Pandas 数据处理-排序与排名的深度探索【第69篇—python:文本数据处理】
文章目录
- Pandas 数据处理-排序与排名的深度探索
- 1. sort_index方法
- 2. sort_values方法
- 3. rank方法
- 4. 多列排序
- 5. 排名方法的参数详解
- 6. 处理重复值
- 7. 对索引进行排名
- 8. 多级索引排序与排名
- 9. 更高级的排序自定义
- 10. 性能优化技巧
- 10.1 使用`nsmallest`和`nlargest`
- 10.2 使用`sort_values`的`inplace`参数
- 10.3 使用`merge`进行排名
- 总结
Pandas 数据处理-排序与排名的深度探索
Pandas是Python中广泛使用的数据处理库,提供了丰富的功能来处理和分析数据。在数据分析过程中,经常需要对数据进行排序和排名,以便更好地理解和分析数据。本文将介绍Pandas中常用的排序、排名方法,包括sort_index、sort_values和rank,并通过代码实例和解析来演示它们的使用。

1. sort_index方法
sort_index方法主要用于按照索引进行排序。默认情况下,它会按照索引的升序进行排序,但也可以通过参数指定降序排列。下面是一个简单的例子:
import pandas as pd# 创建一个DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 22, 35],'Score': [85, 90, 75, 95]}df = pd.DataFrame(data, index=[3, 1, 4, 2])# 使用sort_index进行升序排序
df_sorted = df.sort_index()
print("按照索引升序排序:\n", df_sorted)# 使用sort_index进行降序排序
df_sorted_desc = df.sort_index(ascending=False)
print("按照索引降序排序:\n", df_sorted_desc)
在上面的例子中,sort_index方法根据索引进行了升序和降序排序。

2. sort_values方法
sort_values方法用于按照指定列的值进行排序。可以通过by参数指定排序的列,也可以通过ascending参数指定升序或降序。以下是一个示例:
# 使用sort_values按照Age列的值进行升序排序
df_age_sorted = df.sort_values(by='Age')
print("按照Age列升序排序:\n", df_age_sorted)# 使用sort_values按照Score列的值进行降序排序
df_score_sorted_desc = df.sort_values(by='Score', ascending=False)
print("按照Score列降序排序:\n", df_score_sorted_desc)
在上面的例子中,sort_values方法分别根据"Age"列进行升序排序和根据"Score"列进行降序排序。

3. rank方法
rank方法用于为数据分配排名。默认情况下,它根据数值大小进行排名,具有相同数值的元素将分配相同的排名,且排名取平均值。以下是一个例子:
# 使用rank方法为Age列分配排名
df['Age_Rank'] = df['Age'].rank()
print("根据Age列分配排名:\n", df)
在上面的例子中,rank方法为"Age"列分配了排名,并将结果添加到DataFrame中的新列"Age_Rank"中。
通过以上代码实例,我们展示了Pandas中常用的排序、排名方法。这些方法在数据分析和处理中起着重要作用,帮助我们更好地理解和利用数据。阅读本文后,你应该能够灵活运用这些方法来满足不同数据处理的需求。
4. 多列排序
在实际数据分析中,经常需要根据多列的值进行排序。Pandas中,可以通过传递包含多个列名的列表来实现多列排序。以下是一个例子:
# 使用sort_values按照Score列升序、Age列降序排序
df_multi_sorted = df.sort_values(by=['Score', 'Age'], ascending=[True, False])
print("按照Score列升序、Age列降序排序:\n", df_multi_sorted)
在上述例子中,sort_values方法根据"Score"列进行升序排序,然后在"Score"列相同的情况下,根据"Age"列进行降序排序。
5. 排名方法的参数详解
rank方法具有一些可选参数,可以根据实际需求进行调整。以下是一些常用的参数:
method: 指定处理相同值时的方法,默认为"average",表示取平均值。其他可选值包括"min"、“max”、"first"和"dense"等。ascending: 指定排名的升序或降序,默认为True(升序)。na_option: 指定对缺失值的处理方式,默认为"keep",表示保留缺失值;可以设置为"top"或"bottom",表示将缺失值分别排在最前或最后。
# 使用rank方法,设置method和na_option参数
df['Score_Rank'] = df['Score'].rank(method='min', ascending=False, na_option='top')
print("根据Score列分配排名,使用min方法和top参数:\n", df)
在上面的例子中,rank方法使用了"min"方法,即相同值取最小排名,同时将缺失值排在最前。
通过这些参数的合理运用,我们可以更灵活地控制排名方法的行为,以适应不同的数据情况。
6. 处理重复值
在数据集中,可能存在重复的行,而sort_values方法也可以用于处理重复值。通过duplicates和keep参数,我们可以灵活地选择如何处理重复的行。
# 创建含有重复值的DataFrame
data_with_duplicates = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Alice'],'Age': [25, 30, 22, 35, 25],'Score': [85, 90, 75, 95, 85]}df_duplicates = pd.DataFrame(data_with_duplicates)# 使用sort_values处理重复值
df_no_duplicates = df_duplicates.sort_values(by=['Name', 'Age'], keep='first')
print("处理重复值后的DataFrame:\n", df_no_duplicates)
在上述例子中,sort_values方法根据"Name"列和"Age"列排序,并通过keep='first'保留第一次出现的重复行,删除后续的重复行。
7. 对索引进行排名
除了对列进行排序和排名,Pandas也支持对索引进行排序和排名。这对于处理时间序列数据等场景非常有用。
# 对索引进行排序
df_index_sorted = df.sort_index(ascending=False)
print("对索引降序排序:\n", df_index_sorted)# 使用rank方法为索引分配排名
df['Index_Rank'] = df.index.rank()
print("对索引进行排名:\n", df)
在上述例子中,sort_index方法用于对索引进行排序,而rank方法则用于为索引分配排名。
8. 多级索引排序与排名
Pandas支持多级索引,这在处理复杂层次化数据时非常有用。我们可以使用sort_index方法对多级索引进行排序,以及使用rank方法进行排名。
# 创建具有多级索引的DataFrame
index_data = [('Group1', 'A'), ('Group1', 'B'), ('Group2', 'A'), ('Group2', 'B')]
multi_index = pd.MultiIndex.from_tuples(index_data, names=['Group', 'Subgroup'])data_multi_index = {'Age': [25, 30, 22, 35],'Score': [85, 90, 75, 95]}df_multi_index = pd.DataFrame(data_multi_index, index=multi_index)# 对多级索引进行排序
df_multi_sorted = df_multi_index.sort_index(level=['Group', 'Subgroup'], ascending=[True, False])
print("对多级索引排序:\n", df_multi_sorted)# 使用rank方法为多级索引分配排名
df_multi_index['Rank'] = df_multi_index.groupby('Group')['Score'].rank(ascending=False)
print("对多级索引进行排名:\n", df_multi_index)
在上述例子中,sort_index方法根据多级索引中"Group"和"Subgroup"的层级进行排序,而rank方法使用groupby对多级索引的"Group"进行分组,然后为每组内的"Score"列进行排名。

9. 更高级的排序自定义
有时,我们可能需要更高级的排序自定义,例如根据自定义函数或条件进行排序。在这种情况下,可以使用key参数。
# 创建一个DataFrame
data_custom_sort = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 22, 35],'Score': [85, 90, 75, 95]}df_custom_sort = pd.DataFrame(data_custom_sort)# 使用sort_values自定义排序规则
df_custom_sorted = df_custom_sort.sort_values(by='Age', key=lambda x: x % 2)
print("根据Age列进行奇偶排序:\n", df_custom_sorted)
在上述例子中,sort_values方法通过key参数,根据"Age"列的奇偶性进行排序。
10. 性能优化技巧
在处理大规模数据集时,性能优化变得尤为重要。在Pandas中,一些技巧可以帮助提高排序和排名的执行效率。
10.1 使用nsmallest和nlargest
如果只需要获取最小或最大的几行数据,可以使用nsmallest和nlargest方法,它们比完整的排序更高效。
# 使用nsmallest获取Age列最小的两行数据
df_nsmallest = df.nsmallest(2, 'Age')
print("Age列最小的两行数据:\n", df_nsmallest)
10.2 使用sort_values的inplace参数
当对数据进行排序时,可以使用inplace=True参数来直接修改原始DataFrame,而不是创建一个新的排序后的副本。
# 使用sort_values对Score列进行升序排序,直接修改原始DataFrame
df.sort_values(by='Score', inplace=True)
print("原始DataFrame经过Score列升序排序:\n", df)
10.3 使用merge进行排名
对于需要根据其他列的值进行排名的情况,可以使用merge方法结合rank来提高性能。
# 创建一个DataFrame用于排名
rank_df = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Rank_Score': [4, 3, 2, 1]})# 使用merge将排名合并到原始DataFrame
df_merged = pd.merge(df, rank_df, on='Name')
print("将排名合并到原始DataFrame:\n", df_merged)
通过这些性能优化技巧,可以在处理大规模数据时更加高效地进行排序和排名操作,提升代码执行速度。

总结
在本篇技术博客中,我们深入研究了Pandas中的排序和排名方法,包括sort_index、sort_values和rank。通过具体的代码实例和解析,我们详细介绍了这些方法的使用方式,使读者能够更好地理解和应用于实际的数据处理场景。
首先,我们学习了如何使用sort_index方法按照索引对数据进行排序,以及如何控制升序和降序排列。接着,我们探讨了sort_values方法,演示了根据单列或多列的值进行排序的方式,并介绍了处理重复值的方法。在排名方面,我们通过rank方法展示了如何为数据分配排名,以及如何通过一些参数调整排名的行为。
进一步地,我们介绍了多级索引的排序与排名,展示了对复杂层次化数据的处理方法。此外,我们讨论了一些高级排序自定义的技巧,包括使用自定义函数进行排序。
在性能优化方面,我们提出了几种有效的技巧,例如使用nsmallest和nlargest方法、sort_values的inplace参数,以及通过merge方法进行排名。这些技巧有助于在处理大规模数据集时提高代码的执行效率。
总体而言,通过本文的学习,读者应该能够更灵活地运用Pandas中的排序和排名方法,从而在实际的数据分析工作中取得更好的效果。这些技能对于数据科学家、分析师和工程师来说都是非常宝贵的,能够帮助他们更高效、更准确地处理和分析数据。
相关文章:
Pandas 数据处理-排序与排名的深度探索【第69篇—python:文本数据处理】
文章目录 Pandas 数据处理-排序与排名的深度探索1. sort_index方法2. sort_values方法3. rank方法4. 多列排序5. 排名方法的参数详解6. 处理重复值7. 对索引进行排名8. 多级索引排序与排名9. 更高级的排序自定义10. 性能优化技巧10.1 使用nsmallest和nlargest10.2 使用sort_val…...

第8节、双电机多段直线运动【51单片机+L298N步进电机系列教程】
↑↑↑点击上方【目录】,查看本系列全部文章 摘要:前面章节主要介绍了bresenham直线插值运动,本节内容介绍让两个电机完成连续的直线运动,目标是画一个正五角星 一、五角星图介绍 五角星总共10条直线,10个顶点。设定左下角为原点…...
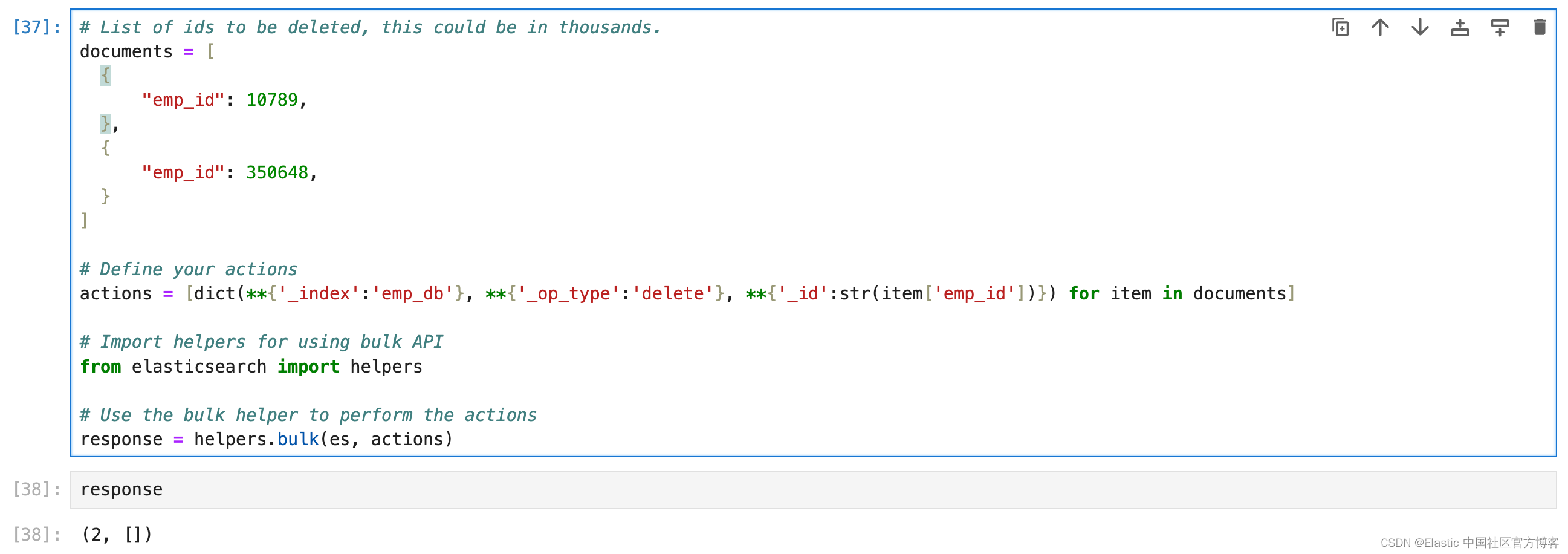
Elasticsearch:基本 CRUD 操作 - Python
在我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”,我详细讲述了如何建立 Elasticsearch 的客户端连接。我们也详述了如何对数据的写入及一些基本操作。在今天的文章中,我们针对数据的 CRUD (cre…...
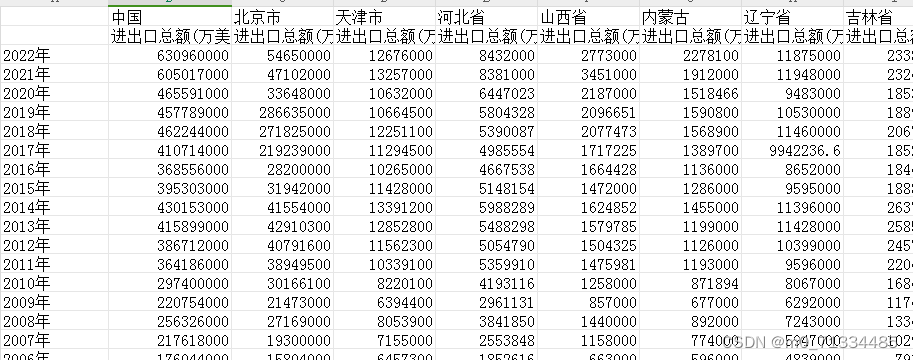
1992-2022年全国及31省对外开放度测算数据(含原始数据+计算结果)(无缺失)
1992-2022年全国及31省对外开放度测算数据(含原始数据计算结果)(无缺失) 1、时间:1992-2022年 2、来源:各省年鉴、国家统计局、统计公报、 3、指标:进出口总额(万美元)…...

JVM之GC垃圾回收
GC垃圾回收 如何判断对象可以回收 引用计数法 如果有对象引用计数加一,没有对象引用,计数减一,如果计数为零,则回收 但是如果存在循环引用,即A对象引用B对象,B对象引用A对象,会造成内存泄漏 可…...

自然语言学习nlp 六
https://www.bilibili.com/video/BV1UG411p7zv?p118 Delta Tuning,尤其是在自然语言处理(NLP)和机器学习领域中,通常指的是对预训练模型进行微调的一种策略。这种策略不是直接更新整个预训练模型的权重,而是仅针对模型…...

fpga 需要掌握哪些基础知识?
个人根据自己的一些心得总结一下fpga 需要掌握的基础知识,希望对你有帮助。 1、数电(必须掌握的基础),然后进阶学模电, 2、掌握HDL(verilog或VHDL)一般建议先学verilog,然后可以学…...

Qt未来市场洞察
跨平台开发:Qt作为一种跨平台的开发框架,具有良好的适应性和灵活性,未来将继续受到广泛应用。随着多设备和多平台应用的增加,Qt的前景在跨平台开发领域将更加广阔。 物联网应用:由于Qt对嵌入式系统和物联网应用的良好支…...

GPT-4模型中的token和Tokenization概念介绍
Token从字面意思上看是游戏代币,用在深度学习中的自然语言处理领域中时,代表着输入文字序列的“代币化”。那么海量语料中的文字序列,就可以转化为海量的代币,用来训练我们的模型。这样我们就能够理解“用于GPT-4训练的token数量大…...

宽字节注入漏洞原理以及修复方法
漏洞名称:宽字节注入 漏洞描述: 宽字节注入是相对于单字节注入而言的,该注入跟HTML页面编码无关,宽字节注入常见于mysql中,GB2312、GBK、GB18030、BIG5、Shift_JIS等这些都是常说的宽字节,实际上只有两字节。宽字节带来的安全问…...

【Linux】SystemV IPC
进程间通信 一、SystemV 共享内存1. 共享内存原理2. 系统调用接口(1)创建共享内存(2)形成 key(3)测试接口(4)关联进程(5)取消关联(6)释…...

iview 页面中判断溢出才使用Tooltip组件
使用方法 <TextTooltip :content"contentValue"></TextTooltip> 给Tooltip再包装一下 <template><Tooltip transfer :content"content" :theme"theme" :disabled"!showTooltip" :max-width"300" :p…...
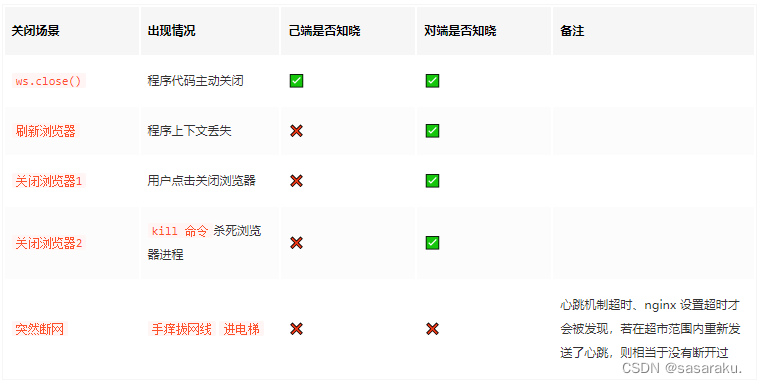
如何使用websocket
如何使用websocket 之前看到过一个面试题:吃饭点餐的小程序里,同一桌的用户点餐菜单如何做到的实时同步? 答案就是:使用websocket使数据变动时服务端实时推送消息给其他用户。 最近在我们自己的项目中我也遇到了类似问题…...
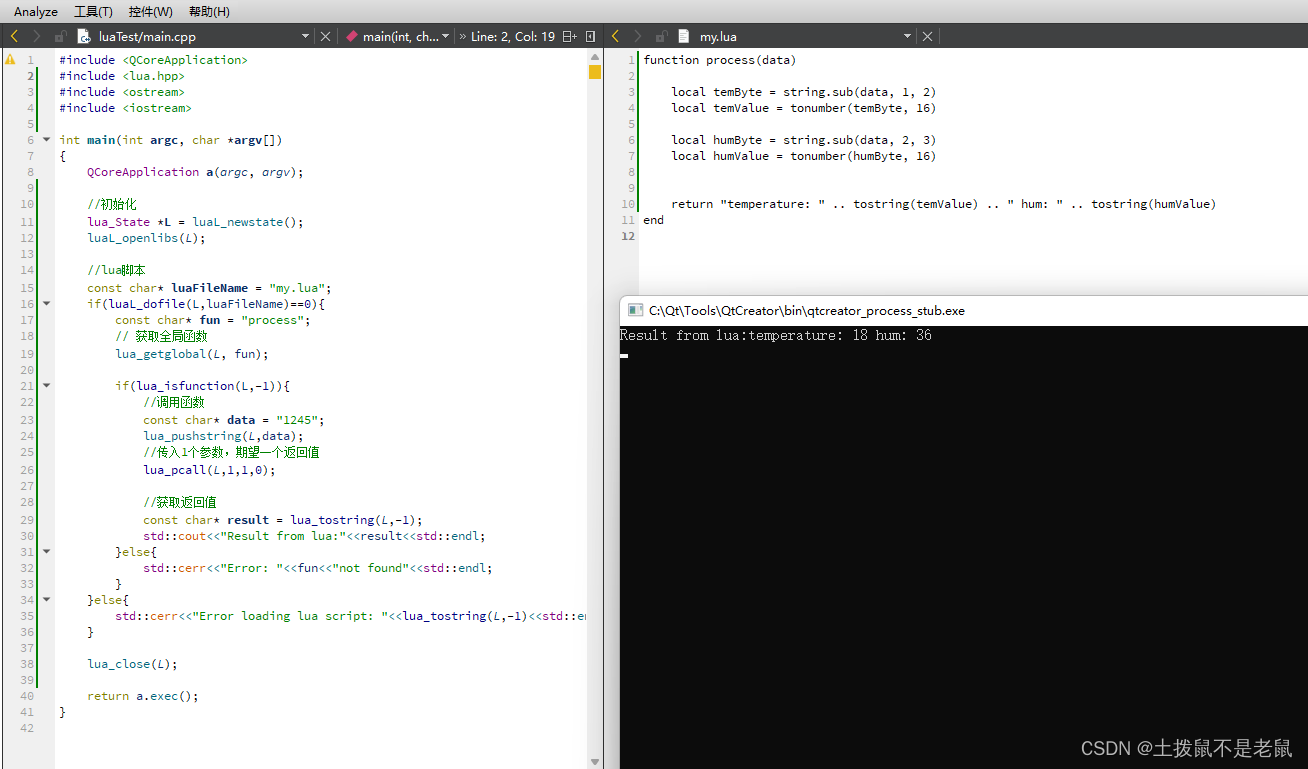
C++ 调用lua 脚本
需求: 使用Qt/C 调用 lua 脚本 扩展原有功能。 步骤: 1,工程中引入 头文件,库文件。lua二进制下载地址(Lua Binaries) 2, 调用脚本内函数。 这里调用lua 脚本中的process函数,并…...
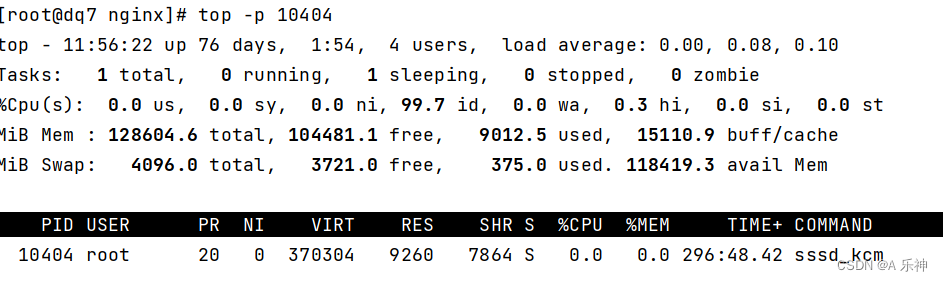
Centos 内存和硬盘占用情况以及top作用
目录 只查看内存使用情况: 内存使用排序取前5个: 硬盘占用情况 定位占用空间最大目录 top查看cpu及内存使用信息 前言-与正文无关 生活远不止眼前的苦劳与奔波,它还充满了无数值得我们去体验和珍惜的美好事物。在这个快节奏的世界中&…...

【数据结构】堆(创建,调整,插入,删除,运用)
目录 堆的概念: 堆的性质: 堆的存储方式: 堆的创建 : 堆的调整: 向下调整: 向上调整: 堆的创建: 建堆的时间复杂度: 向下调整: 向上调整ÿ…...
v-if 和v-for的联合规则及示例
第073个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 提供vue2的一些基本操作:安装、引用,模板使用,computed&a…...

各互联网企业测绘资质调研
公司子公司产品产品介绍资质获得资质时间阿里巴巴高德高德地图作为阿里的全资子公司,中国领先的数字地图内容、导航和位置服务解决方案提供商,互联网地图行业龙头,2021年4月高德实现全月平均日活跃用户数超过1亿的重要里程碑,稳居…...
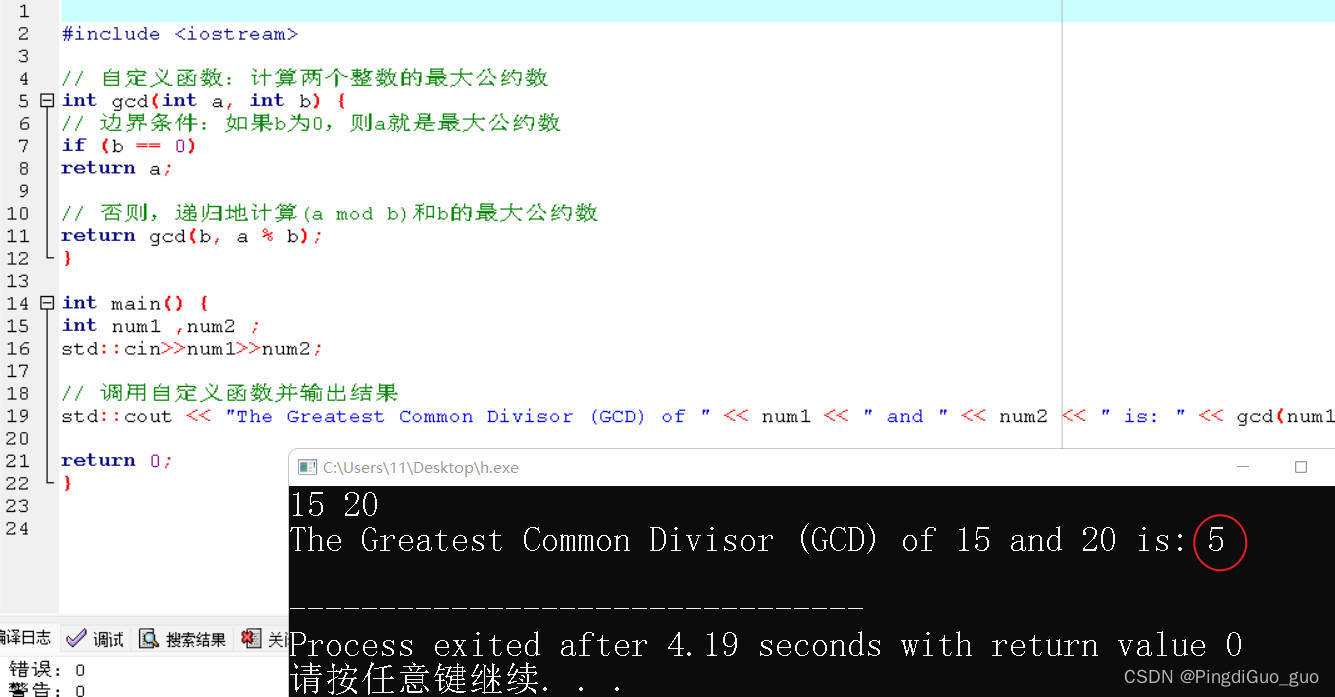
C++自定义函数详解
个人主页:PingdiGuo_guo 收录专栏:C干货专栏 铁汁们新年好呀,今天我们来了解自定义函数。 文章目录 1.数学中的函数 2.什么是自定义函数 3.自定义函数如何使用? 4.值传递和引用传递(形参和实参区分) …...
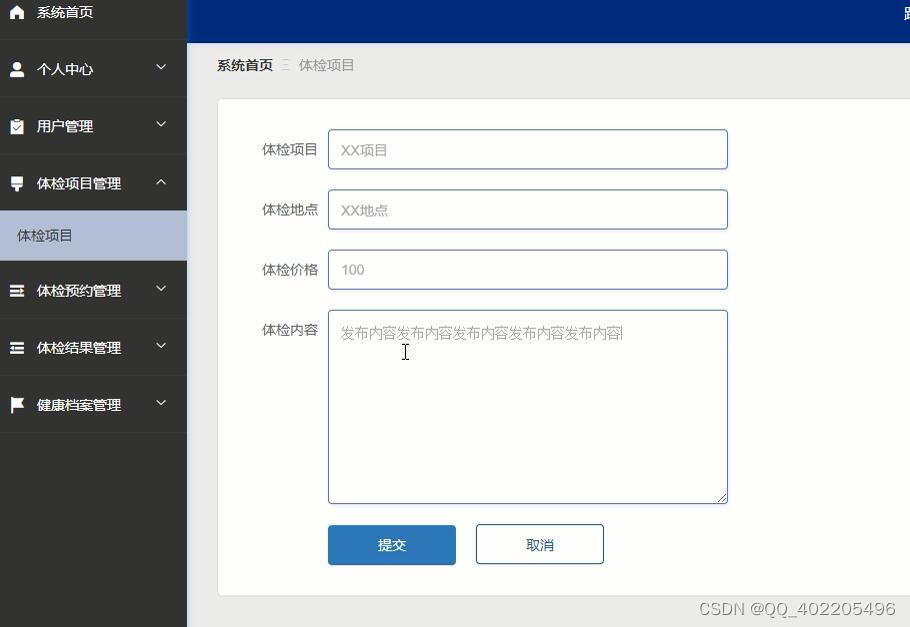
flask+vue+python跨区通勤人员健康体检预约管理系统
跨区通勤人员健康管理系统设计的目的是为用户提供体检项目等功能。 与其它应用程序相比,跨区通勤人员健康的设计主要面向于跨区通勤人员,旨在为管理员和用户提供一个跨区通勤人员健康管理系统。用户可以通过系统及时查看体检预约等。 跨区通勤人员健康管…...

Linux服务器远程桌面实战:xrdp配置与Windows无缝连接指南
1. 为什么需要xrdp远程桌面? 刚接触Linux服务器的朋友经常会问我一个问题:"能不能像Windows那样直接用远程桌面连接?"说实话,我第一次管理Linux服务器时也有同样的困惑。毕竟对于习惯了Windows图形界面的用户来说&#…...

Swift 项目集成 MJRefresh 终极指南:SPM包管理与桥接文件配置详解
Swift 项目集成 MJRefresh 终极指南:SPM包管理与桥接文件配置详解 【免费下载链接】MJRefresh An easy way to use pull-to-refresh. 项目地址: https://gitcode.com/gh_mirrors/mj/MJRefresh MJRefresh 是一款简单易用的下拉刷新框架,能帮助 Swi…...

开源机械爪智能增强:计算机视觉与运动规划赋予抓取超能力
1. 项目概述:当“机械爪”遇上“超能力”如果你玩过抓娃娃机,或者关注过工业自动化,对机械爪(Claw)这个概念一定不陌生。它的核心任务简单直接:识别、定位、抓取。但现实往往骨感——面对形状不规则、材质光…...

频谱分析仪EMC预测试实战:30MHz-1GHz辐射发射定位与整改
1. 项目概述:用频谱分析仪搞定辐射发射预测试如果你是一名硬件工程师,或者正在和电磁兼容(EMC)问题作斗争,那么对30MHz到1000MHz这个频段的辐射发射测试一定不会陌生。这是绝大多数电子产品认证(比如CE、FC…...

北京数据恢复公司哪个公司好
在当今数字化时代,数据的重要性不言而喻。无论是个人用户的珍贵照片、文档,还是企业的重要商业数据,一旦丢失,都可能造成巨大的损失。在北京,有众多的数据恢复公司,那么哪家公司才是最好的选择呢࿱…...
)
告别SSH命令行:用VSCode的Log Viewer插件实时监控Linux syslog日志(附C程序测试)
告别终端监控:在VSCode中实现Linux系统日志可视化追踪 每次调试服务器应用时,你是否也厌倦了在SSH终端和代码编辑器之间反复切换?那些不断滚动的tail -f输出窗口不仅占用宝贵屏幕空间,还让问题排查变成了一场视觉追踪游戏。对于现…...

解密智能工具:3步实现Windows高效安装Android应用
解密智能工具:3步实现Windows高效安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在数字生活日益融合的今天,你是否曾为Windows…...

FinFET与FD-SOI工艺下的IC可靠性验证关键技术
1. 集成电路可靠性验证的挑战与演进在28nm工艺节点之前,芯片设计工程师面临的选择相对简单——只需沿着摩尔定律的轨迹向下一个工艺节点迁移。但随着FinFET和FD-SOI等新型晶体管结构的出现,以及台积电、三星等代工厂推出的多样化工艺节点选项,…...

5分钟搞定Mac Boot Camp驱动部署:Brigadier全攻略
5分钟搞定Mac Boot Camp驱动部署:Brigadier全攻略 【免费下载链接】brigadier Fetch and install Boot Camp ESDs with ease. 项目地址: https://gitcode.com/gh_mirrors/bri/brigadier 还在为Mac安装Windows系统时繁琐的驱动匹配而烦恼吗?每次重…...

告别答辩PPT焦虑:百考通AI如何帮你高效搞定毕业答辩
简洁专业的PPT模板,精准的AI内容生成,在线编辑与一键美化——让毕业答辩的最后一步走得更从容。 又到了一年毕业季,当论文终于定稿,你是否发现自己又面临一座新的大山——毕业答辩PPT?面对几十页的论文文档,…...