python:xml.etree,用 xmltodict 转换为json数据,生成jstree所需的文件
请参阅:java : pdfbox 读取 PDF文件内书签 或者 python:从PDF中提取目录
请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad++ 转换编码。
xml 是 python 标准库,在 D:\Python39\Lib\xml\etree
pip install xmltodict ;
python 用 xml.etree.ElementTree,用 xmltodict 转换为json数据。
编写 txt_xml_etree_json.py 如下
# -*- coding: utf-8 -*-
""" 读目录.txt文件,用 xmltodict转换为json数据 """
import os
import sys
import codecs
import json
import xml.etree.ElementTree as et
import xmltodictif len(sys.argv) ==2:f1 = sys.argv[1]
else:print('usage: python txt_xml_etree_json.py file1.txt')sys.exit(1)if not os.path.exists(f1):print(f"ERROR: {f1} not found.")sys.exit(1)fn,ext = os.path.splitext(f1)
if ext.lower() != '.txt':print('ext is not .txt')sys.exit(2)fp = codecs.open(f1, mode="r", encoding="utf-8")
# 读取第一行:书名
title = fp.readline()
# 创建主题节点
root = et.Element("node")
root.set("id", '1')
root.set("text", title.strip())# 定义状态:
state = et.SubElement(root, "state")
state.set("opened", 'true')
state.set("disabled", 'true')# 用缩排表现层级关系,假设最多5个层级
indent1 = ' '*2
indent2 = ' '*4
indent3 = ' '*6
indent4 = ' '*8n = 2
for line in fp:txt = line.strip()if len(txt) ==0:continuetxt = txt[0:-3] # 去掉行尾的页数if len(txt) >0 and line[0] !=' ':# 创建主题的子节点(1级节点)node1 = et.SubElement(root, "children")node1.set("id", str(n))node1.set("text", txt)p_node = node1 # 寄存父节点elif line.startswith(indent1) and line[2] !=' ':# 创建node1的子节点(2级节点)try: type(node1)except NameError: node2 = et.SubElement(root, "children")else: node2 = et.SubElement(node1, "children")node2.set("id", str(n))node2.set("text", txt)p_node = node2elif line.startswith(indent2) and line[4] !=' ':# 创建node2的子节点(3级节点)try: type(node2)except NameError: node3 = et.SubElement(node1, "children")else: node3 = et.SubElement(node2, "children")node3.set("id", str(n))node3.set("text", txt)p_node = node3elif line.startswith(indent3) and line[6] !=' ':# 创建node3的子节点(4级节点)try: type(node3)except NameError: node4 = et.SubElement(node2, "children")else: node4 = et.SubElement(node3, "children")node4.set("id", str(n))node4.set("text", txt)p_node = node4elif line.startswith(indent4) and line[8] !=' ':# 创建node4的子节点(5级节点)try: type(node4)except NameError: node5 = et.SubElement(p_node, "children")else: node5 = et.SubElement(node4, "children")node5.set("id", str(n))node5.set("text", txt)else:print(txt)n += 1
fp.close()
print(f"line number: {n}")# 转换成 str,方便导出
root_bytes = et.tostring(root, encoding="utf-8")
xml_str = root_bytes.decode()
try:json_dict = xmltodict.parse(xml_str, encoding='utf-8')json_str = json.dumps(json_dict['node'], indent=2)
except:print("xmltodict.parse error!")
# 去掉'@'
json_str = '['+ json_str.replace('\"@','"') +']'
#print(json_str)# 导出.json文件
f2 = fn +'.json'
with codecs.open(f2, 'w', encoding='utf8') as fp:fp.write(json_str)
python 用 xml.etree.ElementTree,用 xmltodict 转换为json数据,jinja2 生成jstree模板所需的文件。
编写 txt_xml_etree_htm.py 如下
# -*- coding: utf-8 -*-
""" 读目录.txt文件,用 xmltodict转换为json数据,生成jstree所需的文件 """
import os
import sys
import codecs
import json
import xml.etree.ElementTree as et
import xmltodict
from jinja2 import Environment,FileSystemLoaderif len(sys.argv) ==2:f1 = sys.argv[1]
else:print('usage: python txt_xml_etree_htm.py file1.txt')sys.exit(1)if not os.path.exists(f1):print(f"ERROR: {f1} not found.")sys.exit(1)fn,ext = os.path.splitext(f1)
if ext.lower() != '.txt':print('ext is not .txt')sys.exit(2)fp = codecs.open(f1, mode="r", encoding="utf-8")
# 读取第一行:书名
title = fp.readline()
# 创建主题节点
root = et.Element("node")
root.set("id", '1')
root.set("text", title.strip())# 定义状态:
state = et.SubElement(root, "state")
state.set("opened", 'true')
state.set("disabled", 'true')# 用缩排表现层级关系,假设最多5个层级
indent1 = ' '*2
indent2 = ' '*4
indent3 = ' '*6
indent4 = ' '*8n = 2
for line in fp:txt = line.strip()if len(txt) ==0:continuetxt = txt[0:-3] # 去掉行尾的页数if len(txt) >0 and line[0] !=' ':# 创建主题的子节点(1级节点)node1 = et.SubElement(root, "children")node1.set("id", str(n))node1.set("text", txt)p_node = node1 # 寄存父节点elif line.startswith(indent1) and line[2] !=' ':# 创建node1的子节点(2级节点)try: type(node1)except NameError: node2 = et.SubElement(root, "children")else: node2 = et.SubElement(node1, "children")node2.set("id", str(n))node2.set("text", txt)p_node = node2elif line.startswith(indent2) and line[4] !=' ':# 创建node2的子节点(3级节点)try: type(node2)except NameError: node3 = et.SubElement(node1, "children")else: node3 = et.SubElement(node2, "children")node3.set("id", str(n))node3.set("text", txt)p_node = node3elif line.startswith(indent3) and line[6] !=' ':# 创建node3的子节点(4级节点)try: type(node3)except NameError: node4 = et.SubElement(node2, "children")else: node4 = et.SubElement(node3, "children")node4.set("id", str(n))node4.set("text", txt)p_node = node4elif line.startswith(indent4) and line[8] !=' ':# 创建node4的子节点(5级节点)try: type(node4)except NameError: node5 = et.SubElement(p_node, "children")else: node5 = et.SubElement(node4, "children")node5.set("id", str(n))node5.set("text", txt)else:print(txt)n += 1
fp.close()
print(f"line number: {n}")# 转换成 str,方便导出
root_bytes = et.tostring(root, encoding="utf-8")
xml_str = root_bytes.decode()
try:json_dict = xmltodict.parse(xml_str, encoding='utf-8')json_str = json.dumps(json_dict['node'], indent=2)
except:print("xmltodict.parse error!")
# 去掉'@'
json_str = '['+ json_str.replace('\"@','"') +']'
#print(json_str)# 使用 jinja2 对html模板文件进行数据替换
env = Environment(loader=FileSystemLoader('d:/python/'))
tpl = env.get_template('jstree_template.htm')
# 导出.html文件
f2 = fn +'.htm'
with codecs.open(f2, 'w', encoding='utf8') as fp:content = tpl.render(title=title.strip(), mydir=json_str)fp.write(content)
https://gitee.com/ 搜索 jstree 下载
https://gitee.com/mirrors/jstree?_from=gitee_search
git clone https://gitee.com/mirrors/jstree.git
编写 jstree 模板文件:jstree_template.htm
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=Edge"><meta name="viewport" content="width=device-width, initial-scale=1"><title>{{title}}</title><script src="../js/jquery-3.2.1.min.js"></script><link rel="stylesheet" href="../js/jstree/dist/themes/default/style.css" /><script src="../js/jstree/dist/jstree.min.js"></script>
</head>
<body><!-- 搜索框 --><div class="search_input"><input type="text" id="search_a" /><img src="../js/jstree/dist/search.png" /></div><div id="treeview1" class="treeview"></div>
<script type="text/javascript">var mydir = {{mydir}};$("#treeview1").jstree({'core' : {"multiple" : false,'data' : mydir,'dblclick_toggle': true},"plugins" : ["search"]});//输入框输入时自动搜索var tout = false;$('#search_a').keyup(function(){if (tout) clearTimeout(tout); tout = setTimeout(function(){$('#treeview1').jstree(true).search($('#search_a').val()); }, 250);});
</script>
</body>
</html>
运行 python txt_xml_etree_htm.py your_pdf_dir.txt
生成 your_pdf_dir.htm
相关文章:

python:xml.etree,用 xmltodict 转换为json数据,生成jstree所需的文件
请参阅:java : pdfbox 读取 PDF文件内书签 或者 python:从PDF中提取目录 请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad 转换编码。 xml 是 python 标准库,在 D:\Python39\Lib\xml\etree pip install …...
)
C#log4net日志保存到Sqlserver数据库表(16)
要将log4net的日志保存到SQL Server数据库表中,你需要配置log4net使用一个数据库追加器(appender),通常是AdoNetAppender。以下是一个示例配置,展示如何将log4net的日志输出配置为写入SQL Server数据库表。 首先&…...
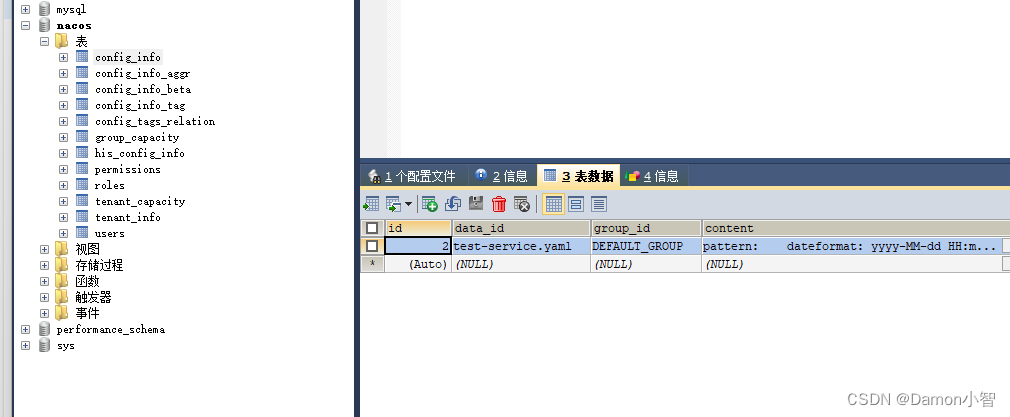
SpringCloud-Nacos集群搭建
本文详细介绍了如何在SpringCloud环境中搭建Nacos集群,为读者提供了一份清晰而详尽的指南。通过逐步演示每个关键步骤,包括安装、配置以及Nginx的负载均衡设置,读者能够轻松理解并操作整个搭建过程。 一、Nacos集群示意图 Nacos࿰…...
软件测试组竞赛规则及说明)
第十五届蓝桥杯全国软件和信息技术专业人才大赛个人赛(软件赛)软件测试组竞赛规则及说明
第十五届蓝桥杯全国软件和信息技术专业人才大赛个人赛 (软件赛)软件测试组竞赛规则及说明 目录...
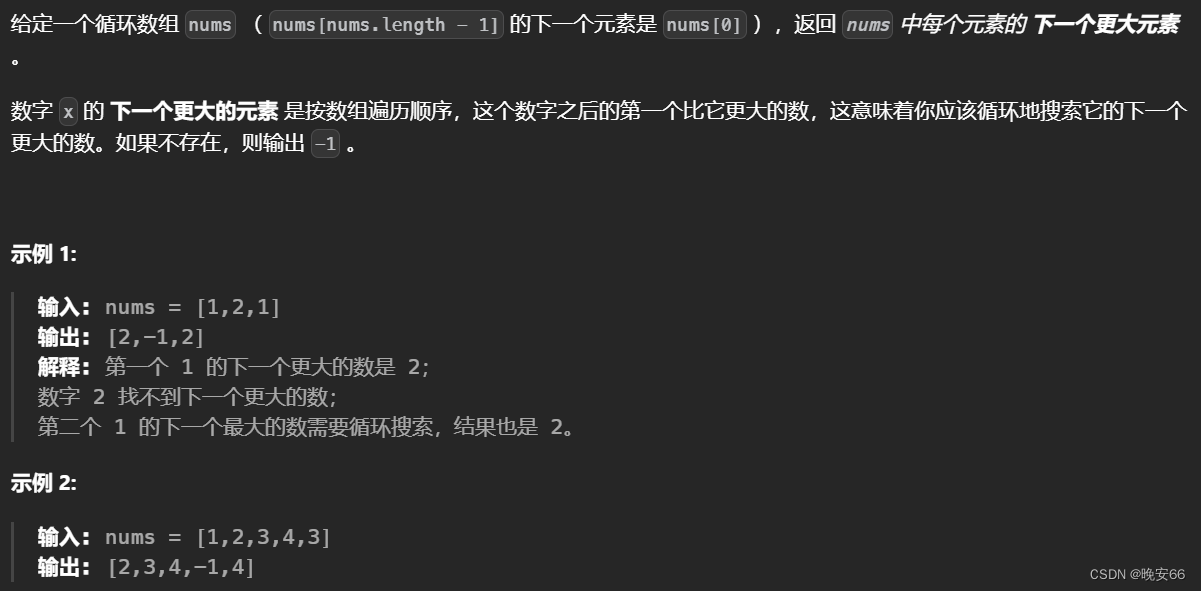
【算法与数据结构】496、503、LeetCode下一个更大元素I II
文章目录 一、496、下一个更大元素 I二、503、下一个更大元素II三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、496、下一个更大元素 I 思路分析:本题思路和【算法与数据结构】739、LeetCode每日温度类似…...

当AGI遇到人形机器人
为什么人类对人形机器人抱有执念 人形机器人是一种模仿人类外形和行为的机器人,它的研究和开发有着多方面的目的和意义。 人形机器人可以更好地适应人类的环境和工具。人类的生活和工作空间都是根据人的尺寸和动作来设计的,例如门、楼梯、桌椅、开关等…...
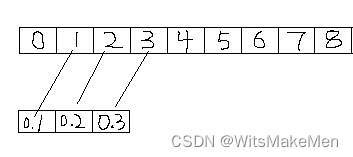
Pytorch卷积层原理和示例 nn.Conv1d卷积 nn.Conv2d卷积
内容列表 一,前提 二,卷积层原理 1.概念 2.作用 3. 卷积过程 三,nn.conv1d 1,函数定义: 2, 参数说明: 3,代码: 4, 分析计算过程 四,nn.conv2d 1, 函数定义 2, 参数: 3, 代码 4, 分析计算过程 …...

Qt 实现无边框窗口1.0
目录 项目需求: 1、没有边框; 2、点击windows系统的状态栏的程序运行图标可实现最大最小化; 3、可以移动窗口; 项目实现: 1、实现 无边框 2、实现 点击windows系统的状态栏的程序运行图标可实现最大最小化 3、实现 窗…...

Flume(二)【Flume 进阶使用】
前言 学数仓的时候发现 flume 落了一点,赶紧补齐。 1、Flume 事务 Source 在往 Channel 发送数据之前会开启一个 Put 事务: doPut:将批量数据写入临时缓冲区 putList(当 source 中的数据达到 batchsize 或者 超过特定的时间就会…...
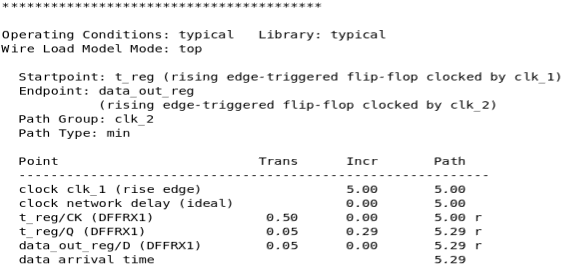
静态时序分析:SDC约束命令set_clock_transition详解
相关阅读 静态时序分析https://blog.csdn.net/weixin_45791458/category_12567571.html?spm1001.2014.3001.5482 在静态时序分析:SDC约束命令create_clock详解一文的最后,我们谈到了针对理想(ideal)时钟,可以使用set_clock_transition命令直…...
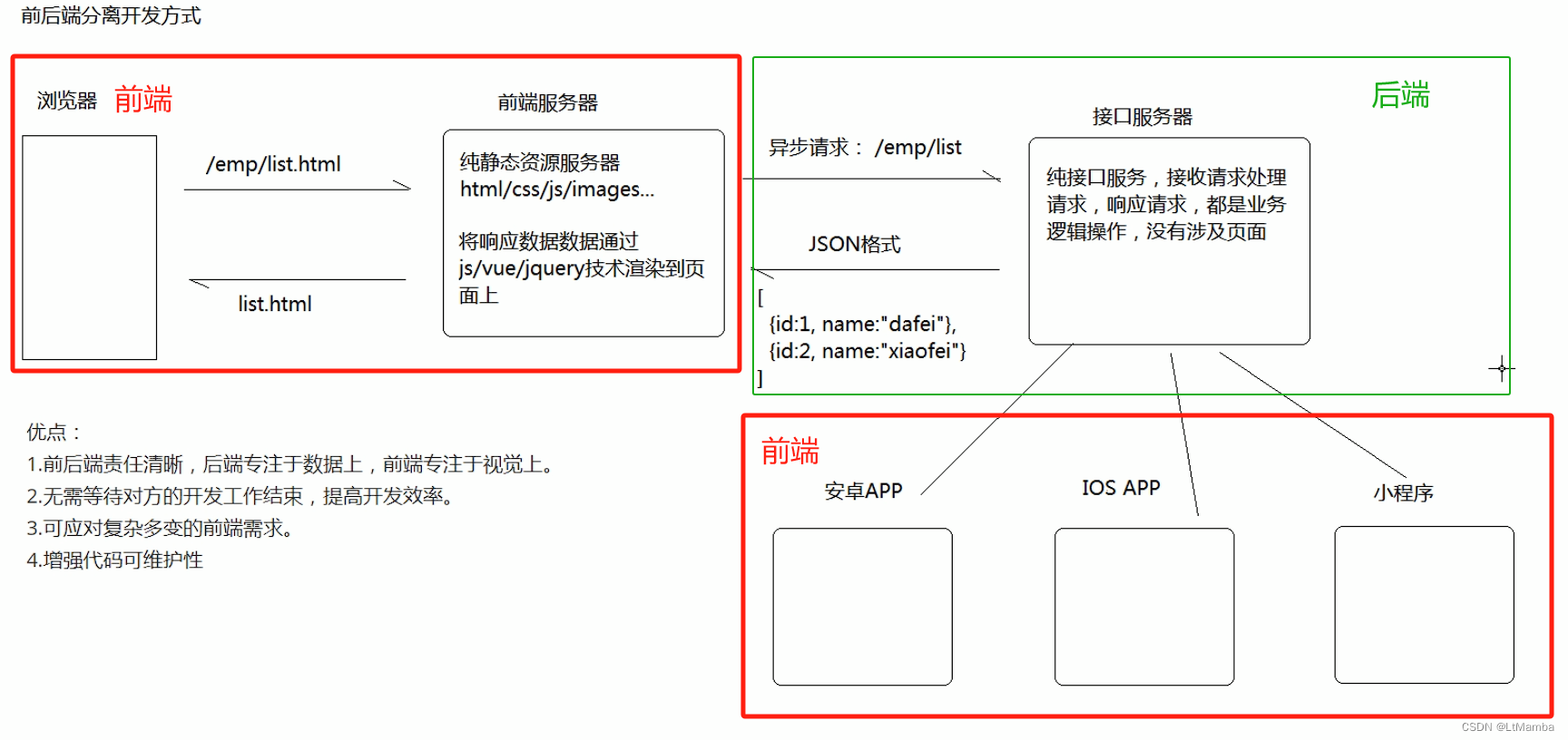
web 发展阶段 -- 详解
1. web 发展阶段 当前处于 移动 web 应用阶段。也是个风口(当然是针对有能力创业的人来说的),如 抖音、快手就是这个时代的产物。 2. web 发展阶段引出前后端分离的过程 2.1 传统开发方式 2.2 前后端分离模式 衍生自移动 web 应用阶段。 3.…...

车载软件架构 —— Adaptive AUTOSAR软件架构中操作系统
车载软件架构 —— Adaptive AUTOSAR软件架构中操作系统 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师(Wechat:gongkenan2013)。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师&…...

前缀和算法-截断数组
5057. 截断数组 - AcWing题库 给定一个长度为 n 的正整数数组 a1,a2,…,an 和一个正整数 p。 现在,要将该数组从中间截断,得到两个非空子数组。 我们规定,一个数组的价值等于数组内所有元素之和模 p 的结果。 我们希望,将给定数组…...

Kubernetes实战:Kubernetes中网络插件calico Daemon Sets显示异常红色
目录 一、排查步骤与解决方案1.1、POD排查问题定位1.2、针对问题解决错误1.3、继续针对问题解决错误 一、排查步骤与解决方案 1.1、POD排查问题定位 我的k8s集群由3个节点组成的,calico在每个节点上都有一个pod,通过kubectl get pod -A命令发现有一个pod的READY 为…...

深入探究:JSONCPP库的使用与原理解析
君子不器 🚀JsonCPP开源项目直达链接 文章目录 简介Json示例小结 JsoncppJson::Value序列化Json::Writer 类Json::FastWriter 类Json::StyledWriter 类Json::StreamWriter 类Json::StreamWriterBuilder 类示例 反序列化Json::Reader 类Json::CharReader 类Json::Ch…...

字节UC伯克利新研究 | Magic-Me:简单有效的主题ID可控视频生成框架
在生成模型领域,针对特定身份(ID)创建内容已经引起了极大的兴趣。在文本到图像生成(T2I)领域,以主题驱动的内容生成已经取得了巨大的进展,使图像中的ID可控。然而,将其扩展到视频生成…...

2024免费人像摄影后期处理工具Portraiture4.1
Portraiture作为一款智能磨皮插件,确实为Photoshop和Lightroom用户带来了极大的便利。通过其先进的人工智能算法,它能够自动识别并处理照片中的人物皮肤、头发和眉毛等部位,实现一键式的磨皮美化效果,极大地简化了后期处理的过程。…...
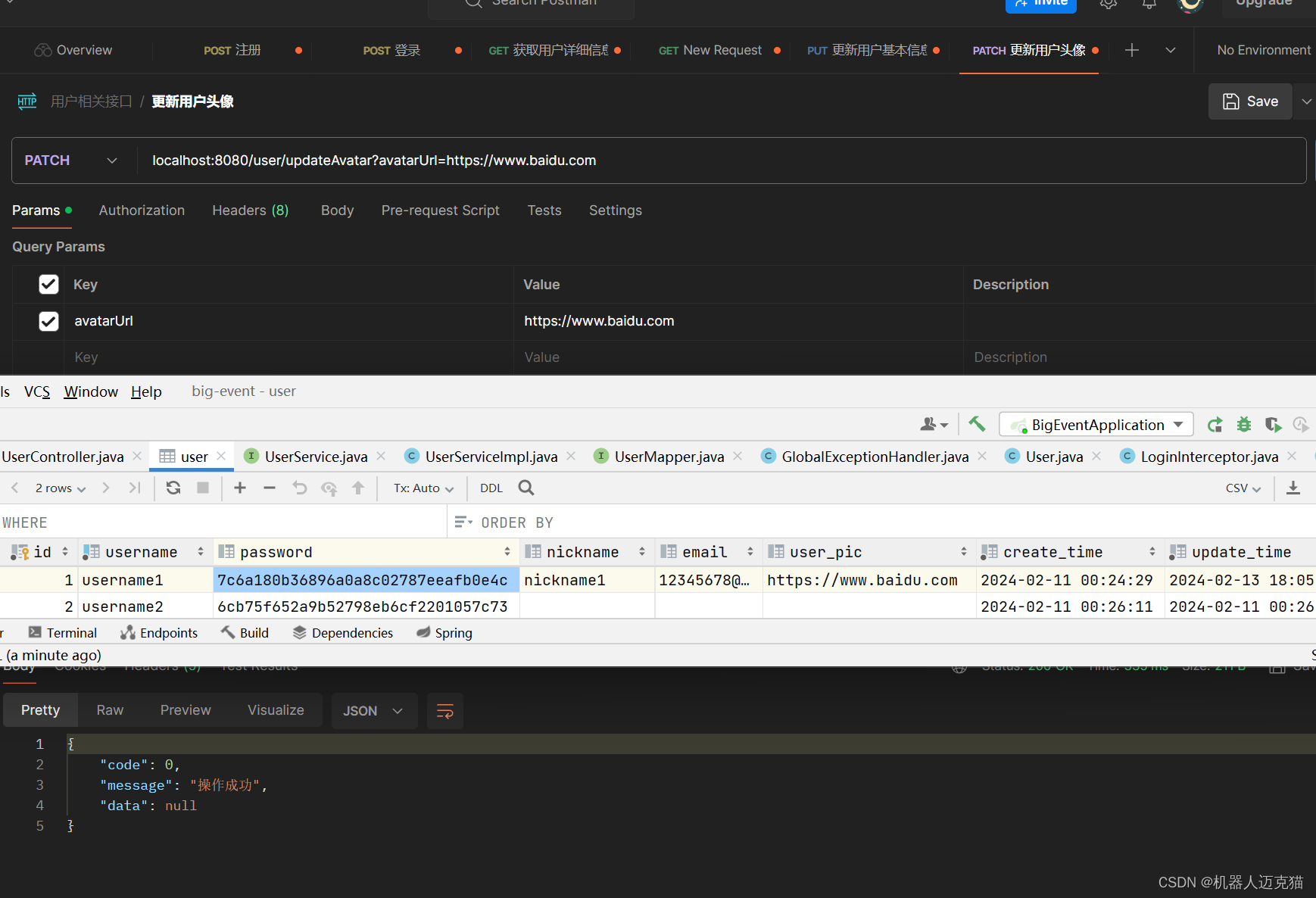
Spring Boot 笔记 010 创建接口_更新用户头像
1.1.1 usercontroller中添加updateAvatar,校验是否为url PatchMapping("updateAvatar")public Result updateAvatar(RequestParam URL String avatarUrl) {userService.updateAvatar(avatarUrl);return Result.success();} 1.1.2 userservice //更新头像…...

认识并使用HttpLoggingInterceptor
目录 一、前情回顾二、HttpLoggingInterceptor1、HttpLoggingInterceptor拦截器是做什么的?2、如何使用HttpLoggingInterceptor?2.1 日志级别2.2 如何看日志?2.2.1 日志级别:BODY2.2.2 日志级别:BASIC2.2.3 日志级别&a…...
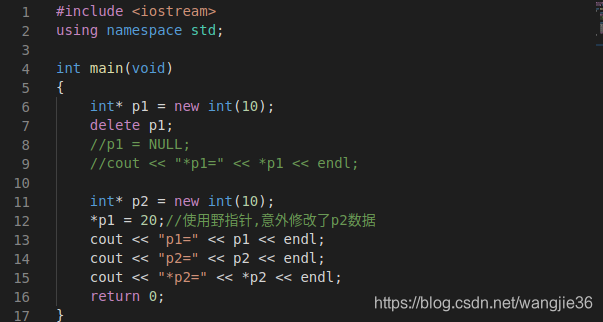
内存块与内存池
(1)在运行过程中,MemoryPool内存池可能会有多个用来满足内存申请请求的内存块,这些内存块是从进程堆中开辟的一个较大的连续内存区域,它由一个MemoryBlock结构体和多个可供分配的内存单元组成,所有内存块组…...

FRED应用:背散射教程
这个教程描述一个有散射性质的简单plano-plano透镜,这样一条入射光就会散射回发射方向。教程首先,在FRED中创建一个新的系统,在树视图中的Geometry上右击,选择“Create New Lens…”并在出现的对话框上点OK按钮,在全局…...

Rust内存安全:所有权、借用与生命周期深度解析
Rust内存安全:所有权、借用与生命周期深度解析 引言 在Rust开发中,内存安全是其最核心的特性。作为一名从Python转向Rust的后端开发者,我深刻体会到Rust在内存安全方面的革命性设计。Rust通过所有权系统、借用机制和生命周期注解࿰…...

GAMES101图形学笔记:从光栅化到路径追踪,我的自学避坑路线图
GAMES101图形学自学指南:从光栅化到路径追踪的实战路线 在B站上拥有数百万播放量的GAMES101课程,已经成为计算机图形学爱好者入门的黄金标准。作为一门融合数学、物理和编程的交叉学科,图形学的学习曲线往往令人望而生畏。本文将分享我自学G…...

深入LAN8720A硬件设计:从REF_CLK模式选择到SMI地址配置,如何为STM32的LWIP DHCP稳定运行打好基础
嵌入式网络硬件设计实战:LAN8720A与STM32的协同优化策略 在嵌入式系统开发中,网络功能的稳定性往往取决于硬件设计与软件配置的完美配合。当工程师面对LWIP协议栈下DHCP功能不稳定、网络时断时续的问题时,很容易将注意力集中在软件调试上&am…...

5个核心功能技巧:用MPh实现COMSOL仿真自动化
5个核心功能技巧:用MPh实现COMSOL仿真自动化 【免费下载链接】MPh Pythonic scripting interface for Comsol Multiphysics 项目地址: https://gitcode.com/gh_mirrors/mp/MPh 你是一个文章写手,你负责为开源项目写专业易懂的文章。今天我们要介绍…...

3个高效方法解决抖音素材管理难题:从零散文件到有序素材库
3个高效方法解决抖音素材管理难题:从零散文件到有序素材库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

光学萌新看过来:用Lighttools 8.4.0配合Solidworks做光机设计,第一步安装和环境配置怎么做?
光学与机械协同设计:Lighttools 8.4.0与Solidworks环境配置全指南 在光机一体化设计领域,光学仿真软件与机械建模工具的协同工作已成为行业标配。对于刚接触光学设计的机械工程师,或是需要将光学分析融入机械设计流程的团队而言,掌…...

GitLab团队协作实战:从分支策略到CI/CD流水线优化指南
1. 项目概述:为什么需要一个专属的GitLab使用指导?在团队协作开发中,版本控制系统是基石,而GitLab作为集代码托管、CI/CD、项目管理于一体的DevOps平台,其重要性不言而喻。然而,对于许多新加入团队的开发者…...

从PyCharm到ArcGIS工具箱:把你的Python地理处理脚本‘打包’成专业工具的保姆级指南
从PyCharm到ArcGIS工具箱:Python地理处理脚本的专业化封装实战 当你在PyCharm中完成了一个完美运行的地理处理脚本,接下来最自然的想法就是让它能被更多非技术同事直接使用。本文将带你跨越开发环境与生产环境的鸿沟,将一个孤立的Python脚本转…...

3分钟掌握Typora LaTeX主题:用Markdown写出专业学术论文的终极指南
3分钟掌握Typora LaTeX主题:用Markdown写出专业学术论文的终极指南 【免费下载链接】typora-latex-theme 将Typora伪装成LaTeX的中文样式主题,本科生轻量级课程论文撰写的好帮手。This is a theme disguising Typora into Chinese LaTeX style. 项目地…...