扩展说明: 指令微调 Llama 2
这篇博客是一篇来自 Meta AI,关于指令微调 Llama 2 的扩展说明。旨在聚焦构建指令数据集,有了它,我们则可以使用自己的指令来微调 Llama 2 基础模型。
目标是构建一个能够基于输入内容来生成指令的模型。这么做背后的逻辑是,模型如此就可以由其他人生成自己的指令数据集。这在当想开发私人个性化定制模型,如发送推特、写邮件等,时很方便。这也意味着你可以通过你的邮件来生成一个指令数据集,然后用它来训练一个模型来为你写邮件。
好,那我们来开始吧?我们将进行:
定义应用场景细节并创建指令的提示词模板
构建指令数据集
使用
trl与SFTTrainer指令微调 Llama 2测试模型、进行推理
1. 定义应用场景细节并创建指令的提示词模板
在描述应用场景前,我们要更好的理解一下究竟什么是指令。
指令是一段文本或提供给大语言模型,类似 Llama,GPT-4 或 Claude,使用的提示词,用来指导它去生成回复。指令可以让人们做到把控对话,约束模型输出更自然、实用的输出,并使这些结果能够对齐用户的目的。制作清晰的、整洁的指令则是生成高质量对话的关键。
指令的例子如下表所示。
| 能力 | 示例指令 |
|---|---|
| 头脑风暴 | 提供一系列新口味的冰淇淋的创意。 |
| 分类 | 根据剧情概要,将这些电影归类为喜剧、戏剧或恐怖片。 |
| 确定性问答 | 用一个单词回答“法国的首都是哪里?” |
| 生成 | 用罗伯特·弗罗斯特的风格写一首关于大自然和季节变化的诗。 |
| 信息提取 | 从这篇短文中提取主要人物的名字。 |
| 开放性问答 | 为什么树叶在秋天会变色?用科学的理由解释一下。 |
| 摘要 | 用 2-3 句话概括一下这篇关于可再生能源最新进展的文章。 |
如开头所述,我们想要微调模型,以便根据输入 (或输出) 生成指令。我们希望将其用作创建合成数据集的方法,以赋予 LLM 和代理个性化能力。
把这个想法转换成一个基础的提示模板,按照 Alpaca 格式.
### Instruction:
Use the Input below to create an instruction, which could have been used to generate the input using an LLM. ### Input:
Dear [boss name],I'm writing to request next week, August 1st through August 4th,
off as paid time off.I have some personal matters to attend to that week that require
me to be out of the office. I wanted to give you as much advance
notice as possible so you can plan accordingly while I am away.Please let me know if you need any additional information from me
or have any concerns with me taking next week off. I appreciate you
considering this request.Thank you, [Your name]### Response:
Write an email to my boss that I need next week 08/01 - 08/04 off.2. 创建指令数据集
在定义了我们的应用场景和提示模板后,我们需要创建自己的指令数据集。创建高质量的指令数据集是获得良好模型性能的关键。研究表明,“对齐,越少越好” 表明,创建高质量、低数量 (大约 1000 个样本) 的数据集可以达到与低质量、高数量的数据集相同的性能。
创建指令数据集有几种方法,包括:
使用现有数据集并将其转换为指令数据集,例如 FLAN
使用现有的 LLM 创建合成指令数据集,例如 Alpaca
人力创建指令数据集,例如 Dolly。
每种方法都有其优缺点,这取决于预算、时间和质量要求。例如,使用现有数据集是最简单的,但可能不适合您的特定用例,而使用人力可能是最准确的,但必然耗时、昂贵。也可以结合几种不同方法来创建指令数据集,如 Orca: Progressive Learning from Complex Explanation Traces of GPT-4.。
为了简单起见,我们将使用 **Dolly**,这是一个开源的指令跟踪记录数据集,由数千名 Databricks 员工在 InstructGPT paper 中描述的几个行为类别中生成,包括头脑风暴、分类、确定性回答、生成、信息提取、开放性回答和摘要。
开始编程吧,首先,我们来安装依赖项。
!pip install "transformers==4.31.0" "datasets==2.13.0" "peft==0.4.0" "accelerate==0.21.0" "bitsandbytes==0.40.2" "trl==0.4.7" "safetensors>=0.3.1" --upgrade我们使用 🤗 Datasets library 的 load_dataset() 方法加载 databricks/databricks-dolly-15k 数据集。
from datasets import load_dataset
from random import randrange# 从hub加载数据集
dataset = load_dataset("databricks/databricks-dolly-15k", split="train")print(f"dataset size: {len(dataset)}")
print(dataset[randrange(len(dataset))])
# dataset size: 15011为了指导我们的模型,我们需要将我们的结构化示例转换为通过指令描述的任务集合。我们定义一个 formatting_function ,它接受一个样本并返回一个符合格式指令的字符串。
def format_instruction(sample):return f"""### Instruction:
Use the Input below to create an instruction, which could have been used to generate the input using an LLM. ### Input:
{sample['response']}### Response:
{sample['instruction']}
"""我们来在一个随机的例子上测试一下我们的结构化函数。
from random import randrangeprint(format_instruction(dataset[randrange(len(dataset))]))3. 使用 trl 和SFTTrainer 指令微调 Llama 2
我们将使用最近在由 Tim Dettmers 等人的发表的论文“QLoRA: Quantization-aware Low-Rank Adapter Tuning for Language Generation”中介绍的方法。QLoRA 是一种新的技术,用于在微调期间减少大型语言模型的内存占用,且并不会降低性能。QLoRA 的 TL;DR; 是这样工作的:
将预训练模型量化为 4bit 位并冻结它。
附加轻量化的、可训练的适配器层。(LoRA)
在使用冻结的量化模型基于文本内容进行微调时,仅微调适配器层参数。
如果您想了解有关 QLoRA 及其工作原理的更多信息,我建议您阅读 Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA 博客文章。
Flash Attention (快速注意力)
Flash Attention 是一种经过重新排序的注意力计算方法,它利用经典技术 (排列、重计算) 来显著加快速度,将序列长度的内存使用量从二次降低到线性。它基于论文“FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”。
TL;DR; 将训练加速了 3 倍。在这儿获得更多信息 FlashAttention。Flash Attention 目前仅支持 Ampere (A10, A40, A100, …) & Hopper (H100, …) GPU。你可以检查一下你的 GPU 是否支持,并用下面的命令来安装它:
注意: 如果您的机器的内存小于 96GB,而 CPU 核心数足够多,请减少 MAX_JOBS 的数量。在我们使用的 g5.2xlarge 上,我们使用了 4 。
python -c "import torch; assert torch.cuda.get_device_capability()[0] >= 8, 'Hardware not supported for Flash Attention'"
pip install ninja packaging
MAX_JOBS=4 pip install flash-attn --no-build-isolation_安装 flash attention 是会需要一些时间 (10-45 分钟)_。
该示例支持对所有 Llama 检查点使用 Flash Attention,但默认是未启用的。要开启 Flash Attention,请取消代码块中这段的注释, # COMMENT IN TO USE FLASH ATTENTION 。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfiguse_flash_attention = False# COMMENT IN TO USE FLASH ATTENTION
# replace attention with flash attention
# if torch.cuda.get_device_capability()[0] >= 8:
# from utils.llama_patch import replace_attn_with_flash_attn
# print("Using flash attention")
# replace_attn_with_flash_attn()
# use_flash_attention = True# Hugging Face 模型id
model_id = "NousResearch/Llama-2-7b-hf" # non-gated
# model_id = "meta-llama/Llama-2-7b-hf" # gated# BitsAndBytesConfig int-4 config
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16
)# 加载模型与分词器
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, use_cache=False, device_map="auto")
model.config.pretraining_tp = 1 # 通过对比doc中的字符串,验证模型是在使用flash attention
if use_flash_attention:from utils.llama_patch import forward assert model.model.layers[0].self_attn.forward.__doc__ == forward.__doc__, "Model is not using flash attention"tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"SFTTrainer 支持与 peft 的本地集成,这使得高效地指令微调LLM变得非常容易。我们只需要创建 LoRAConfig 并将其提供给训练器。
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model# 基于 QLoRA 论文来配置 LoRA
peft_config = LoraConfig(lora_alpha=16,lora_dropout=0.1,r=64,bias="none",task_type="CAUSAL_LM",
)# 为训练准备好模型
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)在开始训练之前,我们需要定义自己想要的超参数 (TrainingArguments)。
from transformers import TrainingArgumentsargs = TrainingArguments(output_dir="llama-7-int4-dolly",num_train_epochs=3,per_device_train_batch_size=6 if use_flash_attention else 4,gradient_accumulation_steps=2,gradient_checkpointing=True,optim="paged_adamw_32bit",logging_steps=10,save_strategy="epoch",learning_rate=2e-4,bf16=True,tf32=True,max_grad_norm=0.3,warmup_ratio=0.03,lr_scheduler_type="constant",disable_tqdm=True # 当配置的参数都正确后可以关闭tqdm
)我们现在有了用来训练模型 SFTTrainer 所需要准备的每一个模块。
from trl import SFTTrainermax_seq_length = 2048 # 数据集的最大长度序列trainer = SFTTrainer(model=model,train_dataset=dataset,peft_config=peft_config,max_seq_length=max_seq_length,tokenizer=tokenizer,packing=True,formatting_func=format_instruction, args=args,
)通过调用 Trainer 实例上的 train() 方法来训练我们的模型。
# 训练
trainer.train() # tqdm关闭后将不显示进度条信息# 保存模型
trainer.save_model()不使用 Flash Attention 的训练过程在 g5.2xlarge 上花费了 03:08:00。实例的成本为 1,212$/h ,总成本为 3.7$ 。
使用 Flash Attention 的训练过程在 g5.2xlarge 上花费了 02:08:00。实例的成本为 1,212$/h ,总成本为 2.6$ 。
使用 Flash Attention 的结果令人满意,速度提高了 1.5 倍,成本降低了 30%。
4. 测试模型、进行推理
在训练完成后,我们想要运行和测试模型。我们会使用 peft 和 transformers 将 LoRA 适配器加载到模型中。
if use_flash_attention:# 停止 flash attentionfrom utils.llama_patch import unplace_flash_attn_with_attnunplace_flash_attn_with_attn()import torch
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizerargs.output_dir = "llama-7-int4-dolly"# 加载基础LLM模型与分词器
model = AutoPeftModelForCausalLM.from_pretrained(args.output_dir,low_cpu_mem_usage=True,torch_dtype=torch.float16,load_in_4bit=True,
)
tokenizer = AutoTokenizer.from_pretrained(args.output_dir)我们来再次用随机样本加载一次数据集,试着来生成一条指令。
from datasets import load_dataset
from random import randrange# 从hub加载数据集并得到一个样本
dataset = load_dataset("databricks/databricks-dolly-15k", split="train")
sample = dataset[randrange(len(dataset))]prompt = f"""### Instruction:
Use the Input below to create an instruction, which could have been used to generate the input using an LLM. ### Input:
{sample['response']}### Response:
"""input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
# with torch.inference_mode():
outputs = model.generate(input_ids=input_ids, max_new_tokens=100, do_sample=True, top_p=0.9,temperature=0.9)print(f"Prompt:\n{sample['response']}\n")
print(f"Generated instruction:\n{tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0][len(prompt):]}")
print(f"Ground truth:\n{sample['instruction']}")太好了!我们的模型可以工作了!如果想要加速我们的模型,我们可以使用 Text Generation Inference 部署它。因此我们需要将我们适配器的参数合并到基础模型中去。
from peft import AutoPeftModelForCausalLMmodel = AutoPeftModelForCausalLM.from_pretrained(args.output_dir,low_cpu_mem_usage=True,
) # 合并 LoRA 与 base model
merged_model = model.merge_and_unload()# 保存合并后的模型
merged_model.save_pretrained("merged_model",safe_serialization=True)
tokenizer.save_pretrained("merged_model")# push合并的模型到hub上
# merged_model.push_to_hub("user/repo")
# tokenizer.push_to_hub("user/repo")原文作者: Philschmid
原文链接: https://www.philschmid.de/instruction-tune-llama-2
译者: Xu Haoran
相关文章:

扩展说明: 指令微调 Llama 2
这篇博客是一篇来自 Meta AI,关于指令微调 Llama 2 的扩展说明。旨在聚焦构建指令数据集,有了它,我们则可以使用自己的指令来微调 Llama 2 基础模型。 目标是构建一个能够基于输入内容来生成指令的模型。这么做背后的逻辑是,模型如…...

VUE 全局设置防重复点击
请求后端防止重复点击,用户点击加入遮罩层,请求完毕关闭遮罩层 我们利用请求拦截器,在用户点击的时候,弹出遮罩层 本文采用i18n国际化 element plus UI,提取你想要的,这里不做简化 完整代码如下…...
备战蓝桥杯---动态规划(基础1)
先看几道比较简单的题: 直接f[i][j]f[i-1][j]f[i][j-1]即可(注意有马的地方赋值为0) 下面是递推循环方式实现的AC代码: #include<bits/stdc.h> using namespace std; #define int long long int a[30][30]; int n,m,x,y; …...
CVE-2018-19518 漏洞复现
CVE-2018-19518 漏洞介绍 IMAP协议(因特网消息访问协议)它的主要作用是邮件客户端可以通过这种协议从邮件服务器上获取邮件的信息,下载邮件等。它运行在TCP/IP协议之上,使用的端口是143。在php中调用的是imap_open函数。 PHP 的…...

Python爬虫实战:抓取猫眼电影排行榜top100#4
爬虫专栏系列:http://t.csdnimg.cn/Oiun0 抓取猫眼电影排行 本节中,我们利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。requests 比 urllib 使用更加方便,而且目前我们还没有系统学习 HTML 解析库,所以这里就…...

Fiddler抓包工具之fiddler界面工具栏介绍
Fiddler界面工具栏介绍 (1)WinConfig:windows 使用了一种叫做“AppContainer”的隔离技术,使得一些流量无法正常捕获,在 fiddler中点击 WinConfig 按钮可以解除这个诅咒,这个与菜单栏 Tools→Win8 Loopback…...

LabVIEW工业监控系统
LabVIEW工业监控系统 介绍了一个基于LabVIEW软件开发的工业监控系统。系统通过虚拟测控技术和先进的数据处理能力,实现对工业过程的高效监控,提升系统的自动化和智能化水平,从而满足现代工业对高效率、高稳定性和低成本的需求。 随着工业自…...

Linux 文件连接:符号链接与硬链接
Linux 文件连接:符号链接与硬链接 介绍 在 Linux 系统中,文件连接是一个强大的概念,它允许我们在文件系统中创建引用,从而使得文件和目录之间产生联系。在本文中,我们将深入探讨两种主要类型的文件连接:符…...

数据分类分级
一段时间没写文章了,最近做政府数据治理方面的项目,数据治理一个重要的内容是数据安全,会涉及数据的分类分级,是数据治理的基础。 随着“十四五”规划推行,数据要素概念与意识全面铺开,国家、政府机构、企业…...

第三十天| 51. N皇后
Leetcode 51. N皇后 题目链接:51 N皇后 题干:按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击。 给你一个整…...
pythn-scipy 查漏补缺
1. 2. 3. 4. 5. 6. 7. 8. 9. 偏度 skewness,峰度 kurtosis...

【JavaScript 漫游】【013】Date 对象知识点摘录
文章简介 本文为【JavaScript 漫游】专栏的第 013 篇文章,记录了 JS 语言中 Date 对象的重要知识点。 普通函数的用法构造函数的用法日期的运算静态方法,包括:Date.now()、Date.parse() 和 Date.UTC()实例方法,包括:…...

vue.config.js和webpack.config.js区别
webpack.config.js和vue.config.js的区别 webpack.config.js是webpack的配置文件,所有使用webpack作为打包工具的项目都可以使用,vue的项目可以使用,react的项目也可以使用。 vue.config.js是vue项目的配置文件,专用于vue项目。…...

H12-821_73
73.某台路由器Router LSA如图所示,下列说法中错误的是? A.本路由器的Router ID为10.0.12.1 B.本路由器为DR C.本路由器已建立邻接关系 D.本路由器支持外部路由引入 答案:B 注释: LSA中的链路信息Link ID,Data…...
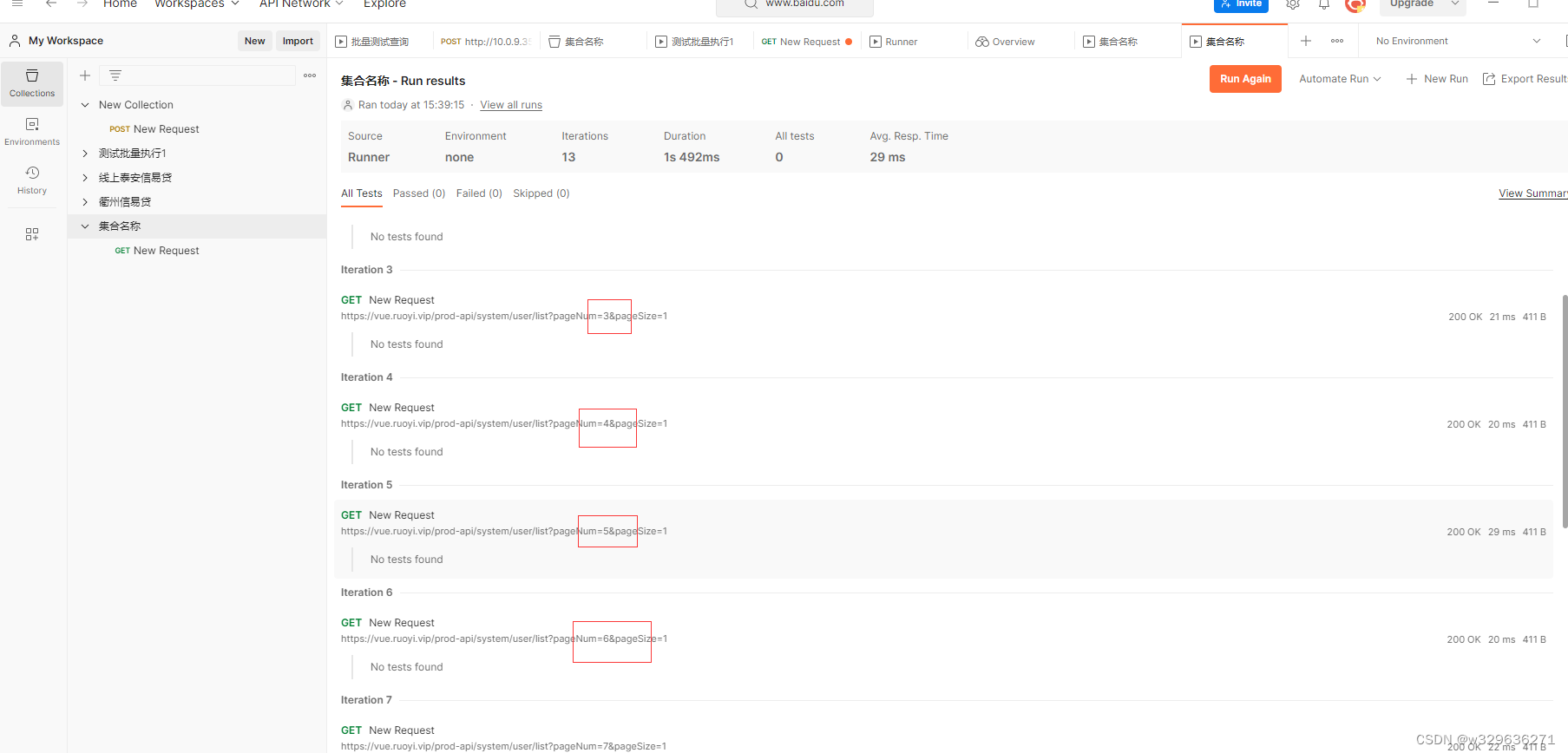
postman执行批量测试
1.背景 有许多的人常常需要使用第三方系统进行重复的数据查询,本文介绍使用PostMan的方式对数据进行批量的查询,减少重复的劳动。 2.工具下载 3.初入门 一、如图示进行点击,创建collection 二、输入对应的名称 三、创建Request并进行查…...

蓝桥杯基础知识8 list
蓝桥杯基础知识8 list 01 list 的定义和结构 lits使用频率较低,是一种双向链表容器,是标准模板库(STL)提供的一种序列容器,lsit容器以节点(node)的形式存储元素,使用指针将这些节点链…...
【DDD】学习笔记-理解领域模型
Eric Evans 的领域驱动设计是对软件设计领域的一次重新审视,是在面向对象语言大行其道时对数据建模的“拨乱反正”。Eric 强调了模型的重要性,例如他在书中总结了模型在领域驱动设计中的作用包括: 模型和设计的核心互相影响模型是团队所有成…...

v-if 和v-show 的区别
第074个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 提供vue2的一些基本操作:安装、引用,模板使用,computed&a…...

LabVIEW网络测控系统
LabVIEW网络测控系统 介绍了基于LabVIEW的网络测控系统的开发与应用,通过网络技术实现了远程的数据采集、监控和控制。系统采用LabVIEW软件与网络通信技术相结合,提高了系统的灵活性和扩展性,适用于各种工业和科研领域的远程测控需求。 随着…...

攻防世界 CTF Web方向 引导模式-难度1 —— 11-20题 wp精讲
PHP2 题目描述: 暂无 根据dirsearch的结果,只有index.php存在,里面也什么都没有 index.phps存在源码泄露,访问index.phps 由获取的代码可知,需要url解码(urldecode )后验证id为admin则通过 网页工具不能直接对字母进行url编码 …...

打破设计孤岛:用AI思维重新连接Figma与代码编辑器
打破设计孤岛:用AI思维重新连接Figma与代码编辑器 【免费下载链接】cursor-talk-to-figma-mcp TalkToFigma: MCP integration between AI Agent (Cursor, Claude Code) and Figma, allowing Agentic AI to communicate with Figma for reading designs and modifyin…...

怎么快速降AI率?答辩前1周从60%降到10%以内实操指南!
怎么快速降AI率?答辩前1周从60%降到10%以内实操指南! 答辩前 1 周拿到 AI 率 65% 报告,是什么具体场景? 周一早上 9 点。我硕士答辩定在下周一上午 9 点——还有整整 7 天。导师周日晚发消息:「答辩前再送一次维普看…...

PADS VX2.4 封装制作避坑指南:从0402电阻封装实战说清Layer_25和阻焊层
PADS VX2.4 封装制作避坑指南:从0402电阻封装实战说清Layer_25和阻焊层 在PCB设计领域,封装制作看似基础却暗藏玄机。许多工程师在原理图设计阶段游刃有余,却在封装制作环节频频踩坑,导致后期生产出现焊接不良、丝印覆盖焊盘等问题…...

从PLINK到CMplot:三步绘制高颜值SNP密度图
1. 从PLINK数据到SNP密度图:为什么需要可视化 做基因组分析的朋友都知道,拿到原始数据后的第一件事就是检查数据质量。我刚开始做GWAS研究时,导师问的第一个问题就是:"你的SNP在染色体上分布均匀吗?"当时我就…...

Revelation光影包:物理渲染与启发式算法的视觉革命
Revelation光影包:物理渲染与启发式算法的视觉革命 【免费下载链接】Revelation An explorative shaderpack for Minecraft: Java Edition 项目地址: https://gitcode.com/gh_mirrors/re/Revelation Revelation不仅仅是一个Minecraft光影包——它是基于物理渲…...

浏览器扩展开发实战:光标交互防火墙的设计与实现
1. 项目概述与核心价值最近在折腾浏览器插件开发,偶然在GitHub上看到了一个名为“Raidu Firewall Cursor Extension”的项目。光看这个名字,就让我这个对网络安全和效率工具都感兴趣的老码农眼前一亮。这玩意儿本质上是一个浏览器扩展,但它把…...

Matlab控制建模实战:从开环到闭环的传递函数构建
1. 从零开始认识传递函数 第一次接触控制系统的朋友可能会被"传递函数"这个概念吓到,但其实它就像是我们日常生活中的"快递单号"。想象一下,你在网上购物时,商家把货物(输入信号)交给快递公司&…...

ENVI处理SPOT影像避坑指南:波段选错、阈值设偏?手把手教你精准提取城市地物
ENVI处理SPOT影像避坑指南:波段选错、阈值设偏?手把手教你精准提取城市地物 城市地物精准提取是遥感应用中的基础性难题。当面对SPOT系列卫星影像时,许多用户会发现:明明按照标准流程操作,提取结果却总出现水体与阴影混…...

5分钟搞定安卓APK签名:SignatureTools图形化签名工具终极指南
5分钟搞定安卓APK签名:SignatureTools图形化签名工具终极指南 【免费下载链接】SignatureTools 🎡使用JavaFx编写的安卓Apk签名&渠道写入工具,方便快速进行v1&v2签名。 项目地址: https://gitcode.com/gh_mirrors/si/SignatureTool…...

3步构建企业级数据平台:从零到百万级数据管理的NocoDB实战指南
3步构建企业级数据平台:从零到百万级数据管理的NocoDB实战指南 【免费下载链接】nocodb 🔥 🔥 🔥 A Free & Self-hostable Airtable Alternative 项目地址: https://gitcode.com/GitHub_Trending/no/nocodb 在数字化转…...