Elasticsearch:基本 CRUD 操作 - Python
在我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”,我详细讲述了如何建立 Elasticsearch 的客户端连接。我们也详述了如何对数据的写入及一些基本操作。在今天的文章中,我们针对数据的 CRUD (create, read, update 及 delete) 做更进一步的描述。

创建客户端连接接
我们需要安装 Elasticsearch 的依赖包:
pip3 install elasticsearch$ pip3 install elasticsearch
Looking in indexes: http://mirrors.aliyun.com/pypi/simple/
Requirement already satisfied: elasticsearch in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (8.12.0)
Requirement already satisfied: elastic-transport<9,>=8 in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elasticsearch) (8.10.0)
Requirement already satisfied: urllib3<3,>=1.26.2 in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elastic-transport<9,>=8->elasticsearch) (2.1.0)
Requirement already satisfied: certifi in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elastic-transport<9,>=8->elasticsearch) (2023.11.17)
$ pip3 list | grep elasticsearch
elasticsearch 8.12.0
rag-elasticsearch 0.0.1 /Users/liuxg/python/rag-elasticsearch/my-app/packages/rag-elasticsearch我们使用如下的代码来建立一个客户端连接:
from elasticsearch import Elasticsearchelastic_user = "elastic"
elastic_password = "xnLj56lTrH98Lf_6n76y"url = f"https://{elastic_user}:{elastic_password}@localhost:9200"
es = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)print(es.info())在上面,我们需要使用自己的 Elasticsearch 集群的用户信息及证书代替上面的值。更多信息,请详细参阅文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。
创建文档
要添加新文档,你可以使用索引 API。 如果未指定文档 ID,Elasticsearch 会生成一个。 使用索引 API,你可以一次添加一个文档。
# Data to be indexed
document = {"emp_id": 1,"age": 30,"email": "example@example.com","name": "John Doe","role": "Developer","dob": "1992-01-01","mobile_no": "1234567890","educational": {"10": 87.5,"12": 90.0,"graduation": 8.4,"post_graduation": 9.1},"stack": ["Python", "Elasticsearch", "React"]
}# Indexing the document
response = es.index(index="emp_db", document=document)我们可以在 Kibana 中进行查看:
GET emp_db/_search响应将有以下内容:

- _index:存储文档的索引的名称。
- _id:分配给文档的唯一标识符。 如果您在为文档建立索引时未指定 ID,Elasticsearch 会自动生成一个 ID,如本例所示。
- _version:文档的版本号。 对于新创建的文档,该值从 1 开始,并随着每次更新而递增。
- result:指示操作完成,在本例中文档已创建。 如果文档已经存在并且已更新,则会显示 “updated”。
要一次添加多个文档,请使用 bulk API。 为了使用 bulk API,数据需要采用特定格式。 示例实际文档应位于 _source 中,每个文档应具有 _op_type 和 _index 。 它应该是这样的:
通过 bulk API 添加数据:
actions = [ {"_index": "emp_db", "_op_type": "create", "_source": {"field1": "value1"}}, {"_index": "emp_db", "_op_type": "create", "_source": {"field2": "value2"}} # Add more actions as needed
]# List of data to be indexed, this could be in thousands.
documents = [{"emp_id": 250349,"age": 26,"email": "abc@xyz.com","name": "abc","role": "Developer","dob": "1997-01-01","mobile_no": "12345678","educational": {"10": 87.5,"12": 90.0,"graduation": 8.4,"post_graduation": 9.1},"stack": ["Python", "PySpark", "AWS"]},{"emp_id": 10789,"name": "abc","age": 27,"email": "abc@xyz.com","role": "linux admin","dob": "1996-12-10","mobile_no": "12345678","educational": {"10": 87.5,"12": 90.0,"graduation": 8.4,"post_graduation": 9.1},"stack": ["Linux", "AWS"]},{"emp_id": 350648,"name": "Sandeep","age": 27,"email": "def@xyz.com","role": "seller support"}
]# Define your actions
actions = [dict(**{'_index':'emp_db'}, **{'_op_type':'create'}, **{'_id':str(item['emp_id'])}, **{'_source':item}) for item in documents]# Import helpers for using bulk API
from elasticsearch import helpers# Use the bulk helper to perform the actions
bulk_response = helpers.bulk(es, actions)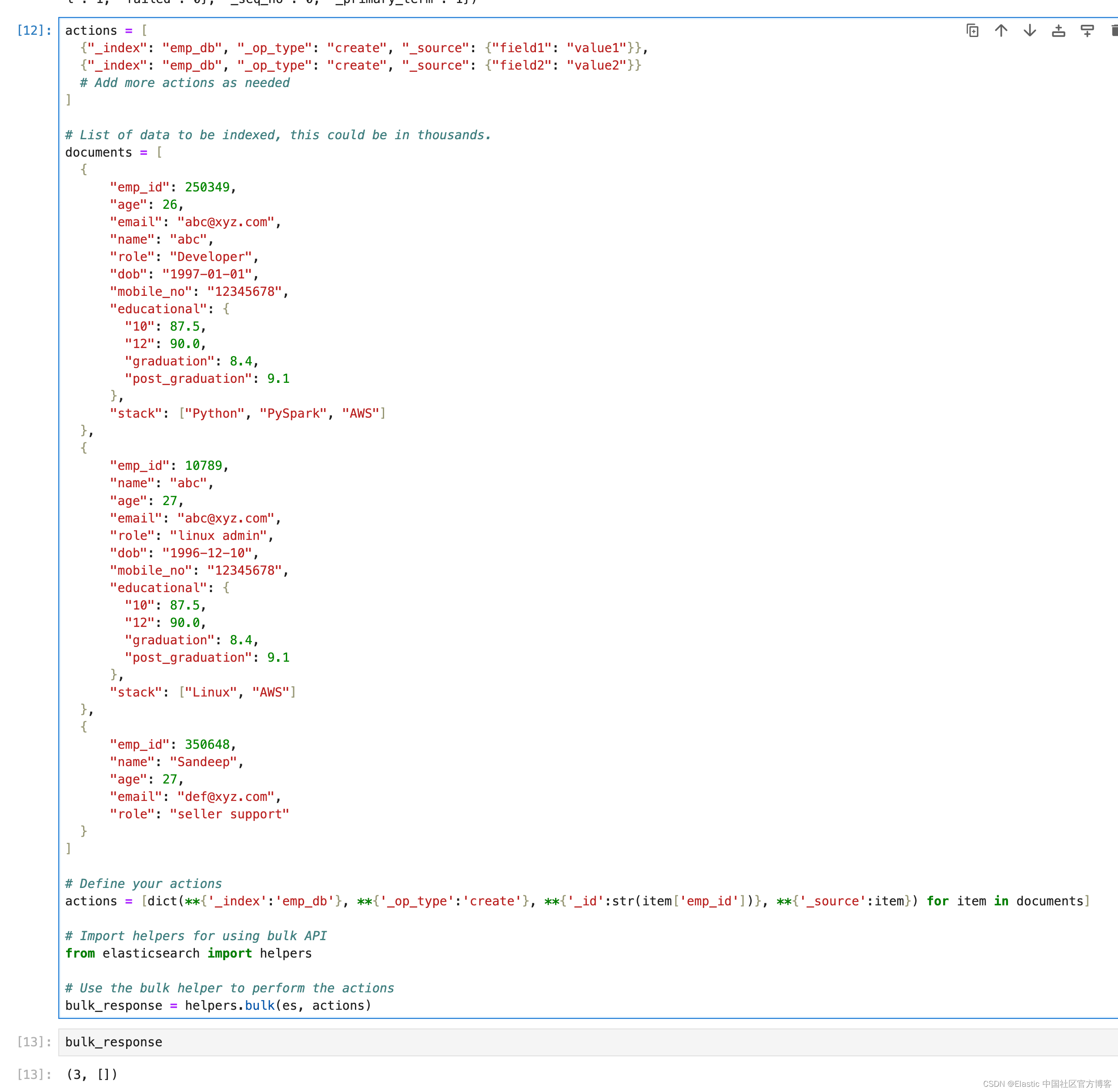
所有批量操作都具有相同的响应结构。
Elasticsearch Python 客户端中 helpers.bulk 方法的输出 (3, []) 表明批量操作已成功执行。 让我们分解一下响应:
3 :这是在批量操作中成功处理的操作(例如索引、更新或删除文档)的数量。
[] :这个空列表表明批量操作期间没有错误。 如果存在任何错误,此列表将包含失败操作的错误详细信息。
- 3 :这是在批量操作中成功处理的操作(例如索引、更新或删除文档)的数量。
- [] :这个空列表表明批量操作期间没有错误。 如果存在任何错误,此列表将包含失败操作的错误详细信息。
读写操作
要检索文档,请使用 get API 和文档 ID。
response = es.get(index="emp_db", id=250349)
除了 _index 、 _id 、 _version 之外
- found :表示在索引中找到了具有给定 id 的文档。
- _source :包含文档的实际数据。
使用 mget API 检索多个文档:
doc_ids = [{"emp_id":250349},{"emp_id":350648}
]# Define your actions
docs = [dict(**{'_index':'emp_db'}, **{'_id':str(item['emp_id'])}) for item in doc_ids]# Retrieve the documents
response = es.mget(body={"docs": docs})
更新文档
要更新现有文档,请使用 update API。 这可以部分更新文档。 通过 update API,你可以一次添加一个文档。
document = {"emp_id": 250349,"role": "sr software engineer"
}response = es.update(index="emp_db", id=document["emp_id"], doc=document)响应将有 _index 、 _id 、 _version 、 result 。

通过 bulk API 更新数据:

删除文档
要删除文档,请使用 delete API。 使用 delete API,你一次只能删除一个文档。
es.delete(index="emp_db", id=250349)
响应将有 _index 、 _id 、 _version 、 result 。
通过 bulk API 删除数据。
# List of ids to be deleted, this could be in thousands.
documents = [{"emp_id": 10789,},{"emp_id": 350648,}
]# Define your actions
actions = [dict(**{'_index':'emp_db'}, **{'_op_type':'delete'}, **{'_id':str(item['emp_id'])}) for item in documents]# Import helpers for using bulk API
from elasticsearch import helpers# Use the bulk helper to perform the actions
response = helpers.bulk(es, actions)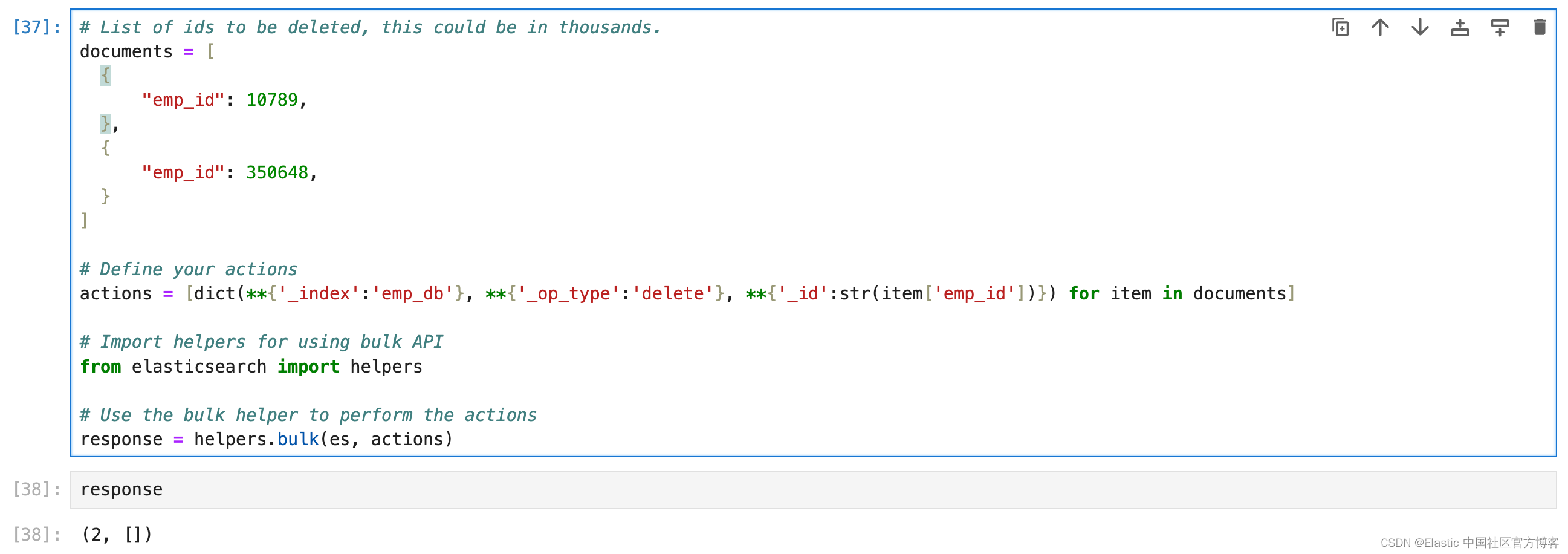
恭喜,你已成功完成 CRUD 操作。 在这篇博客中,你了解了基本的 CRUD 操作。
完整的 jupyter notebook,请在地址下载:https://github.com/liu-xiao-guo/elasticsearch-python-notebooks/blob/main/elasticsearch_crud.ipynb
相关文章:
Elasticsearch:基本 CRUD 操作 - Python
在我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”,我详细讲述了如何建立 Elasticsearch 的客户端连接。我们也详述了如何对数据的写入及一些基本操作。在今天的文章中,我们针对数据的 CRUD (cre…...
1992-2022年全国及31省对外开放度测算数据(含原始数据+计算结果)(无缺失)
1992-2022年全国及31省对外开放度测算数据(含原始数据计算结果)(无缺失) 1、时间:1992-2022年 2、来源:各省年鉴、国家统计局、统计公报、 3、指标:进出口总额(万美元)…...

JVM之GC垃圾回收
GC垃圾回收 如何判断对象可以回收 引用计数法 如果有对象引用计数加一,没有对象引用,计数减一,如果计数为零,则回收 但是如果存在循环引用,即A对象引用B对象,B对象引用A对象,会造成内存泄漏 可…...

自然语言学习nlp 六
https://www.bilibili.com/video/BV1UG411p7zv?p118 Delta Tuning,尤其是在自然语言处理(NLP)和机器学习领域中,通常指的是对预训练模型进行微调的一种策略。这种策略不是直接更新整个预训练模型的权重,而是仅针对模型…...

fpga 需要掌握哪些基础知识?
个人根据自己的一些心得总结一下fpga 需要掌握的基础知识,希望对你有帮助。 1、数电(必须掌握的基础),然后进阶学模电, 2、掌握HDL(verilog或VHDL)一般建议先学verilog,然后可以学…...

Qt未来市场洞察
跨平台开发:Qt作为一种跨平台的开发框架,具有良好的适应性和灵活性,未来将继续受到广泛应用。随着多设备和多平台应用的增加,Qt的前景在跨平台开发领域将更加广阔。 物联网应用:由于Qt对嵌入式系统和物联网应用的良好支…...

GPT-4模型中的token和Tokenization概念介绍
Token从字面意思上看是游戏代币,用在深度学习中的自然语言处理领域中时,代表着输入文字序列的“代币化”。那么海量语料中的文字序列,就可以转化为海量的代币,用来训练我们的模型。这样我们就能够理解“用于GPT-4训练的token数量大…...

宽字节注入漏洞原理以及修复方法
漏洞名称:宽字节注入 漏洞描述: 宽字节注入是相对于单字节注入而言的,该注入跟HTML页面编码无关,宽字节注入常见于mysql中,GB2312、GBK、GB18030、BIG5、Shift_JIS等这些都是常说的宽字节,实际上只有两字节。宽字节带来的安全问…...

【Linux】SystemV IPC
进程间通信 一、SystemV 共享内存1. 共享内存原理2. 系统调用接口(1)创建共享内存(2)形成 key(3)测试接口(4)关联进程(5)取消关联(6)释…...

iview 页面中判断溢出才使用Tooltip组件
使用方法 <TextTooltip :content"contentValue"></TextTooltip> 给Tooltip再包装一下 <template><Tooltip transfer :content"content" :theme"theme" :disabled"!showTooltip" :max-width"300" :p…...
如何使用websocket
如何使用websocket 之前看到过一个面试题:吃饭点餐的小程序里,同一桌的用户点餐菜单如何做到的实时同步? 答案就是:使用websocket使数据变动时服务端实时推送消息给其他用户。 最近在我们自己的项目中我也遇到了类似问题…...
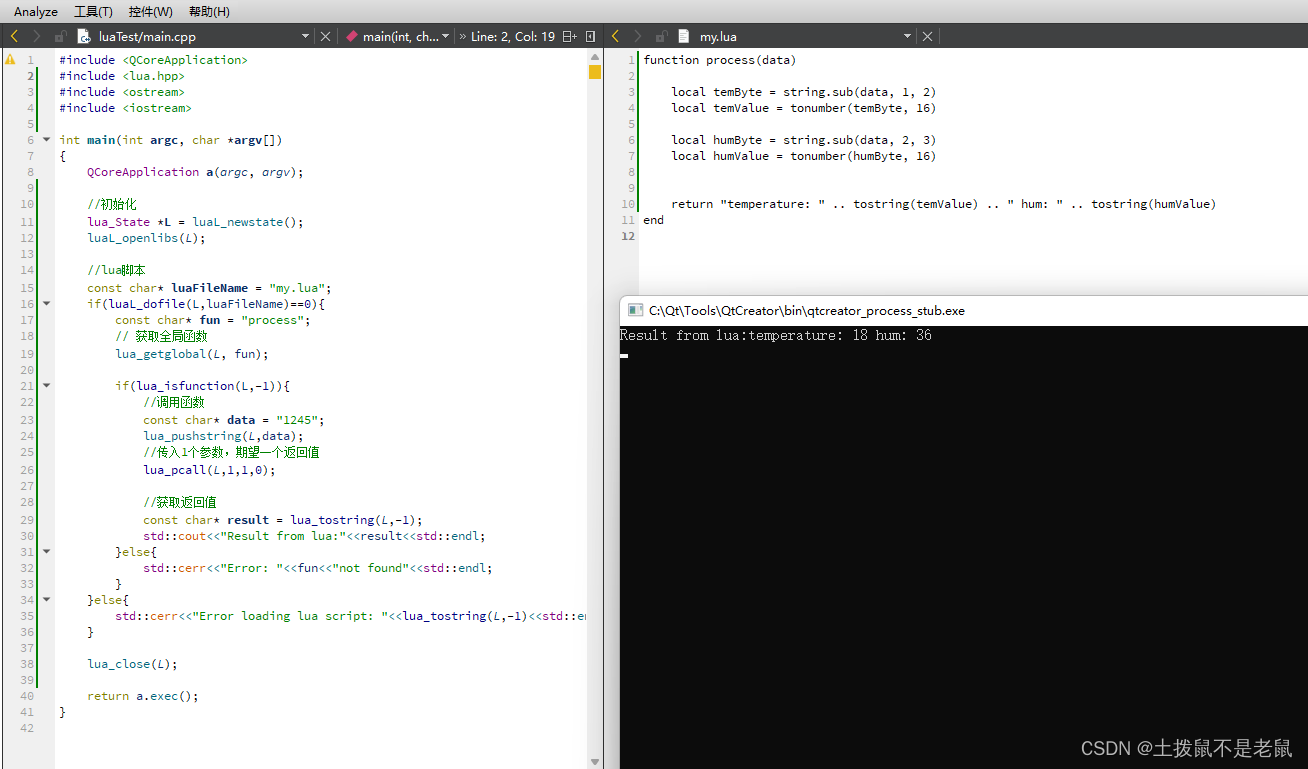
C++ 调用lua 脚本
需求: 使用Qt/C 调用 lua 脚本 扩展原有功能。 步骤: 1,工程中引入 头文件,库文件。lua二进制下载地址(Lua Binaries) 2, 调用脚本内函数。 这里调用lua 脚本中的process函数,并…...
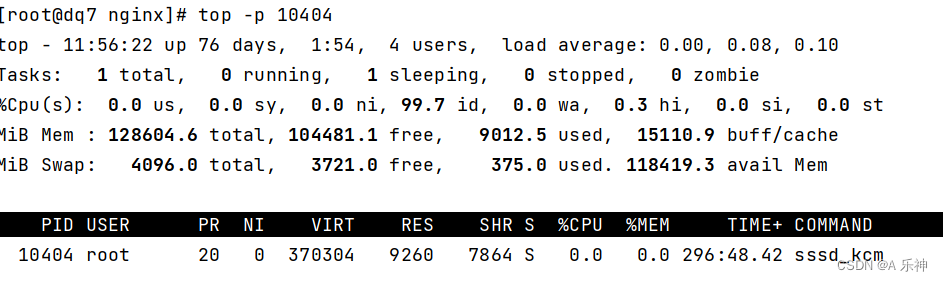
Centos 内存和硬盘占用情况以及top作用
目录 只查看内存使用情况: 内存使用排序取前5个: 硬盘占用情况 定位占用空间最大目录 top查看cpu及内存使用信息 前言-与正文无关 生活远不止眼前的苦劳与奔波,它还充满了无数值得我们去体验和珍惜的美好事物。在这个快节奏的世界中&…...

【数据结构】堆(创建,调整,插入,删除,运用)
目录 堆的概念: 堆的性质: 堆的存储方式: 堆的创建 : 堆的调整: 向下调整: 向上调整: 堆的创建: 建堆的时间复杂度: 向下调整: 向上调整ÿ…...
v-if 和v-for的联合规则及示例
第073个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 提供vue2的一些基本操作:安装、引用,模板使用,computed&a…...

各互联网企业测绘资质调研
公司子公司产品产品介绍资质获得资质时间阿里巴巴高德高德地图作为阿里的全资子公司,中国领先的数字地图内容、导航和位置服务解决方案提供商,互联网地图行业龙头,2021年4月高德实现全月平均日活跃用户数超过1亿的重要里程碑,稳居…...
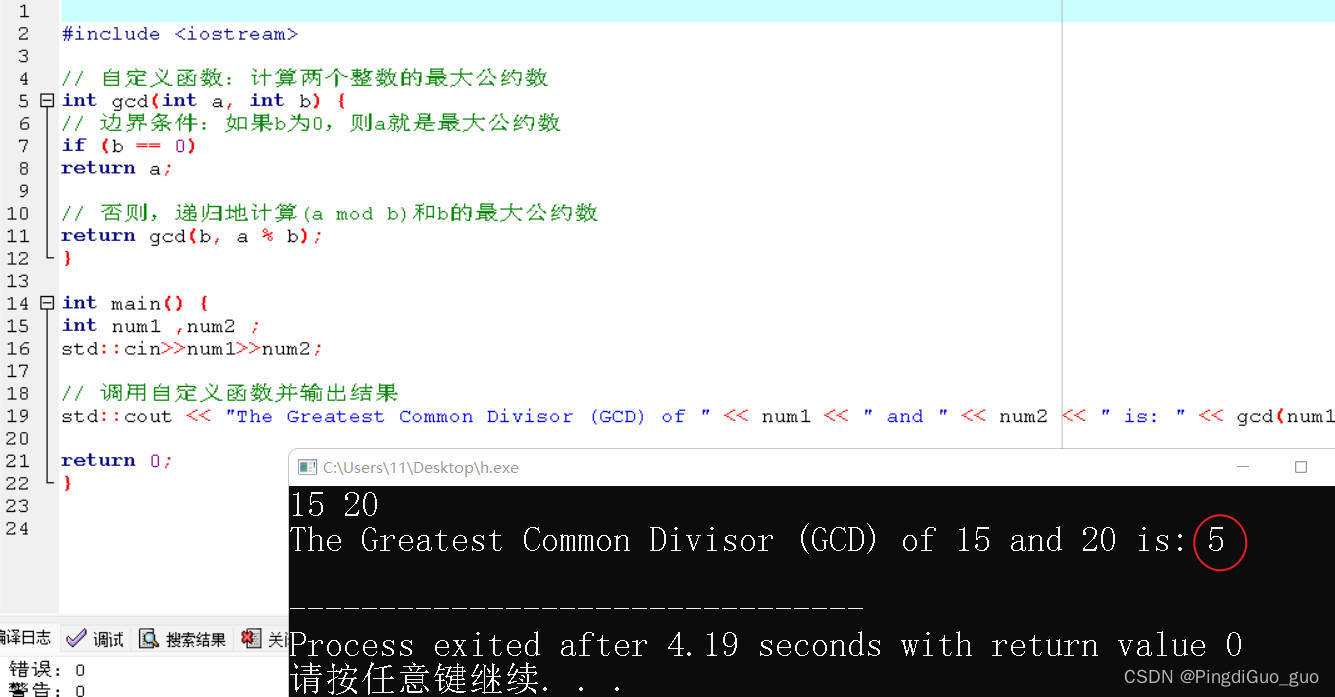
C++自定义函数详解
个人主页:PingdiGuo_guo 收录专栏:C干货专栏 铁汁们新年好呀,今天我们来了解自定义函数。 文章目录 1.数学中的函数 2.什么是自定义函数 3.自定义函数如何使用? 4.值传递和引用传递(形参和实参区分) …...
flask+vue+python跨区通勤人员健康体检预约管理系统
跨区通勤人员健康管理系统设计的目的是为用户提供体检项目等功能。 与其它应用程序相比,跨区通勤人员健康的设计主要面向于跨区通勤人员,旨在为管理员和用户提供一个跨区通勤人员健康管理系统。用户可以通过系统及时查看体检预约等。 跨区通勤人员健康管…...

Spring Boot动态加载Jar包与动态配置技术探究
Spring Boot动态加载Jar包与动态配置技术探究 1. 引言 在当今快节奏的软件开发领域,高效的开发框架是保持竞争力的关键。Spring Boot作为一款快速开发框架,以其简化配置、内嵌Web服务器、强大的开发工具等特性,成为众多开发者的首选。其背后…...

Lua metatable metamethod
示例代码 《programming in lua》里有一个案例很详细,就是写一个集合类的table,其负责筛选出table中不重复的元素并组合成一个新的table。本人按照自己的方式默写了一次,结果发现大差不差,代码如下: Set {} --集合--…...

Claude集成Spring Boot全链路实践:从零搭建智能API网关的7步标准化流程
更多请点击: https://intelliparadigm.com 第一章:Claude集成Spring Boot全链路实践:从零搭建智能API网关的7步标准化流程 环境准备与依赖声明 确保 JDK 17、Maven 3.8 和 Spring Boot 3.2.x 基础环境就绪。在 pom.xml 中引入 Claude 官方…...

终极邮件营销自动化指南:工程师如何快速搭建高效邮件营销系统
终极邮件营销自动化指南:工程师如何快速搭建高效邮件营销系统 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for-Engineers…...

构建AI智能体技能超市:标准化工作流与多平台适配实践
1. 项目概述:一个面向AI智能体的“技能超市”如果你和我一样,每天都在和Codex、Claude、Cursor这些AI助手打交道,那你肯定也遇到过这样的场景:想让AI帮你生成一份规范的Git提交信息、自动更新文档索引,或者为一个新项目…...

Vibe Annotations:AI编程时代的视觉反馈工具,精准沟通前端修改意图
1. 项目概述:一个为AI编程时代量身定制的视觉反馈工具如果你和我一样,每天都在和AI编程助手(比如Cursor、Claude Code)打交道,那你肯定遇到过这个痛点:想让它帮你改一个网页按钮的颜色,或者调整…...

电源完整性设计:电容模型、去耦策略与测量验证实战解析
1. 电容与去耦:从概念到实战的深度解析上周我们聊了聊去耦电容在电源完整性设计中的一些基本概念和时机选择,算是开了个头。这周咱们继续深入,把这块硬骨头啃得更透一些。很多工程师,尤其是刚入行的朋友,常常觉得电容选…...

Fomu FPGA工作坊:从LED闪烁到RISC-V软核的微型硬件开发指南
1. 项目概述:当FPGA遇见指尖,一场硬件的微型革命如果你对嵌入式开发、硬件编程感兴趣,但又觉得传统的FPGA开发板笨重、昂贵且入门门槛高,那么im-tomu/fomu-workshop这个项目可能会让你眼前一亮。这不仅仅是一个代码仓库࿰…...

Midjourney咖啡印相为何总偏灰?揭秘RGB→Lab→咖啡染料光谱响应的3层色彩断层及校正算法
更多请点击: https://intelliparadigm.com 第一章:Midjourney咖啡印相为何总偏灰?揭秘RGB→Lab→咖啡染料光谱响应的3层色彩断层及校正算法 咖啡印相(Coffee Cyanotype)作为一种新兴的生物友好型物理输出工艺…...

【DeepSeek开发者垂直搜索实战指南】:3大行业落地案例+5个避坑要点,限时公开内部调优参数
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开发者垂直搜索应用案例全景概览 DeepSeek系列大模型凭借其开源、高性能与强推理能力,正被广泛集成至开发者垂直搜索场景中——从代码片段检索、API文档语义查找,到私有…...

IC场景XR全息通信_CSDN
6G IC场景XR/全息通信技术深度分析 摘要: 6G时代的沉浸式通信(Immersive Communication, IC)是实现"存在感"传输的核心场景,其中XR与全息通信技术对网络提出了Tbps级速率和亚毫秒级延迟的极限需求。本文从技术需求量化、…...
)
RT-Thread Sensor框架实战:5分钟搞定INA226电流电压功率监测(含I2C避坑指南)
RT-Thread Sensor框架实战:5分钟搞定INA226电流电压功率监测(含I2C避坑指南) 在嵌入式系统开发中,精准监测电流、电压和功率是许多应用场景的核心需求,无论是电池管理系统、智能硬件功耗分析,还是工业设备状…...