网络原理(HTTP篇)
网络原理HTTP
- 前言
- HTTP
- HTTP的工作流程
- 抓包工具
- 抓取HTTP报文
- HTTP报文格式
- 请求报文具体细节
- 首行
- URL
- URL的基本格式
- URL encode
- 方法
- 报头(header)
- Host
- Content-Length 和 Content-Type
- User-Agent(UA)
- Referer
- Cookie(重要)
前言
如图:HTTP/3.0之前 是基于TCP实现的。到了HTTP3.0版本,则是基于UDP实现的
![![[Pasted image 20240203093906.png]]](https://img-blog.csdnimg.cn/direct/8df6f895465942998067dfede8a087f3.png)
HTTP
HTTP,全称为 “超文本传输协议”,现在最新版本为 HTTP/3.0,但主流使用的仍然是HTTP/1.1版本。
什么叫超文本?
我们知道,文本文件其实就是字符串文件(即能在 UTF8/GBK 等码表上找到合法字符的字符串)而超文本文件,就不仅仅是字符串,还能携带一些图片(如HTTP、HTML)
超文本之后,还有富文本(Word文档),能够支持的格式更多了~
HTTP的工作流程
HTTP/1.1 采用 持续连接 方式。服务器在发送响应后,仍然保持这条连接,使同一个客户端(浏览器)和该服务器可以继续在这条连接上传输后续的HTTP请求报文和响应报文。
HTTP还使用了 流水线 工作方式以提高效率。即浏览器在收到HTTP响应报文之前就能够连续发送多个请求报文。这样就能节省很多个RTT时间,使得TCP连接中的空闲时间很少。
HTTP的交互是非常经典的 “一问一答” 模式:
抓包工具
借助一个抓包工具fiddler 来学习HTTP的报文格式
wireshark:功能很全,可以抓各种协议数据包,但使用起来也相对复杂
fiddler:专注于抓取 HTTP 的包
注:使用fiddler时,需要进行设置:因为网络上大部分的请求都是基于 HTTPS(HTTPS在HTTP基础上进行了加密,安装证书就可以让fiddler对HTTPS的报文进行解密)。
![![[Pasted image 20240203115455.png]]](https://img-blog.csdnimg.cn/direct/21f6e5fdfdbc4358b6a6e4df00516227.png)
注:打开一个网站,浏览器和服务器之间的 HTTP 交互并不是只有一次,通常会有很多次。第一次交互是拿到这个页面的 HTML,HTML还会依赖CSS和JS等,HTML被浏览器加载后,又会触发一些其他的http请求,获取到CSS、js等,当执行js时,js代码里又可能触发很多的http请求。经过多次这样拉扯之后,才会呈现浏览器里所看到的内容。
抓取HTTP报文
随便进入一个网站:
蓝色的表示返回的是一个 html,这个往往是访问一个网站的入口请求,选中这个请求并双击
![![[Pasted image 20240203130905.png]]](https://img-blog.csdnimg.cn/direct/4614ee8b88d24f41ae4ef64dad2068f1.png)
这个是HTTP请求
![![[Pasted image 20240203131041.png]]](https://img-blog.csdnimg.cn/direct/fd56a3a8e78c482ab777185170317b6f.png)
这是请求的响应报文
![![[Pasted image 20240203131100.png]]](https://img-blog.csdnimg.cn/direct/0e17671677f34360917228ff800aaa12.png)
用记事本打卡响应报文内容:会看到乱码
这里的数据被压缩成乱码。因为网络传输中,带宽是一个比较贵的硬件资源,为了节省带宽,就可以把响应数据进行压缩(一般都是压缩响应,请求报文不太需要),压缩和解压缩的过程是需要消耗时间和CPU的
![![[Pasted image 20240203131115.png]]](https://img-blog.csdnimg.cn/direct/bdbdf24ed4f24c48b47352a55d7921ac.png)
![![[Pasted image 20240203131218.png]]](https://img-blog.csdnimg.cn/direct/71ac859fee494feaa81a2163ae2baabc.png)
解压缩之后就能看到正常的响应内容数据了
![![[Pasted image 20240203131230.png]]](https://img-blog.csdnimg.cn/direct/85b64381b2e743679642054d6eb0e0da.png)
注:这种灰色的请求与响应,是由于浏览器和服务器之间要进行多次网络交互,为了提升效率,就会把一些固定不变的内容在浏览器本地的硬盘上进行缓存(如css、图片、js很少发生改变的数据)。保存到硬盘上后,后续再请求,就可以直接从硬盘上读取数据,减少了网络交互的开销。(可以使用 ctrl + F5 强制刷新,强制读取服务器数据)
![![[Pasted image 20240204123611.png]]](https://img-blog.csdnimg.cn/direct/4161bae3797746bbab5d32a5f0fa4658.png)
HTTP报文格式
HTTP请求报文格式,包含4个部分:
-
首行。首行分为三个部分:方法(method)、URL、HTTP的版本号,三者用空格分割
![![[Pasted image 20240203131937.png]]](https://img-blog.csdnimg.cn/direct/c03a76f791884b67bccfd363402bc678.png)
-
请求头(Header)
从第二行开始,红框圈住部分就叫请求头。类似于TCP报头/IP报头,携带了重要的属性信息(只不过TCP/IP是以二进制携带的,HTTP是以文本内容携带)
HTTP的请求头部分是通过键值对来组织的(Key-Value),每个键值对占一行。键和值之间使用:加上(空格)来分割的。键值对有哪些,分别是什么含义,都是HTTP协议规定的,后续详解。
![![[Pasted image 20240203132051.png]]](https://img-blog.csdnimg.cn/direct/f9679ec8149a4db8be9ad4a3cc39b43d.png)
![![[Pasted image 20240203132521.png]]](https://img-blog.csdnimg.cn/direct/fdbfe3db5d34490f819365a4c5850966.png)
-
空行:表示一个报文的结束标记
![![[Pasted image 20240203132716.png]]](https://img-blog.csdnimg.cn/direct/25a1311af241438aa3ddbeca62c056e7.png)
-
正文(body):http的载荷部分(有的http请求有body,有些则没有,这很正常)
HTTP响应报文格式,包含4个部分:
-
首行:三个部分(版本号、状态码、状态码描述)
状态码表示这一次请求是成功还是失败,失败的原因是什么。
就像卸载Python不开管理员权限就会出现2503/2502状态码![![[Pasted image 20240203133012.png]]](https://img-blog.csdnimg.cn/direct/10b324b09dea4c87a9c565fdbcb6645d.png)
-
响应头。也是由键值对组成(
Key-Value),通过冒号+空格来分割(:)![![[Pasted image 20240203133937.png]]](https://img-blog.csdnimg.cn/direct/9e5a9d657b0d48b2ada376fa6c340ef4.png)
-
空行:报文结束标记
![![[Pasted image 20240203133923.png]]](https://img-blog.csdnimg.cn/direct/b837686517df4825bf078aae463ff1bf.png)
-
正文(body):数据载荷部分
可以看到响应的载荷是html
![![[Pasted image 20240203134005.png]]](https://img-blog.csdnimg.cn/direct/449e717472b049d882c6bc69da2ddc31.png)
请求报文具体细节
首行
URL
URL(唯一资源定位符):描述一个网络上的资源位置
URI(唯一资源标识符):只是一个标识,用来区别于其他资源的标识。(角度不同,有时URI也可以表示URL)
这两个东西表示的含义是差不多的,严格说URI的范围比URL更广一些。URL特指你这个东西在网络的哪里。
URL的基本格式
![![[Pasted image 20240203162244.png]]](https://img-blog.csdnimg.cn/direct/28dca8c3d6684d6e98801cac96f842d7.png)
协议方案名:顾名思义,指该网站所用的协议
登录信息(已弃用):毕竟将用户名、密码直接放在这上面是很不安全的操作
服务器地址:由于DNS域名解析系统,这里显示的是域名,用对应的IP地址也可以访问到
服务器端口号:可以指定,也可以不写。不带端口号,浏览器就会取默认值(因为这些服务器都很有名,http: 80;https: 443)
带层次的文件路径:标识资源在网络上的位置
想知道资源位置,要做的:
- 通过 IP地址 知道服务器在哪
- 通过 端口号 知道对应程序在哪
- 最后通过这个路径知道是访问哪个资源(这和之前章节说的 “文件” 又串起来了,绝对路径就是表示一个文件,知道那个文件在哪)
查询字符串:针对请求的内容做的补充说明
查询字符串,是客户端给服务器传递信息的重要途径,也是以键值对的方式来组织的。因为每个网站业务逻辑不同,需要补充的信息也是不同的,所以键值对的内容都是由程序员自定义的
![![[Pasted image 20240203163303.png]]](https://img-blog.csdnimg.cn/direct/d2c0ce65624b418389c9546874c80ad9.png)
结合上述的 IP地址、端口号、路径、查询字符串,就可以 “精确” 描述出一个网络资源的位置了
片段标识符:标识当前页面的某个部分,通过不同的片段标识可以完成页面内的跳转。
URL encode
查询字符串(query string):是程序员自动义的键值对。但在URL中,本身有些符号具有特殊含义(如 / 、: 等),如果两者的符号冲突,就会导致一些很严重的bug(比如网页跳转失败!)
所以我们就需要对这类特殊符号,在自定义的时候,将其 “转义”
PS:对于汉字来说,也是要进行转义的!汉字的 UTF8/GBK 等编码值,可能其中某个字节恰好和某个符号的 ASCII 码值冲突!
给一个特殊符号的例子:打开包含 C++ 字样的网站,可以看到 %2B%2B,因为 + 在ASCII码表中,用 16进制 表示,就是 2B,并且加上 % 表示这是转义后的内容
![![[Pasted image 20240203164332.png]]](https://img-blog.csdnimg.cn/direct/caa290c0e98f4674a30c88a7f7c598f3.png)
再来看看汉字的情况:
注:网页中的URL看到的就是汉字本身,而不是转义后的内容,因为网页将它经过了处理,一旦将该URL复制粘贴出来,就不是汉字,而是转义后的内容了
![![[Pasted image 20240203164809.png]]](https://img-blog.csdnimg.cn/direct/2ff1a0bbbc1749d19cb43df6233b0116.png)
方法
![![[Pasted image 20240204111446.png]]](https://img-blog.csdnimg.cn/direct/3925a26043fb453d821062a054738a0c.png)
为什么说这些语义仅是作者的一厢情愿?
因为别忘了,HTTP协议是工作在应用层的,这些方法的作用是可以由程序员自定义的。也就是说,完全可以用 GET 来上传数据,POST 来获取数据。怎么写,就靠程序员自行约定了。
报头(header)
header 的整体格式是 “键值对” 结构
Host
Host:表示服务器主机的地址和端口(URL里其实也已经有Host了)
![![[Pasted image 20240204121412.png]]](https://img-blog.csdnimg.cn/direct/c71d943eeabf409e9ce656581aefb544.png)
这里的 Host 与 URL 中的 IP地址、端口等信息,绝大部分情况下都是一样的。
少数情况可能不同。
少数情况:如使用翻墙代理软件,URL中的IP和端口指向的是代理服务器,而Host中指向的则是最终服务器
Content-Length 和 Content-Type
Content-Length:表示 body 中的数据长度
通过这个长度,就可以处理 “粘包问题”,因为HTTP协议底层是基于TCP实现的!
如果是没有
body的请求 / 响应,则直接使用 “空行” 作为数据包之间的分割符。
如果有body,空行就不是结束标记了,而是从空行开始读取body数据,此时就以Content-Length来作为数据包之间的边界。
Content-Type:表示请求中的 body 的数据格式。body 可以传输很多种格式,包括程序员也可以自己约定任意的格式,但有些格式是非常常见的,需要去了解。
请求中的常见格式:
application/json:
body就是 json 格式的数据application/x-www-form-urlencoded:称为 “form表单”,通过 HTML 中的 form 标签构造出来的一种格式,这个格式的特点是把
query string放到body中。(这个格式也可以用来上传文件)multipart/form-data:主要是上传文件时使用的。(这种form表单提交数据的方式越来越少了,现在还是 json 偏多)
响应中的常见格式:
text/plain:纯文本
text/html:html
text/css:css
application/javascript:js
application/json
image/png
image/jpg
…
注:正常来说,响应报文只要有 body,都会有 Content-Type;但也有例外,如果响应报文确实没有 Content-Type,也没有 body,此时有些容错能力很强的浏览器,也能尽可能将这些数据正确显示出来(如 Chrome 浏览器)。
User-Agent(UA)
![![[Pasted image 20240204132819.png]]](https://img-blog.csdnimg.cn/direct/119eb5c6c7be481d96540126ae2f2189.png)
显而易见:UA描述了用户使用啥样的设备进行上网
Referer
Referer:描述了这个页面是从哪个页面跳转过来的。(也就是能知道当前页面的上一级页面是啥)
Cookie(重要)
Cookie:一种浏览器本地持久化存储数据的机制(即将数据存到硬盘里)
浏览器作为计算机应用层软件,能否直接读写本地硬盘文件?
当然可以,系统提供了 API 来操作文件,作为一个应用层程序,当然可以调用这些 API 了。那么浏览器上运行的网页,能否通过浏览器提供的 API 来读写本地硬盘文件?
理论上是可以的,但是浏览器禁止了这种做法。因为要保障安全性,总不能点进一个网站,你的电脑就直接中病毒了吧。但是,有些网站,将一些信息保存在浏览器,是一种刚需,比如登录网站的用户信息。
所以浏览器提供了 Cookie 这样的 API,能够有限度地存储数据,而不是直接访问本地文件系统。(类似于 Cookie 的机制,还有 LocalStorage、IndexDB)
Cookie 也是按照键值对的格式来保存信息。
Cookie最大的作用,就是让服务器对这个客户端有一个清楚的认识。
关于 Cookie 的几个重要结论:
Cookie 从哪里来?
通常都是客户端首次访问服务器,服务器返回给浏览器的Cookie 到哪里去了?
Cookie 会存储在浏览器本地主机的硬盘上,后续每次访问服务器都会带上 Cookie(让服务器对这个客户端的信息有个认识,从而返回这个客户端以前在这个页面存留的对应信息)Cookie 中存的是什么?
存的是键值对数据,同query string一样,这里的内容是由程序员自定义完成Cookie 在浏览器中是如何组织的?
就跟给数据分目录一样,Cookie 是通过域名来分类的。(这也好理解,每个人在不同的网页上,肯定是用不同的账户)Cookie 的作用?
用来在客户端保存数据,其中最主要的就是保存用户的身份标识。
上传数据给服务器,服务器就能返回这个用户对应的数据信息。
PS:浏览器中保存的账户密码,是另一个保存机制,并不是 Cookie。
相关文章:
网络原理(HTTP篇)
网络原理HTTP 前言HTTPHTTP的工作流程抓包工具抓取HTTP报文HTTP报文格式 请求报文具体细节首行URLURL的基本格式URL encode 方法 报头(header)HostContent-Length 和 Content-TypeUser-Agent(UA)RefererCookie(重要) 前言 如图&a…...

关于油封密封件你了解多少?
油封也称为轴封或旋转轴封,旨在防止设备中的润滑剂泄漏,并防止外部污染物进入机械。它们通常用于泵和电机等旋转设备,在固定部件和移动部件之间提供密封界面。 油封的有效性很大程度上取决于其材料。不同的材料具有不同程度的耐热性、耐压性…...

Leetcode 72 编辑距离
题意理解: 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换一个字符 将word1转换为word2,可以进行三种操作:增、删、改&am…...

羊大师揭秘,如何挑选出好牧场的奶羊,该怎么看
羊大师揭秘,如何挑选出好牧场的奶羊,该怎么看 了解牧场的管理和环境:好的牧场应该有规范的管理制度,环境整洁,草场茂盛,为奶羊提供了充足的食物和良好的生活环境。在这样的牧场中,奶羊能够得到…...

MySQL数据库基础(八):DML数据操作语言
文章目录 DML数据操作语言 一、DML包括哪些SQL语句 二、数据的增删改(重点) 1、数据的增加操作 2、数据的修改操作 3、数据的删除操作 DML数据操作语言 一、DML包括哪些SQL语句 insert插入、update更新、delete删除 二、数据的增删改(…...
Hive——CTE 公共表达式)
(09)Hive——CTE 公共表达式
目录 1.语法 2. 使用场景 select语句 chaining CTEs 链式 union语句 insert into 语句 create table as 语句 前言 Common Table Expressions(CTE):公共表达式是一个临时的结果集,该结果集是从with子句中指定的查询派生而来…...
Spring 用法学习总结(四)之 JdbcTemplate 连接数据库
🐉目录 9 JdbcTemplate 9 JdbcTemplate Spring 框架对 JDBC 进行了封装,使用 JdbcTemplate 方便实现对数据库操作 相关包: 百度网盘链接https://pan.baidu.com/s/1Gw1l6VKc-p4gdqDyD626cg?pwd6666 创建properties配置文件 💥注意…...
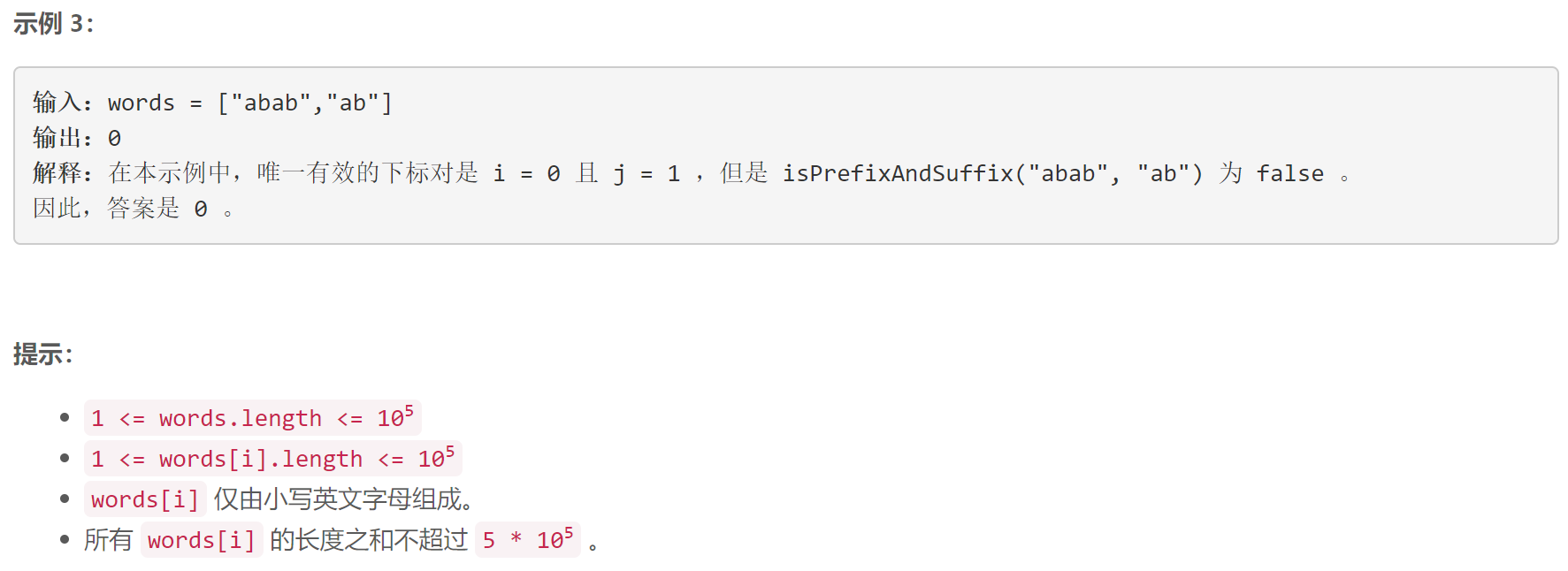
第 385 场 LeetCode 周赛题解
A 统计前后缀下标对 I 模拟 class Solution { public:int countPrefixSuffixPairs(vector<string> &words) {int n words.size();int res 0;for (int i 0; i < n; i)for (int j i 1; j < n; j)if (words[i].size() < words[j].size()) {int li words[…...

什么是RabbitMQ?
一、引言 RabbitMQ是一个开源的消息代理软件,用于在分布式系统中传递消息。它实现了高级消息队列协议(AMQP),提供了一种可靠的、强大的、灵活的消息传递机制,使得不同应用程序或组件之间可以轻松地进行通信。 二、概念…...
JWT登录验证前后端设计与实现笔记
设计内容 前端 配置全局前置路由守卫axios拦截器登录页面和主页 后端 JWT的封装登录接口中间件放行mysql数据库的连接 详细设计 路由设计 配置全局前置守卫,如果访问的是登录页面则放行,不是则进入判断是否有token,没有则拦截回到登录…...

自定义类型详解 ----结构体,位段,枚举,联合
目录 结构体 1.不完全声明 2.结构体的自引用 3.定义与初始化 4.结构体内存对齐与结构体类型的大小 结构体嵌套问题 位段 1.什么是位段? 2.位段的内存分配 枚举 1.枚举类型的定义 2.枚举的优点 联合(共同体) 1.联合体类型的声明以…...

VueCLI核心知识综合案例TodoList
目录 1 拿到一个功能模块首先需要拆分组件: 2 使用组件实现静态页面的效果 3 分析数据保存在哪个组件 4 实现添加数据 5 实现复选框勾选 6 实现数据的删除 7 实现底部组件中数据的统计 8 实现勾选全部的小复选框来实现大复选框的勾选 9 实现勾选大复选框来…...

关于cuda路径问题
问题:Could not load dynamic library ‘libcudart.so.11.0’ 原因:调用系统环境下的cuda但系统环境没有装cuda 解决: 1.在系统环境装cuda,但如果每权限就不好操作; 2.用虚拟环境装好的cuda路径丢给环境变量 暂时性&am…...
六、Spring/Spring Boot整合ActiveMQ
Spring/Spring Boot整合ActiveMQ 一、Spring整合ActiveMQ1.pom.xml2.Queue - 队列2.1 applicationContext.xml2.2 生产者2.3 消费者 3.Topic - 主题3.1 applicationContext.xml3.2 生产者3.3 消费者 4.消费者 - 监听器4.1 编写监听器类4.2 配置监听器4.3 生产者消费者一体 二、…...
使用docker搭建springBoot/springCloud服务)
树莓派4B(Raspberry Pi 4B)使用docker搭建springBoot/springCloud服务
树莓派4B(Raspberry Pi 4B)使用docker搭建springBoot/springCloud服务 前提:本文基于Ubuntu,Java8,SpringBoot 2.6.13讲解 准备工作 准备SpringBoot/SpringCloud项目jar包 用 maven 打包springBoot/springCloud项目&…...
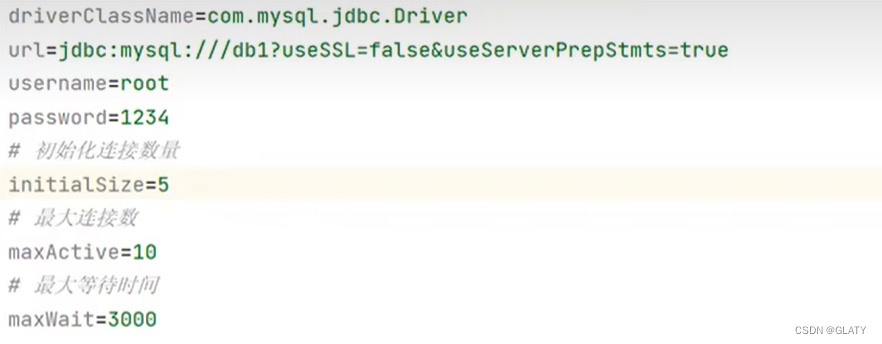
数据库设计、JDBC、数据库连接池
数据库设计 数据库设计概念 数据库设计就是根据业务 系统的具体需求,结合我们所选用的DBMS,为这个业务系统构造出最优的数据存储模型。建立数据库中的表结构以及表与表之间的关联关系的过程。有哪些表?表里有哪些字段?表和表之间有什么关系? 数据库设计的步骤…...
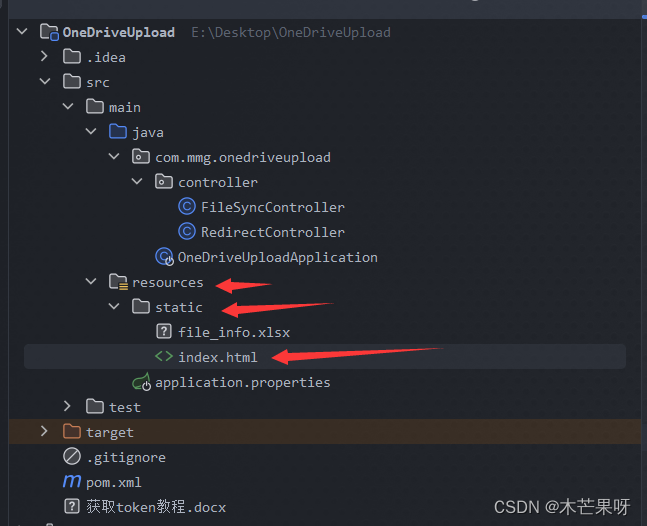
SpringBoot实现OneDrive文件上传
SpringBoot实现OneDrive文件上传 源码 OneDriveUpload: SpringBoot实现OneDrive文件上传 获取accessToken步骤 参考文档:针对 OneDrive API 的 Microsoft 帐户授权 - OneDrive dev center | Microsoft Learn 1.访问Azure创建应用Microsoft Azure,使…...

C++初阶:容器适配器介绍、stack和queue常用接口详解及模拟实现
介绍完了list类的相关内容后:C初阶:适合新手的手撕list(模拟实现list) 接下来进入新的篇章,stack和queue的介绍以及模拟: 文章目录 1.stack的初步介绍2.stack的使用3.queue的初步介绍4.queue的使用5.容器适…...

GRUB and the Boot Process on UEFI-based x86 Systems
background info : BIOS and UEFI-CSDN博客 The UEFI-based platform reads the partition table on the system storage and mounts the EFI System Partition (ESP), a VFAT partition labeled with a particular globally unique identifier (GUID). The ESP contains EFI a…...
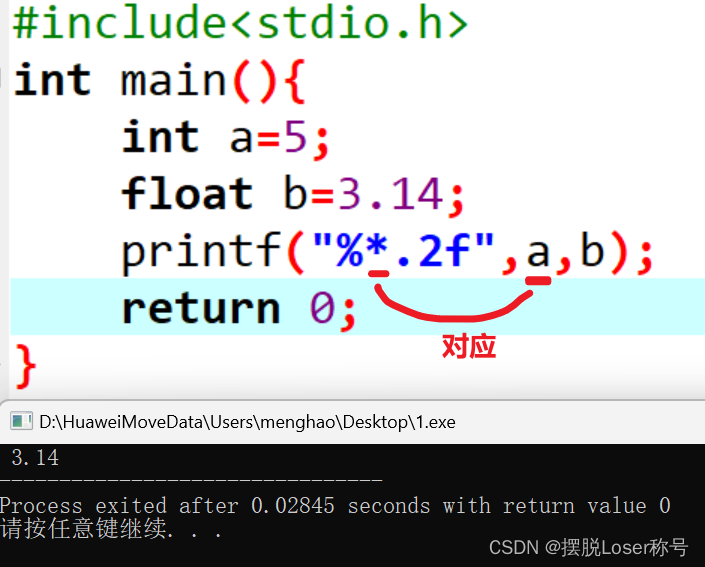
2.C语言——输入输出
1.字符输入输出函数 1.输入:getchar() 字面意思,接收单个字符,使用方法 char a; a getchar();实际上效果等同于char a; scanf("%c",&a);2.输出:putchar() 2.格式化输入输出函数 1.输入:scanf() 格式: scanf(“格式控制…...

从入门到精通:wrk压力测试实战与性能调优全攻略
1. 为什么你需要wrk压力测试工具 第一次接触性能测试时,我像大多数开发者一样,用浏览器刷新页面来"感受"系统快慢。直到某次上线后服务器崩溃,才明白这种原始方法有多不靠谱。后来发现wrk这个工具,它彻底改变了我的性能…...

无人机巡检避坑指南:用YOLOv5n做罂粟识别,这些光照和遮挡问题怎么解决?
无人机巡检实战:YOLOv5n在复杂环境下的罂粟识别优化策略 清晨的露珠还挂在叶片上,无人机已经盘旋在田野上空。对于从事智能巡检的工程师来说,这样的场景再熟悉不过——但随之而来的挑战也令人头疼:强烈的晨光让部分区域过曝&#…...

5步掌握VideoDownloadHelper:让网页视频下载变得简单高效
5步掌握VideoDownloadHelper:让网页视频下载变得简单高效 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾经遇到过这样的…...

LinkSwift:终极免费网盘直链下载助手完整使用指南
LinkSwift:终极免费网盘直链下载助手完整使用指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

保姆级教程:用STM32+ESP8266+微信小程序,5分钟搞定Onenet数据上传与设备控制
零基础实战:STM32ESP8266微信小程序极速对接Onenet全指南 在物联网技术快速普及的今天,许多嵌入式开发者都希望快速搭建一个完整的智能设备系统。本文将带你用最简单的方式,通过STM32微控制器、ESP8266 WiFi模块和微信小程序,实现…...

红队实战靶场搭建与ATTCK攻击链复现
1. 红队靶场环境搭建全流程 搭建红队实战靶场是安全研究的必修课,但很多新手常被复杂的网络配置劝退。我去年给某金融企业做内网渗透培训时,就遇到过学员集体卡在靶机互连阶段的尴尬场面。下面分享一套经过20企业实战验证的搭建方法。 首先需要准备三台虚…...

架构实战:面向特种设备合规的非侵入式机器人跨层调度解耦设计
摘要: 在智能园区的多机协同配送业务中,如果上位机调度系统直接与底层品牌各异的电梯强耦合,不仅研发适配成本高,且入侵特种设备总线的方案极难通过国家特种设备检验局的安全审核。面对合规双重限制,架构师亟需一种高度…...
)
告别‘悲’:当AssetStudio遇到加密的AssetBundle,试试这几款替代工具(附实战对比)
突破加密壁垒:Unity资源逆向工程全工具链实战指南 当AssetStudio面对加密的AssetBundle时,开发者常陷入困境。本文将系统梳理Unity资源逆向工程的完整解决方案,从基础提取到高级解密技术,提供一套可落地的工具链选择策略。 1. 加密…...
)
解决Arm Compiler许可证平台不匹配错误(FLEXnet -89)
1. 问题现象与背景解析 最近在调试基于Arm架构的嵌入式系统时,遇到了一个棘手的许可证错误。当尝试使用Arm Compiler 6进行代码编译时,突然弹出了以下错误信息: Error: C3397E: Cannot obtain license for Arm_Compiler (feature compiler)…...

解放Windows潜能:APK安装器让安卓应用在电脑上完美运行
解放Windows潜能:APK安装器让安卓应用在电脑上完美运行 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾梦想过在Windows电脑上直接运行手机应用&am…...