人工智能|推荐系统——基于tensorflow的个性化电影推荐系统实战(有前端)
代码下载:
基于tensorflow的个性化电影推荐系统实战(有前端).zip资源-CSDN文库
项目简介:
- dl_re_web : Web 项目的文件夹
- re_sys: Web app
- model:百度云下载之后,把model放到该文件夹下
- recommend: 网络模型相关
- data: 训练数据集文件夹
- DataSet.py:数据集加载相关
- re_model.py: 网络模型类
- utils.py:工具、爬虫
- static :Web 页面静态资源
- templates : 为 Web 页面的 Html 页面
- venv:Django 项目资源文件夹
- db.sqlite3 : Django 自带的数据库
- manage.py: Django 执行脚本
- 网络模型.vsdx:网络模型图(visio)
- deep-learning-README.pdf:README的pdf版,如果github的README显示存在问题请下载这个文件
- 项目背景
本系统将神经网络在自然语言处理与电影推荐相结合,利用MovieLens数据集训练一个基于文本的卷积神经网络,实现电影个性化推荐系统。最后使用django框架并结合豆瓣爬虫,搭建推荐系统web端服务。
-
主要实现功能
给用户推荐喜欢的电影
推荐相似的电影
推荐看过的用户还喜欢看的电影
-
网络模型
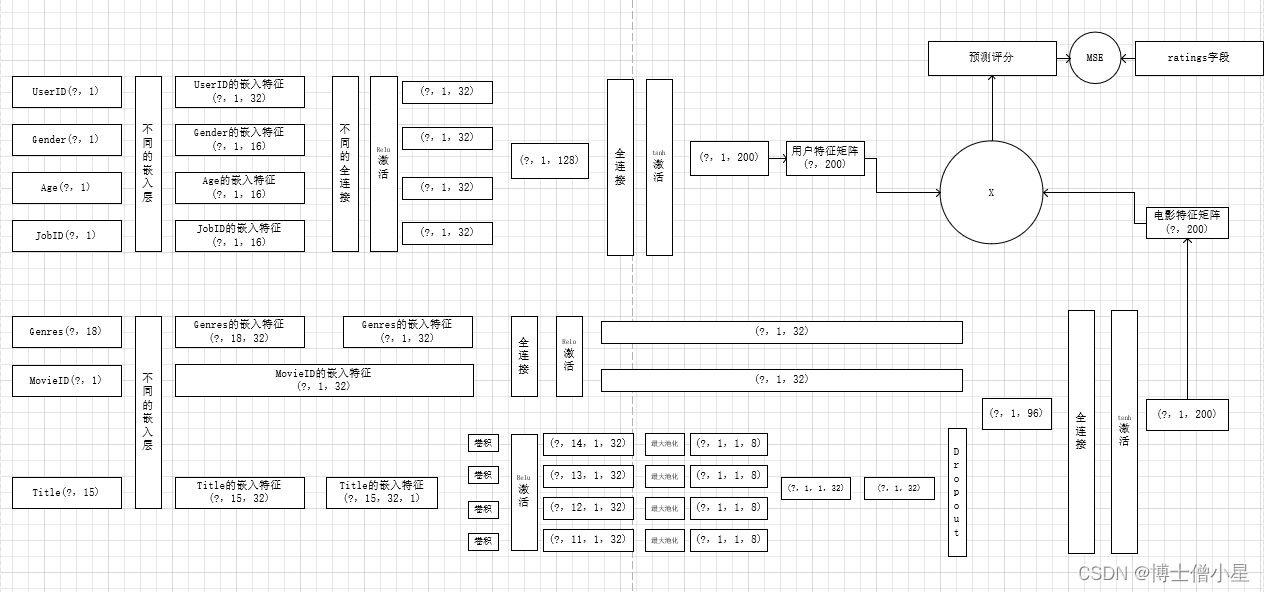
一. 数据处理
1. MovieLens数据集
用户数据users.dat
性别字段:将‘F’ 和 ‘M’转换为0和1
年龄字段:转为连续数字
电影数据movies.dat
流派字段:部分电影不仅只有一个分类,所以将该字段转为数字列表
标题字段:同上,创建英文标题的数字字典,并生成数字列表,并去掉标题中的年份
注:为方便网络处理,以上两字段长度需要统一
评分数据ratings.dat
数据处理完之后将三个表做 inner merge,并保存为模型文件 data_preprocess.pkl
2. 处理后的数据

我们看到部分字段是类型性变量,如 UserID、MovieID 这样非常稀疏的变量,如果使用
one-hot,那么数据的维度会急剧膨胀,算法的效率也会大打折扣。
二. 建模&训练
针对处理后数据的不同字段进行模型的搭建
1. 嵌入层
根据上文,为了解决数据稀疏问题,
One-hot的矩阵相乘可以简化为查表操作,这大大降低了运算量。我们不是每一个词用一个向量来代替,而是替换为用于查找嵌入矩阵中向量的索引,在网络的训练过程中,嵌入向量也会更新,我们也就可以探索在高维空间中词语之间的相似性。
本系统使用tensorflow的
tf.nn.embedding_lookup,就是根据input_ids中的id,寻找embeddings中的第id行。比如input_ids=[1,3,5],则找出embeddings中第1,3,5行,组成一个tensor返回。tf.nn.embedding_lookup不是简单的查表,id对应的向量是可以训练的,训练参数个数应该是category num*embedding size,也可以说lookup是一种全连接层。
- 解析:
- 创建嵌入矩阵,我们要决定每一个索引需要分配多少个 潜在因子,这大体上意味着我们想要多长的向量,通常使用的情况是长度分配为32和50,此处选择32和16,所以我们看到各字段嵌入矩阵的shape第1个维度,也就是第2个数字要么为32,要么为16;
- 而嵌入矩阵第0个纬度为6041、2、7、21,也就是嵌入矩阵的行数,也就代表着这四个字段unique值有多少个,例如Gender的值只有0和1(经过数据处理)其嵌入矩阵就有2行
- 到现在,想必大家可以清楚嵌入矩阵的好处了,我们以
UserId字段为例子,使用one-hot编码,数据就需要增加数据量x6041个数据,如果数据量较大,或者字段的unique值较多,在训练时则会耗费大量资源,但是如果使用嵌入矩阵,我们仅仅只用创建一个6041x32的矩阵,然后使用tf.nn.embedding_lookup与UserID字段的数据进行全连接(相当于查表操作),即可用一个一维的长度为32的数组表示出该UserID,大大简化了运算的耗时。- 在上一点已经讲过使用
tf.nn.embedding_lookup与UserID字段的数据进行全连接(相当于查表操作),则每个嵌入层的shape应该是这样的(数据量,字段长度,索引长度),数据量可以设计为每个epoch的大小;对于User数据来说,字段长度都为1,因为用一个值就能表示改独一无二的值,如果对于文本,则可能需要使用数组来表示,即字段长度可能大于1,稍后会在Movie数据处理中进一步解释;索引长度则是嵌入矩阵的潜在因子。
例子:对数据集字段UserID、Gender、Age、JobID分别构建嵌入矩阵和嵌入层
def create_user_embedding(self, uid, user_gender, user_age, user_job):with tf.name_scope("user_embedding"):uid_embed_matrix = tf.Variable(tf.random_uniform([self.uid_max, self.embed_dim], -1, 1),name="uid_embed_matrix") # (6041,32)uid_embed_layer = tf.nn.embedding_lookup(uid_embed_matrix, uid, name="uid_embed_layer") # (?,1,32)gender_embed_matrix = tf.Variable(tf.random_uniform([self.gender_max, self.embed_dim // 2], -1, 1),name="gender_embed_matrix") # (2,16)gender_embed_layer = tf.nn.embedding_lookup(gender_embed_matrix, user_gender, name="gender_embed_layer") # (?,1,16)age_embed_matrix = tf.Variable(tf.random_uniform([self.age_max, self.embed_dim // 2], -1, 1),name="age_embed_matrix") # (7,16)age_embed_layer = tf.nn.embedding_lookup(age_embed_matrix, user_age, name="age_embed_layer")# (?,1,16)job_embed_matrix = tf.Variable(tf.random_uniform([self.job_max, self.embed_dim // 2], -1, 1),name="job_embed_matrix") # (21,16)job_embed_layer = tf.nn.embedding_lookup(job_embed_matrix, user_job, name="job_embed_layer")# (?,1,16)return uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer类似地,我们在相应代码中分别创建了电影数据的MovieID、Genres、Title的嵌入矩阵,其中需要特别注意的是:
- Title嵌入层的shape是
(?,15,32),“?”代表了一个epoch的数量,32代表了自定义选择的潜在因子数量,15则代表了该字段的每一个unique值都需要一个长度为15的向量来表示。- Genres嵌入层的shape是
(?,1,32),由于一个电影的Genres(电影的类型),可能属于多个类别,所以该字段的需要做特殊的处理,即把第1纬度上的向量进行加和,这样做其实削减了特征的表现,但是又防止比如仅仅只推荐相关类型的电影。
- 综上,经过嵌入层,我们得到一下模型:
针对User数据
| 模型名称 | shape |
|---|---|
| uid_embed_matrix | (6041,32) |
| gender_embed_matrix | (2,16) |
| age_embed_matrix | (7,16) |
| job_embed_matrix | (21,16) |
| uid_embed_layer | (?,1,32) |
| gender_embed_layer | (?,1,16) |
| age_embed_layer | (?,1,16) |
| job_embed_layer | (?,1,16) |
针对Movie数据
| 模型名称 | shape |
|---|---|
| movie_id_embed_matrix | (3953,32) |
| movie_categories_embed_matrix | (19,32) |
| movie_title_embed_matrix | (5215,32) |
| movie_id_embed_layer | (?,1,32) |
| movie_categories_embed_layer | (?,1,32) |
| movie_title_embed_layer | (?,15,32) |
2. 文本卷积层
本文仅介绍了推导过程,并为介绍卷积层设计的思路。设计思路请看参考文献
文本卷积层仅涉及到电影数据的Title字段,其实Genres字段也是可以进行文本卷积设计的,但是上文解释过,考虑到推荐数据字段的影响,对Genres仅设计了常规的网络。
卷积过程涉及到一下几个参数:
| name&value | 解释 |
|---|---|
| windows_size=[2,3,4,5] | 不同卷积的滑动窗口是可变的 |
| fliter_num=8 | 卷积核(滤波器)的数量 |
| filter_weight =(windows_size,32,1,fliter_num) | 卷积核的权重,四个参数分别为(高度,宽度,输入通道数,输出通道数) |
| filter_bias=8 | 卷积核的偏置=卷积核的输出通道数=卷积核的数量 |
-
过程
我们将Title字段潜入层的输出
movie_title_embed_layer(shape=(?,15,32)),作为卷积层的输入,所以我们先把movie_title_embed_layer扩展一个维度,shape变为(?,15,32,1),四个参数分别为(batch,height,width,channels)movie_title_embed_layer_expand = tf.expand_dims(movie_title_embed_layer, -1) # 在最后加上一个维度
使用不同尺寸的卷积核做卷积和最大池化,相关参数的变化不再赘述
pool_layer_lst = [] for window_size in self.window_sizes:with tf.name_scope("movie_txt_conv_maxpool_{}".format(window_size)):# 卷积核权重 filter_weights = tf.Variable(tf.truncated_normal([window_size, self.embed_dim, 1, self.filter_num], stddev=0.1),name="filter_weights") # 卷积核偏执 filter_bias = tf.Variable(tf.constant(0.1, shape=[self.filter_num]), name="filter_bias")# 卷积层 第一个参数为:输入 第二个参数为:卷积核权重 第三个参数为:步长conv_layer = tf.nn.conv2d(movie_title_embed_layer_expand, filter_weights, [1, 1, 1, 1], padding="VALID",name="conv_layer")# 激活层 参数的shape保持不变relu_layer = tf.nn.relu(tf.nn.bias_add(conv_layer, filter_bias), name="relu_layer")# 池化层 第一个参数为:输入 第二个参数为:池化窗口大小 第三个参数为:步长 maxpool_layer = tf.nn.max_pool(relu_layer, [1, self.sentences_size - window_size + 1, 1, 1],[1, 1, 1, 1],padding="VALID", name="maxpool_layer")pool_layer_lst.append(maxpool_layer)可得到:
widow_size filter_weights filter_bias conv_layer relu_layer maxpool_layer 2 (2,32,1,8) 8 (?,14,1,8) (?,14,1,8) (?,1,1,8) 3 (3,32,1,8) 8 (?,13,1,8) (?,14,1,8) (?,1,1,8) 4 (4,32,1,8) 8 (?,12,1,8) (?,14,1,8) (?,1,1,8) 5 (5,32,1,8) 8 (?,11,1,8) (?,14,1,8) (?,1,1,8) 例子解析:
我们考虑window_size=2的情况,首先我们得到嵌入层输出,并对其增加一个维度得到
movie_title_embed_layer_expand(shape=(?,15,32,1)),其作为卷积层的输入。 卷积核的参数
filter_weights为(2,32,1,8),表示卷积核的高度为2,宽度为32,输入通道为1,输出通道为32。其中输出通道与上一层的输入通道相同。 卷积层在各个维度上的步长都为1,且padding的方式为VALID,则可得到卷基层的shape为(?,14,1,8)。
卷积之后使用relu函数进行激活,并且加上偏置,shape保持不变。
最大池化的窗口为(1,14,1,1),且在每个维度上的步长都为1,即可得到池化后的shape为(?,1,1,8)。
依次类推,当window_size为其他时,也能得到池化层输出shape为(?,1,1,8)。
得到四个卷积、池化的输出之后,我们使用如下代码将池化层的输出根据第3维,也就是第四个参数相连,变形为(?,1,1,32),再变形为三维(?,1,32)。
pool_layer = tf.concat(pool_layer_lst, 3, name="pool_layer") #(?,1,1,32) max_num = len(self.window_sizes) * self.filter_num # 32 pool_layer_flat = tf.reshape(pool_layer, [-1, 1, max_num], name="pool_layer_flat") #(?,1,32) 其实仅仅是减少了一个纬度,?仍然为每一批批量
最后为了正则化防止过拟合,经过dropout层处理,输出shape为(?,1,32)。
3. 全连接层
对上文所得到的嵌入层的输出和卷基层的输出进行全连接。
- 对User数据的嵌入层进行全连接,最终得到输出特征的shape为(?,200)
def create_user_feature_layer(self, uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer):with tf.name_scope("user_fc"):# 第一层全连接 改变最后一维uid_fc_layer = tf.layers.dense(uid_embed_layer, self.embed_dim, name="uid_fc_layer", activation=tf.nn.relu)gender_fc_layer = tf.layers.dense(gender_embed_layer, self.embed_dim, name="gender_fc_layer",activation=tf.nn.relu)age_fc_layer = tf.layers.dense(age_embed_layer, self.embed_dim, name="age_fc_layer", activation=tf.nn.relu)job_fc_layer = tf.layers.dense(job_embed_layer, self.embed_dim, name="job_fc_layer", activation=tf.nn.relu)# (?,1,32)# 第二层全连接user_combine_layer = tf.concat([uid_fc_layer, gender_fc_layer, age_fc_layer, job_fc_layer], 2)# (?, 1, 128)user_combine_layer = tf.contrib.layers.fully_connected(user_combine_layer, 200, tf.tanh) # (?, 1, 200)user_combine_layer_flat = tf.reshape(user_combine_layer, [-1, 200]) #(?,200)return user_combine_layer, user_combine_layer_flat- 同理对Movie数据同样进行两层全连接,最终得到输出特征的shape为(?,200)
def create_movie_feature_layer(self, movie_id_embed_layer, movie_categories_embed_layer, dropout_layer):with tf.name_scope("movie_fc"):# 第一层全连接movie_id_fc_layer = tf.layers.dense(movie_id_embed_layer, self.embed_dim, name="movie_id_fc_layer",activation=tf.nn.relu) #(?,1,32)movie_categories_fc_layer = tf.layers.dense(movie_categories_embed_layer, self.embed_dim,name="movie_categories_fc_layer", activation=tf.nn.relu)#(?,1,32)# 第二层全连接movie_combine_layer = tf.concat([movie_id_fc_layer, movie_categories_fc_layer, dropout_layer],2) # (?, 1, 96)movie_combine_layer = tf.contrib.layers.fully_connected(movie_combine_layer, 200, tf.tanh) # (?, 1, 200)movie_combine_layer_flat = tf.reshape(movie_combine_layer, [-1, 200])return movie_combine_layer, movie_combine_layer_flat4. 构建计算图&训练
构建计算图,训练。问题回归为简单的将用户特征和电影特征做矩阵乘法得到一个预测评分,损失为均方误差。
inference = tf.reduce_sum(user_combine_layer_flat * movie_combine_layer_flat, axis=1)
inference = tf.expand_dims(inference, axis=1)
cost = tf.losses.mean_squared_error(targets, inference)
loss = tf.reduce_mean(cost)
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(lr) # 传入学习率
gradients = optimizer.compute_gradients(loss) # cost
train_op = optimizer.apply_gradients(gradients, global_step=global_step)- 模型保存
保存的模型包括:处理后的训练数据、训练完成后的网络、用户特征矩阵、电影特征矩阵。
- 损失图像
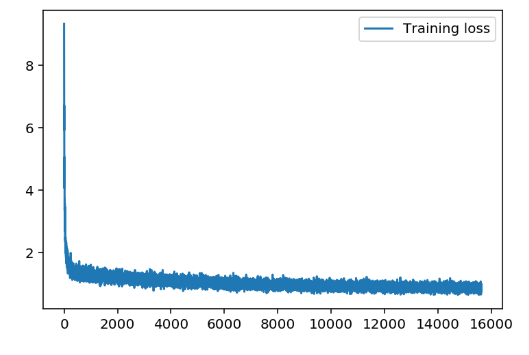
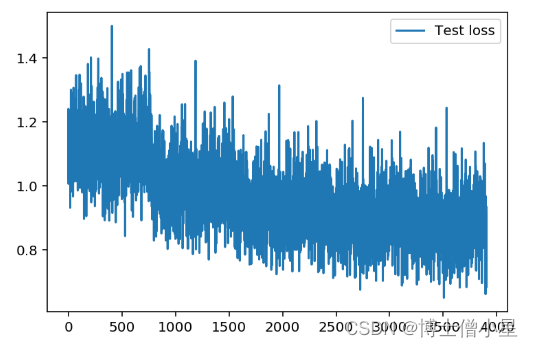
- 经过简单的调参。
batch_size对Loss的影响较大,但是batch_size过大,损失会有比较大的抖动情况。随着学习率逐渐减小,损失会先减小后增大,所以最终确定参数还是原作者的固定参数效果较好。
5. 推荐
加了随机因素保证对相同电影推荐时推荐结果的不一致
-
给用户推荐喜欢的电影:使用用户特征向量与电影特征矩阵计算所有电影的评分,取评分最高的 topK个
-
推荐相似的电影:计算选择电影特征向量与整个电影特征矩阵的余弦相似度,取相似度最大的 topK 个
-
推荐看过的用户还喜欢看的电影
3.1 首先选出喜欢某个电影的 topK 个人,得到这几个人的用户特征向量
3.2 计算这几个人对所有电影的评分
3.3 选择每个人评分最高的电影作为推荐
三. Web展示端
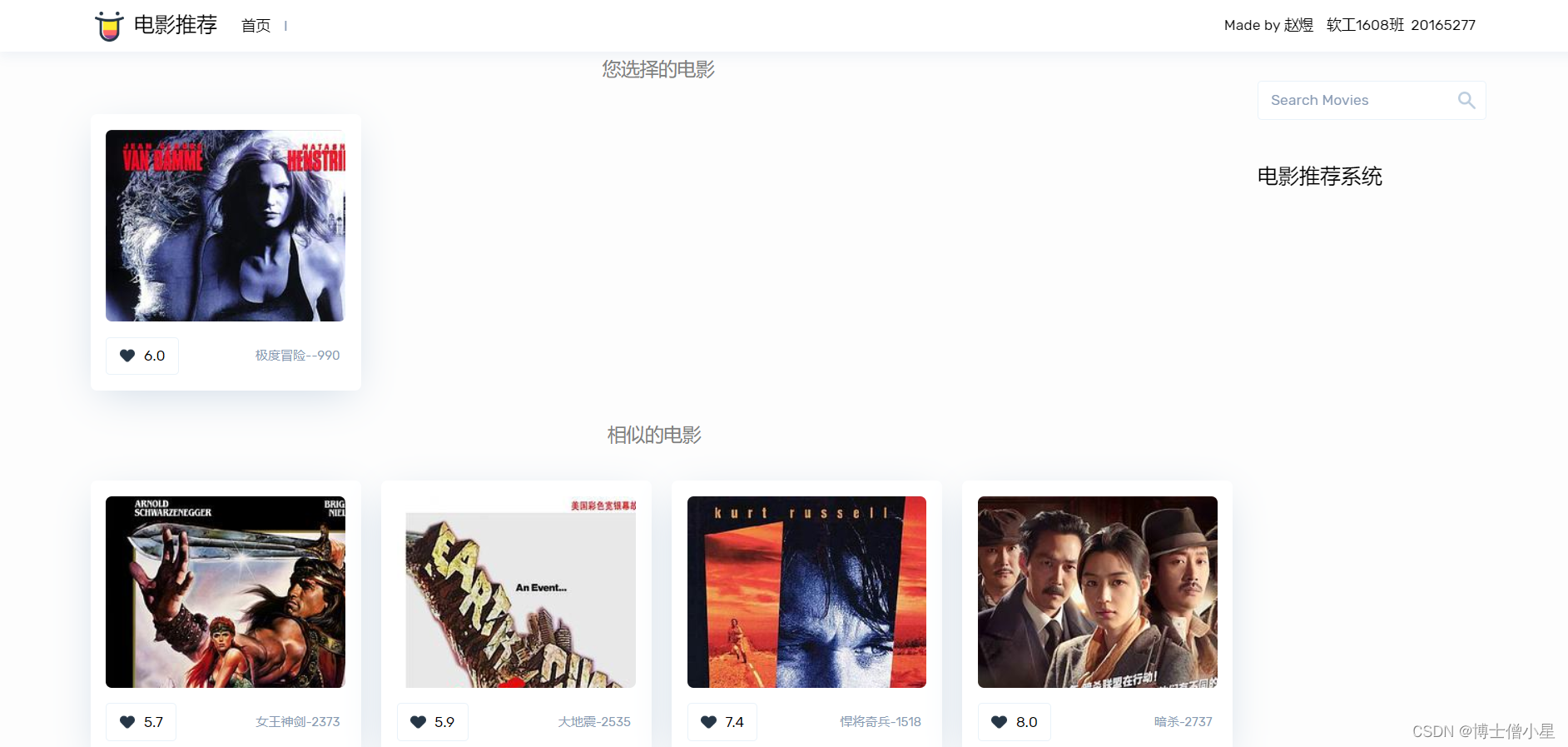
1. django框架开发web
由于给定的数据集中并未有用户的其它信息,所以仅展示了“推荐相似的电影”和“推荐看过的用户还喜欢看的电影”,没有展示“给用户推荐喜欢的电影”这个模块,并且数据集也未有电影的中文名称、图片等数据,所以我在web项目中加了一个豆瓣的爬虫,每次推荐都请求数据,并进行相应的解析和封装。
在服务器启动的时候就加载模型,并且把tensorflow的session提前封装好,在调用相关方法时,直接传入该全局session,避免了每次请求都加载模型。
前端请求推荐的耗时大部分是爬虫请求的耗时,并且访问频率过快会被豆瓣拒绝请求一段时间.
2. 展示截图

-
后台推荐结果
给用户推荐喜欢的电影
-

推荐相似的电影

推荐看过的用户还喜欢看的电影

四. 实验项目自评与总结
通过本次实验深度学习算是跨入了门槛,对tensorflow框架的基本使用有了一定的了解,并且此次实验的选题为推荐,是我比较喜欢的一个方向,之前对协同过滤等算法有所研究,此次利用深层网络对数据的特征进行提取更加深了我对推荐的理解。
当然,本次实验的核心代码和模型架构是copy的,但我对模型的每一步都进行了演算推导,并整理成该文档,除此我把源码进行了面向对象封装,增强了源码的复用性和可用性,对推荐相关方法也进行了微小的调整,解决了模型多次加载问题,最后增加了该项目的web展示端。
此次实验收货颇丰,但是该系统还存在一系列问题:如模型的局限性,即该系统只能对数据集中的电影和用户进行推荐,我没有再找到具有相关字段的数据,所以训练数据量相对较小,适用性也比较窄。
网络中有很多对MovieLens数据集的推荐算法,我想在学习了相关算法之后,能把这些算法用到工业界或者传统业会比针对一个已存在几十年的数据集提高那百分之零点几的准确率或降低微小的误差更有意义,当然,要解决的问题也会更多,加油吧!
以下是我的推导手稿截图:


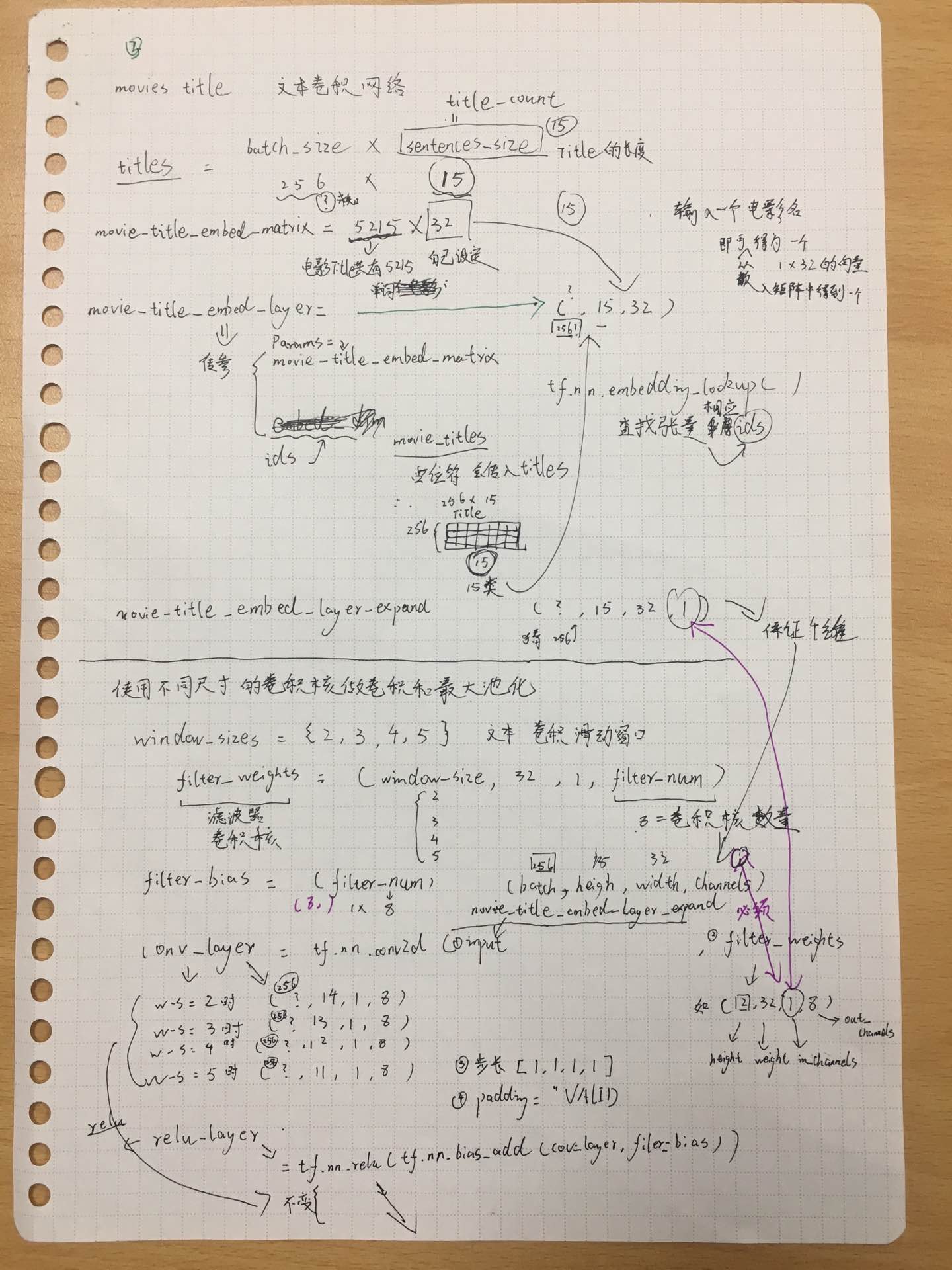
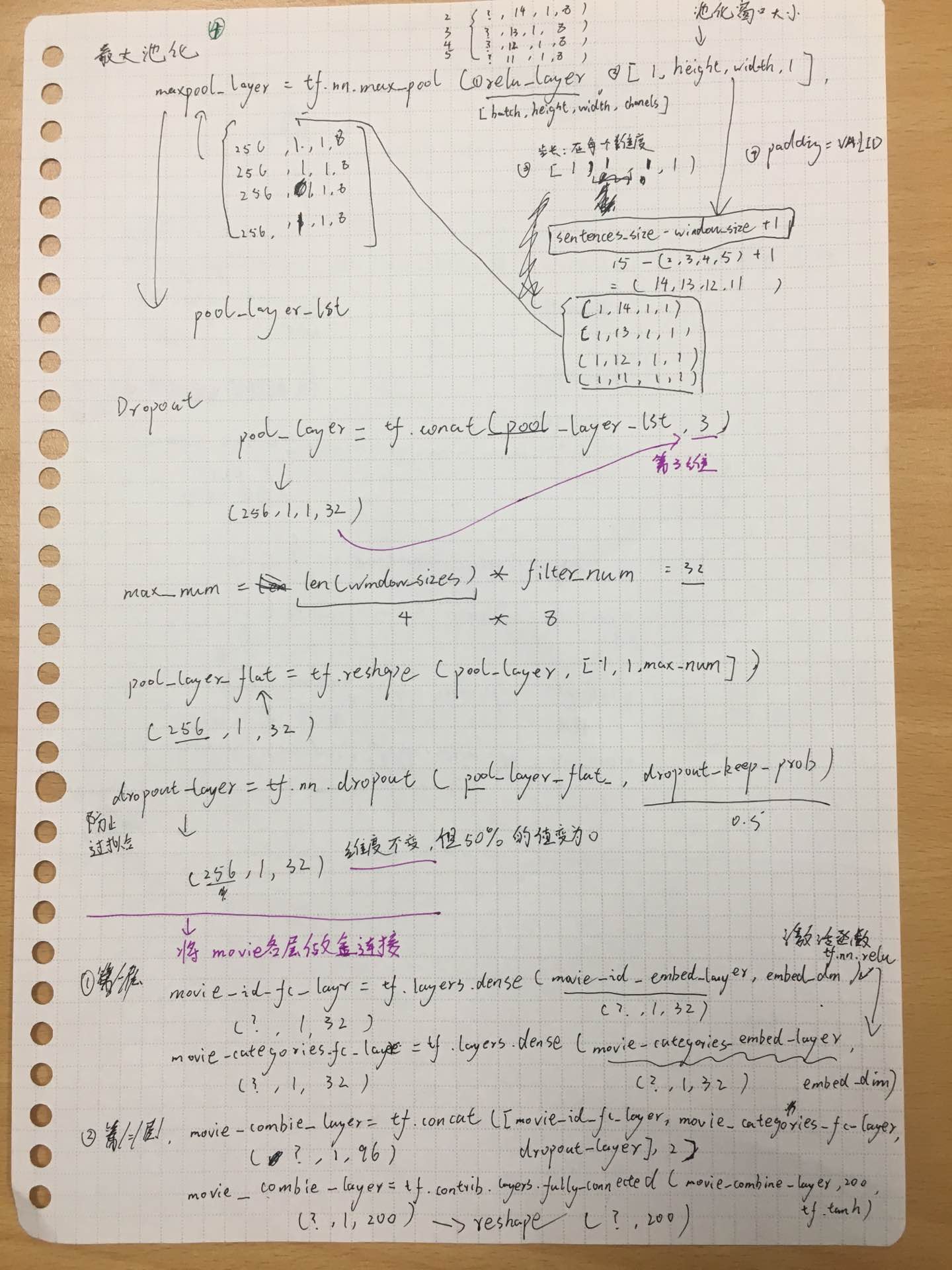
五. 参考文献
【1】Convolutional Neural Networks for Sentence Classification
【2】Understanding Convolutional Neural Networks for NLP
相关文章:
人工智能|推荐系统——基于tensorflow的个性化电影推荐系统实战(有前端)
代码下载: 基于tensorflow的个性化电影推荐系统实战(有前端).zip资源-CSDN文库 项目简介: dl_re_web : Web 项目的文件夹re_sys: Web app model:百度云下载之后,把model放到该文件夹下recommend: 网络模型相…...
Hive SQL编译成MapReduce任务的过程
目录 一、架构及组件介绍 1.1 Hive底层架构 1.2 Hive组件 1.3 Hive与Hadoop交互过程 二、Hive SQL 编译成MR任务的流程 2.1 HQL转换为MR源码整体流程介绍 2.2 程序入口—CliDriver 2.3 HQL编译成MR任务的详细过程—Driver 2.3.1 将HQL语句转换成AST抽象语法树 词法、语…...

【C++】快速上手map、multimap、set、multiset
文章目录 一、前言二、set / multiset1. 常见应用2. 核心操作 三、map / multimap1. 常见应用2. 核心操作 一、前言 S T L STL STL 中的关联式容器分为树型结构和哈希结构,树型结构主要有四种: s e t set set、 m u l t i s e t multiset multiset、 m a…...
【分享】图解ADS+JLINK调试ARM
文章是对LPC2148而写的,但是对三星的44B0芯片同样适用,只需要在选择时将相应的CPU选择的S3C44B0就可以了。 JLINK在ADS下调试心得 前两天一个客户用jlink在ADS下调试LPC2148总报错,这个错误我之前在调试LPC2200的时候也碰到过,后…...
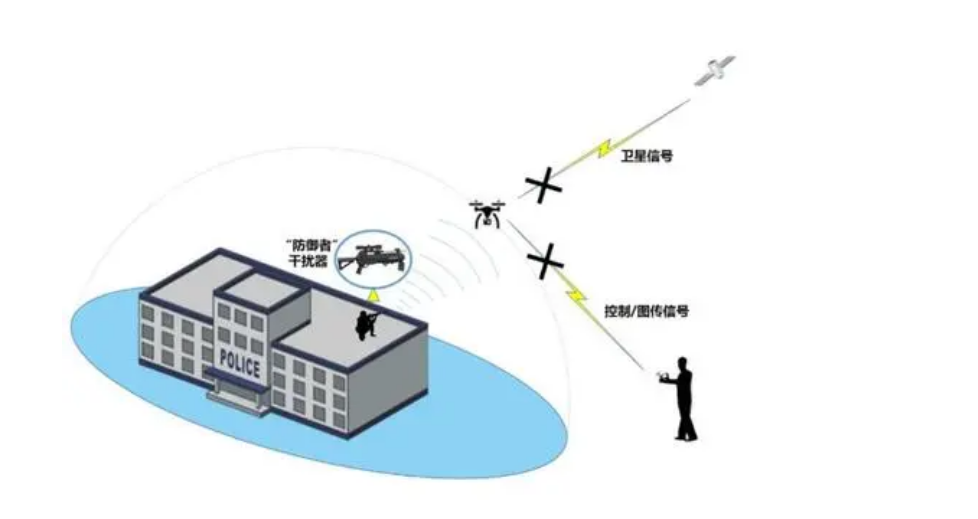
反无人机系统技术分析,无人机反制技术理论基础,无人机技术详解
近年来,经过大疆、parrot、3d robotics等公司不断的努力,具有强大功能的消费级无人机价格不断降低,操作简便性不断提高,无人机正快速地从尖端的军用设备转入大众市场,成为普通民众手中的玩具。 然而,随着消…...
Kotlin和Java 单例模式
Java 和Kotlin的单例模式其实很像,只是Kotlin一部分单例可以用对象类和委托lazy来实现 Java /*** 懒汉式,线程不安全*/ class Singleton {private static Singleton instance;private Singleton() {}public static Singleton getInstance() {if (insta…...
)
软考 系统分析师系列知识点之信息系统战略规划方法(9)
接前一篇文章:软考 系统分析师系列知识点之信息系统战略规划方法(8) 所属章节: 第7章. 企业信息化战略与实施 第4节. 信息系统战略规划方法 7.4.5 信息工程方法 信息工程(Information Engineering,IE&…...
政安晨:示例演绎TensorFlow的官方指南(一){基础知识}
为什么要示例演绎? 既然有了官方指南,咱们在官方指南上看看就可以了,为什么还要写示例演绎的文章呢? 其实对于初步了解TensorFlow的小伙伴们而言,示例演绎才是最重要的。 官方文档已经假定了您已经具备了相当合适的…...

node - 与数据库交互
在Web开发中,与数据库交互是常见的需求,用于持久化存储、检索和操作数据。不同的后端技术和数据库类型(如关系型数据库和非关系型数据库)有着不同的交互方式。下面介绍几种常见的数据库交互方法。 关系型数据库 关系型数据库(如MySQL、PostgreSQL、SQLite)使用结构化查…...

速盾:2024年cdn在5g时代重要吗
在2024年,随着5G技术的普及与应用,内容分发网络(Content Delivery Network,CDN)在数字化时代中的重要性将进一步巩固和扩大。CDN是一种用于快速、高效地分发网络内容的基础设施,它通过将内容部署在全球各地…...
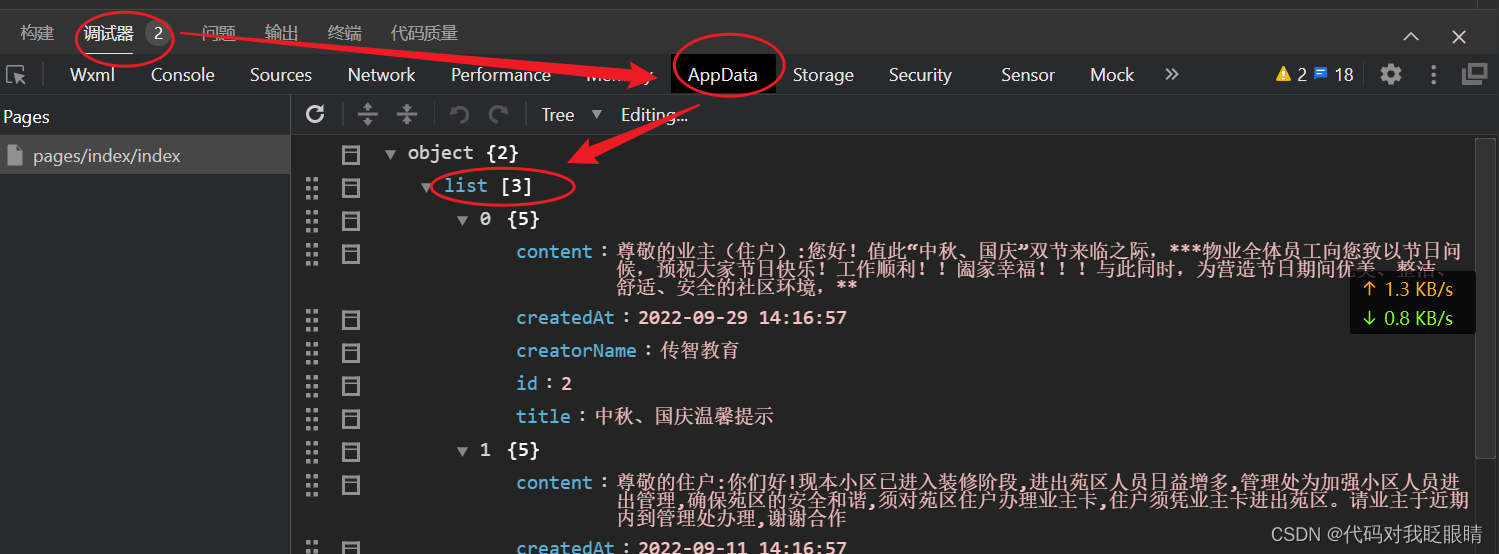
微信小程序(四十一)wechat-http的使用
注释很详细,直接上代码 上一篇 新增内容: 1.模块下载 2.模块的使用 在终端输入npm install wechat-http 没有安装成功vue的先看之前的一篇 微信小程序(二十)Vant组件库的配置- 如果按以上的成功配置出现如下报错先输入以下语句 …...

所有设计模式大全及学习链接
文章目录 创建型设计模式结构型设计模式行为型设计模式 创建型设计模式 一种创建对象的设计模式,它们提供了一种灵活的方式来创建对象,同时隐藏了对象的创建细节。以下是常见的创建型设计模式: 工厂方法模式(Factory Method Patte…...
【Java程序设计】【C00264】基于Springboot的原创歌曲分享平台(有论文)
基于Springboot的原创歌曲分享平台(有论文) 项目简介项目获取开发环境项目技术运行截图 项目简介 这是一个基于Springboot的原创歌曲分享平台 本系统分为平台功能模块、管理员功能模块以及用户功能模块。 平台功能模块:在平台首页可以查看首…...

2024年,要特别注意这两个方位
家居风水对每个家庭都非常重要,可在无形中影响到人们的事业、财富以及健康运势。俗话说:“风水轮流转”,2024年为甲辰龙年,斗转星移、九宫飞星将改变宫位,新一年的磁场即将启动,方位的吉凶也会重新变动&…...
【Chrono Engine学习总结】5-sensor-5.1-sensor基础并创建一个lidar
由于Chrono的官方教程在一些细节方面解释的并不清楚,自己做了一些尝试,做学习总结。 1、Sensor模块 Sensor模块是附加模块,需要单独安装。参考:【Chrono Engine学习总结】1-安装配置与程序运行 Sensor Module Tutorial Sensor …...

springboot/ssm学生信息管理系统Java学生在线选课考试管理系统
springboot/ssm学生信息管理系统Java学生在线选课考试管理系统 开发语言:Java 框架:springboot(可改ssm) vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.…...
three.js 箭头ArrowHelper的实践应用
效果: 代码: <template><div><el-container><el-main><div class"box-card-left"><div id"threejs" style"border: 1px solid red"></div></div></el-main></…...

力扣hot2--哈希
推荐博客: for(auto i : v)遍历容器元素_for auto 遍历-CSDN博客 字母异位词都有一个特点:也就是对这个词排序之后结果会相同。所以将排序之后的string作为key,将排序之后能变成key的单词组vector<string>作为value。 class Solution …...
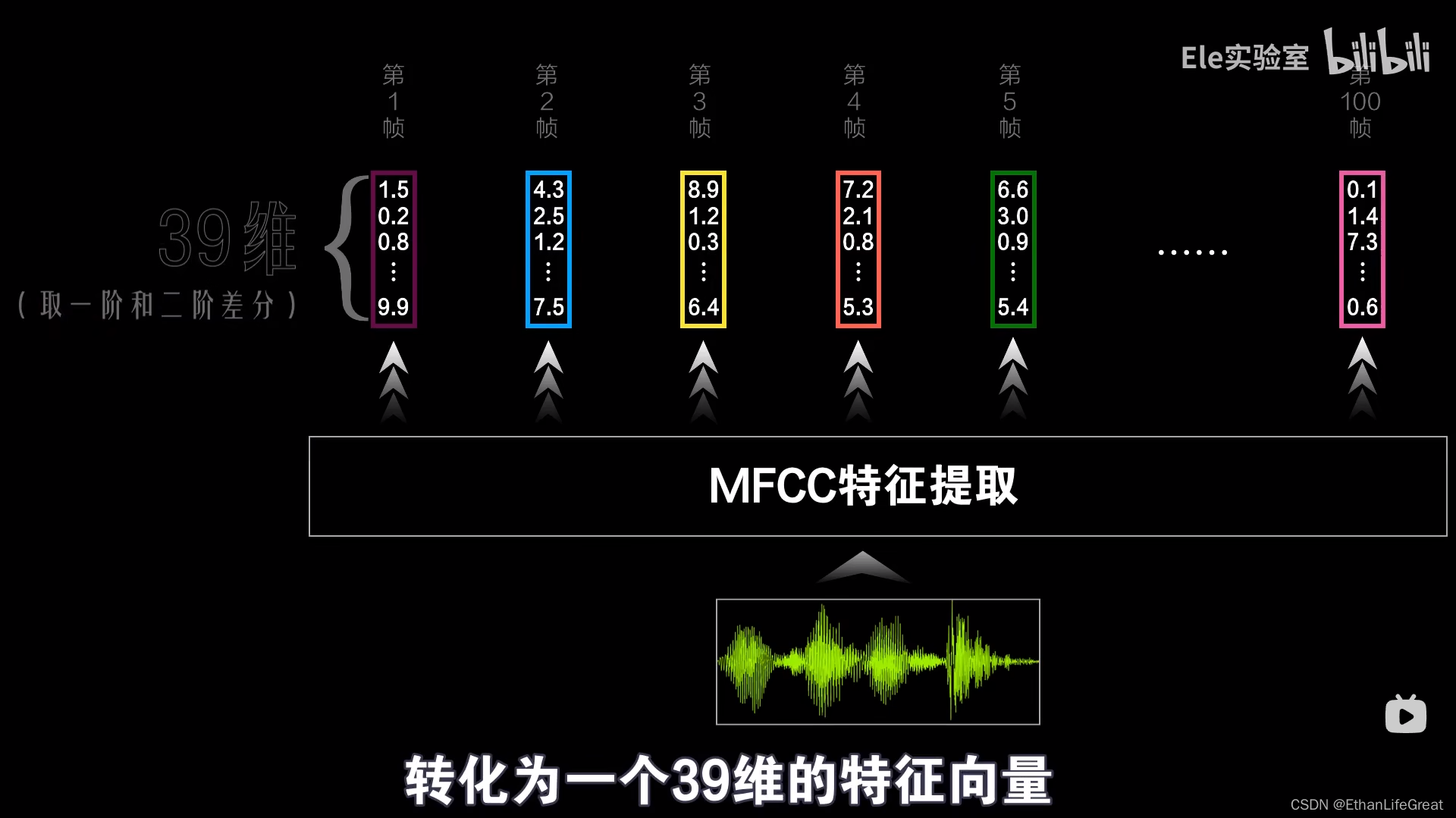
【正在更新】从零开始认识语音识别:DNN-HMM混合系统语音识别(ASR)原理
摘要 | Abstract 这是一篇对语音识别中的一种热门技术——DNN-HMM混合系统原理的透彻介绍。本文自2月10日开始撰写,计划一星期内写完。 1.前言 | Introduction 近期想深入了解语音识别(ASR)中隐马尔可夫模型(HMM)和深度神经网络-隐马尔可夫(DNN-HMM)混合模型&#…...
thinkphp+vue企业产品展示网站f7enu
本文首先介绍了企业产品展示网站管理技术的发展背景与发展现状,然后遵循软件常规开发流程,首先针对系统选取适用的语言和开发平台,根据需求分析制定模块并设计数据库结构,再根据系统总体功能模块的设计绘制系统的功能模块图&#…...

你还在手动切Relax Mode?3行Discord Bot脚本自动识别任务优先级并智能分流——附GitHub可运行代码
更多请点击: https://intelliparadigm.com 第一章:Relax Mode的本质与Discord任务分流的底层逻辑 Relax Mode并非一种简单的“低负载”开关,而是基于事件驱动与资源感知的动态调度策略。其核心在于将非实时性、可延迟、可重试的后台任务&…...

为团队 CLI 工具统一配置 Taotoken 作为后端模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为团队 CLI 工具统一配置 Taotoken 作为后端模型服务 当团队开发的内部命令行工具需要集成大模型能力时,直接对接多个厂…...

5分钟快速上手WuWa-Mod:解锁《鸣潮》游戏无限潜能的终极指南
5分钟快速上手WuWa-Mod:解锁《鸣潮》游戏无限潜能的终极指南 【免费下载链接】wuwa-mod Wuthering Waves pak mods 项目地址: https://gitcode.com/GitHub_Trending/wu/wuwa-mod 还在为《鸣潮》游戏中的技能冷却时间烦恼吗?想要体验无限体力、自动…...

深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱
深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱 【免费下载链接】IDR Interactive Delphi Reconstructor 项目地址: https://gitcode.com/gh_mirrors/id/IDR 你是否曾经面对一个Delphi编译的程序,却无法理解它的内部逻辑?或者需要…...
)
一机多版本Quartus共存?教你修复USB Blaster识别冲突(修改JTAG服务路径详解)
多版本Quartus共存时的USB Blaster识别冲突解决方案 当我们需要在同一台电脑上安装多个版本的Quartus软件时(比如为了兼容不同时期的FPGA项目),经常会遇到一个棘手问题:USB Blaster无法被正确识别。这种情况通常发生在安装了新旧两…...

一键解决Windows运行库问题:Visual C++ AIO完整安装指南
一键解决Windows运行库问题:Visual C AIO完整安装指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的困扰:新下载…...

Perplexity社会新闻搜索响应延迟突增47%?独家披露其底层新闻图谱更新机制与3类高危缓存失效场景
更多请点击: https://kaifayun.com 第一章:Perplexity社会新闻搜索响应延迟突增47%?独家披露其底层新闻图谱更新机制与3类高危缓存失效场景 Perplexity 社会新闻搜索服务近期观测到 P95 响应延迟从 320ms 飙升至 468ms,增幅达 4…...

drf-nested-routers测试指南:确保嵌套路由稳定性的完整方案
drf-nested-routers测试指南:确保嵌套路由稳定性的完整方案 【免费下载链接】drf-nested-routers Nested Routers for Django Rest Framework 项目地址: https://gitcode.com/gh_mirrors/dr/drf-nested-routers drf-nested-routers是Django Rest Framework的…...

openLCA 2.6.2 完整安装与使用指南:免费开源的生命周期评估解决方案
openLCA 2.6.2 完整安装与使用指南:免费开源的生命周期评估解决方案 【免费下载链接】olca-app Source code of openLCA 项目地址: https://gitcode.com/gh_mirrors/ol/olca-app openLCA 是一款功能强大的开源生命周期评估软件,专门用于产品从原材…...

工业控制新方案:电容HMI与字符LCD组合应用实战
1. 项目概述:当经典LCD遇上电容触控,工业控制的新解法最近在做一个产线设备升级的项目,客户对操作界面的要求突然拔高了不少:既要能看清复杂的工艺参数,又要求操作像手机一样流畅,还得扛得住车间里的油污、…...