爬虫-华为云空间备忘录导出到docx-selenium控制浏览器行为-python数据处理
背景+适用情况介绍
老的荣耀手机属于华为云系统,家里人换了新荣耀手机属于荣耀云系统无法通过云空间将备忘录转移到新手机,不想让他们一个一个搞,于是整了一晚上想办法爬取下来。从网页抓取下来,然后存到docx文档中(包括文字和图片,别的形式的内容请举一反三) 多行图片多行文字sample:

本方法Cons:不能复制到荣耀云里,因为捣了半天这荣耀云根本就没有除了手机之外可以访问的方法
续:别人告诉我有荣耀云win客户端,本来还想看看导入,太抽象了,竟然说
,辣鸡
别的思路
手机内部自动化保存为文档后处理
华为手机备忘录批量导出txt╳ 全自动版 ╳By 免ROOT自动化助手
cons:这个up是导出一条删除一条,我不想删除,它有for循环但是要付费,付费倒不是啥别太贵就行毕竟人家做的工具,但是一看还要注册登录,,,
fiddler抓包方式抓所有笔记页面
华为手机备忘录批量导出文字和图片
cons:看了一下需要手动一个一个点笔记,不想动了
前置准备
- 首先确定老手机在设置的主账号登录进去或者注册是华为云,让家里注册了一下,然后打开同步把数据同步到云端,登录华为云空间可以看到所有的备忘录,点进去记录第一个备忘录的URL后面都要用
- 需要chrome(查看版本:右上角三个点-help-about)和版本匹配的chromedriver(别的可以控制浏览器控件如firefox也可以,我这样用)
chromedriver.exe的目录需要加入环境变量path,cmd运行 chromedriver 可测试,如果调用里自定义位置可以尝试path参数,库接口已更新与文档不匹配 - python环境
代码步骤
in simulate
-
第一次扫码登录,登录完毕python控制台任意enter继续,自动保存cookies到cookies.json后续不用登录
-
手动浏览器f12分析元素可知中间一列是每页链接列表,右边一列是点击后的笔记标题时间内容,找到dom树下到达这个元素的路径,可覆盖到元素然后右键复制path-xpath得到,示例如下:


-
对每个元素点击,滑动到下一个(必须滑动,为了点击下一个做准备,否则直接代码点击超出视窗的元素无法加载右侧笔记内容)
-
相关知识链接
– selenium-python document
– xPath examples 注意dom css中序数是从1开始
– 滑动界面外的元素问题
– 获取元素标签内容和属性值例子 -
根据xpath提取标题,时间,内容,内容由分析可知是一个一个div行叠加的,图文都是在行中,所以内循环提取一行一行内容
-
内循环-图:request无法下载?控制浏览器下载,从默认目录移动到当前/img下并加上jpg后缀(因为看了一下上传只能传jpg,下载时候看了一下都可以用jpg打开)图文件名保存在列表中备用(应该没有重复的)
-
重新组成数据格式如下,or whatever you want,然后存到result.json
– [title0, time0, [content0 line0 text, content0 line1 img name, …]]
– [title1, …]
in result_to_doc
- 很简单一行一行写入
- 相关链接
– python-docx quick start 注意docx库实际要装的是python-docx,如果import docx有错看装的对不对
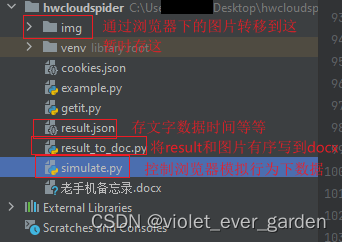
project结构以及代码
simulate.py
import json
import os
import shutil
import timeimport requests as requests
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import Bydef login_and_save_to_cookies(driver, url):# driver = webdriver.Chrome()driver.get(url)val = input("Manually login now. Enter anything if finished")# time.sleep(20) # Let the user actually see something!cookies = driver.get_cookies()# 转换成字符串保存json_cookie = json.dumps(cookies)# 保存到txt文件with open('cookies.json', 'w') as f:f.write(json_cookie)print('cookies保存成功!')def login_with_cookies(driver):with open('cookies.json','r',encoding='utf8') as f:cookies = json.loads(f.read())# 给浏览器添加cookiesfor cookie in cookies:driver.add_cookie(cookie)# 刷新网页,cookies才会成功,后面我们直接跳转就不用刷新了# driver.refresh()if __name__ == '__main__':driver = webdriver.Chrome()# 笔记的第一页url,后面需要用到url = 'https://cloud.huawei.com/home#/notepad/note/allNote/note/xxxxxxxxxxxxxxxxxxxxxxx'# 加载已有cookies之前至少得先访问一遍driver.get(url)time.sleep(5) # 需要等待加载完# 切换成中文language_button = driver.find_element(By.XPATH,'//*[@id="Cloudlogin"]/div[1]/div[1]/div[2]/a[1]/span[1]')ActionChains(driver).click(language_button).perform() # single clickchinese_button = driver.find_element(By.XPATH,'//*[@id="scroller"]/ul/li[65]/div')ActionChains(driver).click(chinese_button).perform() # single clicktime.sleep(5)val = input("If using existing cookies, type 'n', manually login type anything else")if val != 'n':login_and_save_to_cookies(driver, url)login_with_cookies(driver)time.sleep(5)driver.get(url)time.sleep(5)# driver.find_element(By.)note_center_items = driver.find_elements(By.CLASS_NAME, "note_item")note_titles = []note_times = []note_contents = []chrome_download_directory = "C:\\Users\\xxxxxxxxxxxxxx\\Downloads\\" # 浏览器默认下载路径img_store_directory = "./img/" # 都需要以/结尾以便后面拼接for note_center_item in note_center_items:# print(note_center_item.get_attribute("autokey"))ac = note_center_item# ActionChains(driver).scroll_to_element(ac).perform()ActionChains(driver).click(ac).perform() # single clickdriver.execute_script("arguments[0].scrollIntoView(true);", ac) # 必须滑动,不然点击视窗外的元素无法加载右侧笔记内容time.sleep(5)title_element = driver.find_element(By.XPATH,'//*[@id="note_title_editor"]/div/div[6]/div[1]/div/div/div/div[5]/pre/span')time_element = driver.find_element(By.XPATH,'//*[@id="app"]/div[6]/div[3]/div/div[1]/div[4]/div[2]/div/span[1]')content_multiline_container_element = driver.find_element(By.XPATH,'//*[@id="note_detail_editor"]/div/div[6]/div[1]/div/div/div/div[5]')content_singleline_containers = content_multiline_container_element.find_elements(By.XPATH, './div')note_content = []for i in range(len(content_singleline_containers)):content_singleline_container = content_singleline_containers[i]try:# is an imageimg_element = content_singleline_container.find_element(By.XPATH, './div/div/img')img_src = img_element.get_attribute("src")# 用浏览器下载,这里request好像不行driver.get(img_src)# cur_img = requests.get(img_src)# note_content.append(cur_img)# 等待下载完time.sleep(3)# 转移,加jpg后缀因为这里都是jpg格式downloaded_file_name = img_src.split("/")[-1]shutil.move(chrome_download_directory + downloaded_file_name, img_store_directory)os.rename(img_store_directory + downloaded_file_name, img_store_directory + downloaded_file_name + '.jpg')note_content.append(downloaded_file_name + '.jpg') # 标记位置except:# is textnote_content.append(content_singleline_container.text) # 可以直接获取最里面的值, 也可以通过./pre/span/span获取最里面的元素再获取text# 如果全是文字可以直接合并成段落# if i < len(content_singleline_containers) - 1:# note_content += "\n"note_title = title_element.textnote_time = time_element.textnote_titles.append(note_title)note_times.append(note_time)note_contents.append(note_content)print(note_title)print(note_time)print(note_content)print(len(note_titles), len(note_times), len(note_contents))result = []for i in range(len(note_titles)):result.append([note_titles[i], note_times[i], note_contents[i]])with open('result.json', 'w') as f:json.dump(result, f)# f = open("result.txt", "w")# for i in range(len(note_times)):# f.write(note_times[i])# f.write(note_contents[i])# f.write("\n")# f.close()# time.sleep(20)result_to_doc.py
import jsonfrom docx import Document
from docx.shared import Inchesdocument = Document()with open('result.json', 'r') as f:data_json = json.load(f)img_store_directory = "./img/"
for note_title, note_time, note_content in data_json:if len(note_title) > 0:# 这里很多都是空标题所以如果空就不写入document.add_paragraph(note_title)document.add_paragraph(note_time)for note_content_line in note_content:if note_content_line.split('.')[-1] == 'jpg':# is an imagedocument.add_picture(img_store_directory + note_content_line, width=Inches(5))else:document.add_paragraph(note_content_line)document.add_paragraph("\n")document.save('备忘录.docx')
相关文章:
爬虫-华为云空间备忘录导出到docx-selenium控制浏览器行为-python数据处理
背景适用情况介绍 老的荣耀手机属于华为云系统,家里人换了新荣耀手机属于荣耀云系统无法通过云空间将备忘录转移到新手机,不想让他们一个一个搞,于是整了一晚上想办法爬取下来。从网页抓取下来,然后存到docx文档中(包…...

网络安全的新防线:主动进攻,预防为先
进攻性安全(Offensive security)是指一系列主动安全策略,这些策略与恶意行为者在现实世界的攻击中使用的策略相同,区别在于其目的是加强而非损害网络安全。常见的进攻性安全方法包括红队、渗透测试和漏洞评估。 进攻性安全行动通常…...
基于java springboot+mybatis学生学科竞赛管理管理系统设计和实现
基于java springbootmybatis学生学科竞赛管理管理系统设计和实现 🍅 作者主页 央顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承接各…...
秒懂百科,C++如此简单丨第二十一天:栈和队列
目录 前言 Everyday English 栈(Stack) 图文解释 实现添加删除元素 实现查看清空栈 完整代码 运行示例 栈的选择题 队列(Queue) 图文解释 队列的基本用法 完整代码 运行结果 队列的好处 结尾 前言 今天我们将…...

STM32-开发环境之STM32CubeMX
目录 STM32CubeMX介绍 STM32CubeMX特性 应用场景 其他事项 STM32CubeMX介绍 STM32CubeMX是ST公司(意法半导体)推出的一款图形化工具,也是配置和初始化C代码生成器。它主要服务于STM32微控制器的配置和开发。 STM32CubeMX特性 1.直观选…...

[晓理紫]CCF系列会议截稿时间订阅
CCF系列会议截稿时间订阅 VX 关注{晓理紫},每日更新最新CCF系列会议信息,如感兴趣,请转发给有需要的同学,谢谢支持!! 如果你感觉对你有所帮助,请关注我,每日准时为你推送最新CCF会议…...
重复导航到当前位置引起的。Vue Router 提供了一种机制,阻止重复导航到相同的路由路径。
代码: <!-- 侧边栏 --><el-col :span"12" :style"{ width: 200px }"><el-menu default-active"first" class"el-menu-vertical-demo" select"handleMenuSelect"><el-menu-item index"…...

如何在 Angular 中使用 Flex 布局
介绍 Flex Layout 是一个组件引擎,允许您使用 CSS Flexbox 创建页面布局,并提供一组指令供您在模板中使用。 该库是用纯 TypeScript 编写的,因此不需要外部样式表。它还提供了一种在不同断点上指定不同指令以创建响应式布局的方法。 在本教…...

通俗的讲解什么是机器学习之损失函数
想象一下,你在玩一个靶心射击的游戏,你的目标是尽可能让箭簇命中靶心。在这个游戏中,损失函数可以看作是测量你的箭簇与靶心距离的规则。损失函数的值越小,意味着你的箭簇离靶心越近,你的射击技能越好。 在机器学习中…...
快速搭建PyTorch环境:Miniconda一步到位
快速搭建PyTorch环境:Miniconda一步到位 🌵文章目录🌵 🌳一、为何选择Miniconda搭建PyTorch环境?🌳🌳二、Miniconda安装指南:轻松上手🌳🌳三、PyTorch与Minic…...
图灵日记之java奇妙历险记--抽象类和接口
目录 抽象类概念抽象类语法 接口概念规则使用特性实现多个接口接口的继承接口使用实例Clonable接口和深拷贝抽象类和接口的区别 Object类 抽象类 概念 在面向对象的概念中,所有对象都是通过类来描述的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够…...

批量给元素添加进场动画;获取文本光标位置;项目国际化
批量给元素添加进场动画 api及参数参考:https://juejin.cn/post/7310977323484971071 简单实现: addAnimationClass(){//交叉观察器if (window?.IntersectionObserver) {//获取所有需要添加进场动画的元素,放到一个数组let items [...do…...
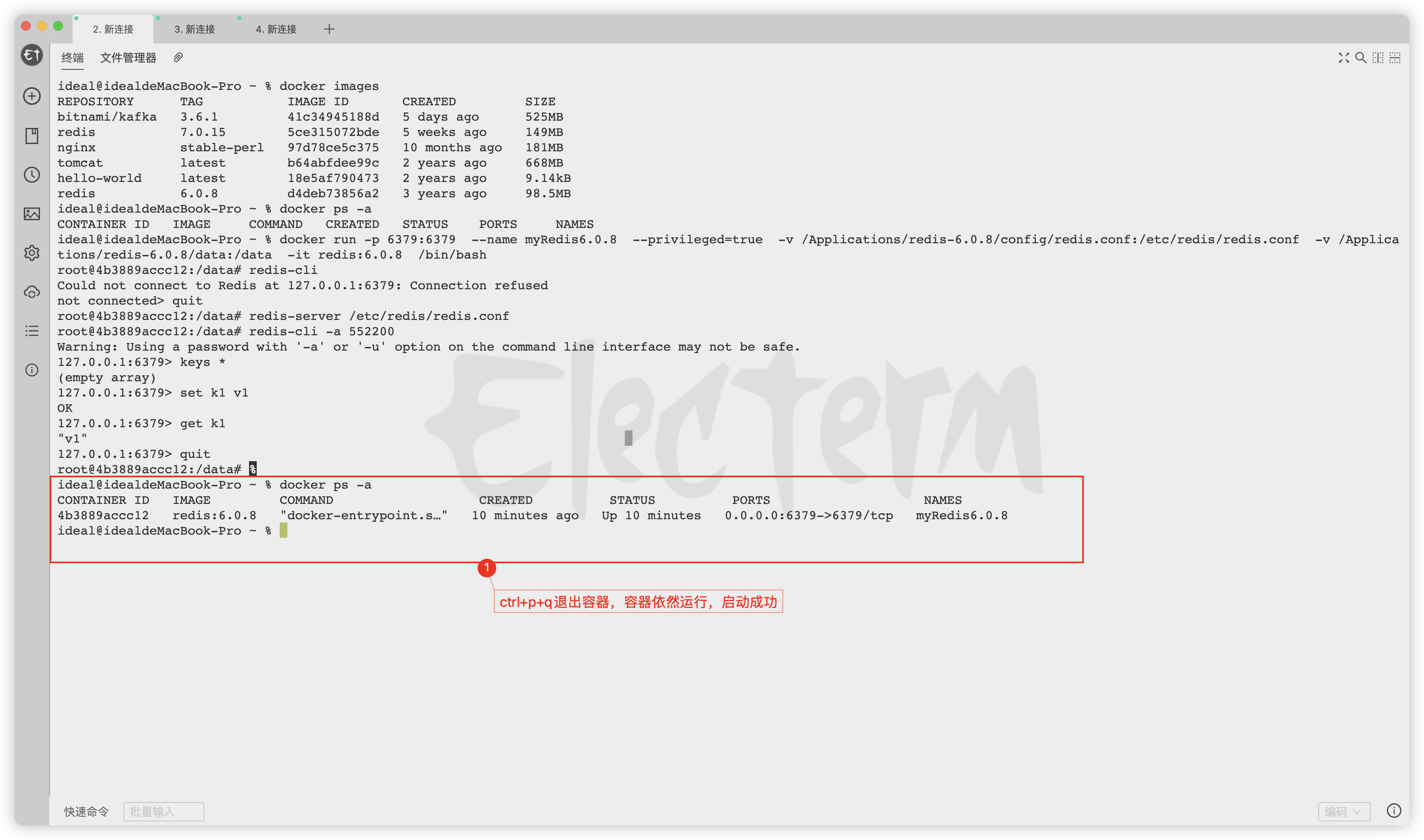
解决:docker创建Redis容器成功,但无法启动Redis容器、也无报错提示
解决:docker创建Redis容器成功,但无法启动Redis容器、也无报错提示 一问题描述:1.docker若是直接简单使用run命令,但不挂载容器数据卷等参数,则可以启动Redis容器2.docker复杂使用run命令,使用指定redis.co…...
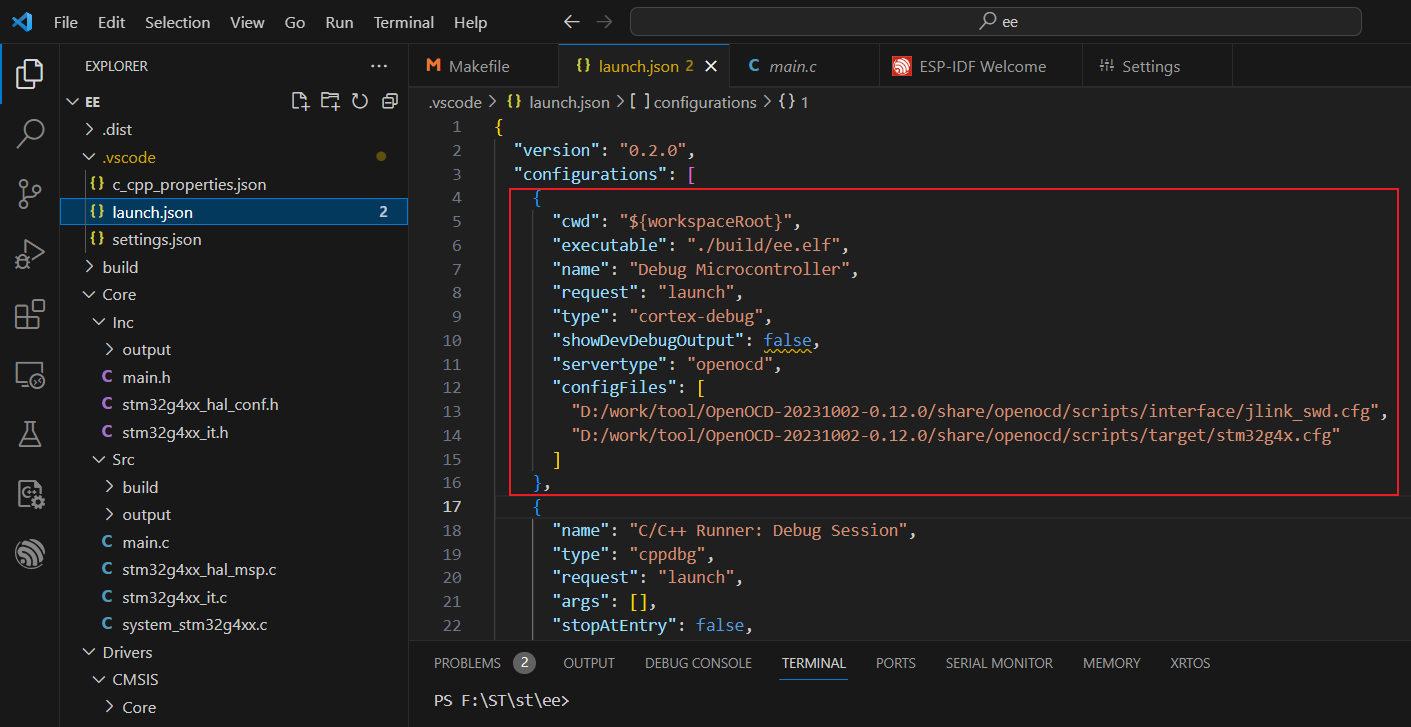
Jlink+OpenOCD+STM32 Vscode 下载和调试环境搭建
对于 Mingw 的安装比较困难,国内的网无法正常在线下载组件, 需要手动下载 x86_64-8.1.0-release-posix-seh-rt_v6-rev0.7z 版本的软件包,添加环境变量,并将 mingw32-make.exe 名字改成 make.exe。 对于 OpenOCD,需要…...

单片机在物联网中的应用
单片机,这个小巧的电子设备,可能听起来有点技术性,但它实际上是物联网世界中的一个超级英雄。简单来说,单片机就像是各种智能设备的大脑,它能让设备“思考”和“行动”。由于其体积小、成本低、功耗低、易于编程等特点…...
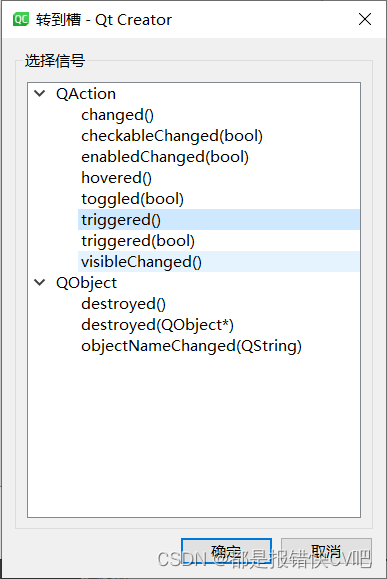
16.Qt 工具栏生成
目录 前言: 技能: 内容: 1. 界面添加 2. 信号槽 功能实现 参考: 前言: 基于QMainWindow,生成菜单下面的工具栏,可以当作菜单功能的快捷键,也可以完成新的功能 直接在UI文件中…...
【Linux内核】从0开始入门Linux Kernel源码
🌈 博客个人主页:Chris在Coding 🎥 本文所属专栏:[Linux内核] ❤️ 前置学习专栏:[Linux学习]从0到1 ⏰ 我们仍在旅途 目录 …...
SQL Service 2008 的安装与配置
点击添加当前用户...
Apache POI | Java操作Excel文件
目录 1、介绍 2、代码示例 2.1、将数据写入Excel文件 2.2、读取Excel文件中的数据 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步…...

vue 学习definproperty方法
definproperty方法是Vue很重要的一个底层方法,掌握他的原理很重要,下面通过代码说明问题: <!DOCTYPE html> <html><head><meta charset"UTF-8" /><title>回顾Object.defineproperty方法</title&…...

终极风扇控制解决方案:FanControl让Windows散热管理变得简单高效
终极风扇控制解决方案:FanControl让Windows散热管理变得简单高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_T…...

npm publish前必看:如何用命令行优雅搞定2FA,避免发布包时卡壳
npm publish前必看:如何用命令行优雅搞定2FA,避免发布包时卡壳 在npm生态中,发布包是开发者日常工作中不可或缺的一环。然而,随着安全要求的提高,双因素身份验证(2FA)已成为保护账户安全的重要措…...

别再手动贴图了!LOD1.3建模的智能纹理库怎么用?手把手教你配置大势智慧材质模板
LOD1.3建模革命:智能纹理库的实战配置指南 当清晨的第一缕阳光透过窗户洒在建模师的工作台上,那些曾经需要数小时手动贴图的建筑模型,如今只需几分钟就能自动完成纹理匹配。这不是未来场景,而是LOD1.3建模中智能纹理库技术带来的…...

抖音下载器技术方案:重构短视频内容采集架构的90%效率提升方案
抖音下载器技术方案:重构短视频内容采集架构的90%效率提升方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallba…...

抖音去水印下载器终极指南:批量保存视频、音乐、图集和直播
抖音去水印下载器终极指南:批量保存视频、音乐、图集和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

全新UI 阅后即焚V2正式版系统源码_全开源_安全加密传输
概述 在数字化信息交流日益频繁的今天,如何安全、私密地传输敏感数据(如商业机密、登录凭证、个人隐私)已成为企业和个人用户共同面临的严峻挑战。传统的即时通讯工具往往存在聊天记录留存、云端备份等安全隐患,难以满足“阅后即…...

【Android】CloneTTS最强朗读听书引擎-可克隆一切音色
【Android】CloneTTS最强朗读听书引擎-可克隆一切音色 链接:https://pan.xunlei.com/s/VOsu4mh3O_d7zjeERkKPfcG4A1?pwddi3y# CloneTTS 是一款运行在安卓系统本地的文字转语音(TTS)原生引擎,允许用户离线克隆所需的声音并直接使用该声音来朗读书籍或长…...

MLT框架的“Producer”到底有多智能?深入loader.dict与avformat揭秘媒体文件自动解析
MLT框架的“Producer”智能解析机制:从loader.dict到avformat的深度探索 当你在MLT框架中写下Producer(profile, nullptr, "video.mp4")这样一行看似简单的代码时,背后其实隐藏着一套精妙的媒体文件自动解析系统。这个系统能够根据文件扩展名、…...

3分钟解锁音乐自由:ncmdump让网易云音乐NCM文件随处播放
3分钟解锁音乐自由:ncmdump让网易云音乐NCM文件随处播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的歌曲只能在特定客户端播放而烦恼吗?当您精心收藏的音乐被NCM加密格式束缚&…...

探索OpenHarmony蓝牙BLE测试HAP:高效验证与优化
探索OpenHarmony蓝牙BLE测试HAP:高效验证与优化 【下载地址】OpenHarmony鸿蒙蓝牙ble测试hap 本仓库提供的是用于OpenHarmony系统下的蓝牙BLE(低功耗蓝牙)测试HAP(HarmonyOS Ability Package)。此HAP旨在帮助开发者和测…...