Hadoop-IDEA开发平台搭建
1.安装下载Hadoop文件
1)hadoop-3.3.5 将下载的文件保存到英文路径下,名称一定要短。否则容易出问题;
2)解压下载下来的文件,配置环境变量
3)我的电脑-属性-高级设置-环境变量
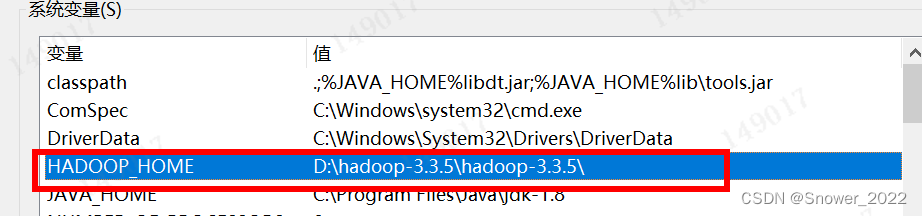
4.详细配置文件如下:
| HADOOP_HOME: | D:\ProgramFiles\hadoop-3.3.5 |
| 系统 path: | %HADOOP_HOME%\bin 和 %HADOOP_HOME%\sbin |
2.安装windows环境依赖
需要有windows客户端依赖资料路径下的依赖文件(已上传到平台),拷贝 winutils.exe 到hadoop的bin文件夹: ~\hadoop-3.3.5\bin;再把 hadoop.dll 拷贝到 C:\Windows\System32。

6)验证Hadoop环境变量是否正常。
鼠标双击运行:winutils.exe,若没有报错,一闪而过,就可以了。(如果报如下错误:找不到MSVCR120.dll。说明缺少微软运行库(正版系统往往有这个问题)。再资料包里面有对应的微软运行库安装包双击安装即可。)
3.安装JDK-1.8.371和IDEA 2023
1)注册oracle账号后,下载地址: https://www.oracle.com/java/technologies/downloads/#java8-windows
2)安装的时候,可以只安装 jdk1.8,不安装独立的jre。若电脑上有多个JDK版本,需要在配置环境变量的时候小心。

3)验证java 是否安装成功:cmd - 中输入名: java -version

4) 下载好IDEA2023,可从官网下载安装。(IntelliJ IDEA – 领先的 Java 和 Kotlin IDE)
插件需要下载下,另外激活可参见-IDEA PyCharm WebStorm PhpStorm Jetbrains全家桶最新破解激活码 - 爱激活网
4.打开工程目录-创建项目工程


按照上述的内容填写后,建立Maven 工程。
5.修改配置文件中的依赖
1)添加junit插件 - test 插件 2)添加org.slf4j --日志
pom.xml文件中的依赖项如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<!-- 一定要把下面的这个scope注释掉-->
<!-- <scope>test</scope>-->
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>
添加配置文件后,在页面又上角有个M图标,可以点击下,会自动刷新,之后需要从Maven仓库依赖 dependency;

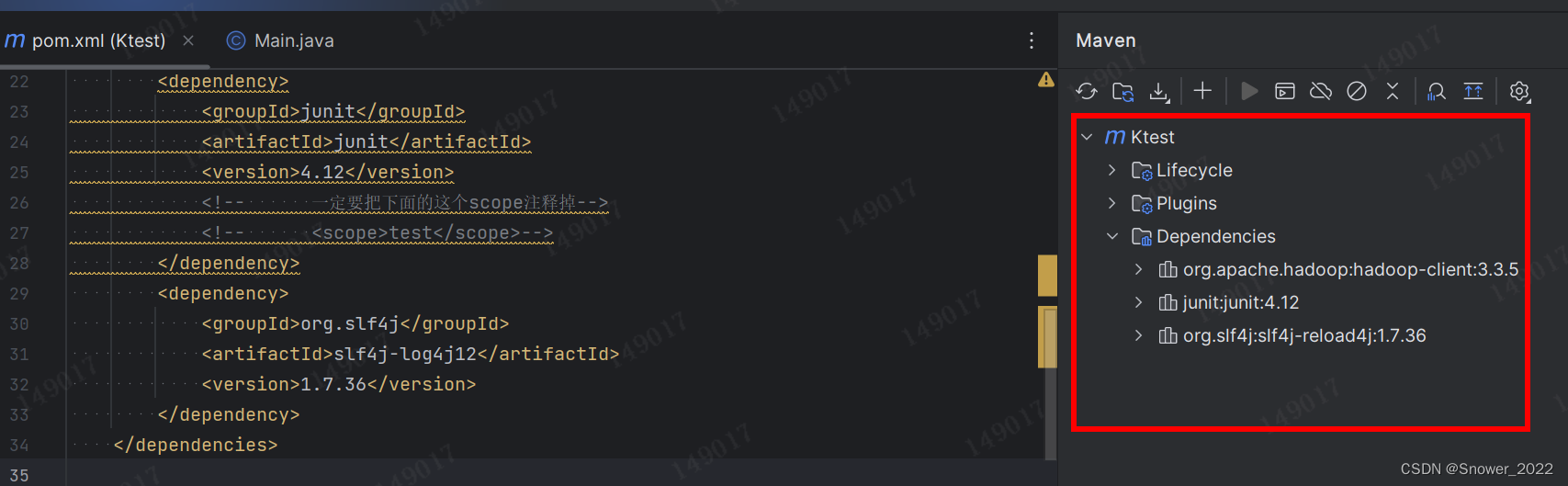
一定要和服务器上安装的版本一致:

6.为工程配置日志文件
在 IDEA中创建一个Maven工程 Ktest,并导入相应的依赖坐标+日志添加
在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
6.在包下面新建一个类名

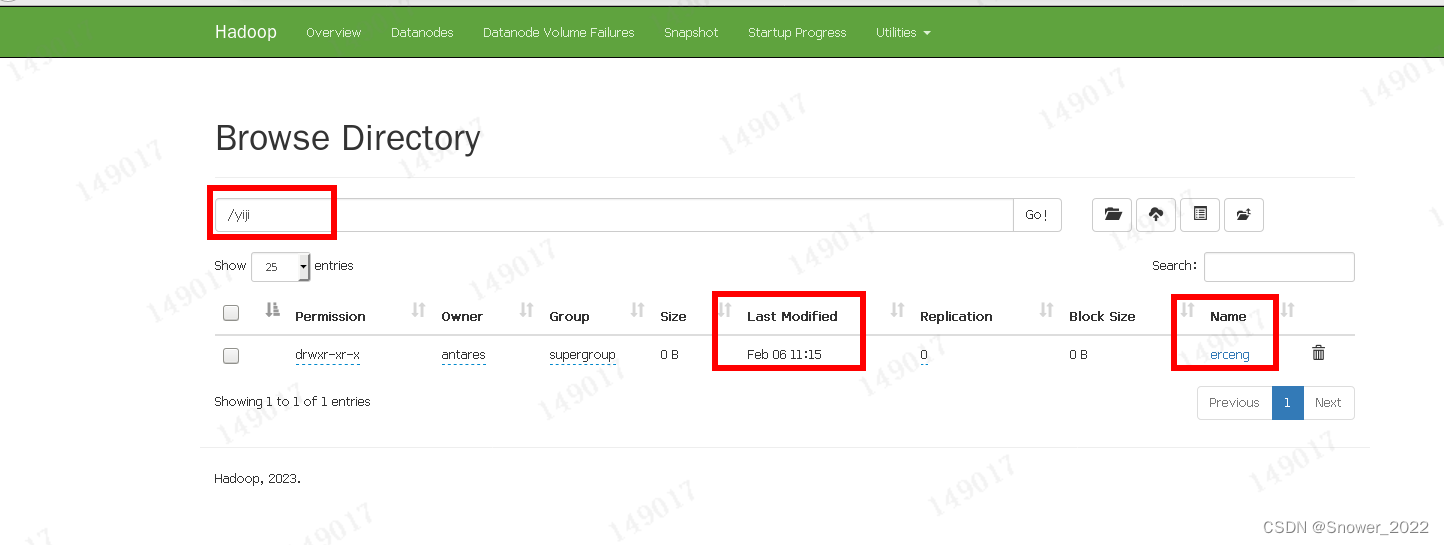
7.在服务器上尝试创建文件夹
编写代码-在HDFS文件系统中写入一个 `/yiji/ercengmulu` 的文件.
-------------------------------------------------------------------------------------
package org.example;import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.Test;import java.io.IOException; import java.net.URI; import java.net.URISyntaxException;public class Testt{@Test //引入当时添加的Junitpublic void testMkdirs() throws URISyntaxException,IOException,InterruptedException{//创建连接集群的Name Node地址URI uri = new URI("hdfs://hadoop102:8020");//创建配置项Configuration conf = new Configuration();//指定用户String user = "antares";//获取客户端对象FileSystem fs = FileSystem.get(uri,conf,user);fs.mkdirs(new Path("/yiji/ercengmulu"));fs.close();} }
8. 打开服务器上的部署的服务
hadoop102:8020 --- 需要在服务器端打开Hadoop,之后才能运行刚刚创建的类。
测试通过。
相关文章:
Hadoop-IDEA开发平台搭建
1.安装下载Hadoop文件 1)hadoop-3.3.5 将下载的文件保存到英文路径下,名称一定要短。否则容易出问题; 2)解压下载下来的文件,配置环境变量 3)我的电脑-属性-高级设置-环境变量 4.详细配置文件如下&#…...

block任务块、rescue和always、loop循环、role角色概述、role角色应用、ansible-vault、sudo提权、特殊的主机清单变量
任务块 可以通过block关键字,将多个任务组合到一起可以将整个block任务组,一起控制是否要执行 # 如果webservers组中的主机系统发行版是Rocky,则安装并启动nginx[rootpubserver ansible]# vim block1.yml---- name: block taskshosts: webse…...
Qt:QFileDialog
目录 一、介绍 二、功能 三、具体事例 1、将某个界面保存为图片,后缀名可选PNG、JPEG、SVG等 一、介绍 QFileDialog提供了一个对话框,允许用户选择文件或者目录,也允许用户遍历文件系统,用以选择一个或多个文件或者目录。 QF…...

我的QQ编程学习群
欢迎大家加入我的QQ编程学习群。 群号:950365002 群里面有许多的大学生大佬,有编程上的疑惑可以随时问,也可以聊一些休闲的东西。 热烈欢迎大家加入!! 上限:150人。...

【C++】类与对象(四)——初始化列表|explicit关键字|static成员|友元|匿名对象
前言: 初始化列表,explicit关键字,static成员,友元,匿名对象 文章目录 一、构造函数的初始化列表1.1 构造函数体内赋值1.2 初始化列表 二、explicit关键字三、static成员四、友元4.1 友元函数4.2 友元类 五、内部类六、…...
ChatGPT高效提问—prompt常见用法
ChatGPT高效提问—prompt常见用法 1.1 角色扮演 prompt最为常见的用法是ChatGPT进行角色扮演。通常我们在和ChatGPT对话时,最常用的方式是一问一答,把ChatGPT当作一个单纯的“陪聊者”。而当我们通过prompt为ChatGPT赋予角色属性后,即使…...
使用vite创建vue+ts项目,整合常用插件(scss、vue-router、pinia、axios等)和配置
一、检查node版本 指令:node -v 为什么要检查node版本? Vite 需要 Node.js 版本 18,20。然而,有些模板需要依赖更高的 Node 版本才能正常运行,当你的包管理器发出警告时,请注意升级你的 Node 版本。 二、创…...
泛型、Trait 和生命周期(上)
目录 1、提取函数来减少重复 2、在函数定义中使用泛型 3、结构体定义中的泛型 4、枚举定义中的泛型 5、方法定义中的泛型 6、泛型代码的性能 每一门编程语言都有高效处理重复概念的工具。在 Rust 中其工具之一就是 泛型(generics)。泛型是具体类型…...

<网络安全>《18 数据安全交换系统》
1 概念 企业为了保护核心数据安全,都会采取一些措施,比如做网络隔离划分,分成了不同的安全级别网络,或者安全域,接下来就是需要建设跨网络、跨安全域的安全数据交换系统,将安全保障与数据交换功能有机整合…...
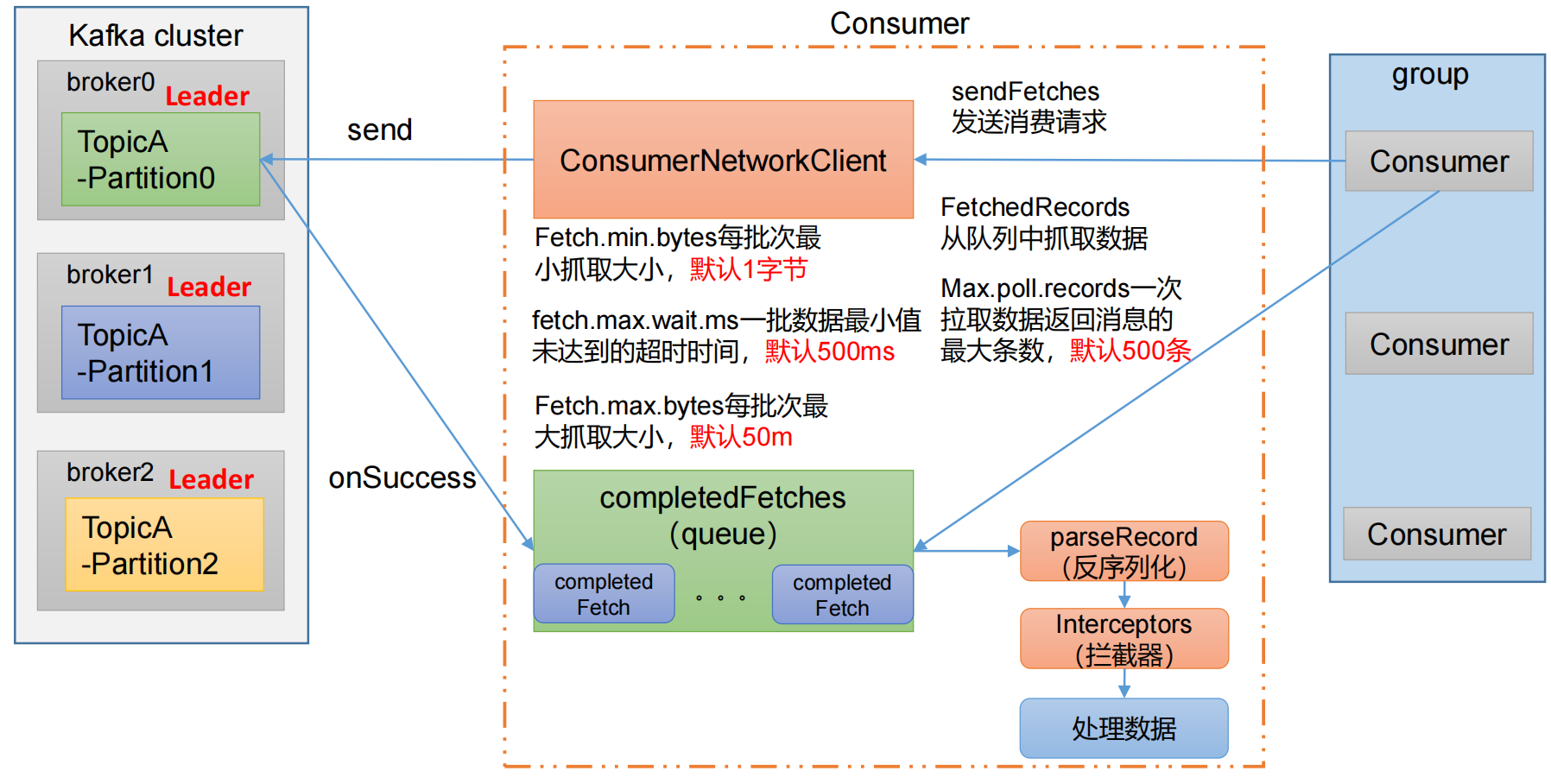
Kafka 生产调优
Kafka生产调优 文章目录 Kafka生产调优一、Kafka 硬件配置选择场景说明服务器台数选择磁盘选择内存选择CPU选择 二、Kafka Broker调优Broker 核心参数配置服役新节点/退役旧节点增加副本因子调整分区副本存储 三、Kafka 生产者调优生产者如何提高吞吐量数据可靠性数据去重数据乱…...
springboot162基于SpringBoot的体育馆管理系统的设计与实现
体育馆管理系统 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本体育馆管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕…...

Interpolator:在Android中方便使用一些常见的CubicBezier贝塞尔曲线动画效果
说明 方便在Android中使用Interpolator一些常见的CubicBezier贝塞尔曲线动画效果。 示意图如下 import android.view.animation.Interpolator import androidx.core.view.animation.PathInterpolatorCompat/*** 参考* android https://yisibl.github.io/cubic-bezier* 实现常…...
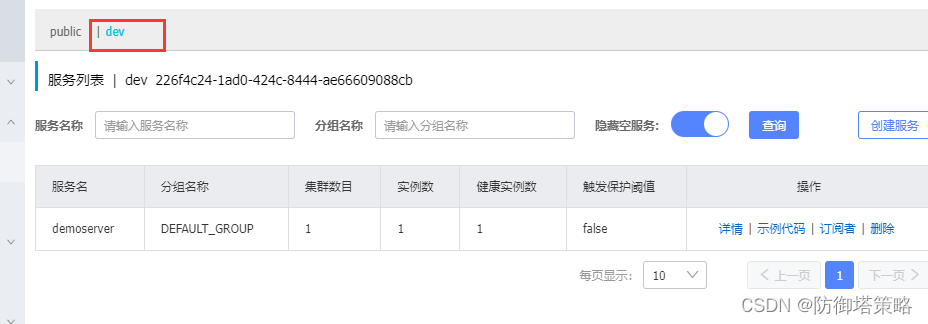
Nacos安装,服务注册,负载均衡配置,权重配置以及环境隔离
1. 安装 首先从官网下载 nacos 安装包,注意是下载 nacos-server Nacos官网 | Nacos 官方社区 | Nacos 下载 | Nacos 下载完毕后,解压找到文件夹bin,文本打开startup.cmd 修改配置如下 然后双击 startup.cmd 启动 nacos服务,默认…...

Vue3导出数据为txt文件
在Vue3中,可以通过使用Blob对象以及URL.createObjectURL()方法导出txt文档。 首先,你需要在Vue组件中创建一个方法来生成txt文档的内容。 //res.value.code 数据源 //type:格式设置 //form.name是下载文件的自定义名字 const downLoad ()&…...

Simulink中getConfigSet用法
目录 语法 说明 示例 获取配置集 getConfigSet的功能是从模型中获取配置集或配置引用。 语法 myConfigObj getConfigSet(model, configObjName) 说明 myConfigObj getConfigSet(model, configObjName) 返回关联到 model 并命名为 configObjName 的配置集或配置引用。 …...

【Algorithms 4】算法(第4版)学习笔记 05 - 2.2 归并排序
文章目录 前言参考目录学习笔记1:归并排序的简单演示1.1:基本思路1.2:归并排序的 demo 演示1.3:代码实现2:自顶向下的归并排序2.1:比较次数与访问次数的证明2.2:代码优化2.3:优化后代…...

mybatis mapper sql include用法实现sql块复用
一、总SQL <select id"getxxxMonitorData"resultType"com.xxx.module.system.dal.dataobject.xxx.xxxDO"><include refid"getxxxMonitorDataBaseSql"></include><include refid"whereContent"></include&…...
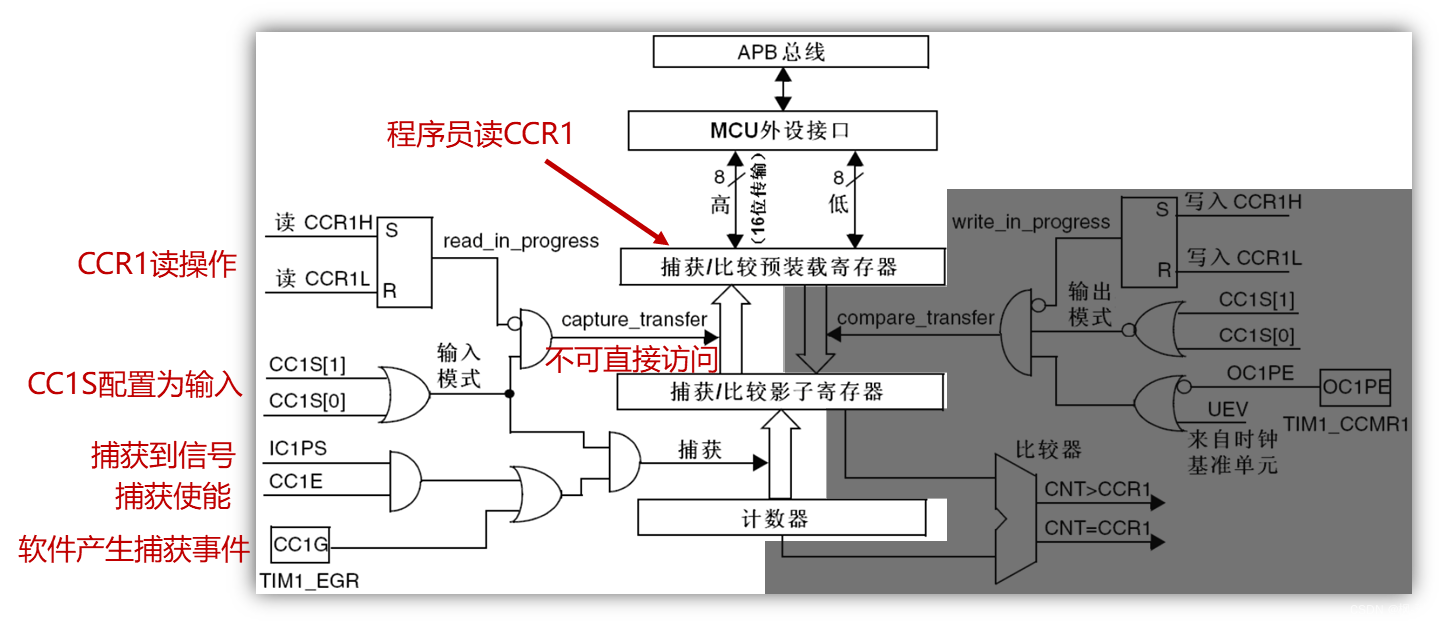
正点原子--STM32通用定时器学习笔记(2)
1. 通用定时器输入捕获部分框图介绍 捕获/比较通道的输入部分(通道1) 采样频率:控制寄存器 1(TIMx_CR1)的CKD[1:0] ⬇⬇⬇滤波方式选择: 捕获/ 比较模式寄存器 1(TIMx_CCMR1)的输入捕获部分⬇⬇…...

Flask实现异步调用sqlalchemy的模型类
事情是这样的,我这边需要在一次请求里面,搞一个异步不阻碍的任务,来执行耗时的操作。 一开始,我准备写的代码是这样的: from flask import Flask import time from concurrent.futures import ThreadPoolExecutorexec…...

Pocket2Mol + Generation of Atom Positions生成原子位置的方法有什么?联合概率是什么?
联合概率: 联合概率是统计学中的一个概念,用于描述两个或多个随机事件同时发生的概率。当我们谈论多个变量的联合概率时,我们是在探讨这些变量同时取特定值的概率。 让我们简化一下概念: 假设你有一个骰子(六面&…...

新手福音:通过快马平台生成带详解代码,轻松完成openclaw首次本地部署
今天想和大家分享一个特别适合新手的实践项目——在本地部署openclaw。作为一个刚接触AI部署的小白,我最初看到各种复杂的配置步骤就头大,直到发现了InsCode(快马)平台,整个过程变得简单多了。下面就把我的经验整理成笔记,希望能帮…...

M2LOrder模型在AI编程助手场景的应用:代码注释情感分析
M2LOrder模型在AI编程助手场景的应用:代码注释情感分析 1. 引言 你有没有在代码注释里写过“这里有个天坑,后面的人小心”或者“TODO: 这个逻辑太绕了,得重构”?这些看似随手的吐槽,其实藏着开发者最真实的情绪。代码…...

3个技巧让Poppins字体为你的设计项目增添国际范儿
3个技巧让Poppins字体为你的设计项目增添国际范儿 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 还在为多语言项目找不到统一风格的字体而烦恼吗?Poppins这款现代几…...

M1 Mac 8GB内存跑不动7B模型?手把手教你用1.5B版DeepSeek+RAGFlow搭建个人知识库
M1 Mac 8GB内存跑不动7B模型?手把手教你用1.5B版DeepSeekRAGFlow搭建个人知识库 当M1 Mac用户尝试在本地部署大语言模型时,8GB内存往往成为难以逾越的障碍。特别是运行7B参数模型时,内存不足导致的崩溃和卡顿让许多开发者望而却步。本文将分…...
为什么MedNeXt能超越Transformer?揭秘大卷积核在医学图像分割中的独特优势
MedNeXt如何用大卷积核重塑医学图像分割?技术优势全解析 当你在深夜的医院影像科,看着屏幕上模糊的CT扫描图,试图从那些灰度渐变中分辨出肿瘤边界时,是否会想过AI模型眼中的世界?医学图像分割——这个决定患者治疗方案…...
)
告别Swagger注解污染:用smart-doc + Maven插件5分钟生成整洁API文档(SpringBoot实战)
零侵入API文档革命:smart-doc在SpringBoot项目中的极致实践 如果你曾经被Swagger注解污染代码所困扰,或是厌倦了在业务逻辑中嵌入大量文档相关注解,那么smart-doc可能会成为你API文档管理的新选择。作为一款基于源码解析的文档生成工具&#…...

新手福音:用快马平台将vmware官网概念转化为可交互的虚拟机演示代码
作为一名刚接触虚拟化技术的新手,我最近在VMware官网上看到了关于虚拟机的基础概念介绍。虽然理论知识很全面,但总觉得少了点动手实践的环节。直到发现了InsCode(快马)平台,它让我能够把抽象的概念快速转化为可运行的代码,这种学习…...

从FamNet到通用计数:小样本学习如何让AI“数”遍万物
1. 小样本计数的革命:从专用工具到通用能力 记得我第一次接触物体计数任务时,用的还是专门针对人群计数的模型。当时为了统计商场人流量,不得不专门训练一个模型。后来遇到统计停车场的需求,又要重新收集数据训练新模型。这种&quo…...

Stable Diffusion v1.5 Archive 镜像实测:5步完成部署,快速体验文生图
Stable Diffusion v1.5 Archive 镜像实测:5步完成部署,快速体验文生图 1. 开篇:为什么选择SD1.5 Archive版本 Stable Diffusion作为当前最热门的开源AI绘画模型,已经迭代了多个版本。其中v1.5作为经典版本,在图像质量…...

Umi-OCR技术解密:离线文字识别的3大创新与全行业实践指南
Umi-OCR技术解密:离线文字识别的3大创新与全行业实践指南 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/G…...