此处采用xPath的方式,获取这些类型的所有xPath。
4、获取目录页中各种类型的人生格言链接
根据以上分析,获取目录页中各种类型的人生格言的链接代码如下:
import pprintimport requests from lxml import etree header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'} index_url = 'http://www.mouxiao.com/renshenggeyan/index.html' r = requests.get(index_url,headers=header) # 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。 # 故采用apparent_encoding方法,禁止requests模块自动编码。 r.encoding = r.apparent_encoding # 采用xpath的方式定位获取链接所在位置 html = etree.HTML(r.text) links = html.xpath('//ul[@class="readers-list"]//a/@href') # 采用格式化打印,打印一下links内容 pprint.pprint(links)运行结果如下(部分图):
根据上面的抓包分析,我们需要的链接是以数字开头的,但运行结果中却出现了大量不以数字开头的链接。这是为什么?继续抓包分析:
我们发现栏目导航中的人生格言的链接所在位置跟上面抓包分析的多种类型的人生格言的链接所在位置是一致的。所以使用xPath定位链接时,把栏目导航中的链接也定位到了,但我们不需要栏目导航中的链接。根据前面分析,可知我们需要的链接是以数字开头的。则,可以采用正则表达式,筛选出所需的链接。代码如下:
import pprint import reimport requests from lxml import etree header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'} index_url = 'http://www.mouxiao.com/renshenggeyan/index.html' r = requests.get(index_url,headers=header) # 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。 # 故采用apparent_encoding方法,禁止requests模块自动编码。 r.encoding = r.apparent_encoding # 采用xpath的方式定位获取链接所在位置 html = etree.HTML(r.text) links = html.xpath('//ul[@class="readers-list"]//a/@href') # 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表 matched_links = [] for link in links:# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中if re.findall(r'^\d+\.html', link):matched_links.append(link) # 采用格式化打印,打印一下links内容 pprint.pprint(matched_links)结果如下:
此处,成功获取到所需要的目录页中各种类型的人生格言的链接了。(非常开心!!!)
5、获取下一页的链接
根据上面分析,因为点击下一页跳转的出现的界面还有其他类型的人生格言,故下一页也需要获取其链接。因为,这样就可以通过下一页,来继续获取根据上面的抓包方式,可以定位到下一页的链接所在位置。通过xPath的方式,可以定位获取得到。
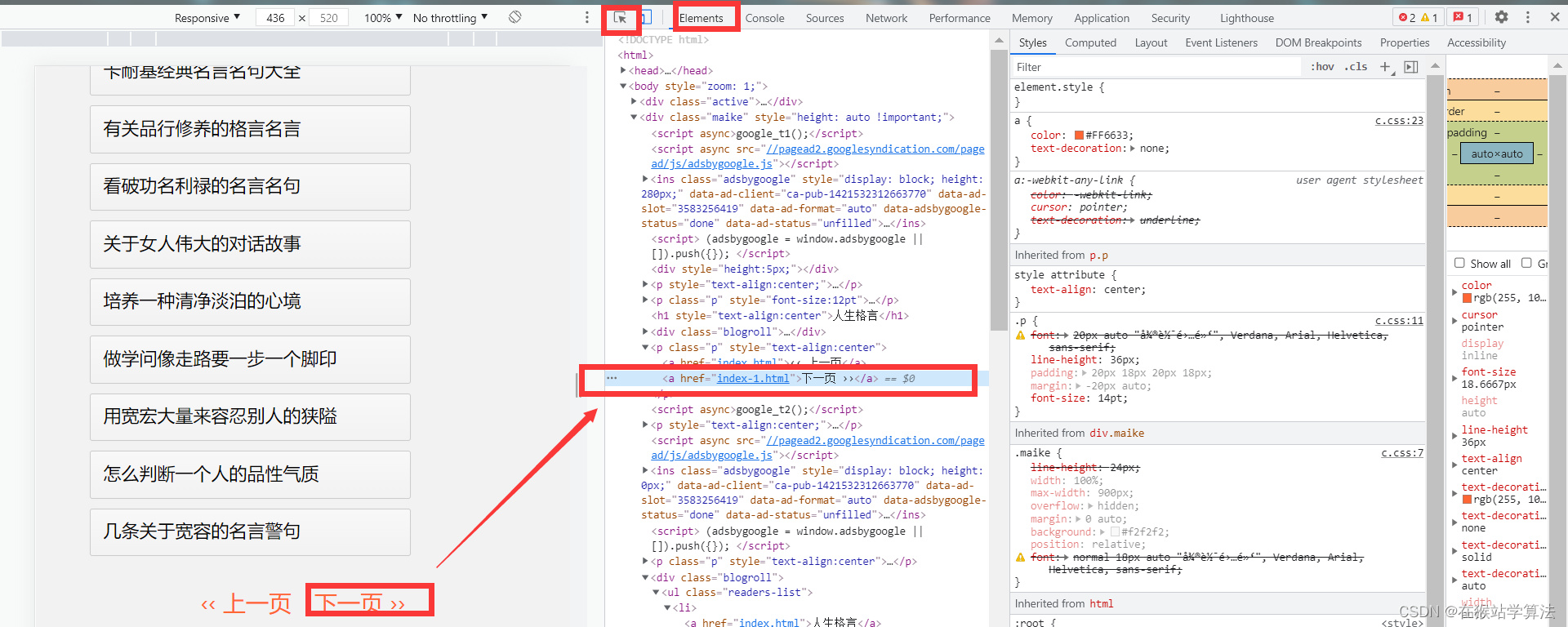
代码如下:
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):#请求当前网页的源代码r = requests.get(url, headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 定位到下一页的url地址html = etree.HTML(r.text)next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')[3]# 因为所获取的下一页地址是相对地址,故进行补全next_page = 'http://www.mouxiao.com/renshenggeyan/'+ next_page# 如果下一页地址和当前页地址不相等,则将下一页地址返回if next_page != url:return next_page5、获取人生格言的具体内容
当点击进入一个类型的人生格言,我们会进入到该类型的具体人生格言内容。
对其抓包分析:
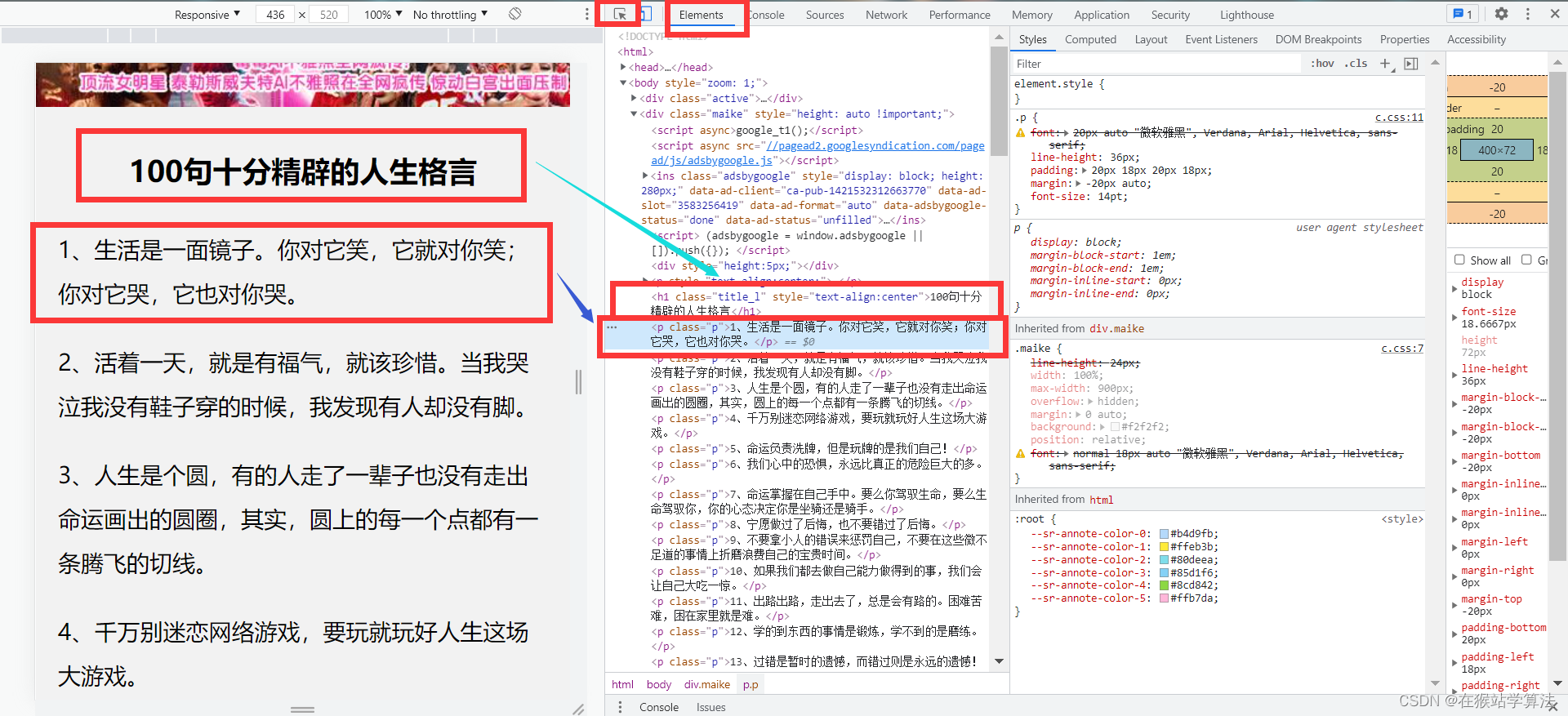
据此,我们定位到了标题和具体人生格言的所在网页源代码的位置。采用xPath方式,进行定位。代码如下:
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):# 请求当前网页的源代码r = requests.get(url,headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 解析源代码提取具体格言内容和标题# 获取网页源代码html = etree.HTML(r.text)# 获取格言内容content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')# 使用 join() 方法将列表中的元素用换行符连接起来content = '\n'.join(content)# 获取标题title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]return title,content6、 下载保存
根据以上内容,已经获取到了人生格言的具体内容和标题的函数--get_content。只需要将具体人生格言页的链接输入进去,调用get_content函数,采用open方法即可进行下载保存。
title, content = get_content(link1)with open(f'格言/{title}.txt','w',encoding='utf-8') as f:f.write('\t'+title + '\n\n')f.write(content)print(f'已下载...{title}')三、所有代码及具体步骤
1、具体步骤
1、获取格言页网页源代码2、提取格言内容3、获取目录页网页源代码4、解析目录页,提取链接(各种类型的人生格言链接和下一页链接)5、下载并保存所有格言
2、所有代码如下:
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):# 请求当前网页的源代码r = requests.get(url,headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 解析源代码提取具体格言内容和标题# 获取网页源代码html = etree.HTML(r.text)# 获取格言内容content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')# 使用 join() 方法将列表中的元素用换行符连接起来content = '\n'.join(content)# 获取标题title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]# 返回标题和内容return title,content
# 当前页面
index_url = 'http://www.mouxiao.com/renshenggeyan/index.html'
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):# 请求当前网页的源代码r = requests.get(index_url,headers=header)# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。# 故采用apparent_encoding方法,禁止requests模块自动编码。r.encoding = r.apparent_encoding# 采用xpath的方式定位获取链接所在位置html = etree.HTML(r.text)links = html.xpath('//ul[@class="readers-list"]//a/@href')# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表matched_links = []for link in links:# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中if re.findall(r'^\d+\.html', link):matched_links.append(link)# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载for link in matched_links:# link中获取的链接是相对地址,需要补全前面的地址link1 = 'http://www.mouxiao.com/renshenggeyan/'+link# 调用get_content方法下载内容和标题并保存到本地title, content = get_content(link1)with open(f'格言/{title}.txt','w',encoding='utf-8') as f:f.write('\t'+title + '\n\n')f.write(content)print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):#请求当前网页的源代码r = requests.get(url, headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 定位到下一页的url地址html = etree.HTML(r.text)next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')[3]# 因为所获取的下一页地址是相对地址,故进行补全next_page = 'http://www.mouxiao.com/renshenggeyan/'+ next_page# 如果下一页地址和当前页地址不相等,则将下一页地址返回if next_page != url:return next_page
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:print(f"正在下载第{n}页...")print("下载地址为:"+index_url)pageupload_play(index_url)page = get_nextpage(index_url)index_url = pageif index_url==None:breakn+=13、运行结果
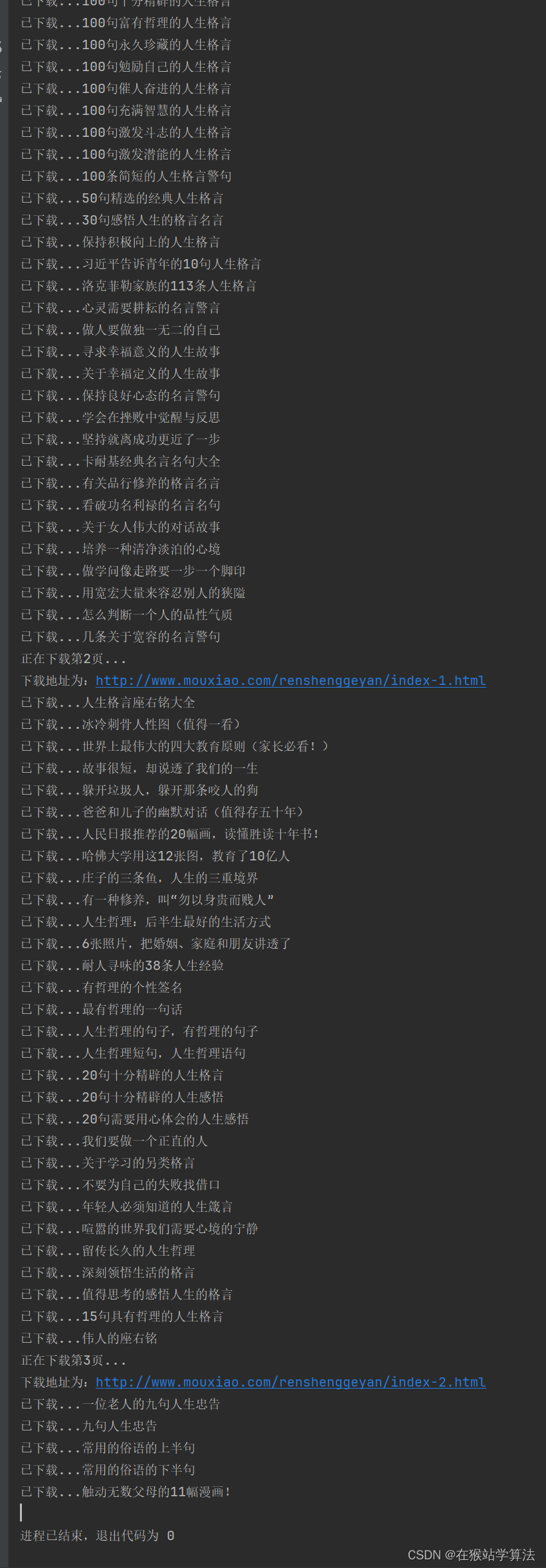
相关文章:
Python进阶--爬取下载人生格言(基于格言网的Python3爬虫)
目录 一、此处需要安装第三方库: 二、抓包分析及Python代码 1、打开人生格言网(人生格言-人生格言大全_格言网)进行抓包分析 2、请求模块的代码 3、抓包分析人生格言界面 4、获取目录页中各种类型的人生格言链接 5、获取下一页的链接 5、获取人生…...

FastAdmin
PHP 推荐链接FastAdmin禁用模板布局后台不需要验证权限的接口配置 推荐链接 链接目录 FastAdmin 禁用模板布局 /** 在application/common/controller/Backend.php里面的 _initialize() 方法里面有// 如果有使用模板布局if ($this->layout) {$this->view->engine-…...

Java设计模式大全:23种常见的设计模式详解(一)
本系列文章简介: 设计模式是在软件开发过程中,经过实践和总结得到的一套解决特定问题的可复用的模板。它是一种在特定情境中经过验证的经验和技巧的集合,可以帮助开发人员设计出高效、可维护、可扩展和可复用的软件系统。设计模式提供了一种在…...

SaperaCamExpert(相机专家)中文使用指南
参考:SaperaCamExpert中文使用指南.PDF 文章目录 软件介绍安装首次打开资源占用率功能主界面布局菜单栏FileViewPre-Processing:预处理 Tools: 快捷键:新建;打开;保存;帮助Device窗体属性树图像…...

ES鉴权设计以及相关探讨
文章目录 1. es的鉴权设计2. es鉴权应用范围3. es鉴权的常用方法3.1 认证体系3.2 x-pack认证3.2.1 开启并配置 X-Pack 的认证与鉴权3.2.2 默认用户和角色3.2.3 创建用户和角色3.2.4 通过用户名和密码访问es 4. 参考文档 鉴权,分别由鉴和权组成 鉴: 表示…...

为什么SpringBoot胖Jar不好
公平地说,我有时会怀念 JavaEE 流行的日子。 当然,当时的情况很复杂,但整个 JavaEE 平台设计合理,符合企业开发的需要。 我可以很轻松地将当时的 JavaEE 应用服务器与现代 Kubernetes 架构进行比较,后者现在也有同样…...

Java学习笔记2024/2/6
练习三:验证码 需求: 定义方法实现随机产生一个5位的验证码 验证码格式: 长度为5 前四位是大写字母或者小写字母 最后一位是数字 package com.angus.comprehensiveExercise; import java.util.Random; public class test3 {publ…...

2024 高级前端面试题之 前端安全模块 「精选篇」
该内容主要整理关于 前端安全模块 的相关面试题,其他内容面试题请移步至 「最新最全的前端面试题集锦」 查看。 前端安全模块精选篇 1. 代码注入XSS如何攻击如何防御cookie 如何防范 XSS 攻击 2. 跨站请求伪造CSRF3. 浏览器同源策略 SOP4. 跨域资源共享 CORS5. 密码…...

SpringBoot Security安全认证框架初始化流程认证流程之源码分析
SpringBoot Security安全认证框架初始化流程&认证流程之源码分析 以RuoYi-Vue前后端分离版本为例分析SpringBoot Security安全认证框架初始化流程&认证流程的源码分析 目录 SpringBoot Security安全认证框架初始化流程&认证流程之源码分析一、SpringBoot Security安…...

2024美赛预测算法 | 回归预测 | Matlab基于RIME-LSSVM霜冰算法优化最小二乘支持向量机的数据多输入单输出回归预测
2024美赛预测算法 | 回归预测 | Matlab基于RIME-LSSVM霜冰算法优化最小二乘支持向量机的数据多输入单输出回归预测 目录 2024美赛预测算法 | 回归预测 | Matlab基于RIME-LSSVM霜冰算法优化最小二乘支持向量机的数据多输入单输出回归预测预测效果基本介绍程序设计参考资料 预测效…...

test1
1...
远程主机可能不符合 glibc 和 libstdc++ Vs Code 服务器的先决条件
vscode连接远程主机报错,原因官方已经公布过了,需要远程主机 glibc>2.28,所以Ubuntu18及以下版本没法再远程连接了,其他Linux系统执行ldd --version查看glibc版本自行判断。 解决方案建议: 不要再想升级glibc了 问题…...

备战蓝桥杯---数据结构与STL应用(进阶2)
本文将主要围绕有关map的今典应用展开: 下面我用图进行分析: 下面为AC代码: #include<bits/stdc.h> using namespace std; struct Point {int x,y;bool operator < (const Point & r) const {return x < r.x || ( x r.x &a…...

SpringBoot:多环境配置
多环境配置demo代码:点击查看LearnSpringBoot02 点击查看更多的SpringBoot教程 方式一、多个properties文件配置 注意:创建properties文件,命名规则:application-(环境名称) 示例:application-dev.proper…...
)
input框中添加一个 X(关闭/清空按钮)
要在输入框(<input> 元素)中添加一个 X(关闭/清空按钮),可以使用 CSS 和 JavaScript 实现。 HTML: <div class"input-container"><input type"text" id"myInput…...

Unity3d Shader篇(三)— 片元半兰伯特着色器解析
文章目录 前言一、片元半兰伯特着色器是什么?1. 片元漫反射着色器的工作原理2. 片元半兰伯特着色器的优缺点优点:缺点: 3. 公式 二、使用步骤1. Shader 属性定义2. SubShader 设置3. 渲染 Pass4. 定义结构体和顶点着色器函数5. 片元着色器函数…...
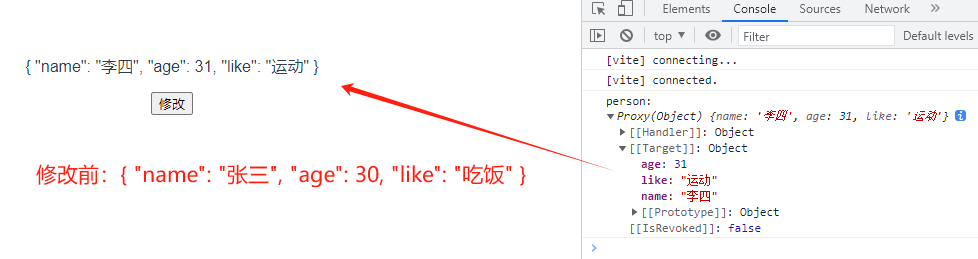
【vue3学习P5-P10】vue3语法;vue响应式实现
0、vue2和vue3对比 框架版本API方式双向绑定原理domFragmentsTree-Shakingvue2选项式API(Options API)基于Object.defineProperty(监听)实现,不能双向绑定对象类型的数据【通过Object.defineProperty里面的set和get做…...

相机图像质量研究(3)图像质量测试介绍
系列文章目录 相机图像质量研究(1)Camera成像流程介绍 相机图像质量研究(2)ISP专用平台调优介绍 相机图像质量研究(3)图像质量测试介绍 相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距 相机图像质量研究(5)常见问题总结:光学结构对成…...
)
PaddleDetection学习5——使用Paddle-Lite在 Android 上实现实时的人脸检测(C++)
使用Paddle-Lite在 Android 上实现实时的人脸检测 1 环境准备2. 部署步骤2.1 下载Paddle-Lite-Demo2.2 运行face_detection_demo项目3 使用Opencv对后处理进行优化4 开启手机摄像头进行人脸检测1 环境准备 参考前一篇在 Android 上使用Paddle-Lite实现实时的目标检测功能 2. …...
全套电气自动化样例图纸分享,使用SuperWorks自动化版免费设计软件!
今天给大家分享一套完备的电气自动化样例图纸,结构准确、内容清晰,适合初学者入门操作练习。 整套图纸包含图纸目录、原理图、端子列表、连接列表、元件列表、接线图,具有较高的参考价值,请大家点击自行下载文件! 1e8…...

【限时开源】FastAPI 2.0 AI流式SDK v1.0:内置token计数、流控限速、断点续传、前端SSE自动重连——仅开放首批200个GitHub Star领取资格
第一章:FastAPI 2.0 异步 AI 流式响应的核心演进与架构定位FastAPI 2.0 将原生异步流式响应能力从实验性支持升级为一级公民,彻底重构了 AI 应用服务端的实时交互范式。其核心演进体现在对 StreamingResponse 的深度重写、对 ASGI 3.0 协议的精准适配&am…...

ssm+java2026年毕设数据分析教学网站【源码+论文】
本系统(程序源码)带文档lw万字以上 文末可获取一份本项目的java源码和数据库参考。系统程序文件列表开题报告内容一、选题背景关于会议管理问题的研究,现有研究主要以传统OA办公系统或通用协同办公平台为主,专门针对会议全生命周期…...

Sentaurus实战解析:SiC NMOS仿真中的关键参数设置与优化
1. SiC NMOS仿真基础与Sentaurus环境搭建 碳化硅(SiC)功率器件因其优异的耐高温、高压特性,正在电力电子领域掀起一场革命。作为第三代半导体材料的代表,SiC的临界击穿电场强度达到硅的10倍,热导率更是硅的3倍。但在实际器件开发中࿰…...

事件驱动RTOS EventOS的创新设计与应用实践
1. 事件驱动型RTOS的创新设计 在嵌入式系统开发领域,实时操作系统(RTOS)一直是关键基础设施。传统RTOS如FreeRTOS、uC/OS等大多采用基于时间片轮转的任务调度机制,而EventOS则开创性地采用了事件驱动架构,这在资源受限的嵌入式环境中具有独特…...

App启动总览
特征 / 步骤 冷启动 (Cold Start) 温启动 (Warm Start) 热启动 (Hot Start) 速度 最慢 🐢 中等 🏃 最快 🚀 进程创建 ✅ 需要 ❌ 跳过 ❌ 跳过 Application.onCreate() ✅ 需要调用 ❌ 跳过 ❌ 跳过 Activity.onCreate() ✅ 需要调用 ✅ 需要调用 ❌ 跳过 Activity.onSta…...

学网络安全需要学编程吗?
作为数字化时代的守护者岗位,网络安全一直备受瞩目并引发热议,那么学网络安全需要学编程吗?学多久才可以就业?我们通过这篇文章来了解一下。学网络安全需要学编程吗?当然需要,网络安全需要学习编程。编程能力是网络安全领域的基础技能之一…...

Qwen3.5-35B-AWQ-4bit企业应用指南:教育题图解析、医疗影像初筛、办公文档理解
Qwen3.5-35B-AWQ-4bit企业应用指南:教育题图解析、医疗影像初筛、办公文档理解 1. 引言:当AI学会“看图说话”,企业效率能提升多少? 想象一下这样的场景:一位老师需要快速从几十张试卷中找出典型错题,一位…...

Vue3+Vant4移动端架构设计:现代化移动应用工程实践
Vue3Vant4移动端架构设计:现代化移动应用工程实践 【免费下载链接】vue3-vant4-mobile 👋👋👋 基于Vue3.2、vite3、vant4、pinia2、Typescript、windicss 等主流技术开发,集成 Dark Mode(暗黑)模式和系统主题色&#x…...

UE5模型加载避坑指南:为什么你的Runtime OBJ导入总是丢失材质?
UE5运行时OBJ材质丢失终极解决方案:从原理到工具函数全解析 当你在UE5中动态加载OBJ模型时,是否遇到过这样的场景:模型虽然成功加载,但所有材质都变成了难看的粉色默认材质?这可能是技术美术和程序化生成领域最常见的痛…...

Atmosphere-stable开源项目实战指南:从基础到进阶的完整路径
Atmosphere-stable开源项目实战指南:从基础到进阶的完整路径 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 一、认知基础:如何理解Atmosphere自定义固件࿱…...