爬虫练习——动态网页的爬取(股票和百度翻译)

动态网页也是字面意思:实时更新的那种
还有就是你在股票这个网站上,翻页。他的地址是不变的
是动态的加载,真正我不太清楚,只知道他是不变的。如果用静态网页的方法就不可行了。
静态网页的翻页,是网址是有规律的。
还有就是:
在百度翻译中你总是在百度翻译一个网站上 ,并没有因此而改变。(意思就是不是查一个单词,换一个网址)
正文开始了哈:
先来看成品和代码;
如果想要其他东西,只要改对应的地方。就可以拿到对于的数据。
import os
import requests
import re
import jsonwenjian = input("您要保存的文件名:")
img_path = f"./{wenjian}/" # 指定保存地址
if not os.path.exists(img_path):print("您没有这个文件为您新建一个文件:")os.mkdir(img_path)
else:print(f"您有这个文件夹,将为您保存在“{wenjian}”中")
count=0
url = "https://63.push2.eastmoney.com/api/qt/clist/get?"hearders = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'
}
#for i in range(1,281,1):
for i in range(1,281,1):count+=1params = {'cb': 'jQuery1124010908871949611432_1707493179217','pn': f'{i}','pz': '20','po': '1','np': '1','ut': 'bd1d9ddb04089700cf9c27f6f7426281','fltt': '2','invt': '2','wbp2u': '|0|0|0|web','fid': 'f3','fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048','fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152','_': '1707493179252'}resqonse = requests.get(url,headers=hearders,params=params).text#print(resqonse)obj = re.compile(r"jQuery1124010908871949611432_1707493179217\((?P<json>.*?)\);")#给正则表达式的匹配的东西起个名字,叫json(?P<name>.*?)content = obj.search(resqonse).group('json')#在reqonse中搜索json的正则表达式#print(content)#print(f"第一次拿到的是content他的类型为{type(content)}")#转换成字典dic = json.loads(content)#print(dic)#print(f"改为字典为dic类型为{type(dic)}")#拿数据diff = dic['data']['diff'] #想要拿名字和股票编号。他们在data里的diff中for i in diff:name = i['f14']num = i['f12']#print(f"他的名字是: {name}——{num}")end = name+'-------'+num+"\n"f = open(f"{img_path}{wenjian}.txt", 'a')f.write(end)print(f"第{count}页打印完成")一般在XHR和JS文件中找到想要的数据

要加入params和headers你会发现页数的改变是跟着 params中的'pn'在变,所以在页数改变的同时,'pn'也再改变。
上述代码中,加入新东西的是---Json
Json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
1.dumps和dump:
dump比Dumps多了一个操作,对于文件的写入。改为数据类型然后写入文件
# fp = open(f'{img_path}.txt', 'w',encoding='utf-8')
# json.dump(dic,fp=fp,ensure_ascii=False),中文的写入
2.毕竟是学习,就截屏了做个笔记。
import jsona="[1,2,3,4]"
b='{"k1":1,"k2":2}'#当字符串为字典时{}外面必须是''单引号{}里面必须是""双引号print (json.loads(a) )
[1, 2, 3, 4]print (json.loads(b) )
{'k2': 2, 'k1': 1}

上面这个就很简单了到目前来说,简单指的是可以看懂!!!
上面还有一个关于给自己正则表达式找到的起名字的写法,代码后面我有注释,不再多说!!!
下面是百度翻译的读取,顺便做了个翻译系统:
这个我就是多查了计次。
import json
import requests
import os
Myflag=1
img_path = '百度翻译'
img_path = f"./{img_path}/" # 指定保存地址
if not os.path.exists(img_path):print("您没有这个文件为您新建一个文件---")os.mkdir(img_path)
else:print(f"百度翻译——结果为您保存在{img_path}文件夹中")
url = "https://fanyi.baidu.com/sug"
while Myflag!="0":wenjian = input("您要查询的单词是:")header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'}data = {'kw':f'{wenjian}'}response = requests.post(url = url,headers = header,data = data)dic = response.json()data = dic['data']print(f"您所查询的{wenjian}的意思是:")for i in data:data = i['k']translate = i['v']end=data+'————————'+translate+'\n'ending = "\n\n\n================================================\n\n\n\n"print(f'{data}————————{translate}')f = open(f"{img_path}{wenjian}.txt", 'a')f.write(end)f = open(f"{img_path}{wenjian}.txt", 'a')ending = "\n\n\n================================================\n\n\n\n"f.write(ending)print("保存完成")Myflag = input("退出选‘0’,如果想退出请按任意键:")print("您退出单词查询")# fp = open(f'{img_path}.txt', 'w',encoding='utf-8')
# json.dump(dic,fp=fp,ensure_ascii=False)总体来说,要找清楚,你要查询的请求方式。这个为post,到现在用过的请求方式为get。
post中要加入data!!!也就是百度翻译的要翻译的内容!!!
你会发现这里没有用json转换一下,因为这个本事得到的是一个‘dic’的
而上一个用正则表达式得到的名字为json的东西是str,要改为dic,然后分析文件。
上面写入文件的操作在我前面有写到,前面的文章。多看几个就会了。!!!
新年快乐!!!!
相关文章:
爬虫练习——动态网页的爬取(股票和百度翻译)
动态网页也是字面意思:实时更新的那种 还有就是你在股票这个网站上,翻页。他的地址是不变的 是动态的加载,真正我不太清楚,只知道他是不变的。如果用静态网页的方法就不可行了。 静态网页的翻页,是网址是有规律的。 …...

Name or service not known问题解决和分析过程解析
目 录 一、问题描述 二、问题查处过程 (一)为何不能识别到bogon (二)为何会出现bogon (三)能不能更改bogon (四)能识别其他host的名字 三、问题分析 四、问题解决 …...

emmet语法
一.html $排序 直接.dem或#two是默认div 内容可写{}里 二.css 直接写首字母 三.格式化 一次(右键格式化) 永久...

【PTA主观题】8-1 文件操作
题目要求 编写函数int input(FILE * fp),录入学生的信息,自定义录入结束方式,但至少包括学号、姓名、班级、分数和登录密码,并按照学号排序后以二进制方式存入stus.dat,函数返回学生数量;定义函数void enc…...
机器学习算法决策树
决策树的介绍 决策树是一种常见的分类模型,在金融风控、医疗辅助诊断等诸多行业具有较为广泛的应用。决策树的核心思想是基于树结构对数据进行划分,这种思想是人类处理问题时的本能方法。例如在婚恋市场中,女方通常会先询问男方是否有房产&a…...

ssh和sftp服务分离
目录 一、增加sftp的deamon二、增加sftp的service三、其他配套文件四、修改配置文件五、分别重启两个服务: 由于安全需要,客户这边想把sftp使用的端口与ssh使用的端口分开。 我们知道sftp没有自己的服务器守护进程,它需要依赖sshd守护进程来…...
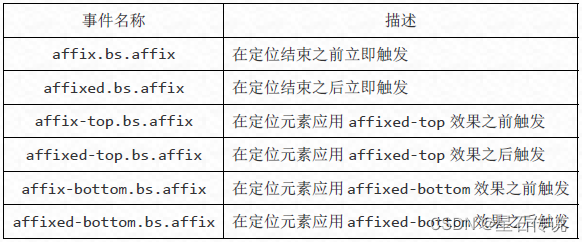
Bootstrap学习三
Bootstrap学习三 文章目录 前言四、Bootstrap插件4.1. 插件概览4.1.1. data属性4.1.2. 编程方式的API4.1.3. 避免命名空间冲突4.1.4. 事件 4.2. 模态框4.2.1. 引入4.2.2. 基本结构4.2.3. 基本使用4.2.4. 触发模态框的方法 4.3. 下拉菜单和滚动监听4.3.1. 下拉菜单4.3.2. 滚动监…...

第77讲用户管理功能实现
用户管理功能实现 前端: views/user/index.vue <template><el-card><el-row :gutter"20" class"header"><el-col :span"7"><el-input placeholder"请输入用户昵称..." clearable v-model"…...
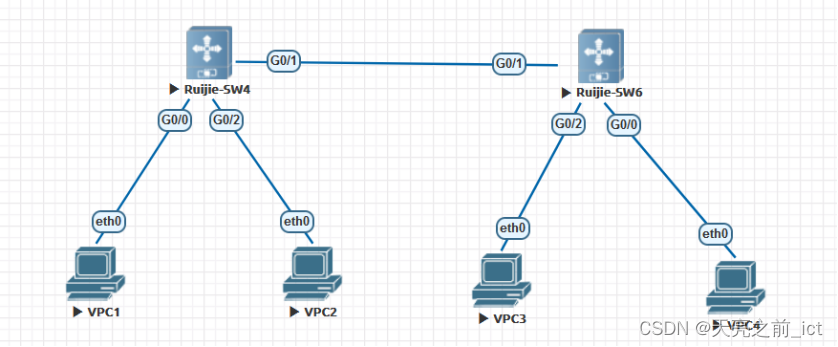
锐捷(十九)锐捷设备的接入安全
1、PC1的IP地址和mac地址做全局静态ARP绑定; 全局下:address-bind 192.168.1.1 mac(pc1) G0/2:ip verify source port-securityarp-check 2、PC2的IP地址和MAC地址做全局IPMAC绑定: Address-bind 192.168.1.2 0050.7966.6807Ad…...
)
【MySQL题】——基础概念论述(二)
🎃个人专栏: 🐬 算法设计与分析:算法设计与分析_IT闫的博客-CSDN博客 🐳Java基础:Java基础_IT闫的博客-CSDN博客 🐋c语言:c语言_IT闫的博客-CSDN博客 🐟MySQL:…...
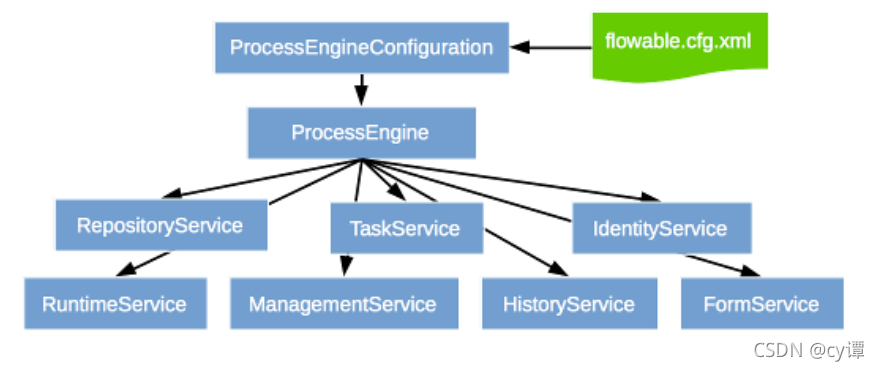
Spring Boot + flowable 快速实现工作流
背景 使用flowable自带的flowable-ui制作流程图 使用springboot开发流程使用的接口完成流程的业务功能 文章来源:https://blog.csdn.net/zhan107876/article/details/120815560 一、flowable-ui部署运行 flowable-6.6.0 运行 官方demo 参考文档: htt…...
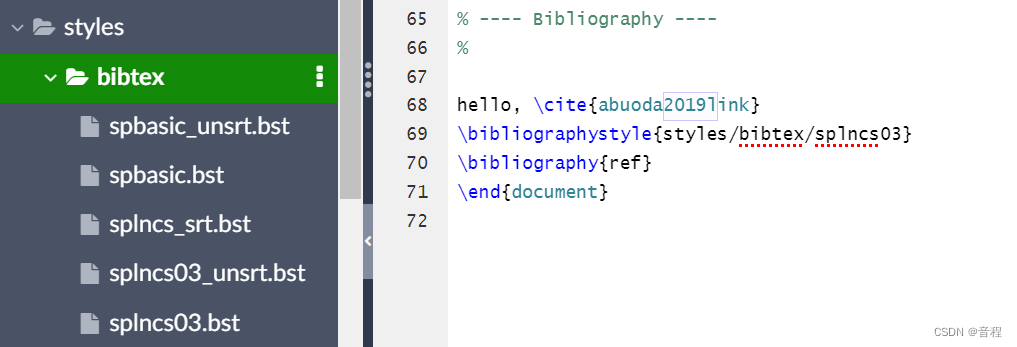
(已解决)LaTeX Error: File `svproc.cls‘ not found. (用Springer LNCS 会议Proceedings模板)
会议要求使用LNCS模板,并给了获取模板链接:https://www.springer.com/gp/authors-editors/conference-proceedings/conference-proceedings-guidelines。我在里面下载了latex模板之后,编译那个author.tex发现抱错: 解决办法&#…...

Spring Boot 自定义指标
Spring Boot 自定义指标 阅读本文需要对一些前置技术有所了解,下面列出的一些前置技术是必须要了解的。 Prometheus:这是一个时序数据库,我们的指标数据一般保存在这个数据库中。Grafana:借助Grafana可以将Prometheus中的数据以图表的方式展示出来。Micrometer:是一个用于…...
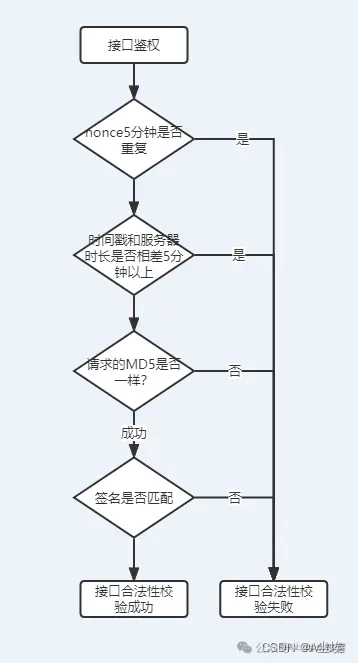
安全的接口访问策略
渗透测试 一、Token与签名 一般客户端和服务端的设计过程中,大部分分为有状态和无状态接口。 一般用户登录状态下,判断用户是否有权限或者能否请求接口,都是根据用户登录成功后,服务端授予的token进行控制的。 但并不是说有了tok…...
最佳视频转换器软件:2024年视频格式转换的选择
我们生活在一个充满数字视频的世界,但提供的内容远不止您最喜欢的流媒体服务目录。虽然我们深受喜爱的设备在播放各种自制和下载的视频文件方面变得越来越好,但在很多情况下您都需要从一种格式转换为另一种格式。 经过大量测试, 我们尝试过…...

深入理解 Nginx 插件及功能优化指南
深入理解 Nginx 插件及功能优化指南 深入理解 Nginx 插件及功能优化指南1. Nginx 插件介绍1.1 HTTP 模块插件ngx_http_rewrite_modulengx_http_access_module 1.2 过滤器插件ngx_http_gzip_modulengx_http_ssl_module 1.3 负载均衡插件ngx_http_upstream_modulengx_http_upstre…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Blank组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Blank组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、Blank组件 空白填充组件,在容器主轴方向上,空白填充组件具…...

InternLM大模型实战-4.XTuner大模型低成本微调实战
文章目录 前言笔记正文XTuner支持模型和数据集 微调原理跟随文档学习快速上手自定义微调准备数据准备配置文件 MS-Agent微调 前言 本文是对于InternLM全链路开源体系系列课程的学习笔记。【XTuner 大模型单卡低成本微调实战】 https://www.bilibili.com/video/BV1yK4y1B75J/?…...

【SpringBoot篇】解决Redis分布式锁的 误删问题 和 原子性问题
文章目录 🍔Redis的分布式锁🛸误删问题🎈解决方法🔎代码实现 🛸原子性问题🌹Lua脚本 ⭐利用Java代码调用Lua脚本改造分布式锁🔎代码实现 🍔Redis的分布式锁 Redis的分布式锁是通过利…...

蓝桥杯Web应用开发-CSS3 新特性【练习三:文本阴影】
文本阴影 text-shadow 属性 给文本内容添加阴影的效果。 文本阴影的语法格式如下: text-shadow: x-offset y-offset blur color;• x-offset 是沿 x 轴方向的偏移距离,允许负值,必须参数。 • y-offset 是沿 y 轴方向的偏移距离,…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能
BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否觉得网易云音乐PC版功能有限,界面单调?…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...