Python爬虫实战:抓取猫眼电影排行榜top100#4
爬虫专栏系列:http://t.csdnimg.cn/Oiun0
抓取猫眼电影排行
本节中,我们利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。requests 比 urllib 使用更加方便,而且目前我们还没有系统学习 HTML 解析库,所以这里就选用正则表达式来作为解析工具。
同时我会放出Xpath和Beautiful Soup版本的源代码,便于有基础的同学尝试。
1. 本节目标
本节中,我们要提取出猫眼电影 TOP100 的电影名称、时间、评分、图片等信息,提取的站点 URL 为 http://maoyan.com/board/4,提取的结果会以文件形式保存下来。
2. 准备工作
在本节开始之前,请确保已经正确安装好了 requests 库。如果没有安装,可以参考Python爬虫请求库安装-CSDN博客的安装说明。
3. 抓取分析
我们需要抓取的目标站点为http://maoyan.com/board/4,打开之后便可以查看到榜单信息,如图所示。
榜单信息
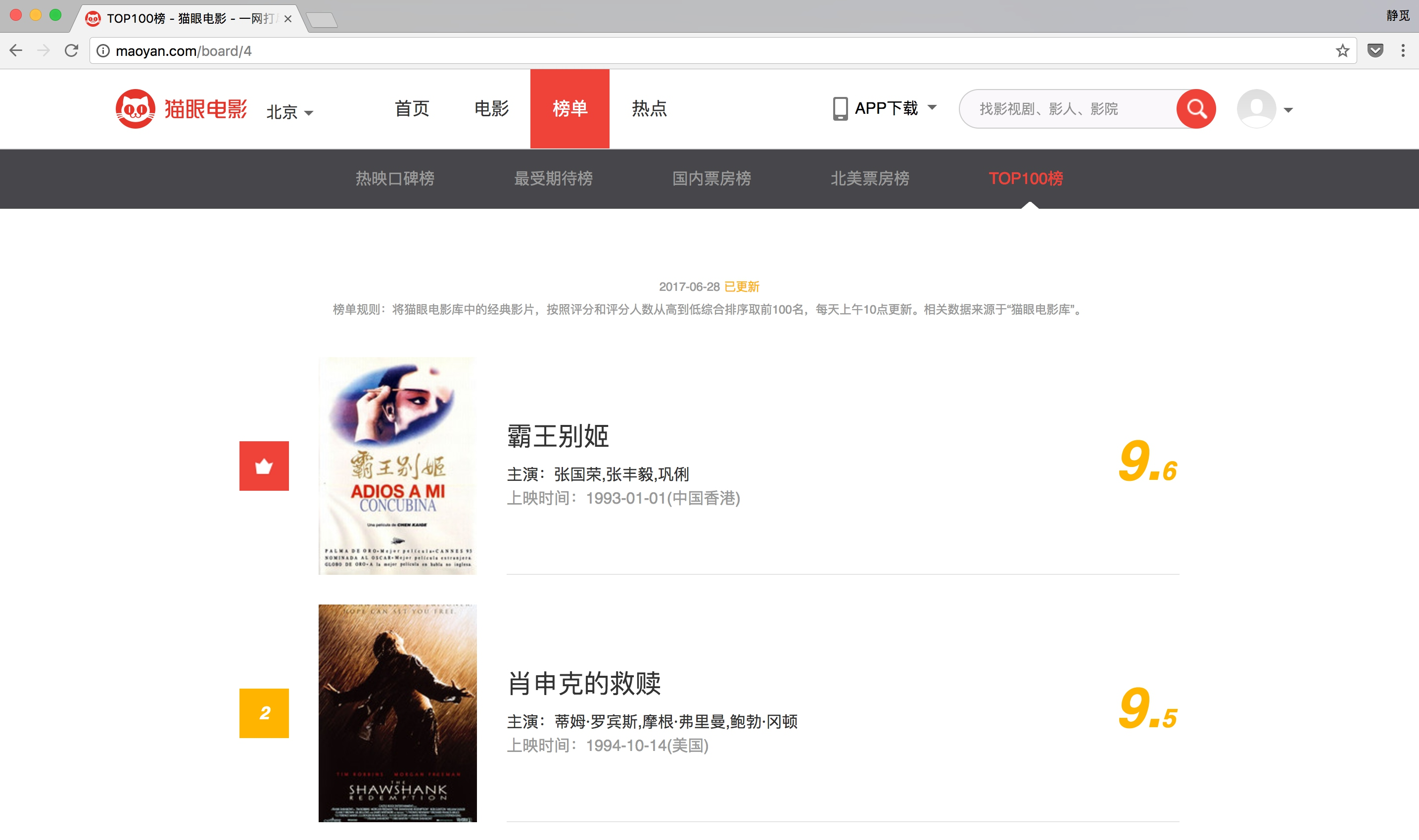
排名第一的电影是霸王别姬,页面中显示的有效信息有影片名称、主演、上映时间、上映地区、评分、图片等信息。
将网页滚动到最下方,可以发现有分页的列表,直接点击第 2 页,观察页面的 URL 和内容发生了怎样的变化,如图所示。

可以发现页面的 URL 变成 TOP100榜 - 猫眼电影 - 一网打尽好电影,比之前的 URL 多了一个参数,那就是 offset=10,而目前显示的结果是排行 11~20 名的电影,初步推断这是一个偏移量的参数。再点击下一页,发现页面的 URL 变成了 猫眼验证中心,参数 offset 变成了 20,而显示的结果是排行 21~30 的电影。
由此可以总结出规律,offset 代表偏移量值,如果偏移量为 n,则显示的电影序号就是 n+1 到 n+10,每页显示 10 个。所以,如果想获取 TOP100 电影,只需要分开请求 10 次,而 10 次的 offset 参数分别设置为 0、10、20…90 即可,这样获取不同的页面之后,再用正则表达式提取出相关信息,就可以得到 TOP100 的所有电影信息了。
4. 抓取首页
接下来用代码实现这个过程。首先抓取第一页的内容。我们实现了 get_one_page 方法,并给它传入 url 参数。然后将抓取的页面结果返回,再通过 main 方法调用。初步代码实现如下:
import requests
def get_one_page(url): headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' }
response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None
def main(): url = 'http://maoyan.com/board/4' html = get_one_page(url) print(html)
main()
这样运行之后,就可以成功获取首页的源代码了。获取源代码后,就需要解析页面,提取出我们想要的信息。
5. 正则提取
接下来,回到网页看一下页面的真实源码。在开发者模式下的 Network 监听组件中查看源代码,如图所示。
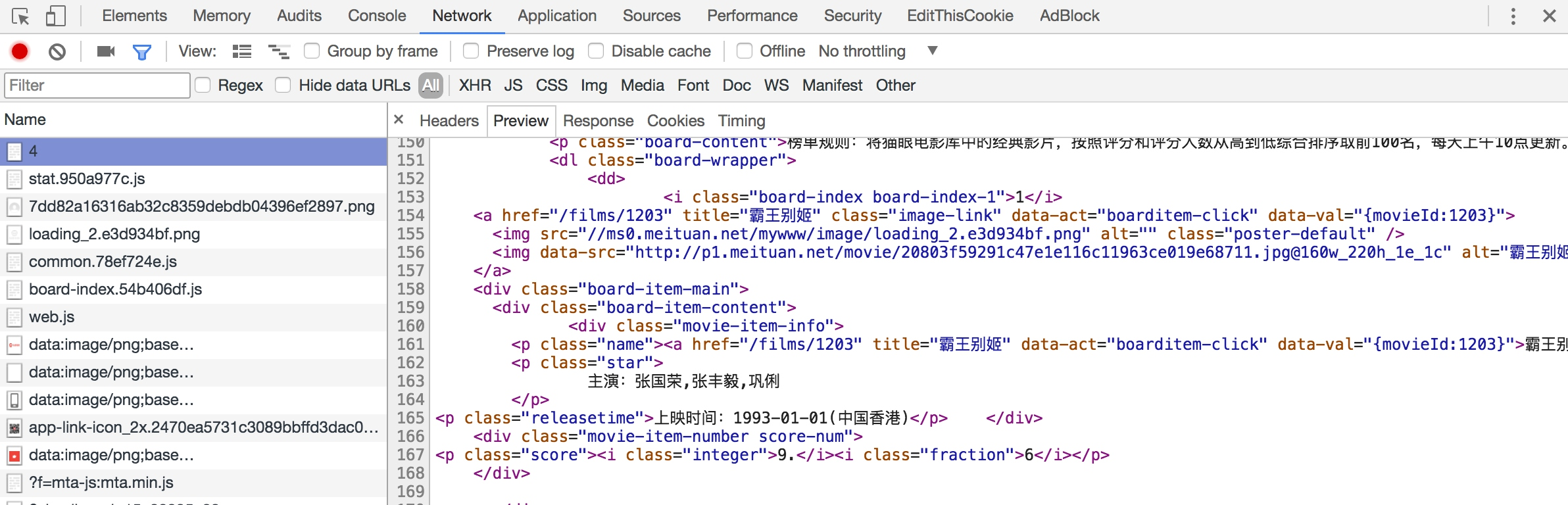
注意,这里不要在 Elements 选项卡中直接查看源码,因为那里的源码可能经过 JavaScript 操作而与原始请求不同,而是需要从 Network 选项卡部分查看原始请求得到的源码。
查看其中一个条目的源代码,如图所示。

可以看到,一部电影信息对应的源代码是一个 dd 节点,我们用正则表达式来提取这里面的一些电影信息。首先,需要提取它的排名信息。而它的排名信息是在 class 为 board-index 的 i 节点内,这里利用非贪婪匹配来提取 i 节点内的信息,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>随后需要提取电影的图片。可以看到,后面有 a 节点,其内部有两个 img 节点。经过检查后发现,第二个 img 节点的 data-src 属性是图片的链接。这里提取第二个 img 节点的 data-src 属性,正则表达式可以改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"再往后,需要提取电影的名称,它在后面的 p 节点内,class 为 name。所以,可以用 name 做一个标志位,然后进一步提取到其内 a 节点的正文内容,此时正则表达式改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>再提取主演、发布时间、评分等内容时,都是同样的原理。最后,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>这样一个正则表达式可以匹配一个电影的结果,里面匹配了 7 个信息。接下来,通过调用 findall 方法提取出所有的内容。
接下来,我们再定义解析页面的方法 parse_one_page,主要是通过正则表达式来从结果中提取出我们想要的内容,实现代码如下:
def parse_one_page(html):pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',re.S)items = re.findall(pattern, html)print(items)
这样就可以成功地将一页的 10 个电影信息都提取出来,这是一个列表形式,输出结果如下:
[('1', 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', ' 霸王别姬 ', '\n 主演:张国荣,张丰毅,巩俐 \n ', ' 上映时间:1993-01-01(中国香港)', '9.', '6'), ('2', 'http://p0.meituan.net/movie/__40191813__4767047.jpg@160w_220h_1e_1c', ' 肖申克的救赎 ', '\n 主演:蒂姆・罗宾斯,摩根・弗里曼,鲍勃・冈顿 \n ', ' 上映时间:1994-10-14(美国)', '9.', '5'), ('3', 'http://p0.meituan.net/movie/fc9d78dd2ce84d20e53b6d1ae2eea4fb1515304.jpg@160w_220h_1e_1c', ' 这个杀手不太冷 ', '\n 主演:让・雷诺,加里・奥德曼,娜塔莉・波特曼 \n ', ' 上映时间:1994-09-14(法国)', '9.', '5'), ('4', 'http://p0.meituan.net/movie/23/6009725.jpg@160w_220h_1e_1c', ' 罗马假日 ', '\n 主演:格利高利・派克,奥黛丽・赫本,埃迪・艾伯特 \n ', ' 上映时间:1953-09-02(美国)', '9.', '1'), ('5', 'http://p0.meituan.net/movie/53/1541925.jpg@160w_220h_1e_1c', ' 阿甘正传 ', '\n 主演:汤姆・汉克斯,罗宾・怀特,加里・西尼斯 \n ', ' 上映时间:1994-07-06(美国)', '9.', '4'), ('6', 'http://p0.meituan.net/movie/11/324629.jpg@160w_220h_1e_1c', ' 泰坦尼克号 ', '\n 主演:莱昂纳多・迪卡普里奥,凯特・温丝莱特,比利・赞恩 \n ', ' 上映时间:1998-04-03', '9.', '5'), ('7', 'http://p0.meituan.net/movie/99/678407.jpg@160w_220h_1e_1c', ' 龙猫 ', '\n 主演:日高法子,坂本千夏,糸井重里 \n ', ' 上映时间:1988-04-16(日本)', '9.', '2'), ('8', 'http://p0.meituan.net/movie/92/8212889.jpg@160w_220h_1e_1c', ' 教父 ', '\n 主演:马龙・白兰度,阿尔・帕西诺,詹姆斯・凯恩 \n ', ' 上映时间:1972-03-24(美国)', '9.', '3'), ('9', 'http://p0.meituan.net/movie/62/109878.jpg@160w_220h_1e_1c', ' 唐伯虎点秋香 ', '\n 主演:周星驰,巩俐,郑佩佩 \n ', ' 上映时间:1993-07-01(中国香港)', '9.', '2'), ('10', 'http://p0.meituan.net/movie/9bf7d7b81001a9cf8adbac5a7cf7d766132425.jpg@160w_220h_1e_1c', ' 千与千寻 ', '\n 主演:柊瑠美,入野自由,夏木真理 \n ', ' 上映时间:2001-07-20(日本)', '9.', '3')]
但这样还不够,数据比较杂乱,我们再将匹配结果处理一下,遍历提取结果并生成字典,此时方法改写如下:
def parse_one_page(html):pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',re.S)items = re.findall(pattern, html)for item in items:yield {'index': item[0],'image': item[1],'title': item[2].strip(),'actor': item[3].strip()[3:] if len(item[3]) > 3 else '','time': item[4].strip()[5:] if len(item[4]) > 5 else '','score': item[5].strip() + item[6].strip()}
这样就可以成功提取出电影的排名、图片、标题、演员、时间、评分等内容了,并把它赋值为一个个的字典,形成结构化数据。运行结果如下:
{'image': 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'actor': ' 张国荣,张丰毅,巩俐 ', 'score': '9.6', 'index': '1', 'title': ' 霸王别姬 ', 'time': '1993-01-01(中国香港)'}
{'image': 'http://p0.meituan.net/movie/__40191813__4767047.jpg@160w_220h_1e_1c', 'actor': ' 蒂姆・罗宾斯,摩根・弗里曼,鲍勃・冈顿 ', 'score': '9.5', 'index': '2', 'title': ' 肖申克的救赎 ', 'time': '1994-10-14(美国)'}
{'image': 'http://p0.meituan.net/movie/fc9d78dd2ce84d20e53b6d1ae2eea4fb1515304.jpg@160w_220h_1e_1c', 'actor': ' 让・雷诺,加里・奥德曼,娜塔莉・波特曼 ', 'score': '9.5', 'index': '3', 'title': ' 这个杀手不太冷 ', 'time': '1994-09-14(法国)'}
{'image': 'http://p0.meituan.net/movie/23/6009725.jpg@160w_220h_1e_1c', 'actor': ' 格利高利・派克,奥黛丽・赫本,埃迪・艾伯特 ', 'score': '9.1', 'index': '4', 'title': ' 罗马假日 ', 'time': '1953-09-02(美国)'}
{'image': 'http://p0.meituan.net/movie/53/1541925.jpg@160w_220h_1e_1c', 'actor': ' 汤姆・汉克斯,罗宾・怀特,加里・西尼斯 ', 'score': '9.4', 'index': '5', 'title': ' 阿甘正传 ', 'time': '1994-07-06(美国)'}
{'image': 'http://p0.meituan.net/movie/11/324629.jpg@160w_220h_1e_1c', 'actor': ' 莱昂纳多・迪卡普里奥,凯特・温丝莱特,比利・赞恩 ', 'score': '9.5', 'index': '6', 'title': ' 泰坦尼克号 ', 'time': '1998-04-03'}
{'image': 'http://p0.meituan.net/movie/99/678407.jpg@160w_220h_1e_1c', 'actor': ' 日高法子,坂本千夏,糸井重里 ', 'score': '9.2', 'index': '7', 'title': ' 龙猫 ', 'time': '1988-04-16(日本)'}
{'image': 'http://p0.meituan.net/movie/92/8212889.jpg@160w_220h_1e_1c', 'actor': ' 马龙・白兰度,阿尔・帕西诺,詹姆斯・凯恩 ', 'score': '9.3', 'index': '8', 'title': ' 教父 ', 'time': '1972-03-24(美国)'}
{'image': 'http://p0.meituan.net/movie/62/109878.jpg@160w_220h_1e_1c', 'actor': ' 周星驰,巩俐,郑佩佩 ', 'score': '9.2', 'index': '9', 'title': ' 唐伯虎点秋香 ', 'time': '1993-07-01(中国香港)'}
{'image': 'http://p0.meituan.net/movie/9bf7d7b81001a9cf8adbac5a7cf7d766132425.jpg@160w_220h_1e_1c', 'actor': ' 柊瑠美,入野自由,夏木真理 ', 'score': '9.3', 'index': '10', 'title': ' 千与千寻 ', 'time': '2001-07-20(日本)'}
到此为止,我们就成功提取了单页的电影信息。
6. 写入文件
随后,我们将提取的结果写入文件,这里直接写入到一个文本文件中。这里通过 JSON 库的 dumps 方法实现字典的序列化,并指定 ensure_ascii 参数为 False,这样可以保证输出结果是中文形式而不是 Unicode 编码。代码如下:
def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: print(type(json.dumps(content))) f.write(json.dumps(content, ensure_ascii=False)+'\n')
通过调用 write_to_file 方法即可实现将字典写入到文本文件的过程,此处的 content 参数就是一部电影的提取结果,是一个字典。
7. 整合代码
最后,实现 main 方法来调用前面实现的方法,将单页的电影结果写入到文件。相关代码如下:
def main(): url = 'http://maoyan.com/board/4' html = get_one_page(url) for item in parse_one_page(html): write_to_file(item)
到此为止,我们就完成了单页电影的提取,也就是首页的 10 部电影可以成功提取并保存到文本文件中了。
8. 分页爬取
因为我们需要抓取的是 TOP100 的电影,所以还需要遍历一下,给这个链接传入 offset 参数,实现其他 90 部电影的爬取,此时添加如下调用即可:
if __name__ == '__main__': for i in range(10): main(offset=i * 10)
这里还需要将 main 方法修改一下,接收一个 offset 值作为偏移量,然后构造 URL 进行爬取。实现代码如下:
def main(offset): url = 'http://maoyan.com/board/4?offset=' + str(offset) html = get_one_page(url) for item in parse_one_page(html): print(item) write_to_file(item)
到此为止,我们的猫眼电影 TOP100 的爬虫就全部完成了,再稍微整理一下,完整的代码如下:
正则表达式版本
import json
import requests
from requests.exceptions import RequestException
import re
import time def get_one_page(url): try: headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' }response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestException: return None def parse_one_page(html): pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) items = re.findall(pattern, html) for item in items: yield {'index': item[0], 'image': item[1], 'title': item[2], 'actor': item[3].strip()[3:], 'time': item[4].strip()[5:], 'score': item[5] + item[6] } def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) + '\n') def main(offset): url = 'http://maoyan.com/board/4?offset=' + str(offset) html = get_one_page(url) for item in parse_one_page(html): print(item) write_to_file(item) if __name__ == '__main__': for i in range(10): main(offset=i * 10) time.sleep(1)Xpath版本
from lxml import etreedef parse_one_page_xpath(html):root = etree.HTML(html)items = root.xpath('//dd[@class="board-index"]')for item in items:yield {'index': item.xpath('.//i[@class="board-index"]/text()')[0],'image': item.xpath('.//img[@class="board-index-img"]/@data-src')[0],'title': item.xpath('.//a/text()')[0],'actor': item.xpath('.//p[@class="star"]/text()')[0][3:].strip(),'time': item.xpath('.//p[@class="releasetime"]/text()')[0][5:].strip(),'score': item.xpath('.//i[@class="integer"]/text()')[0] + item.xpath('.//i[@class="fraction"]/text()')[0]}# 修改main函数来使用XPath版本
def main(offset):url = 'http://maoyan.com/board/4?offset=' + str(offset)html = get_one_page(url)for item in parse_one_page_xpath(html):print(item)write_to_file(item)if __name__ == '__main__': for i in range(10): main(offset=i * 10) time.sleep(1)Beautiful Soup版本
from bs4 import BeautifulSoupdef parse_one_page_bs(html):soup = BeautifulSoup(html, 'html.parser')items = soup.find_all('dd', class_='board-index')for item in items:yield {'index': item.find(i_class='board-index').get_text(),'image': item.find(img_class='board-index-img')['data-src'],'title': item.find(a_tag=True).get_text(),'actor': item.find(p_class='star').get_text()[3:].strip(),'time': item.find(p_class='releasetime').get_text()[5:].strip(),'score': item.find(i_class='integer').get_text() + item.find(i_class='fraction').get_text()}# 修改main函数来使用BeautifulSoup版本
def main(offset):url = 'http://maoyan.com/board/4?offset=' + str(offset)html = get_one_page(url)for item in parse_one_page_bs(html):print(item)write_to_file(item)if __name__ == '__main__': for i in range(10): main(offset=i * 10) time.sleep(1)现在猫眼多了反爬虫,如果速度过快,则会无响应,所以这里又增加了一个延时等待。
9. 运行结果
最后,我们运行一下代码,输出结果类似如下:
{'index': '1', 'image': 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'title': ' 霸王别姬 ', 'actor': ' 张国荣,张丰毅,巩俐 ', 'time': '1993-01-01(中国香港)', 'score': '9.6'}
{'index': '2', 'image': 'http://p0.meituan.net/movie/__40191813__4767047.jpg@160w_220h_1e_1c', 'title': ' 肖申克的救赎 ', 'actor': ' 蒂姆・罗宾斯,摩根・弗里曼,鲍勃・冈顿 ', 'time': '1994-10-14(美国)', 'score': '9.5'}
...
{'index': '98', 'image': 'http://p0.meituan.net/movie/76/7073389.jpg@160w_220h_1e_1c', 'title': ' 东京物语 ', 'actor': ' 笠智众,原节子,杉村春子 ', 'time': '1953-11-03(日本)', 'score': '9.1'}
{'index': '99', 'image': 'http://p0.meituan.net/movie/52/3420293.jpg@160w_220h_1e_1c', 'title': ' 我爱你 ', 'actor': ' 宋在河,李彩恩,吉海延 ', 'time': '2011-02-17(韩国)', 'score': '9.0'}
{'index': '100', 'image': 'http://p1.meituan.net/movie/__44335138__8470779.jpg@160w_220h_1e_1c', 'title': ' 迁徙的鸟 ', 'actor': ' 雅克・贝汉,菲利普・拉波洛,Philippe Labro', 'time': '2001-12-12(法国)', 'score': '9.1'}
这里省略了中间的部分输出结果。可以看到,这样就成功地把 TOP100 的电影信息爬取下来了。
这时我们再看下文本文件,结果如图所示。
运行结果

可以看到,电影信息也已全部保存到了文本文件中了,大功告成!
本节中,我们通过爬取猫眼 TOP100 的电影信息练习了 requests 和正则表达式的用法。这是一个最基础的实例,希望大家可以通过这个实例对爬虫的实现有一个最基本的思路,也对这两个库的用法有更深一步的了解。
如果本文对你有帮助,不要忘记点赞,收藏+关注,你的支持是我最大的动力!
相关文章:
Python爬虫实战:抓取猫眼电影排行榜top100#4
爬虫专栏系列:http://t.csdnimg.cn/Oiun0 抓取猫眼电影排行 本节中,我们利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。requests 比 urllib 使用更加方便,而且目前我们还没有系统学习 HTML 解析库,所以这里就…...

Fiddler抓包工具之fiddler界面工具栏介绍
Fiddler界面工具栏介绍 (1)WinConfig:windows 使用了一种叫做“AppContainer”的隔离技术,使得一些流量无法正常捕获,在 fiddler中点击 WinConfig 按钮可以解除这个诅咒,这个与菜单栏 Tools→Win8 Loopback…...

LabVIEW工业监控系统
LabVIEW工业监控系统 介绍了一个基于LabVIEW软件开发的工业监控系统。系统通过虚拟测控技术和先进的数据处理能力,实现对工业过程的高效监控,提升系统的自动化和智能化水平,从而满足现代工业对高效率、高稳定性和低成本的需求。 随着工业自…...

Linux 文件连接:符号链接与硬链接
Linux 文件连接:符号链接与硬链接 介绍 在 Linux 系统中,文件连接是一个强大的概念,它允许我们在文件系统中创建引用,从而使得文件和目录之间产生联系。在本文中,我们将深入探讨两种主要类型的文件连接:符…...

数据分类分级
一段时间没写文章了,最近做政府数据治理方面的项目,数据治理一个重要的内容是数据安全,会涉及数据的分类分级,是数据治理的基础。 随着“十四五”规划推行,数据要素概念与意识全面铺开,国家、政府机构、企业…...

第三十天| 51. N皇后
Leetcode 51. N皇后 题目链接:51 N皇后 题干:按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击。 给你一个整…...
pythn-scipy 查漏补缺
1. 2. 3. 4. 5. 6. 7. 8. 9. 偏度 skewness,峰度 kurtosis...

【JavaScript 漫游】【013】Date 对象知识点摘录
文章简介 本文为【JavaScript 漫游】专栏的第 013 篇文章,记录了 JS 语言中 Date 对象的重要知识点。 普通函数的用法构造函数的用法日期的运算静态方法,包括:Date.now()、Date.parse() 和 Date.UTC()实例方法,包括:…...

vue.config.js和webpack.config.js区别
webpack.config.js和vue.config.js的区别 webpack.config.js是webpack的配置文件,所有使用webpack作为打包工具的项目都可以使用,vue的项目可以使用,react的项目也可以使用。 vue.config.js是vue项目的配置文件,专用于vue项目。…...

H12-821_73
73.某台路由器Router LSA如图所示,下列说法中错误的是? A.本路由器的Router ID为10.0.12.1 B.本路由器为DR C.本路由器已建立邻接关系 D.本路由器支持外部路由引入 答案:B 注释: LSA中的链路信息Link ID,Data…...
postman执行批量测试
1.背景 有许多的人常常需要使用第三方系统进行重复的数据查询,本文介绍使用PostMan的方式对数据进行批量的查询,减少重复的劳动。 2.工具下载 3.初入门 一、如图示进行点击,创建collection 二、输入对应的名称 三、创建Request并进行查…...

蓝桥杯基础知识8 list
蓝桥杯基础知识8 list 01 list 的定义和结构 lits使用频率较低,是一种双向链表容器,是标准模板库(STL)提供的一种序列容器,lsit容器以节点(node)的形式存储元素,使用指针将这些节点链…...
【DDD】学习笔记-理解领域模型
Eric Evans 的领域驱动设计是对软件设计领域的一次重新审视,是在面向对象语言大行其道时对数据建模的“拨乱反正”。Eric 强调了模型的重要性,例如他在书中总结了模型在领域驱动设计中的作用包括: 模型和设计的核心互相影响模型是团队所有成…...

v-if 和v-show 的区别
第074个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 提供vue2的一些基本操作:安装、引用,模板使用,computed&a…...

LabVIEW网络测控系统
LabVIEW网络测控系统 介绍了基于LabVIEW的网络测控系统的开发与应用,通过网络技术实现了远程的数据采集、监控和控制。系统采用LabVIEW软件与网络通信技术相结合,提高了系统的灵活性和扩展性,适用于各种工业和科研领域的远程测控需求。 随着…...

攻防世界 CTF Web方向 引导模式-难度1 —— 11-20题 wp精讲
PHP2 题目描述: 暂无 根据dirsearch的结果,只有index.php存在,里面也什么都没有 index.phps存在源码泄露,访问index.phps 由获取的代码可知,需要url解码(urldecode )后验证id为admin则通过 网页工具不能直接对字母进行url编码 …...

华为Eth-Trunk级联堆叠接入IPTV网络部署案例
Eth-Trunk级联堆叠接入IPTV网络部署案例 组网图形 图2 Eth-Trunk级联堆叠IPTV基本组网图 方案简介配置注意事项组网需求数据规划配置思路操作步骤配置文件 方案简介 随着IPTV业务的迅速发展,IPTV平台承载的用户也越来越多,用户对IPTV直播业务的可靠性…...
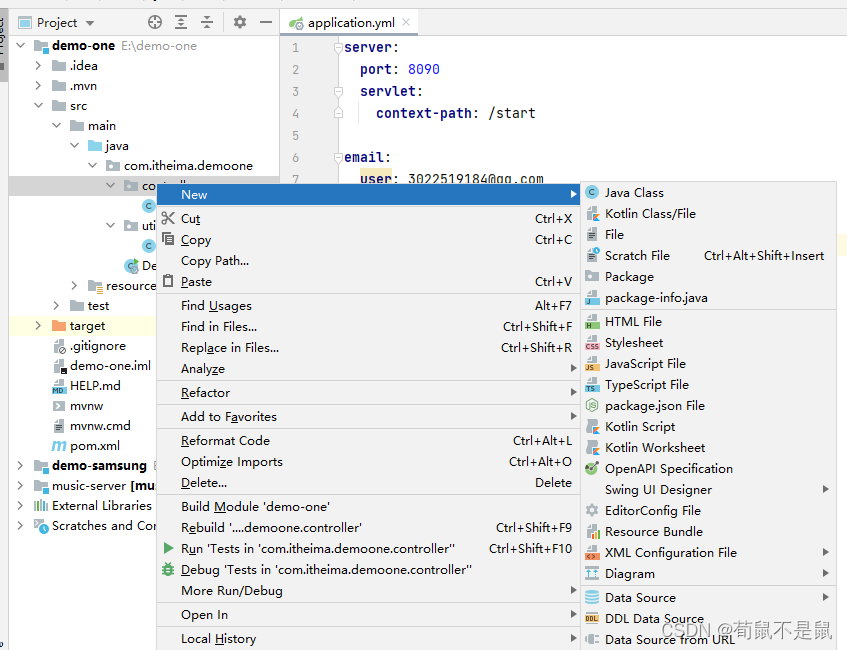
idea: 无法创建Java Class文件(SpringBoot)已解决
第一:点击file-->project Sructure... 第二步:点击Moudules 选择自己需要创建java的文件夹(我这里选择的是main)右键点击Sources,然后点击OK即可 然后就可以创建java类了...

ChinaXiv:中科院科技论文预发布平台
文章目录 Main彩蛋 Main 主页:https://chinaxiv.org/home.htm 彩蛋...
)
【人工智能】Fine-tuning 微调:解析深度学习中的利器(7)
在深度学习领域,Fine-tuning 微调是一项重要而强大的技术,它为我们提供了在特定任务上充分利用预训练模型的途径。本文将深入讨论 Fine-tuning 的定义、原理、实际操作以及其在不同场景中的应用,最后简要探讨Fine-tuning 的整体架构。 1. Fi…...

AMD Ryzen终极调试指南:7步解锁SMUDebugTool硬件级控制
AMD Ryzen终极调试指南:7步解锁SMUDebugTool硬件级控制 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://g…...

掌握TA-Lib Python技术分析库:从入门到精通的完整指南 [特殊字符]
掌握TA-Lib Python技术分析库:从入门到精通的完整指南 🚀 【免费下载链接】ta-lib-python Python wrapper for TA-Lib (http://ta-lib.org/). 项目地址: https://gitcode.com/gh_mirrors/ta/ta-lib-python TA-Lib Python技术分析库是金融量化交易…...

Nooploop TOFSense激光测距模块:从快速上手指南到多平台实战应用
1. Nooploop TOFSense激光测距模块初体验 第一次拿到TOFSense激光测距模块时,我完全被它的小巧体积震惊了。这个比火柴盒大不了多少的装置,居然能实现0.1-12米的精确测距,精度高达1cm!作为一名经常在无人机项目中折腾的嵌入式工程…...

第五课:YOLOv5-Lite模型适配AK3918AV130转换实战
文章目录一、课程导学二、课程核心关键词三、模型转换整体原理与流程概述四、YOLOv5-Lite转ONNX标准化实战五、安凯微工具链模型适配与量化实战六、AK3918AV130专属模型编译实战七、模型仿真校验与异常排查八、课堂实操示例九、本节课核心总结十、课后作业十一、课程回顾总结上…...

从零开始设计千兆交换机:基于RTL8367S/SC芯片的硬件开发包获取与核心电路设计要点
从零开始设计千兆交换机:基于RTL8367S/SC芯片的硬件开发包获取与核心电路设计要点 在当今高速网络设备开发领域,千兆交换机作为基础网络设施的核心组件,其性能与稳定性直接决定了整个网络系统的表现。对于硬件工程师而言,基于RTL8…...

突破性创新:Midscene.js如何用AI视觉驱动重塑跨平台自动化测试
突破性创新:Midscene.js如何用AI视觉驱动重塑跨平台自动化测试 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在当今复杂的软件生态中,跨…...

Python量化交易框架解析:从数据到实盘的完整实现
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“ZJHuang915/PythonQuantTrading”。光看名字,很多朋友可能就明白了,这是一个用Python做量化交易的代码仓库。我花了点时间把整个项目翻了一遍,发现它不是一个简单…...

3大高级功能揭秘:用Python玩转B站API的终极指南
3大高级功能揭秘:用Python玩转B站API的终极指南 【免费下载链接】bilibili-api 哔哩哔哩常用API调用。支持视频、番剧、用户、频道、音频等功能。原仓库地址:https://github.com/MoyuScript/bilibili-api 项目地址: https://gitcode.com/gh_mirrors/bi…...

CPU Cache初始化:从硬件复位到软件使能的底层原理与工程实践
1. 项目概述:从开机到高速缓存就绪当按下电脑的电源键,屏幕上开始跑起一行行代码时,我们看到的通常是BIOS自检、操作系统加载的宏大叙事。但在这背后,有一个对性能影响巨大却又极其低调的“幕后英雄”正在悄然启动,它就…...

基于语义检索的LLM工具发现框架:从原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想把手头的几个大语言模型(LLM)能力整合到自己的工具链里,发现一个挺头疼的问题:模型本身很强大,但让它去精准调用外部工具(比如查数据库、发…...