【C++】C++11上
C++11上
- 1.C++11简介
- 2.统一的列表初始化
- 2.1 {} 初始化
- 2.2 initializer_list
- 3.变量类型推导
- 3.1auto
- 3.2decltype
- 3.3nullptr
- 4.范围for循环
- 5.final与override
- 6.智能指针
- 7. STL中一些变化
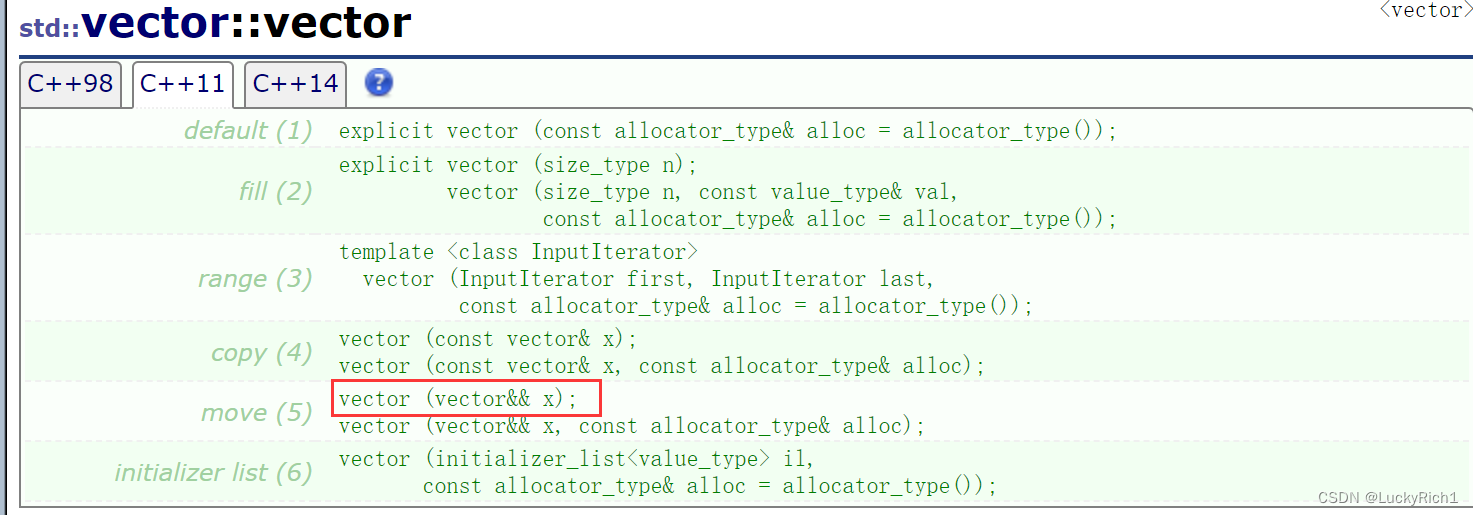
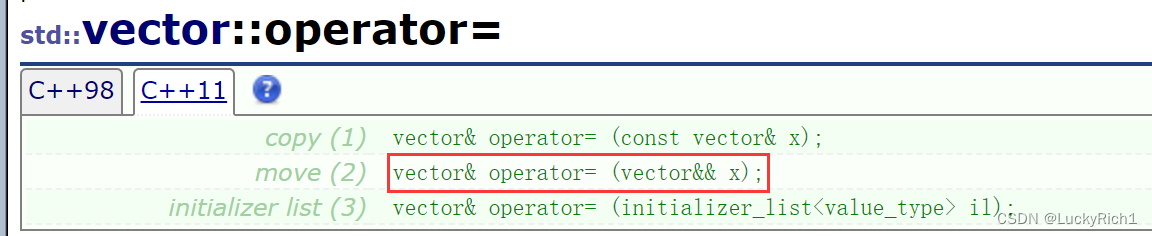
- 8.右值引用和移动语义
- 8.1左值引用和右值引用
- 8.2左值引用与右值引用比较
- 8.3右值引用使用场景和意义
- 9.新的类功能
1.C++11简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,
C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个重点去学习。C++11增加的语法特性非常篇幅非常多,我们这里没办法一 一讲解,所以这里主要讲解实际中比较实用的语法。
C++11
2.统一的列表初始化
2.1 {} 初始化
在C++98中,标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定。比如:
struct Point
{int _x;int _y;
};int main()
{int array1[] = { 1, 2, 3, 4, 5 };int array2[5] = { 0 };Point p = { 1, 2 };return 0;
}
C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
int main()
{//C++98Point p1 = { 1,2 };int array1[] = { 1, 2, 3, 4, 5 };//C++11Point p2{ 1,2 };int array2[]{ 1,2,3,4,5 };//C++98int x1 = 10;//C++11int x2 = { 10 };int x3{ 10 };return 0;
}
以前{ }只能初始化结构数组,现在一切皆可以{ }初始化。但是上面不建议使用{ }初始化,传统方式可读性更好一些,看懂即可。
最好使用地方在下面这里
int* p3 = new int[10];//以前new不好初始化
int* p4 = new int[10]{ 0,1,2,3,4 };//现在就可以{}初始化,C++11支持的
Point* p5 = new Point[2]{ {1,2},{3,4} };//结构对象{}初始化之后,然后再{}初始化数组
创建对象时也可以使用列表初始化方式调用构造函数初始化
class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}
private:int _year;int _month;int _day;
};int main()
{Date d1(2022, 1, 1); // 以前初始化// C++11支持的列表初始化,这里会调用构造函数初始化Date d2{ 2022, 1, 2 };return 0;
}
2.2 initializer_list
initializer_list文档介绍
以前我们可能见过这样初始化,这是怎么回事,见过这么多参数调用构造函数的吗,怎么做到的?
int main()
{vector<int> v = { 1,2,3,4 };list<int> lt = { 1,2,3,4,5,6,7 };
}
这里首先说明一点C++给{ }一个类型,是initializer_list类型,它会去匹配自定义类型的构造函数。
int main()
{Date d{ 2022, 1, 1 };//这里是调用构造auto l1 = { 1,2,3,4,5,6 };//这里是识别成initializer_lis数组,上面vector,list也都是识别成initializer_lis数组去初始化cout << typeid(l1).name() << endl;
}
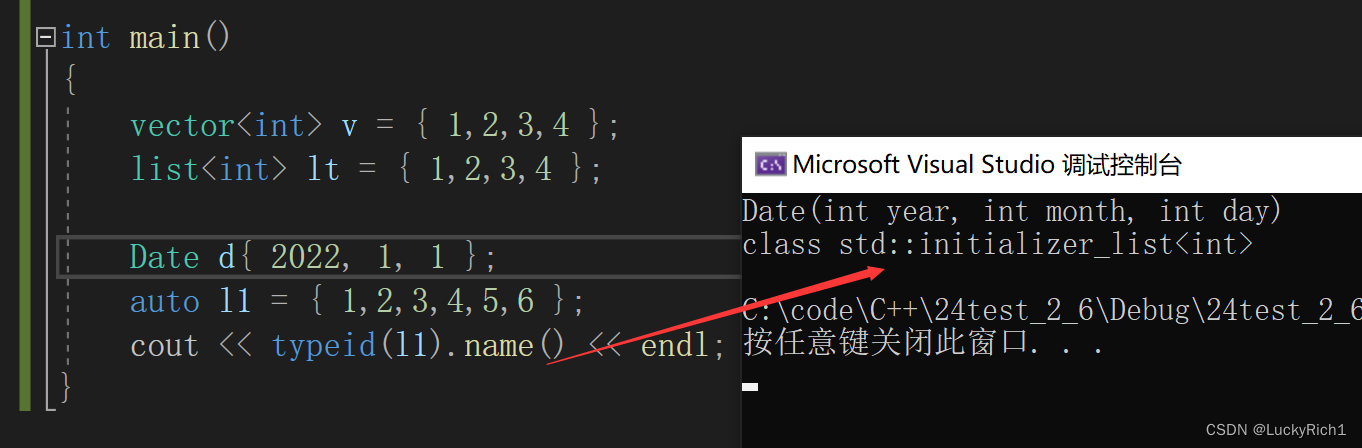


initializer_list可以认为是对常量数组(存在常量区)进行封装,里面有两个指针指向常量区数组的开始和结束的地址。begin,end迭代器就是一个原生指针。
有了initializer_list,所有容器都支持initializer_list的构造函数,所以vector,list都可以那样初始化。不管是几个参数都可以传给initializer_list对象。
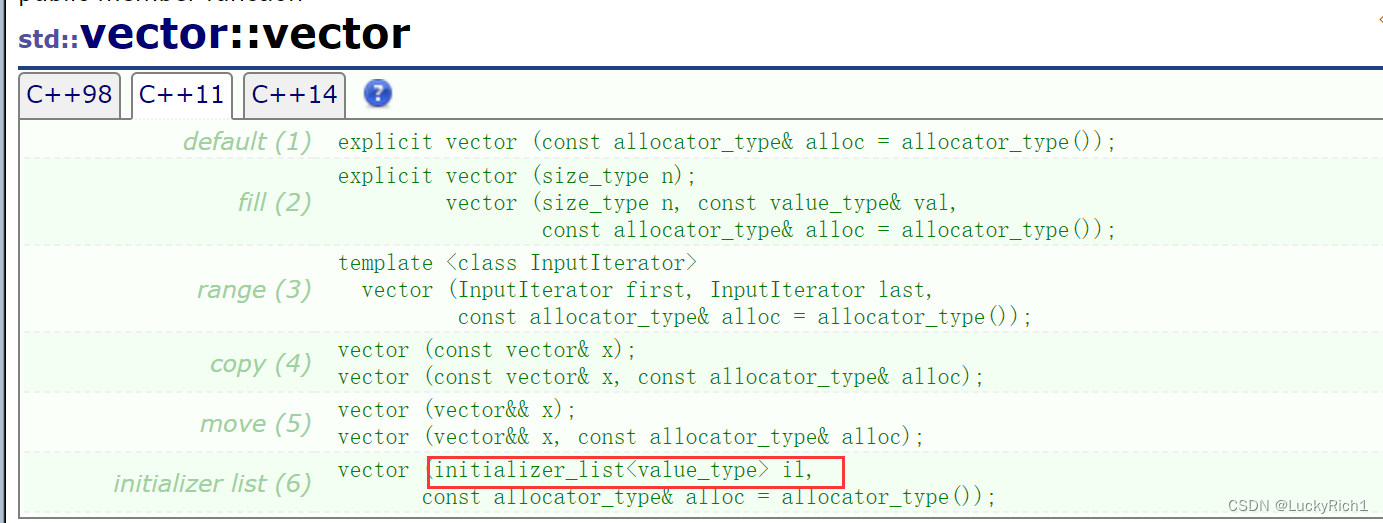
以前模拟实现过vector,现在给自己的vector增加支持initializer_list构造函数。
这是没实现的样子。
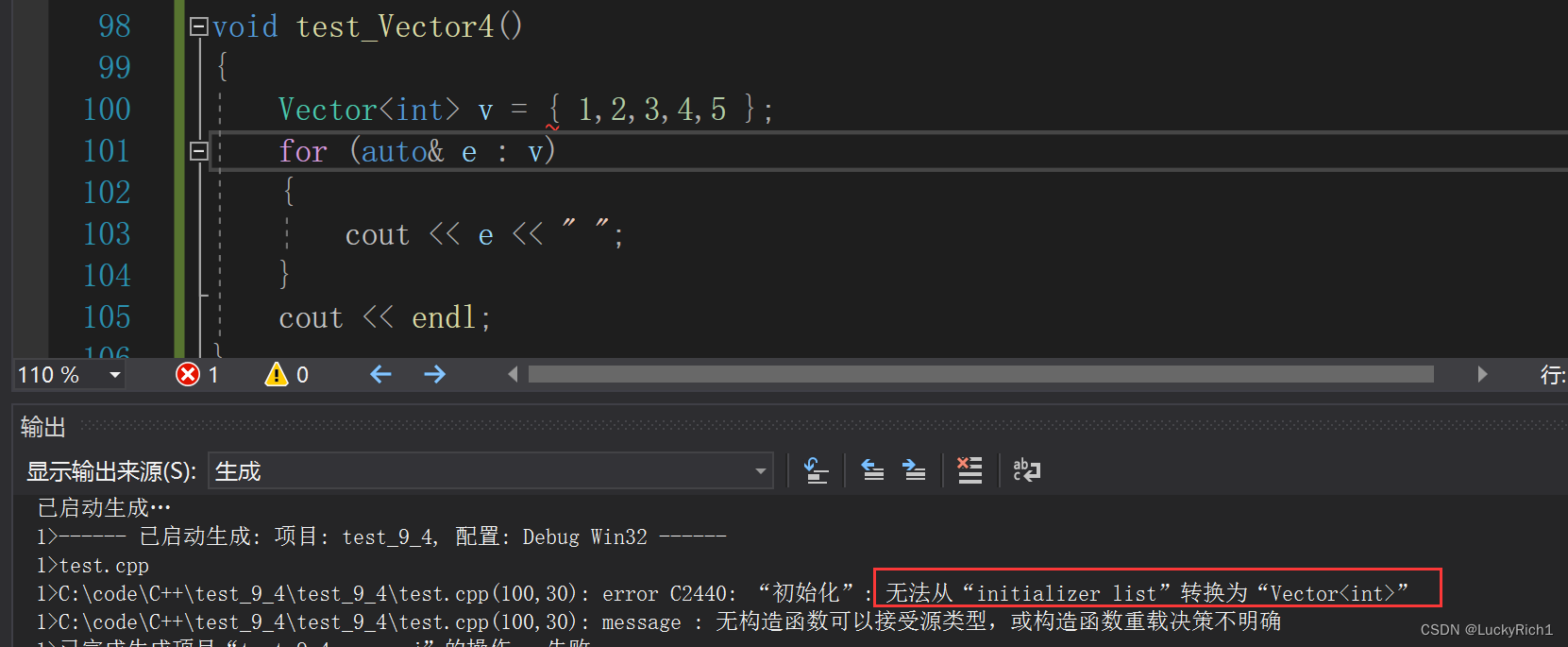
增加支持initializer_list的构造函数
#include<initializer_list>Vector(initializer_list<T> l1):_start(0), _finish(0), _endofstorage(0)
{reserve(l1.size());//可以提前开辟好空间for (auto& e : l1)//底层是迭代器{push_back(e);}
}
现在就没问题了
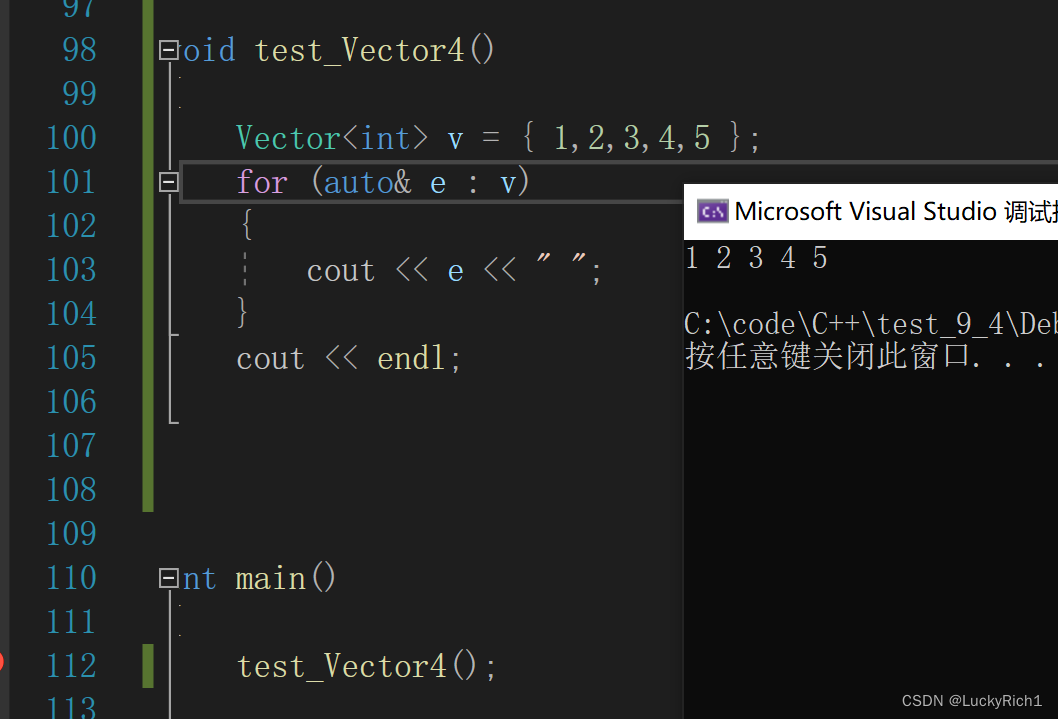
下面的写法现在就能看懂了。
//里面{}是调用日期类的构造函数生成匿名对象
//外面{}是日期类常量对象数组,去调用vector支持initializer_list的构造函数
vector<Date> v = { {1,1,1},{2,2,2},{3,3,3} };//里面{}调用pair的构造函数生成pair匿名对象
//外面{}是pair常量对象数组,去调用map支持initializer_list的构造函数
map<string, string> dict = { {"sort","排序"},{"string","字符串"} };
注意容器initializer_list不能直接引用,必须加const,因为可以认为initializer_list是由常量数组转化得到的,临时对象具有常性。
//构造
List(const initializer_list<T>& l1)
{empty_initialize();for (auto& e : l1){push_back(e);}
}
3.变量类型推导
3.1auto
根据右边传的值可以自动推导左边对象的类型。用的很多这里不再叙述。
3.2decltype
关键字decltype将变量的类型声明为表达式指定的类型。
也就是说decltype根据表达式推导这个类型,然后用这个类型去定义变量。
int main()
{int x = 0;cout << typeid(x).name() << endl;//typeid().name()只能将类型转换成字符串//typeid(x).name() y;//绝不可能再去定义一个变量decltype(x) y;//推导出x的类型,来定义yreturn 0;
}
// decltype的一些使用使用场景
template<class T1, class T2>
void F(T1 t1, T2 t2)
{//比如这里都传的是int还好说,ret定义成int//但是一个是int,一个是double,ret还被定成int就出现精度丢失的问题decltype(t1 * t2) ret=t1*t2;cout << typeid(ret).name() << endl;
}
3.3nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空针。
这里是C++的一个bug,使用NULL可能在类型匹配的时候出现问题,比如你期望匹配成指针结果匹配成了0。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
4.范围for循环
这个在前面容器一直在用,这里不再细说。
5.final与override
这个在继承和多态的时候说过。
6.智能指针
后面专门说这个智能指针。
7. STL中一些变化
新容器
用红色圈起来是C++11中的一些几个新容器,但是实际最有用的是unordered_map和unordered_set。这两个我们前面已经进行了非常详细的讲解,
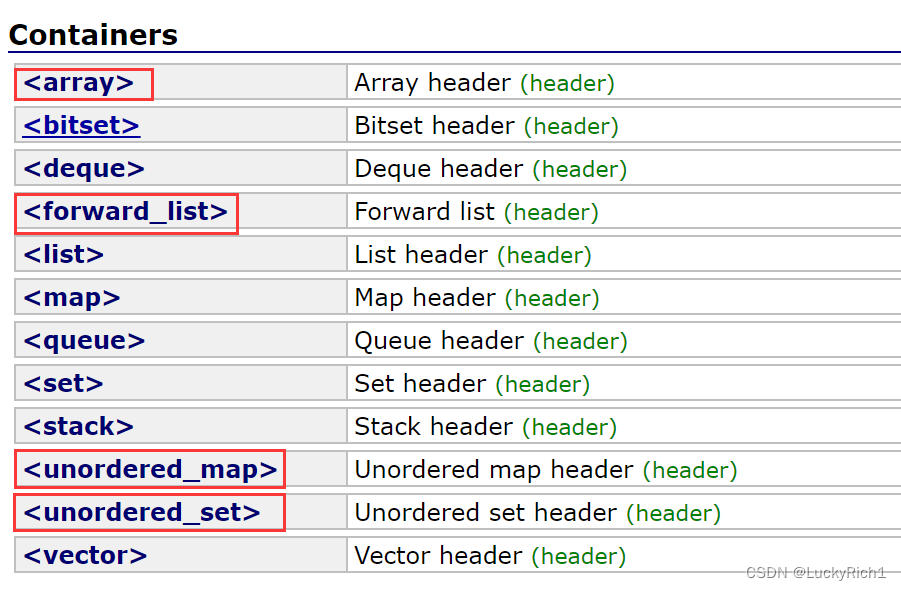
array是固定大小的容器,所以它有一个非类型模板参数。

array是一个固定大小的数组,vector是一个动态数组。
array其实对比的是静态数组
int main()
{array<int, 10> a1;int a2[10];a2[10] = 1;//报错a2[20] =1;//正常a2[30];//正常a1[1];//报错
}
array相比于静态数组的有什么优势呢?
静态数组越界读不会报错,越界写会抽查报错。而array对于读写都会检查。注意是因为[ ]成员函数里面会做检查。
但是实际上我们用vector更多。并且vector提供的接口也更多!
forward_list是一个单链表,
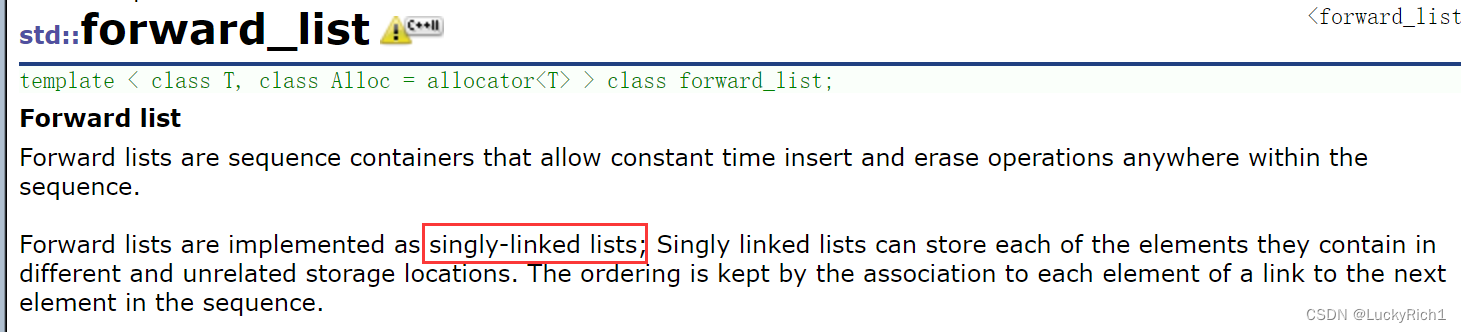
只有单向迭代器

只提供头插头删,没有提供尾插尾删,因为每次都要找尾不方便!并且insert,erase也是在结点后面插入和删除。

对比list只有每个结点节省一个指针的优势,其他地方都没有list好用!
C++11更新真正有用的是unordered_map和unordered_set,前面都学过这里不说了。
容器中的一些新方法
觉得调用迭代器的const版本和非const版本不明显,就新增下面的,不过确实很鸡肋。

最有作用的是emplace系列的插入
emplace_back 对应 push_back
emplace 对应 insert

它和右值引用和可变模板参数有关,在有些场景下可以提高效率。

8.右值引用和移动语义
8.1左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值?什么是右值?
在赋值符号左边的就是左值
能修改的就是左指
在赋值符号右边的就是右值
这样的说话对不对?
第一句是半对,左值既可以出现在左边又可以出现在右边。后面两句话都是不对的。
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
int main()
{// 以下的p、b、c、*p都是左值int* p = new int(0);int b = 1;const int c = 2;// 以下几个是对上面左值的左值引用int*& rp = p;int& rb = b;const int& rc = c;int& pvalue = *p;return 0;
}
左值和右值最大的区别就是左值可以取地址。
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。右值引用就是对右值的引用,给右值取别名。
int main()
{double x = 1.1, y = 2.2;// 以下几个都是常见的右值10;x + y;fmin(x, y);// 以下几个都是对右值的右值引用int&& rr1 = 10;double&& rr2 = x + y;double&& rr3 = fmin(x, y);// 这里编译会报错:error C2106: “=”: 左操作数必须为左值10 = 1;x + y = 1;fmin(x, y) = 1;return 0;
}
8.2左值引用与右值引用比较
左值引用总结:
- 左值引用只能引用左值,不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值。
int main()
{// 左值引用只能引用左值,不能引用右值。int a = 10;int& ra1 = a; // ra为a的别名//int& ra2 = 10; // 编译失败,因为10是右值// const左值引用既可引用左值,也可引用右值。const int& ra3 = 10;//const修饰之后不能修改const int& ra4 = a;//权限缩小return 0;
}
右值引用总结:
- 右值引用只能右值,不能引用左值。
- 但是右值引用可以move以后的左值。
int main()
{// 右值引用只能右值,不能引用左值。int&& r1 = 10;// error C2440: “初始化”: 无法从“int”转换为“int &&”// message : 无法将左值绑定到右值引用int a = 10;int&& r2 = a;// 右值引用可以引用move以后的左值int&& r3 = std::move(a);return 0;
}
8.3右值引用使用场景和意义
先考虑一个问题:左值引用的意义是什么?
函数传参,函数传返回值 - - - 用引用减少拷贝!
但左值引用没有彻底解决问题!
它只是彻底解决函数传参的问题,传左指和右值都可以。和出了作用域还在的函数传返回值问题。
template<class T>
void func1(const T& x)
{
}template<class T>
const T& func2(const T& x)
{//..return x;
}int main()
{vector<int> v(10, 0);func1(v);//传左值func1(vector<int>(10, 0));//传右值return 0;
}
但是没有解决出了作用域不在函数返回值问题
template<class T>
T func3(const T& x)
{T ret;//..return ret;//不能用引用返回,ret出了作用域就销毁了,这里就相当于野指针的问题
}
并且传值返回铁铁的是一个深拷贝,如果是一个int,string都还好说,但是如下面的杨辉三角传值返回一个vector的vector就很麻烦了
vector<vector<int>> generate(int numRows) {vector<vector<int>> vv(numRows);for (int i = 0; i < numRows; ++i){vv[i].resize(i + 1, 1);}for (int i = 2; i < numRows; ++i){for (int j = 1; j < i; ++j){vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];}}return vv;
}
在我们没学C++11这个问题如何解决呢?
// 解决方案:换成输出型参数,就没了深了拷贝
// 但用起来很别扭
void generate(int numRows, vector<vector<int>>& vv) {vv.resize(numRows);for (int i = 0; i < numRows; ++i){vv[i].resize(i + 1, 1);}for (int i = 2; i < numRows; ++i){for (int j = 1; j < i; ++j){vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];}}
}
而右值引用的价值之一就是补齐这个最后一块短板!解决出了作用域不在函数返回值如上面导致深拷贝的问题。
右值引用是下面这样直接解决问题的吗?
template<class T>
T&& func2(const T& x)
{//..T ret;return ret;
}
不能,这样并不能解决出了作用域就销毁的问题!
接下来用自己写的string来看看右值引用到底怎么解决这个问题的。
namespace bit
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s){cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);}// 赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}~string(){delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0; // 不包含最后做标识的\0};//整型变成字符串string to_string(int value){bool flag = true;if (value < 0){flag = false;value = 0 - value;}bit::string str;while (value > 0){int x = value % 10;value /= 10;str += ('0' + x);}if (flag == false){str += '-';}std::reverse(str.begin(), str.end());return str;}
}int main()
{bit::string ret = bit::to_string(-1234);return 0;
}
本来传值返回是怎么解决这个问题的,调用了几次拷贝构造?
本来是两次拷贝构造,但是编译器优化就只有一次拷贝构造

一般函数调用之前会建立栈帧,建立栈帧之前会做两件事情,压参数和压返回值在两个栈帧之前。然后函数调用结束之后销毁栈帧不会影响它。下面是不优化的情况。

优化的情况
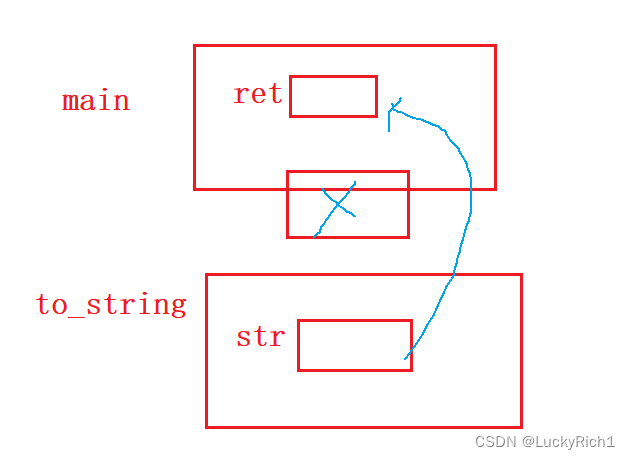
向下面这样写编译器就不能优化的,优化也是有自己的规则的!
连续的拷贝构造才能优化成一个拷贝构造。不能优化就中间产生一个临时对象。
int main()
{bit::string ret;ret= bit::to_string(-1234);return 0;
}
这里多打印一个深拷贝是因为赋值重载是现代写法复用拷贝构造。

但是即使这里优化还是有一个拷贝构造- -深拷贝!只是从两次变成了一次,没有彻底解决问题!
C++11是如何解决这样问题呢?
以前我们有一个const左值引用,既能接收左值也能接收右值。

如果提供一个右值引用的版本,这个时候给一个左值对象会匹配谁,右值对象会匹配谁?
以前没有右值引用,左值右值都走const
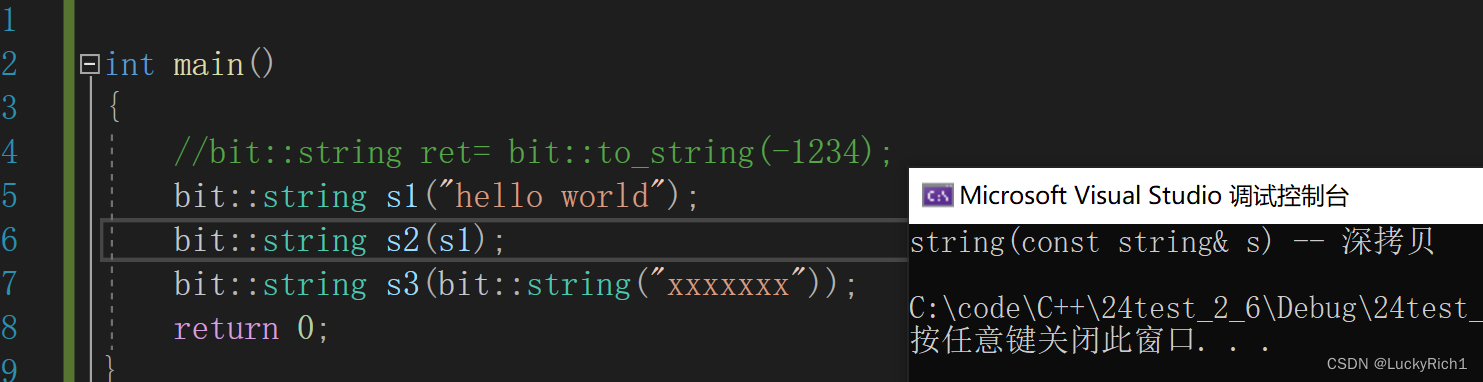
为什么这里只有一次拷贝构造(s2调用的)。s3为什么没有?
这是因为被编译器优化了,编译器把构造+拷贝构造优化成直接构造了。
现在有了右值引用,左值走左值引用,右值走右值引用。
右值刚才说了有字面常量,表达式的值,函数返回值等等
C++11又将右值进行了细分:
1.纯右值(内置类型表达式的值)
2.将亡值(自定义类型表达式的值)
将亡值代表即将死亡的值,如果是左值说明还在用只能深拷贝。而如果是将亡值本来也可以做深拷贝但是没有必要,不如你我之间交换一下把。
//移动构造
string(string&& s)
{cout << "string(const string& s) -- 移动拷贝" << endl;swap(s);
}
为什么敢做移动构造?
因为它的参数是右值引用,右值引用和左值引用同时在的话可以把左值和右值区分开来,是左值就去匹配左值引用的拷贝构造,是右值就去匹配右值引用的移动构造,右值引用这里拿到的将亡值,你都要亡了里面就不用做深拷贝了直接拿过来。
所以移动构造是专门用来移动将亡值。


是将亡值这个移动构造就会进行资源转移!所以使用要注意!
现在有了移动构造再看刚才出了作用域不在的函数返回值的问题。

现在再也不怕传值返回了,但是前提是你这个传值返回的对象实现移动构造!
像深拷贝的类移动构造才有意义,像那种日期类浅拷贝和内置类型移动构造就没有意义。
现在还有一个赋值的问题没有解决

赋值给的是将亡值就没必要深拷贝了,也是你我交换
//移动赋值
string& operator=(string&& s)
{cout << "string& operator=(string s) -- 移动赋值" << endl;swap(s);return *this;
}

总结一下:
右值引用和左值引用减少拷贝原理不太一样
左值引用是取别名,直接起作用
右值引用是间接起作用,实现移动构造和移动赋值,在拷贝的场景中,如果是右值(将亡值),转移资源
库里面的容器都是深拷贝因此都实现了移动构造和移动赋值
这里补充说明一点上面故意没说的。右值是一些字面常量等等为什么可以进行交换。
需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可以取到该位置的地址,也就是说例如:不能取字面量10的地址,但是rr1引用后,可以对rr1取地址,也可以修改rr1。如果不想rr1被修改,可以用const int&& rr1 去引用,是不是感觉很神奇,这个了解一下实际中右值引用的使用场景并不在于此,这个特性也不重要。
可以理解成右值引用之后这个值变成左值了,可以对rr1修改,也可以对rr1取地址,这样是未来支持移动构造移动赋值不然右值根本无法交换
int main()
{double x = 1.1, y = 2.2;int&& rr1 = 10;const double&& rr2 = x + y;rr1++;//注意这里++的不是10它是常量不能修改,只是单独开个空间把它存起来可以认为存到栈里了然后才能修改rr1,取地址rr1//rr2++;//报错cout << &rr1 << endl;cout << &rr2 << endl;return 0;
}
上面就是右值引用的价值之一:补齐最后一块短板,传值返回的拷贝问题。
右值引用的价值之二:对于插入一些右值数据,也可以减少拷贝。
以前插入没有实现移动构造的时候这里都是深拷贝
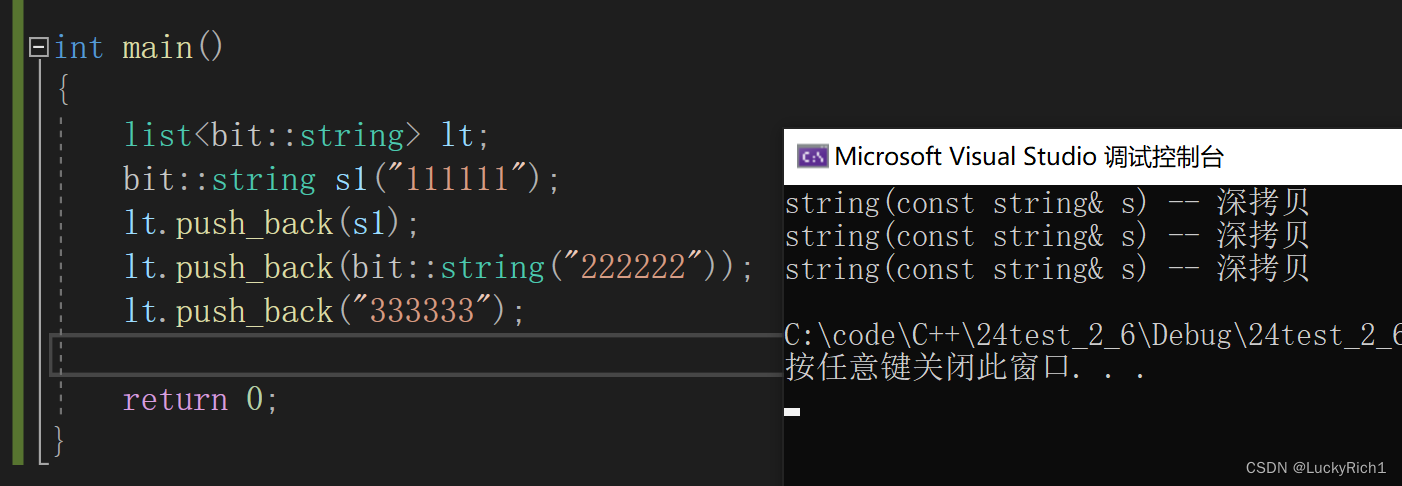
只有左值引用,都只走深拷贝
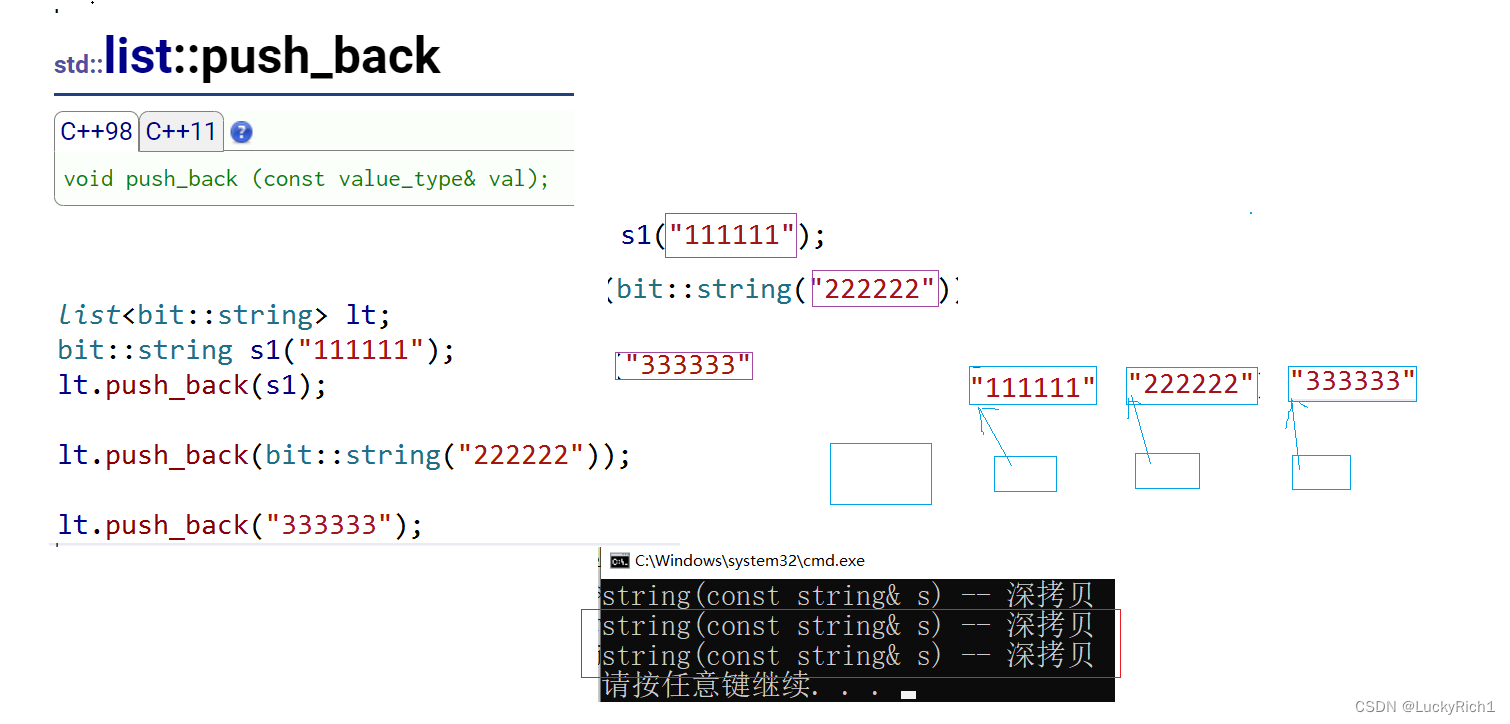
如果提供一个右值版本。是左值不敢移动走的是深拷贝,右值将亡值走的是移动构造
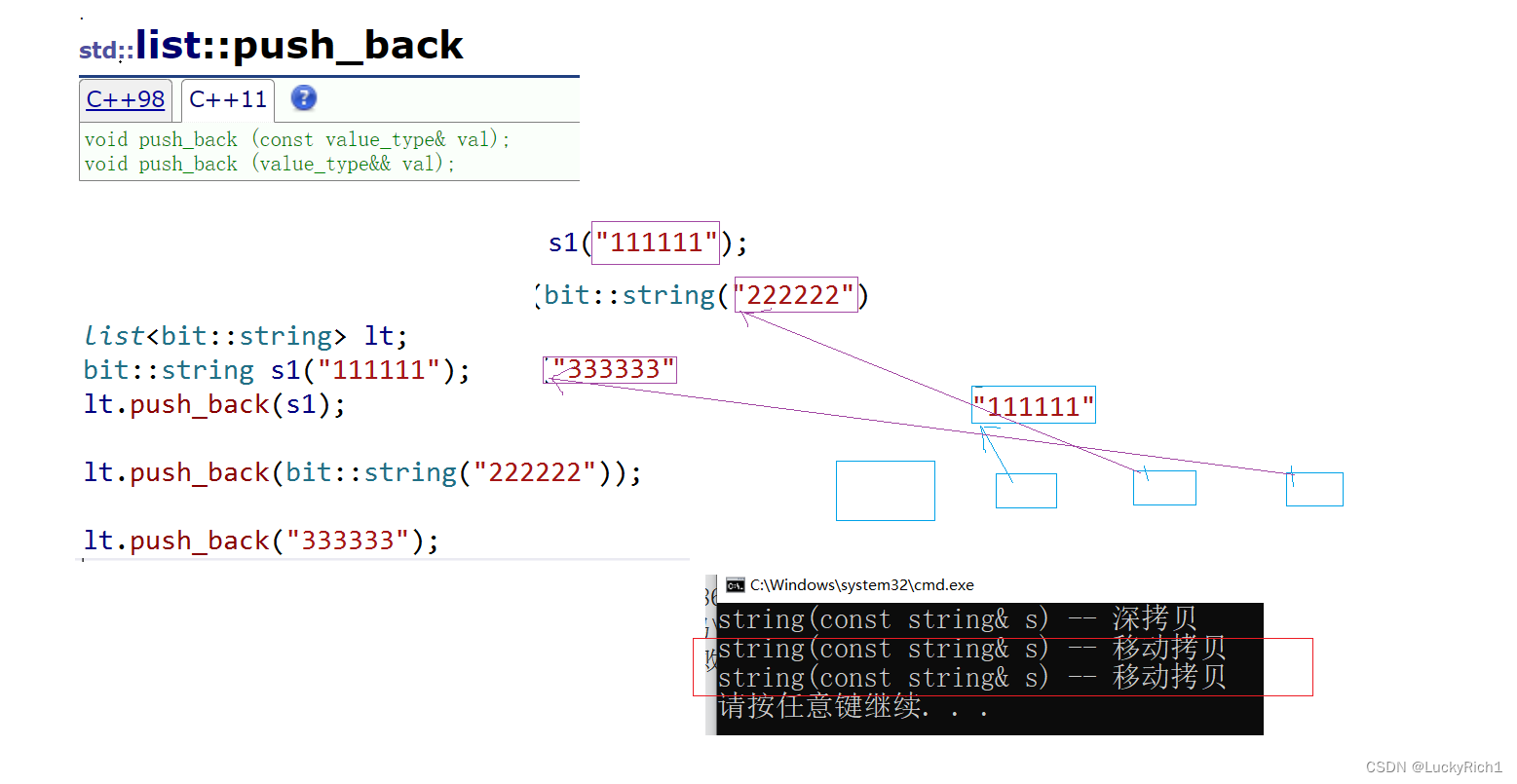
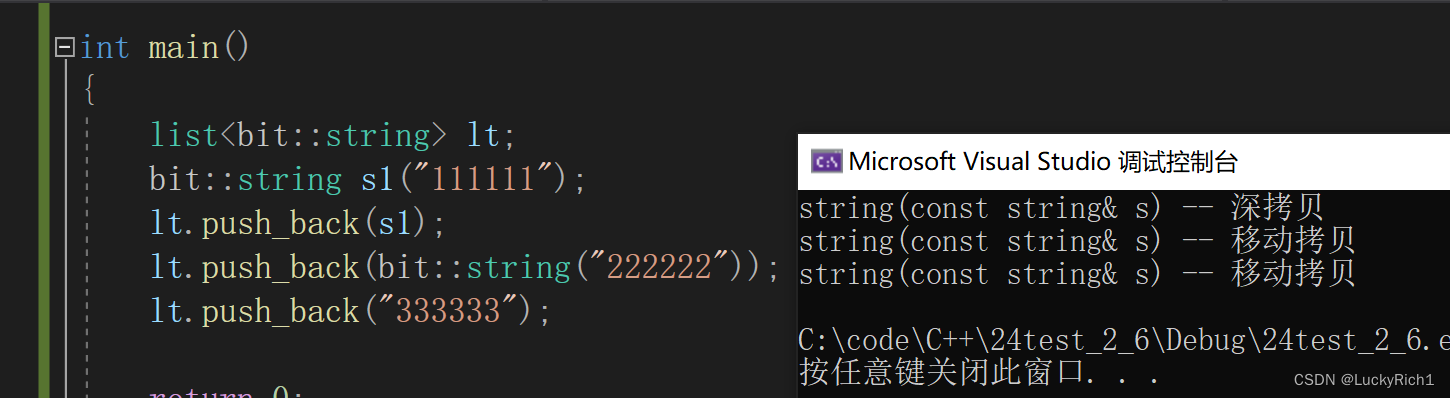
上面是库里面实现的list的插入有右值版本的。现在我们把自己模拟实现的list实现一下右值插入看一看。
下面只体现了主要要说的东西
//链表结点
template<class T>
struct __List_node
{__List_node* _prev;__List_node* _next;T _date;__List_node(const T& val):_prev(nullptr),_next(nullptr),_date(val){}//右值应用版本构造__List_node(T&& val):_prev(nullptr), _next(nullptr), _date(val){}
};template<class T>
class List
{//每次都要写太长了,所以typedef一下typedef __List_node<T> node;public:void empty_initialize(){_head = new node(T());_head->_prev = _head;_head->_next = _head;_size = 0;}//构造List(const initializer_list<T>& l1){empty_initialize();for (auto& e : l1){push_back(e);}}List(){empty_initialize();}void push_back(const T& x) {insert(end(), x);}//右值引用版本push_backvoid push_back(T&& x){insert(end(), x);}iterator insert(iterator pos, const T& val) {node* newnode = new node(val);node* cur = pos._pnode;node* prev = cur->_prev;prev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;//++_size;return iterator(newnode);}//右值引用版本insertiterator insert(iterator pos, T&& val){node* newnode = new node(val);node* cur = pos._pnode;node* prev = cur->_prev;prev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;//++_size;return iterator(newnode);}private:node* _head;size_t _size;
};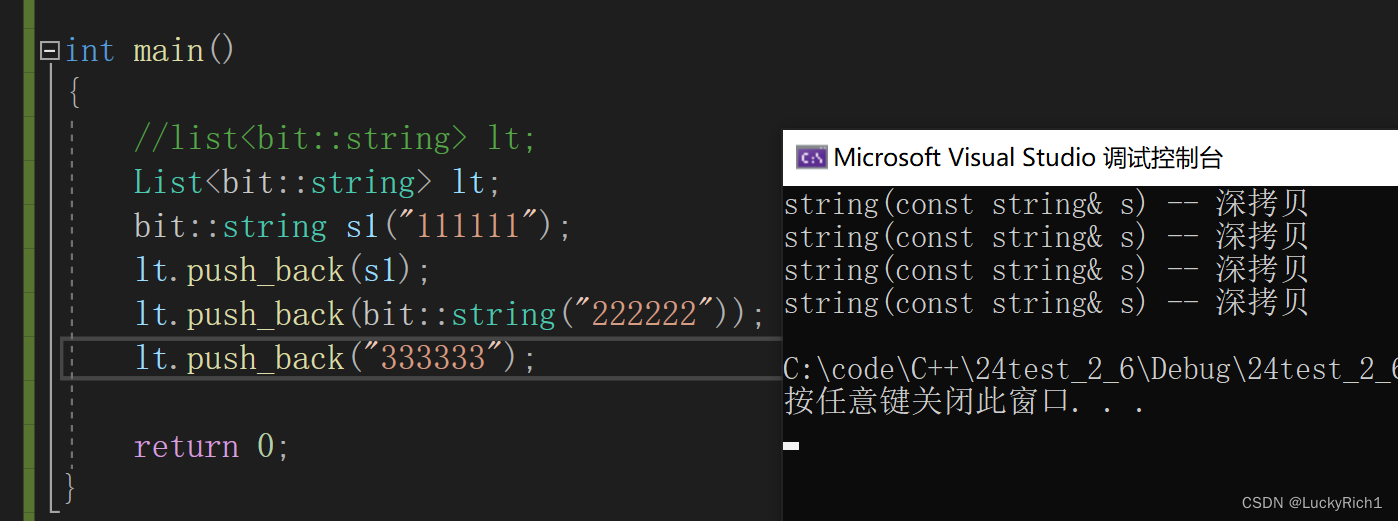
为什么这里写了右值版本的插入还是深拷贝?
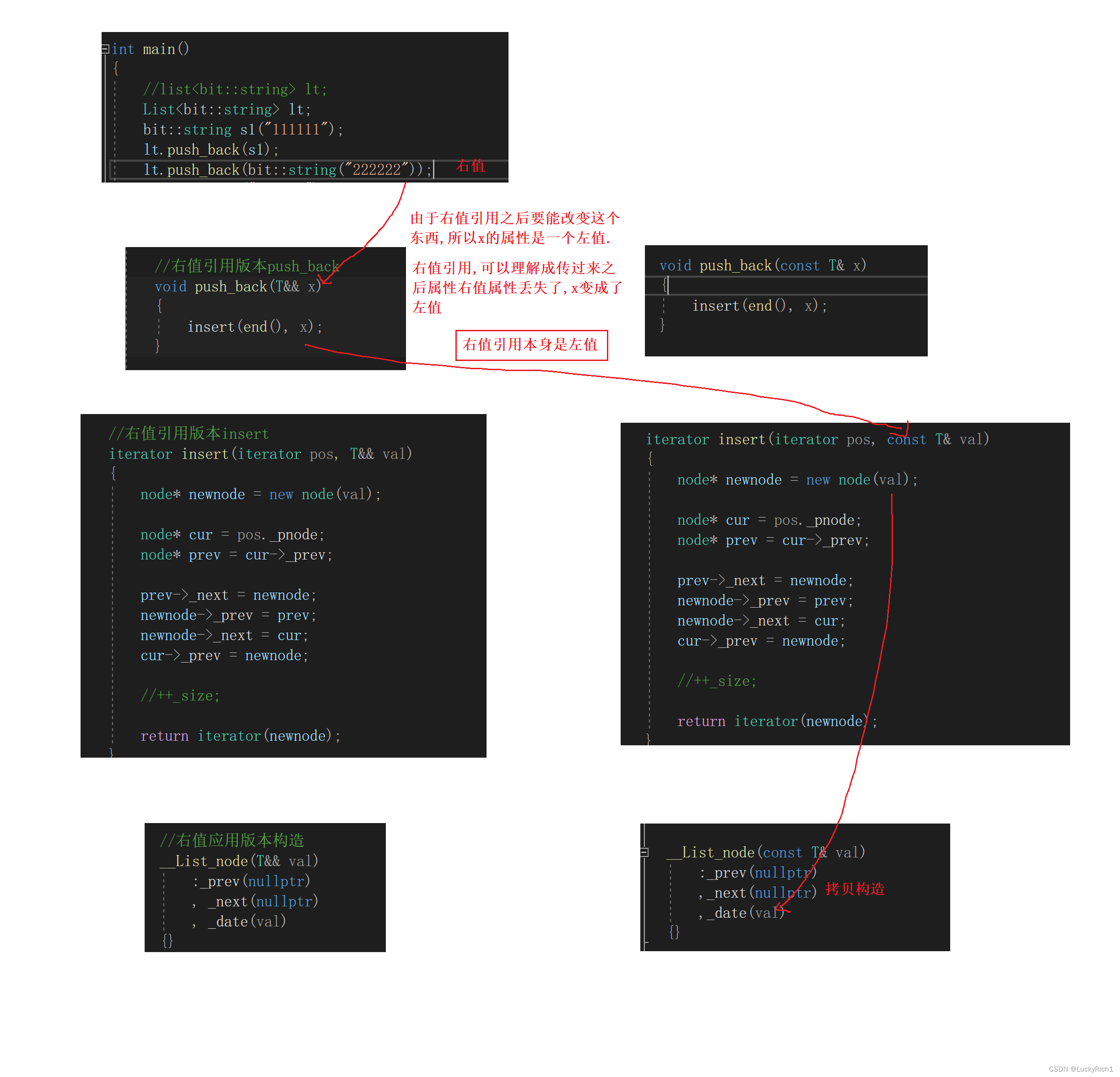
这里可以考虑把每一个右值引用之后在往下传参都move一下
//右值引用版本构造
__List_node(T&& val):_prev(nullptr), _next(nullptr), _date(move(val))
{}//右值引用版本push_back
void push_back(T&& x)
{insert(end(), move(x));
}//右值引用版本insert
iterator insert(iterator pos, T&& val)
{node* newnode = new node(move(val));node* cur = pos._pnode;node* prev = cur->_prev;prev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;//++_size;return iterator(newnode);
}
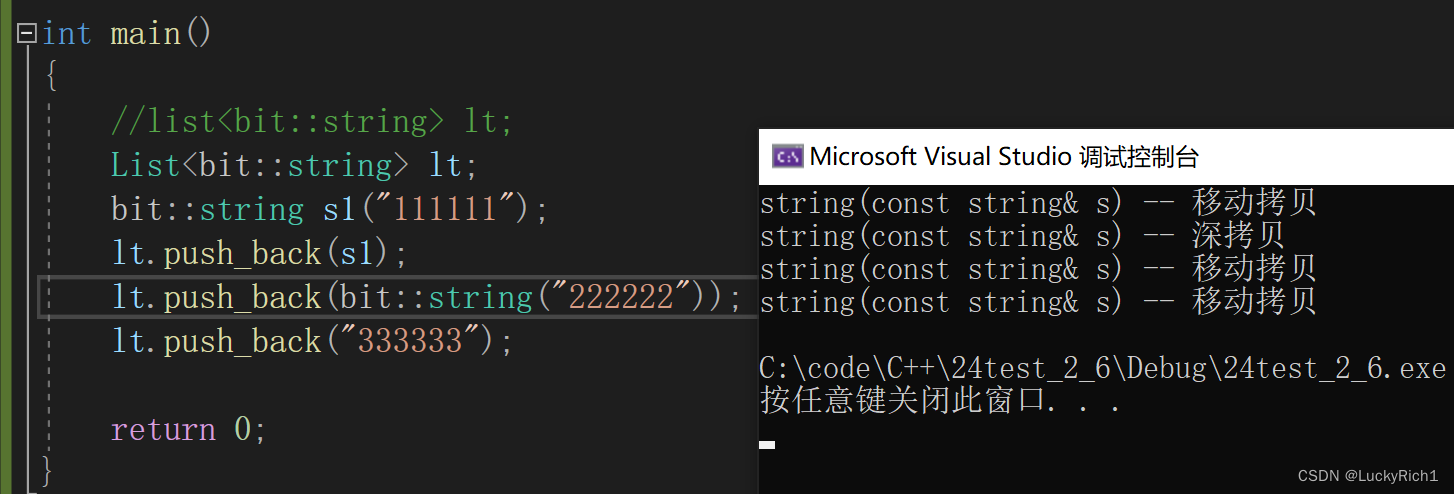
不过一般不太用move这种方式,而是用下面这种方式。
有些时候要区分左值和右值,但有些时候不想区分是左值还是右值。
对于普通函数必须要区分左值和右值。
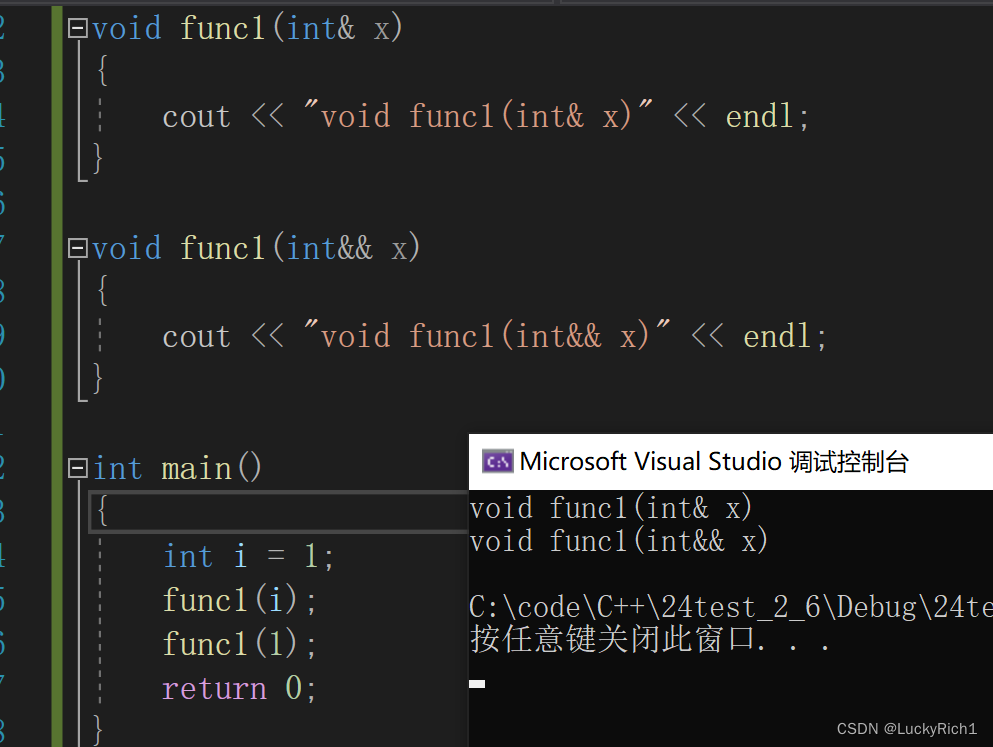
左值引用左值,const左值引用可以引用右值
右值引用右值,右值引用move之后的左值,不能直接引用左值
但对于模板C++11做了一些扩张
模板右值引用既可以引用左值也可以引用右值 —>万能引用(引用折叠)
传的是左值就是左值引用,传的是右值就是右值引用
最牛的的地方是也可以传const左值,const右值
注意左值,右值 t++ 可以
const左值,const右值 t++ 不可以
//万能引用
template<typename T>
void PerfectForward(T&& t)
{t++;//Fun(t);
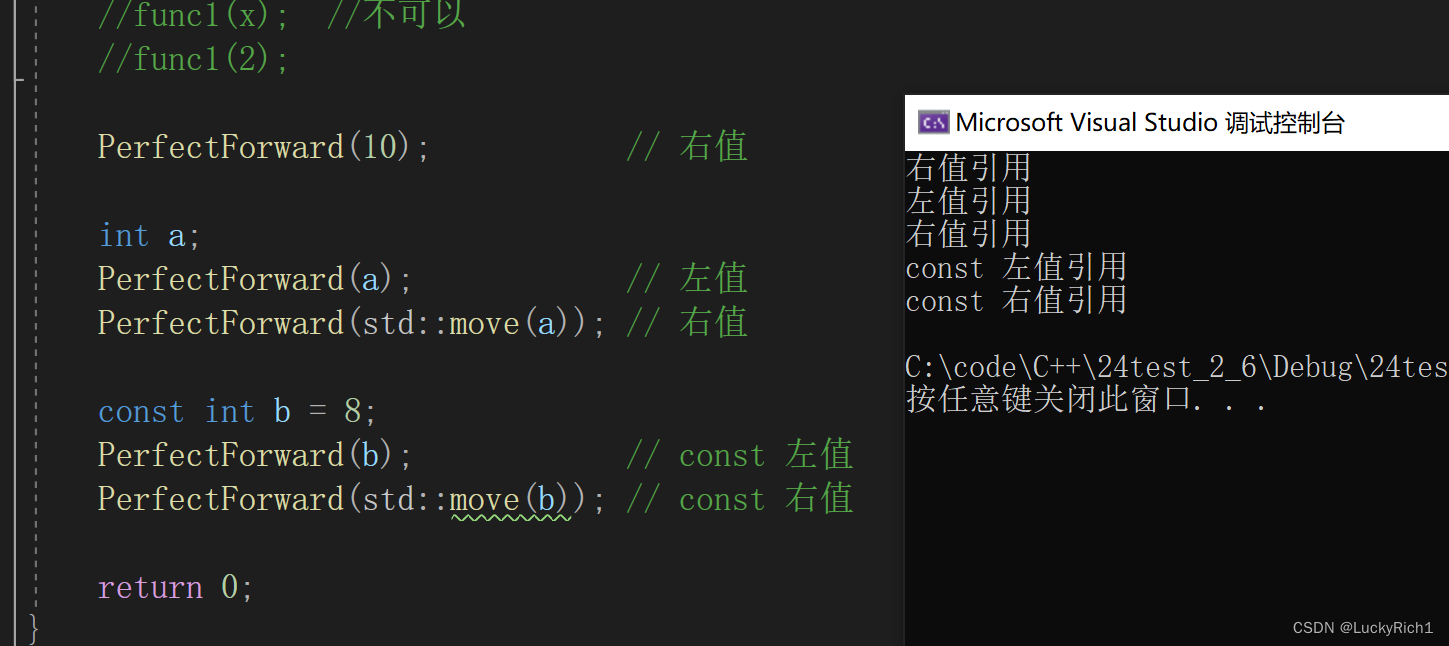
}int main()
{//int x = 1;//func1(x); //不可以//func1(2);PerfectForward(10); // 右值int a;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值return 0;
}
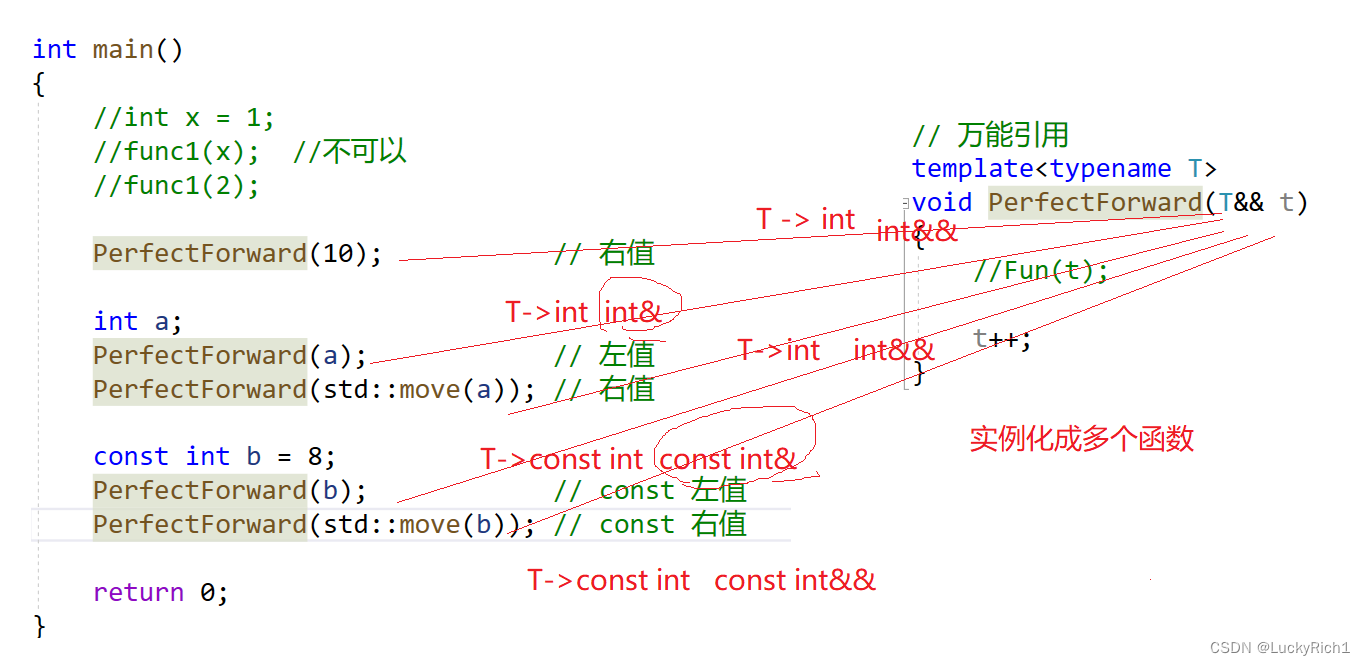
猜一猜下面的会调用那个Fun
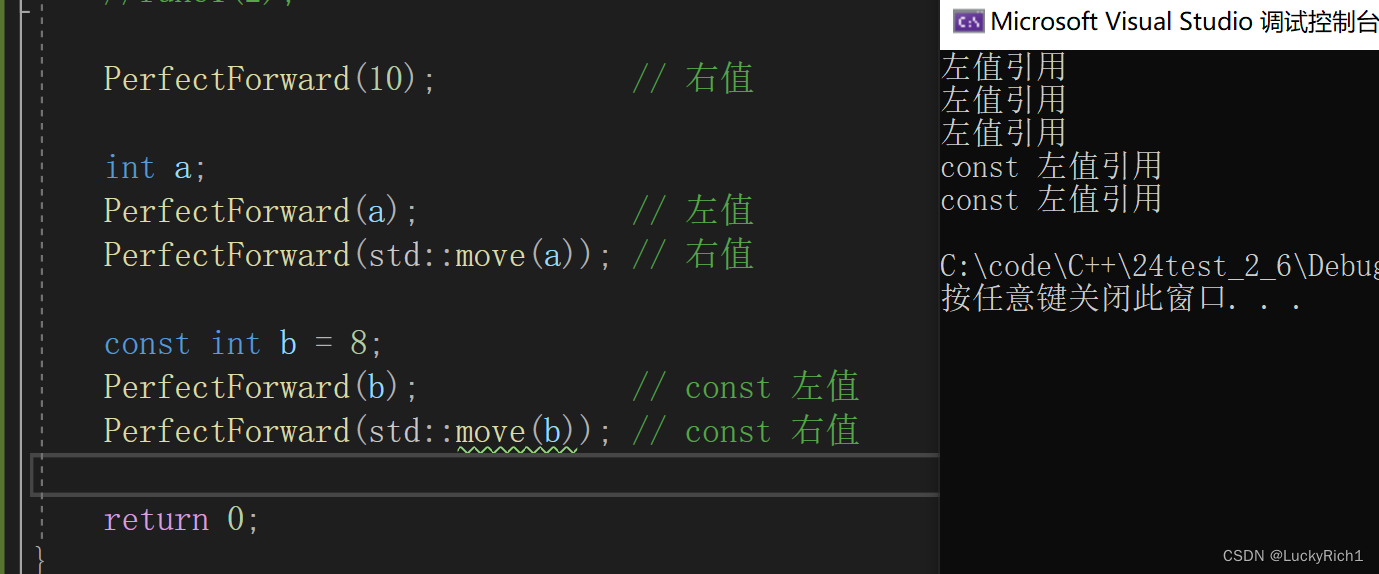
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }//万能引用
template<typename T>
void PerfectForward(T&& t)
{Fun(t);
}int main()
{//int x = 1;//func1(x); //不可以//func1(2);PerfectForward(10); // 右值int a;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值return 0;
}
怎么都调用的是Fun左值引用?
这是因为右值是右值引用,但是万一你就在Fun中交换资源呢?所以右值引用在传递的时候它的属性都是左值
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }//万能引用
template<typename T>
void PerfectForward(T&& t)
{//t可能是左值,可能是右值Fun(move(t));
}
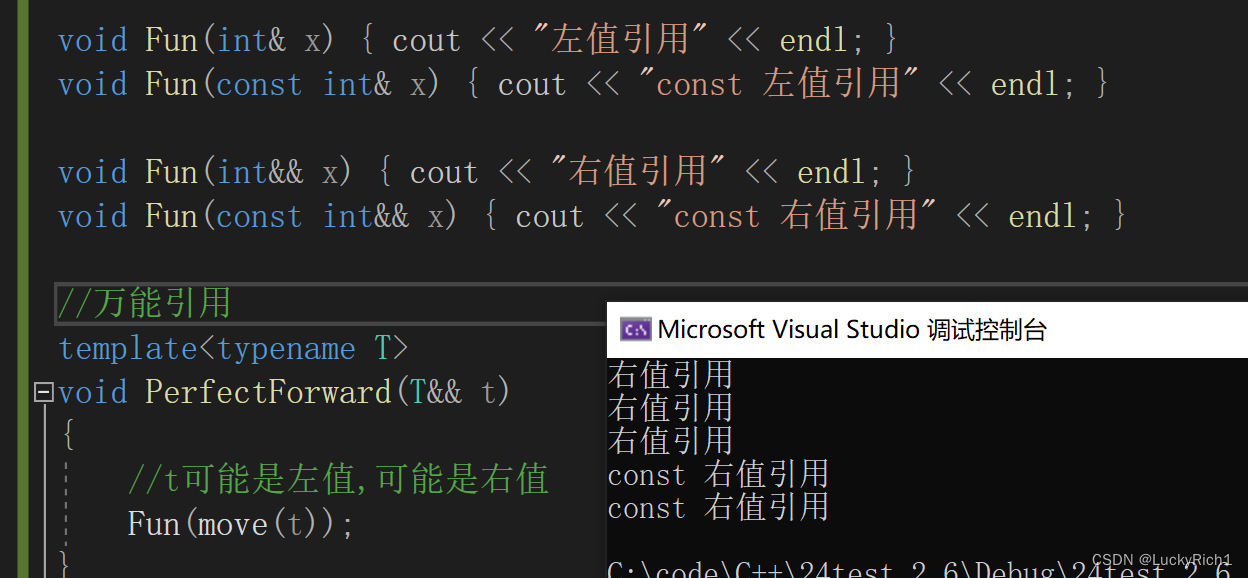
move不能解决这里的问题,全都是右值了
真正解决方法:完美转发 保持它的属性
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }//万能引用
template<typename T>
void PerfectForward(T&& t)
{//t可能是左值,可能是右值//Fun(move(t));//不能解决问题//完美转发Fun(std::forward<T>(t))
}
是左值往下传还是左值,是右值往下传还是右值
刚才的自己实现的list的模板对一些插入等成员函数我们是否直接可以使用万能应用呢?
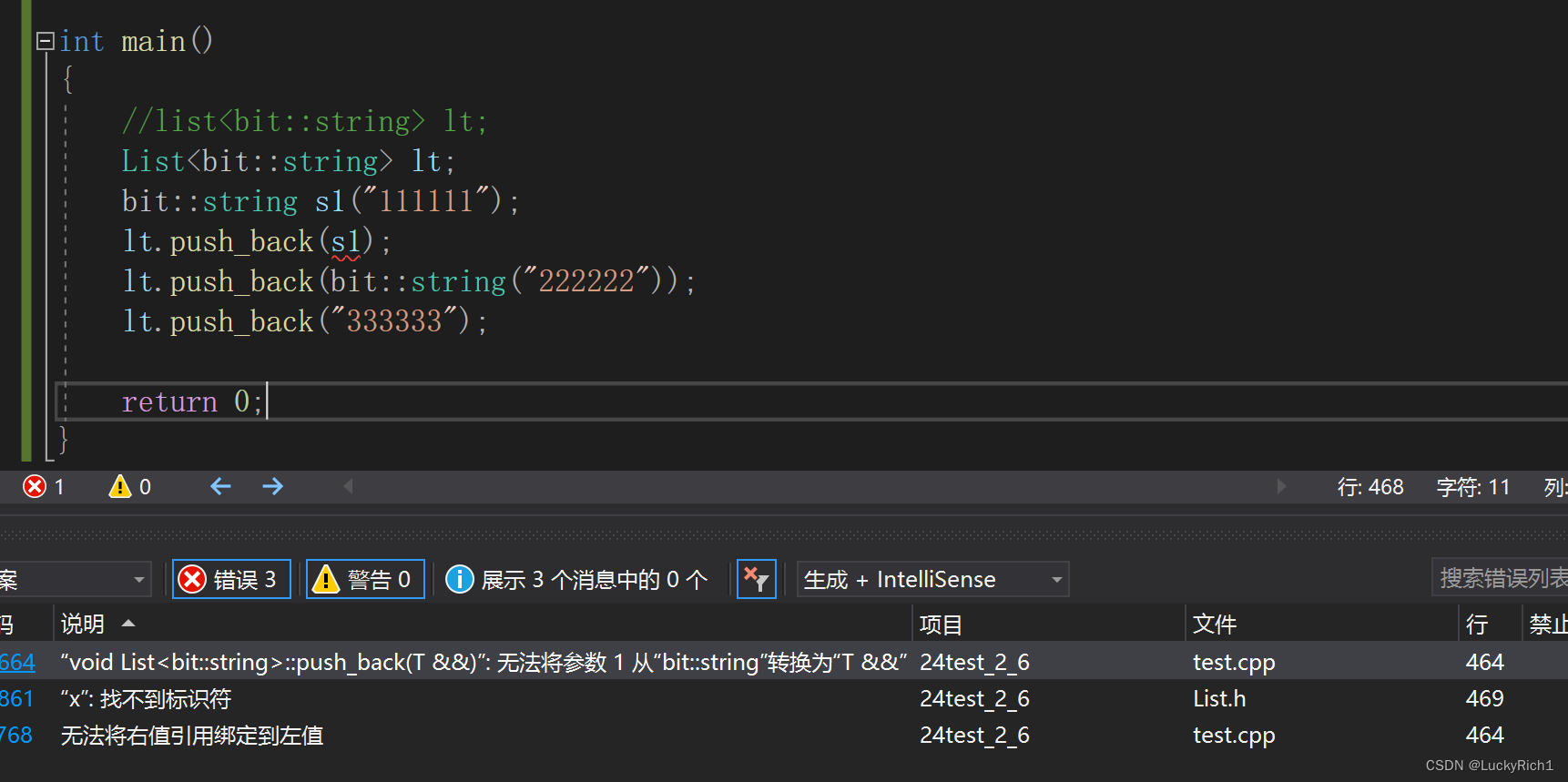
答案是不行!
传左值的时候有问题,因为当你实际调用push_back的时候已经不是模板了,而是已经早被实例化出来的了! T已经被实实在在的确定了!如果要使用必须是在模板被推导的时候。
下面把list实现刚才的完美转发,move是把左值强制变成右值。
//右值应用版本构造
__List_node(T&& val):_prev(nullptr), _next(nullptr), _date(std::forward(val))
{}//右值引用版本push_back
void push_back(T&& x)
{insert(end(), std::forward(x));
}//右值引用版本insert
iterator insert(iterator pos, T&& val)
{node* newnode = new node(std::forward(val));node* cur = pos._pnode;node* prev = cur->_prev;prev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;//++_size;return iterator(newnode);
}
9.新的类功能
默认成员函数
原来C++类中,有6个默认成员函数:
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
最后重要的是前4个,后两个用处不大。默认成员函数就是我们不写编译器会生成一个默认的。
C++11 新增了两个:移动构造函数和移动赋值运算符重载。
针对移动构造函数和移动赋值运算符重载有一些需要注意的点如下:
如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝(浅拷贝),自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造
完全类似)
如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
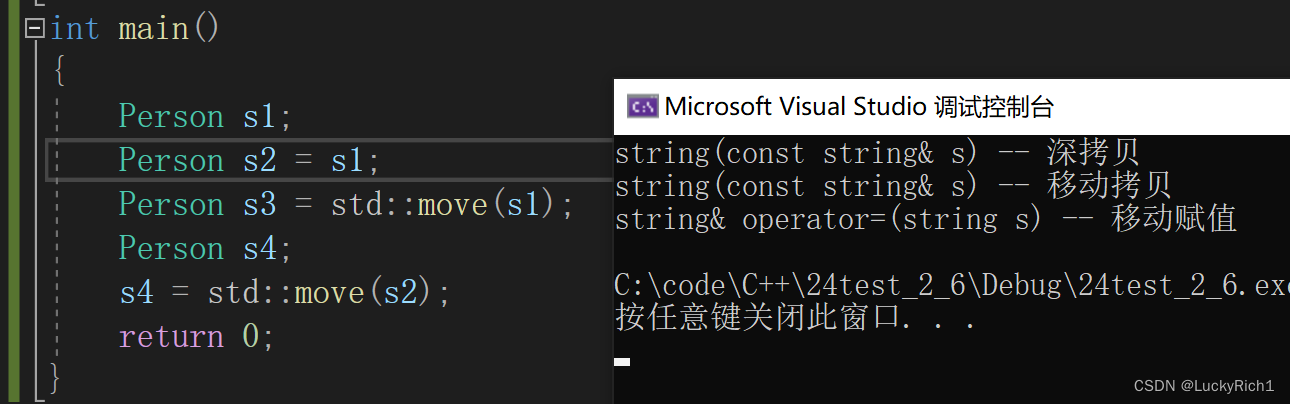
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}/*Person(const Person& p):_name(p._name),_age(p._age){}*//*Person& operator=(const Person& p){if(this != &p){_name = p._name;_age = p._age;}return *this;}*//*~Person(){}*/
private:bit::string _name;int _age;
};int main()
{Person s1;Person s2 = s1;Person s3 = std::move(s1);Person s4;s4 = std::move(s2);return 0;
}
上面没有实现拷贝构造,赋值重载,析构编译器会自动生成默认的移动构造和移动赋值,对内置类型进行值拷贝,对自定义类型如果实现移动构造和移动赋值就去调没有实现就去调拷贝构造和赋值重载!
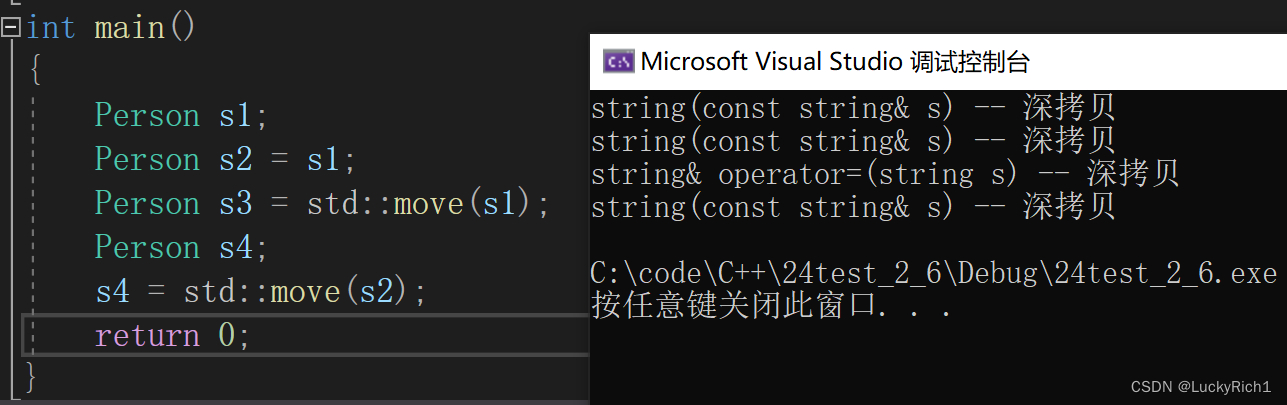
只要实现拷贝构造,赋值重载,析构中任意一个,就不会默认生成移动构造移动赋值,下面就会调用拷贝构造和赋值重载进行深拷贝!虽然下面我们都屏蔽了但是编译器会默认生成拷贝构造和赋值重载。
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}/*Person(const Person& p):_name(p._name),_age(p._age){}*//*Person& operator=(const Person& p){if(this != &p){_name = p._name;_age = p._age;}return *this;}*/~Person(){}private:bit::string _name;int _age;
};
int main()
{Person s1;Person s2 = s1;Person s3 = std::move(s1);Person s4;s4 = std::move(s2);return 0;
}
类成员变量初始化
C++11允许在类定义时给成员变量初始缺省值,默认生成构造函数会使用这些缺省值初始化,这个我们在类和对象默认就讲了,这里就不再细讲了。
强制生成默认函数的关键字default:
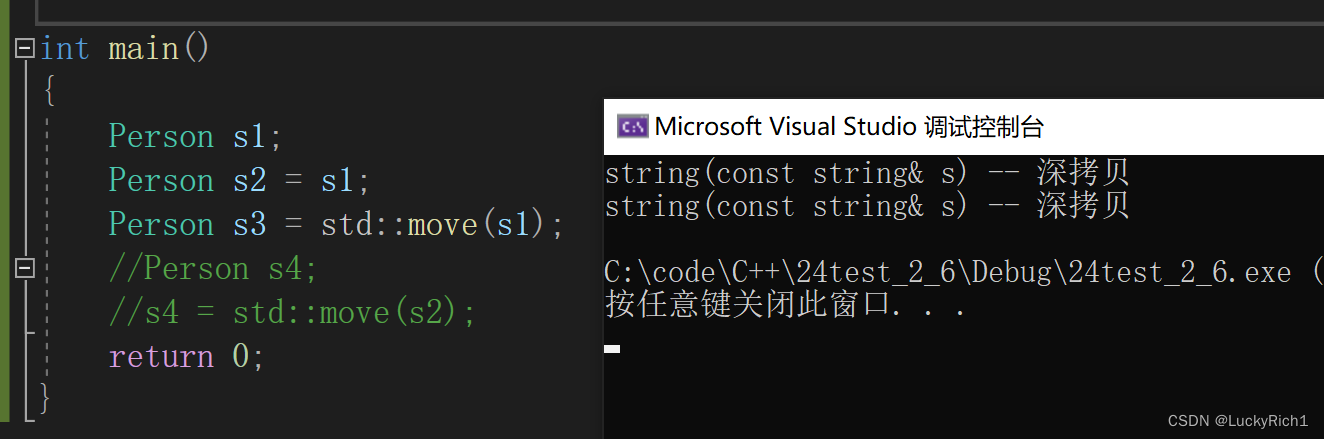
C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以使用default关键字显示指定移动构造生成。
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}Person(const Person& p):_name(p._name),_age(p._age){}Person(Person&& p):_name(p._name), _age(p._age){}//。。。private:bit::string _name;int _age;
};int main()
{Person s1;Person s2 = s1;Person s3 = std::move(s1);return 0;
}
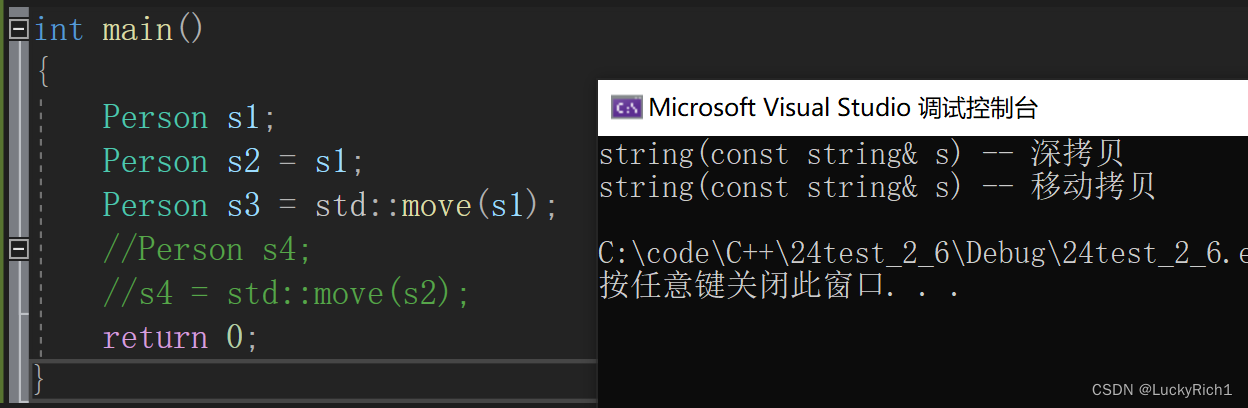
这里即使写了移动构造也要注意要使用完美转发不然传过去就变成了左值,在往下传走的是深拷贝。
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}Person(const Person& p):_name(p._name),_age(p._age){}Person(Person&& p):_name(std::forward<bit::string>(p._name)), _age(p._age){}//。。。
private:bit::string _name;int _age;
}
写起来很麻烦了,明明默认生成的很方便,那我们可以想让它强制自动生成一个怎么办呢?
default:强制生成默认函数(只针对默认成员函数)
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}Person(const Person& p):_name(p._name),_age(p._age){}Person(Person&& p) = default;//强制生成移动构造//Person(Person&& p)// :_name(std::forward<bit::string>(p._name))// , _age(p._age)//{}//。。。
private:bit::string _name;int _age;
}
对应的还有一个delete:禁止生成默认函数
如果想要限制某些默认函数的生成,在C++98中,是该函数设置成private,并且只声明补丁已,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
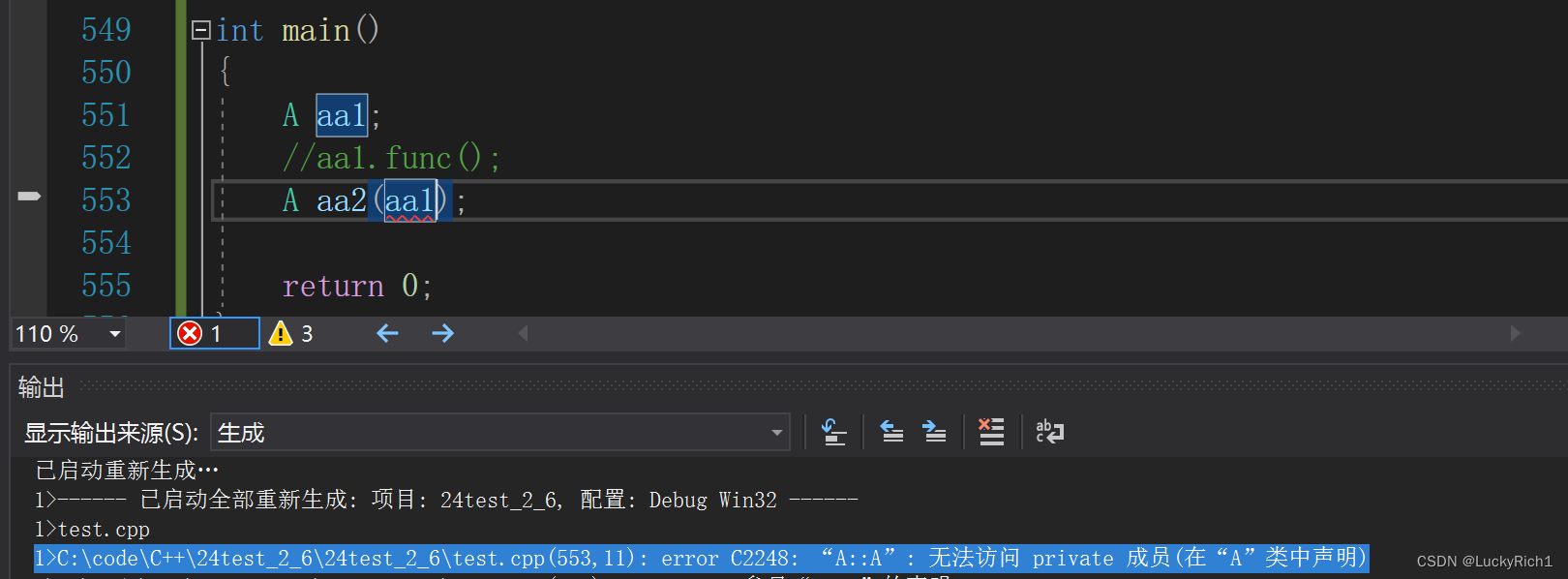
下面有个问题,不想让A类对象被拷贝有没有什么方法?
这里有一个好办法,把拷贝构造函数函数写成私有的。
// 不想让A类对象被拷贝
class A
{
public:A(){}~A(){delete[] p;}private:A(const A& aa):p(aa.p){}private:int* p = new int[10];
};int main()
{A aa1;A aa2(aa1);return 0;
}
但是有这种可能,别人在A类内部进行拷贝
class A
{
public:void func(){A tmp(*this);}A(){}~A(){delete[] p;}private:A(const A& aa):p(aa.p){}private:int* p = new int[10];
};int main()
{A aa1;aa1.func();//A aa2(aa1);return 0;
}
如何把内部拷贝也给去掉呢?
C++98 只声明不实现,声明为私有!
// 不想让A类对象被拷贝
class A
{
public:void func(){A tmp(*this);}A(){}~A(){delete[] p;}private://A(const A& aa)// :p(aa.p)//{}// 只声明不实现,声明为私有 C++98A(const A& aa);
private:int* p = new int[10];
};
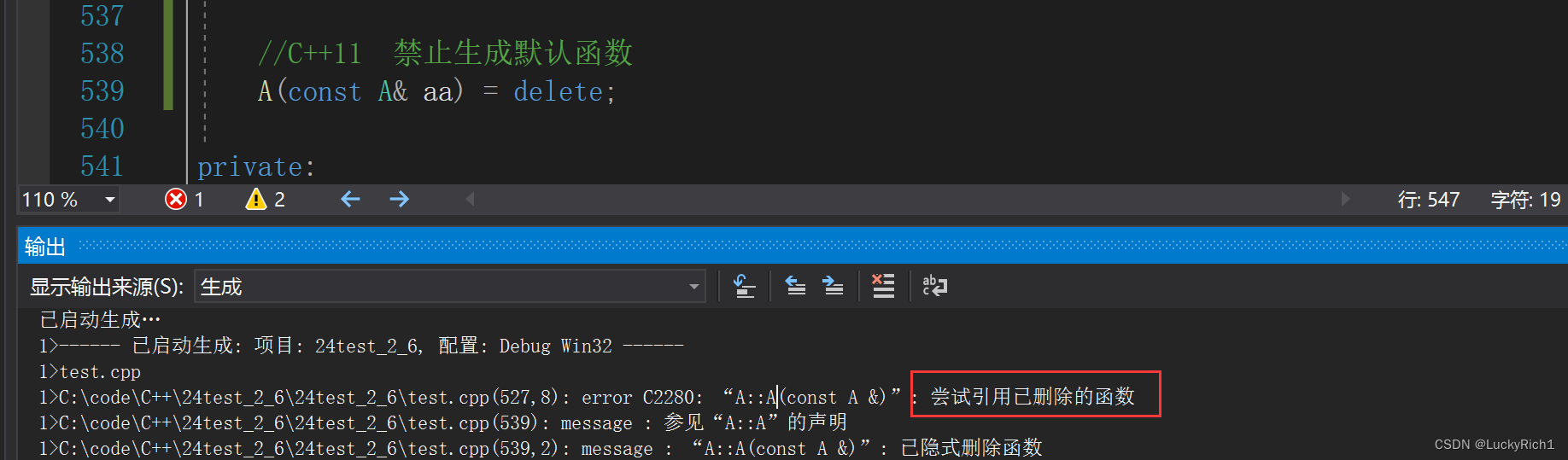
C++11 delete禁止生成默认函数
// 不想让A类对象被拷贝
class A
{
public:void func(){A tmp(*this);}A(){}~A(){delete[] p;}//C++11 禁止生成默认函数A(const A& aa) = delete;private://A(const A& aa)// :p(aa.p)//{}// 只声明不实现,声明为私有 C++98//A(const A& aa);
相关文章:
【C++】C++11上
C11上 1.C11简介2.统一的列表初始化2.1 {} 初始化2.2 initializer_list 3.变量类型推导3.1auto3.2decltype3.3nullptr 4.范围for循环5.final与override6.智能指针7. STL中一些变化8.右值引用和移动语义8.1左值引用和右值引用8.2左值引用与右值引用比较8.3右值引用使用场景和意义…...

【前端高频面试题--git篇】
🚀 作者 :“码上有前” 🚀 文章简介 :前端高频面试题 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 前端高频面试题--git篇 往期精彩内容常用命令git add 和 git stage 有什么区别怎么使用git连接…...

c++创建对象
c创建对象 1.声明一个对象,然后使用默认构造函数来创建对象: class MyClass { public:MyClass() {// 构造函数代码} };int main() {MyClass obj; // 声明并创建一个对象return 0; }2.使用new和指针动态创建对象:不会自动释放 使用 new 运算…...

软件实例分享,洗车店系统管理软件会员卡电子系统教程
软件实例分享,洗车店系统管理软件会员卡电子系统教程 一、前言 以下软件教程以 佳易王洗车店会员管理软件V16.0为例说明 软件文件下载可以点击最下方官网卡片——软件下载——试用版软件下载 1、会员卡号可以绑定车牌号或手机号 2、卡号也可以直接使用手机号&a…...

【Docker进阶】镜像制作-用Dockerfile制作镜像(一)
进阶一 docker镜像制作 文章目录 进阶一 docker镜像制作用dockerfile制作镜像dockerfile是什么dockerfile格式为什么需要dockerfileDockerfile指令集合FROMMAINTAINERLABELCOPYENVWORKDIR 用dockerfile制作镜像 用快照制作镜像的缺陷: 黑盒不可重复臃肿 docker…...

数据密集型应用系统设计
数据密集型应用系统设计 原文完整版PDF:https://pan.quark.cn/s/d5a34151fee9 这本书的作者是少有的从工业界干到学术界的牛人,知识面广得惊人,也善于举一反三,知识之间互相关联,比如有个地方把读路径比作programming …...
分布式文件系统 SpringBoot+FastDFS+Vue.js【一】
分布式文件系统 SpringBootFastDFSVue.js【一】 一、分布式文件系统1.1.文件系统1.2.什么是分布式文件系统1.3.分布式文件系统的出现1.3.主流的分布式文件系统1.4.分布式文件服务提供商1.4.1.阿里OSS1.4.2.七牛云存储1.4.3.百度云存储 二、fastDFS2.1.fastDSF介绍2.2.为什么要使…...
【PyQt】11-QTextEdit、QPushButton
文章目录 前言一、文本输入-QTextEdit1.1 代码1.2 运行结果 二、QPushButton2.1.1 按钮上添加文本2.1.2 按键的弹跳效果2.1.3 两个信号可以绑定一个槽。2.1.4 带图标的按键运行结果 2.1.5 按键不可用以及回车默认完整代码2.2 单选按键控件运行结果 2.3 复选框(多选框…...
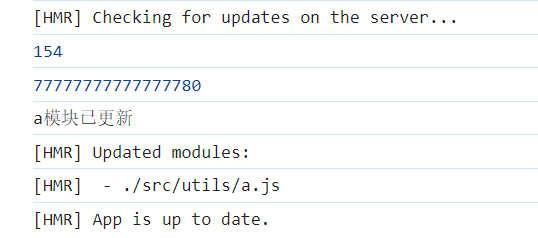
初识webpack(二)解析resolve、插件plugins、dev-server
目录 (一)webpack的解析(resolve) 1.resovle.alias 2.resolve.extensions 3.resolve.mainFiles (二) plugin插件 1.CleanWebpackPlugin 2.HtmlWebpackPlugin 3.DefinePlugin (三)webpack-dev-server 1.开启本地服务器 2.HMR模块热替换 3.devServer的更多配置项 (…...
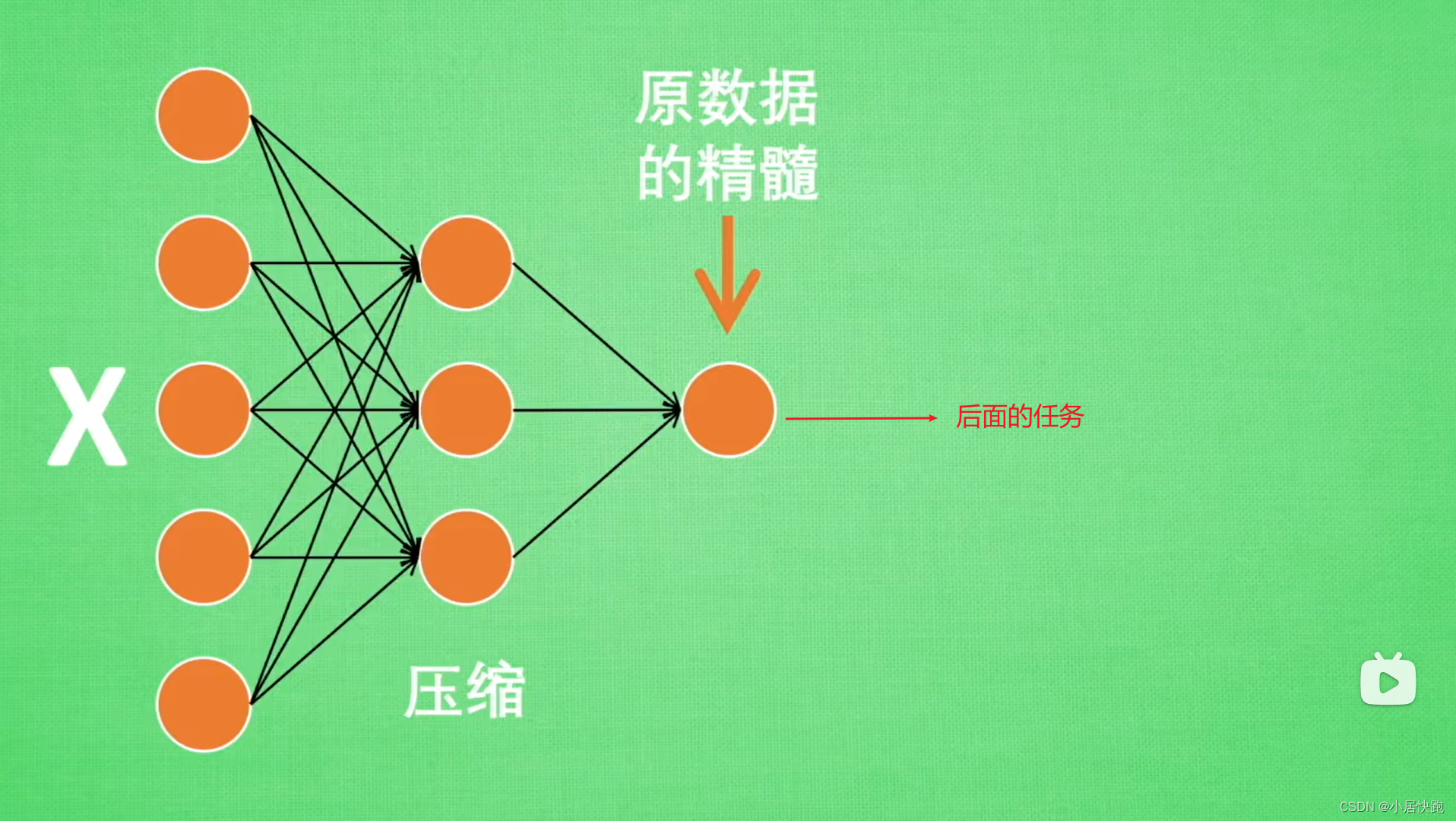
什么是自编码器Auto-Encoder?
来源:https://www.bilibili.com/video/BV1Vx411j78H/?spm_id_from333.1007.0.0&vd_sourcef66cebc7ed6819c67fca9b4fa3785d39 为什么要压缩呢? 让神经网络直接从上千万个神经元中学习是一件很吃力的事情,因此通过压缩提取出原图片中最具代…...

openGauss学习笔记-219 openGauss性能调优-确定性能调优范围-硬件瓶颈点分析-网络
文章目录 openGauss学习笔记-219 openGauss性能调优-确定性能调优范围-硬件瓶颈点分析-网络219.1 查看网络状况 openGauss学习笔记-219 openGauss性能调优-确定性能调优范围-硬件瓶颈点分析-网络 获取openGauss节点的CPU、内存、I/O和网络资源使用情况,确认这些资源…...
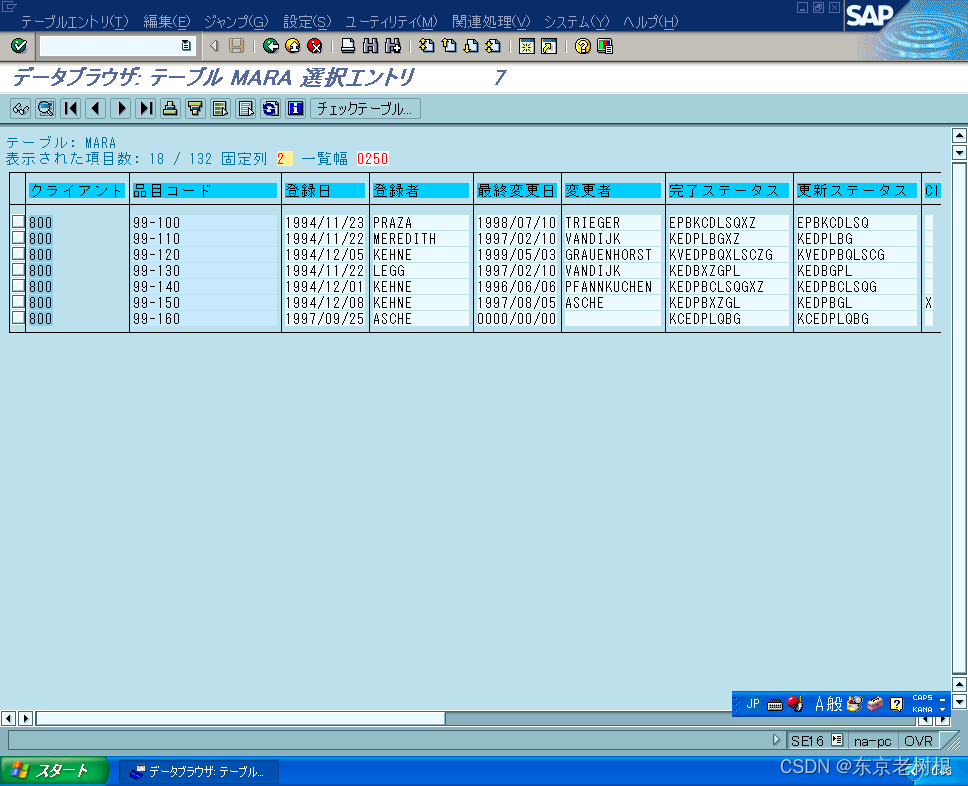
SAP PP学习笔记- 豆知识01 - 怎么查询既存品目
SAP系统当中已经有哪些品目要怎么查询呢? 1,MM60 品目一览 这里可以输入Plant,然后可以查询该工厂的所有品目。 2,SE16 > MARA MARA 品目一般Data,存放的是品目基本信息。 如果要查询该品目属于哪个Plant&#x…...

相机的机身马达有什么用?
新手疑问: 为什么我的尼康D3200相机明明拥有拍视频能力,但是拍摄视频时却不能对焦 科普时间 那是因为你的相机缺少机身马达,并且你所使用的镜头也没有马达!机身马达是用于给镜头提供对焦动力的装置。它的作用是使相机具备自动对焦功能。如…...
拿捏c语言指针(上)
目录 前言 编辑 指针 内存与地址 计算机常见单位 理解编址 取地址,指针变量,解引用 取地址 指针变量 解引用 指针变量大小 指针类型的作用 char*解引用后 指针-整数 应用 void*指针 const修饰指针变量 const修饰普通变量 const修饰指…...

JVM指令手册
栈和局部变量操作将常量压入栈的指令 aconst_null 将null对象引用压入栈 iconst_m1 将int类型常量-1压入栈 iconst_0 将int类型常量0压入栈 iconst_1 将int类型常量1压入操作数栈 iconst_2 将int类型常量2压入栈 iconst_3 将int类型常量3压入栈 iconst_4 将int类型常量4…...
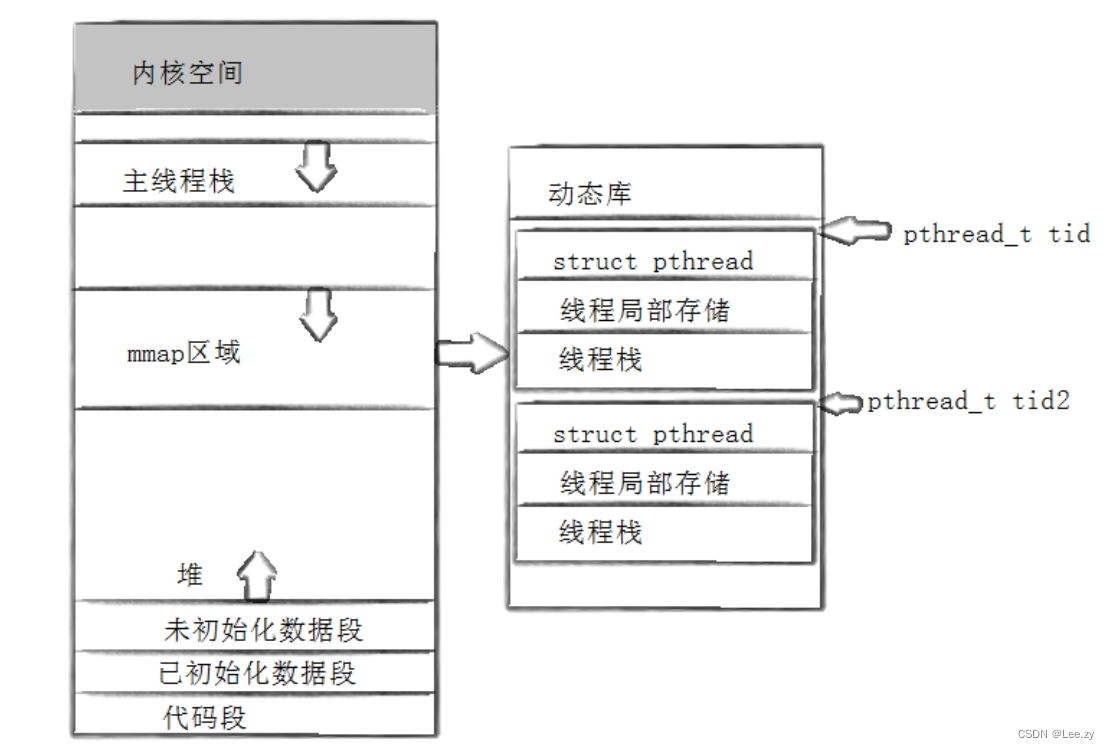
Linux之多线程
目录 一、进程与线程 1.1 进程的概念 1.2 线程的概念 1.3 线程的优点 1.4 线程的缺点 1.5 线程异常 1.6 线程用途 二、线程控制 2.1 POSIX线程库 2.2 创建一个新的线程 2.3 线程ID及进程地址空间布局 2.4 线程终止 2.5 线程等待 2.6 线程分离 一、进程与线程 在…...

TestNG invocationCount属性
有时我们会遇到这样的问题,比如如何多次运行一个测试用例?invocationCount是这个问题的答案。在这篇文章中,我们将讨论在TestNG中与Test annotation一起使用的invocationCount属性。 这个属性有什么作用,或者调用计数有什么用&am…...

关于maven项目中无法通过邮件服务器发送邮件的补充解决方案
1、问题及解决方法 我的一篇文章中提到使用代码发送电子邮件,但是maven项目中无法执行成功,现在我找到了解决办法,只要引入依赖时同时引入下面两个依赖就行了,我无法找到原因主要是使用单元测试方法运行,它居然不报错&…...
树形dp 笔记
树的最长路径 给定一棵树,树中包含 n 个结点(编号1~n)和 n−1 条无向边,每条边都有一个权值。 现在请你找到树中的一条最长路径。 换句话说,要找到一条路径,使得使得路径两端的点的距离最远。 注意&…...
2024-02-08 Unity 编辑器开发之编辑器拓展1 —— 自定义菜单栏
文章目录 1 特殊文件夹 Editor2 在 Unity 菜单栏中添加自定义页签3 在 Hierarchy 窗口中添加自定义页签4 在 Project 窗口中添加自定义页签5 在菜单栏的 Component 菜单添加脚本6 在 Inspector 为脚本右键添加菜单7 加入快捷键8 小结 1 特殊文件夹 Editor Editor 文件夹是 …...

HoRain云--Skills 工作原理
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

深入解析Enso:构建高性能可编程代理与API网关的Go框架
1. 项目概述:一个被低估的“瑞士军刀”如果你在开源社区里混迹过一段时间,大概率见过这样的场景:一个项目仓库,名字起得挺酷,比如“Enso”,简介里写着“一个现代化的代理工具”,但点进去一看&am…...

TencentDB Agent Memory 架构拆解:告别 Agent 失忆,构建四层可追溯记忆与上下文治理系统
拆解 TencentDB Agent Memory 如何用分层记忆、上下文卸载和降级检索,让 Agent 留住工作现场。 原文链接:AI 小老六 Agent 真正难用的地方,往往不是它不会调用工具,而是它记不住工作现场。 你刚给它讲完项目背景、编码偏好、部署…...

告别混合写法!详解Nginx 1.25.1中独立的http2指令配置与性能影响
Nginx 1.25.1 HTTP/2配置革新:架构演进与性能实践指南 当Nginx 1.25.1的更新日志中出现"http2指令独立"这一行文字时,许多资深运维工程师的配置管理哲学正在被悄然改写。这不仅仅是语法糖的调整,而是反映了Web服务器架构设计从&quo…...

RV1126 NPU部署ResNet50全流程:从PyTorch训练到嵌入式板端推理
1. 项目概述:从零到一,在RV1126上跑通ResNet50最近在折腾一块EASY-EAI-Nano开发板,核心是瑞芯微的RV1126芯片,这玩意儿带了个NPU,不拿来跑跑AI模型实在说不过去。手头正好有个车辆分类的需求,就想试试经典的…...

别再死记硬背真值表了!用Verilog手搓半减器/全减器,从波形图反推逻辑门设计
从波形图反推逻辑门:Verilog减法器的逆向工程实践 数字电路初学者常陷入"真值表→逻辑表达式→电路实现"的传统学习路径,却难以理解信号流动的本质。本文将以波形图逆向分析为核心,带您用Verilog实现半减器与全减器,掌握…...

终极免费音频智能分割工具:快速解放你的音频处理工作流
终极免费音频智能分割工具:快速解放你的音频处理工作流 【免费下载链接】audio-slicer A simple GUI application that slices audio with silence detection 项目地址: https://gitcode.com/gh_mirrors/aud/audio-slicer 还在为处理长音频文件而烦恼吗&…...

彻底告别ThinkPad风扇噪音:TPFanCtrl2终极静音方案揭秘
彻底告别ThinkPad风扇噪音:TPFanCtrl2终极静音方案揭秘 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否厌倦了ThinkPad笔记本在轻度使用时风扇就狂转…...

当Agent开始自我调试、自我迭代——斯坦福CRFM最新实验揭示:自主进化阈值将在18个月内被突破
更多请点击: https://intelliparadigm.com 第一章:当Agent开始自我调试、自我迭代——斯坦福CRFM最新实验揭示:自主进化阈值将在18个月内被突破 核心突破:从工具调用到元认知闭环 斯坦福CRFM团队在2024年Q2发布的《Self-Improvi…...

技术视角:分布式投票系统的异步解耦架构与多语言协同实践
技术视角:分布式投票系统的异步解耦架构与多语言协同实践 【免费下载链接】example-voting-app Example Docker Compose app 项目地址: https://gitcode.com/gh_mirrors/exa/example-voting-app 在当今企业级应用架构设计中,如何平衡高并发处理、…...