详述FlinkSql Join操作
FlinkSql 的 Join
Flink 官网将其分为了 Joins 和 Window Joins两个大类,其中里面又分了很多 Join 方式
参考文档:
Joins | Apache Flink
Window JOIN | Apache Flink
Joins
官网介绍共有6种方式:
-
Regular Join:流与流的 Join,包括 Inner Join、Outer Equal Join
-
Interval Join:流与流的 Join,两条流一段时间区间内的 Join
-
Temporal Join:流与流的 Join,包括事件时间,处理时间的 Temporal Join,类似于离线中的快照 Join
-
Lookup Join:流与外部维表的 Join
-
Array Expansion:表字段的列转行,类似于 Hive 的 explode 数据炸开的列转行
-
Table Function:自定义函数的表字段的列转行,支持 Inner Join 和 Left Outer Join

Regular Join
写法上和传统数据库没有区别,关联条件支持等值和非等值Join,有Inner Join 和 Outer Join(Left Join、Right Join、FULL JOIN)
有人问我为什么要特别区分内外连接,后面会用到
内连接是通过匹配两个表之间的共同列,返回满足连接条件的行。只有在连接条件匹配的情况下,才会返回结果。
外连接是在内连接的基础上,还包括了不满足连接条件的行。
SELECT order_id, uid, price, user_name
FROM order a
Left JOIN user b
ON a.uid = b.uid
顺便了解一下流是怎么 Join 的:
和离线不同,离线是一批数据一起运算的,完成后输出结果
FlinkSql是Dynamic Table的概念,数据在 State 里面,每来一条数据就会对左右两边的数据进行关联
Regular Join 的 State 默认是永久保存的,为了避免 State 无限膨胀,可以根据情况决定是否设置状态清理:table.exec.state.ttl(目前是根据更新时间来判断是否过期,而非访问时间)
再来看看几种 Join ,其中outer Join产生的回撤流是和传统离线方式有很大区别的:
首先不考虑数据源有回撤的情况,Regular Join在 Outer Join 时会产生回撤流,L-左表、R-右表
-
Inner Join:两条流 Join 到才输出
+[L, R],关联不上不会输出 -
Left Join:当左流数据到达之后就会直接输出
可以 Join 到右流则输出 +[L,R],Join 不到右流输出 +[L,null])
如果之后右流之后数据到达之后,发现左流之前输出过没有 Join 到的数据
则会发起回撤流,先输出 -[L,null],然后在输出一条 +[L,R]
-
Right Join:有 Left Join 一样,只是逻辑相反
-
Full Join:和Left原理一样,左流或者右流的数据到达之后,无论有没有 Join 到另外一条流的数据,都会输出,如果一条流的数据到达之后,发现之前另一条流之前输出过没有 Join 到的数据,则会发起回撤流
对右流来说:Join 到输出 +[L,R],没 Join 到输出 +[null,R],左流数据到达后回撤 -[null,R],输出 +[L,R]
对左流来说:Join 到输出 +[L,R],没 Join 到输出 +[L,null]),右流数据到达后回撤 -[L, null],输出 +[L,R]
图解:
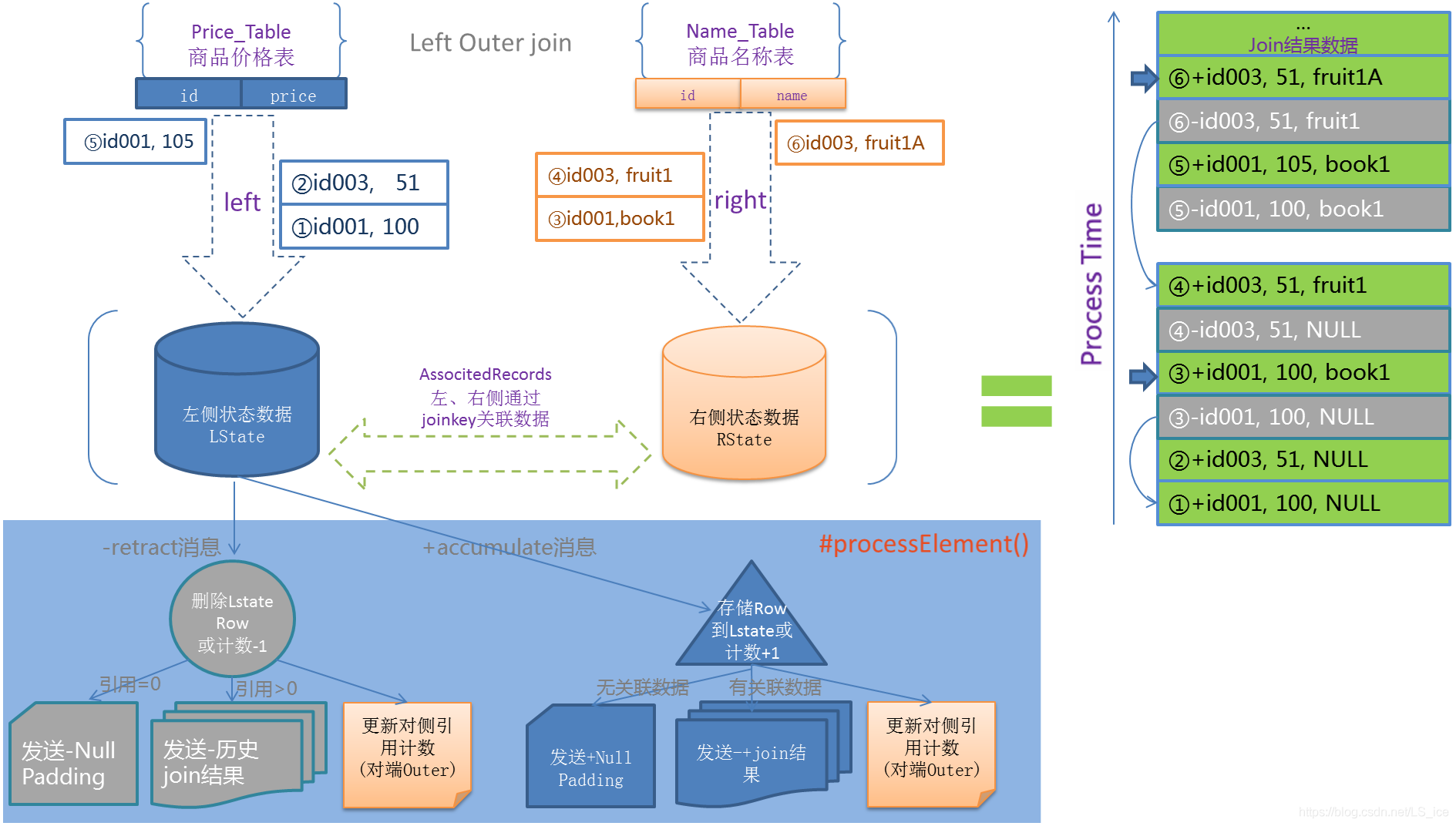
inner join 和 lef join 输出结果示例:
inner join
+I[5, d, 5, f]
+I[5, d, 5, 8]
+I[3, 4, 3, 0]
left join
+I[3, 4ab, null, null]
+I[5, f3c, 5, c05]
+I[5, 6e2, 5, c05]
-D[3, 4ab, null, null]
+I[3, 4ab, 3, 765]关于 Regular Join 的注意事项:
-
实时 Regular Join 可以不是
等值 join。等值 join和非等值 join区别在于,等值 join数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;非等值 join数据 shuffle 策略是 Global,所有数据发往一个并发,按照非等值条件进行关联 -
Join 的流程是左流新来一条数据之后,会和右流中符合条件的所有数据做 Join,然后输出,如果是outer join会立即输出之后产生回撤流
-
流的上游是无限的数据,所以要做到关联的话,Flink 会将两条流的所有数据都存储在 State 中,所以 Flink 任务的 State 会无限增大,因此你需要为 State 配置合适的 TTL,以防止 State 过大。
Interval Join
Interval Join 只支持普通 Append 数据流,不支持含 Retract 的动态表
Interval Join 左右表仅在某个时间范围(给定上界和下界)内进行关联,这个时间区间支持event time 和 processing time两种语义,如果是 event time,会根据区间和Watermark自动清理状态
场景示例:用户下单产生订单信息,用户必须在下单后一个小时以内付款,输出付款的订单信息
SELECTo.orderId,o.productName,p.payType,o.orderTime,cast(payTime as timestamp) as payTime
FROM Orders o
JOIN Payment p
ON o.orderId = p.orderId
AND p.payTime BETWEEN orderTime AND orderTime + INTERVAL ‘1’ HOURInterval Join 几种方式,需要注意 Interval Join 不会产生回撤流:
-
Inner Join:只有两条流 Join 到才输出,输出
+[L, R] -
Left Join:和 Regular Join 不同,左流数据到达之后,如果没有 Join 到右流的数据,就会等待(放在 State 中等),如果之后右流之后数据到达之后,发现能和刚刚那条左流数据 Join 到,这时输出
+[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间)。如果发现发现左流 State 中的数据过期了,就把左流中过期的数据从 State 中删除,然后输出+[L, null](这时候其实已经延迟了),如果右流 State 中的数据过期了,就直接从 State 中删除 -
Right Join:同 Left Join,逻辑相反
-
Full Join:流任务中,左流或者右流的数据到达之后,如果没有 Join 到另外一条流的数据,就会等待(左流放在左流对应的 State 中等,右流放在右流对应的 State 中等),如果之后另一条流数据到达之后,发现能和刚刚那条数据 Join 到,则会输出
+[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间),发现 State 中的数据能够过期了,就将这些数据从 State 中删除并且输出(左流过期输出+[L, null],右流过期输出-[null, R])
图解:
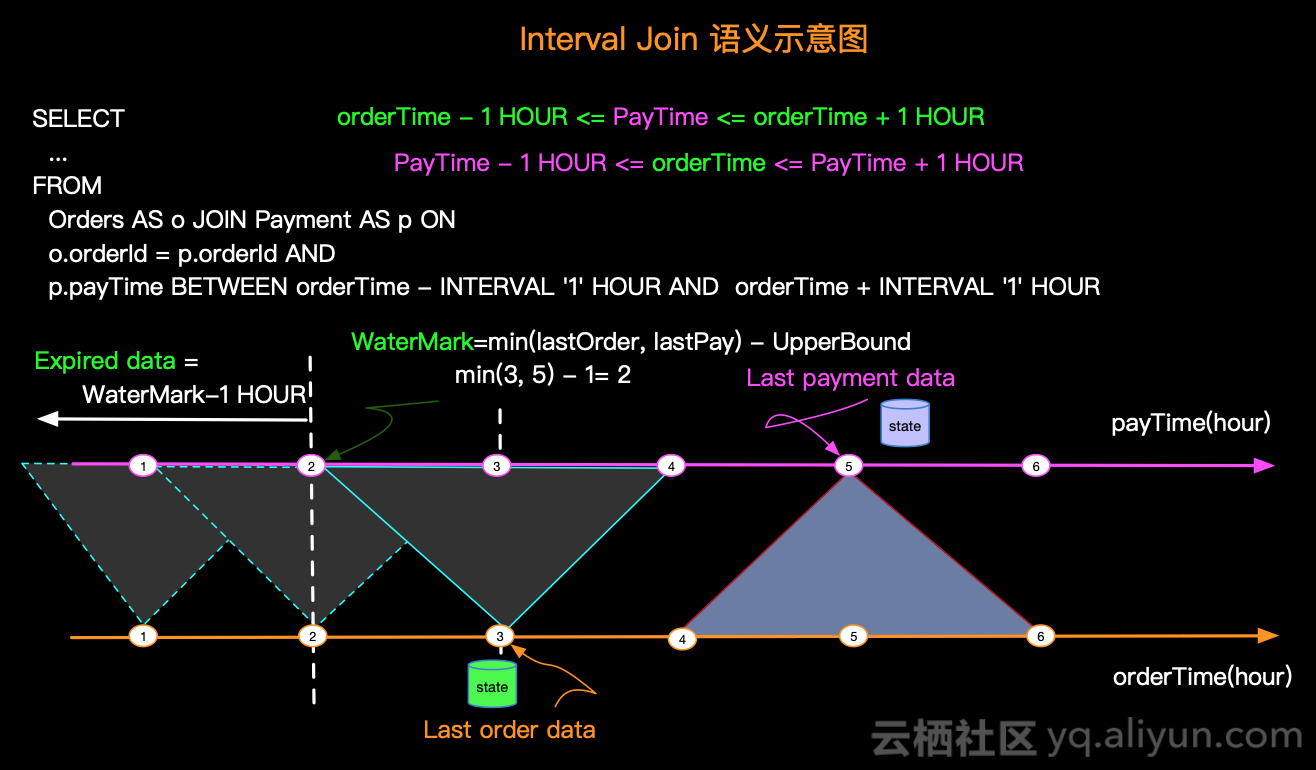
inner join不用多说,看看 left join 输出结果示例:
+I[6, e, 6, 7]
+I[11, d, null, null]
+I[7, b, null, null]
+I[8, 0, 8, 3]
+I[13, 6, null, null]关于 Interval Join 的注意事项:
-
实时 Interval Join 可以不是 等值 join。等值 join 和 非等值 join 区别在于,等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;非等值 join 数据 shuffle 策略是 Global,所有数据发往一个并发,然后将满足条件的数据进行关联输出
-
outer join 不会产生回撤流,关联不上会在 State 过期时发送数据,会有延迟
Temporal Joins
这种关联方式同样是传统数据库没有的,但是会发现和数仓的拉链表Join有点类似
Temporal Join 支持和 Verisoned Table 进行关联,也支持 event time 和 processing time 两种语义,支持inner join 和 left join 两种方式
事件时间 ,在解决多版本问题时有奇效:
-
事件时间的 Temporal Join 一定要给左右两张表都设置 Watermark
-
事件时间的 Temporal Join 一定要把 Versioned Table 的主键包含在 Join on 的条件中
--官网案例
CREATE TABLE orders (order_id STRING,price DECIMAL(32,2),currency STRING,order_time TIMESTAMP(3),WATERMARK FOR order_time AS order_time - INTERVAL '15' SECOND
) WITH (/* ... */);-- 必须定义一个 versioned table
CREATE TABLE currency_rates (currency STRING,conversion_rate DECIMAL(32, 2),update_time TIMESTAMP(3) METADATA FROM `values.source.timestamp` VIRTUAL,WATERMARK FOR update_time AS update_time - INTERVAL '15' SECOND,PRIMARY KEY(currency) NOT ENFORCED
) WITH ('connector' = 'kafka'/* ... */
);SELECT order_id,price,orders.currency,conversion_rate,order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;order_id price currency conversion_rate order_time
======== ===== ======== =============== =========
o_001 11.11 EUR 1.14 12:00:00
o_002 12.51 EUR 1.10 12:06:00Flink SQL 会为 Versioned Table 维护 Primary Key 下的所有历史时间版本的数据,然后根据左表Orders的事件时间关联到对应时间的 Versioned Table 的汇率
Processing Time,由于是处理时间,只维护了最新的状态数据,不需要关心历史版本的数据,直接根据LeftTable数据到达的时间关联最新的数据
另外还支持 Temporal Table Functionv Join,但是一般不怎么用(至少我基本不这样写)
SELECTo_amount, r_rate
FROMOrders,LATERAL TABLE (Rates(o_proctime))
WHEREr_currency = o_currencyLookup Join
Lookup Join 通常用于关联外部系统数据(比如Mysql、Hbase等),但是目前只支持 processing time,只能以处理时间关联最新的数据(这个最新是有代价的)
实际用起来其实会发现功能上和 version table 的processing 类似
-- 官网案例,需要定义一个外部存储的表
CREATE TEMPORARY TABLE Customers (id INT,name STRING,country STRING,zip STRING
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://mysqlhost:3306/customerdb','table-name' = 'customers'
);-- enrich each order with customer information
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS oJOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS cON o.customer_id = c.id;待办:lookup支持cache,cache的异步查询原理,数据更新的延迟,参数调优等等
Array Expansion
常见的用法就是类似Spark 的 lateral view expload(arr)
SELECT order_id, tag
FROM Orders CROSS JOIN UNNEST(tagArray) AS t (tag)Table Function
其实和 Array Expansion 功能类似,但是 Table Function 本质上是个 UDTF 函数,并且支持自定义函数
Window Joins
见 FlinkSql 窗口函数
语法示例:
SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id,COALESCE(L.window_start, R.window_start) as window_start,COALESCE(L.window_end, R.window_end) as window_end
FROM (SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))) L
INNER JOIN (SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))) R
ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;SELECT *
FROM (SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))) L WHERE EXISTS (SELECT * FROM (SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end);相关文章:
详述FlinkSql Join操作
FlinkSql 的 Join Flink 官网将其分为了 Joins 和 Window Joins两个大类,其中里面又分了很多 Join 方式 参考文档: Joins | Apache Flink Window JOIN | Apache Flink Joins 官网介绍共有6种方式: Regular Join:流与流的 Joi…...

Ajax+JSON学习二
AjaxJSON学习二 文章目录 前言三、前后端数据交互3.1. GET请求3.2. POST请求3.3. jQuery 中的 Ajax3.4. Ajax 的替代品:fetch3.5. 小结 四、JSON4.1. JSON简介4.2. JSON 语法规则4.3. JSON的解析和序列化 总结 前言 三、前后端数据交互 3.1. GET请求 GET 请求一般用…...
STM32单片机的基本原理与应用(六)
串口测试实验 基本原理 在串口实验中,是通过mini_USB线搭建终端与电脑端(也可称终端,为做区分称电脑端)的“桥梁”,电脑端的串口调试助手通过mini_USB线向终端发送信息,由CH340芯片将USB接口进行转换&…...

《MySQL 简易速速上手小册》第4章:数据安全性管理(2024 最新版)
文章目录 4.1 用户认证和权限控制4.1.1 基础知识4.1.2 重点案例:使用 Python 管理 MySQL 用户权限4.1.3 拓展案例 4.2 防止 SQL 注入和其他安全威胁4.2.1 基础知识4.2.2 重点案例:使用 Python 和 MySQL 进行安全的数据查询4.2.3 拓展案例 4.3 数据加密和…...

VUE学习之路——列表渲染
<p v-for"item in items">{{ item }}</p>使用v-for进行列表的渲染。 这仅仅是一个简单的demo,使用v-for可以用来遍历数组和对象,具体如下: 注意:遍历数组或对象的时候,()…...
CentOS 安装 redis 7.2
nginx官网 https://redis.io/download/ 把鼠标放到这里,复制下载地址 在服务器找个文件夹执行命令 wget https://github.com/redis/redis/archive/7.2.4.tar.gz tar -zxvf 7.2.4.tar.gz make make install 看到这几行就说明安装成功了 不放心的话再查看下b…...
运维自动化bingo前端
项目目录结构介绍 项目创建完成之后,我们会看到bingo_web项目其实是一个文件夹,我们进入到文件夹内部就会发现一些目录和文件,我们简单回顾一下里面的部分核心目录与文件。 ├─node_modules/ # node的包目录,项目运行的依赖包…...
Project2013下载安装教程,保姆级教程,附安装包和工具
前言 Project是一款项目管理软件,不仅可以快速、准确地创建项目计划,而且可以帮助项目经理实现项目进度、成本的控制、分析和预测,使项目工期大大缩短,资源得到有效利用,提高经济效益。软件设计目的在于协助专案经理发…...

【机器学习与自然语言处理】预训练 Pre-Training 各种经典方法的概念汇总
【机器学习与自然语言处理】预训练 Pre-Training 各种经典方法的概念汇总 前言请看此正文预训练 Pre-Training无监督学习 unsupervised learning概念:标签PCA 主成分分析(Principal Component Analysis)降维算法LSA 潜在语义分析(…...
Mac电脑如何通过终端隐藏应用程序?
在我们使用Mac电脑的时候难免会遇到想要不想看到某个应用程序又不想卸载它们。值得庆幸的是,macOS具有一些强大的文件管理功能,允许用户轻松隐藏(以及稍后显示)文件甚至应用程序。 那么,Mac电脑如何通过终端隐藏应用程…...

linker list
linker list是利用lds 描述符实现同类型数据连续排布的一种机制。 下面是uboot里面的应用说明 lds文件里面需要增加section描述: . ALIGN(4);.u_boot_list : {KEEP(*(SORT(.u_boot_list*)));}linker_list.h: /* SPDX-License-Identifier: GPL-2.0 */ /** include…...
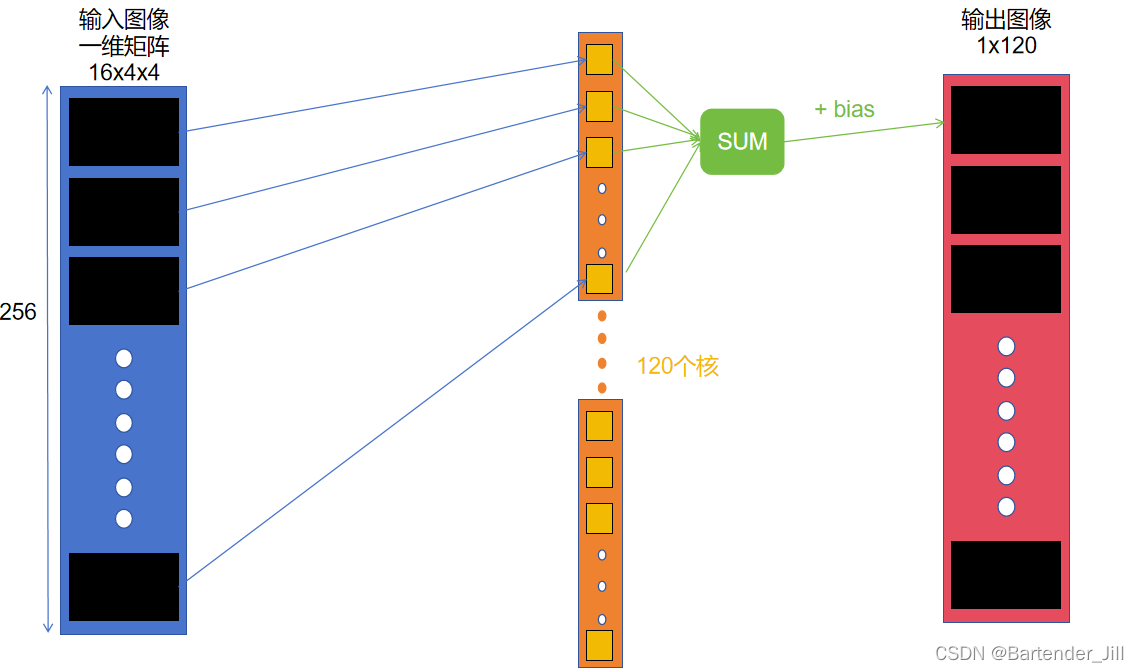
[CUDA手搓]从零开始用C++ CUDA搭建一个卷积神经网络(LeNet),了解神经网络各个层背后算法原理
文章目录 前言一、所需环境二、实现思路2.1. 定义了LeNet网络模型结构,并训练了20次2.2 以txt格式导出训练结果(模型的各个层权重偏置等参数)2.3 (可选)以pth格式导出训练结果,以方便后期调试2.4 C CUDA要做的事 三、C CUDA具体实现3.1 新建.cu文件并填好…...

【开源】基于JAVA+Vue+SpringBoot的数据可视化的智慧河南大屏
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、系统展示四、核心代码4.1 数据模块 A4.2 数据模块 B4.3 数据模块 C4.4 数据模块 D4.5 数据模块 E 五、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBootMySQL的数据可视化的智慧河南大屏,包含了GDP、…...
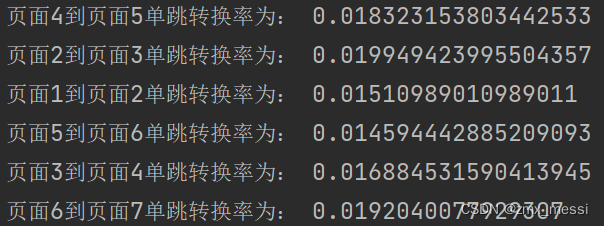
页面单跳转换率统计案例分析
需求说明 页面单跳转化率 计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳, 那么单跳转化率就是要统计…...

眸思MouSi:“听见世界” — 用多模态大模型点亮盲人生活
文章目录 1. Introduction1.1 APP细节展示2. Demo2.1 论文链接2.2 联系方式3. Experiment3.1 多专家的结合是否有效?3.2 如何更好的将多专家整合在一起?Reference让盲人听见世界,复旦眸思大模型打破视觉界限,用科技点亮新生活 1. Introduction 在这个世界上,视力是探索万…...
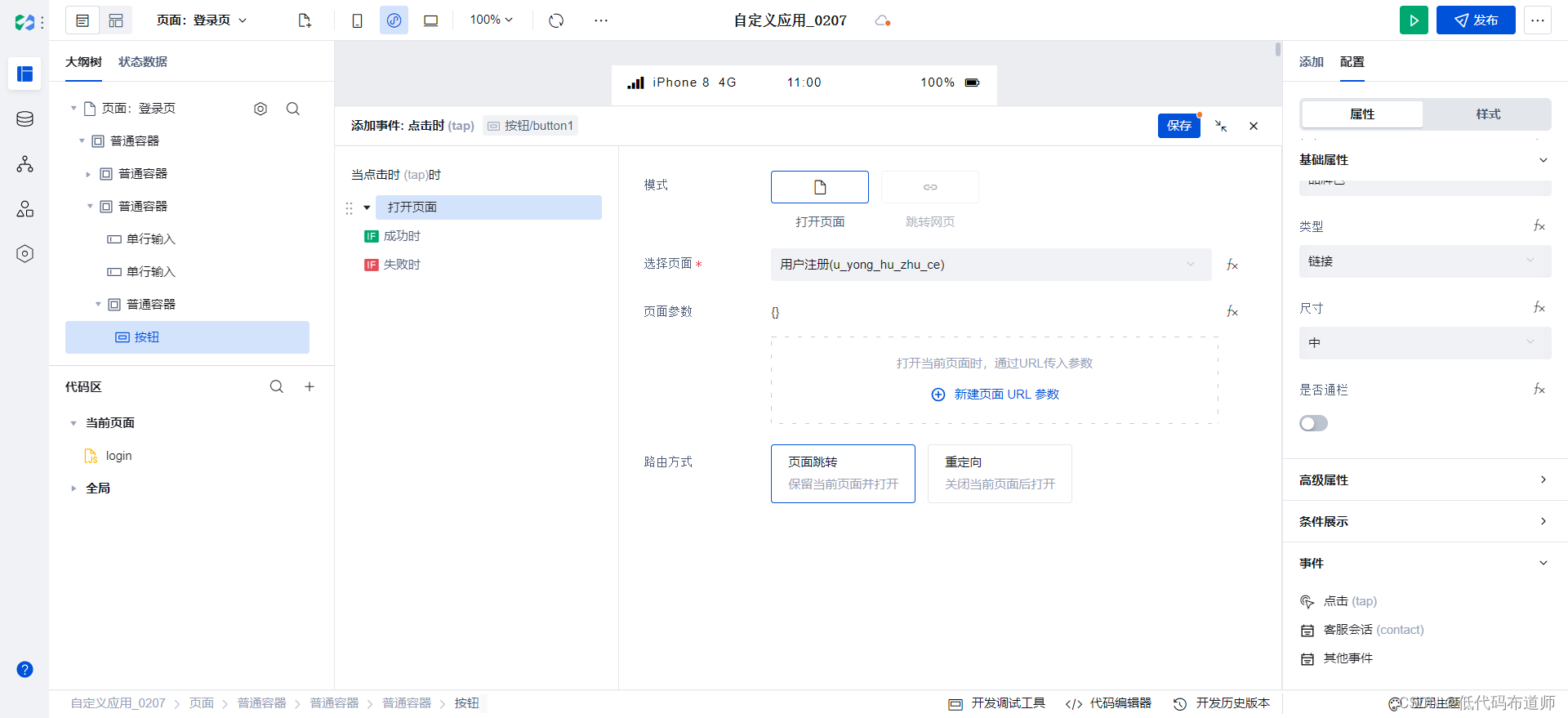
电商小程序05用户注册
目录 1 搭建页面2 设置默认跳转总结 我们上一篇拆解了登录功能,如果用户没有账号就需要注册了。本篇我们介绍一下注册功能的实现。 1 搭建页面 打开应用,点击左上角的新建页面 输入页面的名称,用户注册 删掉网格布局,添加表单容…...
什么是UI设计?
用户界面(UI)它是人与机器互动的载体,也是用户体验(UX)一个组成部分。用户界面由视觉设计 (即传达产品的外观和感觉) 和交互设计 (即元素的功能和逻辑组织) 两部分组成。用户界面设计的目标是创建一个用户界面…...
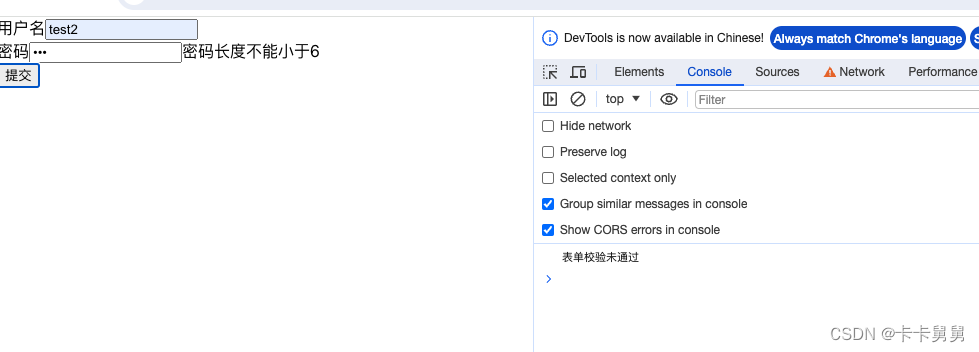
React 实现表单组件
表单是html的基础元素,接下来我会用React实现一个表单组件。支持包括输入状态管理,表单验证,错误信息展示,表单提交,动态表单元素等功能。 数据状态 表单元素的输入状态管理,可以基于react state 实现。 …...
PlantUML绘制UML图教程
UML(Unified Modeling Language)是一种通用的建模语言,广泛用于软件开发中对系统进行可视化建模。PlantUML是一款强大的工具,通过简单的文本描述,能够生成UML图,包括类图、时序图、用例图等。PlantUML是一款…...

自学Python第二十二天- Django框架(六) django的实用插件:cron、APScheduler
django-crontab 和 django-cron 有时候需要django在后台不断的执行一个任务,简单的可以通过中间件来实现,但是中间件是根据请求触发的。如果需要定时执行任务,则需要使用到一些插件。 django-crontab 和 django-cron 是常用的用于处理定时任…...

收藏!AI时代程序员是消失还是逆袭?小白程序员必看大模型逆袭指南
收藏!AI时代程序员是消失还是逆袭?小白程序员必看大模型逆袭指南 文章探讨了AI对程序员行业的影响,指出AI抢走了程序员一半的饭碗,但也为另一半人打开了高阶职场的大门。初级岗位因AI工具普及而面临失业风险,但高级技术…...

ScienceClaw:基于Python的学术爬虫工具,高效抓取文献与课程资料
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“ScienceClaw”,作者是beita6969。光看这个名字,你可能觉得有点摸不着头脑——“科学爪”?这到底是干嘛的?作为一个在开源社区混迹多年的老鸟…...

如何在3分钟内实现iOS设备虚拟定位?iFakeLocation实战指南
如何在3分钟内实现iOS设备虚拟定位?iFakeLocation实战指南 【免费下载链接】iFakeLocation Simulate locations on iOS devices on Windows, Mac and Ubuntu. 项目地址: https://gitcode.com/gh_mirrors/if/iFakeLocation 在iOS应用开发与测试中,…...

高性能事件存储引擎Chronicle:原理、部署与生产实践指南
1. 项目概述与核心价值最近在折腾日志和事件数据的管理,发现一个挺有意思的开源项目,叫tensakulabs/chronicle。这名字起得挺贴切,“编年史”,一听就知道是跟记录、存储历史事件相关的。简单来说,Chronicle 是一个高性…...

构建离线文档ETL管道:用Python实现PDF/Word智能转Markdown优化LLM输入
1. 项目概述:为什么我们需要一个离线的文档转换工具?如果你和我一样,经常需要把一堆PDF、Word文档甚至扫描件喂给本地的大语言模型(比如Ollama、LM Studio),那你肯定遇到过这个痛点:模型宝贵的上…...

【PyTorch实战】从零构建CNN模型:MNIST手写数字识别全流程解析
1. 环境准备与数据加载 第一次接触PyTorch时,我对着官方文档折腾了半天环境配置。后来发现用Anaconda管理Python环境真是省心,这里分享我的配置经验。建议先安装Anaconda最新版,然后创建专属环境: conda create -n pytorch_env py…...

Unity性能优化实战:Mesh Baker 纹理合并与UV重映射详解
1. 为什么需要纹理合并与UV重映射 在开发开放世界游戏时,场景中往往会出现大量重复的建筑、植被等模型。每个模型通常都有自己的材质球和贴图,这会导致两个严重问题:首先是Draw Call数量激增,每个材质球都会产生一次Draw Call&…...
)
别再只用GitHub了!手把手教你用GitLab搭建团队专属代码仓库(从群组到项目实战)
别再只用GitHub了!手把手教你用GitLab搭建团队专属代码仓库(从群组到项目实战) 在开源生态中,GitHub无疑是代码托管平台的代名词。但对于需要私有化部署和精细权限控制的团队而言,GitLab提供了更完整的DevOps解决方案。…...

蓝奏云直链解析:从繁琐到一键的下载革命
蓝奏云直链解析:从繁琐到一键的下载革命 【免费下载链接】LanzouAPI 蓝奏云直链,蓝奏api,蓝奏解析,蓝奏云解析API,蓝奏云带密码解析 项目地址: https://gitcode.com/gh_mirrors/la/LanzouAPI 你是否厌倦了蓝奏云…...

党建知识竞赛系统推荐:满足各级党组织需求的智能化工具
🚩 党建知识竞赛系统推荐:满足各级党组织需求的智能化工具创新党员教育形式 提升学习实效 推动智慧党建🎯 一、核心价值与功能需求在新时代加强党的建设背景下,如何创新党员教育形式、提升学习实效,是各级党组织面临…...