fast.ai 机器学习笔记(二)
机器学习 1:第 5 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-5-df45f0c99618译者:飞龙
协议:CC BY-NC-SA 4.0
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
视频
复习
- 测试集,训练集,验证集和 OOB
我们有一个数据集,其中有很多行,我们有一些因变量。机器学习和其他任何工作之间的区别是什么?区别在于,在机器学习中,我们关心的是泛化准确性或泛化错误,而在其他几乎所有情况下,我们只关心我们能够如何将观察结果映射到。所以,泛化是机器学习的关键独特部分。如果我们想知道我们是否做得好,我们需要知道我们是否做得好泛化。如果我们不知道这一点,我们什么也不知道。
问题:泛化,你是指缩放吗?能够扩展吗?[1:26] 不,我一点也不是指缩放。缩放在许多领域中是重要的。就像好吧,我们有一个在我的电脑上使用 1 万个项目的东西,现在我需要让它每秒处理 1 万个项目。所以缩放很重要,但不仅仅是对于机器学习,而是对于我们投入生产的几乎所有东西都很重要。泛化是我说的,好吧,这是一个可以预测猫和狗的模型。我看了五张猫的图片和五张狗的图片,我建立了一个完美的模型。然后我看了另一组五只猫和狗,结果全都错了。所以在这种情况下,它学到的不是猫和狗之间的区别,而是学到了那五只具体的猫长什么样,那五只具体的狗长什么样。或者我建立了一个预测特定产品的杂货销售模型,比如上个月新泽西的卫生纸销售,然后我把它投入生产,它扩展得很好(换句话说,延迟很低,没有高 CPU 负载),但它无法预测除了新泽西的卫生纸之外的任何东西。事实证明,它只在上个月做得好,而不是下个月。这些都是泛化失败。
人们检查泛化能力最常见的方法是创建一个随机样本。他们会随机选择几行数据并将其提取到一个测试集中。然后他们会在其余的行上构建所有模型,当他们完成时,他们会检查在测试集上获得的准确性(其余的行被称为训练集)。所以在建模过程结束时,在训练集上,他们得到了 99%的准确性,预测猫和狗,最后,他们会将其与测试集进行比较,以确保模型真正泛化。
现在的问题是,如果不行怎么办?嗯,我可以回去改变一些超参数,做一些数据增强,或者尝试创建一个更具泛化性的模型。然后我再次回去,做了所有这些之后,检查结果仍然不好。我会一遍又一遍地这样做,直到最终,在尝试了五十次之后,它泛化了。但它真的泛化了吗?因为也许我所做的一切只是偶然找到了这个恰好适用于那个测试集的模型,因为我尝试了五十种不同的方法。所以如果我有一个东西,巧合地 5%的时间是正确的,那么很可能不会偶然得到一个好的结果。所以我们通常会将第二个数据集(验证集)放在一边。然后,不在验证集或测试集中的所有内容现在都是训练集。我们训练一个模型,对其进行验证以查看其是否泛化,重复几次。然后当我们最终得到了我们认为会根据验证集成功泛化的东西(在项目结束时),我们会对其进行测试。
问题:所以基本上通过制作这两层测试集和验证集,如果一个对了另一个错了,你就是在双重检查你的错误?它检查我们是否过度拟合验证集。所以如果我们一遍又一遍地使用验证集,那么我们最终可能得不到一组适用于训练集和验证集的可泛化的超参数,而只是一组恰好适用于训练集和验证集的超参数。所以如果我们对验证集尝试了 50 种不同的模型,然后在所有这些之后,我们再对测试集进行检查,结果仍然是泛化的,那么我们会说好的,我们实际上已经得到了一个可泛化的模型。如果不是,那么就会说我们实际上现在过度拟合了验证集。在那一点上,你会陷入麻烦。因为你没有留下任何东西。所以想法是在建模过程中使用有效的技术,以防止这种情况发生。但如果它确实发生了,你希望找出原因——你需要那个测试集,否则当你投入生产时,结果却不能泛化,那将是一个非常糟糕的结果。你最终会发现点击你的广告的人会减少,或者销售你的产品会减少,或者为高风险车辆提供汽车保险的人会减少。
问题:所以只是为了确保,我们需要检查验证集和测试集是否一致,还是只保留测试集?如果你像我刚刚做的那样随机抽样,没有特定的原因需要检查,只要它们足够大。但我们将在稍后的不同情境中回答你的问题。
我们学到的另一个随机森林的技巧是一种不需要验证集的方法。我们学到的方法是使用 OOB 分数。这个想法是,每次我们在随机森林中训练一棵树时,都会有一些观察结果被保留,因为这就是我们获得一些随机性的方式。因此,让我们基于这些保留样本计算每棵树的分数,然后通过对每行不参与训练的树进行平均,得到整个森林的分数。因此,OOB 分数给我们提供了与验证分数非常相似的东西,但平均来看,它稍微差一些。为什么?因为每一行都将使用一部分树来进行预测,而树越少,我们知道预测就越不准确。这是一个微妙的问题,如果你没有理解,那就在这一周内考虑一下,直到你明白为什么,因为这是对你对随机森林理解的一个非常有趣的测试。为什么 OOB 分数平均来看比你的验证分数差一些?它们都使用随机保留的子集。
总的来说,这通常足够了。那么在使用随机森林时为什么还要有一个验证集呢?如果是一个随机选择的验证集,严格来说并不是必需的,但你有四个层次的测试——所以你可以在 OOB 上测试,当那个工作良好时,你可以在验证集上测试,希望到检查测试集时不会有什么意外,这将是一个很好的理由。
Kaggle 的做法是相当聪明的。Kaggle 的做法是将测试集分成两部分:一个公共部分和一个私有部分。他们不告诉你哪个是哪个。所以你将你的预测提交给 Kaggle,然后随机选择其中 30%用来告诉你排行榜分数。但是在比赛结束时,这部分将被丢弃,他们将使用另外 70%来计算你的真实分数。这样做的目的是确保你不会持续使用来自排行榜的反馈来找出一组在公共部分表现良好但实际上不具有泛化性的超参数。这是一个很好的测试。这也是为什么在比赛结束时使用 Kaggle 是一个很好的做法的原因之一,因为在比赛的最后一天,当他们使用私有测试集时,你的排名会下降一百名,然后你会明白,这就是过拟合的感觉,练习和获得这种感觉要比在公司中有数亿美元的风险要好得多。
这就像是可能的最简单情况,你可以使用一个随机样本作为你的验证集。为什么我可能无法使用一个随机样本作为我的验证集,或者可能失败呢?我的观点是,通过使用一个随机验证集,我们可能会对我们的模型完全产生错误的看法。要记住的重要事情是,当你构建一个模型时,你总是会有一个系统误差,即你将在比构建模型时晚的时间使用该模型。你将在生产中使用它,到那时,世界已经不同于你现在所处的世界,即使在构建模型时,你使用的数据也比今天的数据旧。因此,在你构建模型的数据和实际使用的数据之间存在一些滞后。大部分时间,如果不是大部分时间,这是很重要的。
因此,如果我们正在预测谁会在新泽西购买卫生纸,而我们需要两周时间将其投入生产,并且我们使用了过去几年的数据进行预测,那时情况可能会大不相同。特别是我们的验证集,如果我们随机抽样,而且是从四年的时间段中抽取的,那么绝大多数数据将是一年多以前的。也许新泽西人的购买习惯可能已经发生了巨大变化。也许他们现在正经历着严重的经济衰退,无法再购买高质量的卫生纸。或者也许他们的造纸工业飞速发展,突然间他们购买更多卫生纸,因为价格便宜。世界在变化,因此如果你为验证集使用随机样本,那么实际上你正在检查你在预测完全过时的事物方面有多好?你有多擅长预测四年前发生的事情?这并不有趣。因此,在实践中,每当有一些时间因素时,我们要做的是假设我们已经按时间排序,我们将使用最新的部分作为我们的验证集。我想,实际上应该正确地执行:

这是我们的验证集,这是我们的测试集。所以剩下的就是我们的训练集,我们使用它并尝试能够建立一个模型,使其仍然适用于比模型建立时更晚的时间。因此,我们不仅仅是在某种抽象意义上测试泛化性能,而是在一个非常具体的时间意义上,即它是否能泛化到未来。
问题:正如您所说,数据中存在一些时间顺序,那么在这种情况下,是明智地使用整个数据进行训练,还是只使用最近的一些数据集进行训练?是的,这是一个完全不同的问题。那么如何确保验证集的质量良好呢?我在所有训练数据上构建了一个随机森林。它在训练数据上看起来不错,在 OOB 上也看起来不错。这实际上是有 OOB 的一个很好的原因。如果在 OOB 上看起来不错,那么这意味着你在统计意义上没有过拟合。它在一个随机样本上表现良好。但是然后在验证集上看起来不好。那么发生了什么?嗯,发生的是你在某种程度上未能预测未来。你只是预测了过去,所以 Suraj 有一个关于如何解决这个问题的想法。好吧,也许我们应该只训练,也许我们不应该使用整个训练集。我们应该只尝试最近的一段时间。现在缺点是,我们现在使用的数据更少,因此我们可以创建更少的丰富模型,但好处是,这是更为最新的数据。这是你必须尝试的事情。大多数机器学习函数都有能力为每一行提供一个权重。例如,对于随机森林,你可以在每一行上设置一个权重,并以某种概率随机选择该行。因此,我们可以设置概率,使得最近的行有更高的被选中的概率。这可能非常有效。这是你必须尝试的事情,如果你没有一个代表未来的验证集,与你正在训练的数据相比,你就无法知道哪些技术是有效的。
你如何在数据量和数据新旧之间做出妥协?我倾向于这样做,当我遇到这种时间问题时,也许大部分时间都是这样,一旦我在验证集上找到了一个表现良好的模型,我就不会直接在测试集上使用那个模型,因为测试集比训练集要远得多。所以我会重新构建那个模型,但这次我会将训练和验证集合并起来重新训练模型。在那一点上,你没有办法对验证集进行测试,所以你必须确保你有一个可重现的脚本或笔记本,以确保完全相同的步骤,因为如果你出错了,你会发现在测试集上出现了问题。所以我在实践中所做的是,我需要知道我的验证集是否真正代表了测试集。所以我在训练集上建立了五个模型,并尝试让它们在我认为它们有多好的方面有所不同。然后我在验证集上对我的五个模型进行评分,然后我也在测试集上对它们进行评分。所以我没有作弊,因为我没有使用来自测试集的任何反馈来改变我的超参数——我只是用它来检查我的验证集。所以我从验证集和测试集中得到了五个分数,然后我检查它们是否在一条线上。如果不是,那么你将无法从验证集中获得足够好的反馈。所以继续这个过程,直到你得到一条线,这可能会很棘手。试图创建尽可能接近真实结果的东西是困难的。在现实世界中,创建测试集也是如此——测试集必须尽可能接近生产。那么实际使用这个产品的客户组合是什么样的,你构建模型和投入生产之间实际会有多少时间?你能够多频繁地更新模型?这些都是在构建测试集时需要考虑的事情。
问题:所以首先你在训练数据上建立了五个模型,如果没有得到直线关系,就改变你的验证和测试集?通常你不能真正改变测试集,所以这是假设测试集已经给定,你改变验证集。所以如果你开始用一个随机样本验证集,然后结果千奇百怪,你意识到哦,我应该选择最近的两个月。然后你选择了最近的两个月,结果还是千奇百怪,你意识到哦,我应该选择从每个月的第一天到第十五天,然后不断改变验证集,直到找到一个能够反映你的测试集结果的集合。
问题:对于五个模型,你可能从随机数据、平均值等开始?也许不是五个糟糕的模型,但你想要一些变化,尤其是你想要一些在时间上可能泛化得更好的模型。一个是在整个训练集上训练的,一个是在最后两周训练的,一个是在最后六周训练的,一个使用了很多列可能会过拟合一些。所以你想要知道如果我的验证集在时间上无法泛化,我想看到这一点,如果在统计上无法泛化,我也想看到这一点。
问题:你能详细解释一下你所说的改变验证集以使其表示测试集是什么意思吗?看起来是什么样子?让我们以杂货竞赛为例,我们试图预测接下来两周的杂货销售额。Terrance 和我尝试过的可能的验证集是:
-
随机样本(4 年)
-
最近一个月的数据(7 月 15 日至 8 月 15 日)
-
过去的两周(8 月 1 日至 15 日)
-
一个月前的同一天范围(7 月 15 日至 30 日)
这个比赛中的测试集是 8 月 15 日至 30 日。所以上面是我们尝试的四个不同的验证集。随机的结果是完全不稳定的。上个月的结果不错但也不是很好。过去的两周,有一些看起来不好,但总体上还不错。一个月前的同一天范围内,他们有一个基本完美的线。
问题:我们到底是在与测试集中的什么进行比较?我建立了 5 个模型,可能是 1.只是预测平均值,2.对整个数据集进行某种简单的组平均,3.对过去一个月的数据进行某种组平均,4.构建整个数据集的随机森林,5.从过去三周构建随机森林。在每一个上,我计算验证分数。然后我在整个训练集上重新训练模型,并在测试集上进行相同的计算。所以现在每个点告诉我它在验证集上表现如何,它在测试集上表现如何。如果验证集有用,我们会说每次验证分数提高,测试集分数也应该提高。
问题:当你说“重新训练”时,你是指在训练和验证集上重新训练模型吗?是的,所以一旦我得到了基于训练集的验证分数,然后在训练和验证集上重新训练,并与测试集进行对比。
问题:通过测试集,你是指将其提交到 Kaggle 并检查分数吗?如果是 Kaggle,那么你的测试集就是 Kaggle 的排行榜。在现实世界中,测试集是你放在一边的第三个数据集。这第三个数据集反映真实世界生产差异是机器学习项目中最重要的一步。为什么这是最重要的一步?因为如果你搞砸了其他一切但没有搞砸这个,你会知道你搞砸了。如果你有一个好的测试集,那么你会知道你搞砸了,因为你搞砸了其他东西并测试了它,结果不尽人意,没关系。你不会毁掉公司。如果你搞砸了创建测试集,那将是可怕的。因为那样你就不知道自己是否犯了错误。你尝试构建一个模型,你在测试集上测试它,看起来不错。但测试集并不代表真实世界环境。所以你实际上不知道你是否会毁掉公司。希望你有逐渐将事物投入生产的方式,这样你就不会真的毁掉公司,但至少会毁掉你在工作中的声誉。哦,Jeremy 试图将这个东西投入生产,在第一周我们尝试的队伍中,他们的销售额减半了,我们再也不会让 Jeremy 做机器学习工作了。但如果 Jeremy 使用了适当的测试集,那么他会知道,哦,这只有我的验证集说的一半好,我会继续尝试。现在我不会惹麻烦了。我实际上很喜欢 Jeremy - 他能提前识别出将会出现泛化问题的情况。
这是每个人在机器学习课程中都会谈论一点的事情,但通常停在你学到了 sklearn 中有一个叫做 make train_test_split的东西,它返回这些东西,然后你就可以继续了,或者这里是交叉验证函数。这些东西总是给你随机样本的事实告诉你,如果不是大部分时间,你不应该使用它们。随机森林免费提供 OOB,这很有用,但只告诉你这在统计意义上是泛化的,而不是在实际意义上。
交叉验证
在课外,你们一直在讨论很多,这让我觉得有人一直在过分强调这种技术的价值。所以我会解释什么是交叉验证,然后解释为什么你大部分时间可能不应该使用它。
交叉验证意味着我们不只是拿出一个验证集,而是拿出五个,例如。所以让我们首先假设我们要随机洗牌数据。这是至关重要的。
-
随机洗牌数据。
-
将其分成五组
-
对于模型 №1,我们将第一个称为验证集,底部四个称为训练集。
-
我们将训练并检查验证,得到一些 RMSE、R²等。
-
我们将重复这个过程五次,然后取 RMSE、R²等的平均值,这是交叉验证的平均准确度。
使用交叉验证相比标准验证集的好处是什么?你可以使用所有的数据。你不必留下任何东西。而且你还有一个小小的好处,你现在有了五个模型,可以将它们组合在一起,每个模型使用了 80%的数据。有时这种集成可以很有帮助。
有哪些原因你不会使用交叉验证呢?对于大型数据集,它会花费很长时间。我们必须拟合五个模型而不是一个,所以时间是一个关键的缺点。如果我们在进行深度学习,需要一天的时间来运行,突然之间需要五天,或者我们需要 5 个 GPU。那么关于我之前关于验证集的问题呢?我们之前对为什么随机验证集是一个问题的担忧在这里完全相关。这些验证集是随机的,所以如果一个随机验证集对你的问题不合适,很可能是因为,例如,时间问题,那么这五个验证集都不好。它们都是随机的。所以如果你有像之前一样的时间数据,就没有办法进行交叉验证,或者没有好的方法进行交叉验证。你希望你的验证集尽可能接近测试集,而你不能通过随机抽样不同的东西来做到这一点。你可能不需要进行交叉验证,因为在现实世界中,我们通常并没有那么少的数据 —— 除非你的数据是基于一些非常昂贵的标记过程或一些昂贵的实验。但如今,数据科学家并不经常做这种工作。有些人在做,如果是这样,那么这是一个问题,但我们大多数人不是。所以我们可能不需要。即使我们这样做了,它会花费很多时间,即使我们这样做了并花费了所有的时间,它可能会给我们完全错误的答案,因为随机验证集对我们的问题是不合适的。
我不会花太多时间在交叉验证上,因为我认为它是一个有趣的工具,易于使用(sklearn 有一个可以使用的交叉验证工具),但在我看来,它并不经常是你工具箱中的重要部分。有时会用到。所以这就是验证集。
树解释[38:02]
树解释器是做什么的,它是如何做到的呢?让我们从树解释器的输出开始[38:51]。这里是一棵树:

树的根在任何分割之前。因此,10.189 是我们训练集中所有选项的平均对数价格。然后,如果我选择 Coupler_System ≤ 0.5,那么我们得到一个平均值为 10.345(共 16815 个子集)。在 Coupler_System ≤0.5 的人中,我们然后取 Enclosure ≤ 2.0 的子集,那里的平均对数价格为 9.955。然后最后一步是 ModelID ≤ 4573.0,这给我们 10.226。

然后我们可以计算每个额外标准对平均对数价格的变化。我们可以将其绘制为所谓的瀑布图。瀑布图是我知道的最有用的图之一,奇怪的是,Python 中没有任何工具可以绘制它们。这是其中一种情况,管理咨询和商业领域中每个人都经常使用瀑布图,而学术界却不知道这些是什么。每当你有一个起点、一些变化和一个终点时,瀑布图几乎总是展示它们的最佳方式。

在 Excel 2016 中,它是内置的。你只需点击插入瀑布图,它就在那里。如果你想成为一个英雄,为 matplotlib 创建一个瀑布图包,将其放在 pip 上,每个人都会喜欢你的。实际上,这些非常容易构建。你基本上做一个堆叠柱状图,底部全是白色。你可以做到这一点,但如果你能整理好它,把点放在正确的位置并精心着色,那将是非常棒的。我认为你们都有能力做到,这对你的作品集来说将是一件了不起的事情。
一般来说,它们从所有开始,然后逐个变化,然后所有这些的总和将等于最终预测[43:38]。所以如果我们只是做一个决策树,有人问“为什么这个特定拍卖的预测是这个特定价格?”,这就是你可以回答“因为这三个事物产生了这三个影响”的方式。
对于随机森林,我们可以在所有树中执行相同的操作。所以每次我们看到联接器时,我们累加那个变化。每次我们看到围栏时,我们累加那个变化,依此类推。然后将它们全部组合在一起,我们就得到了树解释器的功能。所以你可以查看树解释器的源代码,它并不是非常复杂的逻辑。或者你可以自己构建它,看看它是如何做到这一点的。
from treeinterpreter import treeinterpreter as ti
df_train, df_valid = split_vals(df_raw[df_keep.columns], n_trn)
row = X_valid.values[None,0]; row
'''
array([[4364751, 2300944, 665, 172, 1.0, 1999, 3726.0, 3, 3232, 1111, 0, 63, 0, 5, 17, 35, 4, 4, 0, 1, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 12, 0, 0, 0, 0, 0, 3, 0, 0, 0, 2, 19, 29, 3, 2, 1, 0, 0, 0, 0, 0, 2010, 9, 37,16, 3, 259, False, False, False, False, False, False, 7912, False, False]], dtype=object)
'''
prediction, bias, contributions = ti.predict(m, row)
所以当你使用随机森林模型对某个特定拍卖进行 treeinterpreter.predict 时(在这种情况下是零索引行),它告诉你:
-
prediction: 与随机森林预测相同 -
偏差: 这将始终是相同的 - 这是树中每个随机样本的每个人的平均销售价格 -
contributions: 每次我们在树中看到特定列出现时所有贡献的总和。
prediction[0], bias[0]
'''
(9.1909688098736275, 10.10606580677884)
'''
上次我犯了一个错误,没有正确排序这个。所以这次 np.argsort 是一个非常方便的函数。它实际上并不对 contributions[0] 进行排序,它只是告诉你如果对其进行排序,每个项目将移动到哪里。所以现在通过将 idxs 传递给每个列、级别和贡献,我可以按正确的顺序打印出所有这些。
idxs = np.argsort(contributions[0])
[o for o in zip(df_keep.columns[idxs], df_valid.iloc[0][idxs], contributions[0][idxs])
]
'''
[('ProductSize', 'Mini', -0.54680742853695008),('age', 11, -0.12507089451852943),('fiProductClassDesc','Hydraulic Excavator, Track - 3.0 to 4.0 Metric Tons',-0.11143111128570773),('fiModelDesc', 'KX1212', -0.065155113754146801),('fiSecondaryDesc', nan, -0.055237427792181749),('Enclosure', 'EROPS', -0.050467175593900217),('fiModelDescriptor', nan, -0.042354676935508852),('saleElapsed', 7912, -0.019642242073500914),('saleDay', 16, -0.012812993479652724),('Tire_Size', nan, -0.0029687660942271598),('SalesID', 4364751, -0.0010443985823001434),('saleDayofyear', 259, -0.00086540581130196688),('Drive_System', nan, 0.0015385818526195915),('Hydraulics', 'Standard', 0.0022411701338458821),('state', 'Ohio', 0.0037587658190299409),('ProductGroupDesc', 'Track Excavators', 0.0067688906745931197),('ProductGroup', 'TEX', 0.014654732626326661),('MachineID', 2300944, 0.015578052196894499),('Hydraulics_Flow', nan, 0.028973749866174004),('ModelID', 665, 0.038307429579276284),('Coupler_System', nan, 0.052509808150765114),('YearMade', 1999, 0.071829996446492878)]
'''
所以小型工业设备意味着它更便宜。如果它是最近制造的,那就意味着更昂贵,等等。所以这实际上对 Kaggle 不会有太大帮助,因为你只需要预测。但在生产环境甚至是预生产阶段,这将对你有很大帮助。所以任何一个好的经理应该做的事情是,如果你说这里有一个机器学习模型,我认为我们应该使用它,他们应该离开并抓取一些实际客户或实际拍卖的例子,检查你的模型是否看起来直观。如果它说我的预测是很多人会真的喜欢这部糟糕的电影,而实际上是“哇,那是一部真的糟糕的电影”,那么他们会回来问你“解释一下为什么你的模型告诉我我会喜欢这部电影,因为我讨厌那部电影”。然后你可以回答说,这是因为你喜欢这部电影,因为你是这个年龄段,你是这个性别,平均而言,实际上像你这样的人确实喜欢那部电影。
问题:每个元组的第二个元素是什么[47:25]?这是说对于这一行,‘ProductSize’是’Mini’,它已经 11 岁了,等等。所以它只是反馈并告诉你。因为这实际上就是它的样子:
array([[4364751, 2300944, 665, 172, 1.0, 1999, 3726.0, 3, 3232, 1111, 0, 63, 0, 5, 17, 35, 4, 4, 0, 1, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 12, 0, 0, 0, 0, 0, 3, 0, 0, 0, 2, 19, 29, 3, 2, 1, 0, 0, 0, 0, 0, 2010, 9, 37,16, 3, 259, False, False, False, False, False, False, 7912, False, False]], dtype=object)
就是这些数字。所以我只是回到原始数据中实际提取出每个描述性版本。
所以如果我们把所有的贡献加在一起,然后加到偏差中,那将给我们最终的预测。
contributions[0].sum()*-0.7383536391949419*
这是一个几乎完全未知的技术,这个特定的库也几乎完全未知。所以这是一个展示很多人不知道的东西的绝佳机会。在我看来,这是非常关键的,但很少有人这样做。
所以这基本上是随机森林解释部分的结束,希望你现在已经看到足够多,当有人说我们不能使用现代机器学习技术,因为它们是不可解释的黑匣子时,你有足够的信息来说你是在胡说。它们是非常可解释的,我们刚刚做的事情——试图用线性模型做到这一点,祝你好运。即使你可以用线性模型做类似的事情,试图做到不给你完全错误答案并且你不知道它是错误答案将是一个真正的挑战。
外推[49:23]
在我们尝试构建自己的随机森林之前,我们要做的最后一步是处理这个棘手的外推问题。所以在这种情况下,如果我们看一下我们最近树的准确性,我们仍然在我们的验证分数和训练分数之间有很大的差异。

实际上,在这种情况下,OOB(0.89420)和验证(0.89319)之间的差异实际上非常接近。所以如果有很大的差异,我会非常担心我们是否正确处理了时间方面的问题。这是最近的模型:

在 Kaggle 上,你需要那个最后的小数点。在现实世界中,我可能会停在这里。但很多时候你会看到你的验证分数和 OOB 分数之间有很大的差异,我想向你展示如何处理这个问题,特别是因为我们知道 OOB 分数应该稍微差一点,因为它使用的树较少,所以这让我感觉我们应该做得更好一点。我们应该能够做得更好一点的方法是更好地处理时间组件。
当涉及外推时,随机森林存在问题。当你有一个包含四年销售数据的数据集时,你创建了你的树,它说如果它在某个特定的商店和某个特定的物品上特价,这里是平均价格。它实际上告诉我们整个训练集上的平均价格,这可能相当古老。所以当你想要向前迈进到下个月的价格时,它从未见过下个月。而线性模型可以找到时间和价格之间的关系,即使我们只有这么多数据,当你预测未来的某事时,它可以外推。但是随机森林做不到这一点。如果你考虑一下,树无法说下个月价格会更高。所以有几种处理这个问题的方法,我们将在接下来的几堂课中讨论,但一个简单的方法就是尽量避免使用时间变量作为预测因子,如果有其他东西可以使用,可以给我们更好或更强的关系,那实际上会在未来起作用[52:19]。
因此,在这种情况下,我想要做的第一件事是弄清楚我们的验证集和训练集之间的差异。如果我了解我们的验证集和训练集之间的差异,那么这告诉我哪些预测变量具有强烈的时间成分,因此到了未来时间段可能是无关紧要的。因此,我做了一些非常有趣的事情,我创建了一个随机森林,其中我的因变量是“是否在验证集中”(is_valid)。我回去拿到了整个数据框,包括训练和验证全部在一起,然后我创建了一个新列叫做is_valid,我将其设置为 1,然后对于所有在训练集中的东西,我将其设置为 0。因此,我有了一个新列,只是这个是否在验证集中,然后我将其用作我的因变量并构建一个随机森林。这是一个随机森林,不是为了预测价格,而是为了预测这是否在验证集中。因此,如果您的变量不是时间相关的,那么应该不可能弄清楚某样东西是否在验证集中。
df_ext = df_keep.copy()
df_ext['is_valid'] = 1
df_ext.is_valid[:n_trn] = 0
x, y, nas = proc_df(df_ext, 'is_valid')
这是 Kaggle 中的一个很棒的技巧,因为他们通常不会告诉您测试集是否是随机样本。因此,您可以将测试集和训练集放在一起,创建一个新列叫做is_test,看看您是否可以预测它。如果可以,那么您就没有一个随机样本,这意味着您必须弄清楚如何从中创建一个验证集。
m = RandomForestClassifier(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(x, y);
m.oob_score_
'''
0.99998753505765037
'''
在这种情况下,我可以看到我没有一个随机样本,因为我的验证集可以用 0.9999 的 R²来预测。
因此,如果我查看特征重要性,最重要的是SalesID[54:36]。这非常有趣。它清楚地告诉我们SalesID不是一个随机标识符,而可能是随着时间的推移而连续设置的某些东西——我们只是增加SalesID。saleElapsed是自我们数据集中第一个日期以来的天数,因此不足为奇,它也是一个很好的预测变量。有趣的是MachineID——显然每台机器也被标记为一些连续的标识符,然后重要性大幅下降,所以我们就到此为止。
fi = rf_feat_importance(m, x); fi[:10]

接下来让我们获取前三个,然后我们可以查看它们在训练集和验证集中的值。[55:22]
feats='SalesID', 'saleElapsed', 'MachineID'.describe()

(X_valid[feats]/1000).describe()

例如,我们可以看到,销售 ID 在训练集中平均为 180 万,在验证集中为 580 万(请注意该值已除以 1000)。因此,您可以确认它们是非常不同的。
所以让我们把它们删除。
x.drop(feats, axis=1, inplace=True)
m = RandomForestClassifier(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(x, y);
m.oob_score_
'''
0.9789018385789966
'''
所以在我删除它们之后,现在让我们看看我是否可以预测某样东西是否在验证集中。我仍然可以用 0.98 的 R²来预测。
fi = rf_feat_importance(m, x); fi[:10]

一旦您删除了一些东西,其他东西就会浮现出来,现在显然老年——年龄较大的东西更有可能在验证集中,因为在训练集中的早期阶段,它们还不可能那么老。YearMade 也是同样的原因。因此,我们也可以尝试删除这些——从第一个中删除SalesID、saleElapsed、MachineID,从第二个中删除age、YearMade和saleDayofyear。它们都是与时间有关的特征。如果它们很重要,我仍然希望它们出现在我的随机森林中。但如果它们不重要,那么如果有其他一些非时间相关的变量效果一样好——那将更好。因为现在我将拥有一个更好地泛化时间的模型。
set_rf_samples(50000)
feats=['SalesID', 'saleElapsed', 'MachineID', 'age', 'YearMade', 'saleDayofyear']X_train, X_valid = split_vals(df_keep, n_trn)
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.21136509778791376, 0.2493668921196425, 0.90909393040946562, 0.88894821098056087, 0.89255408392415925]
'''
所以在这里,我将逐个查看这些特征并逐个删除,重新训练一个新的随机森林,并打印出分数。在我们做任何这些之前,我们的验证分数是 0.88,OOB 是 0.89。你可以看到,当我删除 SalesID 时,我的分数上升了。这正是我们所希望的。我们删除了一个时间相关的变量,还有其他变量可以找到类似的关系而不依赖于时间。因此,删除它导致我们的验证分数上升。现在 OOB 没有上升,因为这实际上在统计上是一个有用的预测变量,但它是一个时间相关的变量,我们有一个时间相关的验证集。这是非常微妙的,但它可能非常重要。它试图找到能够提供跨时间泛化预测的因素,这里是你可以看到的方式。
for f in feats:df_subs = df_keep.drop(f, axis=1)X_train, X_valid = split_vals(df_subs, n_trn)m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True)m.fit(X_train, y_train)print(f)print_score(m)
SalesID
'''
[0.20918653475938534, 0.2459966629213187, 0.9053273181678706, 0.89192968797265737, 0.89245205174299469]
'''
saleElapsed
'''
[0.2194124612957369, 0.2546442621643524, 0.90358104739129086, 0.8841980790762114, 0.88681881032219145]
'''
MachineID
'''
[0.206612984511148, 0.24446409479358033, 0.90312476862123559, 0.89327205732490311, 0.89501553584754967]
'''
age
'''
[0.21317740718919814, 0.2471719147150774, 0.90260198977488226, 0.89089460707372525, 0.89185129799503315]
'''
YearMade
'''
[0.21305398932040326, 0.2534570148977216, 0.90555219348567462, 0.88527538596974953, 0.89158854973045432]
'''
saleDayofyear
'''
[0.21320711524847227, 0.24629839782893828, 0.90881970943169987, 0.89166441133215968, 0.89272793857941679]
'''
我们肯定应该删除SalesID,但saleElapsed没有变得更好,所以我们不想要。MachineID变得更好了-从 0.888 到 0.893,所以实际上好了很多。age有点变好了。YearMade变得更糟了,saleDayofyear有点变好了。
reset_rf_samples()
现在我们可以说,让我们摆脱那三个我们知道摆脱它实际上使它变得更好的东西。因此,我们现在达到了 0.915!所以我们摆脱了三个时间相关的因素,现在如我们所料,我们的验证比 OOB 更好。
df_subs = df_keep.drop(['SalesID', 'MachineID', 'saleDayofyear'], axis=1
)
X_train, X_valid = split_vals(df_subs, n_trn)
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.1418970082803121, 0.21779153679471935, 0.96040441863389681, 0.91529091848161925, 0.90918594039522138]
'''
所以那是一个非常成功的方法,现在我们可以检查特征的重要性。
plot_fi(rf_feat_importance(m, X_train));

np.save('tmp/subs_cols.npy', np.array(df_subs.columns))
让我们继续说好吧,那真是相当不错。现在让它静置一段时间,给它 160 棵树,让它消化一下,看看效果如何。
我们的最终模型!
m = RandomForestRegressor(n_estimators=160, max_features=0.5, n_jobs=-1, oob_score=True
)
%time m.fit(X_train, y_train)
print_score(m)
'''
CPU times: user 6min 3s, sys: 2.75 s, total: 6min 6s
Wall time: 16.7 s
[0.08104912951128229, 0.2109679613161783, 0.9865755186304942, 0.92051576728916762, 0.9143700001430598]
'''
正如你所看到的,我们进行了所有的解释,所有的微调基本上都是用较小的模型/子集进行的,最后,我们运行了整个过程。实际上,这只花了 16 秒,所以我们现在的 RMSE 是 0.21。现在我们可以将其与 Kaggle 进行比较。不幸的是,这是一个较旧的比赛,我们不允许再参加,看看我们会取得怎样的成绩。所以我们能做的最好的就是检查它是否看起来我们可能会根据他们的验证集做得很好,所以应该在正确的范围内。根据这一点,我们本来会得第一名。
我认为这是一系列有趣的步骤。所以你可以在你的 Kaggle 项目和更重要的是你的现实世界项目中按照相同的步骤进行。其中一个挑战是一旦你离开这个学习环境,突然间你周围都是从来没有足够时间的人,他们总是希望你赶快,他们总是告诉你这样做然后那样做。你需要找到时间远离一下然后回来,因为这是一个你可以使用的真正的现实世界建模过程。当我说它提供了世界级的结果时,我的意思是真的。赢得这个比赛的人,Leustagos,不幸地去世了,但他是有史以来最顶尖的 Kaggle 竞争者。我相信他赢得了数十个比赛,所以如果我们能够得到一个甚至接近他的分数,那么我们做得真的很好。
澄清:这两者之间 R²的变化不仅仅是因为我们删除了这三个预测因子。我们还进行了reset_rf_samples()。因此,要真正看到仅仅删除的影响,我们需要将其与之前的最终步骤进行比较。

实际上与 0.907 的验证相比。因此,删除这三个因素使我们的分数从 0.907 提高到 0.915。最终,当然最重要的是我们的最终模型,但只是澄清一下。
从头开始编写随机森林!
笔记本
我的原始计划是实时进行,但当我开始做的时候,我意识到那样会很无聊,所以,我们可能会一起更多地走一遍代码。
实现随机森林算法实际上是相当棘手的,不是因为代码很棘手。一般来说,大多数随机森林算法在概念上都很容易。一般来说,学术论文和书籍往往让它们看起来很困难,但从概念上讲并不困难。困难的是把所有细节搞对,知道什么时候是对的。换句话说,我们需要一种好的测试方法。因此,如果我们要重新实现已经存在的东西,比如说我们想在一些不同的框架、不同的语言、不同的操作系统中创建一个随机森林,我总是从已经存在的东西开始。因此,在这种情况下,我们只是把它作为学习练习,用 Python 编写一个随机森林,因此为了测试,我将把它与现有的随机森林实现进行比较。
这是至关重要的。每当你在涉及机器学习中的非平凡量的代码时,知道你是对还是错是最困难的部分。我总是假设在每一步都搞砸了一切,所以我在想,好吧,假设我搞砸了,我怎么知道我搞砸了。然后令我惊讶的是,有时候我实际上做对了,然后我可以继续。但大多数时候,我做错了,所以不幸的是,对于机器学习来说,有很多方法可以让你出错,而不会给你错误。它们只会让你的结果稍微不那么好,这就是你想要发现的。
%load_ext autoreload
%autoreload 2
%matplotlib inlinefrom fastai.imports import *
from fastai.structured import *
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from IPython.display import display
from sklearn import metrics
因此,考虑到我想要将其与现有实现进行比较,我将使用我们现有的数据集,我们现有的验证集,然后为了简化事情,我只会从两列开始。因此,让我们继续开始编写一个随机森林。
PATH = "data/bulldozers/"df_raw = pd.read_feather('tmp/bulldozers-raw')
df_trn, y_trn, nas = proc_df(df_raw, 'SalePrice')
def split_vals(a,n): return a[:n], a[n:]
n_valid = 12000
n_trn = len(df_trn)-n_valid
X_train, X_valid = split_vals(df_trn, n_trn)
y_train, y_valid = split_vals(y_trn, n_trn)
raw_train, raw_valid = split_vals(df_raw, n_trn)
x_sub = X_train[['YearMade', 'MachineHoursCurrentMeter']]
我写代码的方式几乎都是自顶向下的,就像我的教学一样。因此,从顶部开始,我假设我想要的一切都已经存在。换句话说,我想要做的第一件事是,我将称之为树集合。要创建一个随机森林,我首先要问的问题是我需要传入什么。我需要初始化我的随机森林。我将需要:
-
x:一些自变量 -
y:一些因变量 -
n_trees:选择我想要的树的数量 -
sample_sz:我将从一开始使用样本大小参数,因此您希望每个样本有多大 -
min_leaf:然后可能是一些可选参数,表示最小叶子大小。
class TreeEnsemble():def __init__(self, x, y, n_trees, sample_sz, min_leaf=5):np.random.seed(42)self.x,self.y,self.sample_sz,self.min_leaf = x,y,sample_sz,min_leafself.trees = [self.create_tree() for i in range(n_trees)]def create_tree(self):rnd_idxs = np.random.permutation(len(self.y))[:self.sample_sz]return DecisionTree(self.x.iloc[rnd_idxs], self.y[rnd_idxs],min_leaf=self.min_leaf)def predict(self, x):return np.mean([t.predict(x) for t in self.trees], axis=0)
对于测试,最好使用一个固定的随机种子,这样每次都会得到相同的结果。np.random.seed(42)是设置随机种子的方法。也许值得一提的是,对于那些不熟悉的人来说,计算机上的随机数生成器根本不是随机的。它们实际上被称为伪随机数生成器,它们的作用是在给定一些初始起点(在这种情况下是 42)的情况下,生成一系列确定性(始终相同)的数字,这些数字被设计为:
-
尽可能与前一个数字不相关
-
尽可能不可预测
-
尽可能与具有不同随机种子的东西不相关(因此以 42 开头的序列中的第二个数字应该与以 41 开头的序列中的第二个数字非常不同)
通常,它们涉及使用大素数,取模等等。这是一个有趣的数学领域。如果你想要真正的随机数,唯一的方法就是你可以购买一种叫做硬件随机数生成器的硬件,里面会有一点放射性物质,以及一些检测它输出了多少东西的东西,或者会有一些硬件设备。
问题:当前系统时间是否是有效的随机数生成器[1:09:25]?这可能是一个随机种子(我们用来启动函数的东西)。一个非常有趣的领域是,在您的计算机中,如果您没有设置随机种子,它会被设置为什么。通常,人们会使用当前时间来确保安全性 - 显然,我们在安全方面使用了很多随机数,比如如果您正在生成 SSH 密钥,它需要是随机的。事实证明,人们可以大致确定您创建密钥的时间。他们可以查看id_rsa的时间戳,然后尝试在该时间戳周围的所有不同纳秒起始点上尝试随机数生成器,并找出您的密钥。因此,在实践中,许多需要高度随机性的应用程序实际上都有一步说“请移动鼠标并在键盘上输入一段时间的随机内容”,这样就可以让您成为“熵”的来源。另一种方法是他们会查看一些日志文件的哈希值或类似的东西。这是一个非常有趣的领域。
在我们的情况下,我们的目的实际上是消除随机性[1:10:48]。所以我们说,好吧,生成一系列以 42 开始的伪随机数,所以它应该始终相同。
如果您在 Python 面向对象方面没有做过太多事情,这基本上是标准习语,至少我是这样写的,大多数人不这样写,但是如果您传入五个要保存在此对象内部的东西,那么您基本上必须说self.x = x,等等。我们可以从元组中赋值给元组。

这是我的编码方式。大多数人认为这很糟糕,但我更喜欢一次看到所有东西,这样我就知道在我的代码中,每当我看到类似这样的东西时,它总是在方法中设置的所有内容。如果我以不同的方式做,那么现在一半的代码会从页面底部消失,你就看不到了。
这是我考虑的第一件事 - 要创建一个随机森林,您需要哪些信息。然后我需要将该信息存储在我的对象内部,然后我需要创建一些树。随机森林是一些树的集合。因此,我基本上想到使用列表推导来创建一组树。我们有多少棵树?我们有n_trees棵树。这就是我们要求的。range(n_trees)给我从 0 到n_trees-1的数字。因此,如果我创建一个列表推导,循环遍历该范围,每次调用create_tree,我现在有了n_trees棵树。
为了写这个,我根本不用思考。这一切都是显而易见的。所以我把思考推迟到了这一点,就像好吧,我们没有东西来创建一棵树。好吧,没关系。但让我们假装我们有。如果我们有了,我们现在创建了一个随机森林。我们仍然需要在此基础上做一些事情。例如,一旦我们有了它,我们需要一个预测函数。好的,让我们写一个预测函数。在随机森林中如何进行预测?对于特定的行(或行),遍历每棵树,计算其预测。因此,这里是一个列表推导,它正在为x的每棵树计算预测。我不知道x是一行还是多行,这并不重要,只要tree.predict对其起作用。一旦你有了一系列东西,要知道的一个很酷的事情是你可以传递numpy.mean一个常规的非 numpy 列表,它将取平均值 - 你只需要告诉它axis=0表示跨列表平均。因此,这将返回每棵树的.predict()的平均值。
我发现列表推导允许我按照大脑的方式编写代码[1:14:24]。你可以将这些单词翻译成这段代码,或者你可以将这段代码翻译成单词。所以当我写代码时,我希望它尽可能像那样。我希望它是可读的,所以希望当你查看 fast.ai 代码时,试图理解 Jeremy 是如何做 x 的,我尽量以一种你可以阅读并在脑海中转化为英语的方式来写东西。
我们几乎已经完成了我们的随机森林的编写,不是吗[1:15:29]?现在我们只需要编写create_tree。我们将从数据的随机样本构建一个决策树(即非随机树)。所以再次,我们在这里延迟了任何实际的思考过程。我们基本上说好吧,我们可以选择一些随机 ID。这是一个很好的技巧要知道。如果你调用np.random.permutation传入一个int,它会给你一个从零到那个int的随机洗牌序列。所以如果你获取那个的前:n项,那现在就是一个随机子样本。所以这里不是在这里做引导法(即我们不是在进行有放回的抽样),我认为这是可以接受的。对于我的随机森林,我决定它将是一种我们进行子抽样而不是引导法的情况。

np.random.permutation(len(self.y))[:self.sample_sz]
所以这是一个很好的代码行,知道如何编写,因为它经常出现。我发现在机器学习中,我使用的大多数算法都有些随机,所以我经常需要某种随机样本。
就我个人而言,我更喜欢这种方式,而不是引导法,因为我觉得大多数时候,我们拥有的数据比我们一次想要放入树中的数据要多[1:18:54]。当 Breiman 创建随机森林时,是 1999 年,那是一个非常不同的世界。现在我们有太多的数据。所以人们倾向于启动一个 Spark 集群,当他们没有意义时,他们会在数百台机器上运行它,因为如果他们每次只使用一个子样本,他们可以在一台机器上完成。Spark 的开销是巨大的 I/O 开销。如果你在单台机器上做某事,通常会快上数百倍,因为你没有这种 I/O 开销,而且编写算法也更容易,可视化更容易,更便宜等等。所以我几乎总是避免分布式计算,我一生都是这样。即使在 25 年前我开始学习机器学习时,我也没有使用集群,因为我总觉得无论我现在用集群能做什么,五年后我都可以用一台机器做到。所以为什么不专注于始终尽可能地在一台机器上做得更好呢。这将更具互动性和迭代性。
所以再次,我们延迟思考到必须编写决策树的时候[1:20:26]。希望你能明白这种自顶向下的方法,目标是我们将不断延迟思考,直到最终我们不知不觉地写完整个东西而不必实际思考。请注意,你永远不必设计任何东西。你只需说,如果有人已经给我提供了我需要的确切 API,我该如何使用它?然后实现下一个阶段,我需要实现的确切 API 是什么?你继续下去,直到最终你注意到哦,这已经存在了。
这假设我们有一个名为DecisionTree的类,所以我们将不得不创建它。我们知道我们将不得不传递什么,因为我们刚刚传递了它。所以我们传递了x和y的随机样本。我们知道决策树将包含决策树,这些决策树本身包含决策树。因此,当我们沿着决策树向下走时,原始数据的某个子集将被包含在内,因此我将传递我们实际上将在这里使用的数据的索引。所以最初,它是整个随机样本。我们还传递min_leaf的大小。因此,我们为构建随机森林所做的一切,我们将传递给决策树,除了当然不包括对于决策树无关的num_tree。
class DecisionTree():def __init__(self, x, y, idxs=None, min_leaf=5):if idxs is None: idxs=np.arange(len(y))self.x,self.y,self.idxs,self.min_leaf = x,y,idxs,min_leafself.n,self.c = len(idxs), x.shape[1]self.val = np.mean(y[idxs])self.score = float('inf')self.find_varsplit()# This just does one decision; we'll make it recursive laterdef find_varsplit(self):for i in range(self.c): self.find_better_split(i)# We'll write this later!def find_better_split(self, var_idx): pass@propertydef split_name(self): return self.x.columns[self.var_idx]@propertydef split_col(self): return self.x.values[self.idxs,self.var_idx] @propertydef is_leaf(self): return self.score == float('inf')def __repr__(self):s = f'n: {self.n}; val:{self.val}'if not self.is_leaf:s += f'; score:{self.score}; split:{self.split}; var:{self.split_name}'return s
-
self.n: 这棵树中有多少行(我们给定的索引数量) -
self.c: 我们有多少列(独立变量中有多少列) -
self.val: 对于这棵树,它的预测是什么。这棵树的预测是我们依赖变量的均值。当我们谈论索引时,我们并不是在谈论用于创建树的随机抽样。我们假设这棵树现在有一些随机样本。在决策树内部,整个随机抽样的过程已经消失了。那是由随机森林完成的。所以在这一点上,我们正在构建的只是一棵普通的决策树。它不以任何方式是随机抽样的任何东西。所以索引实际上是我们到目前为止在这棵树中得到的数据的哪个子集。
一个快速的面向对象编程入门
我会跳过这部分,但这里有关于self的有趣内容:
你可以随意命名它。如果你把它命名为除了“self”之外的任何其他名称,每个人都会讨厌你,你是个坏人。
机器学习 1:第 6 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-6-14bbb8180d49译者:飞龙
协议:CC BY-NC-SA 4.0
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
视频 / 幻灯片
我们已经看过很多不同的随机森林解释技术,论坛上有一些问题是这些到底有什么用?它们如何帮助我在 Kaggle 上获得更好的分数,我的答案是“它们不一定会”。因此,我想更多地谈谈为什么我们要做机器学习。这有什么意义?为了回答这个问题,我想向你展示一些非常重要的东西,即人们主要在商业中如何使用机器学习的例子,因为这是你们大多数人在结束后可能会在某家公司工作。我将向你展示机器学习的应用,这些应用要么基于我自己亲身参与的事情,要么是我知道直接在做这些事情的人,因此这些都不是假设的——这些都是人们正在做的实际事情,我有直接或间接的了解。
两组应用[1:26]
-
水平:在商业中,水平意味着跨不同类型的业务进行的事情。即涉及营销的所有事情。
-
垂直:在企业内部或供应链或流程中进行的某些事情。
水平应用
几乎每家公司都必须尝试向其客户销售更多产品,因此进行营销。因此,这些框中的每一个都是人们在营销中使用机器学习的一些示例:

让我们举个例子——流失。流失是指试图预测谁会离开的模型。最近在电信领域做了一些流失建模。我们试图弄清楚这家大型手机公司的哪些客户会离开。这本身并不那么有趣。构建一个高度预测性的模型,说 Jeremy Howard 几乎肯定会在下个月离开,可能并不那么有帮助,因为如果我几乎肯定会在下个月离开,你可能无法做任何事情——为了留住我,成本可能太高。
因此,为了理解我们为什么要进行流失建模,我有一个可能对你有帮助的小框架:设计出色的数据产品。几年前我和几位同事一起写了这篇文章,在其中,我描述了我将机器学习模型转化为赚钱的东西的经验。基本技巧是我称之为驱动器方法,这是这四个步骤:

定义目标[3:48]
将机器学习项目转化为实际有用的起点是知道我试图实现什么,这意味着我试图实现高 ROC 曲线下面积或尝试实现类之间的巨大差异。这可能是我试图销售更多的书,或者我试图减少下个月离开的客户数量,或者我试图更早地检测肺癌。这些都是目标。因此,目标是公司或组织实际想要的东西。没有公司或组织是为了创建更准确的预测模型而存在的。这是有原因的。所以这就是你的目标。显然,这是最重要的事情。如果你不知道你为何建模,那么你不可能做好这项工作。希望人们开始在数据科学领域意识到这一点,但有趣的是,很少有人谈论但同样重要的是下一步,即杠杆。
杠杆[5:04]
杠杆是组织可以实际采取的行动,以推动目标的实现。所以让我们以流失建模为例。组织可以采取什么杠杆来减少离开的客户数量?他们可以打电话给某人,问:“你满意吗?我们能做些什么?”他们可以在下个月购买价值 20 美元的产品时赠送免费的钢笔或其他物品。你可以给他们提供特别优惠。所以这些就是杠杆。当你作为数据科学家工作时,不断回头思考我们试图实现什么(我们指的是组织),以及我们如何实现它,即我们可以做哪些实际的事情来实现这个目标。因此,构建模型绝对不是杠杆,但它可以帮助你使用杠杆。
数据[7:01]
接下来的步骤是组织拥有哪些数据可能帮助他们设置杠杆以实现目标。这不是指他们在项目开始时给你的数据。而是从第一原则的角度考虑——好吧,我在一家电信公司工作,他们给了我一些特定的数据,但我肯定他们必须知道他们的客户住在哪里,上个月打了多少电话,打了多少次客服电话等等。所以想一想,如果我们试图决定主动给谁提供特别优惠,那么我们想要弄清楚我们有哪些信息可能帮助我们确定谁会对此做出积极或消极的反应。也许更有趣的是,如果我们正在进行欺诈算法。我们试图弄清楚谁不会支付他们从商店拿出的手机,他们正在进行某种 12 个月的付款计划,然后我们再也没有见到他们。在这种情况下,我们可以获得的数据,数据库中有什么并不重要,重要的是当客户在商店时我们可以获得什么数据。因此,我们通常会受到我们实际可以使用的数据的限制。因此,我们需要知道我试图实现什么目标,这个组织实际上可以具体做些什么来改变结果,以及在做出决定时,他们拥有或可以收集到哪些数据。
模型[8:45]
然后我把所有这些放在一起的方式是通过一个模型。这不是一个预测模型,而是一个模拟模型。我在这篇论文中给出的一个主要例子是,我花了很多年时间建立的一个模型,即如果一个保险公司改变他们的价格,这将如何影响他们的盈利能力。通常你的模拟模型包含了许多预测模型。比如,我有一个叫做弹性模型的预测模型,它说对于一个特定的客户,如果我们为他们的某个产品收取一个特定的价格,他们会在新业务时和一年后续保的概率是多少。然后还有另一个预测模型,即他们会提出索赔的概率以及索赔金额是多少。然后你可以将这些模型结合起来,然后说好,如果我们将我们的定价降低 10%适用于 18 到 25 岁的所有人,然后我们可以通过这些模型运行,将它们结合成一个模拟,那么我们在 10 年后的市场份额的整体影响是 X,我们的成本是 Y,我们的利润是 Z 等等。
实际上,大多数时候,你真的更关心那个模拟的结果,而不是直接关心预测模型。但大多数人目前并没有有效地做到这一点。例如,当我去亚马逊时,我读了道格拉斯·亚当斯的所有书,所以在我读完所有道格拉斯·亚当斯的书之后,下次我去亚马逊,他们说你想买道格拉斯·亚当斯的全部作品吗。这是在我已经买了他的每一本书之后。从机器学习的角度来看,一些数据科学家可能会说,购买道格拉斯·亚当斯的一本书的人通常会继续购买他的全部作品。但向我推荐购买道格拉斯·亚当斯的全部作品并不明智。这实际上在很多方面都不明智。不仅是因为我不太可能购买一个我已经有每一本书的合集,而且这也不会改变我的购买行为。我已经了解道格拉斯·亚当斯,我已经知道我喜欢他,所以占用你宝贵的网页空间来告诉我,嘿,也许你应该购买更多你已经熟悉并多次购买的作者的作品实际上不会改变我的行为。那么,如果亚马逊不是创建一个预测模型,而是建立一个能够模拟的优化模型,然后说如果我们向杰里米展示这个广告,他会有多大可能继续购买这本书,如果我不向他展示这个广告,他会有多大可能继续购买这本书。这就是对立事实。对立事实是否则会发生什么,然后你可以计算差异,然后说我们应该推荐他什么才能最大程度地改变他的行为。所以最大程度地导致更多的书籍,所以你可能会说,哦,他从来没有买过特里·普拉切特的书,他可能不了解特里·普拉切特,但很多喜欢道格拉斯·亚当斯的人确实喜欢特里·普拉切特,所以让我们向他介绍一个新的作者。
因此,一方面是预测模型,另一方面是优化模型之间的区别。所以这两者往往是相辅相成的。首先,我们有一个模拟模型。模拟模型是在说,如果我们把特里·普拉切特的书放在亚马逊的首页上给杰里米·霍华德看,会发生什么。他有 94%的概率会购买。这告诉我们,通过这个杠杆,我今天应该在杰里米的首页上放什么,我们说好,把特里·普拉切特放在首页上的不同设置会产生最高的模拟结果。然后这就是最大化我们从杰里米今天访问亚马逊网站中的利润的事情。
一般来说,你的预测模型会输入到这个模拟模型中,但你必须考虑它们如何共同工作。例如,让我们回到流失问题。结果表明,Jeremy Howard 很可能会在下个月离开他的手机公司。我们该怎么办?让我们给他打电话。我可以告诉你,如果我的手机公司现在给我打电话说“只是打电话告诉你我们爱你”,我会立刻取消。那将是一个糟糕的主意。因此,你会想要一个模拟模型,来说 Jeremy 现在接到电话后改变行为的概率是多少。所以我有一个杠杆是给他打电话。另一方面,如果明天我收到一封信,说每个月你和我们在一起,我们会给你十万美元。那肯定会改变我的行为,对吧?但是将这个输入到模拟模型中,结果是这将是一个不盈利的选择。你看到这是如何相互配合的吗?
所以当我们看流失这样的问题时,我们要考虑我们可以拉动的杠杆是什么。我们可以用什么样的数据构建什么样的模型来帮助我们更好地拉动这些杠杆以实现我们的目标。当你这样思考时,你会意识到这些应用的绝大部分实际上并不是关于预测模型。它们是关于解释的。它们是关于理解“如果发生了什么”。因此,我们可以实际使用我们的随机森林特征重要性告诉我们我们实际上可以做些什么来产生影响。然后我们可以使用部分依赖来构建这种模拟模型,来说如果我们改变了那个,会发生什么。
所以有很多例子,当你思考你正在处理的机器学习问题时,我希望你考虑为什么有人会关心这个问题。对他们来说一个好的答案是什么样的,你如何实际上对这个业务产生积极影响。所以如果你在创建一个 Kaggle 内核,试着从竞赛组织者的角度思考。他们想知道什么,你如何给他们这些信息。另一方面,像欺诈检测,你可能只是想知道谁是欺诈的。所以你可能只关心预测模型。但是你必须仔细考虑这里的数据可用性。所以好吧,我们需要知道在我们即将向他们交付产品时谁是欺诈的。例如,查看一个月后可用的数据是没有意义的。所以你必须考虑你正在工作的实际运营约束。
人力资源应用。
在人力资源领域有很多有趣的应用,比如员工流失,这是另一种流失模型,其中发现杰里米·霍华德已经厌倦了讲课,他明天就要离开了。你会怎么做?知道这个事实实际上并不会有帮助。那将会太迟了。你实际上想要一个模型,告诉你什么样的人会离开 USF,结果发现每个去楼下咖啡厅的人都会离开 USF。我猜他们的食物很糟糕或者其他什么原因。或者我们支付不到 50 万美元一年的人都会离开 USF,因为他们无法负担旧金山的基本住房。因此,你可以使用员工流失模型,不是为了知道哪些员工讨厌我们,而是为什么员工离开。再次强调,真正重要的是解释。
问题:对于流失模型,听起来你需要预测两个预测因子——一个是流失,另一个是你需要优化你的利润。那么它是如何工作的[18:30]?是的,确切地说,这就是模拟模型的全部内容。你找出我们试图最大化的目标,即公司的盈利能力。你可以创建一个相当简单的 Excel 模型或其他模型,它说这是收入,这是成本,成本等于我们雇佣的人数乘以他们的工资等。在这个 Excel 模型中,有一些单元格/输入是随机的或不确定的。但我们可以用模型来预测,这就是我要做的,我要说好,我们需要一个预测模型,来预测如果我们改变他们的工资,某人留下的可能性有多大,如果我现在增加他们的工资,明年他们离开的可能性有多大等。因此,你需要一堆不同的模型,然后你可以用简单的商业逻辑将它们绑定在一起,然后进行优化。然后你可以说,如果我给杰里米·霍华德 50 万美元,那可能是一个非常好的主意,如果我付给他更少,那可能就不是了,或者其他什么。你可以找出整体影响。所以我真的很惊讶,为什么这么少的人这样做。但大多数行业中的人用 AUC 或 RMSE 等来衡量他们的模型,这实际上并不是你真正想要的。
更多水平应用…[22:04]
潜在客户优先级是一个非常有趣的领域。我展示的每一个方框,通常都可以找到一家或多家公司,他们的唯一工作就是构建该领域的模型。因此,有很多公司销售潜在客户优先级系统,但问题是我们如何利用这些信息。如果我们的最佳潜在客户是杰里米,他是最有可能购买的人。这意味着我应该派一个销售人员去找杰里米,还是不应该?如果他很有可能购买,为什么我要浪费时间呢。因此,你真的需要一种模拟,来告诉你如果我派出最好的销售人员去鼓励他签约,杰里米的行为可能会发生什么变化。我认为今天世界上有很多机会让数据科学家不仅仅局限于预测建模,而是将所有内容整合在一起。
垂直应用[23:29]
除了这些基本适用于每家公司的横向应用之外,还有许多应用程序是针对世界各地的每个部分特定的。对于那些最终进入医疗保健领域的人,你们中的一些人将成为这些领域的专家之一。比如再入院风险。那么这位患者再次入院的概率是多少呢?根据司法管辖区的细节,当有人再次入院时,这可能对医院造成灾难。如果你发现这位患者有高再入院的可能性,你会怎么做?再次,预测模型本身是有帮助的。它更多地暗示我们不应该立即让他们回家,因为他们会再次入院。但如果我们有树解释器,并且它告诉我们,他们高风险的原因是因为我们没有最近的心电图。没有最近的心电图,我们就无法对他们的心脏健康有高度的信心。在这种情况下,我们不会说让他们在医院呆两周,而是让他们做一个心电图。因此,这是解释和预测准确性之间的互动。
问题:所以我理解你的意思是,预测模型确实很棒,但为了真正回答这些问题,我们确实需要专注于这些模型的可解释性?是的,我想是这样。更具体地说,我正在说我们刚刚学习了一整套随机森林解释技术,所以我正在试图证明为什么。原因是因为我会说大多数时候解释是我们关心的事情。你可以创建一个图表或表格而不需要机器学习,实际上这就是大多数世界的工作方式。大多数经理们在没有任何机器学习的情况下构建各种表格和图表。但他们经常做出糟糕的决定,因为他们不知道他们感兴趣的目标的特征重要性,所以他们创建的表格实际上是那些最不重要的东西。或者他们只是做一个单变量图表,而不是一个部分依赖图,所以他们实际上没有意识到他们认为自己在看的关系完全是由其他因素造成的。所以我在争论数据科学家应该更深入地参与战略,并尝试使用机器学习来真正帮助企业实现所有目标。有一些公司像 dunnhumby 这样的公司,他们什么都不做,只做零售应用的机器学习。我相信有一种 dunnhumby 产品可以帮助你弄清楚,如果我把我的新店放在这个位置而不是那个位置,有多少人会在那里购物。或者如果我把尿布放在商店的这个部分而不是那个部分,这将如何影响购买行为等等。因此,也很重要意识到,在技术媒体或其他地方你经常听到的机器学习应用的子集是这种极其偏见的微小子集,谷歌和 Facebook 做的就是这种。而实际上让世界运转的绝大部分应用是这些实际上帮助人们制造东西、购买东西、销售东西、建造东西等等的应用。
问题:关于树的解释,我们看了哪个特征对于特定观察结果更重要。对于企业来说,他们有大量数据,他们希望对很多观察结果进行这种解释,那么他们如何自动化呢?他们设置阈值吗[27:50]?绝大多数机器学习模型并不自动化任何东西。它们被设计为向人类提供信息。所以例如,如果你是一个保险公司的客服电话操作员,你的客户问你为什么我的续保费比上次贵了 500 美元,那么希望保险公司在你的终端提供那些显示树解释结果的小屏幕。这样你就可以跳过去告诉客户,去年你住在一个车辆被盗率较低的邮政编码区,而今年你还把车换成了更贵的车。所以这并不是关于阈值和自动化,而是关于让这些模型输出对组织中的决策者可用,无论是在顶层战略层面,比如我们是否要关闭整个产品,还是在操作层面,比如与客户进行个别讨论。
另一个例子是飞机调度和登机口管理。有很多公司在做这个,基本上是有人在机场,他们的工作是告诉每架飞机去哪个登机口,什么时候关闭舱门等等。所以这个想法是给他们一个软件,里面有他们需要做出良好决策所需的信息。所以机器学习模型最终嵌入在那个软件中,比如说,那架目前从迈阿密飞来的飞机,有 48%的概率会晚 5 分钟以上,如果晚了,那么整个航站楼会受到影响,例如。这就是这些东西是如何结合在一起的。
其他应用[31:02]

有很多应用,我希望你花一些时间去思考它们。和你的朋友坐下来,谈论一些例子。比如说,我们如何进行制造业的故障分析,谁会做这个,为什么会做这个,他们可能会使用什么样的模型,可能会使用什么样的数据。开始练习并获得感觉。然后当你在工作场所和经理们交谈时,你希望能立即认识到你正在交谈的人——他们想要实现什么,他们有哪些杠杆可以拉动,他们有哪些数据可用来拉动这些杠杆以实现那个目标,因此我们如何构建模型来帮助他们做到这一点,他们可能需要做出什么样的预测。这样你就可以与这些人进行深思熟虑的共情对话,然后说“为了减少离开的客户数量,我猜你正在努力找出应该给谁提供更好的定价”等等。
问题:社会科学中人们面临的解释问题是否可以使用机器学习或者已经被使用,或者这并不是真正的领域[32:29]?我与社会科学领域的人们进行了很多关于这个问题的讨论,目前机器学习在经济学或心理学等领域并没有得到很好的应用。但我相信它可以,原因正如我们所讨论的那样。因此,如果您要尝试进行某种行为经济学研究,并且试图理解为什么有些人的行为与其他人不同,使用具有特征重要性图的随机森林将是一个很好的开始。更有趣的是,如果您尝试进行某种基于大型社交网络数据集的社会学实验或分析,在那里您进行了一项观察性研究,您真的想要尝试提取所有外生变量的来源(即所有外部发生的事情),因此如果您使用具有随机森林的部分依赖图,这将自动发生。几年前,我在麻省理工学院做了一个关于数字实验的第一次会议的演讲,这次会议真正讨论了我们如何在诸如社交网络等数字环境中进行实验,经济学家们都使用经典的统计检验方法,但在这种情况下,我与之交谈的经济学家们对此非常着迷,他们实际上要求我在麻省理工学院为经济学系的各种教员和研究生们举办一个机器学习入门课程。其中一些人已经写了一些相当有名的书籍,希望这对他们有所帮助。现在还处于早期阶段,但这是一个巨大的机会。但正如 Yannet 所说,仍然存在很多怀疑。这种怀疑主要来自对这种完全不同方法的陌生感。因此,如果您花了 20 年时间研究计量经济学,然后有人过来说这是一种完全不同于计量经济学家所做的所有事情的方法,那么您的第一反应自然会是“证明它”。这是公平的,但我认为随着时间的推移,下一代与机器学习一起成长的人们中,一些人将进入社会科学领域,他们将产生前所未有的巨大影响,人们将开始感到惊讶。就像计算机视觉中发生的一样。当计算机视觉花了很长时间的人们说“也许你应该使用深度学习来进行计算机视觉”,而计算机视觉领域的每个人都说“证明它。我们在计算机视觉中有几十年的工作,开发了令人惊叹的特征检测器。”然后在 2012 年,辛顿和克里赞斯基出现了,他们说“我们的模型比你们的好两倍,而我们刚刚开始” ,每个人都被说服了。如今,几乎每个计算机视觉研究人员基本上都使用深度学习。因此,我认为在这个领域也会出现这样的时刻。
随机森林解释方法[37:17]
在谈论它们为什么重要之后,让我们现在提醒自己它们是什么。
基于树方差的置信度
这告诉我们什么?为什么我们对此感兴趣?它是如何计算的?
树的预测方差。通常预测只是平均值,这是树的方差。
在这里填充一个细节,我们通常只取一行/观察结果,然后找出我们对此有多自信(即树中有多少方差)或者我们可以像我们在这里做的那样为不同的组找出答案[39:34]。

我们在这里所做的是看是否有任何我们非常不确定的组(这可能是由于观察很少)。我认为更重要的是当你在操作中使用这个时。比如说你正在做一个信用决策算法。所以我们正在确定 Jeremy 是一个好风险还是一个坏风险。我们应该借给他一百万美元吗。随机森林说“我认为他是一个好风险,但我一点也不自信。” 在这种情况下,我们可能会说好吧,也许我不应该给他一百万美元。而在另一种情况下,如果随机森林说“我认为他是一个好风险,而且我非常确定”,那么我们就更愿意给他一百万美元。而且我是一个非常好的风险。所以请随意给我一百万美元。我之前检查过随机森林——在另一个笔记本中。不在 repo 里 😆
对于我来说,很难给你们直接的经验,因为这种单个观察解释实际上是你需要把它放到前线的那种东西。这不是你在 Kaggle 上可以真正使用的东西,而更像是如果你实际上在发布一些可能会花费很多钱的大决策的算法,你可能不太关心随机森林的平均预测,而更可能是你实际上关心平均值减去几个标准差(即最坏情况的预测)。也许有一个我们不确定的整个组,所以这是基于树方差的置信度。
特征重要性 [42:36]
学生: 基本上是为了找出哪些特征是重要的。你取每个特征,洗牌特征中的值,然后检查预测如何变化。如果非常不同,那意味着该特征实际上很重要;否则就不那么重要。
Jeremy: 那太棒了。一切都是完全正确的。有一些细节被略过了一点。还有其他人想要详细描述一下它是如何计算的吗?我们如何准确计算特定特征的重要性?
学生: 在构建随机森林模型后,你取每一列并随机洗牌它。然后运行一个预测并检查验证分数。如果在洗牌其中一列后变糟了,那意味着那列很重要,所以它具有更高的重要性。我不太确定我们如何量化特征的重要性。
Jeremy: 好的,很好。你知道我们如何量化特征的重要性吗?那是一个很好的描述。为了量化,我们可以计算 R²或某种得分的差异。所以假设我们有我们的因变量是价格,还有一堆独立变量,包括制造年份。我们使用所有这些来构建一个随机森林,这给我们我们的预测。然后我们可以比较得到 R²、RMSE,或者你对模型感兴趣的任何东西。

现在关键的是我不想重新训练整个随机森林。那太慢又无聊了,所以使用现有的随机森林。我如何找出年份的重要性呢?建议是,让我们随机洗牌整个列。现在那一列完全没用了。它的均值、分布都是一样的。关于它的一切都是一样的,但实际年份制造和现在那一列之间根本没有联系。我已经随机洗牌了。所以现在我把这个新版本放到同一个随机森林中(所以没有重新训练),得到一些新的ŷ(ym)。然后我可以将其与实际值进行比较,得到 RMSE(ym)。所以现在我可以开始创建一个小表,我有原始 RMSE(例如为 3),年份制造混乱的 RMSE 为 2。围栏混乱的 RMSE 为 2.5。然后我只需要取这些差值。对于年份制造,重要性为 1,围栏为 0.5,等等。在我洗牌了那个变量之后,我的模型变得更糟了多少。

问题:所有的重要性加起来会等于一吗?老实说,我从来没有看过单位是什么,所以我不太确定。如果有人感兴趣,我们可以在这周内查看一下。看一下 sklearn 的代码,看看这些度量单位到底是什么,因为我从来没有费心去检查。虽然我不会专门检查度量单位,但我会检查相对重要性。这里有一个例子。

所以,与其只说前十名,昨天一个实习生问我一个特征重要性的问题,他们说“哦,我认为这三个很重要”,我指出排名第一的比第二个重要一千倍。所以看看这里的相对数字。所以在这种情况下,就像“不要看前三名,看那个重要一千倍的,忽略其他所有的。”你的自然倾向是想要准确和小心,但这就是你需要覆盖的地方,要非常实际。这个东西重要一千倍。不要花时间在其他任何事情上。然后你可以去和你的项目经理谈谈,告诉他这个东西重要一千倍。然后他们可能会说“哦,那是个错误。它不应该在那里。我们实际上在决策时没有那个信息,或者由于某种原因我们实际上不能使用那个变量。”那么你可以移除它并查看。或者他们可能会说“天哪,我完全不知道那比其他所有东西加起来都重要得多。所以让我们忘掉这个随机森林的东西,专注于理解如何更好地收集那个变量并更好地使用那个变量。”这是一个经常出现的情况,实际上昨天刚刚发生了另一个地方。另一个实习生问我“我正在做这个医学诊断项目,我的 R²是 0.95,这是一个据说很难诊断的疾病。这是随机森林天才还是出了什么问题?”我说记住,建立随机森林之后你要做的第二件事是进行特征重要性分析,所以进行特征重要性分析,你可能会发现排名第一的列是不应该在那里的。这就是发生的事情。他半小时后回到我这里,他说“是的,我做了特征重要性分析,你是对的。排名第一的列基本上是另一个对因变量的编码。我把它移除了,现在我的 R²是-0.1,这是一个改进。”
我喜欢看的另一件事是这个图表:

基本上它说的是在哪些方面趋于平缓,我应该真正关注哪些方面。这是最重要的。当我在电信行业进行信用评分时,我发现有九个变量基本上可以准确预测谁最终会支付他们的电话费,谁不会。除了最终得到一个每年节省三十亿美元欺诈和信用成本的模型外,它还让他们基本上重新调整了他们的流程,以便更好地收集这九个变量。
部分依赖 [50:46]
这是一个有趣的问题。非常重要,但在某种程度上有点难以理解。

让我们稍后再来看如何计算这个问题,但首先要意识到的是,绝大多数情况下,当有人向您展示一个图表时,它将是一个单变量图表,只会从数据库中获取数据,然后绘制 X 与 Y。然后管理人员往往希望做出决策。所以可能会是“哦,这里有一个下降,所以我们应该停止处理 1990 年至 1995 年之间制造的设备”。这是一个大问题,因为现实世界的数据中有很多这样的相互作用。也许在那些东西被出售的时候正值经济衰退,或者也许在那个时候,人们更多地购买了不同类型的设备。因此,通常我们实际上想知道的是,在其他所有条件相等的情况下,YearMade 和 SalePrice 之间的关系。因为如果您考虑到驱动器方法的杠杆思想,您真的希望一个模型说如果我改变这个杠杆,它将如何改变我的目标。通过使用部分依赖来分开它们,您可以说实际上这是 YearMade 和 SalePrice 之间的关系,在其他所有条件相等的情况下:

那么我们如何计算呢?
学生:例如,对于变量 YearMade,您保持所有其他变量不变。然后,您将传递 YearMade 的每个值,然后训练模型。因此,对于每个模型,您将有浅蓝色线条,中位数将是黄色线条。
Jeremy:那么让我们尝试绘制出来。通过“保持其他一切不变”,她的意思是将它们保持为数据集中的任何值。就像我们进行特征重要性时一样,我们将保持数据集的其余部分不变。我们将对 YearMade 进行部分依赖图。因此,我们有所有这些其他数据行,我们将保持它们不变。与其随机洗牌 YearMade,我们将用完全相同的东西——1960 来替换每个值。就像以前一样,我们现在将通过我们尚未重新训练或更改的现有随机森林来传递这些数据,以获得一组预测y1960。然后我们可以在图表上绘制出来——YearMade 与部分依赖。

现在我们可以为 1961 年、1962 年、1963 年等等做到这一点。我们可以对所有这些平均做到这一点,或者我们可以只对其中一个做到这一点。因此,当我们只对其中一个做到这一点,并且改变它的 YearMade 并将这个单个事物通过我们的模型,这给我们一个这些蓝线中的一个。因此,每一条这些蓝线都是一个单独的行,当我们将其 YearMade 从 1960 年改变到 2008 年。因此,我们可以简单地取所有这些蓝线的中位数,以便平均地说,YearMade 和价格之间的关系是什么,其他所有事物都相等。为什么它有效呢?为什么这个过程告诉我们 YearMade 和价格之间的关系,其他所有事物都相等呢?也许考虑一个非常简化的方法会有帮助。一个非常简化的方法会说什么是平均拍卖?什么是平均销售日期,我们最常见的机器类型是什么?我们主要在哪个地点销售物品?然后我们可以得出一个代表平均拍卖的单行,然后我们可以说,好的,让我们通过随机森林运行这一行,但用 1960 年替换它的 YearMade,然后再用 1961 年再做一次,我们可以在我们的小图表上绘制这些。这将给我们一个 YearMade 和销售价格之间关系的版本,其他所有事物都相等。但是如果拖拉机看起来像那样,而挖掘机看起来像一条平直的线:

然后取平均值会隐藏这些完全不同的关系的事实。因此,我们基本上说,好吧,我们的数据告诉我们我们倾向于销售什么样的东西,我们倾向于向谁销售,以及我们倾向于何时销售,所以让我们利用这一点。然后我们实际上发现,对于每一条蓝线,这里有这些关系的实际例子。因此,我们可以做的是除了绘制中位数之外,我们可以进行聚类分析,找出几种不同的形状。

在这种情况下,它们看起来基本上是同一件事的不同版本,具有不同的斜率,所以我从中得出的主要结论是销售价格与制造年份之间的关系基本上是一条直线。请记住,这是销售价格的对数,因此实际上向我们展示了一个指数。这就是我会引入领域专业知识的地方,比如“好吧,事物随着时间按照一个恒定比率贬值,因此,我会预期较旧的东西制造年份具有这种指数形状。”所以这就是我提到的,我的机器学习项目的开始,我通常尽量避免使用尽可能多的领域专业知识,让数据说话。因此,今天早上我收到的一个问题是“有一个销售 ID 和型号 ID,我应该抛弃它们,对吧?因为它们只是 ID。”不要。不要对数据做任何假设。保留它们,如果它们被证明是非常重要的预测因子,你会想要找出原因。但是,现在我已经完成了我的特征重要性,我已经从那个树状图中提取出了一些东西(即冗余特征),我正在查看部分依赖性,现在我在思考,这种形状是否符合我的预期?因此,更好的做法是,在绘制之前,首先考虑我期望这种形状是什么。因为事后向自己证明,哦,我知道它会看起来像这样,总是很容易。所以你期望什么形状,然后它是那种形状吗?在这种情况下,我会说这是我所期望的。而之前的图表则不符合我的预期。因此,部分依赖性图表真正揭示了潜在的真相。
问题:假设您有 20 个重要特征,您会为每一个特征测量偏依赖性吗?如果有 20 个重要特征,那么我将对所有这些特征进行偏依赖性分析,其中重要意味着它是一个我实际可以控制的杠杆,其大小的幅度与其他十九个特征的差异不大,您知道,基于所有这些因素,这是一个我应该关心的特征,那么我将想要了解它是如何相关的。在我的经验中,拥有这么多在操作和建模角度上都重要的特征是相当不寻常的。
问题:您如何定义重要性?重要意味着它是一个杠杆(即我可以改变的东西),它位于这个尾巴(左侧)的尖端:

或者它可能不是直接的杠杆。也许它像邮政编码一样,我实际上无法告诉我的客户在哪里居住,但我可以将我的新营销注意力集中在不同的邮政编码上。
问题:对于每一对特征组合进行成对洗牌,保持其他所有内容不变,以查看交互作用并比较分数是否有意义?你不会为了偏依赖性而这样做。我认为您的问题实际上是在询问我们是否可以为特征重要性这样做。我认为交互特征重要性是一个非常重要且有趣的问题。但是通过随机洗牌每一对列来做到这一点,如果您有一百列,这听起来计算量很大,可能不可行。所以我要做的是在我们讨论树解释器之后,我将谈论一个有趣但在很大程度上未被探索的方法,这可能会起作用。
树解释器
Prince:我认为这更像是特征重要性,但特征重要性是针对完整的随机森林模型,而这个树解释器是针对特定观察的特征重要性。所以让我们说这是关于医院再入院的。如果患者 A 将要再次入院,那么对于该特定患者,哪个特征会产生影响,我们如何改变这种情况。它是从平均预测开始计算,然后看每个特征如何改变该特定患者的行为。
Jeremy:我在微笑,因为这是我很长时间以来听到的最好的技术沟通示例之一,所以思考为什么这么有效是非常有意义的。Prince 所做的是,他尽可能具体地举例说明。人类在理解抽象概念方面要差得多。因此,如果您说“它需要某种特征,然后在该特征的观察中”,而不是医院再入院。因此,我们举了一个具体的例子。他做的另一件非常有效的事情是将类比与我们已经理解的东西联系起来。因此,我们已经理解了数据集中所有行的特征重要性的概念。因此,现在我们将为单个行执行此操作。因此,我真的希望我们从这次经验中学到如何成为有效的技术沟通者。因此,Prince 在使用我们可以利用的所有技巧进行有效的技术沟通方面是一个非常好的榜样。希望您觉得这个解释有用。除了向您展示它是什么样子之外,我没有太多要补充。
使用树解释器,我们挑选出一行:

还记得我们在一开始谈到的置信区间吗(即基于树方差的置信度)?我们说你主要用于一行。所以这也是为一行。就像“为什么这个患者可能会再次入院?”这是我们关于该患者或在这种情况下该拍卖会的所有信息。为什么这个拍卖会这么贵?然后我们调用ti.predict,我们得到价格的预测,偏差(即树的根 - 这只是每个人的平均价格,所以这总是一样的),然后是贡献,即这些事情有多重要:

我们计算的方法是说一开始,平均价格是 10。然后我们根据围栏进行分割。对于那些有这个围栏的人,平均价格是 9.5。然后我们根据制造年份小于 1990 进行分割,对于那些有这个制造年份的人,平均价格是 9.7。然后我们根据米数进行分割,对于这个分支,我们得到了 9.4。

然后我们有一个特定的拍卖会,我们通过树传递它。碰巧它走了最顶层的路径。一行只能通过树有一条路径。所以我们最终到了 9.4。然后我们可以创建一个小表格。当我们逐步进行时,我们从顶部开始,我们从 10 开始 - 这是我们的偏差。我们说围栏导致了从 10 变为 9.5(即-0.5)。制造年份将其从 9.5 变为 9.7(即+0.2),然后米数将其从 9.7 降至 9.4(-0.3)。然后如果我们把所有这些加在一起(10-0.5+0.2-0.3),哎呀,那就是预测。

这让我们来到我们的 Excel 电子表格:

上周,我们使用 Excel 进行了这项工作,因为没有一个很好的 Python 库可以制作瀑布图。所以我们看到我们得到了我们的起点这是偏差,然后我们有我们每个贡献,最后我们得到了我们的总数。现在世界变得更美好了,因为 Chris 为我们创建了一个 Python 瀑布图模块,并将其放在 pip 上。所以我们再也不必使用 Excel 了。我想指出,瀑布图至少在我从事业务以来一直在商业沟通中非常重要 - 大约 25 年了。Python 可能已经有几十年的历史了。但尽管如此,Python 世界中没有人真正想到“你知道,我要制作一个瀑布图”,所以直到两天前它们才存在,也就是说这个世界充满了应该存在但不存在的东西。而且并不一定需要花费很多时间来构建。Chris 花了大约 8 个小时,所以数量相当可观但不过分。现在以后,当人们想要 Python 瀑布图时,他们将最终到达 Chris 的 Github 存储库,并希望找到许多其他美国大学的贡献者,他们使其变得更好。
为了帮助改进 Chris 的 Python 瀑布,您需要知道如何做到这一点。因此,您需要提交一个拉取请求。如果您使用一个叫做hub的东西,那么提交拉取请求将变得非常容易。他们建议您将git别名为hub,因为事实证明,hub 实际上是 git 的一个严格的超集。它让您可以执行git fork,git push和git pull-request,然后您现在已经向 Chris 发送了一个拉取请求。没有 hub,这实际上是一种痛苦,需要像去网站并填写表格之类的事情。因此,这给您没有理由不提交拉取请求。我提到这一点是因为当您面试工作时,我可以向您保证,您正在与之交谈的人将检查您的 github,如果他们看到您有提交经过深思熟虑的拉取请求并被接受到有趣的库,那看起来很棒。这看起来很棒,因为它表明您是一个实际做出贡献的人。它还表明,如果它们被接受,那么您知道如何创建符合人们编码标准、具有适当文档、通过测试和覆盖率等的代码。因此,当人们看着您并说哦,这里是一个有着成功贡献历史的人,接受了开源库的拉取请求,这是您作品集的一个很好的部分。您可以具体引用它。因此,无论是我是构建 Python 瀑布的人,这是我的存储库,还是我是为 Python 瀑布贡献货币数字格式化的人,这是我的拉取请求。每当您在使用任何开源软件时看到某些不正常的东西,这不是问题,而是一个很好的机会,因为您可以修复它并发送拉取请求。所以试一试。第一次有拉取请求被接受时,感觉真的很棒。当然,一个很大的机会是 fastai 库。由于我们的一位学生,我们现在对fastai.structured库的大部分文档字符串都有了,这也是通过拉取请求完成的。
有人对如何计算这些随机森林解释方法或为什么我们可能想要使用它们有任何问题吗?在本周末,您将需要能够从头开始构建所有这些。
问题:只是看着树解释器,我注意到一些值是nan。我明白为什么要保留它们在树中,但nan如何有特征重要性呢?让我把问题传递给你。为什么不呢?换句话说,Pandas 中如何处理nan,因此在树中呢?有人记得,注意这些都是分类变量,Pandas 如何处理分类变量中的nan,fastai 又是如何处理的?Pandas 将它们设置为-1 类别代码,而 fastai 将所有类别代码加一,因此最终变为零。换句话说,记住,当它到达随机森林时,它只是一个数字,只是零。然后我们将其映射回这里的描述。所以问题实际上是为什么随机森林不能在零上分裂?它只是另一个数字。所以它可以是nan,高,中,低= 0,1,2,3。因此,缺失值是通常教得很糟糕的事情之一。通常人们被教导要删除具有缺失值的列或删除具有缺失值的行,或者替换缺失值。这绝不是我们想要的,因为缺失通常是非常非常有趣的。因此,我们实际上从我们的特征重要性中学到,耦合器系统nan是最重要的特征之一。出于某种原因,嗯,我可以猜测,对吧?耦合器系统nan可能意味着这是一种没有耦合器系统的工业设备。现在我不知道是什么类型,但显然是更昂贵的类型。
我参加了一个为大学拨款研究成功而举办的比赛,迄今为止最重要的预测因素是某些字段是否为空[1:15:41]。结果表明,这是数据泄漏,这些字段大多数情况下只在研究拨款被接受后填写。所以这让我赢得了那个 Kaggle 比赛,但实际上并没有对大学有太大帮助。
外推[1:16:16]
我要做一些冒险和危险的事情,我们将进行一些现场编码。我们要进行一些现场编码的原因是我想和你一起探索外推,我也想让你感受一下在这个笔记本环境中如何快速编写代码。这是你在现实世界和考试中需要做的事情,快速创建我们将要讨论的代码。
每当我尝试调查某事的行为时,我都非常喜欢创建合成数据集,因为如果我有一个合成数据集,我知道它应该如何表现。
提醒我,我们在做这个之前,我承诺我们会谈论交互重要性,我差点忘了。
交互重要性[1:17:24]
树解释器告诉我们基于树中差异的特定行的贡献。我们可以为数据集中的每一行计算这个值并将它们相加。这将告诉我们特征的重要性。它将以不同的方式告诉我们特征的重要性。评估特征重要性的一种方法是逐个对列进行洗牌。另一种方法是为每一行进行树解释并将它们相加。两种方法都没有更正确的一种。它们实际上都被广泛使用,所以这是一种类型 1 和类型 2 的特征重要性。所以我们可以尝试扩展一下。不仅仅是单变量特征重要性,还有交互特征重要性。现在这里有一点。我要描述的东西很容易描述。当随机森林首次被发明时,Breiman 就描述过这个方法,它也是 Salford 系统商业软件产品的一部分,他们拥有随机森林的商标。但我不知道它是任何开源库的一部分,我从来没有看到过一篇真正研究它的学术论文。所以我要在这里描述的是一个巨大的机会,但也像有很多细节需要完善。但这里是基本思想。
这里的这个特定差异(红色)不仅仅是因为 year made,而是因为 year made 和 enclosure 的组合[1:19:15]:

这是 9.7 的原因是因为 enclosure 在这个分支中,year made 在这个分支中。换句话说,我们可以说 enclosure 与 year made 的交互作用是-0.3。
那么 9.5 和 9.4 之间的差异呢?那是 year made 和表计上的小时数的交互作用。我在这里使用星号不是表示“乘”,而是表示“与…交互”。这是一种常见的做法,就像 R 的公式也是这样做的。所以 year made 与表计的交互作用贡献了-0.1。

也许我们还可以说从 10 到 9.4,这也显示了仪表和围栏之间的相互作用,中间有一件事。所以我们可以说仪表与围栏的相互作用等于…应该是多少呢?应该是-0.6 吗?有些方式似乎不公平,因为我们还包括了年份的影响。所以也许应该是-0.6,也许我们应该加回这个 0.2(9.5 → 9.7)。这些都是我实际上不知道答案的细节。我们应该如何最好地为这条路径中的每对变量分配贡献?但从概念上来说,我们可以。该路径中的变量对都代表相互作用。
问题:为什么你不强制它们在树中相邻[1:21:47]?我不会说这是错误的方法。但我不认为这是正确的方法。因为在这条路径中,仪表和围栏是相互作用的。所以似乎不承认这种贡献是在丢弃信息。但我不确定。几年前,我在 Kaggle 的员工中有一个实际上对此进行了一些研发,他们确实发现了(我不够接近知道他们如何处理这些细节),但他们做得相当不错。但不幸的是,它从未成为软件产品问世。但也许你们中的一群人可以聚在一起并构建。做一些搜索来检查,但我真的不认为任何开源库中有任何相互作用特征重要性部分。
问题:但这样会排除那些在相互作用之前并不重要的变量之间的相互作用吗?所以说,如果你的行永远不选择沿着那条路径分裂,但是那个变量与另一个变量的相互作用成为你最重要的分裂。我不认为会发生这种情况。因为如果有一个相互作用是重要的,只是因为它是一个相互作用(而不是在单变量基础上),它有时会出现,假设你将最大特征设置为小于一,因此它会出现在某些路径中。
问题:相互作用是什么意思?是乘法、比率、加法吗?相互作用意味着出现在树的同一路径上。在上面的例子中,由于我们在围栏上分支,然后在年份上分支,所以围栏和年份之间存在相互作用。因此,要达到 9.7,我们必须有某个特定的围栏值和某个特定的年份值。
问题:如果你走在你试图观察的两件事之间的中间叶子上,你也会考虑最终的度量是什么吗?我的意思是,如果我们向下延伸树,你会有很多度量,既包括你试图观察的两件事,也包括中间步骤。似乎有一种方法可以在它们之间平均信息吗?也许有。我认为我们应该在论坛上讨论这个。我觉得这很有趣,希望我们能构建出一些伟大的东西,但我需要进行现场编码。这是一个很好的讨论。继续思考并进行一些实验。
回到现场编码。
因此,为了尝试这个,你几乎肯定想先创建一个合成数据集。就像 y = x1 + x2 + x1*x2 或者其他什么。有一些你知道存在交互效应,有一些你知道不存在交互效应,你想确保最终得到的特征重要性是你期望的。
所以可能第一步是使用树解释器风格的单变量特征重要性。这种方法的一个好处是,你拥有多少数据并不重要。你只需要遍历树来计算特征重要性。所以你应该能够以一种相当快速的方式编写代码,所以即使只用纯 Python 编写,也可能足够快,这取决于你的树的大小。
我们将讨论外推和我想要做的第一件事是创建一个具有简单线性关系的合成数据集。我们将假装它就像一个时间序列。所以我们需要创建一些 x 值。创建这种类型的合成数据的最简单方法是使用linspace,它默认创建 50 个观测值在开始和结束之间均匀分布的数据。


然后我们将创建一个因变量,所以让我们假设 x 和 y 之间存在线性关系,并且让我们添加一点随机性。在低和高之间使用random.uniform,所以我们可以添加-0.2 到 0.2 之间的某个值,例如。

接下来我们需要一个形状,基本上就是你想要这些随机数的维度是什么,显然我们希望它们与x的形状相同。所以我们可以直接说x.shape。

换句话说,(50,)是x.shape。记住,当你看到括号里有逗号的时候,那就是一个只有一个元素的元组。所以这是形状为 50,我们添加了 50 个随机数。现在我们可以绘制这些数值。

好的,这就是我们的数据。当你作为数据科学家工作或在这门课程中做考试时,你需要能够快速地创建一个类似的数据集,将其绘制在图表中而不用考虑太多。正如你所看到的,你不必真的记住太多东西。你只需要知道如何按shift + tab来检查参数的名称,搜索一下,或者尝试找到linspace如果你忘记了它的名字。
所以让我们假设这是我们的数据。我们现在要构建一个随机森林模型,我想要构建一个随机森林模型,让它像一个时间序列一样运行。所以我将左边部分作为训练集。然后将右边部分作为我们的验证或测试集,就像我们在购物或推土机中所做的那样。

我们可以使用与我们在split_vals中使用的完全相同的代码。所以我们可以说:
x_trn, x_val = x[:40], x[40:]
这将数据分为前 40 个和后 10 个。我们可以对 y 做同样的操作。
y_trn, y_val = y[:40], y[40:]
接下来要做的是创建一个随机森林并拟合它,这需要 x 和 y。
m = RandomForestRegressor().fit(x, y)
这实际上会导致错误,原因是它期望 x 是一个矩阵,而不是一个向量,因为它期望 x 有多列数据。
重要的是要知道,只有一列的矩阵和向量不是同一回事。
所以如果我尝试运行这个代码,“预期 2D 数组,实际得到 1D 数组”:

所以我们需要将一维数组转换为二维数组。记住我说过x.shape是(50,)。所以x有一个轴,x 的秩是 1。变量的秩等于它的形状的长度 - 它有多少个轴。我们可以将向量看作是秩为 1 的数组,将矩阵看作是秩为 2 的数组。我很少使用向量和矩阵这样的词,因为它们有点毫无意义 - 它们只是更一般的东西的具体例子,它们都是 N 维张量或 N 维数组。所以 N 维数组可以说是秩为 N 的张量。它们基本上意味着相同的事情。物理学家听到这个会很疯狂,因为对于物理学家来说,张量有一个非常具体的含义,但在机器学习中,我们通常以相同的方式使用它。
那么我们如何将一维数组转换为二维数组。我们可以这样做的方法有几种,但基本上我们是切片。冒号(:)表示给我在那个轴上的所有东西。:, None表示给我第一个轴上的所有东西(这是我们唯一拥有的轴),然后None是一个特殊的索引器,表示在这里添加一个单位轴。所以让我给你看看。

它的形状是(50, 1),所以它是秩为 2 的。它有两个轴。其中一个是一个非常无聊的轴 - 它是一个长度为一的轴。所以让我们将None移到左边。这是(1, 50)。然后提醒你,原始的是(50,)。

所以你可以看到我可以将None作为一个特殊的索引器放在那里引入一个新的单位轴。x[None, :]有一行和五十列。x[:, None]有五十行和一列 - 这就是我们想要的。在这门课程和深度学习课程中,这种对秩和维度的玩耍将变得越来越重要。所以花很多时间用 None 切片,用其他东西切片,尝试创建三维、四维张量等。我会向你展示两个技巧。
第一个是你永远不需要写,:,因为它总是被假定的。所以这些是完全相同的:

你会在代码中一直看到这样的写法,所以你需要认识到它。
第二个技巧是x[:, None]是在第二维度(或我猜是索引 1 维度)添加一个轴。如果我总是想把它放在最后一个维度怎么办?通常我们的张量在我们不注意的情况下改变维度,因为你从一个单通道图像变成了一个三通道图像,或者你从一个单个图像变成了一个图像的小批量。突然之间,新的维度出现了。所以为了让事情更一般化,我会说...,这意味着你需要多少维度来填充这个。所以在这种情况下(x[…, None].shape),它是完全相同的,但我总是尝试以这种方式写,因为这意味着当我得到更高维度的张量时,它将继续工作。
所以在这种情况下,我想要 50 行和一列,所以我会称之为 x1。现在让我们在这里使用它,这样就是一个二维数组,所以我可以创建我的随机森林。

然后我可以绘制出来,这就是你需要打开大脑的地方,因为今天早上的人们非常快地理解了这一点,这是非常令人印象深刻的。我将绘制y_trn与m.predict(x_trn)。在我开始之前,这会是什么样子?它应该基本上是一样的。我们的预测希望与实际相同。所以这应该落在一条线上,但有一些随机性,所以不会完全相同。

那是容易的。现在让我们做困难的,有趣的那个。那会是什么样子?

想想树的作用,想想右边有一个验证集,左边有一个训练集:

所以想想森林只是一堆树。
Tim: 我猜测由于所有新数据实际上都在原始范围之外,所以它们基本上都是一样的 - 就像一个巨大的群体。
Jeremy: 是的,对。所以忘掉森林,让我们创建一棵树。所以我们可能首先在这里分裂,然后在这里分裂,… 所以我们的最终分裂是最右边的节点。当我们从验证集中取一个时,它会将其通过森林,最终预测最右边的平均值。它无法预测比那更高的任何东西,因为没有更高的东西可以平均。

因此,要意识到随机森林并不是魔法。它只是返回附近观察值的平均值,其中附近在这种“树空间”中。所以让我们运行它,看看 Tim 是不是对的。

天啊,太糟糕了。如果你不知道随机森林是如何工作的,那么这将完全搞砸你。如果你认为它实际上能够对任何它以前没有见过的数据进行外推,尤其是未来的时间段,那就错了。它只是无法做到。它只是对它已经看到的东西进行平均。这就是它能做的全部。
好的,我们将讨论如何避免这个问题。在上一课中,我们稍微谈到通过避免不必要的时间相关变量来避免这个问题。但最终,如果你真的有一个看起来像这样的时间序列,我们实际上必须处理一个问题。我们可以处理这个问题的一种方法是使用神经网络。使用一些实际上具有可以拟合这样的函数或形状的东西,这样它将可以很好地外推:

另一种方法是使用你们在早上课上学到的所有时间序列技术来拟合某种时间序列,然后去趋势化。然后你会得到去趋势化的点,然后使用随机森林来预测这些点。这特别酷,因为想象一下你的随机森林实际上试图预测两种不同状态的数据。所以蓝色的在下面,红色的在上面。

如果你尝试使用随机森林,它将做得相当糟糕,因为时间看起来更加重要。所以它基本上仍然会像这样分裂,然后像那样分裂,最终一旦到达左下角,它会像“哦,好吧,现在我可以看到两种状态之间的差异了。”

换句话说,当你有这么大的时间序列时,直到每棵树都处理时间,你才能看到随机森林中的其他关系。因此,解决这个问题的一种方法是使用梯度提升机(GBM)。GBM 的作用是创建一棵小树,然后通过第一棵小树运行所有内容(可能是时间树),然后计算残差,下一棵小树只是预测残差。所以这有点像去趋势化,对吧?GBM 仍然无法对未来进行外推,但至少它们可以更方便地处理时间相关数据。
在接下来的几周里,我们将更多地讨论这个问题,最终的解决方案将是使用神经网络。但是现在,使用某种时间序列分析,去趋势化,然后在随机森林上使用它并不是一种坏技术。如果你在玩类似厄瓜多尔杂货竞赛之类的东西,那将是一个非常好的东西来尝试。
机器学习 1:第 7 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-7-69c50bc5e9af译者:飞龙
协议:CC BY-NC-SA 4.0
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
视频
我们将完成从头开始构建我们自己的随机森林!但在此之前,我想解决一些在这一周中出现的问题。
随机森林在一般情况下的位置
我们大约花了一半的课程时间来讲解随机森林,然后在今天之后,这门课程的第二半将广义地讲解神经网络。这是因为这两者代表了覆盖几乎所有你可能需要做的技术的两个关键类别。随机森林属于决策树集成技术类别,与梯度提升机是另一种关键类型,还有一些变体,比如极端随机树。它们的好处是它们非常易解释,可扩展,灵活,适用于大多数类型的数据。它们的缺点是它们完全不会对超出你所见范围的数据进行外推,就像我们在上周课程结束时看到的那样。但它们是一个很好的起点。我认为有很多机器学习工具的目录,很多课程和书籍并没有试图筛选出来,说对于这些问题,使用这个,对于那些问题,使用那个,完了。但它们更像是这里有 100 种不同算法的描述,而你根本不需要它们。比如,我不明白为什么今天你会使用支持向量机。我想不出任何理由去做那样的事情。人们在 90 年代喜欢研究它们,因为它们在理论上非常优雅,你可以写很多关于支持向量机的数学,人们确实这样做了,但实际上我认为它们没有任何用武之地。
在详尽的列表中,有很多技术可以包括在人们采用机器学习问题的每一种方式中,但我更愿意告诉你如何实际解决机器学习问题。我们即将结束今天的第一堂课,这是一种决策树集成的一种类型,在第二部分,Yanett 将告诉你另一种关键类型,即梯度提升,我们即将启动下一课程,介绍神经网络,其中包括各种广义线性模型(GLM)、岭回归、弹性网络套索、逻辑回归等都是神经网络的变体。
有趣的是,创造随机森林的 Leo Breiman 在他的晚年才做出了这一成就,不幸的是,他在之后不久就去世了。因此,关于随机森林的学术文献很少,部分原因是因为在那个时候支持向量机(SVM)开始流行,其他人没有关注它们。另一个原因是随机森林在理论层面上相当难以理解(在理论上分析它们),很难撰写关于它们的会议论文或学术论文。因此,关于它们的研究并不多。但近年来出现了一股新的经验机器学习浪潮,关注的是什么实际上有效。Kaggle 是其中的一部分,但也有像亚马逊和谷歌这样的公司利用机器学习赚取大量利润。因此,如今很多人都在写关于决策树集成的文章,并为决策树集成创建更好的软件,如 GBM 和 xgboost,以及 R 的 ranger 和 scikit-learn 等等。但很多这方面的工作是在工业界而不是学术界进行的,但这是令人鼓舞的。当然,目前在学术界进行的深度学习工作比决策树集成要多,但两者都在取得很大进展。如果看看今天用于决策树集成的软件包,排名前五或六名的最好的软件包,我不确定其中有哪个在五年前真的存在,也许除了 sklearn 之外,甚至三年前也没有。这是一个好的现象。但我认为还有很多工作要做。比如,上周我们讨论了找出哪些交互作用最重要的问题。你们中一些人在论坛中指出,实际上已经有一个梯度提升机的项目,这很棒,但似乎还没有类似的项目用于随机森林。随机森林相比 GBM 有一个很好的优势,那就是它们更难出错,更容易扩展。因此,希望这个社区可以帮助解决这个问题。
您的验证集大小 [5:42]
另一个我在这周期间遇到的问题是关于验证集的大小。它应该有多大呢?所以要回答这个关于验证集需要多大的问题,你首先需要回答这个算法的准确度我需要知道多精确。如果你的验证集显示这是 70%的准确率,如果有人问说,那是 75%还是 65%还是 70%,答案是“我不知道,这个范围内的任何值都足够接近”,那就是一个答案。另一方面,如果是 70%还是 70.01%还是 69.99%呢?那又是另一回事了。所以你需要先问自己,我需要多准确。
例如,在深度学习课程中,我们一直在研究狗和猫的图像,我们所研究的模型在验证集上的准确率大约为 99.4%,99.5%。验证集的大小为 2000。实际上,让我们在 Excel 中做这个,这会更容易一些。因此,错误的数量大约是(1 - 准确率) * n。

所以我们大约有 12 只错误。我们拥有的猫的数量是一半,所以错误的猫的数量大约是 6 只。然后我们运行了一个新模型,发现准确率提高到了 99.2%。然后就像,好吧,这个模型在找猫方面是否不太好?嗯,它多找错了 2 只猫,所以可能不是。这重要吗?99.4 和 99.2 有关系吗?如果不是关于猫和狗,而是关于发现欺诈,那么 0.6%的错误率和 0.8%的错误率之间的差异就相当于欺诈成本的 25%,这可能是巨大的。
今年早些时候,ImageNet 发布时真的很有趣,新的竞赛结果出来了,错误率从 3%降到了 2%,我看到很多人在互联网上,一些著名的机器学习研究人员都觉得,一些中国人把准确率从 97%提高到了 98% —— 这在统计上甚至不重要,谁在乎呢。但实际上我觉得哇塞,这支中国团队刚刚超越了最先进的图像识别技术,旧技术的准确率比新技术低了 50%。这才是正确的思考方式,不是吗。因为我们试图识别哪些西红柿是成熟的,哪些不是,而旧方法,有 50%的时间多让进了未成熟的西红柿,或者说有 50%的时间,我们接受了欺诈性的客户。这是一个非常大的差异。所以仅仅因为这个特定的验证集,我们看不出 6 和 8 的区别,并不意味着 0.2%的差异不重要。它可能很重要。所以我的经验法则是,你实际上看了多少观察值,我希望这个数字通常要高于 22。为什么是 22?因为 22 是 t-分布大致变成正态分布的魔法数字。所以你可能已经学过,t-分布是小数据集的正态分布。换句话说,一旦我们有了 22 个或更多的东西,它开始在两个意义上表现得有点正常,就像它更加稳定,你可以更好地理解它。所以当有人问我是否有足够的东西时,我通常会说你是否有 22 个感兴趣的事物的观察值。所以如果你在研究肺癌,你有一个数据集,其中有一千个没有肺癌的人和 20 个患有肺癌的人,我会说我非常怀疑我们会取得多少进展,因为我们甚至没有得到你想要的 20 个东西。同样适用于验证集。如果你没有你想要的 20 个东西,那很可能是没有用的,或者说不符合我们需要的准确度水平。这不是加减 20,只是我在考虑时会有点小心。
问题:所以清楚一点,你想要每组样本的数量是 22,就像在验证集、测试集和训练集中一样吗?所以我的意思是,如果任何一组中某个类别的样本少于 22 个,那么在那一点上就会变得非常不稳定。这就像是第一个经验法则。但接下来我会开始练习我们学到的关于二项分布或伯努利分布的知识。那么 n 个样本和概率 p 的二项分布的均值是多少?n*p。n 乘以 p 就是均值。所以如果你有 50%的机会抛硬币得到正面,你抛 100 次,平均得到 50 次正面。那么标准差是多少?n*p*(1-p)。

所以第一个数字你不必记住——这是直观明显的。第二个数字是一个你要永远记住的数字,因为它不仅经常出现,你与之合作的人都会忘记,所以你会成为对话中唯一能立即说出“我们不必运行这个 100 次,我可以立即告诉你这是二项式,它将是n*p*(1-p)的人。
然后是标准误差。标准误差是指如果你运行一堆试验,每次得到一个平均值,那么平均值的标准偏差是多少。我不认为你们已经涵盖了这个内容。这是非常重要的,因为这意味着如果你训练了一百个模型,每次验证集的准确率就像是一个分布的平均值。因此,验证集准确率的标准偏差可以用标准误差来计算,这等于标准偏差除以 n 的平方根。

因此,确定我的验证集是否足够大的一种方法是,每次使用完全相同的超参数训练模型 5 次,然后查看每次的验证集准确率,可以计算出 5 个数字的平均值和标准差,或者可以使用最大值和最小值。但为了节省时间,您可以立即确定,我有一个 0.99 的准确率,无论我是否正确地识别了猫。因此,标准差等于 0.99 * 0.01,然后可以得到标准误差。因此,您需要的验证集大小,就像它必须足够大,以便您对准确性的洞察对于您特定的业务问题足够好。因此,简单的方法是选择一个大小为一千的验证集,训练 5 个模型,查看验证集准确率的变化情况,如果它们都足够接近您所需的水平,那么就可以了。如果不是,也许您应该使其更大,或者考虑改用交叉验证。因此,可以看到,这取决于您试图做什么,您的较不常见类别有多常见,以及您的模型有多准确。
问题:关于较少常见的类别,如果你少于 22 个,比如你有一个样本,比如是一个脸,我只有一个来自那个特定国家的代表,我是把它放入训练集并增加多样性,还是完全从数据集中删除,或者我把它放入测试集而不是验证集?所以你肯定不能把它放入测试集或验证集,因为你在问我能否识别我以前从未见过的东西。但实际上,关于我能否识别我以前从未见过的东西,实际上有一个专门用于这个目的的模型类别——它被称为一次性学习,你只能看到一次东西,然后必须再次识别它,或者零次学习,你必须识别你以前从未见过的东西。我们在本课程中不会涵盖它们,但它们对于像人脸识别这样的事情可能会有用,比如这是我以前见过的同一个人吗。所以一般来说,显然,为了使这样的事情起作用,不是你以前从未见过一个脸,而是你以前从未见过 Melissa 的脸。所以你看到 Melissa 的脸一次,然后你必须再次识别它。所以一般来说,你的验证集和测试集需要具有与你将在实际生产中看到的观察频率相同的混合或频率。你的训练集应该每个类别有相等数量,如果没有,只需复制较少常见的类别直到相等。我想我们之前提到过这篇论文,一篇最近发表的论文,他们尝试了许多不同的方法来训练不平衡的数据集,并一直发现,直到较少常见的类别与较常见的类别大小相同为止,过采样较少常见的类别总是正确的做法。所以你可以简单地复制,比如我只有十个患癌症的人的例子,而没有百个,所以我可以再复制这 10 个另外 90 次,这在一定程度上是一种内存效率低下的方式,包括我认为 sklearn 的随机森林有一个类别权重参数,每次你进行自助抽样或重新采样时,我希望你以更高的概率对较少常见的类别进行抽样。或者如果你正在进行深度学习,确保在你的小批量中,不是随机抽样,而是较少常见的类别的分层样本更频繁地被选中。
回到完成随机森林的部分 18:39
笔记本
让我们回到完成随机森林的工作。今天我们要做的是完成编写我们的随机森林,然后在今天之后,你的作业就是拿这节课并添加我们学到的所有随机森林解释算法。显然,为了能够做到这一点,你需要完全理解这节课的工作原理,所以在我们进行时,请尽可能多地提问。提醒一下,我们再次使用推土机 Kaggle 竞赛数据集。我们将其分为 12,000 个验证集(最后 12,000 条记录),为了更容易跟踪我们的工作,我们将从中挑选两列开始:YearMade和MachineHoursCurrentMeter。
from fastai.imports import *
from fastai.structured import *
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from IPython.display import display
from sklearn import metrics
PATH = "data/bulldozers/"df_raw = pd.read_feather('tmp/bulldozers-raw')
df_trn, y_trn, nas = proc_df(df_raw, 'SalePrice')
def split_vals(a,n): return a[:n], a[n:]
n_valid = 12000
n_trn = len(df_trn)-n_valid
X_train, X_valid = split_vals(df_trn, n_trn)
y_train, y_valid = split_vals(y_trn, n_trn)
raw_train, raw_valid = split_vals(df_raw, n_trn)
x_sub = X_train[['YearMade', 'MachineHoursCurrentMeter']]
上次我们做的是创建了一个树集合,这个树集合包含了一堆树,实际上是一个包含n_trees棵树的列表,每次我们只是调用create_tree。create_tree包含了一个样本大小(sample_sz)的随机索引(rnd_idxs)。这里是无重复抽样。所以记住,自助法意味着有放回抽样。通常在 scikit-learn 中,如果有 n 行数据,我们用有放回抽样抽取 n 行数据,这意味着很多行会出现多次。所以每次我们得到一个不同的样本,但它的大小总是与原始数据集相同。然后我们有一个set_rf_samples函数,我们可以使用它进行少于 n 行的有放回抽样。create_tree再次做的是无重复抽样sample_sz行。因为我们对从零到self.y-1的数字进行排列,然后抽取其中的前self.sample_sz个。实际上有一种更快的方法可以做到这一点。你可以直接使用np.random.choice(而不是np.random.permutation),这是一种稍微更直接的方法,但这种方法也可以。所以rnd_idxs是我们n_trees棵树中的一个的随机样本。然后我们将创建一个DecisionTree。我们的决策树,我们不会传递所有的x,而是传递这些特定的索引,记住 x 是一个 Pandas DataFrame,所以如果我们想用一堆整数对其进行索引,我们使用iloc(整数位置),这使得它在索引方面的行为就像 numpy 一样。现在y向量是 numpy,所以我们可以直接对其进行索引。然后我们将跟踪最小叶子大小(min_leaf)。
class TreeEnsemble():def __init__(self, x, y, n_trees, sample_sz, min_leaf=5):np.random.seed(42)self.x,self.y,self.sample_sz,self.min_leaf = x,y,sample_sz,min_leafself.trees = [self.create_tree() for i in range(n_trees)]def create_tree(self):rnd_idxs = np.random.permutation(len(self.y))[:self.sample_sz]return DecisionTree(self.x.iloc[rnd_idxs], self.y[rnd_idxs],min_leaf=self.min_leaf)
然后在集成中我们真正需要的另一件事情就是一个地方来进行预测。因此我们只需要对每棵树的预测取平均值。就是这样。
def predict(self, x):return np.mean([t.predict(x) for t in self.trees], axis=0)
class DecisionTree():def __init__(self, x, y, idxs=None, min_leaf=5):self.x,self.y,self.idxs,self.min_leaf = x,y,idxs,min_leafm = TreeEnsemble(X_train, y_train, n_trees=10, sample_sz=1000, min_leaf=3)
然后为了能够运行它,我们需要一个决策树类,因为它被create_tree调用。所以我们开始吧。这就是起点。接下来我们需要做的是完善我们的决策树。所要记住的重要一点是我们所有的随机性都发生在TreeEnsemble中。我们将要创建的 DecisionTree 类中没有随机性。
问题:现在我们正在构建一个随机树回归器,这就是为什么我们要取树输出的平均值。如果我们要处理分类,我们要取最大值吗?就像分类器会给你零或一[22:36]?不,我仍然会取平均值。因此,每棵树都会告诉你叶节点中包含猫的百分比和包含狗的百分比。然后我会平均所有这些百分比,并说在所有树上平均,有 19%的猫和 81%的狗。
随机树分类器几乎与随机树回归器相同,或者几乎可以相同。我们今天要使用的技术基本上完全适用于分类。对于二元分类,您可以使用完全相同的代码。对于多类分类,您只需要更改数据结构,使其像一个独热编码矩阵或一个整数列表,您将其视为一个独热编码矩阵。
所以我们的决策树,记住,我们的想法是我们要尽量避免思考,所以我们基本上会写成如果我们需要的一切已经存在的样子。我们知道当我们创建决策树时,我们将传入 x、y 和最小叶子大小。所以在这里我们需要确保在__init__中有x、y和min_leaf。还有一件事是,当我们将树分割成子树时,我们需要跟踪哪些行索引进入了树的左侧,哪些进入了树的右侧。所以我们还会有一个叫做idxs的东西。起初,我们根本不费心传入idxs,所以如果没有传入idxs(即if idxs is None),那么我们就会将其设置为 y 的整个长度。np.arange在 Python 中与range相同,但它返回一个 numpy 数组。所以决策树的根包含所有行。这实际上就是决策树根的定义(第 0 行,第 1 行,直到第 y-1 行)。我们将存储我们得到的所有信息。我们将跟踪有多少行,有多少列。
然后树中的每个叶子和每个节点都有一个值/预测。该预测只是等于因变量的平均值。因此,树中的每个节点,用idxs索引的y是在树的这一分支中的因变量的值,因此这里是平均值。树中的一些节点还有一个分数,这就像这里的分割有多有效。但只有在它不是叶子节点时才会成立。叶子节点没有进一步的分割。在创建树时,我们还没有进行任何分割,因此其分数开始时为无穷大。构建了树的根节点后,我们的下一个任务是找出应该在哪个变量上进行分割,以及应该在该变量的哪个水平上进行分割。因此,让我们假设有一个可以做到这一点的东西——find_varsplit。然后我们就完成了。
class DecisionTree():def __init__(self, x, y, idxs=None, min_leaf=5):if idxs is None: idxs=np.arange(len(y))self.x,self.y,self.idxs,self.min_leaf = x,y,idxs,min_leafself.n,self.c = len(idxs), x.shape[1]self.val = np.mean(y[idxs])self.score = float('inf')self.find_varsplit()
那么我们如何找到一个变量来分割呢?嗯,我们可以逐个检查每个潜在的变量,所以c包含我们拥有的列数,逐个检查并查看是否能在该列上找到比目前更好的分割。现在请注意,这并不是完整的随机森林定义。这是假设最大特征被设置为全部的情况。请记住,我们可以将最大特征设置为 0.5,这样我们就不会检查从零到c的所有数字,而是会随机检查从零到c的一半数字。因此,如果您想将其转换为支持最大特征的随机森林,您可以轻松添加一行代码来实现。但是在我们今天的实现中,我们不打算这样做。因此,我们只需要找到更好的分割点,由于我们目前不感兴趣,所以现在我们将其留空。
# This just does one decision; we'll make it recursive laterdef find_varsplit(self):for i in range(self.c): self.find_better_split(i)# We'll write this later!def find_better_split(self, var_idx): pass@propertydef split_name(self): return self.x.columns[self.var_idx]@propertydef split_col(self): return self.x.values[self.idxs,self.var_idx]@propertydef is_leaf(self): return self.score == float('inf')def __repr__(self):s = f'n: {self.n}; val:{self.val}'if not self.is_leaf:s += f'; score:{self.score}; split:{self.split}; var: {self.split_name}'return s
在开始编写一个类时,我喜欢做的另一件事是,我想要有一种方法来打印出该类中的内容。如果你输入 print,后面跟着一个对象,或者在 Jupyter Notebook 中,你只需输入对象的名称。目前,它只是打印出<__main__.DecisionTree at 0x7f645ec22358>,这并不是很有帮助。所以如果我们想要用有用的东西来替换它,我们必须定义一个特殊的 Python 方法,名为__repr__,以获得这个对象的表示。所以当我们在 Jupyter Notebook 单元格中基本上只写出名称时,在幕后,它调用那个函数,而该方法的默认实现只是打印出那些无用的东西。所以我们可以替换它,而不是说让我们创建一个格式化字符串,在这里我们将打印出f'n: **{self.n}**; val:**{self.val}'**,所以这个节点中有多少行,以及因变量的平均值是多少。然后,如果它不是叶节点,也就是说如果它有一个分裂,那么我们还应该能够打印出分数,我们分裂出的值,以及我们分裂的变量。现在你会注意到这里,self.is_leaf被定义为一个方法,但我后面没有加括号。这是一种特殊类型的方法,称为属性。属性看起来像一个普通的变量,但实际上是动态计算的。所以当我调用is_leaf时,实际上调用的是**def** is_leaf(self)函数。但我有这个特殊的装饰器@property。这意味着当你调用它时,你不必包括括号。所以它会说这是一个叶子还是不是。所以叶子是我们不分裂的东西。如果我们没有对它进行分裂,那么它的分数仍然设置为无穷大,这就是我的逻辑。
这个@符号被称为装饰器。基本上是告诉 Python 关于你的方法的更多信息的一种方式。任何之前使用过像 Flask 或类似框架进行过 web 编程的人都必须声明这个方法将响应 URL 的这一部分,要么是 POST,要么是 GET,并将其放在一个特殊的装饰器中。在幕后,这告诉 Python 以一种特殊的方式处理这个方法。所以@property是另一个装饰器。如果你在 Python 中变得更加高级,你实际上可以学习如何编写自己的装饰器,就像之前提到的那样,基本上插入一些额外的代码,但现在只需要知道有一堆预定义的装饰器可以用来改变我们的方法的行为,其中之一就是@property,这基本上意味着你不再需要加括号,当然这意味着你不能再添加任何参数了,只能是self。
问题:如果分数是无穷大,为什么它是叶子?无穷大不是意味着你在根节点吗?不,无穷大意味着你不在根节点。它意味着你在叶子节点。所以根节点将会有一个分裂,假设我们找到一个。一切都会分裂,直到我们到达底部(即叶子节点),所以叶子节点的分数将是无穷大,因为它们不会分裂。
m = TreeEnsemble(X_train, y_train, n_trees=10, sample_sz=1000,min_leaf=3
)
m.trees[0]
'''
n: 1000; val:10.079014121552744
'''
这就是我们的决策树。它并没有做太多事情,但至少我们可以创建一个集成。10 棵树,样本量为 1,000,我们可以打印出来。现在当我们输入m.trees[0]时,它不会显示<__main__.DecisionTree at 0x7f645ec22358>,而是显示我们要求它显示的内容。这是叶子节点,因为我们还没有在其上进行分割,所以我们没有更多要说的。
然后索引是,所有从零到一千的数字,因为树的基础包含了一切。这是随机样本中的所有内容,因为当我们到达决策树的时候,我们不再需要担心随机森林中的任何随机性。
给定变量找到最佳分割点
让我们尝试编写找到分割点的函数。因此,我们需要实现find_better_split。它将接受一个变量的索引,并找出最佳的分割点,确定它是否比我们目前为止的任何分割更好,对于第一个变量,答案总是肯定的,因为到目前为止最好的分割点是没有分割,这是无穷糟糕的。
所以让我们首先确保我们有东西可以进行比较。我们要进行比较的是 scikit-learn 的随机森林。我们需要确保 scikit-learn 的随机森林获得与我们完全相同的数据,因此我们首先创建集成,从中提取一棵树,然后找出这棵树使用了哪个特定的随机样本x和y,然后将它们存储起来,以便我们可以将它们传递给 scikit-learn(这样我们就有完全相同的信息)。
ens = TreeEnsemble(x_sub, y_train, 1, 1000)
tree = ens.trees[0]
x_samp,y_samp = tree.x, tree.y
所以让我们继续使用 scikit-learn 创建一个随机森林。一个树(n_estimators),一个决策(max_depth),没有自助采样,所以整个数据集。所以这应该与我们即将创建的东西完全相同。让我们试试看。
m = RandomForestRegressor(n_estimators=1, max_depth=1,bootstrap=False
)
m.fit(x_samp, y_samp)
draw_tree(m.estimators_[0], x_samp, precision=2)

我们需要定义find_better_split函数,并且它需要一个变量。让我们定义我们的x(即自变量),说好,它是树中的所有内容,但只有在这个节点中的那些索引,而在树的顶部是所有内容,只有这一个变量(var_idx)。然后对于我们的y,它就是在这个节点中的索引处的因变量。所以这就是我们的x和y。
让我们现在逐个检查我们独立变量中的每个值。我会告诉你接下来会发生什么。假设我们的独立变量是 YearMade,它不会按顺序排列。所以我们要去到第一行,然后说好,这里的 YearMade 是 3。那么我要做的是尝试计算如果我们决定以数字 3 为分支时的得分。我需要知道哪些行大于 3,哪些行小于或等于 3,它们将成为我的左侧和右侧。然后我们需要一个得分。我们可以使用很多得分,所以在随机森林中,我们称之为信息增益。信息增益就像我们的得分因为我们将数据分成这两组而变得更好了多少。我们可以用很多方法来计算它:基尼系数、交叉熵、均方根误差等等。如果你考虑一下,有一个均方根误差的替代公式,数学上与一个约束尺度内相同,但稍微容易处理一些,那就是我们要找到一个分割点,使得这两组数据的标准差尽可能低。所以我想找到一个分割点,把所有的猫放在这边,所有的狗放在那边。所以如果这些都是猫,那些都是狗,那么这边的标准差为零,那边的标准差也为零。否则,这是一群完全随机混合的猫和狗,那是一群完全随机混合的猫和狗,它们的标准差会高得多。明白了吗?事实证明,如果找到一个最小化这两组标准差或者具体来说是两个标准差的加权平均的分割点,数学上与最小化均方根误差是相同的。如果你想的话,课后你可以自己证明这一点。

首先,我们需要找到,将其分成两组[37:29]。那么所有大于三的东西在哪里?4、6 和 4。所以我们需要它们价格的标准差。

接下来是标准差小于或等于 3,我们只需取这两者的加权平均值,这就是我们的得分。如果我们在 3 上分割,那就是我们的得分。

然后下一步是尝试在 4 上分割,尝试在 1 上分割,尝试在 6 上分割,多余地再次尝试在 4 上分割,然后再次在 1 上分割,找出哪个效果最好。这就是我们的代码:
def find_better_split(self, var_idx):x,y = self.x.values[self.idxs,var_idx], self.y[self.idxs] for i in range(1,self.n-1):lhs = x<=x[i]rhs = x>x[i]if rhs.sum()==0: continuelhs_std = y[lhs].std()rhs_std = y[rhs].std()curr_score = lhs_std*lhs.sum() + rhs_std*rhs.sum()if curr_score<self.score: self.var_idx,self.score,self.split = var_idx,curr_score,x[i]
我们将逐行进行,假设左侧是x中小于或等于特定值的任何值。右侧是x中大于此特定值的每个值。
lhs 和 rhs 中将包含什么数据类型?它们实际上会包含什么?它们将是布尔数组,我们可以将其视为零和一。因此,lhs 将是一个数组,每次它不小于或等于时为 false;否则为 true,而 rhs 将是相反的布尔数组。现在我们不能对空集合取标准差,所以如果没有任何大于这个数字 (x[i]) 的值,那么 rhs 将全部为 false,这意味着总和为零。在这种情况下,让我们不再继续这一步,因为没有什么可以取标准差,显然这不是一个有用的分割。
假设我们已经走到这一步,现在我们可以计算左侧和右侧的标准差,然后取加权平均值或求和,这两者对于一个标量来说是相同的,因此这就是我们的得分。然后我们可以检查这个得分是否比迄今为止的最佳得分更好,我们迄今为止的最佳得分,最初将其初始化为无穷大,因此最初这是更好的。如果更好,让我们存储所有我们需要的信息:哪个变量找到了这个更好的分割,我们找到的得分是多少,以及我们分割的值是多少。就是这样。如果我们运行这个,并且我正在使用%timeit,它会看这个命令运行需要多长时间,并试图给出一个统计上有效的度量,这样你就可以看到,它已经运行了 10 次以获得平均值,然后又运行了 7 次以获得运行间的平均值和标准差,所以它花了我 76 毫秒加减 11。
%timeit find_better_split(tree,1)
tree
'''
76.6 ms ± 11.8 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
n: 1000; val:10.079014121552744; score:681.0184057251435; split:3744.0; var:MachineHoursCurrentMeter
'''
所以让我们来检查这是否有效。find_better_split(tree, 0),0 代表YearMade,1 代表MachineHoursCurrentMeter,所以当我们用 1 时,我们得到了MachineHoursCurrentMeter,得分为 681.0184057251435,然后我们再次用零运行,得到了更好的分数(658),并分割了 1974。
find_better_split(tree,0); tree
'''
n: 1000; val:10.079014121552744; score:658.5510186055949; split:1974.0; var:YearMade
'''
所以 1974 年,让我们与上面的 scikit-learn 的随机森林进行比较,是的,这棵树也是这样做的。所以我们确认了这种方法给出了与 sklearn 的随机森林相同的结果。你还可以在这里看到值 10.08 与 sklearn 的根节点的值匹配。所以我们有了一个可以处理一个分割的东西。

问题:为什么我们不在 x 上放一个 unique?因为我还没有尝试优化性能。你可以在 Excel 中看到我检查了这个1两次,4两次,这是不必要的。
好的,Yannet 已经在考虑性能,这是好事。那告诉我这段代码的计算复杂度是多少?
{kind=link}
O(n²) 是因为有一个循环和 x<=x[i],我们必须检查每个值,看它是否小于 x[i]。了解如何快速计算计算复杂度是很有用的。我可以保证你做的大多数面试都会要求你即兴计算计算复杂度。而且当你编码时,你希望它成为第二天性。这种技巧基本上是“有循环吗?”如果有,那么显然我们要做这个 n 次,所以涉及到一个 n。循环里面还有循环吗?如果有,那么你需要将它们两个相乘。在这种情况下,没有。循环里面有任何不是常数时间操作的东西吗?所以你可能会看到一个排序在里面,你只需要知道排序是 nlog(n) —— 这应该是第二天性的。如果你看到一个矩阵相乘,你需要知道那是什么。在这种情况下,有一些东西在进行逐元素数组操作,所以要留意任何地方,numpy 在对数组的每个值做一些操作。在这种情况下,它正在检查每个 x 的值是否小于一个常数,所以它将不得不这样做 n 次。所以要将这个扩展成一个计算复杂度,你只需要将循环中的事物数量乘以循环内部的最高计算复杂度,n 次 n 是 n²。
问题:在这种情况下,我们不能只是预先对列表进行排序,然后进行一次nlog(n)的计算吗?有很多事情可以做来加快速度,所以在这个阶段我们只关心的是计算复杂度。但绝对可以。当然,它肯定不是最好的。所以接下来我们要做的就是这个。就像好吧,n²不太好,所以让我们试着让它变得更好。
所以这是我尝试改进的地方。首先,标准差的方程式是什么?

实际上,我们通常不使用那个公式,因为它要求我们多次计算x减去平均值。有谁知道只需要 x 和 x²的公式吗?

www.wolframalpha.com/input/?i=standard+deviation
这是一个非常好的知识点,因为现在你可以计算任何东西的方差或标准偏差。你只需要首先抓取列本身。列的平方。只要你把它们存储在某个地方,你就可以立即计算标准偏差。
所以这对我们有用的原因是,如果我们首先对我们的数据进行排序。然后如果你考虑一下,当我们一步一步地向下走时,每一组都与左边的前一组完全相同,只是多了一件东西,右边则少了一件东西。因此,我们只需要跟踪 x 的总和和 x²的总和,我们只需在左边添加一个东西,x²再添加一个东西,在右边移除一个东西。因此,我们不必每次都遍历整个数据集,因此我们可以将其转化为 O(n)算法。这就是我在这里所做的一切:
tree = TreeEnsemble(x_sub, y_train, 1, 1000).trees[0]
def std_agg(cnt, s1, s2): return math.sqrt((s2/cnt) - (s1/cnt)**2)def find_better_split_foo(self, var_idx):x,y = self.x.values[self.idxs,var_idx], self.y[self.idxs]sort_idx = np.argsort(x)sort_y,sort_x = y[sort_idx], x[sort_idx]rhs_cnt,rhs_sum,rhs_sum2 = self.n, sort_y.sum(), (sort_y**2).sum()lhs_cnt,lhs_sum,lhs_sum2 = 0,0.,0.for i in range(0,self.n-self.min_leaf-1):xi,yi = sort_x[i],sort_y[i]lhs_cnt += 1; rhs_cnt -= 1lhs_sum += yi; rhs_sum -= yilhs_sum2 += yi**2; rhs_sum2 -= yi**2if i<self.min_leaf or xi==sort_x[i+1]:continuelhs_std = std_agg(lhs_cnt, lhs_sum, lhs_sum2)rhs_std = std_agg(rhs_cnt, rhs_sum, rhs_sum2)curr_score = lhs_std*lhs_cnt + rhs_std*rhs_cntif curr_score<self.score: self.var_idx,self.score,self.split = var_idx,curr_score,xi
我对数据进行排序,然后我会跟踪右侧的事物数量(rhs_cnt),右侧事物的总和(rhs_sum)和右侧的平方和(rhs_sum2)。最初所有事物都在右侧。因此最初n是计数,y.sum()是右侧的总和,y²(y**2)的总和是右侧的平方和。然后最初左侧没有任何事物,因此为零。然后我们只需要循环遍历每个观察值:
-
左手计数加一,右手计数减一。
-
将值加到左手总和,从右手总和减去。
-
将值的平方加到左手,从右手减去。
现在我们需要小心,因为如果我们说小于或等于一,例如,我们不会停在第一行,而是必须将该组中的所有内容都包括在内。

所以我要做的另一件事是确保下一个值不同于这个值。如果是的话,我会跳过它。所以我只是要再次检查这个值和下一个值不相同(**if** xi==sort_x[i+1]:)。只要它们不相同,我就可以继续前进,通过传入计数、总和和平方和来计算我的标准偏差。那个公式就在那里:

现在我们可以对右侧进行同样的操作,这样我们就可以像之前一样计算加权平均分数,下面的所有行都是一样的。
所以我们把 O(n²)的算法转换成了 O(n)的算法。一般来说,像这样的东西会给你带来比将某些东西推送到 Spark 集群或者更快的 RAM 或者在 CPU 中使用更多核心等更多价值。这是你想要改进你的代码的方式。具体来说,编写代码时不要过多考虑性能。运行它,看看它是否对你的需求足够快。如果是,那么你就完成了。如果不是,进行性能分析。在 Jupyter 中,你可以使用%prun,它会告诉你算法中时间花在哪里。然后你可以去看看实际花费时间的部分,思考它在算法上是否尽可能高效。在这种情况下,我们运行它,从 76 毫秒降到不到 2 毫秒。现在一些新手可能会认为“哦,太好了,我节省了 60 多毫秒”,但关键是这将被运行数千万次。所以 76 毫秒版本太慢了,对于实际使用的任何随机森林来说都是不切实际的。而另一方面,我找到的 1 毫秒版本实际上是相当可接受的。
%timeit find_better_split_foo(tree,1)
tree
'''
2.2 ms ± 148 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
n: 1000; val:10.079014121552744; score:658.5510186055565; split:1974.0; var:YearMade
'''
然后检查,数字应该与之前完全相同,而且确实如此。
find_better_split_foo(tree,0); tree
'''
n: 1000; val:10.079014121552744; score:658.5510186055565; split:1974.0; var:YearMade
'''
现在我们有了一个函数find_better_split,它可以做我们想要的事情,我想把它插入到我的DecisionTree类中。这是一个非常酷的 Python 技巧。Python 可以动态执行所有操作,因此我们实际上可以说DecisionTree中名为find_better_split的方法就是我刚刚创建的那个函数。
DecisionTree.find_better_split = find_better_split_foo
将其放在该类中。现在我告诉你这件事稍微令人困惑的地方是,左边的find_better_split和右边的find_better_split实际上并没有任何关系。它们只是恰好以相同的顺序拥有相同的字母。所以我可以将其命名为find_better_split_foo,然后我可以调用它。现在我的函数实际上被称为find_better_split_foo,但我期望调用的方法是名为 DecisionTree.find_better_split 的东西。所以在这里,我可以说:
DecisionTree.find_better_split = find_better_split_foo
在使用的每种语言中,了解命名空间的工作原理是很重要的。其中最重要的一点是了解它是如何确定名称所指的内容的。所以这里(DecisionTree.find_varsplit)意味着DecisionTree类内部定义的find_better_split,而不是其他地方。右边的这个意味着全局命名空间中的find_better_split_foo。许多语言没有全局命名空间,但 Python 有。因此,即使它们恰好以相同的顺序拥有相同的字母,它们也不以任何方式指向相同的内容。就像这边的家庭可能有一个叫 Jeremy 的人,而我的家庭也有一个叫 Jeremy 的人。我们的名字恰好相同,但我们并不是同一个人。
现在我们已经将find_better_split方法放入了具有这个新定义的DecisionTree中,当我现在调用TreeEnsemble构造函数时,决策树集合构造函数会调用create_tree,create_tree实例化DecisionTree,DecisionTree调用find_varsplit,它会遍历每一列以查看是否可以找到更好的分割点,我们现在已经定义了find_better_split,因此当我们创建TreeEnsemble时,它已经执行了这个分割点。
tree = TreeEnsemble(x_sub, y_train, 1, 1000).trees[0]; tree
'''
n: 1000; val:10.079014121552744; score:658.5510186055565; split:1974.0; var:YearMade
'''
好的。这很不错,对吧?我们一次只做一点点,测试每一步。当你们实现随机森林解释技术时,你们可能想尝试以这种方式编程,检查每一步是否与 scikit-learn 所做的匹配,或者与你们构建的测试匹配。
完整的单棵树[55:13]
在这一点上,我们应该尝试更深入地探究。现在让我们将 max_depth 设置为 2。这是 scikit-learn 所做的。在 YearMade 74 处中断后,它接着在 MachineHoursCurrentMeter 2956 处中断。
m = RandomForestRegressor(n_estimators=1, max_depth=2, bootstrap=False
)
m.fit(x_samp, y_samp)
draw_tree(m.estimators_[0], x_samp, precision=2)

所以我们有一个叫做find_varsplit的东西,它只是遍历每一列,尝试看看是否有更好的分割点。但实际上,我们需要再进一步。我们不仅需要遍历每一列,看看这个节点是否有更好的分割点,而且还需要看看我们刚刚创建的左侧和右侧是否有更好的分割点。换句话说,左侧和右侧应该成为决策树本身。

在右侧创建这棵树和在左侧创建这棵树之间没有任何区别,除了左侧包含 159 个样本,右侧包含一千个。

因此,第一行代码与之前完全相同。然后我们检查它是否是叶节点。如果是叶节点,那么我们就没有更多的事情要做了。这意味着我们就在底部,没有进行分割,所以我们不需要做任何进一步的操作。另一方面,如果它不是叶节点,那么我们需要将其分割成左侧和右侧。现在,早些时候,我们创建了一个左侧和右侧的布尔数组。最好是有一个索引数组,因为我们不想在每个节点中都有一个完整的布尔数组。因为请记住,尽管在这个大小的树中看起来似乎没有很多节点,但当它完全展开时,底层(即如果最小叶大小为 1)包含与整个数据集相同数量的节点。因此,如果每个节点都包含整个数据集大小的完整布尔数组,那么内存需求会增加。另一方面,如果我们只存储此节点中所有内容的索引,那么它将变得越来越小。
def find_varsplit(self):for i in range(self.c): self.find_better_split(i)if self.is_leaf: returnx = self.split_collhs = np.nonzero(x<=self.split)[0]rhs = np.nonzero(x>self.split)[0]self.lhs = DecisionTree(self.x, self.y, self.idxs[lhs])self.rhs = DecisionTree(self.x, self.y, self.idxs[rhs])
np.nonzero 与x<=self.split完全相同,它得到布尔数组,但将其转换为true的索引[58:07]。因此,这个lhs现在是左侧和右侧的索引列表。现在我们有了左侧和右侧的索引,我们现在可以继续创建一个决策树。所以self.lhs是我们左侧的决策树,self.rhs是我们右侧的决策树。我们不需要做其他事情。我们已经写好了这些。我们已经有一个可以创建决策树的构造函数。所以当你真正思考这在做什么时,会有点让人头疼,对吧?因为find_varsplit被调用的原因是因为决策树构造函数调用了它。但是find_varsplit本身又调用了决策树构造函数。所以我们实际上有循环递归。我并不聪明到足以能够思考递归,所以我选择不去想。我只是写出我的意思,然后不再考虑。我想要什么?找到一个变量分割。我必须遍历每一列,看看是否有更好的东西,如果成功进行了分割,找出左侧和右侧,然后将它们转换为决策树。现在尝试思考这两种方法如何相互调用会让我发疯,但我不需要这样做。我知道我有一个有效的决策树构造函数,我知道我有一个有效的find_varsplit,所以就这样。这就是我进行递归编程的方式,就是假装我没有。我只是忽略它。这是我的建议。你们中很多人可能足够聪明,能够比我更好地思考这个问题,那就好。如果你能的话。
DecisionTree.find_varsplit = find_varsplit
所以现在我已经写好了,我可以将其打补丁到 DecisionTree 类中,一旦我这样做了,TreeEnsemble 构造函数将会使用它,因为 Python 是动态的。
tree = TreeEnsemble(x_sub, y_train, 1, 1000).trees[0]; tree
'''
n: 1000; val:10.079014121552744; score:658.5510186055565; split:1974.0; var:YearMade
'''
现在我可以检查1:00:31。我的左手边应该有 159 个样本和值为 9.66。
tree.lhs
'''
n: 159; val:9.660892662981706; score:76.82696888346362; split:2800.0; var:MachineHoursCurrentMeter
'''
右手边,841 个样本和 10.15。
tree.rhs
'''
n: 841; val:10.158064432982941; score:571.4803525045031; split:2005.0; var:YearMade
'''
左手边的左手边,150 个样本和 9.62。
tree.lhs.lhs
'''
n: 150; val:9.619280538108496; score:71.15906938383463; split:1000.0; var:YearMade
'''
所以你可以看到,因为我并不聪明到足以编写机器学习算法,不仅我第一次写不正确,通常每一行我写的都是错误的。所以我总是从这样的假设开始,我刚刚输入的代码几乎肯定是错误的。我只需要看看为什么以及如何。所以我只是确保。最终我会到达这样一个点,让我很惊讶的是,它不再出错了。所以在这里,我可以感觉到好吧,如果所有这些事情碰巧与 scikit-learn 完全相同,那将是令人惊讶的。所以看起来还不错。
tree.lhs.rhs
'''
n: 9; val:10.354428077535193
'''
预测 [1:01:43]
现在我们有了一个可以构建整个树的东西,我们想要有一个可以计算预测的东西。所以提醒一下,我们已经有了一个可以为TreeEnsemble计算预测的东西(通过调用tree.predict(x)),但在DecisionTree中没有叫做tree.predict的东西,所以我们需要写一个。

为了让这更有趣,让我们开始增加我们使用的列数。
cols = ['MachineID', 'YearMade', 'MachineHoursCurrentMeter','ProductSize', 'Enclosure','Coupler_System', 'saleYear'
]
让我们再次创建我们的TreeEnsemble。
%time tree = TreeEnsemble(X_train[cols], y_train, 1, 1000).trees[0]
x_samp,y_samp = tree.x, tree.y
'''
CPU times: user 288 ms, sys: 12 ms, total: 300 ms
Wall time: 297 ms
'''
这一次,让我们将最大深度设为 3。
m = RandomForestRegressor(n_estimators=1, max_depth=3, bootstrap=False
)
m.fit(x_samp, y_samp)
draw_tree(m.estimators_[0], x_samp, precision=2, ratio=0.9, size=7)

所以现在我们的树变得更加有趣。现在让我们定义如何为树创建一组预测。因此,树的一组预测就是每一行的预测。就是这样。这就是我们的预测。因此,树的预测是数组中每一行的预测。所以再次,我们跳过思考,思考很困难。所以让我们继续推迟。这个**for** xi **in** x很方便,对吧?请注意,无论数组的秩如何,您都可以使用 numpy 数组中的for blah。无论数组中的轴数是多少。它的作用是遍历主轴。
这些概念在我们进入越来越多的神经网络时将变得非常重要,因为我们将一直在进行张量计算。因此,向量的主轴是向量本身。矩阵的主轴是行。三维张量的主轴是表示切片的矩阵等等。在这种情况下,因为 x 是一个矩阵,这将循环遍历行。如果您以这种方式编写您的张量代码,那么它将很好地推广到更高的维度。在这个 x 中有多少维度并不重要。这将循环遍历每个主轴。因此,我们现在可以称之为 DecisionTree.predict。
def predict(self, x): return np.array([self.predict_row(xi) for xi in x])
所以我需要做的就是编写predict_row。我一直在拖延思考,这很好,实际上我需要做工作的地方,现在基本上是微不足道的。如果我们在叶节点,那么预测值就等于我们在原始树构造函数中计算的那个值(即y的平均值)。如果不是叶节点,那么我们必须弄清楚是沿左路径还是右路径进行预测。因此,如果这一行中的变量(xi[self.var_idx])小于或等于我们决定拆分的值,则我们沿左路径前进;否则我们沿右路径前进。然后,确定我们想要的路径/树之后,我们只需在其上调用predict_row。再次,我们无意中创建了递归的东西。如果是叶节点,则返回该值;否则根据需要返回左侧或右侧的预测值。
def predict_row(self, xi):if self.is_leaf: return self.valt = self.lhs if xi[self.var_idx]<=self.split else self.rhsreturn t.predict_row(xi)
DecisionTree.predict_row = predict_row
注意这里的self.lhs **if** xi[self.var_idx]<=self.split **else** self.rhs,这个 if 与上面的 if 没有任何关系:
if something:x= do1()
else:x= do2()
上面的这个 if 是一个控制流语句,告诉 Python 沿着这条路径或那条路径进行一些计算。下面的这个 if 是一个返回值的运算符。
x = do1() if something else do2()
所以你们做过 C 或 C++的人会认出它与这个是完全相同的(即三元运算符):
x = something ? do1() : do2()
基本上我们要做的是,我们要得到一个值,如果something为真,我们会说这个值是(do1()),否则是另一个值(do2())。你可以用冗长的方式来写,但那将需要写 4 行代码来做一件事,而且还需要你编写的代码,如果你自己或向别人阅读时,表达方式并不自然。我想说“我要走的树是左边,如果变量小于分割值,否则是右边。所以我想按照我思考或说代码的方式来编写我的代码。因此,这种三元运算符对此非常有帮助。
所以现在我已经对一行进行了预测,我可以将其放入我的类中:
DecisionTree.predict = predict
现在我可以计算预测。
%time preds = tree.predict(X_valid[cols].values)
'''
CPU times: user 156 ms, sys: 4 ms, total: 160 ms
Wall time: 162 ms
'''
现在我可以将我的实际数据与我的预测数据进行对比。当你做散点图时,通常会有很多点重叠在一起,所以一个好的技巧是使用 alpha。Alpha 表示透明度,不仅在 matplotlib 中,在世界上几乎所有的图形包中都是如此。因此,如果将 alpha 设置为小于 1,那么这意味着你需要将 20 个点叠加在一起才能完全显示为蓝色。这是一个很好的方法来看看有多少点重叠在一起 - 散点图的一个好技巧。
plt.scatter(preds, y_valid, alpha=0.05)

这是我的 R²。
metrics.r2_score(preds, y_valid)
'''
0.50371522136882341
'''
那么现在让我们继续进行一个没有最大分裂次数的随机森林,我们的树集合也没有最大分裂次数,我们可以将我们的 R²与他们的 R²进行比较。
m = RandomForestRegressor(n_estimators=1, min_samples_leaf=5, bootstrap=False
)
%time m.fit(x_samp, y_samp)
preds = m.predict(X_valid[cols].values)
plt.scatter(preds, y_valid, alpha=0.05)

metrics.r2_score(preds, y_valid)
'''
0.47541053100694797
'''
它们并不相同,但实际上我们的稍微好一点。我不知道我们做了什么不同,但我们会接受它😊 所以现在我们有了一个对于一个只有一棵树的森林,在使用一个真实的实际数据集(推土机的蓝皮书)进行验证时,与 scikit-learn 相比提供了同样好的准确性。
把它放在一起
让我们继续完善这个。现在我想要做的是创建一个包含这段代码的包。我通过创建一个方法,再创建一个方法,然后将它们拼接在一起来创建这个包。现在我回到笔记本中,收集了所有实现方法的单元格,然后将它们全部粘贴在一起。
class TreeEnsemble():def __init__(self, x, y, n_trees, sample_sz, min_leaf=5):np.random.seed(42)self.x,self.y,self.sample_sz,self.min_leaf = x,y,sample_sz,min_leafself.trees = [self.create_tree() for i in range(n_trees)] def create_tree(self):idxs = np.random.permutation(len(self.y))[:self.sample_sz]return DecisionTree(self.x.iloc[idxs], self.y[idxs], idxs=np.array(range(self.sample_sz)), min_leaf=self.min_leaf)def predict(self, x):return np.mean([t.predict(x) for t in self.trees], axis=0)def std_agg(cnt, s1, s2): return math.sqrt((s2/cnt) - (s1/cnt)**2)class DecisionTree():def __init__(self, x, y, idxs, min_leaf=5):self.x,self.y,self.idxs,self.min_leaf = x,y,idxs,min_leafself.n,self.c = len(idxs), x.shape[1]self.val = np.mean(y[idxs])self.score = float('inf')self.find_varsplit()def find_varsplit(self):for i in range(self.c): self.find_better_split(i)if self.score == float('inf'): returnx = self.split_collhs = np.nonzero(x<=self.split)[0]rhs = np.nonzero(x>self.split)[0]self.lhs = DecisionTree(self.x, self.y, self.idxs[lhs])self.rhs = DecisionTree(self.x, self.y, self.idxs[rhs]) def find_better_split(self, var_idx):x,y = self.x.values[self.idxs,var_idx], self.y[self.idxs]sort_idx = np.argsort(x)sort_y,sort_x = y[sort_idx], x[sort_idx]rhs_cnt,rhs_sum,rhs_sum2 = self.n,sort_y.sum(),(sort_y**2).sum()lhs_cnt,lhs_sum,lhs_sum2 = 0,0.,0. for i in range(0,self.n-self.min_leaf-1):xi,yi = sort_x[i],sort_y[i]lhs_cnt += 1; rhs_cnt -= 1lhs_sum += yi; rhs_sum -= yilhs_sum2 += yi**2; rhs_sum2 -= yi**2if i<self.min_leaf or xi==sort_x[i+1]:continue lhs_std = std_agg(lhs_cnt, lhs_sum, lhs_sum2)rhs_std = std_agg(rhs_cnt, rhs_sum, rhs_sum2)curr_score = lhs_std*lhs_cnt + rhs_std*rhs_cntif curr_score<self.score: self.var_idx,self.score,self.split = var_idx,curr_score,xi @propertydef split_name(self): return self.x.columns[self.var_idx]@propertydef split_col(self): return self.x.values[self.idxs,self.var_idx] @propertydef is_leaf(self): return self.score == float('inf')def __repr__(self):s = f'n: **{self.n}**; val:**{self.val}**'if not self.is_leaf:s += f'; score:**{self.score}**; split:**{self.split}**; var:**{self.split_name}**'return s def predict(self, x):return np.array([self.predict_row(xi) for xi in x]) def predict_row(self, xi):if self.is_leaf: return self.valt = self.lhs if xi[self.var_idx]<=self.split else self.rhsreturn t.predict_row(xi)
就是这样。这就是我们一起编写的代码。
ens = TreeEnsemble(X_train[cols], y_train, 5, 1000)
preds = ens.predict(X_valid[cols].values)
plt.scatter(y_valid, preds, alpha=0.1, s=6);

metrics.r2_score(y_valid, preds)
'''
0.71011741571071241
'''
这里我们有一个蓝色推土机的模型,使用了我们完全从头开始编写的随机森林,R²为 71。这很酷。
性能和 Cython
当我尝试比较这个与 scikit-learn 的性能时,这个要慢得多,原因是虽然很多工作是由 numpy 完成的,numpy 是优化良好的 C 代码,但想想树的最底层。如果我们有一百万个数据点,树的底层有大约 500,000 个决策点,底下有一百万个叶子。这就像调用了 500,000 个分割方法,其中包含多次调用 numpy,而 numpy 只有一个要计算的项目。这是非常低效的。这是 Python 在性能方面特别不擅长的事情(即多次调用大量函数)。我们可以看到它并不差。对于 15 年前被认为是相当大的随机森林来说,这被认为是相当不错的性能。但是现在,这至少比应该的速度慢了几百倍。
scikit-learn 的开发人员为了避免这个问题所做的是,他们使用了一种叫做 Cython 的东西来实现。Cython 是 Python 的一个超集。所以你写的任何 Python 代码基本上都可以作为 Cython 来使用。但是 Cython 运行方式有所不同。它不是直接传递给 Python 解释器,而是将其转换为 C 语言,编译,然后运行该 C 代码。这意味着,第一次运行时会花费一些时间,因为需要进行翻译和编译,但之后运行会快得多。所以我想快速向你展示一下这是什么样子,因为你肯定会遇到 Cython 可以帮助你工作的情况,而你大部分一起工作的人可能从未使用过它(甚至可能不知道它的存在),所以拥有这种超能力是非常棒的。
在笔记本中使用 Cython,你可以这样说:
%load_ext Cython
这里是一个 Python 函数fib1:
def fib1(n):a, b = 0, 1while b < n:a, b = b, a + b
这里是一个 Cython 函数。它与顶部的%%cython完全相同。实际上,它的运行速度大约是fib1的两倍,因为它进行了编译。
%%cython
def fib2(n):a, b = 0, 1while b < n:a, b = b, a + b
这里是同样的版本,我使用了一个特殊的 Cython 扩展叫做cdef,它定义了返回值和每个变量的 C 数据类型。基本上这就是你可以用来开始加快运行速度的技巧。在那一点上,现在它知道它不只是一个名为 T 的 Python 对象。所以 fib3,它和之前完全一样,但我们说我们传递给它的东西的数据类型是什么,然后定义每个变量的数据类型。
%%cython
def fib3(int n):cdef int b = 1cdef int a = 0cdef int t = 0while b < n:t = aa = bb = a + b
所以如果我们这样做,现在我们有了一个快 10 倍的东西。
%timeit fib1(50)
'''
705 ns ± 62.5 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
'''
%timeit fib2(50)
'''
362 ns ± 26.5 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
'''
%timeit fib3(50)
'''
70.7 ns ± 4.07 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
'''
这并不需要太多额外的工作,只是用一点 Python 和一些标记,所以知道它的存在是很好的,因为如果有一些定制的东西你想要做,实际上要去 C 语言编译并链接回来是很痛苦的。而在这里做起来相当容易。
问题:当你在使用 Cython 版本时,对于 numpy 数组,是否有特定的 C 类型[1:17:16]?是的,有很多特定的内容用于将 Cython 与 numpy 集成,有一个完整的页面介绍了这些内容。所以我们不用担心过多细节,但你可以阅读那个页面,基本上可以了解基本思想。
使用 NumPy 与 Cython — Cython 0.29a0 文档
cython.readthedocs.io
有这个cimport,基本上是将某种类型的 Python 库导入到代码的 C 部分,然后你可以在 Cython 中使用它。这很简单直接。
所以你现在的任务是实现:
-
基于树方差的置信度
-
特征重要性
-
部分依赖
-
树解释器
对于那个随机森林。删除冗余特征根本不使用随机森林,所以你不必担心这个。外推不是一种解释技术,所以你也不必担心这个。所以只是其他的。所以基于树方差的置信度,我们已经编写了那段代码,所以我怀疑我们在笔记本中拥有的完全相同的代码应该继续工作。所以你可以尝试确保让它工作。特征重要性是通过变量洗牌技术实现的,一旦你让它工作,偏依赖只是几行代码之遥,因为你不是洗牌一列,而是用一个常数值替换它。几乎是相同的代码。
然后树解释器,这将需要您编写一些代码并思考。一旦您编写了树解释器,如果您愿意,您就非常接近创建特征重要性的第二种方法 - 即在所有行中累加重要性的方法。这意味着,您将非常接近进行交互重要性。事实证明,xgboost 实际上有一个非常好的交互重要性库,但似乎没有一个适用于随机森林,因此您可以从使其在我们的版本上运行开始(如果您想进行交互重要性),然后您可以使其在原始的 scikit-learn 版本上运行,这将是一个很酷的贡献。有时,针对自己的实现编写代码更好,因为您可以清楚地看到发生了什么。
如果在任何时候遇到困难,请在论坛上提问。关于如何寻求帮助的整个页面都在维基上有。当你在 Slack 上向同事寻求帮助,当你在 Github 或 Discourse 上向技术社区的人寻求帮助时,正确地寻求帮助将有助于让人们愿意帮助你并能够帮助你。
-
搜索你遇到的错误,看看是否已经有人问过。
-
你已经尝试过如何修复它了吗?
-
你认为出了什么问题?
-
你用的是什么样的电脑?它是如何设置的?软件版本是什么?
-
你确切地输入了什么,确切地发生了什么?
你可以通过截屏来做到这一点,所以确保你有一些非常容易使用的截屏软件。所以如果我要截屏,我只需按下一个按钮,选择区域,复制到剪贴板,转到论坛,粘贴进去,然后就完成了(你甚至可以将图像缩小!)。

更好的做法是,如果有几行代码和错误消息需要查看,可以创建一个 Gist。Gist 是一个很方便的 Github 工具,基本上可以让你分享代码。如果我想要创建一个这样的 Gist,我实际上有一个扩展:

点击那个,给它起个名字,然后点击“公开”。这样就可以将我的 Jupyter 笔记本公开分享。然后我可以复制那个 URL,复制链接位置,然后粘贴到我的论坛帖子中。然后当人们点击它时,他们会立即看到我的笔记本。
现在,这个特定的按钮是一个扩展,所以在 Jupyter 上,您需要点击 Nbextensions,然后点击 Gist-it。当您在那里时,您还应该点击 Collapsible Headings,这是我使用的一个方便的功能,让我可以折叠和展开内容。

如果您打开 Jupyter 时没有看到这个 Nbextensions 按钮,那么只需搜索 Jupyter Nbextensions — 它会告诉您如何使用 pip 安装并设置它。
神经网络广义定义 [1:23:20]
笔记本
除了作业之外,我们已经完成了随机森林,直到下一个课程,当你看到 GBMs 时,我们已经完成了决策树集成。我们将转向广义的神经网络。神经网络将使我们能够超越随机森林的最近邻方法。所有随机森林能做的就是对已经看到的数据进行平均。它不能外推或计算。线性回归可以计算和外推,但只能以非常有限的方式。神经网络给我们带来了两全其美的好处。
我们将从将它们应用于非结构化数据开始。非结构化数据指的是像素、声波振幅或单词 - 数据中所有列中的所有内容都是相同类型,而不是数据库表中有收入、成本、邮政编码和州名(结构化数据)。我们也将用它来处理结构化数据,但稍后再做。非结构化数据稍微容易一些,也是更多人长期以来一直在应用深度学习的领域。
如果您也在学习深度学习课程,您会发现我们将从两个不同的方向接近相同的结论。因此,深度学习课程从解决复杂的卷积神经网络开始,使用复杂的优化方案,我们将逐渐深入了解它们的工作原理。而机器学习课程则更多地从随机梯度下降的实际工作原理开始,我们可以用单层来创建逻辑回归等内容。当我们添加正则化时,它如何给我们提供岭回归、弹性网络套索等内容。当我们添加更多层时,它如何让我们处理更复杂的问题。在这个机器学习课程中,我们只会看到全连接层,我认为下个学期与 Yannet 一起,您可能会看到一些更复杂的方法。因此,这个机器学习课程中,我们将更多地关注矩阵的实际运算过程,而深度学习则更多地关注如何以世界级水平解决真实世界的深度学习问题的最佳实践。
下周,我们将研究经典的 MNIST 问题,即如何识别数字。如果你感兴趣,你可以提前尝试使用随机森林来解决这个问题,你会发现效果不错。考虑到随机森林基本上是一种最近邻的类型(它在树空间中找到最近的邻居),那么随机森林绝对可以识别出这个 9,这些像素与我们在其他图像中看到的像素相似,而且平均来说,它们也是 9。因此,它绝对可以使用随机森林解决这类问题。但我们最终会受到数据限制,因为每次我们增加一个决策点,我们的数据大致减半,所以这就限制了我们可以进行的计算量。而神经网络,我们将能够使用大量的参数,通过我们将学习的正则化技巧,我们将能够进行大量的计算,实际上我们几乎没有什么限制可以计算的结果。
祝你在随机森林解释方面好运,下次再见。
相关文章:
fast.ai 机器学习笔记(二)
机器学习 1:第 5 课 原文:medium.com/hiromi_suenaga/machine-learning-1-lesson-5-df45f0c99618 译者:飞龙 协议:CC BY-NC-SA 4.0 来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更…...

vue3 elementplus DateTimePicker 日期时间设置默认时间为当天
DateTimePicker里面有个自带属性 可以实现这个需求,如图: // 设置当前当天时间范围 00: 00: 00 - 23:59:59 const currentDate [setDefaultDate(0), setDefaultDate(1)]const setDefaultDate (type:number ): string > {let t ;let date new Da…...

2024年笔记--centos docker离线安装启动失败
Failed to start Docker Application Container Engine 错误如下: [rootel70 docker]# systemctl start docker.service Job for docker.service failed because start of the service was attempted too often. See "systemctl status docker.service" …...
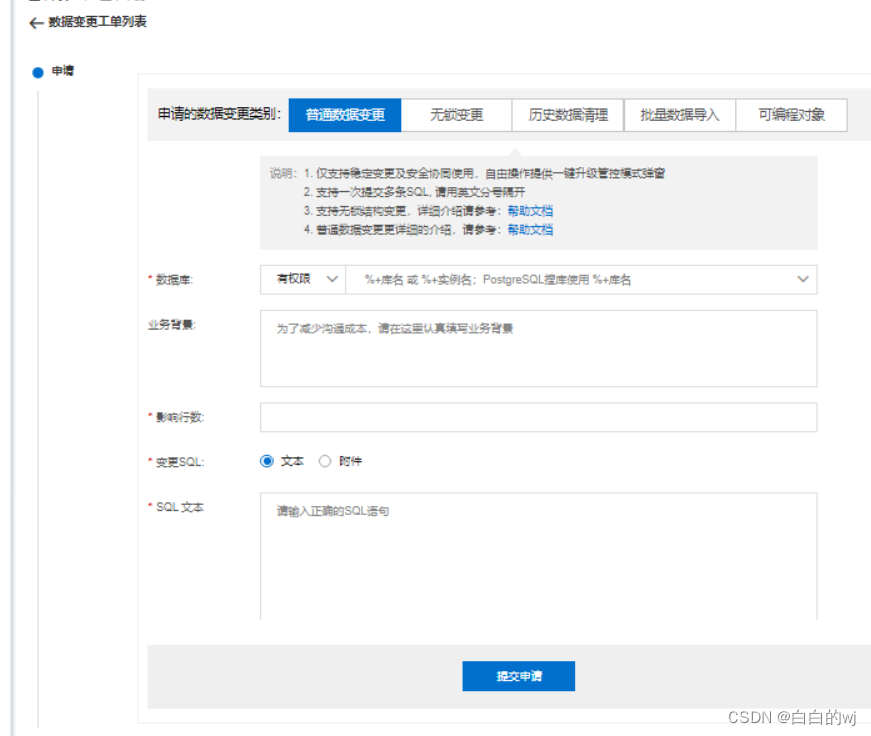
2024.2.10 DMS(数据库管理系统)初体验
数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。用户通过DBMS访问数据库中的数据,数据库管…...

zk集群--集群同步
1.概述 前面一章分析了集群下启动阶段选举过程,一旦完成选举,通过执行QuorumPeer的setPeerState将设置好选举结束后自身的状态。然后,将再次执行QuorumPeer的run的新的一轮循环, QuorumPeer的run的每一轮循环,先判断…...

复习面经哦
1.函数可以变量提升 JavaScript 中的函数存在变量提升的概念,这意味着在执行代码之前,函数声明会被提升到其作用域的顶部。这使得你可以在函数声明之前调用函数。然而,这种行为只适用于函数声明,而不是函数表达式。 下面是一些关…...
vector)
c++ STL系列——(二)vector
引言 在现代C编程中,std::vector是最常用的动态数组实现之一,它是C标准模板库(STL)的一部分。vector提供了一种方式,以单一数据结构来存储元素集合,并且可以动态地调整大小以适应新元素。本文将深入探讨ve…...
STM32能够做到数据采集和发送同时进行吗?
STM32能够做到数据采集和发送同时进行吗? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「STM32的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!&am…...

5.Swift常量
Swift 常量 在 Swift 中,除了可以声明变量(使用 var 关键字),还可以声明常量(使用 let 关键字)。常量在赋值后就不能再修改其值,适合用于存储不会改变的数据。以下是关于 Swift 常量的一些重要…...
Linux运行级别 | 管理Linux服务
Linux运行级别 级别: 0关机1单用户2多用户但是不运行nfs网路文件系统3默认的运行级别,给一个黑的屏幕,只能敲命令4未使用5默认的运行级别,图形界面6重启切换运行级别: init x管理Linux服务 systemctl命令…...

Nginx 配置 SSL证书
成功配置SSL证书后,您将能够通过HTTPS加密通道安全访问Nginx服务器。 一、准备材料 SSL证书绑定的域名已完成DNS解析,即您的域名与主机IP地址相互映射。您可以通过DNS验证证书工具,检测域名DNS解析是否生效。具体操作: 【1】登录…...

如何正确理解和获取S参数
S参数是网络参数,定义了反射波和入射波之间的关系,给定频率的S参数矩阵指定端口反射波b的矢量相对于端口入射波a的矢量,如下所示: bS∙a 在此基础上,如下图所示,为一个常见的双端口网络拓扑图:…...

Sping Cloud Hystrix 参数配置、简单使用、DashBoard
Sping Cloud Hystrix 文章目录 Sping Cloud Hystrix一、Hystrix 服务降级二、Hystrix使用示例三、OpenFeign Hystrix四、Hystrix参数HystrixCommand.Setter核心参数Command PropertiesFallback降级配置Circuit Breaker 熔断器配置Metrix 健康统计配置Request Context 相关参数C…...

CSS太极动态图
CSS太极动态图 1. 案例效果 我们今天学习用HTML和CSS实现动态的太极,看一下效果。 2. 分析思路 太极图是由两个旋转的圆组成,一个是黑圆,一个是白圆。实现现原理是使用CSS的动画和渐变背景属性。 首先,为所有元素设置默认值为0…...
TI毫米波雷达开发——High Accuracy Demo 串口数据接收及TLV协议解析 matlab 源码
TI毫米波雷达开发——串口数据接收及TLV协议解析 matlab 源码 前置基础源代码功能说明功能演示视频文件结构01.bin / 02.binParseData.mread_file_and_plot_object_location.mread_serial_port_and_plot_object_location.m函数解析configureSport(comportSnum)readUartCallback…...
基于tomcat运行jenkins常见的报错处理
目录 1.jenkins.util.SystemProperties$Listener错误 升级jdk11可能遇到的坑 2.java.lang.RuntimeException: Fontconfig head is null, check your fonts or fonts configuration 3.There were errors checking the update sites: UnknownHostException:updates.jenkins.i…...

算法学习——LeetCode力扣二叉树篇1
算法学习——LeetCode力扣二叉树篇1 144. 二叉树的前序遍历 144. 二叉树的前序遍历 - 力扣(LeetCode) 描述 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 示例 示例 1: 输入:root [1,null,2,3] 输出&a…...

二叉树的遍历及创建
typedef char T;struct TreeNode {T _data;TreeNode* left;TreeNode* right; }; 1、二叉树的遍历---DFS 3 5 6 …...
图形学:Transform矩阵(3维 2维) 平移,旋转,缩放
0. 简介 在图形学领域中,Transform矩阵(变换矩阵)是一种表示图形对象在二维或三维空间中的位置、方向和大小变化的数学工具。它们用于执行各种图形变换,如平移、旋转、缩放。Transform矩阵通常表示为一个二维或三维矩阵ÿ…...

Docker学习历程
Docker学习历程 Q1、docker还没启动Q2、Docker容器名称冲突的问题Q3:启动minio时发现,容器已经再重启Q4:容器被占用的情况Q5:查看日志 Q1、docker还没启动 docker run --env MODEstandalone --name nacos --restartalways -d -p …...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...