【论文精读】GPT2
摘要
在单一领域数据集上训练单一任务的模型是当前系统普遍缺乏泛化能力的主要原因,要想使用当前的架构构建出稳健的系统,可能需要多任务学习。但多任务需要多数据集,而继续扩大数据集和目标设计的规模是个难以处理的问题,所以只能采取多任务学习的其他框架。
目前在语言任务上表现最佳的多任务学习系统,利用了预训练和监督微调的结合,通用的预训练系统可以在微调后在多个任务上表现良好,但微调仍需要监督数据。故本文做出证明:
- 大型语言模型可以在zero-shot设置中执行下游任务,而不需要任何参数或架构修改的微调

上图为不同尺寸的预训练GPT2在zero-shot设置下执行阅读理解、机器翻译、摘要、问答任务上取得的性能。
框架
方法
本文核心方法是语言建模。 语言建模通常为一组例子 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn)的无监督分布估计,其中每个例子由可变长度的符号序列 ( s 1 , s 2 , . . . , s n ) (s_1,s_2,...,s_n) (s1,s2,...,sn)组成。 因为语言具有顺序性,因此通常将符号上的联合概率分解为条件概率的乘积:
p ( x ) = ∏ i = 1 n p ( s n ∣ s 1 , … , s n − 1 ) p(x)=\prod^n_{i=1}p(s_n|s_1,\dots,s_{n-1}) p(x)=i=1∏np(sn∣s1,…,sn−1)
这种方法允许对 p ( x ) p(x) p(x)以及形如 p ( s n − k , … , s n ∣ s 1 , … , s n − k − 1 ) p(s_{n−k}, …, s_n|s_1, …, s_{n−k−1}) p(sn−k,…,sn∣s1,…,sn−k−1)的条件分布进行可行的采样和估计。若目标为学习单一任务,可以用条件概率 p ( o u t p u t ∣ i n p u t ) p(output|input) p(output∣input)表示,但一个通用系统应该能够针对具体任务并根据输入来生成输出,即 p ( o u t p u t ∣ i n p u t , t a s k ) p(output|input, task) p(output∣input,task),故语言模型可以转换为用符号序列来指定任务,输入和输出表示。例如:
- 翻译任务可以写成 (translate to French,English text,French text)
- 阅读理解任务可以写成(answer the question,document,question,answer)
MQAN(Memory-Question-Answer Network)能够根据这种格式的例子来推断和执行多种不同任务,语言建模也能在无监督的情况下采用MQAN的方式建模。
因此问题变成了在上述配置下能否在实践中优化无监督目标直至收敛。本文实验通过分析语言模型在zero-shot设置下在各种任务上的性能证实,足够大的语言模型能够在这种配置中进行多任务学习,但学习速度比有监督的方法慢得多。
训练数据集
本文没有采用传统的文本数据集,而是创建了一个强调文档质量的网络抓虫,但是人工筛选的数据质量更高但成本也高。所以爬虫抓取了Reddit(一个社交媒体平台)上大量的外部链接,因为Reddit上的外链通常是用户认为比较有趣、有价值的,类似于一种启发式指标,低成本的保证了数据的质量。
基于此创建了数据集WebText,包含了4500万个链接的文本数据。为了从HTML响应中提取文本,使用了Dragnet和Newspaper的组合(本文中展示的所有结果使用的是初版WebText,它不包括2017年12月之后创建的链接),随后经过去重和数据清理后,获得了大约800万份文档,总计40GB的文本。
WebText中删除了所有维基百科的文档,因为它是其他数据集的常见数据源,可能会由于训练数据与测试评估任务的重叠而使分析复杂化。

上图为WebText训练集中发现的英语到法语和法语到英语翻译的例子。
输入表示
通用的语言模型应该能够处理任何字符,但是现有的语言模型通过包含各种预处理操作:lower-casing、tokenization、预设词汇表等。这些操作都会限制语言模型能够处理的字符范围。
综合考虑了OOV(out of vocabulary words)问题和基础词汇表过大(Unicode的全部符号)的问题后,使用经过调整的byte级的BPE算法。byte级的BPE算法有8位即256种不同字符组成的基础词汇表,为了避免诸如’dog’、‘dog?’、'dog!'这种一个词被构建出多个版本的情况,构建策略阻止了BPE除空格外跨字符类别进行任何字节序列的合并,提高了压缩效率。
最终得到50257个词汇量的BPE,该方法可以表示任何Unicode字符组成的字符串,这使得可以在任何数据集上评估模型,无论预处理、标记化或词汇量的大小如何。
模型配置
GPT2使用了Transformer架构,在GPT1模型的基础上做了一些小改动:
- 调整Transformer的decoder,将Layer normalization移动到每个decoder子块的输入位置,并在最后一个decoder子块的自注意层后添加一个额外的Layer normalization
- 初始化时残差层的权重乘以 1 / N 1/\sqrt N 1/N, N N N是残差层的数量
- BPE词汇量扩大到50257个,batch size大小设为512

- 如上图,本文采用12、24、36、48四种不同层数Transformer Decoder,对应tokens序列长度分别为768、1024、1280、1600,对应参数量为117M、345M、762M、1542M的模型测试。最小的模型等同于原始GPT,第二小的模型相当于BERT的最大模型,最大的模型称之为GPT2,比GPT的参数多一个数量级。
实验
Language Modeling

上图为在WebText上预训练的不同尺寸GPT在zero-shot的设置下在其他数据集上的测试结果。观察到,GPT2在8个数据集中的7个实现了最佳水平。在小型数据集上也产生了很大的改进,例如Penn Treebank和WikiText-2。在LAMBADA和Children’s Book Test等长距离依赖性的数据集中,也有了很大的改进。但是在One Billion Word Benchmark上的结果较差,这可能是因为这个数据集较大且有最破坏性的预处理(1BW把句子随机打乱,去掉了所有长距离的结构)。
Children’s Book Test

儿童图书测试(CBT)是用来检验语言模型在不同类别的词上的表现,比如命名实体、名词、动词和介词。评估指标是在完形填空测试中准确地预测被省略的词的可能选项中的正确答案。例:
- 原始文本: I can swim, said Frog. I can swim as well as anything. So can I, said Toad. Don’t you want to race me across the river? Certainly not, said Frog. I don’t want to race you across the river. Suit yourself, said Toad. And he dived into the river and began to swim.
- 完形填空测试: Frog said he could swim as well as __________. A. anything B. anyone C. Toad D. the river
- 正确答案:C. Toad
上图显示了随着模型大小增加,性能稳步提高,并且在这个测试上接近人类水平。GPT2在常见名词上达到了93.3%的新水平,在命名实体上达到了89.1%。
LAMBADA
LAMBADA数据集测试系统对文本中长距离依赖关系的建模能力。任务是预测句子的最后一个单词,这需要至少50个上下文token才能成功预测。GPT-2将以往最优水平从99.8提高到了8.6的困惑度,并将预测准确性从19%提高到了52.66%。添加一个stop-word过滤器作为近似值,将准确性进一步提高到63.24%,使该任务总体上比最以往最优水平提高了4%。
Winograd Schema Challenge

Winograd Schema挑战旨在通过测量系统解决文本中的歧义的能力来衡量其进行常识推理的能力。一个Winograd模式是一对只相差一两个单词且包含歧义的句子,这些歧义在两个句子中以不同方式处理,需要常识才能正确理解 。例:
- 句子1:The trophy would not fit in the brown suitcase because it was too big.
- 句子2:The trophy would not fit in the brown suitcase because it was too small.
- 在这两个句子中,代词“it”指代的对象不同。在第一句中,“it”指的是奖杯,而在第二句中,“it”指的是手提箱。正确解决这种歧义需要使用常识知识。
如上图,GPT2将最先进的系统(SOTA)的准确率提高到70.70%。
Reading Comprehension
CoQA数据集由7个不同领域的文档和关于文档的自然语言对话组成,测试阅读理解能力和模型回答依赖于模型理解对话问题的能力。CoQA数据集包含来自8000个对话的127000对问题和答案,这些对话涉及7个不同领域,每组对话的平均长度为15轮,每一轮对话都由问题和回答组成。 例,针对《哈利·波特》的对话:
- Q:书中第一句是什么? A:Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much.
- Q:他们有孩子吗? A:They had a son called Dudley.
- Q:Dudley有多大? A:He was about to turn eleven years old.
当以文档、相关对话的历史和最终token A为条件时,GPT2使用贪婪解码生成的序列在开发集上达到了55 F1,这个结果近似或超过4个baseline系统中的3个,而且GPT2没有使用其余baseline系统训练中使用的127000多个手工收集的问题答案对。
Summarization

本实验测试GPT2在CNN和每日邮报数据集上提取摘要的能力。为了诱导摘要行为,文章最后面添加TL;DR:文本,并使用k = 2的Top-k随机采样生成100个token,这鼓励了比贪婪解码更抽象的摘要,并使用生成的100个token中前3个句子作为摘要。
如上图,在常用的ROUGE1、2、L指标上,生成的摘要只接近经典神经网络baseline的性能,并且仅略微优于随机从文章中选择3个句子做摘要。当删除任务提示TL;DR:时,GPT2的性能下降了6.4分,这证明了可以用自然语言在语言模型中调用特定任务行为。
Translation
本实验测试GPT2翻译能力。输入设置为示例对的上下文,格式为english sentence = french sentence,然后在最后一个提示english sentence =之后,使用贪心解码从模型中采样,并使用第一个生成的句子作为翻译。
在 WMT-14英-法测试集上,GPT2得到了5BLEU,这比之前在无监督词汇的研究中推断出的双语词汇逐字替换还要差一些。
在 WMT-14法-英测试集上,GPT2获得了11.5BLEU。这超过了一些无监督机器翻译baseline,但仍然远远不及当前最佳无监督机器翻译方法的33.5BLEU。这项任务的表现令人感到惊讶,因为作者故意从WebText中删除了大量的非英语网页,只使用了10MB的法语数据,比先前无监督机器翻译研究使用的法语语料库小500倍。
Question Answering

本实验验证使用语言模型来回答事实性问题的能力。使用自然问题数据集(Natural Questions dataset)作为测试数据集,输入类似于翻译实验。
GPT2对所有问题的回答准确率为4.1%,而最小模型的准确率小于1.0%。这表明模型容量对这类任务的性能影响较大。GPT2对其生成答案的概率校准良好,在其最有信心的1%的问题中,准确率为63.1%。但GPT2的性能仍然远远低于30%至50%一些开放域问答系统。
上图为GPT2对开发集问题产生的30个最自信的答案。
Samples
下列图为GPT2在WebText的测试案例。
Text generation







Summarization

Translation

Question Answering


reference
Alec, R. , Jeffrey, W. , Rewon, C. , David, L. , Dario, A. , & Ilya, S. . (2019). Language Models are Unsupervised Multitask Learners.
相关文章:
【论文精读】GPT2
摘要 在单一领域数据集上训练单一任务的模型是当前系统普遍缺乏泛化能力的主要原因,要想使用当前的架构构建出稳健的系统,可能需要多任务学习。但多任务需要多数据集,而继续扩大数据集和目标设计的规模是个难以处理的问题,所以只能…...

10-k8s中pod的探针
一、探针的概念 一般时候,探针的设置,都是为了优化业务时,需要做的事情;属于后期工作; 1,探针的分类 1,健康状态检查探针:livenessProbe 当我们设置了这个探针之后,检查…...
【Langchain Agent研究】SalesGPT项目介绍(二)
【Langchain Agent研究】SalesGPT项目介绍(一)-CSDN博客 上节课,我们介绍了SalesGPT他的业务流程和技术架构,这节课,我们来关注一下他的项目整体结构、poetry工具和一些工程项目相关的设计。 项目整体结构介绍 我们把…...

《UE5_C++多人TPS完整教程》学习笔记4 ——《P5 局域网连接(LAN Connection)》
本文为B站系列教学视频 《UE5_C多人TPS完整教程》 —— 《P5 局域网连接(LAN Connection)》 的学习笔记,该系列教学视频为 Udemy 课程 《Unreal Engine 5 C Multiplayer Shooter》 的中文字幕翻译版,UP主(也是译者&…...
【运维测试】移动测试自动化知识总结第1篇:移动端测试介绍(md文档已分享)
本系列文章md笔记(已分享)主要讨论移动测试相关知识。主要知识点包括:移动测试分类及android环境搭建,adb常用命令,appium环境搭建及使用,pytest框架学习,PO模式,数据驱动࿰…...

高校疫情防控系统的全栈开发实战
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…...

OpenTitan- 开源安全芯片横空出世
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
简单的edge浏览器插件开发记录
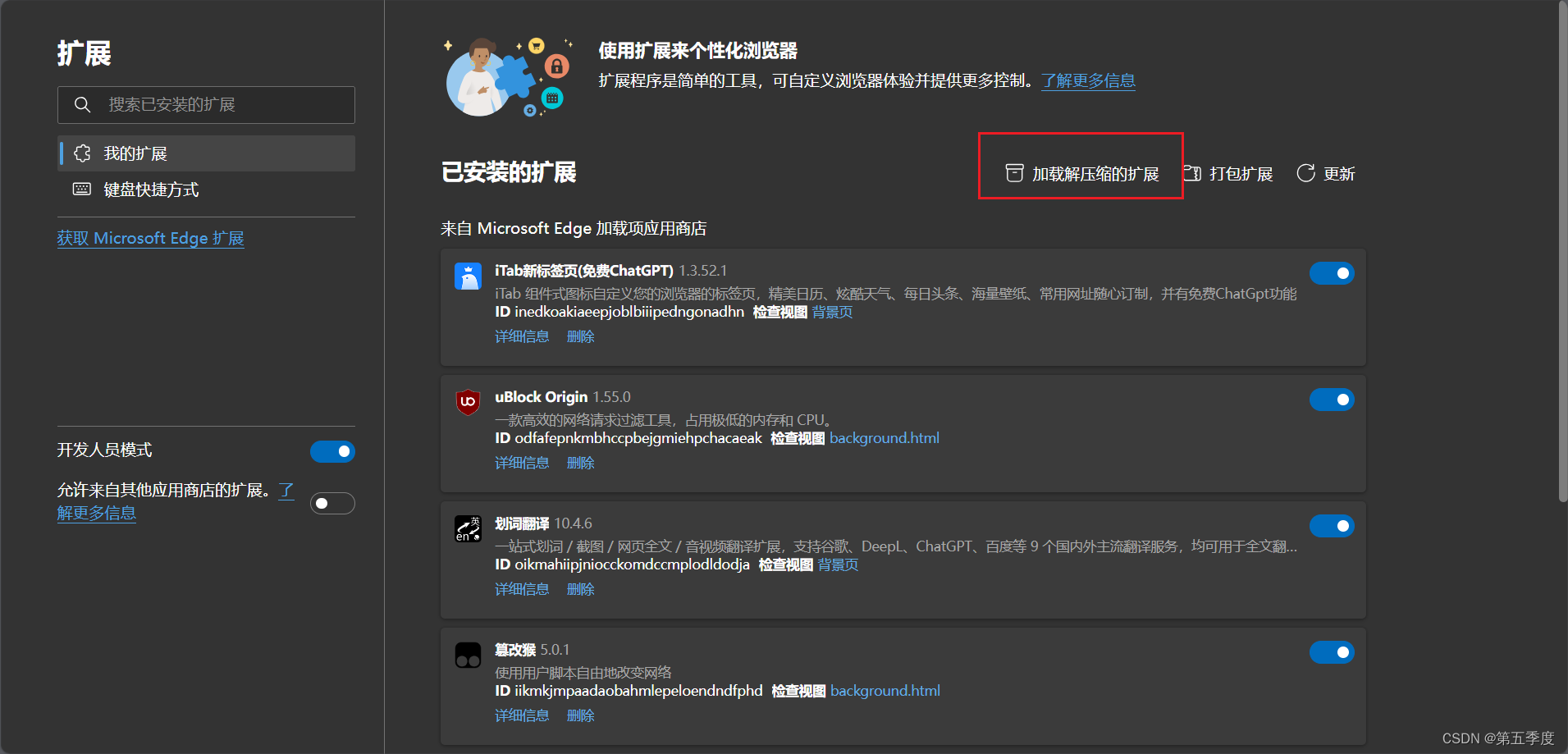
今天在浏览某些网页的时候,我想要屏蔽掉某些信息或者修改网页中的文本的颜色、背景等等。于是在浏览器的控制台中直接输入JavaScript操作dom完成了我想要的功能。但是每次在网页之间跳转该功能都会消失,我需要反复复制粘贴js脚本,无法实现自动…...
WSL下如何使用Ubuntu本地部署Vits2.3-Extra-v2:中文特化修复版(新手从0开始部署教程)
环境: 硬: 台式电脑 1.cpu:I5 11代以上 2.内存16G以上 3.硬盘固态500G以上 4.显卡N卡8G显存以上 20系2070以上 本案例英伟达4070 12G 5.网络可连github 软: Win10 专业版 19045以上 WSL2 -Ubuntu22.04 1.bert-Vits2.3 Extra-v2:…...

Go语言的100个错误使用场景(40-47)|字符串函数方法
前言 大家好,这里是白泽。 《Go语言的100个错误以及如何避免》 是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析100…...
Fluke ADPT 连接器新增对福禄克万用 Fluke 15B Max 的支持
所需设备: 1、Fluke ADPT连接器; 2、Fluke 15B Max; Fluke 15B Max拆机图: 显示界面如下图: 并且可以将波形导出到EXCEL: 福禄克万用表需要自己动手改造!!!...

前端工程化面试题 | 10.精选前端工程化高频面试题
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
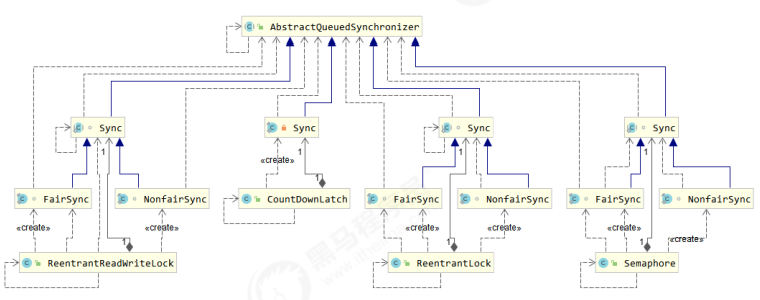
【并发编程】AQS原理
📝个人主页:五敷有你 🔥系列专栏:并发编程 ⛺️稳中求进,晒太阳 1. 概述 全称是 AbstractQueuedSynchronizer,是阻塞式锁和相关的同步器工具的框架 特点: 用 state 属性来表示资源的状…...
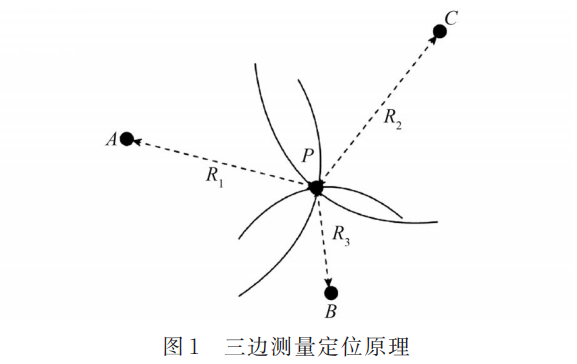
AI:130-基于深度学习的室内导航与定位
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~ 🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带有在本地跑过的关键代码,详细讲解供…...

Leetcode1423.可获得的最大点数
文章目录 题目原题链接思路(逆向思维) 题目 原题链接 Leetcode1423.可获得的最大点数 思路(逆向思维) 由题目可知,从两侧选k张,总数为n张,即从中间选n - k张 nums总和固定,要选k张最…...
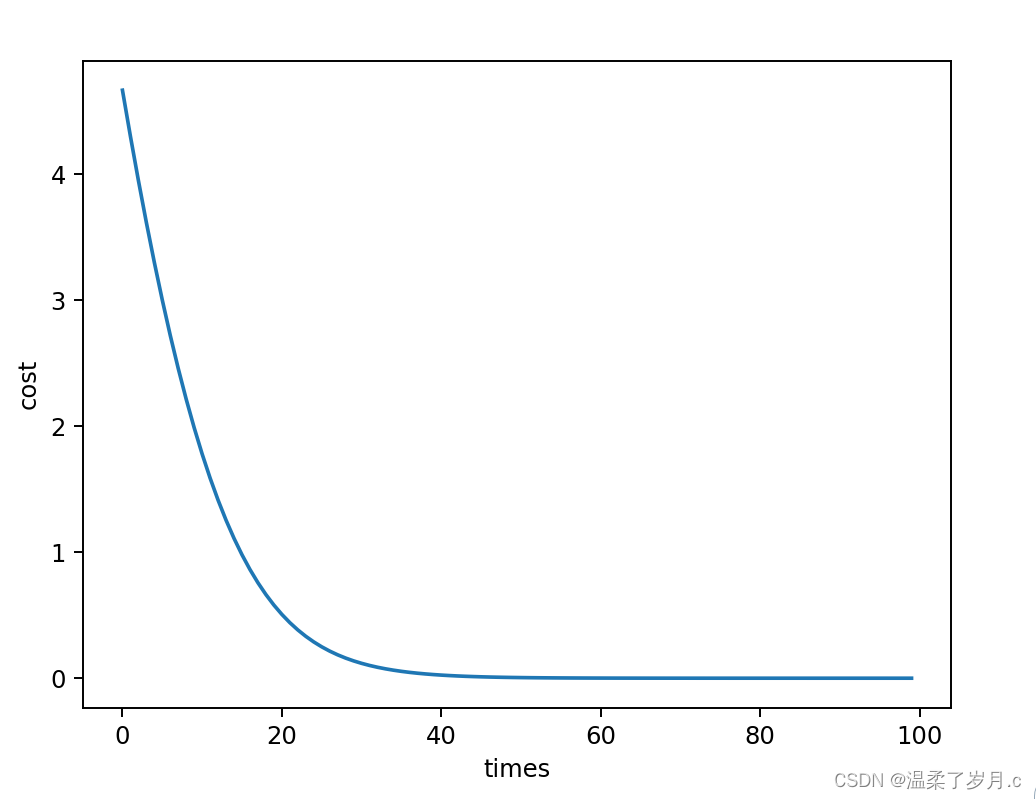
深度学习之梯度下降算法
梯度下降算法 梯度下降算法数学公式结果 梯度下降算法存在的问题随机梯度下降算法 梯度下降算法 数学公式 这里案例是用梯度下降算法,来计算 y w * x 先计算出梯度,再进行梯度的更新 import numpy as np import matplotlib.pyplot as pltx_data [1.0,…...
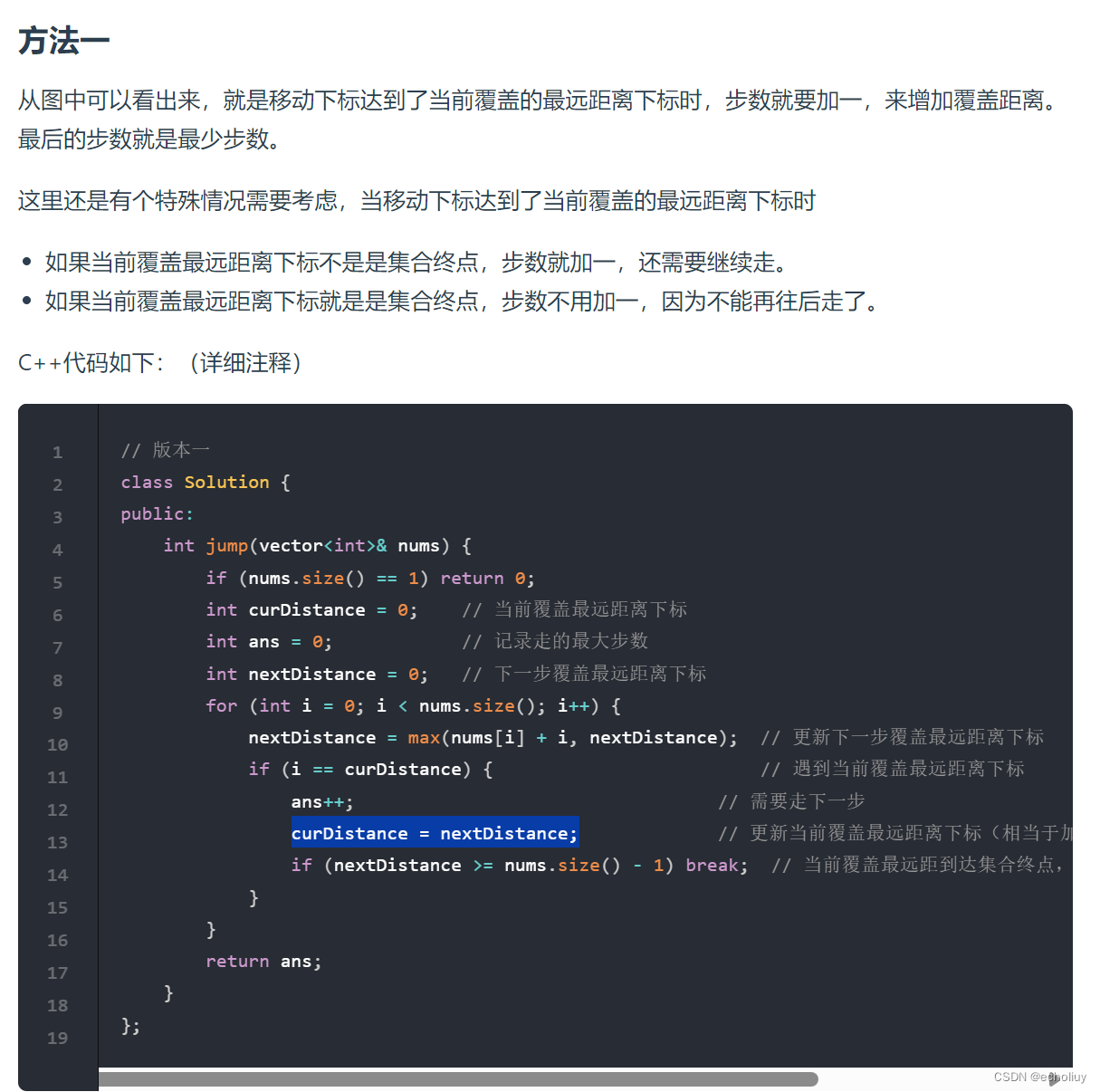
代码随想录第32天|● 122.买卖股票的最佳时机II ● 55. 跳跃游戏 ● 45.跳跃游戏II
文章目录 买卖股票思路一:贪心代码: 思路:动态规划代码: 跳跃游戏思路:贪心找最大范围代码: 跳跃游戏②思路:代码: 方法二:处理方法一的特殊情况 买卖股票 思路一&#x…...
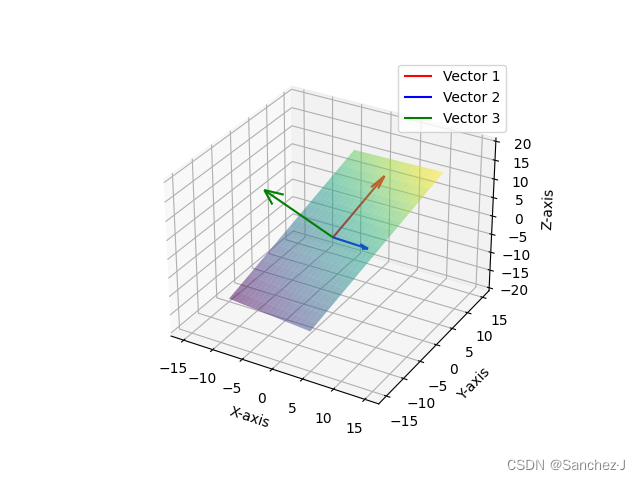
线性代数的本质 2 线性组合、张成的空间、基
基于3Blue1Brown视频的笔记 一种新的看待方式 对于一个向量,比如说,如何看待其中的3和-2? 一开始,我们往往将其看作长度(从向量的首走到尾部,分别在x和y上走的长度)。 在有了数乘后࿰…...

- 工程实践 - 《QPS百万级的有状态服务实践》01 - 存储选型实践
本文属于专栏《构建工业级QPS百万级服务》 《QPS百万级的无状态服务实践》已经完成。截止目前为止,支持需求“给系统传入两个日期,计算间隔有多少天”的QPS百万级服务架构已经完成。如图1: 图1 可是这个架构不能满足需求“给系统传入两个日期…...
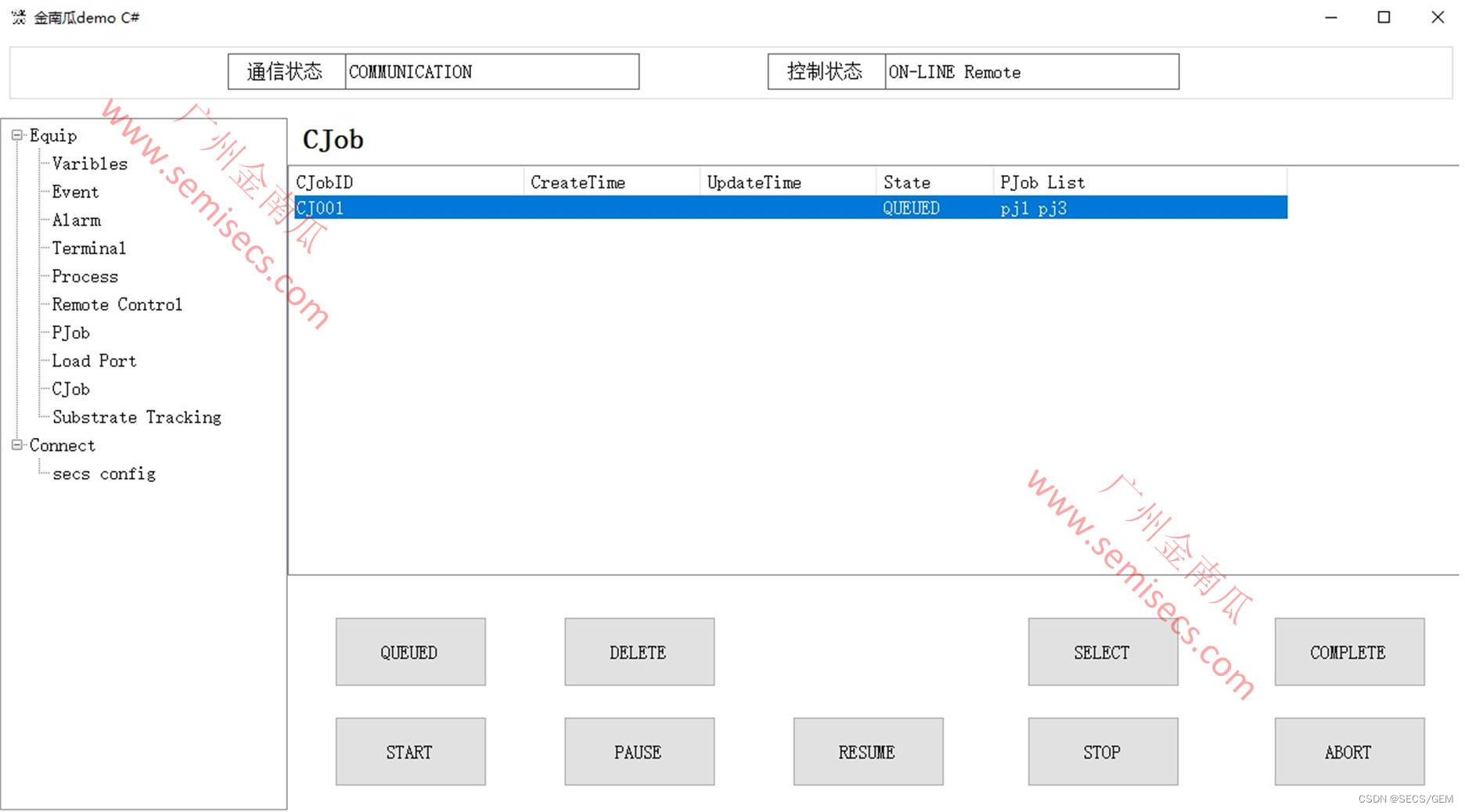
SECS/GEM的HSMS通讯?金南瓜方案
High Speed SECS Message Service (HSMS) 是一种基于 TCP/IP 的协议,它使得 SECS 消息通信更加快速。这通常用作设备间通信的接口。 HSMS 状态逻辑变化(序列): 1.Not Connected:准备初始化 TCP/IP 连接,但尚…...

Photoshop快速导出图层终极指南:如何高效批量处理设计文件
Photoshop快速导出图层终极指南:如何高效批量处理设计文件 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址:…...

Seraphine终极指南:英雄联盟LCU API实战开发与智能BP系统深度解析
Seraphine终极指南:英雄联盟LCU API实战开发与智能BP系统深度解析 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟竞技环境中,数据驱动的决策能力往往决定了胜负的走向。Ser…...

AWS实战|从零搭建高可用Web应用网络架构
1. 为什么需要高可用Web应用架构? 最近帮朋友公司迁移电商平台到AWS时,他们最担心的就是大促期间服务器挂掉。这让我想起三年前自己踩过的坑——当时用单可用区部署的官网,因为一次区域级故障直接宕机8小时。现在回头看,其实只要在…...

OpenHarmony ArkUI Toggle组件实战:红蓝药丸选择器开发详解
1. 项目概述与设计思路最近在整理OpenHarmony应用开发的学习笔记,发现很多初学者在接触到ArkUI的声明式开发范式时,对于如何将UI组件与用户交互、状态管理结合起来,总感觉隔着一层纱。理论看了不少,但一到自己动手,就不…...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...

Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别
Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维…...
)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码) 在嵌入式系统开发中,电压采样是基础却至关重要的环节。许多工程师在使用STM32或DSP内置ADC时,常会遇到精度不足、抗干扰能力差、无法测量差分信…...

Netgear路由器终极救援指南:用nmrpflash免费快速修复变砖设备
Netgear路由器终极救援指南:用nmrpflash免费快速修复变砖设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器在固件升级过程中意外断电,或者刷入错误固件导致…...

NCM格式转换实战指南:ncmdumpGUI全面解析
NCM格式转换实战指南:ncmdumpGUI全面解析 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾为网易云音乐下载的NCM格式音乐无法在其他设备播…...

Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生!
Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Wind…...