LLM少样本示例的上下文学习在Text-to-SQL任务中的探索
导语
本文探索了如何通过各种提示设计策略,来增强大型语言模型(LLMs)在Few-shot In-context Learning中的文本到SQL转换能力。通过使用示例SQL查询的句法结构来检索演示示例,并选择同时追求多样性和相似性的示例可以提高性能,同时,LLMs也从与数据库相关的知识增强中受益。
- 会议:EMNLP 2023 Findings
- 标题:Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
- 链接:https://arxiv.org/abs/2305.12586
1 引言
文本到SQL解析作为信息检索系统的关键组成部分,将自然语言查询转化为可从数据库中检索相关信息的SQL语句。近年来,神经符号设计方法结合了神经网络的功能和符号逻辑的严密性,成为提高系统可靠性和鲁棒性的首选技术。本文的重点在于探索和验证各种提示设计策略,旨在提升大型语言模型在文本到SQL解析任务中的表现,并特别关注于利用SQL查询的句法结构来改进示例选择,实验结果证明了这种方法在提升性能方面的有效性。同时也发现LLMs在某些情况下能从数据库知识增强中受益。本研究在Spider数据集上获得的执行准确度高达84.4,超越了目前最先进的系统和最佳微调系统,突显了所提策略的有效性和实用性

2 方法
2.1 示例选择
该模块的目标是从上下文的示例池中选择一部分标注示例。可以使用的方法如
- 随机选取:从示例池中随机选择。
- 基于kNN的增强示例选择(KATE) :利用句子编码器将所有示例转换为连续向量,并根据输入与示例池的相似度选择k个最相似的示例。
本文提出使用输出SQL查询来选择示例,而不是使用输入问题。这是因为作者认为Text-to-SQL中SQL语句包含比输入问题中更明确的关于问题结构的信息。此外,与只能转换成连续语义向量的自然语言问题不同,SQL查询可以根据其语法转换成离散特征向量。为此,首先将所有池实例的SQL查询转换成离散语法向量。然后,这些元素被映射到二进制特征,表示它们在查询中的存在。推理时,首先使用初步预测器生成SQL查询草稿。然后,应用相同的过程将这个草稿查询转换成离散向量,用于检索演示示例。
作者提出了一种与之前不同的演示选择策略,即寻求平衡演示的相似性和多样性,这是通过将给定示例的表示从表示问题语义的连续值向量更改为捕获SQL语法的离散值向量来实现的。为此,首先将标注示例池划分为表示不同类别的不相交分区(基于难度等级)。给定一个测试实例,使用初步预测器生成一个草稿SQL查询,并根据其类别,检索属于相关分区的候选示例。接下来对示例的离散向量实施k-means聚类,选择靠近每个聚类中心的k个多样化示例用于构建提示。演示选择策略过程概述在算法1中。
2.2 指令中的架构表示
指令对于设计提示至关重要,因为它们通过阐明提供的资源如何帮助推理过程来定义任务。本文主要关注于确定指令中表示结构化知识源的最佳方式,并确定可以增强推理过程的补充资源。
作者首先改变结构化知识的线性化方式。在以前的研究中,诸如数据库或表之类的结构化知识源已被线性化为“文本”序列。相反,本文提议使用“代码”序列来表示数据库,特别是用于最初构建表的CREATE查询,如附录中的清单1和2所示。这种线性化方法为每列提供了数据类型信息,并包含了数据库中所有外键约束的细节。此外,本文修改了指令中的其他资源,比如数据库中的问题和示例条目,使它们符合代码序列样式,通过将它们作为注释附加。
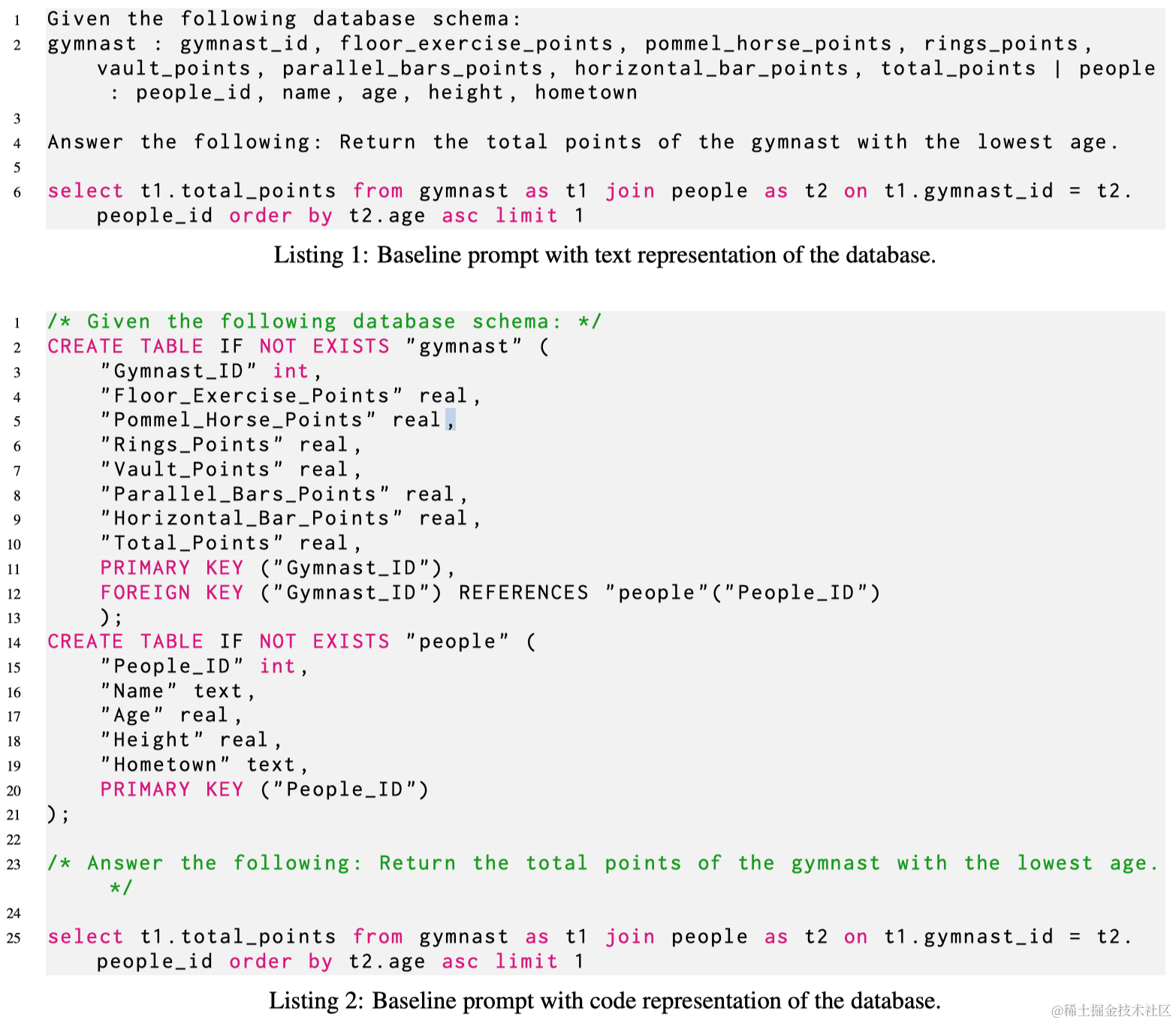
首先通过在整个数据库上下文中阐述每个类和属性的含义来增强每个类和属性的语义。具体来说,使用OpenAI的gpt-3.5-turbo来为每个表中的每列生成自然语言定义,考虑到所有其值和其他列。然后,将这些定义以块注释的形式附加到输入中,或者将它们作为内联注释插入到CREATE查询中。
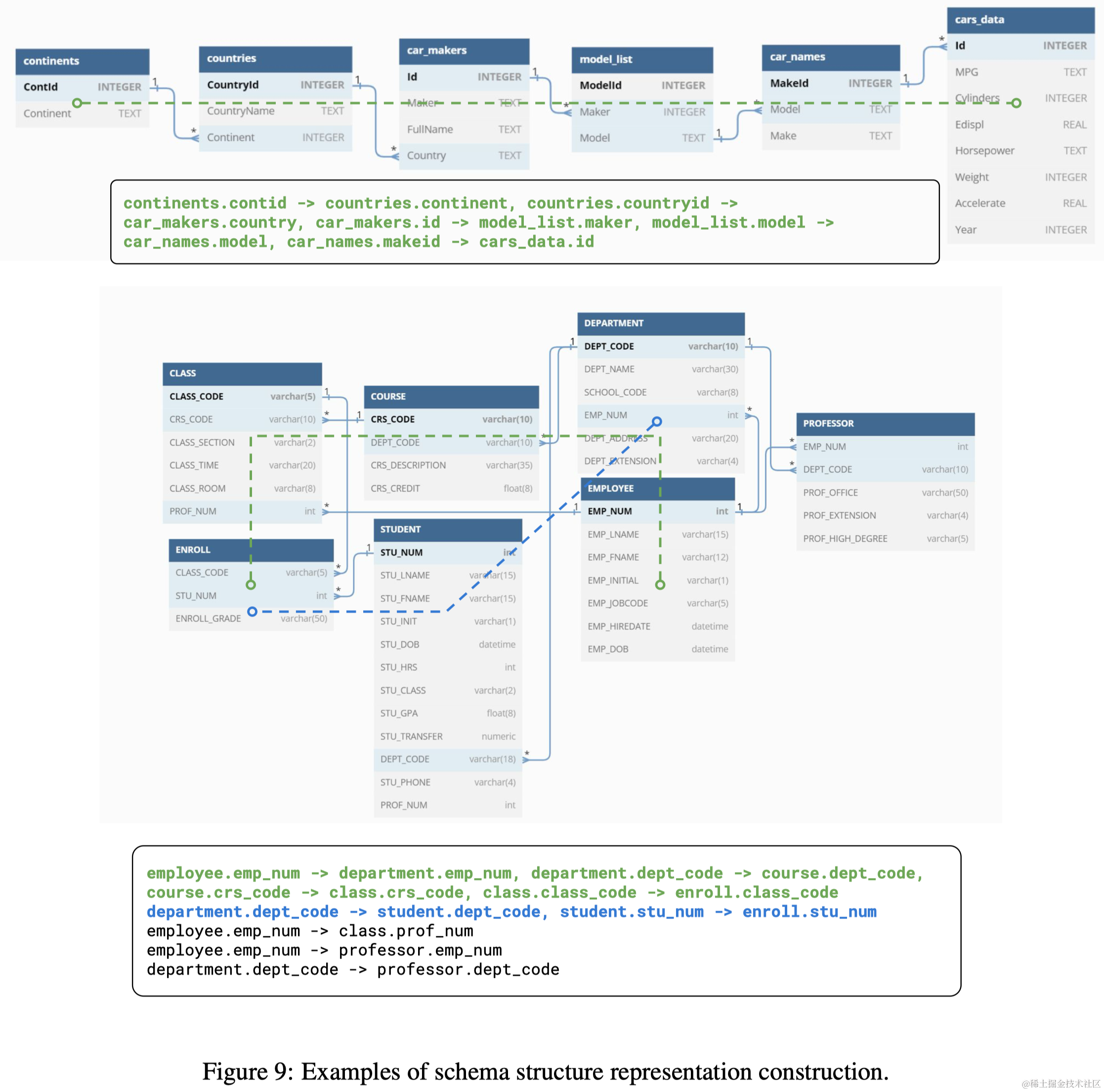
此外,作者建议通过提供一个概述表之间连接的实体关系摘要来增强数据库结构的表示,以指定它们如何连接。如附录中的图9所示,一个数据库的实体关系图被用来列举不同表之间的所有可能路径。这些路径随后根据它们各自的长度以降序排列。这个总结在实验中被证明对于需要组合多个表的测试实例是有用的。清单5进一步展示了如何安排它们来构建提示。

2.3 文本到SQL的综合策略
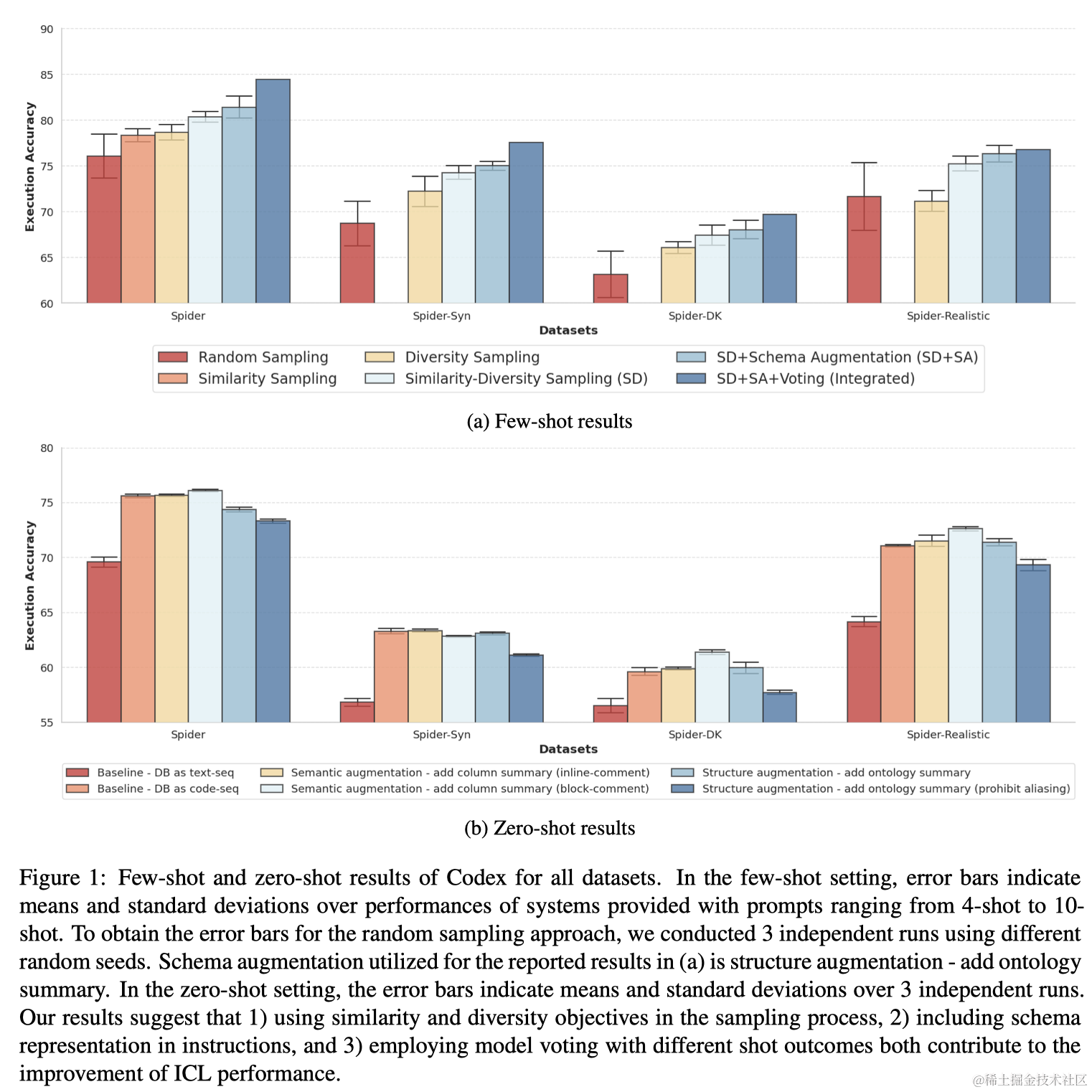
实验发现,通过上下文学习(ICL)训练的模型对示例数量非常敏感,不同数量的示例导致模型性能表现出显著差异。为了在比较不同提示方法时得出有意义的结论,作者展示了具有相同配置但示例数量不同的模型的平均值和标准差。此外,采用多数投票法对表现多样的模型进行决策。具体来说,获取不同模型的贪婪解码预测结果,通过确定性数据库管理系统(DBMS)排除执行错误的预测,然后选择获得多数票的预测。其他整合方法,如自我一致性采样,也是可行的,但本文将其探索留待未来研究。详细结果可在附录的图10、11、12中查看。
作者提出了以下构建文本到SQL任务提示的程序。首先,给定一组注释示例A,建立一个将池子划分为不相交分区 A α , A β A_α , A_β Aα,Aβ 等的分类,每个分区包含SQL查询语法结构相对相似的示例。接下来,应用第2.1节中详述的k-means策略,为每个分区 A j A_j Aj 获取多样化的示例 D j D_j Dj。对于每个示例,通过将数据库转换成多个CREATE查询并增加与模式相关的知识来构建示例。在推理过程中,使用初步模型生成SQL查询草案,用于确定问题类别,进而确定构建提示的相应 D j D_j Dj。使用 D j D_j Dj中不同数量的样本获得多个预测,并通过多数投票得出最终预测。该方法的详细信息展示在算法2中。

3 实验
3.1 实验设置
数据集
- Spider:复杂文本到SQL问题的跨领域数据集。
- Spider-Syn:使用同义词替换Spider问题中的模式相关词汇,评估系统的鲁棒性。
- Spider-DK:在Spider示例中添加领域知识,评估跨领域泛化能力。
- Spider-Realistic:去除列名的明确提及,模拟更现实的文本-表格对齐设置。
模型
- 使用Codex(基于GPT-3的变体)和ChatGPT (gpt-3.5-turbo)来评估不同ICL策略。
- Codex在1到10-shot范围内提供结果,而ChatGPT因最大上下文长度限制仅提供1到5-shot的结果。
评估指标
- 使用执行准确度作为所有实验的评估指标。
Baseline
主要分为Few-shot和Zero-shot上的实验,包括:
- Few-shot
- Random sampling ®: 从样本池中随机选择示例。
- Similarity sampling (S)
- Diversity sampling (D): 从样本池的k-Means聚类中选择多样化示例。
- Similarity-Diversity sampling (SD): 根据算法1选择示例。
- SD + schema augmentation (SA): 通过架构知识增强指令(语义增强或结构增强)。
- SD + SA + Voting: 根据算法2描述的综合策略。
- Zero-shot
- Baseline - DB as text-seq: 文本到SQL任务的标准提示,其中结构化知识被线性化为文本序列。
- Baseline - DB as code-seq: 通过将结构化知识源线性化为多个SQL CREATE查询来改进指令。
- Baseline - DB as code-seq + SA: 通过架构知识增强指令。
3.2 主要结果
作者在code-davinci-002和gpt-3.5-turbo模型上测试了不同示例选择策略的效果。主要发现如下:
- 相似性和多样性目标的采样过程:结合相似性和多样性目标在采样过程中可以获得更好的性能。
- 架构表示的增强:在指令中加入架构表示(就是Listing 5中的最下面的那几行注释)可以提高性能。
- 投票集成策略:结合不同示例数量模型的结果进行投票,可显著提高整体性能。
- 架构增强在零次学习中的效果:将数据库转换为文本序列和CREATE查询的两种提示线性化方法进行了比较。后者显示出明显的性能提升。
- 两种架构增强技术的对比:一种在表中的每列中添加语义信息,另一种加入实体关系知识。结果表明,结构增强(添加本体概要)在Few-shot设置中为Codex带来更大的改进,而语义增强(作为块注释添加列概要)在Zero-shot设置中对Codex以及Few-shot设置中对ChatGPT更有益。
研究显示,通过探索和实施不同的提示设计策略,可以显著提高LLMs在文本到SQL任务中的性能。这些策略不仅包括示例选择的优化,还包括架构表示的增强和投票集成方法的应用。通过这些策略,为利用LLMs在文本到SQL领域中的应用提供了有力的实证支持。
4 分析
4.1 基于预测语法的检索
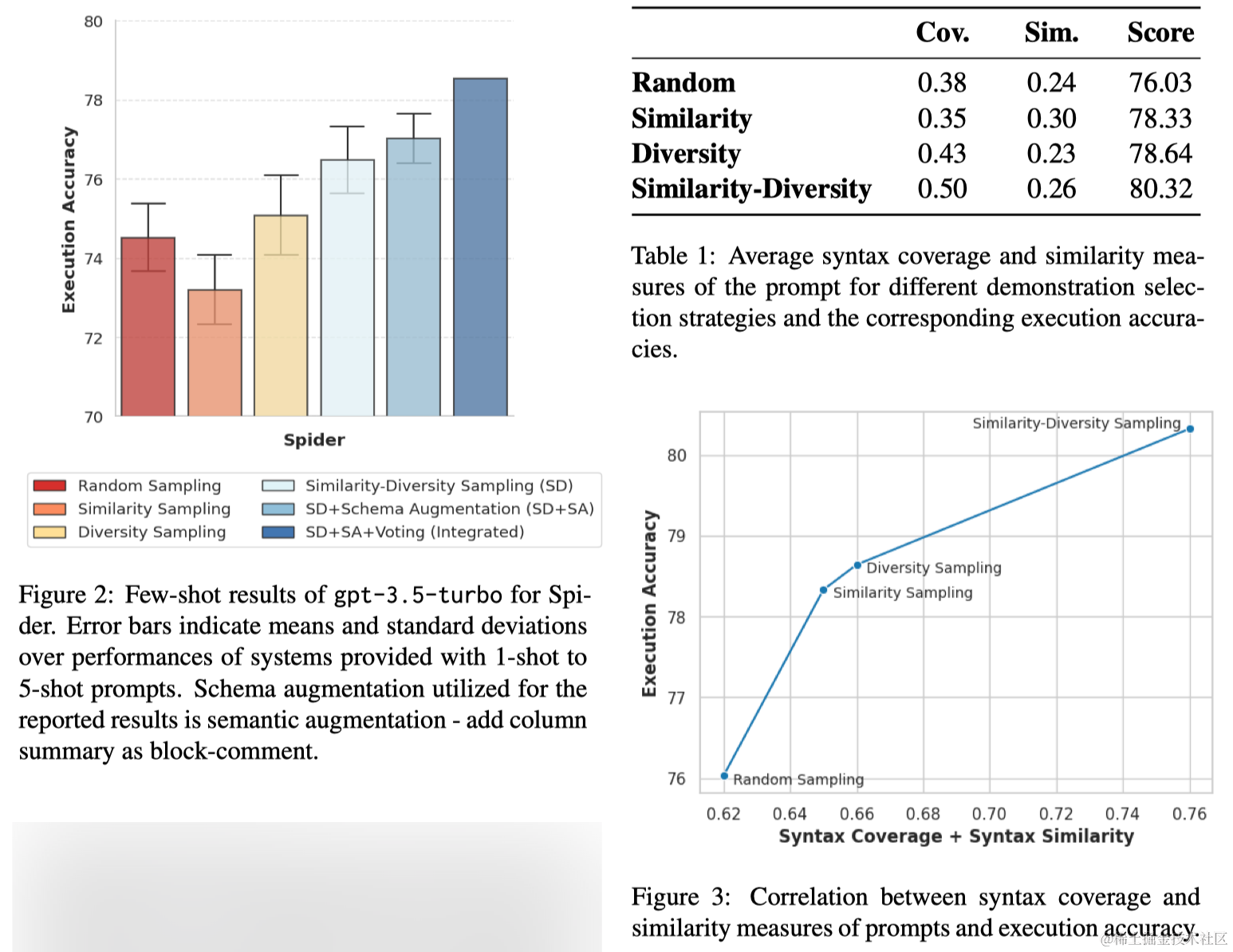
现有的示例选择方法依赖于问题和数据库的语义表示。本文提出了一种专门针对代码生成任务的替代方法,该方法侧重于解决方案代码的语法。检查了不同策略生成的提示中的语法覆盖率和语法相似度。语法覆盖率是通过计算语法元素(关键字、运算符和标识符)的出现次数并将其除以所有语法元素的总数来计算的。另一方面,语法相似度是通过计算预测的SQL的离散向量表示与所选示例的gold SQL向量之间的欧几里得距离的平均值来测量的。如表1所示,这两个度量都有助于选择示例的质量。此外,两个度量的简单求和表明与系统性能的相关性,如图3所示。
作者通过以下理由论证本文策略的有效性:
- 在注释示例池中问题结构的多样性有限的情况下,某些测试问题可能缺乏可用于检索的相似示例;
- 问题/数据库的语义表示和距离度量本身不支持不同问题结构的封装和比较,而SQL语法提供了直接测量问题结构的方法。
鉴于这些限制,最佳策略是选择相似的示例,同时确保尽可能覆盖许多语法示例,以减轻基于相似性检索的潜在失败。
4.2 检索方法的比较分析
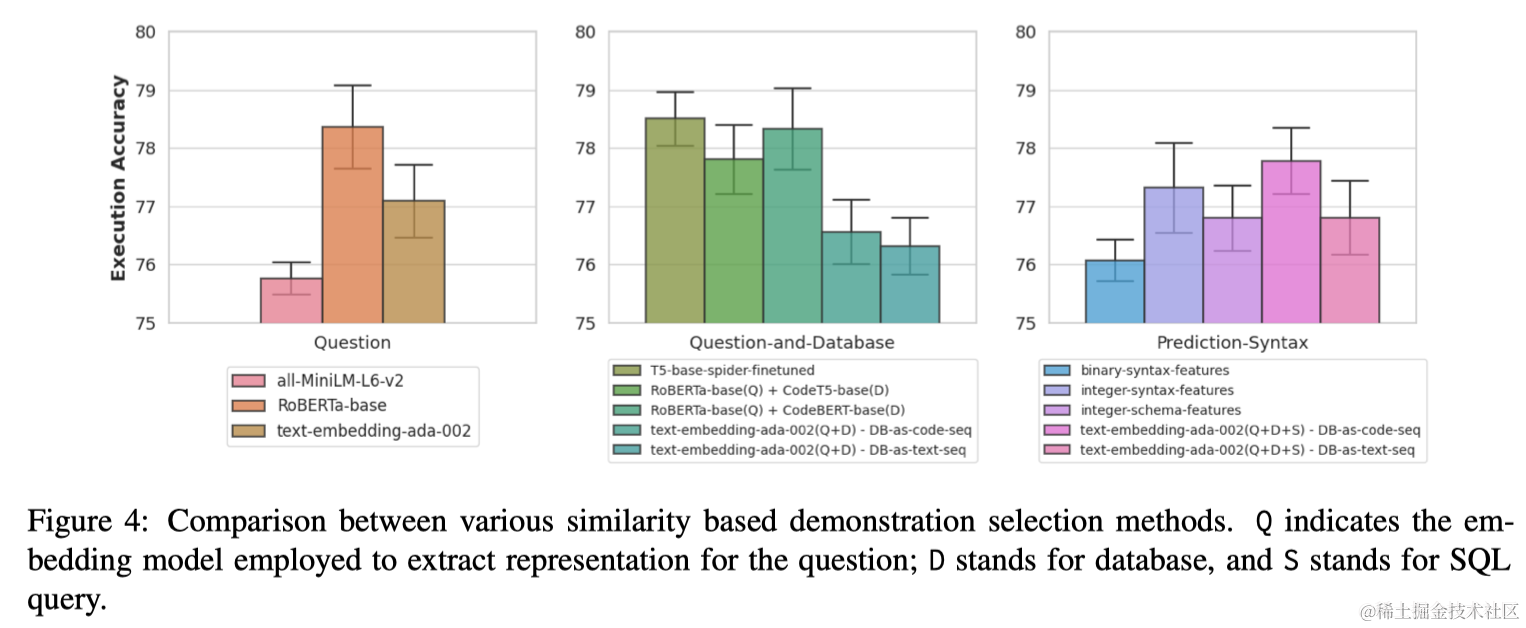
图4展示了各种基于相似度的检索方法性能的比较分析。此次调查的主要变量是为每个示例提取的表示,重点提取和比较以下嵌入类型:
- 由Sentence-BERT,RoBERTa-base、text-embedding-ada-002生成的问题嵌入;
- 结合问题和数据库,通过下面的方法获取embedding:
- 使用单个模型(即在Spider上微调过的T5-base和text-embedding-ada-002)编码线性化文本序列的数据库schema或CREATE查询,
- 使用不同模型,特别是RoBERTa-base用于编码问题和CodeT5-base或CodeBERTbase用于编码数据库;
- 预测SQL的语法嵌入,通过二进制编码来表示SQL语法元素的存在或量化它们的出现次数;
- 使用text-embedding-ada-002编码问题、数据库和预测SQL的嵌入。
关于Text-to-SQL任务的基于相似度的检索方法,可以得出以下结论:
- 问题本身就能有效地代表不同的示例用于检索;
- 与text-embedding-ada-002相比,RoBERTa-base提供了更好的比较嵌入;
- 可以使用未对Text-to-SQL示例进行微调的模型进行基于相似度的检索,同时仍然可以实现与微调模型相当的性能;
- 将数据库线性化为SQL查询有助于提取更好的嵌入。
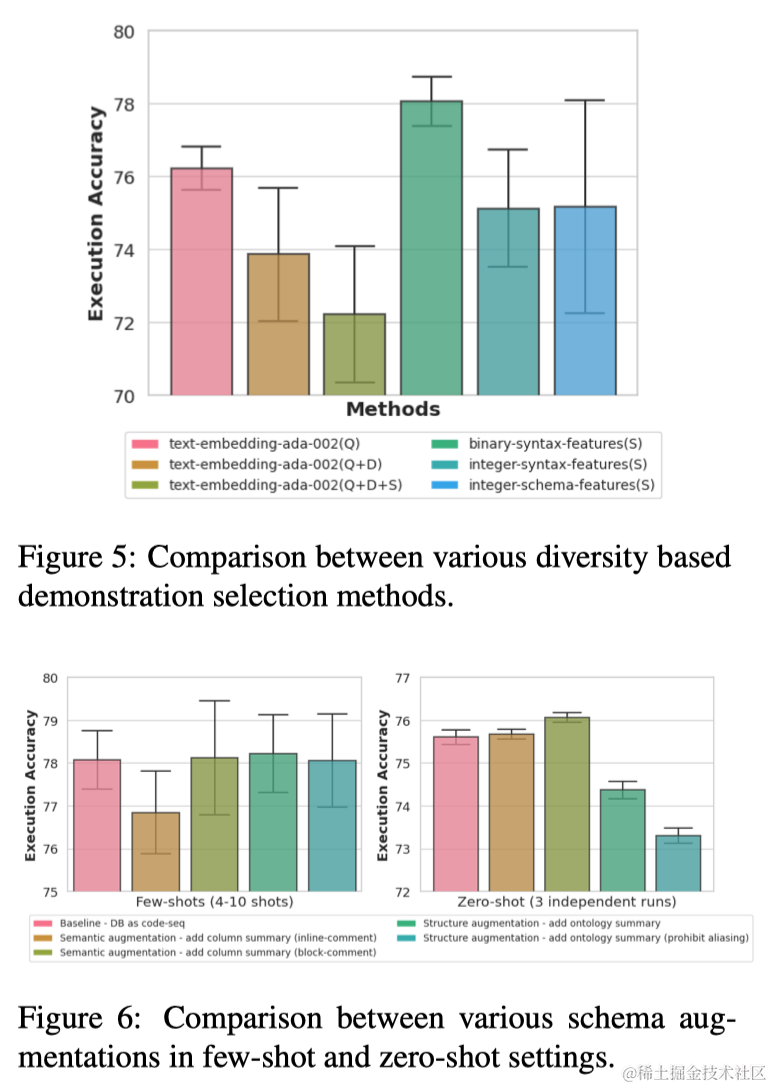
此外,作者还对用于基于多样性的示例选择的多个嵌入进行了比较,包括编码问题、数据库和预测SQL的语义的嵌入,以及捕获预测SQL的语法特征的嵌入。如图5所示,预测SQL的语法嵌入作为基于多样性检索目的对不同示例进行对比的最有效基础。
4.3 架构增强
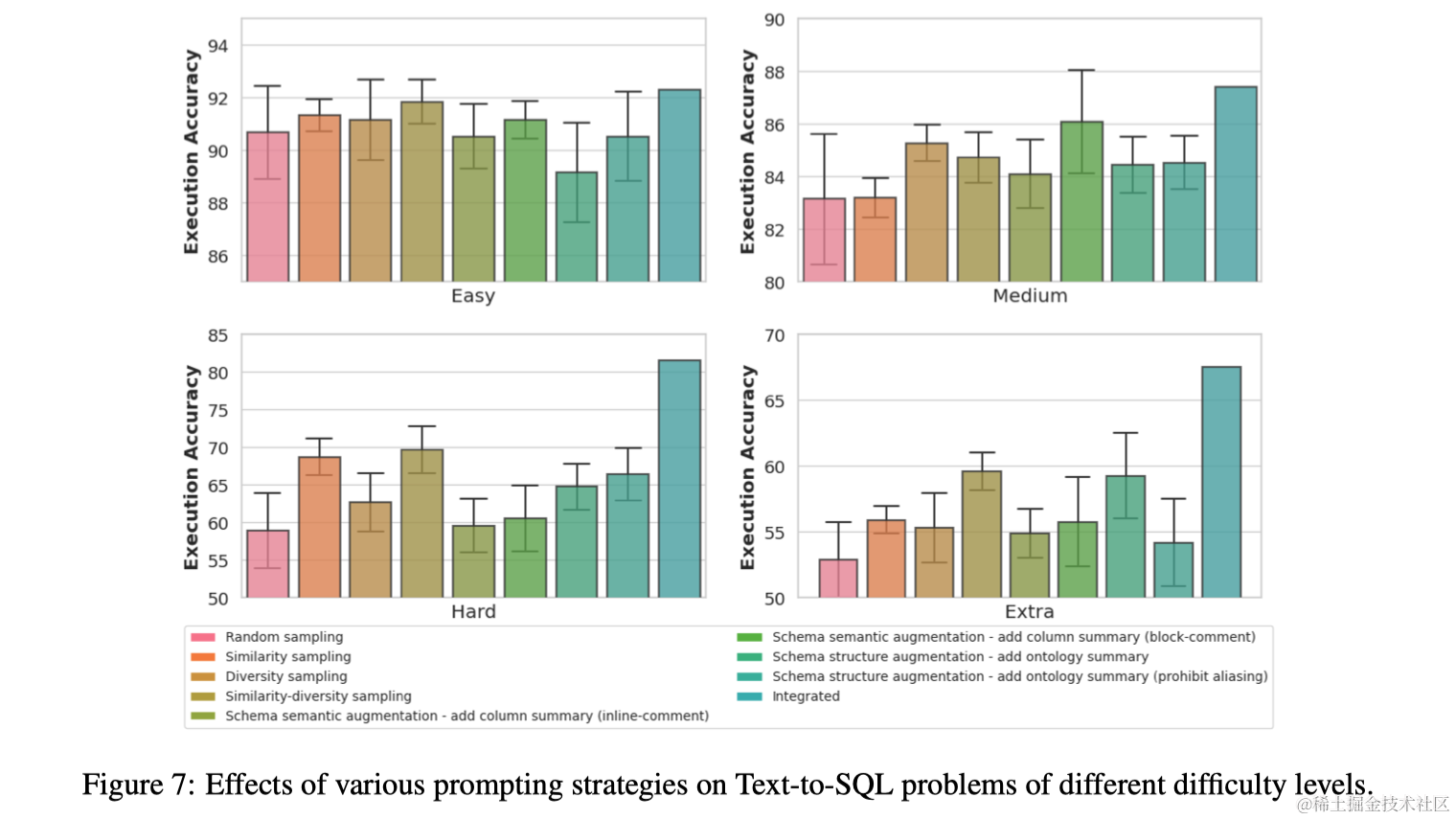
图6展示了对指令应用的各种架构增强的结果。可以观察到,在少数示例设置中改进不明显;然而,在零示例设置中,将所有表格列的描述纳入的语义增强被证明是有益的。
4.4 效果分析
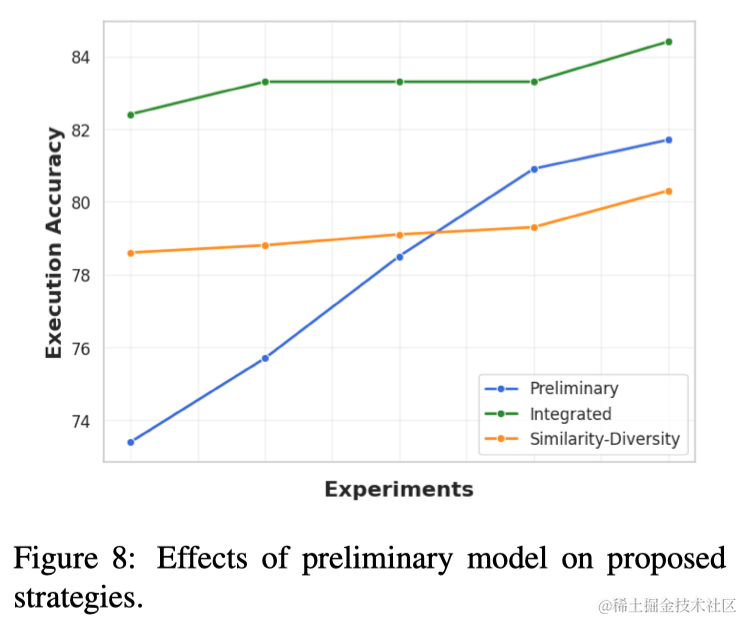
为了确定最受益或最不受益于本文提出的方法的问题类型,本文还评估了不同模型在Spider数据集内各种问题类别的性能。如图7所示,本文的相似性-多样性策略对大多数问题类型都是有益的,除了中等难度的部分,其中包括最多样化的问题。这是相似性基于检索失败和语法覆盖变得更加关键的情况。此外,本文观察到,对于简单和中等难度的部分,增加架构语义更有效(尽管变异性很高),而对于更复杂的问题,增加架构结构更有效。这一观察使本文假设,具有挑战性的问题需要解决更多的表格,因此需要更全面地理解整个数据库结构。最后,综合方法在所有示例中都是有效的,特别是对于那些困难的问题提供了增加的好处。
4.5 初步模型
为评估用于生成草稿SQL的初步模型选择对本文方法的影响,本文对初步模型性能不同的方法进行了测试。图8显示,初步模型对相似性-多样性或综合方法的性能影响相对较小,随着使用更高性能的初步模型而逐渐改善。
5 相关工作
5.1 上下文学习(In-context Learning)
5.1.1 Prompt组织规范
提示组织探究选择和组织上下文示例的任务,这是提高模型性能的关键方面。多项研究提出了衡量示例适用性的指标,以及确定它们的最优排序。Liu等建议通过在嵌入空间采用k-NN方法,选择与测试示例语义相似的示例。Rubin等基于对比学习训练了一个提示检索器,其中示例被分类为正面或负面,如果它们在语言模型生成目标输出时,根据检索的示例和输入,排在概率的前k或后k位。Zhang等建议使用Q Learning来主动选择演示。Su引入了Vote-k方法,用于选择多样化且具代表性的示例进行池构建,然后基于相似性进行检索。
5.1.2 提示格式化
提示工程学关注于探究提示结构对下游任务性能的影响。对于涉及多步推理和较高复杂性的任务,已经开发了思维链提示方法。这种方法涉及将生成过程分布在多个步骤上,并使用模型自身的中间过程作为输入。Wang提出了采样多种不同的思维链,然后通过边际化所有可能的推理路径来选择最一致的答案。Press建议让LLMs提出后续问题是构建思维链过程的有效方式。Zhou提出了一种自动识别最佳提示的方法,通过在模型生成的指令池中搜索,给它们打分,并选择得分最高的提示。
5.2 与表格相关任务的编码
对结构化数据的编码对于各种与表格相关的任务至关重要,包括表格问答和文本到SQL。在表格问答的情况下,通常使用的方法是首先使用弱监督表格解析器来提取相关的表格单元,如有必要,再对检索到的数据应用相应的聚合操作符。例如,TAPAS在BERT模型中引入了额外的嵌入层,以捕获表格结构和数值信息。为了得到给定问题的答案,TAPAS使用两个分类层来预测聚合函数和相应的表格单元。更近期的工作将表格问答视为序列生成任务。他们将表格平铺成文本序列,并使用特殊标记来指示表格结构,同时对表格数据进行编码。文本到SQL是一项将自然语言问题转换为可以在数据库上执行的SQL查询的任务。在这项任务中,表格架构以输入形式提供。编码器应该能够将自然语言问题中的实体提及与架构对齐,同时理解架构结构信息(例如,外键/主键和列类型)。
6 总结
本研究探索了用于文本到SQL领域语义解析任务的各种提示设计方法。本文提出了一种利用示例的SQL语法结构来选择示例演示的方法,强调多样性和相似性作为采样目标。此外,本文发现大型语言模型(LLMs)从与数据库相关的知识增强中受益。未来的研究可以基于本文的发现来检验本文方法在其他领域的可转移性。通过持续改进LLMs在语义解析方面的能力,本文旨在为开发更准确、更稳健和更易理解的问答系统做出贡献。
相关文章:
LLM少样本示例的上下文学习在Text-to-SQL任务中的探索
导语 本文探索了如何通过各种提示设计策略,来增强大型语言模型(LLMs)在Few-shot In-context Learning中的文本到SQL转换能力。通过使用示例SQL查询的句法结构来检索演示示例,并选择同时追求多样性和相似性的示例可以提高性能&…...
双非本科准备秋招(19.2)—— 设计模式之保护式暂停
一、wait & notify wait能让线程进入waiting状态,这时候就需要比较一下和sleep的区别了。 sleep vs wait 1) sleep 是 Thread 方法,而 wait 是 Object 的方法 2) sleep 不需要强制和 synchronized 配合使用,但 wait 强制和 s…...

使用SpringMVC实现功能
目录 一、计算器 1、前端页面 2、服务器处理请求 3、效果 二、用户登陆系统 1、前端页面 (1)登陆页面 (2)欢迎页面 2、前端页面发送请求--服务器处理请求 3、效果 三、留言板 1、前端页面 2、前端页面发送请求 &…...

spring aop实现接口超时处理组件
文章目录 实现思路实现代码starter组件 实现思路 这里使用FutureTask,它通过get方法以阻塞的方式获取执行结果,并设定超时时间: public V get() throws InterruptedException, ExecutionException ;public V get(long timeout, TimeUnit un…...
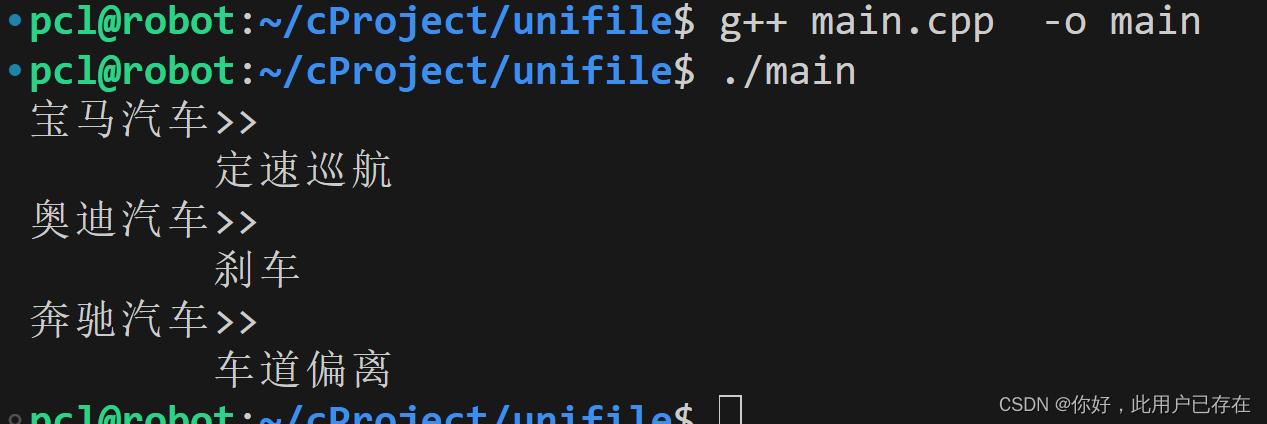
c++设计模式之装饰器模式
作用 为现有类增加功能 案例说明 class Car { public:virtual void show()0; };class Bmw:public Car { public:void show(){cout<<"宝马汽车>>"<<endl;} };class Audi:public Car { public:void show(){cout<<"奥迪汽车>>&q…...

WordPress如何实现随机显示一句话经典语录?怎么添加到评论框中?
我们在一些WordPress网站的顶部或侧边栏或评论框中,经常看到会随机显示一句经典语录,他们是怎么实现的呢? 其实,boke112百科前面跟大家分享的『WordPress集成一言(Hitokoto)API经典语句功能』一文中就提供…...

【退役之重学前端】vite, vue3, vue-router, vuex, ES6学习日记
学习使用vitevue3的所遇问题总结(2024年2月1日) 组件中使用<script>标签忘记加 setup 这会导致Navbar 没有暴露出来,导致使用不了,出现以下报错 这是因为,如果不用setup,就得使用 export default…...

[linux]-总线,设备,驱动,dts
1. 总线BUS 在物理层面上,代表不同的工作时序和电平特性: 总线代表着同类设备需要共同遵守的工作时序,不同的总线对于物理电平的要求是不一样的,对于每个比特的电平维持宽度也是不一样,而总线上传递的命令也会有自己…...

python3实现gitlab备份文件上传腾讯云COS
gitlab备份文件上传腾讯云COS 脚本说明脚本名称:upload.py 假设gitlab备份文件目录:/opt/gitlab/backups gitlab备份文件格式:1706922037_2024_02_06_14.2.1_gitlab_backup.tar1.脚本需和gitlab备份文件同级目录 2.根据备份文件中的日期判断…...

292.Nim游戏
桌子上有一堆石头。 轮流进行自己的回合, 你作为先手 。 每一回合,轮到的人拿掉 1 - 3 块石头。 拿掉最后一块石头的人就是获胜者。 假设你们每一步都是最优解。请编写一个函数,来判断你是否可以在给定石头数量为 n 的情况下赢得游戏。如果可…...
Spring和Spring Boot的区别
Spring 是一个轻量级的 Java 开发框架,它提供了一系列的模块和功能,例如 IoC(控制反转)、AOP(面向方面编程)、数据库访问、Web 开发等。Spring 的目标是使 Java 开发更加简单、高效和可维护。 Spring Boot …...

备战蓝桥杯---动态规划(理论基础)
目录 动态规划的概念: 解决多阶段决策过程最优化的一种方法 阶段: 状态: 决策: 策略: 状态转移方程: 适用的基本条件 1.具有相同的子问题 2.满足最优子结构 3.满足无后效性 动态规划的实现方式…...
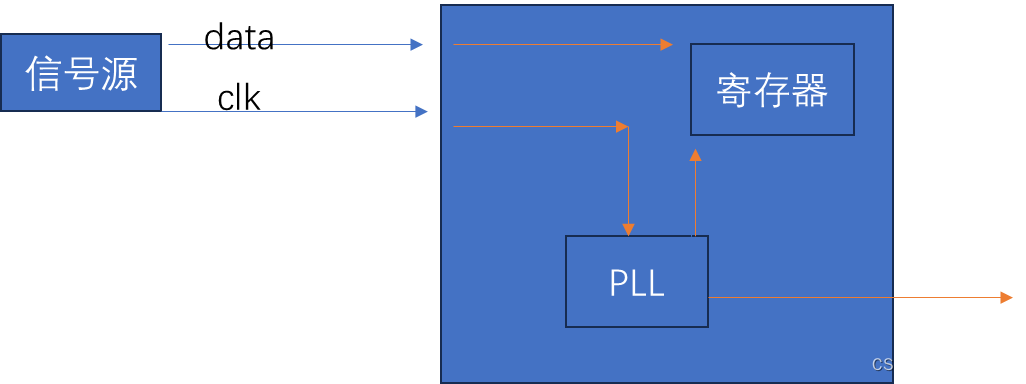
FPGA_ip_pll
常使用插件管理器进行ip核的配置,ip核分为计算,存储,输入输出,视频图像处理,接口,调试等。 一 pll ip核简介 pll 即锁相环,可以对输入到fpga的时钟信号,进行分频,倍频&…...

【实验3】统计某电商网站买家收藏商品数量
文章目录 一、实验目的和要求∶二、实验任务∶三、实验准备方案,包括以下内容:实验内容一、实验环境二、实验内容与步骤(过程及数据记录):三、实验结果分析、思考题解答∶四、感想、体会、建议∶一、实验目的和要求∶ 现有某电商网站用户对商品的收藏数据,记录了用户收藏…...
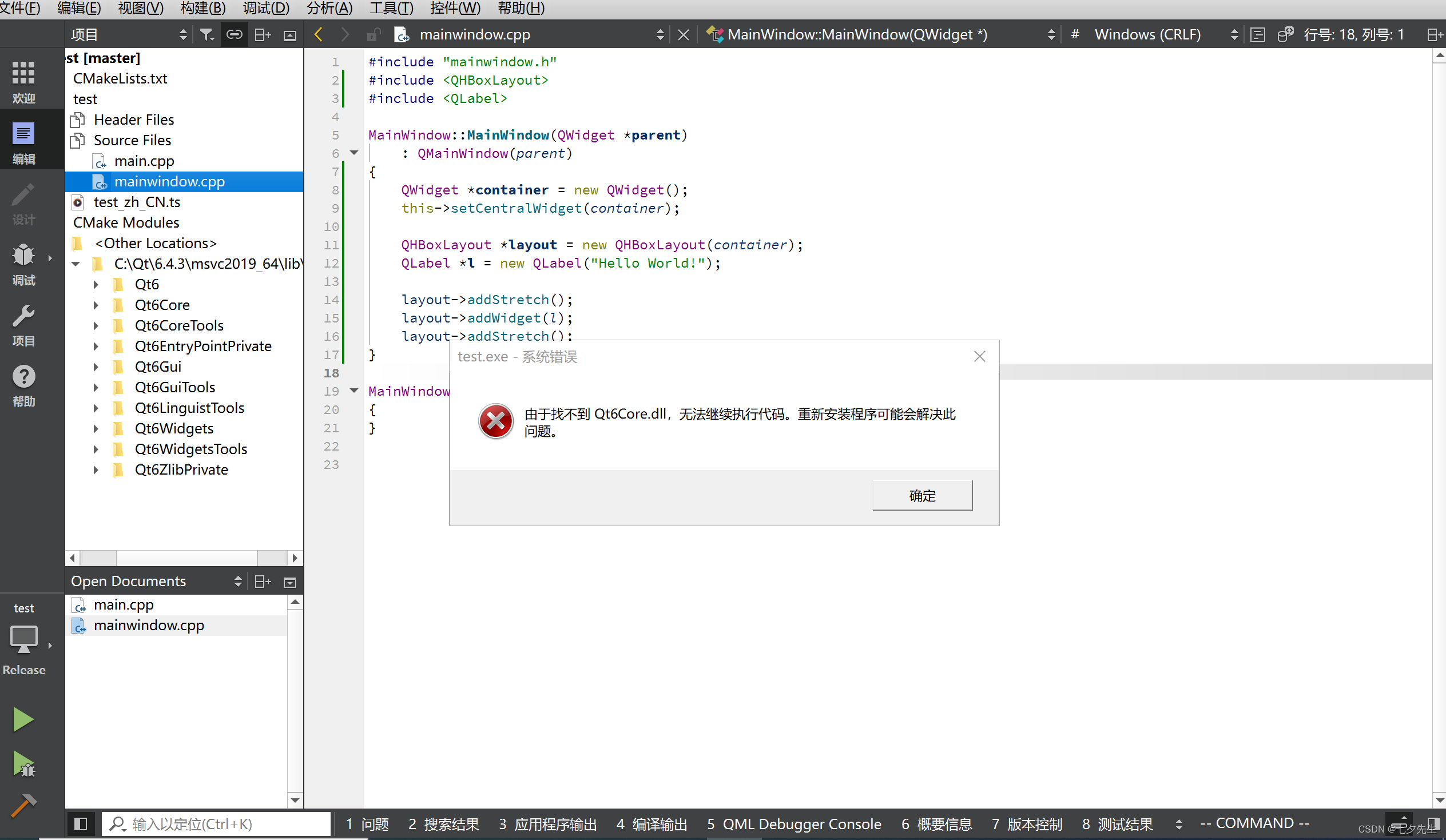
【Qt】Android上运行keeps stopping, Desktop上正常
文章目录 问题 & 背景背景问题 解决方案One More ThingTake Away 问题 & 背景 背景 在文章【Qt】最详细教程,如何从零配置Qt Android安卓环境中,我们在Qt中配置了安卓开发环境,并且能够正常运行。 但笔者在成功配置并完成上述文章…...
算法学习打卡day47|单调栈系列题目
单调栈题目思路 通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了。时间复杂度为O(n)。单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元…...
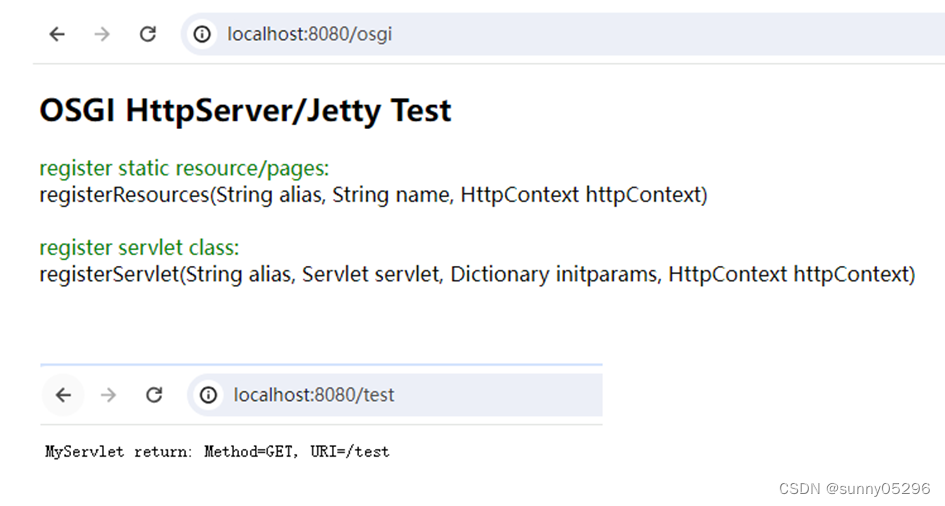
Maven构建OSGI+HttpServer应用
Maven构建OSGIHttpServer应用 官网(https://eclipse.dev/equinox/server/http_in_equinox.php)介绍有两种方式: 一种是基于”org.eclipse.equinox.http”包的轻量级实现,另一种是基于”org.eclipse.equinox.http.jetty”包&#…...

chrome扩展插件常用文件及作用
Chrome扩展通常包含以下常用文件及其作用: manifest.json: 描述了扩展的基本信息,如名称、版本、权限、图标等。定义了扩展的各种组件和功能,包括后台脚本、内容脚本、页面、浏览器动作按钮等。 background.js: 后台脚…...

PdfFactory Pro软件下载以及序列号注册码生成器
PdfFactory Pro注册机是一款针对同名虚拟打印机软件所推出的用户名和序列号生成器。PdfFactory Pro是一款非常专业的PDF虚拟打印软件,通过使用这款注册机,就能帮助用户免费获取注册码,一键激活,永久免费使用。 pdffactory7注册码如…...
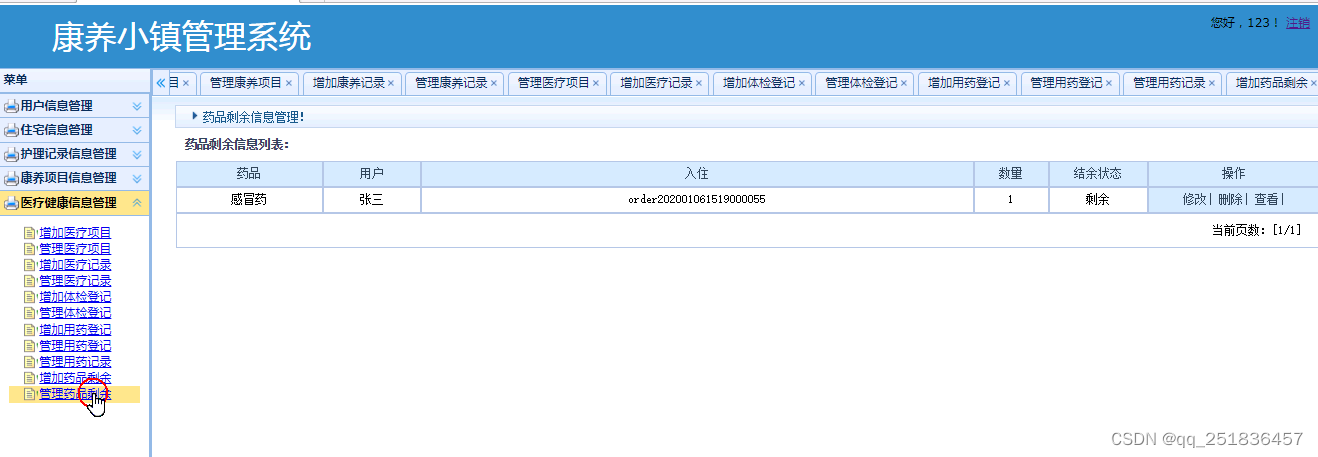
jsp康养小镇管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 JSP康养小镇管理系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql5.0&a…...

5分钟掌握Windows窗口置顶神器:PinWin完整使用指南
5分钟掌握Windows窗口置顶神器:PinWin完整使用指南 【免费下载链接】PinWin Pin any window to be always on top of the screen 项目地址: https://gitcode.com/gh_mirrors/pin/PinWin Windows窗口置顶工具PinWin是一款让你彻底告别频繁窗口切换的神器。无论…...

usehooks-ts:React Hooks工具集,提升开发效率与代码质量
1. 项目概述:一个现代React Hooks的“瑞士军刀”如果你正在用React做项目,尤其是TypeScript项目,那么你大概率经历过这样的场景:为了一个简单的“防抖”功能,去网上搜一段代码,复制粘贴,然后发现…...

5分钟完全掌握ncmdump:专业解密网易云NCM格式实现音乐自由
5分钟完全掌握ncmdump:专业解密网易云NCM格式实现音乐自由 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump ncmdump是一款专业的网易云音乐NCM格式解密工具,能够将加密的NCM音频文件转换为通用的MP3格式&#…...

高效虚拟显示器驱动深度解析:Parsec VDD从原理到实战的完整指南
高效虚拟显示器驱动深度解析:Parsec VDD从原理到实战的完整指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd Parsec Virtual Display Driver (Parsec VDD)是一款基…...

LinkedIn Liger Kernel:移动设备内核定制与性能优化实战
1. 项目概述:一个面向移动设备的开源内核探索如果你在移动设备开发、嵌入式系统或者内核研究的圈子里待过一段时间,大概率听说过或者接触过“Liger Kernel”这个名字。它不是一个商业产品,而是一个在GitHub上由LinkedIn开源并维护的Android内…...

Symbol Opener:基于URI与LSP实现终端代码符号一键跳转
1. 项目概述:一个能让你在终端里“点击”代码符号的插件 如果你和我一样,每天大部分时间都泡在终端里,那你肯定遇到过这个场景:运行 git log 或者 grep 命令,终端输出了一堆函数名、类名,你想立刻跳转…...

构建聚合搜索与阅读工具:一站式信息处理中枢的设计与实践
1. 项目概述:一个聚合搜索与阅读的“信息中枢”最近在折腾一个挺有意思的项目,叫all-net-search-read。光看名字,你可能会觉得这又是一个“聚合搜索”工具,市面上这类工具确实不少。但当我深入去研究和使用它时,发现它…...

IC测试插座技术解析与市场应用实践
1. 行业背景与奖项意义解析在电子制造领域,互连产品如同精密仪器中的"神经末梢",承担着信号传输与能量供给的关键职能。IC测试插座和老化插座作为其中的核心组件,其性能直接影响半导体器件从研发验证到批量生产的全流程可靠性。这类…...

构建数据科学AI代理规则库:从自动化到智能化的关键路径
1. 项目概述:一个为数据科学工作流定制的智能代理规则库最近在GitHub上看到一个挺有意思的项目,叫ds-agent-rules。光看名字,你可能觉得这又是一个平平无奇的规则文件集合。但作为一个在数据科学和自动化领域摸爬滚打多年的从业者,…...

人工智能实操qpfan
一二import cv2 import matplotlib.pyplot as pltimg cv2.imread(./data-aug/cat.png) #img <1> img cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #垂直翻转 #img_flip <2> img_flip cv2.flip(img, 0) #<3> plt.imshow(img_flip) plt.axis(off) plt.show() …...