第3.1章:StarRocks数据导入——Insert into 同步模式
一、概述
在StarRocks中,insert的语法和mysql等数据库的语法类似,并且每次insert into操作都是一次完整的导入事务。
主要的 insertInto 命令包含以下两种:
- insert into tbl select ...
- insert into tbl (col1, col2, ...) values (1, 2, ...), (1,3, ...);
其中第二种命令仅用于demo,不要使用在测试或生产环境中。在StarRocks中,例如使用JDBC或者insertInto导入时,插入1000条左右时很快有类似报错:close index channel failed,主要原因是导入太频繁了,需要降频率攒批导入。
二、高频insert 报错的原因
StarRocks中的数据组织图如下:
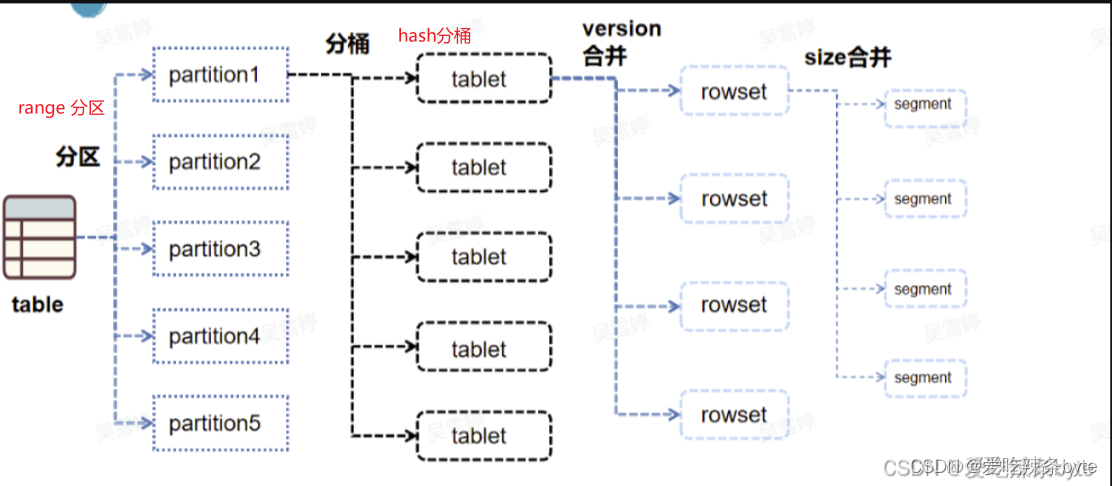
StarRocks中的分区分桶与tablet之间的关系为: table -- > partition --> tablet(物理描述,tablet数据分片是数据划分的最小逻辑单元)
分区是逻辑上的概念,只记录在表的元数据中,每个分区的数据会按照分桶键进行hash分桶,表中的数据经过分区分桶后,就会形成一个个的tablet,且尽量均匀分布在集群的各个BE中。 tablet是StarRocks中数据均衡的最小单位,默认的三副本是指同一个 tablet会在集群中保留三份,每个tablet之间的数据没有交集,在物理上独立存储。集群的副本修复或磁盘均衡,均是以tablet为单位移动或者克隆的。且每次的数据导入、更新或者删除,本质上也是对一个个tablet中的数据进行操作。
StarRocks中的分区分桶见:
第2.4章 StarRocks表设计——分区分桶与副本数-CSDN博客文章浏览阅读504次,点赞21次,收藏9次。2.4 StarRocks表设计——分区分桶与副本数https://blog.csdn.net/SHWAITME/article/details/136140126?spm=1001.2014.3001.5501
一个tablet中包含若干连续的rowset(rowset是逻辑概念),rowset代表tablet中一次数据变更的数据集合(数据变更包括了数据新增,更新或删除等),它是按版本信息进行记录的,每次变更就会生成一个新版本的rowset。一个rowset底层可能会包含多个segment,执行数据导入时,每成功写入一个segment就会增加一个文件块对应。
Segment的概念比较底层(这里不展开),可以借鉴Doris底层存储结构:
https://blog.csdn.net/SHWAITME/article/details/136155008?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136155008%22%2C%22source%22%3A%22SHWAITME%22%7D文章浏览阅读340次,点赞7次,收藏6次。Doris存储层设计介绍1——存储结构设计解析(索引底层结构)https://blog.csdn.net/SHWAITME/article/details/136155008?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136155008%22%2C%22source%22%3A%22SHWAITME%22%7D
对上文提到的数据导入报错close index channel failed进一步解析。在StarRocks中,每次insert into本质都是一次完整的导入事务,即:insert into实际上会在tablet内部生成一个个连续版本号的rowset,对于新增的rowset,起始版本和终止版本是一样的,表示为[ 6-6]、[ 7-7]....[999-999]等。多个 rowset经过compaction会形成一个大的rowset。合并后的起始版本和终止版本是多个版本的并集,如[ 6-6]、[ 7-7]、[8-8]合并后变成 [6-8]。一旦表的某个tablet中同时存在rowset个数达到1000,就会到达阈值,即触发上述报错。
三、降低导入频率
单个tablet中的rowset版本个数过多会什么影响?主要影响两个方面,一个是内存的占用,当rowset的版本过多时,be节点的table_meta部分(主要是其中的rowset元数据部分)占用的内存可能非常多。同时compaction合并消耗内存也会比较大,容易引起oom,影响集群稳定性;二是查询会变慢,因为查询的过程中是需要对tablet中的数据进行解压的,当rowset版本很多,解压会变慢,导致查询scan的耗时增加。综上考虑,StarRocks设置了单表中每个tablet最大阈值为1000的限制。
针对insert into 数据频繁导入引发的rowset版本过多的问题,StarRocksc是利用compaction解决的。compaction可以认为是一个后台的常驻线程,不断的将tablet中的rowset版本进行合并,将小文件合并成有序的大文件。
StarRocks中的compaction操作,分为base compaction(BC) 和cumulative compaction
(CC)。其中cumulative compaction(简称CC)负责将多个最新导入的增量数据进行合并,当增量数据合并后的大小达到一定阈值后,base compaction(简称BC)将基线版本(起始版本start version为0的数据)和与该增量数据版本合并。BC操作因为涉及到基线数据,而基线数据通常比较大,所以操作耗时会比CC长。
BC和CC之间的分界线是cumulative point (cp),它是一个动态变化的版本号,比cp小的数据版本只能触发BC,而比CP大的数据版本,只会触发CC。如下图:

上述分析得出,在StarRocks集群运行时,对表的数据变更操作会不断地产生新版本rowset,后台的常驻线程compaction负责将tablet中的rowset版本进行合并,进而保证集群的整体稳定高效。
综上,快速insert into导致报错:close index channel failed的原因可以总结为:短时间内生成的rowset版本太快,如果compaction不及时,就会造成大量版本堆积,导致累计版本超过了超过了1000,进而触发阈值报错。故为了保障集群的稳定运行及查询效率,需要确保整体的compaction效率要大于rowset的生成速率。容易想到的解决思路一是:部分场景下通过调整compaction的几个参数来加速compaction,例如在be.conf中配置以下参数(配置后需重启BE):
#==每个磁盘 Cumulative Compaction 线程的数目(默认是1)
cumulative_compaction_num_threads_per_disk = 4#==每个磁盘 Base Compaction 线程的数目(默认是1)
base_compaction_num_threads_per_disk = 2#==Cumulative Compaction 线程轮询的间隔(单位是秒,默认值是1)
cumulative_compaction_check_interval_seconds = 2弊端是:compaction任务本身比较耗费cpu,内存和磁盘IO资源,compaction开启的过多会占用过多的机器资源,也会影响查询性能,还可能会造成OOM。上述报错还是需要从数据导入频率这个入手。
理论上,每次导入操作,不论是只导入一条还是十万、百万条,对于StarRocks来说,都是只生成一个新的roswet版本。那么在compaction效率有限的情况下,完全可以通过“攒微批+降频率”来规避roswet版本过多的问题。实际上,若业务实时性要求不高,在机器内存充足的情况下,攒批越大、导入频率越低,对StarRocks集群的稳定性及查询性能的影响就越小。
ps:在StarRocks中有更快的攒批导入方式,即Stream Load
从本地文件系统导入 | StarRocks
STREAM LOAD | StarRocks
compaction合并机制见文章:
第3.2章:Doris数据导入——Compaction机制(1)-CSDN博客文章浏览阅读342次,点赞11次,收藏9次。第3.2章:Doris数据导入——Compaction机制(1)https://blog.csdn.net/SHWAITME/article/details/136172846
四、insert替代用法
可以概括总结为以下几点:
- 高频率小数据:insert into或者JDBC的executeUpdate()方法就完全不要用;
- 低频率小数据:insert into导入几条测试数据可以用,但注意频率;
- 低频率较大数据:insert into tbl values(data1),(data2)……或者类似JDBC executeBatch()方法,可以用,但不推荐,因为有更快的实现方式;
- StarRocks系统内部进行ETL,推荐使用 insert into select 语法;
- 便捷导入其他系统的数据,推荐使用外部表,例如:先构建mysql外部表去映射mysql系统中的数据,通过 insert into select 语法将外部表中的数据导入到 StarRocks表中。
五、insert使用与调优
5.1严格模式
insert into是一种同步的导入方式,导入成功会直接显示导入结果。如果导入失败,insert也会返回错误信息,例如我们导入错误时间格式的数据(数据漏加引号):

(1)针对tracking_url,使用web或者curl命令访问tracking_url,可以查看更详细的错误信息:显示报错原因是:格式不对,强转为null引起的问题,接着可以去排查数据格式。
(2)严格模式enable_insert_strict:当该参数为false时(关闭严格模式),表示一次insert任务只要有一条或以上数据被正确导入,就返回成功。当该参数设置为true时,表示但凡有一条数据错误,则任务整体失败,该参数默认为true。例如:set global enable_insert_strict = false;
ps:当关闭严格模式后,insert即使有错误数据,但只要有一条数据是正常可用的,就会忽视脏数据,保证可用数据的正常导入。此外,enable_insert_strict参数是session参数(当前会话生效),断开当前session后,该参数就会失效,若需要全局修改,可以加上global。
5.2并行度
insert导入语句本质上还是sql,可以通过设置合适的并行度来进行加速。例如可以设置全局并行度为单个BE节点的cpu核数的一半。假设部署的BE服务器core数是16C,那set global parallel_fragment_exec_instance_num = 8。注意:有些场景下,例如:insert into select语句进行StarRocks系统内部的ETL或者通过外部表来拉取数据,当速度过快。一方面可能导致源库压力过大影响源库中的业务,另一方面会导致StarRocks BE的load内存和ColumnPool内存占用较高,影响集群稳定性。所以需要结合实际情况,来设置合适的并行度控制导入速率
5.3超时时间
与insert相关的超时参数有两个:
- query_timeout
可以通过show variables like '%query_timeout%' 语句查看, 该参数是session变量,通过增加global关键词设置全局生效。可以通过set query_timeout = xxx 来增加超时时间,单位是秒(默认为300秒)
- insert_load_default_timeout_second
该参数是fe.conf中的参数,表示导入任务的超时时间(以秒为单位,默认是3600秒,即1小时)。如果导入任务在设定的超时时间内未完成则会被系统取消,变成cancelled。
参考文章:
Insert Into - Apache Doris
通过 INSERT 语句导入数据 | StarRocks
第3.1章:StarRocks数据导入--Insert into_starrocks insert into-CSDN博客
相关文章:

第3.1章:StarRocks数据导入——Insert into 同步模式
一、概述 在StarRocks中,insert的语法和mysql等数据库的语法类似,并且每次insert into操作都是一次完整的导入事务。 主要的 insertInto 命令包含以下两种: insert into tbl select ...insert into tbl (col1, col2, ...) values (1, 2, ...…...

Docker基本使用【数据卷的挂载及常用命令】
镜像和容器:当我们利用docker安装应用时,Docker会自动搜索并下载应用的镜像(image),镜像不仅包含应用本身还包含应用所需要的环境、配置、系统函数库。Docker会在运行镜像时创建一个隔离的环境,称为容器&am…...

5G DTU实现燃气管道数据采集远程管理
随着物联网技术与智慧城市的不断发展,燃气管道户外组网的需求逐渐浮现。在户外组网应用中5G DTU(Data Terminal Unit)发挥着至关重要的作用。5G DTU可用于数据采集、传输与远程管理,能够实现燃气数据的单点或多点采集和传输&#…...

请解释Java中的代理模式,分别介绍静态代理和动态代理
请解释Java中的代理模式,分别介绍静态代理和动态代理 代理模式是一种常见的设计模式,它允许一个对象(代理对象)代表另一个对象(被代理对象)进行访问控制,以控制对对象的访问。代理模式可以在不…...

Python 文件处理指南:打开、读取、写入、追加、创建和删除文件
文件处理是任何Web应用程序的重要部分。Python有多个用于创建、读取、更新和删除文件的函数。 文件处理 在Python中处理文件的关键函数是open()函数。open()函数接受两个参数:文件名和模式。 有四种不同的方法(模式)可以打开文件࿱…...

记录C#导出数据慢的优化方法
Winform程序将数据库中的历史数据导出到Excel中速度慢,导出1000多条数据优化前需要40秒,优化后只需要2秒,4万条数据只需要10秒。 优化前: for (int i 0; i < myDGV.Columns.Count; i) {worksheet.Cells[1, i 1] myDGV.Col…...

Android批量加载图片OOM问题
Android批量加载图片OOM问题 前言使用内存缓存使用磁盘缓存处理配置更改 前言 将单个位图加载到界面中非常简单,但如果您需要同时加载较大的一组图片,则操作起来会比较复杂。实际上,在许多情况下(比如使用 ListView、GridView 或…...

SNAT与DNAT公私网地址转换
前言 SNAT和DNAT是两种重要的网络地址转换技术,它们允许内部网络中的多个主机共享单个公共IP地址,或者将公共IP地址映射到内部网络中的特定主机。这些技术在构建企业级网络和互联网应用程序时非常重要,因为它们可以帮助保护内部网络安全&…...
快速上手Spring Boot整合,开发出优雅可靠的Web应用!
SpringBoot 1,SpringBoot简介1.1 SpringBoot快速入门1.1.1 开发步骤1.1.1.1 创建新模块1.1.1.2 创建 Controller1.1.1.3 启动服务器1.1.1.4 进行测试 1.1.2 对比1.1.3 官网构建工程1.1.3.1 进入SpringBoot官网1.1.3.2 选择依赖1.1.3.3 生成工程 1.1.4 SpringBoot工程…...
-数据库版本控制与迁移)
MySQL高级特性篇(7)-数据库版本控制与迁移
MySQL数据库版本控制与迁移 在软件开发的过程中,数据库版本控制和迁移是非常重要的一部分。这些过程确保了数据库的结构及数据的追踪和更新。在本篇博客中,我们将介绍如何使用Markdown语法来编写MySQL数据库版本控制与迁移的相关内容。 1. 什么是MySQL…...

js判断对象是否为空
给定一个对象或数组,判断它是否为空。 一个空对象不包含任何键值对。 一个空数组不包含任何元素。 输入:obj {"a": 1, "b": 2} 输出:false 解释:这个对象有两个键值对,所以它不为空。var isObje…...

2024前端面试准备之HTML篇
全文链接 1. doctype的作用是什么 DOCTYPE是html5标准网页声明,且必须声明在HTML⽂档的第⼀⾏。来告知浏览器的解析器⽤什么⽂档标准解析这个⽂档,不同的渲染模式会影响到浏览器对于 CSS 代码甚⾄ JavaScript 脚本的解析 ⽂档解析类型有: BackCompat:怪异模式,浏览器使…...
devOps系列(八)efk+prometheus+grafana日志监控和告警
前言 作者目前打算分享一期关于devOps系列的文章,希望对热爱学习和探索的你有所帮助。 文章主要记录一些简洁、高效的运维部署指令,旨在 记录和能够快速地构建系统。就像运维文档或者手册一样,方便进行系统的重建、改造和优化。每篇文章独立…...

考研英语单词29
Day 29 unify v.统一,使成一体【union n.结合,联合,工会,团结 unity n.团结,统一,协调】 offend v.冒犯,使不愉快【offender n.冒犯者 offensive a.冒犯的,无礼的】 d…...
spring-security 过滤器
spring-security过滤器 版本信息过滤器配置过滤器配置相关类图过滤器加载过程创建 HttpSecurity Bean 对象创建过滤器 过滤器作用ExceptionTranslationFilter 自定义过滤器 本章介绍 spring-security 过滤器配置类 HttpSecurity,过滤器加载过程,自定义过…...
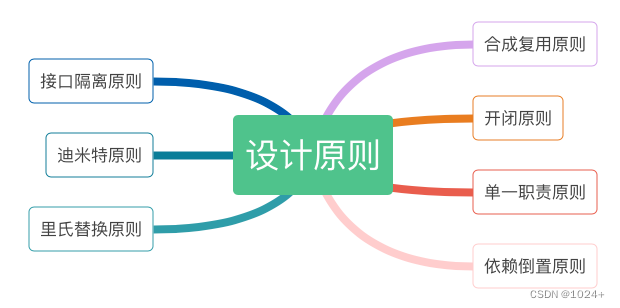
掌握这7种软件设计原则,让你的代码更优雅
掌握这7种软件设计原则,让你的代码更优雅 在软件开发过程中,设计原则是非常重要的指导方针,它们可以帮助我们创建出更加清晰、可维护和可扩展的软件系统。本文将介绍7种常见的软件设计原则,并解释它们如何提升代码质量。 1. 单…...
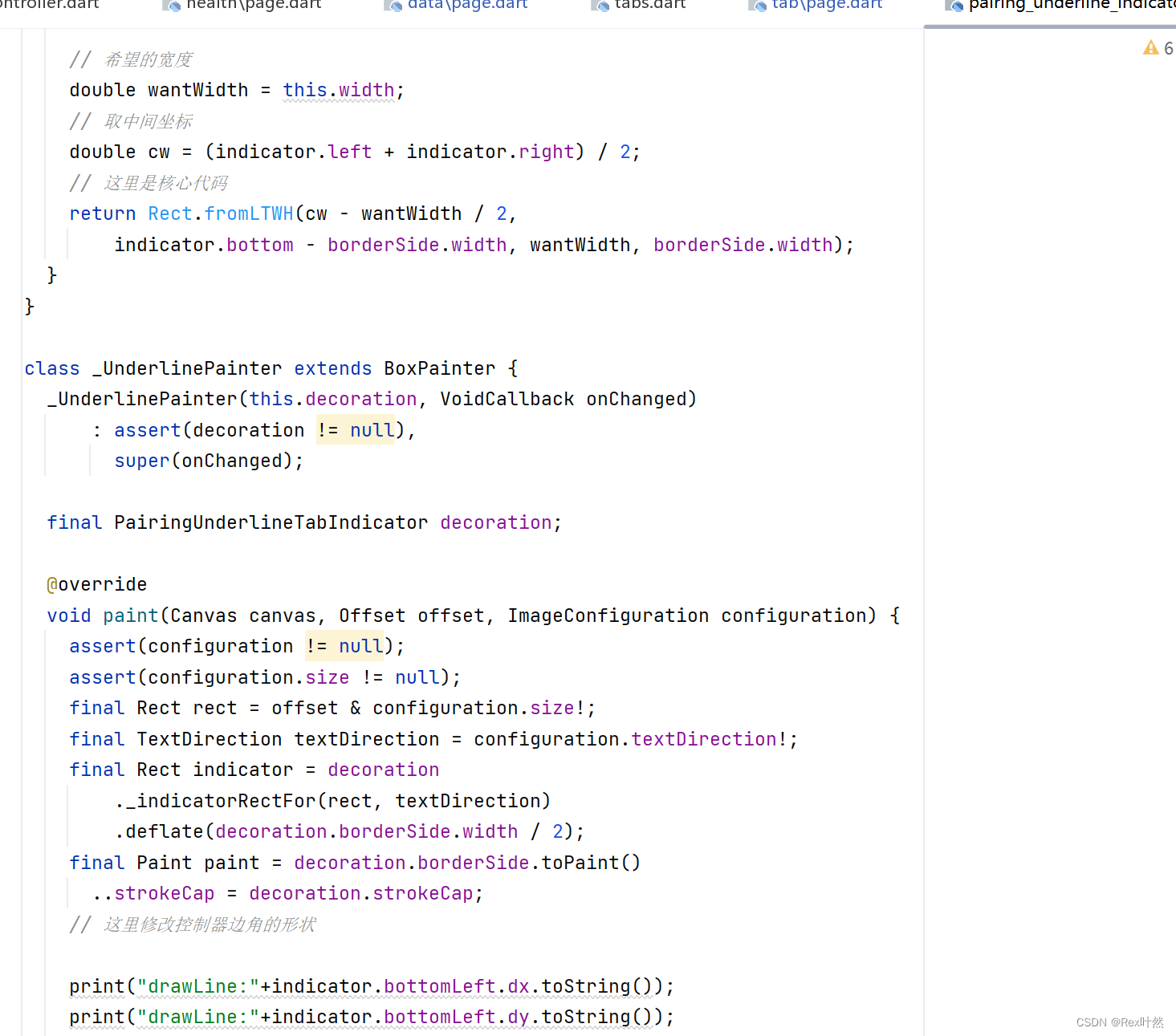
Flutter自定义tabbar任意样式
场景描述 最近在使用遇到几组需要自定义的tabbar或者类似组件,在百度查询资料中通常,需要自定义 TabIndicator extends Decoration 比如上图中的带圆角的指示器这样实现 就很麻烦, 搜出来的相关也是在此之处上自己画,主要再遇…...

Java设计模式【策略模式】
一、前言 1.1 背景 针对某种业务可能存在多种实现方式,传统方式是通过传统if…else…或者switch代码判断; 弊端: 代码可读性差扩展性差难以维护 1.2 简介 策略模式是一种行为型模式,它将对象和行为分开,将行为定…...
(13)Hive调优——动态分区导致的小文件问题
前言 动态分区指的是:分区的字段值是基于查询结果自动推断出来的,核心语法就是insertselect。 具体内容指路文章: https://blog.csdn.net/SHWAITME/article/details/136111924?spm1001.2014.3001.5501文章浏览阅读483次,点赞15次…...

【linux】使用g++调试内存泄露:AddressSanitizer
1、简介 AddressSanitizer(又名 ASan)是 C/C++ 的内存错误检测器。它可以用来检测: 释放后使用(悬空指针) 堆缓冲区溢出 堆栈缓冲区溢出 全局缓冲区溢出 在作用域之后使用 初始化顺序错误 内存泄漏这个工具非常快,只将被检测的程序速度减慢约2倍,而Valgrind将会是程序…...

GBase 8a之listagg/string_agg 函数的反函数实现
GBase8a数据库中 listagg/string_agg 函数的反函数实现一、业务场景背景 在日常数据开发中,我们经常会遇到这种场景:某张表的字段里存储了用逗号(或其他分隔符)拼接的多个值,比如商品分类、标签、关联系统名称等&#…...

SchemaCrawler:终极数据库模式发现与理解工具完全指南
SchemaCrawler:终极数据库模式发现与理解工具完全指南 【免费下载链接】SchemaCrawler Free database schema discovery and comprehension tool 项目地址: https://gitcode.com/gh_mirrors/sc/SchemaCrawler 在当今数据驱动的时代,数据库模式发现…...
)
Array作为顶层参数-优化设计(二)
一、核心代码#include "array_FIFO.h"void array_FIFO (dout_t d_o[4], din_t d_i[4], didx_t idx[4]) { //void array_FIFO (dout_t d_o[4], din_t *d_i, didx_t idx[4]) { #pragma HLS INTERFACE s_axilite register depth4 portd_i //#pragma HLS INTERFACE s_axi…...
)
收藏必备!小白程序员轻松上手大模型:RAG技术实战指南(含评测体系)
本文深入浅出地解析了RAG(检索增强生成)技术在大模型开发中的应用,覆盖了从文档加载、智能切分到索引构建、检索优化、生成调优的全链路实战指南,并介绍了进阶的Graph RAG和多跳推理。特别强调了“可测、可调、可信赖”的RAG工程化…...

软考系统架构设计师实战论文集:自动驾驶与AI云端架构演进
【引言】 自动驾驶的下半场,早已不再局限于单车智能的角逐,而是演变成了一场关乎云端算力、海量数据治理与大模型工程化的全面战役。当接入的车辆规模突破百万级,当每日回传的工况数据达到 PB 级,云端数据平台的可靠性、扩展性与…...

14404黄大年茶思屋榜文144期第四题AI辅助故障自动检测、复现和故障自动定界定位
开源鸿蒙难题揭榜第四题:AI辅助故障自动检测复现定位 AI零偏差标准化脱敏解题全集 摘要 本文严格遵循AI无偏差标准化解题框架,完成鸿蒙第四期系统故障智能运维难题全维度规范化拆解,全文一字未改复刻官方脱敏原题内容,精准还原隐藏…...

微信小程序互助交流
微信小程序互助群 你开发了一个微信小程序, 准备接广告, 卡在了 500 个 UV 这里, 想找大佬帮忙,结果大佬说要收一张费—— 于是我建了一个微信群, 大家互助,免费入群,入群条件: 每人…...

用 ai 生成带货/电商短视频,有哪些工具比较好用?下面推荐几个
在 2026 年,短视频内容已成为驱动电商转化的核心引擎。然而,许多商家仍面临本土化适配难、制作周期长、精品成本高等痛点。本文将针对“怎么用 ai 生成带货视频,有哪些工具比较好用?”以及“AI 生成电商短视频的工具有哪些&#x…...

终极指南:WinDiskWriter - 简单快速制作Windows启动盘的Mac神器
终极指南:WinDiskWriter - 简单快速制作Windows启动盘的Mac神器 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI &…...

二年级下册语文看图写话作文:长大以后做什么
二年级下册语文《长大以后做什么》看图写话,重点是:长大想做什么职业为什么想做以后会怎么努力老师最喜欢“有梦想 有原因 有行动”的内容。我用夸克网盘分享了「二年级下册语文作文」,链接:https://pan.quark.cn/s/3ee38f2d976…...