(16)Hive——企业调优经验
前言
本篇文章主要整理hive-3.1.2版本的企业调优经验,有误请指出~
一、性能评估和优化
1.1 Explain查询计划
使用explain命令可以分析查询计划,查看计划中的资源消耗情况,定位潜在的性能问题,并进行相应的优化。
explain执行计划见文章:
Hive调优——explain执行计划-CSDN博客文章浏览阅读843次,点赞18次,收藏11次。Hive调优——explain执行计划https://blog.csdn.net/SHWAITME/article/details/136092007?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170790242216777224416146%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170790242216777224416146&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-136092007-null-null.nonecase&utm_term=explain&spm=1018.2226.3001.4450
1.2 调整并行度和资源配置
根据集群的配置和资源情况,合理调整Hive查询的并行度和资源分配,可以提高查询的并发性和整体性能。Hive在实现HQL计算运行时,会解析为多个Stage,有时候Stage彼此之间有依赖关系,只能挨个执行,但是在一些别的场景下,很多的Stage之间是没有依赖关系的。
例如Union语句,Join语句等等,这些Stage没有依赖关系,但是Hive依旧默认挨个执行每个Stage,这样会导致性能非常差,我们可以通过修改参数,开启并行执行,当多个Stage之间没有依赖关系时,允许多个Stage并行执行,提高性能。
-- 开启Stage并行化,默认为false
SET hive.exec.parallel=true;
-- 指定并行化线程数,默认为8
SET hive.exec.parallel.thread.number=16;ps:调整并行度的措施,建议在数据量大,sql 逻辑复杂的时候使用。当数据量小或sql逻辑简单时开启并行度,优化效果不明显。
1.3 本地模式
使用hive的过程中,有一些数据量不大的表也会抓换成MapReduce处理,提交到yarn集群时,需要申请资源,等待资源分配,启动JVM进行,再运行Task,一系列的过程比较繁琐,严重影响性能。Hive为解决这个问题,延用了MapReduce中的设计,提供本地计算模式,允许程序不提交给yarn,直接在本地运行。
-- 开启本地模式
set hive.exec.mode.local.auto = true;1.4 Fetch 抓取
Fetch 抓取是指:Hive 中对某些简单的查询可以不必使用 MapReduce 计算。 hive-default.xml.template 配置文件的 hive.fetch.task.conversion 默认是 more。此时在全局查找、字段查找、limit 查找等都不走mapreduce。例如:select * from employees;
二、Hive建表优化
2.1 分区表、分桶表
Hive的相关概念——分区表、分桶表-CSDN博客文章浏览阅读419次,点赞15次,收藏7次。Hive的相关概念——分区表、分桶表https://blog.csdn.net/SHWAITME/article/details/136111924?spm=1001.2014.3001.5502 总结:
- 分区表、分桶表不是建表的必要语法规则,是一种优化手段表,可选;
- 分区好处:用where进行分区过滤,查询指定分区的数据,避免全表扫描
- 分桶好处:基于分桶字段查询时,减少全表扫描;join时可以转换为SMB(Sort Merge Bucket join)
- 分区针对的是数据的存储路径;分桶针对的是数据文件(数据粒度更细)
- 分区字段不能是表中已经存在的字段,分桶的字段必须是表中已经存在的字段
- 分区字段是虚拟字段,其数据并不存储在底层的文件中;
- 分区字段值可以手动指定(静态分区),也可以根据查询结果位置自动推断(动态分区)
- Hive支持多重分区,也就是说在分区的基础上继续分区,支持更细粒度的目录划分
2.2 文件格式及数据压缩优化
详细信息见文章:
(10)Hive的相关概念——文件格式和数据压缩-CSDN博客文章浏览阅读36次。Hive的相关概念——文件格式和数据压缩https://blog.csdn.net/SHWAITME/article/details/136122673
三、HQL—Join优化
Hive Join的底层是通过MapReduce来实现的,Hive实现Join时,为了提高MapReduce任务的性能,提供了多种Join方案来实现。例如:适合小表Join大表的Map Join,大表Join大表的Reduce Join, 以及大表Join的优化方案Bucket Join等。
3.1 Map Join
1)应用场景:小表join大表、小表Join小表
2)概述:Map Join是直接在Map阶段完成join工作,没有Shuffle阶段,从而避免了数据倾斜。
select /*+ mapjoin(b,c)*/ --mapjoin hint 定义小表,多个小表用逗号分隔
...
from t0 a
left join t1 b
on a.id = b.id
left join t2 c
on a.id = c.id;# MapJoin中多个小表用半角逗号(,)分隔,例如/*+ mapjoin(a,b,c)*/。
3)工作机制:使用hadoop中DistributedCache(分布式缓存)将小表广播到每个map任务节点,转换成哈希表加载到内存中,之后在mapper端和大表的分散数据做笛卡尔积,直接输出结果。
![]()
4)Map Join的特点:
- 要使用hadoop中的DistributedCache(分布式缓存)把小数据分布到各个计算节点,每个map节点都要把小数据库加载到内存,按关键字建立索引。
- Map Join没有reduce任务,所以map直接输出结果,即有多少个map任务就会产生多少个结果文件
- Hive3.1.2版本已经对Map Join进行了优化,小表放在左边和右边已经没有区别
- MapJoin在Map阶段会将指定表的数据全部加载在内存中,因此指定的表仅能为小表且表被加载到内存后占用的总内存不得超过512 MB(默认)。由于MaxCompute是压缩存储,因此小表在被加载到内存后,数据大小会急剧膨胀。
5)参数设置:
#设置自动选择 Mapjoin,默认为true
set hive.auto.convert.join = true;
#大表小表的阈值设置(默认25M以下认为是小表)
set hive.mapjoin.smalltable.filesize = 25*1000*1000;3.2 Bucket Join
1)应用场景:大表Join大表
2)概述:将两张表按照相同的规则将数据划分、根据对应的规则的数据进行join、减少了比较次数,提高了性能
3.2.1 Bucket Join
- 语法:clustered by column
- 参数设置:set hive.optimize.bucketmapjoin = true;
- 要求:分桶字段 = Join字段 ,桶的个数相等或者成倍数
3.2.2 SMB Join
Sort Merge Bucket Join:基于有序的数据Join
- 语法:clustered by column sorted by (column )
- 参数设置:
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;- 要求:分桶字段 = 排序字段= Join字段 ,两表的桶的个数相等或者成倍数
- 举例:
# 创建分桶表 bigtable_buck1
create table bigtable_buck1(id bigint,t bigint,uid string,keyword string,url_rank int,click_num int,click_url string
)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';# 加载数据
load data local inpath '/opt/module/data/bigtable' into table
bigtable_buck1;#创建分桶表bigtable_buck2,分桶数和bigtable_buck1的分桶数为倍数关系
create table bigtable_buck2(id bigint,t bigint,uid string,keyword string,url_rank int,click_num int,click_url string
)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';#加载数据
load data local inpath '/opt/module/data/bigtable' into table
bigtable_buck2;#================ SMB Join调优步骤#设置参数
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;# SMB Join
insert overwrite table jointable
select b.id,b.t,b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
3.3 Skew Join
1)应用场景:大表Join大表
2)概述:Skew Join是Hive中一种专门为了避免数据倾斜而设计的特殊的Join过程。这种Join的原理是将Map Join和Reduce Join进行合并,如果某个值出现了数据倾斜,就会将产生数据倾斜的数据单独使用Map Join来实现其他没有产生数据倾斜的数据由Reduce Join来实现,这样就避免Reduce Join中产生数据倾斜的问题,最终将Map Join的结果和Reduce Join的结果进行Union合并
3)SkewJoin Hint 语法
select /*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/ 在select语句中使用上述的Hint提示才会执行MapJoin,其中table_name为倾斜表名,column_name为倾斜列名,value为倾斜Key值。使用示例如下:
#=========性能效率 方法1 < 方法2 <方法3
#=========下面三个级别的hint,指定热点信息越详细,效率越高。#-- 方法1:Hint表名(注意Hint的是表的别名)。
select /*+ skewjoin(a)*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;#-- 方法2:Hint表名和认为可能产生倾斜的列,下面认为a表的id和code列 存在倾斜
select /*+ skewjoin(a(id,code))*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;#-- 方法3:Hint表名和列,并提供产生倾斜的列的值,如果是string类型需要加引号,
#--此案例 认为 (a.id=1 and a.code='xxx') 和 (a.id=3 and a.code='yyy') 的值出现倾斜
select /*+ skewjoin(a(id,code)((1,'xxx'),(3,'yyy')))*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;4)Skew Join参数:
#-- 开启运行过程中skewjoin
set hive.optimize.skewjoin=true;
#-- 如果这个key的出现的次数超过这个范围
set hive.skewjoin.key=100000;
#-- 在编译时判断是否会产生数据倾斜
set hive.optimize.skewjoin.compiletime=true;
#-- 不合并,提升性能
set hive.optimize.union.remove=true;
#-- 如果Hive的底层走的是MapReduce,必须开启这个属性,才能实现不合并
set mapreduce.input.fileinputformat.input.dir.recursive=true;3.4 Reduce Join
1)应用场景:大表Join大表
2)概述:两张表的数据关联会经过shuffle阶段,Hive会自动判断是否满足Map Join,如果不满足Map Join,则自动执行Reduce Join(普通的join方式)
3)阶段阐述:
- map端的主要工作:
生成键值对,以join on 条件中的列作为key,以join之后所关心的列作为value值,在value中还会包含Tag标记信息,用于标明此value对应哪张表
- shuffle的主要工作:
根据key值进行hash分区, 按照hash值将键值对(key-value)发送到不同的reducer中
- reduce端的主要工作:
Reducer通过Tag来识别不同的表中的数据,然后分别做合并操作
4)sql举例:
SELECT pageid, age
FROM page_view
JOIN userinfo
ON page_view.userid = userinfo.userid; sql转化为mr任务流程如下图:

5)Reduce Join方法缺点:
- map阶段没有对数据瘦身,shuffle的网络传输和排序性能很低。
- reduce端需要通过Tag识别来源不同表的数据,很耗内存,容易导致OOM。
四、HQL—Group By
如果分组字段本身存在大量重复值(该字段值也叫做热点key值),group by底层走shuffle,分组聚合会出现数据倾斜的现象,可以使用如下三种方案解决:
| 序号 | 方案 | 说明 |
| 方案一 | 开启Map端聚合 | set hive.map.aggr=true; |
| 方案二 | 数据倾斜时自动负载均衡 | set hive.groupby.skewindata = true; |
| 方案三 | 添加随机数,两阶段聚合 | 热点key加随机数,阶段拆分,两阶段聚合 |
优化方案一:开启Map端聚合
#--开启Map端聚合,默认为true
set hive.map.aggr = true;
#--在Map 端预先聚合操作的条数
set hive.groupby.mapaggr.checkinterval = 100000;
该参数可以将顶层的聚合操作放在 Map 阶段执行,从而减轻shuffle清洗阶段的数据传输和 Reduce阶段的执行时间,提升总体性能
优化方案二:数据倾斜时自动负载均衡
#---有数据倾斜的时候自动负载均衡(默认是 false)
set hive.groupby.skewindata = true;
开启该参数以后,当前程序会自动通过两个MapReduce来运行
- 第一个MapReduce自动进行随机分布到Reducer中(负载均衡),每个Reducer做部分聚合操作,输出结果
- 第二个MapReduce将上一步聚合的结果再按照业务(group by key)进行处理,保障相同的key分发到同一个reduce做最终聚合。
该参数的优化原理是:将M->R阶段 拆解成 M->R->R阶段
引入两级reduce:
第一阶段的shuffle key = group key + 随机数,将热点数据打散,多个reduce并发做部分聚合;
第二阶段的shuffle key = group key,保障相同key分发到同一个reduce做最终聚合;
优化方案三:添加随机数,两阶段聚合(推荐)
#===============优化前
insert overwrite table tblB partition (dt = '2022-10-19')
selectcookie_id,event_query,count(*) as cnt
from tblA
where dt >= '20220718'and dt <= '20221019'and event_query is not null
group by cookie_id, event_query#===============优化后
insert overwrite table tblB partition (dt = '2022-10-19')
selectsplit(tkey, '_')[1] as cookie_id,event_query,#--- 第二阶段2:求出最终的聚合值sum(cnt) as cnt
from (selectconcat_ws('_', cast(ceiling(rand() * 99) as string), cookie_id) as tkey,event_query,#---第一阶段2:先局部聚合得到cntcount(*) as cntfrom tblAwhere dt >= '20220718'and dt <= '20221019'and event_query is not null#--- 第一阶段1:添加[0-99]随机整数,将热点Key值:cookie_id 进行打散( M -->R)group by concat_ws('_', cast(ceiling(rand() * 99) as string), cookie_id),event_query) temp#--- 第二阶段1:对拼接的key值进行切分,还原原本的key值split(tkey, '_')[1] =cookie_id ( R -->R)
group by split(tkey, '_')[1], event_query;优化思路为:
- 第一阶段:对需要聚合的Key值添加随机后缀进行打散,基于加工后的key值进行初步聚合(M-->R1)
- 第二阶段:对加工后的key值进行切分还原,对第一阶段的聚合值进行再次聚合,求出最终结果值(R1-->R2)
五、HQL—非count(distinct) 去重
count (distinct) 使得map端无法预聚合,容易引发reduce端长尾。数据量大可以使用group by替换count ..distinct去实现去重,但是需要注意:如果count(distinct 大量重复数据),group by可能会带来数据倾斜问题(对热点key分组操作,容易导致数据倾斜)。
用group by 替换 count(distinct)的案例见文章:
(12)Hive调优——count distinct去重优化-CSDN博客文章浏览阅读187次,点赞2次,收藏2次。Hive调优——count distinct替换https://blog.csdn.net/SHWAITME/article/details/136118294?spm=1001.2014.3001.5501
六、HQL—优化器引擎
6.1 CBO优化器
- RBO(rule basic optimise)基于规则的优化器,根据设定好的规则来对程序进行优化;
- CBO(cost basic optimise)基于代价的优化器,根据不同场景所需要付出的代价来合适选择优化的方案对数据的分布的信息【数值出现的次数,条数,分布】来综合判断用哪种处理的方案是最佳方案;Hive中支持RBO与CBO这两种引擎,默认使用的是RBO优化器引擎。
根据不同的应用场景,可以选择CBO,设置方式如下:
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;6.2 Analyze分析器
用于提前运行一个MapReduce程序,基于表或者分区的信息构建元数据信息【包含表的信息、分区信息、列的信息】,搭配CBO引擎一起使用。
-- 构建分区信息元数据
ANALYZE TABLE tablename
[PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS [noscan];-- 构建列的元数据
ANALYZE TABLE tablename
[PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS FOR COLUMNS ( columns name1, columns name2...) [noscan];-- 查看元数据
DESC FORMATTED [tablename] [columnname];--分析优化器
--构建表中分区数据的元数据信息
ANALYZE TABLE tb_login_part PARTITION(logindate) COMPUTE STATISTICS;
--构建表中列的数据的元数据信息
ANALYZE TABLE tb_login_part COMPUTE STATISTICS FOR COLUMNS userid;
--查看构建的列的元数据
desc formatted tb_login_part userid;七、HQL—谓词下推(PPD)
谓词下推Predicate Pushdown(PPD):在不影响结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,提升任务性能。
谓词下推的场景分析见文章:
(08)Hive——Join连接、谓词下推-CSDN博客文章浏览阅读1k次,点赞16次,收藏16次。Hive的Join连接https://blog.csdn.net/SHWAITME/article/details/136105973
八、HQL—in/exists 语句
in/exists操作,推荐使用Hive的left semi join(左半连接)进行替代
# in / exists 实现
select a.id, a.name from a where a.id in (select b.id from b);
select a.id, a.name from a where exists (select id from b where a.id =
b.id);#可以使用 join 来改写
select a.id, a.name from a join b on a.id = b.id;#left semi join 实现
select a.id, a.name from a left semi join b on a.id = b.id;left semi join(左半连接)的详细说明见文章:
hive/spark--left semi/anti join_sparksql left semi join-CSDN博客
九、HQL—CTE 公共表达式
拖慢HQL查询效率的原因除了join引发的shuffle过程外,还有一个就是子查询调用次数较多,存在冗余代码块。因此我们可以借助CTE 公共表达式,简单来讲就是:with as 语句,将代码中的子查询事先提取出来(类似临时表),可以避免重复计算。
#==============优化前
selectuid,--每个用户一月份的订单数sum(if(dt = '2018-01', 1, 0)) as m1_count,--每个用户二月份的订单数sum(if(dt = '2018-02', 1, 0)) as m2_count,--每个用户三月份的订单数(当月订单金额超过10元的订单个数)sum(if(dt = '2018-03' and oamount > 10, 1, 0)) m3_count,--当月(3月份)首次下单的金额sum(if(dt = '2018-03' and rk = 1, oamount, 0)) m3_first_amount,--当月(3月份)末次下单的金额(rk =cnt小技巧)sum(if(dt = '2018-03' and rk = cnt, oamount, 0)) m3_last_amount
from (selectoid,uid,otime,date_format(otime, 'yyyy-MM') as dt,oamount,---计算rk的目的是为了获取记录中的第一条row_number() over (partition by uid,date_format(otime, 'yyyy-MM') order by otime) rk,--- 计算cnt的目的是为了获取记录中的最后一条count(*) over (partition by uid,date_format(otime, 'yyyy-MM')) cntfrom t_orderorder by uid) tmp
group by uid
having m1_count > 0and m2_count = 0;#================优化后
with tmp as (selectoid,uid,otime,date_format(otime, 'yyyy-MM') as dt,oamount,---计算rk的目的是为了获取记录中的第一条row_number() over (partition by uid,date_format(otime, 'yyyy-MM') order by otime) rk,--- 计算cnt的目的是为了获取记录中的最后一条count(*) over (partition by uid,date_format(otime, 'yyyy-MM')) cntfrom t_orderorder by uid
)
selectuid,--每个用户一月份的订单数sum(if(dt = '2018-01', 1, 0)) as m1_count,--每个用户二月份的订单数sum(if(dt = '2018-02', 1, 0)) as m2_count,--每个用户三月份的订单数(当月订单金额超过10元的订单个数)sum(if(dt = '2018-03' and oamount > 10, 1, 0)) m3_count,--当月(3月份)首次下单的金额sum(if(dt = '2018-03' and rk = 1, oamount, 0)) m3_first_amount,--当月(3月份)末次下单的金额(rk =cnt小技巧)sum(if(dt = '2018-03' and rk = cnt, oamount, 0)) m3_last_amount
from tmp
group by uid
having m1_count >0 and m2_count=0;ps:hive中的CTE公共表达式文章:
(09)Hive——CTE 公共表达式-CSDN博客文章浏览阅读519次,点赞6次,收藏6次。Hive的CTE 公共表达式https://blog.csdn.net/SHWAITME/article/details/136108359?spm=1001.2014.3001.5501
十、合理设置 Map 及 Reduce 数
1)通常情况下,作业会通过input的目录产生一个或者多个map 任务,map数量主要的决定因素有:input 的文件总个数,input 的文件大小,集群设置的文件块大小。
10.1 复杂文件增加Map数
当input的文件很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,公式:
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))让maxSize低于blocksize,此时公式 computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize))) = maxSize
原map个数= 输入文件的数据量 / computeSliteSize = 输入文件的数据量 / blocksize, 现在map个数=输入文件的数据量 / computeSliteSize = 输入文件的数据量 / maxSize

10.2 合理设置 Reduce 数
10.2.1 调整reduce数的方法一
# 每个reduce任务处理的数据量默认是 256MB
hive.exec.reducers.bytes.per.reducer=256*1000*1000
# 整个MR任务支持开启的reduce数的上限值,默认为1009个
hive.exec.reducers.max=1009
根据该公式可以得知:reduce个数(hdfs上的落地文件数量)是动态计算的
10.2.2 调整reduce数的方法二
在hadoop的mapred-default.xml 文件中修改下列参数,
#设置MR job的Reduce总个数
set mapreduce.job.reduces = 15;ps:reduce个数并不是越多越好
- 过多的启动和初始化reduce也会消耗时间和资源;
- 有多少个reduce就会有多少个输出文件,如果生成了很多个小文件,那么这些小文件作为下一个任务的输入时,则也会出现小文件过多的问题;
- 在设置 reduce 个数时还需要考虑:单个reduce 任务处理数据量大小要合适(避免数据倾斜)
十一、Hive的小文件合并
Hive小文件问题及解决方案,见文章:
(14)Hive调优——合并小文件-CSDN博客文章浏览阅读775次,点赞10次,收藏17次。Hive的小文件问题https://blog.csdn.net/SHWAITME/article/details/136108785?spm=1001.2014.3001.5501
十二、数据倾斜优化
Hive中数据倾斜的解决方案指南见:
(15)Hive调优——数据倾斜的解决指南-CSDN博客文章浏览阅读326次,点赞10次,收藏9次。Hive调优——数据倾斜指南https://blog.csdn.net/SHWAITME/article/details/136092028
参考文章:
大数据从业者必知必会的Hive SQL调优技巧 | 京东云技术团队 - 掘金
Hive SQL优化思路-腾讯云开发者社区-腾讯云
https://zhugezifang.blog.csdn.net/article/details/127447167
https://blog.51cto.com/u_15320818/3253292
3年数据工程师总结:Hive数据倾斜保姆教程(手册指南)
相关文章:
(16)Hive——企业调优经验
前言 本篇文章主要整理hive-3.1.2版本的企业调优经验,有误请指出~ 一、性能评估和优化 1.1 Explain查询计划 使用explain命令可以分析查询计划,查看计划中的资源消耗情况,定位潜在的性能问题,并进行相应的优化。 explain执行计划…...
【详解】图的概念和存储结构(邻接矩阵,邻接表)
目录 图的基本概念: 图的存储结构 邻接矩阵(GraphByMatrix): 基本参数: 初始化: 获取顶点元素在其数组中的下标 : 添加边和权重: 获取顶点的度: 打印图…...

【AIGC】Stable Diffusion介绍
Stable Diffusion 是一个基于 OpenAI 的 Diffusion 模型的扩展版本,它采用了稳定扩散(Stable Diffusion)的技术,旨在提高图像生成和处理的质量。下面是 Stable Diffusion 的详细介绍: 基于 Diffusion 的图像生成&…...
2024.2.18 C++QT 作业
思维导图 练习题 1>定义一个基类 Animal,其中有一个虛函数perform(),用于在子类中实现不同的表演行为。 #include <iostream>using namespace std;class Animal { public:virtual void perform() {cout << "这是一个动…...

【qt创建线程两种方式】
QT使用线程的两种方式 1.案例进度条 案例解析: 如图由组件一个进度条和三个按钮组成,当点击开始的时候进度条由0%到100%,点击暂停,进度条保持之前进度,再次点击暂停变为继续,点击停止按钮进度条停止。 案…...

网络安全-一句话木马
声明 遵纪守法 请严格遵守网络安全法相关条例! 此分享主要用于交流学习,请勿用于非法用途,一切后果自付。 一切未经授权的网络攻击均为违法行为,互联网非法外之地。 反制 大家在知道了常规一句话的木马之后,就可以通…...

在k8s中,使用DirectPV CSI作为分布式存储的优缺点
DirectPV 提供了一种直接将物理卷(Physical Volumes)与 Kubernetes 集群中的 Pod 绑定的机制。 利用 DirectPV,你可以将相应的 PV 直接与节点上的物理存储设备(如磁盘)进行绑定,而无需通过网络存储服务(如 NFS 或 Ceph)来提供存储。这种直接访问物理卷的方式,有助于提…...
自动化AD域枚举和漏洞检测脚本
linWinPwn 是一个 bash 脚本,可自动执行许多 Active Directory 枚举和漏洞检查。该脚本基于很多现有工具实现其功能,其中包括:impacket、bloodhound、netexec、enum4linux-ng、ldapdomaindump、lsassy、smbmap、kerbrute、adidnsdump、certip…...
数据库管理-第151期 Oracle Vector DB AI-03(20240218)
数据库管理151期 2024-02-18 数据库管理-第151期 Oracle Vector DB & AI-03(20240218)1 向量数据库应用场景2 Oracle Vector DB3 Vector数据类型4 Vector运算5 Vector DML插入向量获取向量 总结 数据库管理-第151期 Oracle Vector DB & AI-03&am…...
Vue3+vite搭建基础架构(6)--- 使用vue-router
Vue3vite搭建基础架构(6)--- 使用vue-router 说明官方文档安装vue-router使用vue-router测试vue-router 说明 这里记录下自己在Vue3vite的项目使用vue-router的过程,不使用ts语法,方便以后直接使用。这里承接自己的博客Vue3vite搭…...
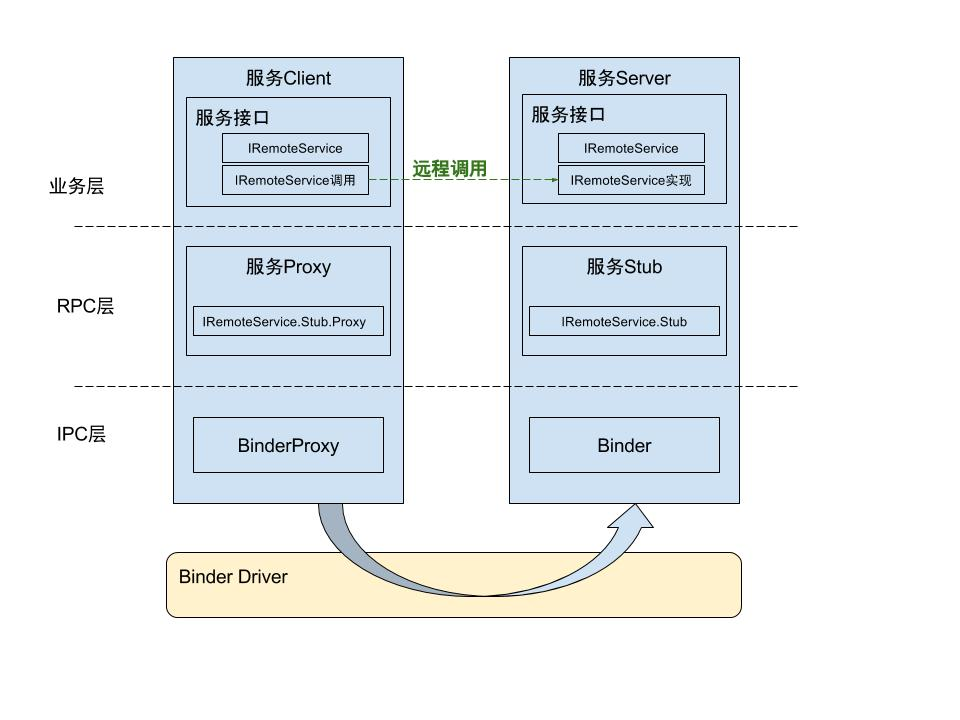
深入解析Android AIDL:实现跨进程通信的利器
深入解析Android AIDL:实现跨进程通信的利器 1. 介绍Android AIDL Android Interface Definition Language (AIDL) 是一种Android系统中的跨进程通信机制。AIDL允许一个应用程序的组件与另一个应用程序的组件通信,并在两者之间传输数据。 AIDL的主要作…...

【笔记】Helm-5 Chart模板指南-14 下一步
下一步 本指南旨在为chart开发者提供对如何使用Helm模板语言的强大理解能力。该模板聚焦于模板开发的技术层面。 但涉及到chart的实际日常开发时,很多内容本指南并没有覆盖到。这里有一些有用的文档链接帮助您创建新的chart: CNCF的 Artifact Hub 是ch…...

axios 官网速通
前言:参考 AXIOS 中文文档 一 起步 1. 介绍 1.1 Axios 是什么? Axios 是一个基于 promise 网络请求库,作用于 node.js 和浏览器中。在服务端使用 node.js 的 http 模块, 在客户端 (浏览端) 使用 XMLHttpRequests。 1.2 安装 $ npm instal…...

luigi,一个好用的 Python 数据管道库!
🏷️个人主页:鼠鼠我捏,要死了捏的主页 🏷️付费专栏:Python专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 前言 大家好,今天为大家分享一个超级厉害的 Python 库 - luigi。 Github地址:https://github.com/spotify/luigi 在大数据时代,处理海量数据已经成…...
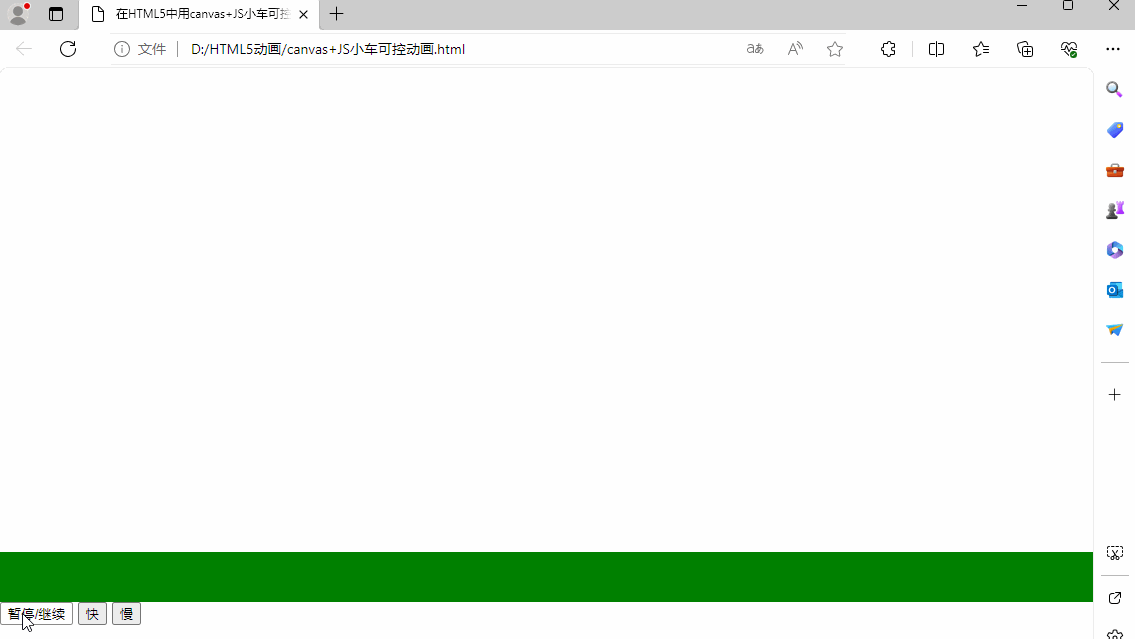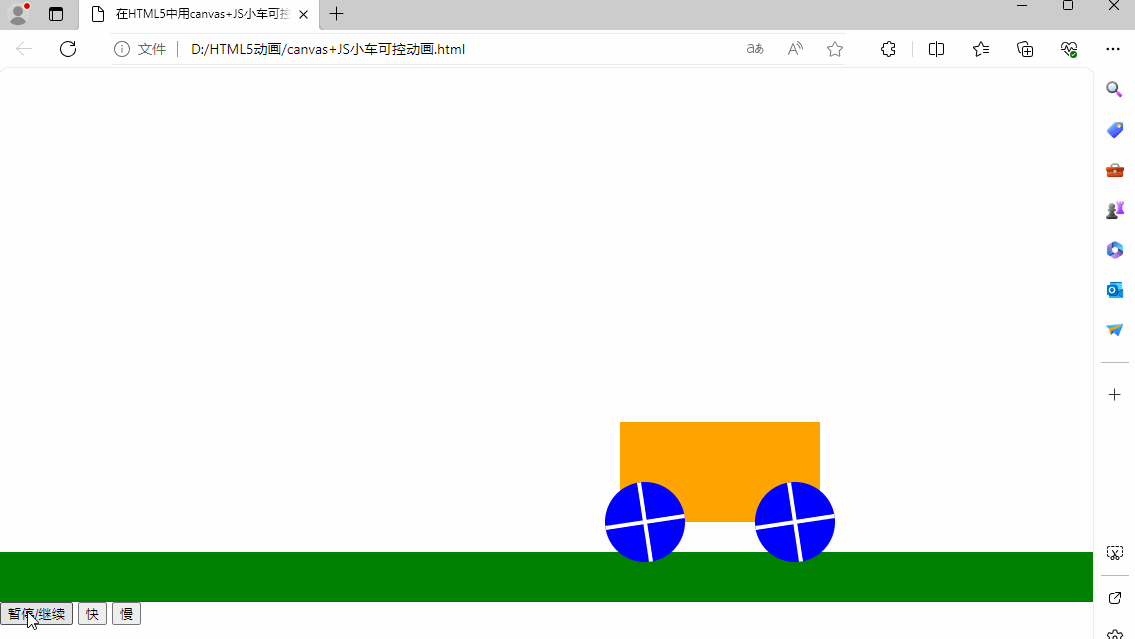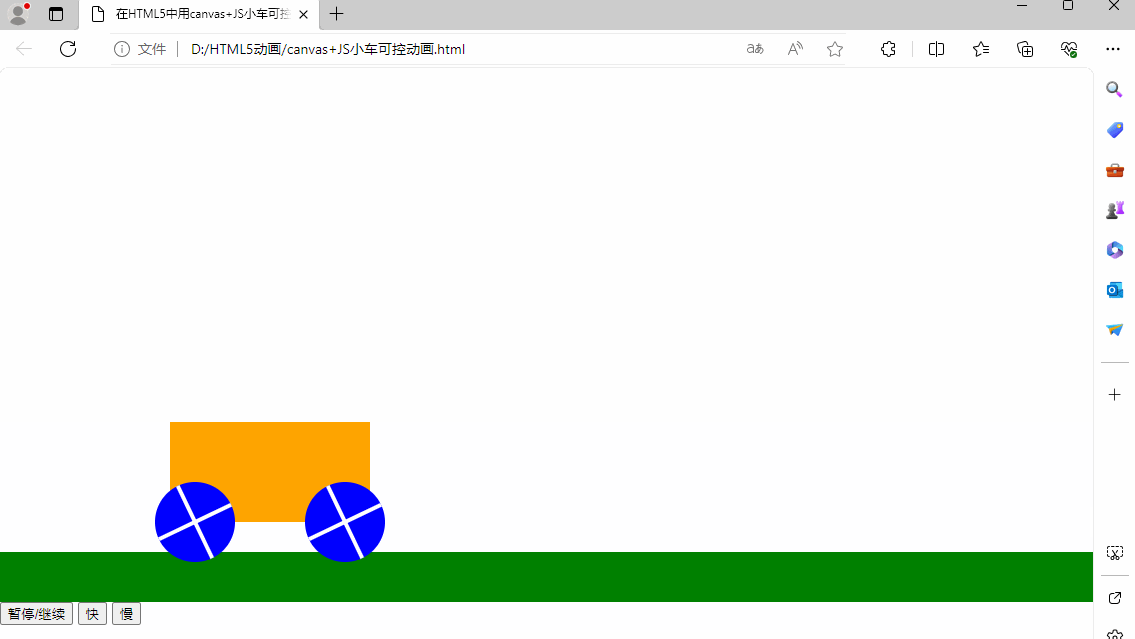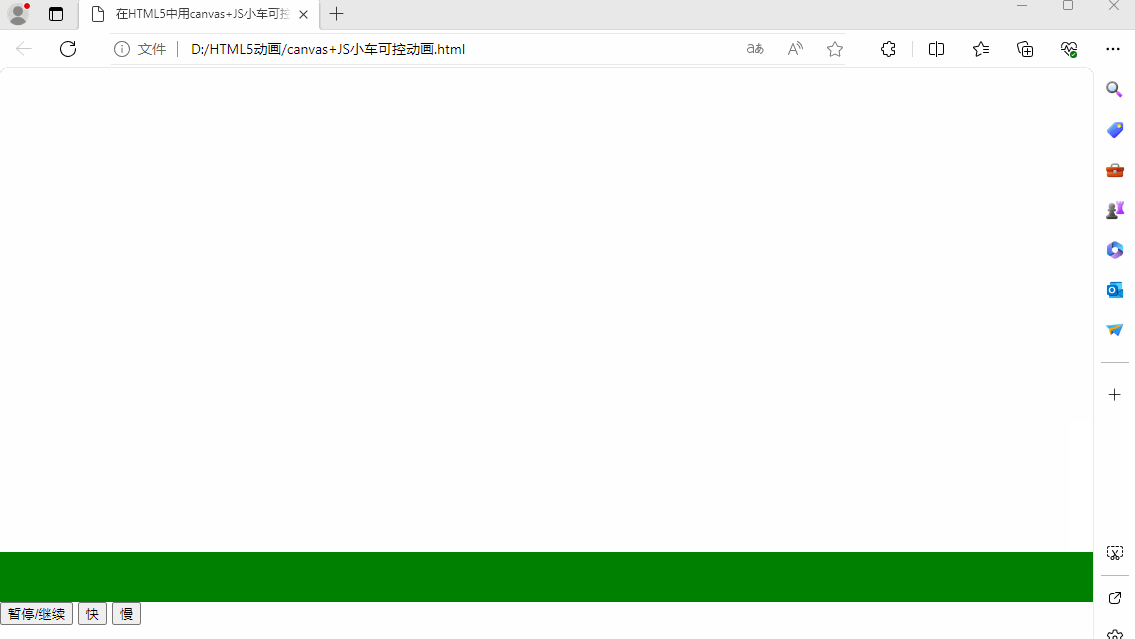
用HTML5实现动画
用HTML5实现动画 要在HTML5中实现动画,可以使用以下几种方法:CSS动画、使用<canvas>元素和JavaScript来实现动画、使用JavaScript动画库。重点介绍前两种。 一、CSS动画 CSS3 动画:使用CSS3的动画属性和关键帧(keyframes&…...

【Linux笔记】进程间通信之管道
一、匿名管道 我们在之前学习进程的时候就知道了一个概念,就是进程间是互相独立的,所以就算是两个进程是父子关系,其中一个进程退出了也不会影响另一个进程。 也因为进程间是互相独立的,所以两个进程间就不能直接的传递信息或者…...
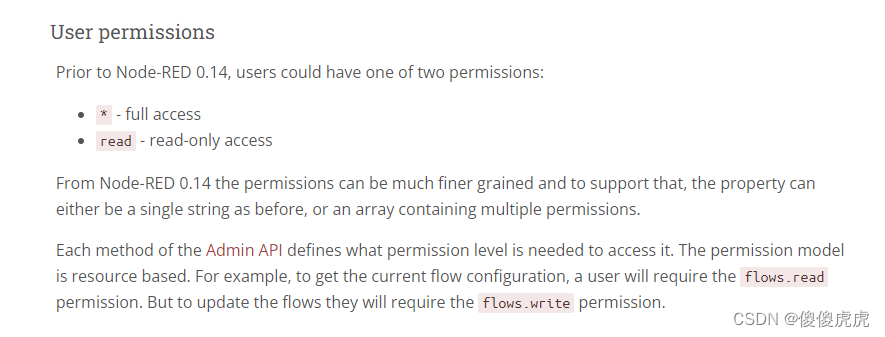
【Node-RED】安全登陆时,账号密码设置
【Node-RED】安全登陆时,账号密码设置 前言实现步骤密码生成setting.js 文件修改 安全权限 前言 Node-RED 在初始下载完成时,登录是无账号密码的。基于安全性考虑,本期博文介绍在安全登陆时,如何进行账号密码设置。当然ÿ…...
-k8s的服务发现机制)
Kubernetes基础(二十一)-k8s的服务发现机制
1 概述 Kubernetes(K8s)是一个强大的容器编排平台,提供了丰富的功能来简化容器化应用的管理。其中之一重要的特性就是服务发现机制,它使得应用程序能够在K8s集群中动态地发现和访问其他服务。本文将深入研究K8s中的服务发现机制&…...

华纳云:docker更新容器镜像的常用方法
更新 Docker 容器镜像可以通过以下几种方法实现: 1. 使用 docker pull 命令手动拉取更新的镜像: docker pull <镜像名>:<标签> 这会拉取指定镜像的最新版本或者指定标签的版本到本地。然后您可以停止并删除现有的容器,使用新的镜…...

什么时候会触发FullGC?描述一下JVM加载class文件的原理机制?
什么时候会触发 FullGC? 除直接调用 System.gc 外,触发 Full GC 执行的情况有如下四种。 1. 旧生代空间不足 旧生代空间只有 在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行 Full GC 后空间仍然不 足,则…...
)
从云服务器到树莓派:不同场景下Linux IP地址类型的管理与查看技巧(ip/nmcli实战)
从云服务器到树莓派:Linux IP地址管理的场景化实战指南在混合计算环境中工作的开发者常常面临一个看似简单却充满陷阱的问题:如何快速确定当前Linux设备的IP地址类型?这个问题在公有云、本地虚拟机和嵌入式设备等不同场景下有着截然不同的答案…...

机器学习数据集伦理实践:从批判性视角审视数据生命周期与权力结构
1. 项目概述:为什么我们需要一本批判性的机器学习数据集实践指南?如果你正在构建一个图像分类模型来识别鸟类,或者利用社交媒体数据研究哥斯达黎加的家庭,又或者你是一位艺术家,正在使用像DALL-E 2这样的模型进行创作&…...

30+个Illustrator脚本解放你的设计时间:告别重复劳动的艺术
30个Illustrator脚本解放你的设计时间:告别重复劳动的艺术 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts Adobe Illustrator是设计师的必备工具,但重复性操…...

渗透测试学习路线:从原生终端到实战靶场的系统路径
1. 这不是“速成课”,而是一张你真正能踩出脚印的地图很多人点开“渗透测试学习路线”时,心里想的是:学三个月能不能接单?能不能进红队?能不能年薪30万?我试过在2019年用两周时间刷完某平台全部CTF入门题&a…...

如何用roop-unleashed三分钟制作专业级AI换脸视频:零门槛人脸替换终极指南
如何用roop-unleashed三分钟制作专业级AI换脸视频:零门槛人脸替换终极指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 还在为复杂的AI换脸工…...

【ChatGPT脑筋急转弯生成实战指南】:20年AI工程师亲授5大提示工程心法,3步产出高智商、零冷场的原创谜题
更多请点击: https://intelliparadigm.com 第一章:ChatGPT脑筋急转弯生成实战导论 脑筋急转弯作为语言智能的微型压力测试场,天然契合大语言模型的语义推理、歧义识别与幽默生成能力。本章聚焦于利用 ChatGPT(以 OpenAI API v1 接…...

如何快速下载并配置TaoToken命令行工具实现一键接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何快速下载并配置TaoToken命令行工具实现一键接入 对于需要在本地或服务器环境接入多个大模型的开发者而言,手动配置…...

5步搭建企业级数据中台:AllData开源解决方案终极指南
5步搭建企业级数据中台:AllData开源解决方案终极指南 【免费下载链接】alldata 🔥🔥 AllData可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为工厂,以大模型应用为上游产品&…...

Thorium浏览器深度解析:如何通过编译优化实现300%性能提升的技术革命
Thorium浏览器深度解析:如何通过编译优化实现300%性能提升的技术革命 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards …...

高效Android刷机工具实战指南:Fastboot Enhance让复杂操作简单化
高效Android刷机工具实战指南:Fastboot Enhance让复杂操作简单化 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 在Android设备管理和…...