【RL】Bellman Equation (贝尔曼等式)
Lecture2: Bellman Equation
State value
考虑grid-world的单步过程:
S t → A t R t + 1 , S t + 1 S_t \xrightarrow[]{A_t} R_{t + 1}, S_{t + 1} StAtRt+1,St+1
- t t t, t + 1 t + 1 t+1:时间戳
- S t S_t St:时间 t t t时所处的state
- A t A_t At:在state S t S_t St时采取的action
- R t + 1 R_{t + 1} Rt+1:在采取 action A t A_t At 之后获得的reward
- S t + 1 S_{t + 1} St+1:在采取 action A t A_t At 之后,state S t S_t St转移后的state
通过概率分布对以上变量的动作进行描述:
- S t → A t S_t \rightarrow A_t St→At: π ( A t = a ∣ S t = s ) \pi (A_t = a | S_t = s) π(At=a∣St=s)
- S t , A t → R t + 1 S_t, A_t \rightarrow R_{t + 1} St,At→Rt+1: p ( R t + 1 = r ∣ S t = s , A t = a ) p(R_{t + 1} =r | S_t = s, A_t = a) p(Rt+1=r∣St=s,At=a)
- S t , A t → S t + 1 S_t, A_t \rightarrow S_{t + 1} St,At→St+1: p ( S t + 1 = s ′ ∣ S t = s , A t = a ) p(S_{t + 1} = s' | S_t = s, A_t = a) p(St+1=s′∣St=s,At=a)
考虑grid-world的多步(multi-step)trajectory:
S t → A t R t + 1 , S t + 1 → A t + 1 R t + 2 , S t + 2 → A t + 2 R t + 3 . . . S_t \xrightarrow[]{A_t} R_{t + 1}, S_{t + 1} \xrightarrow[]{A_{t + 1}} R_{t + 2}, S_{t + 2} \xrightarrow[]{A_{t + 2}} R_{t + 3}... StAtRt+1,St+1At+1Rt+2,St+2At+2Rt+3...
其discounted return为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . G_t = R_{t + 1} + \gamma R_{t + 2} + \gamma^2 R_{t + 3} + ... Gt=Rt+1+γRt+2+γ2Rt+3+...
- γ ∈ [ 0 , 1 ) \gamma \in [0, 1) γ∈[0,1)是折扣率(discount rate)
- 当 R t + 1 , R t + 2 , . . . R_{t + 1}, R_{t + 2}, ... Rt+1,Rt+2,...是随机变量时, G t G_t Gt也是随机变量
G t G_t Gt的期望(expectation; expected value; mean)被定义为state-value function或state value。
v π ( s ) = E [ G t ∣ S t = s ] v_{\pi}(s) = \mathbb{E}[G_t | S_t = s] vπ(s)=E[Gt∣St=s]
- v π ( s ) v_{\pi}(s) vπ(s)是state s s s的函数,是state从 s s s 起始的条件期望。
- v π ( s ) v_{\pi}(s) vπ(s)基于policy π \pi π,对于不同的policy,state value可能会不同
- 其代表了一个state的“价值”。 如果state value越大,代表policy就越好,因为可以获得更大的累积奖励(cumulative rewards)。
注意区分state value和return: state value是从某个state开始可以获得的所有可能return的平均值。如果每一个 π ( a ∣ s ) , p ( r ∣ s , a ) , p ( s ′ ∣ s , a ) \pi(a | s), p(r | s, a), p(s' | s, a) π(a∣s),p(r∣s,a),p(s′∣s,a)是确定的,那么state value和return是相等的。
例:

计算三个样例的state value:
v π 1 ( s 1 ) = 0 + γ 1 + γ 2 1 + ⋯ = γ ( 1 + γ + γ 2 + ⋯ ) = γ 1 − γ v_{\pi_1}(s_1) = 0 + \gamma 1 + \gamma^21 + \cdots = \gamma(1 + \gamma + \gamma^2 + \cdots) = \frac{\gamma}{1 - \gamma} vπ1(s1)=0+γ1+γ21+⋯=γ(1+γ+γ2+⋯)=1−γγ
v π 2 ( s 1 ) = − 1 + γ 1 + γ 2 1 + ⋯ = − 1 + γ ( 1 + γ + γ 2 + ⋯ ) = − 1 + γ 1 − γ v_{\pi_2}(s_1) = -1 + \gamma1 + \gamma^21 + \cdots = -1 + \gamma(1 + \gamma + \gamma^2 + \cdots) = -1 + \frac{\gamma}{1 - \gamma} vπ2(s1)=−1+γ1+γ21+⋯=−1+γ(1+γ+γ2+⋯)=−1+1−γγ
v π 3 ( s 1 ) = 0.5 ( − 1 + γ 1 − γ ) + 0.5 ( γ 1 − γ ) = − 0.5 + γ 1 − γ v_{\pi_3}(s_1) = 0.5(-1 + \frac{\gamma}{1 - \gamma}) + 0.5(\frac{\gamma}{1 - \gamma}) = -0.5 + \frac{\gamma}{1 - \gamma} vπ3(s1)=0.5(−1+1−γγ)+0.5(1−γγ)=−0.5+1−γγ
Bellman equation: Derivation
贝尔曼方程描述了所有state值之间的关系。
考虑一个随机的trajectory:
S t → A t R t + 1 , S t + 1 → A t + 1 R t + 2 , S t + 2 → A t + 2 R t + 3 , … S_t \xrightarrow[]{A_t} R_{t + 1}, S_{t + 1} \xrightarrow[]{A_{t+1}} R_{t + 2}, S_{t + 2} \xrightarrow[]{A_{t+2}} R_{t + 3}, \dots StAtRt+1,St+1At+1Rt+2,St+2At+2Rt+3,…
其return G t G_t Gt可以被计算为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … = R t + 1 + γ ( R t + 2 + γ R t + 3 + … ) = R t + 1 + γ G t + 1 \begin{align*} G_t &= R_{t + 1} + \gamma R_{t + 2} + \gamma^2 R_{t + 3} + \dots\\ &= R_{t + 1} + \gamma(R_{t + 2} + \gamma R_{t + 3} + \dots)\\ &= R_{t + 1} + \gamma G_{t+1} \end{align*} Gt=Rt+1+γRt+2+γ2Rt+3+…=Rt+1+γ(Rt+2+γRt+3+…)=Rt+1+γGt+1
其state value可以计算为:
v π ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] \begin{align*} v_{\pi}(s) &= \mathbb{E}[G_t | S_t = s] \\ & = \mathbb{E}[R_{t + 1} + \gamma G_{t + 1} | S_t = s]\\ &= \mathbb{E}[R_{t + 1} | S_t = s] + \gamma \mathbb{E}[G_{t + 1} | S_t = s] \end{align*} vπ(s)=E[Gt∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1∣St=s]+γE[Gt+1∣St=s]
对于第一项:
E [ R t + 1 ∣ S t = s ] = ∑ a π ( a ∣ s ) E [ R t + 1 ∣ S t = s , A t = a ] = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r \begin{align*} \mathbb{E}[R_{t + 1} | S_t = s] &= \sum_a \pi(a | s) \mathbb{E}[R_{t + 1} | S_t = s, A_t = a] \\ & = \sum_a \pi(a | s)\sum_rp(r | s, a)r \end{align*} E[Rt+1∣St=s]=a∑π(a∣s)E[Rt+1∣St=s,At=a]=a∑π(a∣s)r∑p(r∣s,a)r
这是瞬时reward的期望。
对于第二项:
E [ G t + 1 ∣ S t = s ] = ∑ s ′ E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ E [ G t + 1 ∣ S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) ∑ a p ( s ′ ∣ s , a ) π ( a ∣ s ) \begin{align*} \mathbb{E}[G_{t + 1} | S_t = s] &= \sum_{s'} \mathbb{E}[G_{t + 1} | S_t = s, S_{t + 1} = s']p(s' | s)\\ &= \sum_{s'}\mathbb{E}[G_{t + 1} | S_{t + 1} = s']p(s' | s)\\ &= \sum_{s'} v_{\pi}(s')p(s' |s )\\ &= \sum_{s'} v_{\pi}(s') \sum_a p(s' | s, a)\pi(a | s) \end{align*} E[Gt+1∣St=s]=s′∑E[Gt+1∣St=s,St+1=s′]p(s′∣s)=s′∑E[Gt+1∣St+1=s′]p(s′∣s)=s′∑vπ(s′)p(s′∣s)=s′∑vπ(s′)a∑p(s′∣s,a)π(a∣s)
这是未来reward的期望
因此,可以得到:
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ v π ( s ′ ) ∑ a p ( s ′ ∣ s , a ) π ( a ∣ s ) = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] , ∀ s ∈ S \begin{align*} v_{\pi}(s) &= \mathbb{E}[R_{t + 1} | S_t = s] + \gamma \mathbb{E}[G_{t + 1} | S_t = s]\\ &= \sum_a \pi(a | s)\sum_rp(r | s, a)r + \gamma \sum_{s'} v_{\pi}(s') \sum_a p(s' | s, a)\pi(a | s) \\ &= \sum_a \pi(a | s) \left[ \sum_r p(r | s, a)r + \gamma \sum_{s'}p(s' | s, a) v_{\pi}(s') \right], \;\;\; \forall s \in S \end{align*} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s]=a∑π(a∣s)r∑p(r∣s,a)r+γs′∑vπ(s′)a∑p(s′∣s,a)π(a∣s)=a∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)],∀s∈S
- v π ( s ) v_{\pi}(s) vπ(s)和 π ( s ′ ) \pi(s') π(s′)是需要被计算的state value,可以采用bootstrapping。
- π ( a ∣ s ) \pi(a | s) π(a∣s)是给定的policy,可以通过策略评估(policy evaluation)进行求解。
- p ( r ∣ s , a ) p(r | s, a) p(r∣s,a)和 p ( s ′ ∣ s , a ) p(s' | s, a) p(s′∣s,a)代表动态模型,分为known和unknown。
- 上式叫做贝尔曼等式(Bellman equation),其描述了不同state之间state-value function的关系。
- Bellman equation包含两个部分,瞬时奖励(immediate reward)和未来奖励(future reward)。
例:
对于action:

若policy为:

首先写Bellman equation:
v π ( s ) = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] v_{\pi}(s) = \sum_a \pi(a | s) \left[ \sum_r p(r | s, a)r + \gamma \sum_{s'}p(s' | s, a) v_{\pi}(s') \right] vπ(s)=a∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)]
计算上式各项:
- π ( a = a 3 ∣ s 1 ) = 1 \pi(a = a_3 | s_1) = 1 π(a=a3∣s1)=1, π ( a ≠ a 3 ∣ s 1 ) = 0 \pi(a \ne a_3 | s_1) = 0 π(a=a3∣s1)=0
- p ( s ′ = s 3 ∣ s 1 , a 3 ) = 1 p(s' = s_3 | s_1, a_3) = 1 p(s′=s3∣s1,a3)=1, p ( s ′ ≠ s 3 ∣ s 1 , a 3 ) = 0 p(s' \ne s_3 | s_1, a_3) = 0 p(s′=s3∣s1,a3)=0
- p ( r = 0 ∣ s 1 , a 3 = 1 ) p(r = 0 | s_1, a_3 = 1) p(r=0∣s1,a3=1), p ( r ≠ 0 ∣ s 1 , a 3 ) = 0 p(r \ne 0 | s_1, a_3) = 0 p(r=0∣s1,a3)=0
替换进Bellman equation得:
v π ( s 1 ) = 0 + γ v π ( s 3 ) v_{\pi}(s_1) = 0 + \gamma v_{\pi}(s_3) vπ(s1)=0+γvπ(s3)
同样的,可以计算:
v π ( s 1 ) = 0 + γ v π ( s 3 ) v π ( s 2 ) = 1 + γ v π ( s 4 ) v π ( s 3 ) = 1 + γ v π ( s 4 ) v π ( s 4 ) = 1 + γ v π ( s 4 ) v_{\pi}(s_1) = 0 + \gamma v_{\pi}(s_3)\\ v_{\pi}(s_2) = 1 + \gamma v_{\pi}(s_4)\\ v_{\pi}(s_3) = 1 + \gamma v_{\pi}(s_4)\\ v_{\pi}(s_4) = 1 + \gamma v_{\pi}(s_4)\\ vπ(s1)=0+γvπ(s3)vπ(s2)=1+γvπ(s4)vπ(s3)=1+γvπ(s4)vπ(s4)=1+γvπ(s4)
对于上式,可以从后往前计算:
v π ( s 4 ) = 1 1 − γ v π ( s 3 ) = 1 1 − γ v π ( s 2 ) = 1 1 − γ v π ( s 1 ) = γ 1 − γ v_{\pi}(s_4) = \frac{1}{1 - \gamma}\\ v_{\pi}(s_3) = \frac{1}{1 - \gamma}\\ v_{\pi}(s_2) = \frac{1}{1 - \gamma}\\ v_{\pi}(s_1) = \frac{\gamma}{1 - \gamma}\\ vπ(s4)=1−γ1vπ(s3)=1−γ1vπ(s2)=1−γ1vπ(s1)=1−γγ
若policy为:

则:
v π ( s 1 ) = 0.5 [ 0 + γ v π ( s 3 ) ] + 0.5 [ − 1 + γ v π ( s 2 ) ] v π ( s 2 ) = 1 + γ v π ( s 4 ) v π ( s 3 ) = 1 + γ v π ( s 4 ) v π ( s 4 ) = 1 + γ v π ( s 4 ) v_{\pi}(s_1) = 0.5[0 + \gamma v_{\pi}(s_3)] + 0.5[-1 + \gamma v_{\pi}(s_2)] \\ v_{\pi}(s_2) = 1 + \gamma v_{\pi}(s_4)\\ v_{\pi}(s_3) = 1 + \gamma v_{\pi}(s_4)\\ v_{\pi}(s_4) = 1 + \gamma v_{\pi}(s_4)\\ vπ(s1)=0.5[0+γvπ(s3)]+0.5[−1+γvπ(s2)]vπ(s2)=1+γvπ(s4)vπ(s3)=1+γvπ(s4)vπ(s4)=1+γvπ(s4)
从后往前算:
v π ( s 4 ) = 1 1 − γ v π ( s 3 ) = 1 1 − γ v π ( s 2 ) = 1 1 − γ v π ( s 1 ) = 0.5 [ 0 + γ v π ( s 3 ) ] + 0.5 [ − 1 + γ v π ( s 2 ) ] = − 0.5 + γ 1 − γ v_{\pi}(s_4) = \frac{1}{1 - \gamma} \\ v_{\pi}(s_3) = \frac{1}{1 - \gamma} \\ v_{\pi}(s_2) = \frac{1}{1 - \gamma} \\ \begin{align*} v_{\pi}(s_1) &= 0.5[0 + \gamma v_{\pi}(s_3)] + 0.5[-1 + \gamma v_{\pi}(s_2)] \\ & = -0.5 + \frac{\gamma}{1 - \gamma} \end{align*} vπ(s4)=1−γ1vπ(s3)=1−γ1vπ(s2)=1−γ1vπ(s1)=0.5[0+γvπ(s3)]+0.5[−1+γvπ(s2)]=−0.5+1−γγ
Bellman equation: Matrix-vector form
对于Bellman equation:
v π ( s ) = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] v_{\pi}(s) = \sum_a \pi(a | s) \left[ \sum_r p(r | s, a)r + \gamma \sum_{s'}p(s' | s, a) v_{\pi}(s') \right] vπ(s)=a∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)]
通常是未知的 v π ( s ) v_{\pi}(s) vπ(s)伴随着未知的 v π ( s ′ ) v_{\pi}(s') vπ(s′),这对于每一个 s ∈ S s \in \mathcal{S} s∈S都成立。因此,意味着共有 ∣ S ∣ |\mathcal{S}| ∣S∣个这样的等式。如果将所有的等式,放到一起进行计算,这就构成了Bellman equation的矩阵形式。
将上式展开,写为:
v π ( s ) = r π ( s ) + γ ∑ s ′ p π ( s ′ ∣ s ) v π ( s ′ ) ( 1 ) v_{\pi}(s) = r_{\pi}(s) + \gamma \sum_{s'} p_{\pi}(s' | s)v_{\pi}(s') \;\;\;\;\; (1) vπ(s)=rπ(s)+γs′∑pπ(s′∣s)vπ(s′)(1)
其中:
r π ( s ) : = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r p π ( s ′ ∣ s ) : = ∑ a π ( a ∣ s ) p ( s ′ ∣ s , a ) r_{\pi}(s) := \sum_a \pi(a | s) \sum_r p(r | s, a)r \\ p_{\pi}(s' | s) := \sum_a \pi(a | s) p(s' | s, a) rπ(s):=a∑π(a∣s)r∑p(r∣s,a)rpπ(s′∣s):=a∑π(a∣s)p(s′∣s,a)
为state s s s添加索引 s i , i = 1 , . . . , n s_i, i = 1, ..., n si,i=1,...,n
对于 s i s_i si,其Bellman equation为:
v π ( s i ) = r π ( s i ) + γ ∑ s j p π ( s j ∣ s i ) v π ( s j ) v_{\pi}(s_i) = r_{\pi}(s_i) + \gamma \sum_{s_j} p_{\pi}(s_j | s_i)v_{\pi}(s_j) vπ(si)=rπ(si)+γsj∑pπ(sj∣si)vπ(sj)
将所有的state写为矩阵形式:
v π = r π + γ P π v π \mathbf{v}_{\pi} = \mathbf{r}_{\pi} + \gamma \mathbf{P}_{\pi} \mathbf{v}_{\pi} vπ=rπ+γPπvπ
其中:
- v π = [ v π ( s 1 ) , v π ( s 2 ) , . . . , v π ( s n ) ] T ∈ R n \mathbf{v}_{\pi} = [v_{\pi}(s_1), v_{\pi}(s_2), ..., v_{\pi}(s_n)]^T \in \mathbb{R}^n vπ=[vπ(s1),vπ(s2),...,vπ(sn)]T∈Rn
- r π = [ r π ( s 1 ) , r π ( s 2 ) , . . . , r π ( s n ) ] T ∈ R n \mathbf{r}_{\pi} = [r_{\pi}(s_1), r_{\pi}(s_2), ..., r_{\pi}(s_n)]^T \in \mathbb{R}^n rπ=[rπ(s1),rπ(s2),...,rπ(sn)]T∈Rn
- P π ∈ R n × n \mathbf{P}_{\pi} \in \mathbb{R}^{n \times n} Pπ∈Rn×n,其中, [ P π ] = p π ( s j ∣ s i ) [P_{\pi}] = p_{\pi}(s_j | s_i) [Pπ]=pπ(sj∣si)是state转移矩阵。
假设有四个state,则上式矩阵形式可以写为:
[ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] = [ r π ( s 1 ) r π ( s 2 ) r π ( s 3 ) r π ( s 4 ) ] + γ [ p π ( s 1 ∣ s 1 ) p π ( s 2 ∣ s 1 ) p π ( s 3 ∣ s 1 ) p π ( s 4 ∣ s 1 ) p π ( s 1 ∣ s 2 ) p π ( s 2 ∣ s 2 ) p π ( s 3 ∣ s 2 ) p π ( s 4 ∣ s 2 ) p π ( s 1 ∣ s 3 ) p π ( s 2 ∣ s 3 ) p π ( s 3 ∣ s 3 ) p π ( s 4 ∣ s 3 ) p π ( s 1 ∣ s 4 ) p π ( s 2 ∣ s 4 ) p π ( s 3 ∣ s 4 ) p π ( s 4 ∣ s 4 ) ] [ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] \begin{bmatrix} v_{\pi}(s_1) \\ v_{\pi}(s_2)\\ v_{\pi}(s_3)\\ v_{\pi}(s_4) \end{bmatrix} = \begin{bmatrix} r_{\pi}(s_1) \\ r_{\pi}(s_2)\\ r_{\pi}(s_3)\\ r_{\pi}(s_4) \end{bmatrix} + \gamma \begin{bmatrix} p_{\pi}(s_1 | s_1) &p_{\pi}(s_2 | s_1) &p_{\pi}(s_3 | s_1) &p_{\pi}(s_4 | s_1)\\ p_{\pi}(s_1 | s_2) &p_{\pi}(s_2 | s_2) &p_{\pi}(s_3 | s_2) &p_{\pi}(s_4 | s_2)\\ p_{\pi}(s_1 | s_3) &p_{\pi}(s_2 | s_3) &p_{\pi}(s_3 | s_3) &p_{\pi}(s_4 | s_3)\\ p_{\pi}(s_1 | s_4) &p_{\pi}(s_2 | s_4) &p_{\pi}(s_3 | s_4) &p_{\pi}(s_4 | s_4) \end{bmatrix} \begin{bmatrix} v_{\pi}(s_1) \\ v_{\pi}(s_2)\\ v_{\pi}(s_3)\\ v_{\pi}(s_4) \end{bmatrix} vπ(s1)vπ(s2)vπ(s3)vπ(s4) = rπ(s1)rπ(s2)rπ(s3)rπ(s4) +γ pπ(s1∣s1)pπ(s1∣s2)pπ(s1∣s3)pπ(s1∣s4)pπ(s2∣s1)pπ(s2∣s2)pπ(s2∣s3)pπ(s2∣s4)pπ(s3∣s1)pπ(s3∣s2)pπ(s3∣s3)pπ(s3∣s4)pπ(s4∣s1)pπ(s4∣s2)pπ(s4∣s3)pπ(s4∣s4) vπ(s1)vπ(s2)vπ(s3)vπ(s4)
例,对policy1:

对其求解,得:
[ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] = [ 0 1 1 1 ] + γ [ 0 0 1 0 0 0 0 1 0 0 0 1 0 0 0 1 ] [ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] \begin{bmatrix} v_{\pi}(s_1) \\ v_{\pi}(s_2)\\ v_{\pi}(s_3)\\ v_{\pi}(s_4) \end{bmatrix} = \begin{bmatrix} 0 \\ 1\\ 1\\ 1 \end{bmatrix} + \gamma \begin{bmatrix} 0 &0 &1 &0\\ 0 &0 &0 &1\\ 0 &0 &0 &1\\ 0 &0 &0 &1 \end{bmatrix}\begin{bmatrix} v_{\pi}(s_1) \\ v_{\pi}(s_2)\\ v_{\pi}(s_3)\\ v_{\pi}(s_4) \end{bmatrix} vπ(s1)vπ(s2)vπ(s3)vπ(s4) = 0111 +γ 0000000010000111 vπ(s1)vπ(s2)vπ(s3)vπ(s4)
对policy2:

对其求解,得:
[ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] = [ 0.5 ( 0 ) + 0.5 ( − 1 ) 1 1 1 ] + γ [ 0 0.5 0.5 0 0 0 0 1 0 0 0 1 0 0 0 1 ] [ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] \begin{bmatrix} v_{\pi}(s_1) \\ v_{\pi}(s_2)\\ v_{\pi}(s_3)\\ v_{\pi}(s_4) \end{bmatrix} = \begin{bmatrix} 0.5(0) + 0.5(-1) \\ 1\\ 1\\ 1 \end{bmatrix} + \gamma \begin{bmatrix} 0 &0.5 &0.5 &0\\ 0 &0 &0 &1\\ 0 &0 &0 &1\\ 0 &0 &0 &1 \end{bmatrix}\begin{bmatrix} v_{\pi}(s_1) \\ v_{\pi}(s_2)\\ v_{\pi}(s_3)\\ v_{\pi}(s_4) \end{bmatrix} vπ(s1)vπ(s2)vπ(s3)vπ(s4) = 0.5(0)+0.5(−1)111 +γ 00000.50000.50000111 vπ(s1)vπ(s2)vπ(s3)vπ(s4)
Bellman equation: Solve the state values
对于矩阵形式的Bellman equation:
v π = r π + γ P π v π \mathbf{v}_{\pi} = \mathbf{r}_{\pi} + \gamma \mathbf{P}_{\pi} \mathbf{v}_{\pi} vπ=rπ+γPπvπ
其closed-form的解为:
v π = ( I − γ P π ) − 1 r π \mathbf{v}_{\pi} = (\mathbf{I} - \gamma \mathbf{P}_{\pi})^{-1} \mathbf{r}_{\pi} vπ=(I−γPπ)−1rπ
为了避免求矩阵的逆,可以采用迭代法:
v k + 1 = r + γ P π v k v k → v π = ( I − γ P π ) − 1 r π , k → ∞ \mathbf{v}_{k + 1} = \mathbf{r} + \gamma \mathbf{P}_{\pi} \mathbf{v}_k \\ \mathbf{v}_k \rightarrow \mathbf{v}_{\pi} = (\mathbf{I} - \gamma \mathbf{P}_{\pi})^{-1} \mathbf{r}_{\pi}, \;\;\; k \rightarrow \infty vk+1=r+γPπvkvk→vπ=(I−γPπ)−1rπ,k→∞
以下是对于一个grid-world,在给定policy下,各个state的state value。


可以看到,不同的policy其产生的state value可能是相同的。


可以看到,大多数情况下,不同的policy对state value的影响是比较大的,因此,state value是有效评估policy的一个指标。
Action value
state value: agent从某个state开始可以获得的平均return
action value: agent从某个state开始并采取action可以获得的平均return。
通过action value可以知道当前state下,哪个action是更好的。
定义:
q π ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_{\pi}(s, a) = \mathbb{E}[G_t | S_t = s, A_t = a] qπ(s,a)=E[Gt∣St=s,At=a]
- q π ( s , a ) q_{\pi}(s, a) qπ(s,a)是state、action对的函数
- q π ( s , a ) q_{\pi}(s, a) qπ(s,a)依赖于 π \pi π
根据条件期望公式:
E [ G t ∣ S t = s ] = ∑ a E [ G t ∣ S t = s , A t = a ] π ( a ∣ s ) \mathbb{E}[G_t | S_t = s] = \sum_a \mathbb{E}[G_t | S_t = s, A_t = a] \pi (a | s) E[Gt∣St=s]=a∑E[Gt∣St=s,At=a]π(a∣s)
因此,
v π ( s ) = ∑ a π ( a ∣ s ) q π ( s , a ) ( 2 ) v_{\pi}(s) = \sum_{a} \pi(a | s) q_{\pi}(s, a) \;\;\;\;\; (2) vπ(s)=a∑π(a∣s)qπ(s,a)(2)
对于state value:
v π ( s ) = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] = ∑ a π ( a ∣ s ) ⋅ q π ( s , a ) ( 3 ) \begin{align*} v_{\pi}(s) &= \sum_a \pi(a | s) \left[ \sum_r p(r | s, a)r + \gamma \sum_{s'}p(s' | s, a) v_{\pi}(s') \right]\\ &=\sum_a \pi(a | s) \cdot q_{\pi}(s, a) \end{align*} \;\;\;\;\; (3) vπ(s)=a∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)]=a∑π(a∣s)⋅qπ(s,a)(3)
比较公式(2)与公式(3),可以得到action-value function:
q π ( s , a ) = ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ( 4 ) q_{\pi}(s, a) = \sum_r p(r | s, a)r + \gamma \sum_{s'} p(s' | s, a) v_{\pi}(s') \;\;\;\;\; (4) qπ(s,a)=r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)(4)
通过公式(2)和公式(4)可以发现state value和action value可以相互转化。
例:

求解,得:
q π ( s 1 , a 1 ) = − 1 + γ v π ( s 1 ) q π ( s 1 , a 2 ) = − 1 + γ v π ( s 2 ) q π ( s 1 , a 3 ) = 0 + γ v π ( s 3 ) q π ( s 1 , a 4 ) = − 1 + γ v π ( s 1 ) q π ( s 1 , a 5 ) = 0 + γ v π ( s 1 ) \begin{align*} &q_{\pi}(s_1, a_1) = -1 + \gamma v_{\pi}(s_1)\\ &q_{\pi}(s_1, a_2) = -1 + \gamma v_{\pi}(s_2)\\ &q_{\pi}(s_1, a_3) = 0 + \gamma v_{\pi}(s_3) \\ &q_{\pi}(s_1, a_4) = -1 + \gamma v_{\pi}(s_1) \\ &q_{\pi}(s_1, a_5) = 0 + \gamma v_{\pi}(s_1) \end{align*} qπ(s1,a1)=−1+γvπ(s1)qπ(s1,a2)=−1+γvπ(s2)qπ(s1,a3)=0+γvπ(s3)qπ(s1,a4)=−1+γvπ(s1)qπ(s1,a5)=0+γvπ(s1)
Summary
-
state value: v π ( s ) = E [ G t ∣ S t = s ] v_{\pi}(s) = \mathbb{E}[G_t | S_t = s] vπ(s)=E[Gt∣St=s]
-
action value: q π ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_{\pi}(s, a) = \mathbb{E}[G_t | S_t = s, A_t = a] qπ(s,a)=E[Gt∣St=s,At=a]
-
Bellman equation:
elementwise form
v π ( s ) = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] = ∑ a π ( a ∣ s ) ⋅ q π ( s , a ) \begin{align*} v_{\pi}(s) &= \sum_a \pi(a | s) \left[ \sum_r p(r | s, a)r + \gamma \sum_{s'}p(s' | s, a) v_{\pi}(s') \right]\\ &=\sum_a \pi(a | s) \cdot q_{\pi}(s, a) \end{align*} vπ(s)=a∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)]=a∑π(a∣s)⋅qπ(s,a)
matrix-vector form
v π = r π + γ P v π \mathbf{v}_{\pi} = \mathbf{r}_{\pi} + \gamma \mathbf{P} \mathbf{v}_{\pi} vπ=rπ+γPvπ -
可以通过闭合形式解和迭代法求Bellman equation
以上内容为B站西湖大学智能无人系统 强化学习的数学原理 公开课笔记。
相关文章:
【RL】Bellman Equation (贝尔曼等式)
Lecture2: Bellman Equation State value 考虑grid-world的单步过程: S t → A t R t 1 , S t 1 S_t \xrightarrow[]{A_t} R_{t 1}, S_{t 1} StAt Rt1,St1 t t t, t 1 t 1 t1:时间戳 S t S_t St:时间 t t t时所处的sta…...

PyTorch 2.2大更新!集成FlashAttention-2,性能提升2倍
【新智元导读】新的一年,PyTorch也迎来了重大更新,PyTorch 2.2集成了FlashAttention-2和AOTInductor等新特性,计算性能翻倍。 新的一年,PyTorch也迎来了重大更新! 继去年十月份的PyTorch大会发布了2.1版本之后&#…...

2.9日学习打卡----初学RabbitMQ(四)
2.9日学习打卡 一.RabbitMQ 死信队列 在MQ中,当消息成为死信(Dead message)后,消息中间件可以将其从当前队列发送到另一个队列中,这个队列就是死信队列。而在RabbitMQ中,由于有交换机的概念,实…...

大数据Flume--入门
文章目录 FlumeFlume 定义Flume 基础架构AgentSourceSinkChannelEvent Flume 安装部署安装地址安装部署 Flume 入门案例监控端口数据官方案例实时监控单个追加文件实时监控目录下多个新文件实时监控目录下的多个追加文件 Flume Flume 定义 Flume 是 Cloudera 提供的一个高可用…...

【SQL高频基础题】550.游戏玩法分析IⅣ
这个SQL花了很久。但是有挺多启发的。 如果我们做不出来,就去看答案。 但是看完答案之后,不要着急就去看下一道题,先把这道题吃透,后面的题目就会更有思路。 题目: Table: Activity ----------------------- | Co…...

sheng的学习笔记-部署-目录
标题传送门 sheng的学习笔记-docker部署,原理图,命令,用idea设置docker sheng的学习笔记-docker部署,原理图,命令,用idea设置docker sheng的学习笔记-docker部署springboot sheng的学习笔记-docker部署spri…...

【Java】悲观锁和乐观锁有什么区别?
Java中的悲观锁和乐观锁的主要区别体现在以下几个方面: 加锁策略:悲观锁在操作数据时,总是假设最坏的情况,即认为其他线程会修改数据,因此在读取或操作数据时,会先对数据进行加锁,以保证数据的…...
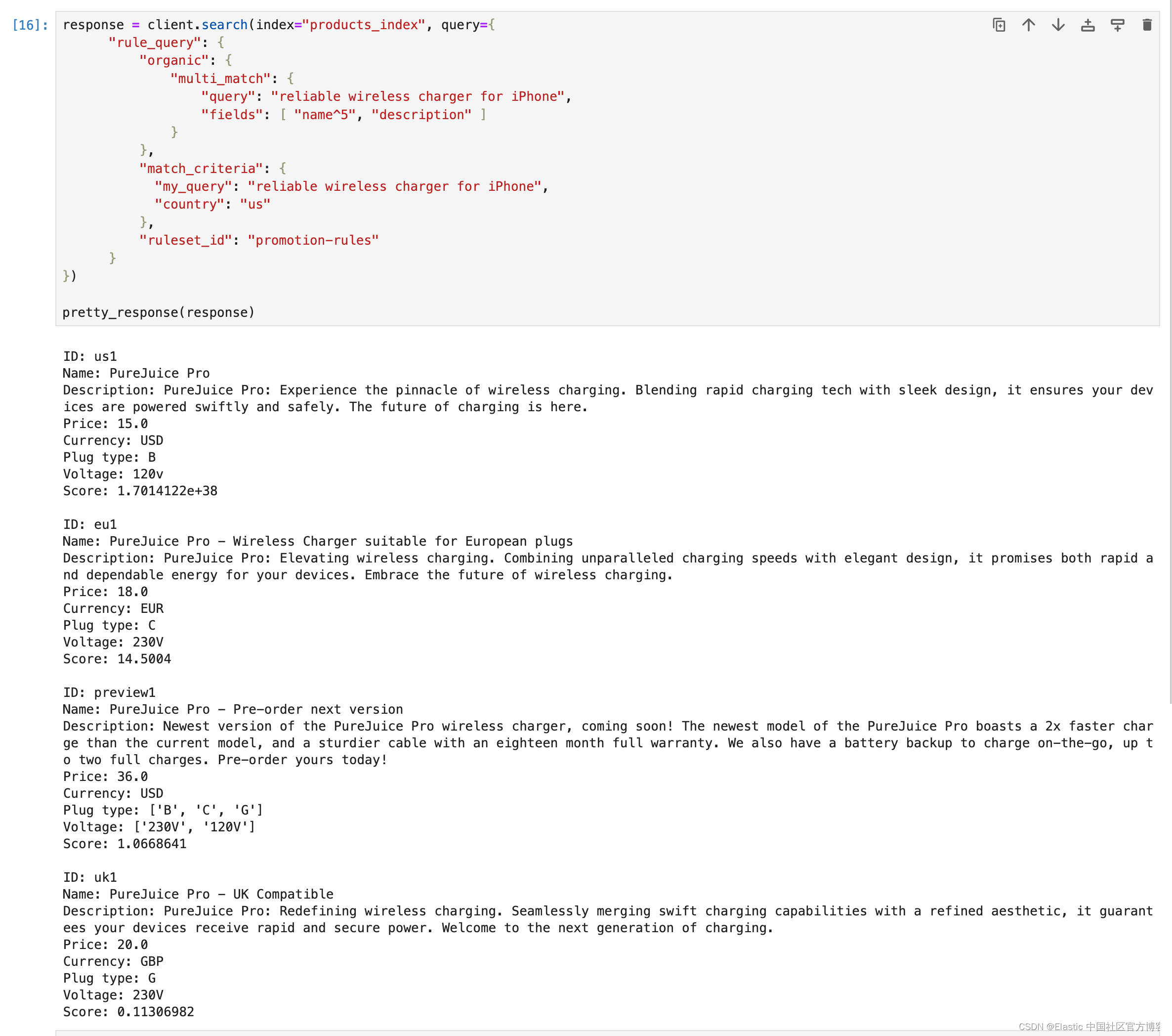
Elasticsearch:使用查询规则(query rules)进行搜索
在之前的文章 “Elasticsearch 8.10 中引入查询规则 - query rules”,我们详述了如何使用 query rules 来进行搜索。这个交互式笔记本将向你介绍如何使用官方 Elasticsearch Python 客户端来使用查询规则。 你将使用 query rules API 将查询规则存储在 Elasticsearc…...
Java核心设计模式:代理设计模式
一、生活中常见的代理案例 房地产中介:客户手里没有房源信息,找一个中介帮忙商品代购:代理者一般有好的资源渠道,降低购物成本(如海外代购,自己不用为了买东西出国) 二、为什么要使用代理 对…...

JSP编程
JSP编程 您需要理解在JSP API的类和接口中定义的用于创建JSP应用程序的各种方法的用法。此外,还要了解各种JSP组件,如在前一部分中学习的JSP动作、JSP指令及JSP脚本。JSP API中定义的类提供了可借助隐式对象通过JSP页面访问的方法。 1. JSP API的类 JSP API是一个可用于创建…...
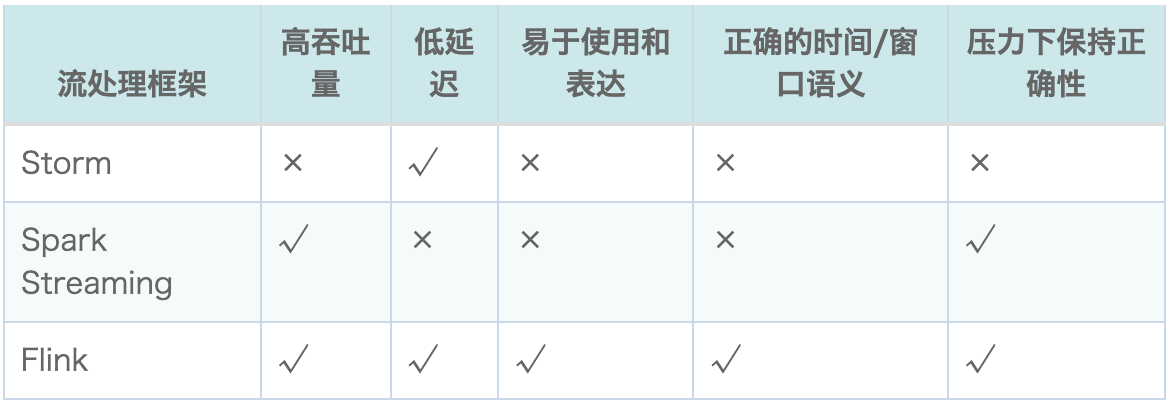
【Flink入门修炼】1-1 为什么要学习 Flink?
流处理和批处理是什么? 什么是 Flink? 为什么要学习 Flink? Flink 有什么特点,能做什么? 本文将为你解答以上问题。 一、批处理和流处理 早些年,大数据处理还主要为批处理,一般按天或小时定时处…...

刘谦龙年春晚魔术模拟
守岁共此时 代码 直接贴代码了,异常处理有点问题,正常流程能跑通 package com.yuhan.snginx.util.chunwan;import java.util.*;/*** author yuhan* since 2024/02/10*/ public class CWMS {static String[] num {"A", "2", &quo…...

re:从0开始的CSS学习之路 9. 盒子水平布局
0. 写在前面 过年也不能停止学习,一停下就难以为继,实属不应 1. 盒子的水平宽度 当一个盒子出现在另一个盒子的内容区时,该盒子的水平宽度“必须”等于父元素内容区的宽度 盒子水平宽度: margin-left border-left padding-lef…...

【MySQL基础】:深入探索DQL数据库查询语言的精髓(上)
🎥 屿小夏 : 个人主页 🔥个人专栏 : MySQL从入门到进阶 🌄 莫道桑榆晚,为霞尚满天! 文章目录 📑前言一. DQL1.1 基本语法1.2 基础查询1.3 条件查询1.3 聚合函数 🌤️ 全篇…...

JavaScript实现轮播图方法
效果图 先来看下效果图,嫌麻烦就不用具体图片来实现了,主要是理清思路。(自动轮播,左右按钮切换图片,小圆点切换图片,鼠标移入暂停轮播,鼠标移出继续轮播) HTML 首先是html内容&am…...

Web课程学习笔记--jsonp的原理与简单实现
jsonp的原理与简单实现 原理 由于同源策略的限制,XmlHttpRequest只允许请求当前源(域名、协议、端口)的资源,为了实现跨域请求,可以通过script标签实现跨域请求,然后在服务端输出JSON数据并执行回调函数&…...
第78讲 修改密码
系统管理实现 修改密码实现 前端 modifyPassword.vue: <template><el-card><el-formref"formRef":model"form":rules"rules"label-width"150px"><el-form-item label"用户名:&quo…...
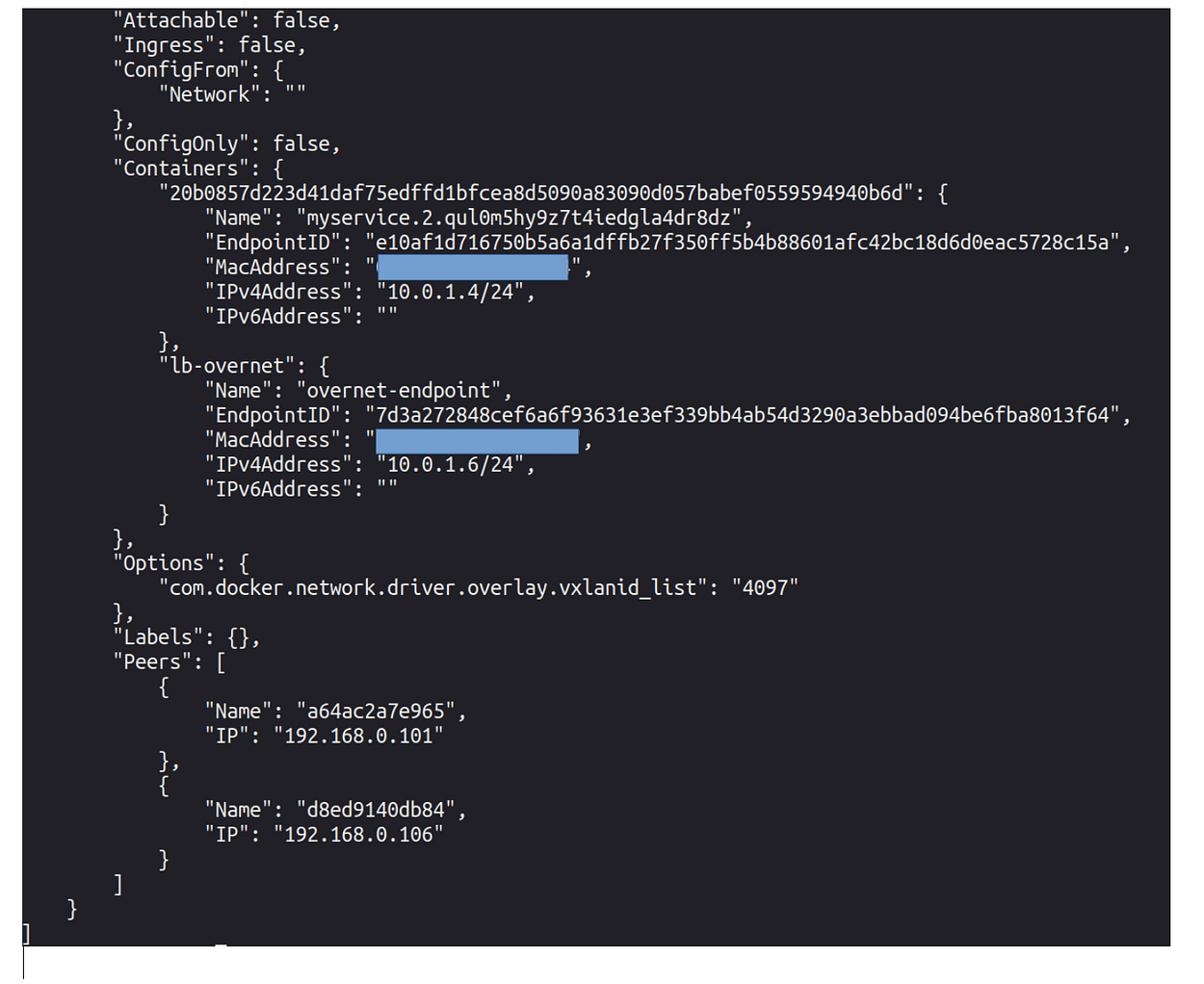
Docker 容器网络:C++ 客户端 — 服务器应用程序。
一、说明 在下面的文章中, 将向您概述 docker 容器之间的通信。docker 通信的验证将通过运行 C 客户端-服务器应用程序和标准“ping”命令来执行。将构建并运行两个单独的 Docker 映像。 由于我会关注 docker 网络方面,因此不会提供 C 详细信息。…...
Android 识别车牌信息
打开我们心爱的Android Studio 导入需要的资源 gradle //开源车牌识别安卓SDK库implementation("com.github.HyperInspire:hyperlpr3-android-sdk:1.0.3")button.setOnClickListener(v -> {Log.d("Test", "");try (InputStream file getAs…...
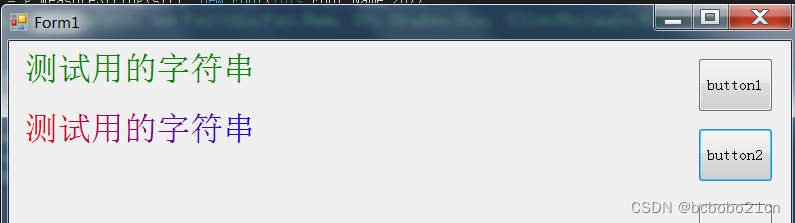
C#在窗体正中输出文字以及输出文字的画刷使用
为了在窗体正中输出文字,需要获得输出文字区域的宽和高,这使用MeasureString方法,方法返回值为Size类型; 然后计算输出的起点的x和y坐标,就可以输出了; using System; using System.Collections.Generic; …...

PlugY:重新定义暗黑破坏神2单机体验的技术突破
PlugY:重新定义暗黑破坏神2单机体验的技术突破 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 暗黑破坏神2作为ARPG游戏的里程碑之作,其单机模…...

如何实现Vuetify与GraphQL Code Generator的完美结合:终极类型安全数据获取指南
如何实现Vuetify与GraphQL Code Generator的完美结合:终极类型安全数据获取指南 【免费下载链接】vuetify 🐉 Vue Component Framework 项目地址: https://gitcode.com/gh_mirrors/vu/vuetify 在现代Web开发中,Vuetify组件框架与Graph…...

STM32F103ZET6【HAL库实战】STM32CubeMX配置高级定时器实现三相电机驱动PWM
1. 为什么需要带死区的互补PWM 在驱动三相无刷电机时,最头疼的问题就是上下桥臂直通。想象一下,如果同一个桥臂的上下两个MOS管同时导通,电源正负极就直接短路了,轻则烧MOS管,重则整个电路板冒烟。我当年第一次调电机驱…...

2026届毕业生推荐的五大降AI率网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 从以下方面着手,能够降低AIGC(人工智能生成内容)的检测特…...

LANCZOS智能压缩+RGB自动转换:Anything to RealCharacters预处理模块详解
LANCZOS智能压缩RGB自动转换:Anything to RealCharacters预处理模块详解 1. 项目概述 Anything to RealCharacters是一款专为RTX 4090显卡设计的2.5D转真人图像转换系统。该系统基于通义千问Qwen-Image-Edit-2511图像编辑模型,集成了专门优化的写实化权…...

AutoGen Studio问题排查:模型服务启动失败解决方案
AutoGen Studio问题排查:模型服务启动失败解决方案 1. 问题现象与初步诊断 当您尝试启动AutoGen Studio时,可能会遇到模型服务无法正常启动的情况。这种情况通常表现为: Web界面可以访问但无法正常调用模型创建会话时长时间无响应测试模型…...

如何在5分钟内完成Blender 3MF插件的终极安装与配置
如何在5分钟内完成Blender 3MF插件的终极安装与配置 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender 3MF插件是一款革命性的开源工具,专为3D打印工作流…...

三步实现Joy-Con模拟Xbox手柄:解决低成本游戏外设适配难题
三步实现Joy-Con模拟Xbox手柄:解决低成本游戏外设适配难题 【免费下载链接】XJoy 项目地址: https://gitcode.com/gh_mirrors/xjo/XJoy 在游戏世界中,拥有合适的控制器往往能带来截然不同的体验。然而,专用游戏手柄动辄数百元的价格让…...

2026年,温州贴纸定制售后哪家强?这份避坑指南请收好
在温州,无论是蓬勃发展的电商产业,还是底蕴深厚的制造业,对高品质、个性化的贴纸、标签需求都日益旺盛。然而,许多企业在定制过程中,都曾踩过“货不对板”、“交付延迟”、“售后无门”的坑。选择一家靠谱的供应商&…...

四足机器人步态调参实战:如何用Walk These Ways控制器实现楼梯穿越与抗干扰行走
四足机器人步态调参实战:Walk These Ways控制器在复杂地形中的应用技巧 当Unitree Go1机器人第一次站在楼梯前时,开发者们面临着一个经典困境——如何让这台在平地上表现优异的机器跨越这道障碍。传统解决方案往往需要重新训练模型或调整底层算法&#…...