AI大模型学习笔记之四:生成式人工智能(AIGC)是如何工作的?
OpenAI 发布 ChatGPT 已经1年多了,生成式人工智能(AIGC)也已经广为人知,我们常常津津乐道于 ChatGPT 和 Claude 这样的人工智能系统能够神奇地生成文本与我们对话,并且能够记忆上下文情境。
Midjunery和DALL·E 这样的AI绘图软件可以通过Prompt 输入文本提示生成多张令人惊艳的美图,看起来相当神奇。

但是,你有没有想过,生成式人工智能(AIGC)究竟是怎么运作的呢?在这篇文章里,我们就来简单了解一下生成式人工智能技术(AIGC)的基本原理,看看它到底能做些什么,还有啥时候你可能不太想依赖它。
一、从有监督学习到生成式人工智能
大多数传统类型的人工智能(如判别式人工智能)都是为了对现有数据进行分类或归类而设计的。相反,生成式人工智能模型的目标是生成前所未见的完全原创的人工制品。
在今天,有监督学习(Supervised Learning)和生成式人工智能(Generative Artificial Intelligence)是当今人工智能领域的两个最重要领域,其重点是创建算法和模型,以便从训练数据集生成与模式相似的新的真实数据。
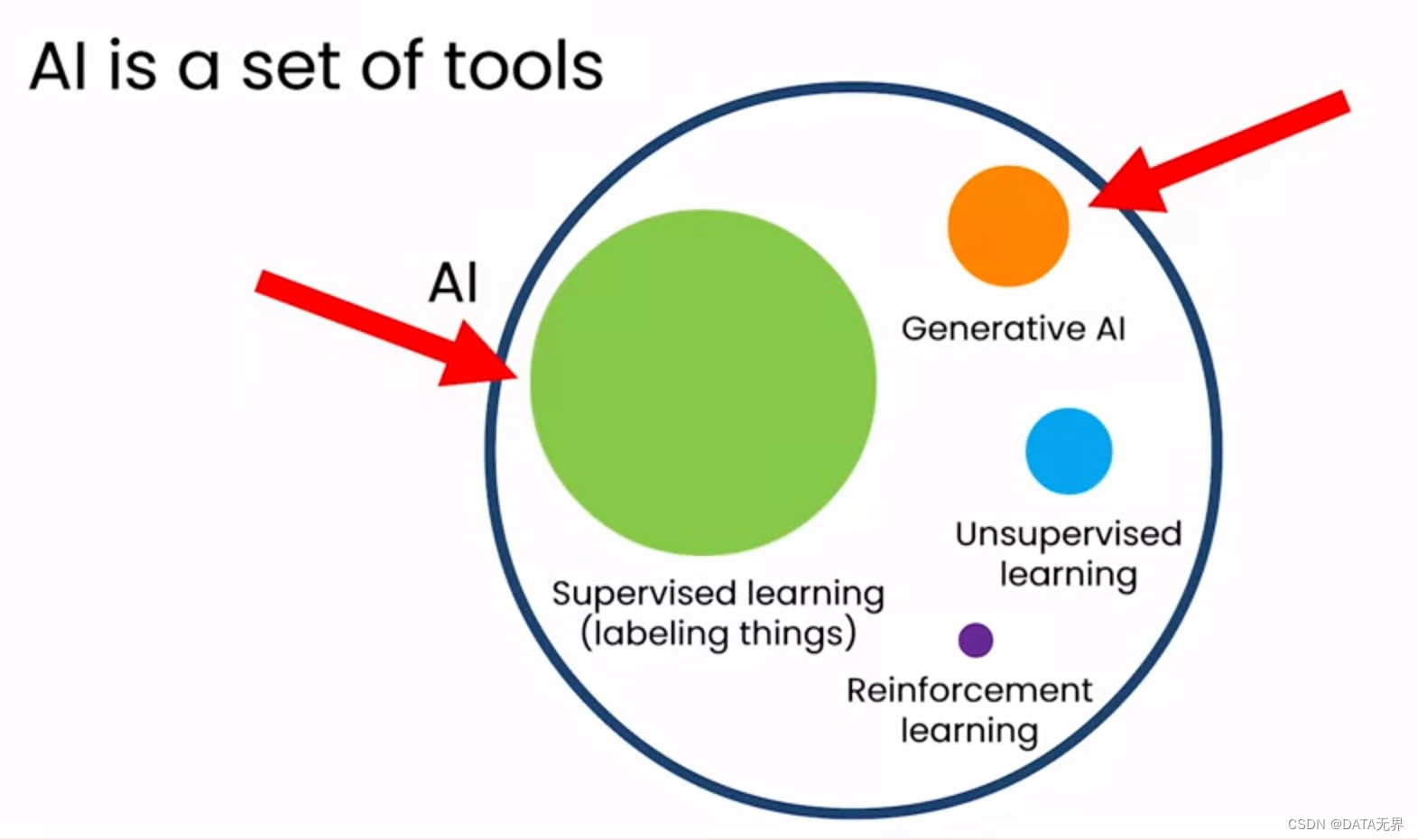
生成式人工智能模型经过训练,可以从庞大的数据集中学习其中的潜在模式,并使用该知识生成与原始数据集相似但不相同的全新样本或数据。

例如,在人类或者猫狗的图像数据集上训练的生成式人工智能算法可以生成全新的人类图像或者猫和狗的图像,这些图像看起来与原始数据集中的图像相似,但不是精确的复制品。因此,"生成 "一词被用来描述它。
生成式人工智能(Generative AI)的涌现标志着人工智能技术的重大进步。
1.1 有监督学习的局限性与挑战
在2010年左右,随着大规模有监督学习逐渐成为主流,人们开始寄希望于大数据能够为AI模型的性能带来质的飞跃。
然而,从那时起,AI 科学家们开始观察到一个令人困扰的问题:尽管我们有大量的数据可供使用,但即使我们向小型AI模型继续提供更多的数据,它们的性能改善并不明显。例如,在构建语音识别系统时,尽管AI接受了数千乃至数十万小时的训练数据,但其准确性与仅使用少量数据的系统相比并无显著提高。这一现象引发了人们对监督学习有效性的怀疑。
进一步的研究表明,仅靠大规模监督学习和大数据集并不能无限地提升 AI 模型的准确性。
这是因为:
-
首先,大规模数据集可能存在着标签噪声或错误,导致模型学习到了不准确的模式。
-
此外,数据可能存在偏差,导致模型在面对新颖数据时表现不佳。
-
其次,随着数据量的增加,模型的容量可能变得不足以有效地利用数据。即使有更多的数据可用,模型也可能因其结构或参数的限制而无法充分利用这些信息。
-
再次,大规模监督学习通常依赖于端到端的训练方法,其中模型直接从输入到输出进行训练。这种方法可能会导致模型在理解数据背后的真实机制方面缺乏深入的抽象能力,从而限制了其性能。
1.2 生成式人工智能的出现
随着人们对监督学习的限制和挑战有了更深入的认识,研究人员开始寻求其他方法来克服这些问题。
在这个过程中,生成式人工智能(Generative Artificial Intelligence)应运而生,并逐渐成为人工智能领域的重要组成部分。
生成式人工智能(AIGC)与传统的机器学习算法不同,它不仅仅局限于对已有数据的分类或预测,而是可以通过学习数据的分布,创造出全新的、以前从未见过的内容,它能够像一座神奇的创意工厂一样,通过Prompt 提示词不断地生产出令人惊叹的全新数据、图像、音频和文本内容。
生成式人工智能与其他类型人工智能之间的另一个关键区别是,生成式人工智能模型通常使用无监督和半监督机器学习算法。

这意味着它们不需要对学习的数据进行预先标记,这使得生成式人工智能在结构化或组织数据稀缺或难以获取的应用中特别有用。
-
这些生成式人工智能系统通常基于深度学习模型构建,这些模型能够从大量的训练数据中学习数据的统计结构和语义信息。
-
其次,生成式模型具有更强的表达能力,能够捕捉数据中的复杂结构和分布。相比之下,传统的监督学习方法可能会受到数据标签的限制,无法完全表达数据的多样性和复杂性。
-
此外,生成式人工智能还为解决监督学习中的标签噪声和数据偏差问题提供了新的途径。通过学习数据的潜在表示,生成式模型可以更好地理解数据背后的真实机制,从而提高模型对噪声和偏差的鲁棒性。
生成式人工智能的出现为人工智能领域带来了新的思路和解决方案,克服了传统监督学习方法的一些限制和挑战。通过结合生成式方法和传统的监督学习技术,我们可以更好地利用数据,提高模型的性能和泛化能力。
二、生成式人工智能的思想
2.1 生成式人工智能的基本工作原理:
生成式人工智能的基本工作原理是通过学习数据的分布特征,从而能够生成与原始数据相似的新数据。其核心思想是从训练数据中学习数据的概率分布,并使用学习到的分布模型来生成新的数据样本。
生成式人工智能通常采用生成对抗网络(GANs)或变分自编码器(VAEs)、Transformer 等模型来实现。
就拿生成对抗网络(GANs)来说,GANs 模型包括两个主要组成部分:
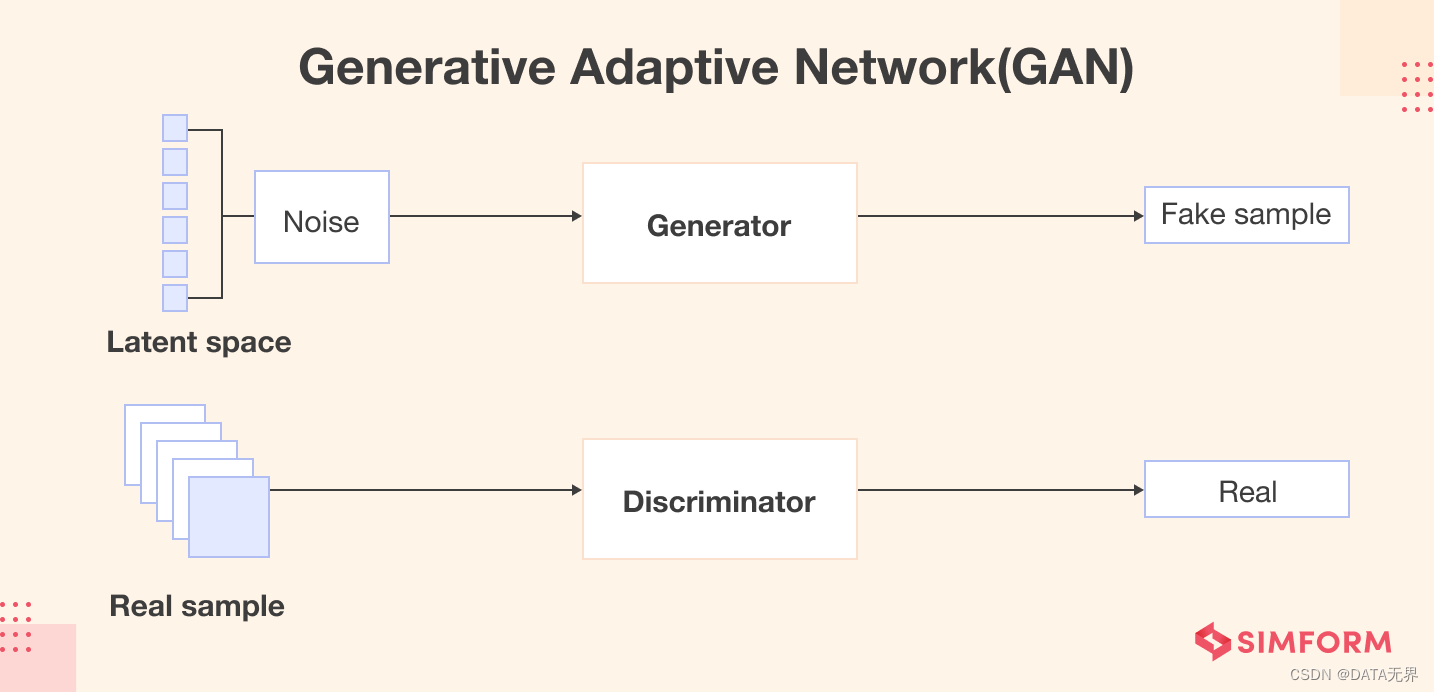
1. 生成器(Generator): 生成器是一个神经网络模型,用来接收一个随机噪声向量或其他形式的输入,并将其映射到数据空间。生成器的目标是通过根据用户输入的分析数据模式来创建新数据。通过不断调整生成器的参数,使得生成的样本尽可能地接近真实场景中的数据分布。
2. 判别器(Discriminator): 判别器也是一个神经网络模型,其任务是对生成器生成的样本与真实数据进行区分,估计样本来自于训练数据的概率。它接收来自生成器产生的样本和真实数据的输入,并尝试将它们分类为真实或伪造。判别器的目标是最大化正确地将真实数据分类为真实样本,同时将生成的样本正确分类为伪造样本。
每当有用户输入时,生成器就会生成新的数据,判别器将分析它的真实性。来自判别器的反馈使算法能够调整生成器参数并不断地重新调整和细化输出。
在数学上可以证明,在任意函数的生成器(G)和判别器(D)空间中,存在唯一的解决方案,使得生成器(Generator)生成的内容可以重现真实训练数据的分布,也就是当判别器 D=0.5 时,生成器 G 产生的信息与输入的信息达到平衡。
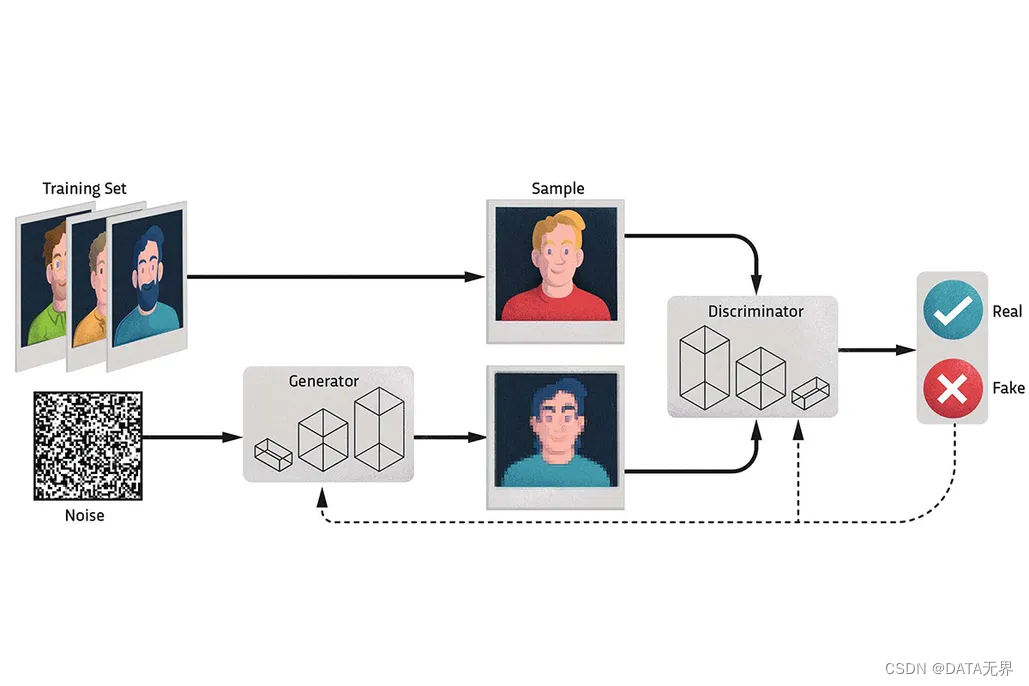
通过训练生成器和判别器的对抗过程,生成式人工智能模型不断地提高生成样本的质量,使得生成的样本更加逼真,并且与真实数据的分布更加接近。这种对抗性训练的过程使得生成器和判别器之间达到一种平衡,最终这个过程一直持续到生成器产生与输入信息无法区分的数据为止。
2.2 生成式人工智能的工作过程
生成式人工智能的工作过程通常如下:
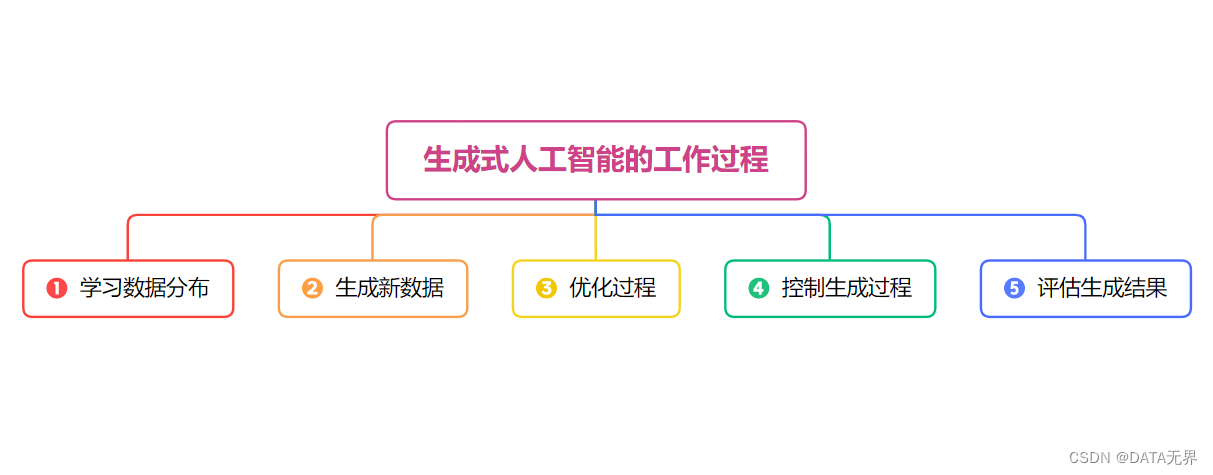
-
学习数据分布:生成式模型首先通过大量的训练数据学习输入数据的分布。这些数据可以是图像、文本、音频等形式。模型通过学习数据的特征和统计分布来理解输入数据的内在规律。
-
生成新数据:一旦生成式模型学习到了数据的分布,它就可以通过随机采样或输入特定的条件来生成新的数据。生成的数据可能具有与训练数据相似的统计特性和结构,但通常是全新的、之前未见过的数据。
-
优化过程:生成式模型的训练通常涉及到一个优化过程,通过最小化生成数据与真实数据之间的差异来调整模型参数。对抗性生成网络(GANs)中使用了对抗训练的思想,包括生成器和判别器两个部分,它们相互竞争并共同提高模型的性能。
-
控制生成过程:一些生成式模型允许用户在生成新数据时提供一些条件或控制参数,以影响生成结果。例如,在生成图像时可以指定生成的图像类别或风格,或者在生成文本时可以指定生成的主题或情感。
-
评估生成结果:生成式模型通常需要经过一定的评估和调优来确保生成的数据质量和多样性。这可能涉及到定量指标如生成数据的多样性、真实度等,以及定性评估如人工评价生成数据的质量和逼真度。然后通过一个称为 "推理 "的过程来完善输出。在推理过程中,模型会调整其输出,以更好地匹配所需的输出或纠正任何错误。这样就能确保生成的输出更加逼真,更符合用户希望看到的效果。
三、如何评估生成式人工智能模型
选择正确的模型对于某些特定的任务至关重要,因为每个任务都有其独特的需求和目标,而不同的生成式人工智能模型也各有其优缺点。比如,某一些模型可能比较擅长生成高质量的图像内容,而另一些模型则更擅长生成顺畅连贯的文本内容。
因此在选择时,需要重视对生成模型进行评估以确定最适合特定任务的模型。这种评估不仅有助于选择正确的模型,还有助于确定需要改进的方面。通过这种方式,可以完善模型并增加实现预期结果的可能性,从而提高人工智能系统的整体成功率。
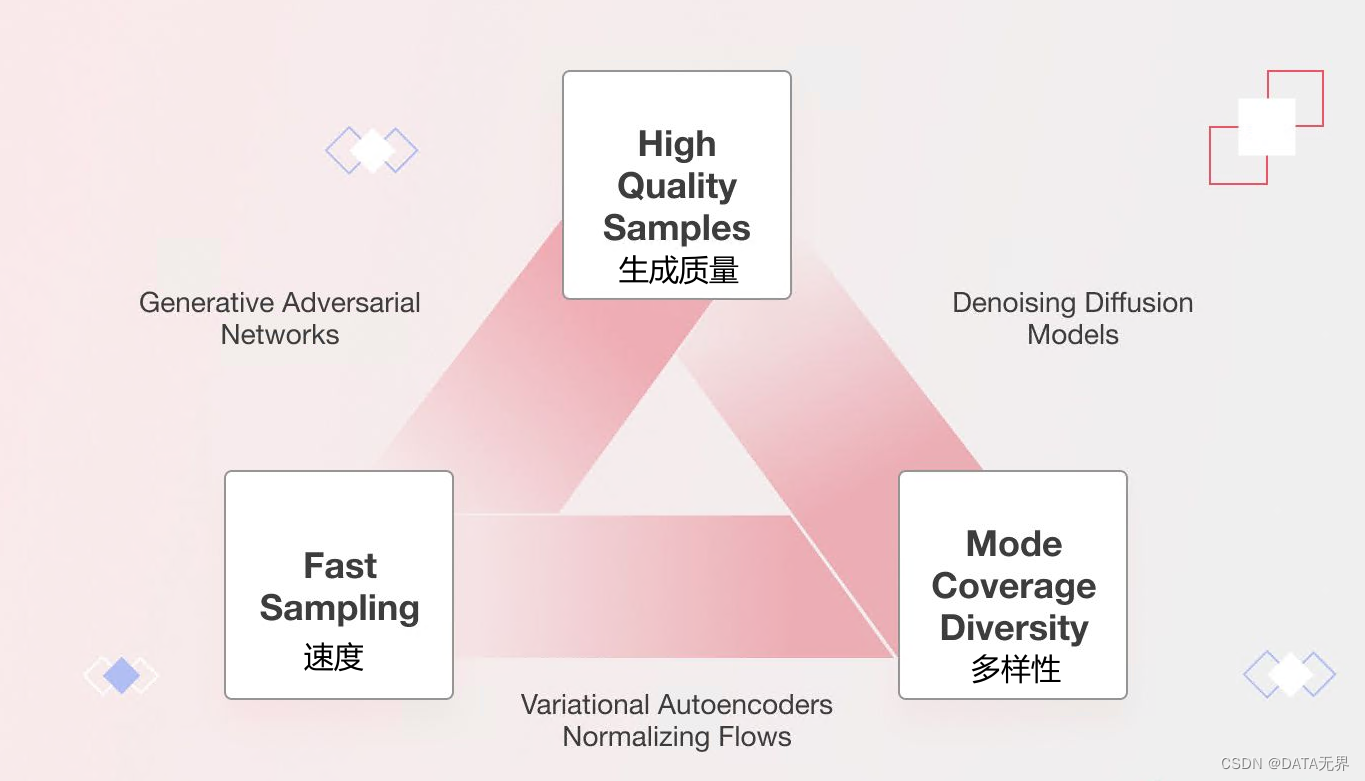
在评估模型时,通常需要考虑三个关键要素:
-
Quality 质量:生成式模型的输出质量至关重要,尤其是在直接与用户交互的应用程序中。例如,在文本生成模型中,前言不搭后语的文本可能会让人感觉一团糟,在语音生成模型中,低质量的语音可能会让人听不懂;而在图像生成模型中,生成的图像最好是能够做到浑然天成,和真实的图像无法区分。
-
Diversity 多样性:优秀的生成式模型应该能够捕获数据分布中的各种模式,而不会降低生成的质量。这种多样性有助于减少模型中不必要的偏差。
-
Speed 速度:许多交互式应用程序需要快速生成结果,例如实时图像编辑,以支持内容创建的工作流程。因此,在评估生成模型时,生成的速度也是一个重要的考量因素。
相关文章:
AI大模型学习笔记之四:生成式人工智能(AIGC)是如何工作的?
OpenAI 发布 ChatGPT 已经1年多了,生成式人工智能(AIGC)也已经广为人知,我们常常津津乐道于 ChatGPT 和 Claude 这样的人工智能系统能够神奇地生成文本与我们对话,并且能够记忆上下文情境。 Midjunery和DALLE 这样的AI…...

bat脚本 创建计划任务 一分钟设置ntp同步周期为60s
要在Windows中使用批处理脚本(.bat)创建一个计划任务来每分钟同步一次NTP时间,你可以使用schtasks命令来创建计划任务。下面是一个示例脚本,展示了如何创建这样一个计划任务: echo off set "taskNameSyncNTP"…...

python数据分析numpy基础之mean用法和示例
1 python数据分析numpy基础之mean用法和示例 python的numpy库的mean()函数,用于计算沿指定轴(一个轴或多个轴)的算术平均值。 用法 numpy.mean(a, axisNone, dtypeNone, outNone, keepdims<no value>, *, where<no value>)描述 返回数组元素的平均值…...

微服务学习 | Springboot整合Dubbo+Nacos实现RPC调用
🏷️个人主页:鼠鼠我捏,要死了捏的主页 🏷️系列专栏:Golang全栈-专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 前些天发现了一个巨牛的人工智能学习网站,通俗易懂&…...

只允许访问固定网址,如何让电脑只能上指定的网站
在企业管理中,确保员工在工作时能够专注于指定的任务和资源至关重要。为了实现这一目标,许多企业选择限制员工电脑的访问权限,只允许他们访问固定的网址或网站。 这种策略不仅有助于提高工作效率,还能减少因不当上网行为带来的安全…...
作业帮 x TiDB丨多元化海量数据业务的支撑
导读 作业帮是一家成立于 2015 年的在线教育品牌,致力于用科技手段助力教育普惠。经过近十年的积累,作业帮运用人工智能、大数据等技术,为学生、老师、家长提供学习、教育解决方案,智能硬件产品等。随着公司产品和业务场景越来越…...

文生图提示词:天气条件
天气和气候 --天气条件 Weather Conditions 涵盖了从基本的天气类型到复杂的气象现象,为描述不同的天气和气候条件提供了丰富的词汇。 Sunny 晴朗 Cloudy 多云 Overcast 阴天 Partly Cloudy 局部多云 Clear 清晰 Foggy 雾 Misty 薄雾 Hazy 朦胧 Rainy 下雨 Showers …...

【nginx实践连载-3】发布VSTO应用
要使用 Nginx 发布 VSTO 应用程序,需要将 ClickOnce 发布文件夹部署到 Nginx 服务器上。以下是一些步骤: 将 ClickOnce 发布文件夹复制到 Nginx 服务器上。确认 Nginx 配置文件中有一个指向 ClickOnce 发布文件夹的位置块。确保Nginx 配置文件中启用了 …...

【前端工程化面试题】使用 webpack 来优化前端性能/ webpack的功能
这个题目实际上就是来回答 webpack 是干啥的,你对webpack的理解,都是一个问题。 (1)对 webpack 的理解 webpack 为啥提出 webpack 是啥 webpack 的主要功能 前端开发通常是基于模块化的,为了提高开发效率࿰…...

思迈特再获国家权威认证:代码自主率98.78%
日前,思迈特软件自主研发的商业智能与数据分析软件(Smartbi Insight)通过中国赛宝实验室(工业和信息化部电子第五研究所)代码扫描测试,Smartbi Insight V11版本扫描测得代码自主率为98.78%的好成绩…...

JavaScript排序
直接看代码 <table border"1" cellspacing"0"><thead class"tou"><tr><td>选择按钮</td><td>汽车编号</td><td>汽车图片</td><td>汽车系列名称</td><td>汽车能源</…...
【读书笔记】ICS设备及应用攻击(一)
工控系统通常是由互联设备所构成的大型复杂系统,这些设备包括类似于人机界面(HMI)、PLC、传感器、执行器以及其他使用协商好的协议进行相互通信的设备。所有交互背后的驱动力都是软件,软件为工控系统中几乎所有部分的运行提供支撑…...

网络原理(HTTP篇)
网络原理HTTP 前言HTTPHTTP的工作流程抓包工具抓取HTTP报文HTTP报文格式 请求报文具体细节首行URLURL的基本格式URL encode 方法 报头(header)HostContent-Length 和 Content-TypeUser-Agent(UA)RefererCookie(重要) 前言 如图&a…...

关于油封密封件你了解多少?
油封也称为轴封或旋转轴封,旨在防止设备中的润滑剂泄漏,并防止外部污染物进入机械。它们通常用于泵和电机等旋转设备,在固定部件和移动部件之间提供密封界面。 油封的有效性很大程度上取决于其材料。不同的材料具有不同程度的耐热性、耐压性…...

Leetcode 72 编辑距离
题意理解: 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换一个字符 将word1转换为word2,可以进行三种操作:增、删、改&am…...

羊大师揭秘,如何挑选出好牧场的奶羊,该怎么看
羊大师揭秘,如何挑选出好牧场的奶羊,该怎么看 了解牧场的管理和环境:好的牧场应该有规范的管理制度,环境整洁,草场茂盛,为奶羊提供了充足的食物和良好的生活环境。在这样的牧场中,奶羊能够得到…...

MySQL数据库基础(八):DML数据操作语言
文章目录 DML数据操作语言 一、DML包括哪些SQL语句 二、数据的增删改(重点) 1、数据的增加操作 2、数据的修改操作 3、数据的删除操作 DML数据操作语言 一、DML包括哪些SQL语句 insert插入、update更新、delete删除 二、数据的增删改(…...
Hive——CTE 公共表达式)
(09)Hive——CTE 公共表达式
目录 1.语法 2. 使用场景 select语句 chaining CTEs 链式 union语句 insert into 语句 create table as 语句 前言 Common Table Expressions(CTE):公共表达式是一个临时的结果集,该结果集是从with子句中指定的查询派生而来…...
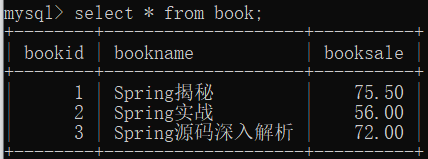
Spring 用法学习总结(四)之 JdbcTemplate 连接数据库
🐉目录 9 JdbcTemplate 9 JdbcTemplate Spring 框架对 JDBC 进行了封装,使用 JdbcTemplate 方便实现对数据库操作 相关包: 百度网盘链接https://pan.baidu.com/s/1Gw1l6VKc-p4gdqDyD626cg?pwd6666 创建properties配置文件 💥注意…...
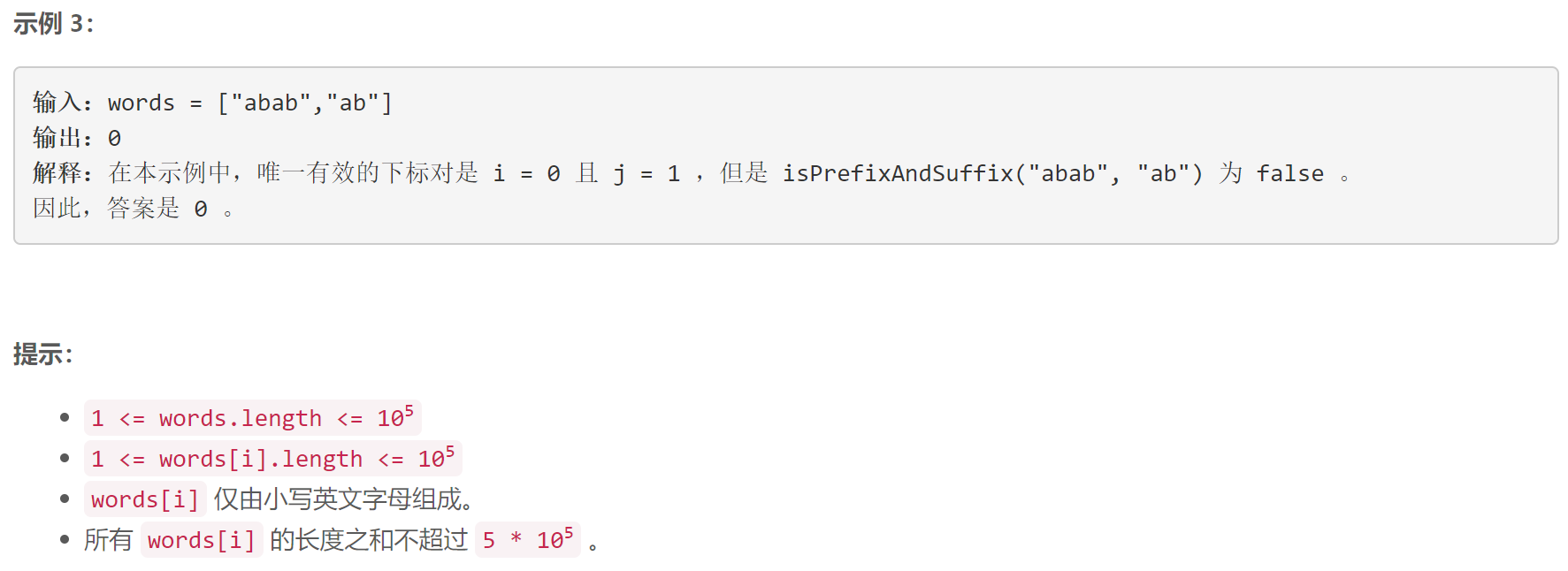
第 385 场 LeetCode 周赛题解
A 统计前后缀下标对 I 模拟 class Solution { public:int countPrefixSuffixPairs(vector<string> &words) {int n words.size();int res 0;for (int i 0; i < n; i)for (int j i 1; j < n; j)if (words[i].size() < words[j].size()) {int li words[…...
Trae日志占用、Trae logs删除、Trae缓存清理、Trae占用C盘、Trae AppData 清理)
Trae日志占用很大解决方法(Windows)Trae日志占用、Trae logs删除、Trae缓存清理、Trae占用C盘、Trae AppData 清理
Trae日志占用很大解决方法(Windows) 关键词:Trae日志占用、Trae logs删除、Trae缓存清理、Trae占用C盘、Trae AppData 清理最近清理电脑磁盘时,发现 C 盘莫名其妙少了十几个 G。作为长期写代码的人,我第一反应就是&…...

为AI智能体项目选择稳定且多模型的后端API供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为AI智能体项目选择稳定且多模型的后端API供应商 在开发AI智能体或自动化工作流时,工程师们面临的核心挑战之一是如何为…...

STM32F405时钟树配置避坑指南:从HSE到APB,手把手教你算对每个外设时钟
STM32F405时钟树配置避坑指南:从HSE到APB,手把手教你算对每个外设时钟 在嵌入式开发中,时钟配置是STM32项目启动的第一步,也是最容易踩坑的环节之一。很多开发者虽然理解了时钟树的基本概念,但在实际项目中仍然会遇到外…...

ETAS ISOLAR-A配置AUTOSAR COM模块实战:从DBC导入到信号超时监控的完整避坑指南
ETAS ISOLAR-A配置AUTOSAR COM模块实战:从DBC导入到信号超时监控的完整避坑指南 在汽车电子领域,AUTOSAR COM模块作为通信堆栈的核心组件,承担着信号路由、协议转换和通信控制的关键职能。对于使用ETAS ISOLAR-A工具链的工程师而言࿰…...

QT无边框窗口实战:从圆角绘制到自定义标题栏与拖拽交互
1. 为什么需要无边框窗口? 现代桌面应用越来越注重视觉体验,传统的系统标题栏往往与整体设计风格格格不入。想象一下,你精心设计了一款深色主题的音乐播放器,顶部却突兀地挂着Windows默认的白色标题栏——这种割裂感正是无边框窗口…...

RocketMQ 源码解析——Controller 高可用切换架构
延伸阅读:🔍「RocketMQ 中文社区」 持续更新源码解析/最佳实践,提供 RocketMQ 专家 AI 答疑服务 一、原理及核心概念浅述 1.1 核心架构 1.2 核心概念 controller:负责管理broker间的主备关系,可以挂在namesrv中&…...

【免费下载】 MATLAB从入门到精通教程 - PDF文档下载指南【matlab下载】
MATLAB从入门到精通教程 - PDF文档下载指南 欢迎来到《MATLAB从入门到精通教程》的资源页面!本资源旨在为所有想要深入学习MATLAB编程语言的学者和工程师提供一份详尽、全面的学习资料。这份权威的PDF文档是英文版,非常适合希望掌握MATLAB核心功能及高级…...

基于GeoDa与R语言的空间数据回归实践技术应用
空间数据是常见的数据形式之一,因此空间数据回归也是最常用的方法之一。由于空间数据之间往往有相关性,它们不满足经典统计学的数据独立性假设,所以回归的理论和建模方式与普通回归模型相比既陌生又复杂。GeoDa与R语言是建立空间回归模型最合…...

DIY USB-C扩展坞:从引脚连接到3D打印,打造开发板专属工作站
1. 项目概述与核心价值如果你和我一样,桌上常年堆着各种开发板,从Arduino Uno到最新的ESP32-S3,每次想插拔USB线调试或者充电,都得在一堆线缆里翻找,板子还容易滑来滑去,那这个项目就是为你准备的。今天我们…...
)
别再死磕PSO了!用Python手把手教你实现GWO灰狼优化算法(附完整代码)
用Python实战GWO灰狼优化算法:告别传统优化方法的局限 在工程优化和机器学习领域,算法选择往往决定了问题求解的效率和质量。传统粒子群优化(PSO)算法虽然广为人知,但其参数调节复杂、易陷入局部最优的缺点也日益明显。灰狼优化算法(Grey Wol…...