OpenAI:Sora视频生成模型技术报告(中文)
概述
视频生成模型作为世界模拟器
我们探索视频数据生成模型的大规模训练。具体来说,我们在可变持续时间、分辨率和宽高比的视频和图像上联合训练文本条件扩散模型。我们利用transformer架构,在视频和图像潜在代码的时空补丁上运行。我们最大的模型Sora能够生成一分钟的高保真视频。我们的结果表明,缩放视频生成模型是构建物理世界通用模拟器的一条有希望的道路。
本技术报告侧重于(1)我们将所有类型的视觉数据转换为统一表示的方法,以便对生成模型进行大规模训练,以及(2)对Sora的能力和局限性的定性评估。本报告不包括模型和实施细节。
之前的许多工作都使用各种方法研究了视频数据的生成建模,包括循环网络、生成对抗网络、自回归变压和扩散模型。这些作品通常侧重于狭义的视觉数据类别、较短的视频或固定大小的视频。Sora是视觉数据的通用模型——它可以生成跨越不同持续时间、宽高比和分辨率的视频和图像,长达一整分钟的高清视频。
1、将视觉数据转化为补丁
我们从大型语言模型中汲取灵感,这些模型通过互联网规模的数据培训获得通才能力。LLM范式的成功部分得益于使用令牌,这些令牌优雅地统一了文本的多种模式——代码、数学和各种自然语言。在这项工作中,我们考虑了视觉数据的生成模型如何继承这些好处。LLM有文本令牌,而Sora有视觉补丁。补丁以前已被证明是视觉数据模型的有效表示。我们发现,补丁是一种高度可扩展和有效的表示,用于训练不同类型的视频和图像的生成模型。

在高水平上,我们通过首先将视频压缩到低维的潜在空间,然后将表示分解为时空补丁,将视频变成补丁 。
2、视频压缩网络
我们训练一个减少视觉数据维度的网络。这个网络将原始视频作为输入,并输出一个在时间和空间上压缩的潜在表示。Sora接受训练,并随后在这个压缩的潜在空间中生成视频。我们还训练了一个相应的解码器模型,将生成的潜能映射回像素空间。
3、时空潜伏补丁
给定一个压缩的输入视频,我们提取一系列作为变压器令牌的时空补丁。此方案也适用于图像,因为图像只是单帧的视频。我们基于补丁的表示使Sora能够对可变分辨率、持续时间和宽高比的视频和图像进行训练。在推理时,我们可以通过在适当大小的网格中排列随机初始化的补丁来控制生成的视频的大小。
4、用于视频生成的缩放transformers
Sora是一个扩散模型给定输入嘈杂的补丁(以及文本提示等调理信息),它经过训练来预测原始的“干净”补丁。重要的是,Sora是一个Diffusion transformer。transformer在各个领域都表现出了显著的缩放特性,包括语言建模、计算机视觉和图像生成。

在这项工作中,我们发现扩散变压器作为视频模型也能有效扩展。下面,随着培训的进行,我们展示了视频样本与固定种子和输入的比较。随着训练计算的提高,样本质量显著提高。
5、可变持续时间、分辨率、宽高比
过去的图像和视频生成方法通常将视频大小、裁剪或修剪为标准尺寸——例如,256x256分辨率的4秒视频。我们发现,以原生规模对数据进行训练会带来一些好处。
采样灵活性
Sora可以采样宽屏1920x1080p视频、垂直1080x1920视频以及介于两者之间的一切。这允许Sora直接以原生宽高比为不同设备创建内容。它还允许我们在以全分辨率生成之前,以较低的尺寸快速制作内容原型——所有这些都使用相同的模型。
改进的框架和构图
我们实证地发现,以原生宽高比进行视频训练可以改善构图和构图。我们将Sora与我们的模型版本进行比较,该模型将所有训练视频裁剪为正方形,这是训练生成模型时的常见做法。在方形作物上训练的模型(左)有时会生成视频,其中主体仅部分出现在视野中。相比之下,Sora(右)的视频改进了框架。


6、语言理解
培训文本到视频生成系统需要大量带有相应文本字幕的视频。我们将DALL·E 330中引入的重新字幕技术应用于视频。我们首先训练一个高度描述性的字幕模型,然后用它来为我们训练集中的所有视频制作文本字幕。我们发现,关于高度描述性视频字幕的培训可以提高文本保真度以及视频的整体质量。
与DALL·E 3类似,我们还利用GPT将简短的用户提示转换为发送到视频模型的更长的详细字幕。这使得Sora能够生成准确遵循用户提示的高质量视频。
7、提示图像和视频
上面和我们登录页面中的所有结果都显示了文本到视频样本。但Sora也可以通过其他输入来提示,例如预先存在的图像或视频。此功能使Sora能够执行广泛的图像和视频编辑任务——创建完美循环视频,动画静态图像,在时间上向前或向后扩展视频等。
动画DALL·E图像
Sora能够生成视频,提供图像和提示作为输入。下面我们展示了基于DALL·E 231和DALL·E 330图像生成的示例视频。
扩展生成的视频
Sora还能够向前或向后扩展视频。以下是四个视频,这些视频都从生成的视频片段开始向后扩展。因此,四个视频中的每一个的开始都与其他视频不同,但所有四个视频都导致相同的结局
我们可以使用这种方法向前和向后扩展视频,以生成无缝的无限循环。
视频到视频编辑
扩散模型使从文本提示编辑图像和视频的方法成为可能。下面我们将这些方法之一,SDEdit,应用于Sora。这项技术使Sora能够改变零拍摄输入视频的风格和环境。
连接视频
我们还可以使用Sora在两个输入视频之间逐步插值,在具有完全不同主题和场景构图的视频之间创建无缝过渡。在下面的示例中,中间的视频在左侧和右侧的相应视频之间插值。
8、图像生成能力
Sora也能够生成图像。我们通过在时间范围为一帧的空间网格中排列高斯噪声补丁来做到这一点。该模型可以生成可变尺寸的图像——分辨率高达2048x2048。

秋天一个女人的特写肖像照,极端细节,浅景深

充满活力的珊瑚礁充斥着五颜六色的鱼类和海洋生物
9、新兴的模拟能力
我们发现,视频模型在大规模训练时表现出许多有趣的紧急能力。这些能力使Sora能够从物理世界中模拟人、动物和环境的某些方面。这些属性在3D、物体等没有任何明确的感应偏导的情况下出现——它们纯粹是规模现象。
3D一致性。Sora可以生成具有动态相机运动的视频。随着相机的移动和旋转,人物和场景元素在三维空间中始终如一地移动
长期连贯性和对象持久性。视频生成系统面临的一个重大挑战是在采样长视频时保持时间一致性。我们发现Sora通常(尽管并非总是如此)能够有效地模拟短期和长期依赖关系。例如,我们的模型可以持续存在人、动物和物体,即使它们被遮挡或离开框架。同样,它可以在单个样本中生成同一角色的多个镜头,在整个视频中保持其外观。
与世界互动。Sora有时可以以简单的方式模拟影响世界状态的行为。例如,画家可以沿着画布留下新的笔触,这些笔触会随着时间的推移而持续下去,或者一个男人可以吃一个汉堡并留下咬痕。
模拟数字世界。Sora还能够模拟人工过程——一个例子是电子游戏。Sora可以同时用基本策略控制《我的世界》中的玩家,同时以高保真度渲染世界及其动态。通过提示Sora的标题提及“Minecraft”,可以激发这些功能。
这些能力表明,视频模型的持续扩展是开发物理和数字世界以及生活在其中的物体、动物和人的高性能模拟器的一条有希望的道路。
讨论
Sora目前作为模拟器表现出许多局限性。例如,它没有准确模拟许多基本相互作用的物理学,比如玻璃破碎。其他相互作用,如吃食物,并不总是能产生物体状态的正确变化。我们在登陆页面中列举了模型的其他常见故障模式,例如在长时间样本中形成的不一致性或物体的自发出现。
我们相信,Sora今天的能力表明,视频模型的持续扩展是开发物理和数字世界以及生活在其中的物体、动物和人的强大模拟器的一条有希望的道路。
参考文献
-
Srivastava、Nitish、Elman Mansimov和Ruslan Salakhudinov。使用lstms无监督地学习视频表示。机器学习国际会议。PMLR,2015年。↩︎
 https://openai.com/research/video-generation-models-as-world-simulators#ref-1-0
https://openai.com/research/video-generation-models-as-world-simulators#ref-1-0 -
Chiappa,Silvia等人。循环环境模拟器。arXiv预印本arXiv:1704.02254(2017)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-2-0 -
Ha、David和Jürgen Schmidhuber。世界模型。arXiv预印本arXiv:1803.10122(2018)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-3-0 -
Vondrick、Carl、Hamed Pirsiavash和Antonio Torralba。生成具有场景动态的视频。神经信息处理系统的进展29(2016)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-4-0 -
Tulyakov,Sergey等人。Mocogan:为视频生成分解运动和内容。IEEE计算机视觉和模式识别会议记录。2018年。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-5-0 -
Clark、Aidan、Jeff Donahue和Karen Simonyan。“复杂数据集上的对抗性视频生成。”arXiv预印本arXiv:1907.06571(2019)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-6-0 -
布鲁克斯,蒂姆,等人。生成动态场景的长视频。神经信息处理系统的进展35(2022):31769-31781。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-7-0 -
Yan,Wilson等人。Videogpt:使用vq-vae和变压器生成视频。arXiv预印本arXiv:2104.10157(2021)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-8-0 -
Wu,Chenfei等人。Nüwa:神经视觉世界创造的视觉合成预训练。欧洲计算机视觉会议。Cham:Springer Nature Switzerland,2022年。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-9-0 -
Ho,Jonathan等人。图像视频:带有扩散模型的高清视频生成。arXiv预印本arXiv:2210.02303(2022)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-10-0 -
布拉特曼,安德烈亚斯等人。调整您的潜在信号:高分辨率视频合成与潜在扩散模型保持一致。IEEE/CVF计算机视觉和模式识别会议记录。2023.↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-11-0 -
Gupta, Agrim, et al.带有扩散模型的逼真视频生成。arXiv预印本arXiv:2312.06662(2023)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-12-0 -
Vaswani,Ashish,等。注意力就是你所需要的。神经信息处理系统的进展30(2017)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-13-0↩︎https://openai.com/research/video-generation-models-as-world-simulators#ref-13-1 -
布朗、汤姆等人。语言模型是很少的学习者。神经信息处理系统的进展33(2020):1877-1901。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-14-0↩︎https://openai.com/research/video-generation-models-as-world-simulators#ref-14-1 -
Dosovitskiy,Alexey等人。一张图像价值16x16字:用于大规模图像识别的变形金刚。arXiv预印本arXiv:2010.11929(2020)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-15-0↩︎https://openai.com/research/video-generation-models-as-world-simulators#ref-15-1 -
Arnab,Anurag等。Vivit:一个视频视觉变压器。IEEE/CVF计算机视觉国际会议记录。2021年。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-16-0↩︎https://openai.com/research/video-generation-models-as-world-simulators#ref-16-1 -
他,凯明等人。蒙面自动编码器是可扩展的视觉学习者。IEEE/CVF计算机视觉和模式识别会议记录。2022.↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-17-0↩︎https://openai.com/research/video-generation-models-as-world-simulators#ref-17-1 -
Dehghani,Mostafa等人。Patch n'Pack:NaViT,适用于任何宽高比和分辨率的视觉变压器。arXiv预印本arXiv:2307.06304(2023)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-18-0↩︎ -
Rombach,Robin,等人。带有潜在扩散模型的高分辨率图像合成。IEEE/CVF计算机视觉和模式识别会议记录。2022.↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-19-0 -
Kingma、Diederik P.和Max Welling。自动编码变体贝叶斯。arXiv预印本arXiv:1312.6114(2013)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-20-0 -
Sohl-Dickstein,Jascha等人。使用非平衡热力学进行深度无监督学习。机器学习国际会议。PMLR,2015年。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-21-0 -
Ho、Jonathan、Ajay Jain和Pieter Abbeel。去诺化扩散概率模型。神经信息处理系统的进展33(2020):6840-6851。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-22-0 -
Nichol、Alexander Quinn和Prafulla Dhariwal。改进了去消化扩散概率模型。机器学习国际会议。PMLR,2021年。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-23-0 -
Dhariwal、Prafulla和Alexander Quinn Nichol。扩散模型在图像合成上击败了GAN。神经信息处理系统的进展。2021年。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-24-0 -
Karras,Tero等人。阐明基于扩散的生成模型的设计空间。神经信息处理系统的进展35(2022):26565-26577。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-25-0 -
Peebles、William和Saining Xie。带有变压器的可扩展扩散模型。IEEE/CVF计算机视觉国际会议记录。2023.↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-26-0 -
Chen、Mark等人。从像素生成预训练。机器学习国际会议。PMLR,2020年。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-27-0 -
Ramesh,Aditya等人。零镜头文本到图像生成。机器学习国际会议。PMLR,2021年。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-28-0 -
Yu,Jiahui等人。缩放内容丰富的文本到图像生成的自动回归模型。arXiv预印本arXiv:2206.10789 2.3(2022):5。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-29-0 -
Betker,James等人。用更好的字幕改善图像生成。计算机科学。https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-30-0↩︎https://openai.com/research/video-generation-models-as-world-simulators#ref-30-1 -
Ramesh,Aditya等人。带有剪辑潜在物的分层文本条件图像生成。arXiv预印本arXiv:2204.06125 1.2(2022):3。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-31-0 -
Meng,Chenlin等人。Sdedit:使用随机微分方程进行引导图像合成和编辑。arXiv预印本arXiv:2108.01073(2021)。↩︎
https://openai.com/research/video-generation-models-as-world-simulators#ref-32-0
相关文章:
OpenAI:Sora视频生成模型技术报告(中文)
概述 视频生成模型作为世界模拟器 我们探索视频数据生成模型的大规模训练。具体来说,我们在可变持续时间、分辨率和宽高比的视频和图像上联合训练文本条件扩散模型。我们利用transformer架构,在视频和图像潜在代码的时空补丁上运行。我们最大的模型Sor…...
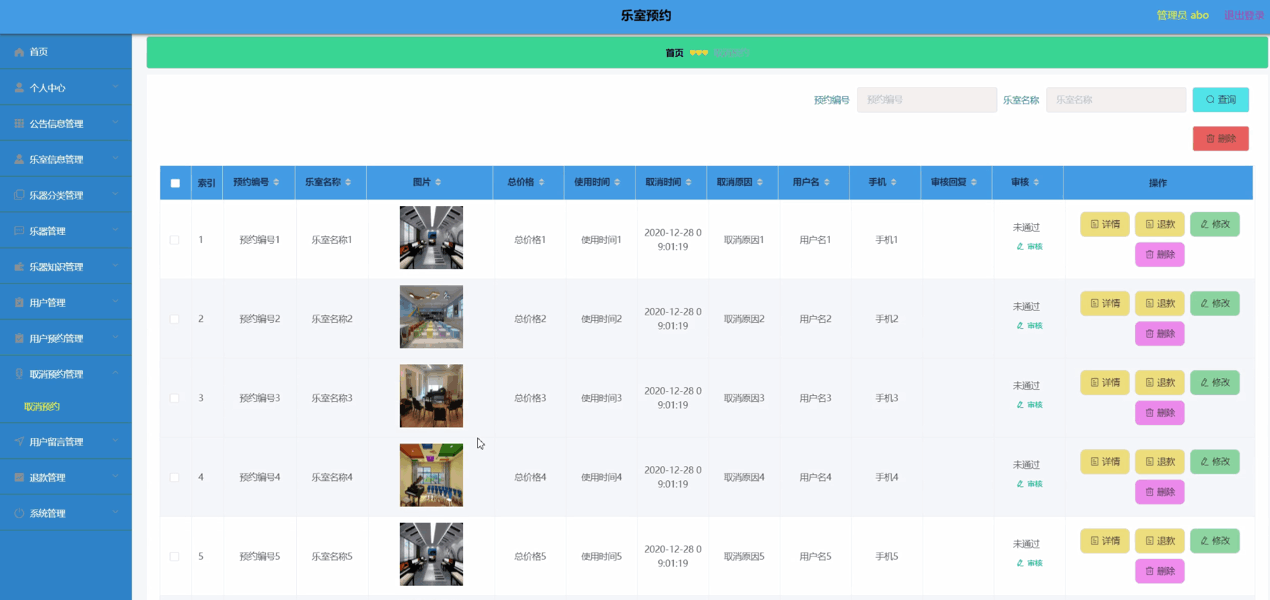
Java基于微信小程序的乐室预约小程序,附源码
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
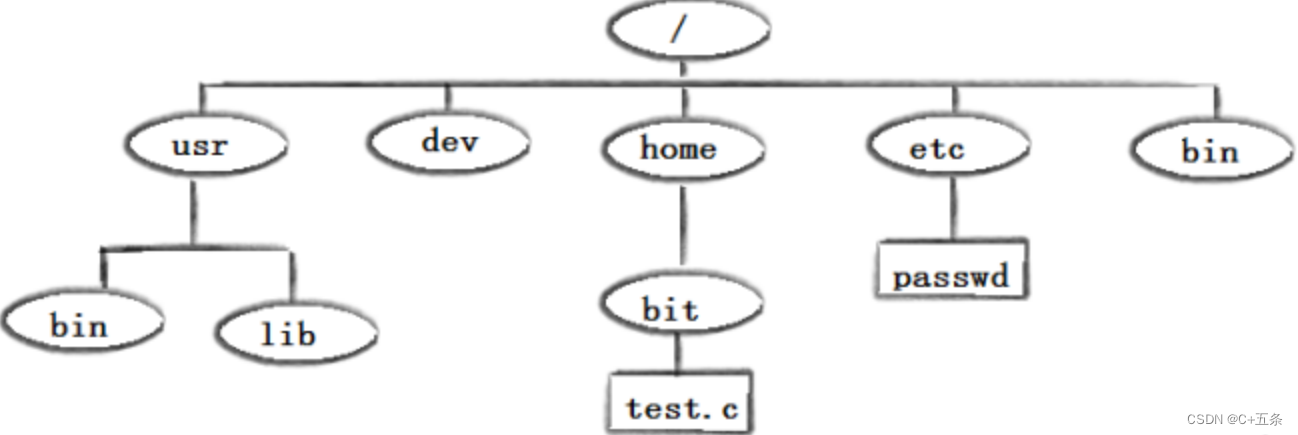
Linux常见指令(一)
目录 一、基本指令 1.1ls指令 1.2pwd指令 1.3cd指令 1.4touch指令 1.5mkdir指令 1.6rmdir指令、rm指令 1.7man指令 1.8cp指令 1.9mv指令 1.10cat 一、基本指令 1.1ls指令 语法 : ls [ 选项 ][ 目录或文件 ] 功能:对于目录,该命令…...

大端和小端传输字节完整版
大端和小端传输字节序 大端和小端一、最高有效位、最低有效位1.MSB(Most significant Bit)最高有效位2.LSB(Least Significant Bit)最低有效位 二、内存地址三、大端和小端四、网络字节序和主机字节序五、C#位操作符六、C#中关于大端和小端的转换七、关于负数八、关于汉字编码以…...

华为23年9月笔试原题,巨详细题解,附有LeetCode测试链接
文章目录 前言思路主要思路关于f函数的剖析Code就到这,铁子们下期见!!!! 前言 铁子们好啊!今天阿辉又给大家来更新新一道好题,下面链接是23年9月27的华为笔试原题,LeetCode上面的ha…...

ES实战--性能提升
触发冲刷的条件: 1.内存缓冲区已满 2.自上次冲刷后超过了一定时间 3.事务日志达到了一定阀值 对名为get-together的Elasticsearch索引执行优化操作,将索引中的数据段(segments)合并到指定的数量1 GET /get-together/_optimize?max_num_segm…...
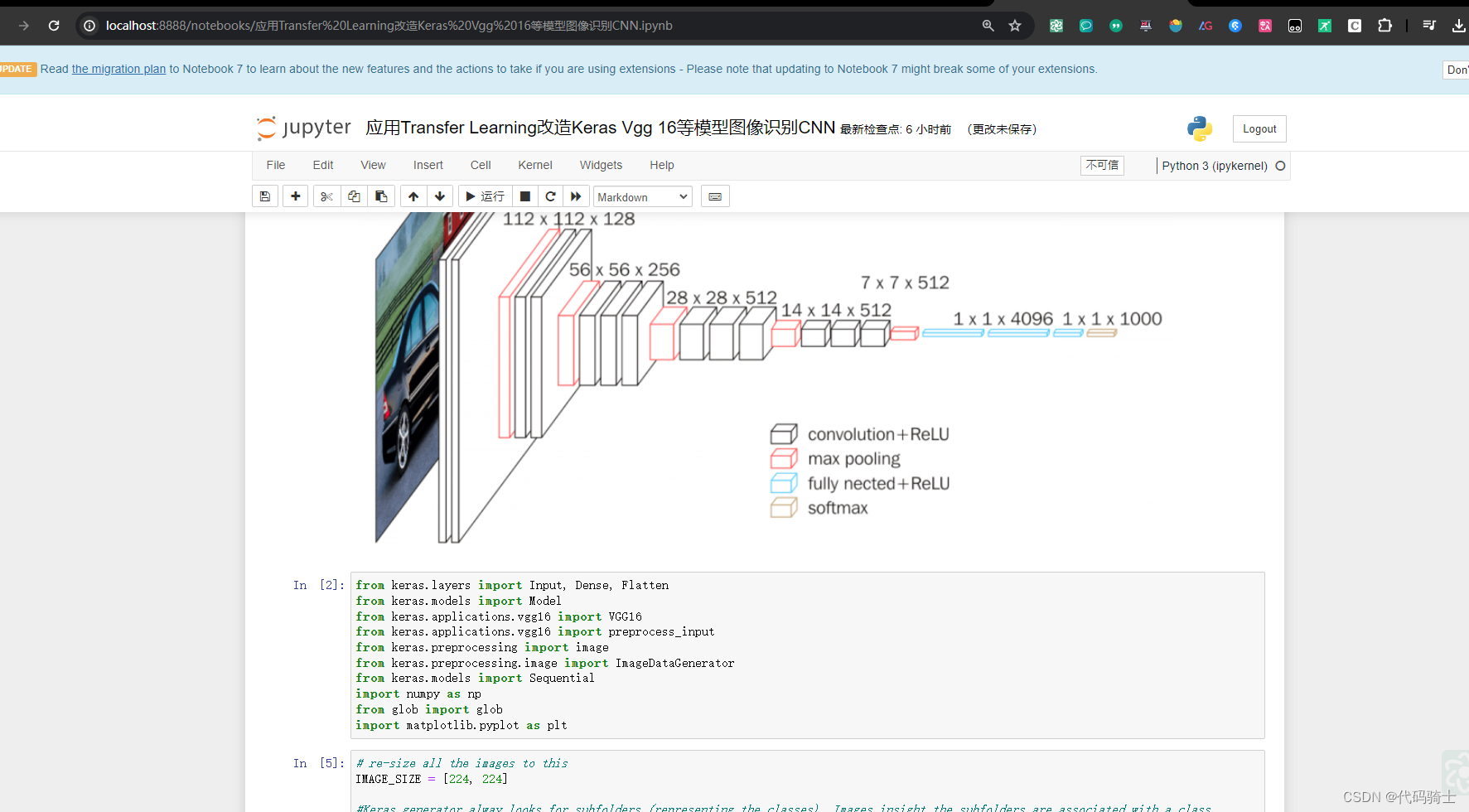
解决ModuleNotFoundError: No module named ‘pysqlite2‘
目录 一、问题描述: 二、问题分析: 三、问题解决: 四、参考文章: 一、问题描述: 在重新安装的anaconda环境中自建了一个新虚拟环境,再安装完jupyter后(pip install jupyter)&am…...
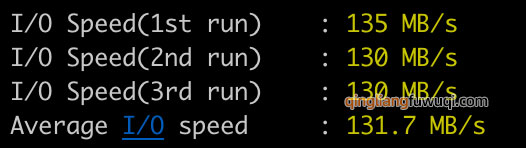
腾讯云4核8G服务器够用吗?能支持多少人?
腾讯云4核8G服务器支持多少人在线访问?支持25人同时访问。实际上程序效率不同支持人数在线人数不同,公网带宽也是影响4核8G服务器并发数的一大因素,假设公网带宽太小,流量直接卡在入口,4核8G配置的CPU内存也会造成计算…...
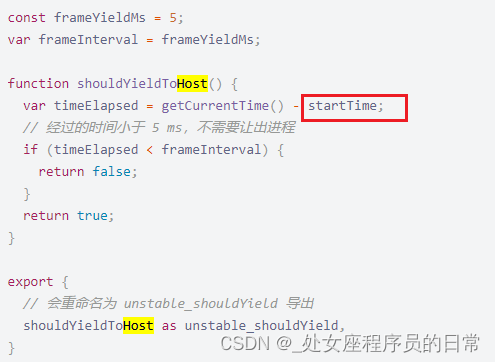
React 的调度系统 Scheduler
原文地址1 原文地址2 其中startTime是任务开始的时间,默认是-1,任务开始时将任务开始时间赋值给了startTime, 这里意思是判断这个任务执行时间是否超过5ms(写死的)。若超过,则要交出。...
微服务OAuth 2.1认证授权Demo方案(Spring Security 6)
文章目录 一、介绍二、auth微服务代码1. SecurityConfig2. UserDetailsService3. 总结 三、gateway微服务代码1. 统一处理CORS问题 四、content微服务代码1. controller2. SecurityConfig3. 解析JWT Utils4. 总结 五、一些坑 书接上文 微服务OAuth 2.1认证授权可行性方案(Sprin…...
)
WSL使用Centos7发行版(rootfs)
参考 导入要与 WSL 一起使用的任何 Linux 发行版 microsoftWSL2 的 2.0 更新彻底解决网络问题install daemon and client binaries on linuxInstall Compose standalone WSL配置 在HOST中,编辑用户目录下的.wslconfig文件 我需要使用docker,测试发现a…...

ClickHouse--04--数据库引擎、Log 系列表引擎、 Special 系列表引擎
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.数据库引擎1.1 Ordinary 默认数据库引擎1.2 MySQL 数据库引擎MySQL 引擎语法字段类型的映射 2.ClickHouse 表引擎3.Log 系列表引擎几种 Log 表引擎的共性是&#…...

docker的底层原理
概述:Docker的底层原理基于容器化技术,通过使用命名空间和控制组等技术实现资源的隔离与管理。 底层原理: 客户端-服务器架构:Docker采用的是Client-Server架构,其中Docker守护进程(daemon)运…...

有关光猫、路由器、交换机、网关的理解
前提 在了解计算机网络的过程中,出现了这四个名词:光猫、路由器、交换机、网络。有点模糊,查阅互联网相关资料,进行整理。如有错误,欢迎大家批评指正。 光猫 首先光猫是物理存在的,大家在家里应该都可以…...

图像旋转翻转变换
题目描述 给定m行n列的图像各像素点灰度值,对其依次进行一系列操作后,求最终图像。 其中,可能的操作及对应字符有如下四种: A:顺时针旋转90度; B:逆时针旋转90度; C:…...
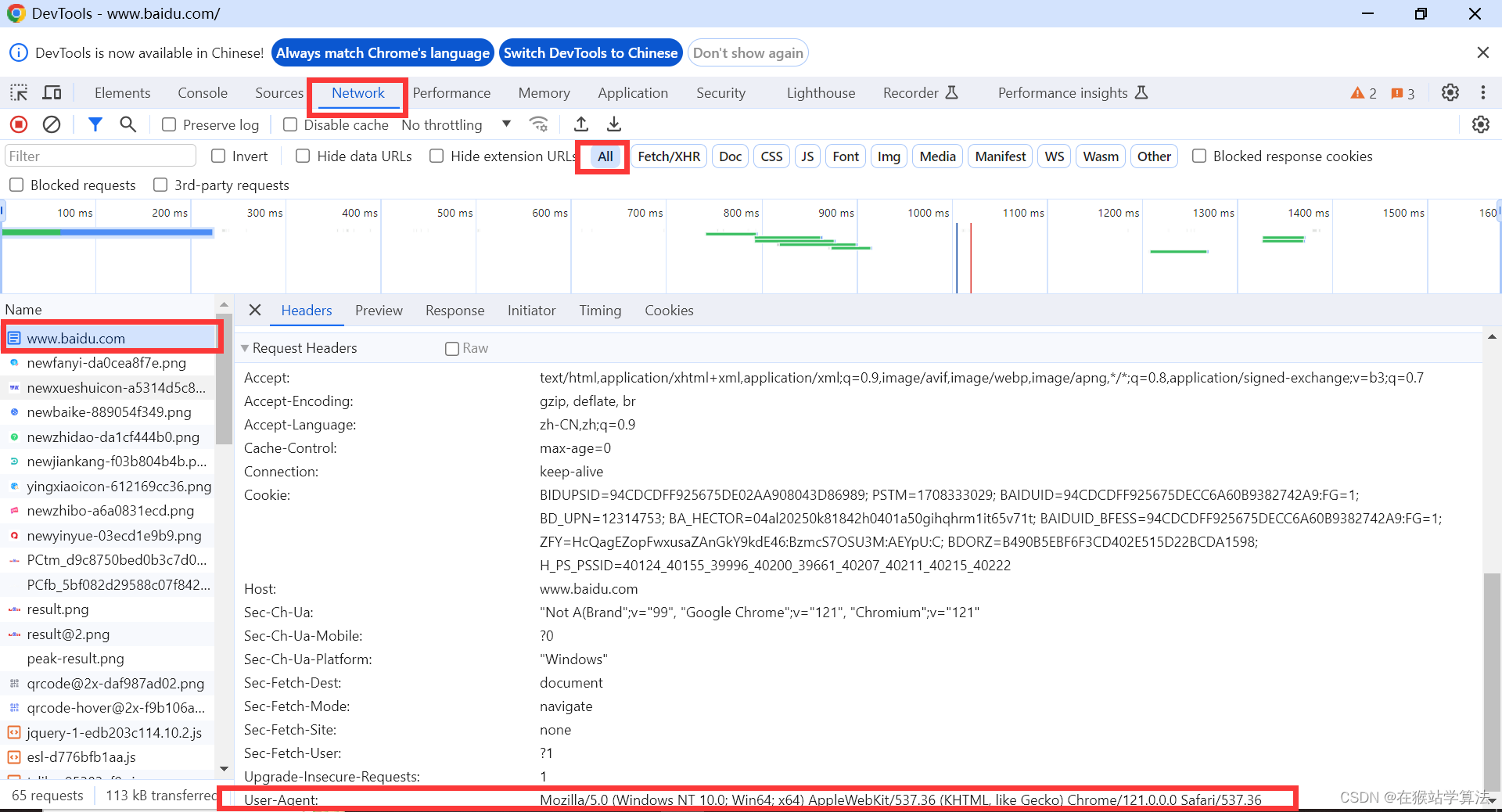
网站常见的反爬手段及反反爬思路
摘要:介绍常见的反爬手段和反反爬思路,内容详细具体,明晰解释每一步,非常适合小白和初学者学习!!! 目录 一、明确几个概念 二、常见的反爬手段及反反爬思路 1、检测user-agent 2、ip 访问频率的限制 …...

GUI—— 从的可执行exe文件中提取jar包并反编译成Java
从exe4j生成的可执行文件中提取嵌入的jar包并反编译成Java代码,可以按照以下步骤操作: 步骤1:提取jar包 1.运行exe程序:首先启动exe4j生成的.exe可执行文件。当它运行时,通常会将内部包含的jar文件解压到临时目录下。…...
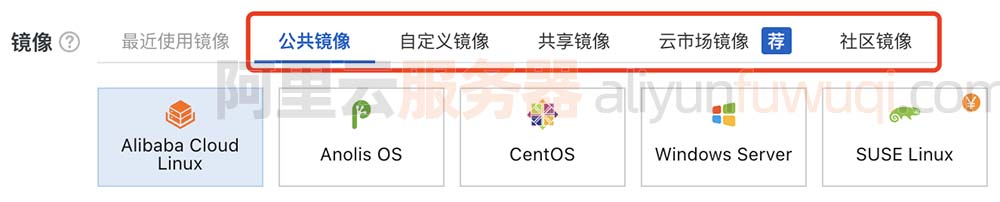
阿里云服务器镜像是什么?如何选择镜像?
阿里云服务器镜像怎么选择?云服务器操作系统镜像分为Linux和Windows两大类,Linux可以选择Alibaba Cloud Linux,Windows可以选择Windows Server 2022数据中心版64位中文版,阿里云服务器网aliyunfuwuqi.com来详细说下阿里云服务器操…...

C语言------一种思路解决实际问题
1.比赛名次问题 ABCDE参加比赛,那么每个人的名次都有5种可能,即1,2,3,4,5; int main() {int a 0;int b 0;int c 0;int d 0;int e 0;for (a 1; a < 5; a){for (b 1; b < 5; b){for…...

前端判断对象为空
一.使用JSON.stringify()方法: JSON.stringify() 是将一个JavaScript对象或值转换为JSON格式字符串,如果最终只得到一个{},就说明他是一个空对象 let obj1 {}; console.log(JSON.stringify(obj1) "{}"); //true 表示为空对象l…...

The Front 末日生存战争游戏专属服务器搭建教程
The Front 末日生存战争游戏专属服务器搭建教程 《The Front》(前线)是一款以末日废土为背景的多人生存建造游戏,玩家在充满战争气息的废土世界中采集资源、建造据点、研发科技、与其他玩家或 NPC 势力展开激烈对抗。自建专属服务器可以让你…...

CI/CD最佳实践:构建高效可靠的持续集成和部署流程
CI/CD最佳实践:构建高效可靠的持续集成和部署流程 一、CI/CD最佳实践概述 1.1 CI/CD最佳实践的定义 CI/CD最佳实践是指在持续集成和持续部署过程中遵循的一系列指导原则和方法。它通过自动化、标准化和可重复的流程,提高软件开发和部署的效率和可靠性。 …...

8个必备的数据采集工具详解,低代码爬虫~
网络爬虫是一种常见的数据采集技术,你可以从网页、 APP上抓取任何想要的公开数据,当然需要在合法前提下。 爬虫使用场景也很多,比如: 搜索引擎机器人爬行网站,分析其内容,然后对其进行排名,比…...

RMSNorm:LLM 里的归一化为什么换成了这个
本文基于昇腾CANN和昇腾NPU,围绕 ops-transformer 仓库的相关技术展开。 LayerNorm 在大模型里被 RMSNorm 替换了。LayerNorm 做了减均值再除方差,RMSNorm 只除均方根——去掉了减均值那一步。少一次 Reduce 操作,在量产推理里省掉 15-20% 的…...

【收藏干货】2026 版大模型推理底层原理拆解!吃透 Prefill/Decode 与 vLLM 核心优化
近两年大模型技术飞速迭代,全面重构了 AI 应用开发体系。日常开发中大家热议模型参数规模、Agent 智能体、多模态交互能力,可真正落地部署上线后,决定产品最终使用体验的核心,往往并非模型本身性能,而是容易被忽略的大…...
】软件工程知识点)
【软件架构师-综合题(3)】软件工程知识点
软件工程这一章围绕一个核心问题展开:软件不是靠灵感写出来的,而是要经过需求、设计、实现、验证、演化这一整条工程链路,被稳定地组织起来。 顺着这条链路去整理,第三章更适合分成六个层次来看:先看开发方法和开发模型…...


别让‘单电源供电’坑了你:运放参考电压旁路电容的选型与避坑全攻略
别让‘单电源供电’坑了你:运放参考电压旁路电容的选型与避坑全攻略 在单电源供电的运算放大器电路中,参考电压的稳定性往往决定了整个系统的性能。许多工程师习惯性地在Vcc/2分压点添加旁路电容,却不知这个看似合理的操作可能引发灾难性振荡…...

从show version到设备‘体检报告’:新手也能看懂的思科路由器健康状态自查指南
从show version到设备‘体检报告’:新手也能看懂的思科路由器健康状态自查指南 当你第一次面对思科路由器的命令行界面,输入show version后看到满屏密密麻麻的信息,是不是感觉像拿到了一份天书般的体检报告?别担心,今天…...

避开Keil开发大坑:从一次CANFD驱动调试,总结C语言数组操作的5个常见陷阱
避开Keil开发大坑:从一次CANFD驱动调试,总结C语言数组操作的5个常见陷阱 调试嵌入式系统的CANFD驱动时,一个看似简单的数组越界问题让我熬了整整三个通宵。当逻辑分析仪终于捕捉到那个幽灵般的非法内存写入时,我才意识到——在Kei…...