【高阶数据结构】B-树详解
文章目录
- 1. 常见的搜索结构
- 2. 问题提出
- 使用平衡二叉树搜索树的缺陷
- 使用哈希表的缺陷
- 3. B-树的概念
- 4. B-树的插入分析
- 插入过程分析
- 插入过程总结
- 5. B-树的代码实现
- 5.1 B-树的结点设计
- 5.2 B-树的查找
- 5.3 B-树的插入实现
- InsertKey
- 插入和分裂
- 测试
- 6. B-树的删除(思想)
- 7. B-树的高度
- 最小高度
- 最大高度
- 8. B-树的性能
- 9. B-树的简单验证(中序遍历)
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树。
那么在此之前,我们也已经学过很多的搜索结构了,我们来一起回顾一下:
1. 常见的搜索结构
以上结构适合用于数据量相对不是很大,能够一次性存放在内存中,进行数据查找的场景(内查找)。
2. 问题提出
如果数据量很大,比如有100G数据,无法一次放进内存中,那就只能放在磁盘上了,如果放在磁盘上,有时需要搜索某些数据,那么该如何处理呢?
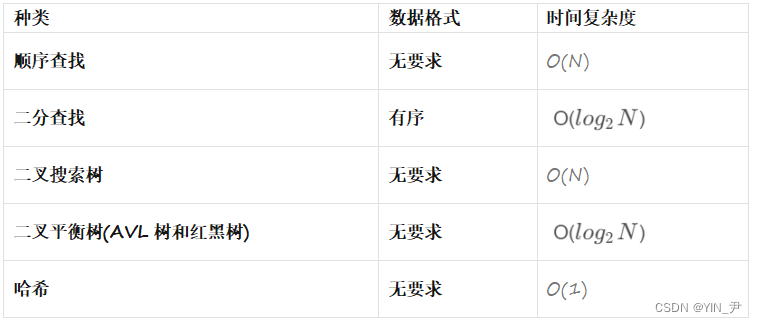
我们可以考虑将关键字及其映射的数据的地址放到一个内存中的搜索树的节点中,当通过搜索树找到要访问数据的关键字时,取这个关键字对应的地址去磁盘访问数据。
但是呢,实际中我们去查找的这个key可能不都是整型:
可能是字符串比如身份证号码,那这时我们还把所有的key和对应数据的地址都存到内存,也可能是存不下的。
那这时候可以做一个改动:
我不再存储key了,只存储地址
那这样的话我如何判断找到了呢?
那就需要拿着当前的地址去访问磁盘进行判断。
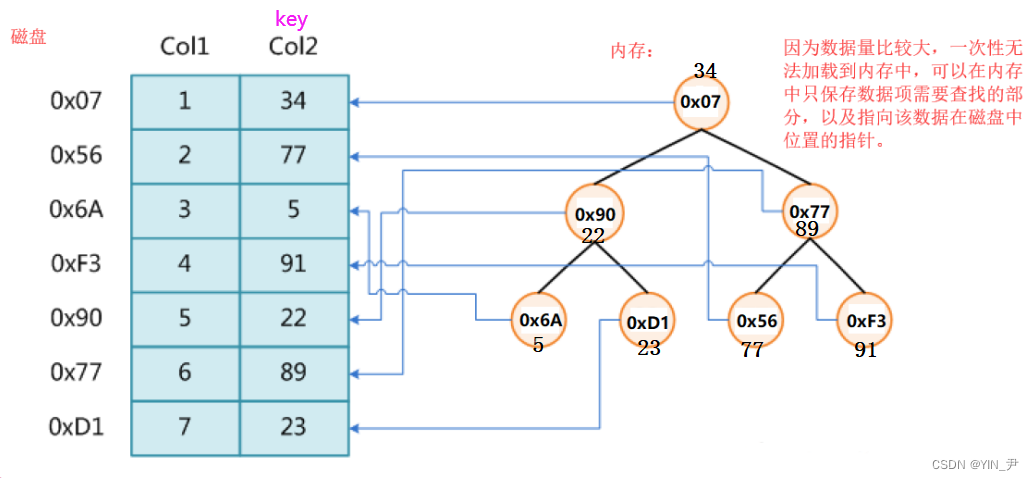
比如现在要找key为77的这个数据,那从根结点开始,首先访问根结点中的地址对应磁盘的数据,是34,那77大于34,所以往右子树找,右子树0x77对应的是89(有一次访问磁盘),77比89小,再去左子树找,左子树地址0x56访问磁盘对应的是77找到了。
那这样做的问题是什么呢?
最坏的情况下我们要进行高度次的查找,那就意味着要进行高度次的磁盘IO。
如果我们使用红黑树或者AVL树的话,就是O( l o g 2 N log_2 N log2N)次。
那如果是在内存中的话,这个查找次数还是很快的,但是现在数据量比较大是在磁盘上存的,而磁盘的速度是很慢的。
所以:
使用平衡二叉树搜索树的缺陷
平衡二叉树搜索树的高度是logN,这个查找次数在内存中是很快的。但是当数据都在磁盘中时,访问磁盘速度很慢,在数据量很大时,logN次的磁盘访问,是一个难以接受的结果。
那如果用哈希表呢?
使用哈希表的缺陷
哈希表的效率很高是O(1),但是一些极端场景下某个位置哈希冲突很严重,导致访问次数剧增,也是难以接受的。
那如何加速对数据的访问呢?
1. 提高IO的速度(SSD相比传统机械硬盘快了不少,但是还是没有得到本质性的提升)
2. 降低树的高度——多叉树平衡树
那我们今天要学的B-树其实就是多叉平衡搜索树
3. B-树的概念
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树并且是绝对平衡,称为B树(后面有一个B树的改进版本B+树,然后有些地方的B树写的的是B-树,注意不要误读成"B减树")。
一棵m阶(m>2)的B树(B树中所有结点的孩子个数的最大值称为B树的阶),是一棵M路的平衡搜索树,可以是空树或者满足一下性质的树:
1. 树中每个结点至多有m棵子树,即至多含有m-1个关键字。
2. 若根结点不是终端结点,则至少有两棵子树。
3. 除根结点外的所有非叶子结点都包含k-1个关键字和k个孩子(终端结点孩子都是NULL),其中 ceil(m/2) ≤ k ≤ m (ceil是向上取整函数)
4. 所有的叶结点都出现在同一层次上,并且不带信息(可以视为外部结点或类似于折半查找判定树的查找失败结点,实际上这些结点不存在,指向这些结点的指针为空)
5. 每个节点中的关键字从小到大(也可以从大到小)排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
6. 每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)其中,Ki(1≤i≤n)为关键字,且Ki<Ki+1(1≤i≤n-1)。Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的关键字均小于Ki+1,Ai+1所指子树所有结点中的关键字均大于Ki+1。(结点中关键字升序的情况下)
n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。
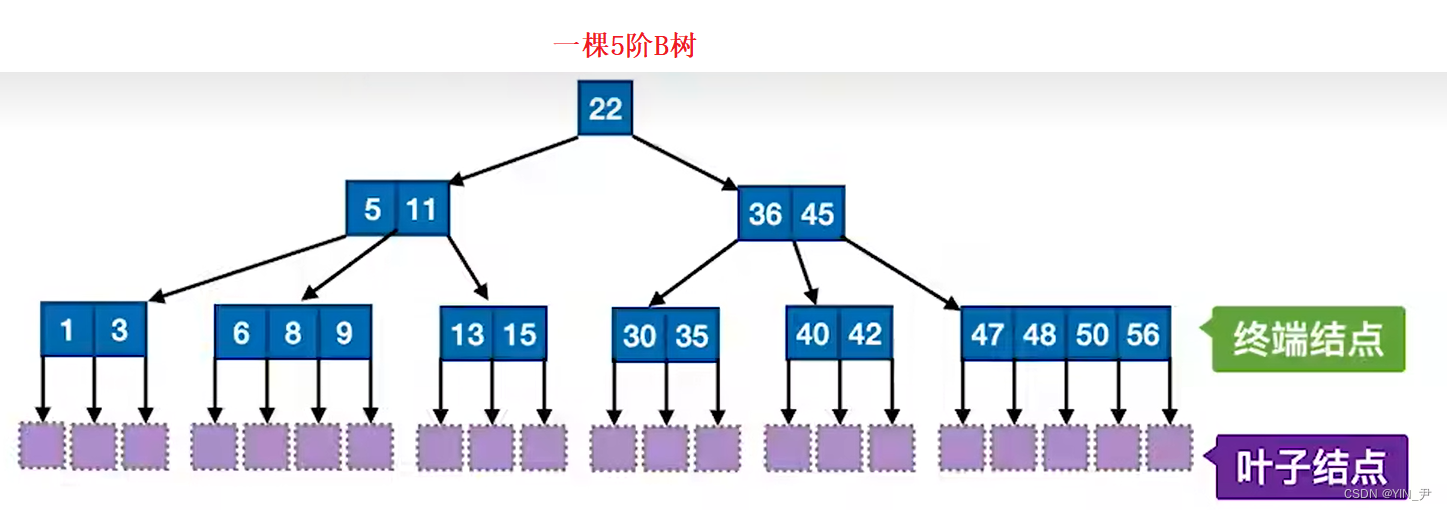
大家可以对照上面的图先来自行理解一下B树的这些性质,等后面我们熟悉了B树的结构之后大家可以再来反复理解这几条性质为什么是这样。

4. B-树的插入分析
那下面我们就来学习一下B-树的插入是怎样的。
那为了方便讲解,也方便大家理解,我们这里选取B-树的阶数取小一点,给一个3:
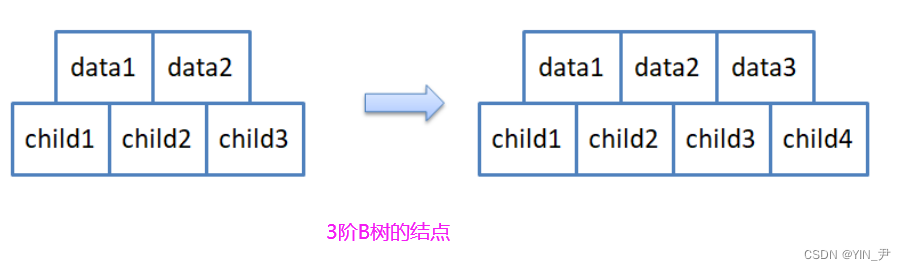
即三阶B-树(三叉平衡树),那每个结点最多存储两个关键字,两个关键字可以将区间分割成三个部分,因此节点应该有三个孩子(子树)
那每个结点的结构就应该是这样的
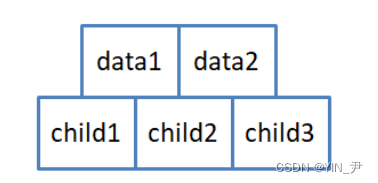
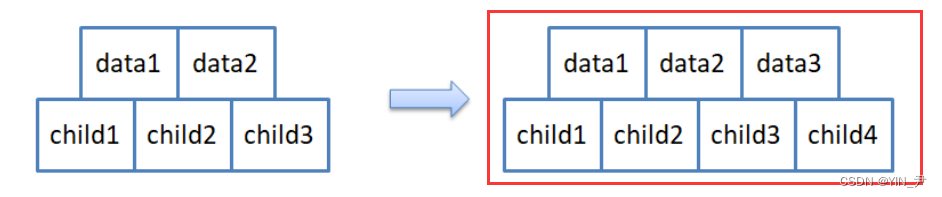
但是呢,为了后续实现起来简单,节点的结构如下:
关键字和孩子我们都多给一个空间(后面大家就能体会到为什么要多给一个)
插入过程分析
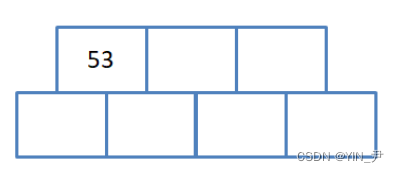
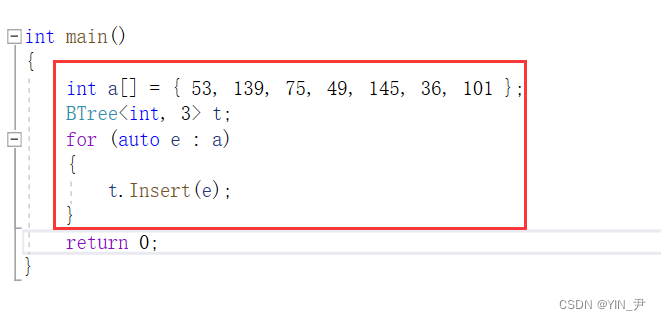
那下面我们就来找一组数据分析一下插入的过程,用序列{53, 139, 75, 49, 145, 36, 101}构建B树的过程如下:
1. 插入53
满足B-树的性质,不用动
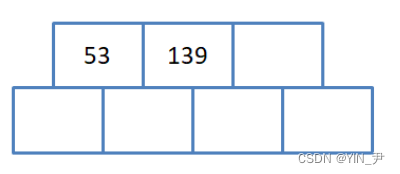
2. 插入139(关键字我们升序排列)
也不用做任何处理
3. 插入75
75插入之后是这样,但是因为我们多开了一个空间,3阶的话每个结点最多3-1=2个关键字。
所以现在这个结点关键字个数超了。
那此时怎么办呢?
要进行一个操作——分裂
怎么分裂呢?
1. 找到关键字序列的中间数,将关键字序列分成两半
2. 新建一个兄弟结点出来,将右半边的m/2个关键字分给兄弟结点
3. 将中间值提给父亲结点,新建结点成为其右孩子(没有父亲就创建新的根)
为什么中位数做父亲?——满足搜索树的大小关系(左<根<右)
4. 结点指针链接起来
那通过这里大家来体会一下上面的规则中为什么要求除根结点外的所有非叶子结点都包含k-1个关键字(ceil(m/2) ≤ k ≤ m,即k的最小值是ceil(m/2)),即最少包含ceil(m/2)-1个关键字。
如果m是奇数比如9,那ceil(m/2)是5个,5-1是4,而9个的话分裂之后正好两边每个结点都是4个关键字,中间的一个提取给父亲。
如果是偶数比如10的话,ceil(m/2)是5,5-1是4,而10个分裂的话,肯定不平均,一边4个(最少的),一边5个,还有一个中间值要提取给父亲。
所以它们最少就是ceil(m/2)-1个关键字。


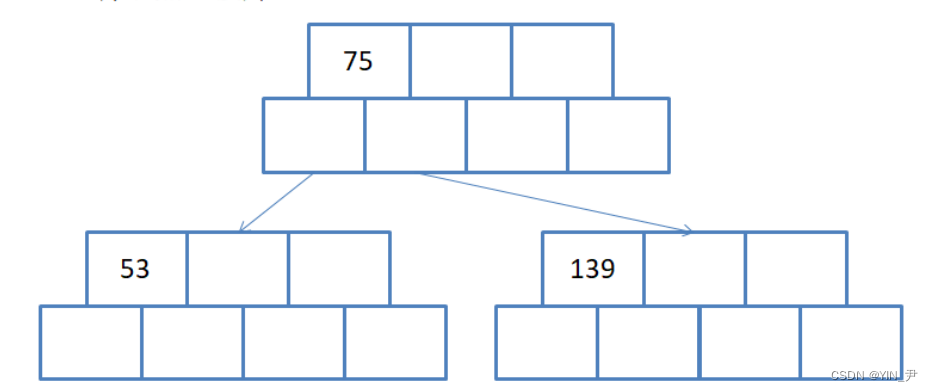
那我们再来插入几个看看:
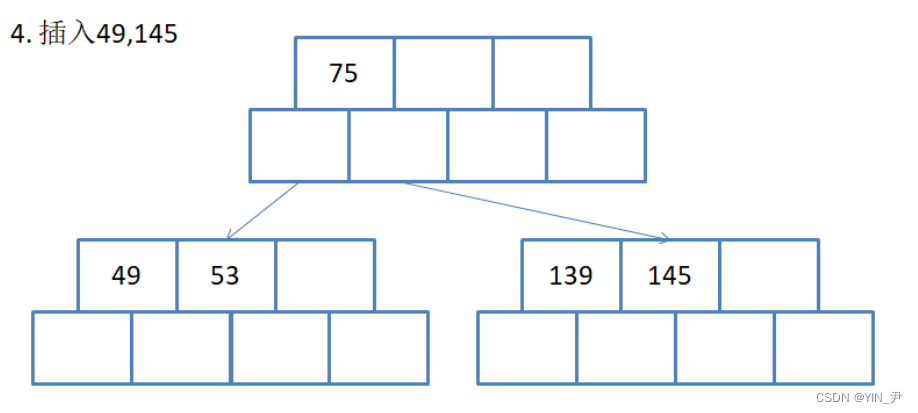
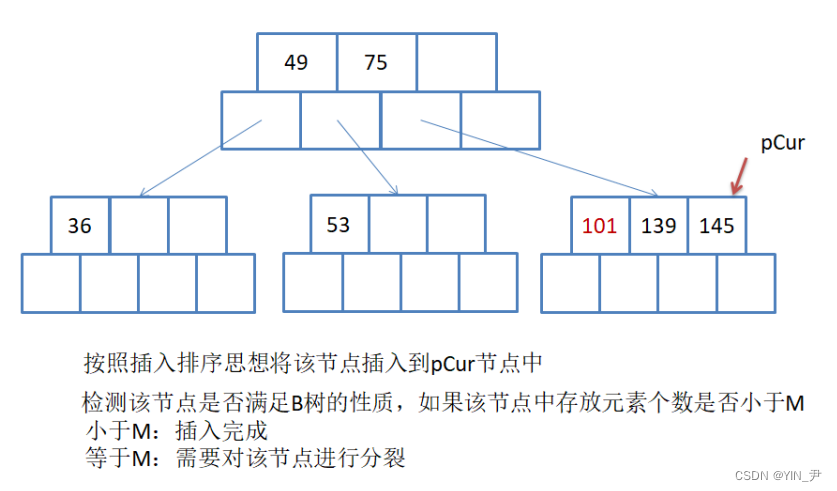
还是我们上面给的那组数据,再往后插入49,145
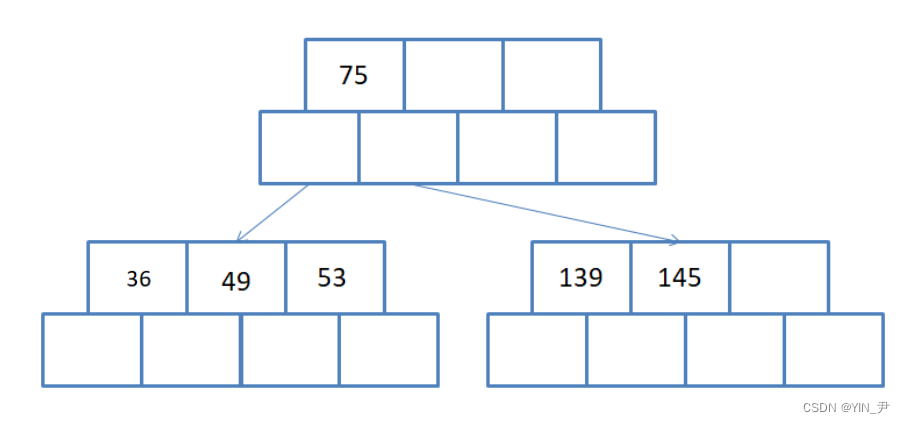
接着再往后,36
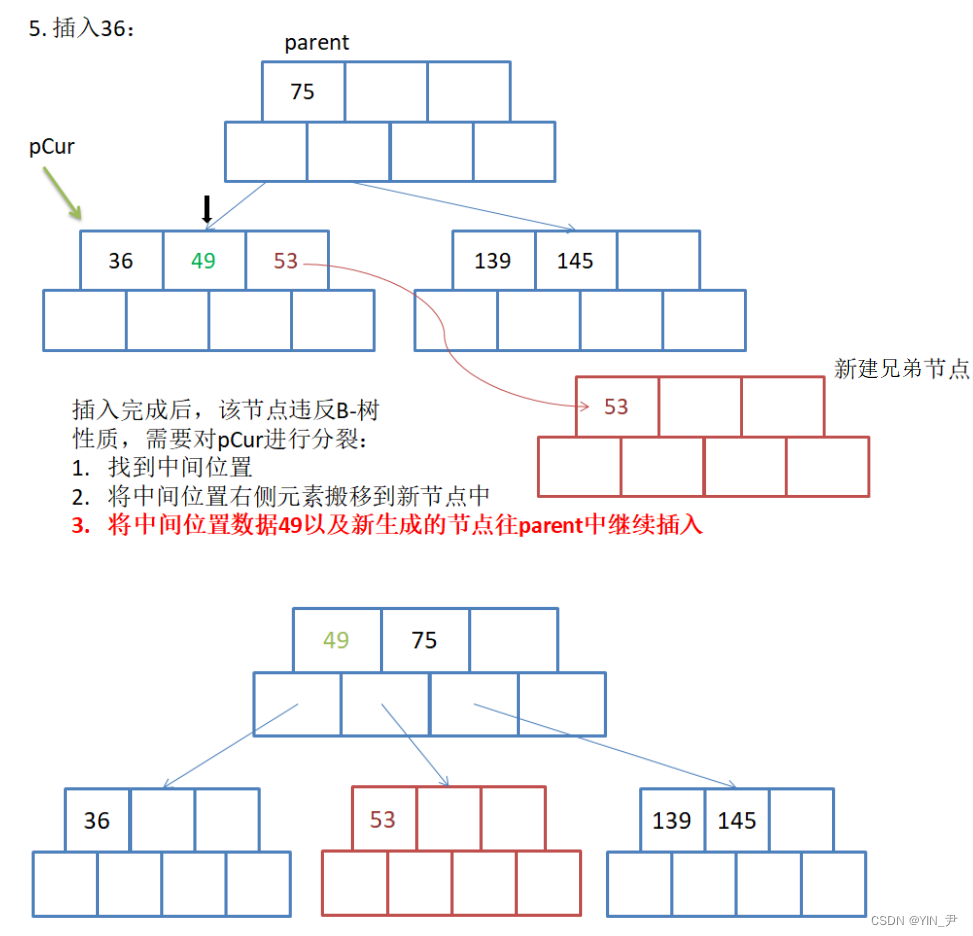
那此时36插入的这个结点又满了,然后就要进行分裂。
大家现在体会,为什么我们要多开一个空间?这样的话我们就可以在插入之后关键字顺序已经调整好的情况下去分裂,就方便很多。
那然后我们来看这里的分裂怎么做?
新增一个兄弟结点之后,相当于它们的父亲结点就多了一个孩子,所以也需要增加一个关键字(关键值始终比孩子少一个),就把中间值提给父亲结点。
49上提插入到父亲,它比75小,所以45往后移(它的孩子也跟着往后移),然后49插入到前面。

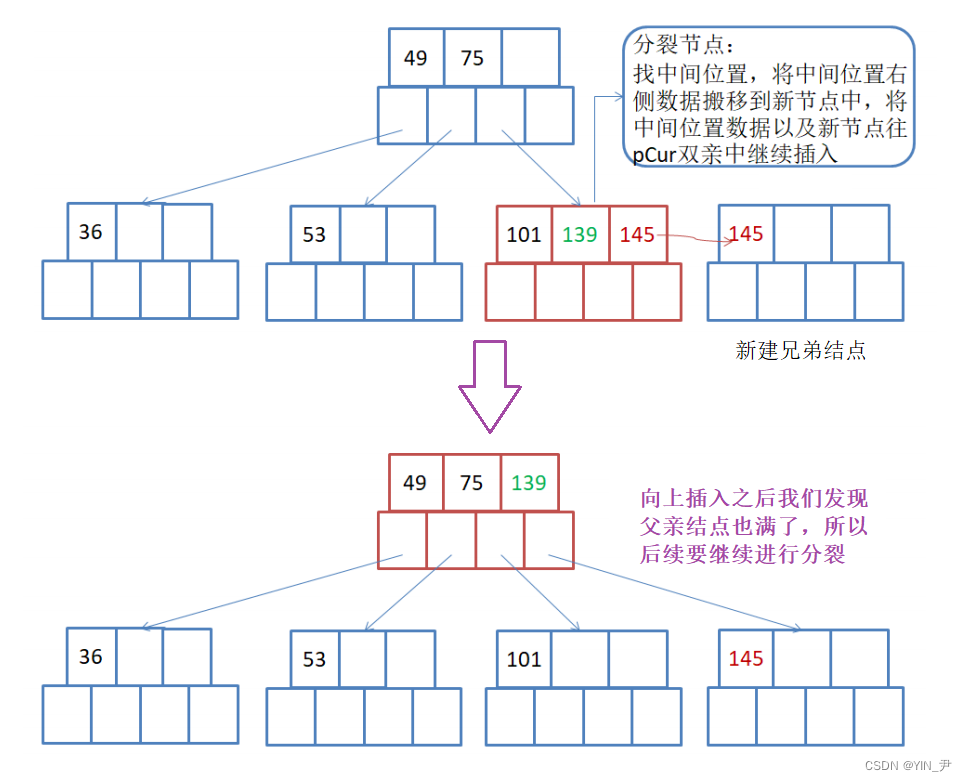
再往下插入101:
那插入之后这个结点的关键字数量大于m-1了,进行分裂
分裂的步骤还是和上面一样
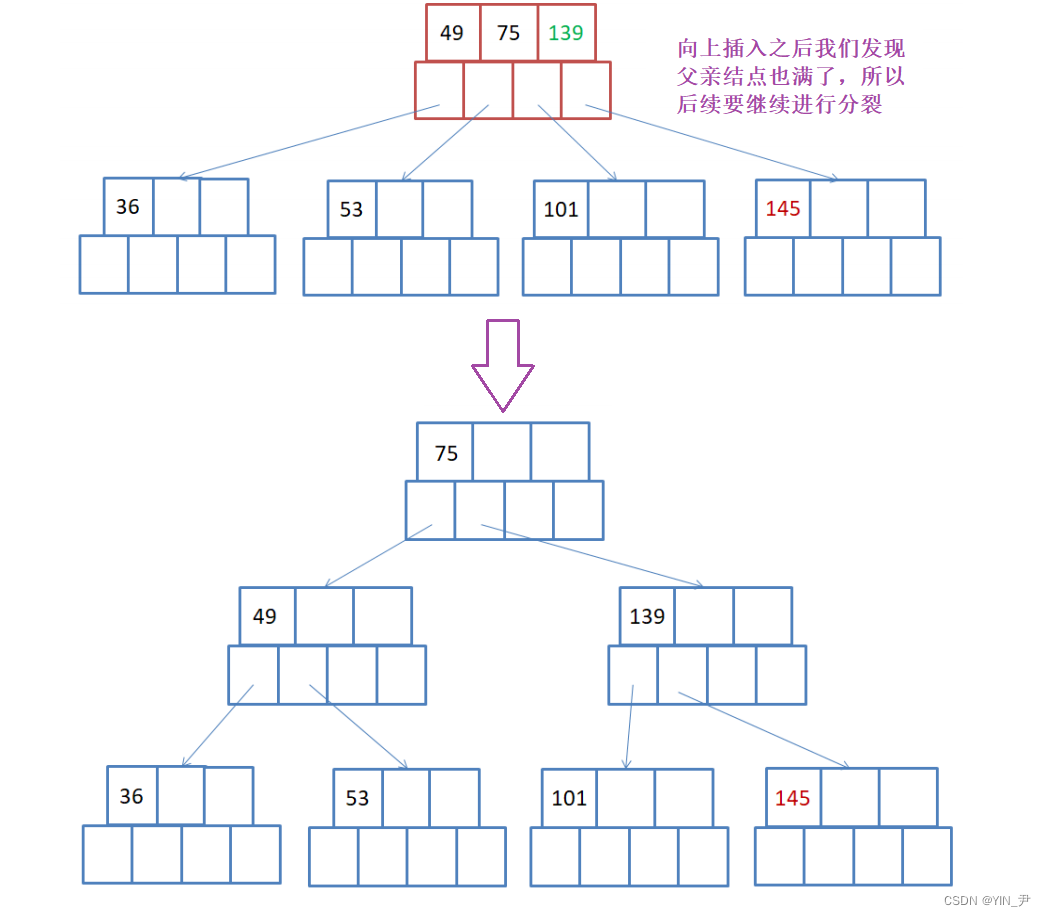
但是此时分裂之后我们发现父亲满了,所以需要继续向上分裂
那这就是一个完整的插入过程。
并且我们会发现B-树每一次插入之后他都是天然的完全平衡,不需要想红黑树AVL树那样,插入之后不满足平衡条件了,再去调整。
并且B-树的平衡是绝对平衡。每一棵树的左右子树高度之差都是0。
为什么他能保持天然的完全平衡呢?
通过上面的插入过程我们很容易发现B-树是向右和向上生成的,只会产生新的兄弟和父亲。
插入过程总结
- 如果树为空,直接插入新节点中,该节点为树的根节点
- 树非空,找待插入关键字在树中的插入位置(注意:找到的插入节点位置一定在终端节点中)
- 检测是否找到插入位置(假设树中的key唯一,即该元素已经存在时则不插入)
- 按照插入排序的思想将该关键字插入到找到的结点中
- 检测该节点关键字数量是否满足B-树的性质:即该节点中的元素个数是否等于M,如果小于则满足,插入结束
- 如果插入后节点不满足B树的性质,需要对该节点进行分裂:
申请新的兄弟节点
找到该节点的中间位置
将该节点中间位置右侧的元素以及其孩子搬移到新节点中
将中间位置元素(新建结点成为其右孩子)提取至父亲结点中插入,从步骤4重复上述操作
5. B-树的代码实现
那下面我们就来写写代码
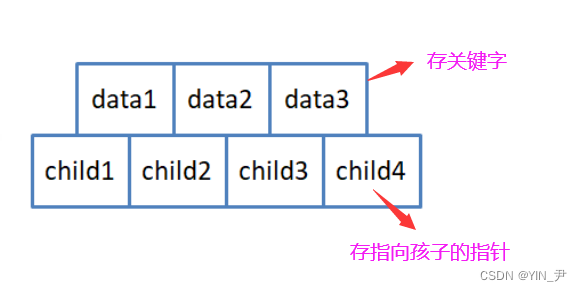
5.1 B-树的结点设计
那首先我们来定义一下B-树的结点:
我们这里还是搞成模板,简单一点,我们就不实现成KV模型了,就搞个K,当然在搞个非类型模板参数M控制B树的阶
template<class K, size_t M>
然后结点的话,我们上面分析过一棵3阶的B-树
为了方便插入之后分裂,我们要多开一个空间:正常每个结点最多M-1个关键字,M个孩子;那增加一个就是M个关键字,M+1个孩子。
那我们如何定义这样一个结构呢?
那这就是两个数组嘛。
然后还需要一个父亲指针,指向父结点;还需要再给一个成员变量记录当前结点实际存储关键字的个数
然后我们也可以写一个默认构造
那结点我们就定义好了

5.2 B-树的查找
那我们先来实现一个find,因为后面插入也要先find嘛:
这里我们实现一个不允许键值冗余的版本,如果存在就不再插入了,如果不存在我们让find直接给我们返回找到的那个要插入位置的结点,便于我们在Insert函数中直接将值插入到该结点中。
画个图我们来分析一下:
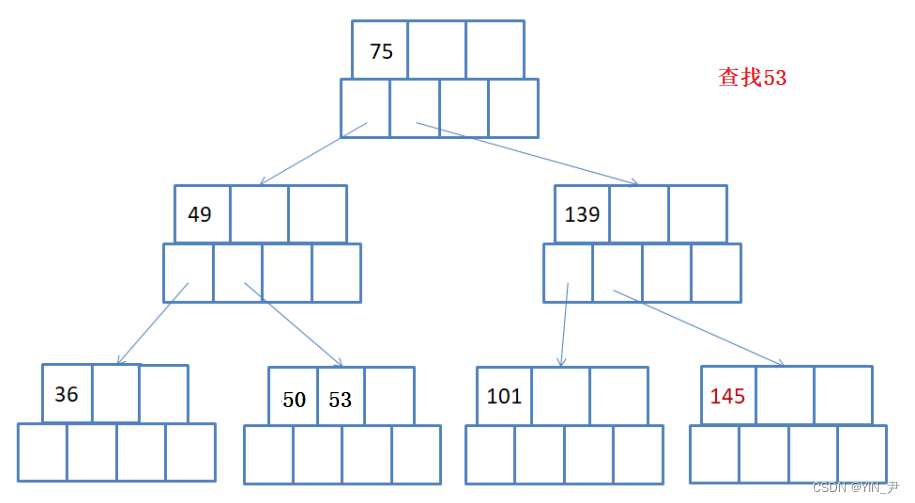
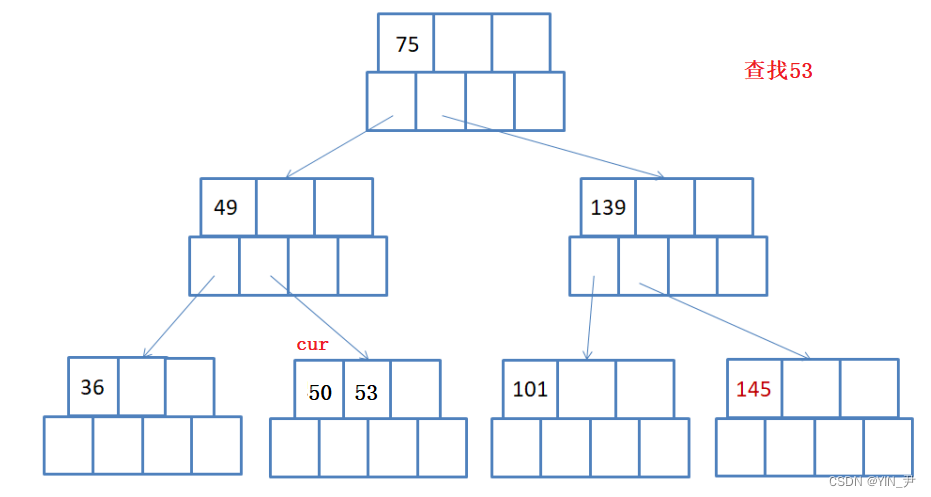
就比如这个图,我们现在要查找53。
那首先和根结点的关键字进行比较,当前根结点只有一个值75,53小于75,所以去他的左子树查找。
那我们来分析一下一个关键字和它的左右孩子之间的关系:
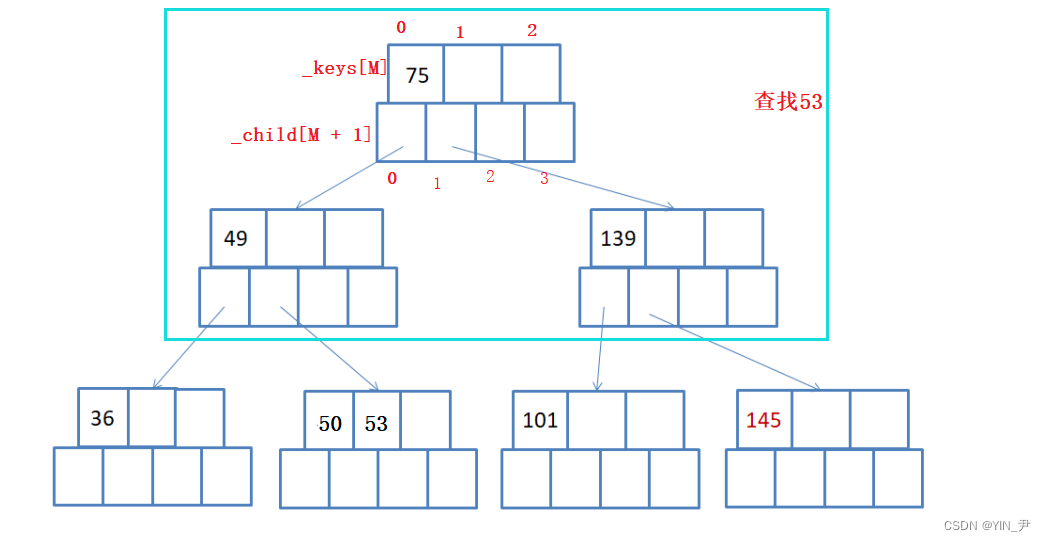
其实很容易看出来,在b-树中
一个关键字的左孩子在_child数组中的下标和该关键字在_keys数组中的下标是一样的,而右孩子的话,比关键字的下标大1
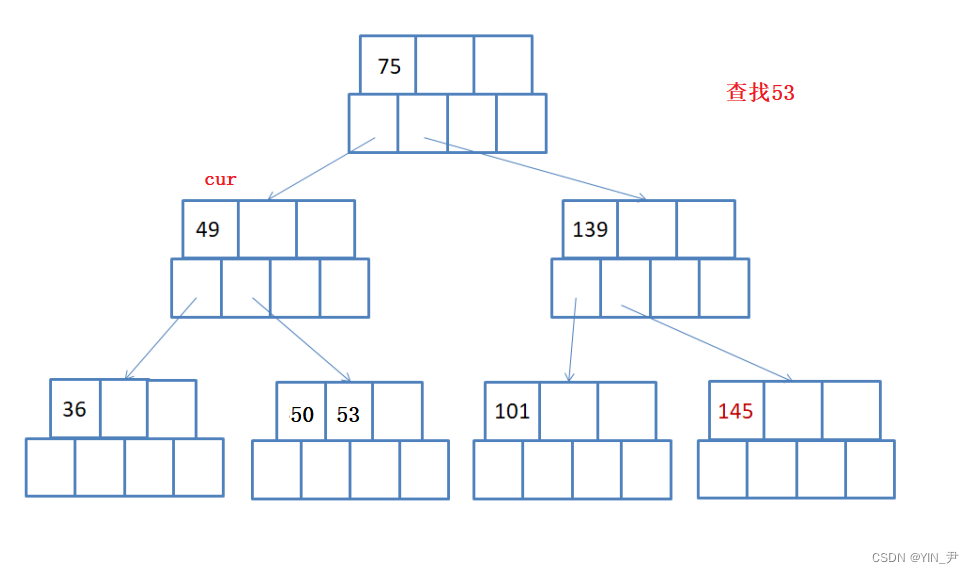
所以就走到它的左子树49这个结点,也只有一个关键字,53大于49,所以再去关键字49的右子树(如果49后面还有关键字的话,就继续跟后面的比)
那此时就走到50,53这个结点。
首先跟第一个关键字50比,比50大,那就继续往后比,后面是53,相等,找到了。
那如果查找52呢(不存在)?
前面是一样的,走到这个结点,比50大,往后比,比53小,所以去53的左子树,53的左子树为空,所以找不到了。

find就写好了:
pair<Node*, int> Find(const K& key)
{Node* parent = nullptr;//从根结点开始找Node* cur = _root;while (cur){// 在一个结点中查找size_t i = 0;while (i < cur->_n){if (key < cur->_keys[i]){break;}else if (key > cur->_keys[i]){++i;}else{return make_pair(cur, i);}}// 往孩子结点去跳parent = cur;cur = cur->_subs[i];}//没找到,返回parentreturn make_pair(parent, -1);
}
5.3 B-树的插入实现
接下来我们来写一下插入:
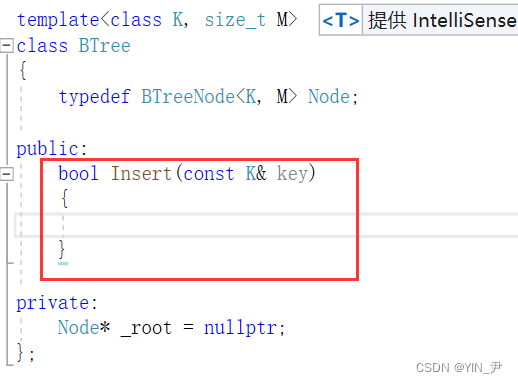
首先如果是第一次插入的话我们需要做一个单独处理:
判断root==nullptr,为空的话就是第一次插入
if (_root == nullptr)
{_root = new Node;_root->_keys[0] = key;_root->_n++;return true;
}
那再往下呢就是已经有结点的情况下插入:
那首先判断一下如果key已经存在,就不再插入
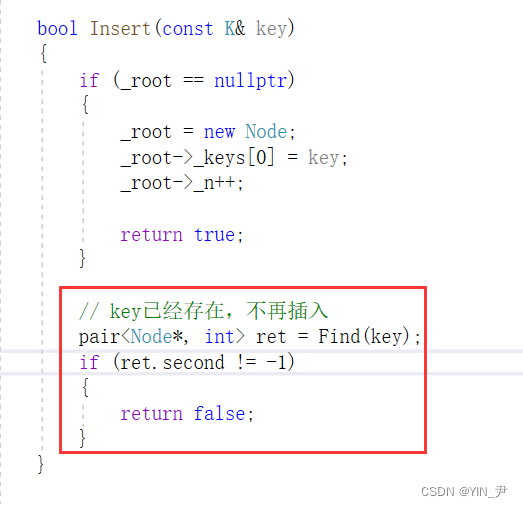
如果不存在,那就去插入(find顺便带回了要插入的那个目标位置的结点)
那我们接收一下find的返回值,在这个结点里面插入即可
InsertKey
那插入的时候需要保证结点里面关键字的顺序,可以用插入排序的思想把新的关键字插进去(如果是分裂之后向父亲插入的话,它可能还有孩子),那我们这里再单独封装一个InsertKey的函数:
代码就是这样的,插入排序如果大家遗忘了可以看之前的文章,还有不理解的地方建议大家看着我们上面分析插入的图走一遍代码
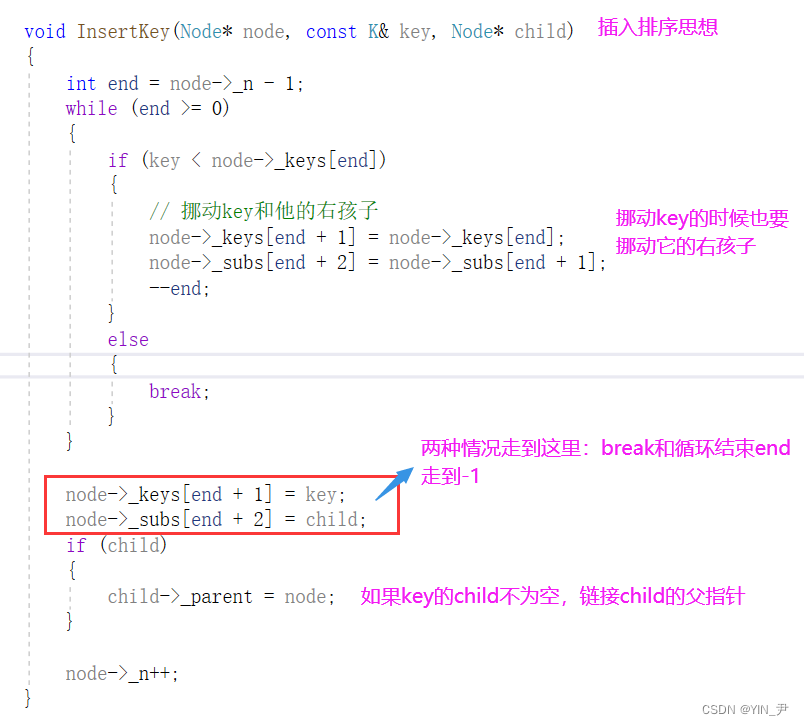
void InsertKey(Node* node, const K& key, Node* child)
{int end = node->_n - 1;while (end >= 0){if (key < node->_keys[end]){// 挪动key和他的右孩子node->_keys[end + 1] = node->_keys[end];node->_subs[end + 2] = node->_subs[end + 1];--end;}else{break;}}node->_keys[end + 1] = key;node->_subs[end + 2] = child;if (child){child->_parent = node;}node->_n++;
}
插入和分裂
然后我们就可以调用InsertKey接口去插入关键字,但是插入的话:
按理说是插入一次,但是如果插入之后存储关键字的数组满了(我们多开了一个空间,满的话就不满足B-树的性质——至多含有m-1个关键字了),就需要进行分裂
分裂的话,就又需要往parent去插入(插入中间值),当然分裂的兄弟结点也要成为parent的孩子(孩子和关键字都增加1,依然符合规则)
然后插入之后满了还需要再往上分裂,所以应该写成一个循环
最终完整的Insert函数:
这里还是比较麻烦的,不过注释写的比较清晰了,我就不过多解释了。
建议大家对照着我们上面画的图去理解。

bool Insert(const K& key)
{if (_root == nullptr){_root = new Node;_root->_keys[0] = key;_root->_n++;return true;}// key已经存在,不再插入pair<Node*, int> ret = Find(key);if (ret.second != -1){return false;}// 如果不存在,find顺便带回了要插入的那个目标位置的结点//因为后面可能需要分裂继续往父结点插入,//所以这里我们接收find的返回值直接命名为parentNode* parent = ret.first;//参数中的key,const修饰不能修改,定义一个newkeyK newKey = key;//分裂的兄弟也要作为孩子插入到父结点,所以再定义一个child//当然第一次插入关键字的时候孩子是空Node* child = nullptr;//有可能多次分裂往上一直插入,所以需要写成循环while (1){InsertKey(parent, newKey, child);// 没有满,插入就结束if (parent->_n < M){return true;}else// 满了就要分裂{size_t mid = M / 2;// 分裂一半[mid+1, M-1]给兄弟Node* brother = new Node;size_t j = 0;size_t i = mid + 1;for (; i <= M - 1; ++i){// 拷贝key和key的左孩子给兄弟结点brother->_keys[j] = parent->_keys[i];brother->_subs[j] = parent->_subs[i];//如果孩子不为空,链接父亲指针if (parent->_subs[i]){parent->_subs[i]->_parent = brother;}++j;// 拷走的key清除重置一下方便调式观察parent->_keys[i] = K();parent->_subs[i] = nullptr;}// 还有最后一个右孩子也拷过去brother->_subs[j] = parent->_subs[i];if (parent->_subs[i]){parent->_subs[i]->_parent = brother;}parent->_subs[i] = nullptr;//重新设置它们的有效关键字数量brother->_n = j;parent->_n -= (brother->_n + 1);//+这个1是因为还提走了中位数K midKey = parent->_keys[mid];//清除重置提走的mid中位数parent->_keys[mid] = K();if (parent->_parent == nullptr)// 说明分裂是根节点{//那要创建新的根_root = new Node;_root->_keys[0] = midKey;//上面分裂的结点及分裂出的兄弟成为新的根的孩子_root->_subs[0] = parent;_root->_subs[1] = brother;_root->_n = 1;//将原结点和分裂的兄弟链接到新的根上parent->_parent = _root;brother->_parent = _root;break;}else// 分裂的不是根,转换成往parent->parent 去插入parent->[mid] 和 brother{newKey = midKey;child = brother;parent = parent->_parent;}}}return true;
}
测试
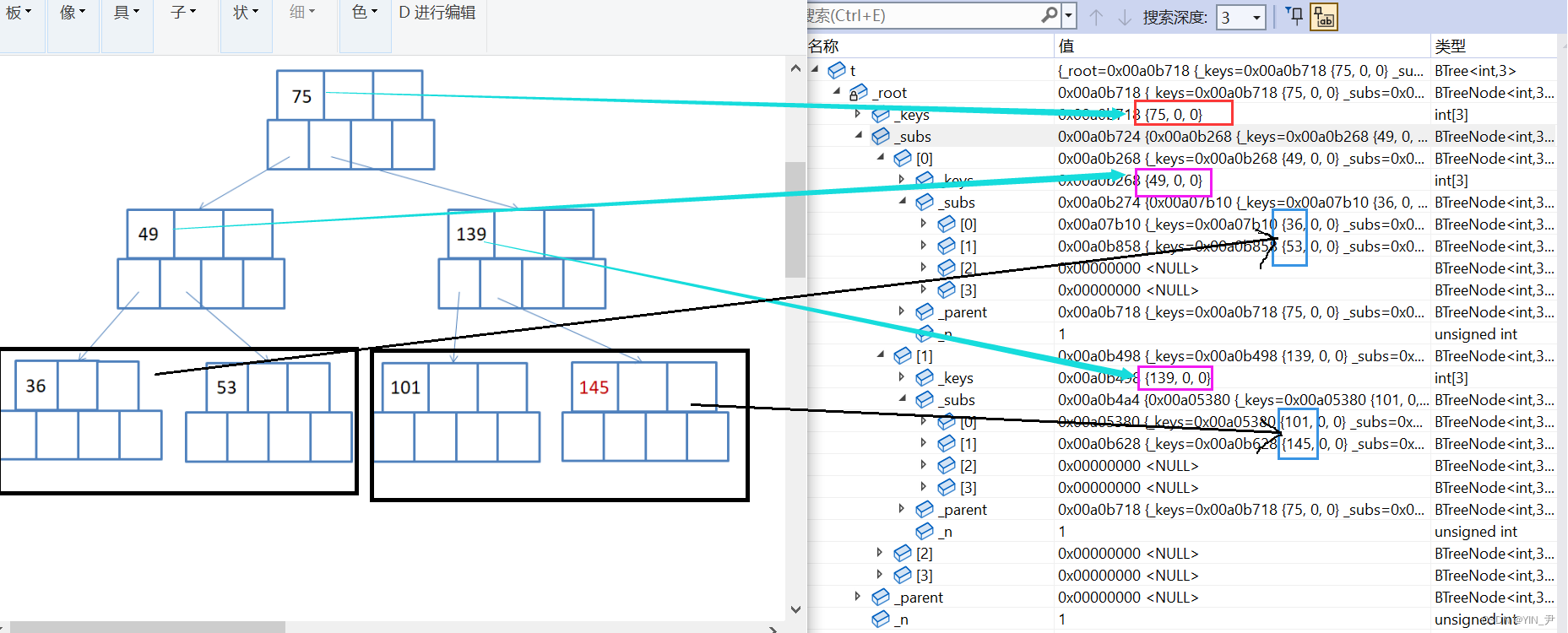
那下面我们就来构建一棵树来测试一下:
就拿我们上面画图分析对应的那棵树:
我们通过监视窗口来观察一下
对比一下,是没什么问题的。
6. B-树的删除(思想)
学习B树的插入足够帮助我们理解B树的特性了,那至于删除呢我们这里可以给大家讲一讲思路,代码的话我们就不实现了,删除的代码也要比插入更加复杂,大家有兴趣的话呢可以参考《算法导论》-- 伪代码和《数据结构-殷人昆》–C++实现代码。
那下面我们来讲一下删除的思想:
同样也需要分情况讨论:
- 删除的关键字在非终端结点
处理方法是:
用其直接前驱或直接后继替代其位置,转化为对“终端结点”的删除
直接前驱:当前关键字左边指针所指子树中“最右下”的元素
直接后继:当前关键字右边指针所指子树中“最左下”的元素
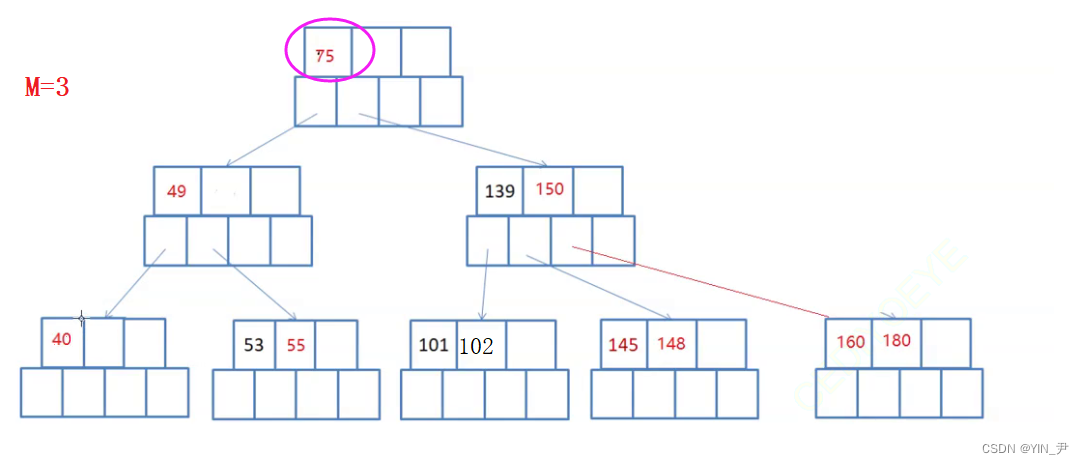
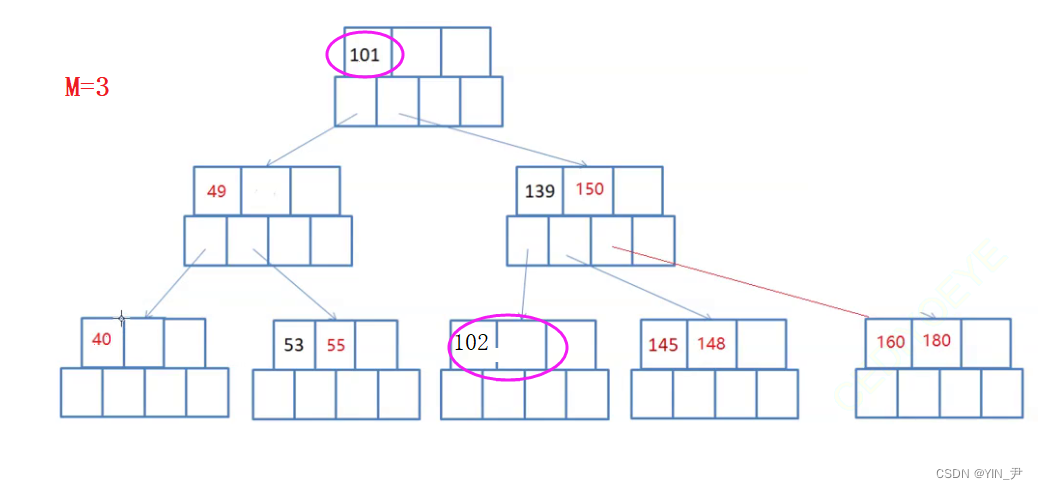
比如:
现在要删除75
首先第一种方法可以用直接前驱55替代其位置
或者用直接后继101替代
所以对非终端结点关键字的删除操作,必然可以转化为对终端结点的删除
所以下面我们重点来讨论终端结点的删除
- 删除的关键字在终端结点且删除后结点关键字个数未低于下限
若删除后结点关键字个数未低于下限ceil(m/2)-1,直接删除,无需做任何其它处理
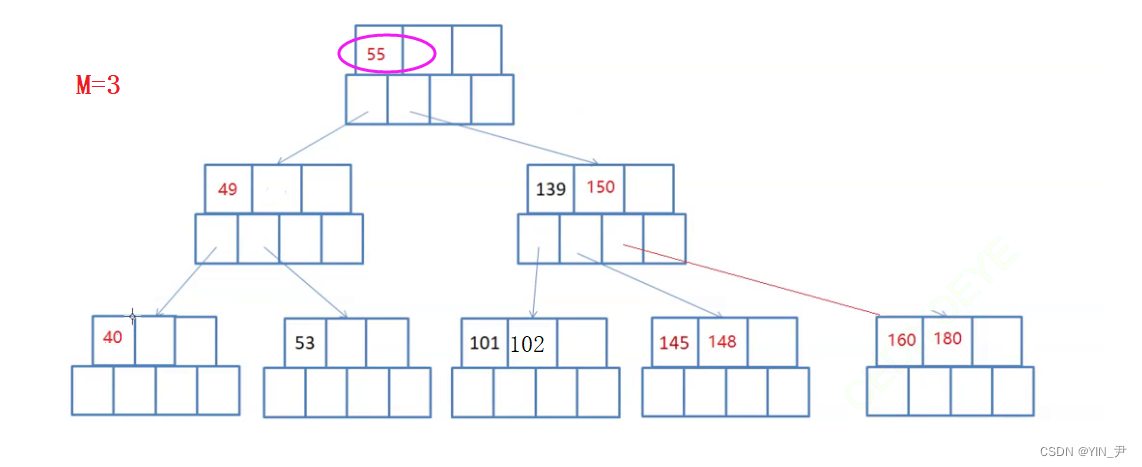
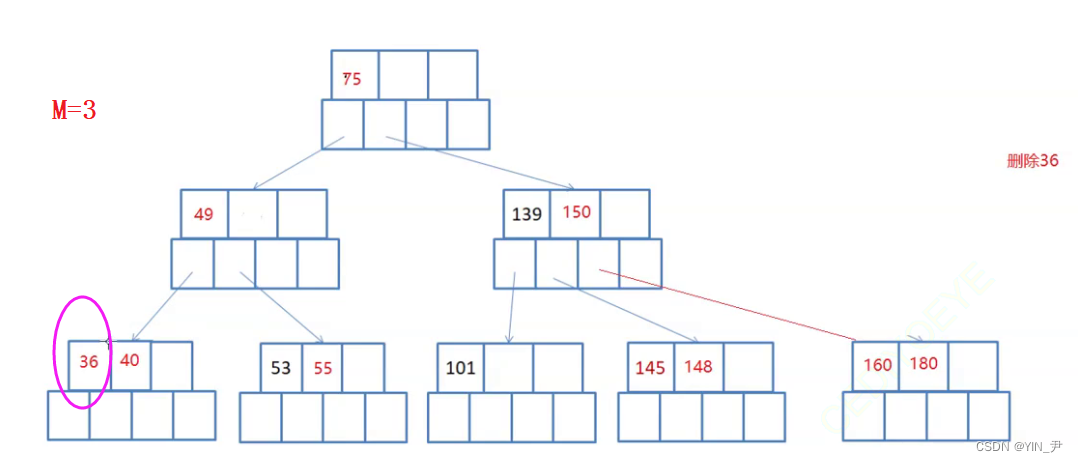
比如:
现在要删除36,所在的结点是终端结点,且删除之后,关键字的个数不少于ceil(3/2)-1=1,所以直接删除即可
那如果删除之后关键字的个数低于下限ceil(m/2)-1呢?
- 若删除的关键字在终端结点且删除后结点关键字个数低于下限ceil(m/2)-1
这时候的处理思路是这样的:
删除之后关键字数量低于下限,那就去“借”结点,跟父亲借,父亲再去跟兄弟借
如果不能借(即借完之后父亲或兄弟关键字个数也不满足了),那就按情况进行合并(可能要合并多次)。
最终使得树重新满足B-树的性质。
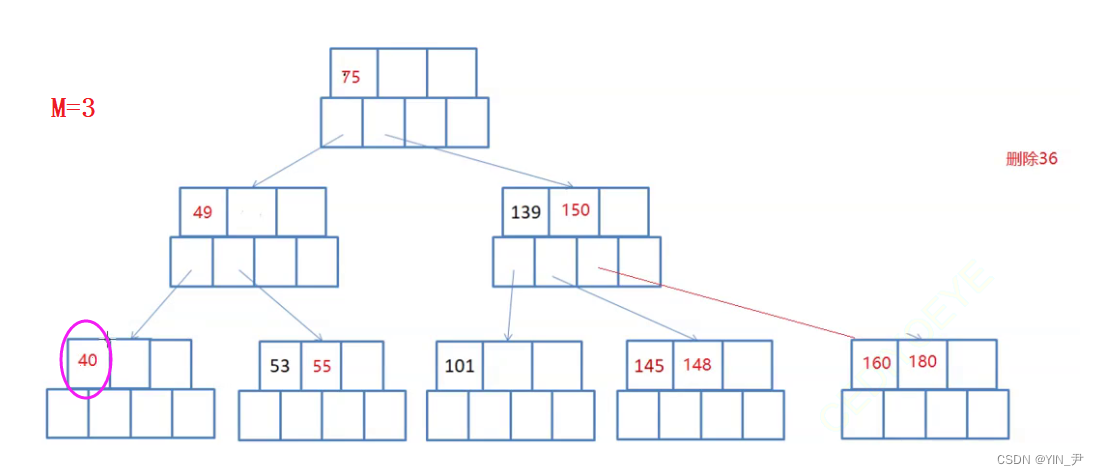
比如:
现在要删40,那40删掉的话这个结点关键字个数就不满足性质了,那就去跟父亲借,49借下来,那这样父亲不满足了,父亲再向兄弟借(要删除的那个关键字所在结点的兄弟结点),53搞上去
变成这样
此时就又符合是一棵B-树了
那如果不能借的情况呢?
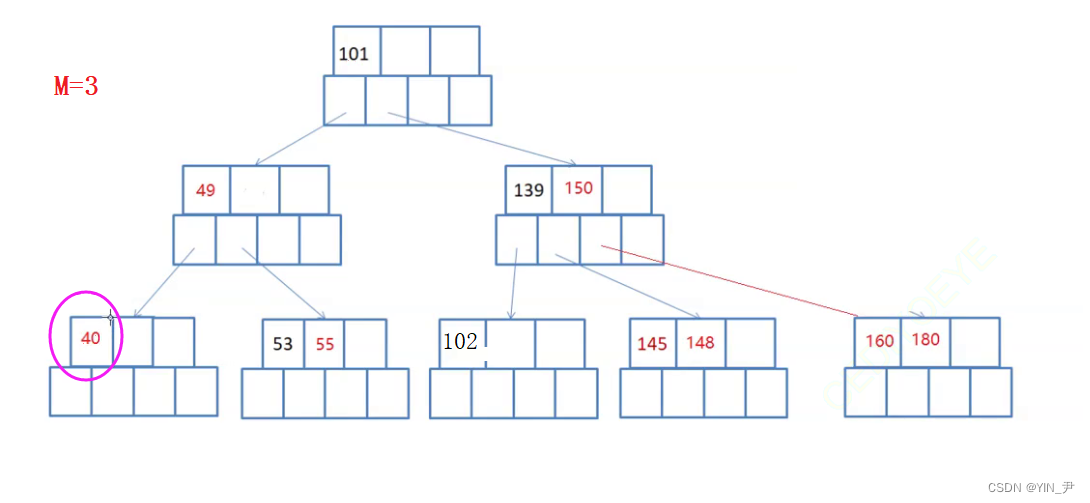
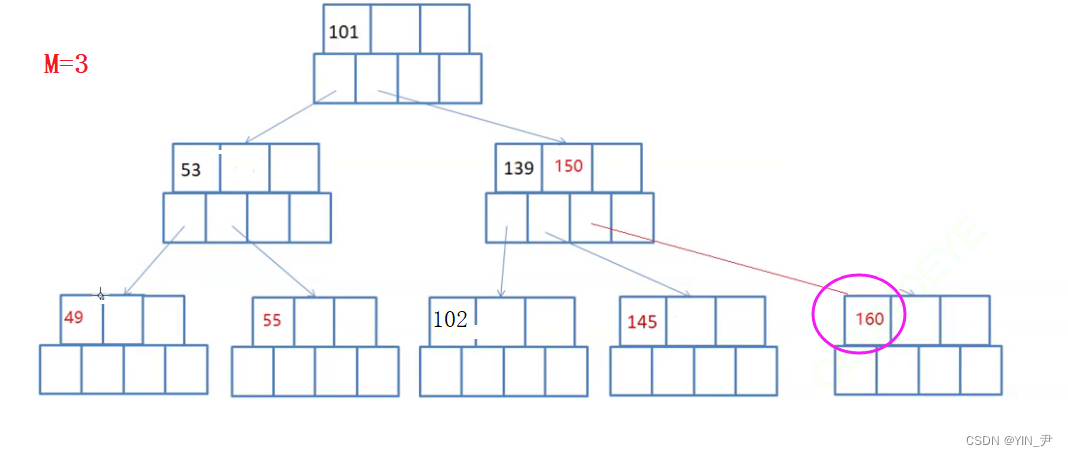
比如:
现在要删除160
160如果跟父亲借的话,150下来,那父亲不满足了,因为3个孩子,必须是2个关键字。而且此时兄弟145所在的这个结点也不能借了。因为此时它只有一个关键字,父亲借走一个的话,就不满足了。
所以此时借结点就不行了,就需要合并了。
如何合并呢?
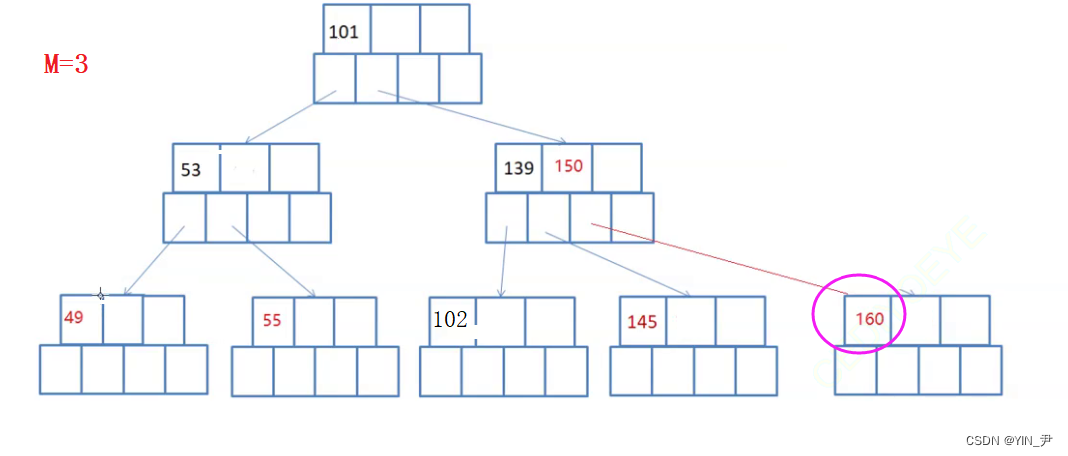
如果结点不够借,则需要将父结点内的关键字与兄弟进行合并。合并后导致父节点关键字数量-1,可能需要继续合并。
那我们先来看这个
这个情况我们分析了不够借,所以要合并。大家看,160删掉的话,父亲就少了一个孩子,那关键字也应该减少一个,所以可以把父结点的150与145这个孩子合并
这样就可以了。
当然还有些情况可能需要多次合并:
比如:
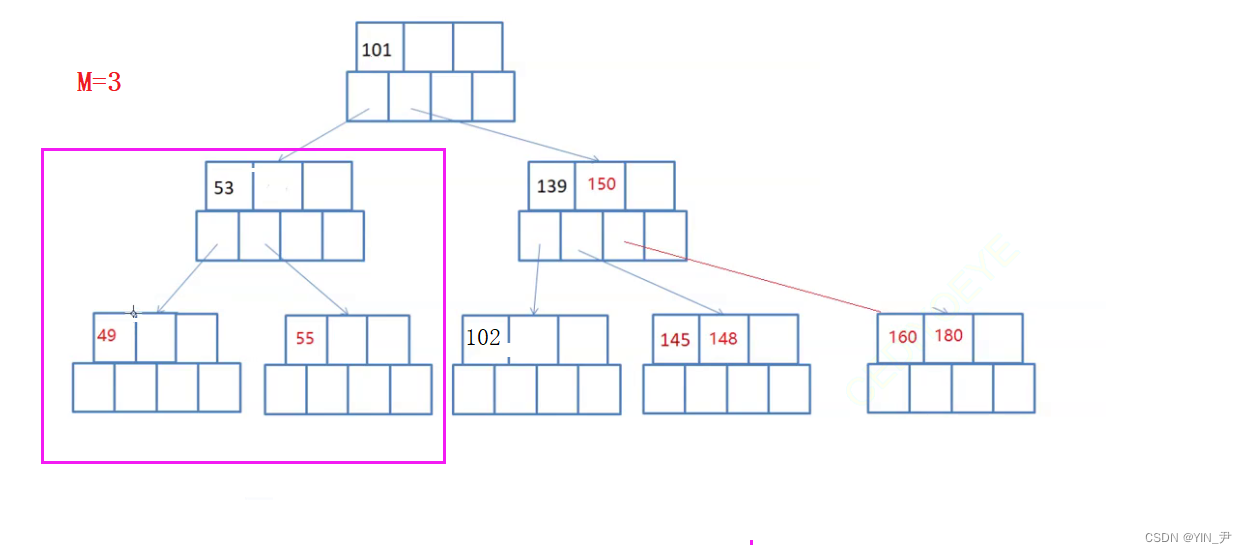
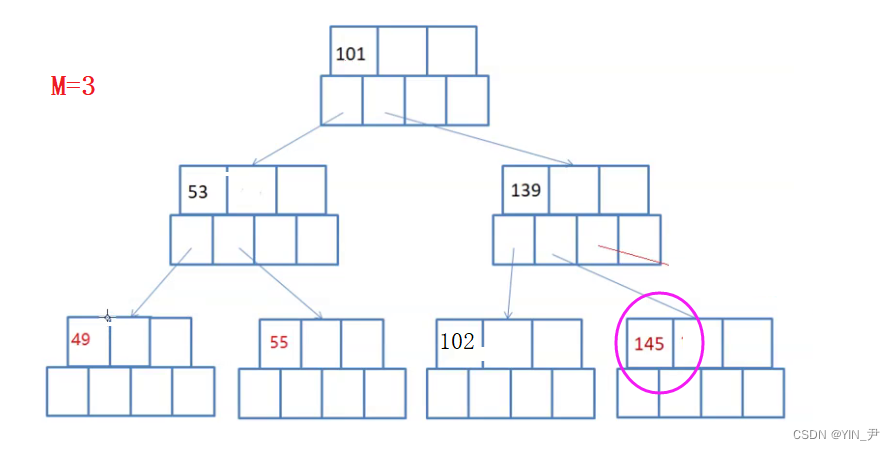
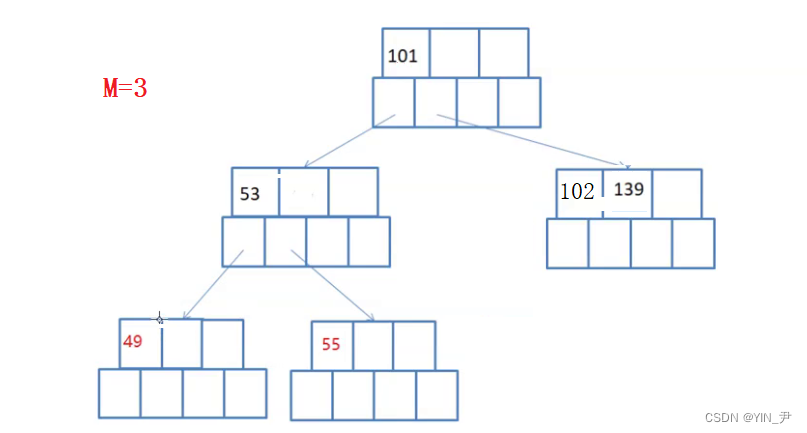
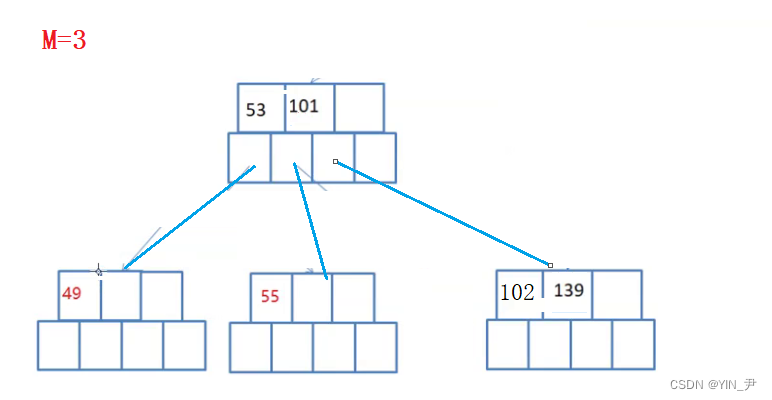
现在要删145,怎么办呢?
肯定是不够借的,所以要合并,确保合并之后依然满足B-树的规则就行了。
大家看这个可以怎么合并:
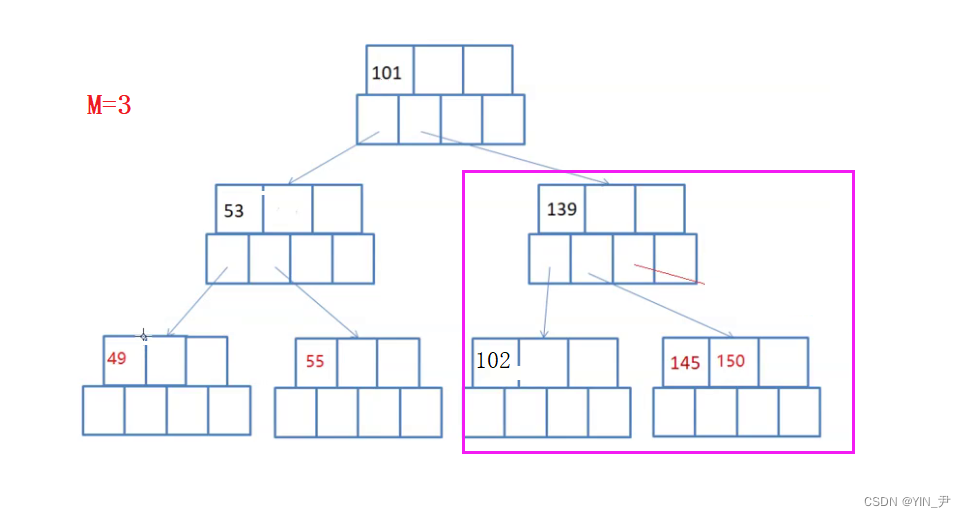
145干掉之后,左子树这里就不满足了,可以先将139跟102合并。
但是此时不平衡了(B-树是绝对平衡的)。
那就要继续合并缩减高度:
很容易看出来,我们可以将101和53合并作为根,这个正好两个关键字,3个孩子
就可以了
7. B-树的高度
问:含n个关键字的m阶B树,最小高度、最大高度是
多少?(注:大部分地方算B树的高度不包括叶子结点即查找失败结点)
最小高度
首先我们来分析一下最小高度:
n个关键字的m阶B树,关键字个数和B-树的阶数已经确定的话,那要让高度最小,我们是不是要让每个结点存的关键字是最满的啊。
那对于m阶的B树来说,每个结点最多m-1个关键字,m个孩子
第一层肯定只有一个根结点(最满的话是m-1个关键字,m个孩子),那第二层最多就有m个结点,每个结点最多m-1关键字,那第三层就是m*m个孩子嘛,以此类推…
那我们假设这个高度是h的话,关键字的总个数n就等于(关键字个数*结点个数):
(m-1)*(1+m+m^2+m^3+…+m^h-1)
即有:
n=(m-1)*(1+m+m^2+m^3+…+m^h-1)
解得最小高度h= l o g m ( n + 1 ) log_m(n+1) logm(n+1)
最大高度
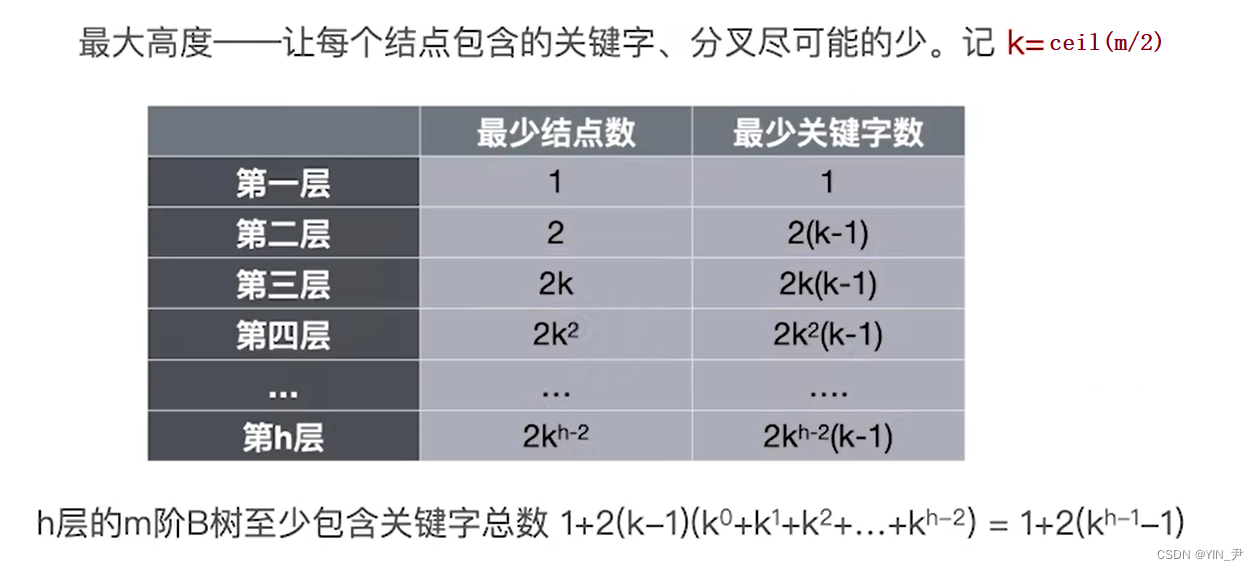
那最大高度呢:
那要让树变得尽可能高的话,那就要让每个结点得关键字数量尽可能少(分支尽可能少)。
第一层只有一个根结点(关键字最少是1,孩子是2),根结点最少两个孩子/分支,所以第二层2个结点。
又因为除了根结点之外的结点最少有ceil(m/2)个孩子,所以第三层就最少有2*ceil(m/2)个结点,第四层就是2*ceil(m/2)^2,以此类推…
第h就是2*ceil(m/2)^h-2个结点。
那么叶子结点(查找失败结点)的个数就是2*ceil(m/2)^h-1
那这里我们不再像上面那样求出总的关键字个数去算,怎么算呢?
这里补充一个结论:n个关键字的B-树必然有n+1个叶子节点
所以我们得出:
n+1=2*ceil(m/2)^h-1
那么解得最大高度h=[ l o g c e i l ( m / 2 ) ( n + 1 ) / 2 log_{ceil(m/2)}(n+1)/2 logceil(m/2)(n+1)/2] +1
当然也可以算出关键字的总个数来求解:
上面我们已经知道每层的结点个数,然后我们知道根结点最少一个关键字,其它结点最少k-1个关键字,k最小是ceil(m/2)
那么第一层就是1个关键字,第二层往后就是该层的节点个数*每个结点的最小关键字个数(k-1)
那么因此就有n=1+2(kh-1-1)
同样解得最大高度:
h=[ l o g c e i l ( m / 2 ) ( n + 1 ) / 2 log_{ceil(m/2)}(n+1)/2 logceil(m/2)(n+1)/2] +1
8. B-树的性能
B-树的效率是很高的,对于N = 62*1000000000个节点,如果度M为1024。
查找的坏最坏就是高度次嘛,h=[ l o g c e i l ( M / 2 ) ( N + 1 ) / 2 log_{ceil(M/2)}(N+1)/2 logceil(M/2)(N+1)/2] +1≈ l o g m / 2 N log_{m/2}N logm/2N
则 l o g m / 2 N log_{m/2}N logm/2N <= 4,即在620亿个元素中,如果这棵树的度为1024,则需要小于4次即可定位到该节点,然后利用二分查找可以快速定位到该元素,大大减少了读取磁盘的次数。
9. B-树的简单验证(中序遍历)
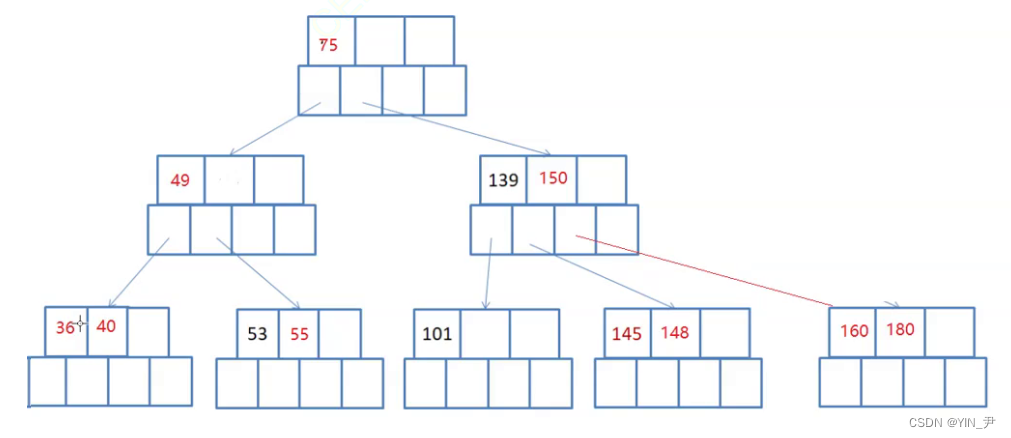
那B-树呢也是搜索树,同样满足左子树<根<右子树,那我们可以对它进行一个验证,看中序遍历是否能得到一个有序序列。
那下面我们就来实现一下B-树的中序遍历:
我们还是来搞一个图对照着分析一下思路:
就拿这个来分析:
对于我们之前学的二叉树来说中序遍历的思想是:左子树、根、右子树
那B-树的话它可能是一个多叉的,那它的中序遍历应该怎么走呢?
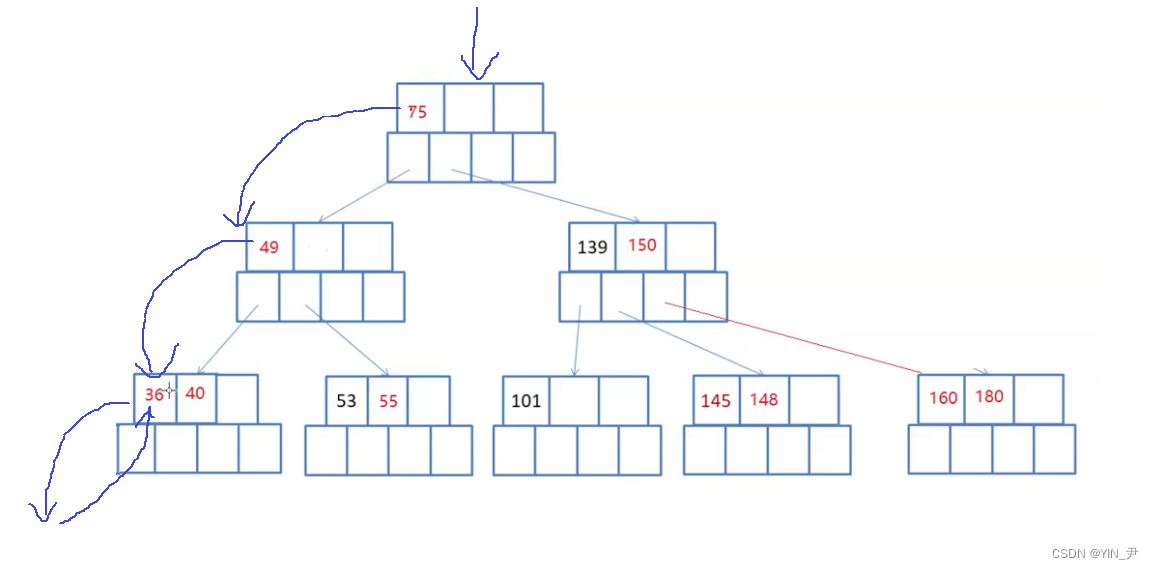
首先肯定还是先访问左子树,搜索树中最左的结点一定是最小的
当然如果算上空结点的话最左的应该是空,左子树,然后依然是根,就是36,36就是最小的,没问题。
左子树、根,那然后呢?
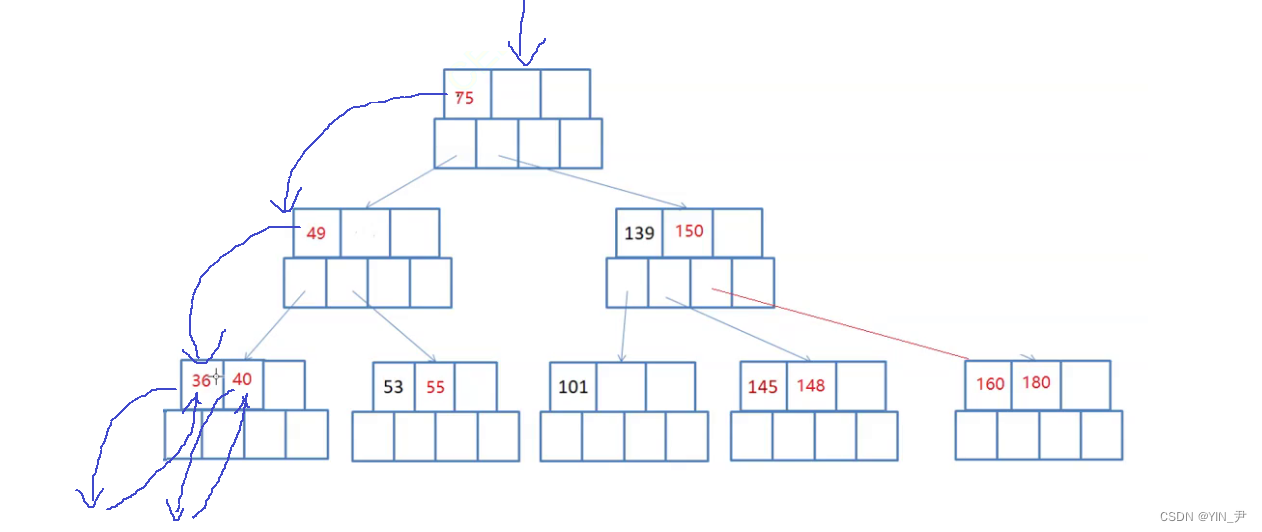
是36的右子树吗?可以认为是36的右子树,但是我们要把它当作40的左孩子看。
36这个关键字访问完,就走到后面的40,对于40,同样是先左子树,再根
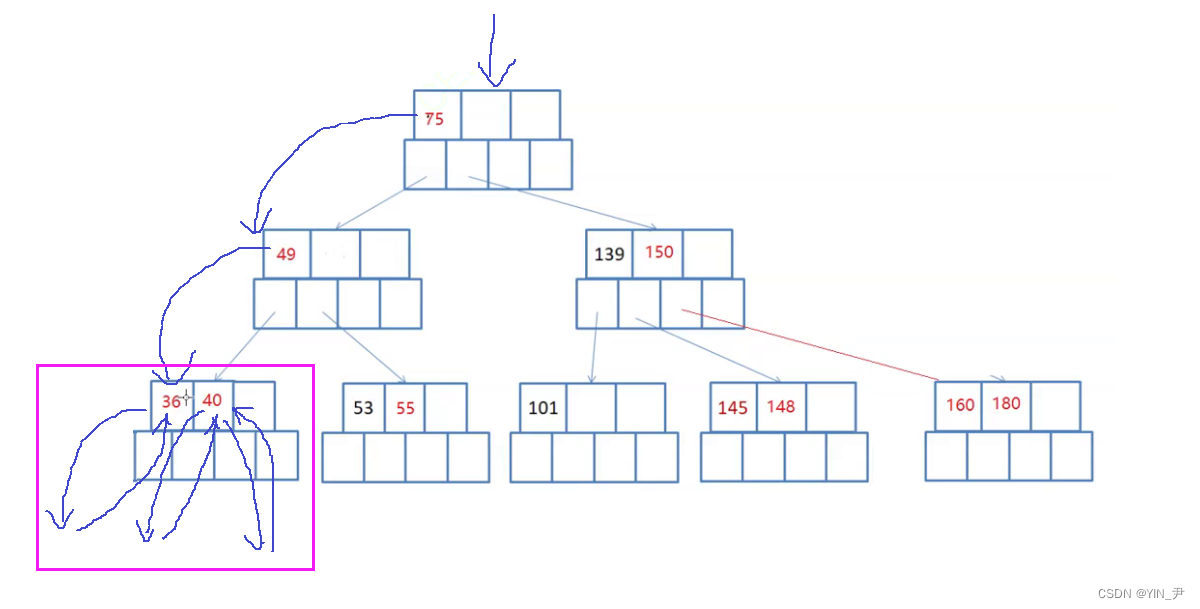
那这个第二个访问到的元素就是40,此时当前结点所有的关键字访问完了,最后再去访问最后一个关键字的右子树:
此时整个结点才被访问完。
那此时就相当于是49的左子树访问完了,然后访问根49,后面就是一样的处理…
🆗,大家看这样就可以了
所以B-树的中序遍历是怎么样的呢?
左子树、根;(下一个关键字的)左子树、根;(再下一个)左子树、根;…(一直往后直至走完最后一个关键字);右子树(最后一个关键字的右子树)
左 根 左 根 … 右
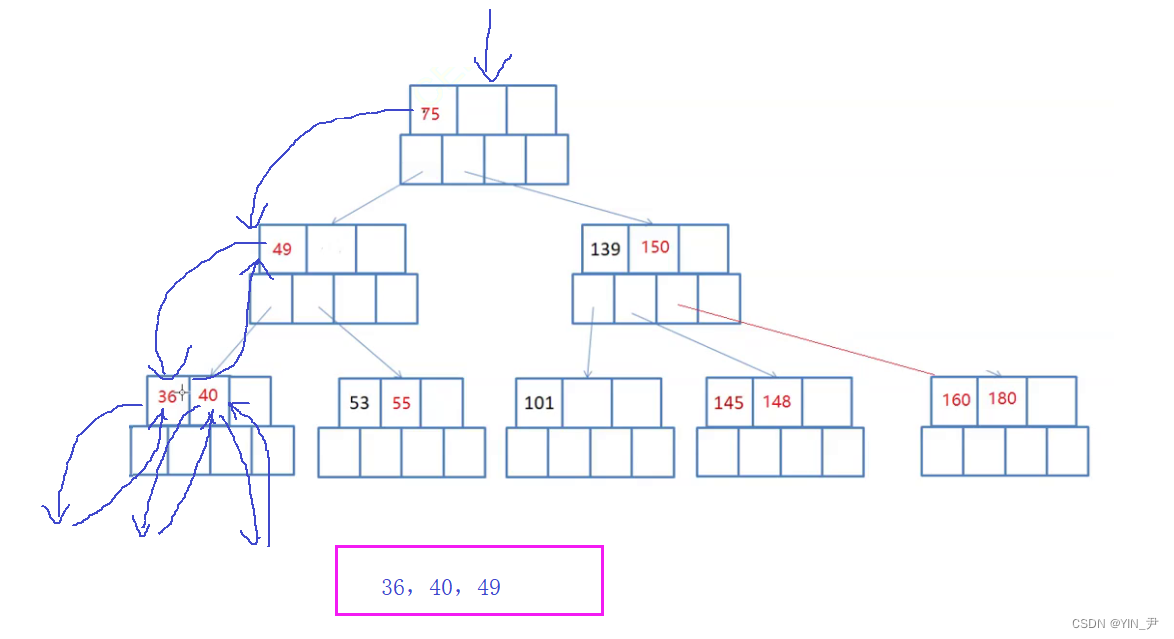
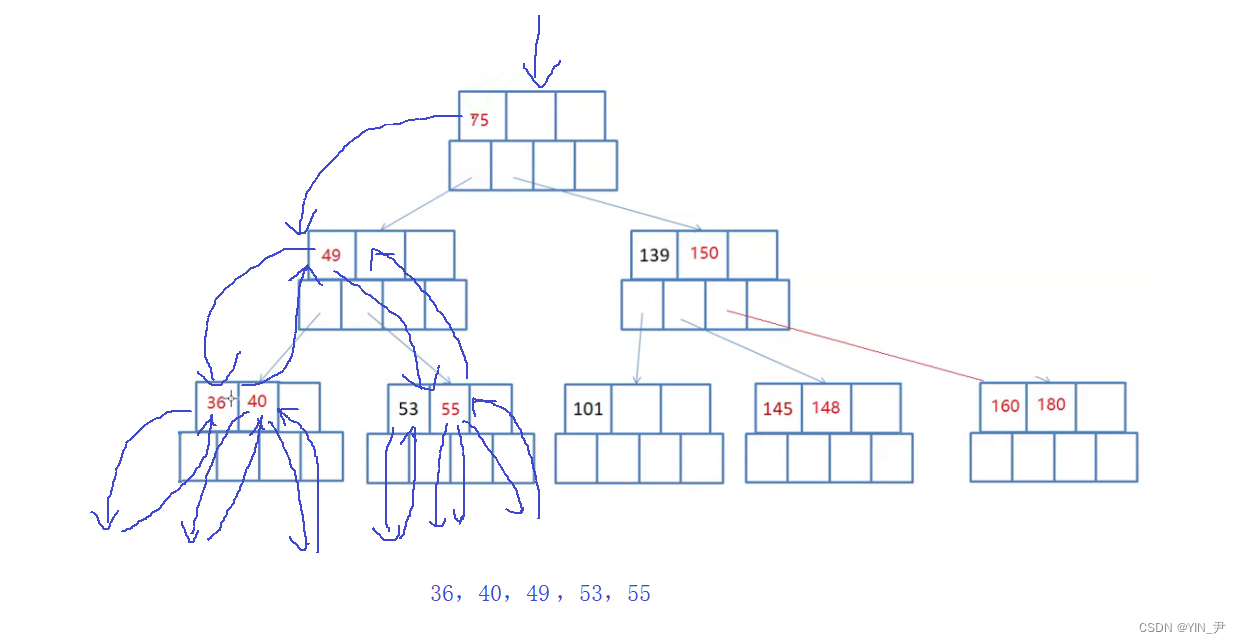
那理清了思路,我来实现一下代码:
注释写的比较清晰,就不多解释了
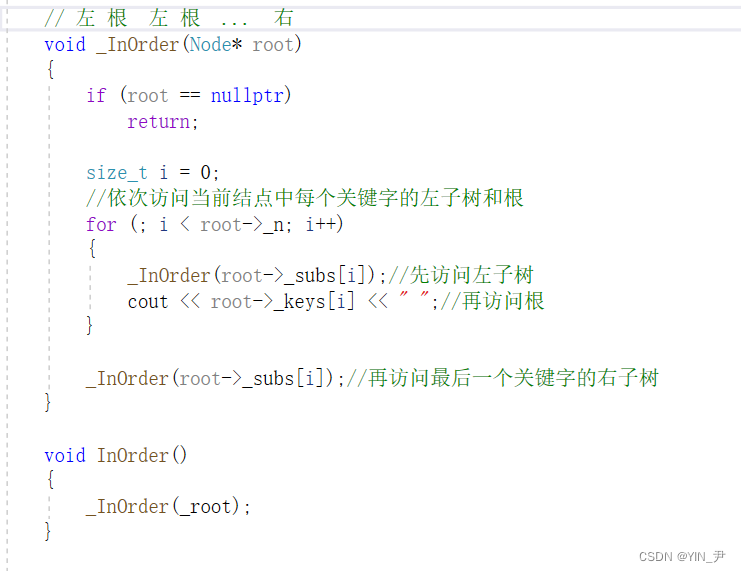
// 左 根 左 根 ... 右
void _InOrder(Node* root)
{if (root == nullptr)return;size_t i = 0;//依次访问当前结点中每个关键字的左子树和根for (; i < root->_n; i++){_InOrder(root->_subs[i]);//先访问左子树cout << root->_keys[i] << " ";//再访问根}_InOrder(root->_subs[i]);//再访问最后一个关键字的右子树
}void InOrder()
{_InOrder(_root);
}
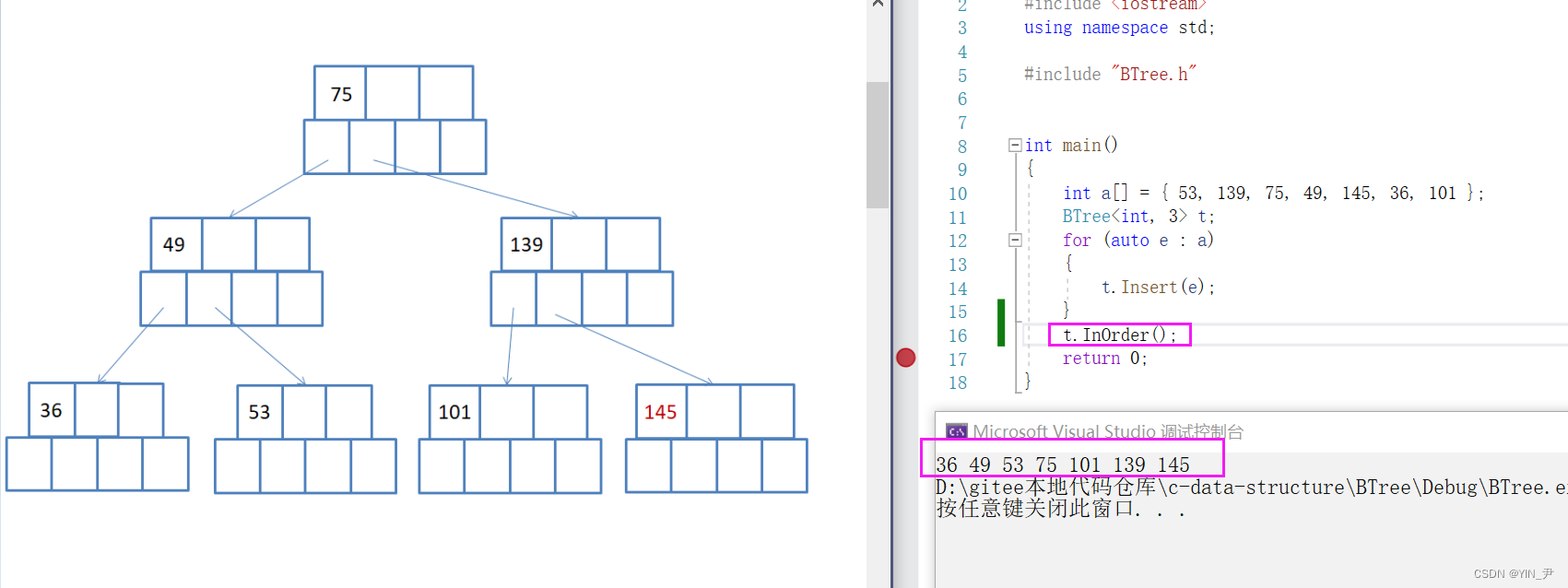
那我们来验证一下呗,中序遍历一下我们上面插入之后的那个B-树:
没有问题!
那对于B-树的讲解我们就先到这里…

相关文章:
【高阶数据结构】B-树详解
文章目录 1. 常见的搜索结构2. 问题提出使用平衡二叉树搜索树的缺陷使用哈希表的缺陷 3. B-树的概念4. B-树的插入分析插入过程分析插入过程总结 5. B-树的代码实现5.1 B-树的结点设计5.2 B-树的查找5.3 B-树的插入实现InsertKey插入和分裂测试 6. B-树的删除(思想&…...
elementui常用组件-个人版(间断更新)
Dialog 对话框 el-dialog <el-dialogtitle"提示":visible.sync"dialogVisible"width"30%":before-close"handleClose"><span>这是一段信息</span><span slot"footer" class"dialog-footer"…...

无人机在化工消防救援中的应用,消防无人机应用场景分析
火灾对社会环境具有较大影响,因此需要重视消防灭火救援工作,注重现代化技术的运用,将无人机应用到救援过程并保障其应用质量。无人机是一项重要技术,便于消防灭火救援操作,使救援过程灵活展开,排除不利影响…...

java设计模式- 建造者模式
一 需求以及实现方式 1.1 需求描述 我们要创建一个表示汽车的复杂对象,汽车包含发动机、轮胎和座椅等部分。用传统方式创建,代码如下 1.2 传统实现方式 1.抽象类 public abstract class BuildCarAbstaract {//引擎public abstract void buildEng…...
【C++航海王:追寻罗杰的编程之路】类与对象你学会了吗?(下)
目录 1 -> 再谈构造函数1.1 -> 构造函数体赋值1.2 -> 初始化列表1.3 -> explicit关键字 2 -> static成员2.1 -> 概念2.2 -> 特性 3 -> 友元3.1 -> 友元函数3.2 -> 友元类 4 -> 内部类5 -> 匿名对象6 -> 拷贝对象时的一些编译器优化 1 -…...

解决TSP旅行商问题3个可以用Python编程的优化路径算法
旅行商问题(Traveling Salesman Problem, TSP)是一个经典的组合优化问题,它要求找到访问一系列城市并返回起点的最短可能路线,同时每个城市仅访问一次。这个问题是NP-hard的,意味着没有已知的多项式时间复杂度的精确算…...

10英寸安卓车载平板电脑丨ONERugged车载工业平板:解决农业工作效率
农业是人类社会的基石之一,而农业工作效率的提升一直是农民和农业专业人士关注的重要议题。随着技术的不断进步,车载工业平板成为了解决农业工作效率的创新解决方案。本文将探讨车载工业平板如何为农业带来巨大的改变,提高农民的工作效率和农…...

Mysql报错:too many connections
1 问题原因 MySQL报错“too many connections”通常是由于数据库的最大连接数超过了MySQL配置的最大限制。有以下几个原因: (1)访问量过高:当MySQL服务器面对大量的并发请求时,已经建立的连接数可能会不足以处理所有的请求,从而导致连接池耗尽、连接被拒绝、出现“too …...
1Panel面板如何安装并结合内网穿透实现远程访问本地管理界面
文章目录 前言1. Linux 安装1Panel2. 安装cpolar内网穿透3. 配置1Panel公网访问地址4. 公网远程访问1Panel管理界面5. 固定1Panel公网地址 前言 1Panel 是一个现代化、开源的 Linux 服务器运维管理面板。高效管理,通过 Web 端轻松管理 Linux 服务器,包括主机监控、…...
的Python导入pandas包,报错:ImportError: No module named ‘_bz2‘)
Linux(Debian系)的Python导入pandas包,报错:ImportError: No module named ‘_bz2‘
前言: 硬件操作系统国产化路漫漫,由此可见华为的厉害。 今天在香橙派上用自己编译的python导入pandas时,报错: from _bz2 import BZ2Compressor, BZ2Decompressor ImportError: No module named _bz2ImportError: No module name…...

React useEffect使用
第一 export default function App() { const [name,setname] useState(huhu) useEffect(()>{ setname(name.substring(0,1).toUpperCase()name.substring(1)) },[name]) //[name,age]//可以有多个参数 //带参数,第一次默认执行一次,第二次name更新…...
三网码支付系统源码,三网免挂有PC软件,有云端源码,附带系统搭建教程
搭建教程 1.先上传云端源码 然后配置Core/Config.php文件里面数据库信息注改;数据库帐号密码 2.云端源码里面Core/Api_Class/Instant_Url_List.php文件配置终端地址注改;第4 http://终端地址/ 3.导入云端数据库 账号admin 密码123456注改࿱…...

编程笔记 html5cssjs 073 JavaScript Object数据类型
编程笔记 html5&css&js 073 JavaScript Object数据类型 一、创建 Object二、Object 类型的属性与方法三、示例四、参考小结 JavaScript 中的 Object 数据类型是该语言中最复杂也最灵活的数据类型之一,它是其他所有内置对象和用户自定义对象的基础。在 JavaS…...
【Linux】基于管道进行进程间通信
进程间通信 一、初识进程间通信1. 进程间通信概念2. 进程间通信分类 二、管道1. 管道概念2. 管道原理3. 匿名管道4. 匿名管道系统接口5. 管道的特性和情况6. 匿名管道的应用(1)命令行(2)进程池 7. 命名管道(1ÿ…...

Vue中间件的讲解案例分析
Vue中间件的讲解案例分析 1. Axios中间件: Axios是一个常用的HTTP客户端,可以与Vue结合使用,处理网络请求和数据获取。您可以创建一个Axios实例,并将其作为Vue的原型属性或插件使用,以便在整个应用程序中共享和使用。…...

【C生万物】C语言分支和循环语句
📚博客主页:爱敲代码的小杨. ✨专栏:《Java SE语法》 | 《数据结构与算法》 | 《C生万物》 ❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️ 🙏小杨水平有…...
Vue代理模式和Nginx反向代理(Vue代理部署不生效)
在使用axios时,经常会遇到跨域问题。为了解决跨域问题,可以在 vue.config.js 文件中配置代理: const { defineConfig } require(vue/cli-service) module.exports defineConfig({transpileDependencies: true,devServer: {port: 7070,prox…...

C语言中的作用域与生命周期
作用域(scope)是程设计概念,通常来说,一段程序代码中所⽤到的名字并不总是有效的,而限定这个名字的可⽤性的代码范围就是这个名字的作用域。 局部变量的作用域是变量所在的局部范围。全局变量的作用域是整个工程&…...

MATLAB计算多边形质心/矩心
前言:不规则四边形的中心 不规则四边形的出心有多种定义,以下是最常见的三种: 1.重心:重心是四边形内部所有顶点连线交点的平均位置。可以通过求解四个顶点坐标的平均值来找到重心。 2.质心:质心是四边形内部所有质点…...

IP地址如何保护网络安全
面对网络攻击时,仅依靠常态化的网络安全防御系统已捉襟见肘,如联合使用IP地址数据可以形成多元化的安全解决方案,全面监控网络活动,发现潜在威胁,制定有针对性的应对措施。 网络攻击追踪 当网站或应用遭受DDoS等网络攻…...

别再让树莓派吃灰了!用腾讯云轻量服务器+frp,5分钟搞定远程SSH和VNC访问
树莓派远程访问实战:5分钟解锁SSH与VNC的轻量级方案 每次打开抽屉看到积灰的树莓派,总有种辜负了这片单板计算机潜力的愧疚感。其实只需一台基础配置的云服务器,就能让闲置设备变身24小时在线的开发工作站。本文将用最简步骤实现:…...
深度探秘:以一次文件打开操作为例)
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例 当我们在终端输入cat /etc/shadow时,系统背后究竟发生了什么?这个看似简单的操作,实际上触发了一系列精妙的安全检查机制。本文将带您深入Linux内…...
)
从学生到工程师:我如何用大学单片机课设代码搞定第一个嵌入式项目(STM8实战)
从学生到工程师:STM8实战中如何将课设代码升级为工业级解决方案 记得大三那年,我第一次在实验室里点亮STM8开发板的LED时,那种成就感至今难忘。但当我真正进入企业参与嵌入式项目开发时,才发现学校里的"标准答案"在真实…...

6.1B激活,三榜开源第一!蚂蚁·安诊儿医疗大模型发布
刚刚,由浙江省卫生健康信息中心、蚂蚁健康与浙江省安诊儿医学人工智能科技有限公司联合研发,迄今为止规模最大、能力最强的开源医疗语言模型 AntAngelMed 发布并开源。模型基于 Ling-flash-2.0,MoE架构,100B 总参数仅激活 6.1B 即…...

群晖DSM 7.2.2视频站恢复指南:三步搞定Video Station完整功能
群晖DSM 7.2.2视频站恢复指南:三步搞定Video Station完整功能 【免费下载链接】Video_Station_for_DSM_722 Script to install Video Station in DSM 7.2.2 and DSM 7.3 项目地址: https://gitcode.com/gh_mirrors/vi/Video_Station_for_DSM_722 还在为升级到…...

AI应用治理平台ZLAR:从网关到统一架构的演进与实践
1. 项目概述:从单一工具到统一平台的演进最近在折腾AI应用开发,特别是涉及到多模型调用、安全审计和策略执行这块,发现很多开源项目都是“各自为政”。比如,你需要一个网关来管理AI模型的访问,又需要一个独立的日志系统…...

luci-app-aliddns:5分钟搞定动态IP远程访问,让家庭网络永不掉线
luci-app-aliddns:5分钟搞定动态IP远程访问,让家庭网络永不掉线 【免费下载链接】luci-app-aliddns OpenWrt/LEDE LuCI for AliDDNS 项目地址: https://gitcode.com/gh_mirrors/lu/luci-app-aliddns 你是否曾经因为家庭宽带的动态IP地址而无法稳定…...

PyQt6 GUI开发实战:构建现代化桌面应用的架构设计指南
PyQt6 GUI开发实战:构建现代化桌面应用的架构设计指南 【免费下载链接】PyQt-Chinese-tutorial PyQt6中文教程 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Chinese-tutorial 在当今软件开发领域,桌面应用依然占据着重要地位,特…...

ClawSuite:模块化网络安全工具集的设计原理与实战应用
1. 项目概述:ClawSuite,一个被低估的网络安全工具集如果你在网络安全领域摸爬滚打过几年,尤其是做过渗透测试或者红队评估,那你肯定对Metasploit、Nmap、Burp Suite这些名字如数家珍。但今天我想聊一个在GitHub上相对低调…...

百度网盘Mac版加速插件:突破下载限制的实用方案
百度网盘Mac版加速插件:突破下载限制的实用方案 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 对于经常使用百度网盘的Mac用户来说&#x…...