深度学习之pytorch实现线性回归
度学习之pytorch实现线性回归
- pytorch用到的函数
- torch.nn.Linearn()函数
- torch.nn.MSELoss()函数
- torch.optim.SGD()
- 代码实现
- 结果分析
pytorch用到的函数
torch.nn.Linearn()函数
torch.nn.Linear(in_features, # 输入的神经元个数out_features, # 输出神经元个数bias=True # 是否包含偏置)
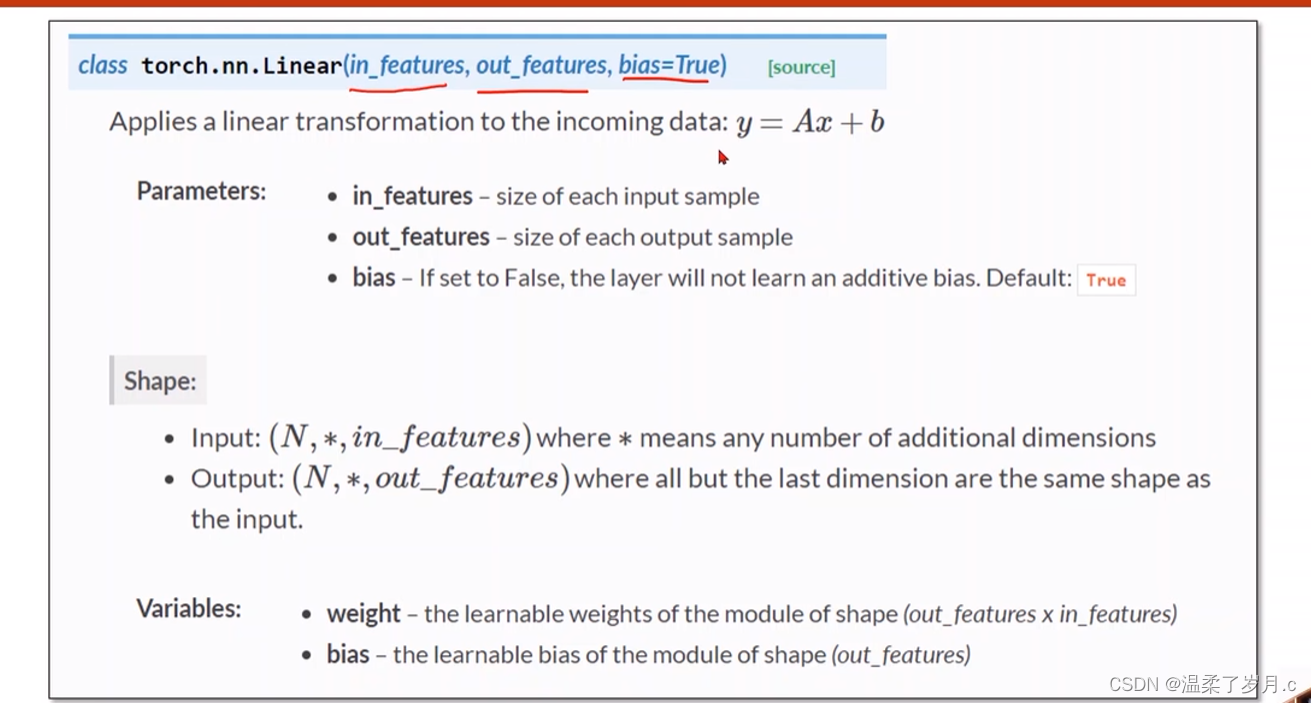
作用j进行线性变换
Linear(1, 1) : 表示一维输入,一维输出
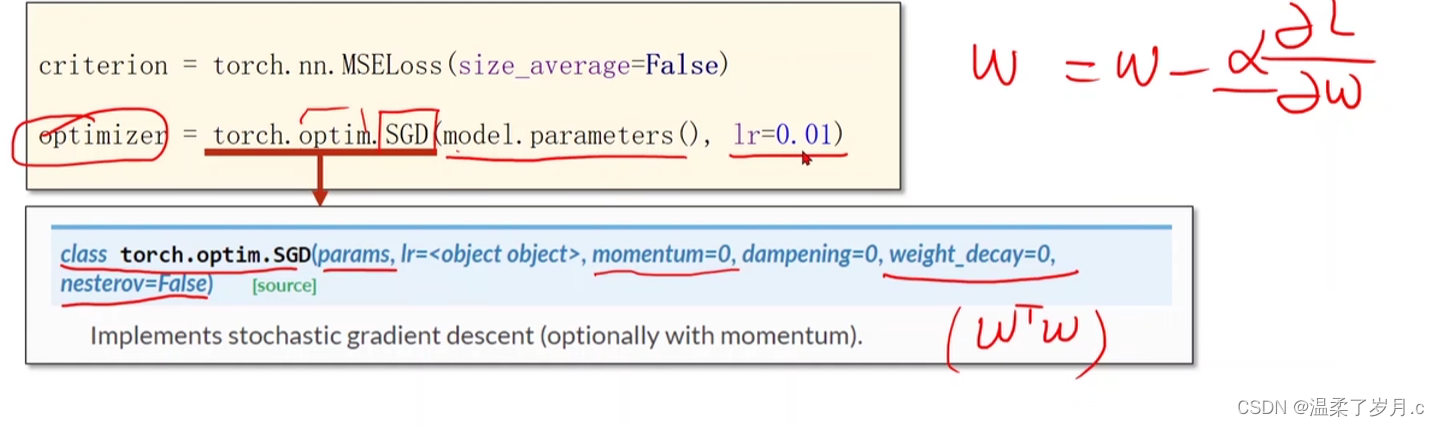
torch.nn.MSELoss()函数

torch.optim.SGD()
优化器对象
代码实现
import torchx_data = torch.tensor([[1.0], [2.0], [3.0]]) # 将x_data设置为tensor类型数据
y_data = torch.tensor([[2.0], [4.0], [6.0]])class LinearModel(torch.nn.Module):def __init__(self):super(LinearModel, self).__init__() # 继承父类self.linear = torch.nn.Linear(1, 1)# 用torch.nn.Linear来构造对象 (y = w * x + b)def forward(self, x):y_pred = self.linear(x) #调用之前的构造的对象(调用构造函数),计算 y = w * x + breturn y_predmodel = LinearModel()criterion = torch.nn.MSELoss(size_average=False) # 定义损失函数,不求平均损失(为False)#优化器对象
# #model.parameters()会扫描module中的所有成员,如果成员中有相应权重,那么都会将结果加到要训练的参数集合上
# #类似权重的更新
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 定义梯度优化器为随机梯度下降for epoch in range(10000): # 训练过程y_pred = model(x_data) # 向前传播,求y_predloss = criterion(y_pred, y_data) # 根据y_pred和y_data求损失print(epoch, loss)# 记住在backward之前要先梯度归零optimizer.zero_grad() # 将优化器数值清零loss.backward() # 反向传播,计算梯度optimizer.step() # 根据梯度更新参数#打印权重和b
print("w = ", model.linear.weight.item())
print("b = ", model.linear.bias.item())#检测模型
x_test = torch.tensor([4.0])
y_test = model(x_test)
print('y_pred = ', y_test.data) # 测试
结果分析
9961 tensor(4.0927e-12, grad_fn=)
9962 tensor(4.0927e-12, grad_fn=)
9963 tensor(4.0927e-12, grad_fn=)
9964 tensor(4.0927e-12, grad_fn=)
9965 tensor(4.0927e-12, grad_fn=)
9966 tensor(4.0927e-12, grad_fn=)
9967 tensor(4.0927e-12, grad_fn=)
9968 tensor(4.0927e-12, grad_fn=)
9969 tensor(4.0927e-12, grad_fn=)
9970 tensor(4.0927e-12, grad_fn=)
9971 tensor(4.0927e-12, grad_fn=)
9972 tensor(4.0927e-12, grad_fn=)
9973 tensor(4.0927e-12, grad_fn=)
9974 tensor(4.0927e-12, grad_fn=)
9975 tensor(4.0927e-12, grad_fn=)
9976 tensor(4.0927e-12, grad_fn=)
9977 tensor(4.0927e-12, grad_fn=)
9978 tensor(4.0927e-12, grad_fn=)
9979 tensor(4.0927e-12, grad_fn=)
9980 tensor(4.0927e-12, grad_fn=)
9981 tensor(4.0927e-12, grad_fn=)
9982 tensor(4.0927e-12, grad_fn=)
9983 tensor(4.0927e-12, grad_fn=)
9984 tensor(4.0927e-12, grad_fn=)
9985 tensor(4.0927e-12, grad_fn=)
9986 tensor(4.0927e-12, grad_fn=)
9987 tensor(4.0927e-12, grad_fn=)
9988 tensor(4.0927e-12, grad_fn=)
9989 tensor(4.0927e-12, grad_fn=)
9990 tensor(4.0927e-12, grad_fn=)
9991 tensor(4.0927e-12, grad_fn=)
9992 tensor(4.0927e-12, grad_fn=)
9993 tensor(4.0927e-12, grad_fn=)
9994 tensor(4.0927e-12, grad_fn=)
9995 tensor(4.0927e-12, grad_fn=)
9996 tensor(4.0927e-12, grad_fn=)
9997 tensor(4.0927e-12, grad_fn=)
9998 tensor(4.0927e-12, grad_fn=)
9999 tensor(4.0927e-12, grad_fn=)
w = 1.9999985694885254
b = 2.979139480885351e-06
y_pred = tensor([8.0000])
因为轮数过多,这里展示后面几轮
模型的准确性,跟轮数的多少有关系 ,如果轮数为100,最后测试结果的y_pred肯定不为8.00,这里轮数为10000,预测结果跟实际结果基本一样
这里是轮数为100,结果是 7点多,有一定误差
0 tensor(101.4680, grad_fn=)
1 tensor(45.8508, grad_fn=)
2 tensor(21.0819, grad_fn=)
3 tensor(10.0458, grad_fn=)
4 tensor(5.1234, grad_fn=)
5 tensor(2.9227, grad_fn=)
6 tensor(1.9338, grad_fn=)
7 tensor(1.4844, grad_fn=)
8 tensor(1.2754, grad_fn=)
9 tensor(1.1736, grad_fn=)
10 tensor(1.1195, grad_fn=)
11 tensor(1.0869, grad_fn=)
12 tensor(1.0639, grad_fn=)
13 tensor(1.0453, grad_fn=)
14 tensor(1.0288, grad_fn=)
15 tensor(1.0134, grad_fn=)
16 tensor(0.9985, grad_fn=)
17 tensor(0.9841, grad_fn=)
18 tensor(0.9699, grad_fn=)
19 tensor(0.9559, grad_fn=)
20 tensor(0.9421, grad_fn=)
21 tensor(0.9286, grad_fn=)
22 tensor(0.9153, grad_fn=)
23 tensor(0.9021, grad_fn=)
24 tensor(0.8891, grad_fn=)
25 tensor(0.8764, grad_fn=)
26 tensor(0.8638, grad_fn=)
27 tensor(0.8513, grad_fn=)
28 tensor(0.8391, grad_fn=)
29 tensor(0.8271, grad_fn=)
30 tensor(0.8152, grad_fn=)
31 tensor(0.8034, grad_fn=)
32 tensor(0.7919, grad_fn=)
33 tensor(0.7805, grad_fn=)
34 tensor(0.7693, grad_fn=)
35 tensor(0.7582, grad_fn=)
36 tensor(0.7474, grad_fn=)
37 tensor(0.7366, grad_fn=)
38 tensor(0.7260, grad_fn=)
39 tensor(0.7156, grad_fn=)
40 tensor(0.7053, grad_fn=)
41 tensor(0.6952, grad_fn=)
42 tensor(0.6852, grad_fn=)
43 tensor(0.6753, grad_fn=)
44 tensor(0.6656, grad_fn=)
45 tensor(0.6561, grad_fn=)
46 tensor(0.6466, grad_fn=)
47 tensor(0.6373, grad_fn=)
48 tensor(0.6282, grad_fn=)
49 tensor(0.6192, grad_fn=)
50 tensor(0.6103, grad_fn=)
51 tensor(0.6015, grad_fn=)
52 tensor(0.5928, grad_fn=)
53 tensor(0.5843, grad_fn=)
54 tensor(0.5759, grad_fn=)
55 tensor(0.5676, grad_fn=)
56 tensor(0.5595, grad_fn=)
57 tensor(0.5514, grad_fn=)
58 tensor(0.5435, grad_fn=)
59 tensor(0.5357, grad_fn=)
60 tensor(0.5280, grad_fn=)
61 tensor(0.5204, grad_fn=)
62 tensor(0.5129, grad_fn=)
63 tensor(0.5056, grad_fn=)
64 tensor(0.4983, grad_fn=)
65 tensor(0.4911, grad_fn=)
66 tensor(0.4841, grad_fn=)
67 tensor(0.4771, grad_fn=)
68 tensor(0.4703, grad_fn=)
69 tensor(0.4635, grad_fn=)
70 tensor(0.4569, grad_fn=)
71 tensor(0.4503, grad_fn=)
72 tensor(0.4438, grad_fn=)
73 tensor(0.4374, grad_fn=)
74 tensor(0.4311, grad_fn=)
75 tensor(0.4250, grad_fn=)
76 tensor(0.4188, grad_fn=)
77 tensor(0.4128, grad_fn=)
78 tensor(0.4069, grad_fn=)
79 tensor(0.4010, grad_fn=)
80 tensor(0.3953, grad_fn=)
81 tensor(0.3896, grad_fn=)
82 tensor(0.3840, grad_fn=)
83 tensor(0.3785, grad_fn=)
84 tensor(0.3730, grad_fn=)
85 tensor(0.3677, grad_fn=)
86 tensor(0.3624, grad_fn=)
87 tensor(0.3572, grad_fn=)
88 tensor(0.3521, grad_fn=)
89 tensor(0.3470, grad_fn=)
90 tensor(0.3420, grad_fn=)
91 tensor(0.3371, grad_fn=)
92 tensor(0.3322, grad_fn=)
93 tensor(0.3275, grad_fn=)
94 tensor(0.3228, grad_fn=)
95 tensor(0.3181, grad_fn=)
96 tensor(0.3136, grad_fn=)
97 tensor(0.3091, grad_fn=)
98 tensor(0.3046, grad_fn=)
99 tensor(0.3002, grad_fn=)
w = 1.6352288722991943
b = 0.8292105793952942
y_pred = tensor([7.3701])
Process finished with exit code 0
相关文章:
深度学习之pytorch实现线性回归
度学习之pytorch实现线性回归 pytorch用到的函数torch.nn.Linearn()函数torch.nn.MSELoss()函数torch.optim.SGD() 代码实现结果分析 pytorch用到的函数 torch.nn.Linearn()函数 torch.nn.Linear(in_features, # 输入的神经元个数out_features, # 输出神经元个数biasTrue # 是…...

Vue3快速上手(八) toRefs和toRef的用法
顾名思义,toRef 就是将其转换为ref的一种实现。详细请看: 一、toRef 1.1 示例 <script langts setup name"toRefsAndtoRef"> // 引入reactive,toRef import { reactive, toRef } from vue // reactive包裹的数据即为响应式对象 let p…...

《数学建模》专栏导读
文章分类 相关概念入门快速建模相关混合整数线性规划(MILP)加速技巧数值问题探讨相关问题解决技巧 相关概念入门 文章相关概念离散优化模型的松弛模型线性松弛问题混合整数线性规划MILP问题中增添约束的影响约束的影响 快速建模相关 文章求解器涉及步…...

App启动优化笔记 1
app大致的启动流程。有Launcher进程,system_server进程,zygote进程,APP进程。 Launcher进程:启动activity来启动应用 system_server进程:(ams是其中的一个binder):发送一个socket消息给Zygote。 zygote进程:收到消息后,fork新的进程,---》app进程启动 APP进程:…...

Spring Boot 笔记 027 添加文章分类
1.1.1 添加分类 <!-- 添加分类弹窗 --> <el-dialog v-model"dialogVisible" title"添加弹层" width"30%"><el-form :model"categoryModel" :rules"rules" label-width"100px" style"padding…...

【SQL】sql记录
1、start with star with 是一种用于层次结构查询的语法,它允许我们从指定的起始节点开始,递归查询与该节点相关联的所有子节点。 SELECT id, name, parent_id from test001 START WITH id 1 CONNECT BY PRIOR id parent_id 2、row_number() over pa…...
-Linux ARM驱动编程第六天-ARM Linux编程之SMP系统 (物联技术666))
嵌入式培训机构四个月实训课程笔记(完整版)-Linux ARM驱动编程第六天-ARM Linux编程之SMP系统 (物联技术666)
链接:https://pan.baidu.com/s/1V0E9IHSoLbpiWJsncmFgdA?pwd1688 提取码:1688 SMP(Symmetric Multi-Processing),对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系…...

html5播放 m3u8
注意:m3u8地址要为网络地址,直接把代码复制为html直接在本地打开,可能不行,需要放在nginx或者apache或者其他的web服务器上运行。 <!DOCTYPE html> <html> <head><meta charsetutf-8 /><title>测试…...

微信小程序按需注入和用时注入
官网链接 按需注入 {"lazyCodeLoading": "requiredComponents" }注意事项 启用按需注入后,小程序仅注入当前访问页面所需的自定义组件和页面代码。未访问的页面、当前页面未声明的自定义组件不会被加载和初始化,对应代码文件将不…...

iPhone 16 组件泄露 揭示了新的相机设计
iPhone 16 的发布似乎已经等了很长一段时间,但下一个苹果旗舰系列可能会在短短 7 个月内与我们见面——而新的组件泄漏让我们对可能即将到来的重新设计有了一些了解。后置摄像头模块。 爆料者 Majin Bu(来自 MacRumors)获得的示意图显示&…...
网络工程师学习笔记——IPV6
20世纪80年代,IETF(Internet Engineering Task Force,因特网工程任务组)发布RFC791,即IPv4协议,标志IPv4正式标准化。在此后的几十年间,IPv4协议成为最主流的协议之一。无数人在IPv4的基础上开发…...
)
【零基础学习CAPL】——CAN报文的发送(LiveCounter——生命信号)
🙋♂️【零基础学习CAPL】系列💁♂️点击跳转 文章目录 1.概述2.面板创建3.系统变量创建4.CAPL实现5.效果5.1.0~15循环发送5.2.固定值发送6.全量脚本1.概述 本章主要介绍带有生命信号LiveCounter的报文发送脚本 一般报文可使用CANoe的IG模块直接发送,但存在循环冗余…...

git提交代码冲突
用idea2023中的git提交代码,出现 error: Your local changes to the following files would be overwritten by merge: ****/****/****/init.lua Please commit your changes or stash them before you merge. Aborting 出现这个错误可能是因为你的本地修改与远…...

树莓派:使用mdadm为重要数据做RAID 1保护
树莓派作为个人服务器可玩性还是有点的。说到服务器,在企业的生成环境中为了保护数据,基本上都会用到RAID技术。比如,服务器两块小容量但高性能的盘做个RAID-1按装操作系统,余下的大容量中性能磁盘做个RAID-5或者RAID-6存放数据。…...

HTML板块左右排列布局——左侧 DIV 固定宽度,右侧 DIV 自适应宽度,填充满剩余页面
我们可以借助CSS中的 float 属性来实现。 实例: 布局需求: 左侧 DIV 固定宽度,右侧 DIV 自适应宽度,填充满剩余页面。 <!DOCTYPE html> <html><head><meta charset"UTF-8"><meta http-e…...

红旗linux安装32bit依赖库
红旗linux安装32bit依赖库 红旗linux安装32bit依赖库 lib下载 红旗-7.3-lib-32.tar.gz 解压压缩包,根据如下进行操作 1.回退glibc(1)查看当前glibc版本[root192 ~]# rpm -qa | grep glibcglibc-common-2.17-157.axs7.1.x86_64glibc-headers-2.17-260.axs7.5.x86_…...
Stable Diffusion教程——使用TensorRT GPU加速提升Stable Diffusion出图速度
概述 Diffusion 模型在生成图像时最大的瓶颈是速度过慢的问题。为了解决这个问题,Stable Diffusion 采用了多种方式来加速图像生成,使得实时图像生成成为可能。最核心的加速是Stable Diffusion 使用了编码器将图像从原始的 3512512 大小转换为更小的 46…...
NFTScan | 02.12~02.18 NFT 市场热点汇总
欢迎来到由 NFT 基础设施 NFTScan 出品的 NFT 生态热点事件每周汇总。 周期:2024.02.12~ 2024.02.18 NFT Hot News 01/ CryptoPunks 推出「Punk in Residence」孵化器计划 2 月 12 日,NFT 项目 CryptoPunks 宣布推出「Punk in Residence」孵化器计划&a…...
使用 apt 源安装 ROCm 6.0.x 在Ubuntu 22.04.01
从源码编译 rocSolver 本人只操作过单个rocm版本的情景,20240218 ubuntu 22.04.01 1,卸载原先的rocm https://docs.amd.com/en/docs-5.1.3/deploy/linux/os-native/uninstall.html # Uninstall single-version ROCm packages sudo apt autoremove ro…...

python函数的定义和调用
1. 函数的基本概念 在编程中,函数就像是一台机器,接受一些输入(参数),进行一些操作,然后产生输出(结果)。这让我们的代码更加模块化和易于理解。 函数是一段封装了一系列语句的代码…...
)
告别点点点!用Ranorex Studio录制你的第一个计算器自动化测试(附详细截图)
从零开始:用Ranorex Studio实现计算器自动化测试的完整指南 第一次接触自动化测试时,那种既期待又忐忑的心情我至今记忆犹新。作为一位长期被重复性手工测试困扰的QA工程师,每天面对相同的测试用例,点击相同的按钮,验证…...
)
5G入网第一步:手把手拆解Msg3 PUSCH传输的时频资源分配(附避坑指南)
5G入网第一步:手把手拆解Msg3 PUSCH传输的时频资源分配(附避坑指南) 当5G终端尝试接入网络时,随机接入流程中的Msg3 PUSCH传输往往是工程师们遇到的第一个技术深水区。作为首个由基站调度的上行共享信道传输,Msg3承载着…...

Scroll Reverser:为什么你的Mac需要这款滚动方向控制神器?
Scroll Reverser:为什么你的Mac需要这款滚动方向控制神器? 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 作为一名设计师,李华每天在MacBook…...

Hermes 的核心架构 Harness:上下文、工具、权限与执行控制
上一篇写 Hermes-Agent,我们选了一条比较笨但好用的路:跟一条消息走一遍。 从终端里敲下一句话,到 Agent 把最后一个字回到屏幕上,中间其实绕了很长一圈: 消息先被入口收进去,变成内部统一的消息…...

车间违规操作难监管?AI Box 智能视频监控系统解决方案
干工控这么多年,我最不愿意看到的就是安全事故。每次听到哪个工厂出了安全事故,心里都特别难受。其实很多安全事故都是因为违规操作引起的,比如不戴安全帽、不系安全带、在车间吸烟等等。传统的监控只能事后追溯,不能事前预警&…...

kernelbase.dll 怎么修复?按电脑小白能看懂的步骤来
看到 kernelbase.dll 缺失,很多人会担心是不是系统坏了。其实大多数 kernelbase.dll 报错都能按步骤排查,不需要一开始就重装系统,也不需要马上去下载单个 DLL 文件。下面这套方法按普通用户能操作的顺序来写。每一步只处理一个方向ÿ…...

Multisim导入自定义三极管S8050/S8550保姆级教程:从SPICE文件到成功仿真
Multisim实战:从零构建S8050三极管模型与仿真验证全流程 在电子电路设计与仿真领域,准确的三极管模型往往是项目成功的关键。许多工程师和爱好者在使用Multisim时都遇到过这样的困境:官方元件库中缺少特定型号的三极管(如常见的S8…...
)
告别卡顿!用GDAL+ObjectARX在AutoCAD里丝滑加载百GB遥感影像(附C++源码)
告别卡顿!用GDALObjectARX在AutoCAD里丝滑加载百GB遥感影像(附C源码) 在GIS和测绘工程领域,处理海量遥感影像数据是家常便饭。但当这些GB级甚至TB级的航拍图、卫星图需要导入AutoCAD进行规划设计时,传统的RasterImage对…...

终极英雄联盟工具箱:如何用League Akari提升你的游戏效率与段位
终极英雄联盟工具箱:如何用League Akari提升你的游戏效率与段位 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款…...

【GPT-4V全面评估】:大语言多模态模型的黎明时代
多模态大模型时代的黎明:GPT-4V(ision)全面能力深度测评 当AI还在为"看图说话"磕磕绊绊时,GPT-4V已经悄悄解锁了"看懂世界"的超能力。它不仅能识别图片里的物体,还能理解梗图的笑点、解数学题、读X光片、甚至帮你操作电脑…...