爬虫知识--01
爬虫介绍
# 爬虫的概念:
通过编程技术(python:request,selenium),获取互联网中的数据(app,小程序,网站),数据清洗(xpaht,lxml)后存到库中(mysql,redis,文件,excel,mongodb)
# 基本思路:
通过编程语言,模拟发送http请求,获取数据,解析,入库
# 过程:爬取过程,解析过程,会遇到反扒
抓app,小程序,会通过抓包工具(charles,Fiddler),抓取手机发送的所有请求
# 爬虫协议:
君子协议:https://xxx/robots.txt
# 百度是个大爬虫:
百度/谷歌搜索引擎,启动了一个爬虫,一刻不停的在互联网中爬取网站,存到库中(es)
用户在百度输入框中,输入搜索内容,去百度的库中搜索,返回给前端,前端点击,去了真正的地址
seo 优化:不花钱,搜索关键词的结果,排的靠前
-伪静态
sem 优化:花钱买关键词
requests模块介绍
# requests模块:模拟发送http请求模块,封装了urlib3(python内置的发送http请求的模块)
爬虫会用
后端: 向其他api接口发送请求
同步
# requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求
# 第三方: pip3 install requests
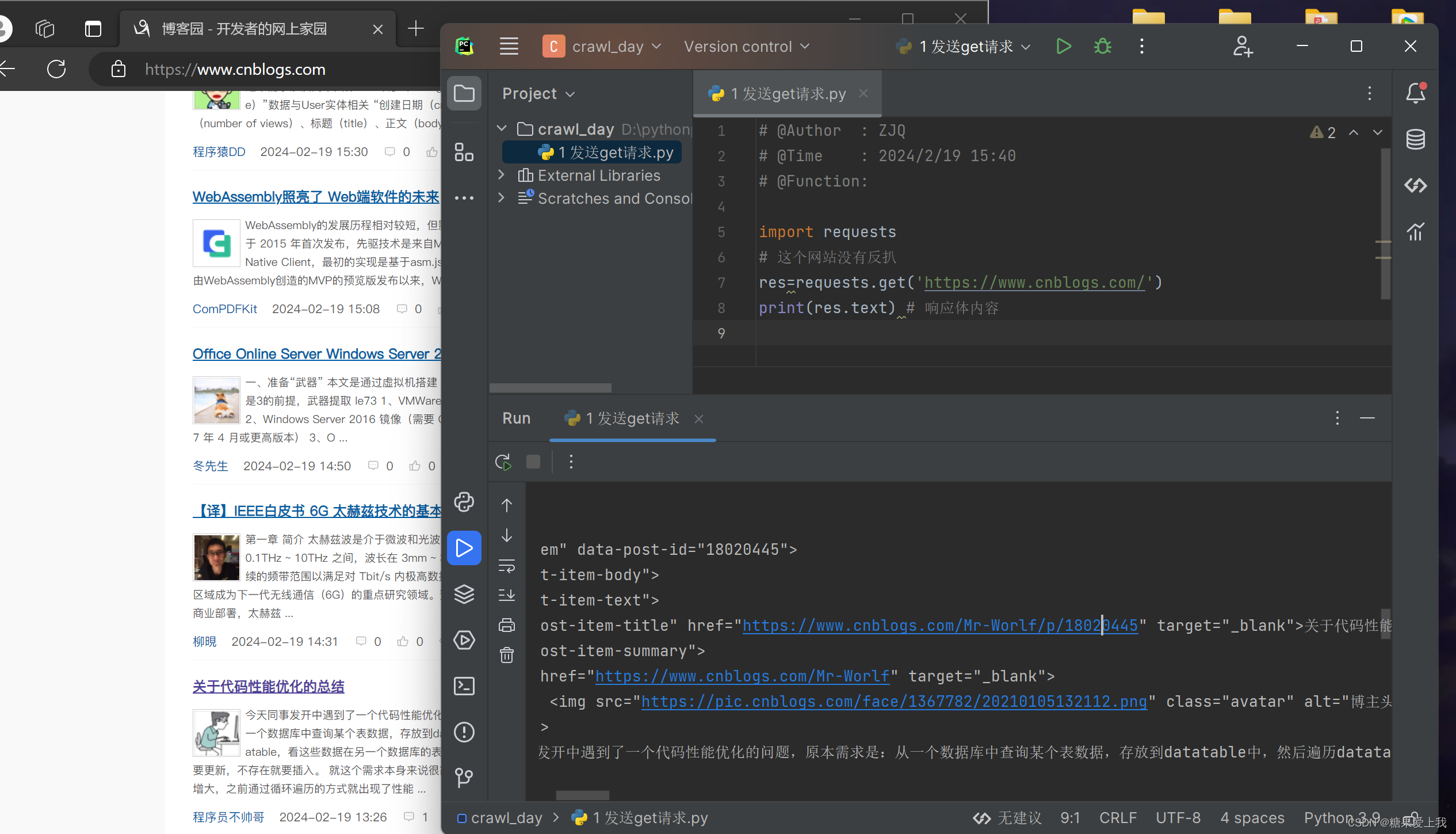
requests发送get请求
# requests可以模拟发送http请求,有的时候,网站会禁止
禁止的原因是:模拟的不像,有的东西没带
# http请求:请求头中没带东西,没带cookie,客户端类型,referer...import requests res=requests.get('https://www.cnblogs.com/') # 这个网站没有反扒 print(res.text) # 响应体内容
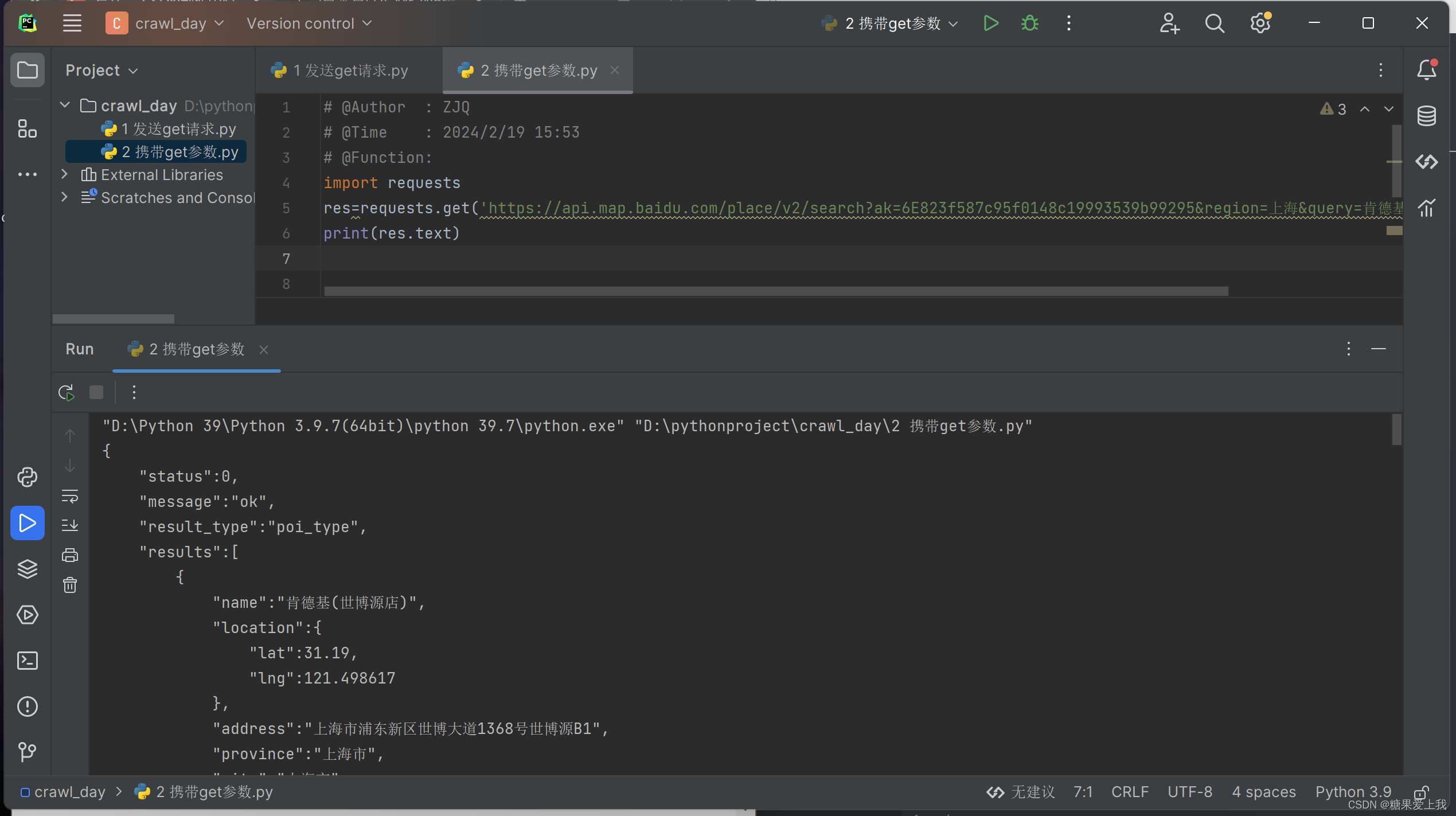
携带get参数
# 携带get参数方式一:
import requests res=requests.get('https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=上海&query=肯德基&output=json') print(res.text)# 携带get参数方式二:
import requests params = {'ak': '6E823f587c95f0148c19993539b99295','region': '上海','query': '肯德基','output': 'json', } res = requests.get('https://api.map.baidu.com/place/v2/search',params=params) print(res.text) # 响应体内容# url 编码和解码:
from urllib.parse import quote,unquote s='上海' # %E4%B8%8A%E6%B5%B7 print(quote(s)) print(unquote('%E4%B8%8A%E6%B5%B7'))
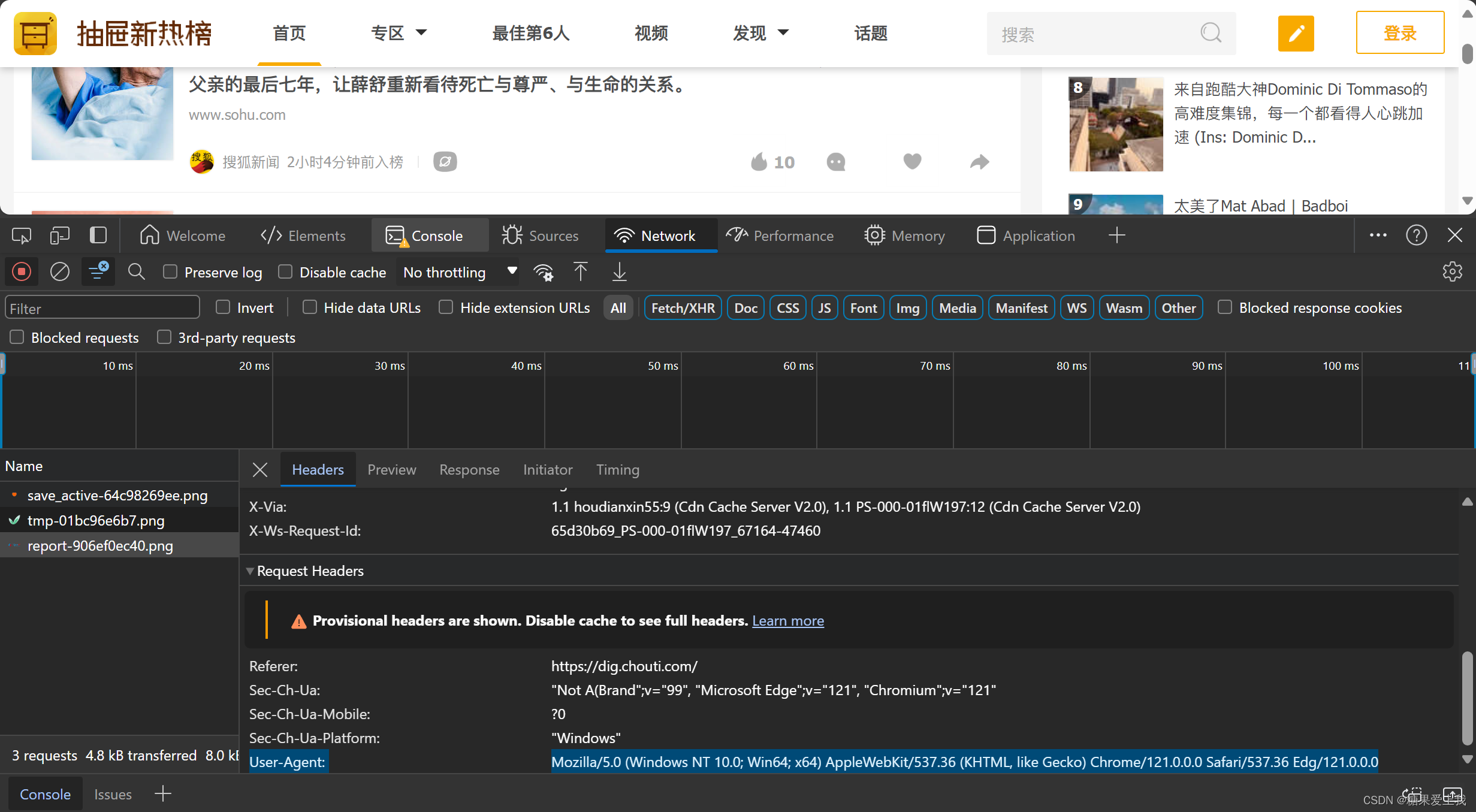
携带请求头
import requests headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } res = requests.get('https://dig.chouti.com/',headers=headers) print(res.text)
发送post请求携带cookie
# 是否登录:有个标志
前后端混合项目:登录信息-->放在cookie中了
前后端分离项目:登录信息--》后端规定的--》放在请求头的# 方式一:放在请求头中
import requests headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36','Cookie': 'deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJiNjEzOGM2OS02ZWRlLTQ3MWItODI4Yy03YTg2ZTE3M2E3NjEiLCJleHBpcmUiOiIxNzEwOTAxNjM1MTMxIn0.JluPFMn3LLUGKeTFPyw7rVwR-BWLiG9V6Ss0RGDHjxw; Hm_lvt_03b2668f8e8699e91d479d62bc7630f1=1708309636; __snaker__id=miaeDoa9MzunPIo0; gdxidpyhxdE=lMhl43kDvnAOqQQcQs9vEoTiy8k90nSwfT3DkVSzGwu3uAQWI9jqa2GcIUvryeOY0kX6kfPuhJUAGrR6ql0iv%2F6mCzqh6DHE1%5CP%2BaIXeUQgLcfqlklCcq2V9CgWbvQRGeRaduwzkcPYwf6CXZiW9a87NxU%2BRlYq57Zq01j2gMK0BaX%2FK%3A1708310847499; token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNzEwOTAxOTY5NTM2In0.eseWTCMqp-yHa7rWgSvPhnWVhhQAgqGIvIgLGbvcBcc; Hm_lpvt_03b2668f8e8699e91d479d62bc7630f1=1708309982' } data = {'linkId': '41566118' # 文章id } # 没有登录---》返回的数据不是咱们想要的 res = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data) print(res.text)# 方式二:放在cookie中
cookie特殊,后期用的频率很高
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36', } data = {'linkId': '41566118' } cookie = {'token': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNzEwOTAxOTY5NTM2In0.eseWTCMqp-yHa7rWgSvPhnWVhhQAgqGIvIgLGbvcBcc' }# 没有登录---》返回的数据不是咱们想要的 res = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data, cookies=cookie) print(res.text)
post请求携带参数
# post请求有三种编码方式:
json,urlencoded,form-data
# 方式一:data参数是urlencoded
以data字典形式携带urlencoded编码,最终会被编码为name=lqz&age=19放在请体中
import requests res=requests.post('地址',data={'name':'lqz','age':19}) # res=requests.post('地址',data=b'name=lqz&age=19')# 方式二:json编码:json
# 以json字典形式携带json编码,最终它会被编码为{'name':'lqz','age':19}放在请体中import requests res=requests.post('地址',json={'name':'lqz','age':19})
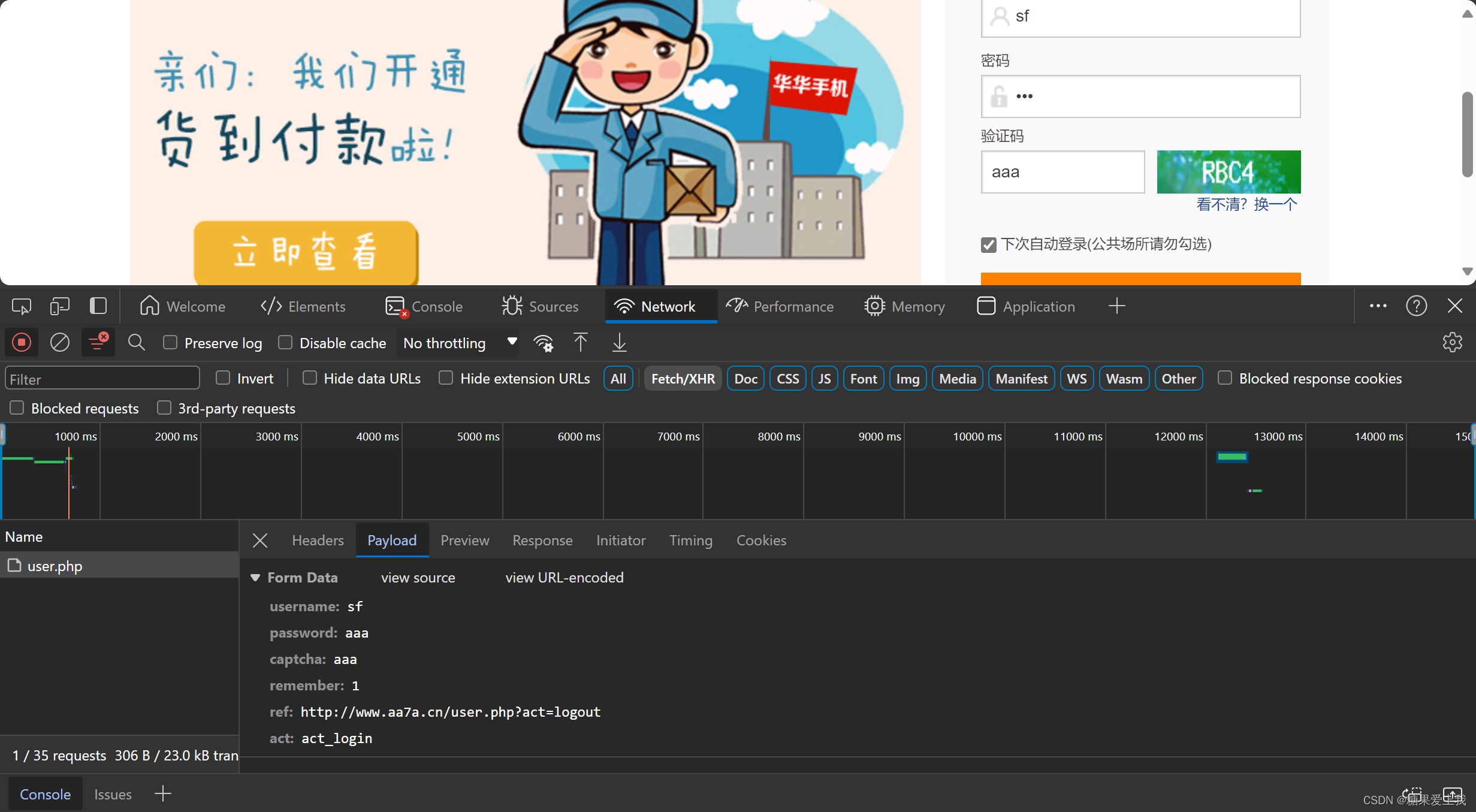
模拟登录
# 登录接口通过post请求,登录后能拿到登录信息,再发请求携带登录信息就是登录状态
可见即可爬
import requestsdata = {'username': '616564099@qq.com','password': 'lqz123','captcha': '3333','remember': '1','ref': ' http://www.aa7a.cn/', # 登录成功,重定向到这个地址'act': 'act_login', } header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } res = requests.post('http://www.aa7a.cn/user.php', headers=header, data=data) print(res.text) # 登录成功的cookie cookies=res.cookies print(cookies)# 向首页发送请求--->携带cookie便是登录状态 res=requests.get('http://www.aa7a.cn/',cookies=cookies) print('616564099@qq.com' in res.text)
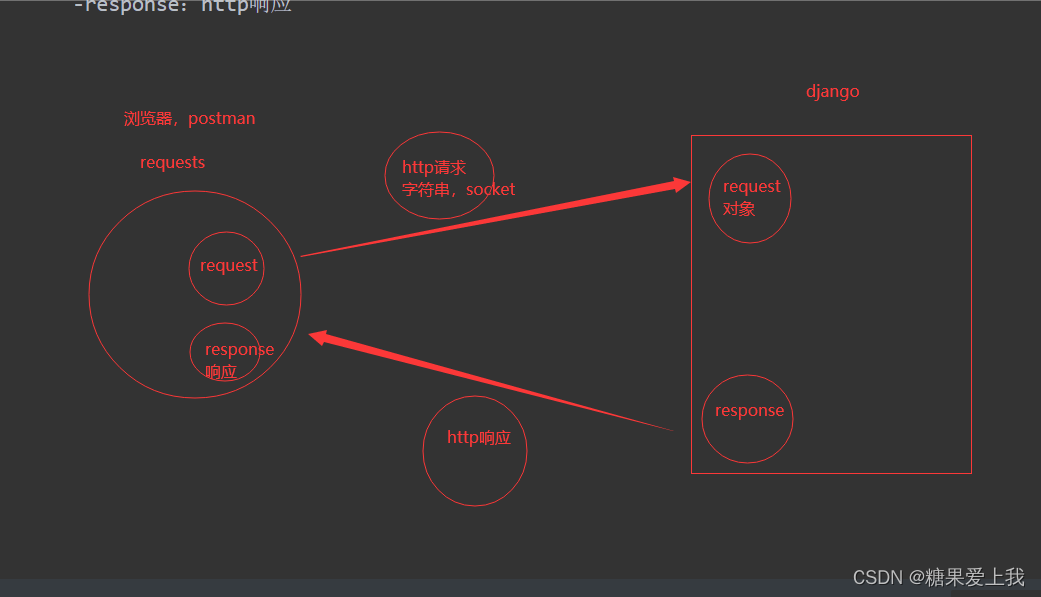
响应对象
# 使用requests模块发送请求: request对象请求头,请求参数,请求体
本质就是http请求,被包装成一个对象
# 响应回来:response对象有http响应,cookie,响应头,响应体...
request:http请求
response:http响应
# 爬取普通图片:import requests header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'} respone = requests.get('https://www.jianshu.com/',headers=header)# 如果下载图片,视频:
图片防盗链,通过referer做的,请求头中有个referer参数,上次访问的地址
import requests header={'Referer':'https://www.tupianzj.com/' } res=requests.get('https://img.lianzhixiu.com/uploads/allimg/180514/9-1P514153131.jpg',headers=header) print(res.content) with open('美女.jpg','wb') as f:f.write(res.content) # 图片,视频---》迭代着把数据保存到本地 # with open('code.jpg','wb') as f: # for line in res.iter_content(chunk_size=1024): # f.write(line)# respone属性:
print(respone.text) # 响应体---》字符串形式 print(respone.content) # 响应体---》bytes格式print(respone.status_code) # 响应状态码 print(respone.headers) # 响应头print(respone.cookies) # 响应的cookie print(respone.cookies.get_dict()) # cookiejar对象--->转成字典格式 print(respone.cookies.items()) # cookie的value值print(respone.url) # 请求地址 print(respone.history) # 访问历史---》重定向,才会有print(respone.encoding) # 编码格式response.iter_content() # 图片,视频---》迭代着把数据保存到本地
ssl 认证
# http和 https:
http:超文本传输协议
https:安全的超文本传输协议,防止被篡改,截取...
https=http+ssl/tls
必须有证书:才能通信import requestsheader = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } respone = requests.get('https://www.jianshu.com/',headers=header,verify=False) # respone = requests.get('https://www.jianshu.com/',headers=header,cert=('/path/server.crt','/path/key')) print(respone.text)
使用代理
# 代理有正向代理和向代理
# 大神写了开源的免费代理:
原理:有些网站提供免费的代理,通过爬虫技术爬取别人的免费代理,验证过后自己用
加入自己的id访问不了,可以使用免费代理生成id再去访问
import requestsres = requests.get('http://demo.spiderpy.cn/get/?type=https') print(res.json()) print(res.json()['proxy'])# 112.30.155.83:12792 header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } # respone = requests.get('https://www.jianshu.com/', headers=header, proxies={'https': res.json()['proxy']}) respone = requests.get('https://www.jianshu.com/', headers=header) print(respone.text)
超时设置,异常处理,上传文件
# 超时:
import requests respone=requests.get('https://www.baidu.com',timeout=0.0001) print(respose.text)# 异常处理:
import requests from requests.exceptions import * #可以查看requests.exceptions获取异常类型 try:r=requests.get('http://www.baidu.com',timeout=0.00001) except RequestException:print('Error') # except ConnectionError: #网络不通 # print('-----') # except Timeout: # print('aaaaa')# 上传文件:
import requests files={'file':open('a.jpg','rb')} respone=requests.post('http://httpbin.org/post',files=files) print(respone.status_code)
今日思维导图:
相关文章:
爬虫知识--01
爬虫介绍 # 爬虫的概念: 通过编程技术(python:request,selenium),获取互联网中的数据(app,小程序,网站),数据清洗(xpaht,lxml)后存到库中(mysql,redis,文件,excel&#x…...
【Azure 架构师学习笔记】- Azure Databricks (7) --Unity Catalog(UC) 基本概念和组件
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Databricks】系列。 接上文 【Azure 架构师学习笔记】- Azure Databricks (6) - 配置Unity Catalog 前言 在以前的Databricks中,主要由Workspace和集群、SQL Warehouse组成, 这两年Databricks公…...
react【六】 React-Router 路由
文章目录 1、Router1.1 路由1.2 认识React-Router1.3 Link和NavLink1.4 Navigate1.5 Not Found页面配置1.6 路由的嵌套1.7 手动路由的跳转1.7.1 在函数式组件中使用hook1.7.2 在类组件中封装高阶组件 1.8 动态路由传递参数1.9 路由的配置文件以及懒加载 1、Router 1.1 路由 1.…...
AUTOSAR CP--chapter7从CAN网络学习Autosar通信
从CAN网络学习Autosar通信 前言缩写词CAN通信在AUTOSAR架构中的传输上位机配置 第六章总结:学习了如何使用工具的自动配置功能,位我们生成系统描述中部分ecu的BSW模块配置,但是自动配置的功能虽然为我们提供了极大的便利,我们仍然…...
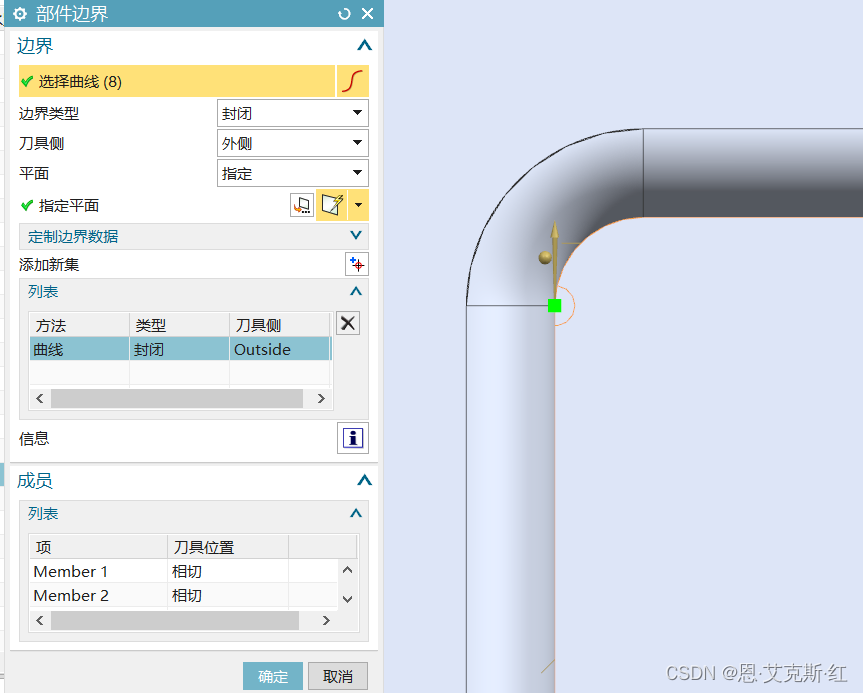
NX/UG二次开发—CAM—平面铣边界准确设置方法
大家在对平面铣设置边界时,经常遇到边界方向与自己期望的不一致,有些人喜欢用检查刀路是否过切来判断,但是对于倒角、负余量等一些情况,刀路本来就是过切的。对于多边界,可以根据选择的曲线来起点和面的方向来确定&…...
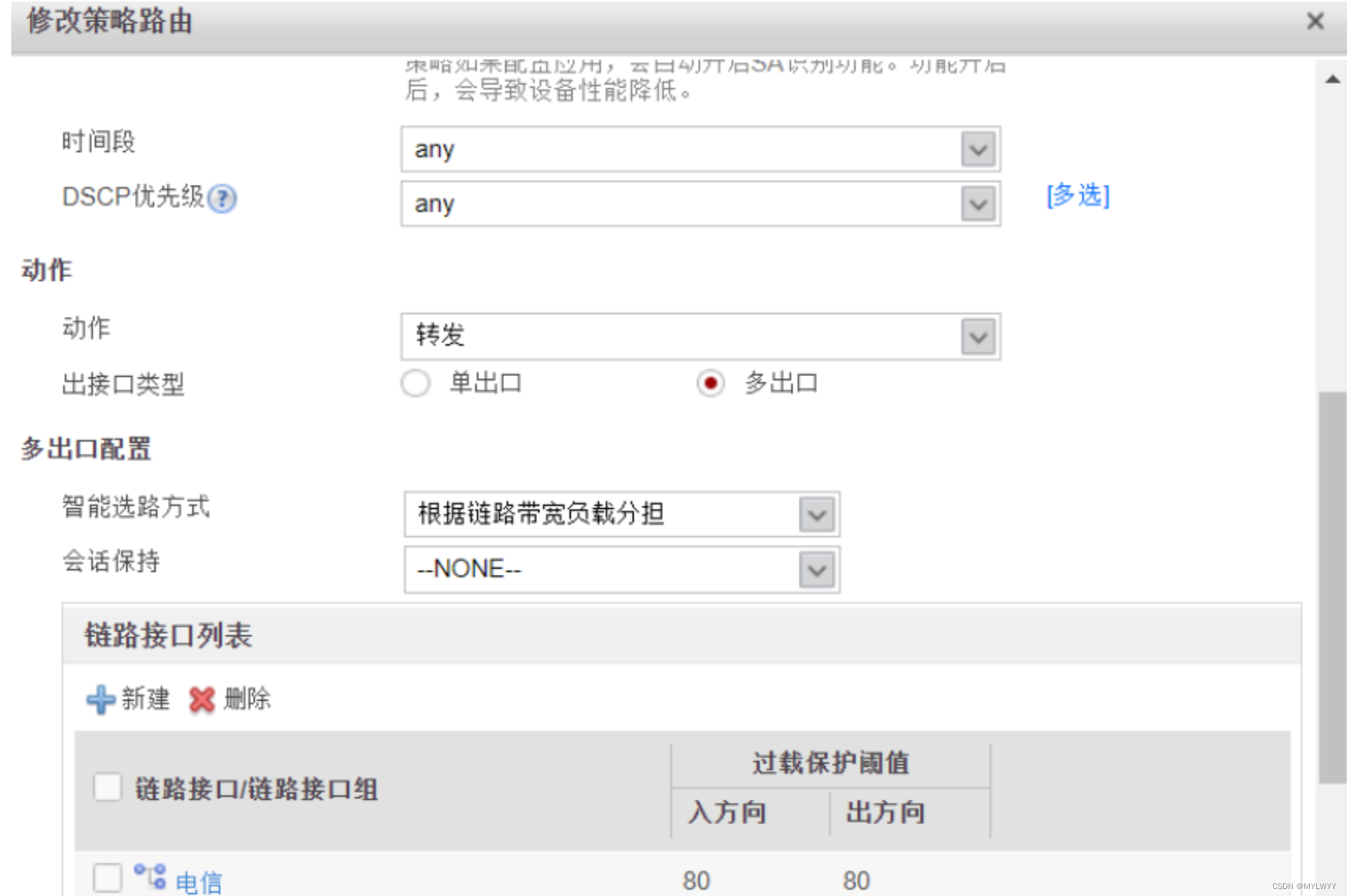
网络安全综合实验
1.实验拓扑 在这里注意因为第四个要求配置双击热备,我们可以第一时间配置,避免二次重复配置消耗时间 4、FW1和FW3组成主备模式的双机热备 具体配置位置在系统-->高可靠性-->双机热备-->配置 这里上行链路有两组,分别为电信和移动&…...
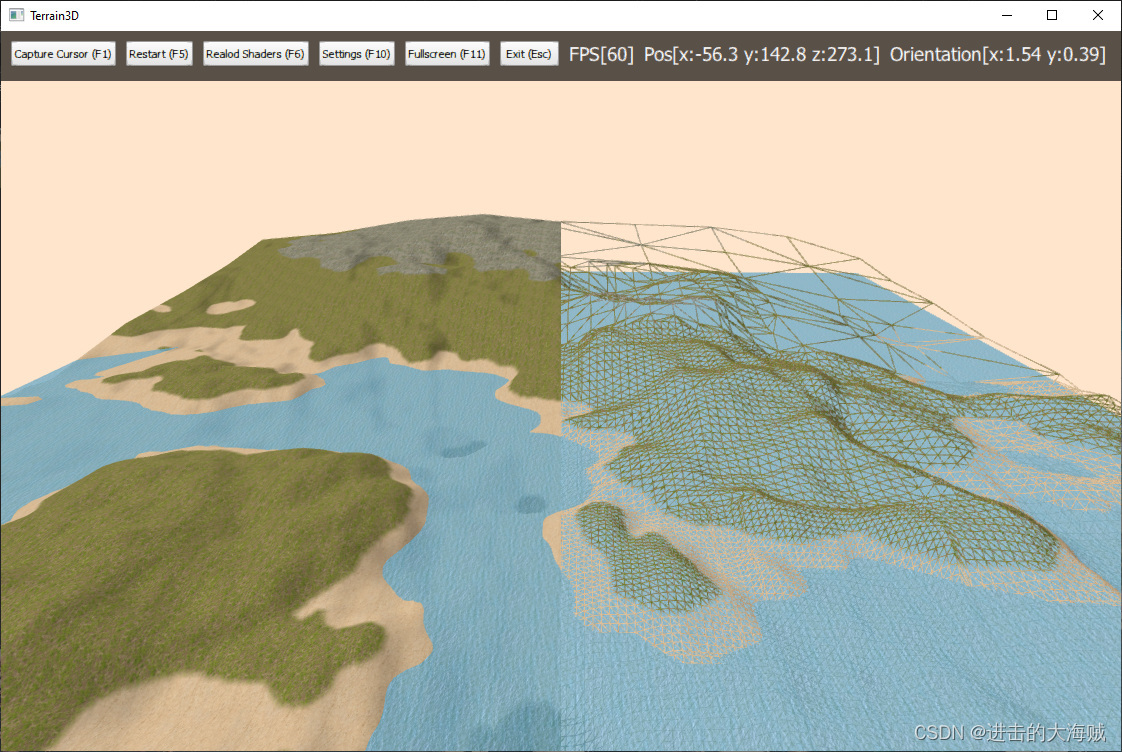
QT-地形3D
QT-地形3D 一、 演示效果二、关键程序三、下载链接 一、 演示效果 二、关键程序 #include "ShaderProgram.h"namespace t3d::core {void ShaderProgram::init() {initializeOpenGLFunctions();loadShaders(); }void ShaderProgram::addShader(const QString &fil…...
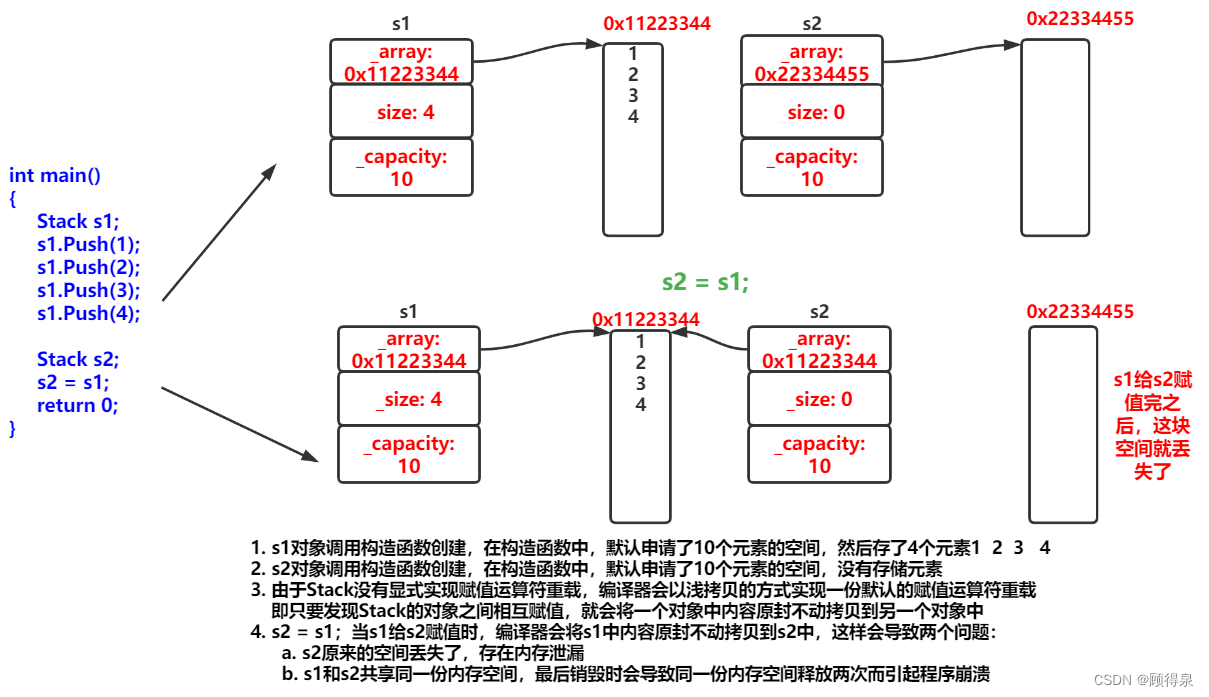
C++拷贝构造函数与赋值运算符重载
顾得泉:个人主页 个人专栏:《Linux操作系统》 《C从入门到精通》 《LeedCode刷题》 键盘敲烂,年薪百万! 一、拷贝构造函数 1.概念 在现实生活中,可能存在一个与你一样的自己,我们称其为双胞胎。 那在创…...

全球各国海外媒体发稿新闻营销推广,英美德意法俄日韩多语言
【本篇由言同数字科技有限公司原创】随着全球市场化程度的加深,品牌出海成为越来越多企业的战略选择。而全球各国媒体的发稿,为品牌出海提供了重要的支持与推动。 第一部分:品牌出海的意义 品牌出海是指企业将自己的品牌、产品和服务推向全…...

将phantomjs制成docker镜像
几个前的一篇文章中介绍了phantomjsecharts生成图表图片的一种方式,但其部署复杂,制作为docker镜像运行就方便多了。文章参见:https://blog.csdn.net/u011943534/article/details/121524397 1、准备echarts 将上次文章中提到过下载的Echart…...

【LeetCode+JavaGuide打卡】Day20|530.二叉搜索树的最小绝对差、501.二叉搜索树中的众数、236. 二叉树的最近公共祖先
学习目标: 530.二叉搜索树的最小绝对差 501.二叉搜索树中的众数 236. 二叉树的最近公共祖先 学习内容: 530.二叉搜索树的最小绝对差 题目链接&&文章讲解 给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值…...

【工具类】开源照片管理工具pthtoprism
1. pthtoprism 1. pthtoprism 1.1. 安装1.2. 管理照片方式 1.2.1. 直接管理原始照片目录1.2.2. 导入照片 1.3. 界面功能1.4. 参考资料 1.1. 安装 wget https://dl.photoprism.app/docker/docker-compose.yml # 修改 docker-compose.yml 文件,具体参考下面内容 d…...

[ linux网络 ] 网关服务器搭建,综合应用SNAT、DNAT转换,dhcp分配、dns分离解析,nfs网络共享以及ssh免密登录
实验准备工作: 网关服务器安装:dhcp bind (yum install -y dhcp bind bind-utlis) server1安装:httpd (yum install -y httpd) 没有网络就搭建本地yum仓库或者配置网卡使其能够上网。 ( 1)网关服务器…...

MySQL全量备份
一、实验素材 1.创建student和score表 (1) student表 create database school; use schoolCREATE TABLE student ( id INT(10) NOT NULL UNIQUE PRIMARY KEY , name VARCHAR(20) NOT NULL , sex VARCHAR(4) , birth YEAR, department VARCHAR(20) , address VARCHAR(50) );(…...
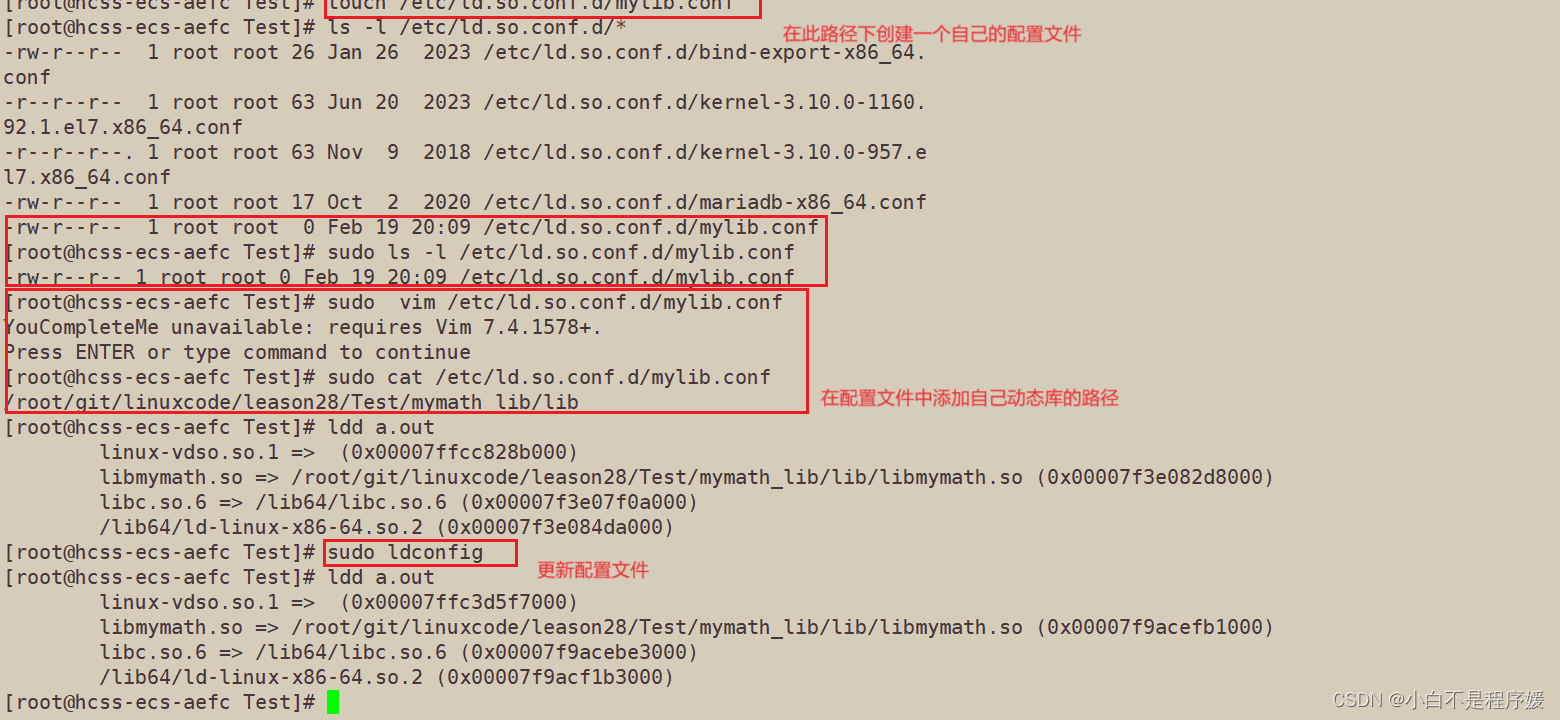
【Linux系统化学习】动静态库 | 软硬链接
目录 硬链接和软链接 硬链接 软链接 动态库和静态库 静态库 静态库的生成 静态库的使用 将库打包和使用 动态库 动态库的生成 动态库的使用 库搜索路径 硬链接和软链接 硬链接 上篇文章我们说到真正找到磁盘上的文件并不是文件名,而是inode。其实在…...

linux-firewalld防火墙端口转发
目的:通过统一地址实现对外同一地址暴露 1.系统配置文件开启 ipv4 端口转发 echo "net.ipv4.ip_forward 1" >> /etc/sysctl.confsysctl -p 2.查看防火墙配置端口转发之前的状态 firewall-cmd --statefirewall-cmd --list-all 3.开启 IP 伪装 firewall-cm…...
adobe软件提示This non-genuine Adobe app will be disabled soon【软件版本】
因为电脑上级路由器装了小飞机,导致本机电脑ps等adobe的系列软件出现了 This non-genuine Adobe app will be disabled soon,烦人的狠,之前有写过一篇通过更改host的教程,现在已经失效了,今天为大家分享一个用软件来屏…...

python coding with ChatGPT 打卡第20天| 二叉搜索树:搜索、验证、最小绝对差、众数
相关推荐 python coding with ChatGPT 打卡第12天| 二叉树:理论基础 python coding with ChatGPT 打卡第13天| 二叉树的深度优先遍历 python coding with ChatGPT 打卡第14天| 二叉树的广度优先遍历 python coding with ChatGPT 打卡第15天| 二叉树:翻转…...

Stable Diffusion——基础模型、VAE、LORA、Embedding各个模型的介绍与使用方法
前言 Stable Diffusion(稳定扩散)是一种生成模型,基于扩散过程来生成高质量的图像。它通过一个渐进过程,从一个简单的噪声开始,逐步转变成目标图像,生成高保真度的图像。这个模型的基础版本是基于扩散过程…...

Python自动化部署与配置管理:Ansible与Docker
Ansible 和 Docker 是两种常用于自动化部署和配置管理的工具。Ansible 是一个基于 Python 的自动化运维工具,可以配置管理、应用部署、任务自动化等。而 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中&…...

高工独家报告|谁在收割2026智驾市场红利?440万辆背后的芯片大洗牌
高工智能汽车研究院发布《2026年中国市场智能汽车SoC芯片行业分析报告》。报告立足中国乘用车市场,基于乘用车前装量产数据库,全面解析智能驾驶SoC(含前视一体机、域控制器及高阶自动驾驶辅助芯片)与智能座舱SoC(含端侧…...

微信小程序 健身服务与轻食间平台系统健身减肥系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能模块技术实现亮点商业模式差异化优势项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 微信…...

Worldquant研究顾问速通
几天时间速通拿了金牌,中间停了一两周,然后仔细研究了下,学了相关知识,搭建自己ai驱动的工作流后每天大约10分钟设置好任务,可探索到10来个可以提交的alpha,目前产出比大约在1/100,simulate100个…...

磁性轴承尺寸如何精准检测?蓝光扫描仪全尺寸3D检测解析
磁悬浮轴承是一种高性能轴承,它利用可控磁力将旋转的转子无接触地悬浮于空间中。作为核心支撑部件,磁性轴承对于定子内圆与转子外圆的同轴度、部件的形位公差提出了极高要求。对于磁性轴承3D尺寸检测,蓝光三维扫描仪凭借其非接触、高精度、高…...

手把手教你把Windows虚拟内存文件pagefile.sys从C盘挪走,给SSD系统盘腾出几十G空间
彻底解放C盘空间:Windows虚拟内存文件迁移全指南 你是否遇到过这样的场景:刚装完系统时C盘还剩下大半空间,用着用着却突然弹出"磁盘空间不足"的警告?打开资源管理器一看,一个名为pagefile.sys的"巨无霸…...

从瑞芯微与飞凌嵌入式合作,看嵌入式核心板选型与产业协同
1. 项目概述:一次合作背后的产业逻辑最近,飞凌嵌入式在瑞芯微的合作伙伴大会上,拿下了“2024年度优秀合作奖”。这事儿在圈内不算大新闻,但如果你拆开来看,会发现它背后其实是一套非常经典的产业合作范本。它讲的不是某…...

MCGS组态软件连接Modbus TCP设备?别急,先搞懂网关的这5种工作模式怎么选
MCGS组态软件连接Modbus TCP设备:网关工作模式深度解析与选型指南 在工业自动化系统中,MCGS组态软件与Modbus TCP设备的稳定通信是数据采集与控制的基础环节。ZLAN5143D作为一款多功能工业网关,其五种工作模式的选择直接影响系统响应速度、数…...

服务器末级缓存优化:指令-数据关联性管理技术
1. 服务器工作负载中的末级缓存挑战在现代多核处理器架构中,共享末级缓存(Shared Last-Level Cache, LLC)的性能优化一直是计算机体系结构研究的核心课题。随着云计算和分布式计算的普及,服务器工作负载呈现出两个显著特征:指令足迹(instruct…...

2026 年 5 月 AI 热点:大模型、硬件、人形机器人全面升级
一、大模型技术突破 | LLM Technology Breakthroughs 1.1 OpenAI GPT‑5.5 正式成为ChatGPT默认模型 | GPT‑5.5 Becomes ChatGPT Default Model 英文内容 | English On May 5, 2026, OpenAI officially rolled out GPT‑5.5 Instant as the new default model for ChatGPT, …...

别再被‘一亿像素’忽悠了!聊聊手机CMOS尺寸、像素和Remosaic那些事儿
手机CMOS尺寸、像素与成像质量的真相:别再被数字游戏迷惑 每次打开手机厂商的发布会,总能看到各种令人眼花缭乱的参数轰炸——"一亿像素"、"超大底传感器"、"超清画质"。这些营销术语让普通消费者一头雾水,甚至…...