机器学习算法决策树
决策树的介绍
决策树是一种常见的分类模型,在金融风控、医疗辅助诊断等诸多行业具有较为广泛的应用。决策树的核心思想是基于树结构对数据进行划分,这种思想是人类处理问题时的本能方法。例如在婚恋市场中,女方通常会先询问男方是否有房产,如果有房产再了解是否有车产,如果有车产再看是否有稳定工作……最后得出是否要深入了解的判断。
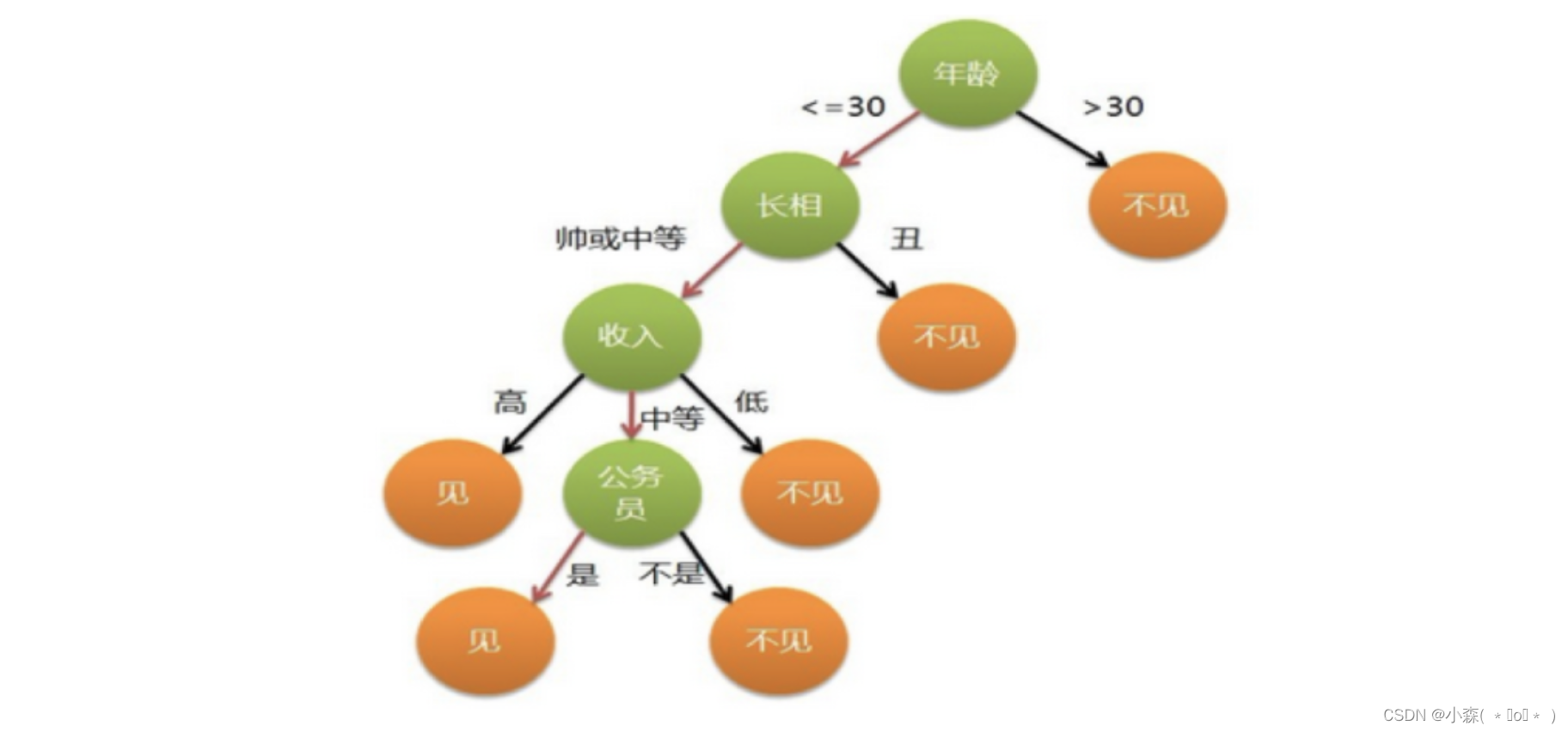
决策树的主要优点:
- 具有很好的解释性,模型可以生成可以理解的规则。
- 可以发现特征的重要程度。
- 模型的计算复杂度较低。
决策树的主要缺点:
- 模型容易过拟合,需要采用减枝技术处理。
- 不能很好利用连续型特征。
- 预测能力有限,无法达到其他强监督模型效果。
- 方差较高,数据分布的轻微改变很容易造成树结构完全不同。
由于决策树模型中自变量与因变量的非线性关系以及决策树简单的计算方法,使得它成为集成学习中最为广泛使用的基模型。梯度提升树,XGBoost以及LightGBM等先进的集成模型都采用了决策树作为基模型,在广告计算、CTR预估、金融风控等领域大放异彩 ,同时决策树在一些明确需要可解释性或者提取分类规则的场景中被广泛应用,而其他机器学习模型在这一点很难做到。例如在医疗辅助系统中,为了方便专业人员发现错误,常常将决策树算法用于辅助病症检测。
决策树的应用
通过sklearn实现决策树分类
import numpy as np
import matplotlib.pyplot as pltfrom sklearn import datasetsiris = datasets.load_iris()
X = iris.data[:,2:]
y = iris.targetplt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==2,0],X[y==2,1])plt.show() 
from sklearn.tree import DecisionTreeClassifiertree = DecisionTreeClassifier(max_depth=2,criterion="entropy")
tree.fit(X,y)依据模型绘制决策树的决策边界
def plot_decision_boundary(model,axis):x0,x1 = np.meshgrid(np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1))X_new = np.c_[x0.ravel(),x1.ravel()]y_predict = model.predict(X_new)zz = y_predict.reshape(x0.shape)from matplotlib.colors import ListedColormapcustom_map = ListedColormap(["#EF9A9A","#FFF59D","#90CAF9"])plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_map)plot_decision_boundary(tree,axis=[0.5,7.5,0,3])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==2,0],X[y==2,1])
plt.show()
实战:
Step: 库函数导入
import numpy as np ## 导入画图库
import matplotlib.pyplot as plt
import seaborn as sns## 导入决策树模型函数
from sklearn.tree import DecisionTreeClassifier
from sklearn import treeStep: 训练模型
## 构造数据集
x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])
y_label = np.array([0, 1, 0, 1, 0, 1])## 调用决策树回归模型
tree_clf = DecisionTreeClassifier()## 调用决策树模型拟合构造的数据集
tree_clf = tree_clf.fit(x_fearures, y_label)Step: 数据和模型可视化
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
plt.show()import graphviz
dot_data = tree.export_graphviz(tree_clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("pengunis")Step:模型预测
x_fearures_new1 = np.array([[0, -1]])
x_fearures_new2 = np.array([[2, 1]])## 在训练集和测试集上分布利用训练好的模型进行预测
y_label_new1_predict = tree_clf.predict(x_fearures_new1)
y_label_new2_predict = tree_clf.predict(x_fearures_new2)print('The New point 1 predict class:\n',y_label_new1_predict)
print('The New point 2 predict class:\n',y_label_new2_predict)ID3 决策树
ID3 树是基于信息增益构建的决策树
- 熵在信息论中代表随机变量不确定度的度量。
- 熵越大,数据的不确定性度越高
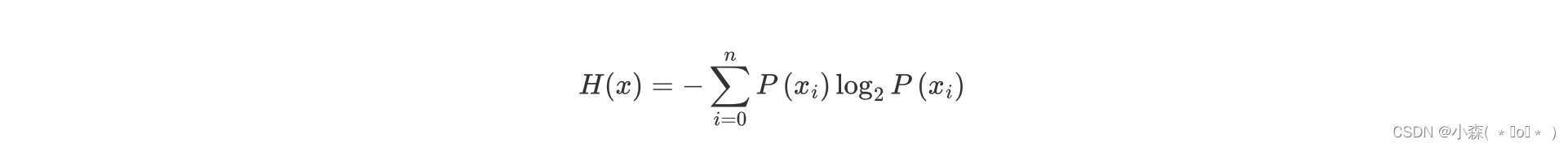
import numpy as np
import matplotlib.pyplot as pltdef entropy(p):return -p*np.log(p)-(1-p)*np.log(1-p)x = np.linspace(0.01,0.99,200)
plt.plot(x,entropy(x))
plt.show() 
信息增益
信息熵是一种衡量数据混乱程度的指标,信息熵越小,则数据的“纯度”越高
ID3算法步骤
- 计算每个特征的信息增益
- 使用信息增益最大的特征将数据集 S 拆分为子集
- 使用该特征(信息增益最大的特征)作为决策树的一个节点
- 使用剩余特征对子集重复上述(1,2,3)过程
C4.5 决策树
信息增益率计算公式

如果某个特征的特征值种类较多,则其内在信息值就越大。特征值种类越多,除以的系数就越大。
如果某个特征的特征值种类较小,则其内在信息值就越小
C4.5算法优缺点
- 优点:分类规则利于理解,准确率高
- 缺点
- 在构造过程中,需要对数据集进行多次的顺序扫描和排序,导致算法的低效
- C4.5只适合于能够驻留内存的数据集,当数据集非常大时,程序无法运行
- 无论是ID3还是C4.5最好在小数据集上使用,当特征取值很多时最好使用C4.5算法。
CART 分类决策树
Cart模型是一种决策树模型,它即可以用于分类,也可以用于回归
(1)决策树生成:用训练数据生成决策树,生成树尽可能大
(2)决策树剪枝:基于损失函数最小化的剪枝,用验证数据对生成的数据进行剪枝。
分类和回归树模型采用不同的最优化策略。Cart回归树使用平方误差最小化策略,Cart分类生成树采用的基尼指数最小化策略。
Criterion这个参数正是用来决定模型特征选择的计算方法的。sklearn提供了两种选择:
-
输入”entropy“,使用信息熵(Entropy)
-
输入”gini“,使用基尼系数(Gini Impurity)
基尼指数:

-
信息增益(ID3)、信息增益率值越大(C4.5),则说明优先选择该特征。
-
基尼指数值越小(cart),则说明优先选择该特征。
剪枝
剪枝是决策树学习算法对付过拟合的主要手段。
在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得"太好"了,以致于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合
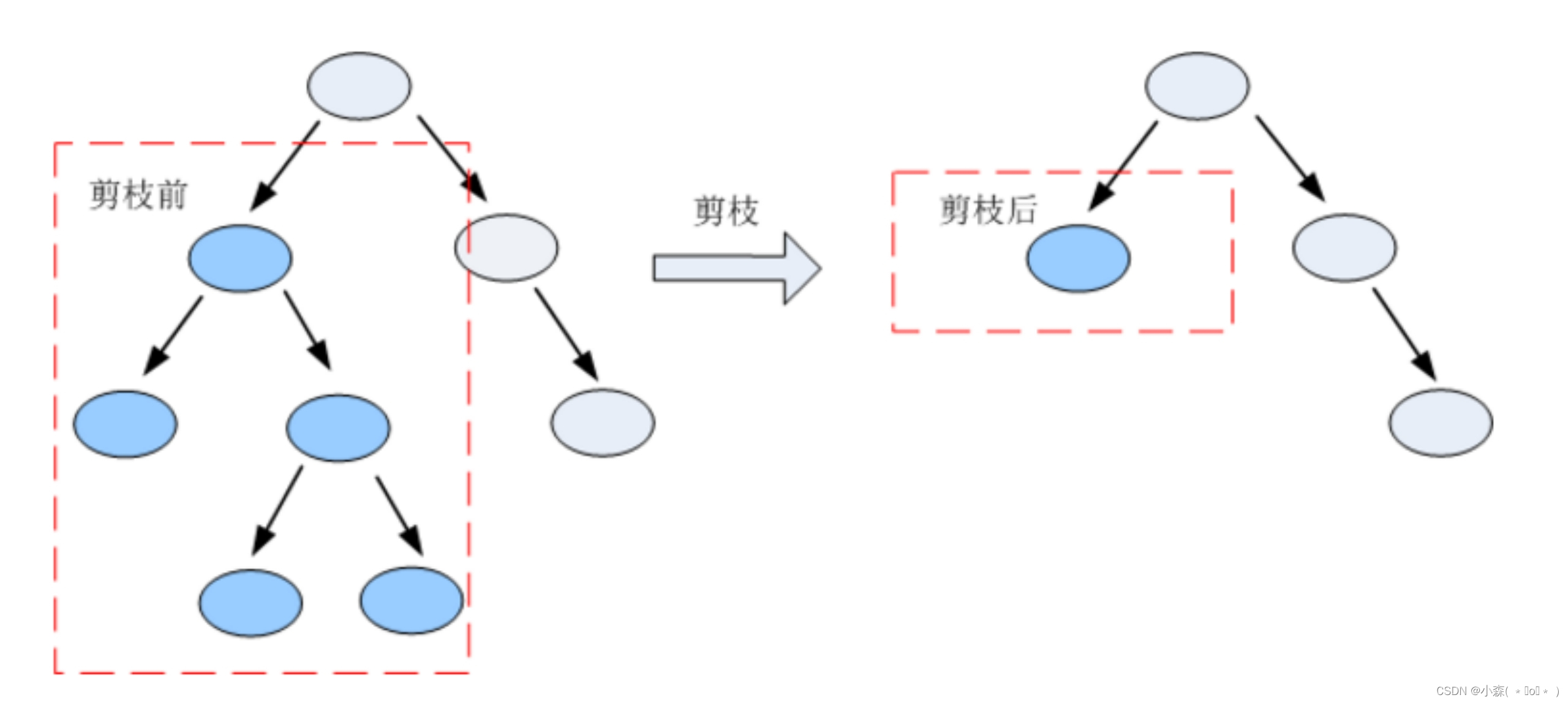
决策树的构建过程是一个递归的过层,所以必须确定停止条件,否则过程将不会停止,树会不停生长。
先剪枝和后剪枝
-
先剪枝就是提前结束决策树的增长。
-
后剪枝是在决策树生长完成之后再进行剪枝的过程。
- 预剪枝使决策树的很多分支没有展开,不单降低了过拟合风险,还显著减少了决策树的训练、测试时间开销。
- 后剪枝比预剪枝保留了更多的分支。一般情况下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝。
相关文章:
机器学习算法决策树
决策树的介绍 决策树是一种常见的分类模型,在金融风控、医疗辅助诊断等诸多行业具有较为广泛的应用。决策树的核心思想是基于树结构对数据进行划分,这种思想是人类处理问题时的本能方法。例如在婚恋市场中,女方通常会先询问男方是否有房产&a…...

ssh和sftp服务分离
目录 一、增加sftp的deamon二、增加sftp的service三、其他配套文件四、修改配置文件五、分别重启两个服务: 由于安全需要,客户这边想把sftp使用的端口与ssh使用的端口分开。 我们知道sftp没有自己的服务器守护进程,它需要依赖sshd守护进程来…...
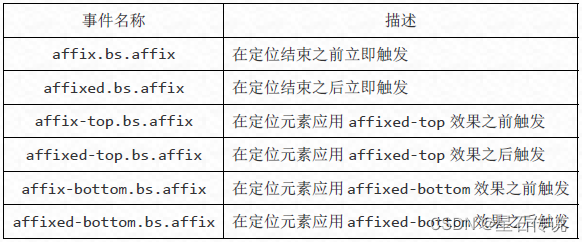
Bootstrap学习三
Bootstrap学习三 文章目录 前言四、Bootstrap插件4.1. 插件概览4.1.1. data属性4.1.2. 编程方式的API4.1.3. 避免命名空间冲突4.1.4. 事件 4.2. 模态框4.2.1. 引入4.2.2. 基本结构4.2.3. 基本使用4.2.4. 触发模态框的方法 4.3. 下拉菜单和滚动监听4.3.1. 下拉菜单4.3.2. 滚动监…...

第77讲用户管理功能实现
用户管理功能实现 前端: views/user/index.vue <template><el-card><el-row :gutter"20" class"header"><el-col :span"7"><el-input placeholder"请输入用户昵称..." clearable v-model"…...
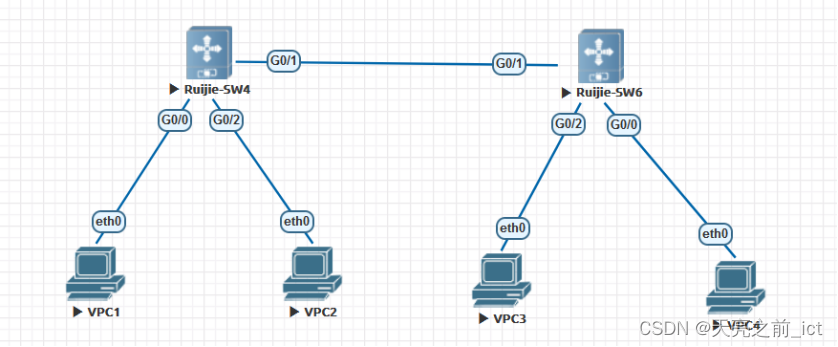
锐捷(十九)锐捷设备的接入安全
1、PC1的IP地址和mac地址做全局静态ARP绑定; 全局下:address-bind 192.168.1.1 mac(pc1) G0/2:ip verify source port-securityarp-check 2、PC2的IP地址和MAC地址做全局IPMAC绑定: Address-bind 192.168.1.2 0050.7966.6807Ad…...
)
【MySQL题】——基础概念论述(二)
🎃个人专栏: 🐬 算法设计与分析:算法设计与分析_IT闫的博客-CSDN博客 🐳Java基础:Java基础_IT闫的博客-CSDN博客 🐋c语言:c语言_IT闫的博客-CSDN博客 🐟MySQL:…...
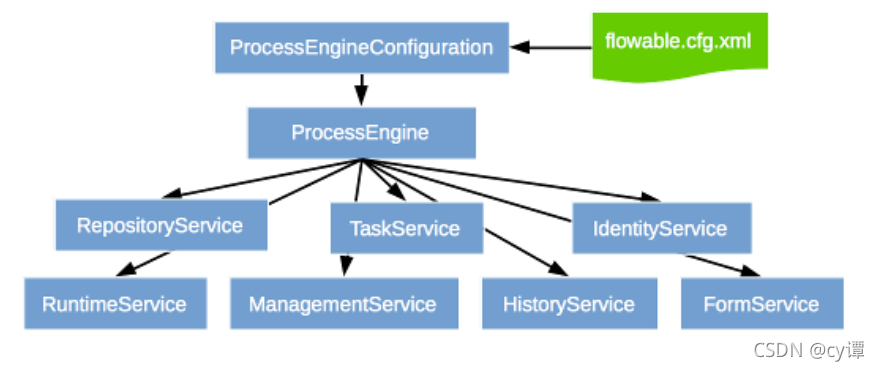
Spring Boot + flowable 快速实现工作流
背景 使用flowable自带的flowable-ui制作流程图 使用springboot开发流程使用的接口完成流程的业务功能 文章来源:https://blog.csdn.net/zhan107876/article/details/120815560 一、flowable-ui部署运行 flowable-6.6.0 运行 官方demo 参考文档: htt…...
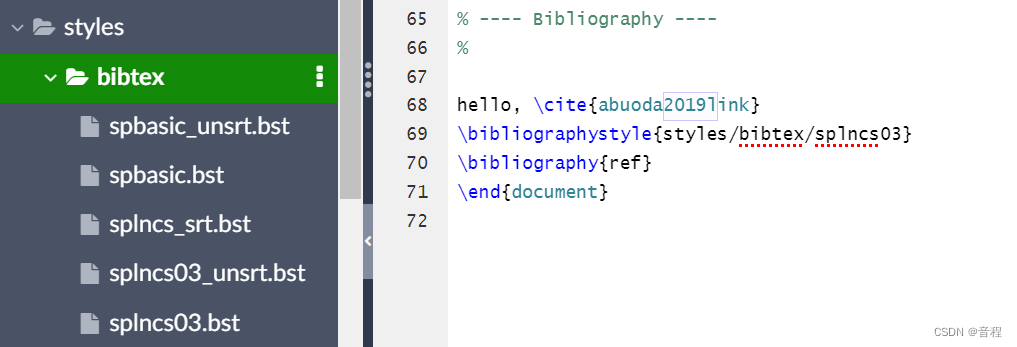
(已解决)LaTeX Error: File `svproc.cls‘ not found. (用Springer LNCS 会议Proceedings模板)
会议要求使用LNCS模板,并给了获取模板链接:https://www.springer.com/gp/authors-editors/conference-proceedings/conference-proceedings-guidelines。我在里面下载了latex模板之后,编译那个author.tex发现抱错: 解决办法&#…...

Spring Boot 自定义指标
Spring Boot 自定义指标 阅读本文需要对一些前置技术有所了解,下面列出的一些前置技术是必须要了解的。 Prometheus:这是一个时序数据库,我们的指标数据一般保存在这个数据库中。Grafana:借助Grafana可以将Prometheus中的数据以图表的方式展示出来。Micrometer:是一个用于…...
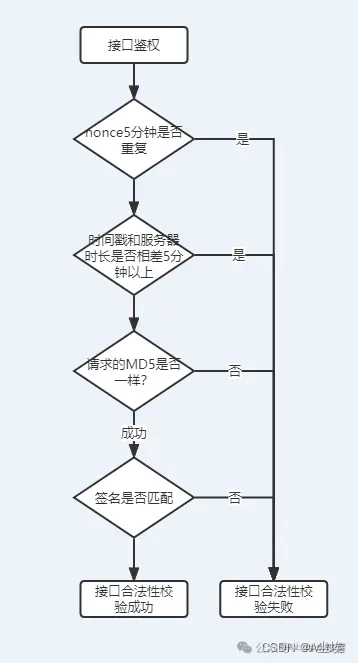
安全的接口访问策略
渗透测试 一、Token与签名 一般客户端和服务端的设计过程中,大部分分为有状态和无状态接口。 一般用户登录状态下,判断用户是否有权限或者能否请求接口,都是根据用户登录成功后,服务端授予的token进行控制的。 但并不是说有了tok…...
最佳视频转换器软件:2024年视频格式转换的选择
我们生活在一个充满数字视频的世界,但提供的内容远不止您最喜欢的流媒体服务目录。虽然我们深受喜爱的设备在播放各种自制和下载的视频文件方面变得越来越好,但在很多情况下您都需要从一种格式转换为另一种格式。 经过大量测试, 我们尝试过…...

深入理解 Nginx 插件及功能优化指南
深入理解 Nginx 插件及功能优化指南 深入理解 Nginx 插件及功能优化指南1. Nginx 插件介绍1.1 HTTP 模块插件ngx_http_rewrite_modulengx_http_access_module 1.2 过滤器插件ngx_http_gzip_modulengx_http_ssl_module 1.3 负载均衡插件ngx_http_upstream_modulengx_http_upstre…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Blank组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Blank组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、Blank组件 空白填充组件,在容器主轴方向上,空白填充组件具…...

InternLM大模型实战-4.XTuner大模型低成本微调实战
文章目录 前言笔记正文XTuner支持模型和数据集 微调原理跟随文档学习快速上手自定义微调准备数据准备配置文件 MS-Agent微调 前言 本文是对于InternLM全链路开源体系系列课程的学习笔记。【XTuner 大模型单卡低成本微调实战】 https://www.bilibili.com/video/BV1yK4y1B75J/?…...

【SpringBoot篇】解决Redis分布式锁的 误删问题 和 原子性问题
文章目录 🍔Redis的分布式锁🛸误删问题🎈解决方法🔎代码实现 🛸原子性问题🌹Lua脚本 ⭐利用Java代码调用Lua脚本改造分布式锁🔎代码实现 🍔Redis的分布式锁 Redis的分布式锁是通过利…...

蓝桥杯Web应用开发-CSS3 新特性【练习三:文本阴影】
文本阴影 text-shadow 属性 给文本内容添加阴影的效果。 文本阴影的语法格式如下: text-shadow: x-offset y-offset blur color;• x-offset 是沿 x 轴方向的偏移距离,允许负值,必须参数。 • y-offset 是沿 y 轴方向的偏移距离,…...

LRU缓存
有人从网络读数据,有人从磁盘读数据,机智的人懂得合理利用缓存加速数据的读取效率,提升程序的性能,搏得上司的赏识,赢得白富美的青睐,进一步走向人生巅峰~ LRU假说 LRU缓存(Least Recently Used…...
ncc匹配提速总结
我们ncc最原始的匹配方法是:学习模板w*h个像素都要带入ncc公式计算 第一种提速,学习模板是w*h,而我们支取其中的w/2*h/2,匹配窗口同理,计算量只有1/4。 另外一种因为ncc是线性匹配,我们在这上面也做了文章࿰…...

人力资源智能化管理项目(day06:员工管理)
学习源码可以看我的个人前端学习笔记 (github.com):qdxzw/humanResourceIntelligentManagementProject 页面结构 <template><div class"container"><div class"app-container"><div class"left"><el-input style&qu…...

Java实现数据可视化的智慧河南大屏 JAVA+Vue+SpringBoot+MySQL
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、系统展示四、核心代码4.1 数据模块 A4.2 数据模块 B4.3 数据模块 C4.4 数据模块 D4.5 数据模块 E 五、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBootMySQL的数据可视化的智慧河南大屏,包含了GDP、…...

通过环境变量管理多个 Taotoken API Key 以实现访问控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过环境变量管理多个 Taotoken API Key 以实现访问控制 在开发过程中,我们常常需要为不同的应用、不同的环境…...

ESP32 Arduino IDE 看门狗实战:从硬件看门狗到Task Watchdog Timer的配置与避坑指南
1. ESP32看门狗机制入门:为什么你的程序总在重启? 刚接触ESP32的开发者经常会遇到一个诡异现象:程序运行得好好的,突然就重启了。这很可能就是看门狗(Watchdog Timer)在作祟。我第一次用ESP32做物联网传感器…...

Netscape 浏览器:互联网时代的先驱者
Netscape 浏览器:互联网时代的先驱者 引言 自互联网诞生以来,浏览器作为连接用户与网络世界的重要工具,见证了互联网的飞速发展。在众多浏览器中,Netscape 浏览器以其创新和引领潮流的特性,成为了互联网时代的先驱者。本文将回顾 Netscape 浏览器的发展历程、技术特点及…...

会话包装器设计:提升API连接弹性与可观测性的工程实践
1. 项目概述:一个被低估的会话管理利器如果你经常和API打交道,尤其是那些需要维护会话状态的服务,肯定遇到过这样的烦恼:每次请求都要手动处理token、处理重连逻辑、管理超时和重试,代码里到处都是重复的胶水代码。更头…...

Web NFC技术入门:在浏览器中实现NFC标签读写与信息管理
1. 项目概述:当NFC遇见浏览器作为一名在嵌入式系统和物联网领域摸爬滚打了十多年的开发者,我经历过无数次需要将物理设备与数字世界连接起来的项目。从早期的红外、蓝牙,到后来的RFID,每次技术迭代都试图让这种连接变得更无缝、更…...

PIC单片机入门实战:基于F1评估板的开发环境搭建与核心外设应用
1. 项目概述:为什么选择F1评估板作为起点?如果你刚开始接触Microchip的PIC单片机,或者是从传统的PIC16F877A这类经典型号转向更现代的架构,面对琳琅满目的开发板可能会有点无从下手。今天我想聊聊我手头这块“Microchip F1评估平台…...

3分钟彻底移除Windows Defender:释放30%系统性能的实战指南
3分钟彻底移除Windows Defender:释放30%系统性能的实战指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirror…...

如何彻底释放惠普OMEN游戏本性能:终极免费硬件控制工具指南
如何彻底释放惠普OMEN游戏本性能:终极免费硬件控制工具指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软件臃肿…...

AI智能体容器化开发实践:基于AgentBox构建安全可复现的沙盒环境
1. 项目概述:AgentBox,一个为AI智能体打造的“沙盒”开发环境最近在折腾AI智能体(Agent)的开发,发现一个挺有意思的现象:很多开发者,包括我自己在内,在初期搭建智能体应用时…...

DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器
DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...