《统计学简易速速上手小册》第6章:多变量数据分析(2024 最新版)

文章目录
- 6.1 主成分分析(PCA)
- 6.1.1 基础知识
- 6.1.2 主要案例:客户细分
- 6.1.3 拓展案例 1:面部识别
- 6.1.4 拓展案例 2:基因数据分析
- 6.2 聚类分析
- 6.2.1 基础知识
- 6.2.2 主要案例:市场细分
- 6.2.3 拓展案例 1:文档聚类
- 6.2.4 拓展案例 2:基因表达数据的聚类
- 6.3 判别分析
- 6.3.1 基础知识
- 6.3.2 主要案例:信用评分模型
- 6.3.3 拓展案例 1:市场细分与目标客户识别
- 6.3.4 拓展案例 2:疾病诊断
6.1 主成分分析(PCA)
主成分分析(PCA)是一种强大的统计工具,用于数据降维和模式识别。它能帮助我们在减少数据复杂度的同时,保留最重要的信息。
6.1.1 基础知识
- PCA的目的和原理:PCA的主要目的是识别数据中的模式,并将数据从原始空间转换到一个新的空间,这个新空间的基是数据的主成分。这可以通过寻找数据最大方差的方向并将其作为第一个主成分,然后寻找与第一个主成分正交且方差最大的方向作为第二个主成分,以此类推。
- PCA的步骤:PCA的步骤包括标准化原始数据、计算协方差矩阵、提取特征值和特征向量、选择主成分、转换到新的空间。
- 解释主成分:每个主成分都能够解释数据的一部分变异性,第一个主成分解释最大的变异性,每个后续的主成分都解释剩余变异性中最大的部分。
6.1.2 主要案例:客户细分
场景:一家零售公司希望通过客户购买历史数据进行客户细分,以便更好地理解客户群体和优化营销策略。
Python 示例:
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import pandas as pd# 假设 df 是包含客户购买历史数据的DataFrame
# 数据标准化
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)# 应用PCA
pca = PCA(n_components=2) # 选择两个主成分
principalComponents = pca.fit_transform(df_scaled)# 将主成分转换为DataFrame
principalDf = pd.DataFrame(data=principalComponents, columns=['principal component 1', 'principal component 2'])# 输出解释的方差比
print(pca.explained_variance_ratio_)
6.1.3 拓展案例 1:面部识别
场景:一个安全系统使用面部识别技术来验证个人身份。由于面部图像数据维度很高,使用PCA来降低数据维度,提高识别算法的效率。
Python 示例:
# 假设 face_images 是面部图像数据集的变量
# 此处代码省略数据加载步骤# 应用PCA进行降维
pca = PCA(n_components=150) # 选择150个主成分
faces_pca = pca.fit_transform(face_images)# 使用降维后的数据进行面部识别处理
# 此处代码省略面部识别具体实现
6.1.4 拓展案例 2:基因数据分析
场景:生物学家使用PCA来分析和可视化基因表达数据,以探索不同样本之间的相似性和差异性。
Python 示例:
# 假设 gene_expression 是基因表达数据的DataFrame
# 数据标准化
scaler = StandardScaler()
gene_expression_scaled = scaler.fit_transform(gene_expression)# 应用PCA
pca = PCA(n_components=3) # 选择三个主成分进行分析
gene_pca = pca.fit_transform(gene_expression_scaled)# 将主成分转换为DataFrame,用于后续分析和可视化
gene_pca_df = pd.DataFrame(data=gene_pca, columns=['PC1', 'PC2', 'PC3'])# 可视化代码省略
通过这些案例,我们可以看到PCA如何在不同领域内帮助我们简化数据,揭示数据结构和模式。无论是进行客户细分、面部识别还是基因数据分析,PCA都是一种有效的工具,使我们能够在降低数据复杂度的同时,捕捉到最关键的信息。

6.2 聚类分析
聚类分析是一种探索性数据分析技术,它试图将数据集中的对象分组,使得组内的对象比组间的对象更为相似。这就像是将一堆不同的水果根据颜色、形状或大小分类,以便更好地管理和使用它们。
6.2.1 基础知识
- 聚类的目的:聚类的主要目的是发现数据内部的自然分组,以揭示数据的结构,为进一步的分析和决策提供依据。
- 常见的聚类算法:
- K-均值聚类(K-means Clustering):通过将数据点分配到K个簇中,使得每个点与其所属簇的中心(质心)之间的距离之和最小化。
- 层次聚类(Hierarchical Clustering):通过连续合并或分割簇来构建簇的层次结构。
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise):基于密度的聚类方法,能够识别噪声数据,对簇的形状和大小没有假设。
- 聚类分析的应用:聚类分析广泛应用于市场细分、社交网络分析、图像分割、生物信息学等领域。
6.2.2 主要案例:市场细分
场景:一家电子商务公司希望通过聚类分析对其客户进行市场细分,以便实施针对性的营销策略。
Python 示例:
from sklearn.cluster import KMeans
import pandas as pd# 假设 df 是包含客户购买行为数据的DataFrame
# 使用K-均值算法进行聚类
kmeans = KMeans(n_clusters=5) # 假设我们想将客户分成5个群体
df['cluster'] = kmeans.fit_predict(df[['feature1', 'feature2', 'feature3']])# 查看聚类结果
print(df.groupby('cluster').mean())
6.2.3 拓展案例 1:文档聚类
场景:一家新闻机构希望自动对成千上万的新闻文章进行分类,以改进文章的组织和推荐。
Python 示例:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans# 假设 documents 包含了需要聚类的文档集合
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(documents)# 使用K-均值算法进行文档聚类
kmeans = KMeans(n_clusters=10) # 分成10个类别
kmeans.fit(X)# 获取聚类结果
clusters = kmeans.labels_
6.2.4 拓展案例 2:基因表达数据的聚类
场景:生物学家希望通过聚类分析来探索在不同条件下表达的基因,以发现功能相关的基因群体。
Python 示例:
from sklearn.cluster import AgglomerativeClustering
import numpy as np# 假设 gene_expression 是基因表达数据的numpy数组
# 使用层次聚类算法
clustering = AgglomerativeClustering(n_clusters=5)
gene_clusters = clustering.fit_predict(gene_expression)# 分析聚类结果
# 此处可以进一步分析每个簇的基因和它们的功能
通过这些案例,我们可以看到聚类分析在不同领域的广泛应用,从市场细分到文档分类,再到基因表达数据的分析。聚类分析帮助我们发现数据中的隐藏模式和结构,为决策提供科学依据。使用Python进行聚类分析,我们可以轻松处理大量数据,快速得到有意义的结果。

6.3 判别分析
判别分析是一种监督学习技术,用于模型构建,以预测或分类观测所属的组别。它基于不同类别之间的差异,确定哪些变量对于区分类别是重要的,并创建一个或多个判别函数来预测类别归属。
6.3.1 基础知识
- 判别分析的基本概念:判别分析通过分析自变量来预测类别变量。它尝试定义不同类别之间的边界,并利用这些边界来确定新观测所属的类别。
- 线性判别分析(LDA):LDA是判别分析中最常用的方法之一,它寻找能最大化类别间分散度同时最小化类别内分散度的线性组合。LDA特别适用于当自变量是连续量且符合正态分布,各类具有相同协方差矩阵时。
- 判别分析的应用:判别分析可以应用于信用评分、客户分类、疾病诊断等多个领域,它帮助我们根据已有数据制定分类规则,并应用这些规则到新数据上。
6.3.2 主要案例:信用评分模型
场景:银行希望开发一个信用评分模型,以预测客户是否有违约的风险。
Python 示例:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd# 加载数据集
data = pd.read_csv('credit_score_data.csv')
X = data.drop('Default', axis=1) # 自变量
y = data['Default'] # 因变量,违约与否# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建LDA模型
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)# 在测试集上评估模型
y_pred = lda.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
6.3.3 拓展案例 1:市场细分与目标客户识别
场景:一家营销公司希望通过判别分析识别潜在的目标客户群体,以便更有效地定位其营销策略。
Python 示例:
# 假设已有包含客户特征和是否为目标客户的标签的数据集
# 此处代码省略数据准备步骤lda = LinearDiscriminantAnalysis()
lda.fit(customer_features, target_label)# 使用模型识别新客户是否为目标客户
# 此处代码省略新客户数据的应用步骤
6.3.4 拓展案例 2:疾病诊断
场景:医疗研究人员希望开发一个模型,用于根据患者的各种生理指标来预测其是否患有特定疾病。
Python 示例:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import pandas as pd# 假设 disease_data 是包含生理指标和疾病状态的DataFrame
# 此处代码省略数据准备步骤lda = LinearDiscriminantAnalysis()
lda.fit(disease_data_features, disease_status)# 使用模型对患者进行诊断
# 此处代码省略诊断应用步骤
通过这些案例,我们可以看
到判别分析在不同场景下的实际应用,从银行的信用评分到营销的目标客户识别,再到医疗领域的疾病诊断。判别分析为我们提供了一种强大的方法,以数据驱动的方式来预测分类,并帮助我们做出更加精准的决策。使用Python进行判别分析,我们可以利用现有的库和工具,快速构建和评估模型。
相关文章:
《统计学简易速速上手小册》第6章:多变量数据分析(2024 最新版)
文章目录 6.1 主成分分析(PCA)6.1.1 基础知识6.1.2 主要案例:客户细分6.1.3 拓展案例 1:面部识别6.1.4 拓展案例 2:基因数据分析 6.2 聚类分析6.2.1 基础知识6.2.2 主要案例:市场细分6.2.3 拓展案例 1&…...

创新S3存储桶检索:Langchain社区S3加载器搭载OpenAI API
在瞬息万变的数据存储和处理领域,将高效的云存储解决方案与先进的 AI 功能相结合,为处理大量数据提供了一种变革性的方法。本文演示了使用 MinIO、Langchain 和 OpenAI 的 GPT-3.5 模型的实际实现,重点总结了存储在 MinIO 存储桶中的文档。 …...

【Linux技术宝典】Linux入门:揭开Linux的神秘面纱
文章目录 官网Linux 环境的搭建方式一、什么是Linux?二、Linux的起源与发展三、Linux的核心组件四、Linux企业应用现状五、Linux的发行版本六、为什么选择Linux?七、总结 Linux,一个在全球范围内广泛应用的开源操作系统,近年来越来…...

C语言---------对操作符的进一步认识
操作符中有⼀些操作符和⼆进制有关系,我们先学习了⼀下⼆进制的和进制转换的知识。 1.原码、反码和补码。 有符号整数的三种表⽰⽅法均有符号位和数值位两部分, 2进制序列中,最⾼位的1位是被当做符号位,剩余的都是数值位。 符号…...
HarmonyOS 鸿蒙 ArkTS ArkUI 页面之间切换转换动画设置
第一步:导入 import promptAction from ohos.promptAction 第二步:在build下方写入 pageTransition(){PageTransitionEnter({ duration: 1200 }).slide(SlideEffect.Right)PageTransitionExit({ delay: 100 }).translate({ x: 100.0, y: 100.0 }).opac…...

《CSS 简易速速上手小册》第8章:CSS 性能优化和可访问性(2024 最新版)
文章目录 8.1 CSS 文件的组织和管理8.1.1 基础知识8.1.2 重点案例:项目样式表结构8.1.3 拓展案例 1:使用BEM命名规范8.1.4 拓展案例 2:利用 Sass 混入创建响应式工具类 8.2 提高网页加载速度的技巧8.2.1 基础知识8.2.2 重点案例:图…...
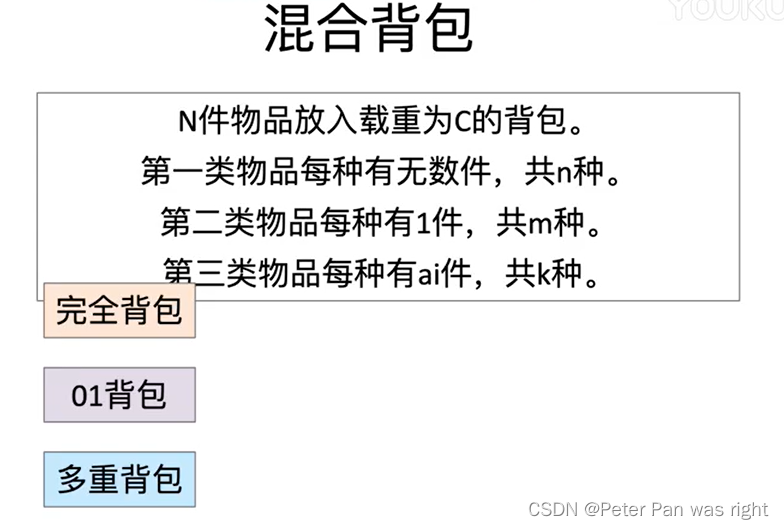
Peter算法小课堂—背包问题
我们已经学过好久好久的动态规划了,动态规划_Peter Pan was right的博客-CSDN博客 那么,我用一张图片来概括一下背包问题。 大家有可能比较疑惑,优化决策怎么优化呢?答案是,滚动数组,一个神秘而简单的东西…...

网易腾讯面试题精选----50 个 Git 面试问题
介绍 Git 是 DevOps 之旅的起点。所以,我只是概述了 50 个快速问题以及 Git 的答案。这些问题非常快,你可以在 DevOps 面试中问。它适合初学者到中级水平。 面试问答 1.问:什么是Git? 答:Git 是一个分布式版本控制系统,允许多个开发人员在一个项目上进行协作并跟踪源代…...

Android CMakeLists.txt语法详解
一.CMake简介 你或许听过好几种 Make 工具,例如 GNU Make ,QT 的 qmake ,微软的 MSnmake,BSD Make(pmake),Makepp,等等。这些 Make 工具遵循着不同的规范和标准,所执行的…...

Vue3快速上手(二)VSCode官方推荐插件安装及配置
一、VSCode官方插件安装,如下图2款插件 在用vite创建的程序里,提示提安装推荐的插件了,如下图: 二、配置 在设置-扩展里找到Volar插件,将Dot Value勾选上。这样在ref()修改变量时,会自动填充.value,无需…...

等保2、3级所需设备
三级等保要求及所需设备 《等级保护基本要求》所需设备 结构安全(G3) b)应保证网络各个部分的宽带满足业务高峰期需要; g)应按照对业务服务的需要次序来指定宽带分配优先级别,保证在网络发生拥堵的时候优先保护重要主机 负载均衡…...
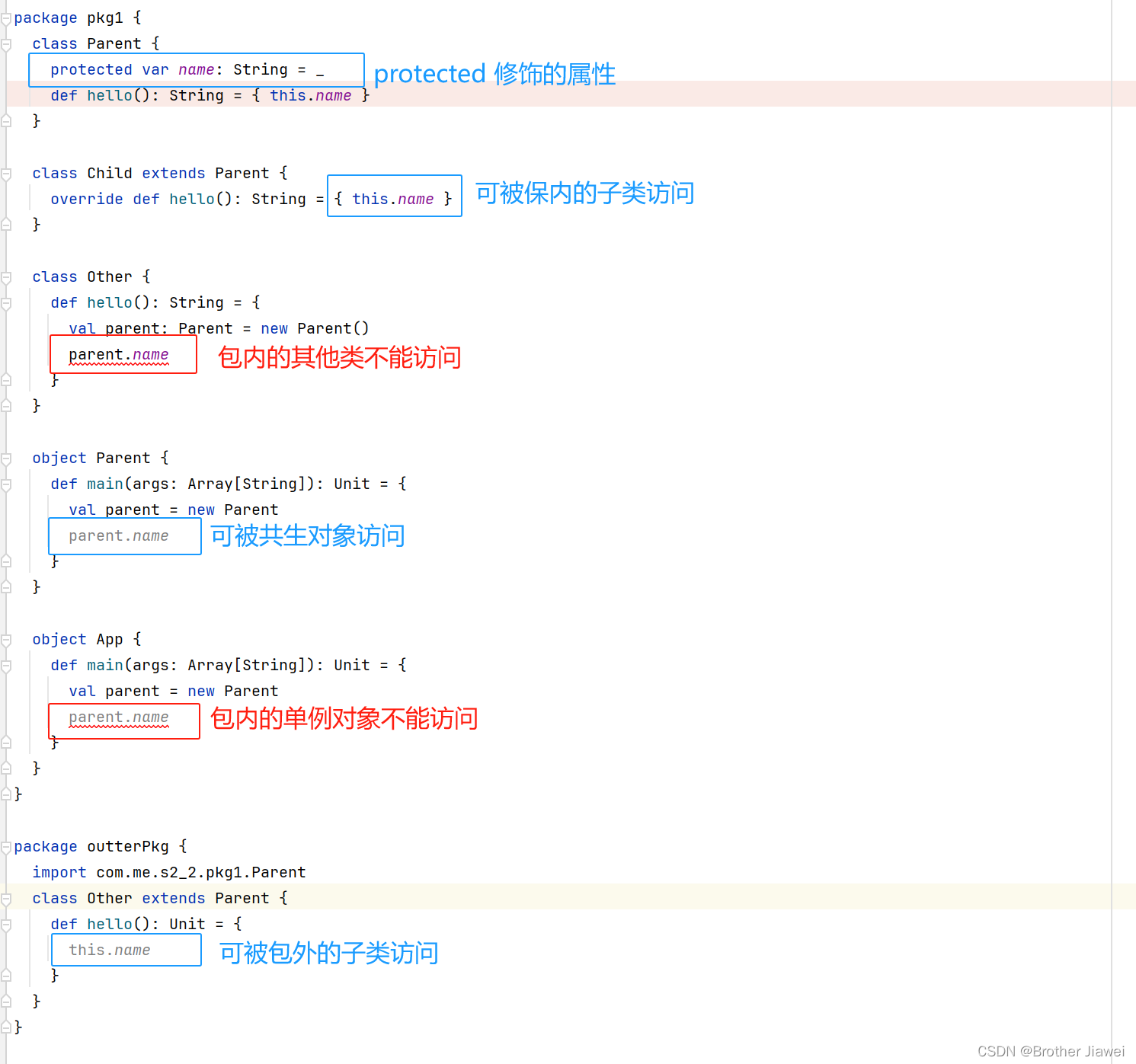
6 scala-面向对象编程基础
Scala 跟 Java 一样,是一门面向对象编程的语言,有类和对象的概念。 1 类与对象 与 Java 一样,Scala 也是通过关键字 class 来定义类,使用关键字 new 创建对象。 要运行我们编写的代码,同样像 Java 一样,…...
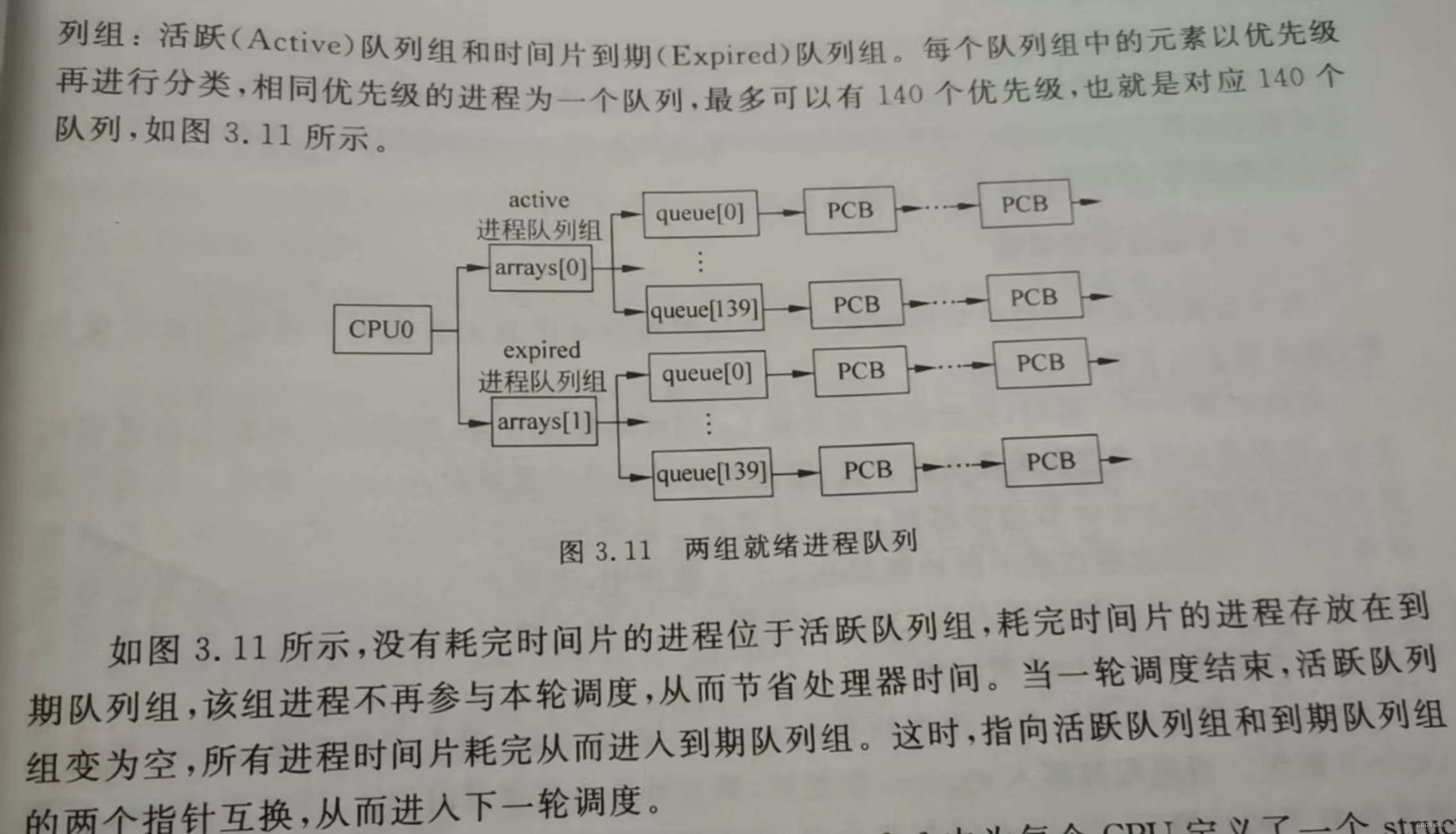
【linux温故】linux调度机制
假如你是设计者,你会设计怎样的调度机制呢? 时间片 最简单的,小学生都能想出来的一种,每个 ready task,按照一个固定的时间片轮流执行。 大家不要抢,挨个儿排队执行。执行完时间片,就排在后面…...

django中如何使用mysql连接池
一:介绍 在Django中使用MySQL时,通常情况下,Django的数据库层会为你管理数据库连接。Django的数据库接口是线程安全的,这意味着它会自动为每个线程创建和管理数据库连接。在大多数情况下,你不需要手动创建线程池来管理…...

3D高斯溅射:面向三维场景的实时渲染技术
1. 前言 高斯溅射技术【1】一经推出,立刻引起学术界和工业界的广泛关注。相比传统的隐式神经散射场渲染技术,高斯溅射依托椭球空间,显性地表示多目图像的三维空间关系,其计算效率和综合性能均有较大的提升,且更容易理…...
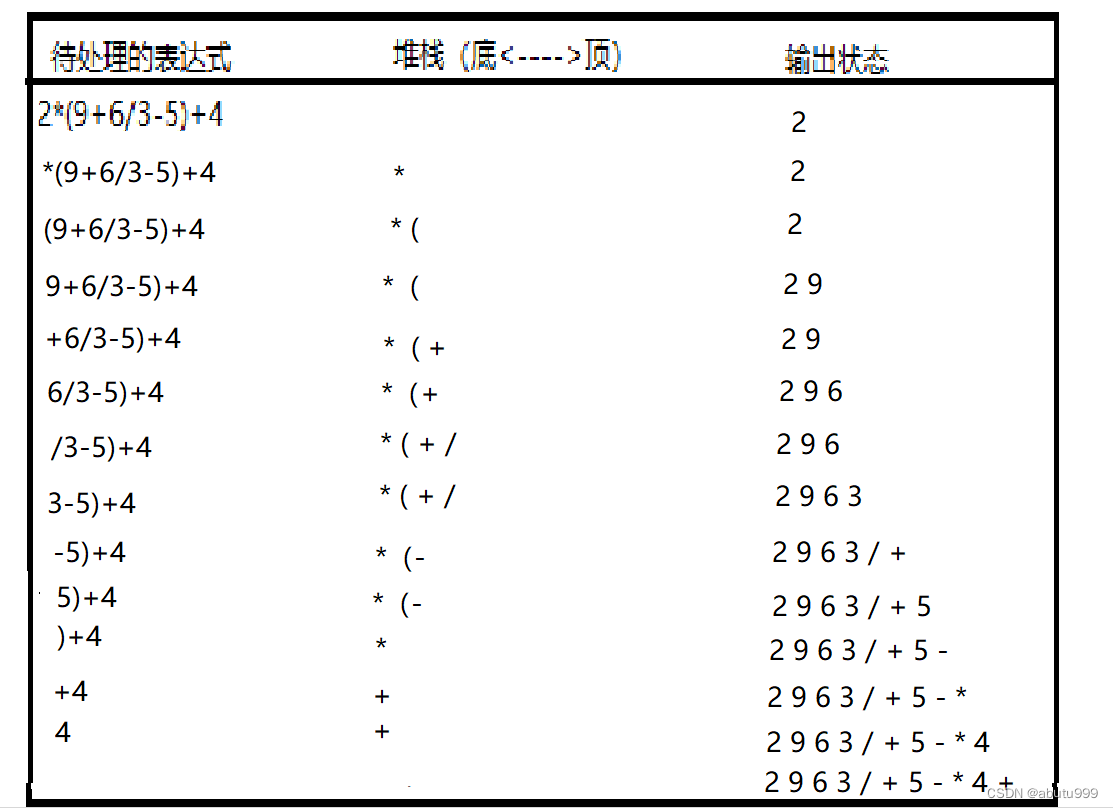
【数据结构】13:表达式转换(中缀表达式转成后缀表达式)
思想: 从头到尾依次读取中缀表达式里的每个对象,对不同对象按照不同的情况处理。 如果遇到空格,跳过如果遇到运算数字,直接输出如果遇到左括号,压栈如果遇到右括号,表示括号里的中缀表达式已经扫描完毕&a…...
-视图的创建和应用)
MySQL进阶查询篇(9)-视图的创建和应用
数据库视图是MySQL中一个非常重要的概念。它是一个虚拟表,由一个查询的结果集组成。数据库视图为用户提供了一种简化数据查询和操作的方式。本文将介绍MySQL数据库视图的创建和应用。 1. 创建数据库视图 要创建MySQL数据库视图,我们使用CREATE VIEW语句…...
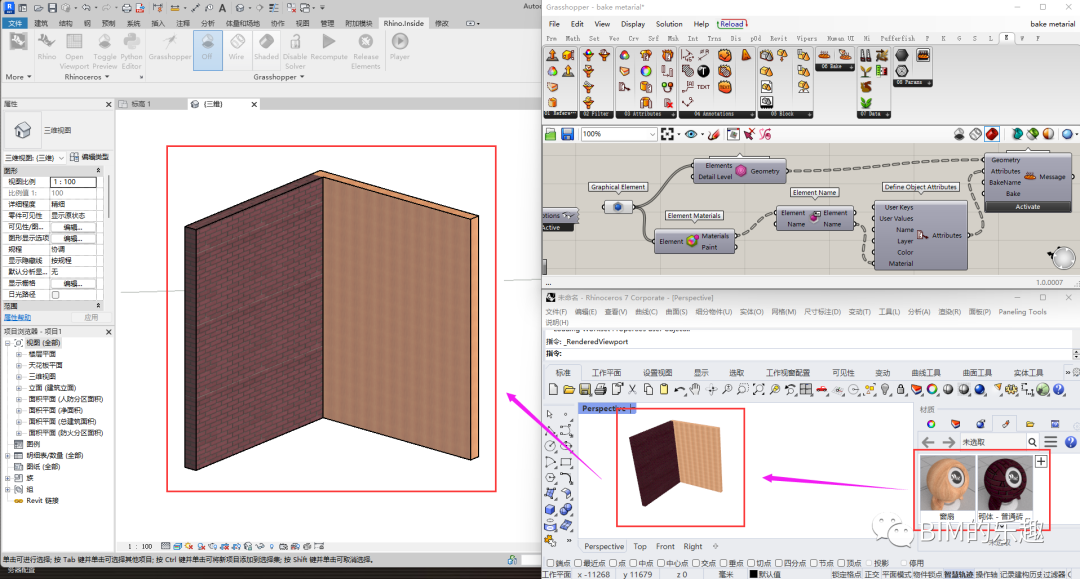
Rhino.Inside带材质将Revit模型bake到Rhino
Hello大家好!我是九哥~ 今天来讲一个小技巧,就是我通常采用RIR将Revit的模型的Geometry Bake到Rhino,肯定是没有材质的,那么如果我们需要带材质那要怎么办呢? 对于会的人,其实挺简单的,只需要…...

随记-Java项目处理SQL注入问题
现象:http://10.xx.xx.xx:xx/services/xxService 存在SQL注入情况 加固意见: 需要对网站所有参数中提交的数据进行过滤,禁止输入“"、"xor"、"or"、”--“、”#“、”select“、”and“等特殊字符;所有…...

精读《js 模块化发展》
1 引言 如今,Javascript 模块化规范非常方便、自然,但这个新规范仅执行了 2 年,就在 4 年前,js 的模块化还停留在运行时支持,10 年前,通过后端模版定义、注释定义模块依赖。对经历过来的人来说,…...

如何在DS918+上免费开启Synology Photos人脸识别功能:完整补丁指南
如何在DS918上免费开启Synology Photos人脸识别功能:完整补丁指南 【免费下载链接】Synology_Photos_Face_Patch Synology Photos Facial Recognition Patch 项目地址: https://gitcode.com/gh_mirrors/sy/Synology_Photos_Face_Patch 你是否曾经在群晖DS918…...

ThinkPad风扇控制终极指南:TPFanCtrl2完全使用教程
ThinkPad风扇控制终极指南:TPFanCtrl2完全使用教程 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾被ThinkPad风扇的突然加速打扰了工作专注&#…...

实战配置:5个提升MPC-HC播放器性能的专业技巧
实战配置:5个提升MPC-HC播放器性能的专业技巧 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc Media Player Classic - Home Cinema࿰…...

狼来了?如果我们正处于AI泡沫中会怎样?
AI 热潮真正的风险,不在模型神话,而在算力账单和 ROI 清算。 原文链接:AI 小老六 每天,我们都能在网络上看到各种关于 AI 未来 的离谱预测。 有人说:“GPT-7 马上就要出来了,它会吞噬所有的软件࿰…...

别再死记硬背节点了!用UE5蓝图系统,像搭积木一样做出你的第一个会动的潜艇
用UE5蓝图系统零代码实现潜艇动画:可视化编程的积木式入门指南 当第一次打开虚幻引擎5的蓝图编辑器时,许多初学者会被密密麻麻的节点和连线吓退。但想象一下,如果这些节点不是晦涩的代码符号,而是乐高积木般的可视化指令块——这就…...

【NotebookLM隐私风险等级评估】:基于NIST SP 800-53的7维度打分模型,你的笔记正在被谁读?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM隐私数据安全 NotebookLM 是 Google 推出的基于用户上传文档构建个性化 AI 助手的工具,其核心优势在于“本地文档理解”,但所有文档均需上传至 Google 云端处理。这意…...

解锁端侧智能:基于BigDL-LLM与Qwen-1.8B-Chat的CPU高效推理实践
1. 为什么要在CPU上部署大模型? 最近两年大模型技术发展迅猛,但大多数应用都依赖昂贵的GPU服务器。我在实际项目中发现,很多中小企业和个人开发者其实更需要能在普通电脑上运行的轻量化方案。这就是为什么基于CPU的大模型部署方案变得越来越…...

SAP KO88结算时,如何用BADI_FINS_ACDOC_POSTING_EVENTS把成本中心塞进自定义字段?
SAP KO88结算实战:通过BADI_FINS_ACDOC_POSTING_EVENTS实现成本中心到自定义字段的精准映射 在SAP工单结算(KO88)的复杂业务场景中,财务凭证的标准化字段往往无法满足企业多维度的分析需求。特别是当需要将特定成本中心信息映射到…...

如何免费解锁WeMod专业版:2026年终极完整指南
如何免费解锁WeMod专业版:2026年终极完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂费用而烦恼吗…...

NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南
NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡优化工具,专为…...